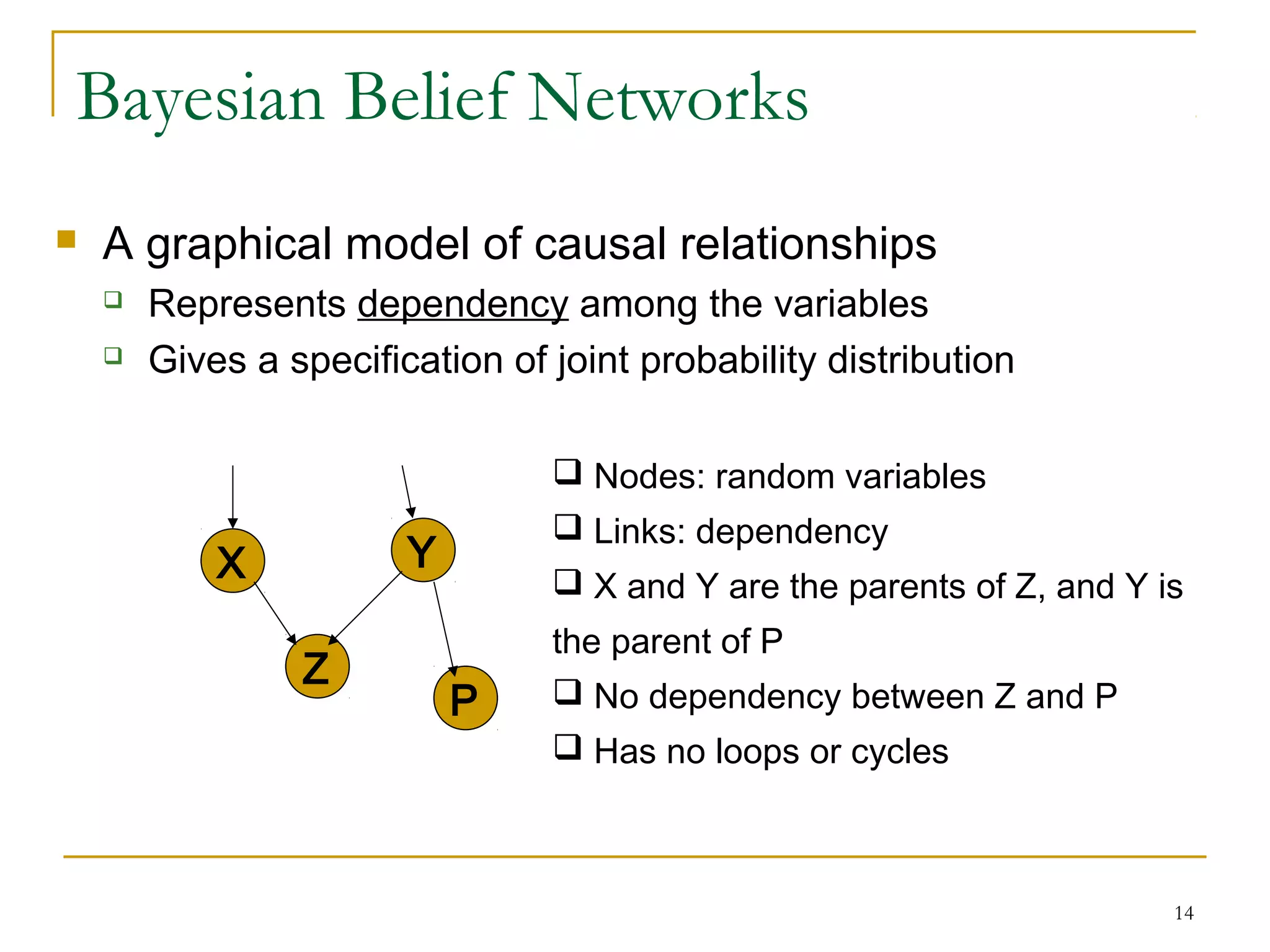
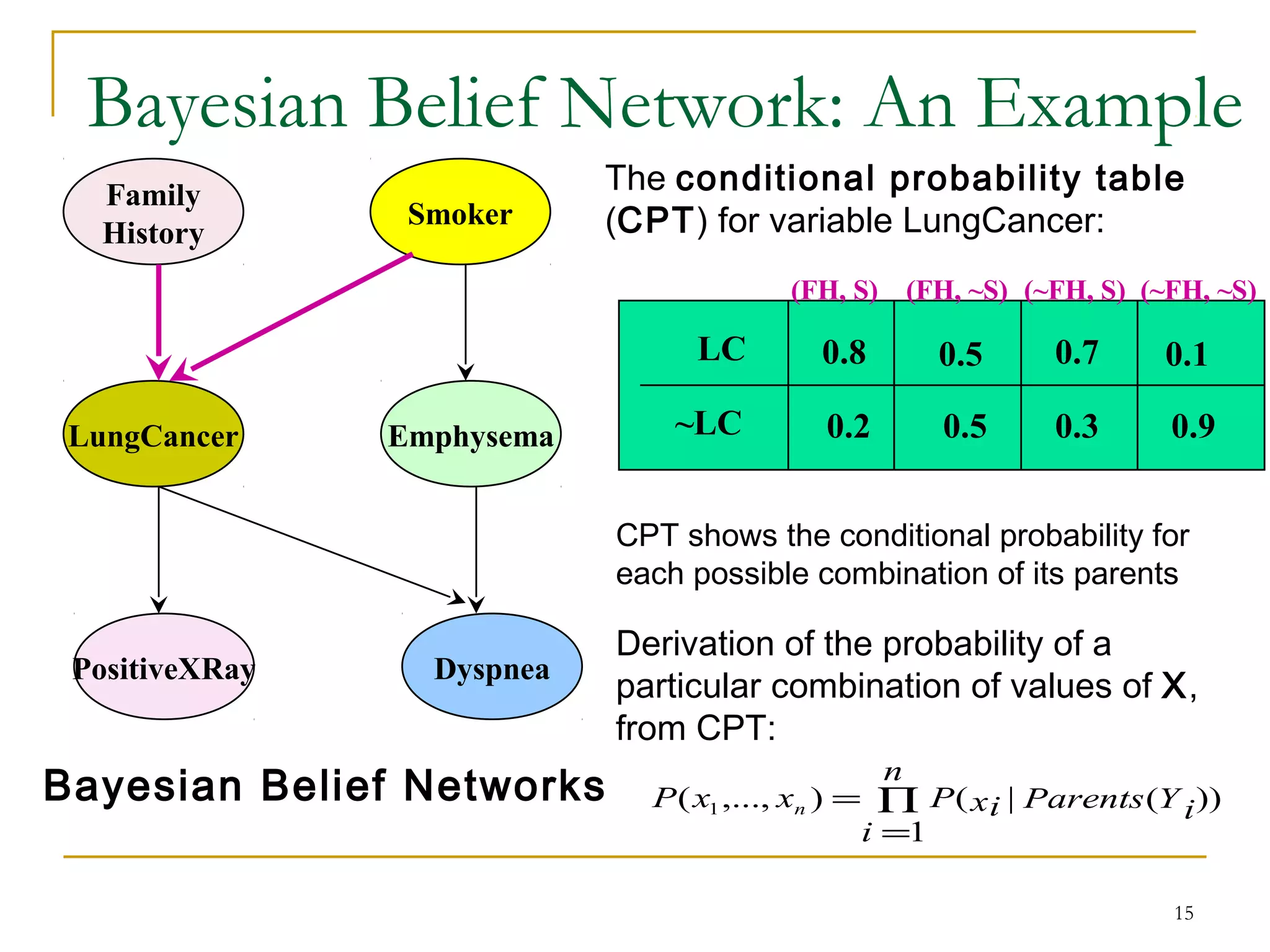
Bayesian classification is a statistical classification method that uses Bayes' theorem to calculate the probability of class membership. It provides probabilistic predictions by calculating the probabilities of classes for new data based on training data. The naive Bayesian classifier is a simple Bayesian model that assumes conditional independence between attributes, allowing faster computation. Bayesian belief networks are graphical models that represent dependencies between variables using a directed acyclic graph and conditional probability tables.


























































































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)
