Download to read offline










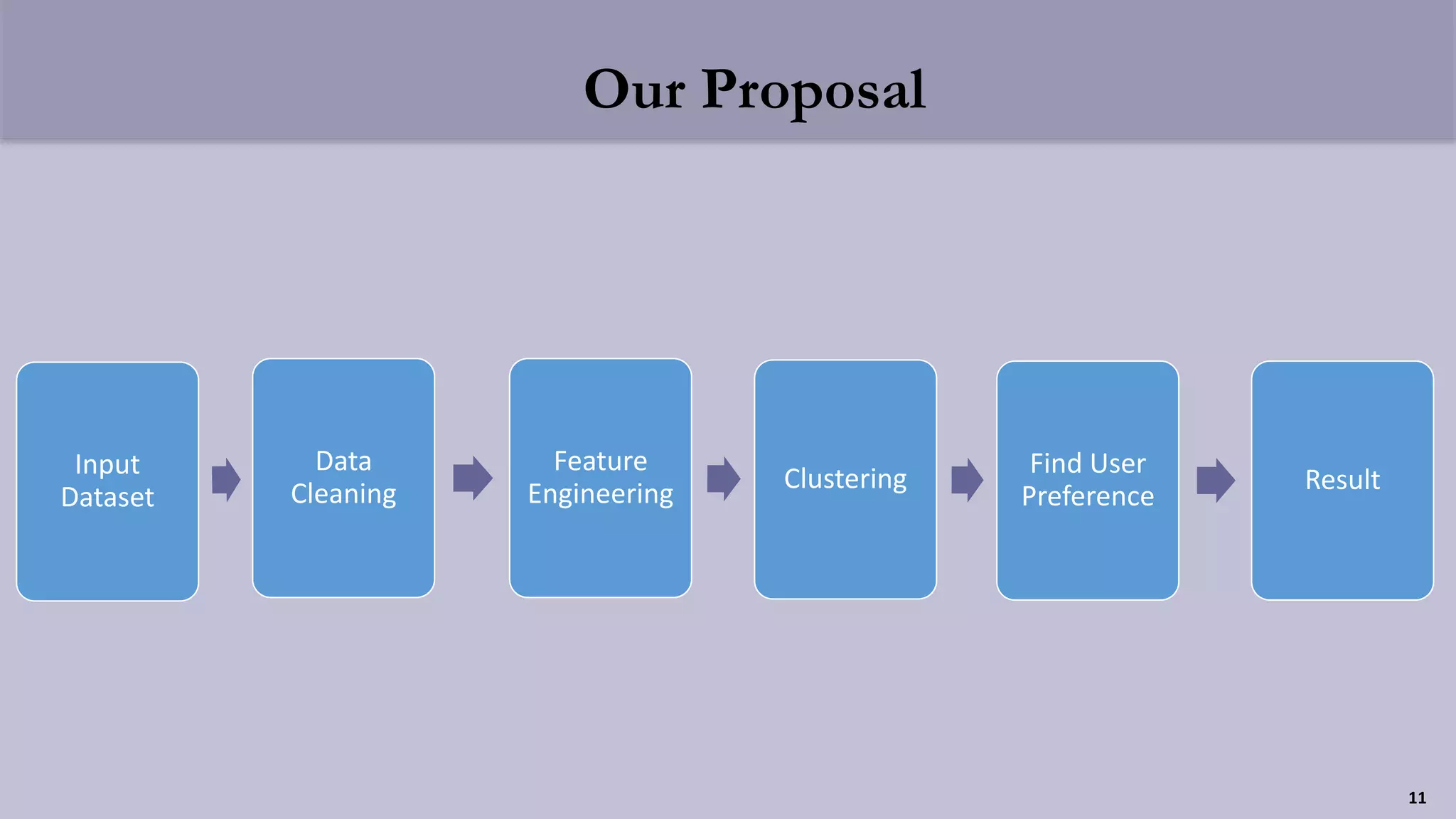


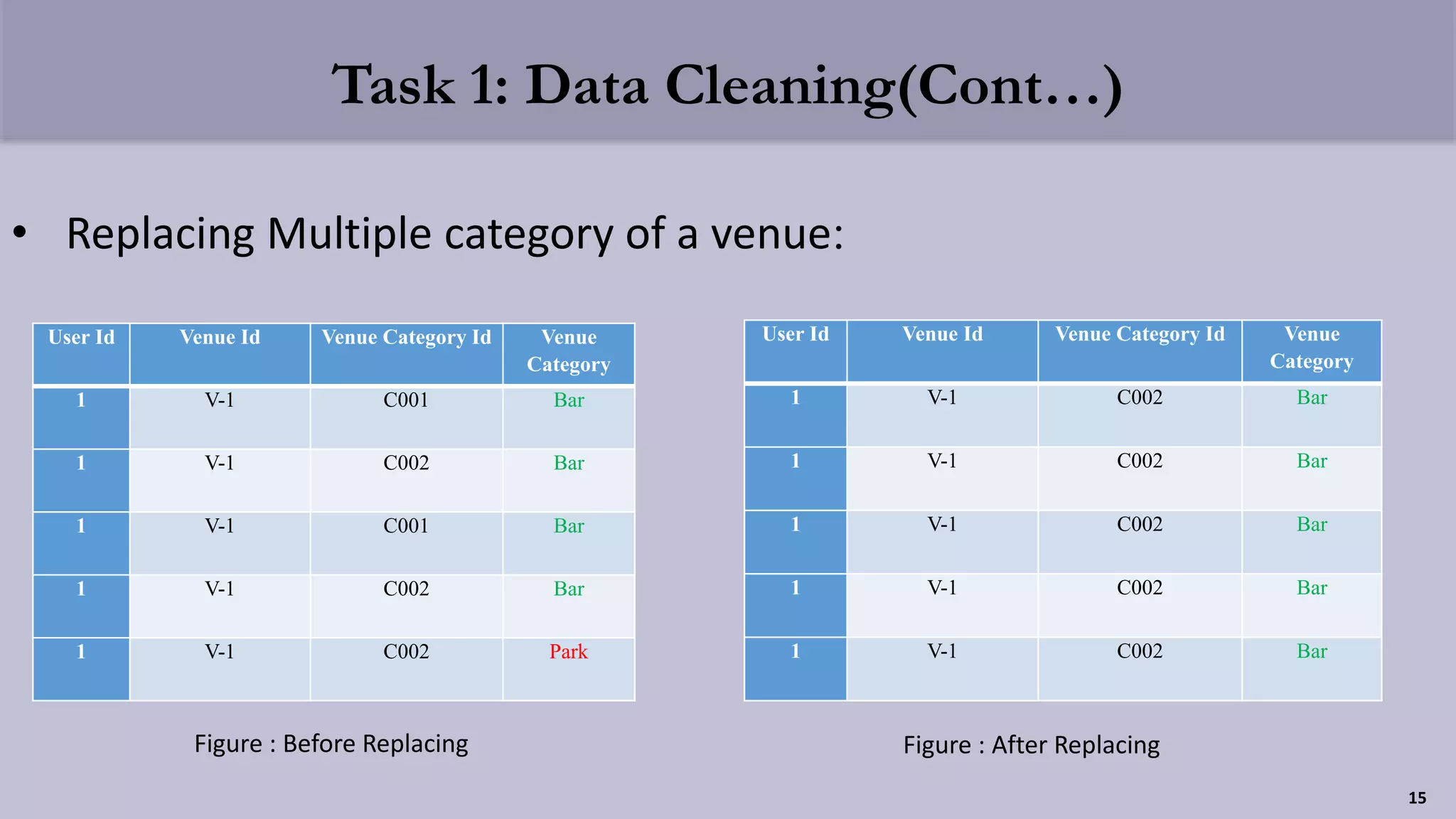
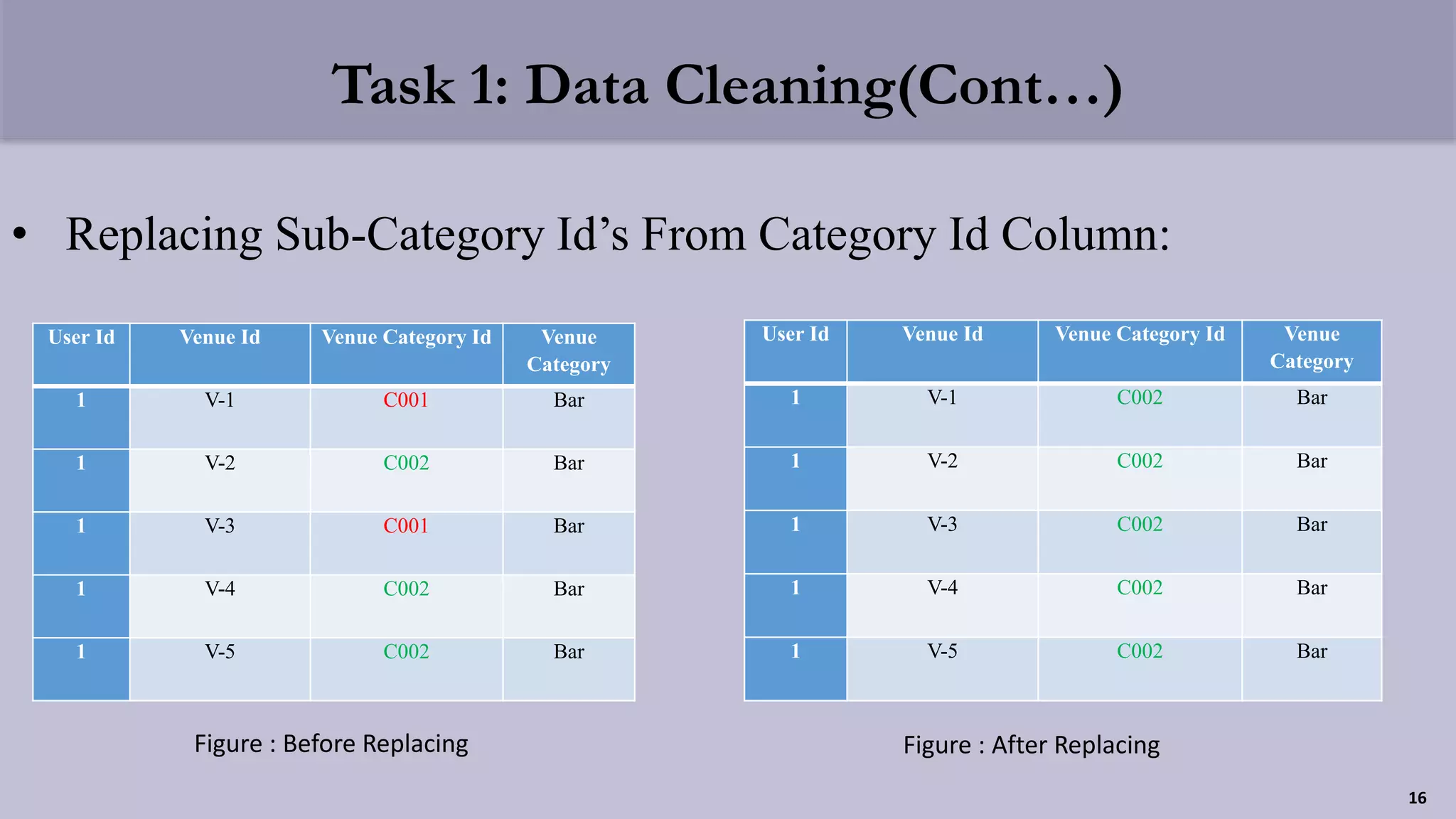







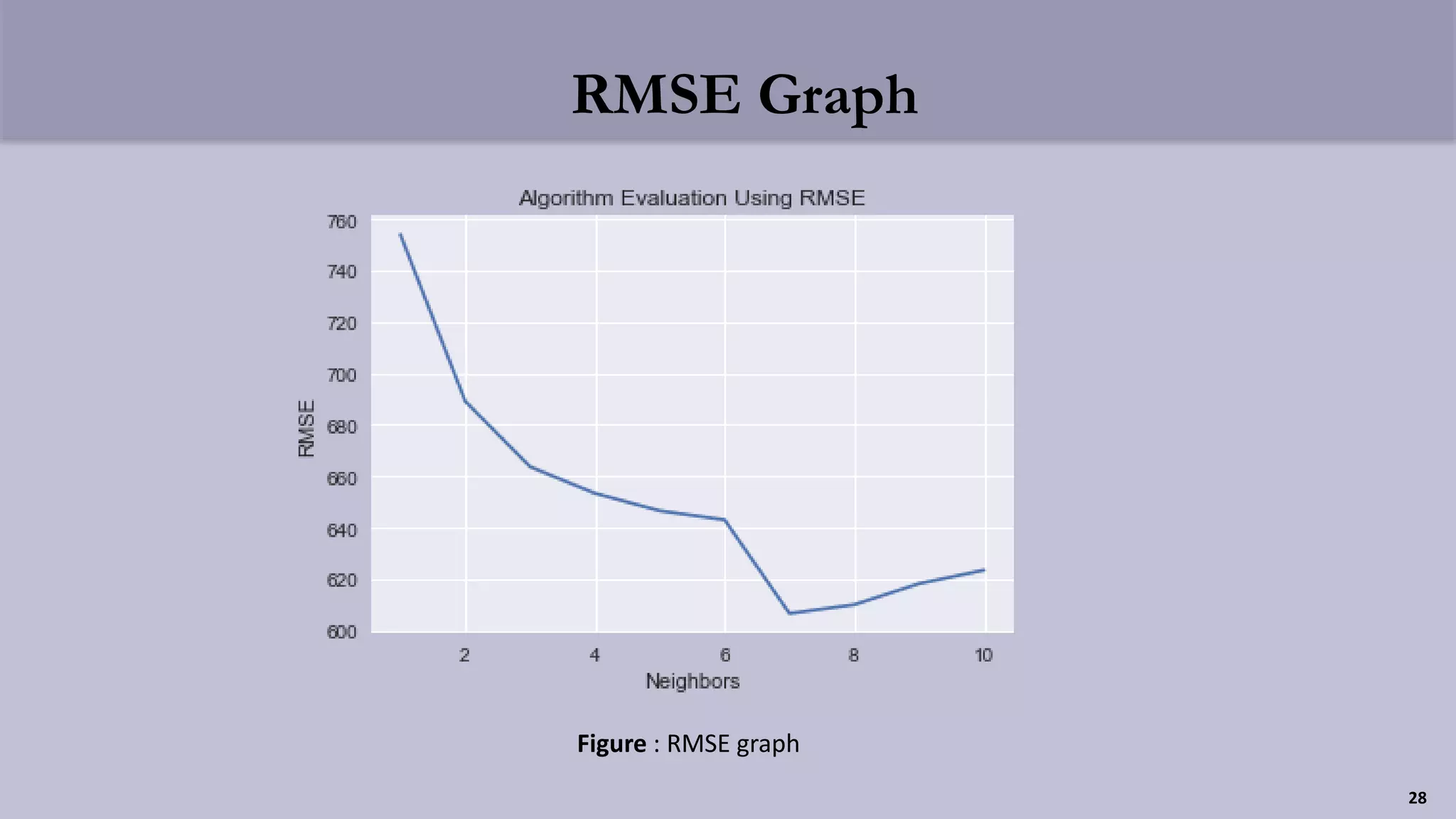
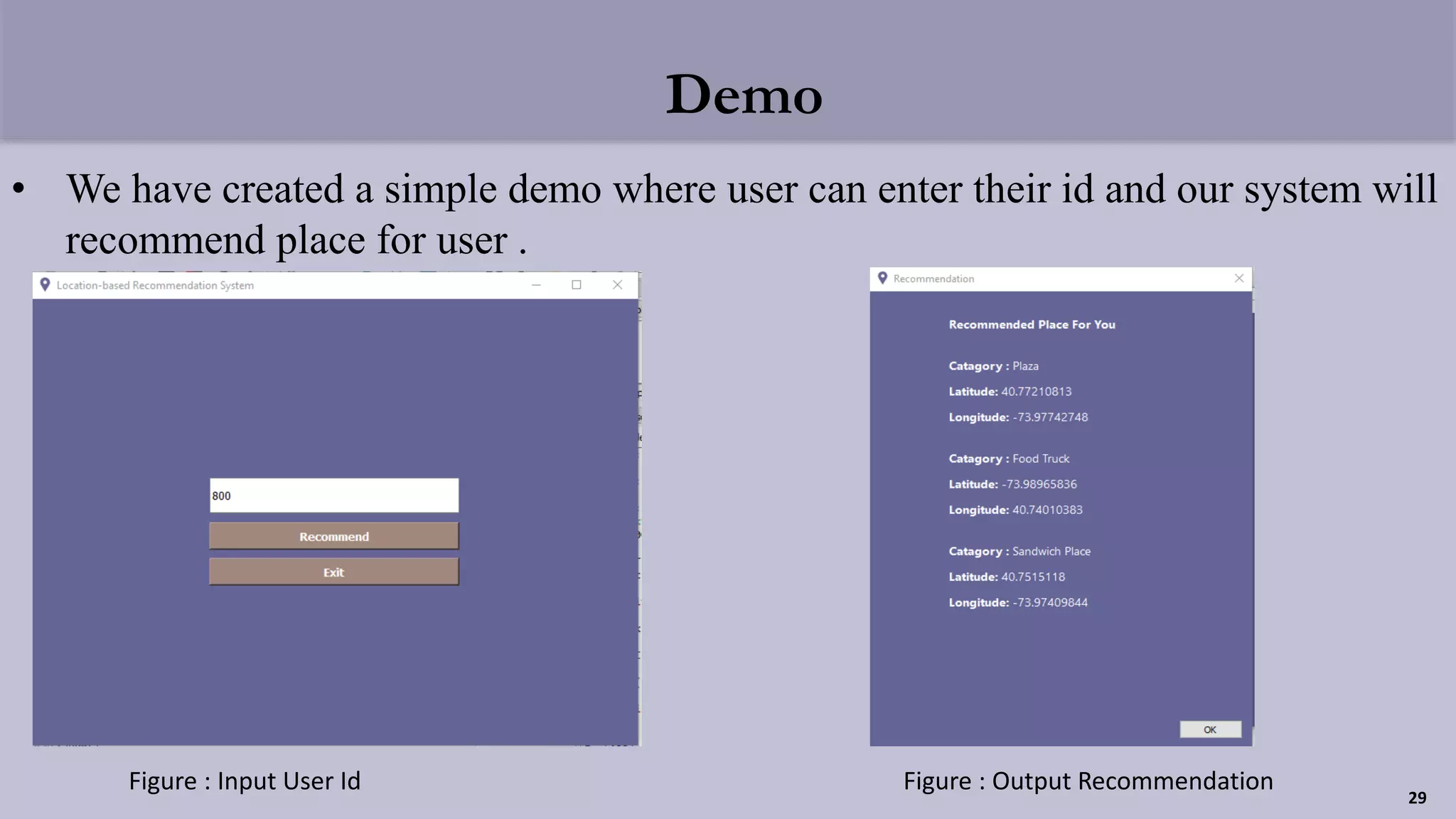


































The document presents a clustering-based location recommendation system developed by students under the supervision of Dr. Mohammad Rezwanul Huq, focusing on addressing the overload of information users face when seeking places to visit. It details the methodology of data cleaning, feature engineering, and clustering to assess user preferences while utilizing the Foursquare NYC check-in dataset. The proposal concludes with evaluation techniques and future work considerations aimed at enhancing the recommendation system's performance.
















![[AFEL] Neighborhood Troubles: On the Value of User Pre-Filtering To Speed Up ...](https://cdn.slidesharecdn.com/ss_thumbnails/cikm18eyrepres-181022081818-thumbnail.jpg?width=640&height=640&fit=bounds)






























