Download as PDF, PPTX

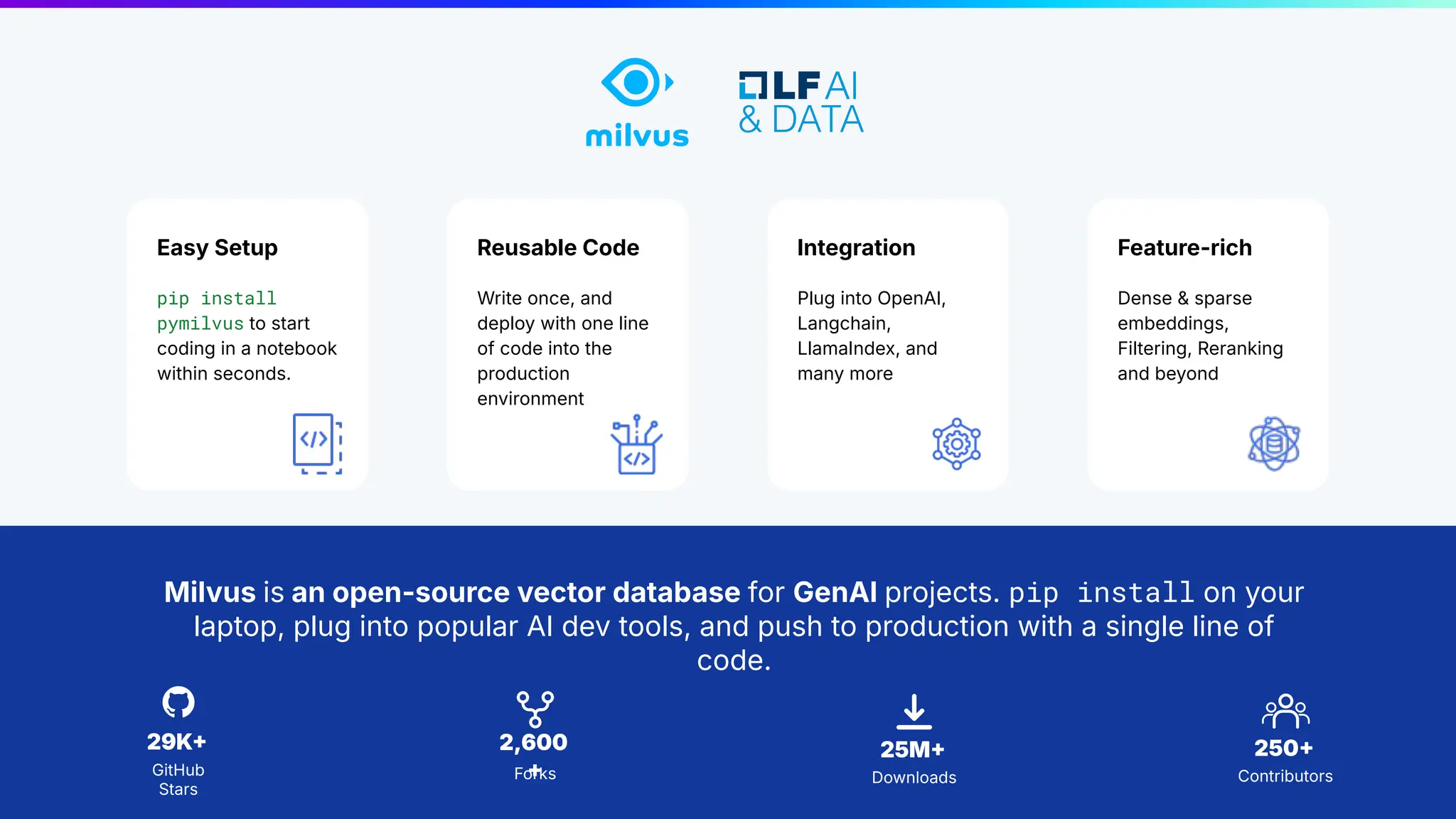
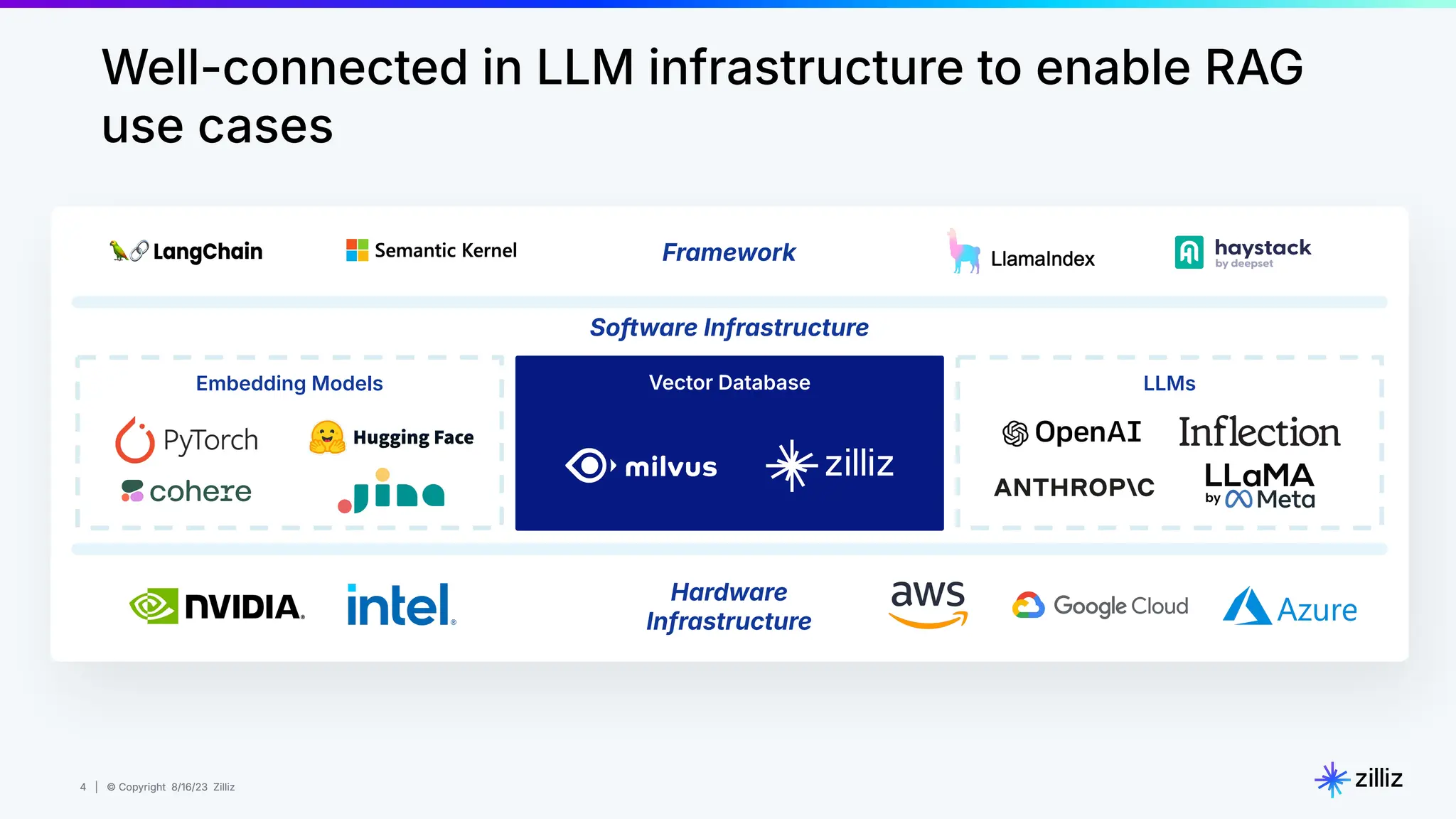


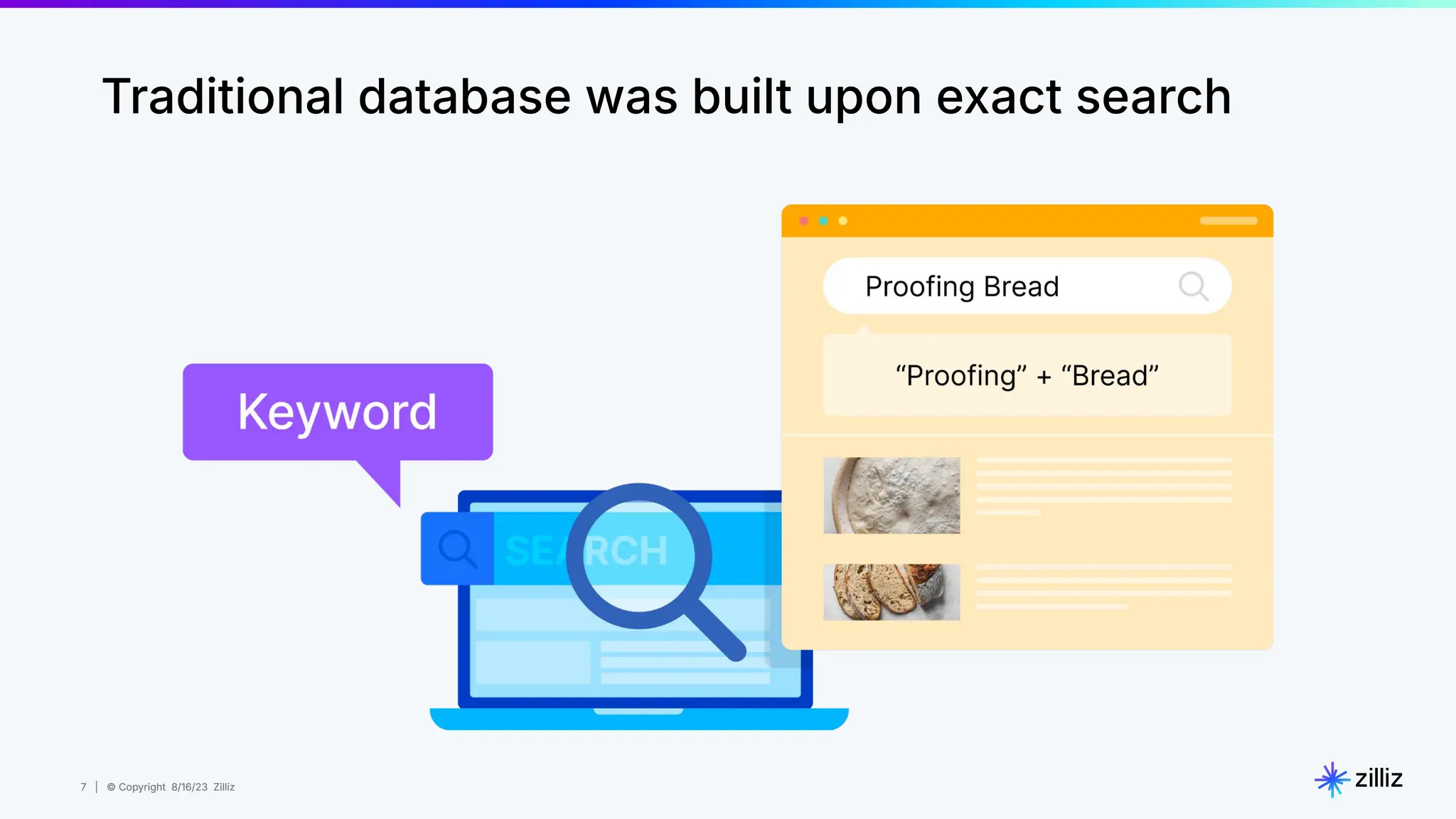
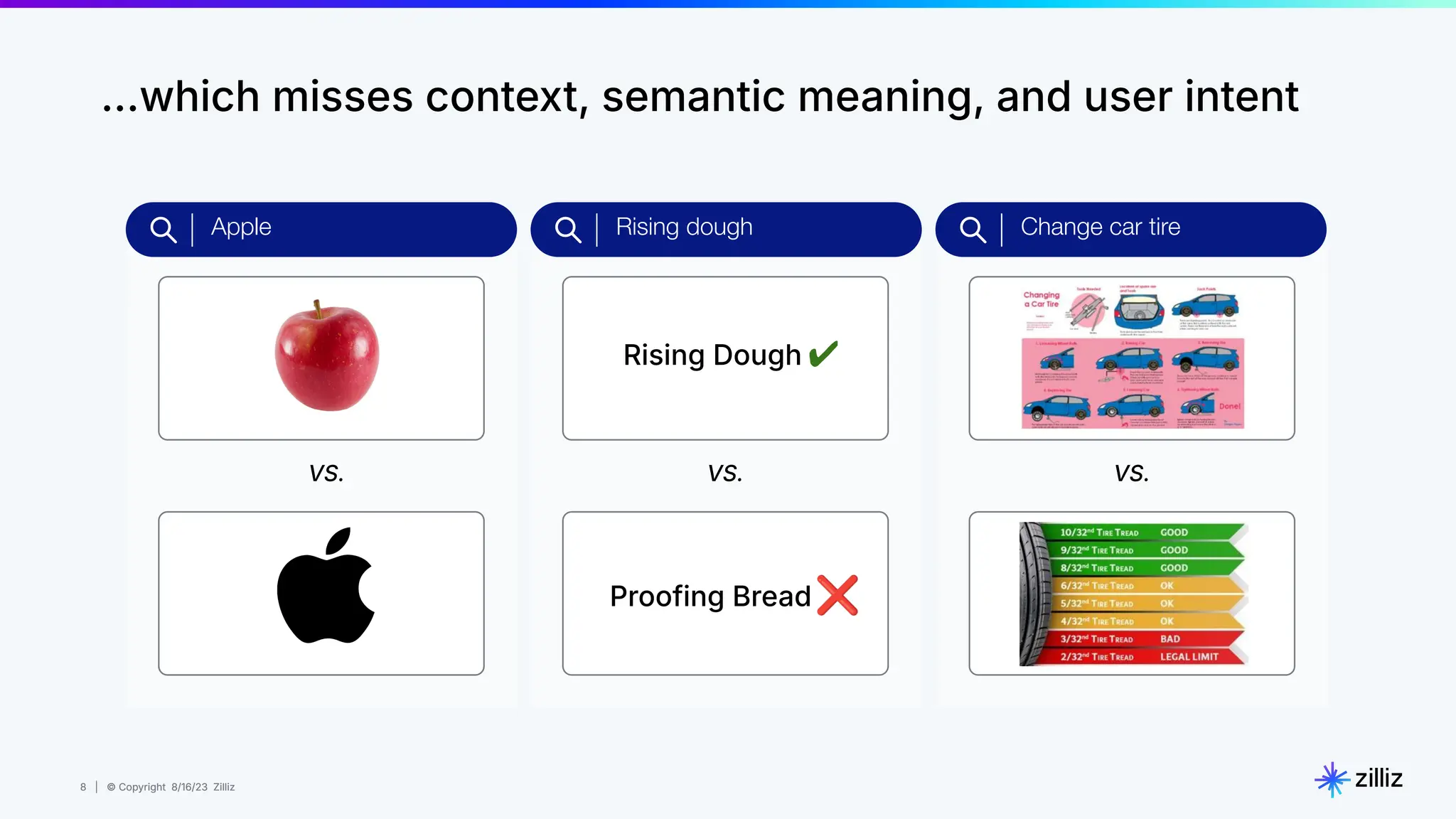
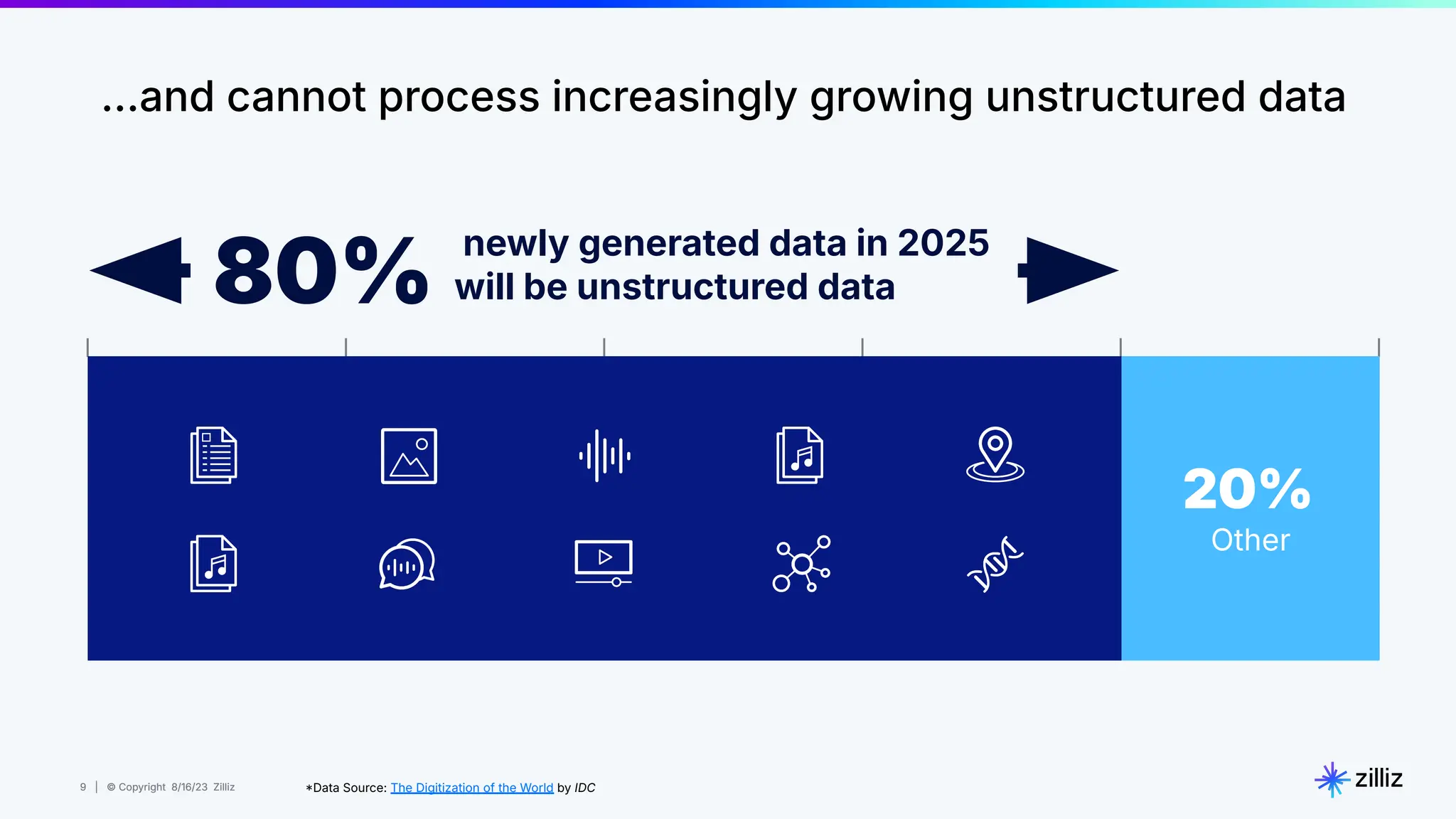
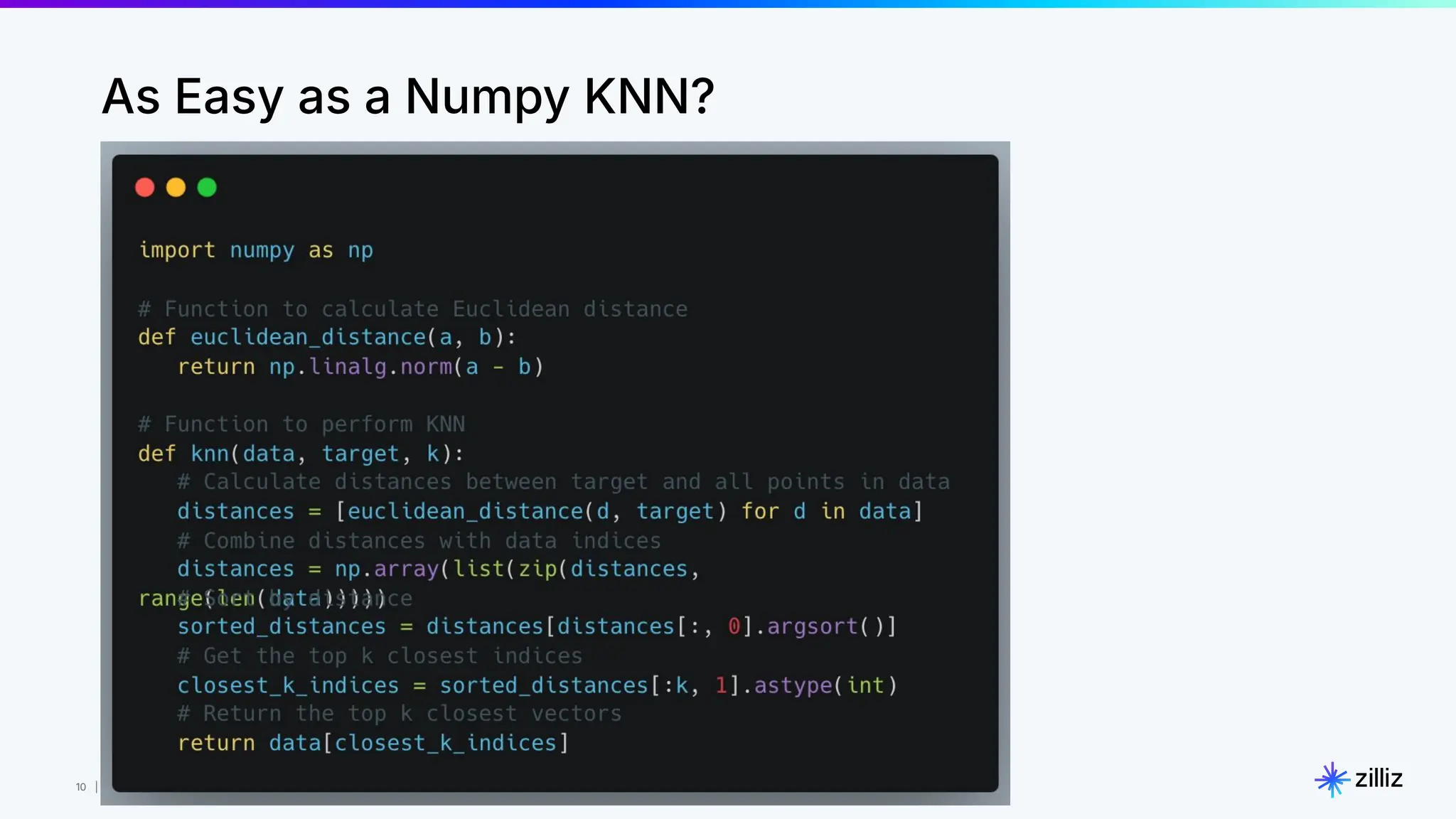
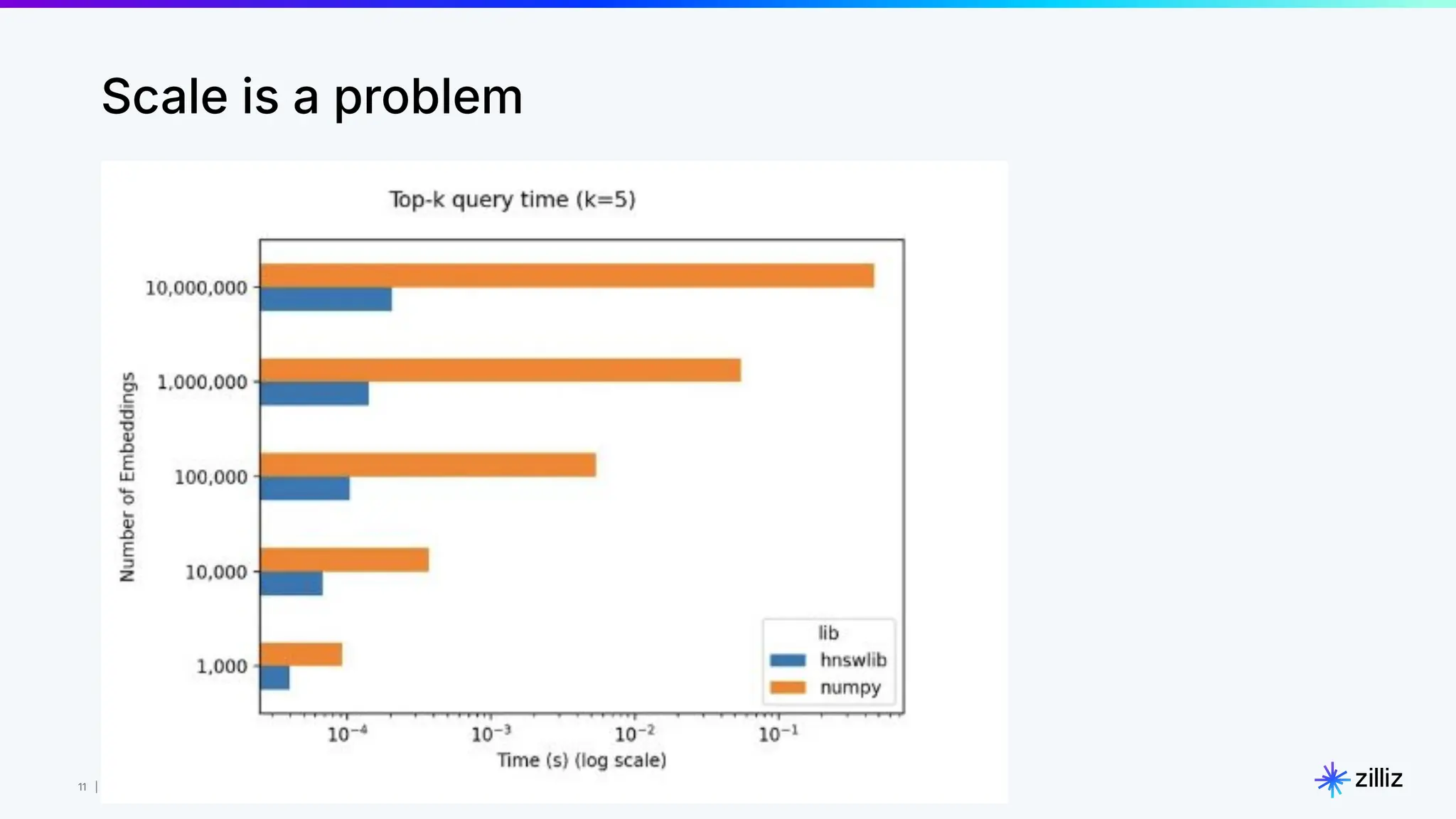


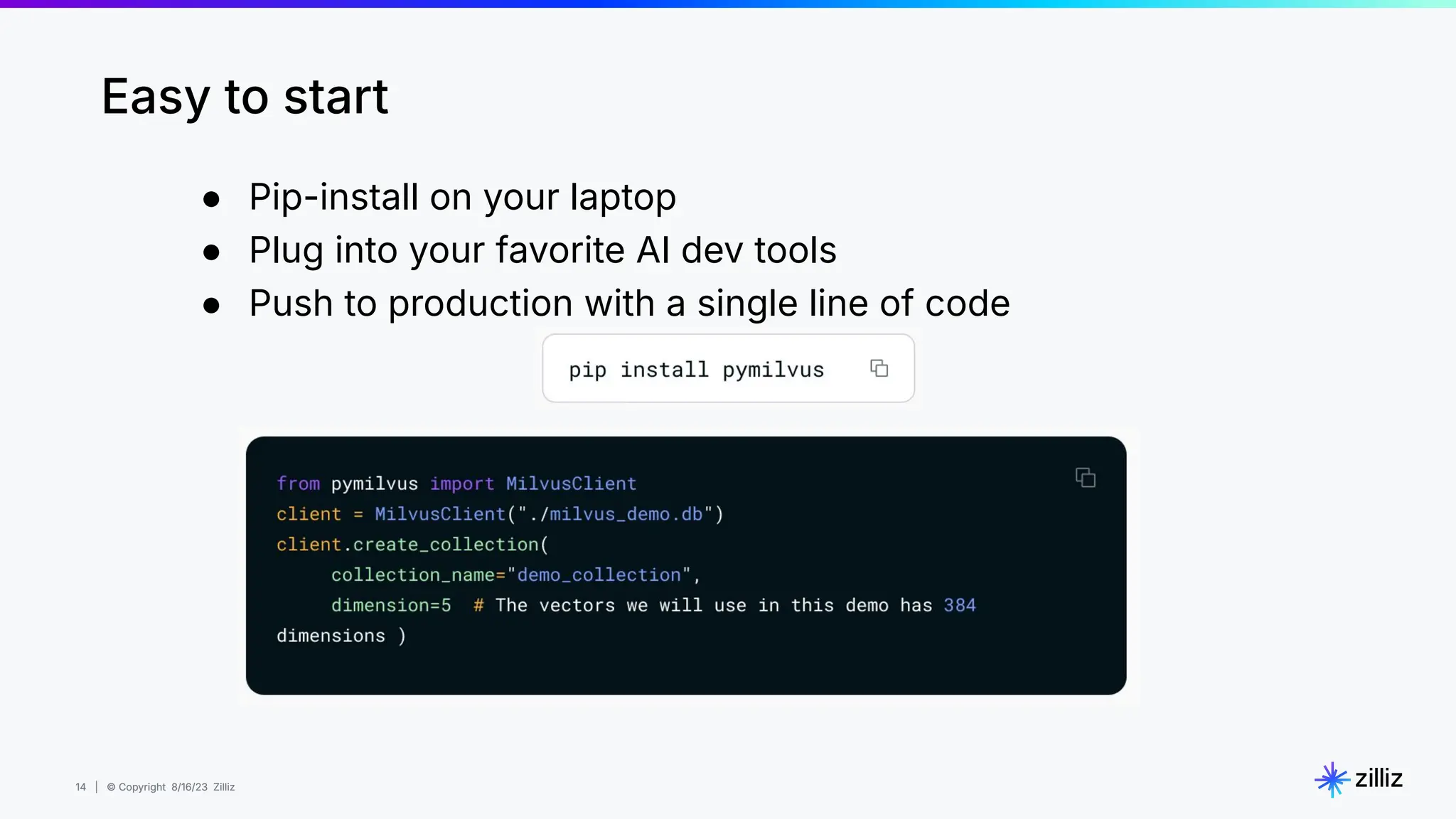

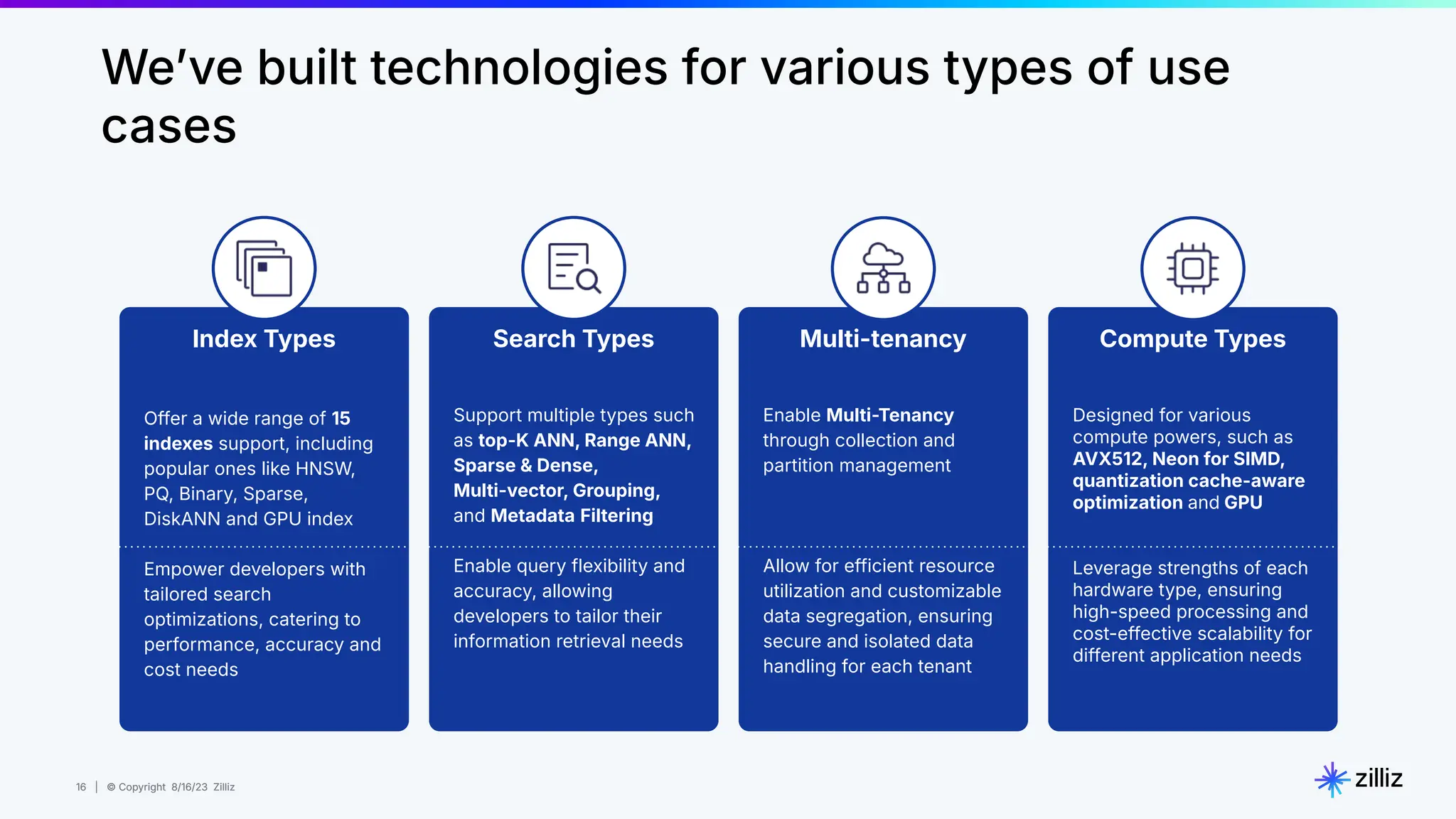

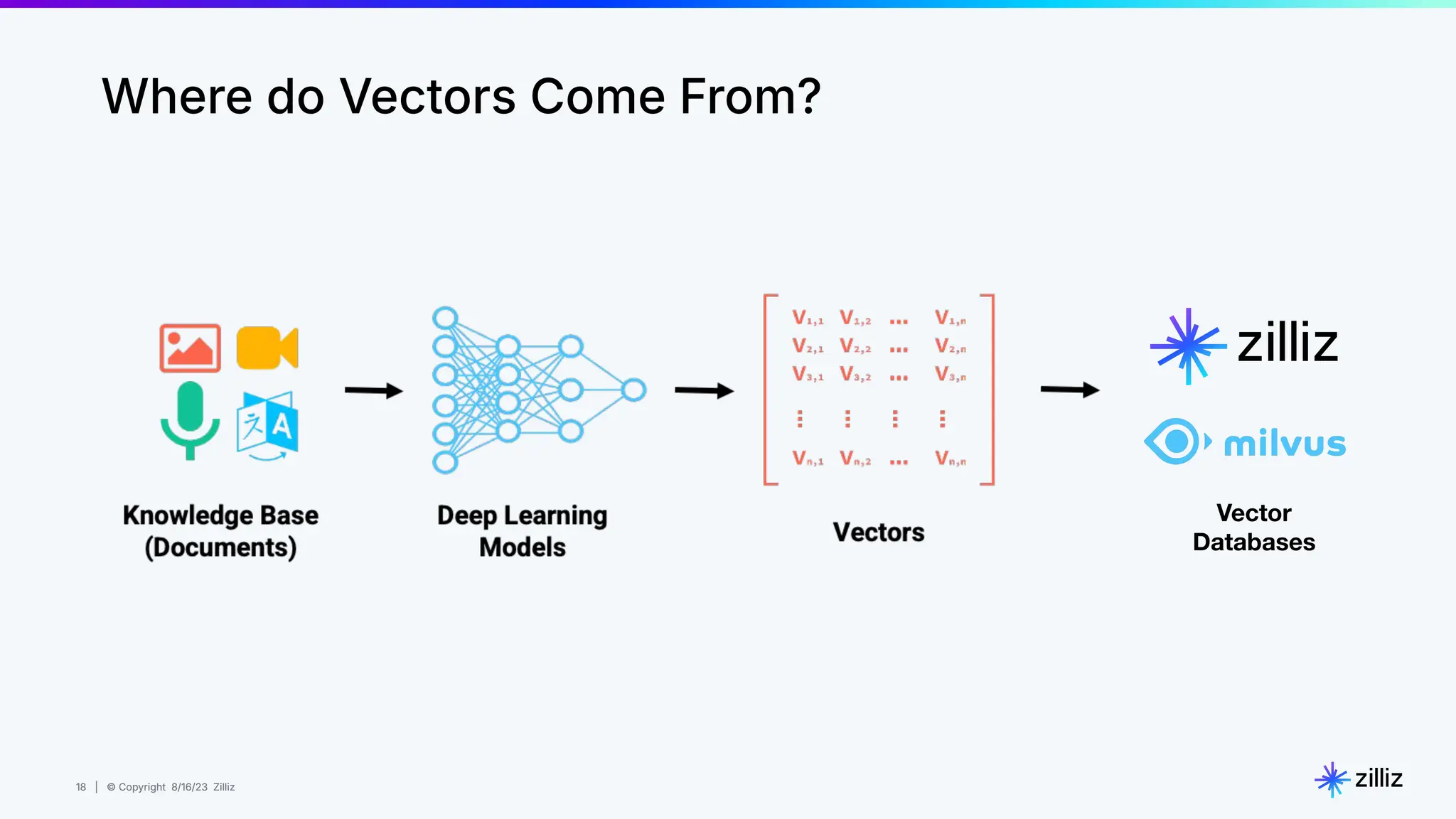
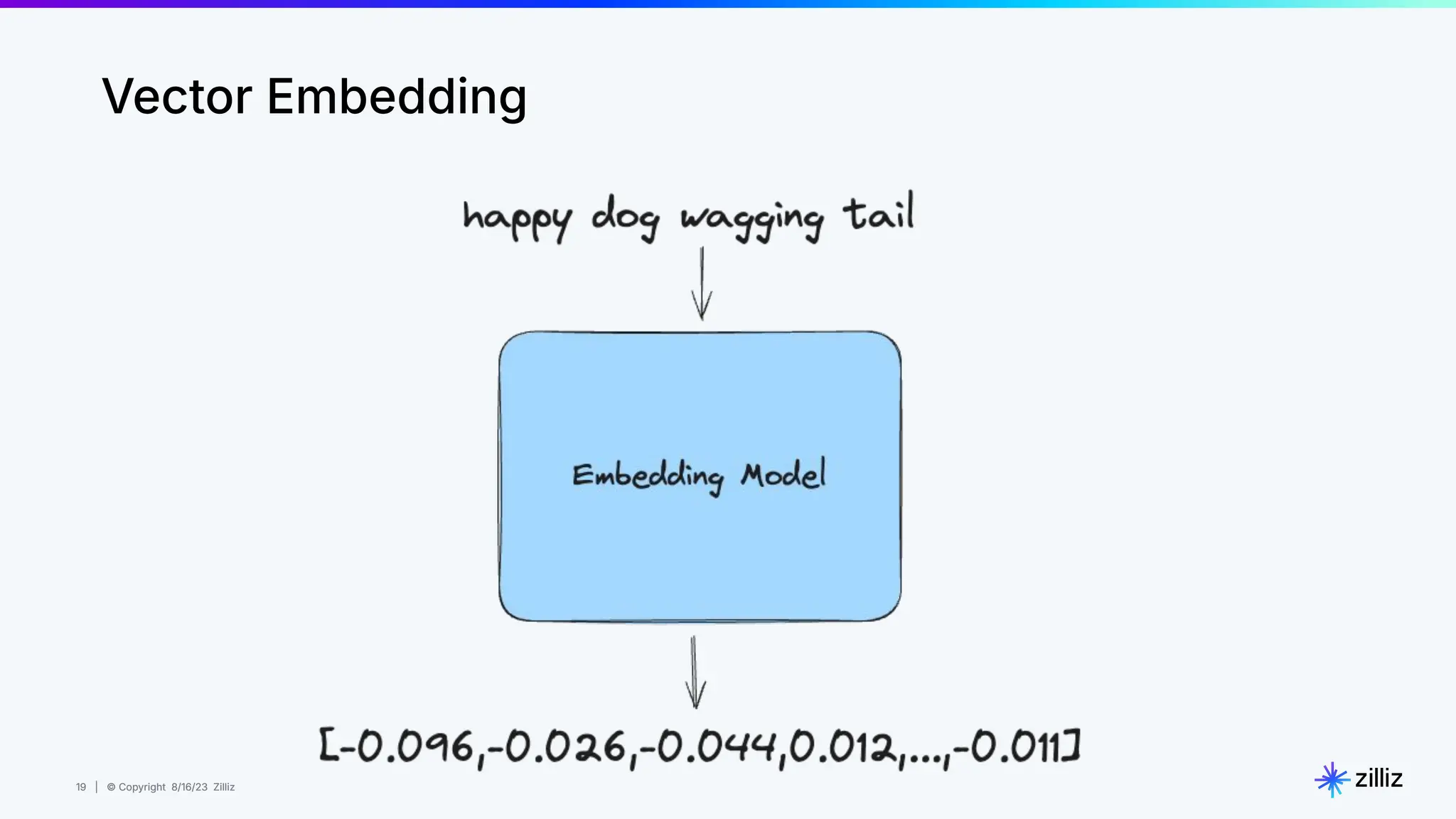
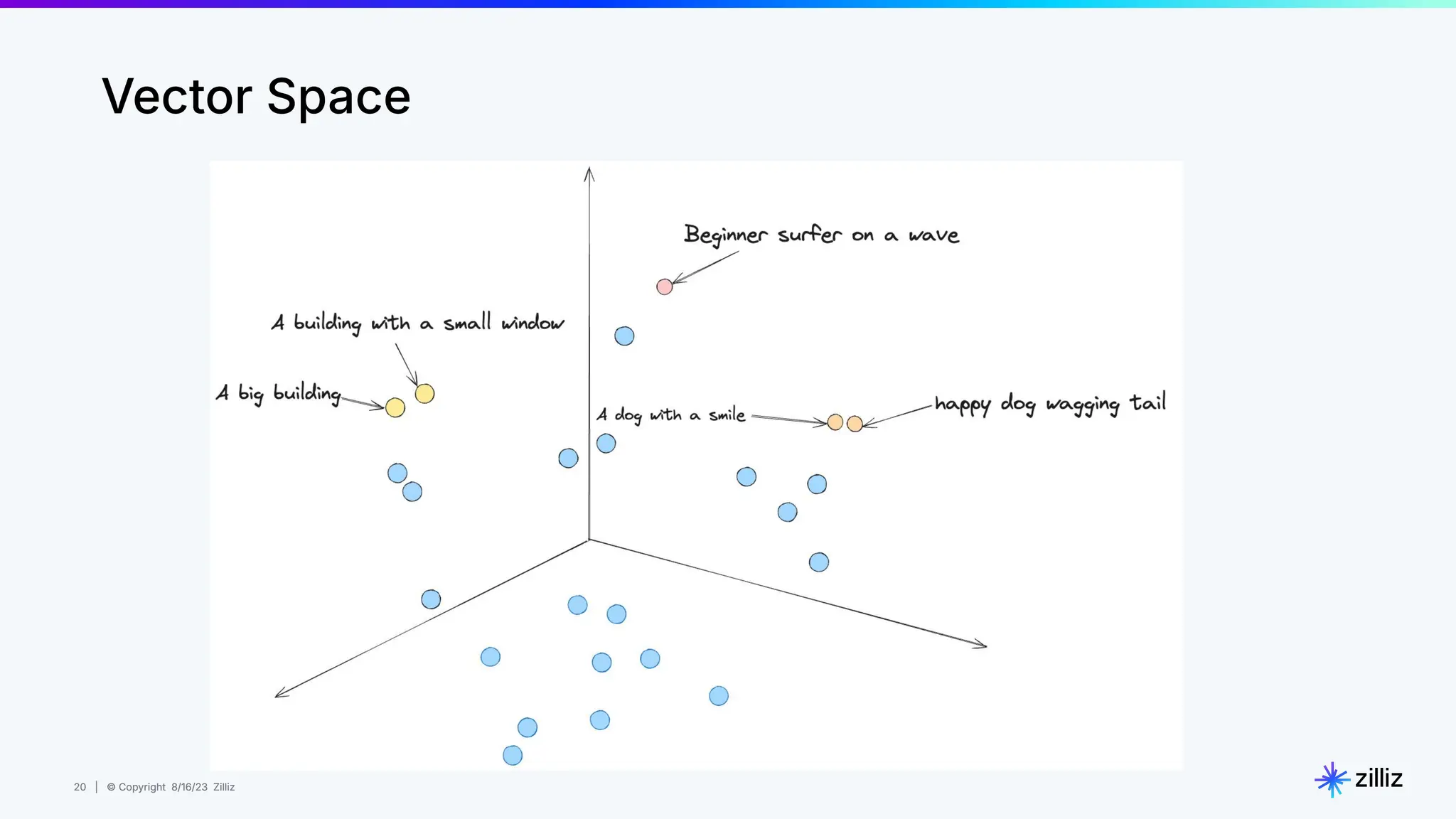

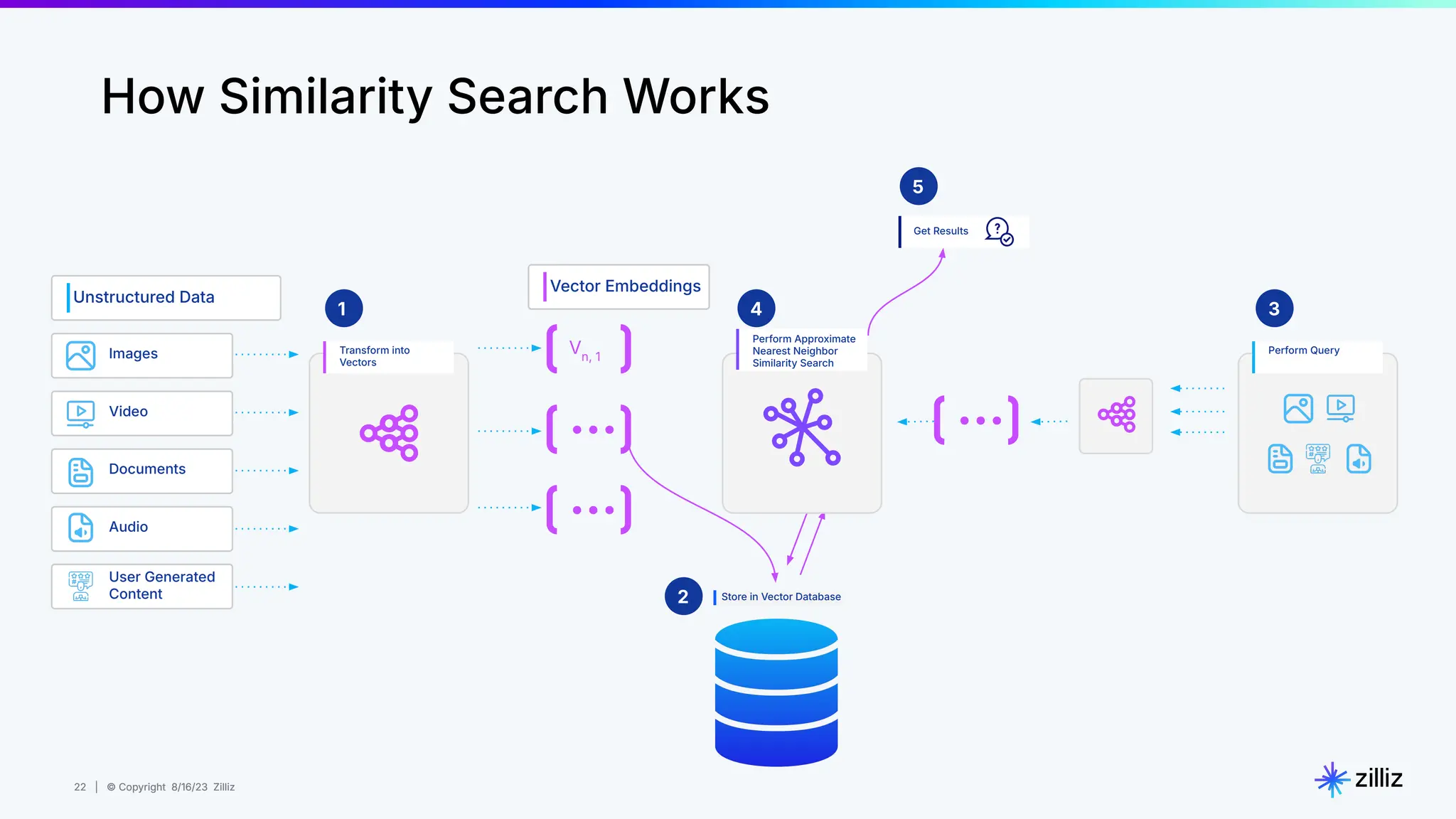


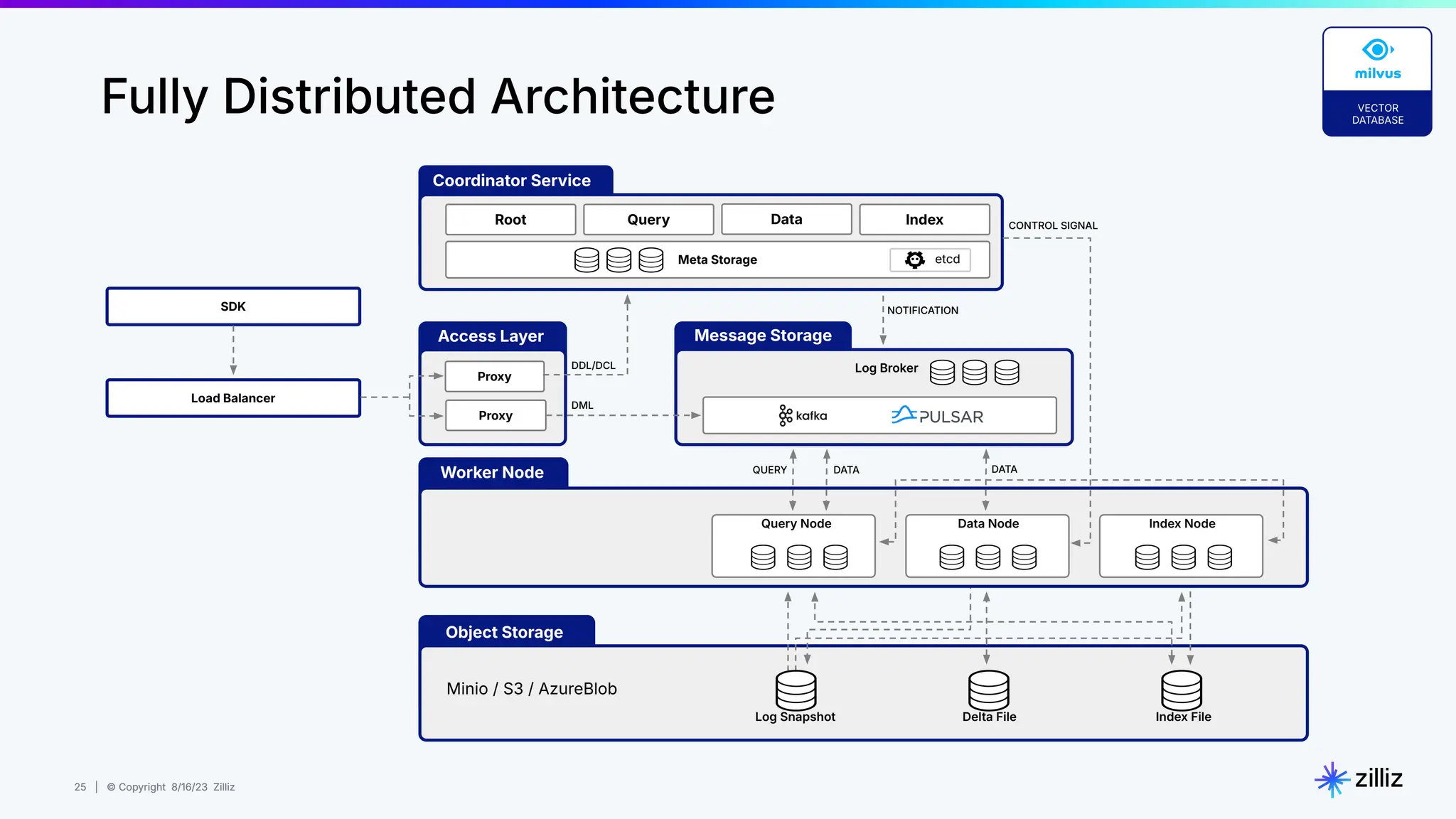
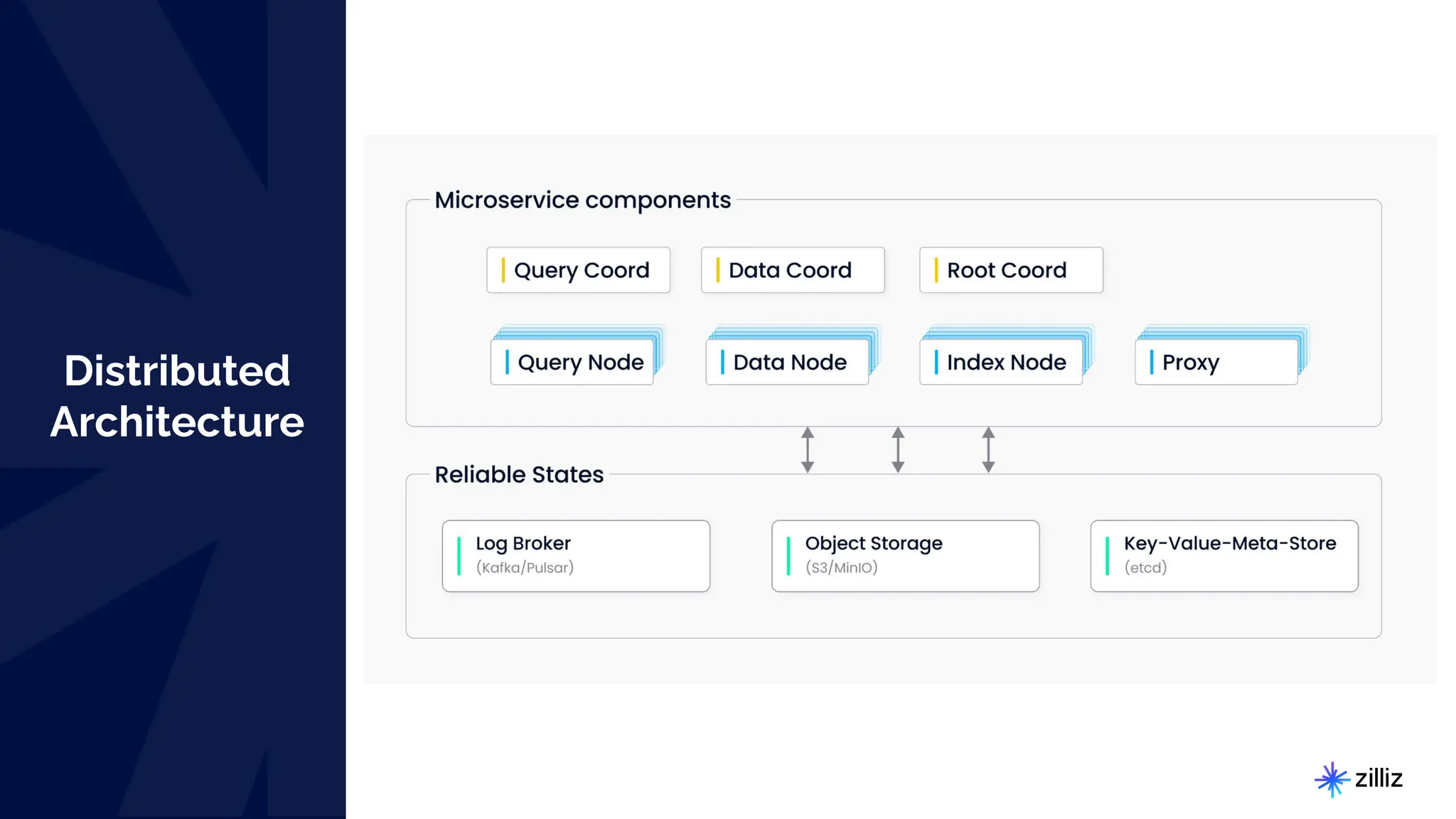
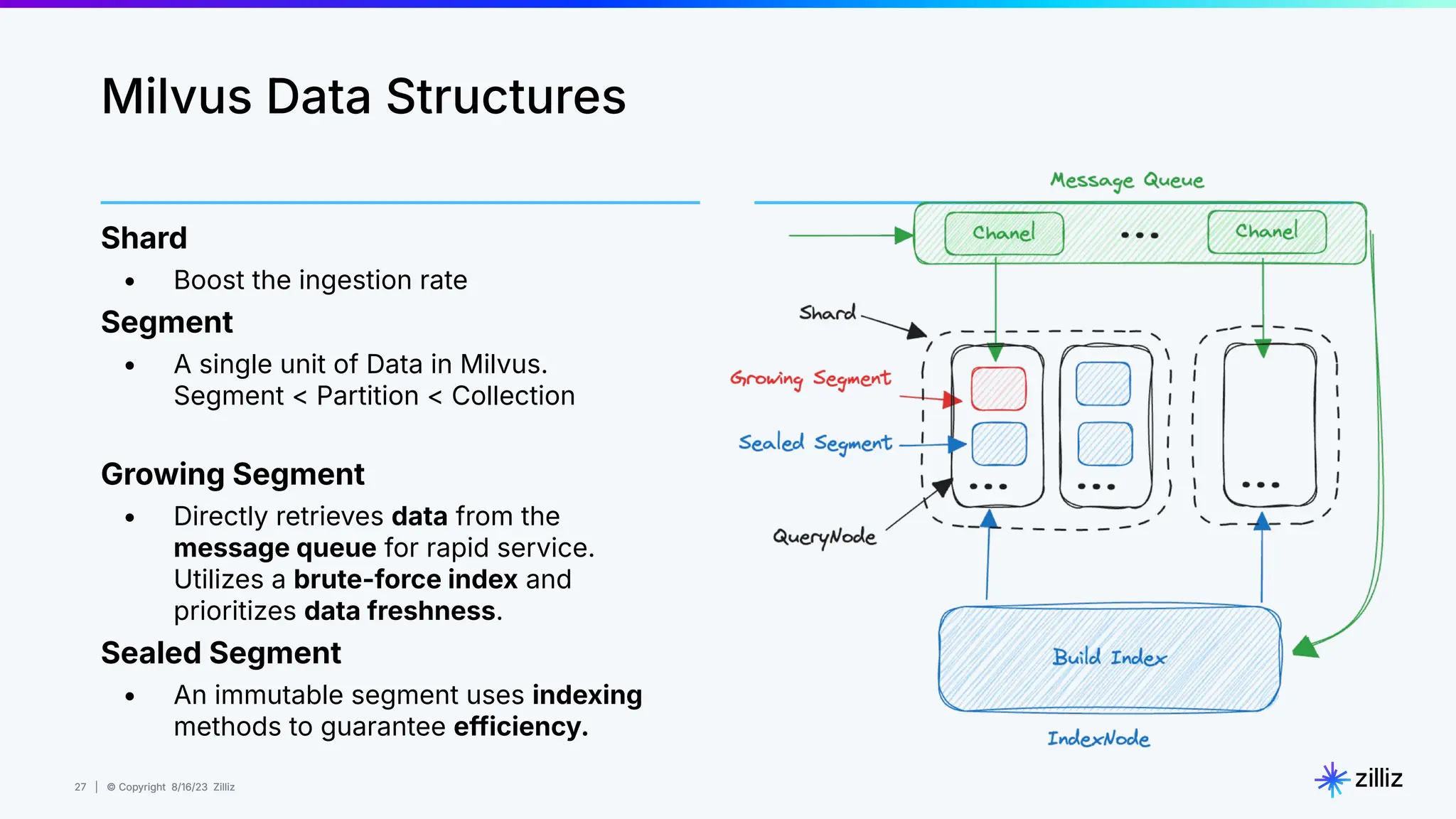
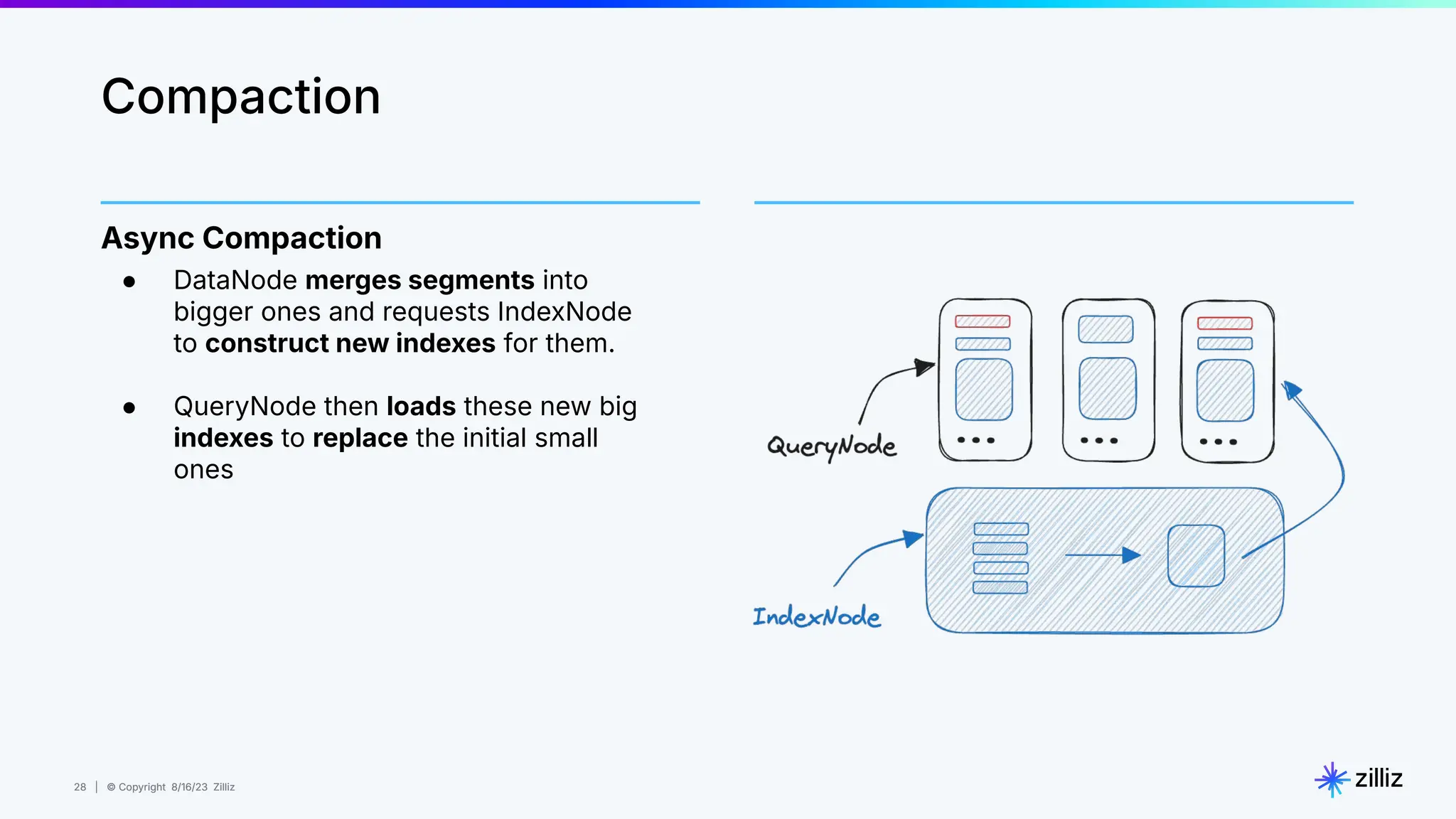





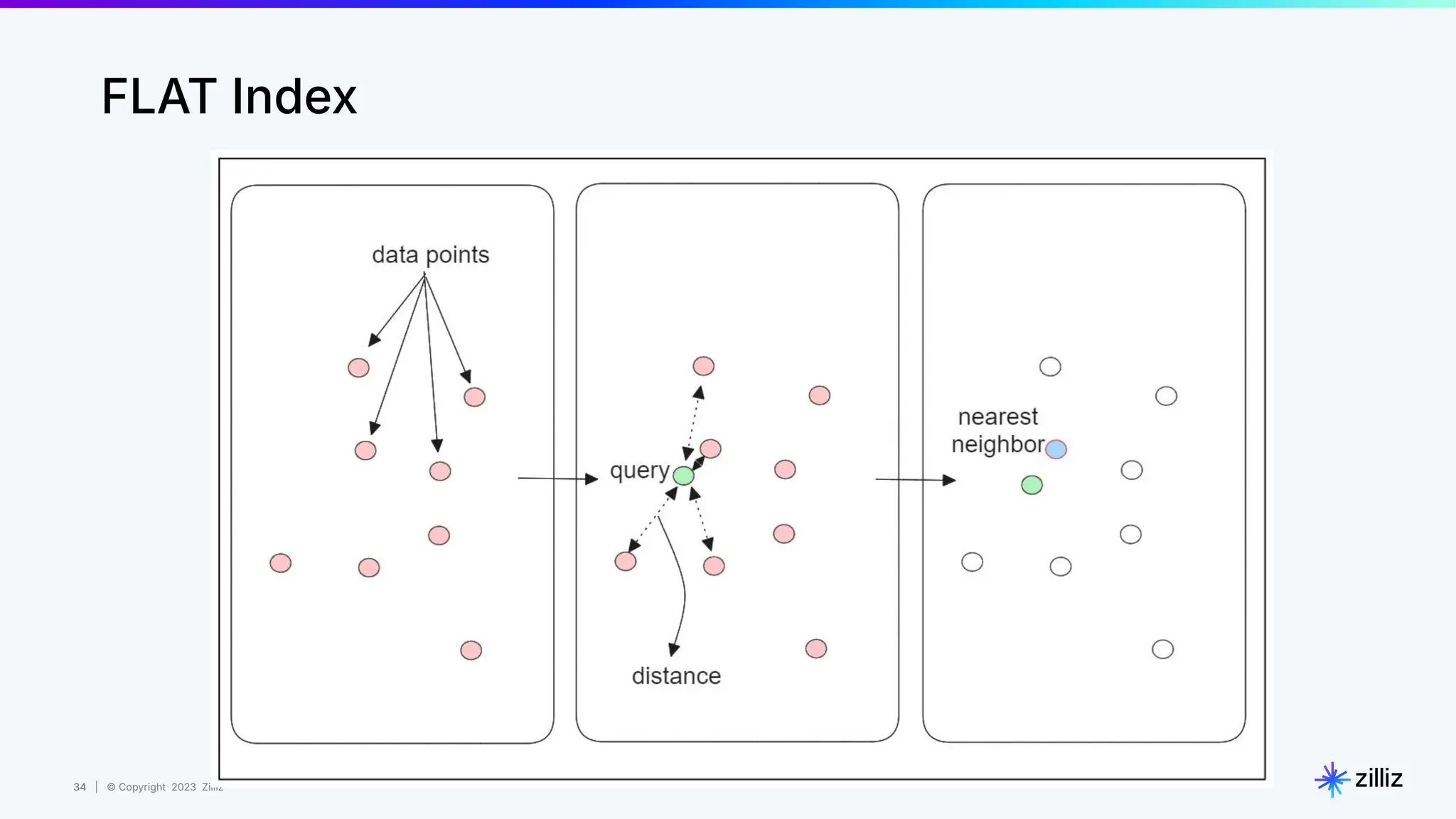

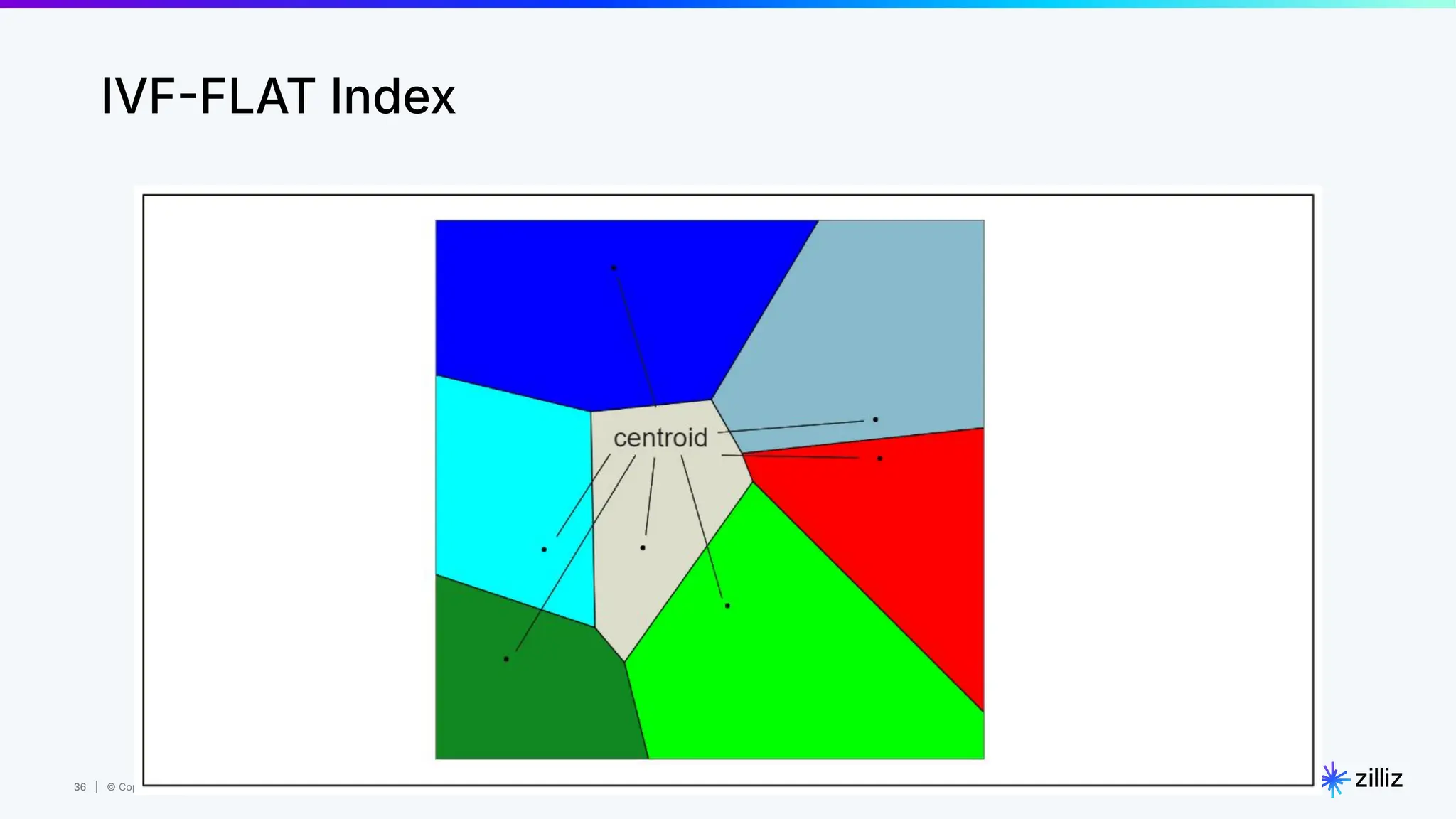
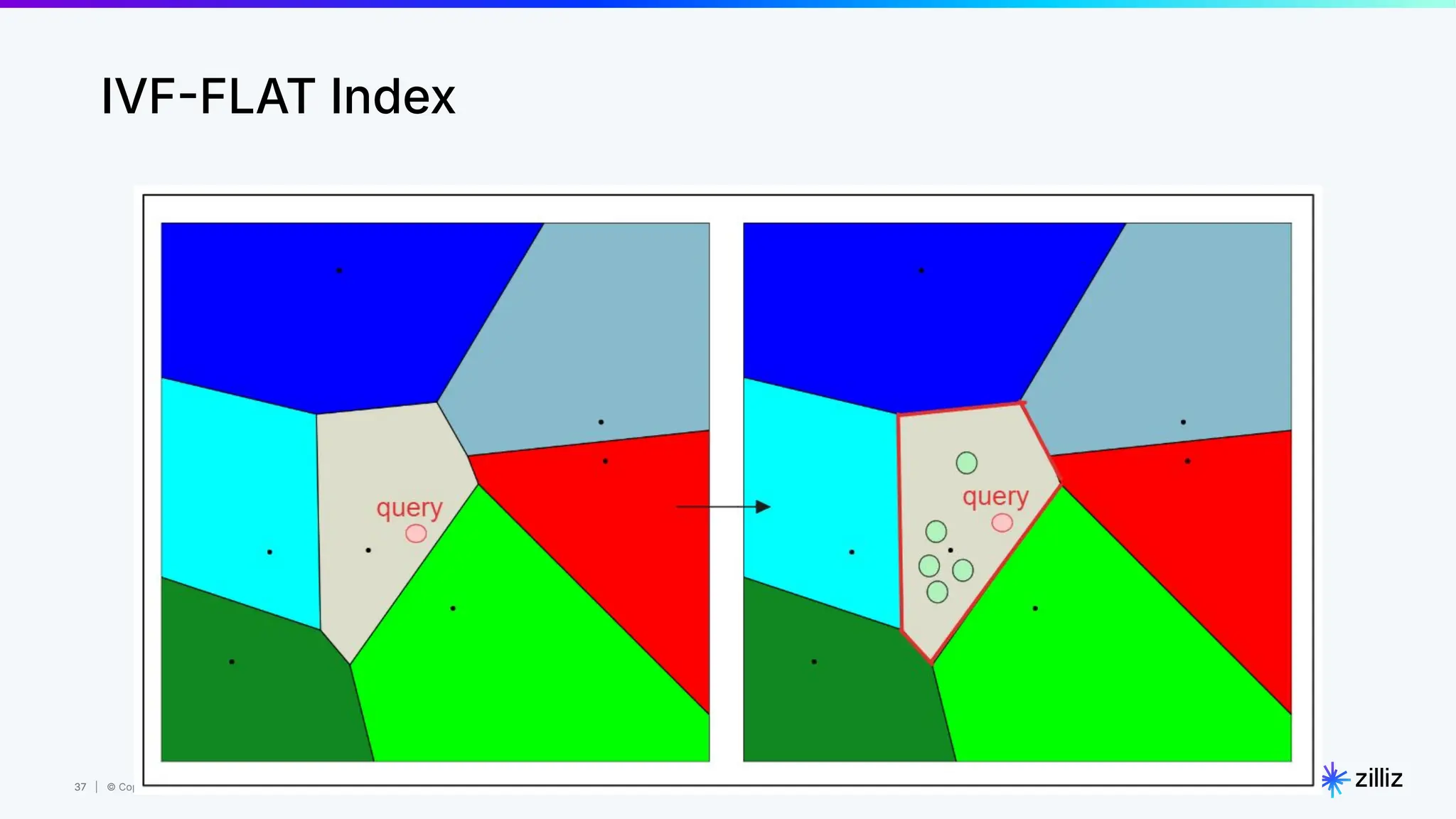
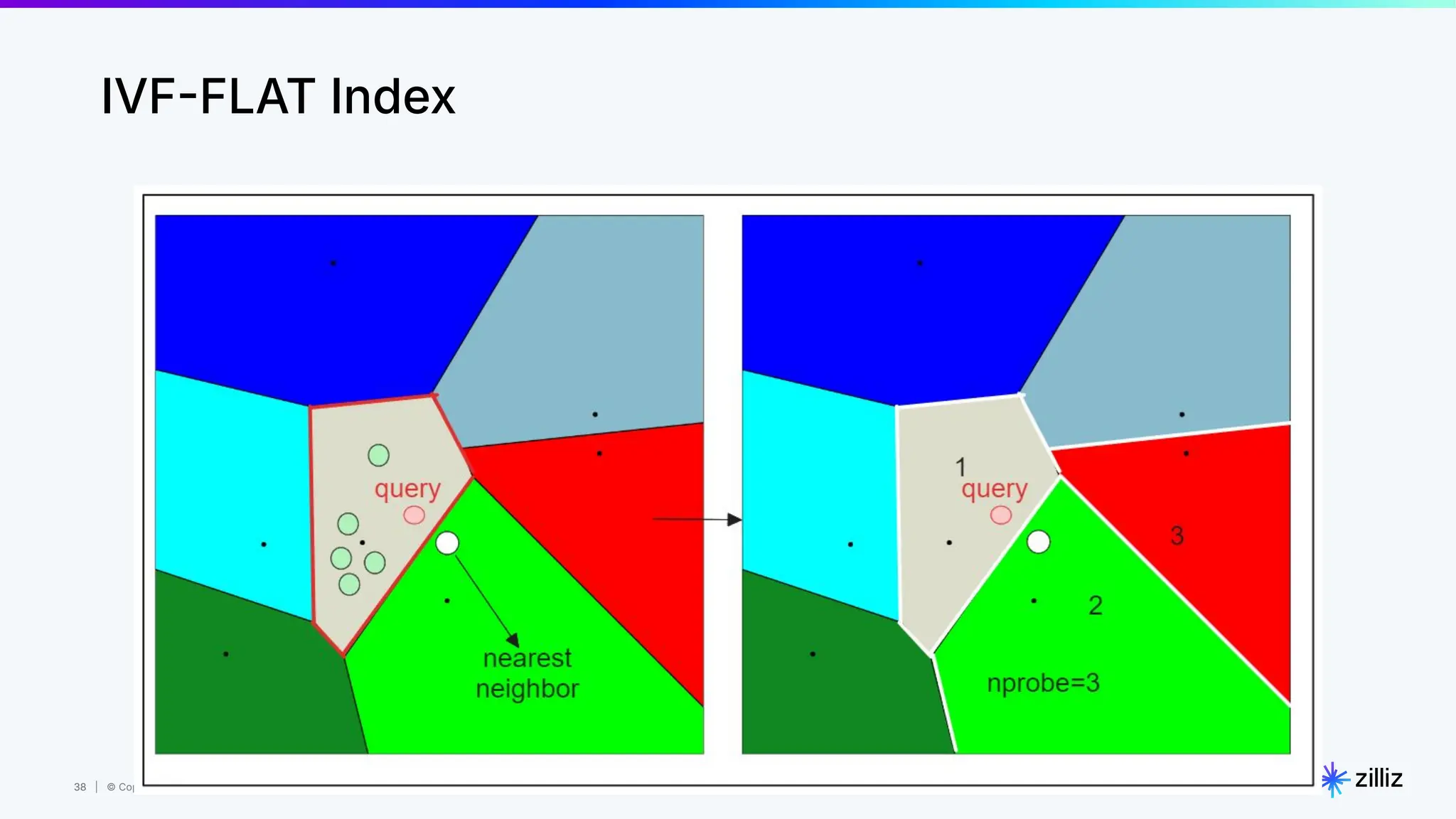

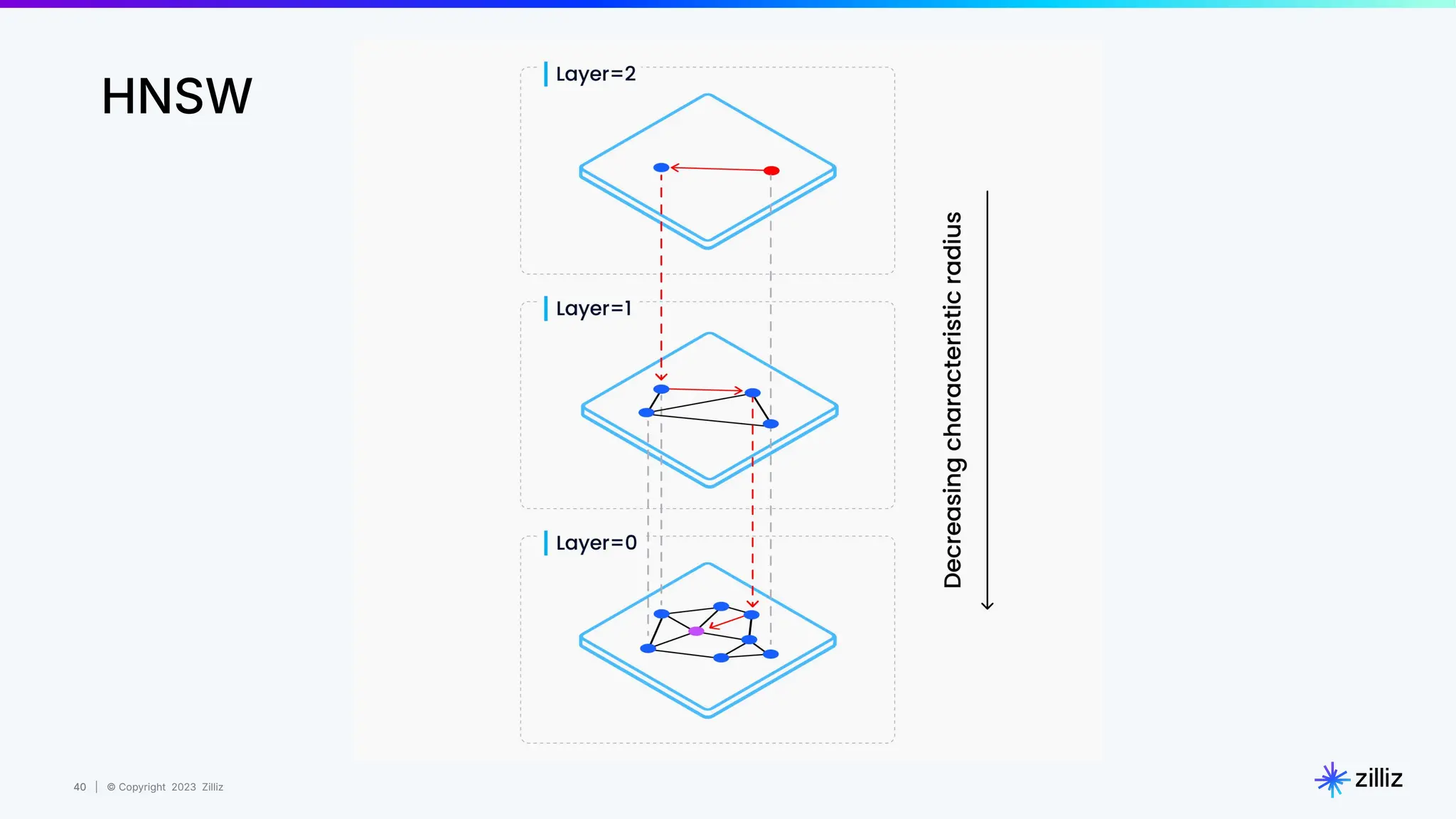








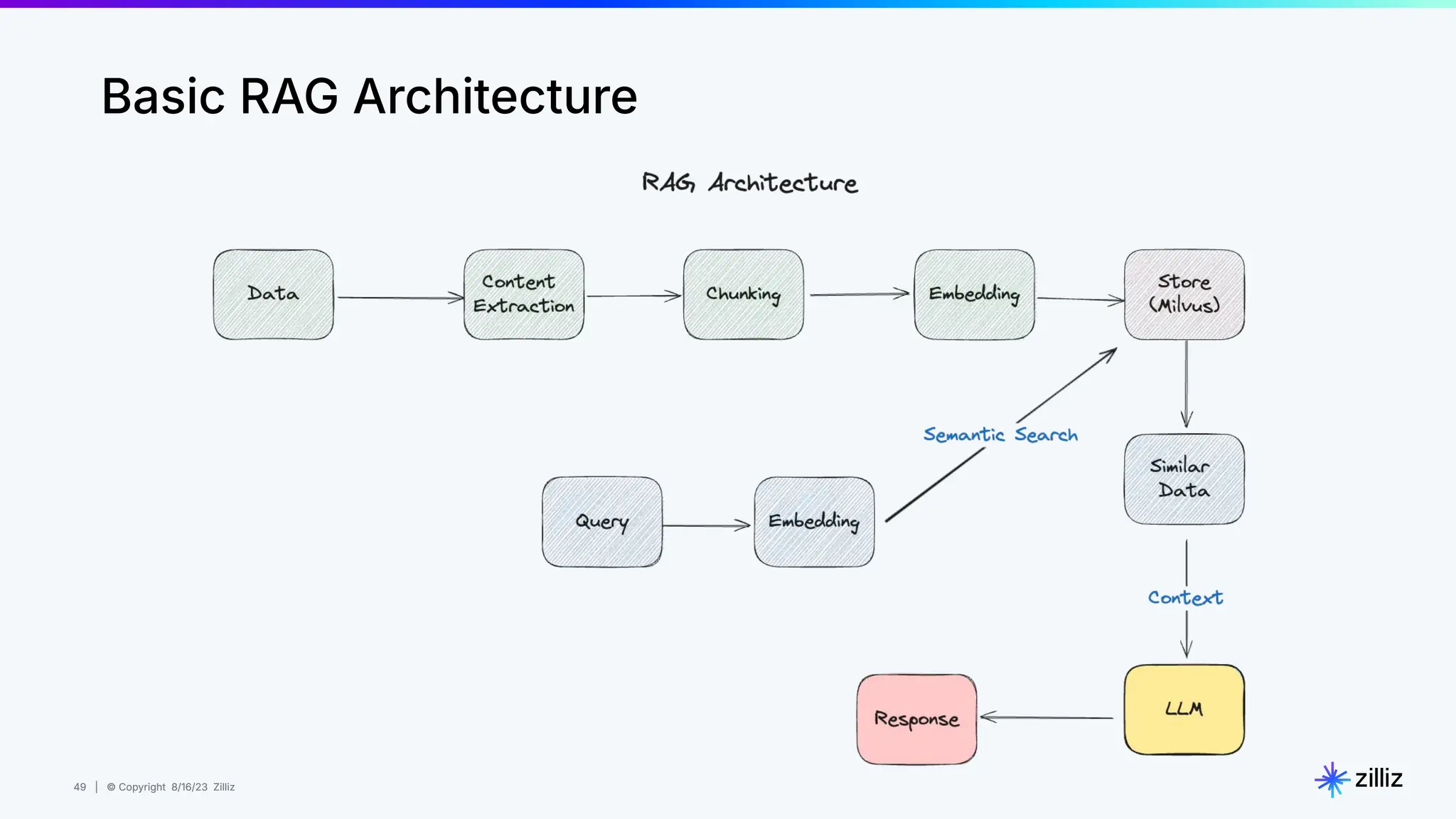
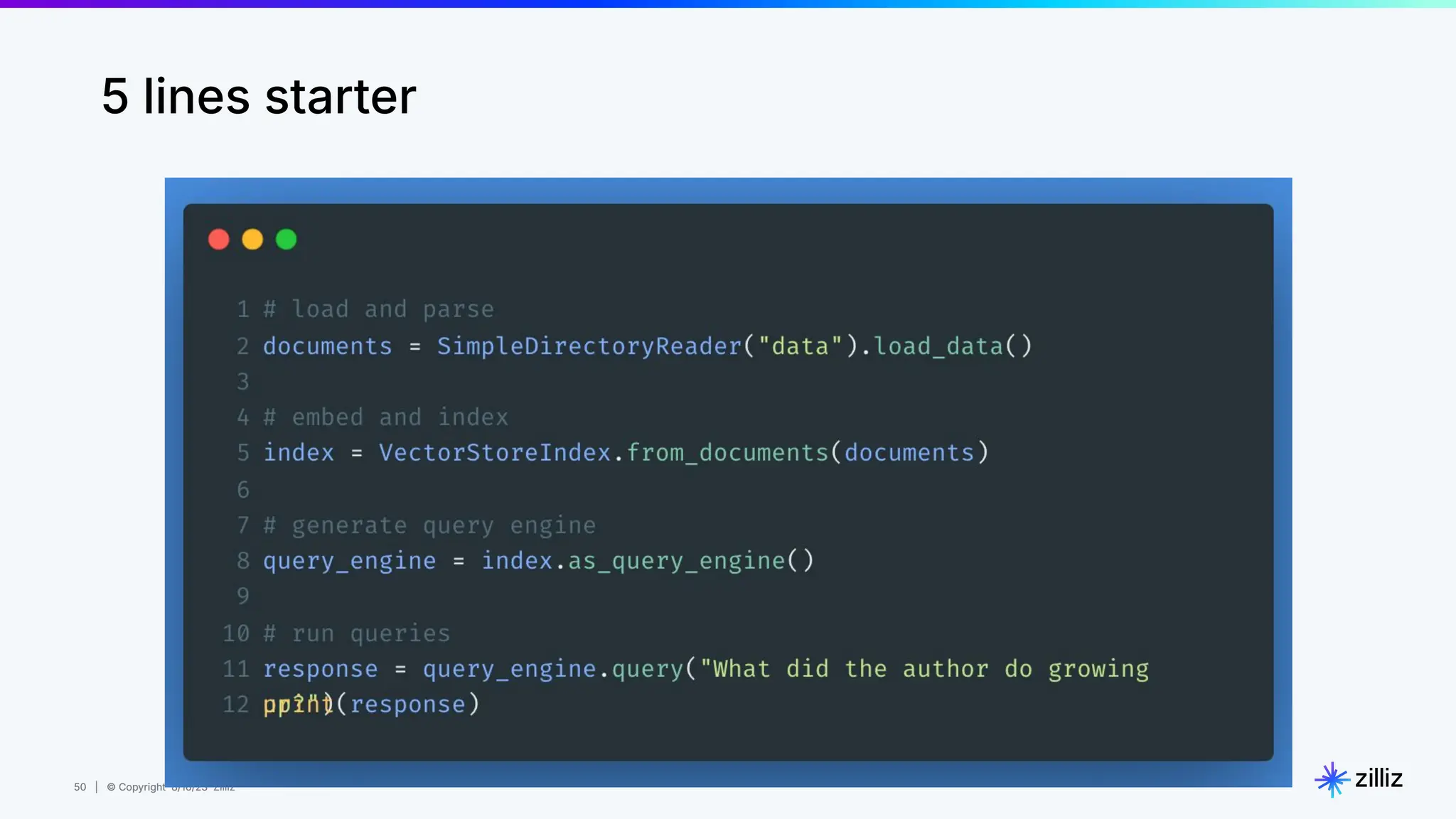



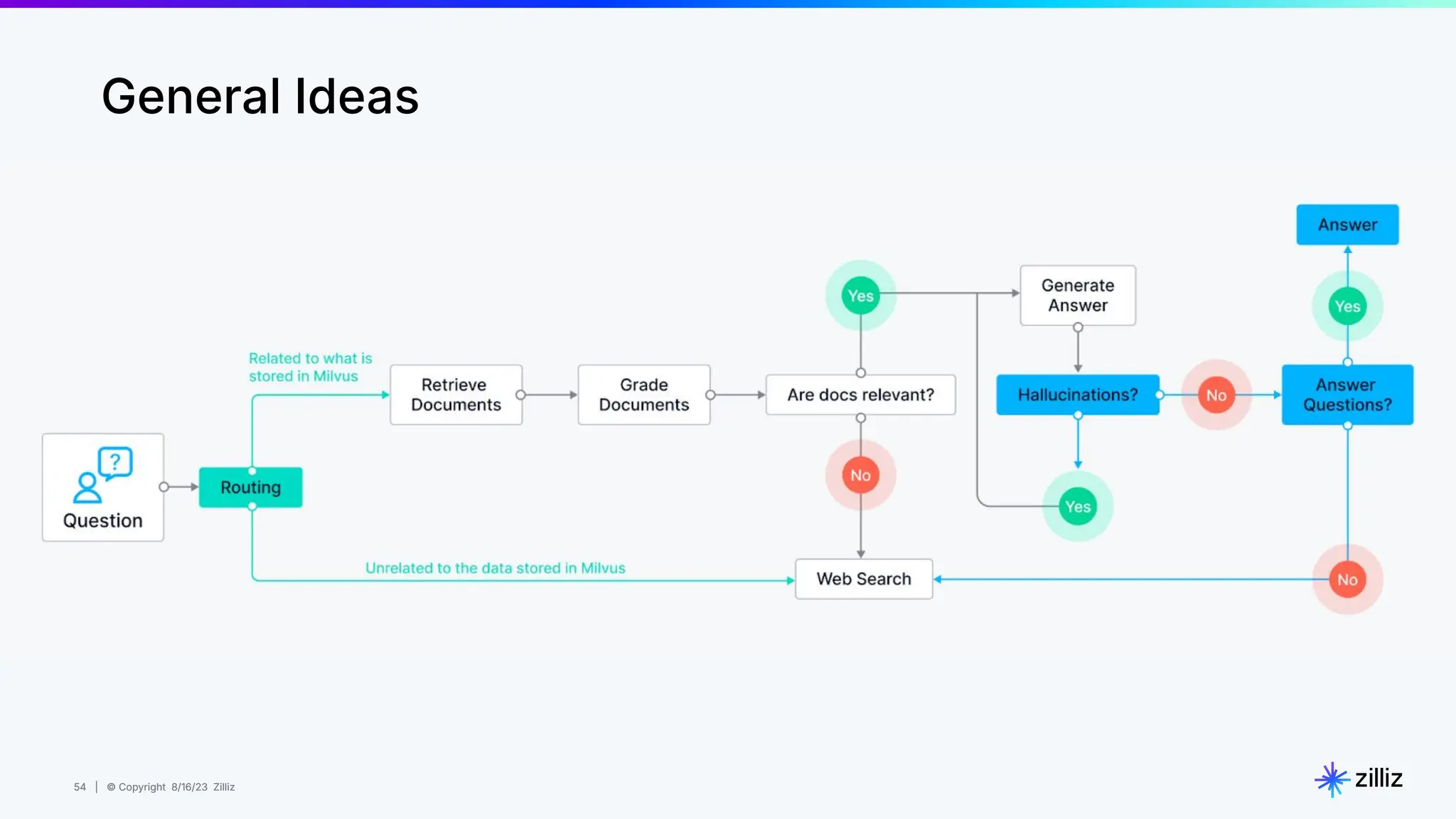



























































Milvus is an open-source vector database designed for generative AI projects, enabling easy integration and quick deployment through a single line of code. It supports a variety of data types and use cases such as recommendation systems, similarity search, and anomaly detection, catering to real-time applications and significant data volumes. The architecture is stateless, leveraging Kubernetes for scalability, while employing innovative indexing and filtering strategies to optimize performance and cost efficiency.



































































