INTRODUCTION-
What is clustering?
Clustering is the Classification of objects into
different groups, or more precisely, the
partitioning a data set into subset (clusters),
so that the data in each subset (ideally) share
some common trait - often according to some
defined distance measure
4.
K-MEANS CLUSTERING
Thek-means algorithm is an algorithm to cluster
n objects based on attributes into k patitions,
where k < n.
It assumes that the object attributes form a vector
space.
5.
An algorithmfor partitioning (or clustering) N
data points into K disjoint subsets Sj
containing data points so as to minimize the
sum-of-squares criterion
where xn is a vector representing the the nth
data point and uj is the geometric centroid of
the data points in Sj.
6.
Simply speakingk-means clustering is an
algorithm to classify or to group the objects
based on attributes/features into K number of
group.
K is positive integer number.
The grouping is done by minimizing the sum
of squares of distances between data and the
corresponding cluster centroid.
Simplify K-means:
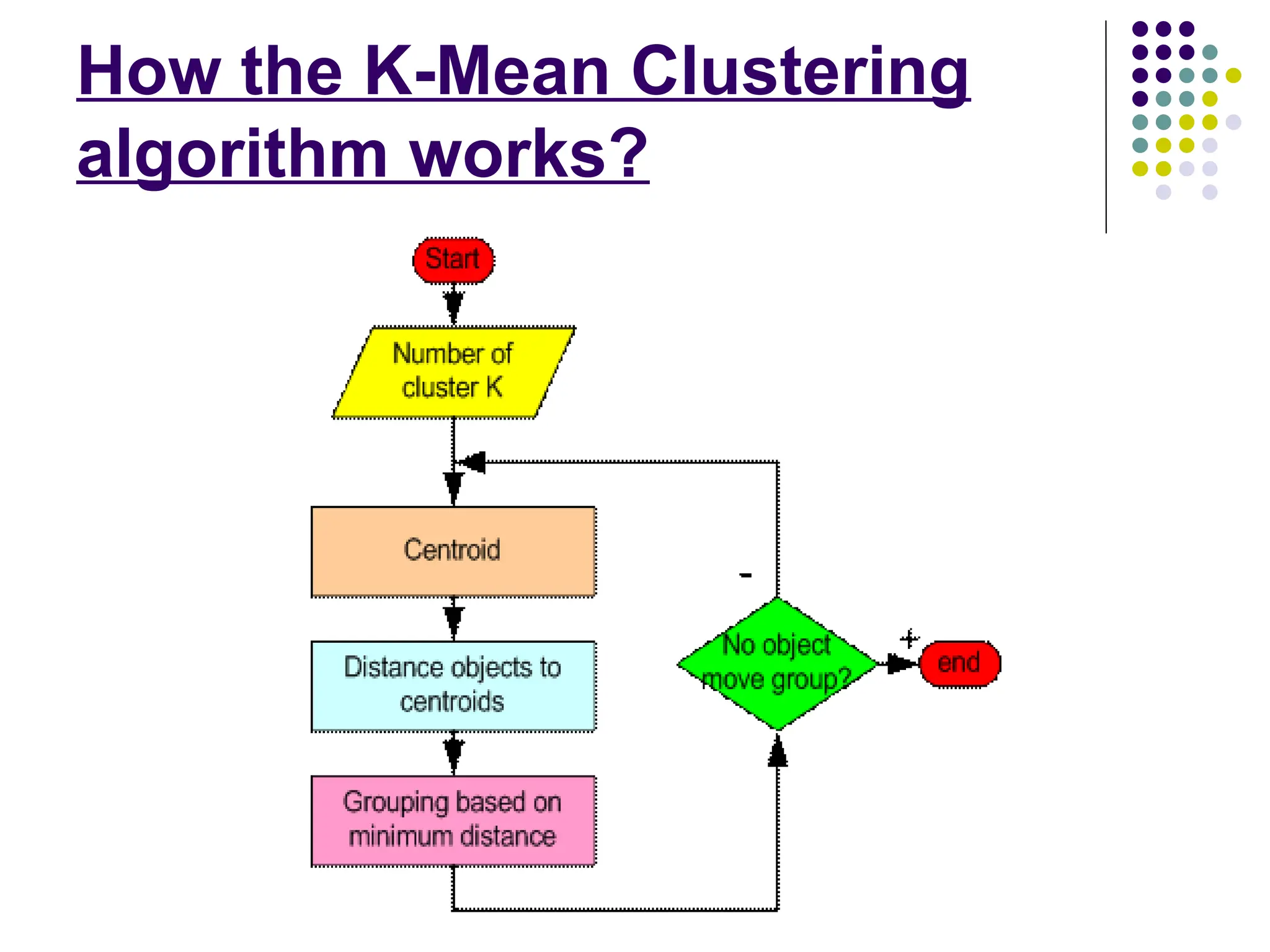
Step 1:Begin with a decision on the value of k =
number of clusters .
Step 2: Put any initial partition that classifies the
data into k clusters. You may assign the
training samples randomly,or systematically
as the following:
1.Take the first k training sample as single-
element clusters
2. Assign each of the remaining (N-k) training
sample to the cluster with the nearest centroid.
After each assignment, recompute the centroid of
the gaining cluster.
9.
Step 3:Take each sample in sequence and
compute its distance from the centroid
of each of the clusters. If a sample is not
currently in the cluster with the
closest centroid, switch this
sample to that cluster and update the
centroid of the cluster gaining the
new sample and the cluster losing the
sample.
Step 4 . Repeat step 3 until convergence is
achieved, that is until a pass through
the training sample causes no new
assignments.
10.
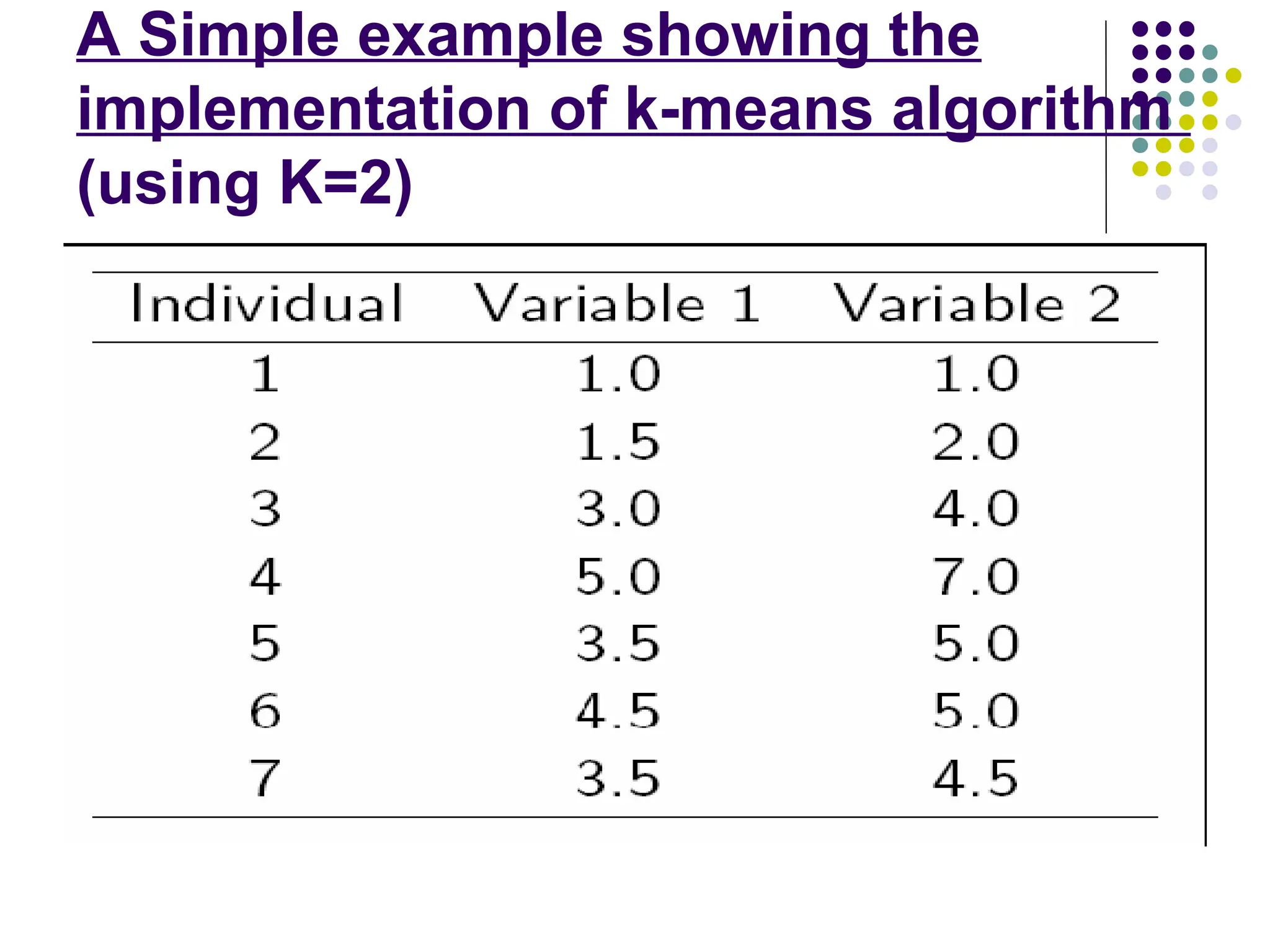
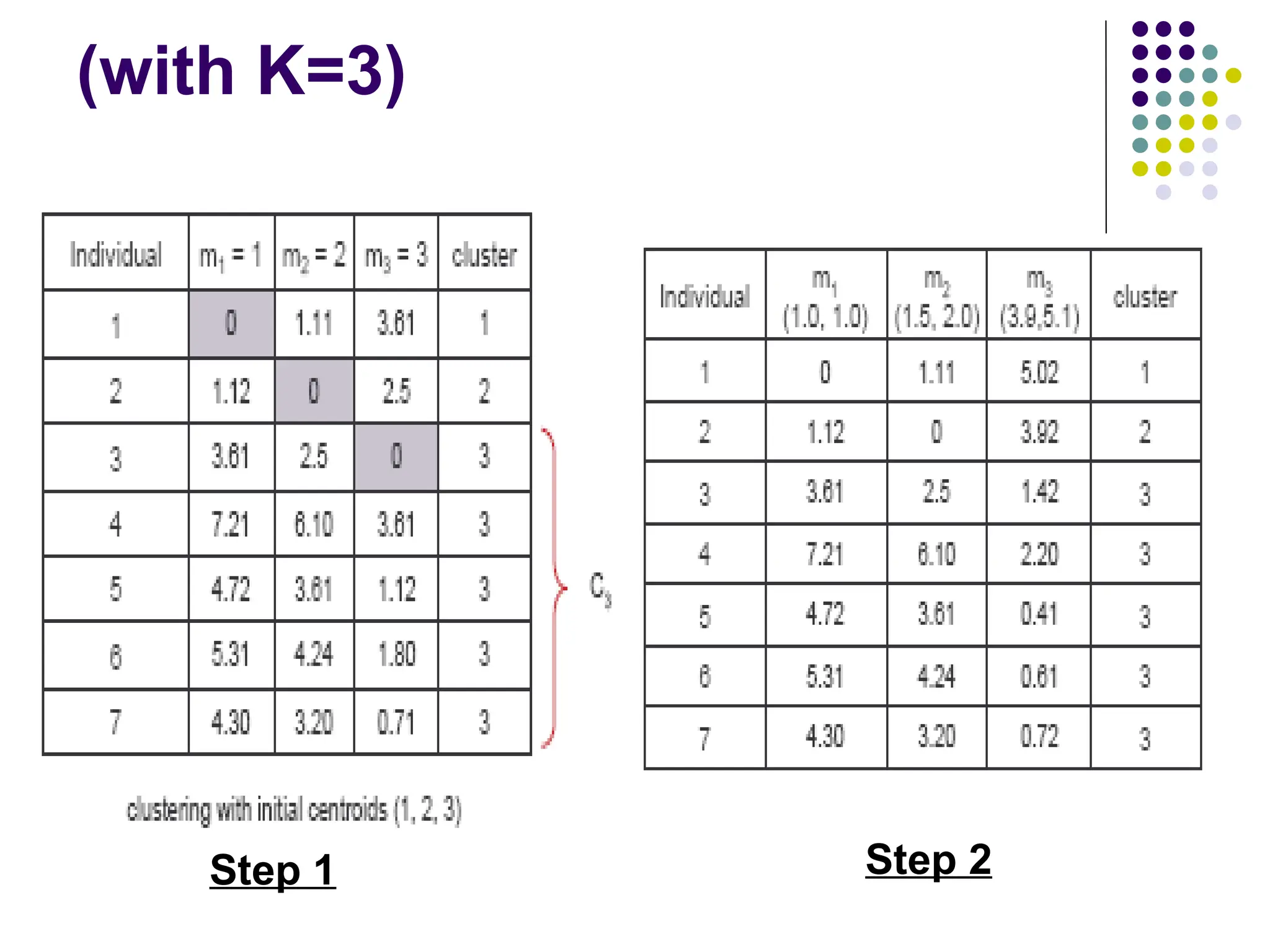
A Simple exampleshowing the
implementation of k-means algorithm
(using K=2)
11.
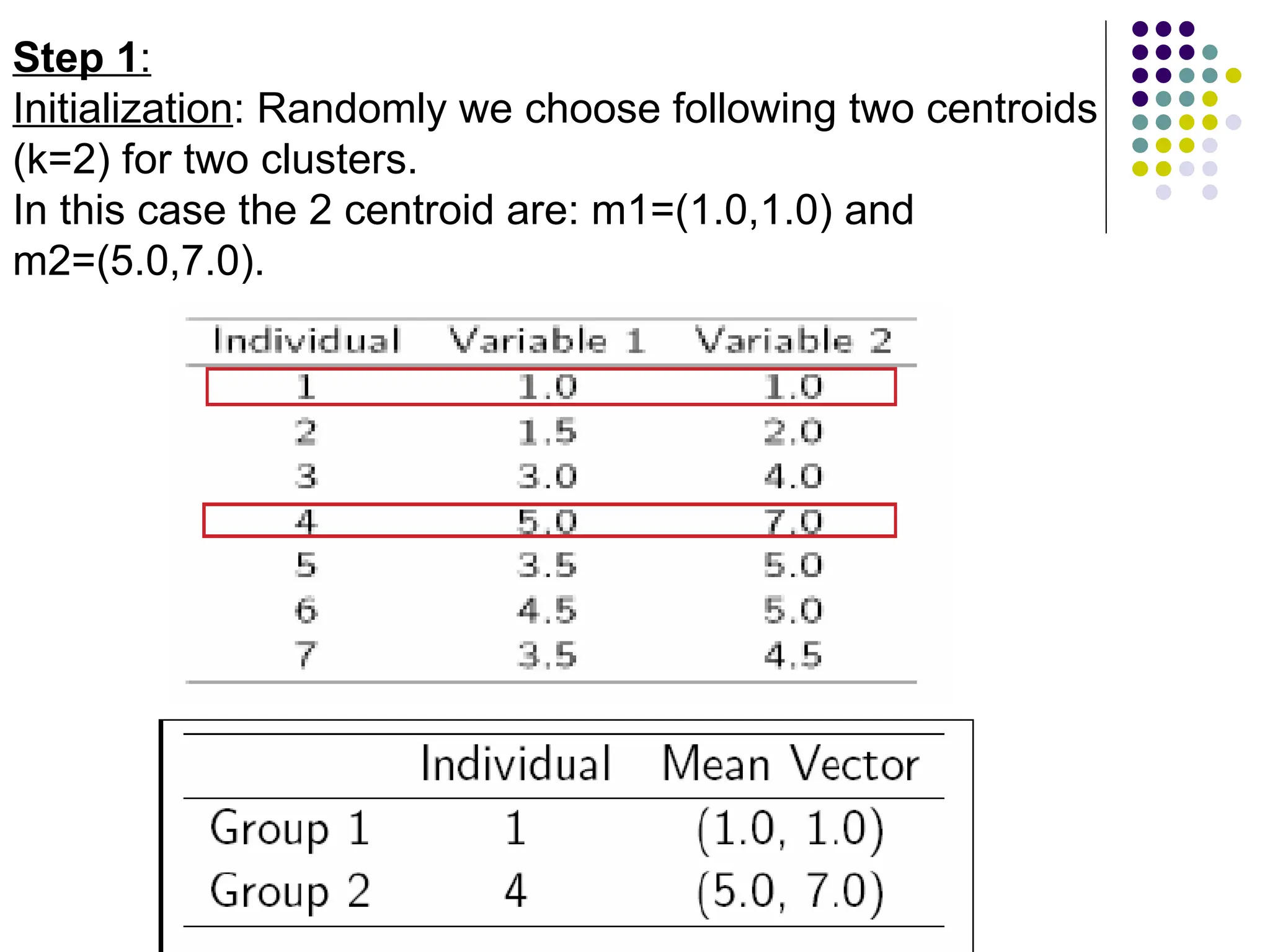
Step 1:
Initialization: Randomlywe choose following two centroids
(k=2) for two clusters.
In this case the 2 centroid are: m1=(1.0,1.0) and
m2=(5.0,7.0).
12.
Step 2:
Thus,we obtain two clusters
containing:
{1,2,3} and {4,5,6,7}.
Their new centroids are:
13.
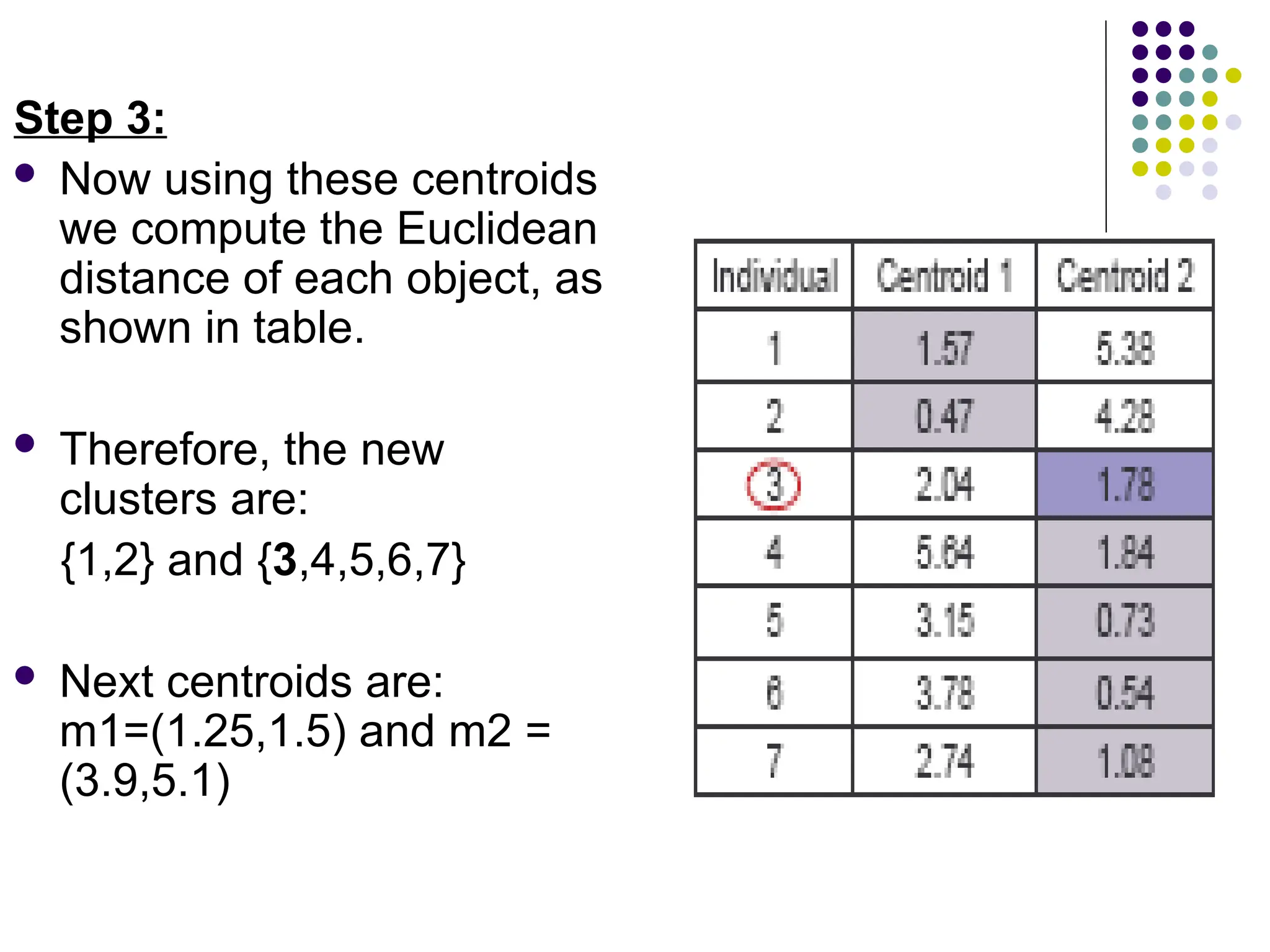
Step 3:
Nowusing these centroids
we compute the Euclidean
distance of each object, as
shown in table.
Therefore, the new
clusters are:
{1,2} and {3,4,5,6,7}
Next centroids are:
m1=(1.25,1.5) and m2 =
(3.9,5.1)
14.
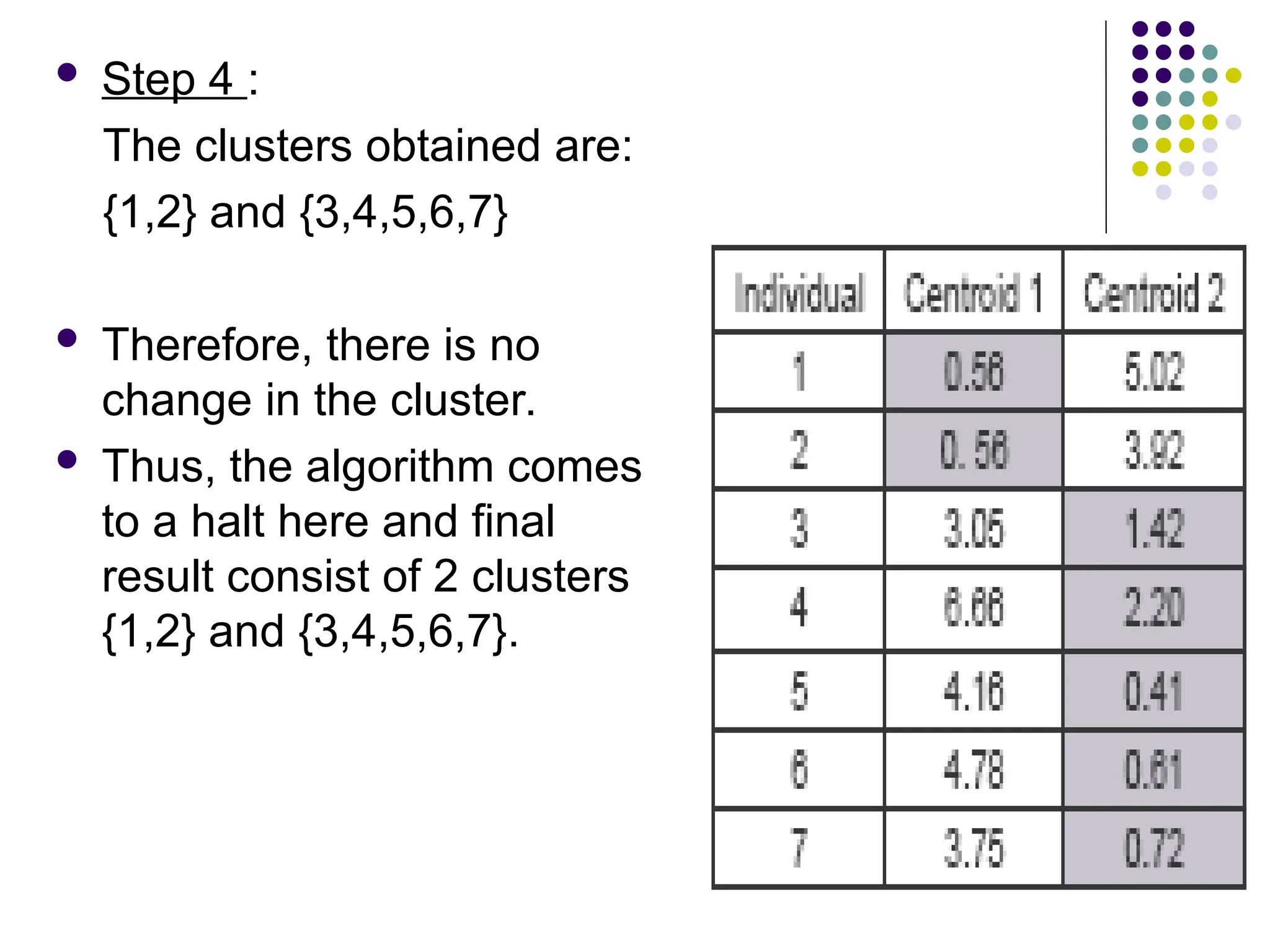
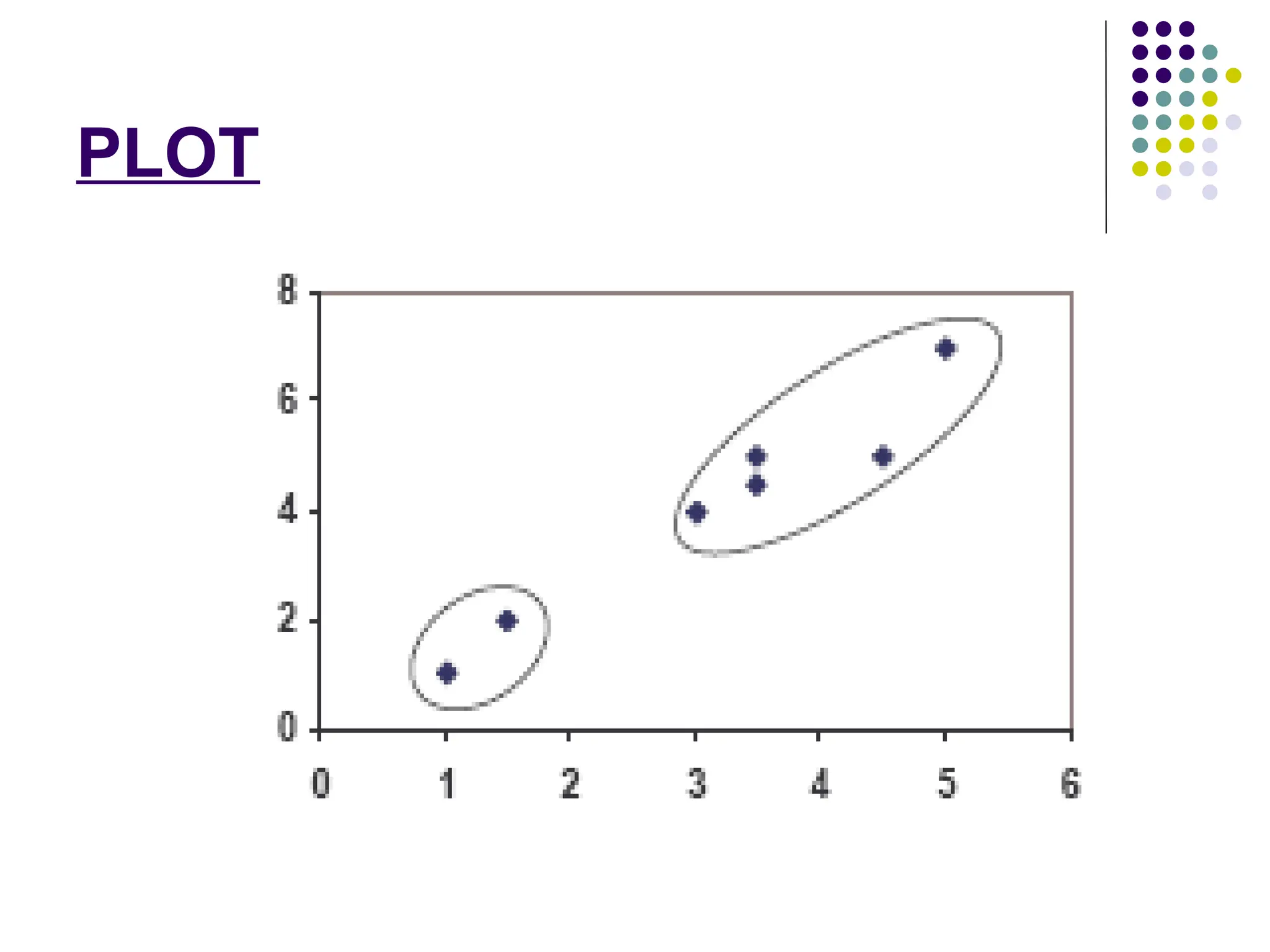
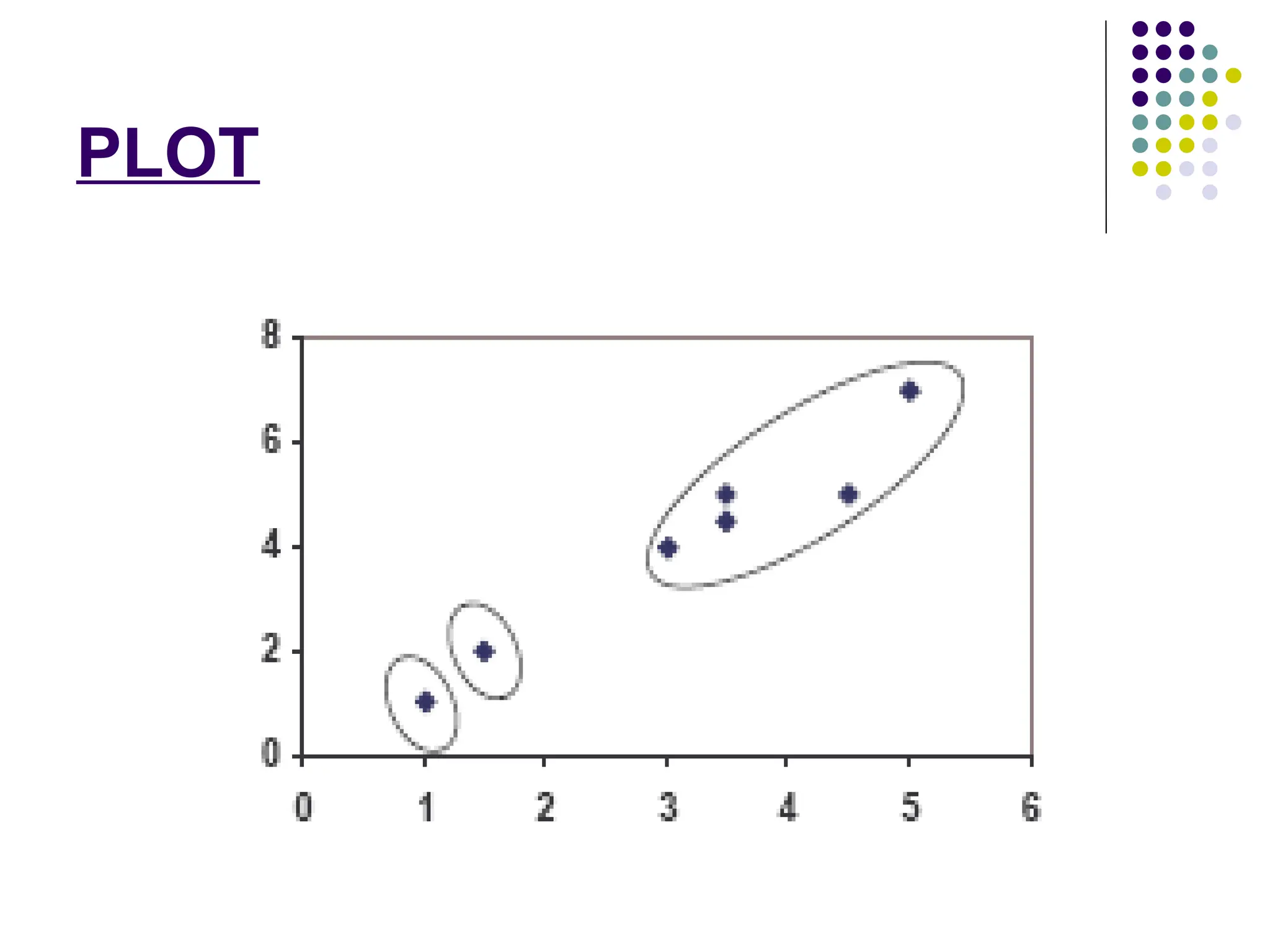
Step 4:
The clusters obtained are:
{1,2} and {3,4,5,6,7}
Therefore, there is no
change in the cluster.
Thus, the algorithm comes
to a halt here and final
result consist of 2 clusters
{1,2} and {3,4,5,6,7}.