Downloaded 349 times






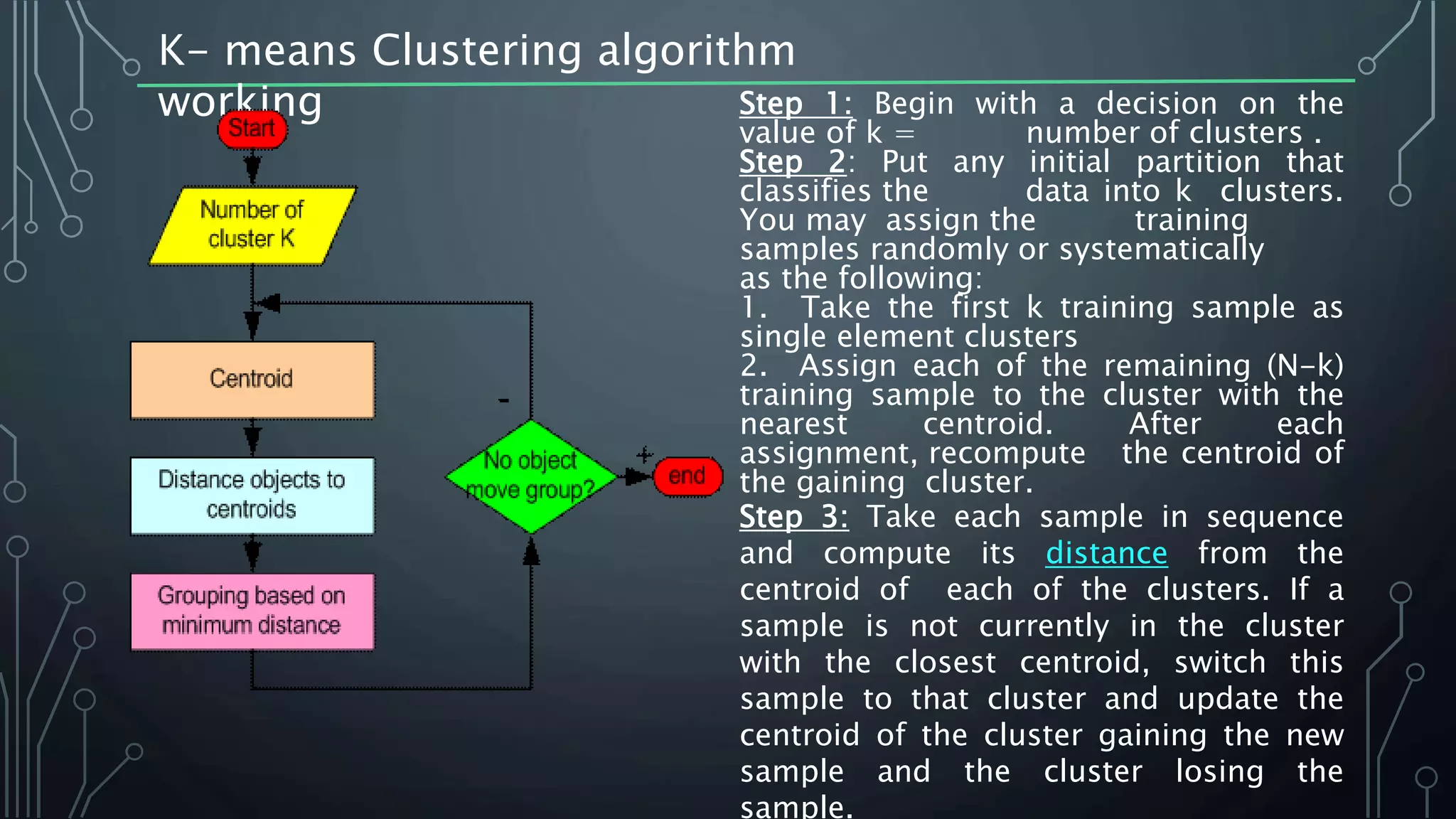



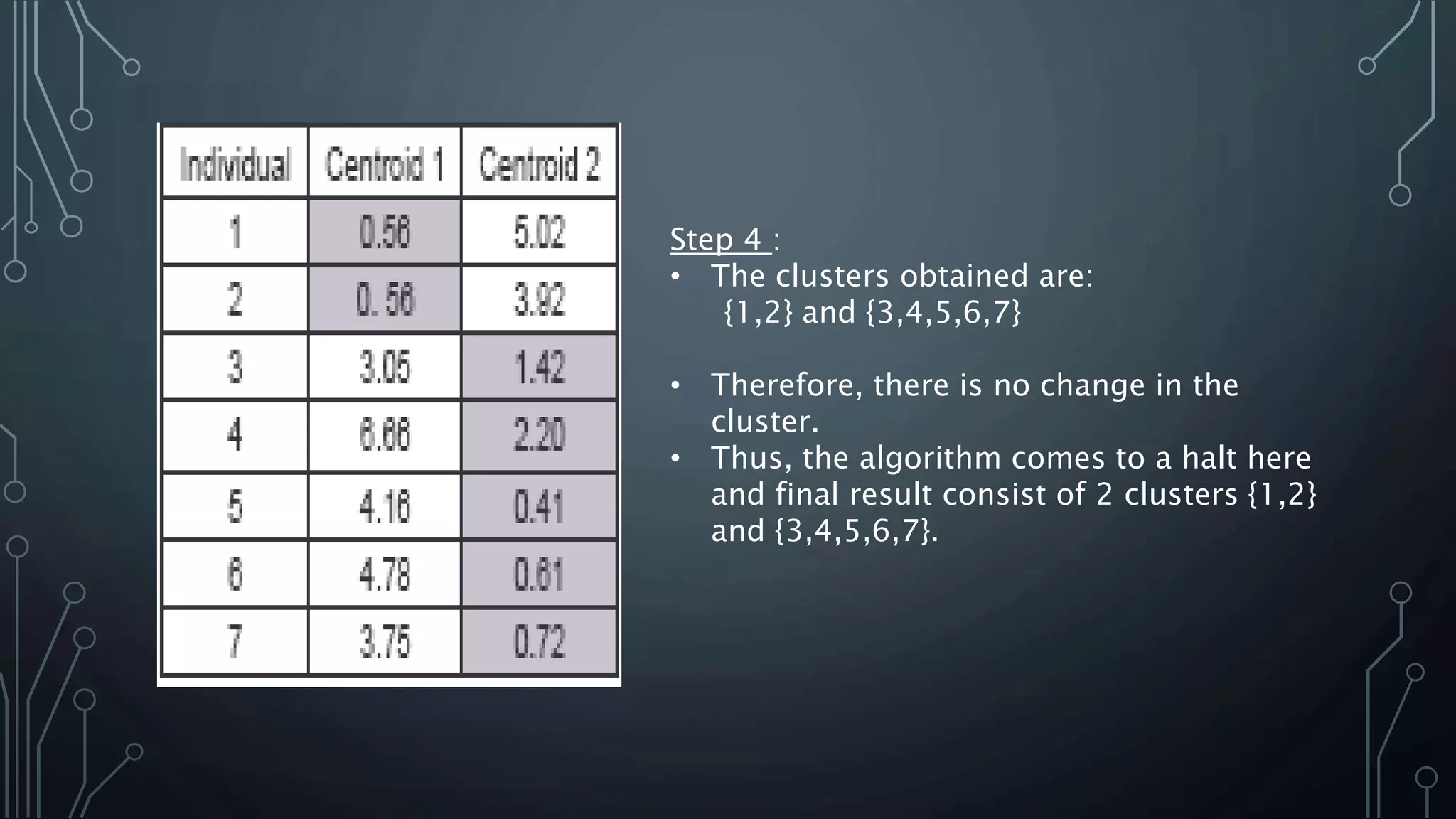
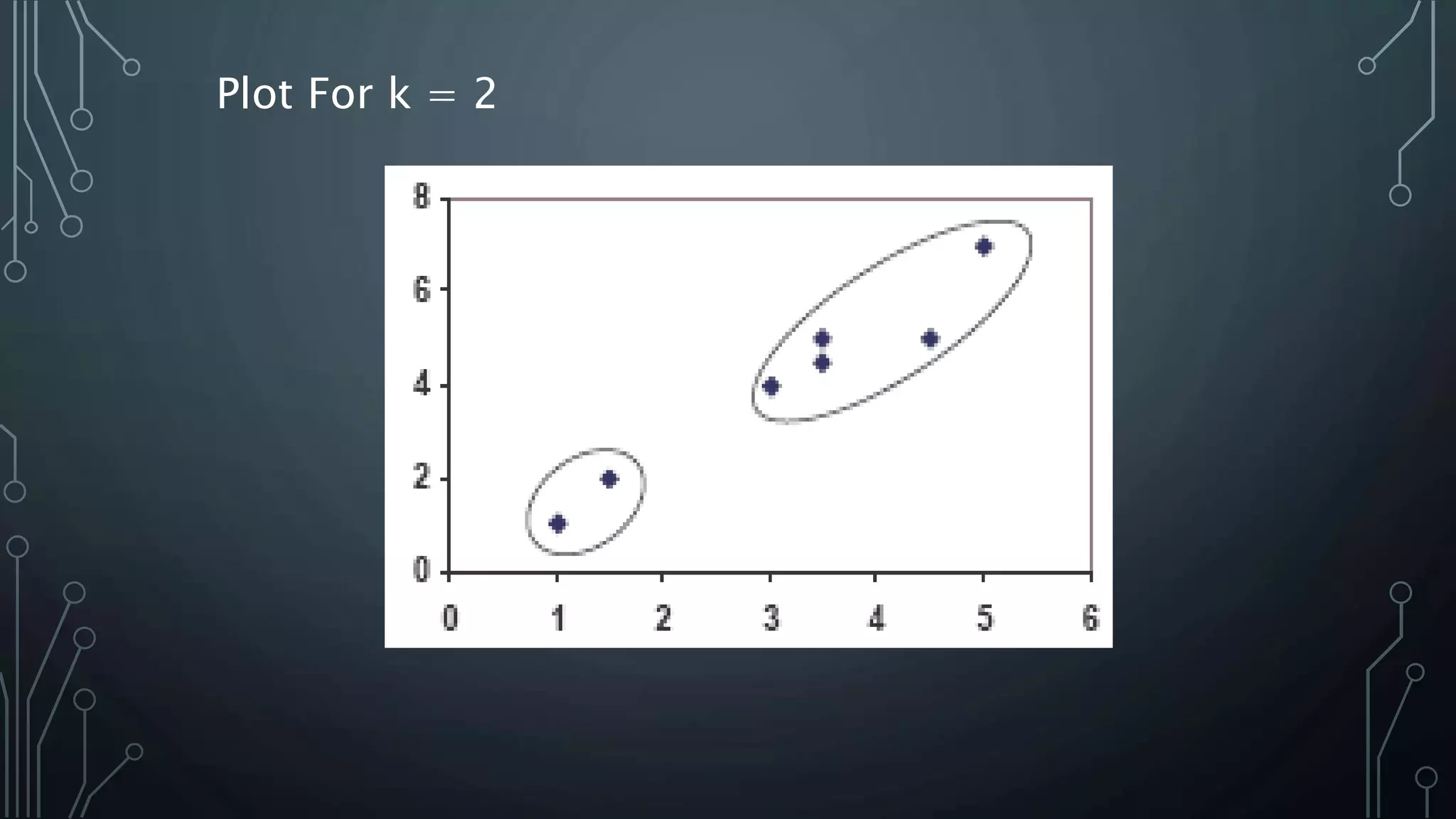
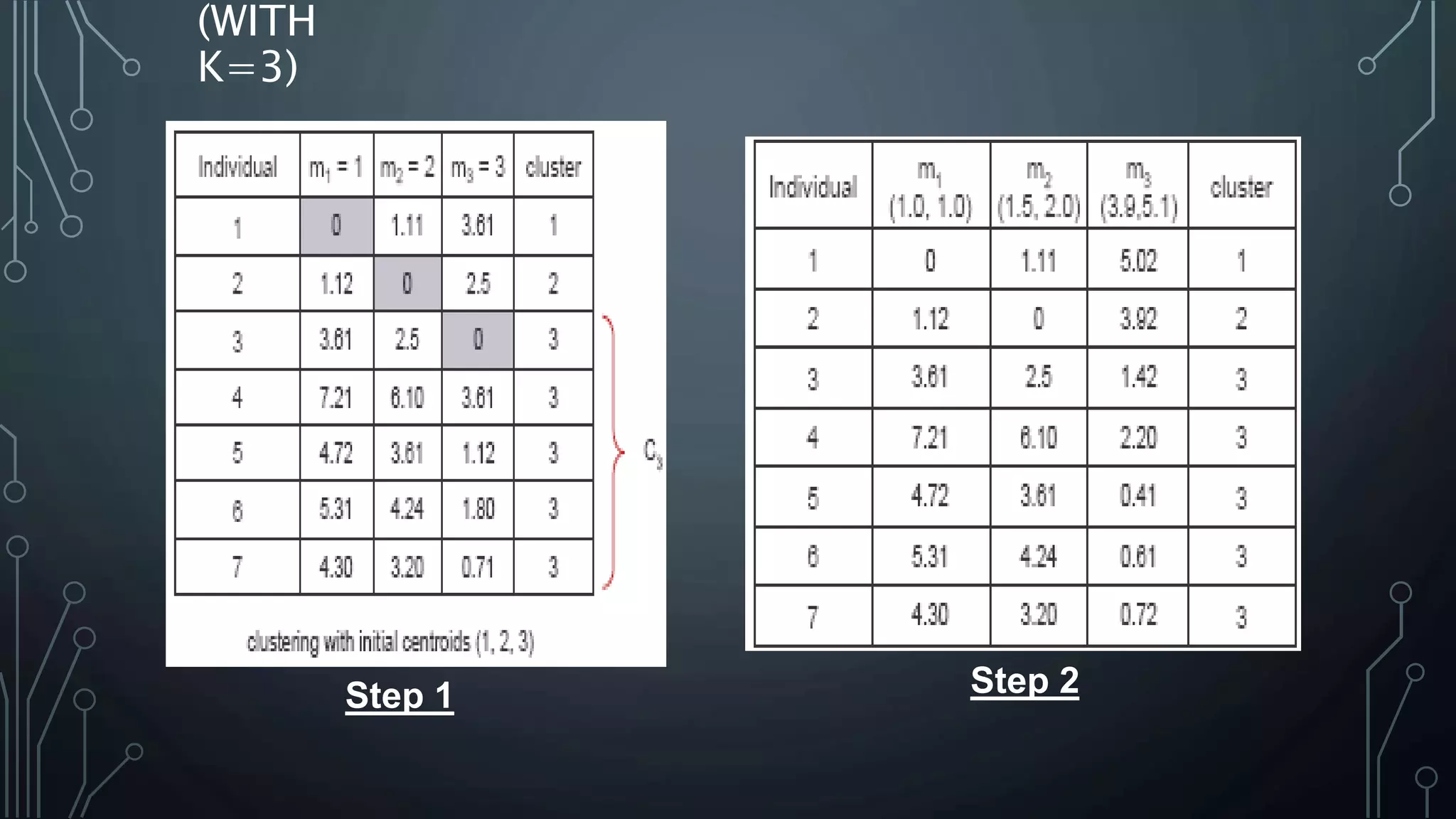
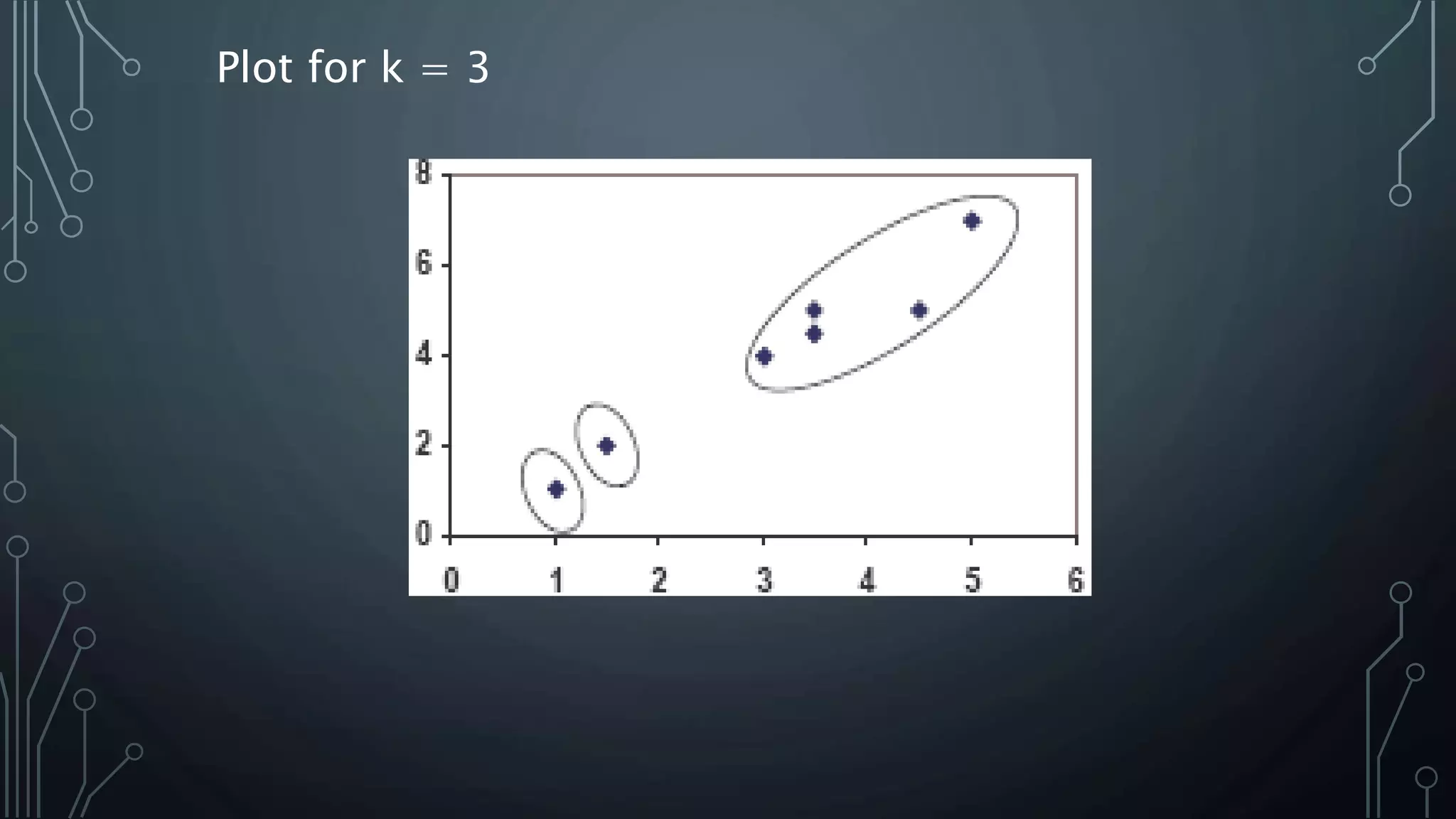

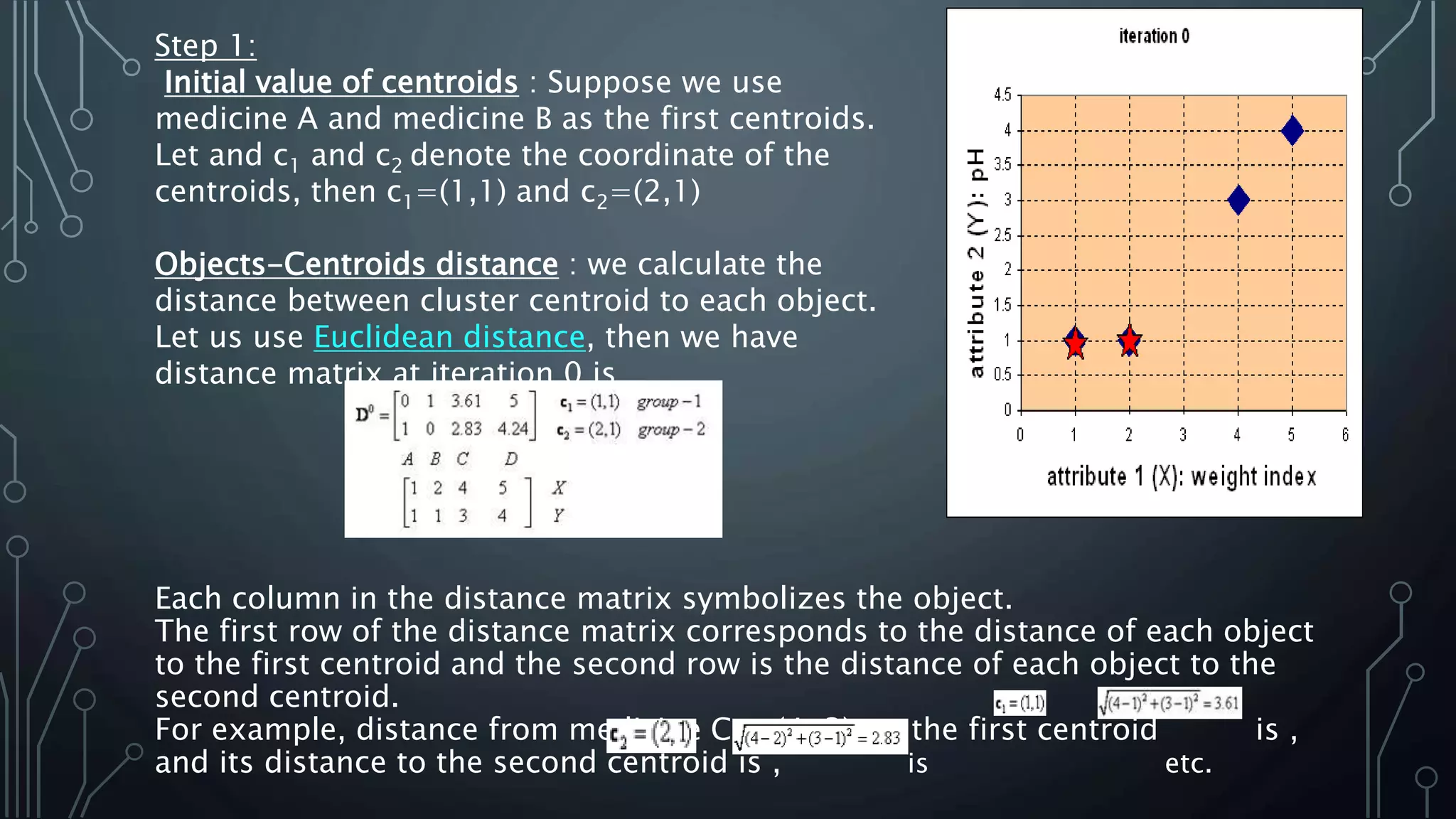
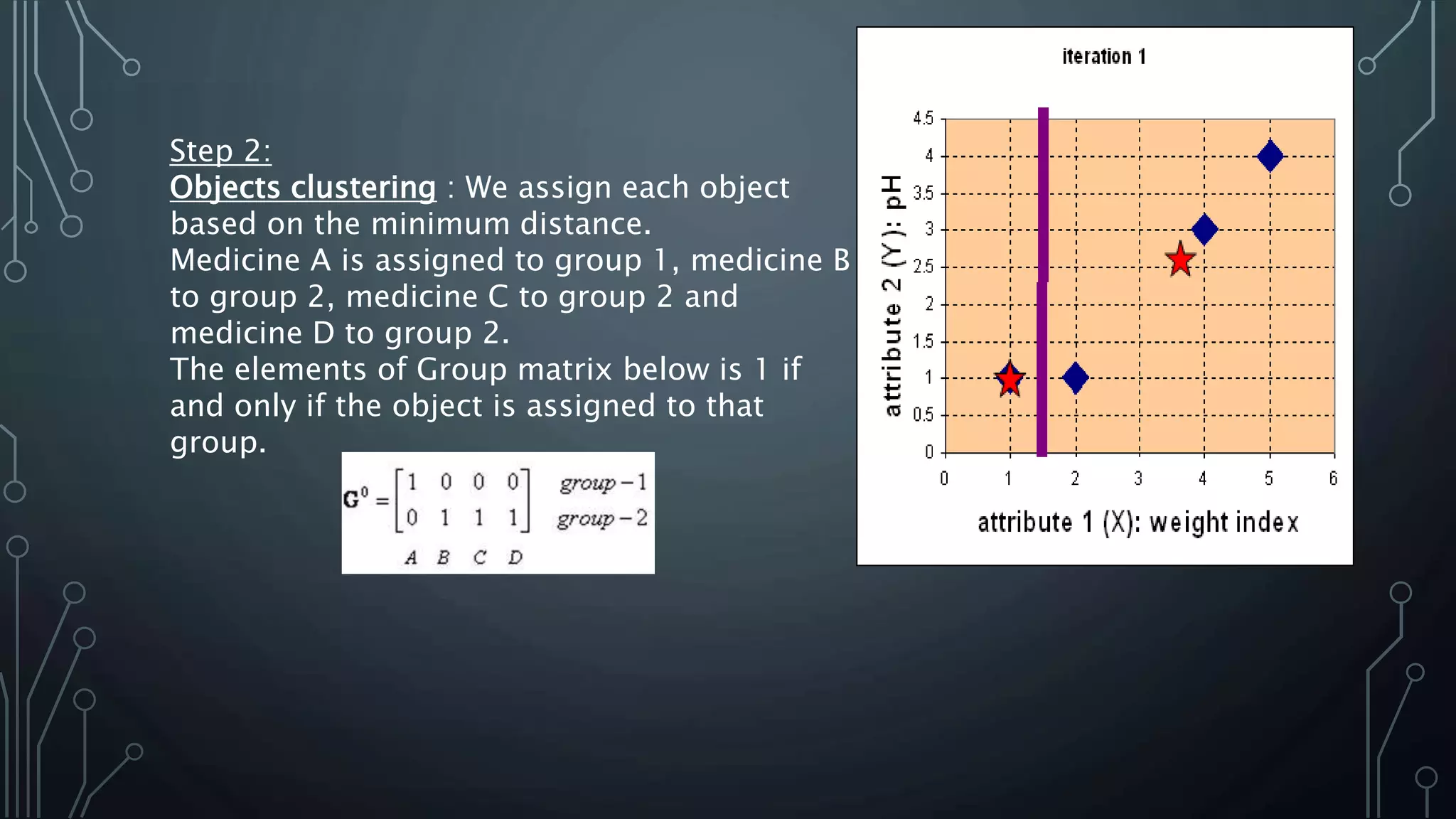

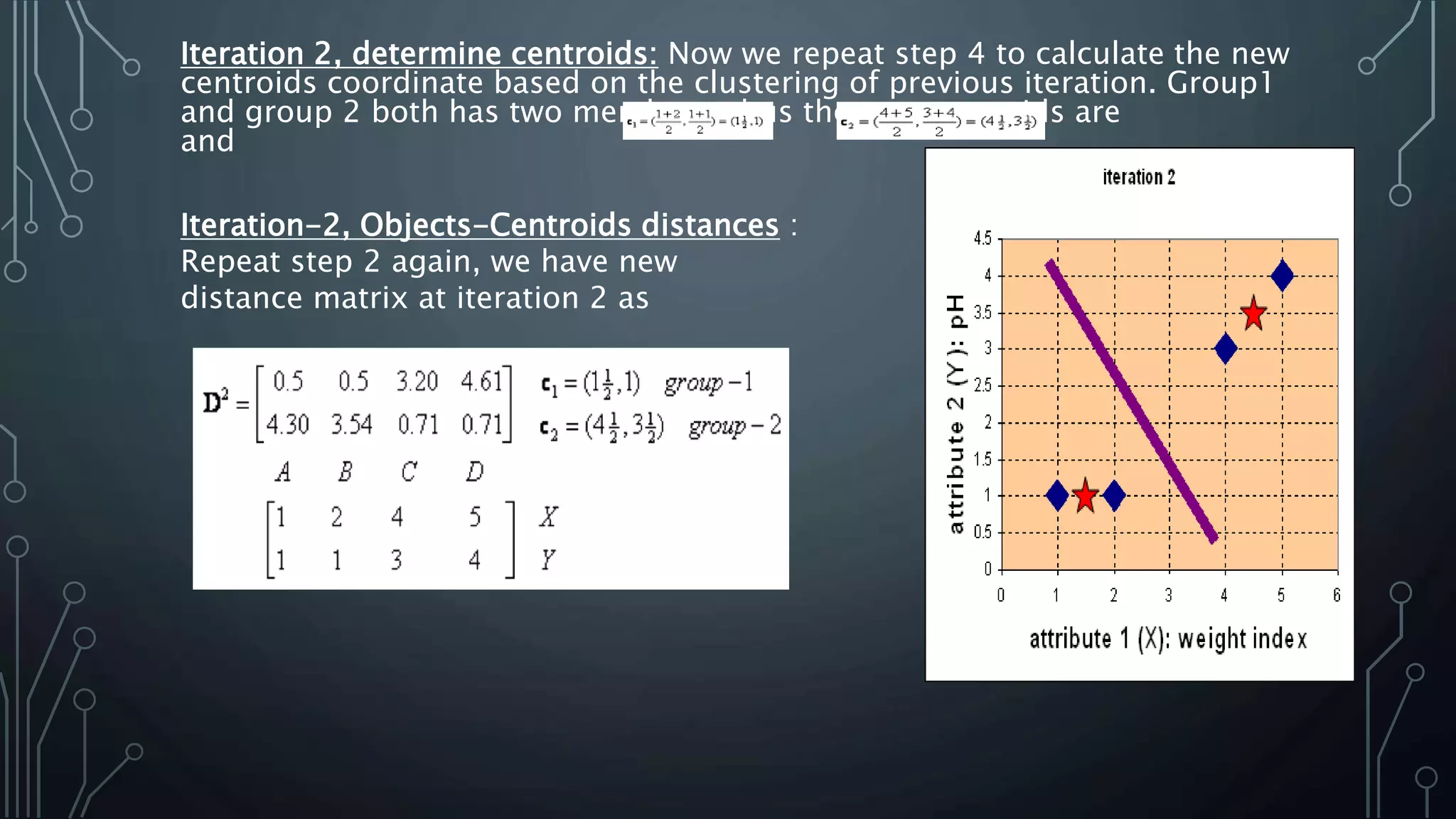






























K-means clustering is an algorithm that groups data points into k clusters based on their attributes and distances from initial cluster center points. It works by first randomly selecting k data points as initial centroids, then assigning all other points to the closest centroid and recalculating the centroids. This process repeats until the centroids are stable or a maximum number of iterations is reached. K-means clustering is widely used for machine learning applications like image segmentation and speech recognition due to its efficiency, but it is sensitive to initialization and assumes spherical clusters of similar size and density.










































































