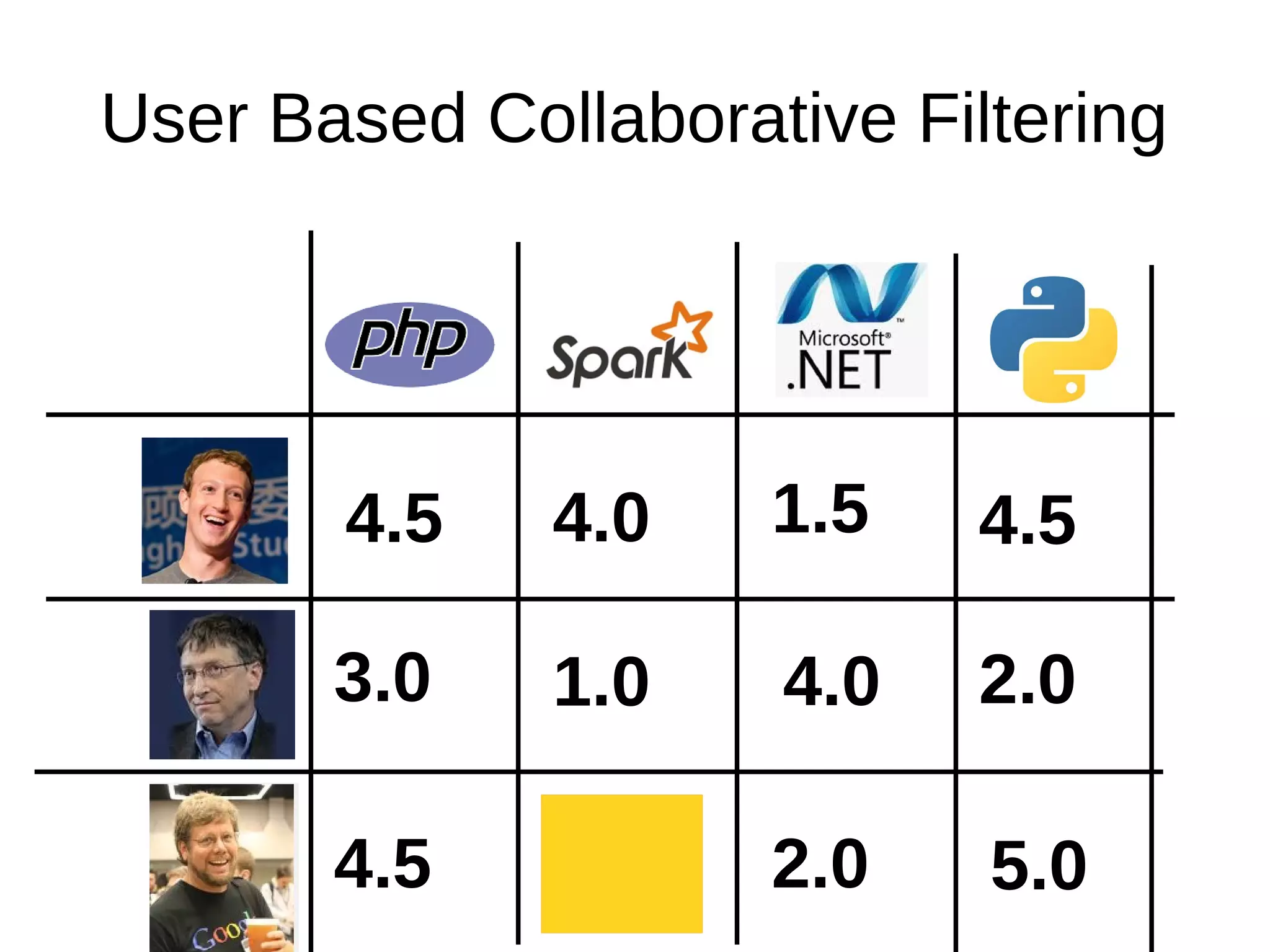
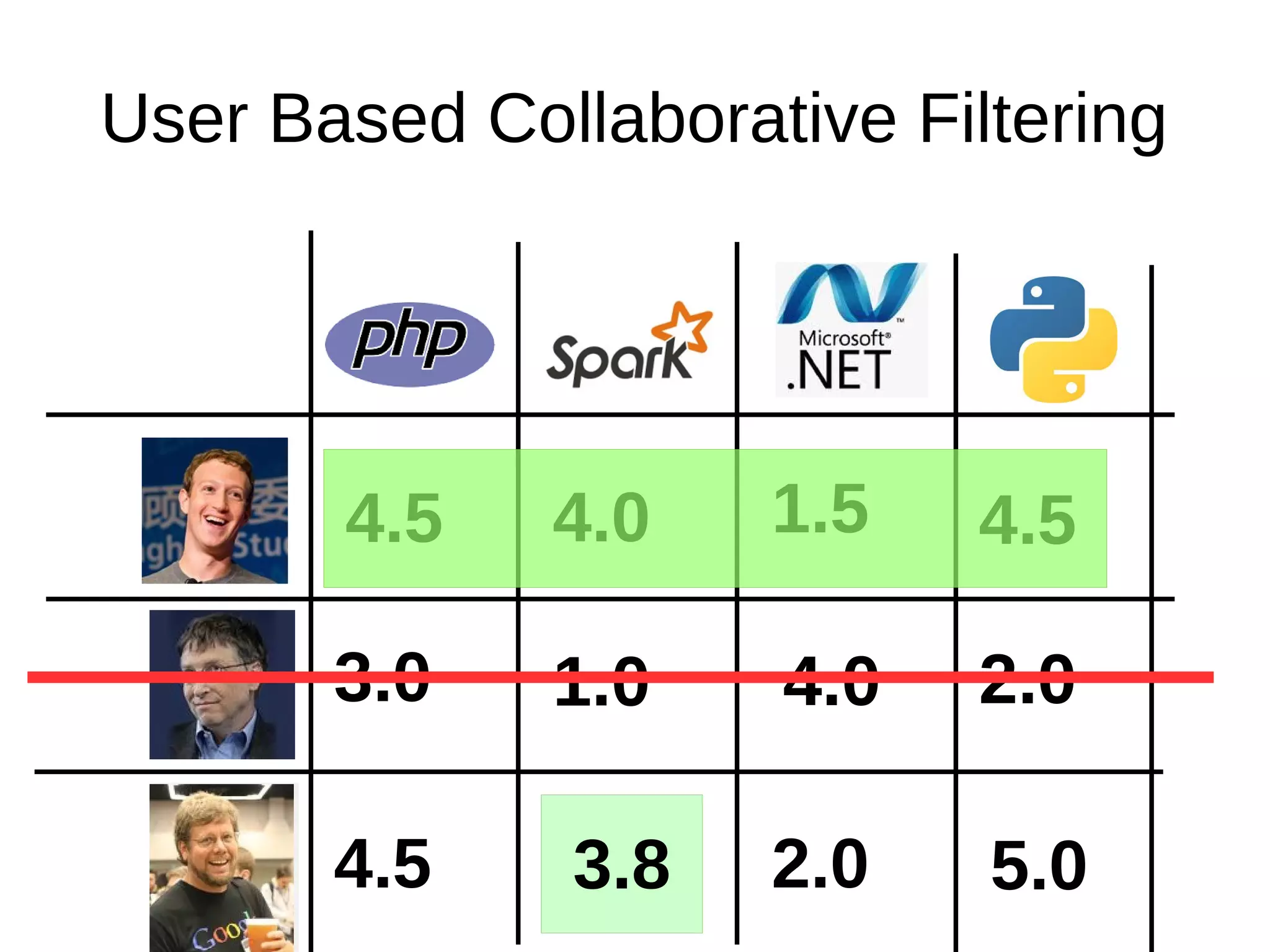
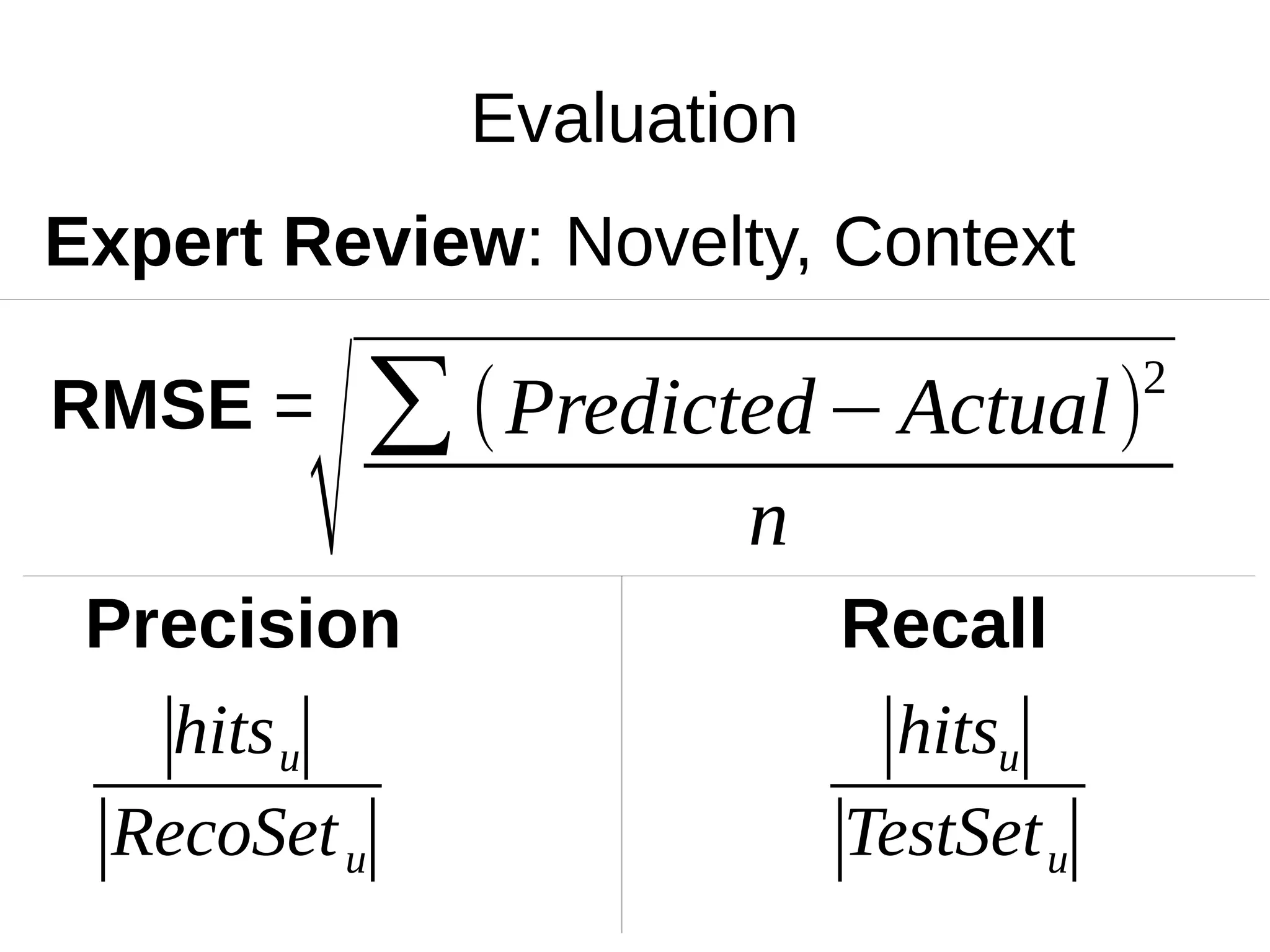
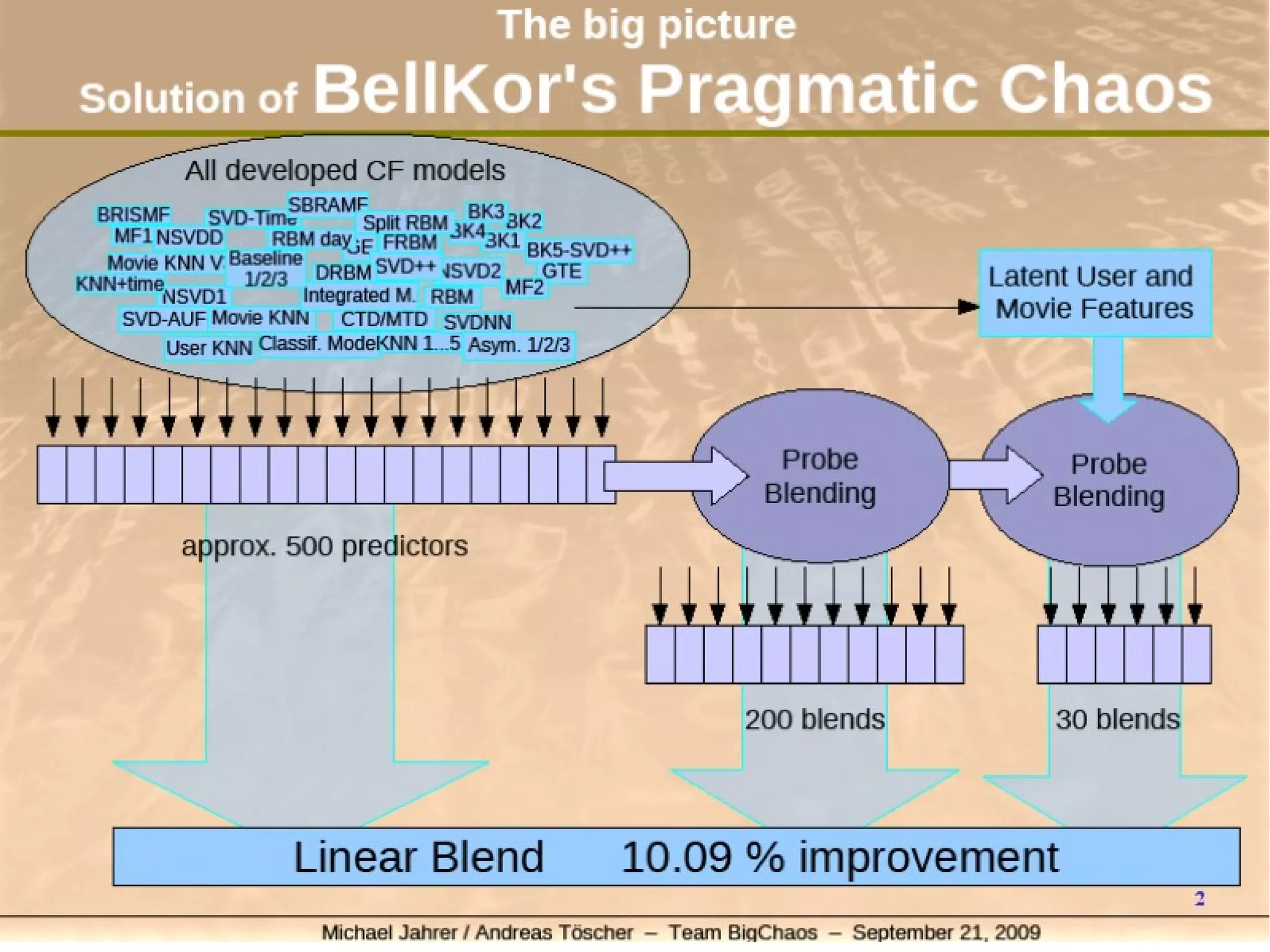
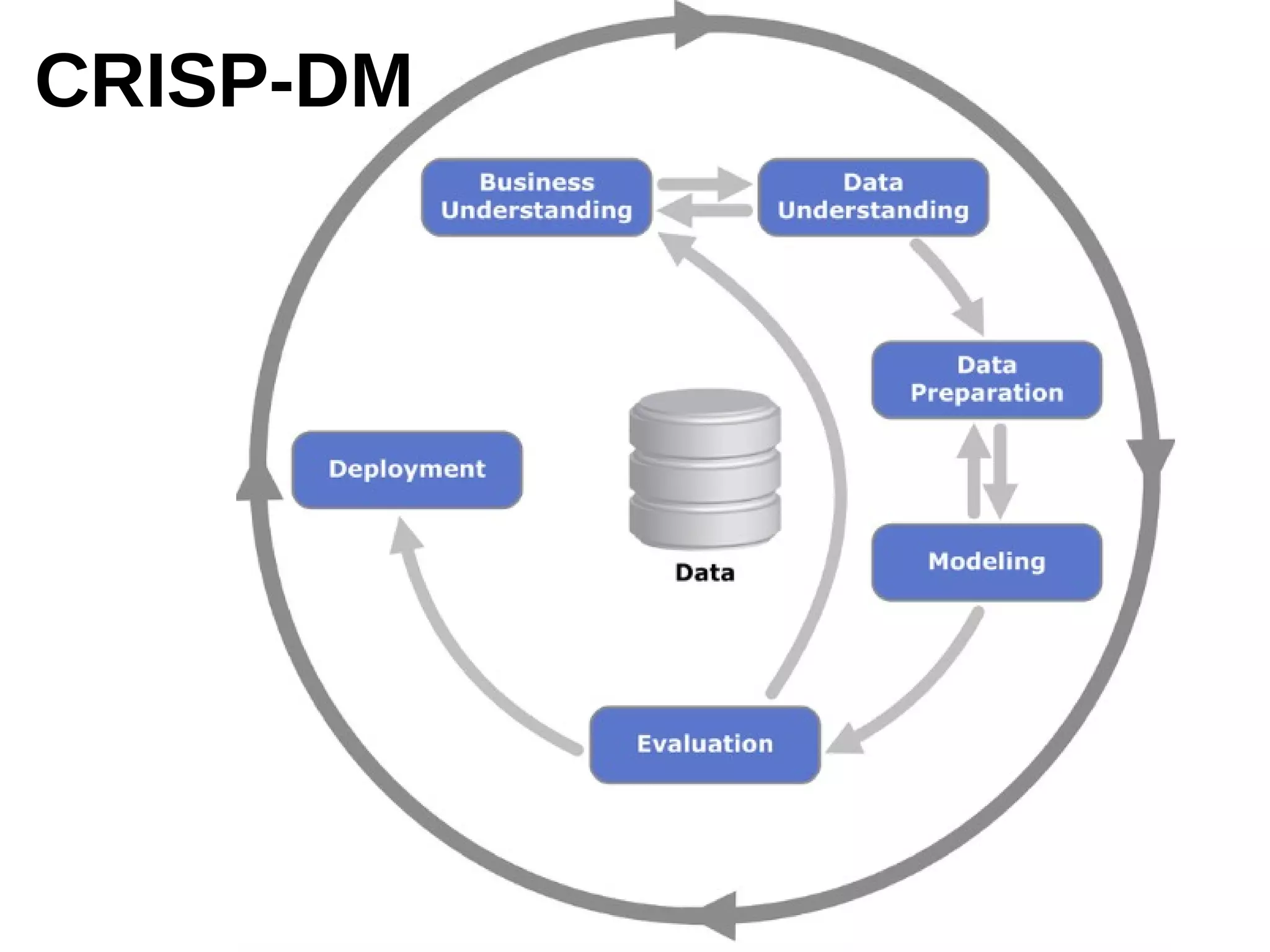
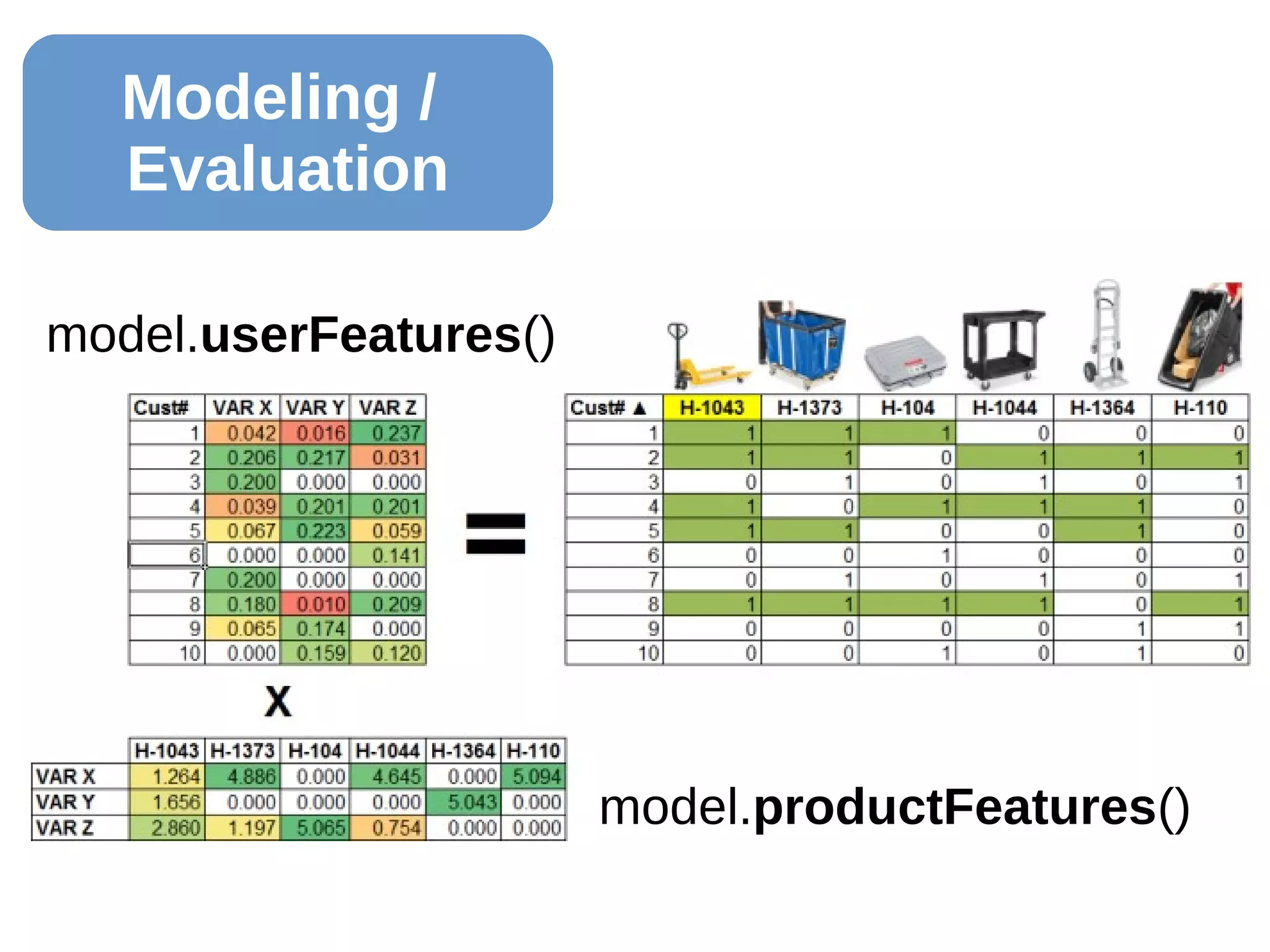
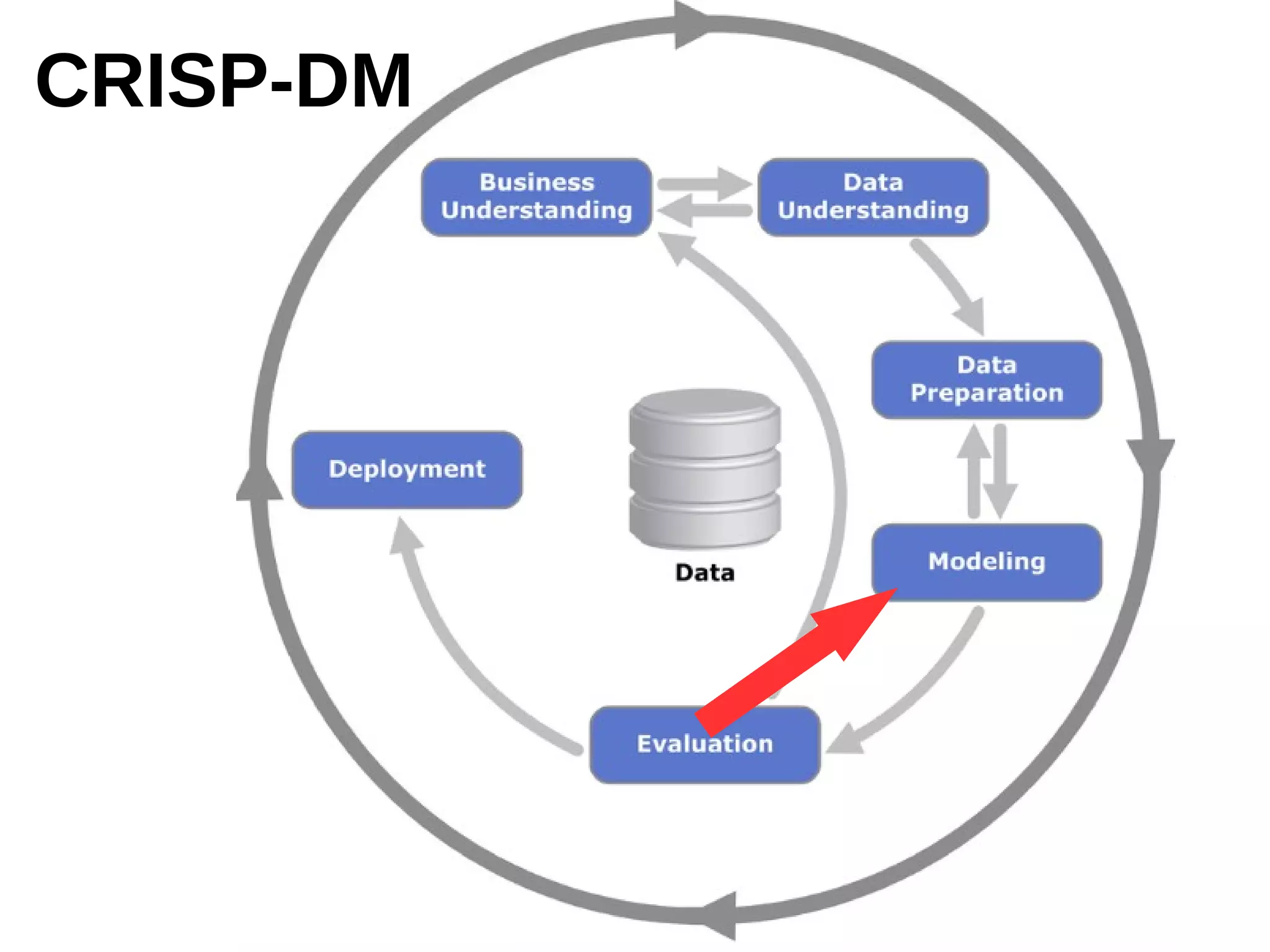
The document outlines the process of building a recommender system using PySpark, covering aspects such as data understanding, preparation, modeling, and evaluation. It details collaborative filtering techniques like user-based and item-based filtering, and includes the use of the Alternating Least Squares (ALS) algorithm for training. The evaluation metrics such as RMSE and the steps for making predictions are also discussed.






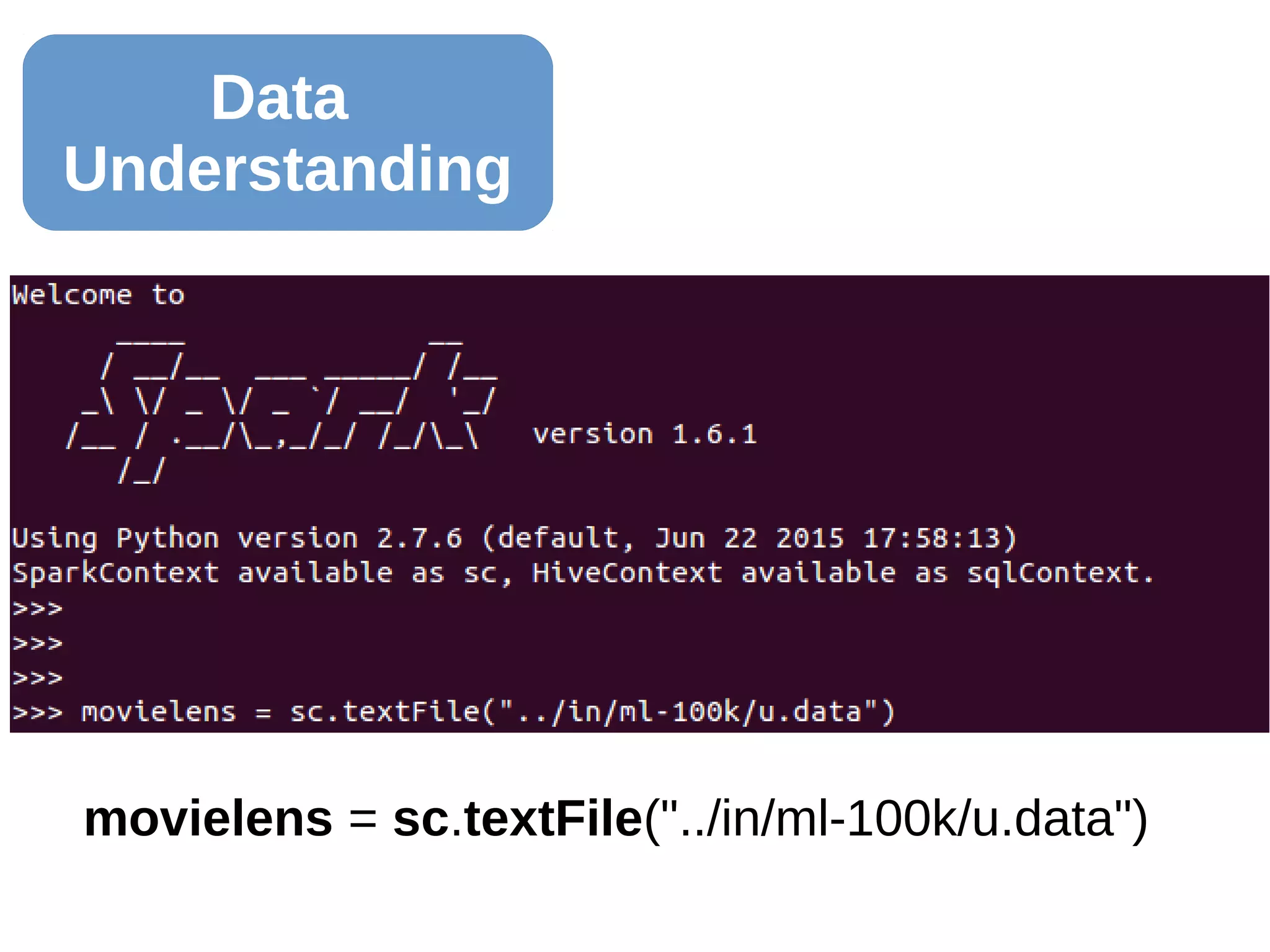
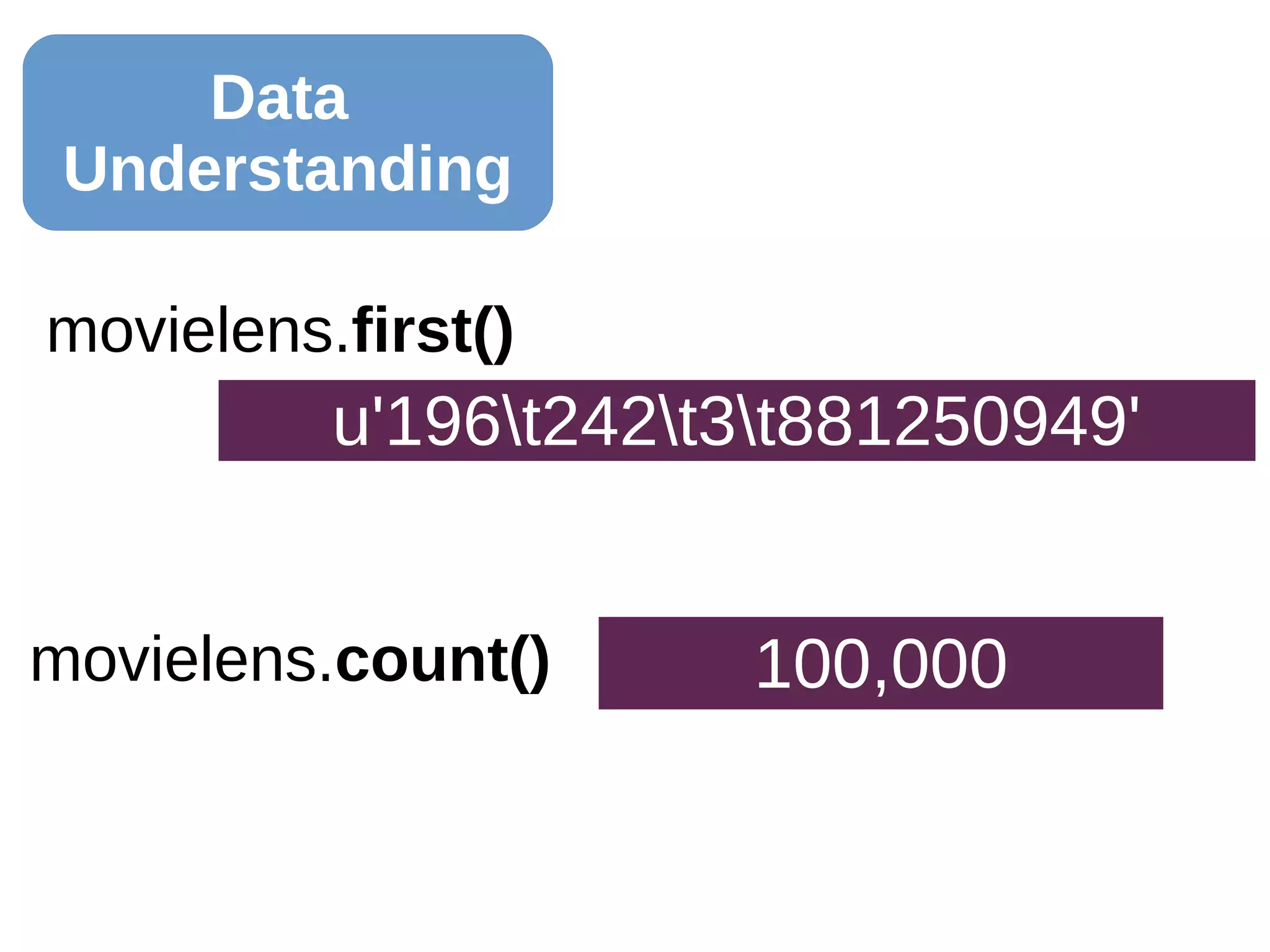
![Data
Understanding
clean_data = movielens.map(lambda x:x.split('t'))
rate = clean_data.map(lambda y: int(y[2]))
rate.mean() 3.52986
3
users = clean_data.map(lambda y: int(y[0]))
users.distinct().count() 943
clean_data.map(lambda y: int(y[1])).
distinct().count() 1,682](https://image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-20-2048.jpg)
![Data
Preparation
from pyspark.mllib.recommendation
import ALS, MatrixFactorizationModel, Rating
mls = movielens.map(lambda l: l.split('t'))
ratings = mls.map(lambda x:
Rating(int(x[0]), int(x[1]), float(x[2])))
Rating(user=196, product=242, rating=3.0)](https://image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-21-2048.jpg)
![Data
Preparation
train, test = ratings.randomSplit([0.7,0.3],7856)
train.count()
70,005
test.count()
29,995
train.cache()
test.cache()](https://image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-22-2048.jpg)


![Modeling /
Evaluation
# Predict Multi Users and Multi Products
# Pre-Processing
pred_input = train.map(lambda x:(x[0],x[1]))
# Lots of Predictions
pred = model.predictAll(pred_input)
#Returns Ratings(user, item, prediction)
(196, 242)
Rating(user=894, product=1560, rating=3.845)](https://image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-26-2048.jpg)
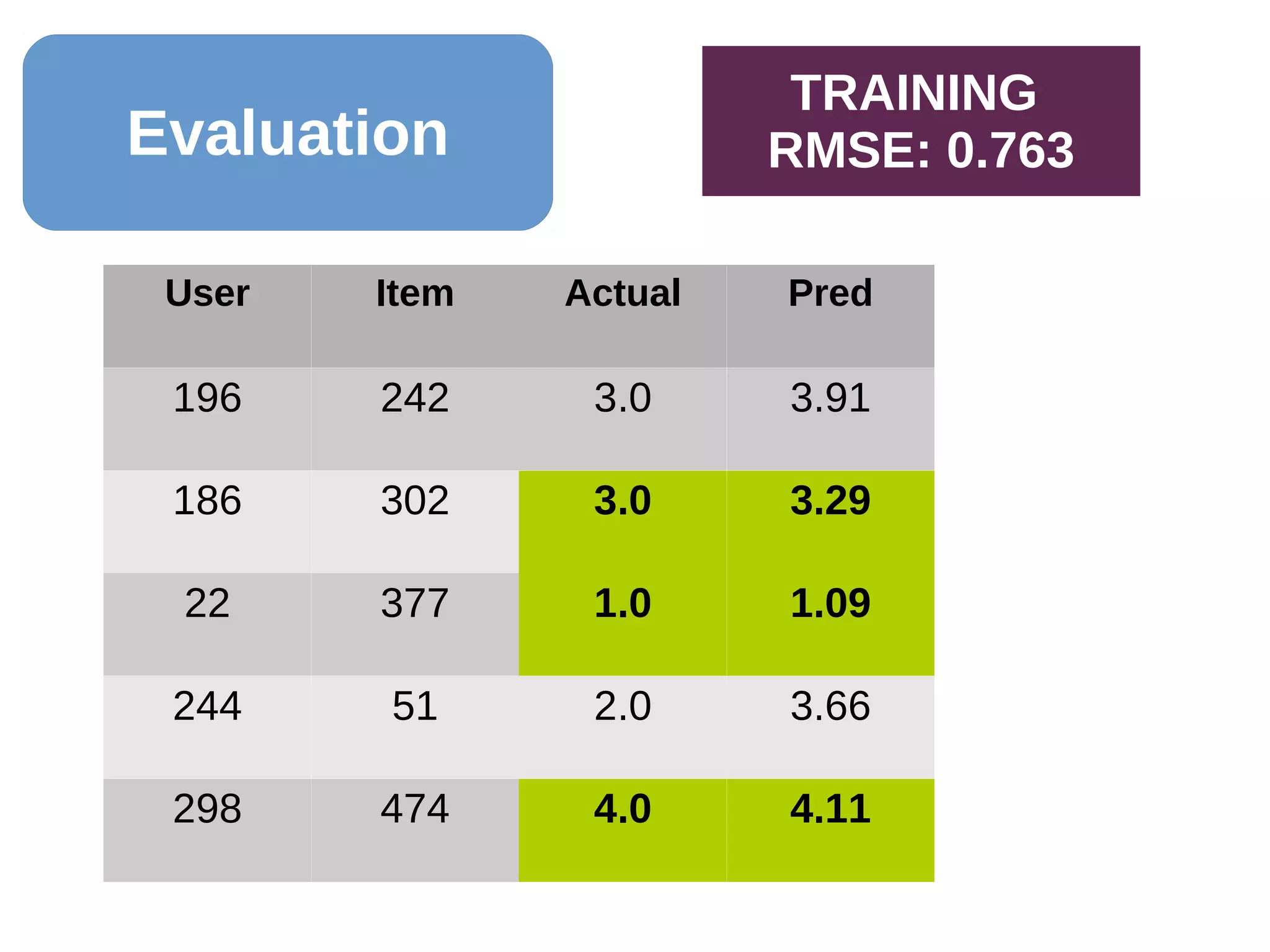
![Evaluation
#Organize the data to make (user, product) the key)
true_reorg = train.map(lambda x:((x[0],x[1]), x[2]))
pred_reorg = pred.map(lambda x:((x[0],x[1]), x[2]))
#Do the actual join
true_pred = true_reorg.join(pred_reorg)
from math import sqrt
MSE = true_pred.map(lambda r: (r[1][0] - r[1][1])**2).mean()
RMSE = sqrt(MSE)
#Results in 0.7629908117414474
((582, 1014), (4.0, 3.397))
((196, 242), 3.0)](https://image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-28-2048.jpg)
![Evaluation
test_input = test.map(lambda x:(x[0],x[1]))
pred_test = model.predictAll(test_input)
test_reorg = test.map(lambda x:((x[0],x[1]), x[2]))
pred_reorg = pred_test.map(lambda x:
((x[0],x[1]), x[2]))
test_pred = test_reorg.join(pred_reorg)
test_MSE = test_pred.map(lambda r:
(r[1][0] - r[1][1])**2).mean()
test_RMSE = sqrt(test_MSE)
TEST
RMSE: 1.0145](https://image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-29-2048.jpg)






















![Data
Understanding
clean_data = movielens.map(lambda x:x.split('t'))
rate = clean_data.map(lambda y: int(y[2]))
rate.mean() 3.52986
3
users = clean_data.map(lambda y: int(y[0]))
users.distinct().count() 943
clean_data.map(lambda y: int(y[1])).
distinct().count() 1,682](https://crownmelresort.com/image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-20-2048.jpg)
![Data
Preparation
from pyspark.mllib.recommendation
import ALS, MatrixFactorizationModel, Rating
mls = movielens.map(lambda l: l.split('t'))
ratings = mls.map(lambda x:
Rating(int(x[0]), int(x[1]), float(x[2])))
Rating(user=196, product=242, rating=3.0)](https://crownmelresort.com/image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-21-2048.jpg)
![Data
Preparation
train, test = ratings.randomSplit([0.7,0.3],7856)
train.count()
70,005
test.count()
29,995
train.cache()
test.cache()](https://crownmelresort.com/image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-22-2048.jpg)



![Modeling /
Evaluation
# Predict Multi Users and Multi Products
# Pre-Processing
pred_input = train.map(lambda x:(x[0],x[1]))
# Lots of Predictions
pred = model.predictAll(pred_input)
#Returns Ratings(user, item, prediction)
(196, 242)
Rating(user=894, product=1560, rating=3.845)](https://crownmelresort.com/image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-26-2048.jpg)

![Evaluation
#Organize the data to make (user, product) the key)
true_reorg = train.map(lambda x:((x[0],x[1]), x[2]))
pred_reorg = pred.map(lambda x:((x[0],x[1]), x[2]))
#Do the actual join
true_pred = true_reorg.join(pred_reorg)
from math import sqrt
MSE = true_pred.map(lambda r: (r[1][0] - r[1][1])**2).mean()
RMSE = sqrt(MSE)
#Results in 0.7629908117414474
((582, 1014), (4.0, 3.397))
((196, 242), 3.0)](https://crownmelresort.com/image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-28-2048.jpg)
![Evaluation
test_input = test.map(lambda x:(x[0],x[1]))
pred_test = model.predictAll(test_input)
test_reorg = test.map(lambda x:((x[0],x[1]), x[2]))
pred_reorg = pred_test.map(lambda x:
((x[0],x[1]), x[2]))
test_pred = test_reorg.join(pred_reorg)
test_MSE = test_pred.map(lambda r:
(r[1][0] - r[1][1])**2).mean()
test_RMSE = sqrt(test_MSE)
TEST
RMSE: 1.0145](https://crownmelresort.com/image.slidesharecdn.com/20160503mkebdrecosys-160501205055/75/Recommender-Systems-with-Apache-Spark-s-ALS-Function-29-2048.jpg)
































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)
















