






























































































The document discusses clustering, specifically k-means clustering, explaining its purpose as an unsupervised learning method for grouping unlabeled data based on feature similarity. It also covers logistic regression, a classification algorithm for binary and multi-classification problems, highlighting its use in predicting outcomes like the malignancy of tumors. Examples and methods such as the elbow method for determining the number of clusters in k-means are also provided.
Introduces clustering, defines it as organizing objects into groups based on similarity, and offers examples like K-Means clustering and organizing books.
Explains K-Means clustering as an unsupervised learning method used for unlabeled data to form clusters based on feature similarity.
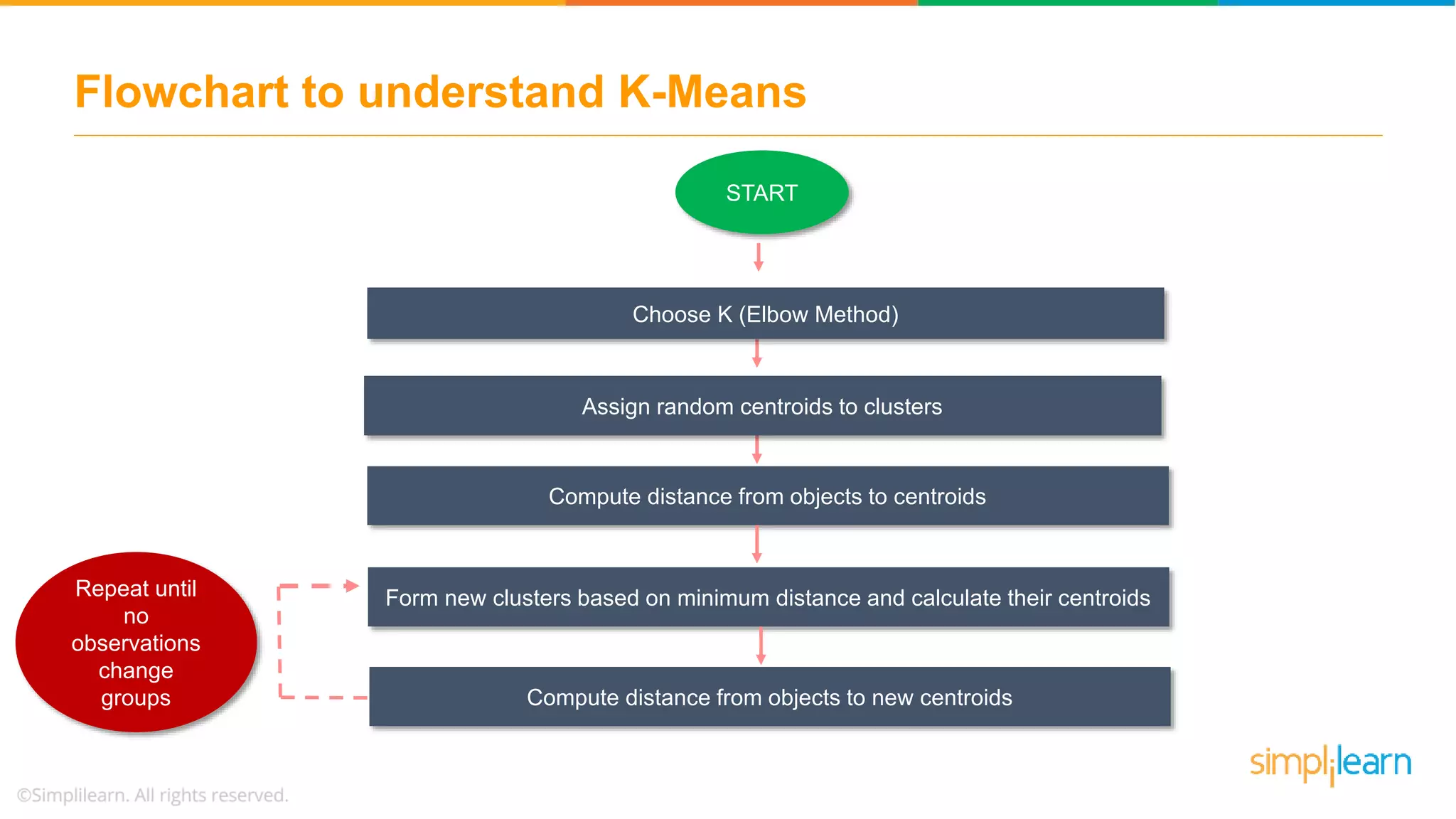
Details the steps for K-Means clustering including initialization of centroids, distance computation, and cluster assignments until stabilization.
Introduces a flowchart to visualize the K-Means clustering process from choosing K to determining stable clusters.
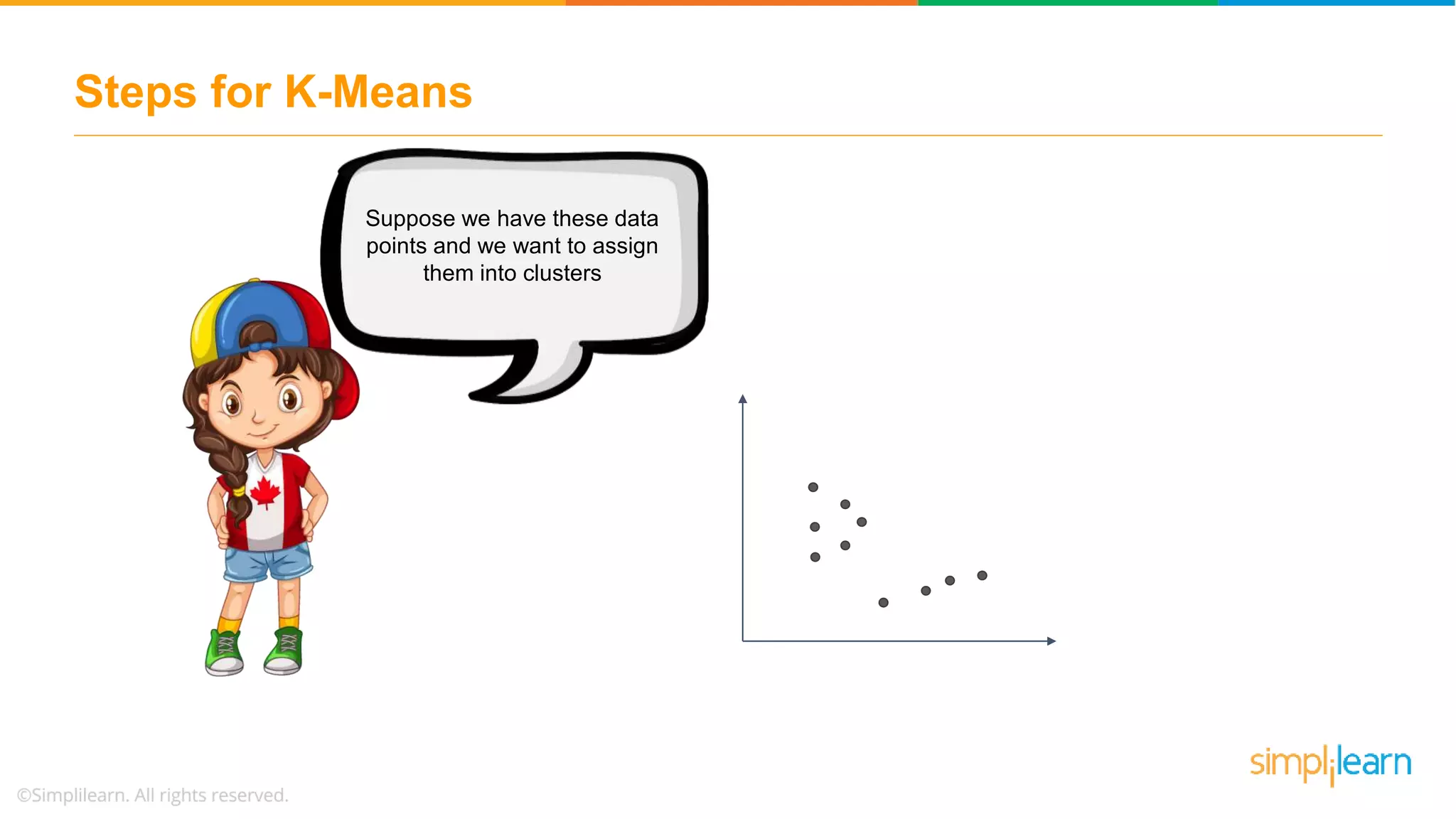
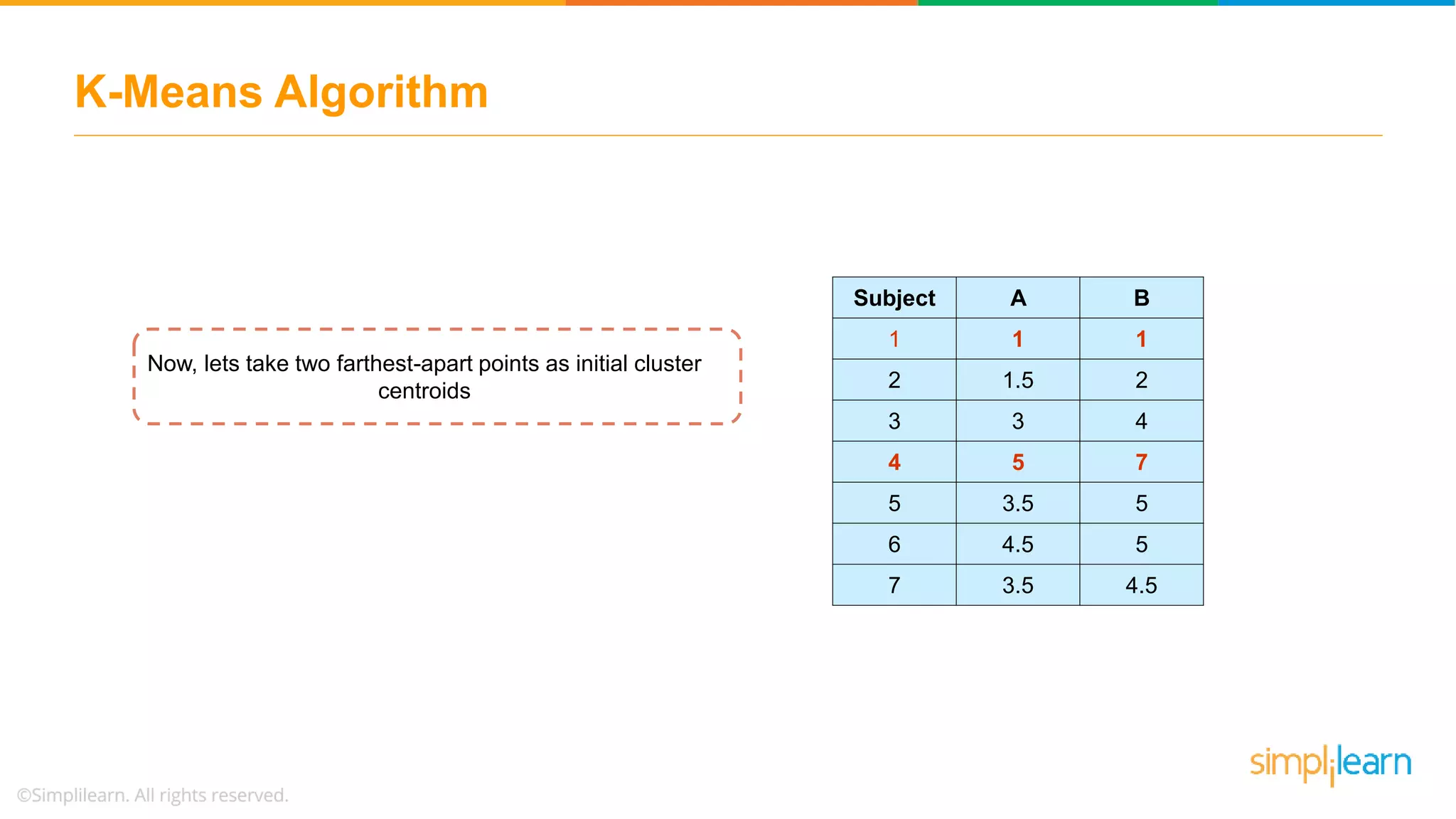
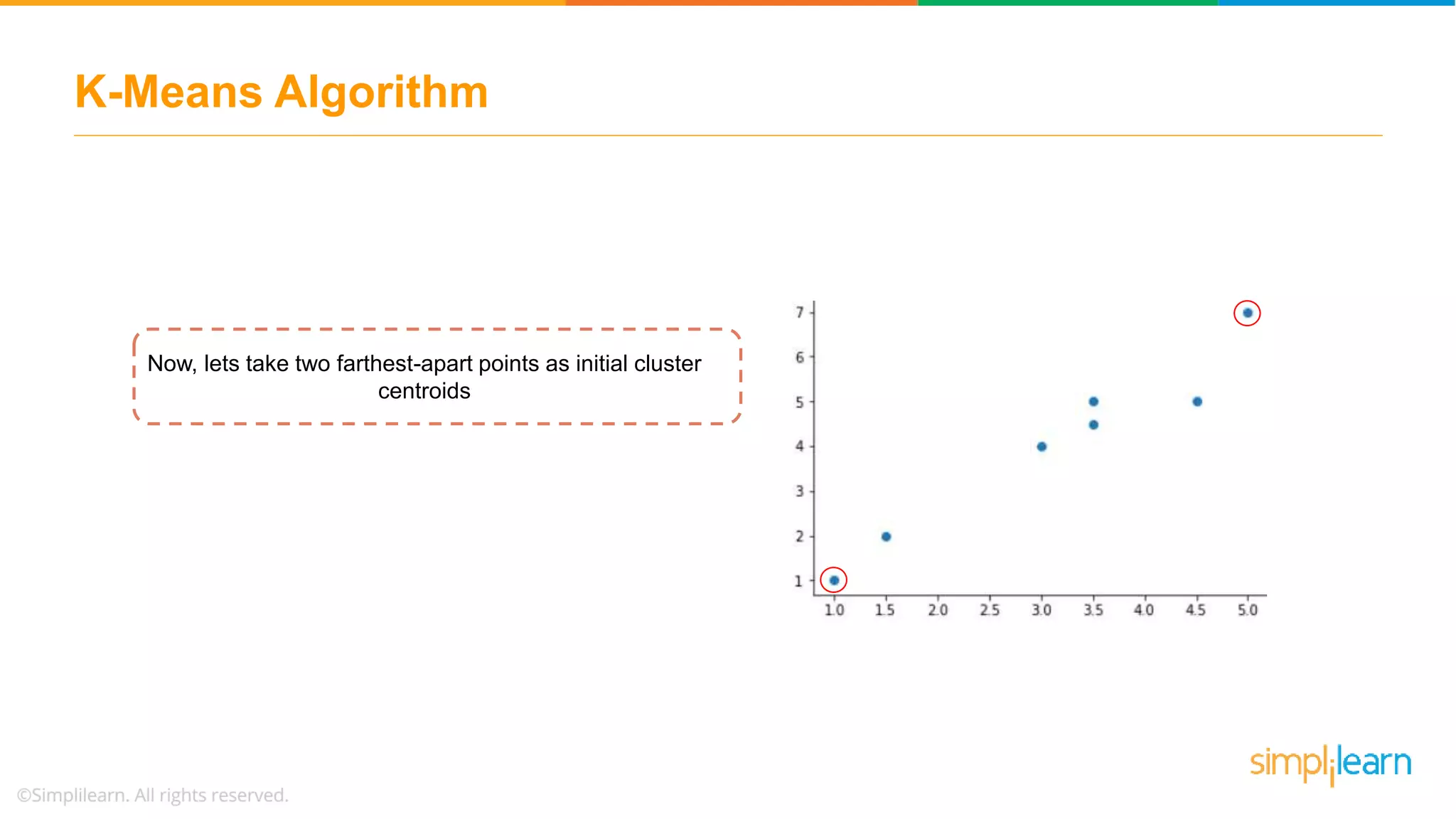
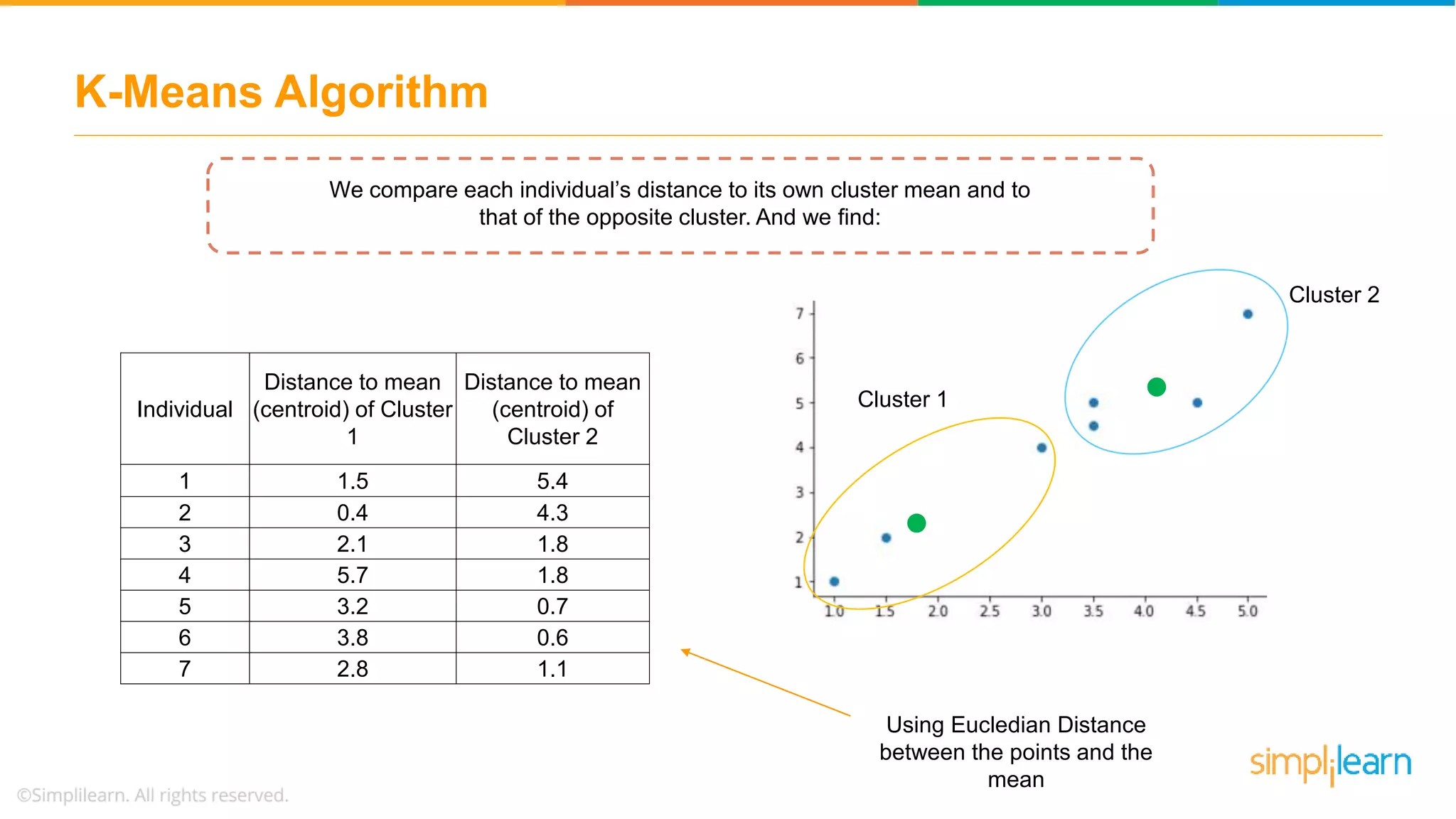
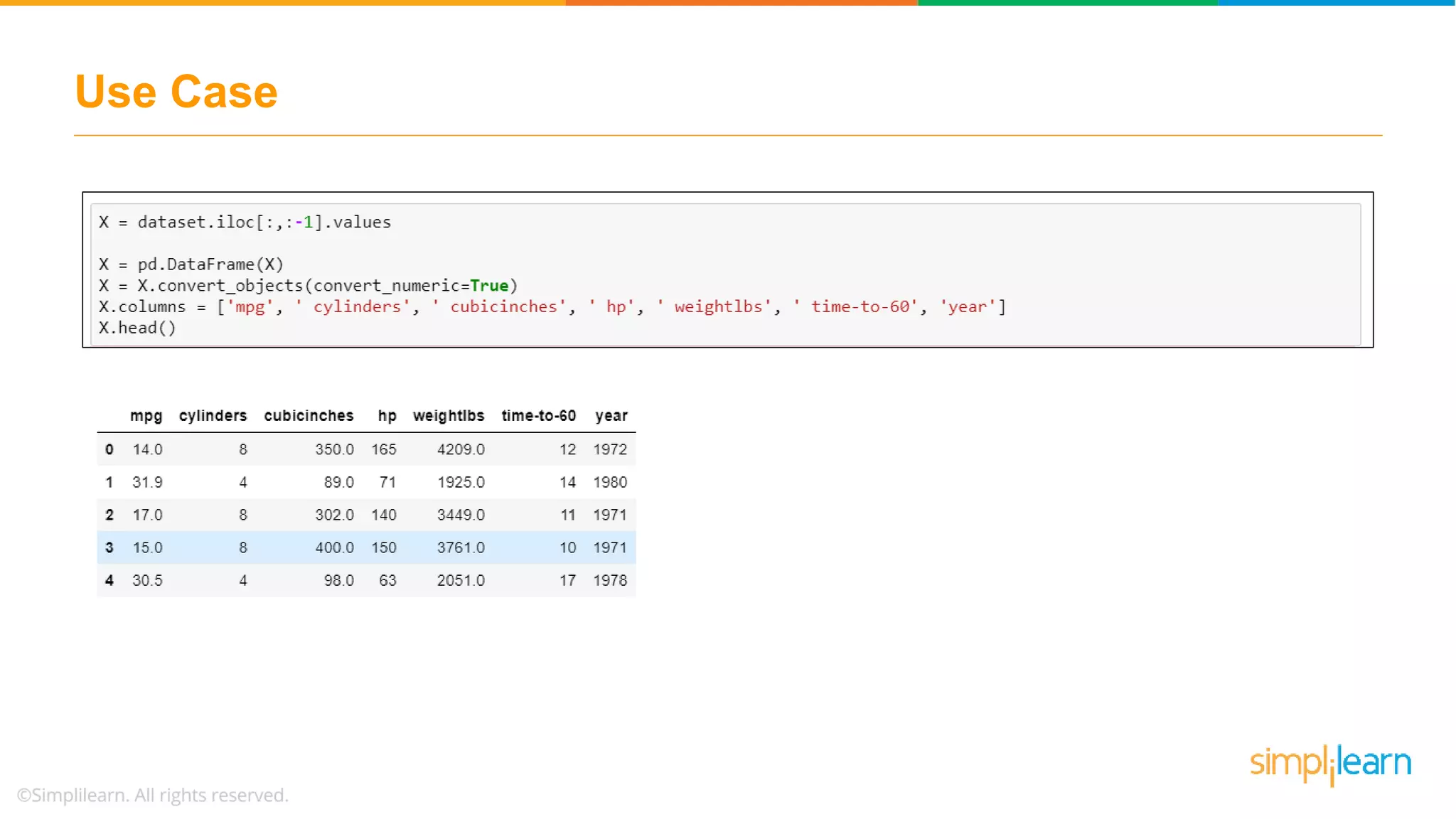
Presents a dataset for K-Means clustering and the method for selecting initial centroids for the clustering process.
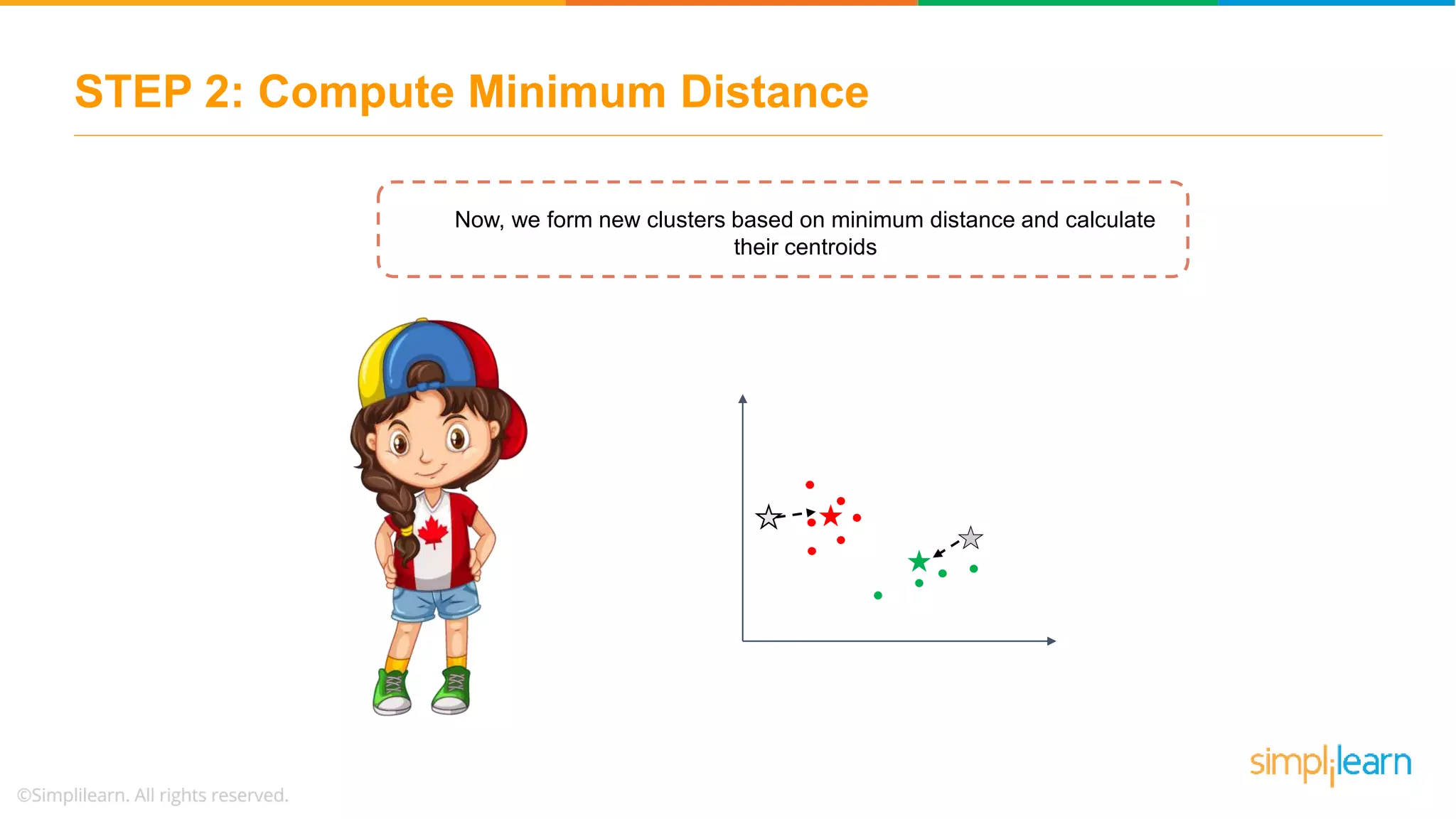
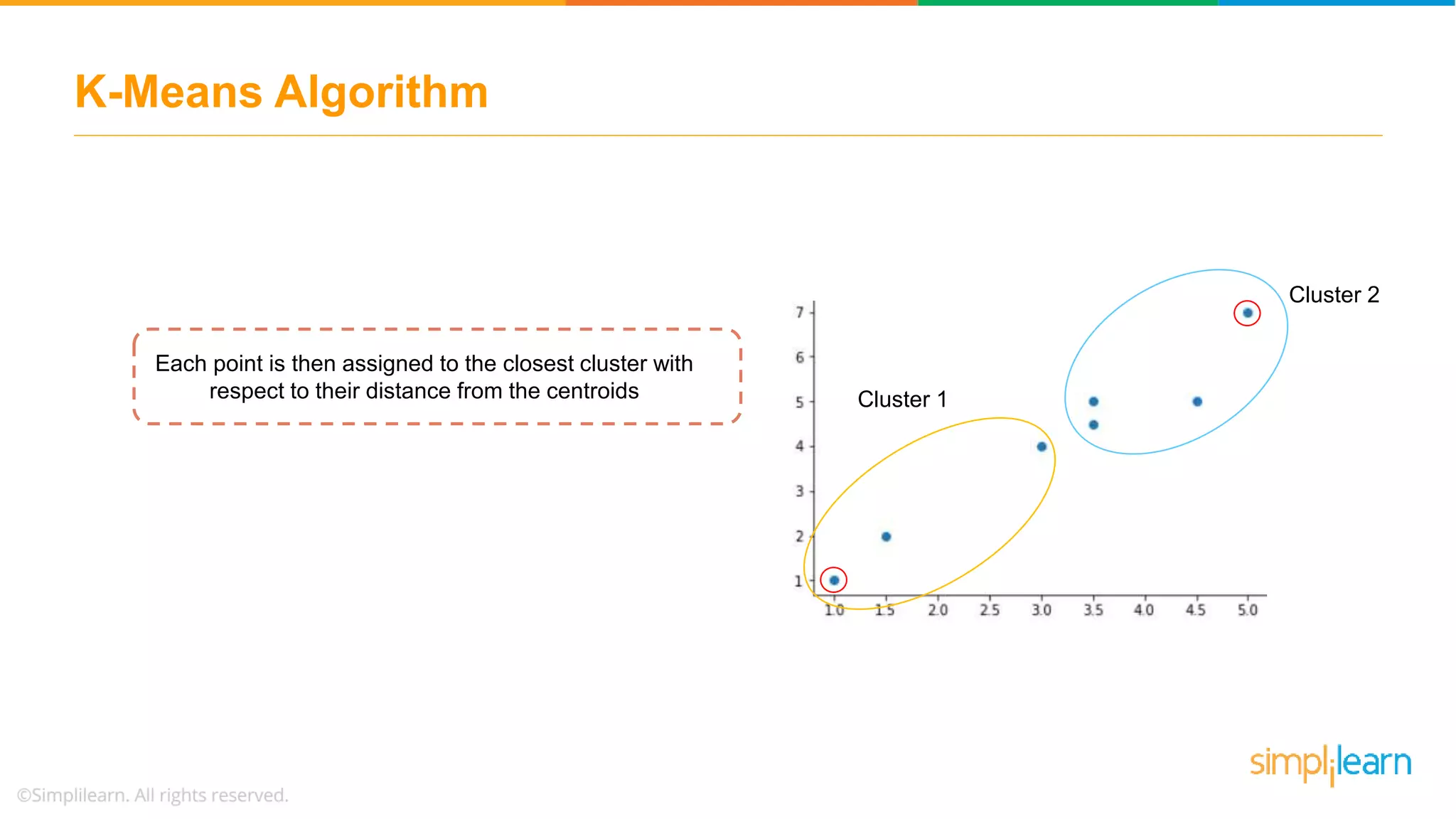
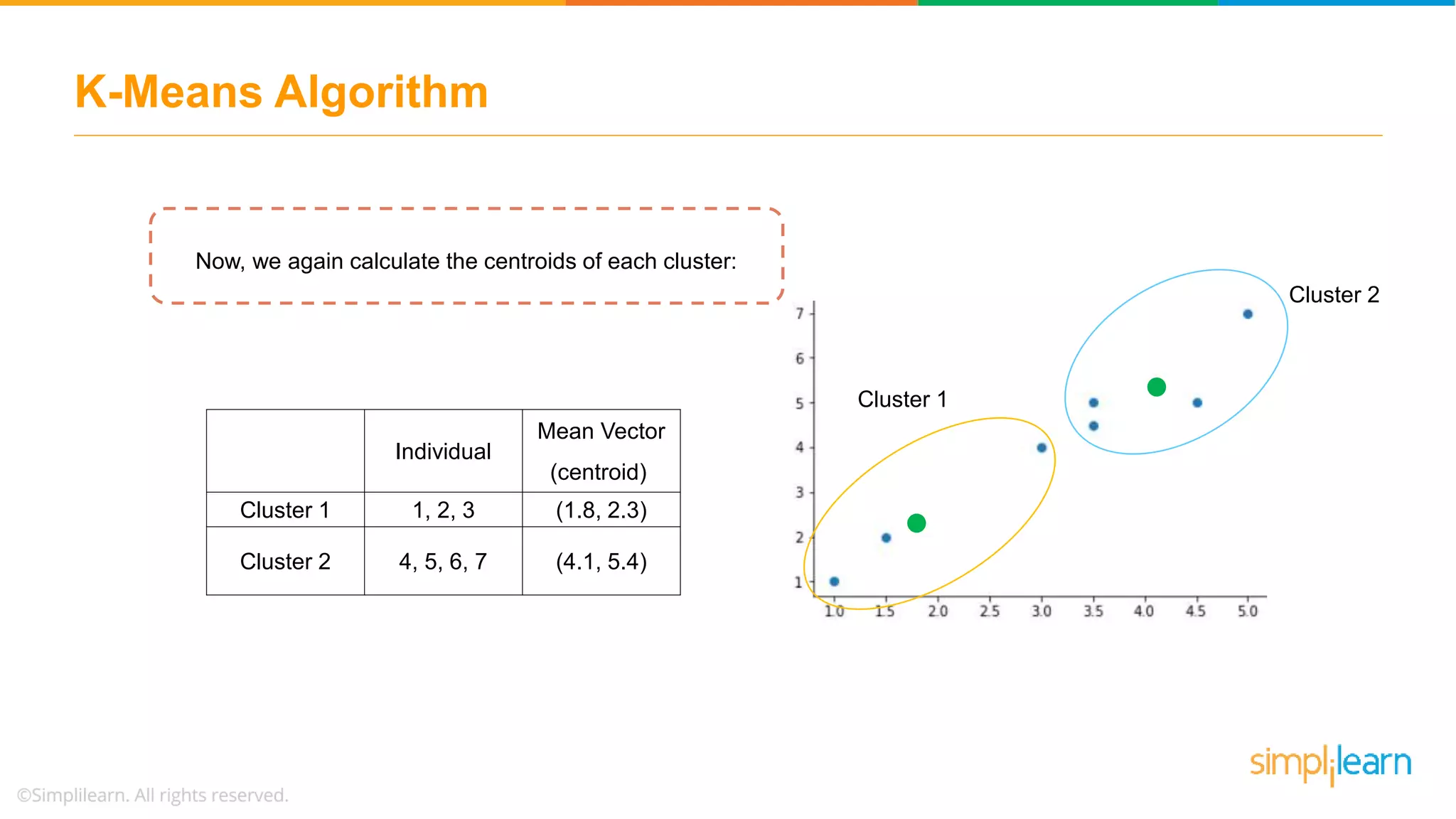
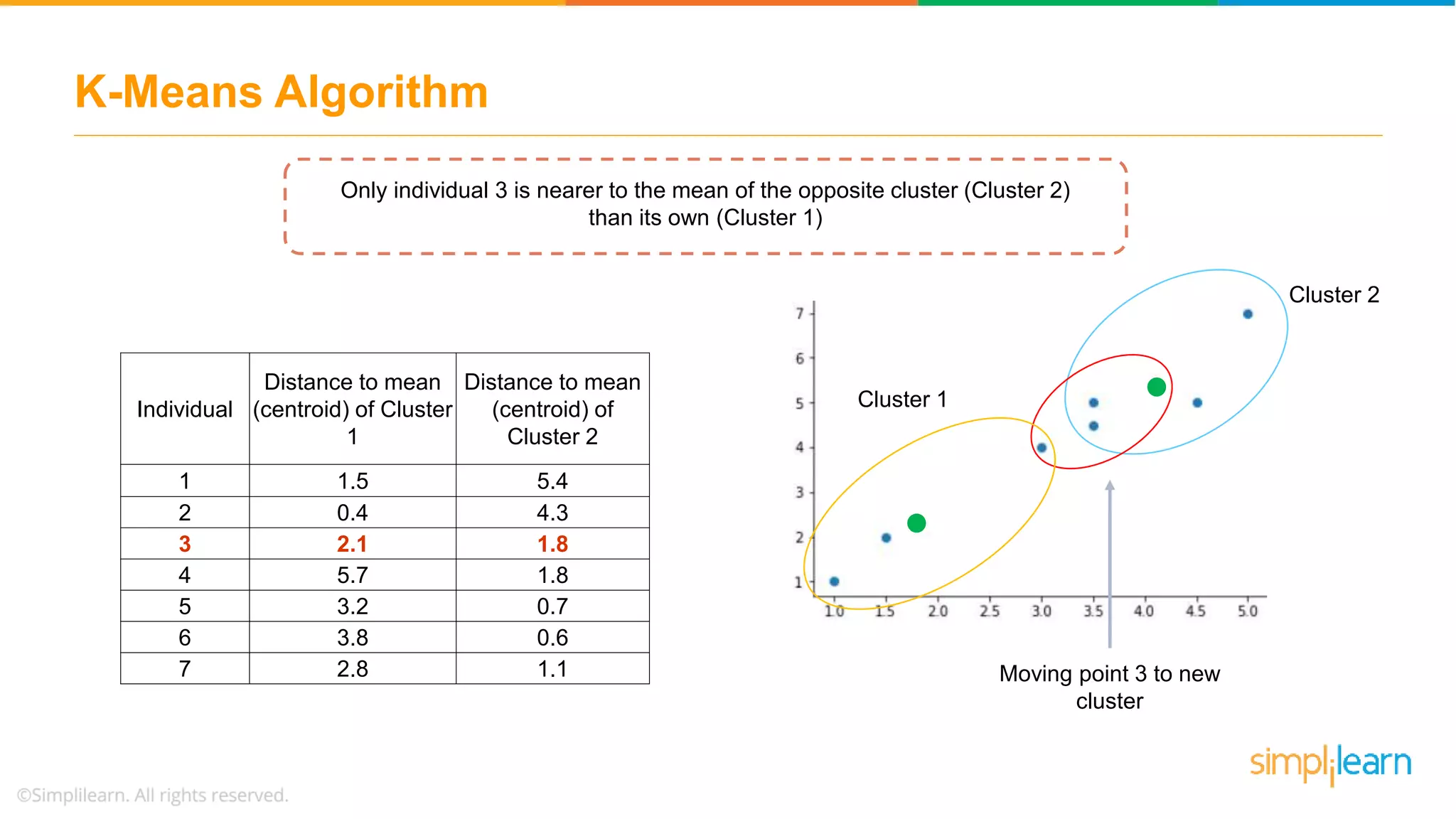
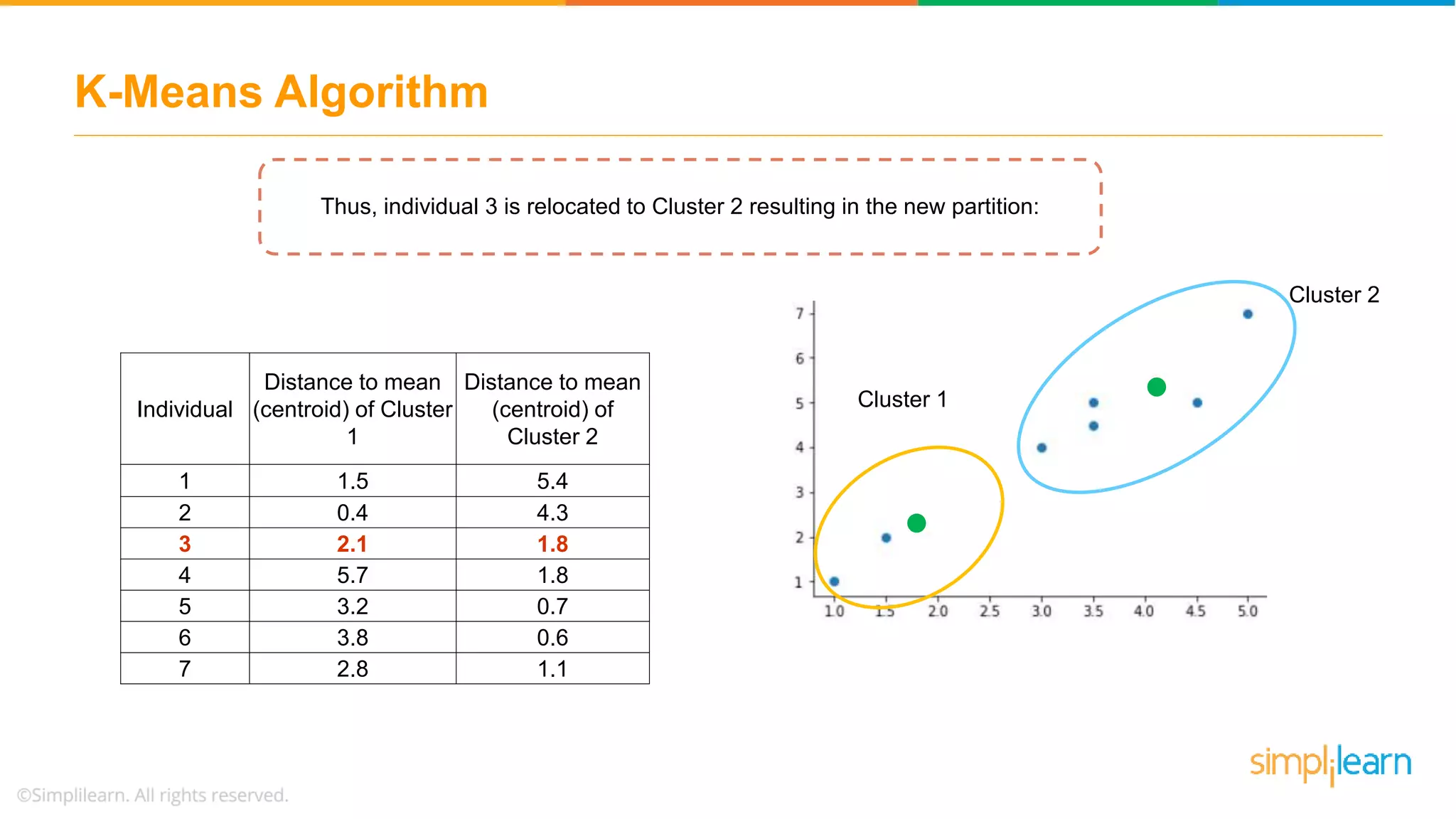
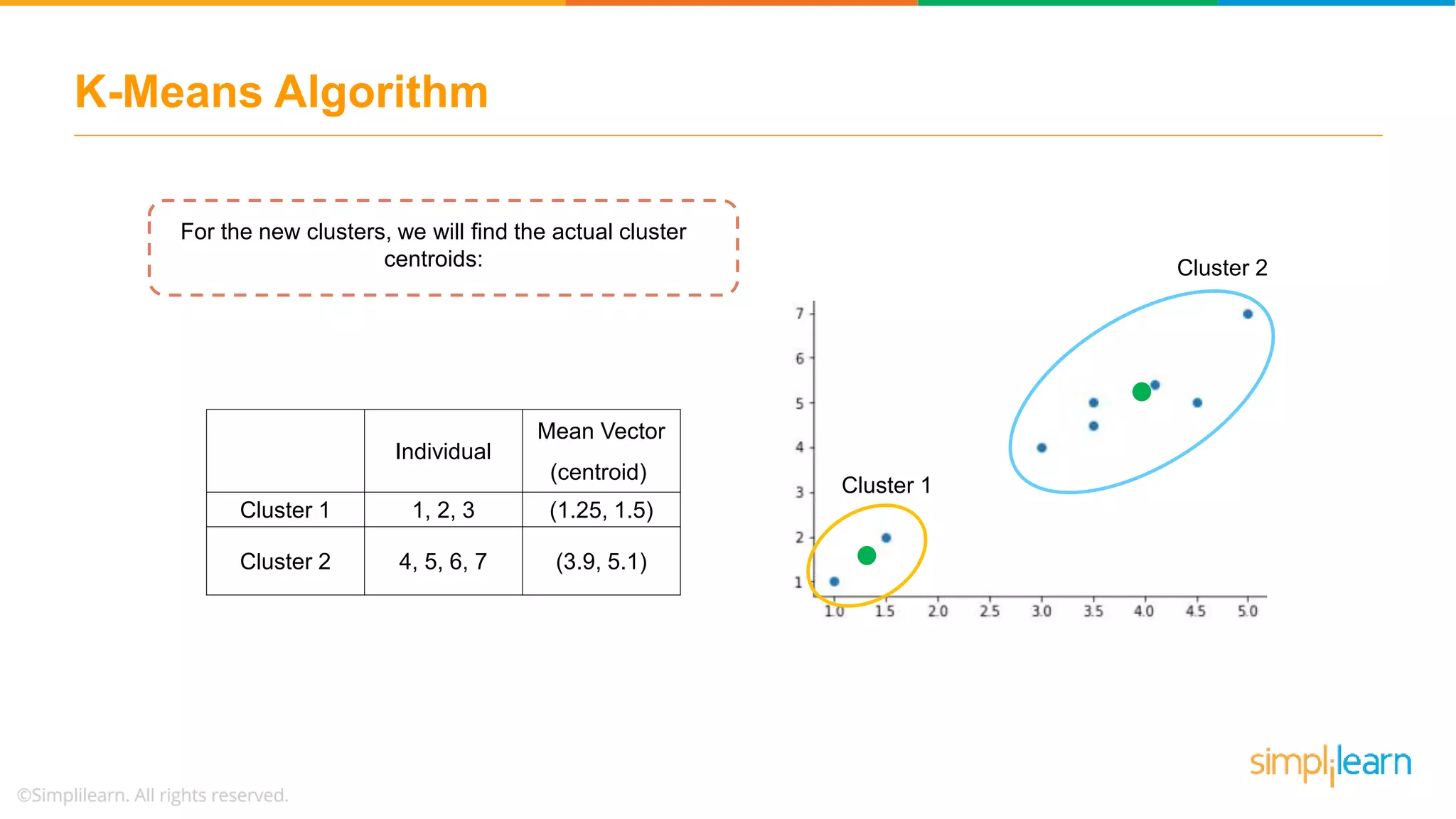
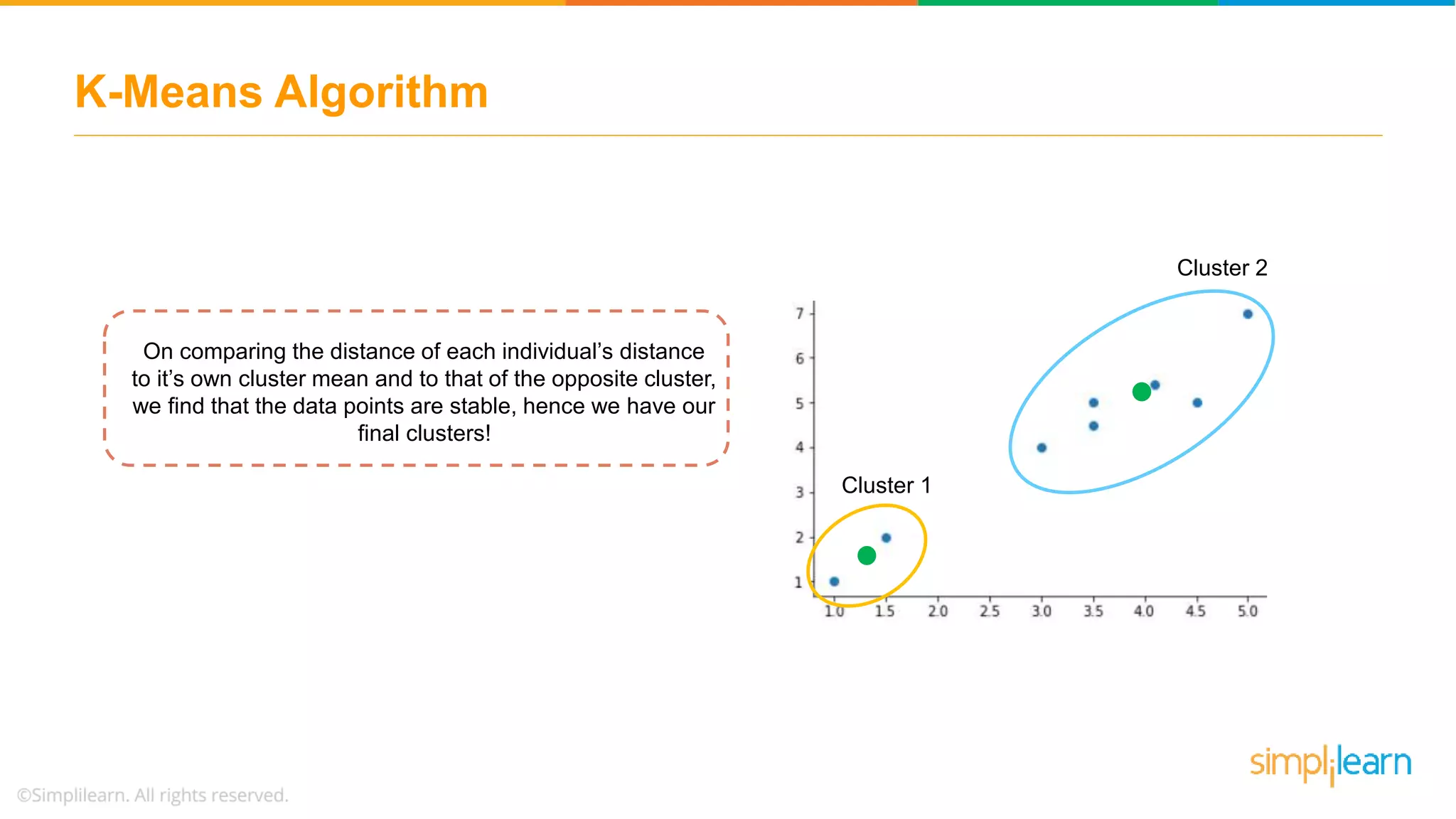
Describes how data points are assigned to clusters, centroid recalculations, and stabilizing clusters with final outputs.
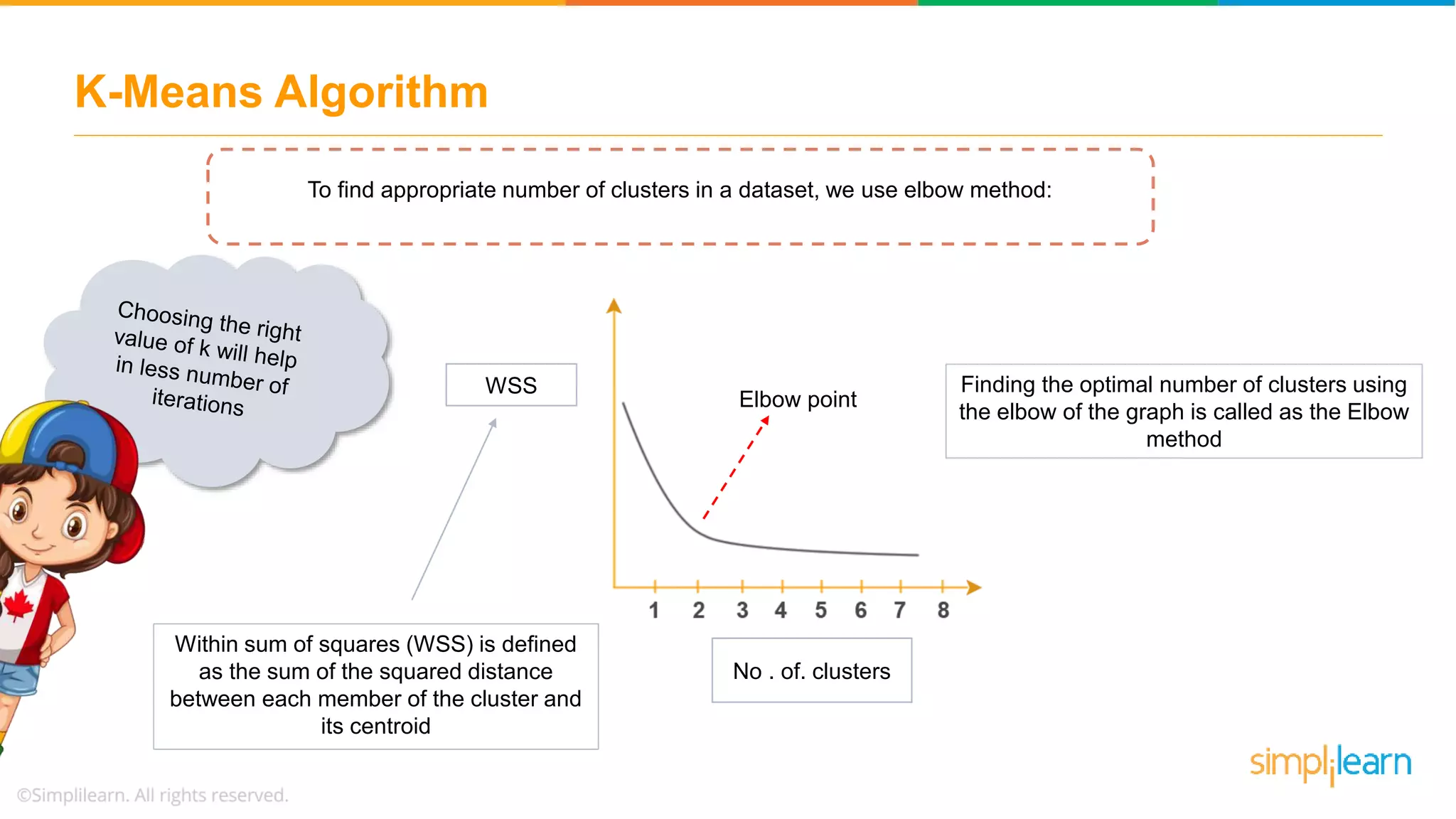
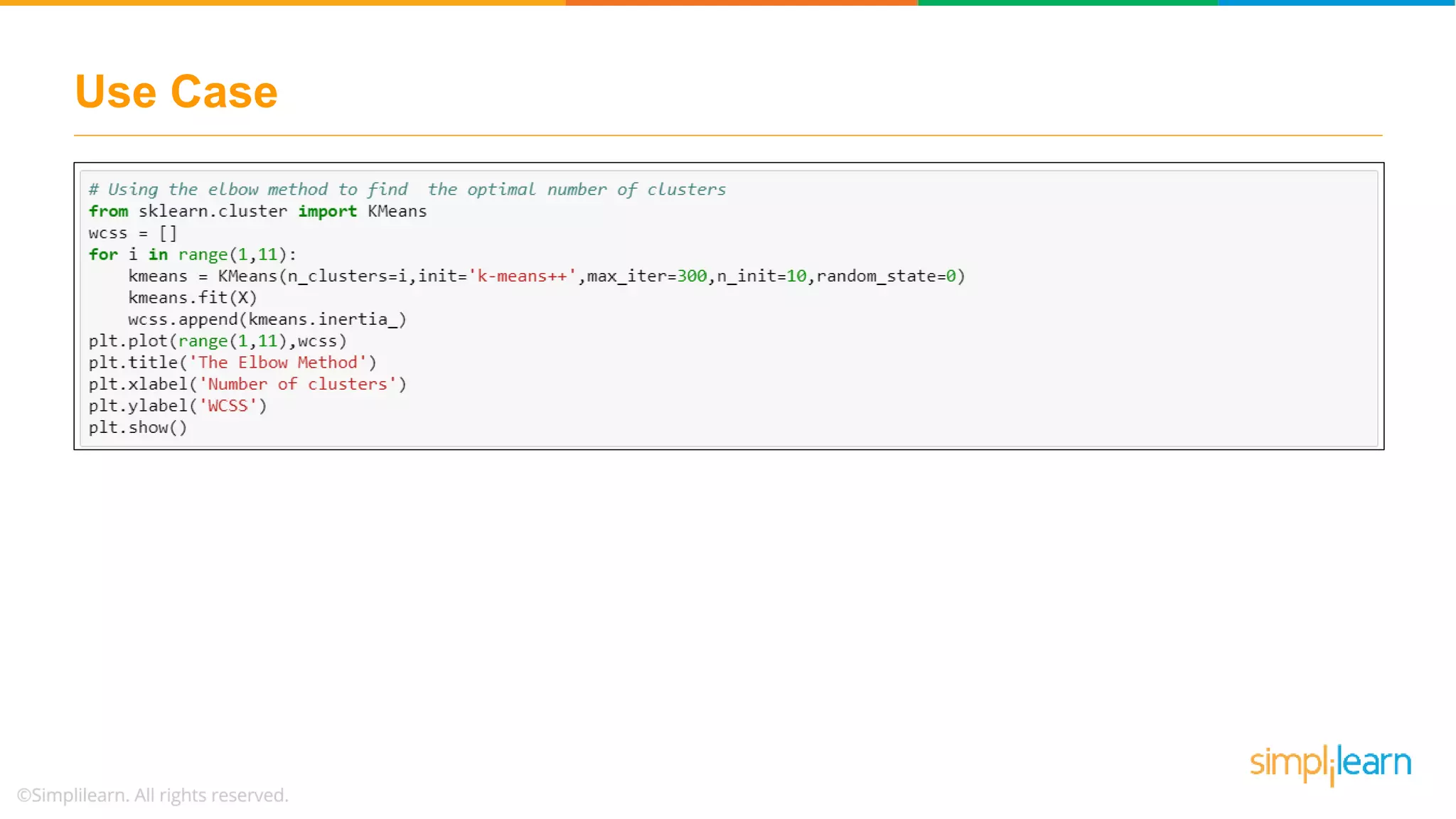
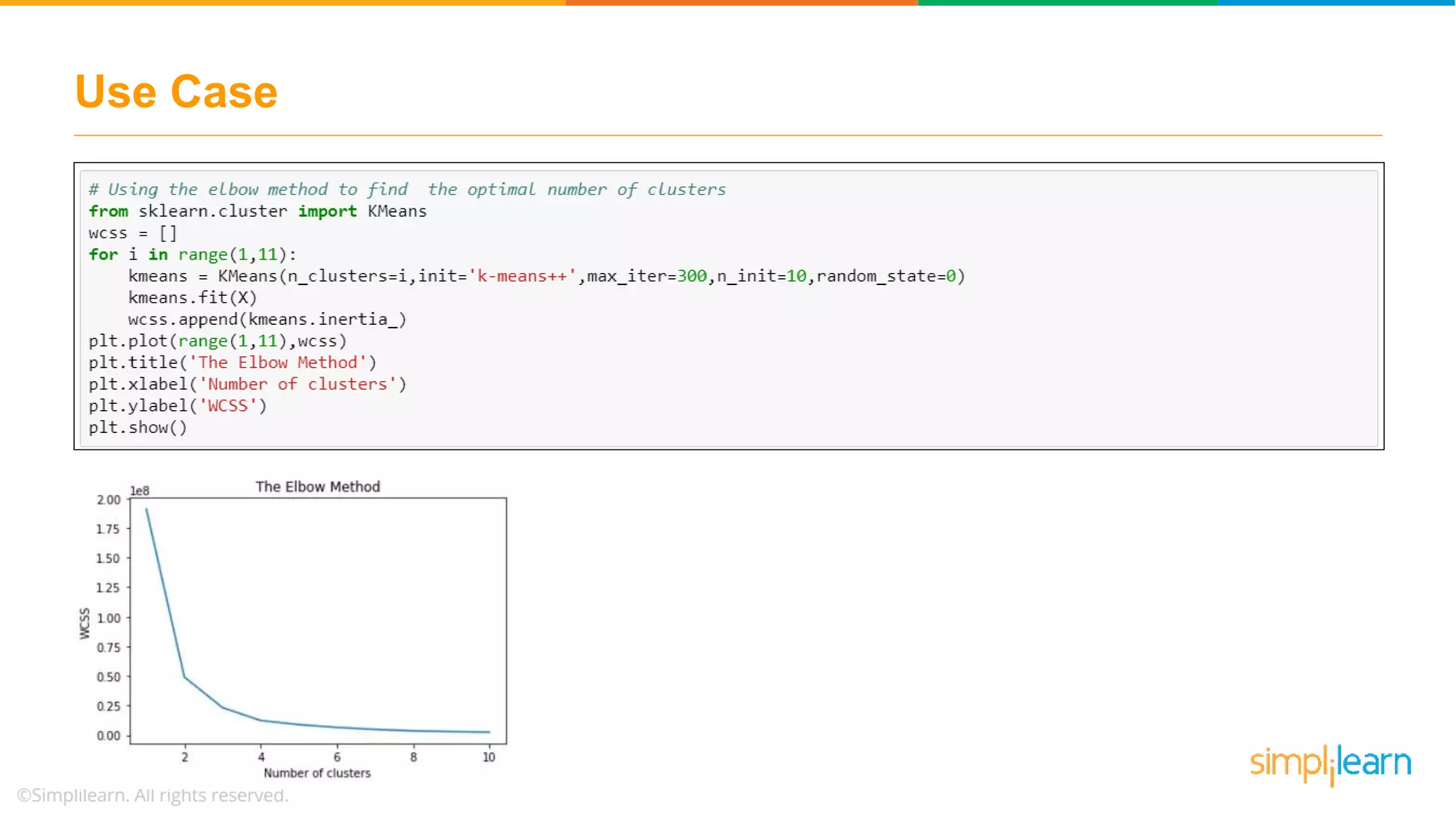
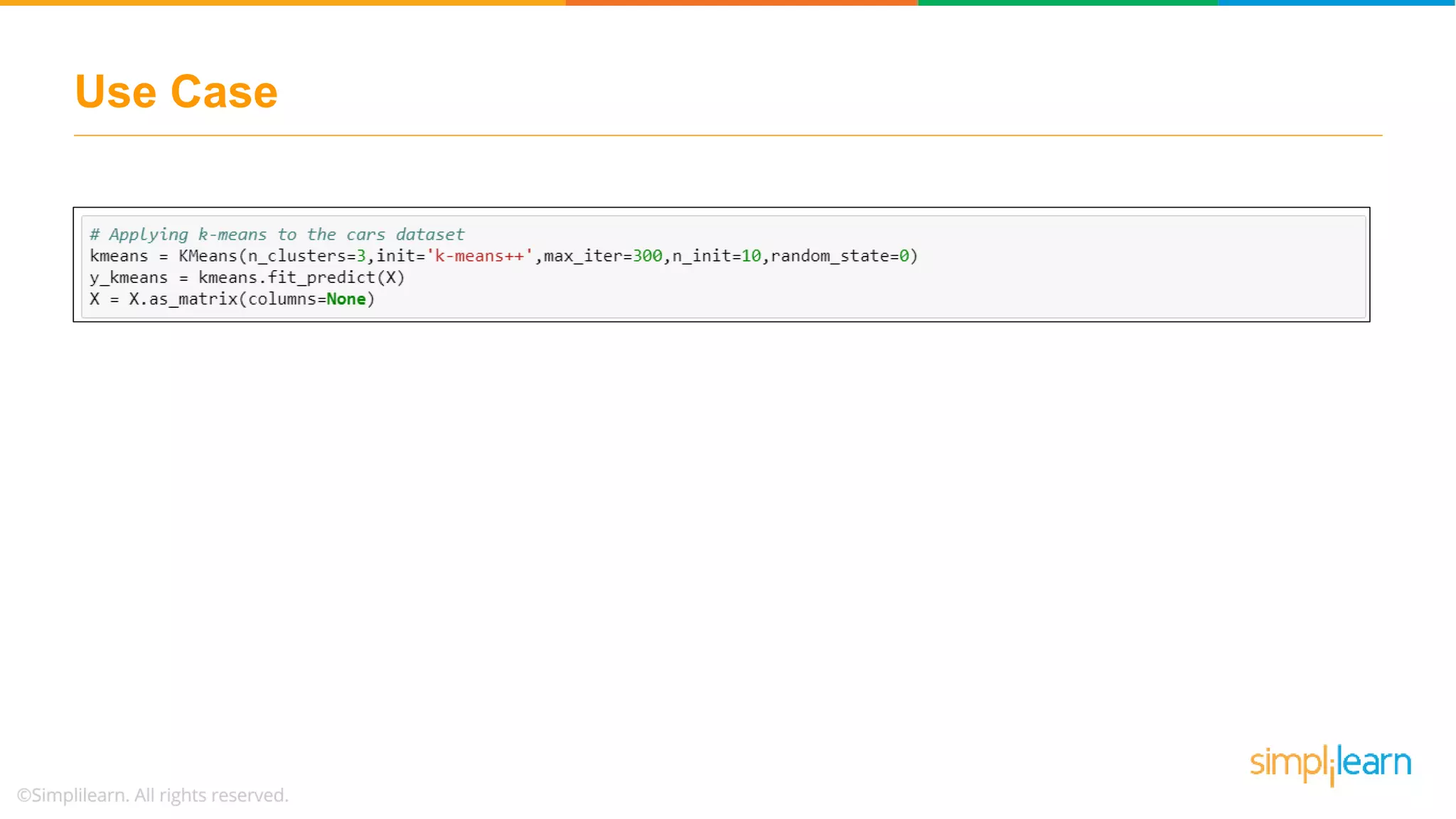
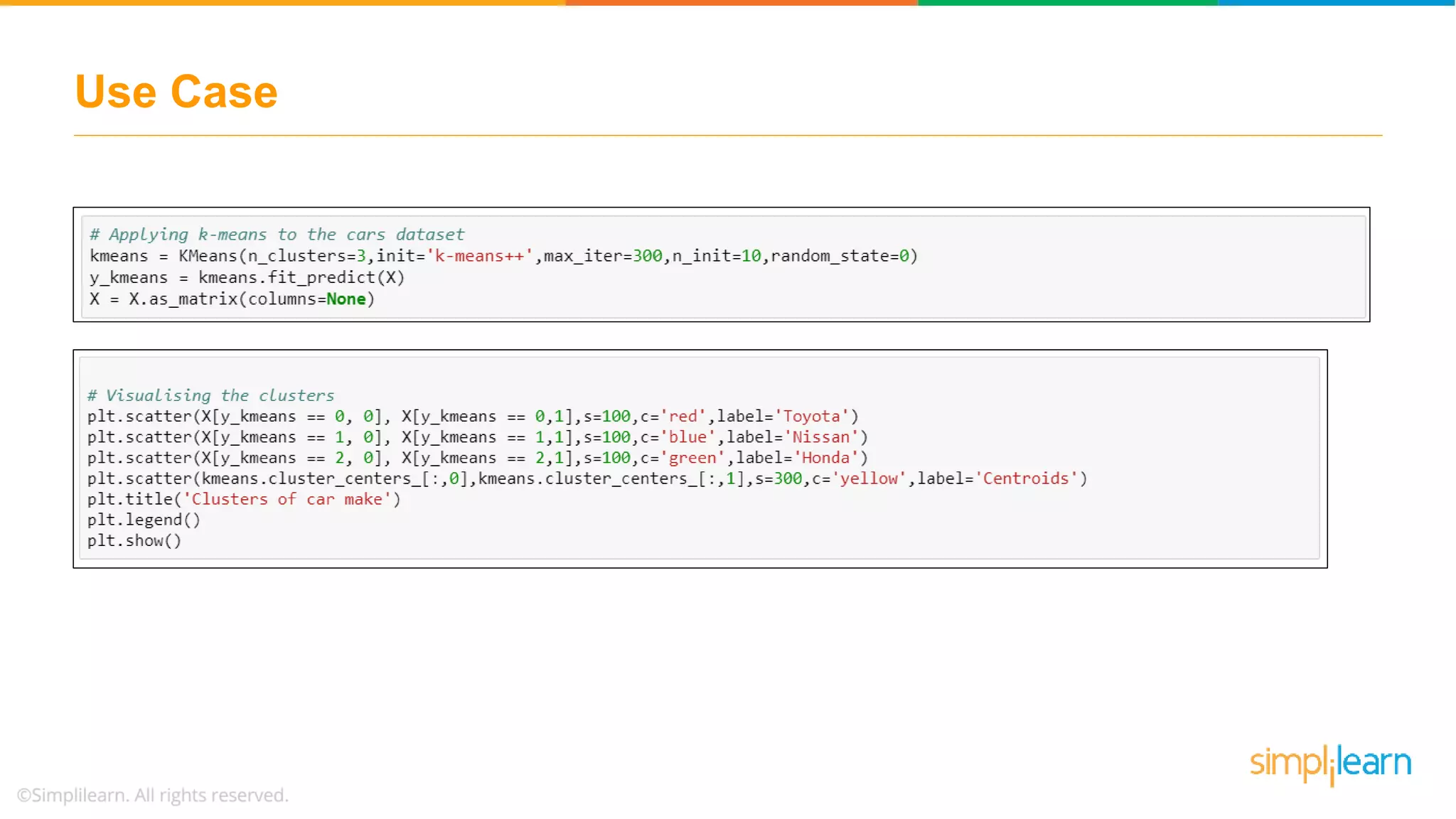
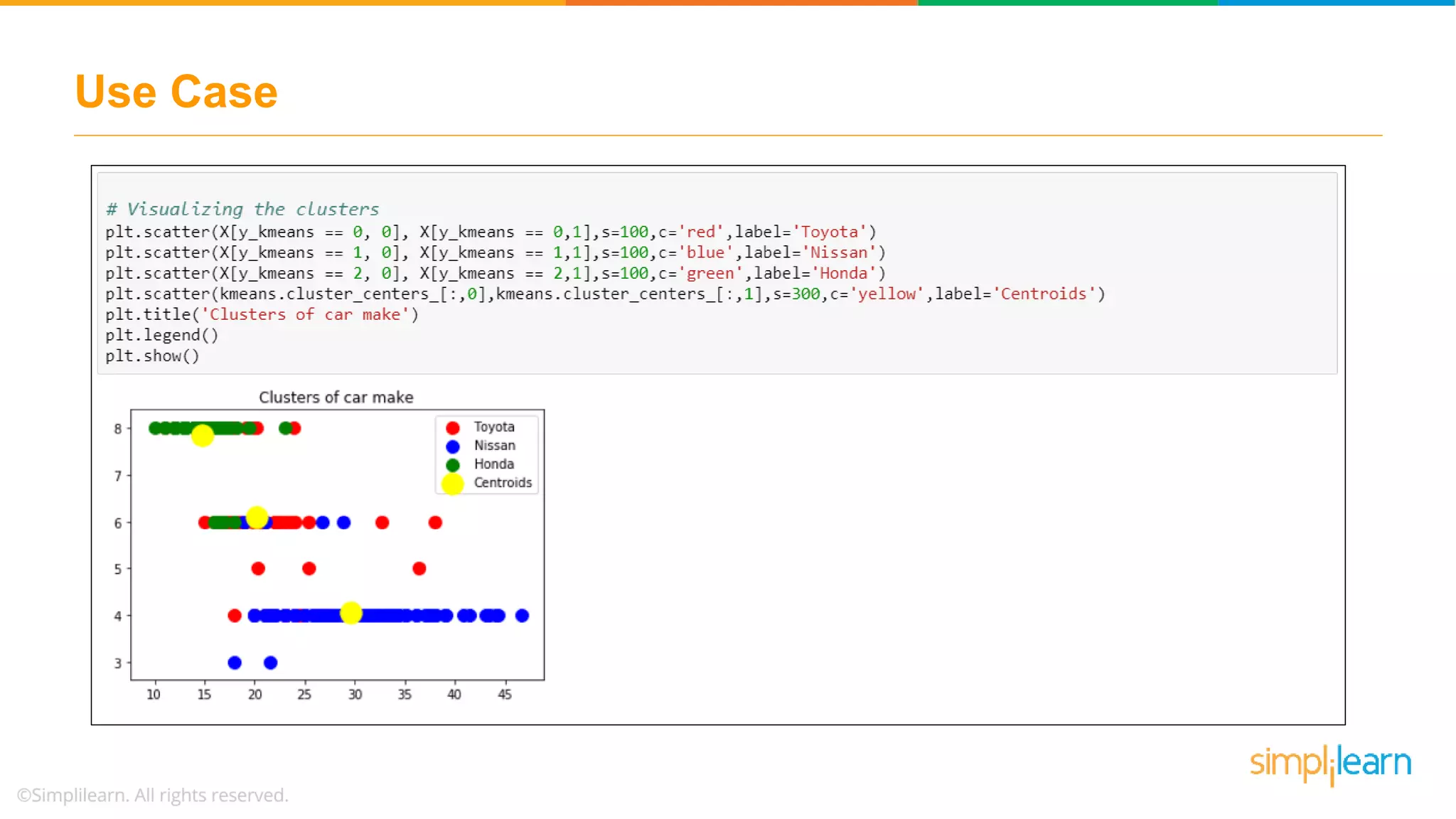
Discusses using the elbow method to select optimal clusters and provides a use case of K-Means clustering for car brands.
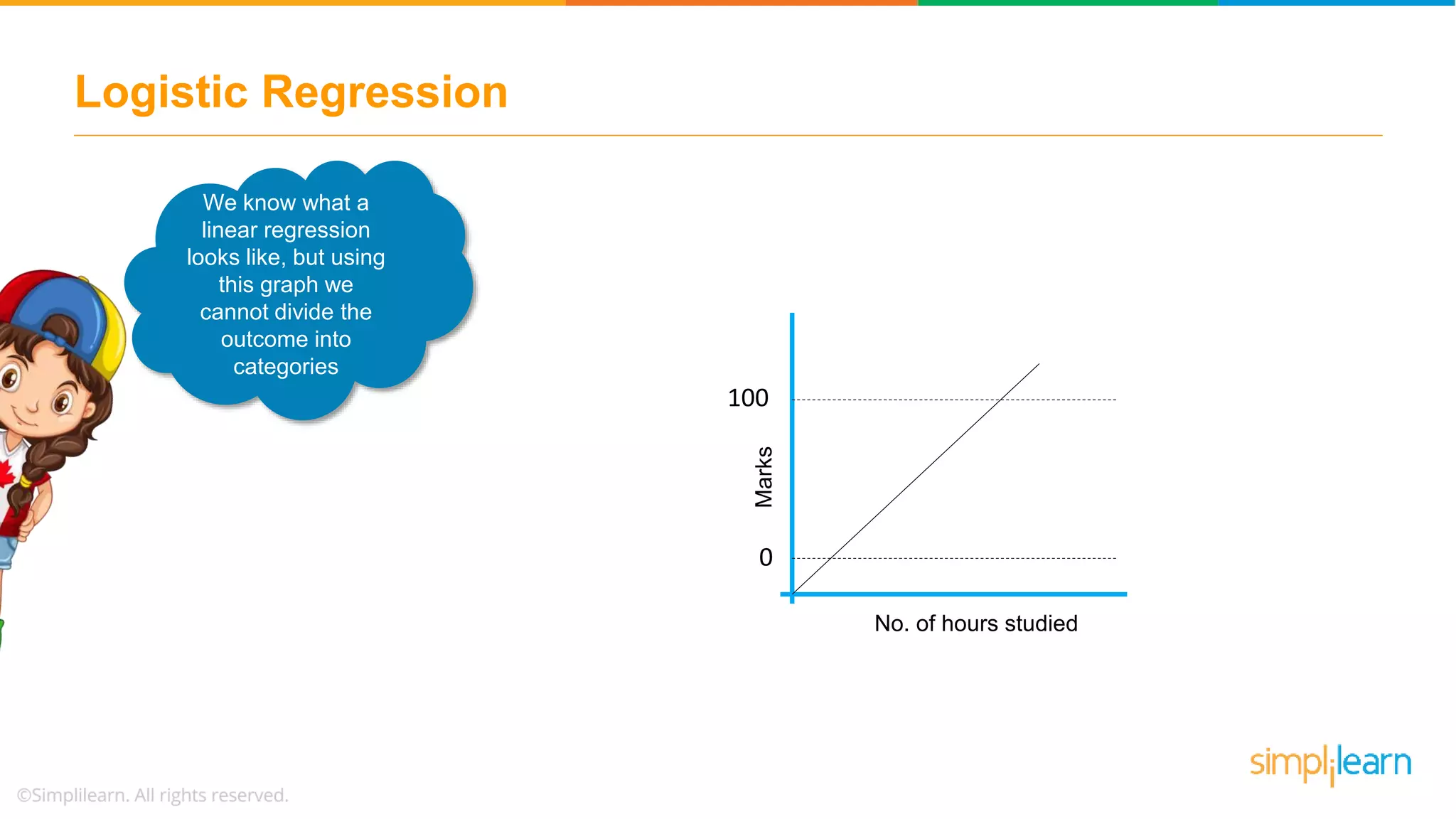
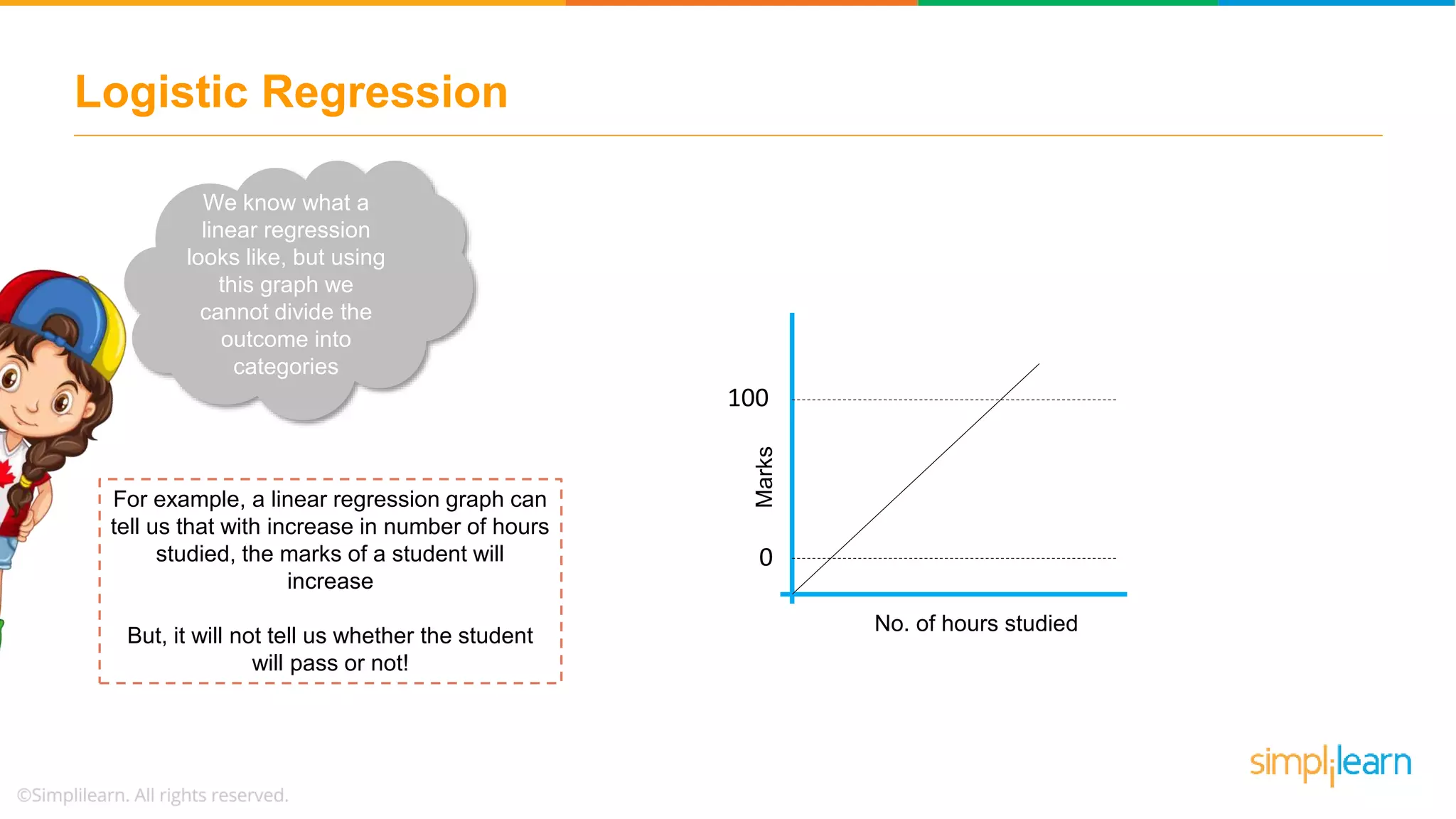
Begins the discussion on logistic regression, clarifying its purpose for classification problems and contrasting it with linear regression.
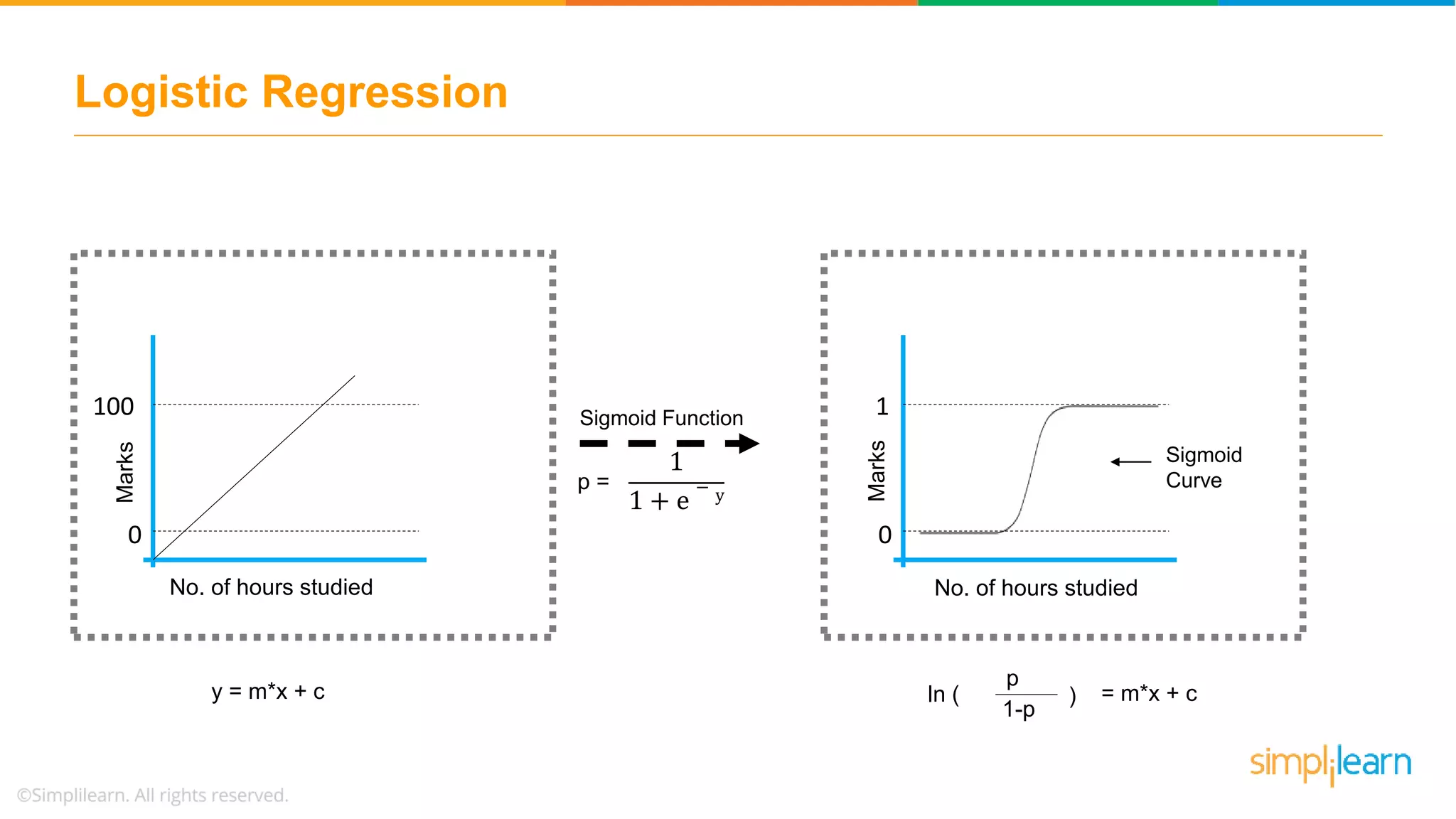
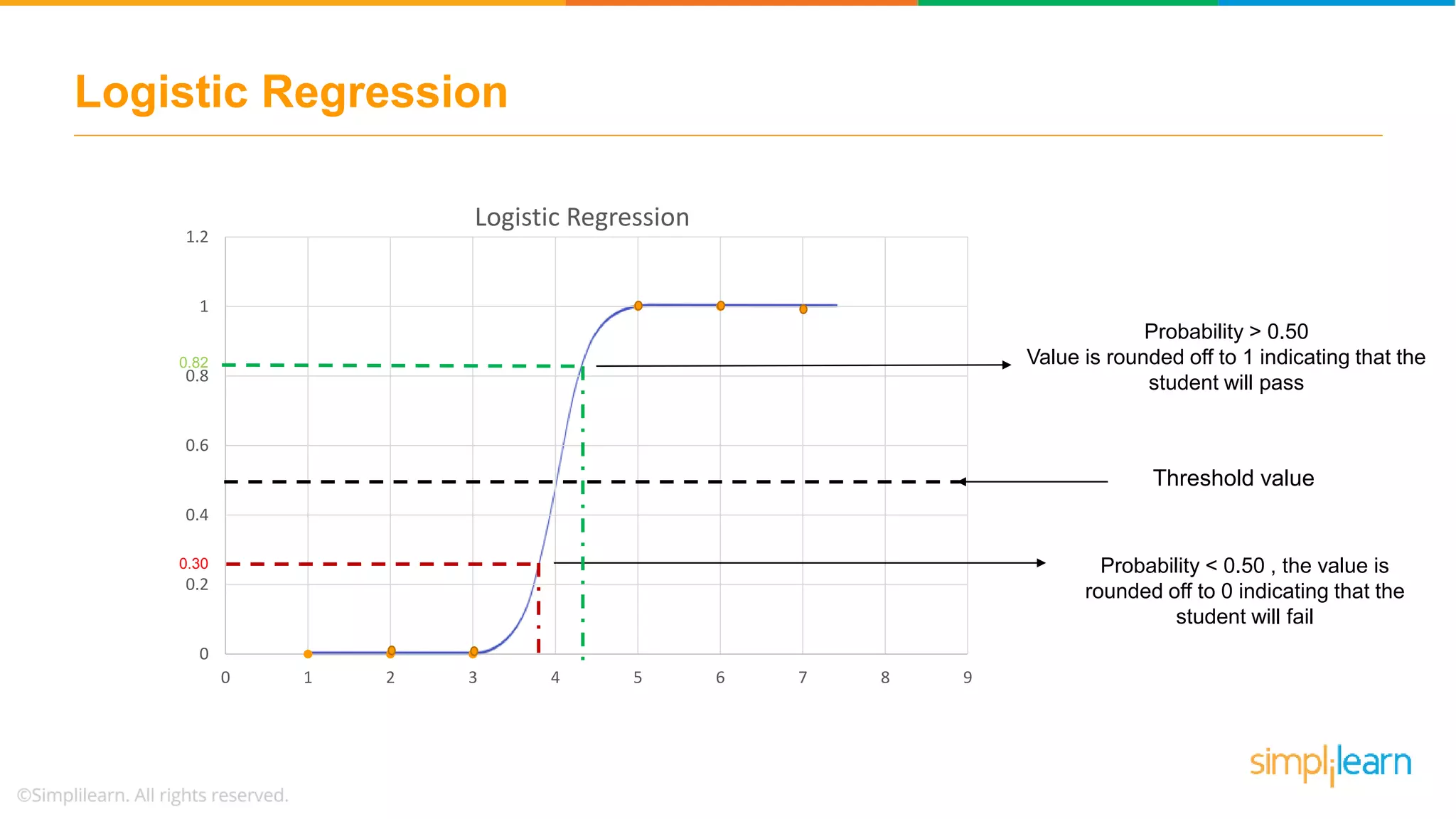
Explains why logistic regression is crucial for categorical outcomes and introduces the sigmoid function in the context of binary outcomes.
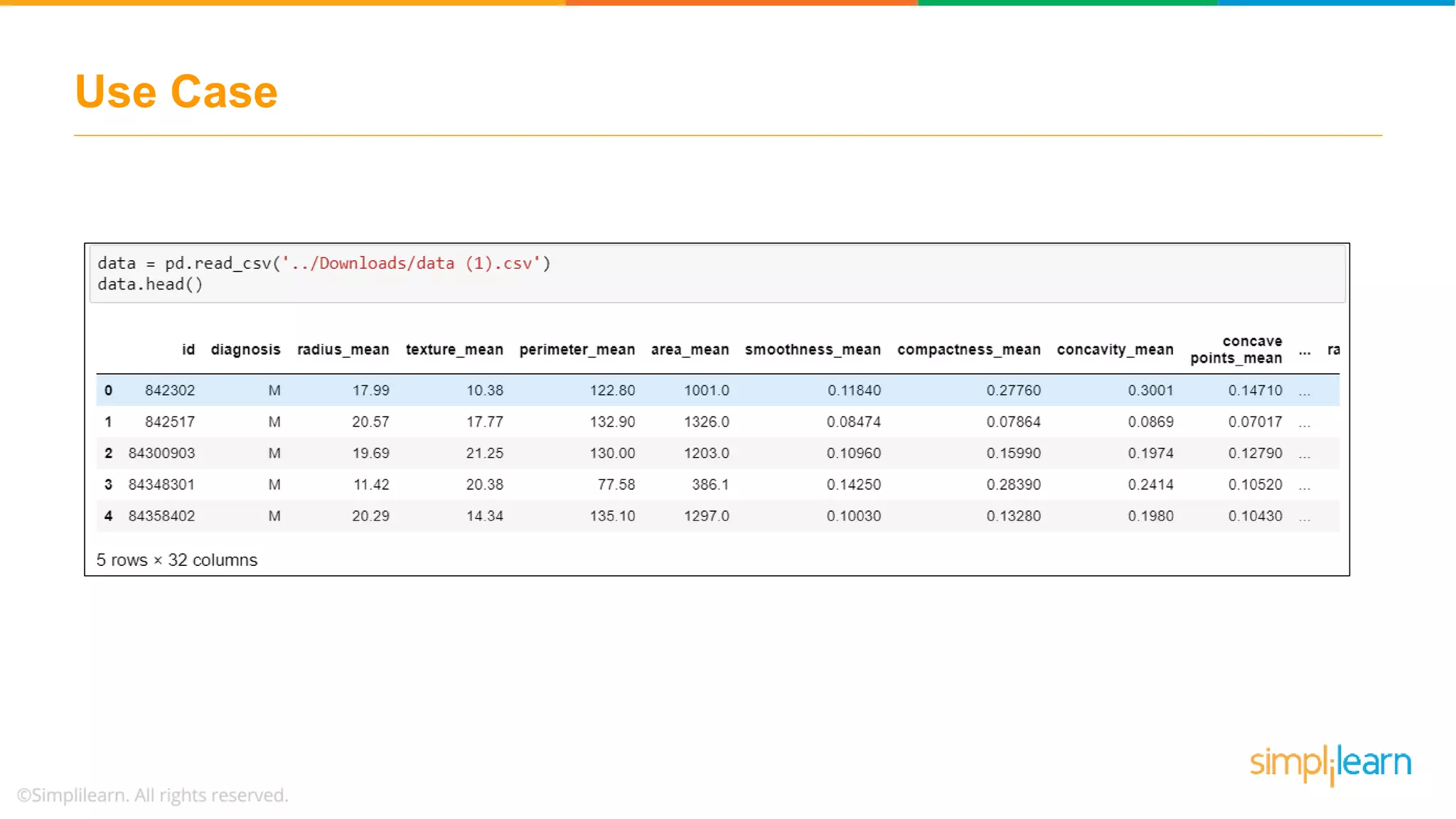
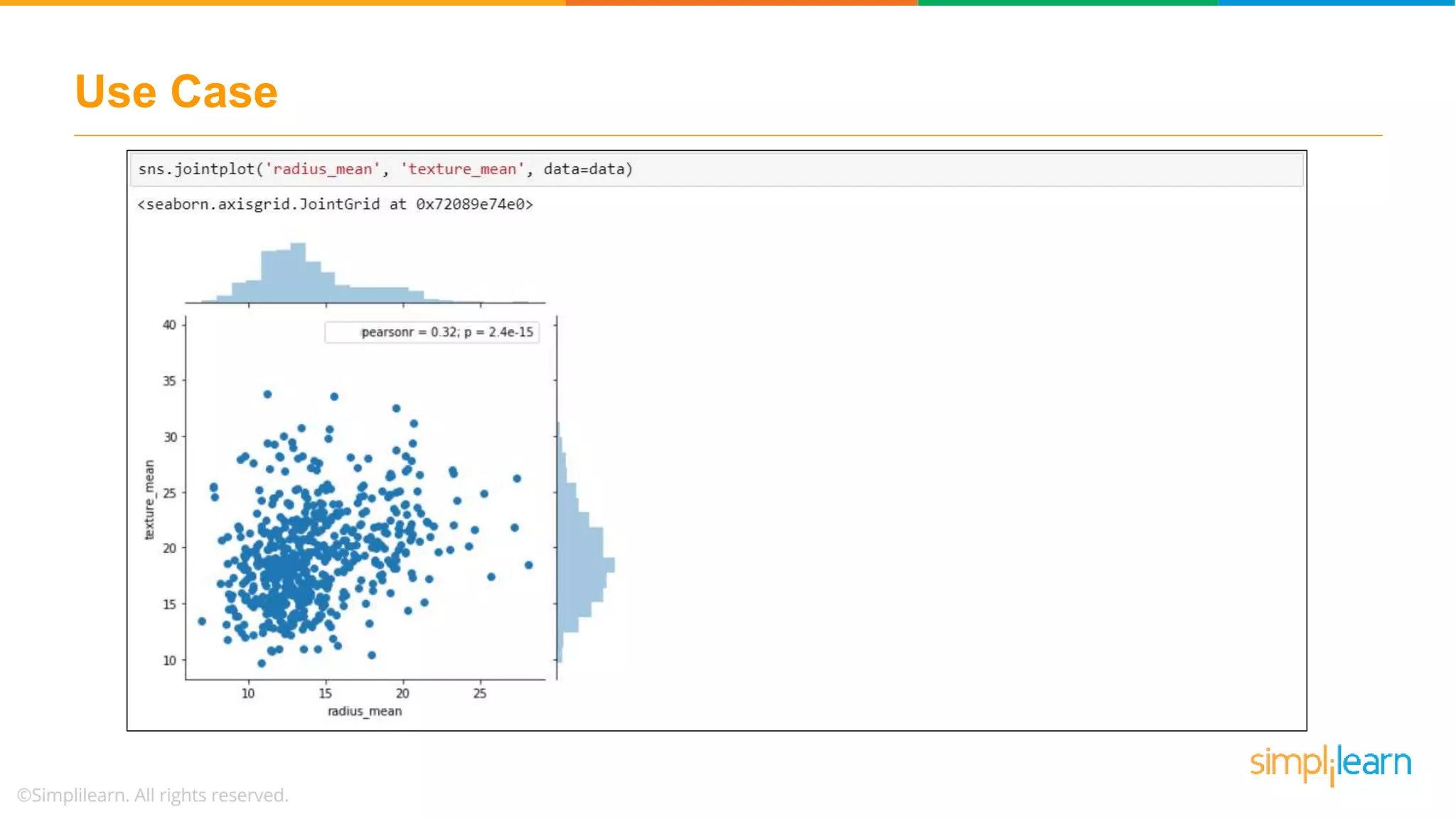
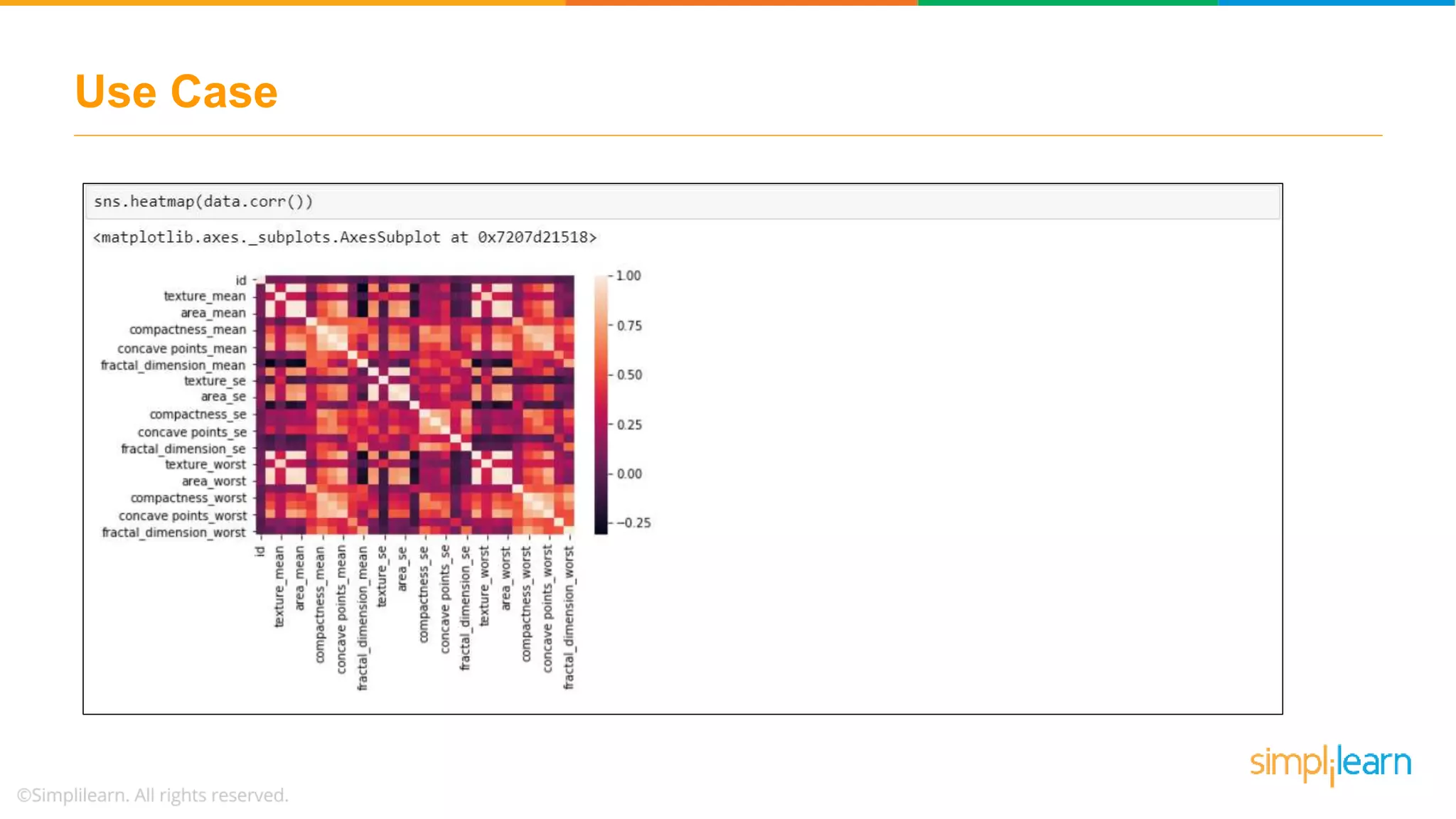
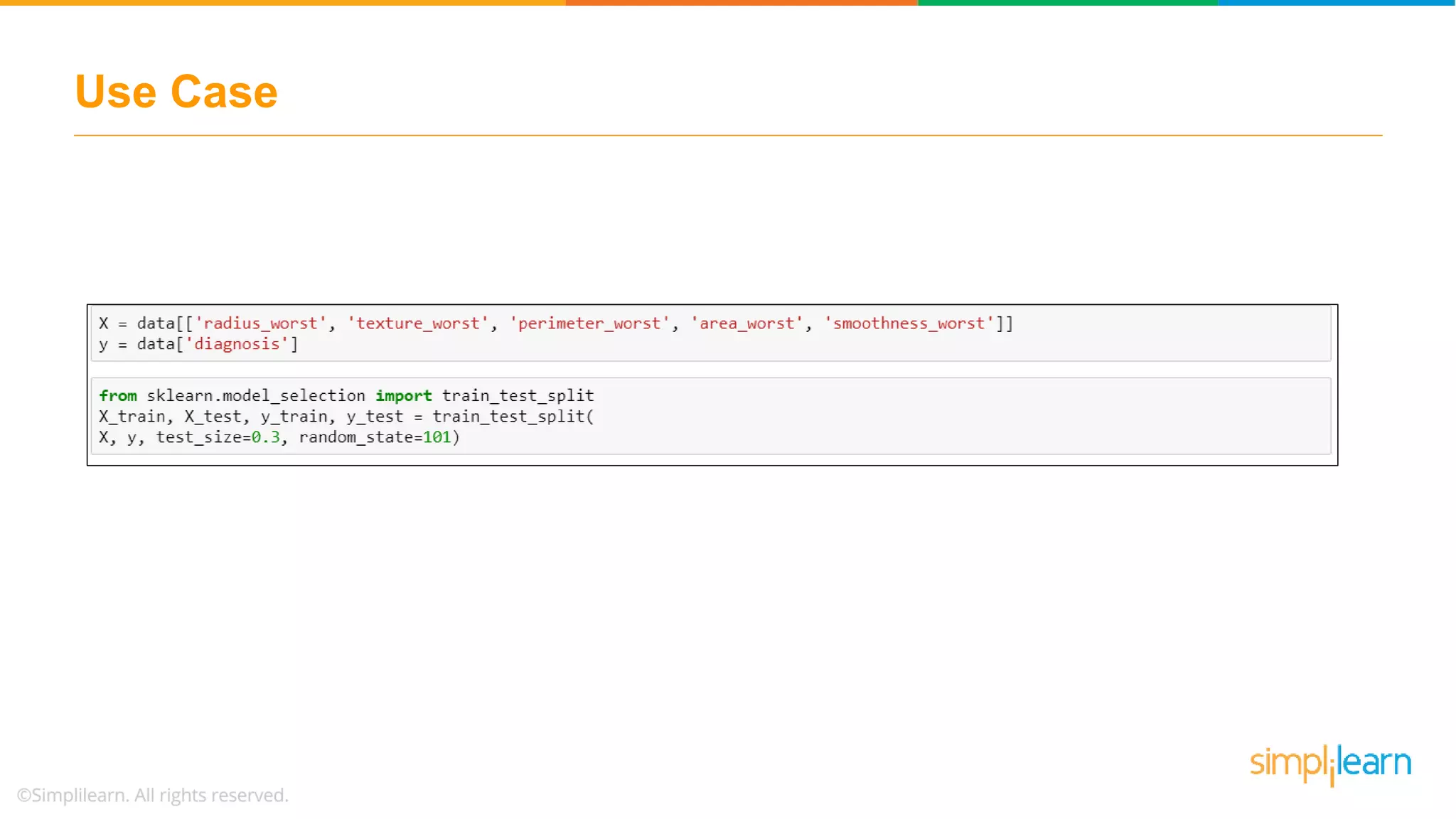
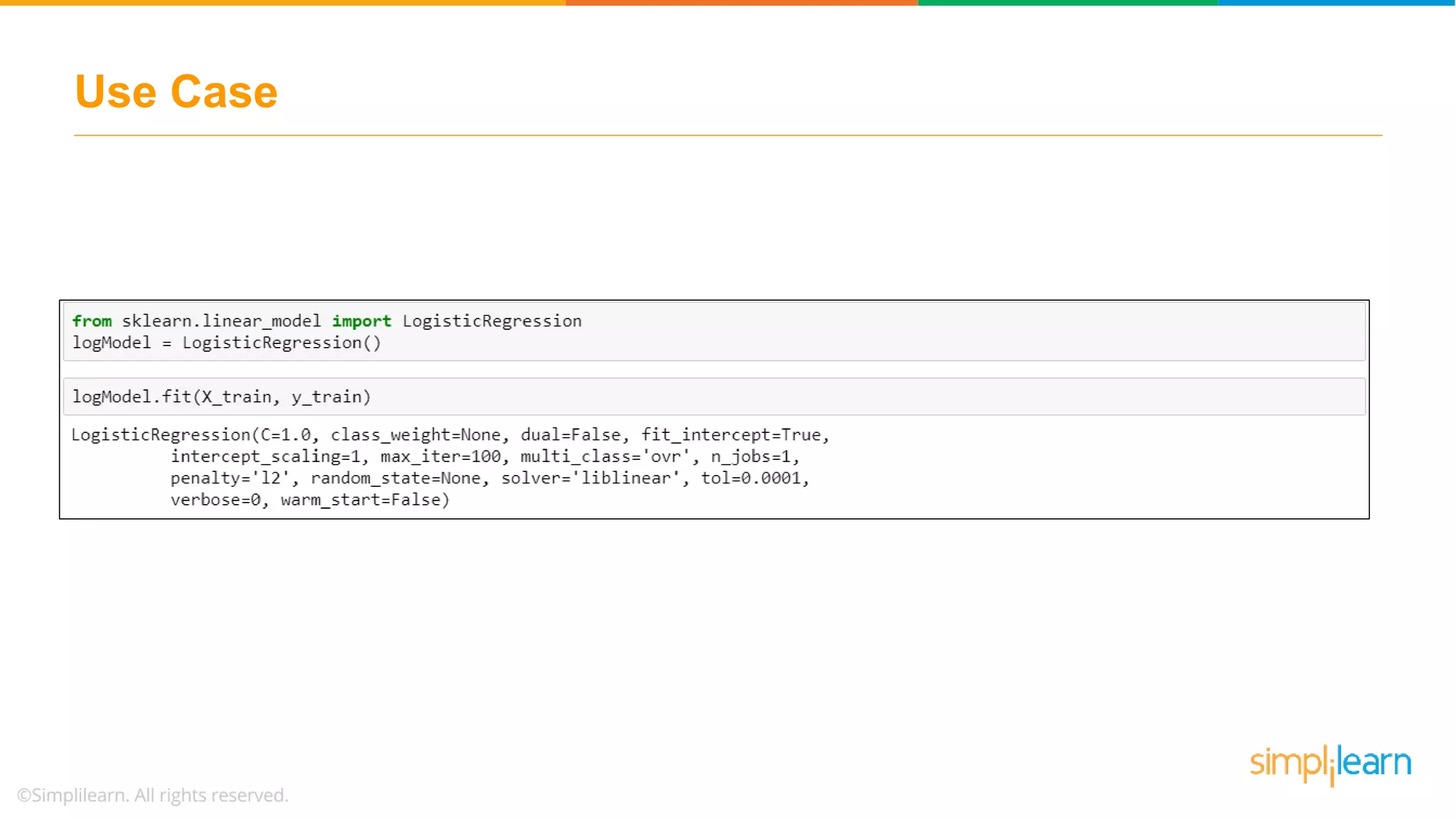
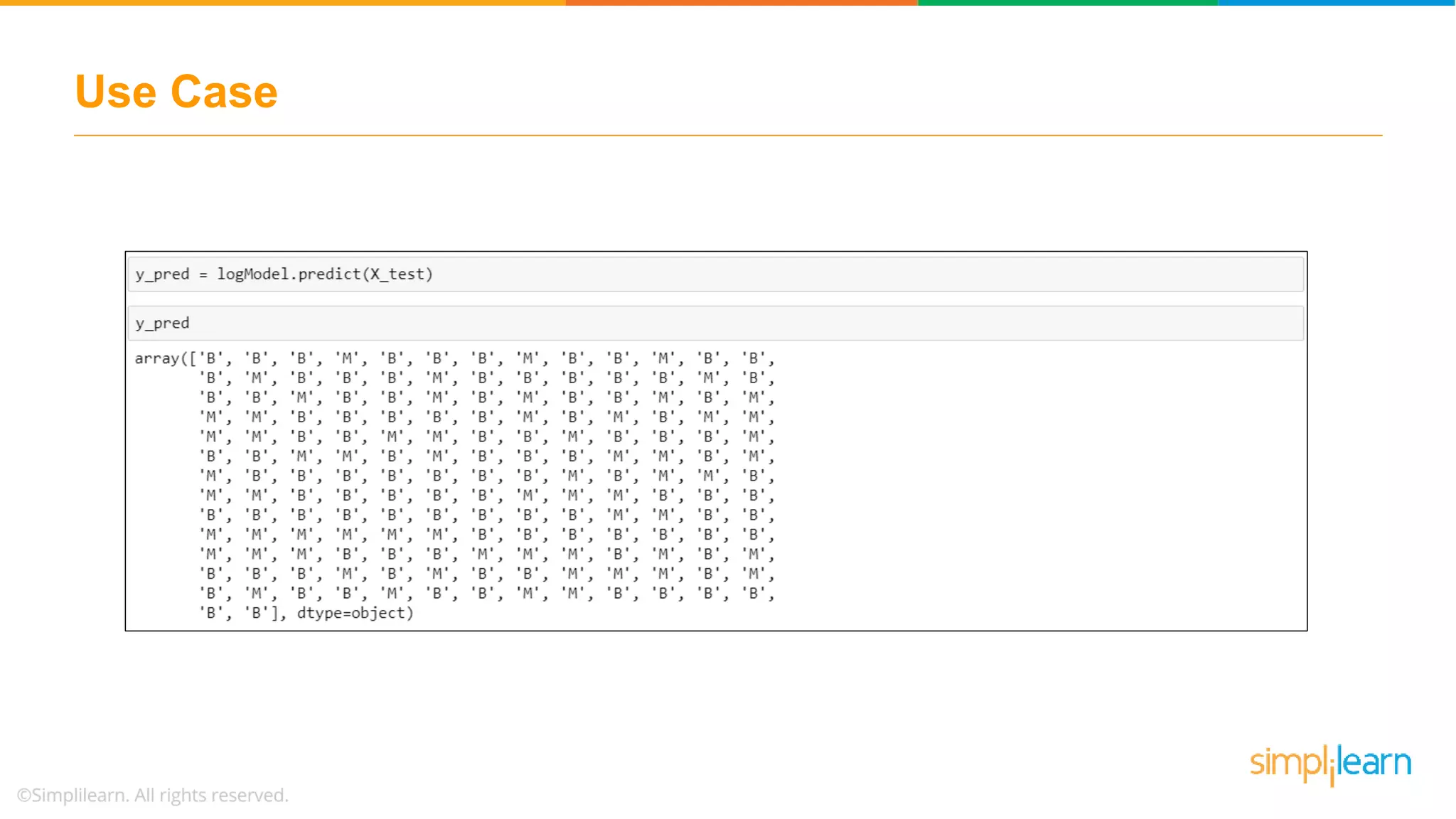
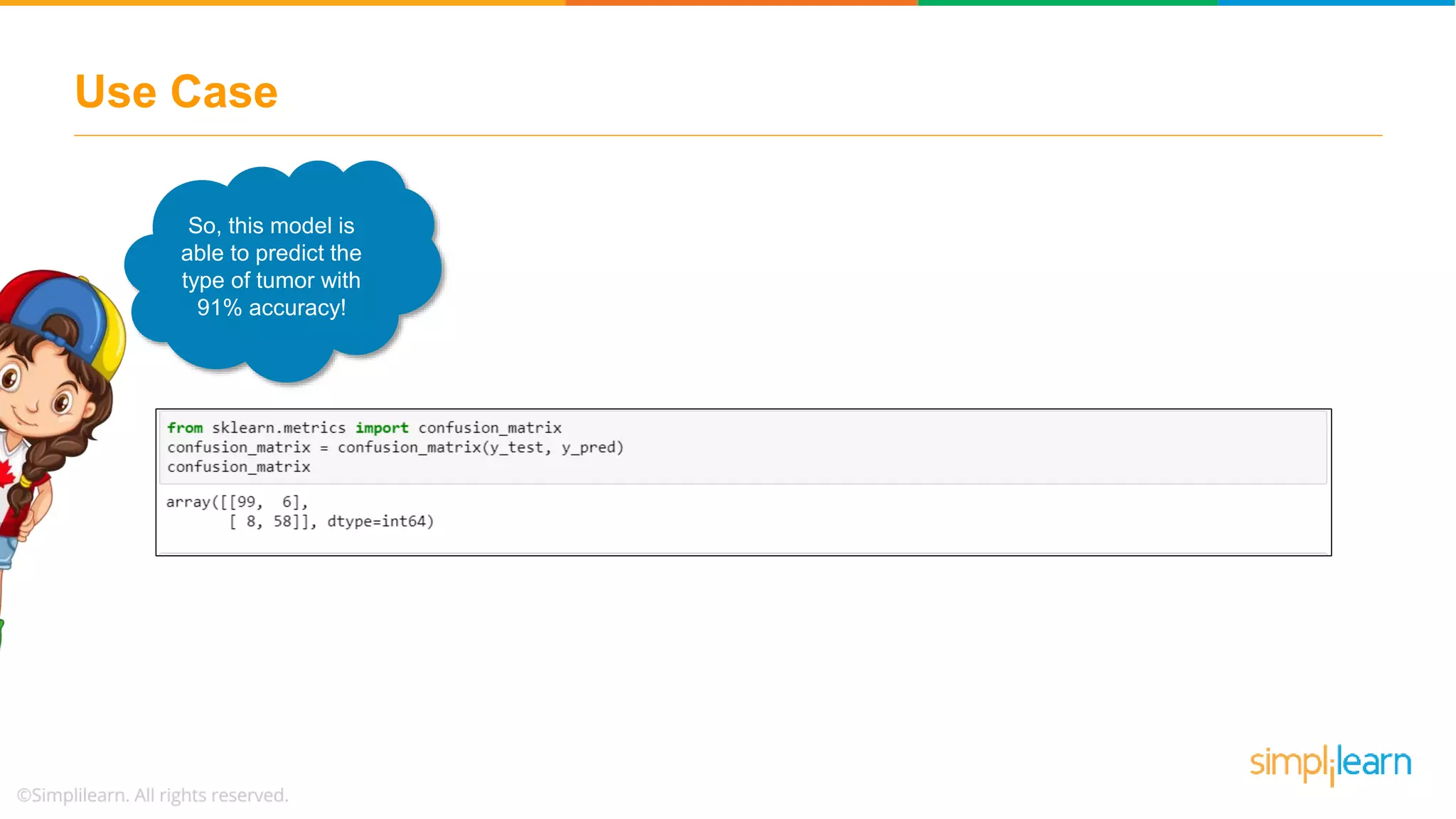
Illustrates a practical logistic regression use case for classifying tumors, achieving a prediction accuracy of 91%.
Explores the concept of data measures and dimensions, providing examples of clustering, classification, and regression use cases.
Summarizes the K-Means elbow method for clustering cars and logistic regression for tumor classification.























































































