
















![What is
Information
Gain?
▪ Measures the reduction in entropy
▪ Decides which attribute should be selected as the
decision node
If S is our total collection,
Information Gain = Entropy(S) – [(Weighted Avg) x Entropy(each feature)]](https://image.slidesharecdn.com/decisiontreealgorithm1-181004103807/75/Decision-Tree-Algorithm-Decision-Tree-in-Python-Machine-Learning-Algorithms-Edureka-31-2048.jpg)








































![What is
Information
Gain?
▪ Measures the reduction in entropy
▪ Decides which attribute should be selected as the
decision node
If S is our total collection,
Information Gain = Entropy(S) – [(Weighted Avg) x Entropy(each feature)]](https://crownmelresort.com/image.slidesharecdn.com/decisiontreealgorithm1-181004103807/75/Decision-Tree-Algorithm-Decision-Tree-in-Python-Machine-Learning-Algorithms-Edureka-31-2048.jpg)


















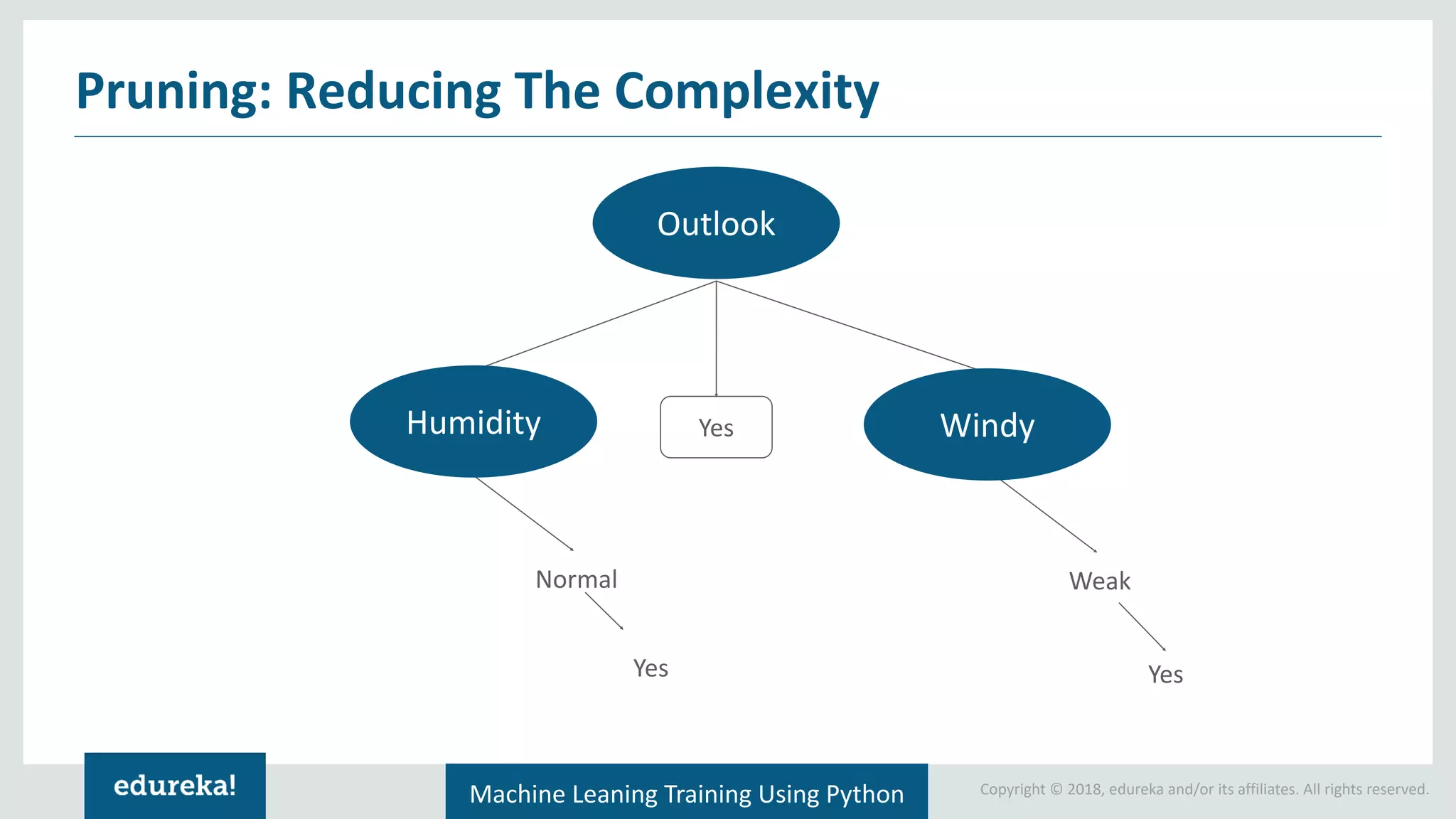
Pruning is the process of removing branches or nodes from a decision tree to simplify it and reduce overfitting. Some key points about pruning: - Pruning reduces the complexity of the decision tree to avoid overfitting to the training data. - It is done to improve the accuracy of the model on new unseen data by removing noisy or unstable parts of the tree. - Common pruning techniques include pre-pruning, cost-complexity pruning, reduced error pruning etc. - The goal of pruning is to find a tree with optimal complexity that balances bias and variance for best generalization on new data. To answer your question - tree based models and linear models each have their own advantages in different situations:
Overview of Machine Learning and the session agenda including classification basics.
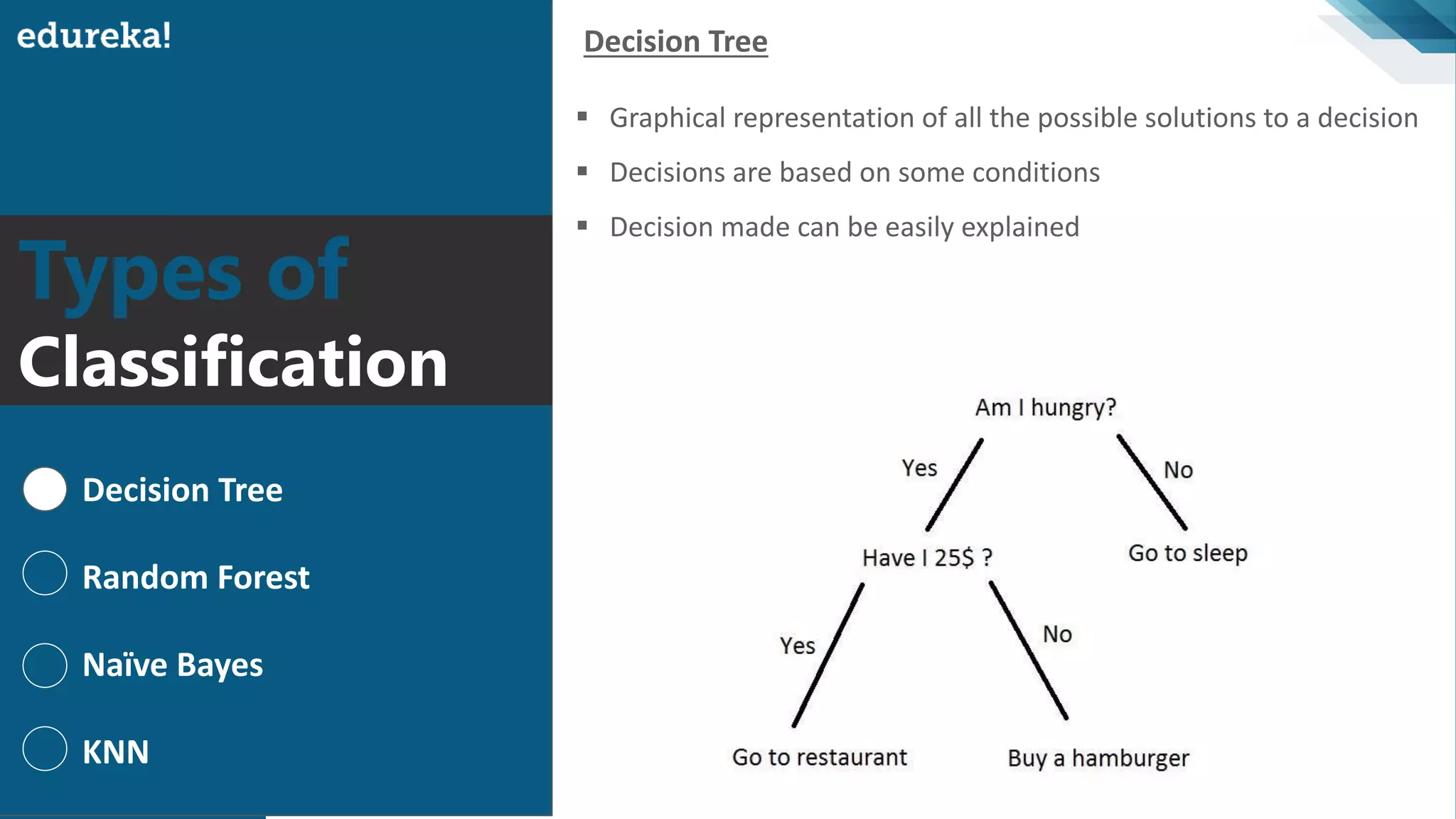
Definition of classification in machine learning, emphasizing dataset segmentation based on conditions.
Different classification methods: Decision Trees, Random Forests, Naive Bayes, KNN, outlining their characteristics.
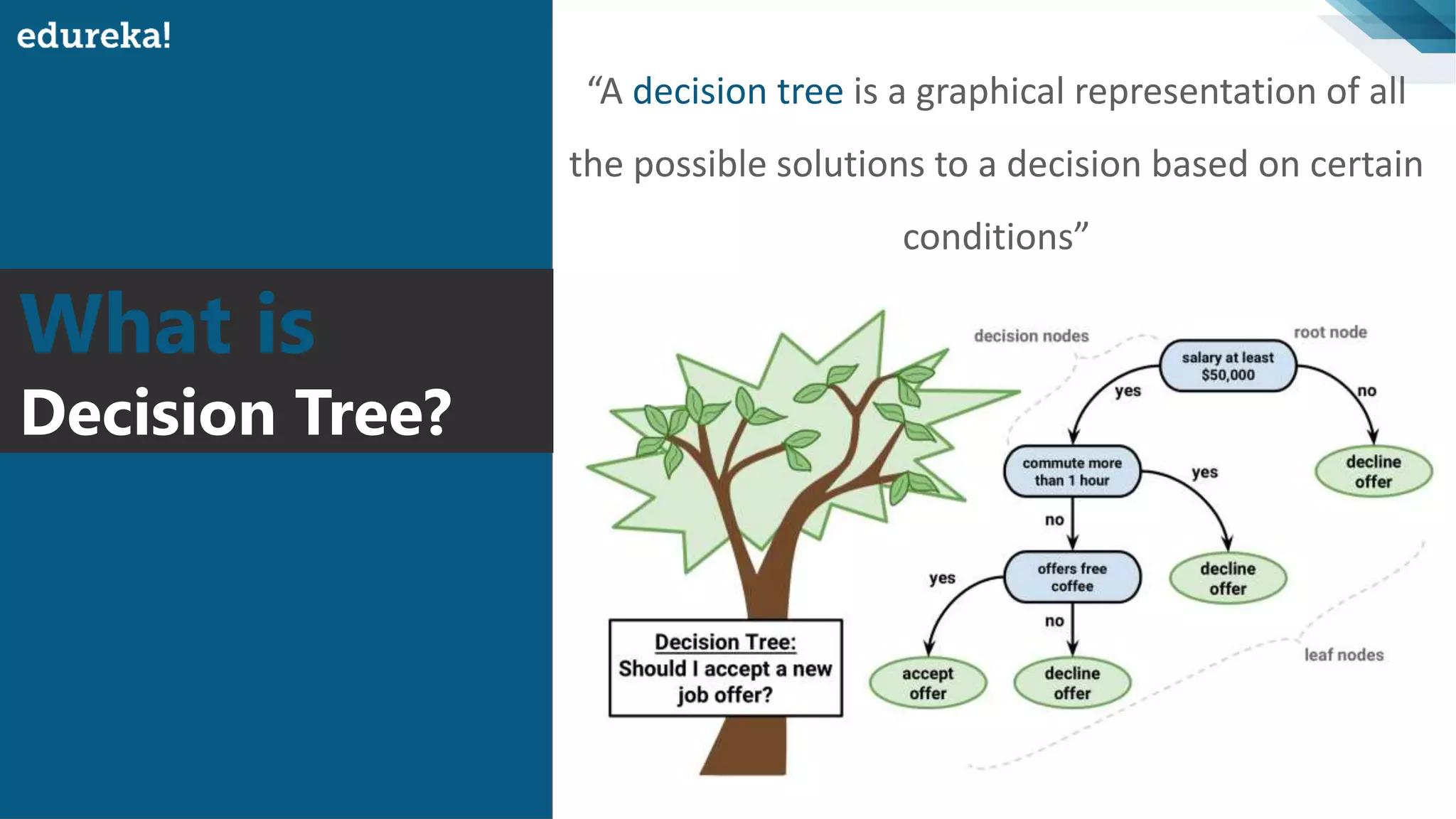
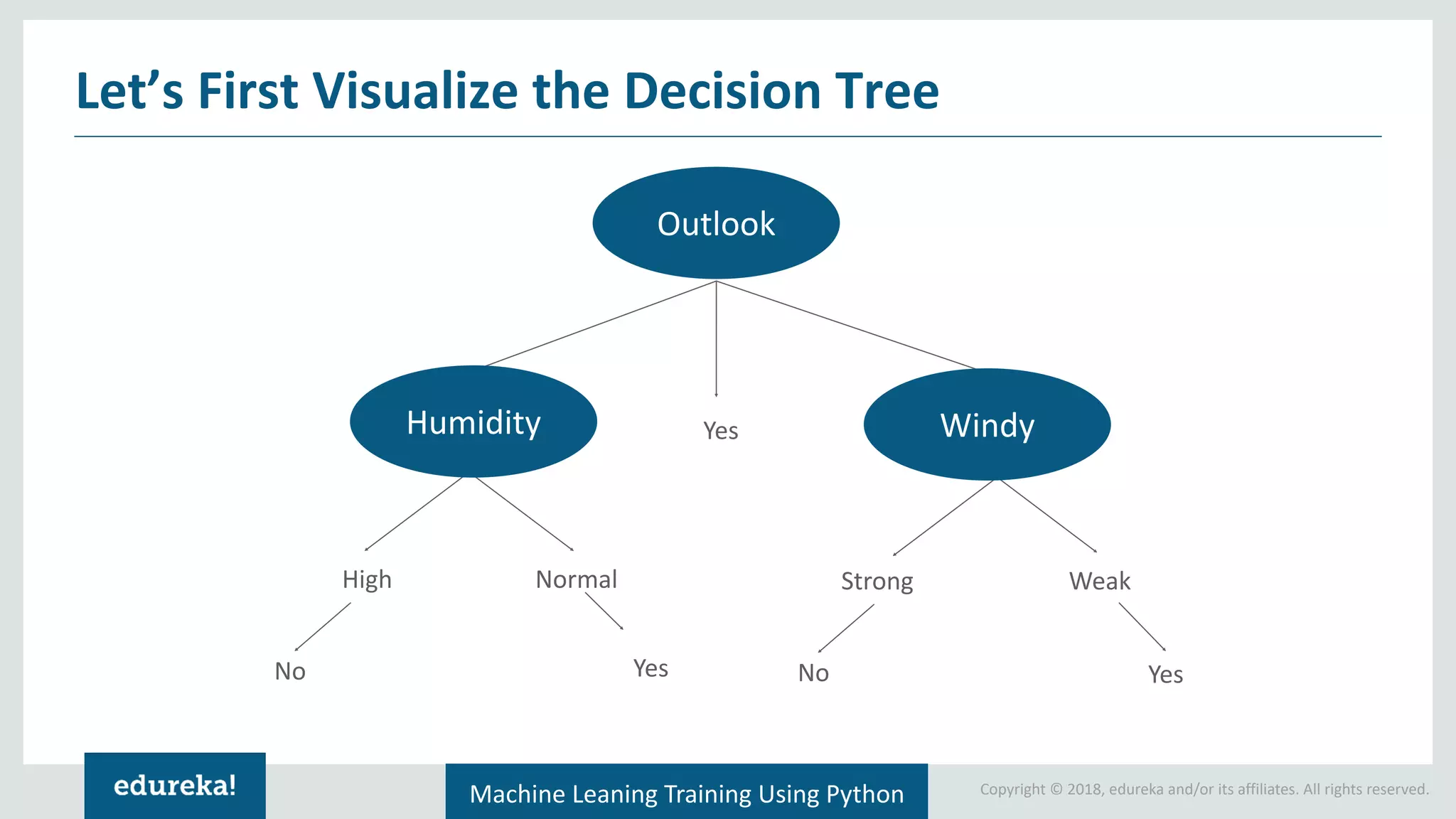
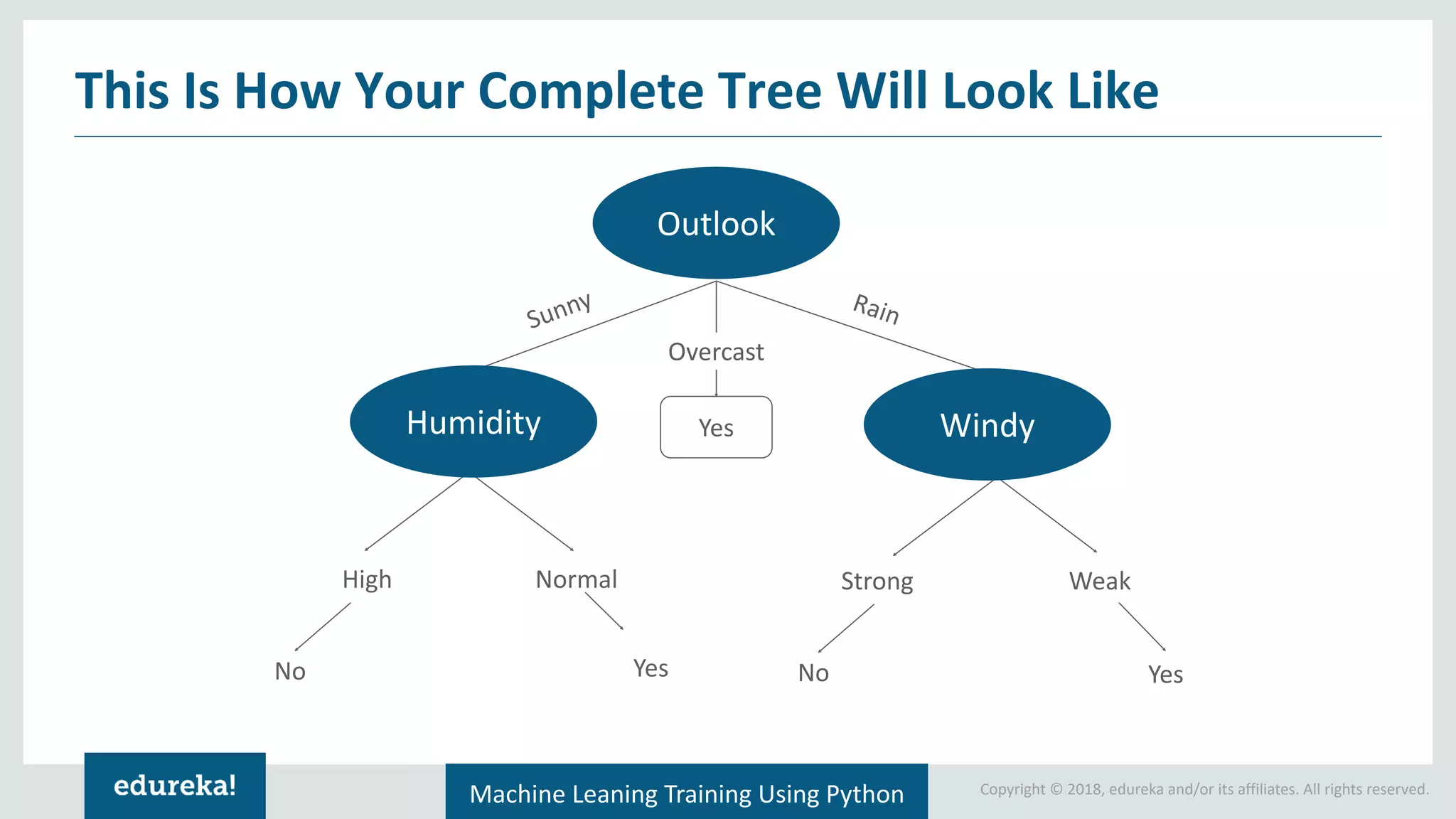
Definition and explanation of decision trees, demonstrating how they visualize solutions based on conditions.
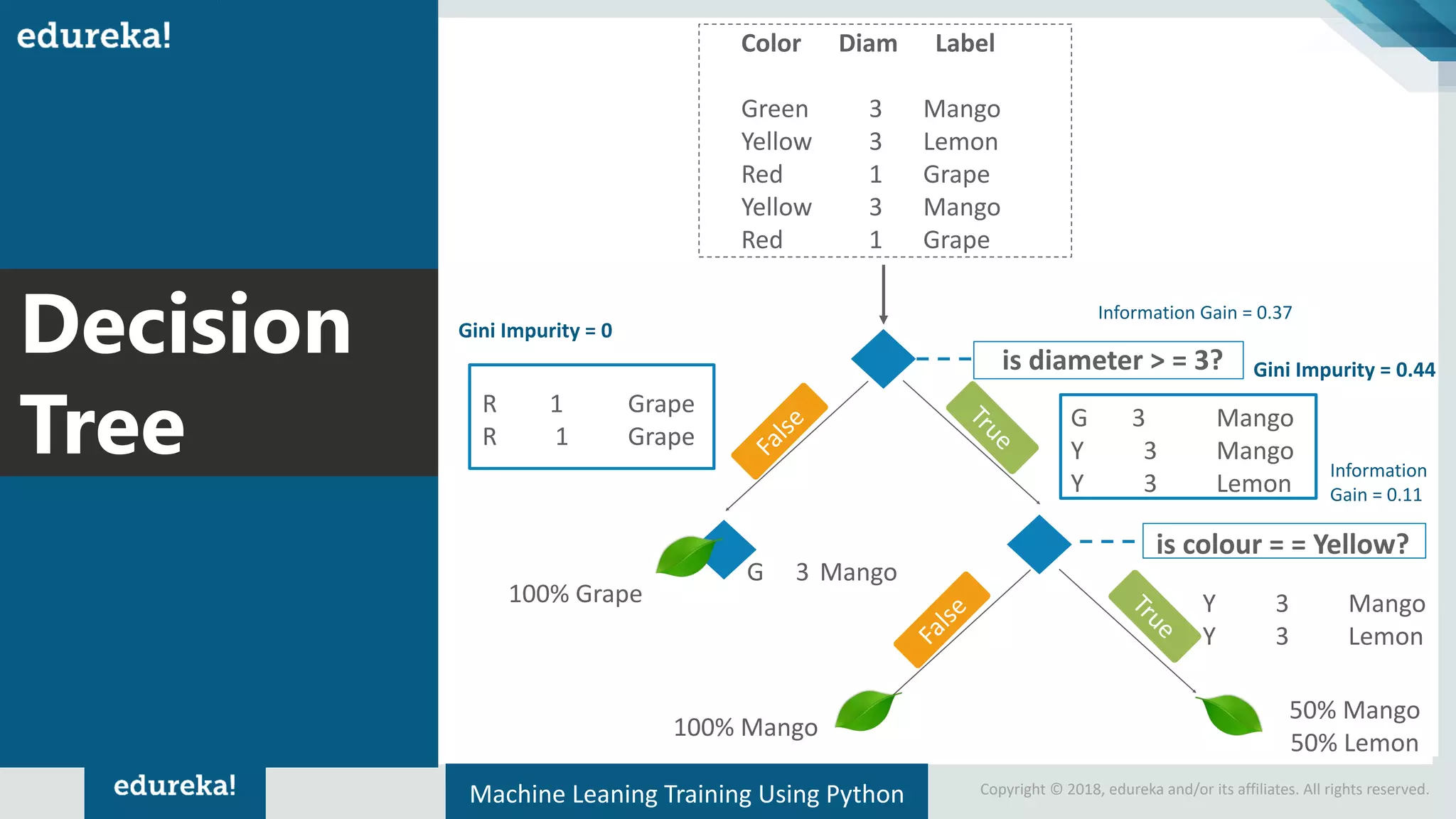
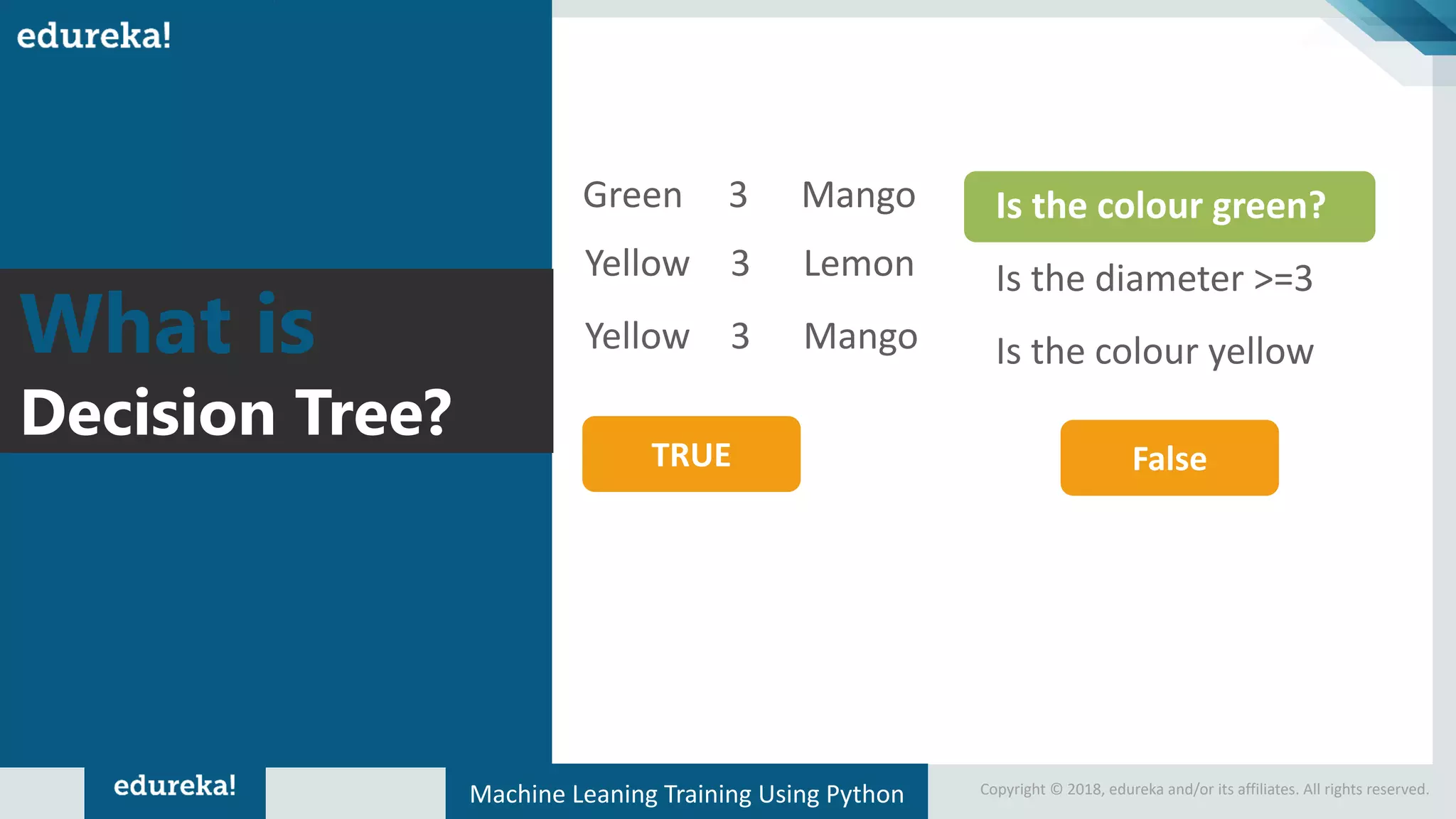
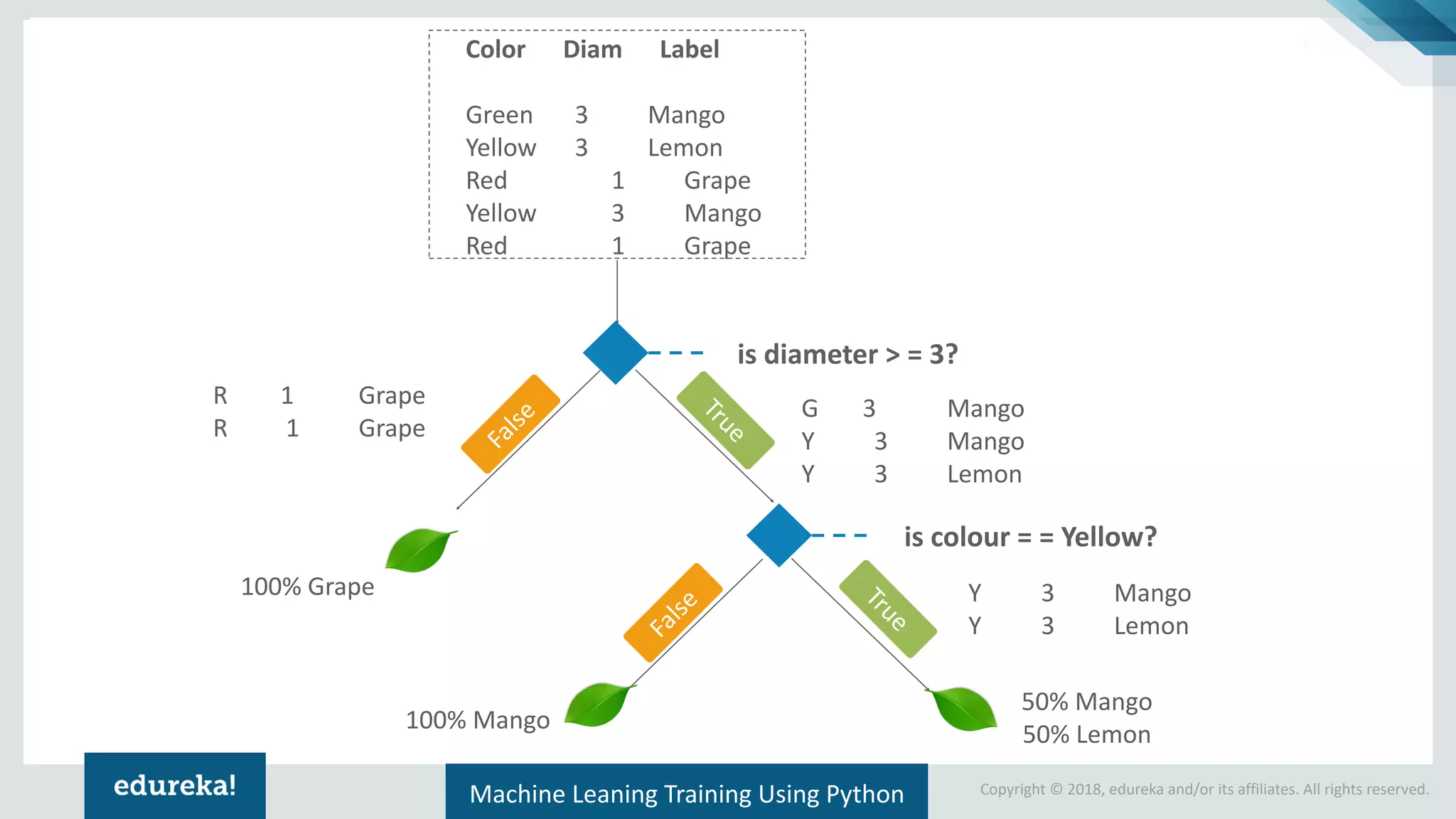
Presentation of a sample dataset with color and diameter, and its representation in a decision tree format.
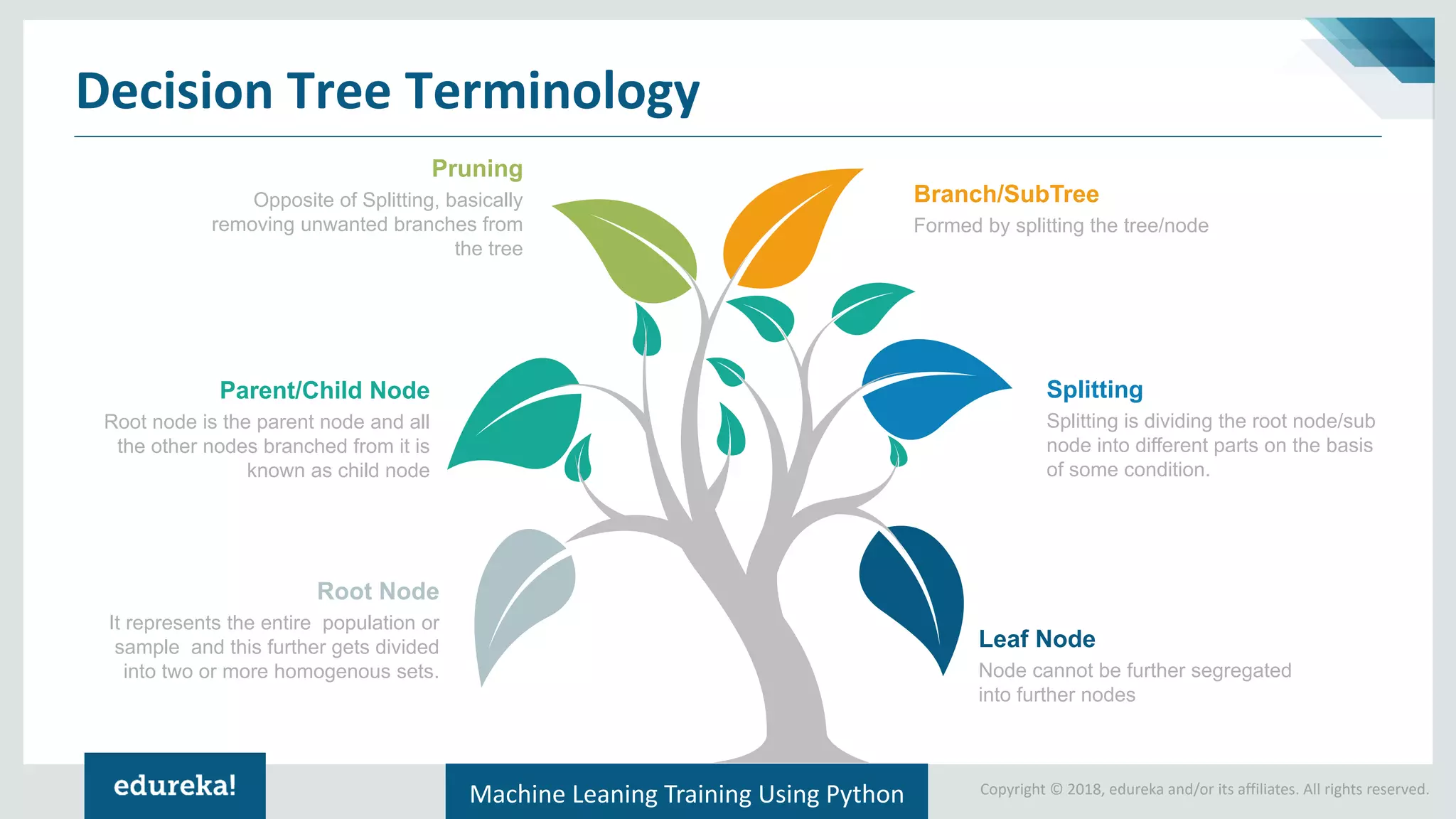
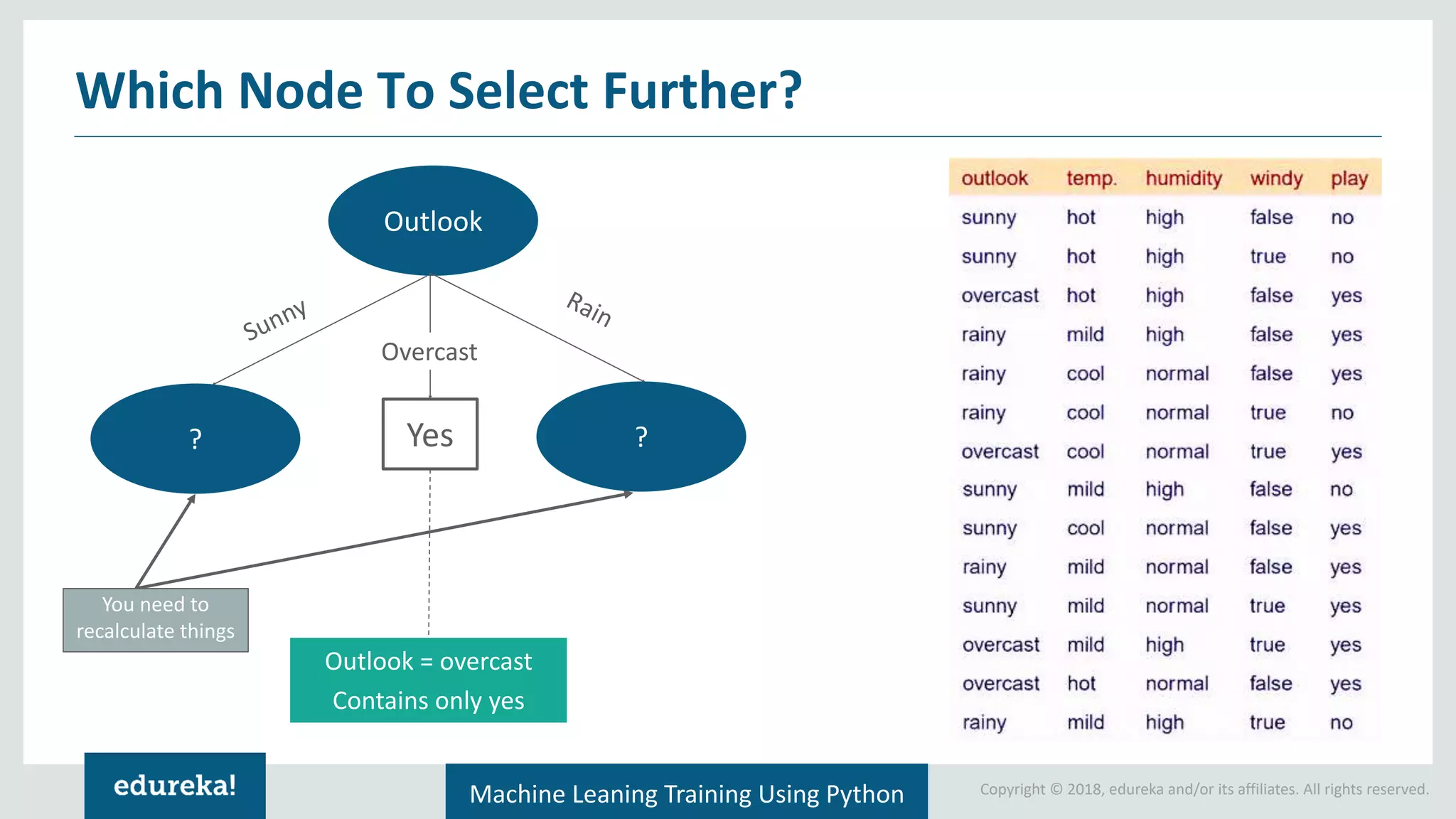
Terminologies associated with decision trees: pruning, root nodes, splitting, leaf nodes, and branches.
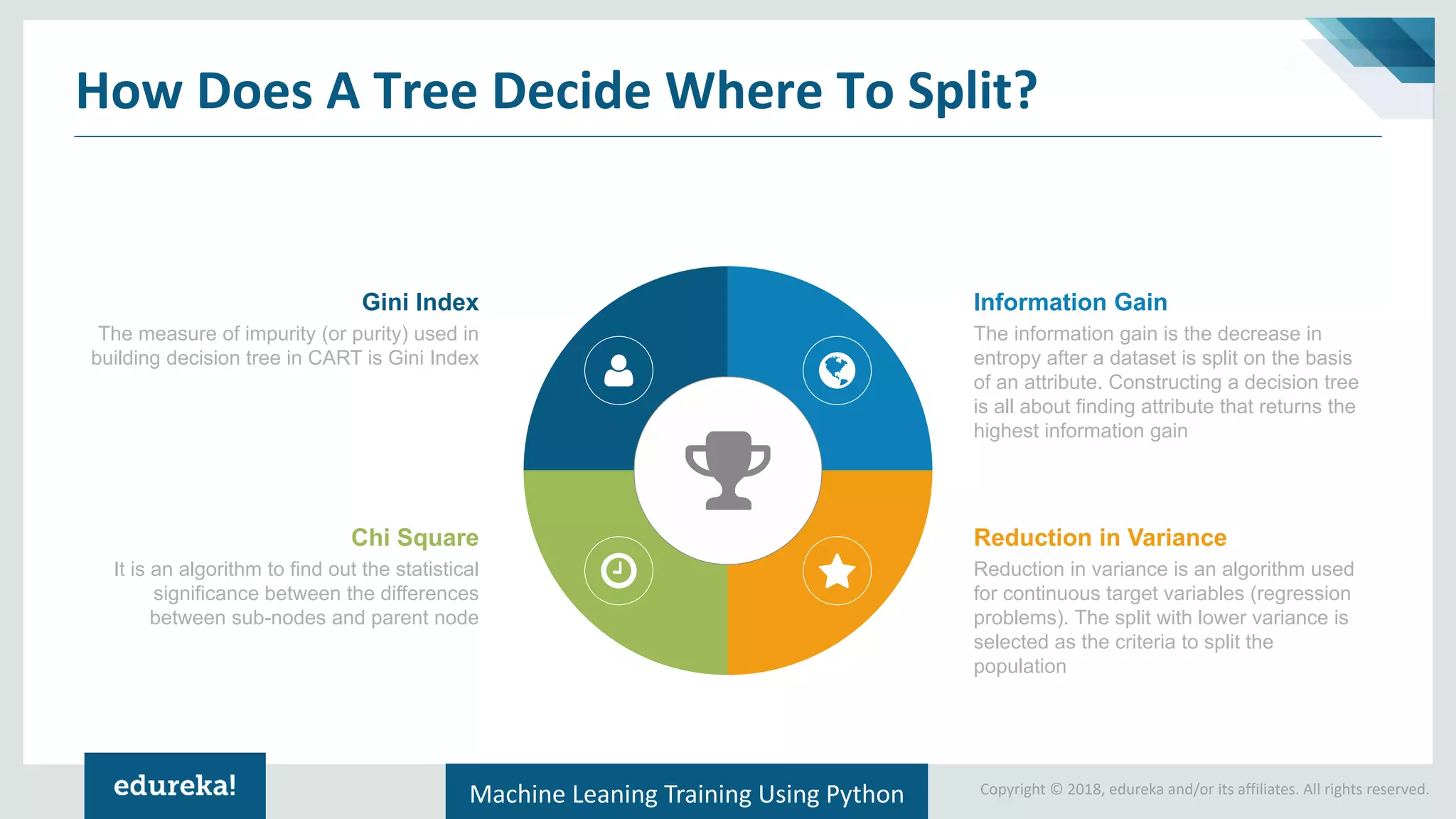
Explains the CART algorithm's decision tree construction with emphasis on visualizing decision-making criteria.
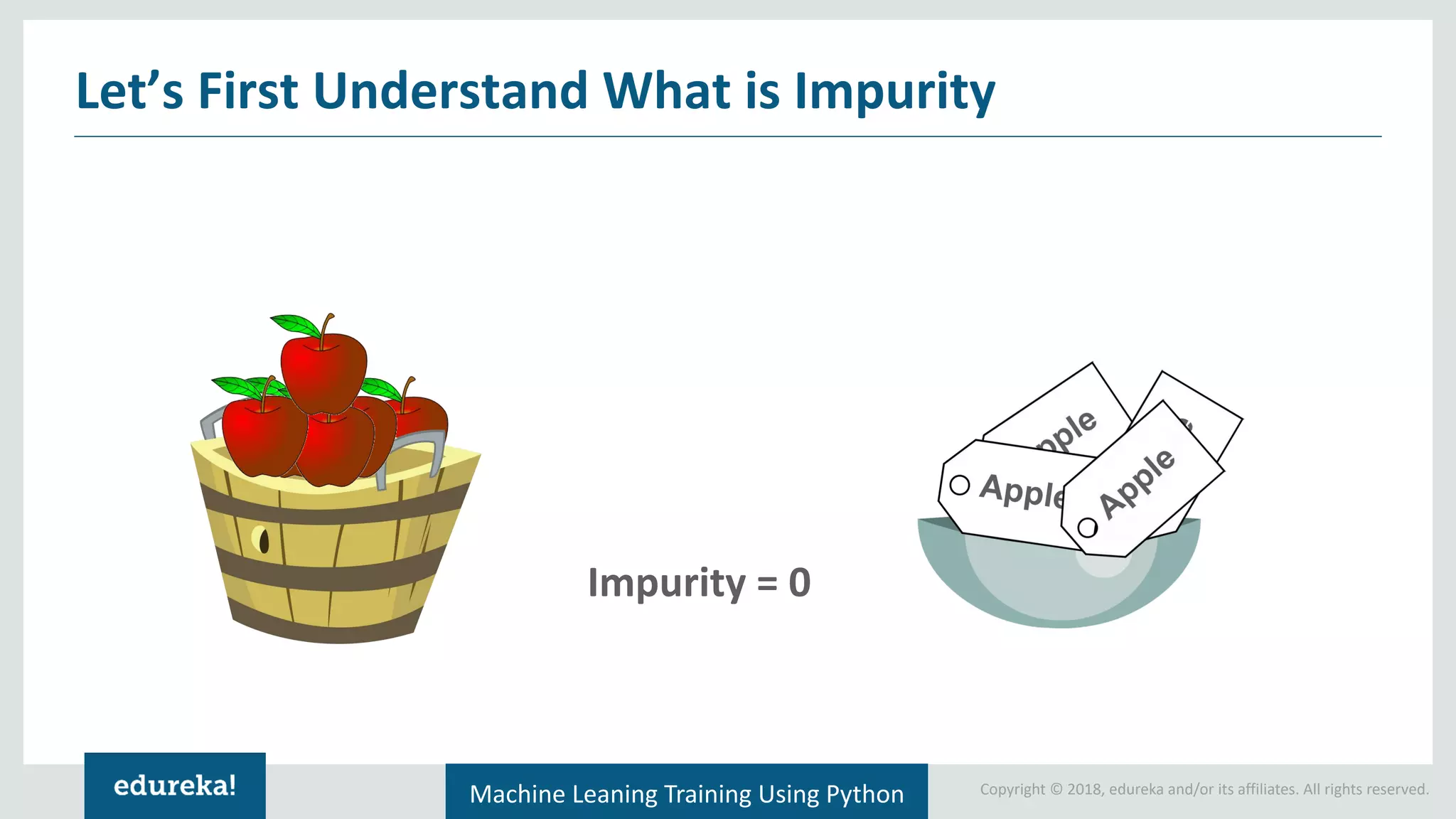
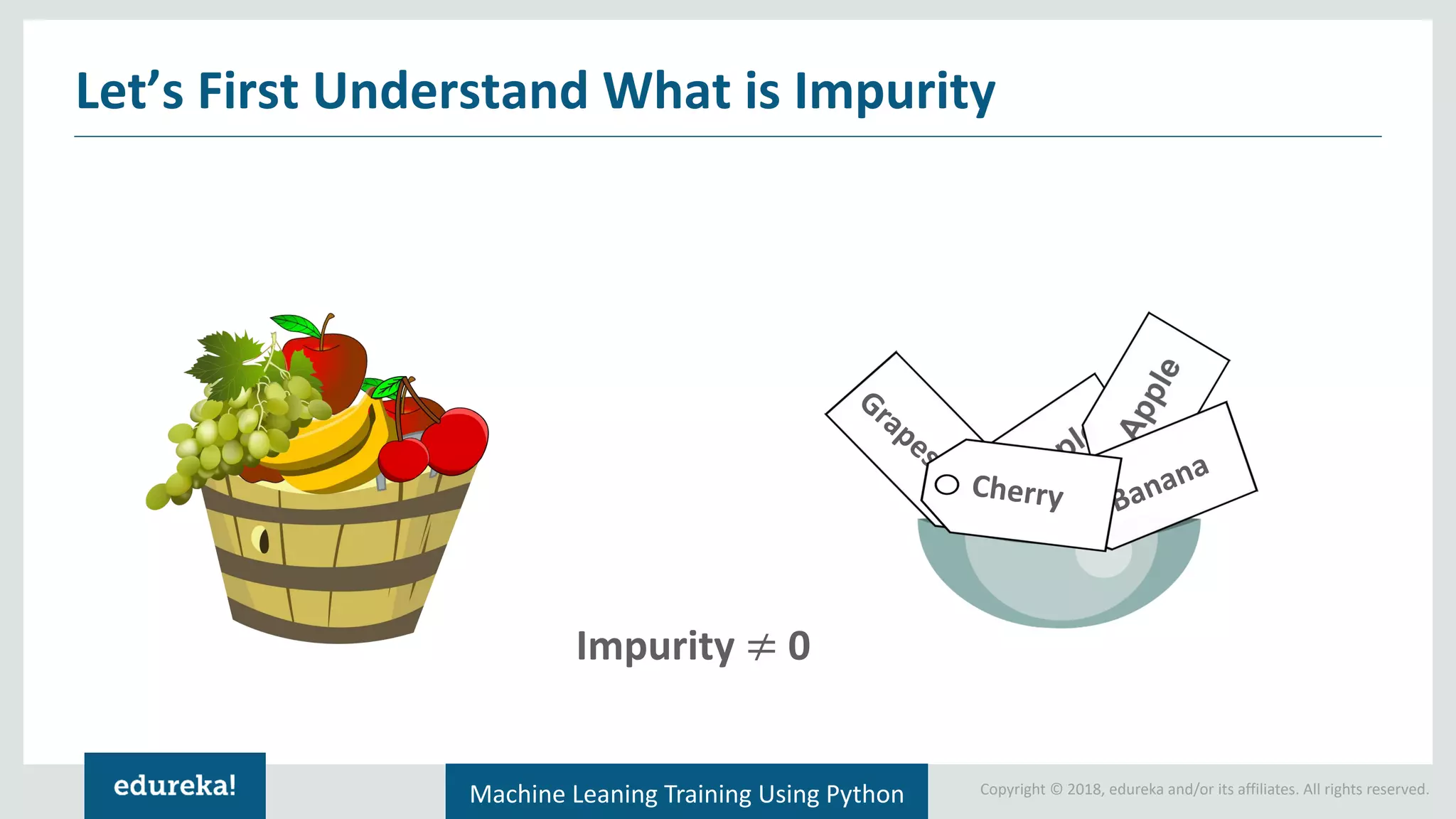
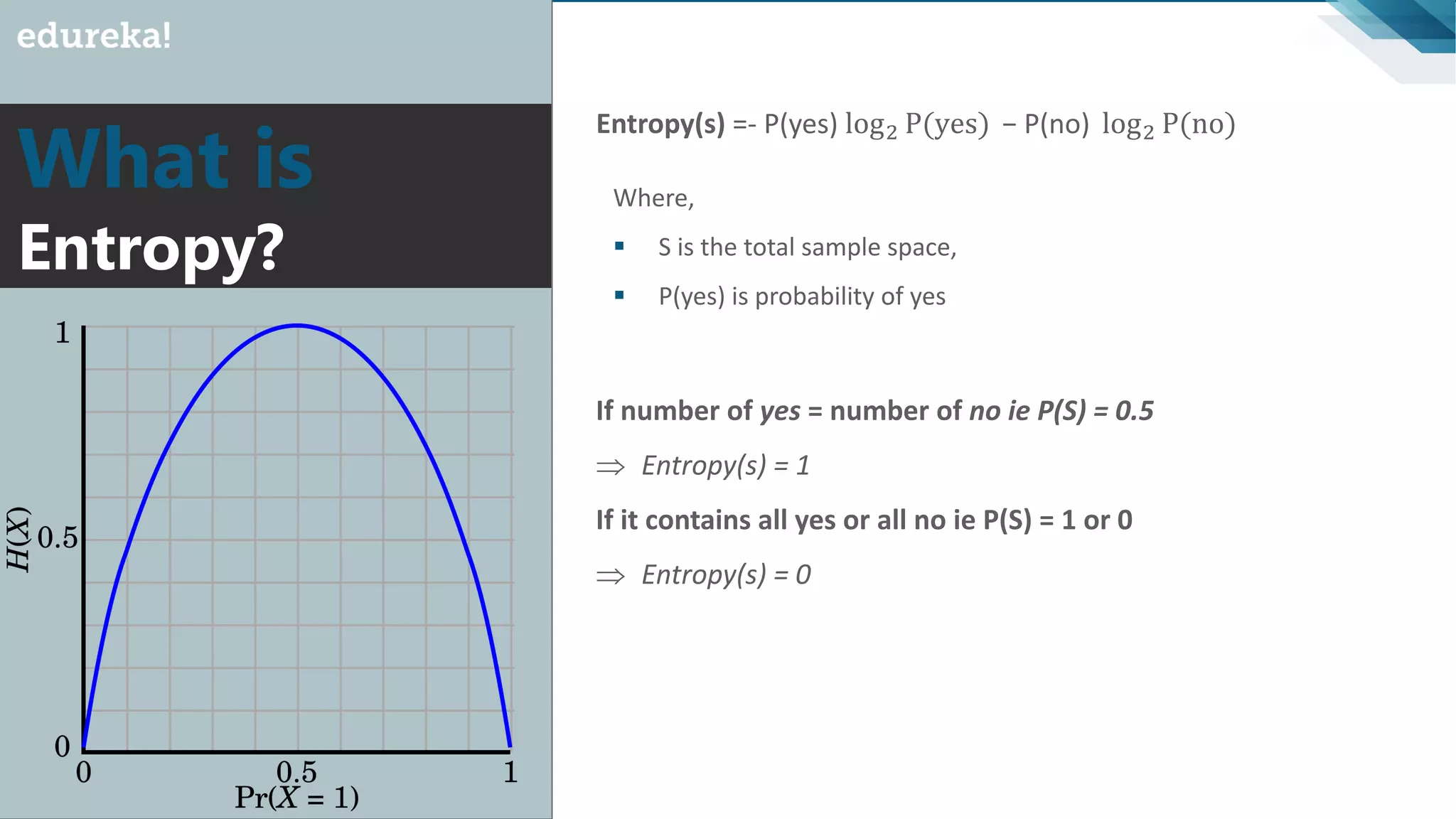
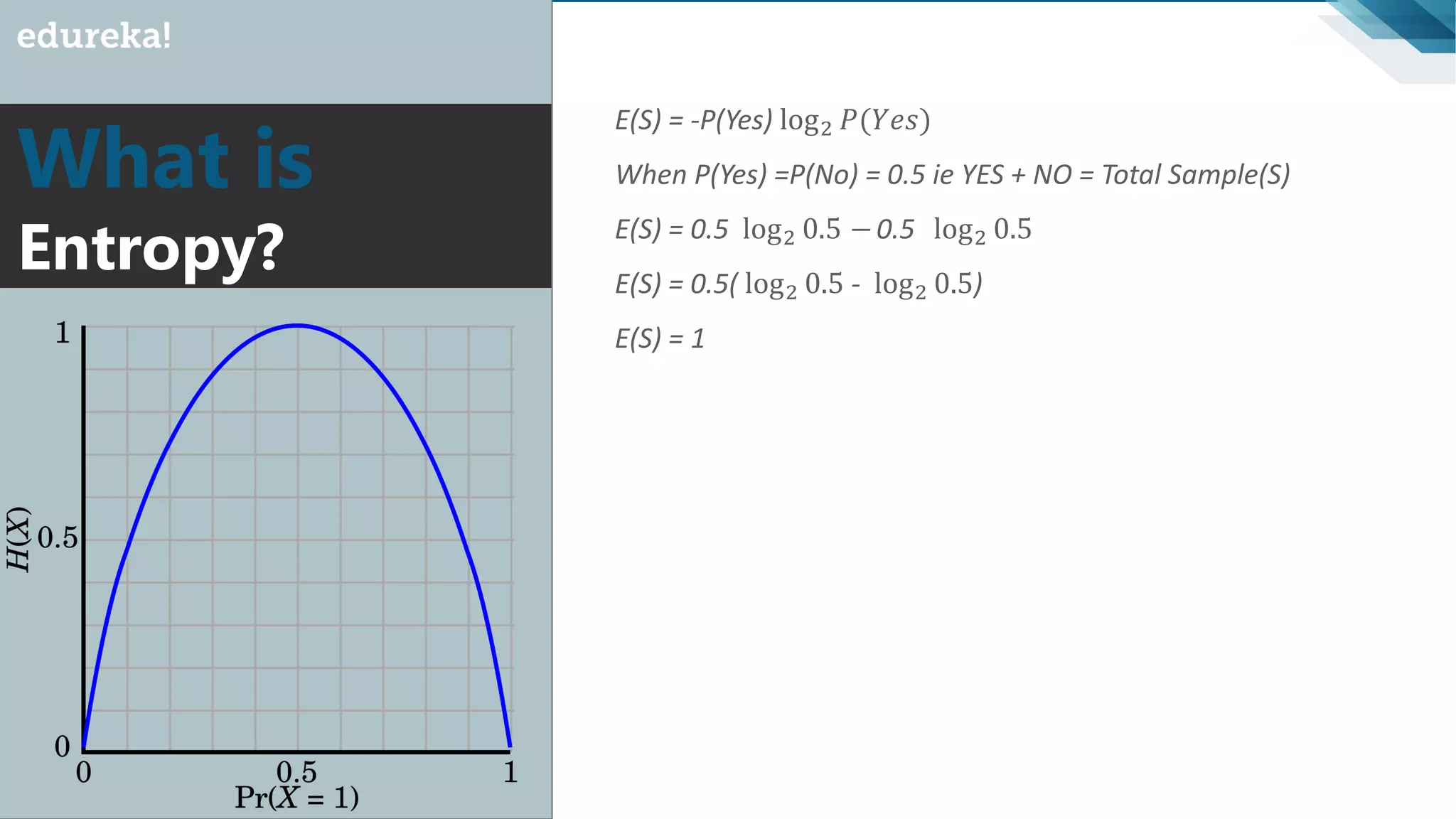
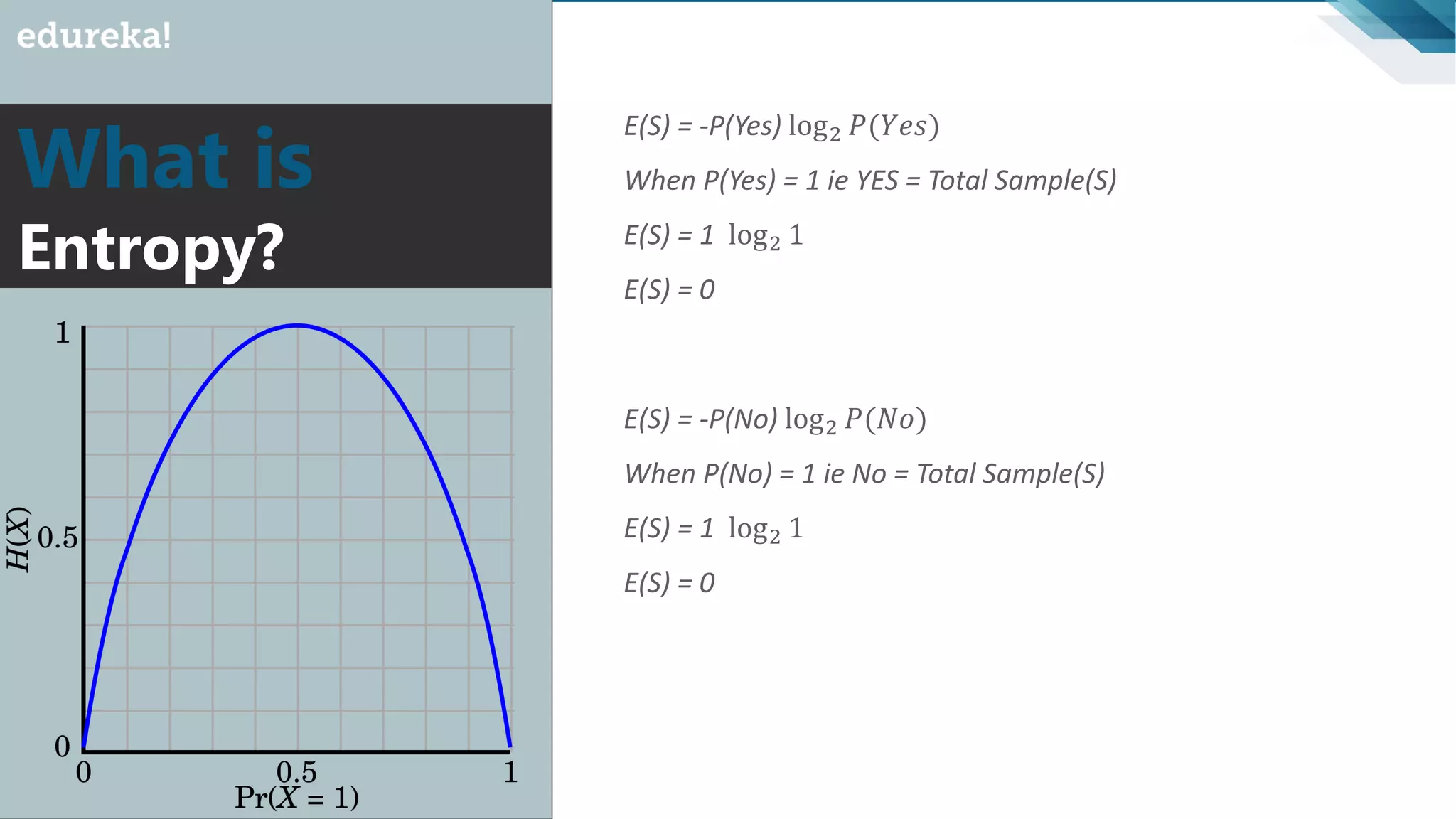
Introduction to impurity and entropy, explanation of how they relate to classification and decision tree splitting.
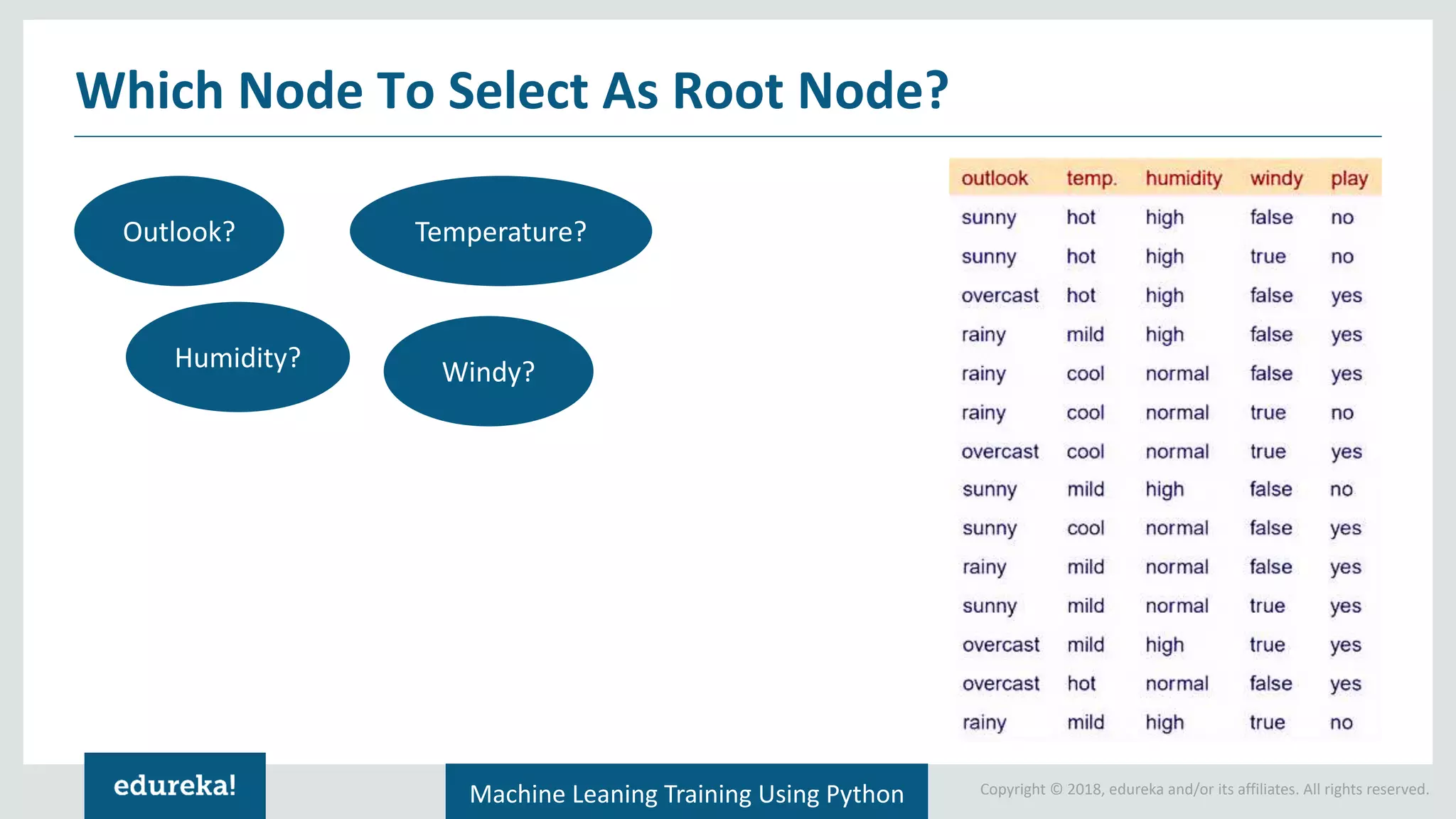
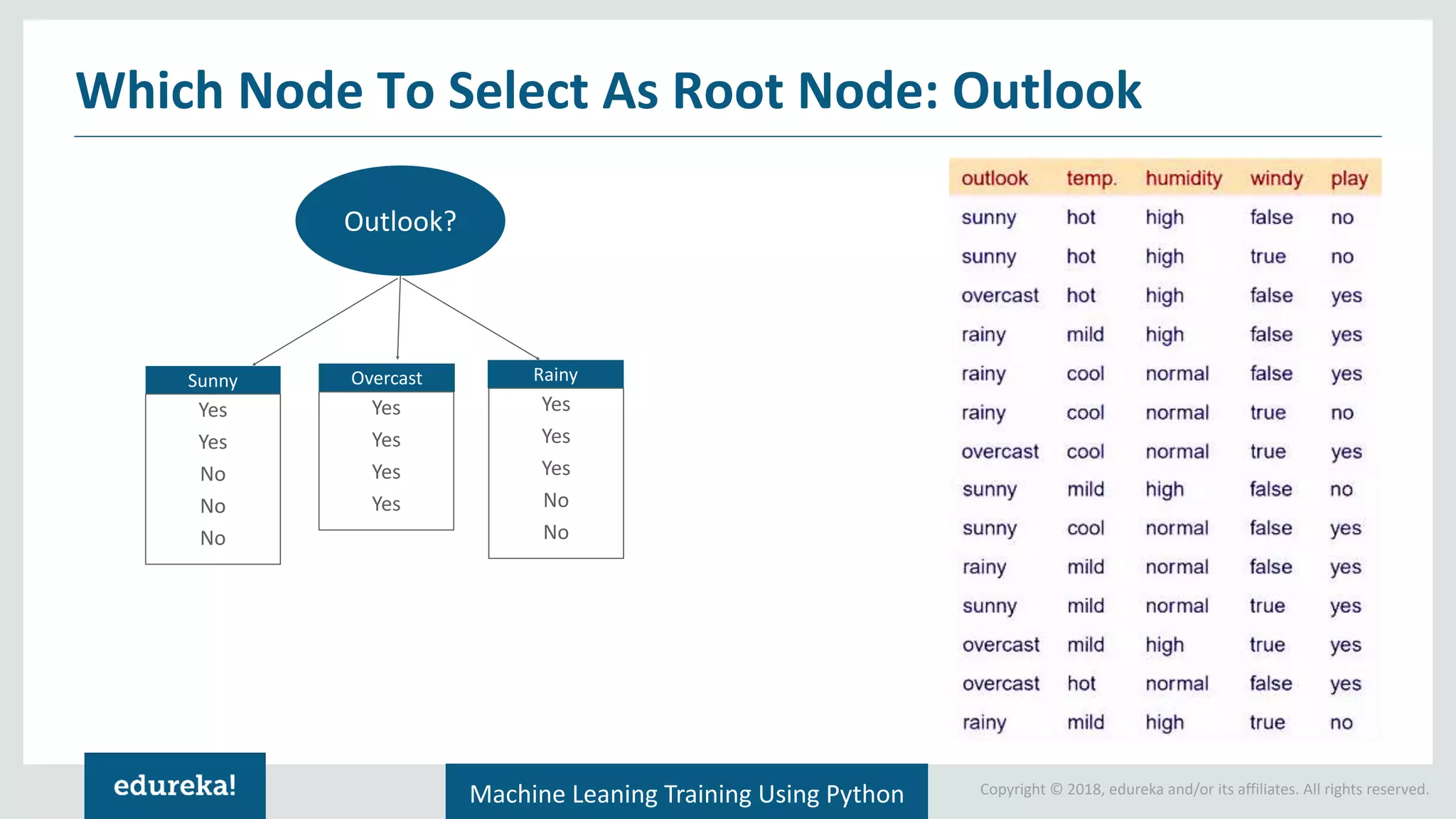
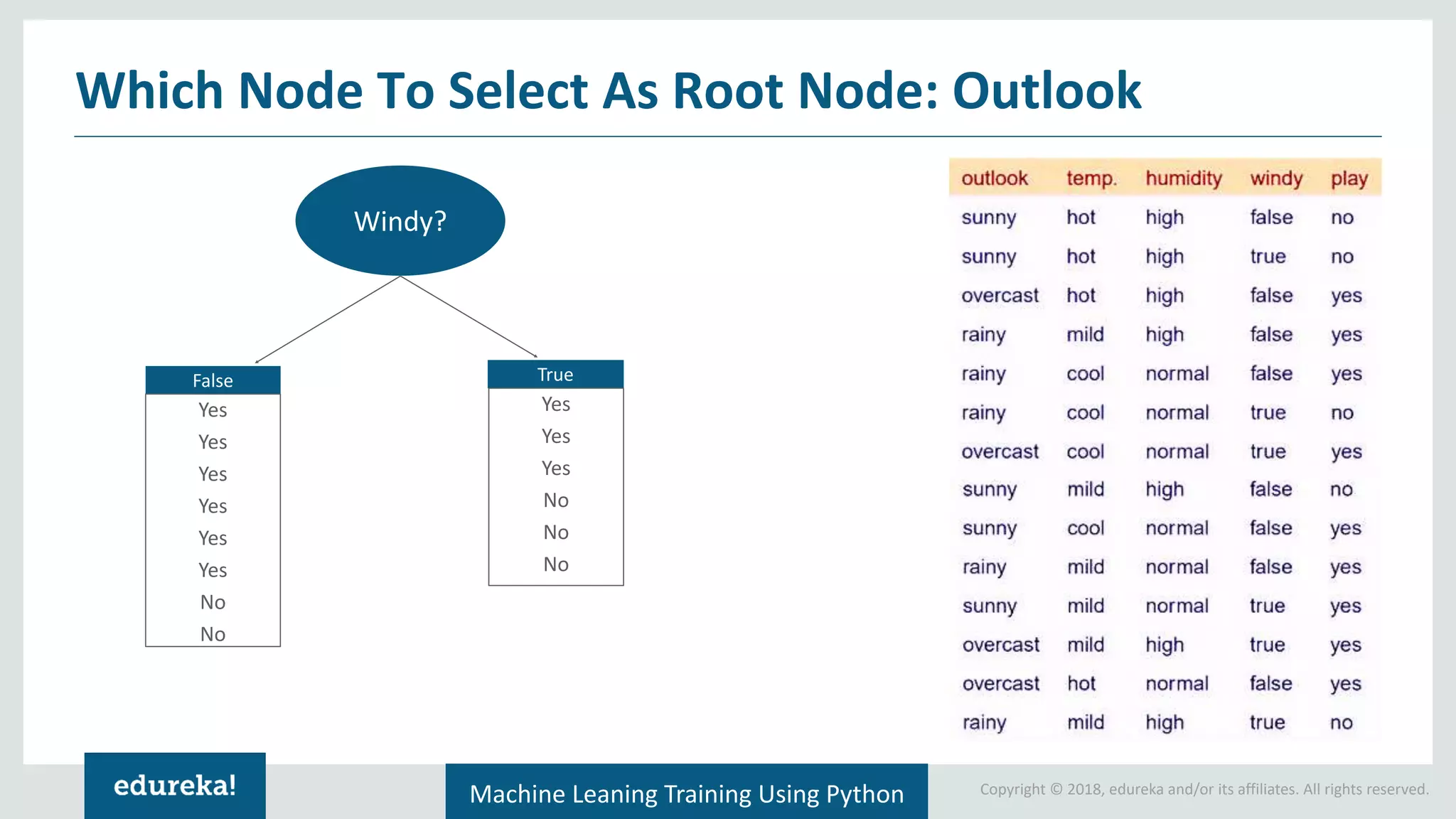
Concept of information gain in decision-making; step-by-step calculation for selecting the root node of a tree.
Discussion on pruning in decision trees to reduce complexity and comparing tree-based models to linear models.























































































