Download to read offline




![11 | © Copyright 2025 Zilliz
11
11 | © Copyright 2025 Zilliz
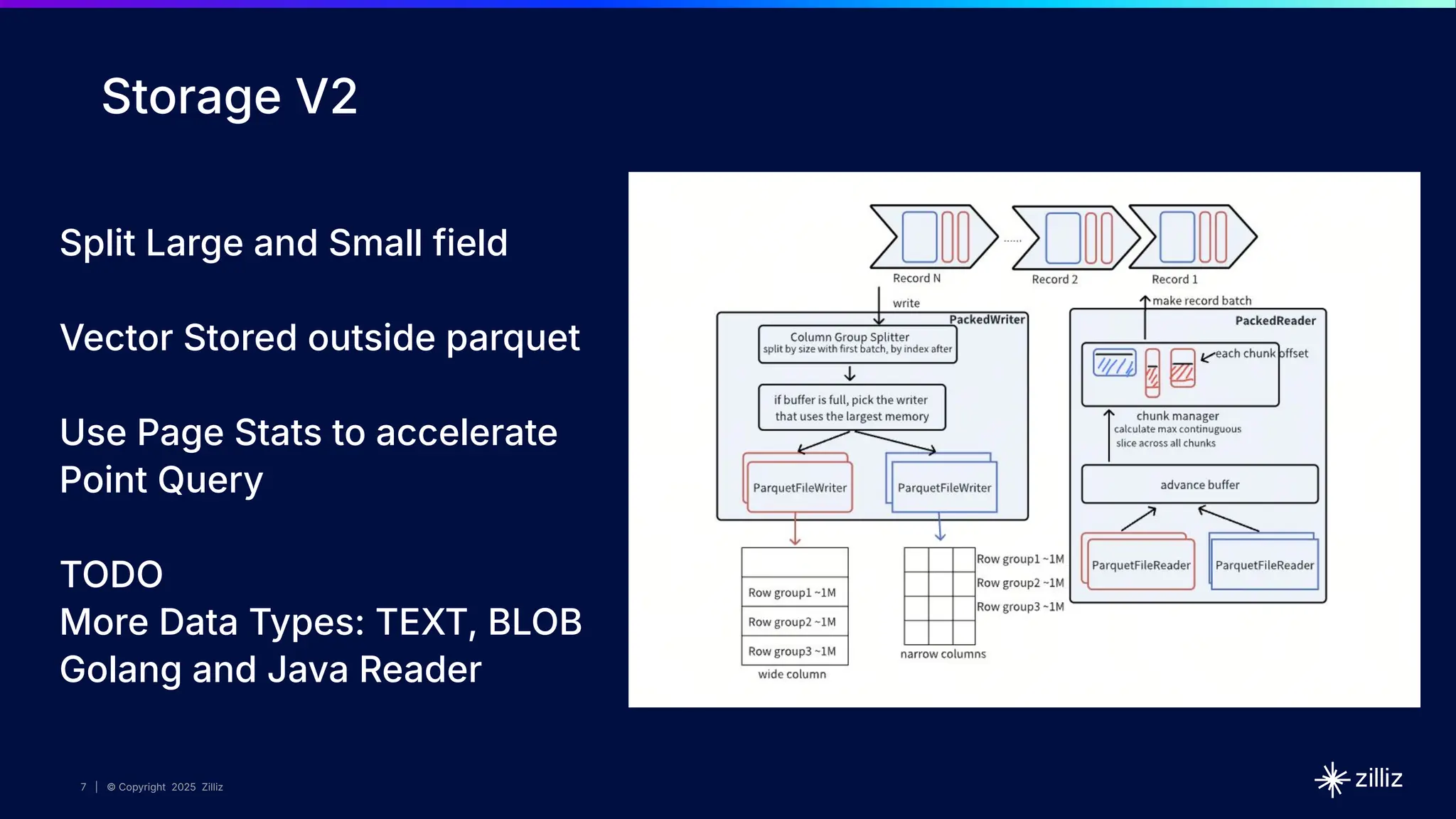
Json Shredding
{"a":10,"b":"str1","d":"42", f:1}
{"a":20,"b":"str2","d":"43", f:2}
{"a":30,"b":"str3","e":"44",f:3}
{"a":40,"b": 1,"d":"foo","e":"baz"}
{"a":50,"b": 2,"d":["23","24"]}
{"a":60,"b": 3,"d":{"e":"bar"},"e":"45"}
Performance Improvement 10310x
in our dynamic field test](https://image.slidesharecdn.com/milvus2-250620214342-947159c1/75/Open-Source-Milvus-Vector-Database-v-2-6-11-2048.jpg)














![11 | © Copyright 2025 Zilliz
11
11 | © Copyright 2025 Zilliz
Json Shredding
{"a":10,"b":"str1","d":"42", f:1}
{"a":20,"b":"str2","d":"43", f:2}
{"a":30,"b":"str3","e":"44",f:3}
{"a":40,"b": 1,"d":"foo","e":"baz"}
{"a":50,"b": 2,"d":["23","24"]}
{"a":60,"b": 3,"d":{"e":"bar"},"e":"45"}
Performance Improvement 10310x
in our dynamic field test](https://crownmelresort.com/image.slidesharecdn.com/milvus2-250620214342-947159c1/75/Open-Source-Milvus-Vector-Database-v-2-6-11-2048.jpg)







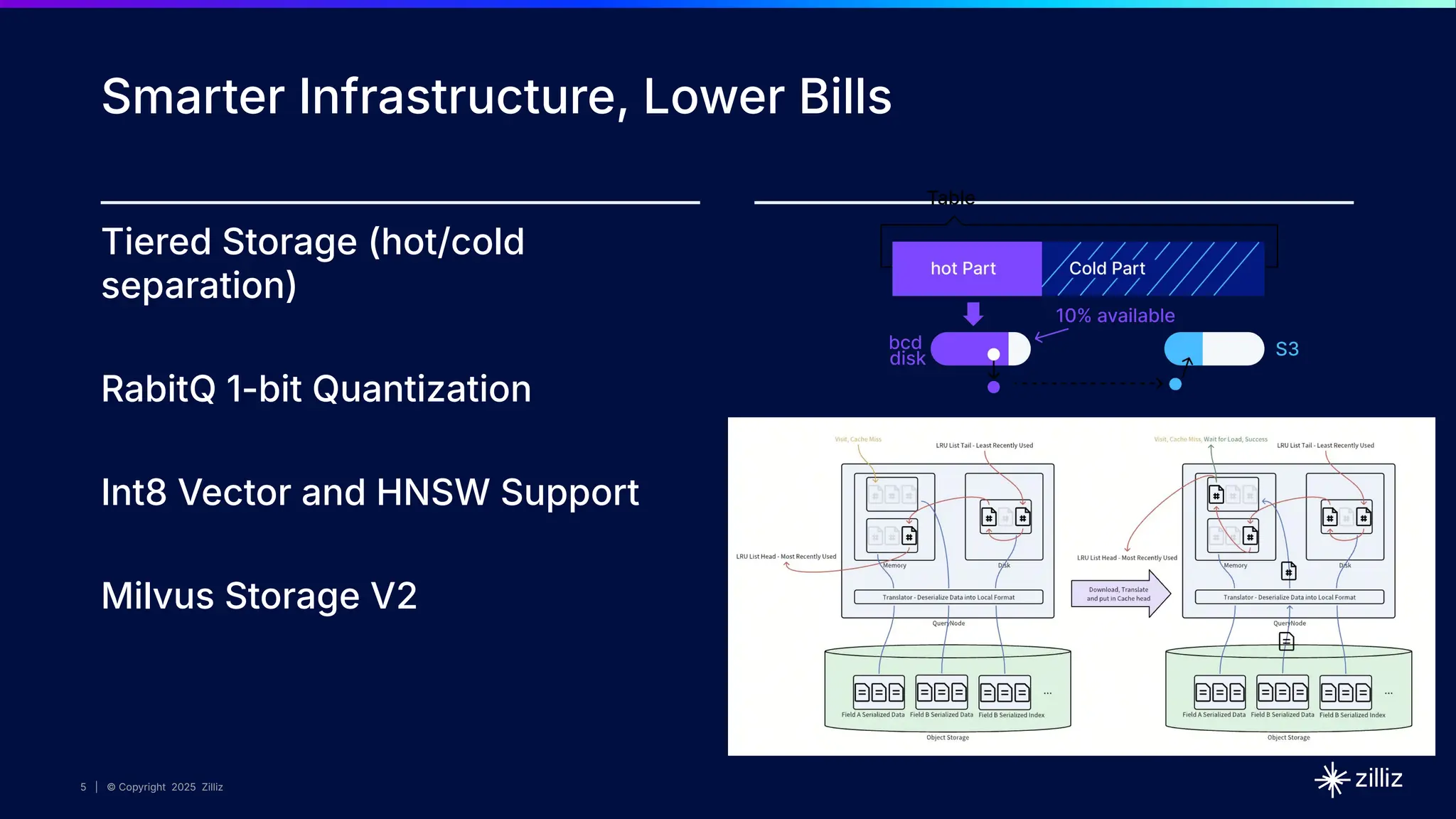
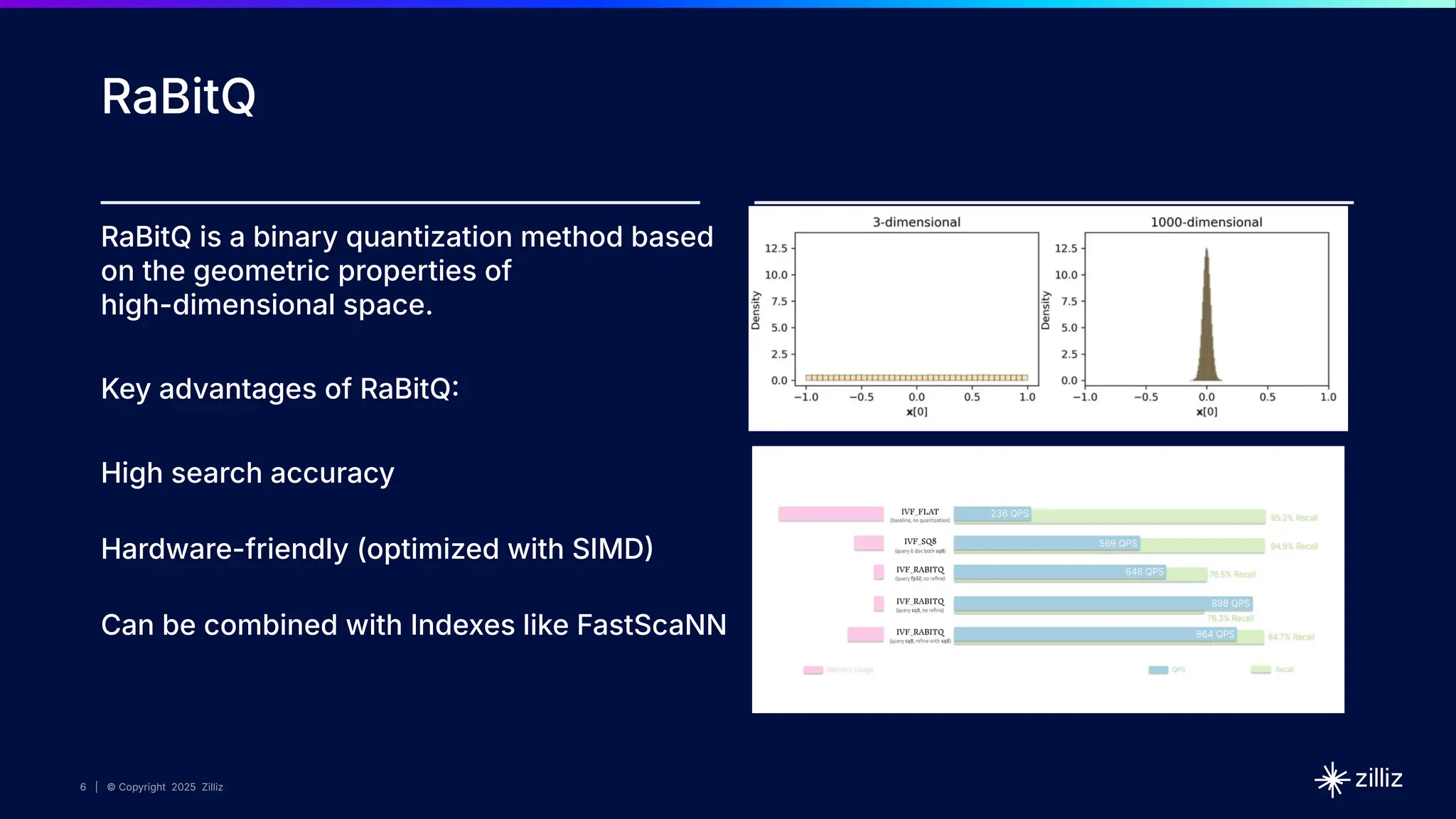
Milvus 2.6 introduces major architectural improvements that dramatically reduce **storage**, **compute**, and **operational** costs—without compromising on performance. - **New Features for All Users**: How **tiered storage**, **vector quantization**, and a **diskless WAL** (with Woodpecker) can **cut infrastructure costs by up to 10X**—ideal for scaling AI workloads affordably. - **For Existing Users**: How **Milvus 2.6** simplifies your operations with new features like **CDC + BulkInsert** for easier data replication and **native package support** that streamlines installation and upgrades (no more manual dependencies or setup headaches!). - How **Milvus 2.6** boosts **developer productivity** with built-in tools for ingestion, **advanced search, analytics, and reranking**—making it easier than ever to iterate and deploy your AI applications. - What's next on the **Milvus roadmap**: Insights into future enhancements and how they’ll further streamline your workflows.

































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

