Download as PDF, PPTX


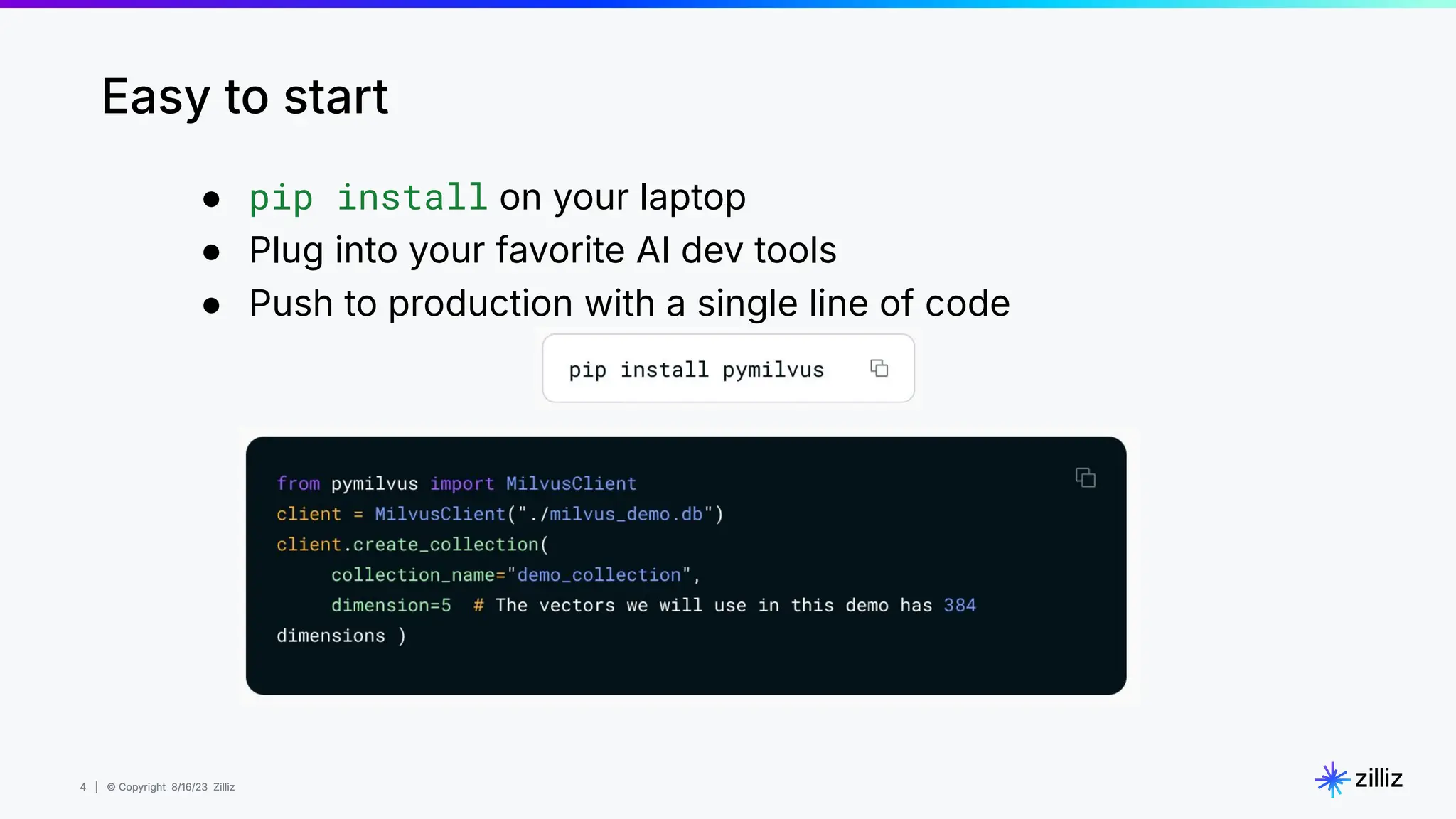





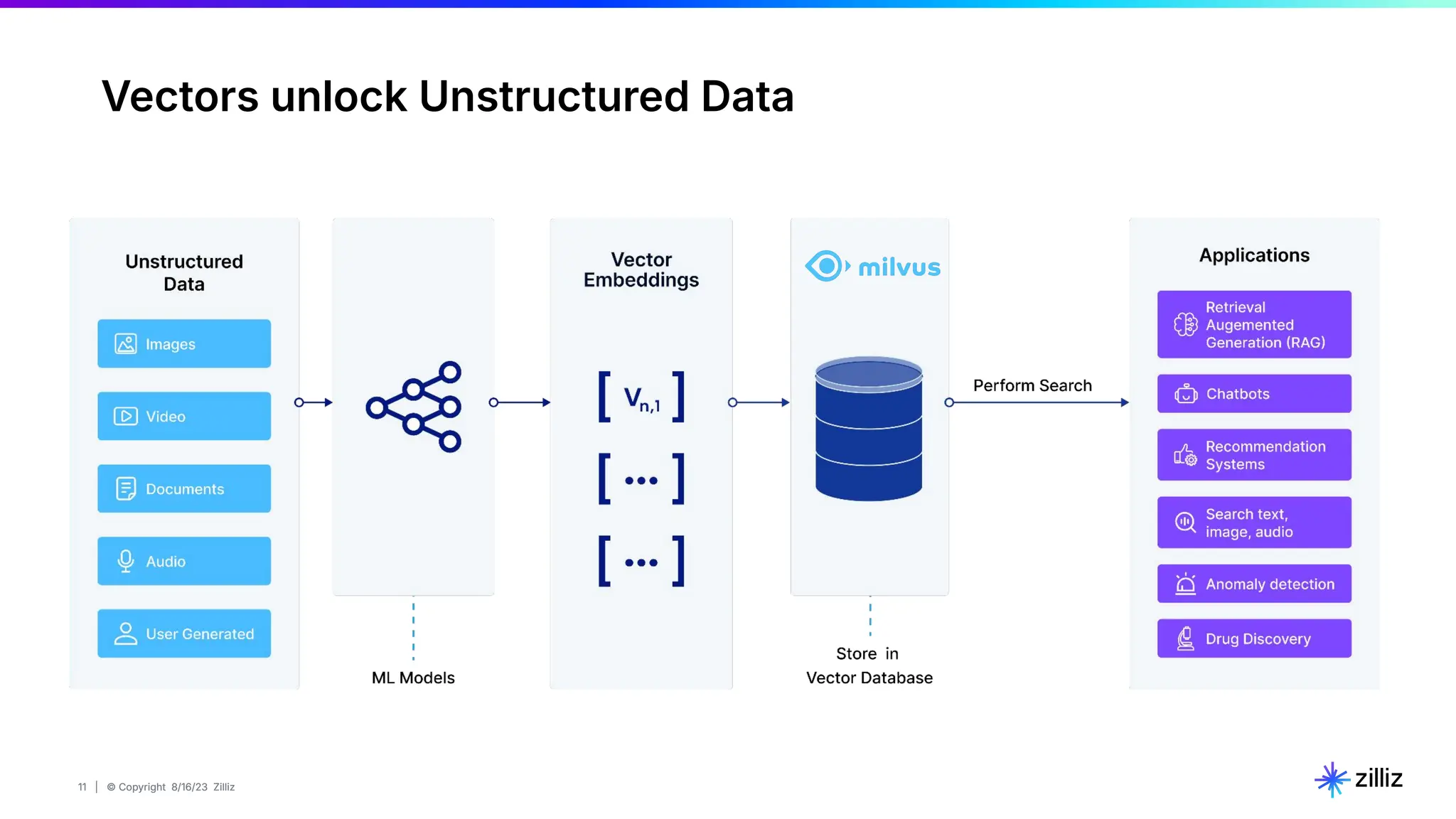
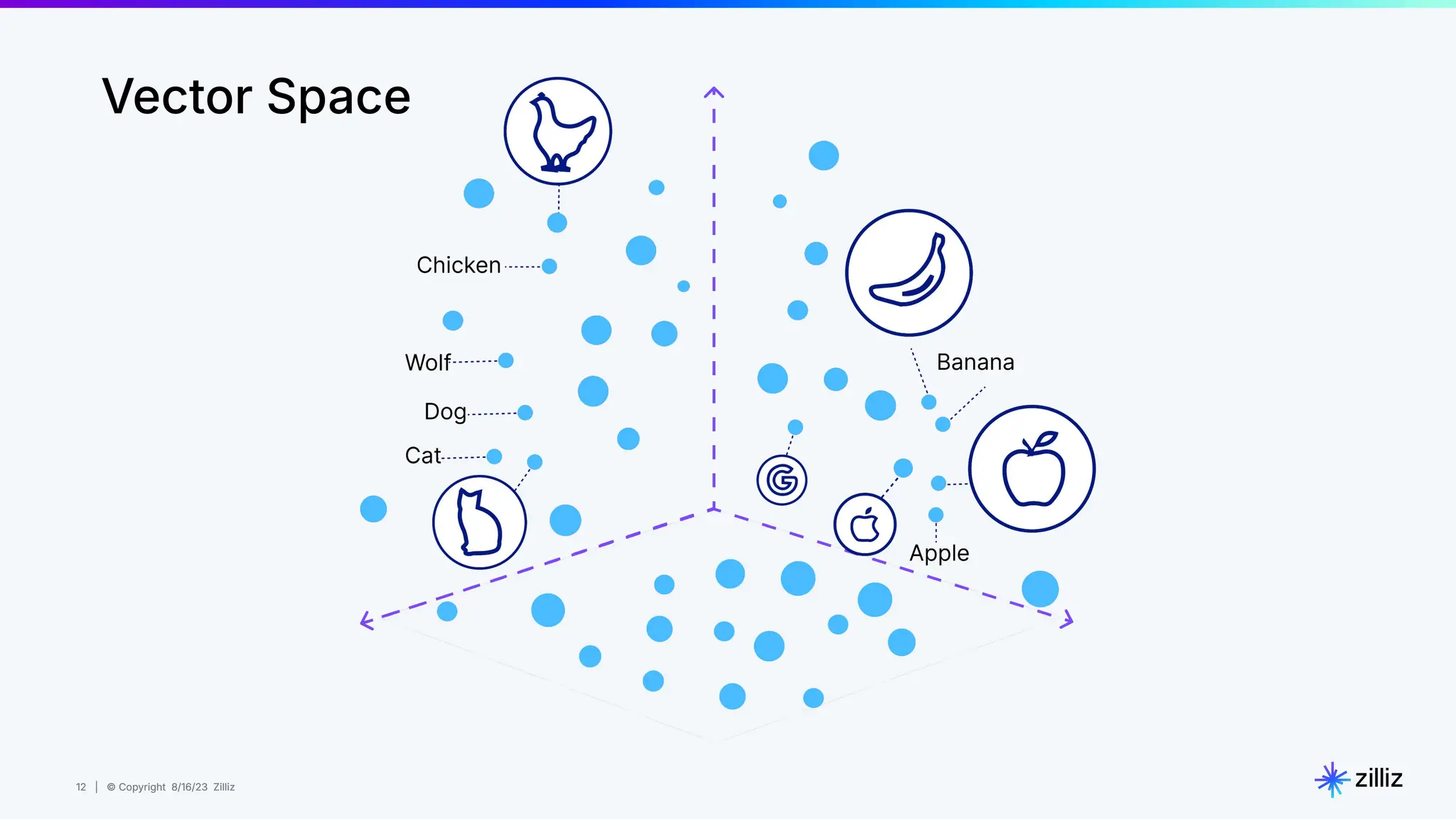
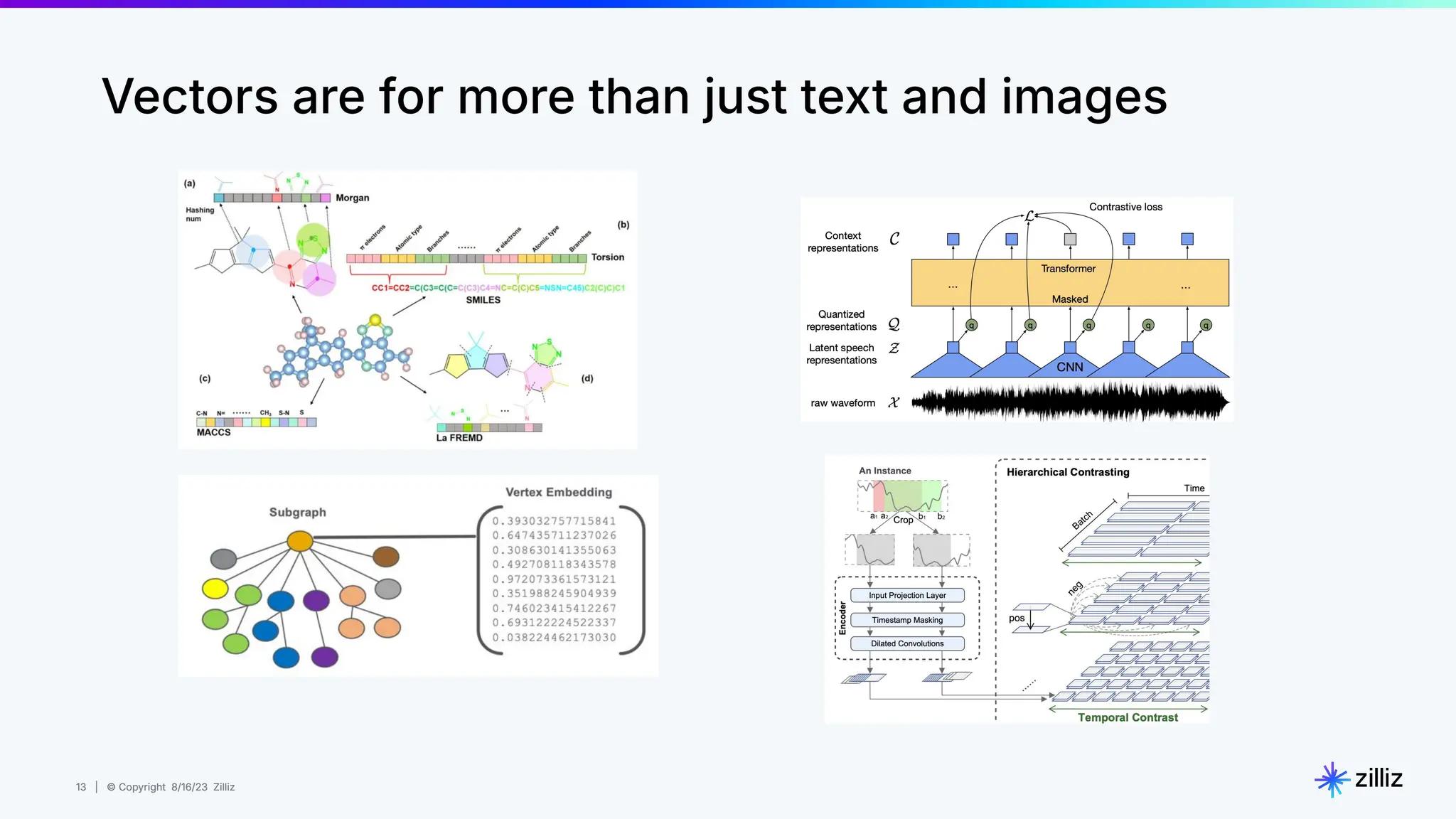
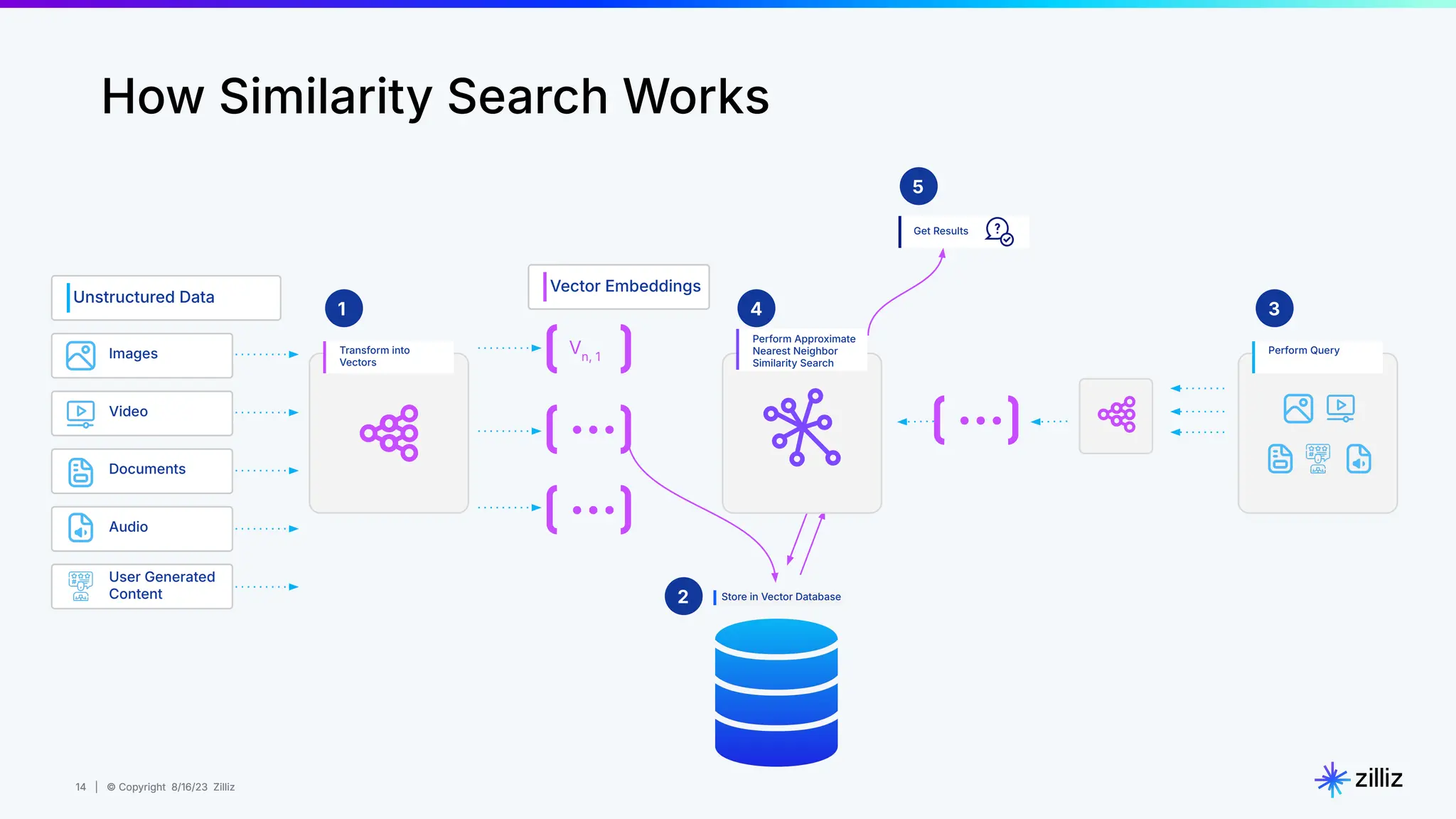

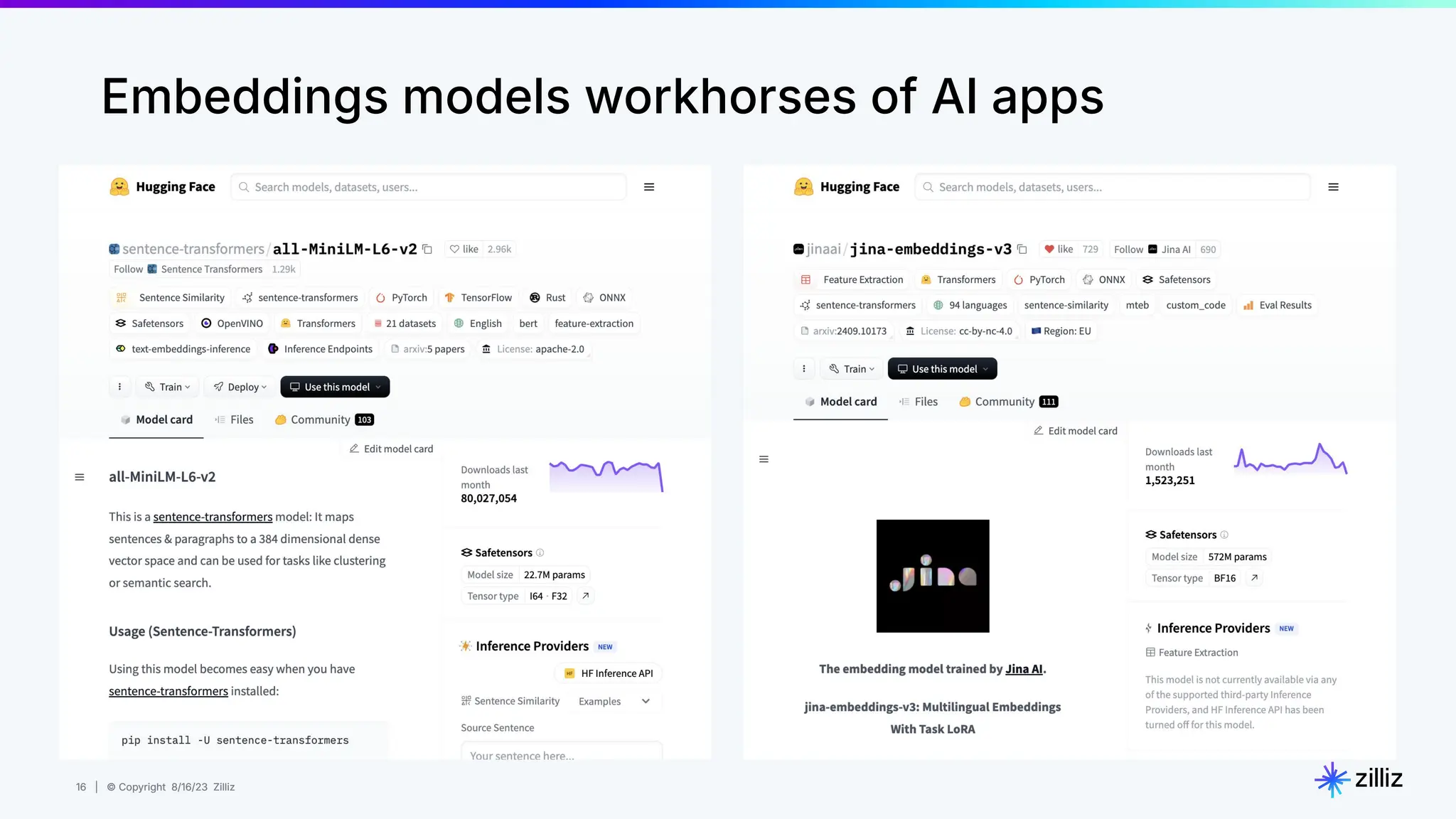




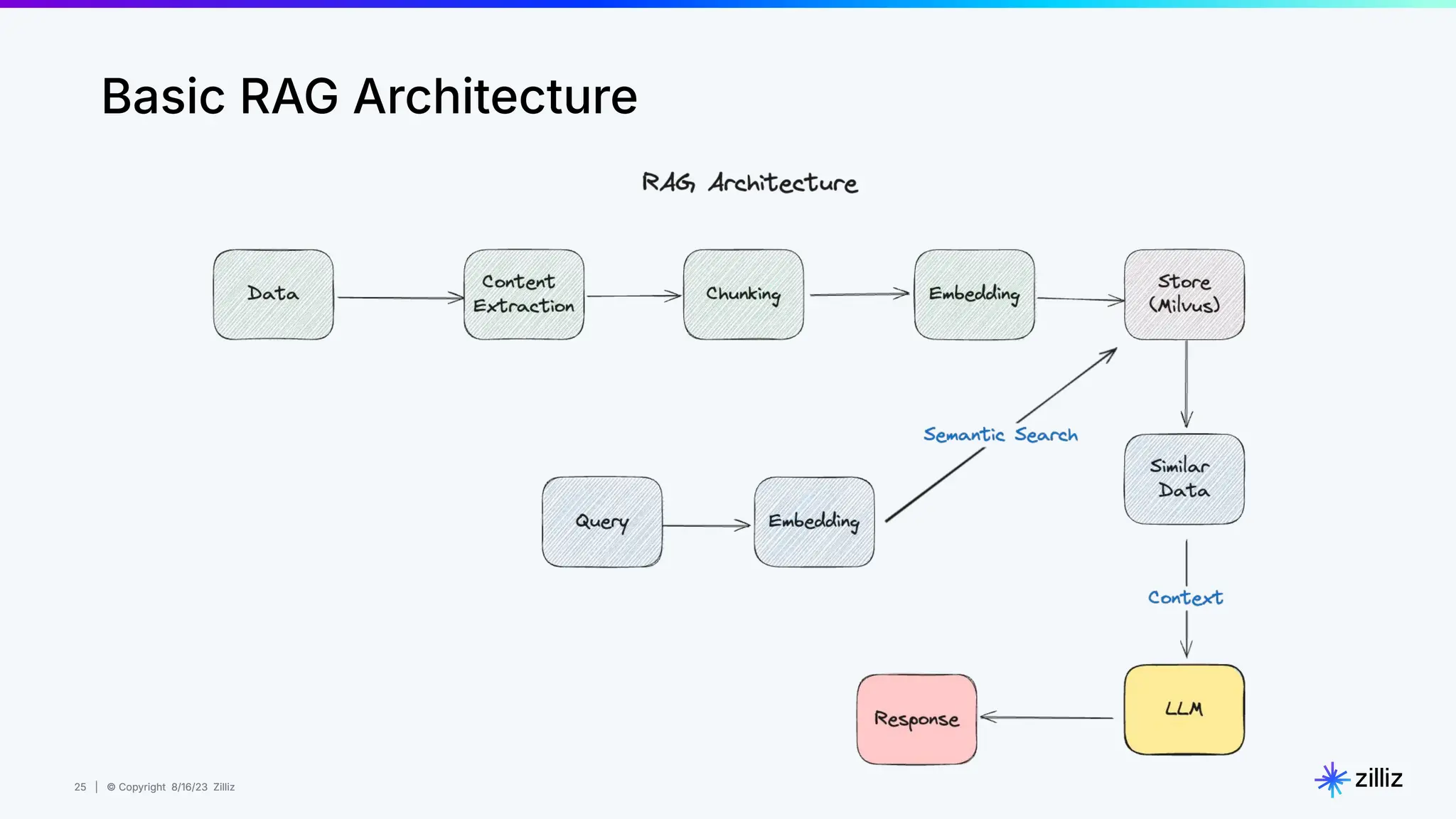
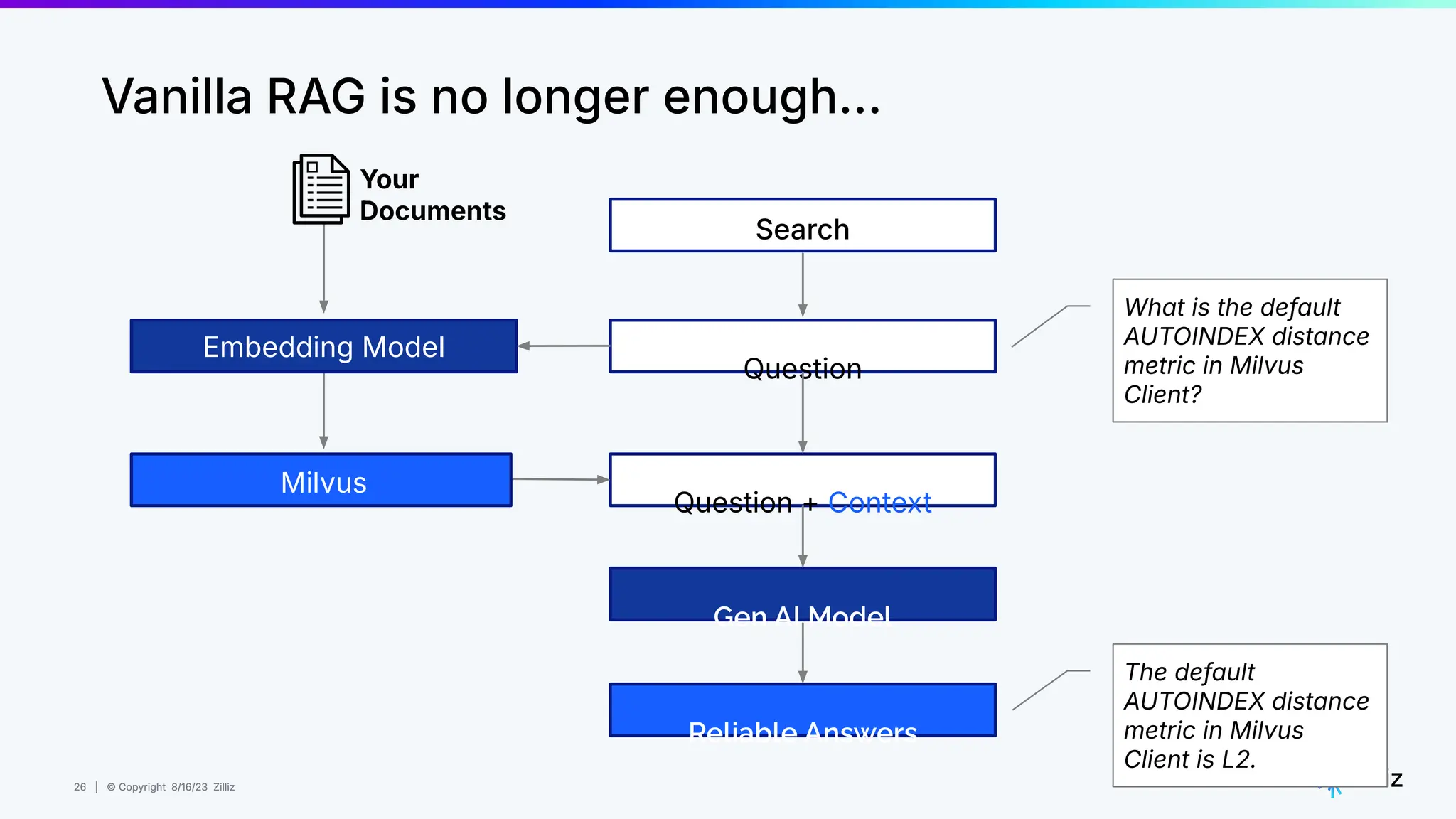
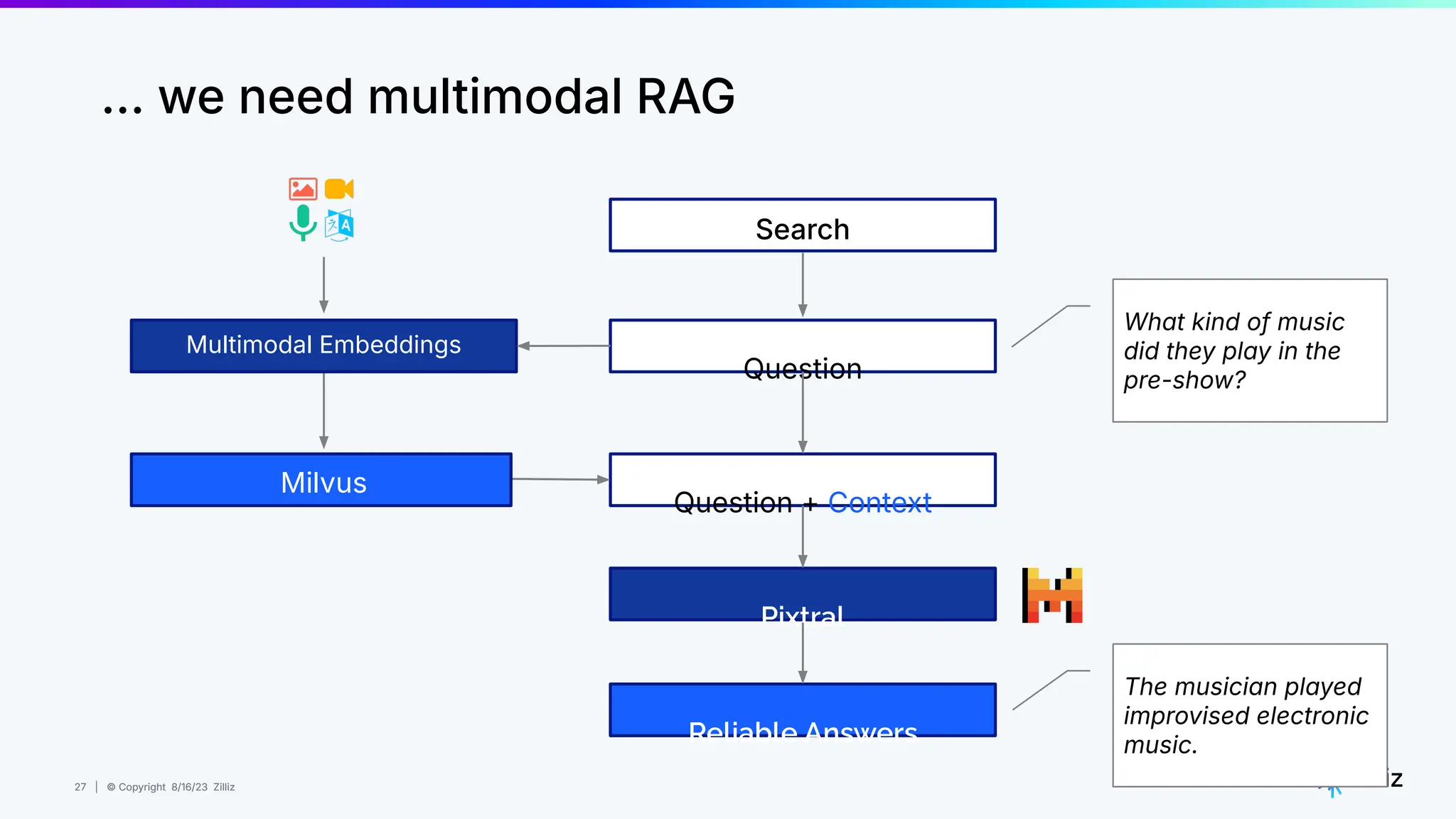





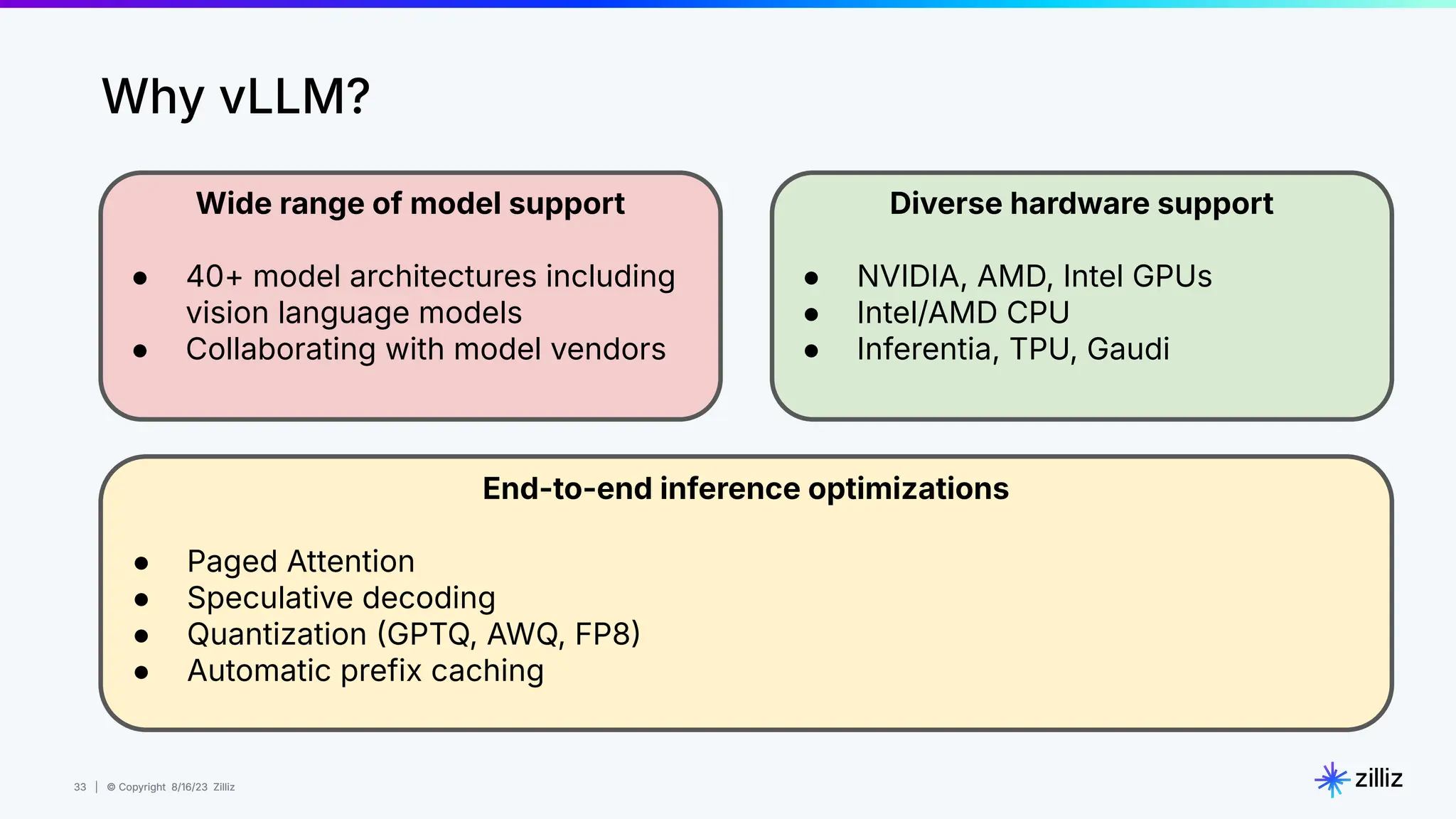


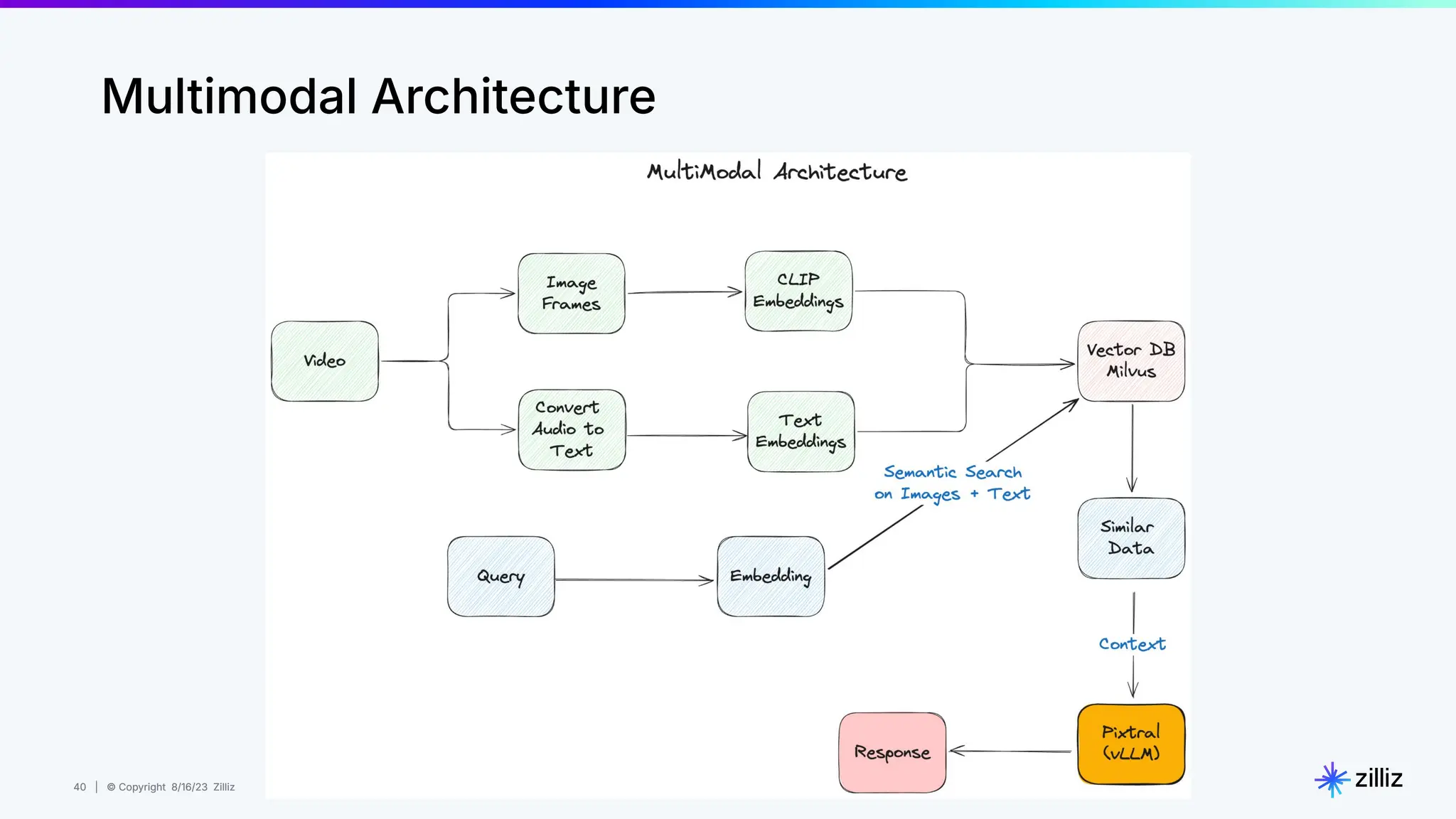



















































About this webinar: While text-based RAG systems have been everywhere in the last year and a half, there is so much more than text data. Images, audio, and documents often need to be processed together to provide meaningful insights, yet most RAG implementations focus solely on text. Think about automated visual inspection systems understanding manufacturing logs and production line images, or robotics systems correlating sensor data with visual feedback. These multimodal scenarios demand RAG systems that go beyond text-only processing. In this talk, we'll walk through how to build a Multimodal RAG system that helps solve this problem. We'll explore the architecture that makes it possible to run such a system and demonstrate how to build one using Milvus, LlamaIndex, and vLLM for deploying open-source LLMs on your infrastructure. Through a live demo, we'll showcase a real-world application processing both images and text queries. Whether you're looking to reduce API costs, maintain data privacy, or gain more control over your AI infrastructure, this session will provide you with actionable insights to implement Multimodal RAG in your organization. Topics covered: - vLLM and self hosting LLMs - Multimodal RAG Demo: a real-world application processing both images and text queries























































































