Downloaded 115 times




![[user; item; time; rating]
𝑅
Batch training
𝑈
item vector
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
PERSISTENT STORAGE](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-14-2048.jpg)
![[user; item; time; rating]
𝑅
Batch training
𝑈
item vector
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
PERSISTENT STORAGE](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-15-2048.jpg)
![[user; item; time; rating]
𝑅
Batch training
𝑈
item vector
3
2
5
5
3
2
5 -6 -1
5 4 -4
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
PERSISTENT STORAGE](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-16-2048.jpg)
![𝑅
Online training
𝑈
item vector
3
2
5
5
3
2
5 -6 -1
5 4 -4
5
1
3
user
vector
5 3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
2 5 4 2 4](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-17-2048.jpg)
![𝑅
Online training
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-18-2048.jpg)
![𝑅
Online training
𝑈
item vector
1
3
5
5
3
2
4 -5 -1
5 4 -4
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-19-2048.jpg)

![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
2 5 4 2 4](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-23-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-24-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4
3
2
6
25 -6 -2
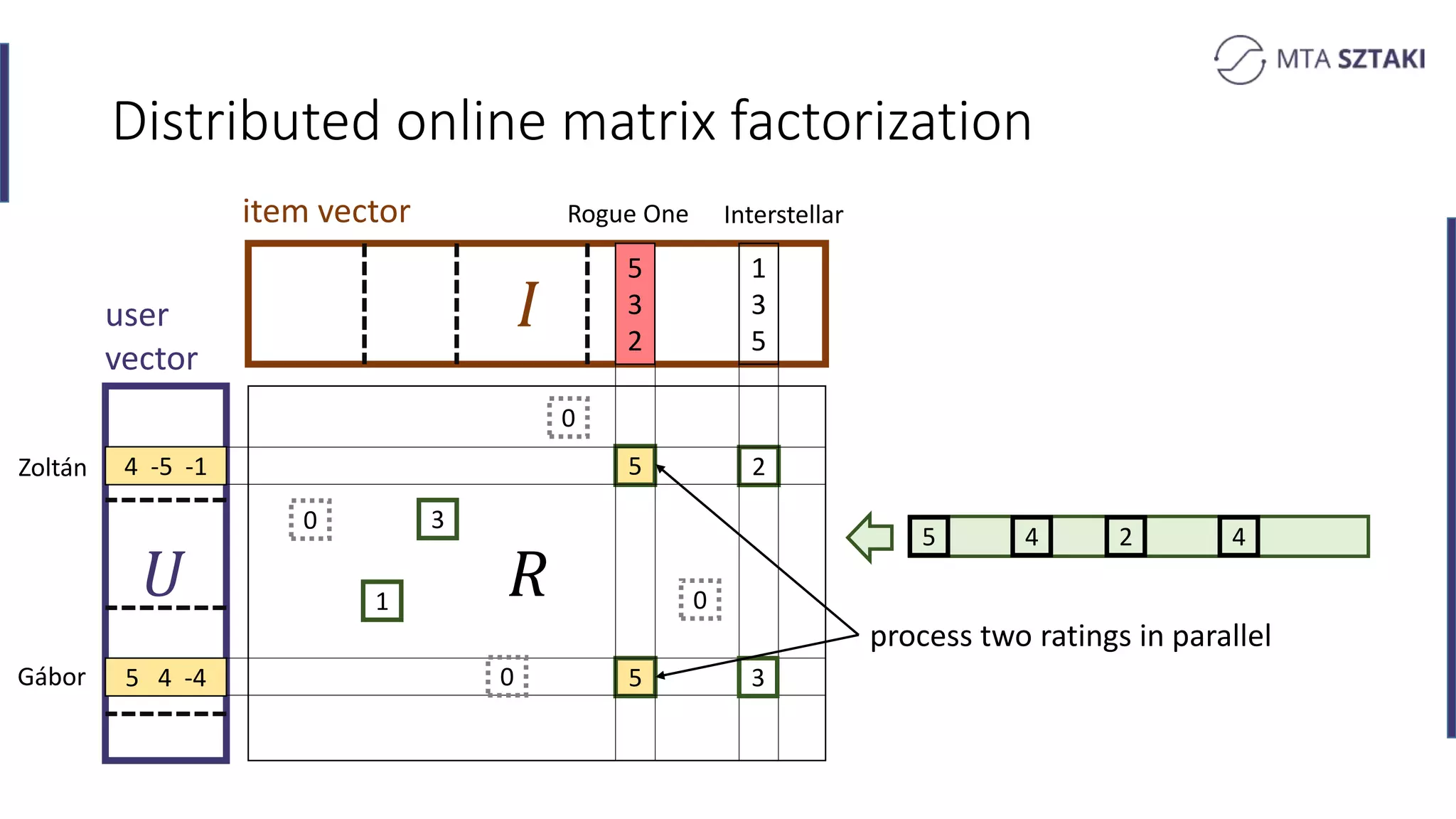
need to co-locate](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-25-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4
1
3
5
24 -3 -1
need to co-locate
then update](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-26-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
1
3
5
5
3
2
4 -5 -1
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4
1
3
5
24 -3 -1
need to co-locate
then update
send updates](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-27-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
we have our input](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-31-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-32-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this
updateStateByKey?](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-33-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this
updateStateByKey?
Use batch DSGD for online updates!
(discussion issue SPARK-6407)](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-34-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this
need to represent factor matrices](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-35-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
ratings.transform { (rs: RDD[Rating]) =>
we have our input
would like to have output like this
use transform to allow RDD operations
need to represent factor matrices](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-36-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
ratings.transform { (rs: RDD[Rating]) =>
val updates = batchDSGD(rs, users, items)
we have our input
would like to have output like this
use transform to allow RDD operations
need to represent factor matrices
compute updates](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-37-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
ratings.transform { (rs: RDD[Rating]) =>
val updates = batchDSGD(rs, users, items)
users = applyUserUpdates(users, updates)
items = applyItemUpdates(items, updates)
updates
}
we have our input
would like to have output like this
use transform to allow RDD operations
need to represent factor matrices
compute updates
apply updates to get updated matrices](https://image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-38-2048.jpg)

















![[user; item; time; rating]
𝑅
Batch training
𝑈
item vector
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
PERSISTENT STORAGE](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-14-2048.jpg)
![[user; item; time; rating]
𝑅
Batch training
𝑈
item vector
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
PERSISTENT STORAGE](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-15-2048.jpg)
![[user; item; time; rating]
𝑅
Batch training
𝑈
item vector
3
2
5
5
3
2
5 -6 -1
5 4 -4
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
PERSISTENT STORAGE](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-16-2048.jpg)
![𝑅
Online training
𝑈
item vector
3
2
5
5
3
2
5 -6 -1
5 4 -4
5
1
3
user
vector
5 3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
2 5 4 2 4](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-17-2048.jpg)
![𝑅
Online training
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-18-2048.jpg)
![𝑅
Online training
𝑈
item vector
1
3
5
5
3
2
4 -5 -1
5 4 -4
5
1
3
user
vector
5
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-19-2048.jpg)



![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
2 5 4 2 4](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-23-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-24-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4
3
2
6
25 -6 -2
need to co-locate](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-25-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
3
2
6
5
3
2
5 -6 -2
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4
1
3
5
24 -3 -1
need to co-locate
then update](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-26-2048.jpg)
![𝑅
Distributed online matrix factorization
𝑈
item vector
1
3
5
5
3
2
4 -5 -1
5 4 -4
1
3
user
vector
2
3
0
0
0
0
Zoltán
Gábor
Rogue One Interstellar
[user; item; time; rating]
5 4 2 4
1
3
5
24 -3 -1
need to co-locate
then update
send updates](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-27-2048.jpg)



![Online MF in Spark
val ratings: DStream[Rating] = ...
we have our input](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-31-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-32-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this
updateStateByKey?](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-33-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this
updateStateByKey?
Use batch DSGD for online updates!
(discussion issue SPARK-6407)](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-34-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
we have our input
would like to have output like this
need to represent factor matrices](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-35-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
ratings.transform { (rs: RDD[Rating]) =>
we have our input
would like to have output like this
use transform to allow RDD operations
need to represent factor matrices](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-36-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
ratings.transform { (rs: RDD[Rating]) =>
val updates = batchDSGD(rs, users, items)
we have our input
would like to have output like this
use transform to allow RDD operations
need to represent factor matrices
compute updates](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-37-2048.jpg)
![Online MF in Spark
val ratings: DStream[Rating] = ...
var users: RDD[(UserId, Vector)] = ...
var items: RDD[(ItemId, Vector)] = ...
val updateStream: DStream[Either[(UserId, Vector), (ItemId, Vector)]] =
ratings.transform { (rs: RDD[Rating]) =>
val updates = batchDSGD(rs, users, items)
users = applyUserUpdates(users, updates)
items = applyItemUpdates(items, updates)
updates
}
we have our input
would like to have output like this
use transform to allow RDD operations
need to represent factor matrices
compute updates
apply updates to get updated matrices](https://crownmelresort.com/image.slidesharecdn.com/april61610hungarianacademyofscienceszvarahermann-170411152807/75/Building-a-Large-Scale-Adaptive-Recommendation-Engine-with-Apache-Flink-and-Spark-38-2048.jpg)





























The document discusses the development of a large-scale adaptive recommendation engine using Apache Flink and Spark, funded by the European Union's Horizon 2020 program. It covers key topics including recommendation systems, matrix factorization, and differences between batch and online methods, while comparing the capabilities of Spark and Flink for implementing these systems. The conclusion emphasizes lessons learned regarding code stability, performance, and handling data skew in machine learning applications.
Introduction to building a recommendation engine using Flink and Spark. Overview of the presenters and their research background.
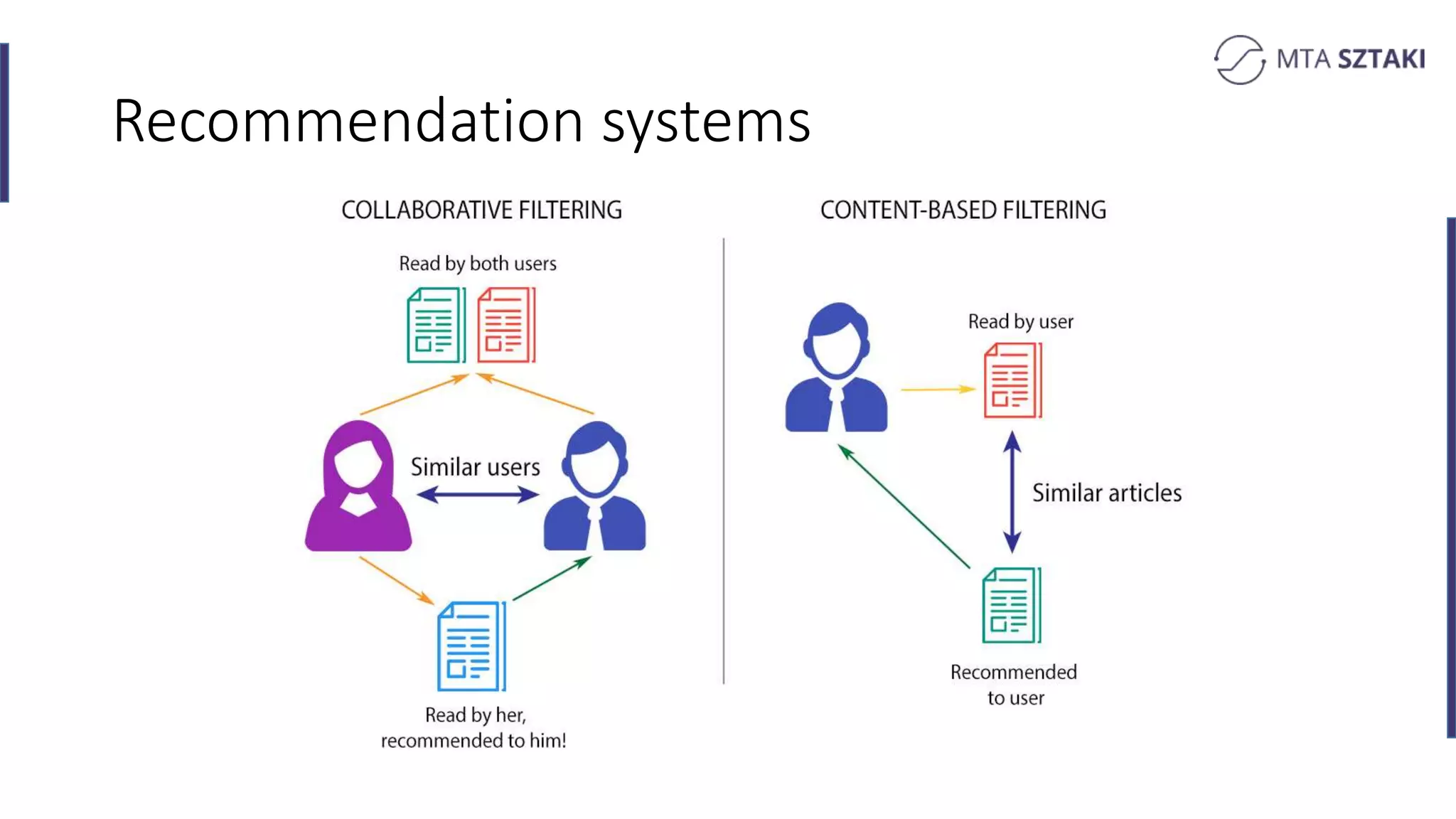
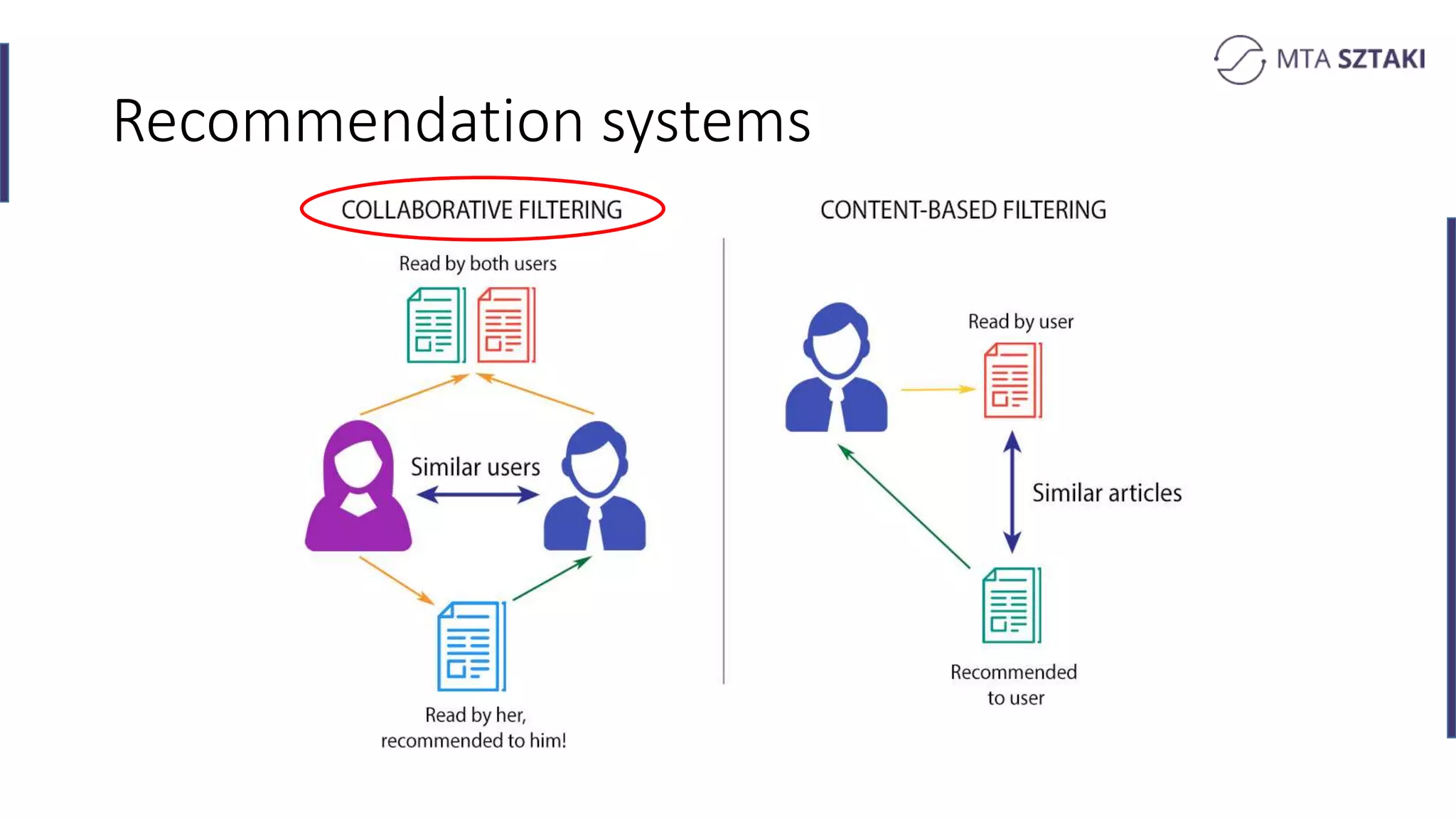
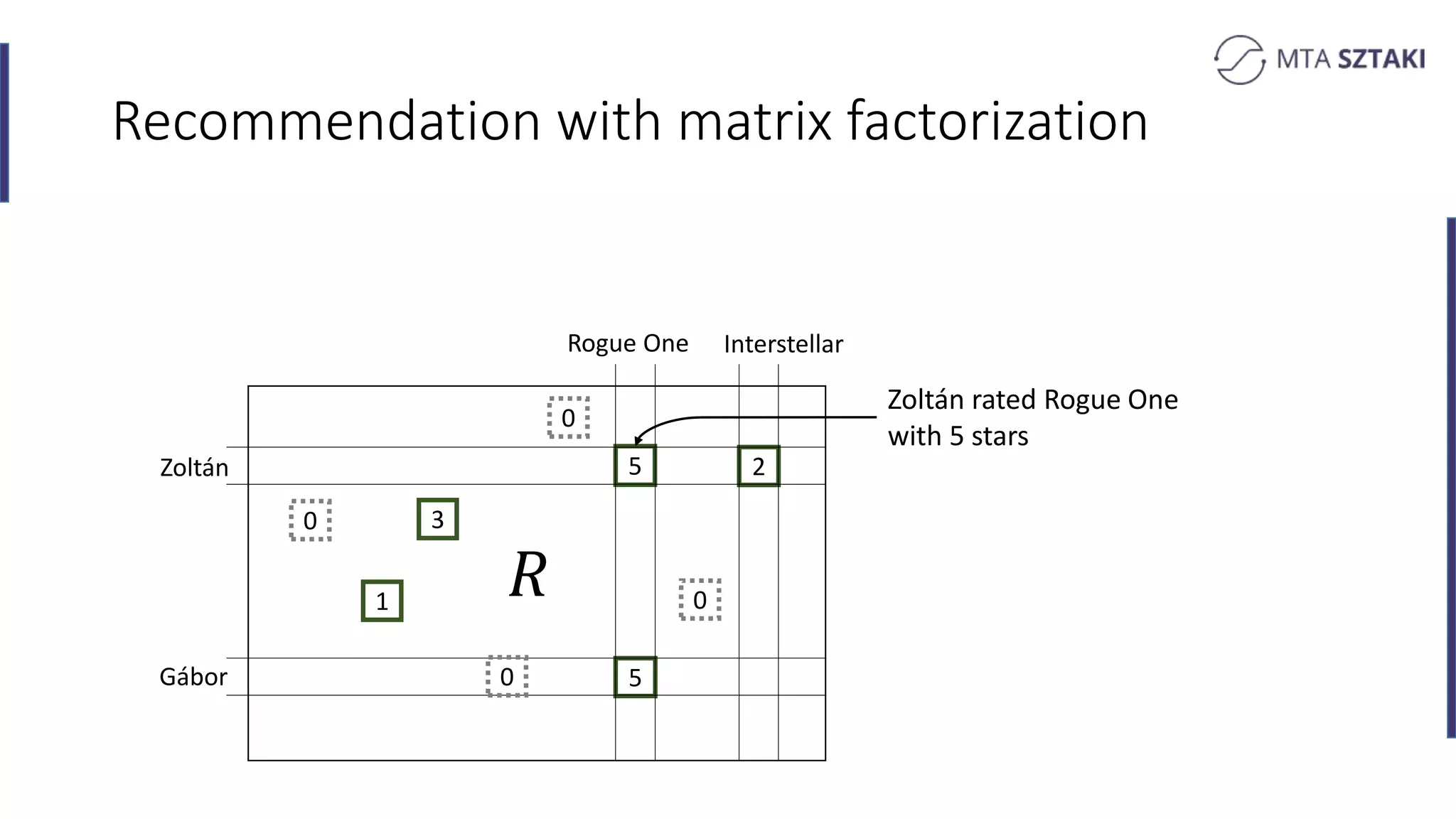
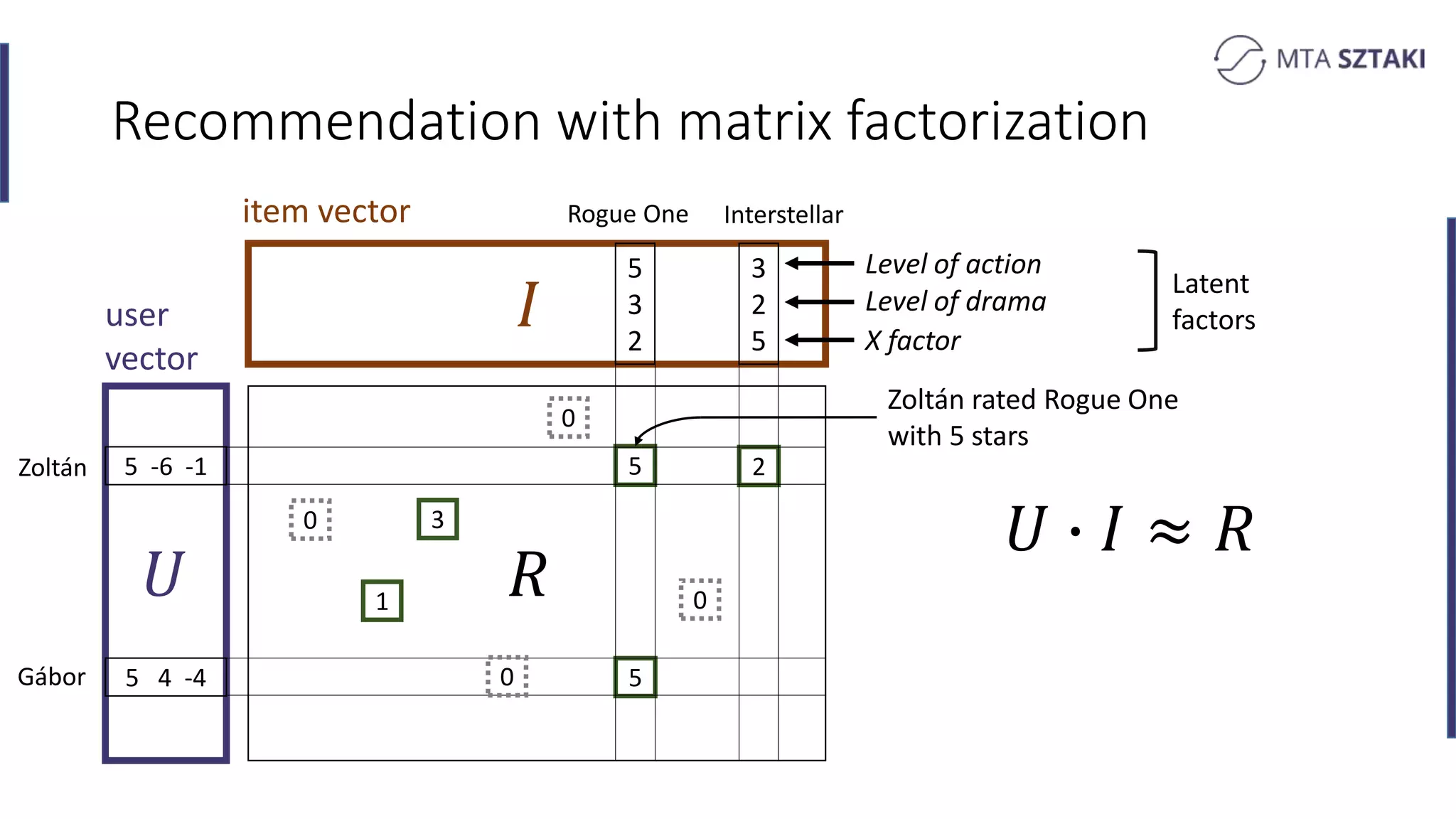
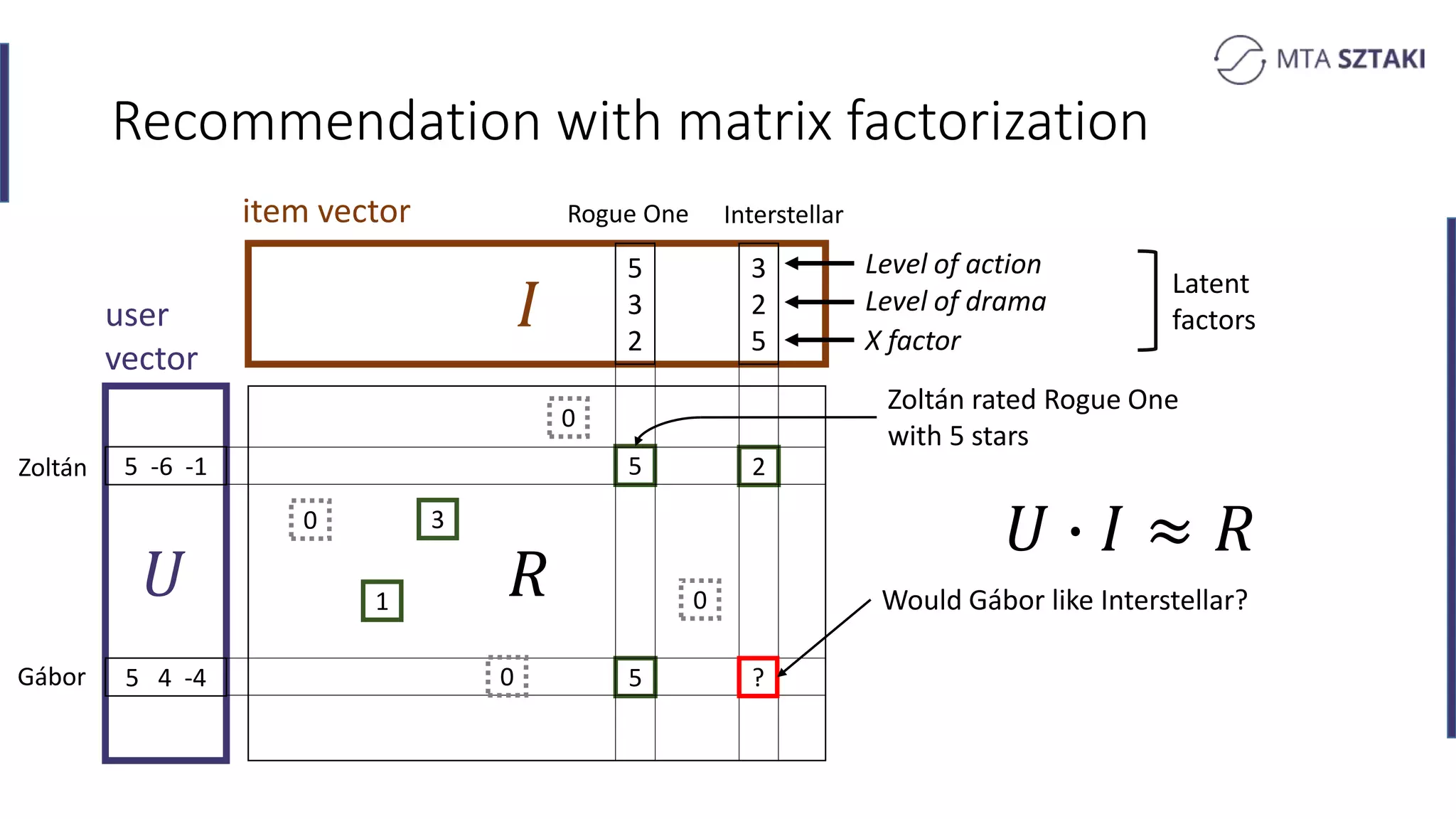
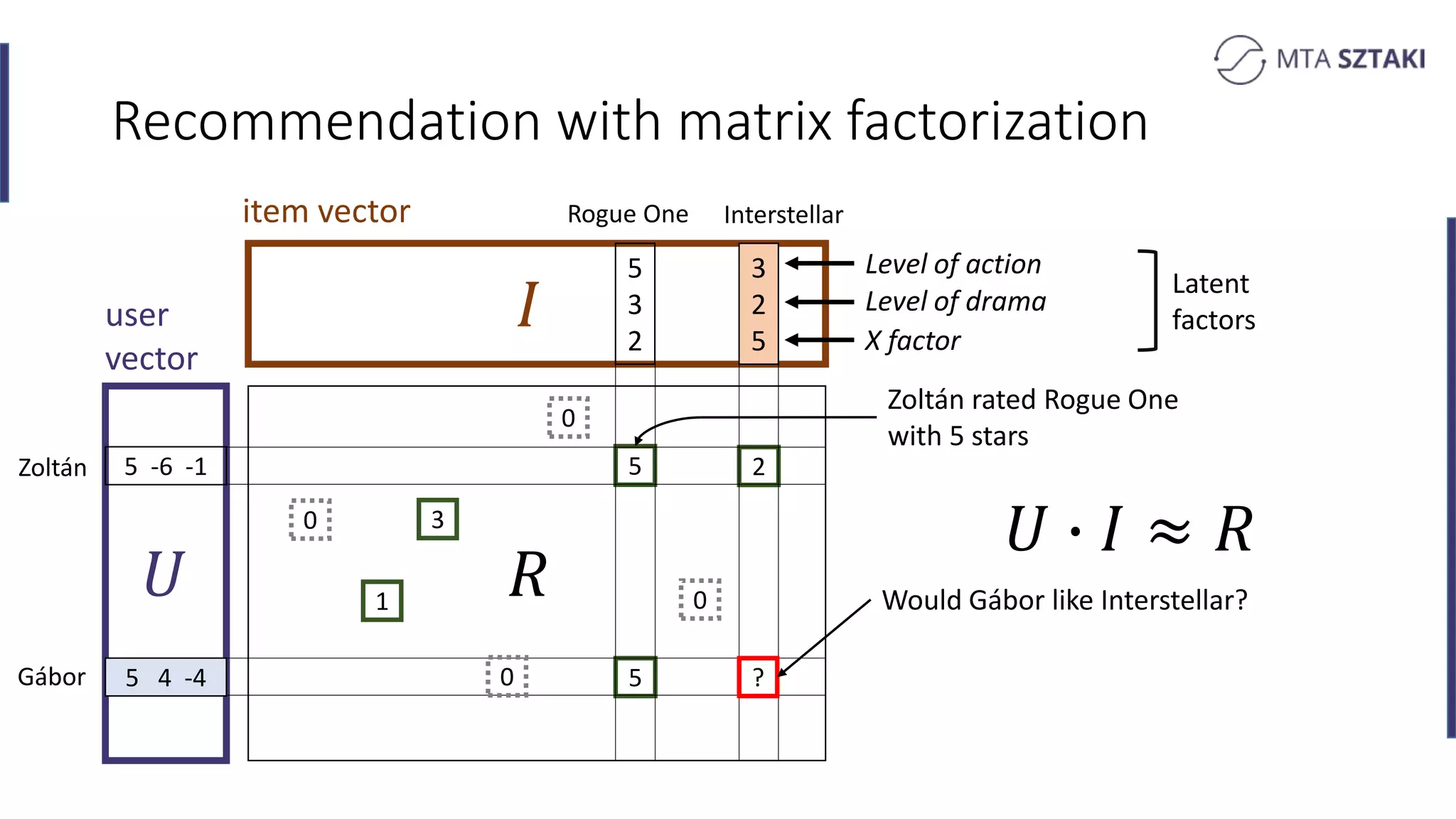
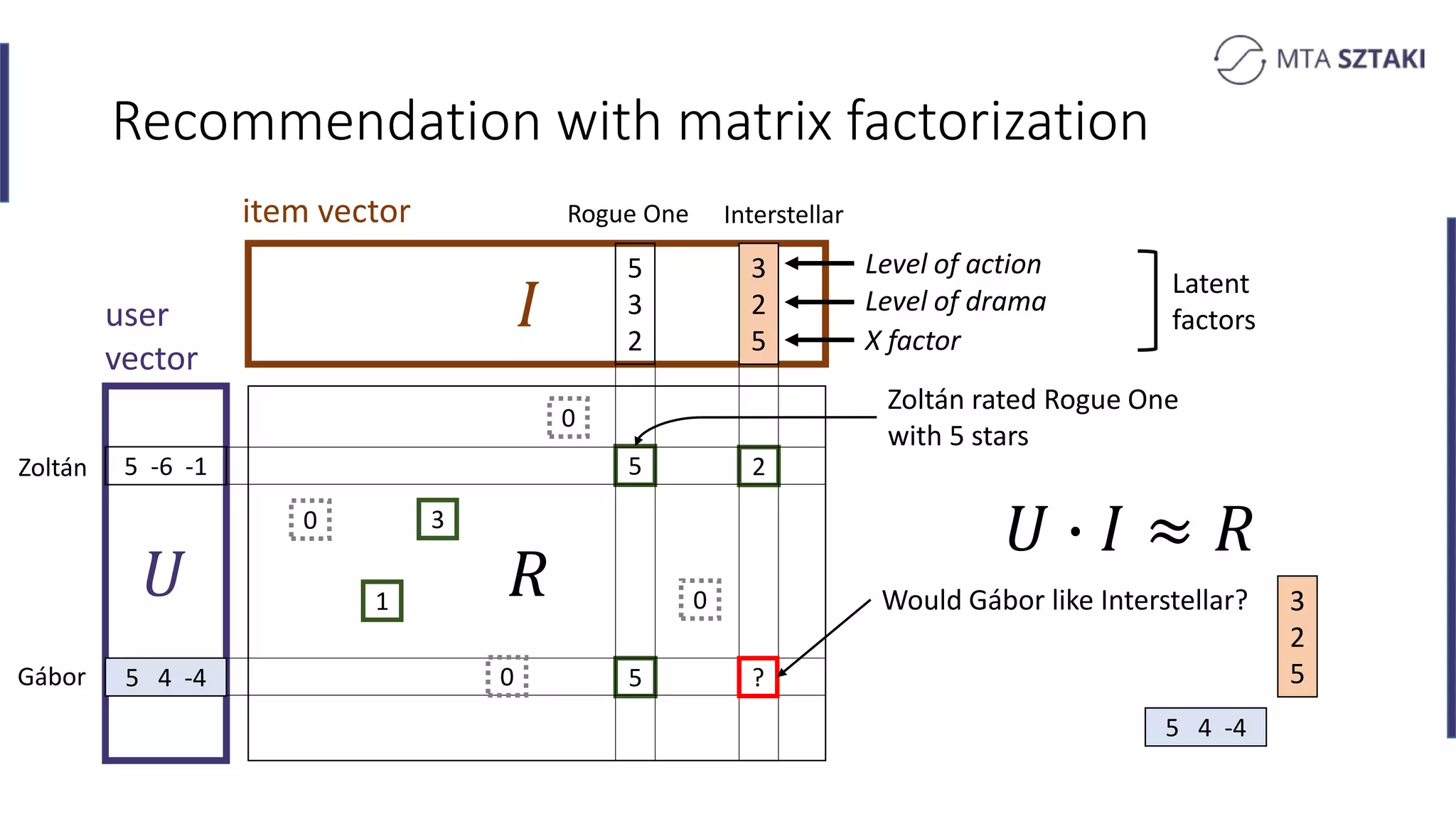
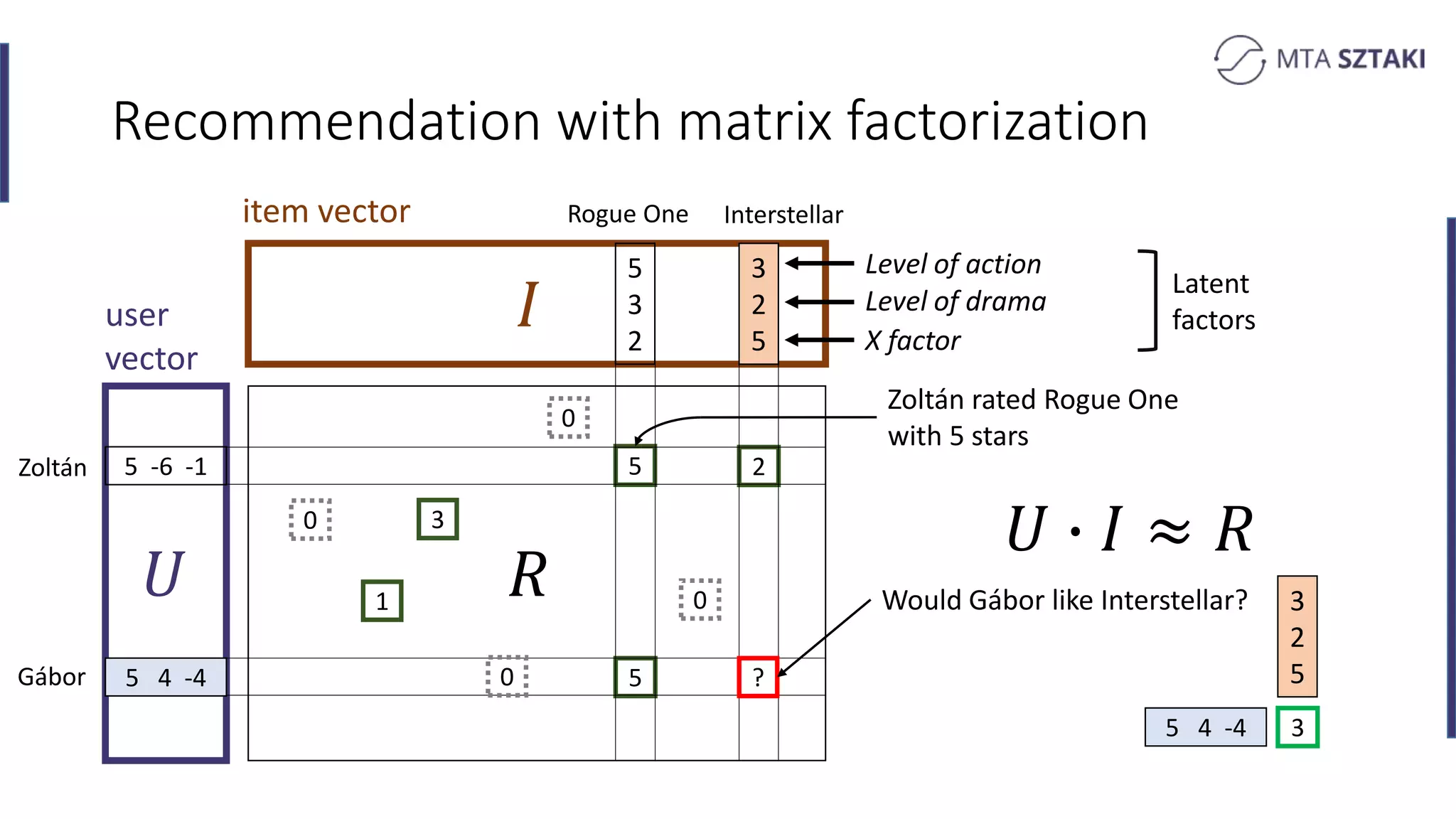
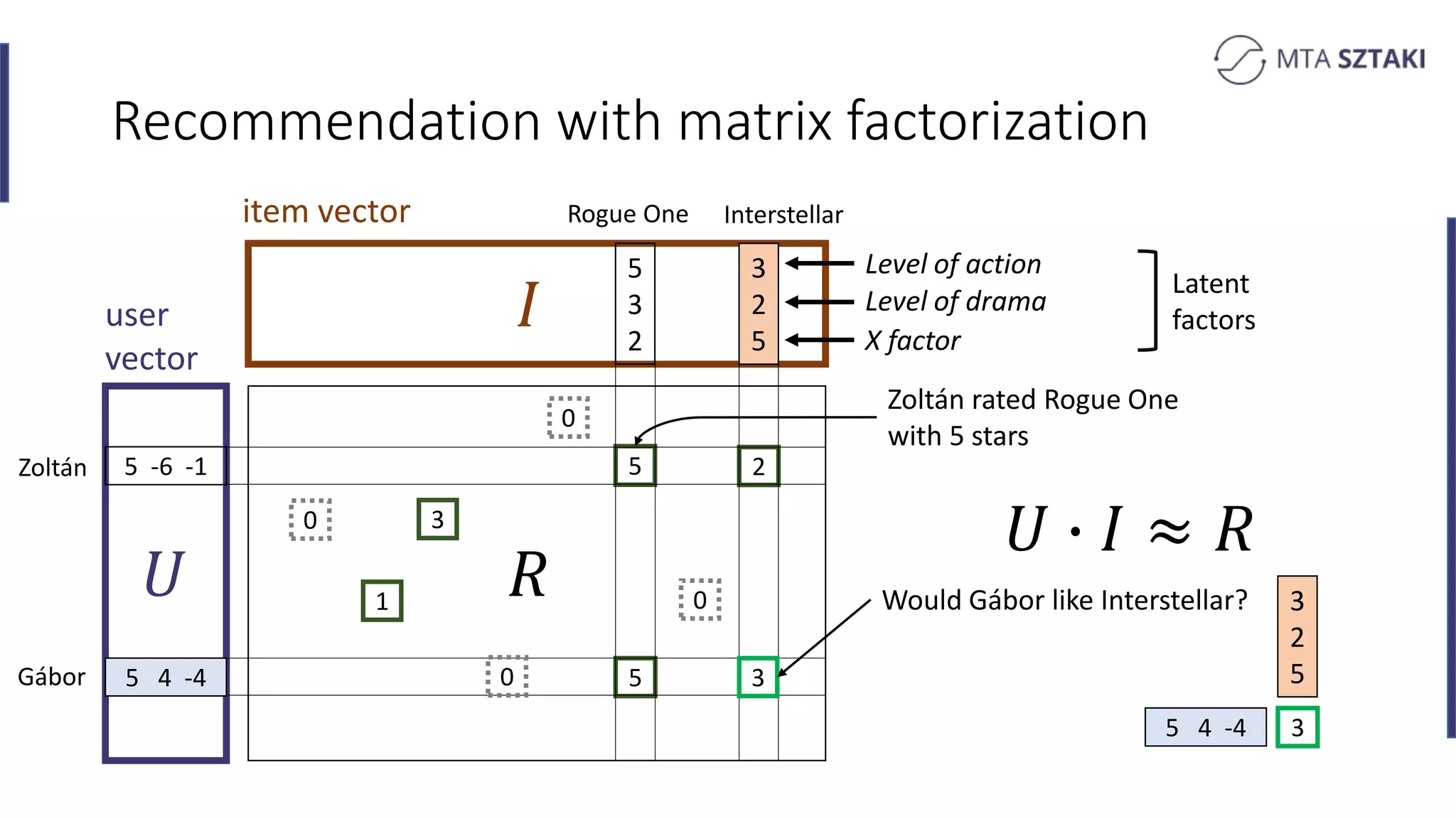
Basics of recommendation systems and matrix factorization techniques. Explanation of user and item vector matrices.
Introduction to batch and online training methods for recommendation systems, including persistent storage.
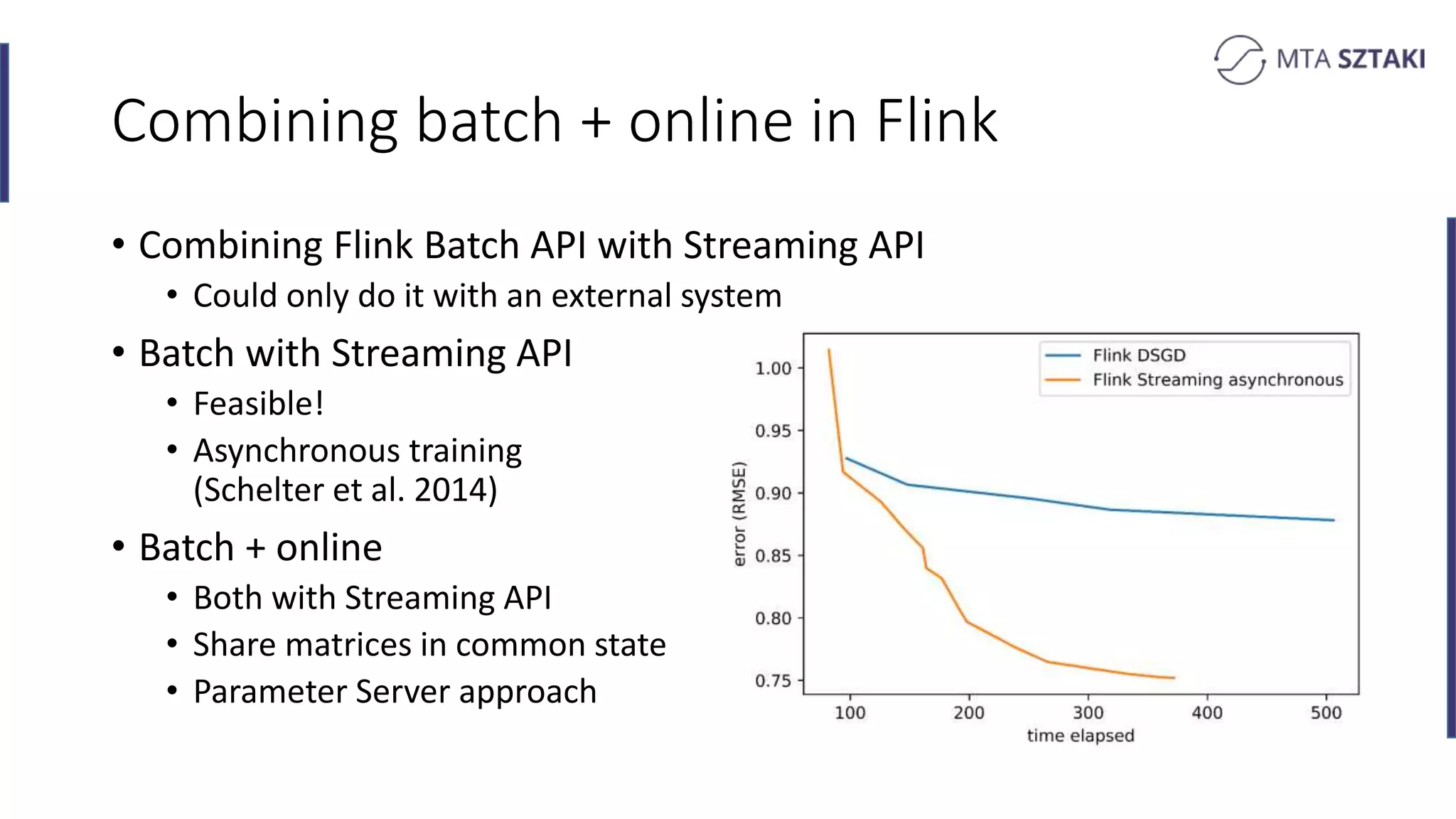
Discussion on scaling recommendation systems, particularly comparing batch and online training.
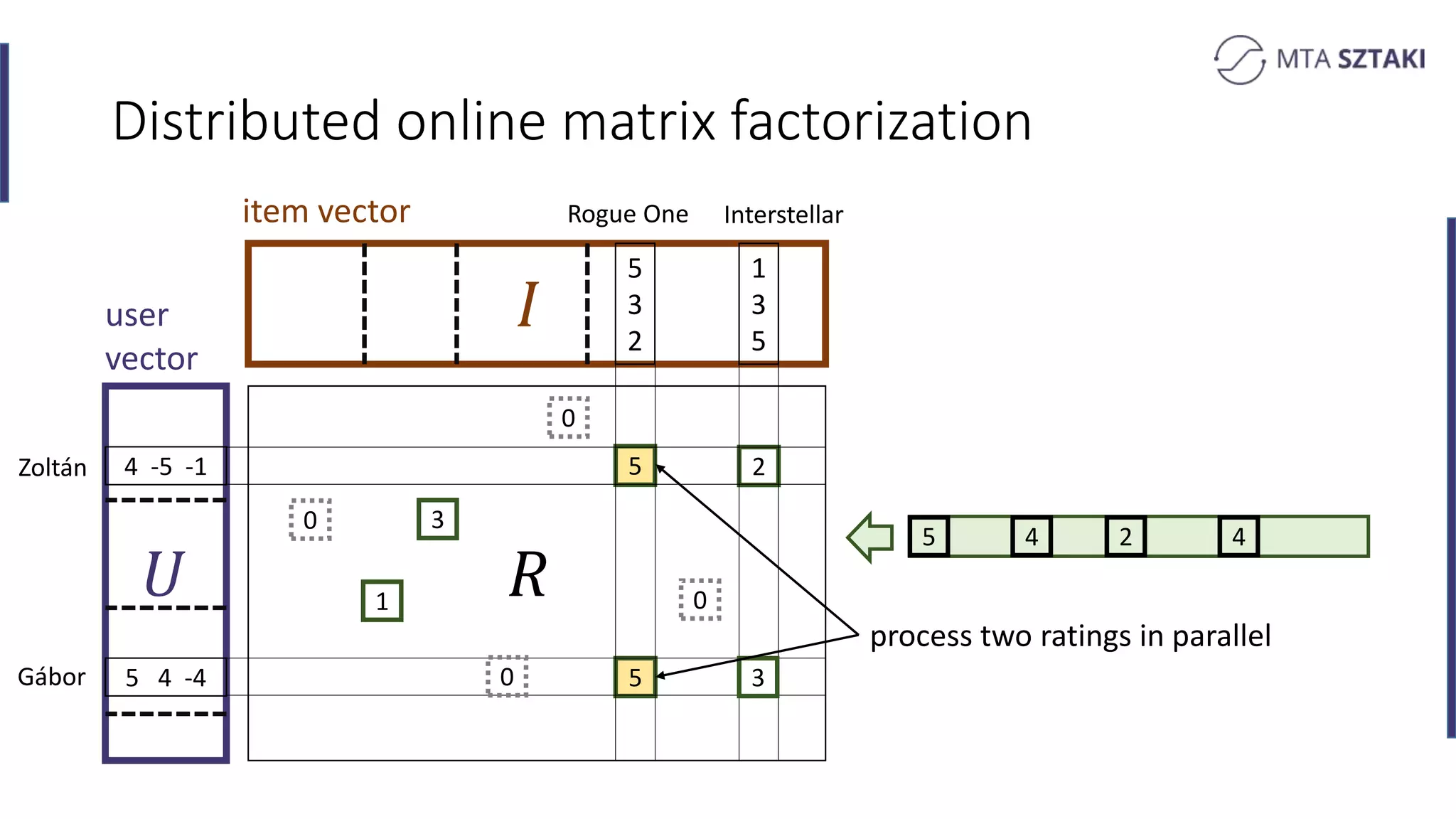
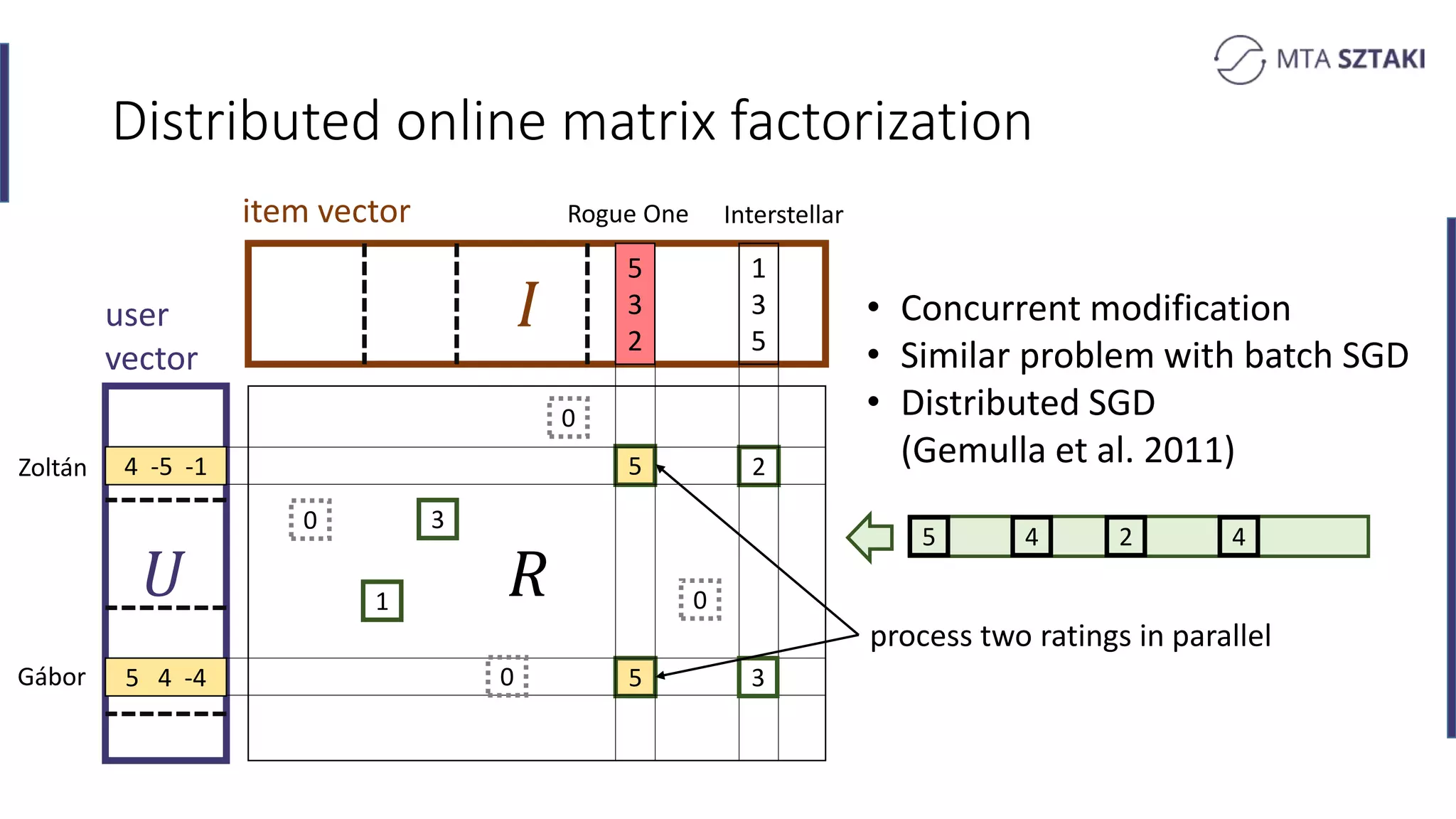
Distributed methods for online matrix factorization. Challenges of co-location and updates.
Implementation details for online matrix factorization in Spark with emphasis on user and item updates.
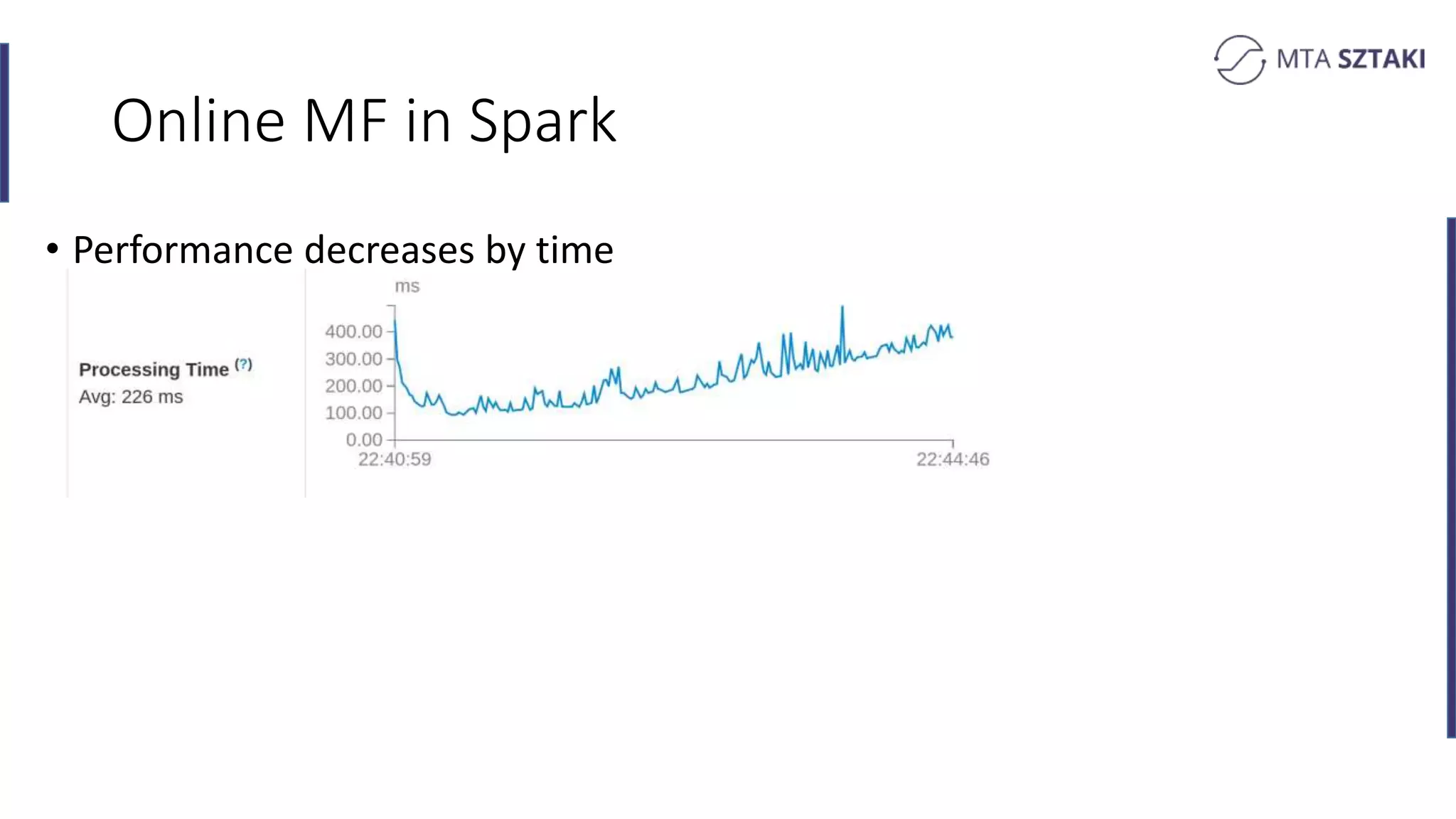
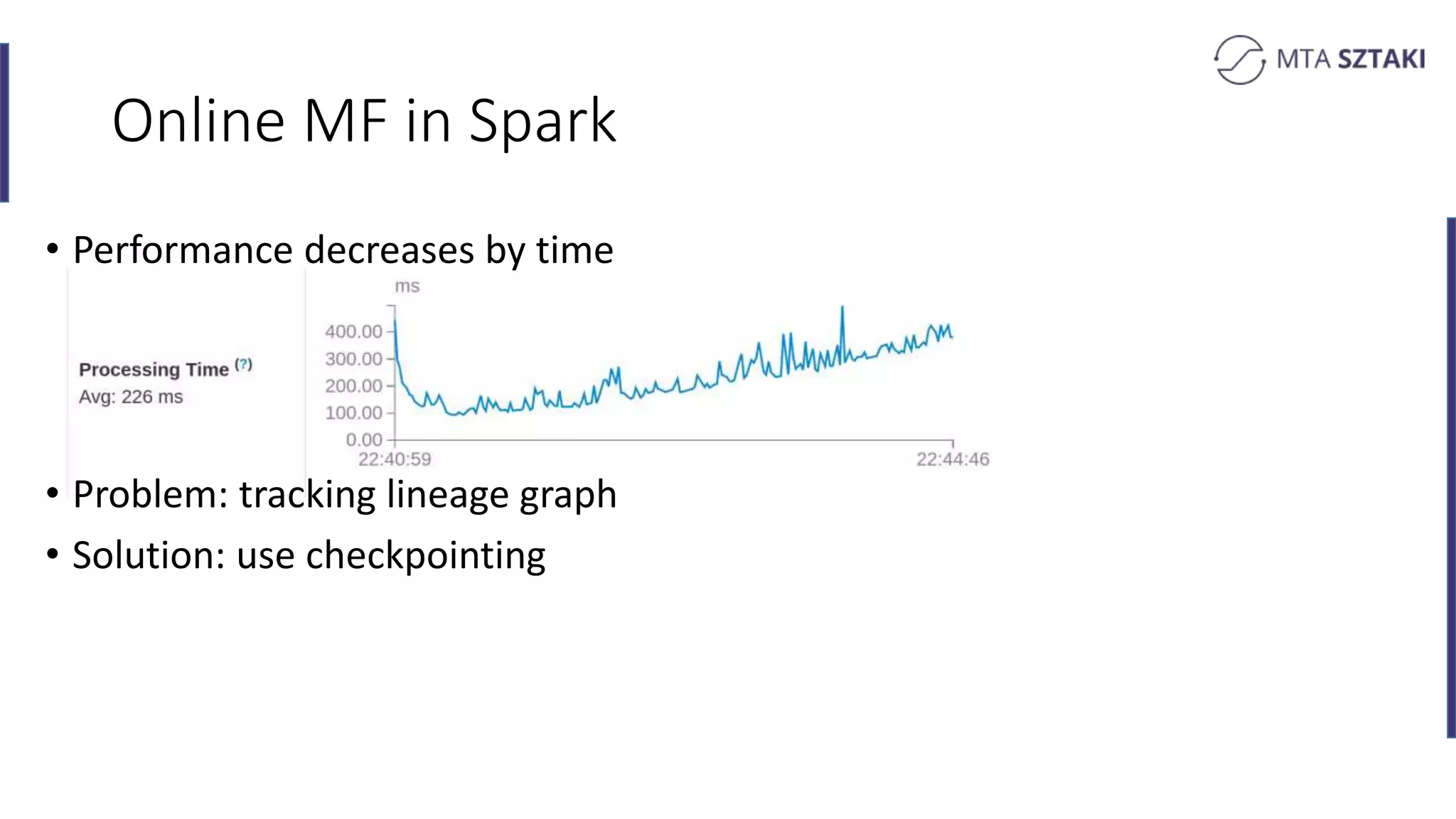
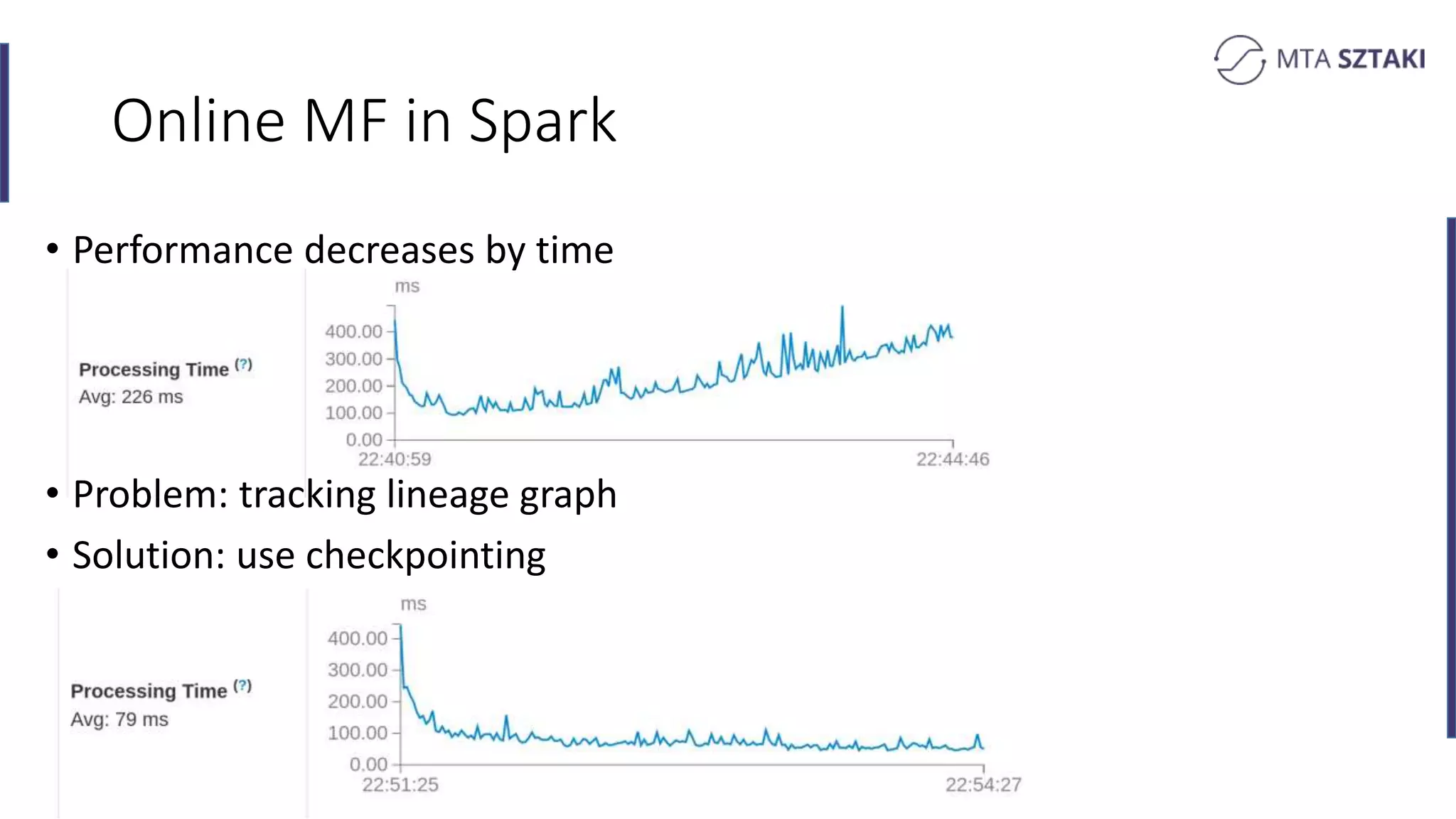
Challenges faced in online MF over time regarding performance and solutions through checkpointing.
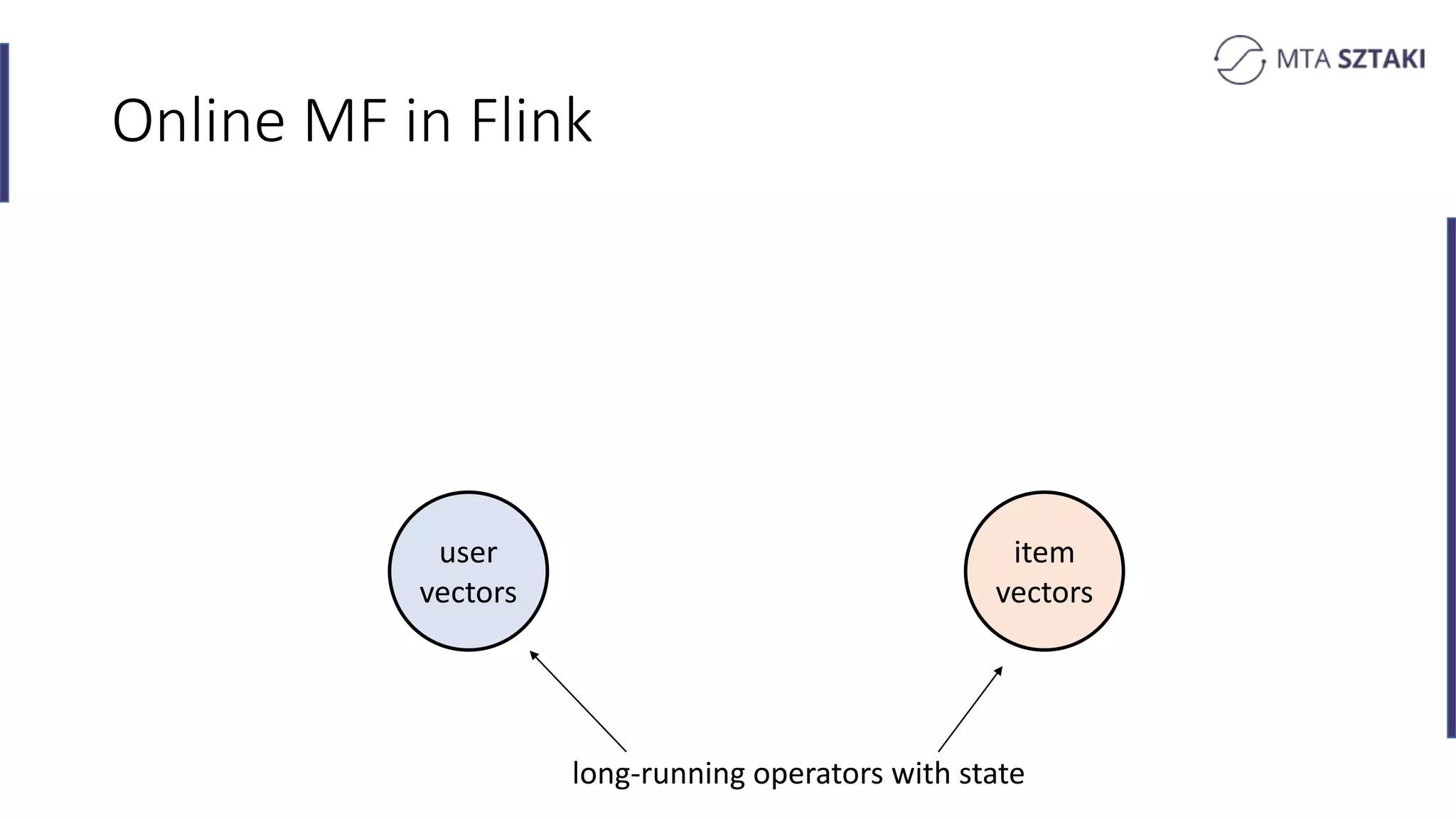
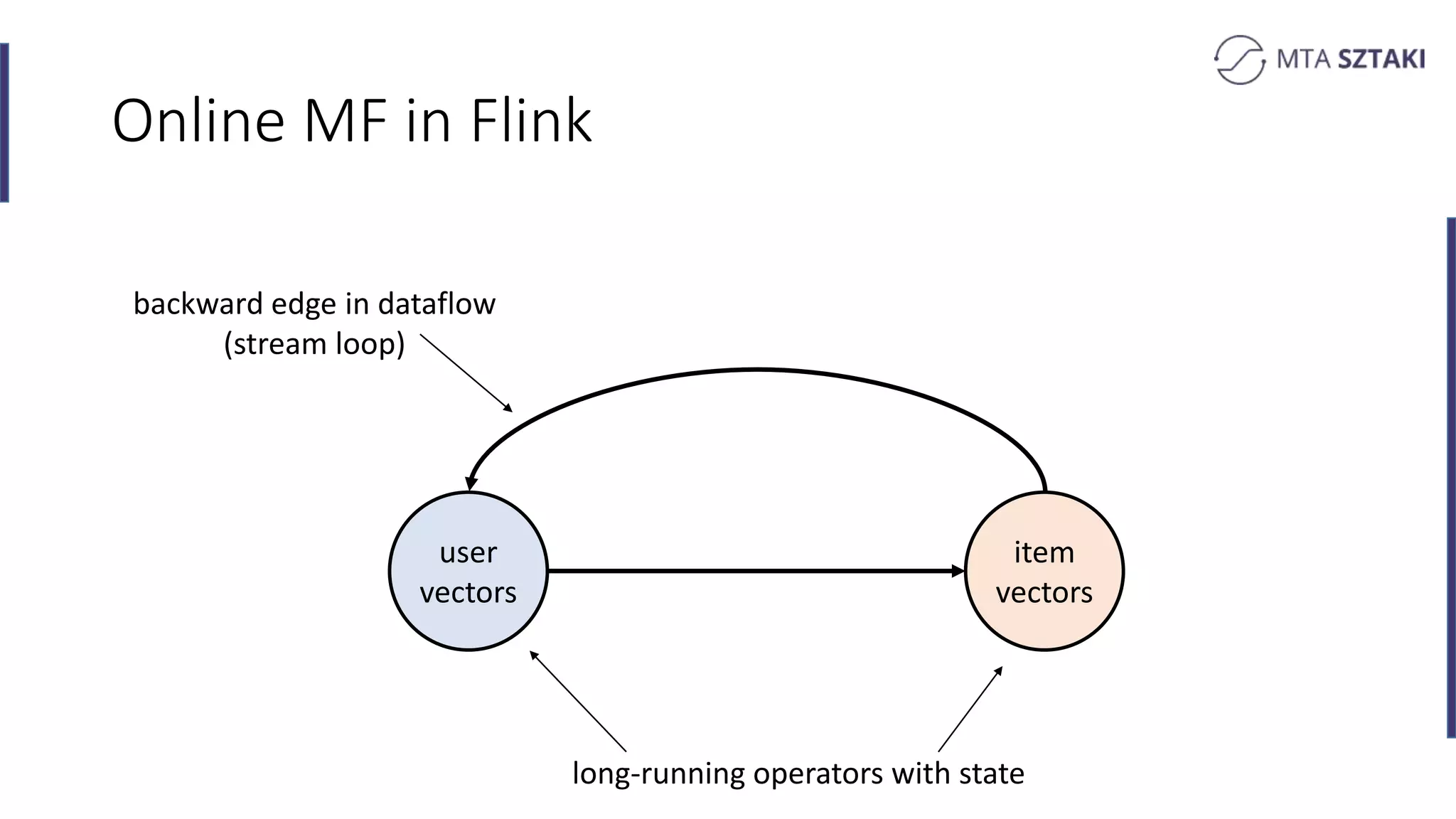
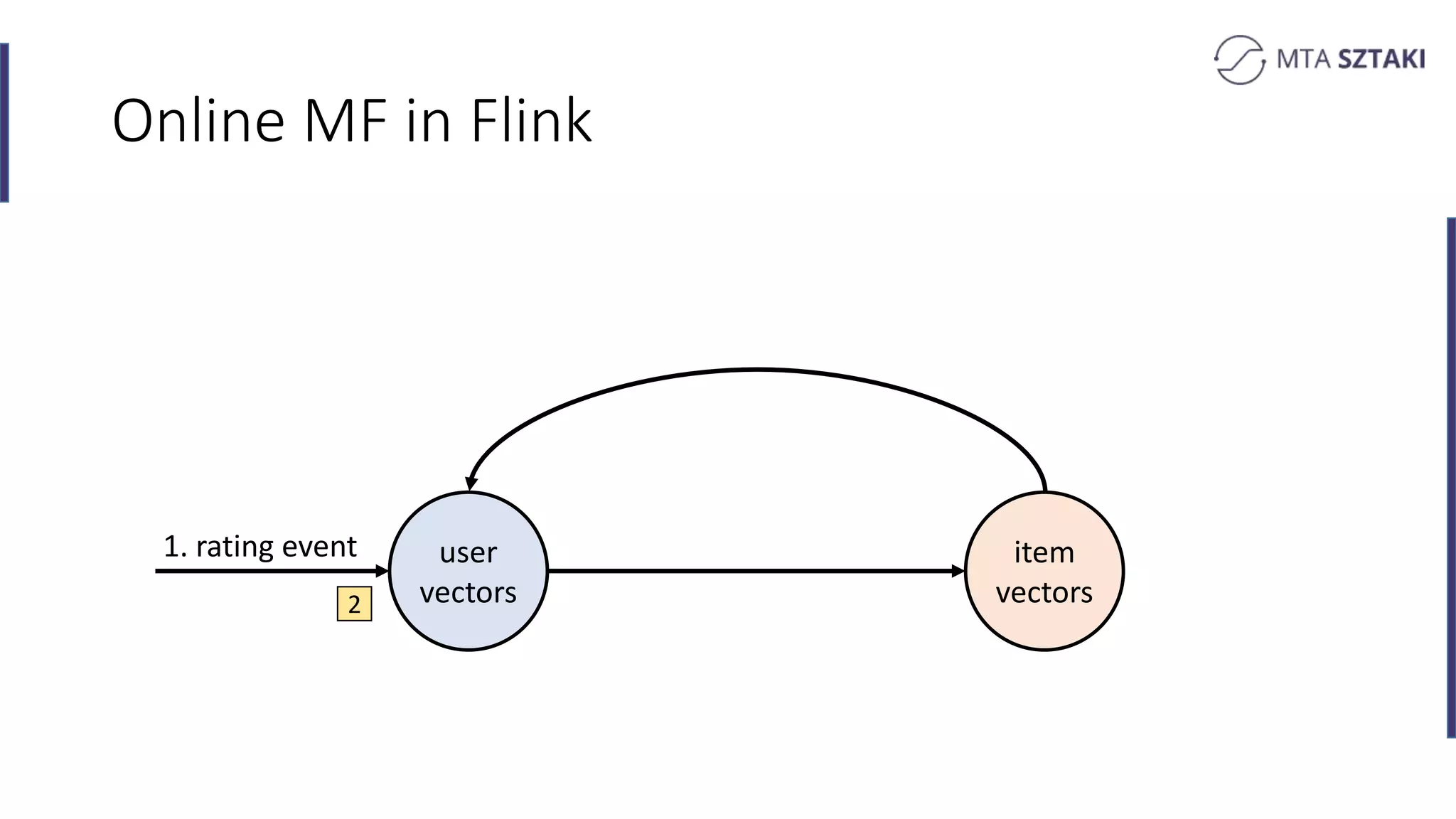
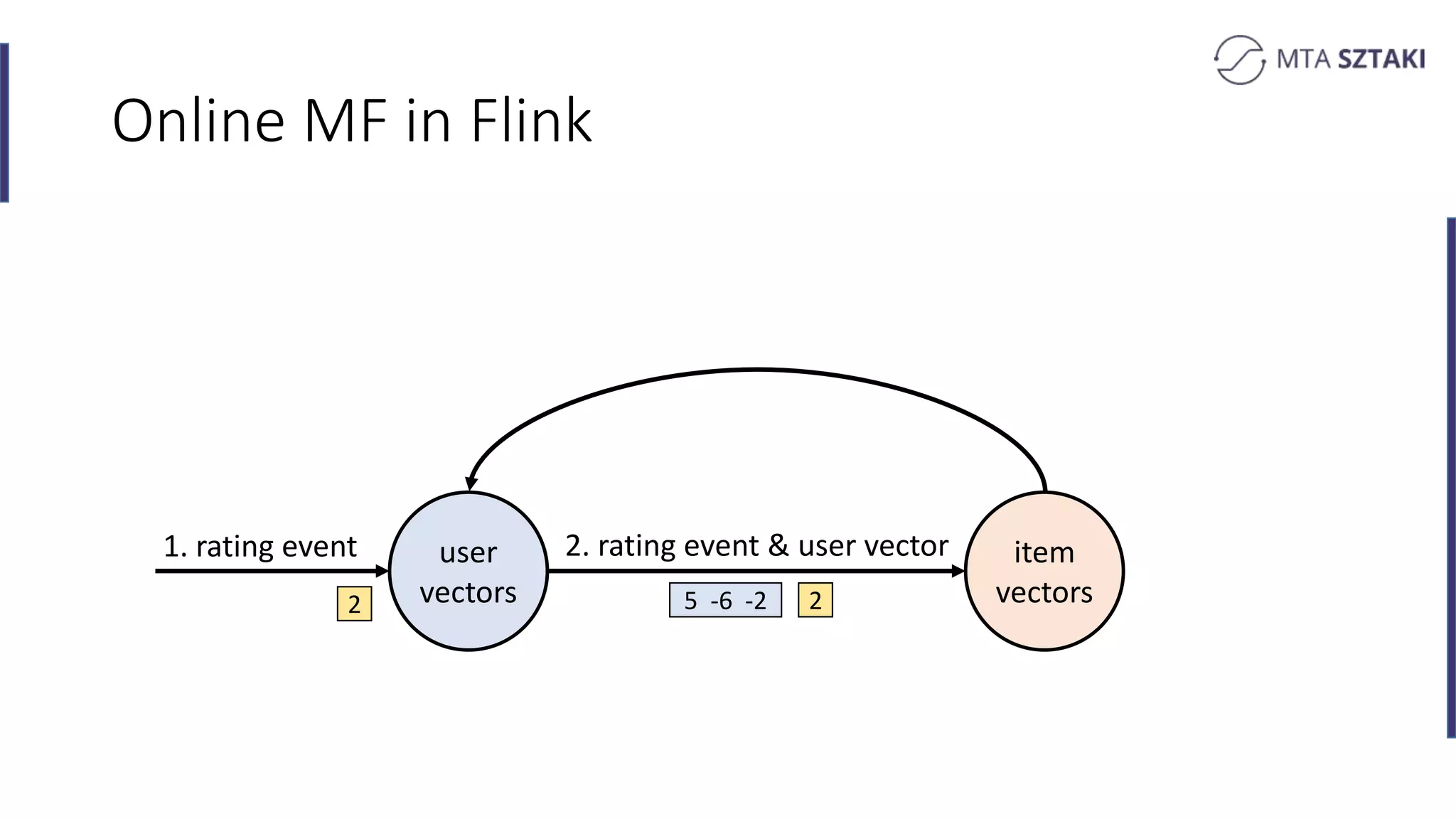
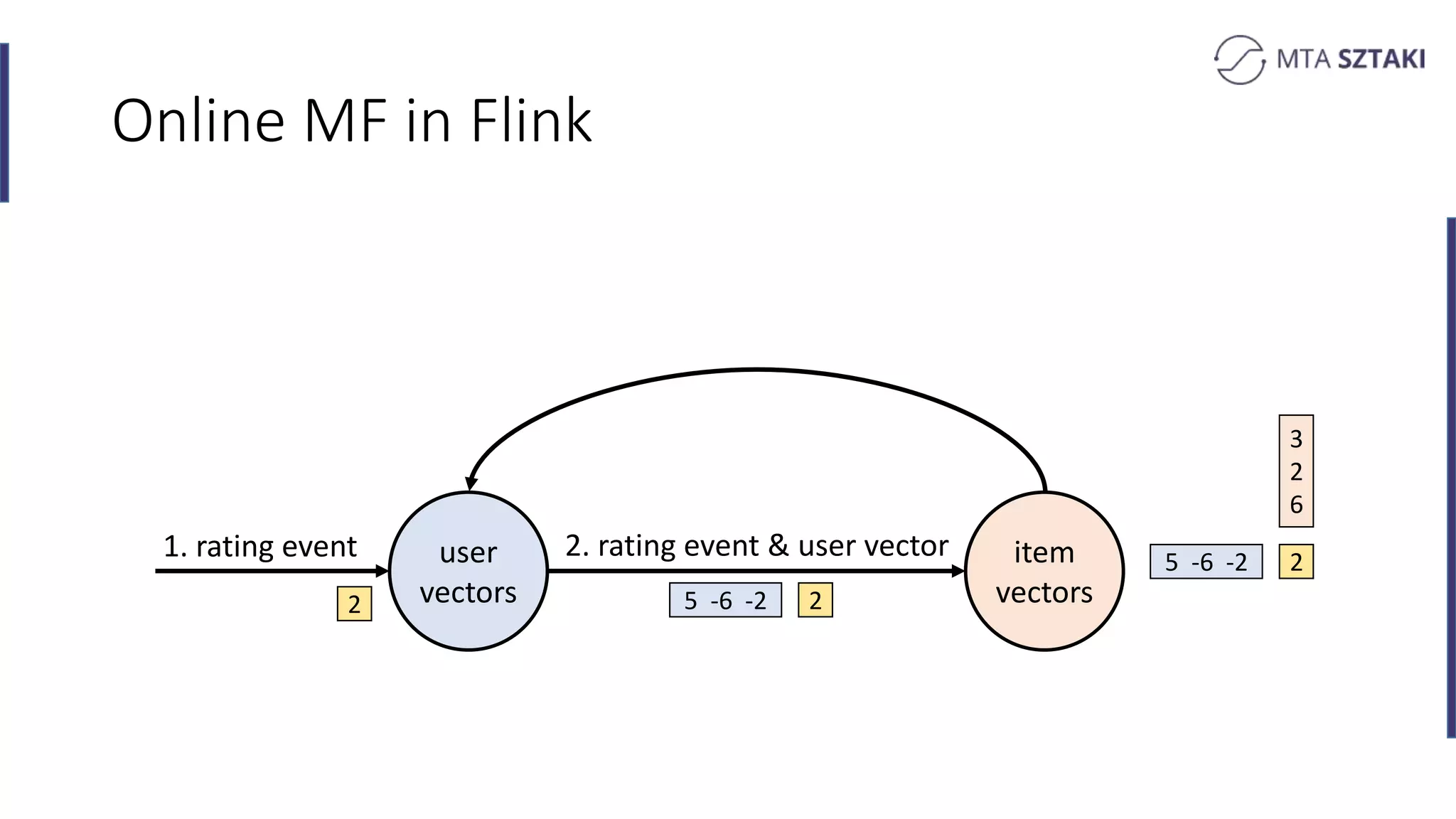
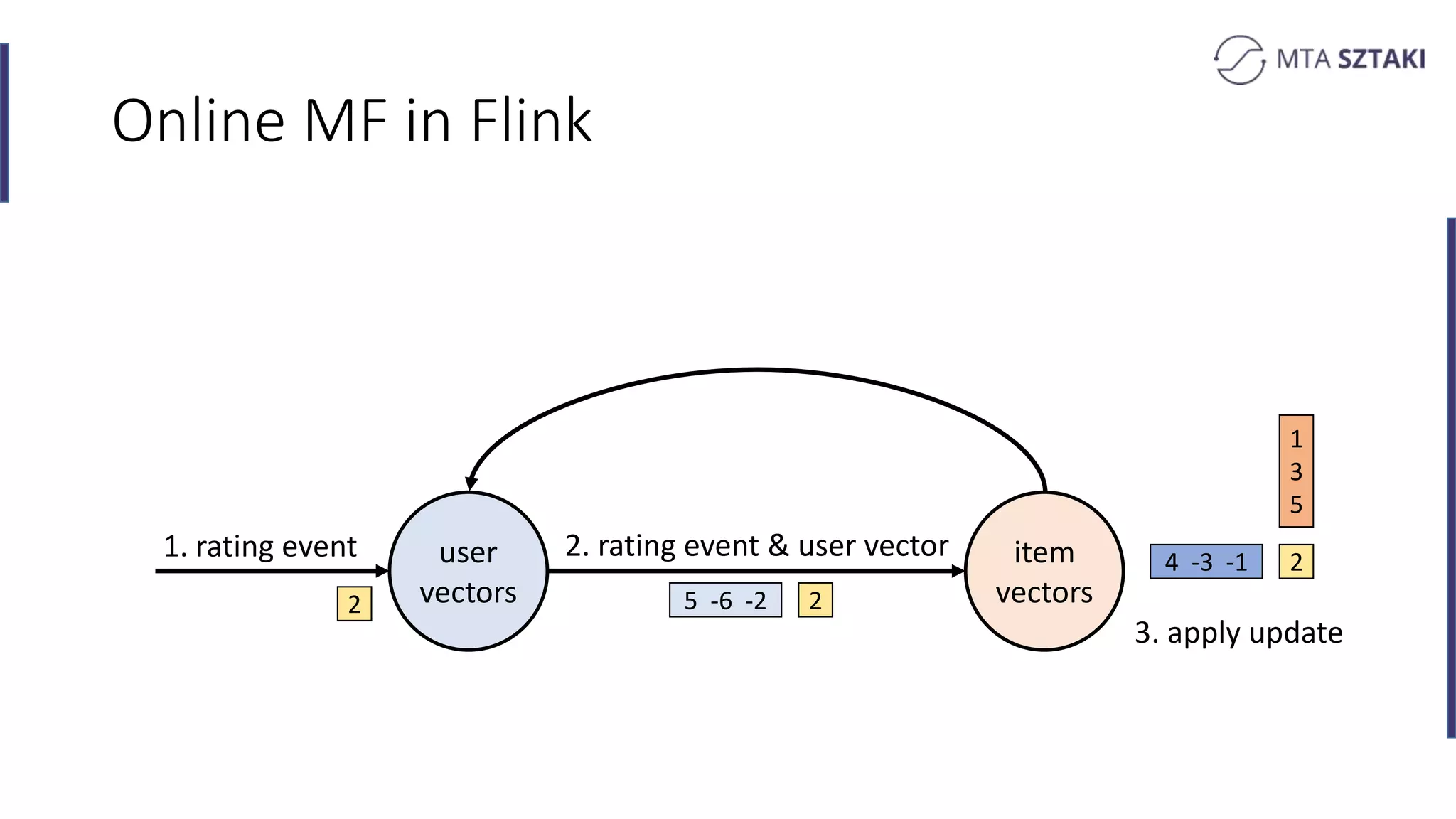
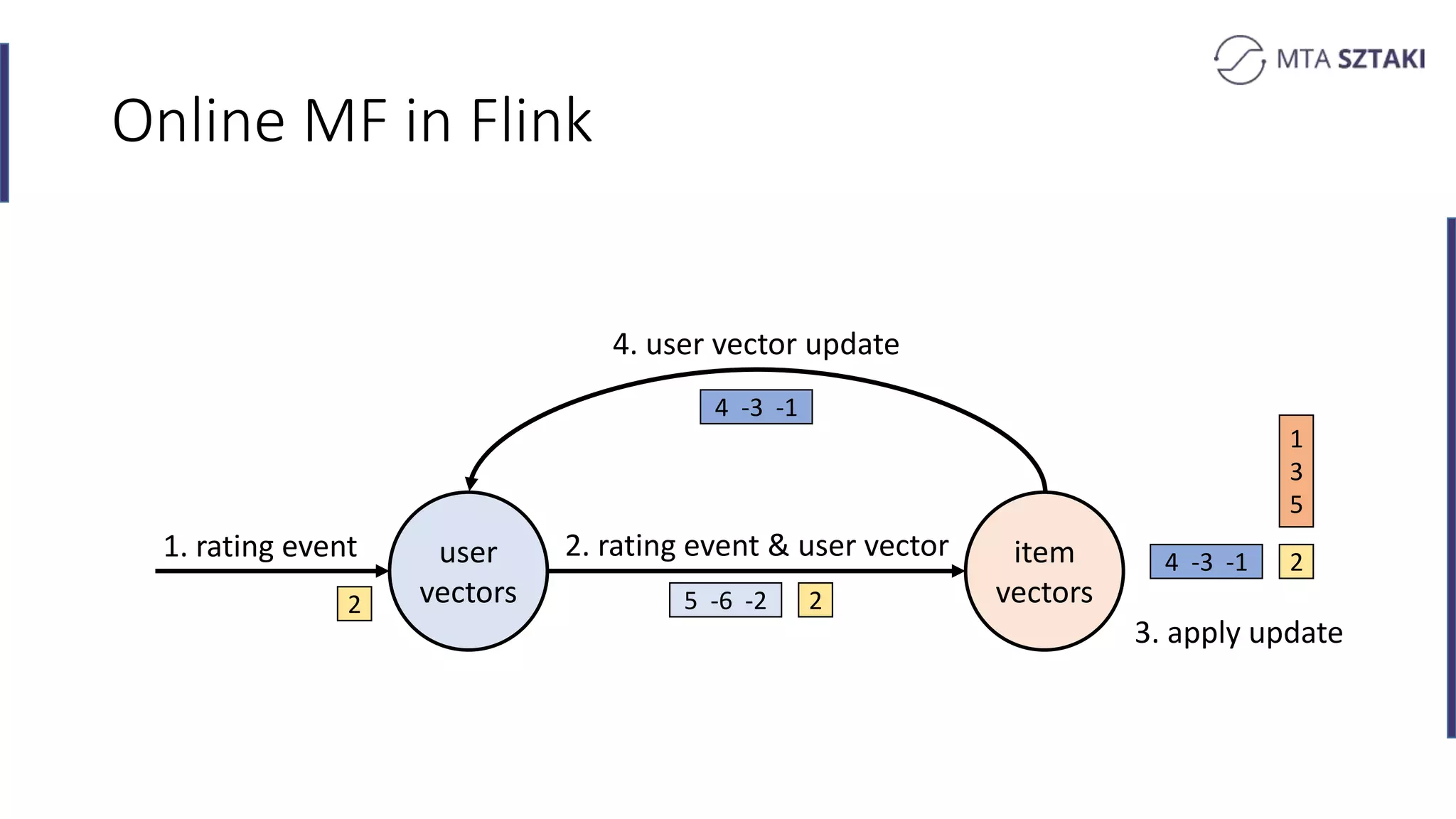
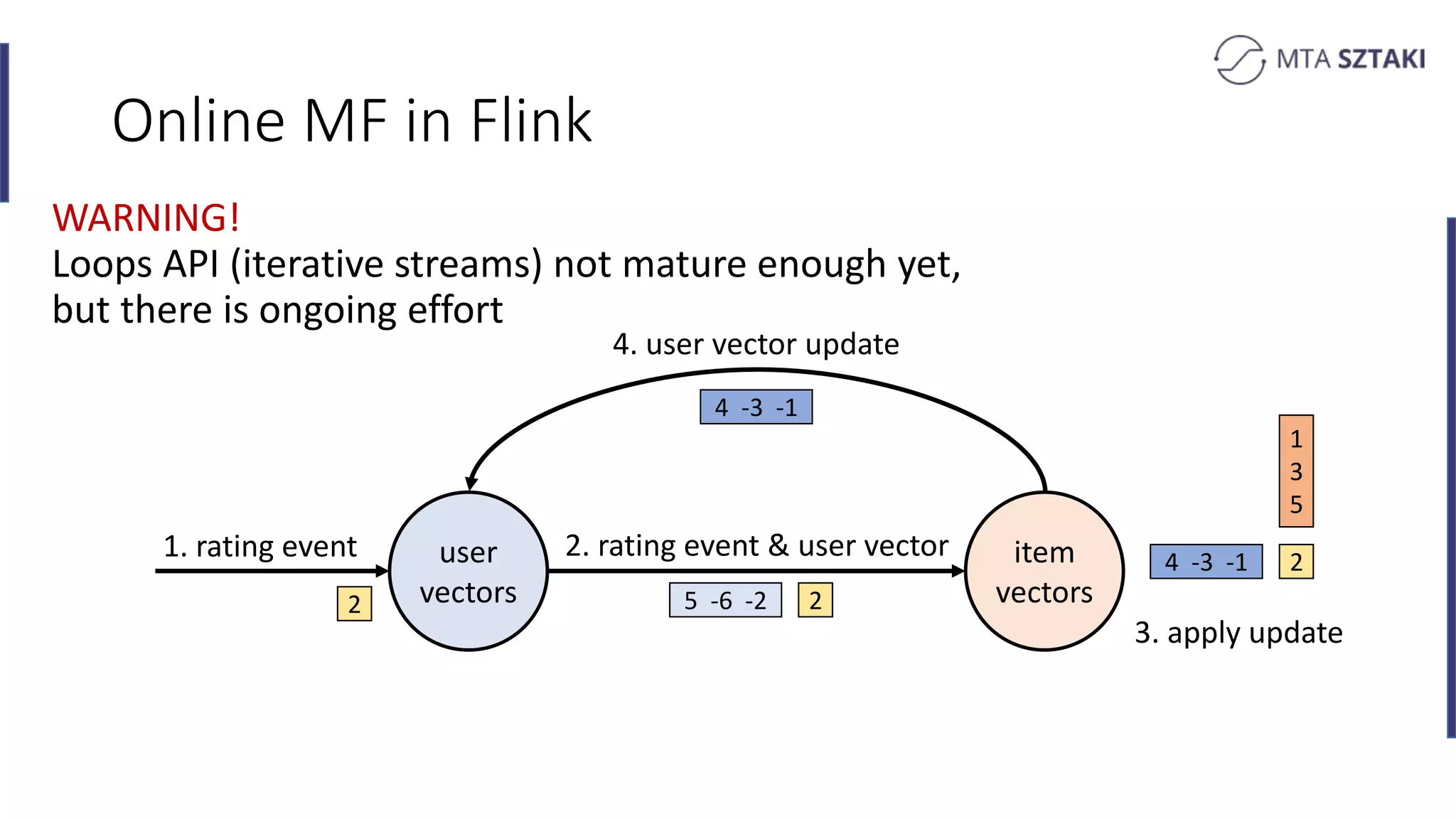
Implementing online matrix factorization in Flink, including operational details with update mechanisms.
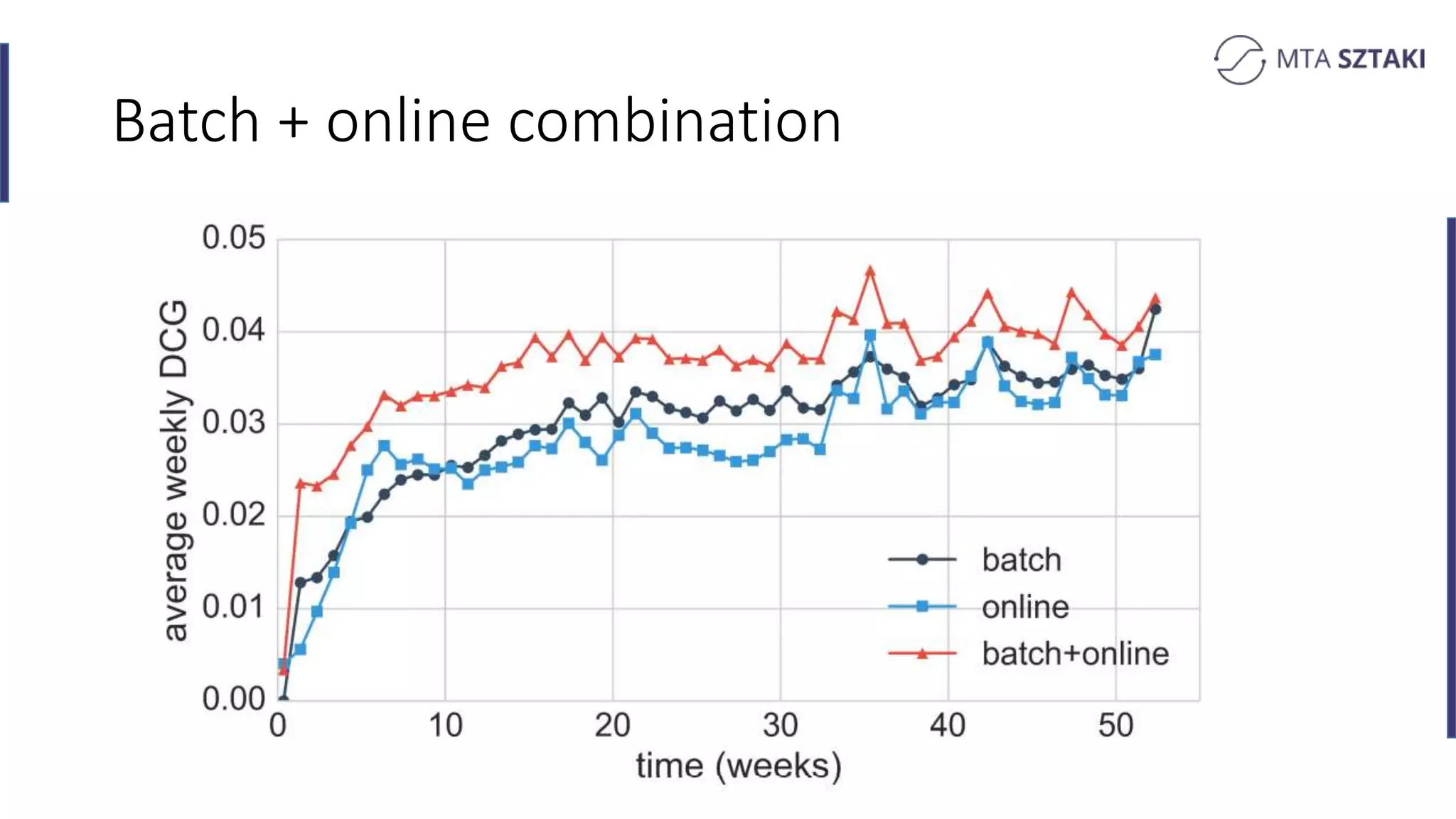
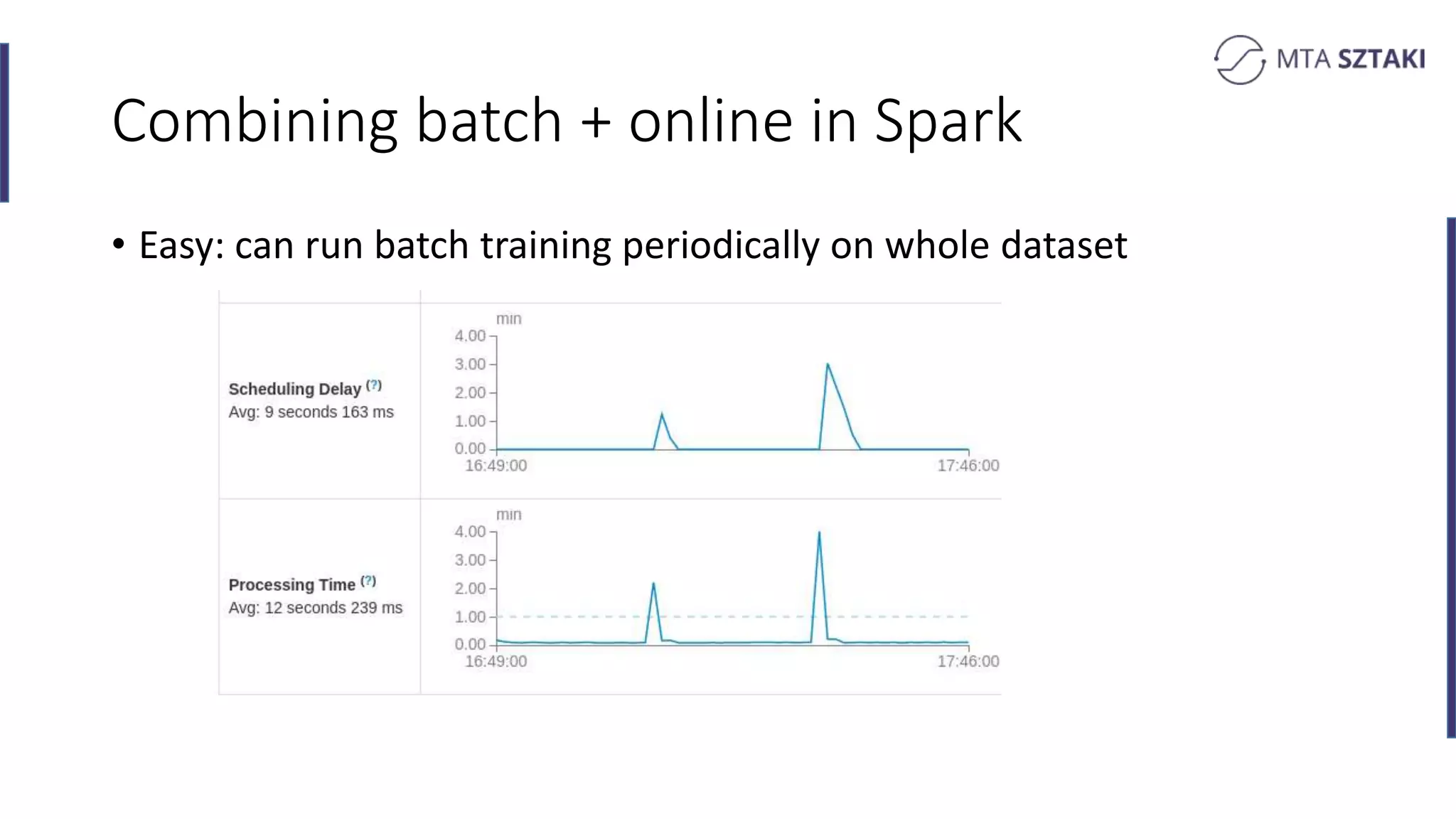
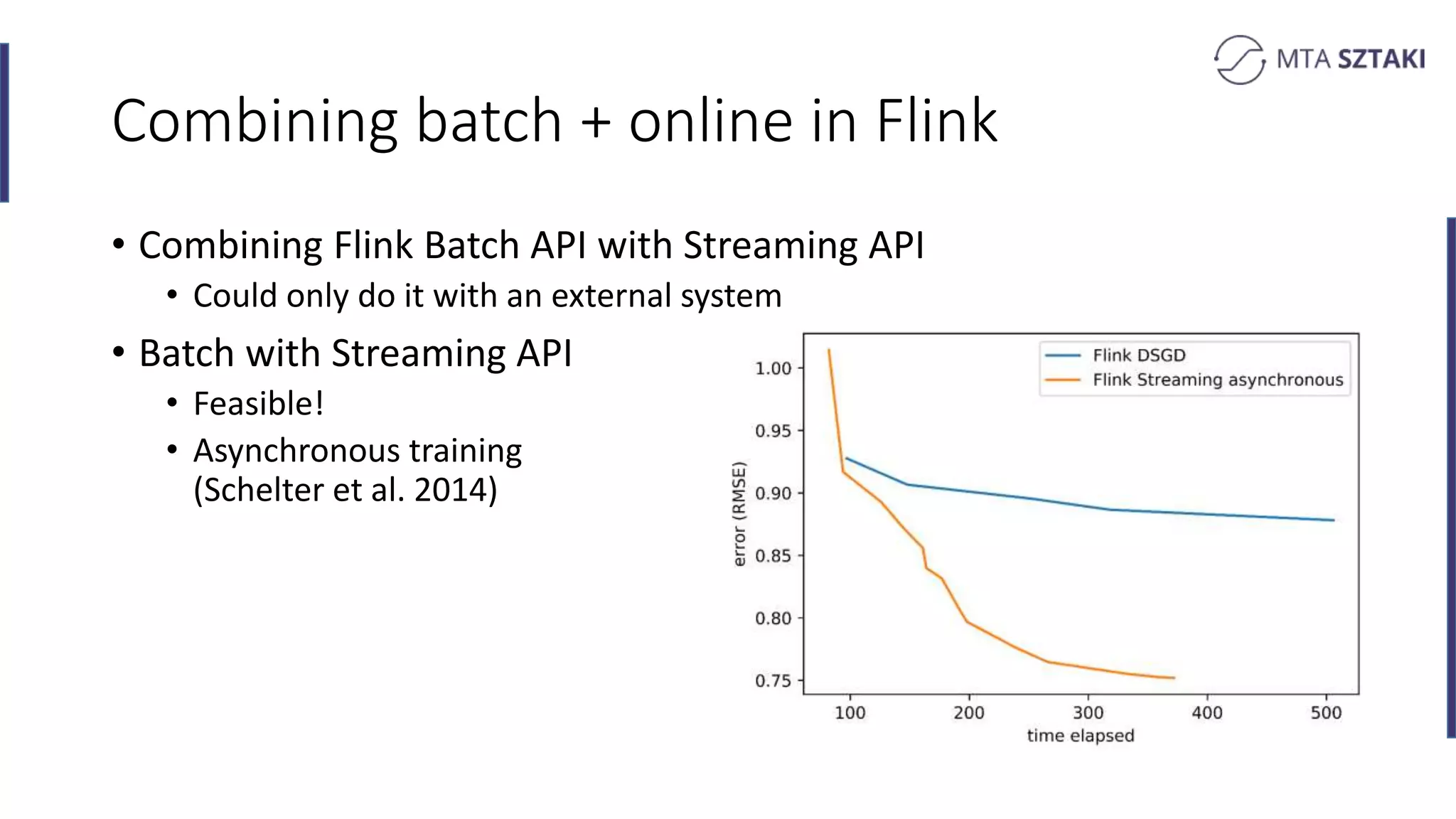
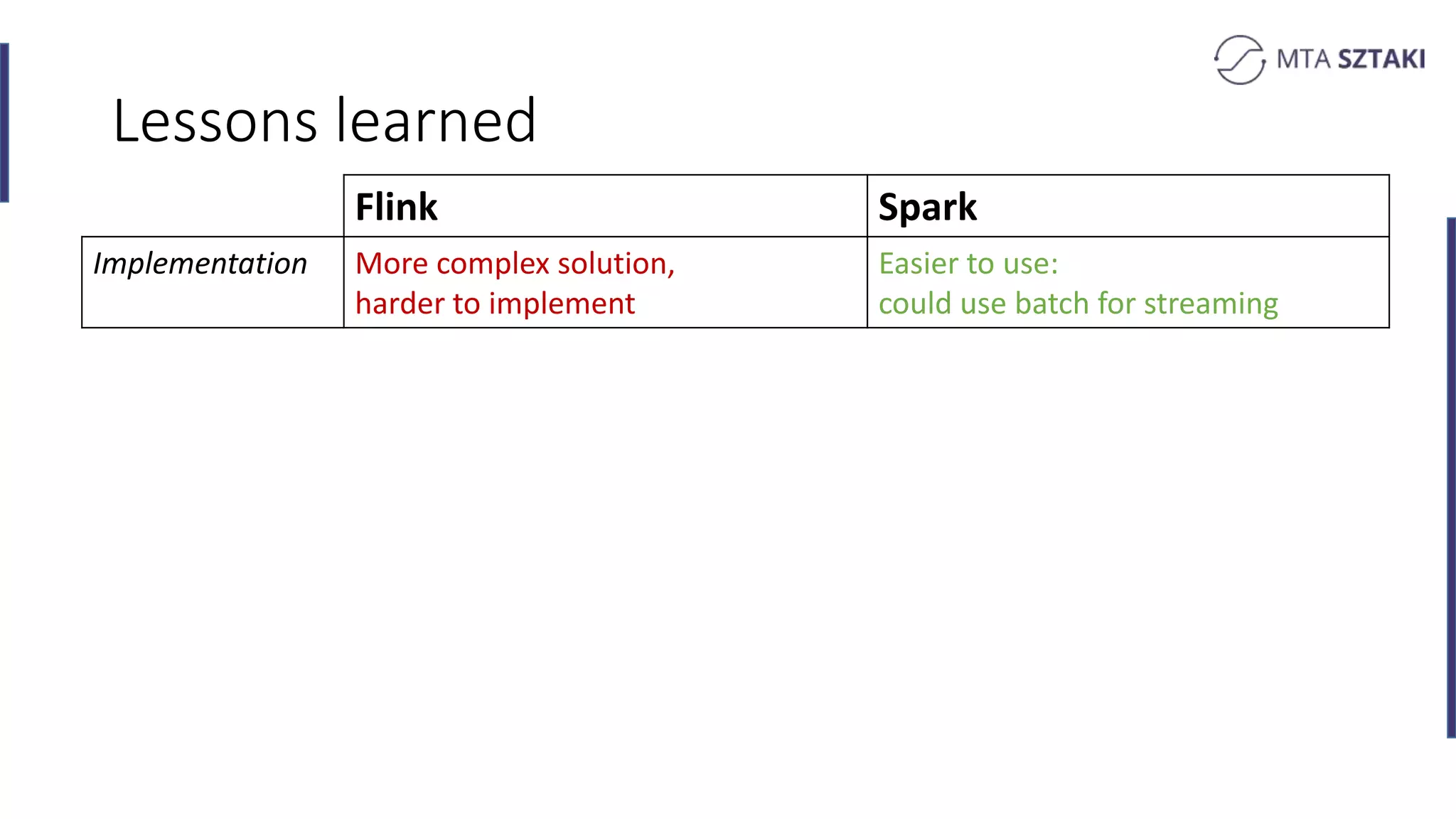
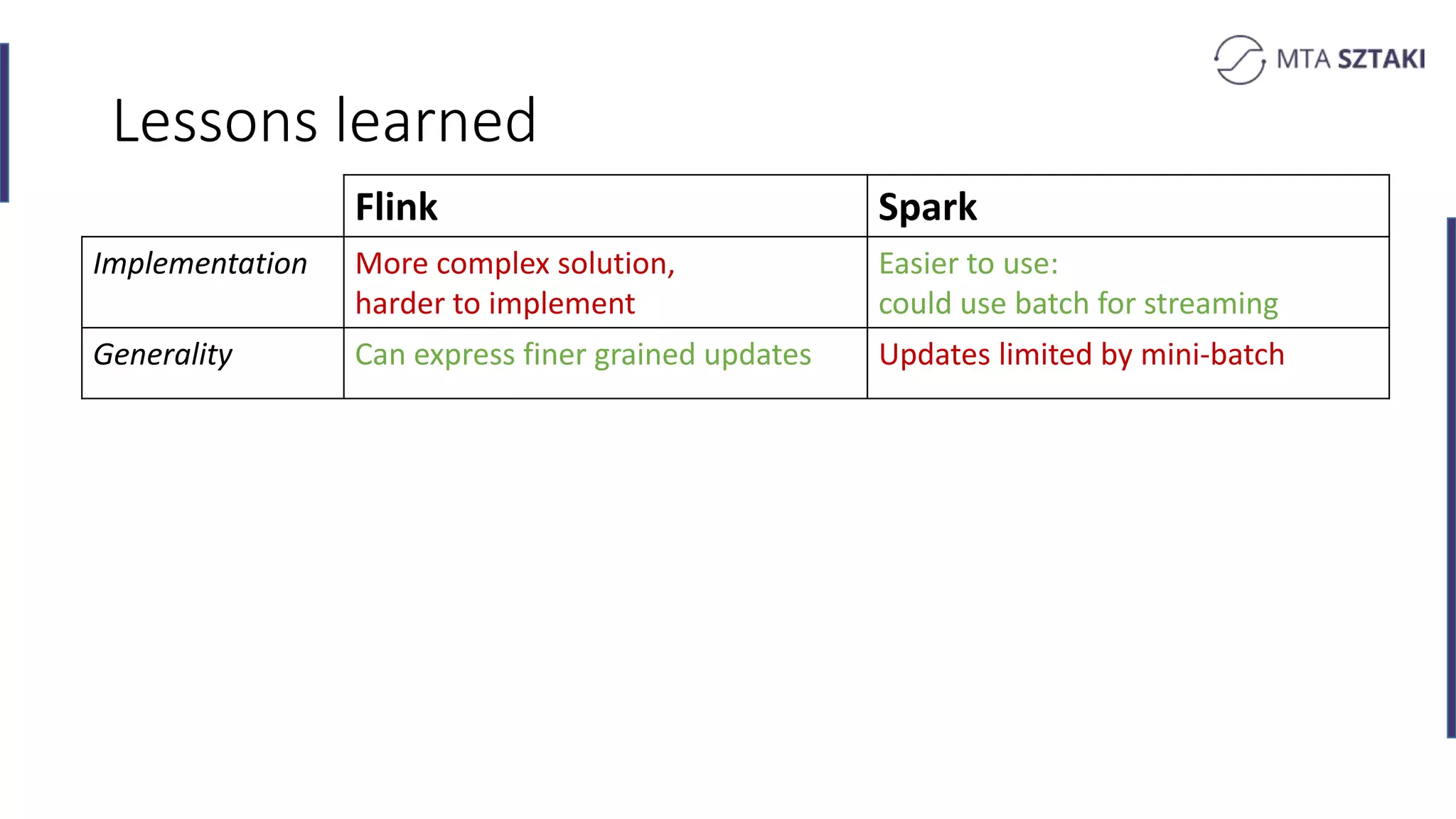
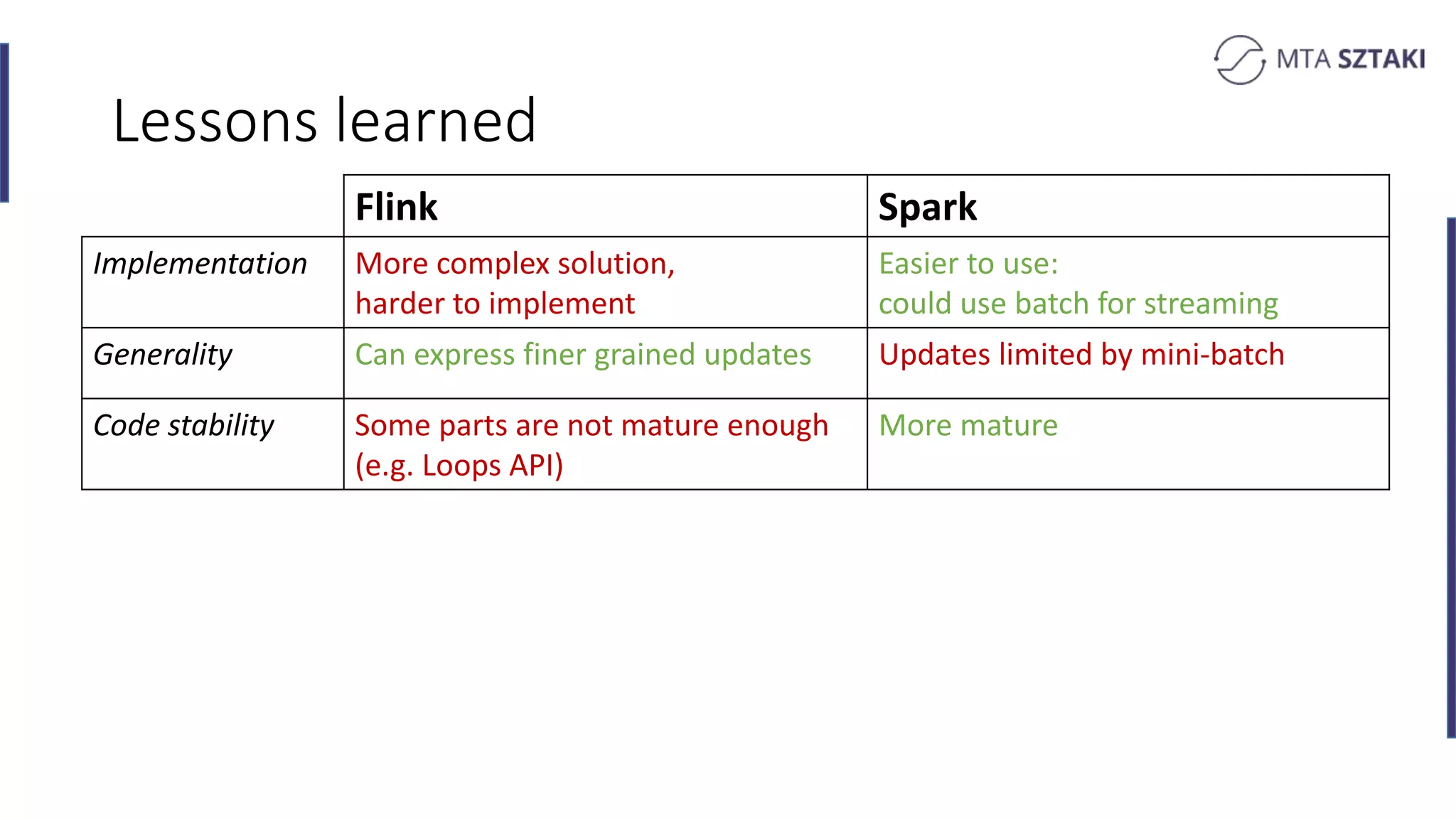
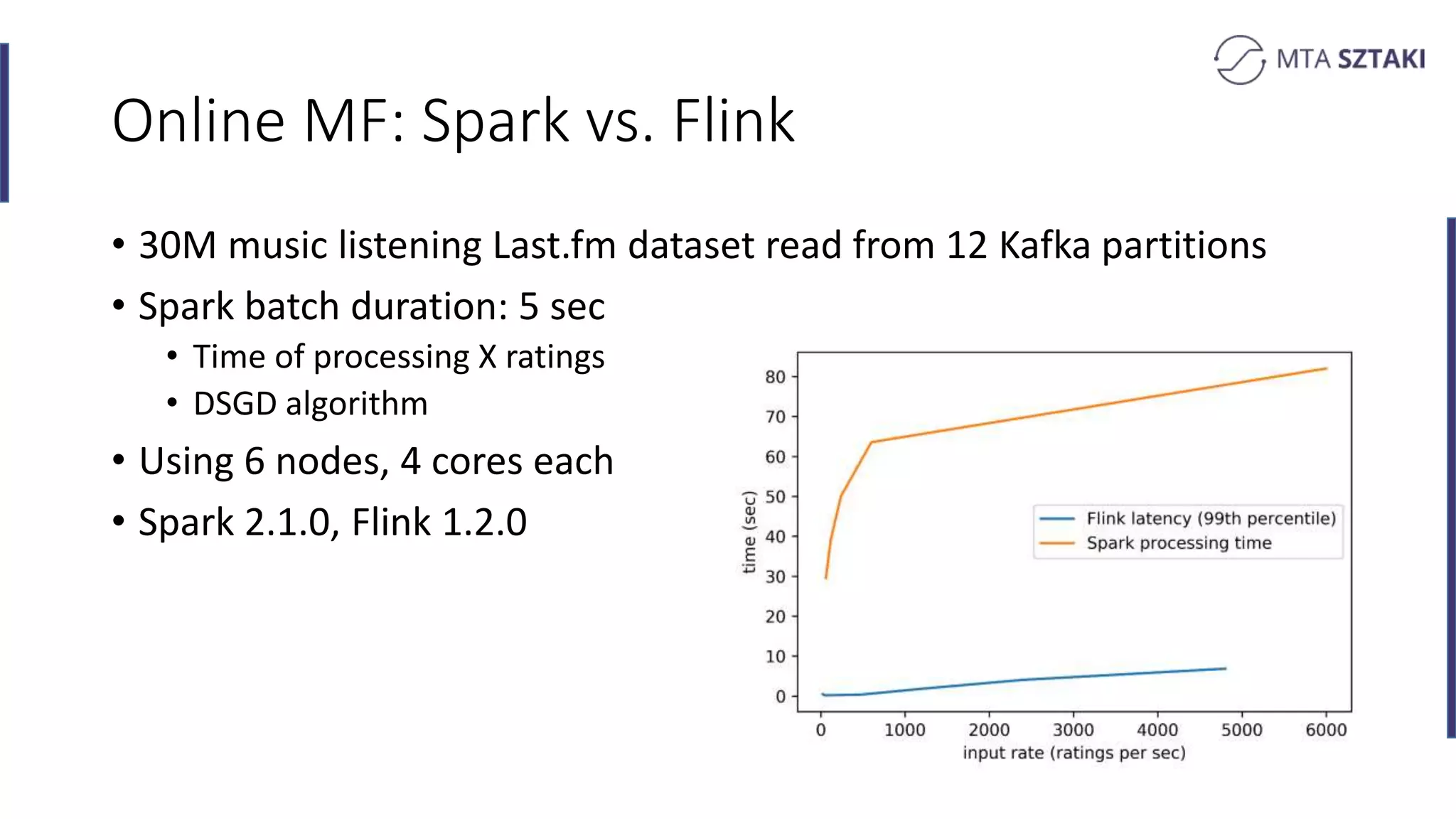
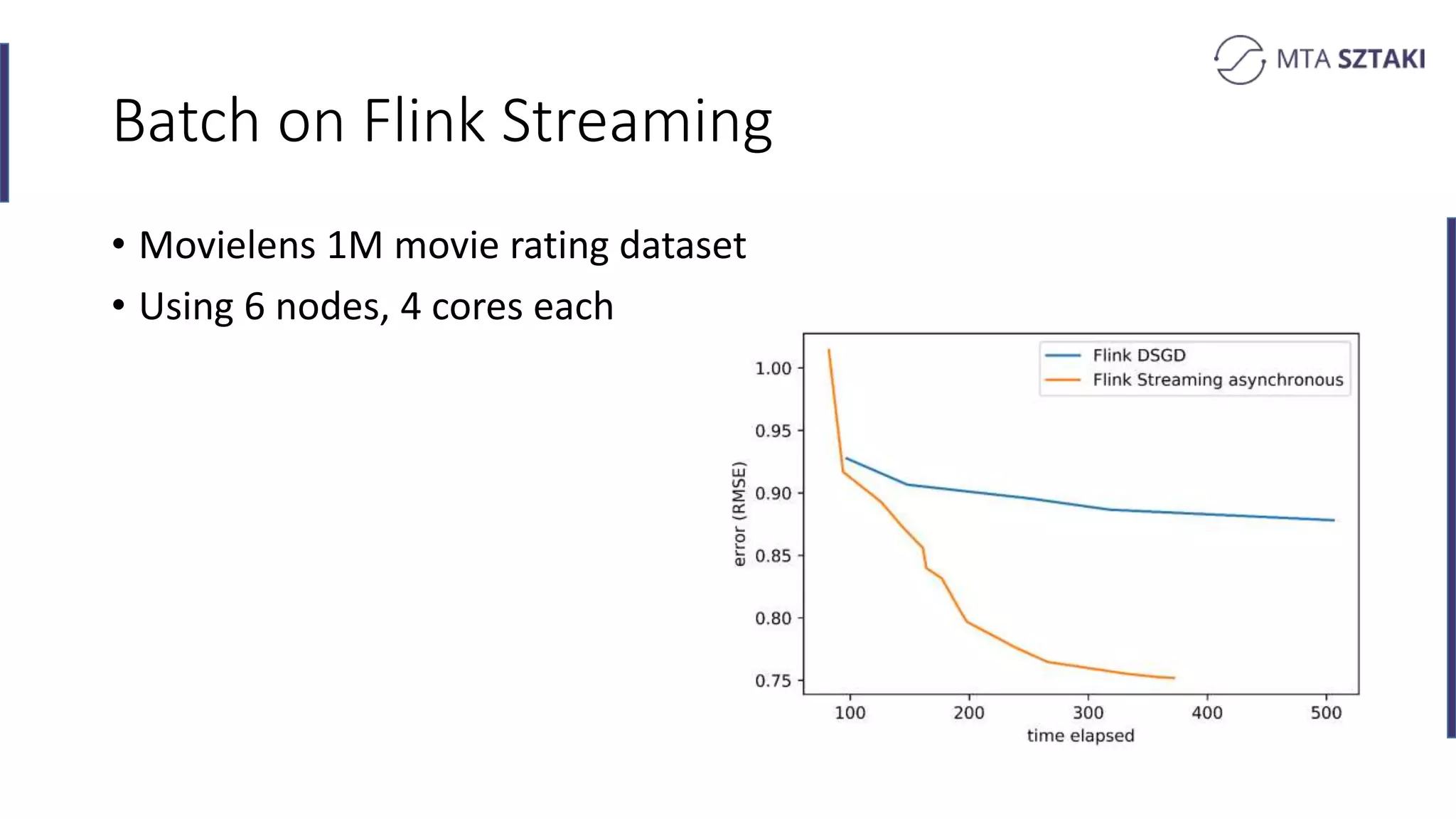
Analysis of the strengths and weaknesses of combining batch and online training in both Spark and Flink.
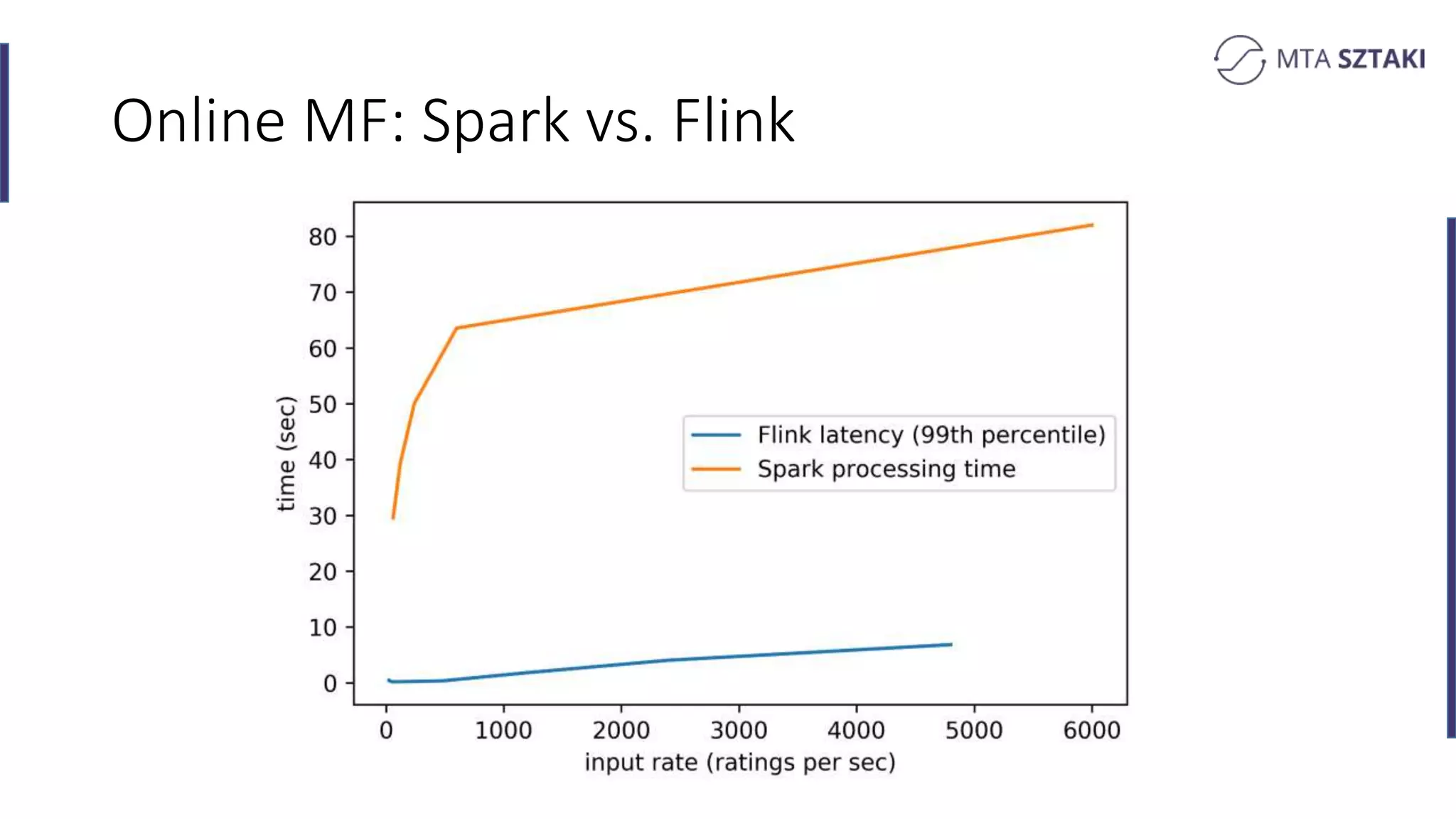
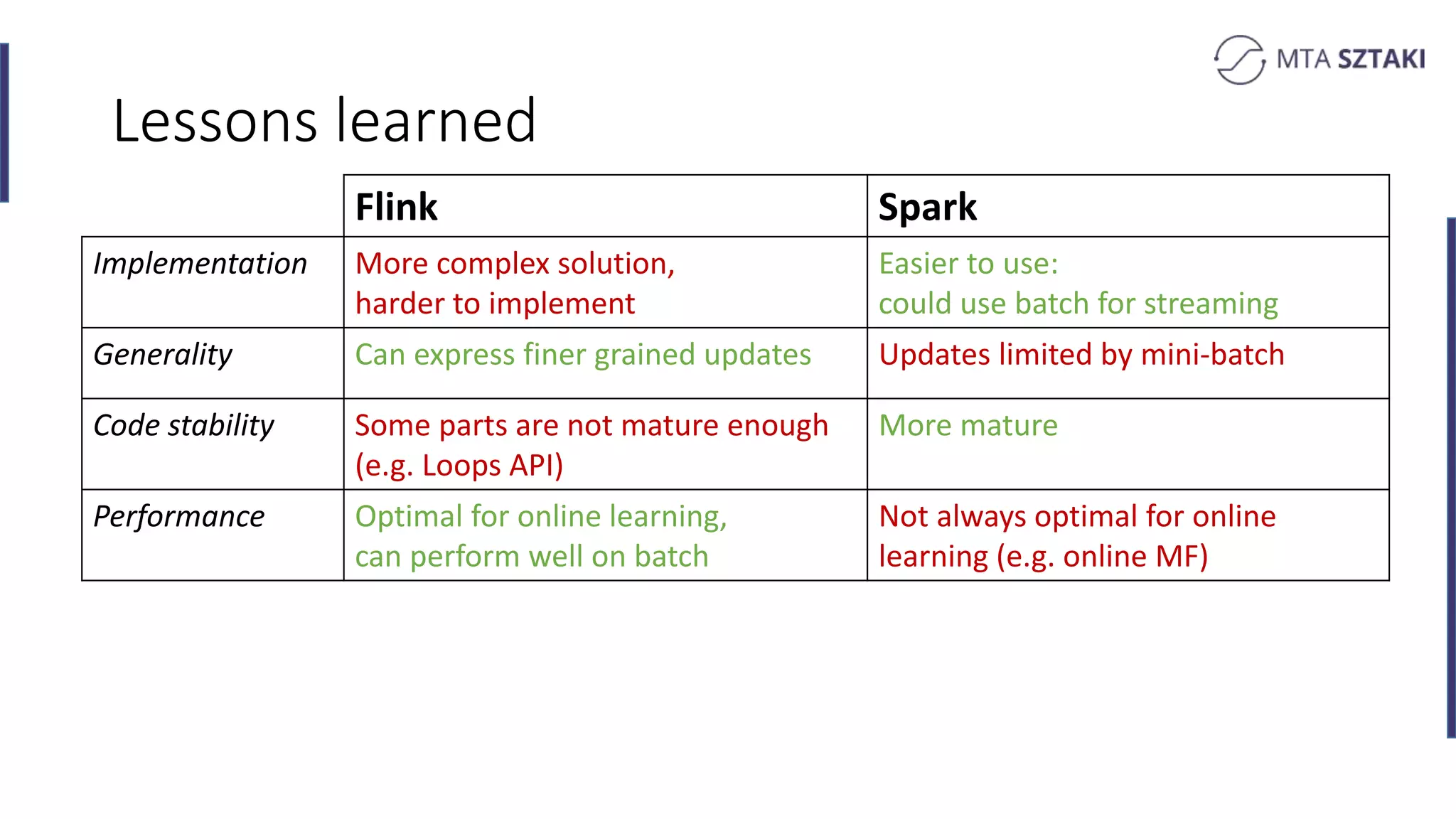
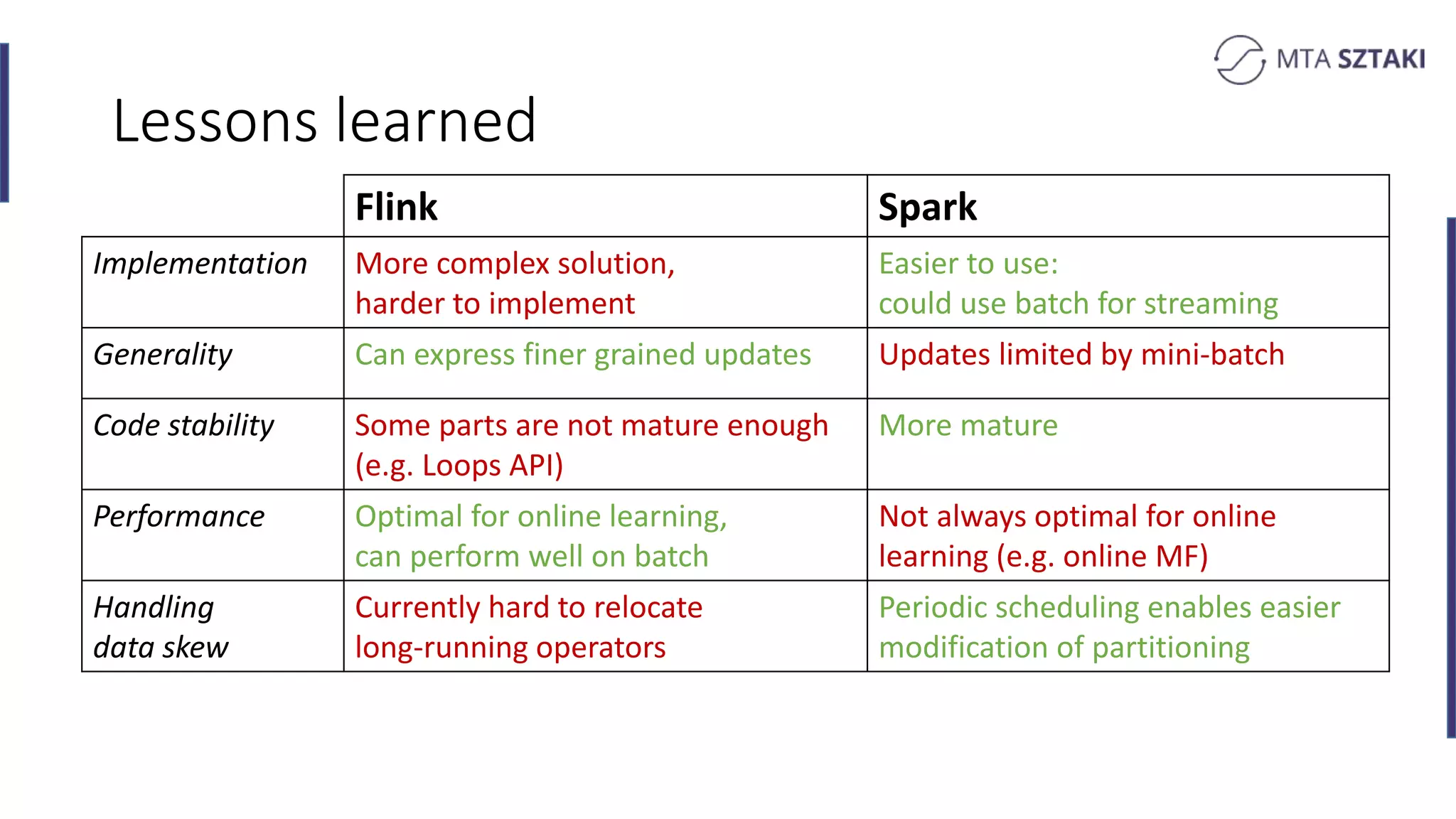
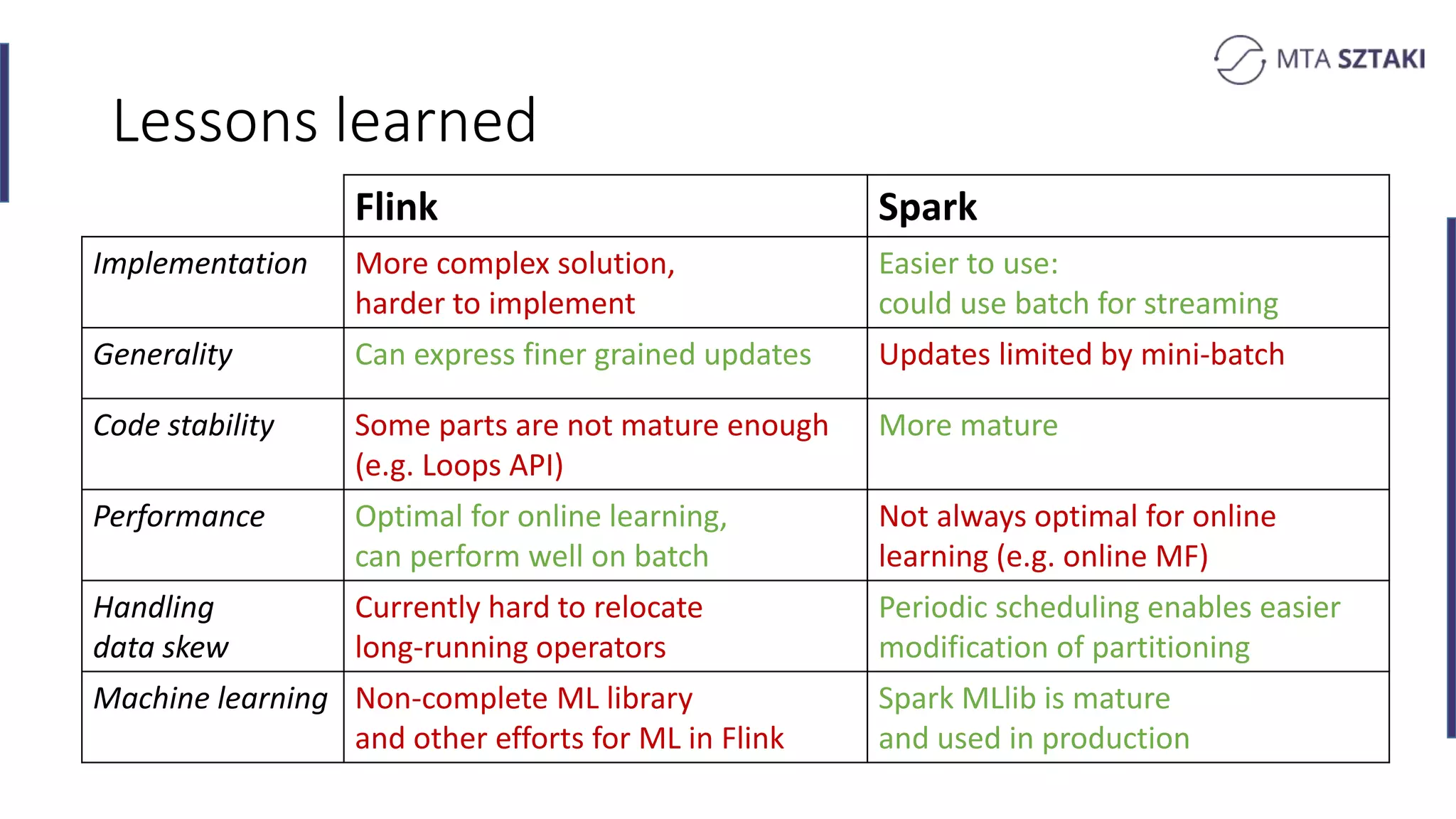
Key takeaways comparing Flink and Spark for recommendation systems including performance and implementation complexity.
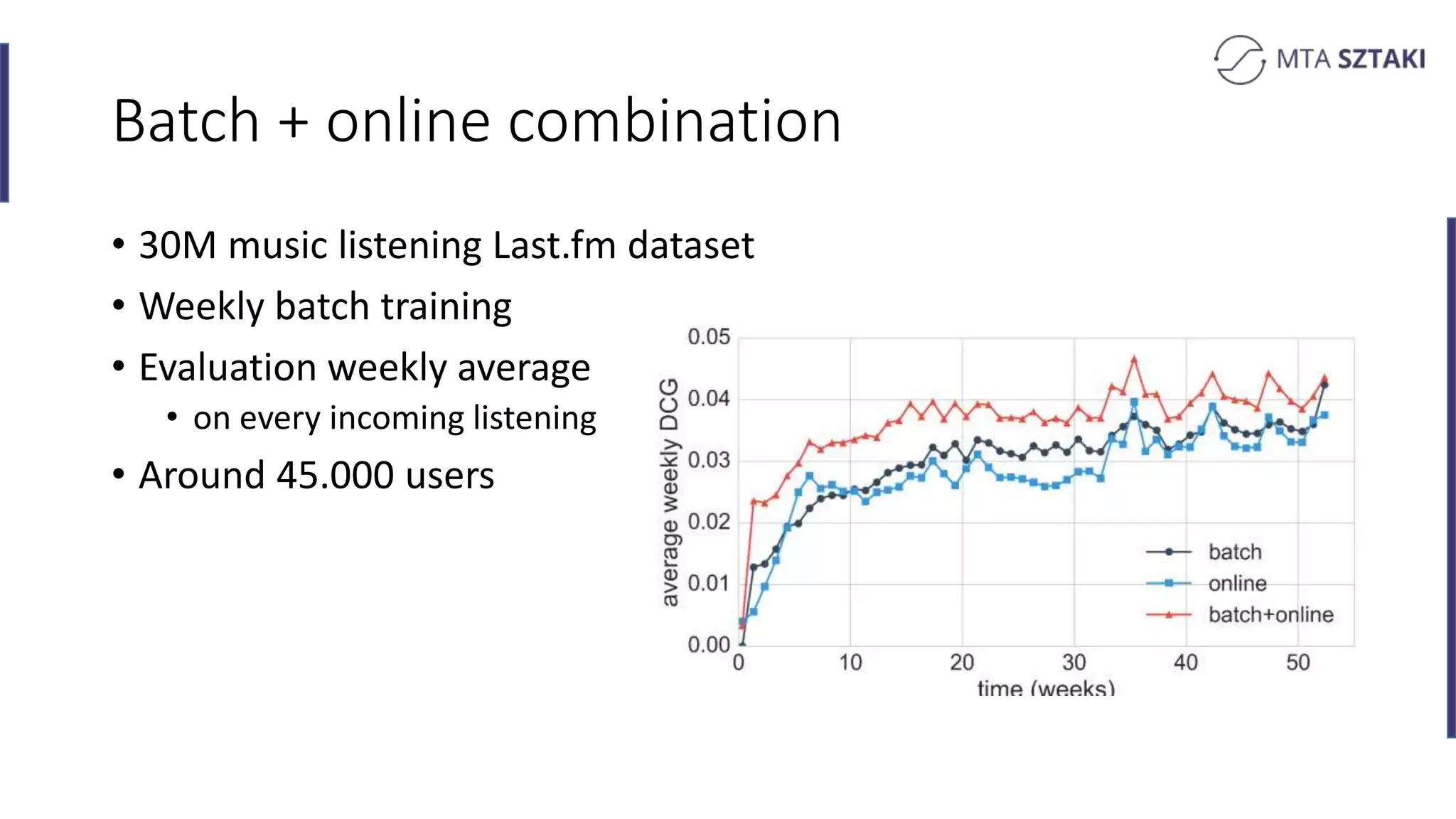
Final remarks and insights on the research conducted, including measurements and datasets used in various tests.




















![[Azure Governance] Lesson 2 : Azure Locks](https://cdn.slidesharecdn.com/ss_thumbnails/azuregovernance-lesson2-azurelocks-190120120003-thumbnail.jpg?width=640&height=640&fit=bounds)














































































