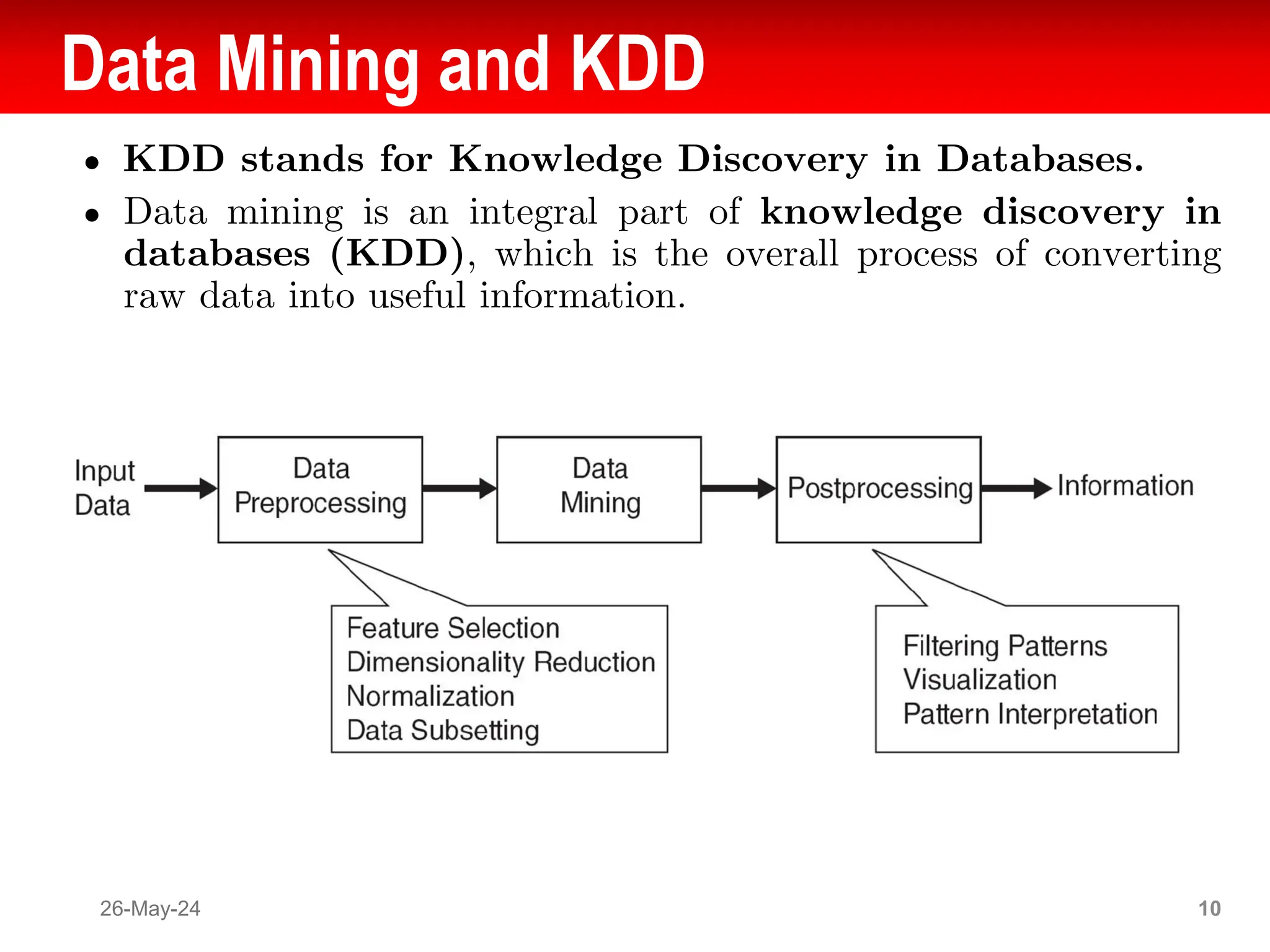
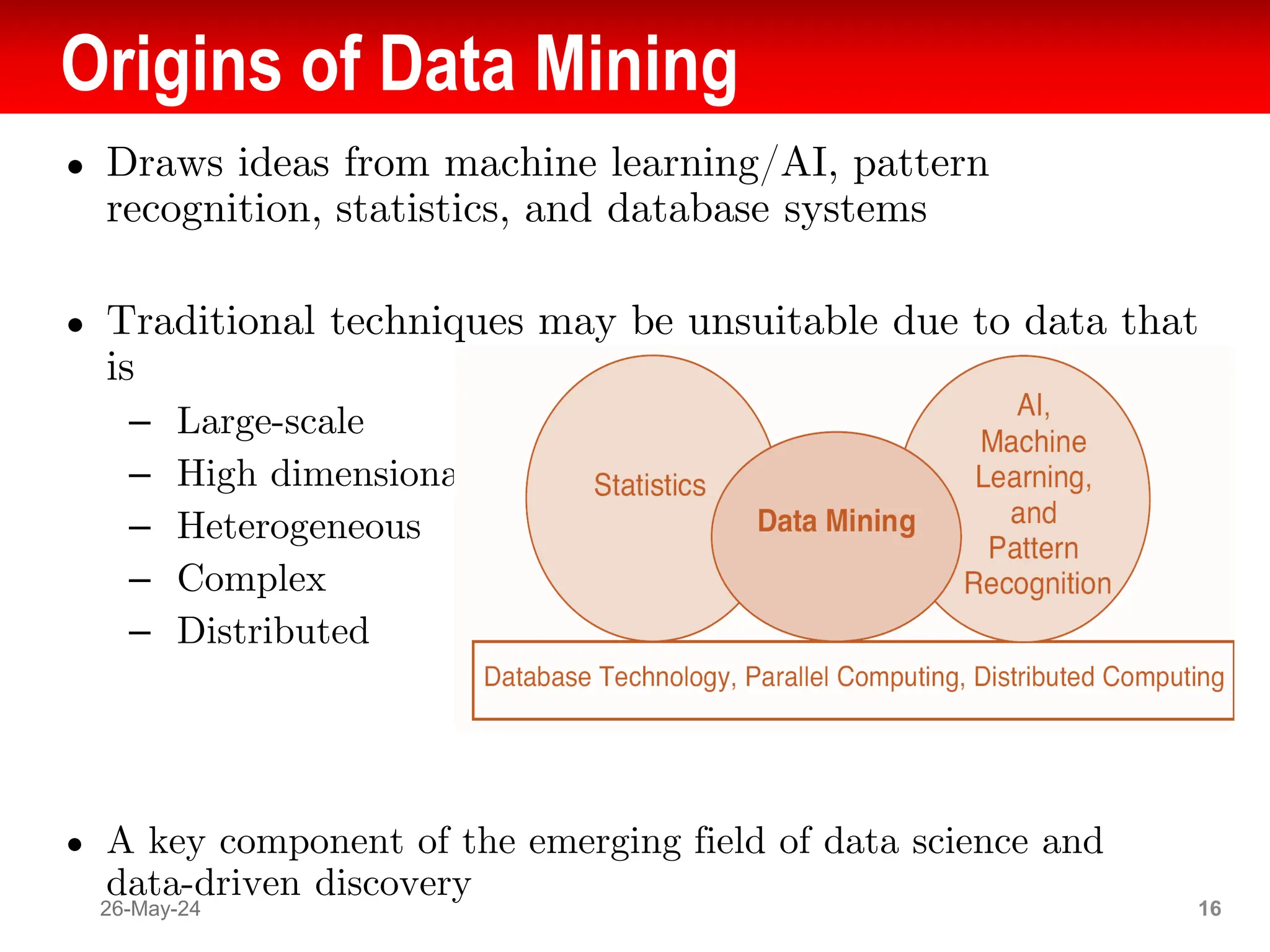
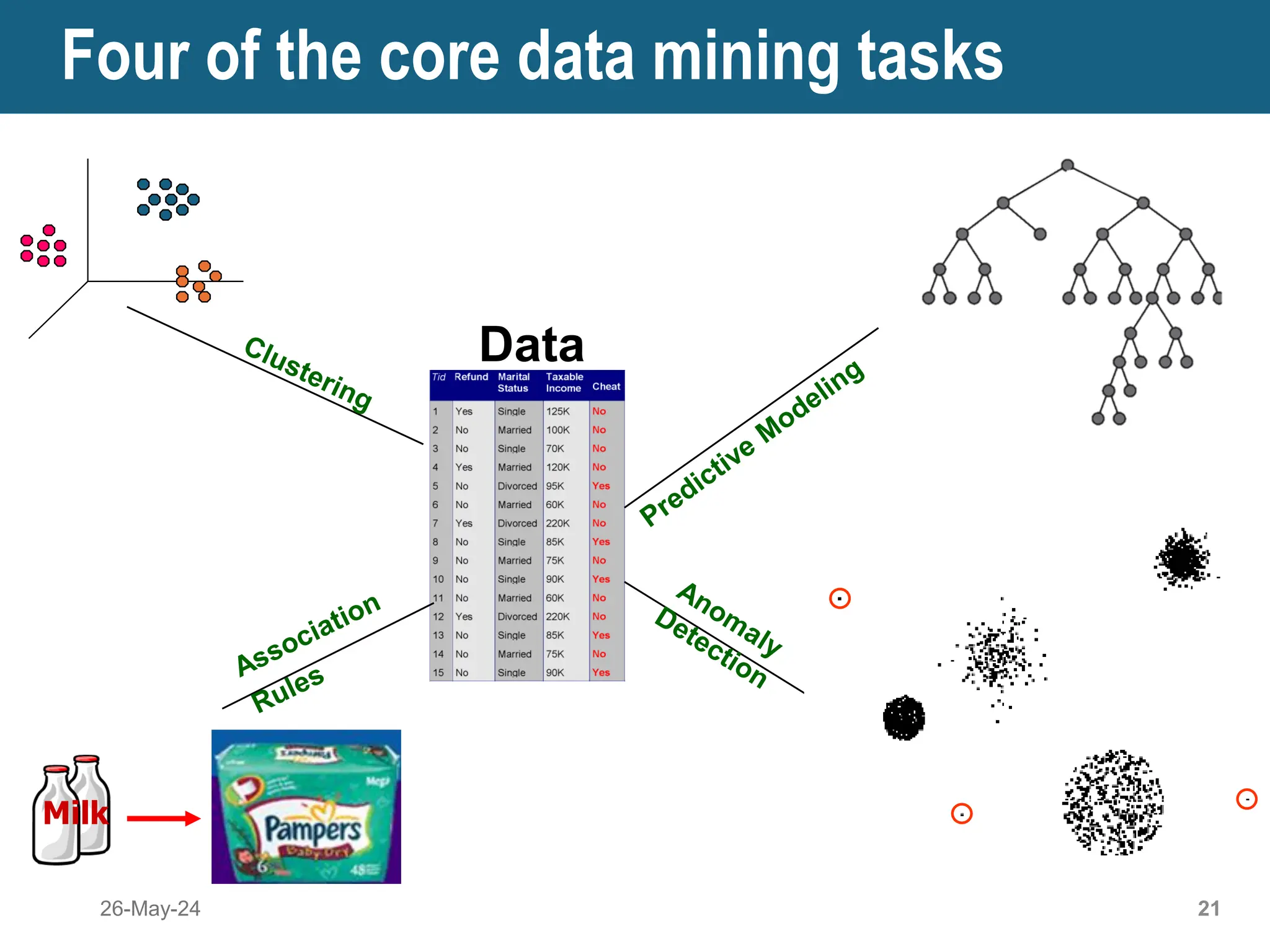
The document provides an introduction to data mining and knowledge discovery, highlighting the vast growth of data and the need for effective techniques to analyze it. Data mining is defined as the process of discovering useful information in large datasets, and it includes various tasks such as prediction and description methods. The document also addresses challenges, origins, and distinctions between data mining and machine learning, emphasizing its significance in improving various sectors like healthcare, environmental science, and market analysis.
















![Data Mining Tasks…
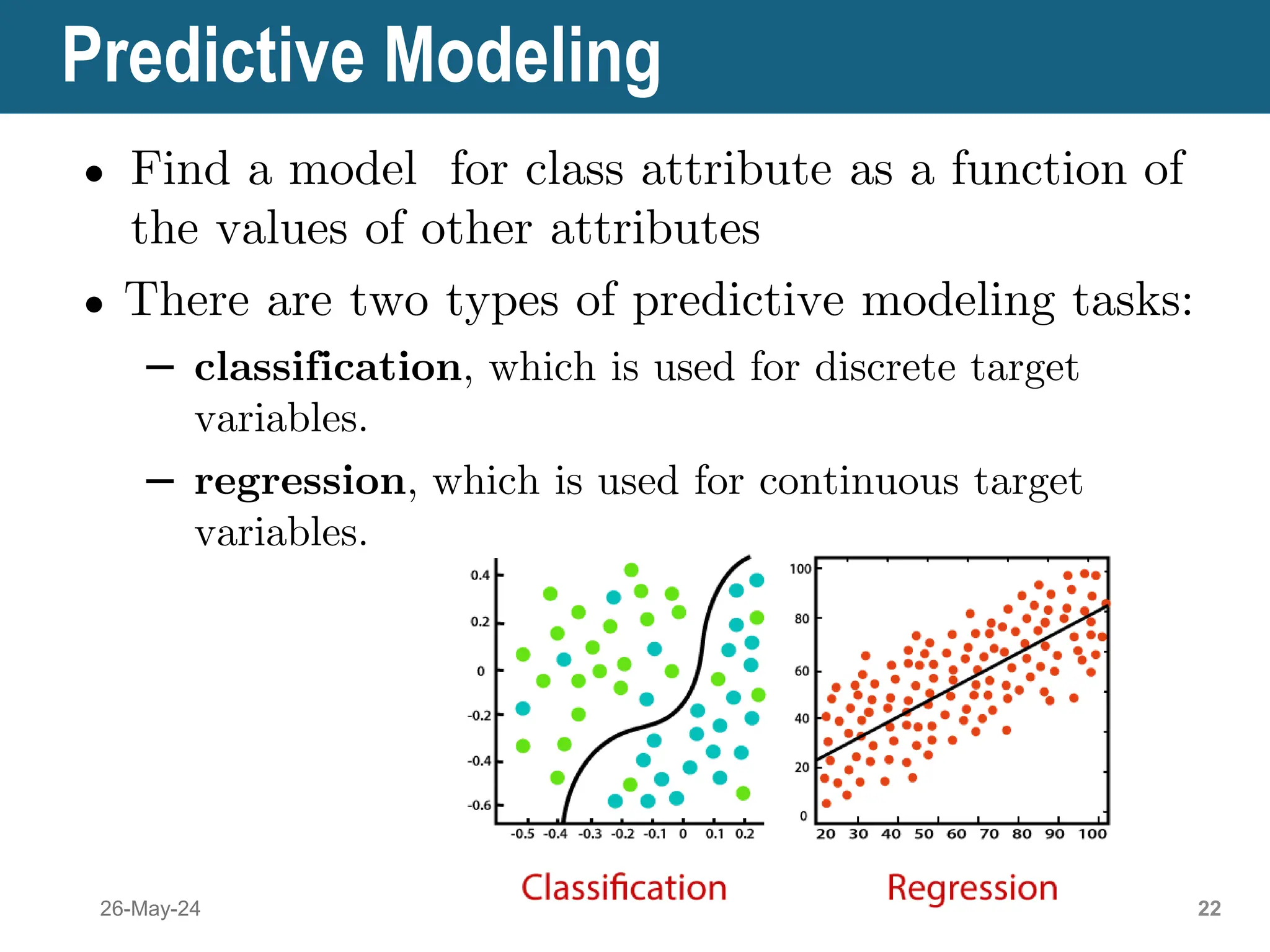
● Prediction Methods
– Use some variables to predict unknown or future
values of other variables.
– The objective of these tasks is to predict the value of a
particular attribute based on the values of other
attributes.
– The attribute to be predicted is commonly known as
the target or dependent variable, while the
attributes used for making the prediction are known as
the explanatory or independent variables.
26-May-24 19
From [Fayyad, et.al.] Advances in Knowledge Discovery and Data Mining, 1996](https://image.slidesharecdn.com/introductiontodatamining-240526031235-cb221b25/75/Introduction-to-Data-Mining-and-Knowledge-DiscoveryChapter-01-19-2048.jpg)





![Classification: Application 3
● Sky Survey Cataloging
– Goal: To predict class (star or galaxy) of sky objects,
especially visually faint ones, based on the telescopic
survey images (from Palomar Observatory).
– 3000 images with 23,040 x 23,040 pixels per image.
– Approach:
◆ Segment the image.
◆ Measure image attributes (features) - 40 of them per object.
◆ Model the class based on these features.
◆ Success Story: Could find 16 new high red-shift quasars, some
of the farthest objects that are difficult to find!
26-May-24 29
From [Fayyad, et.al.] Advances in Knowledge Discovery and Data Mining, 1996](https://image.slidesharecdn.com/introductiontodatamining-240526031235-cb221b25/75/Introduction-to-Data-Mining-and-Knowledge-DiscoveryChapter-01-29-2048.jpg)


























![Data Mining Tasks…
● Prediction Methods
– Use some variables to predict unknown or future
values of other variables.
– The objective of these tasks is to predict the value of a
particular attribute based on the values of other
attributes.
– The attribute to be predicted is commonly known as
the target or dependent variable, while the
attributes used for making the prediction are known as
the explanatory or independent variables.
26-May-24 19
From [Fayyad, et.al.] Advances in Knowledge Discovery and Data Mining, 1996](https://crownmelresort.com/image.slidesharecdn.com/introductiontodatamining-240526031235-cb221b25/75/Introduction-to-Data-Mining-and-Knowledge-DiscoveryChapter-01-19-2048.jpg)









![Classification: Application 3
● Sky Survey Cataloging
– Goal: To predict class (star or galaxy) of sky objects,
especially visually faint ones, based on the telescopic
survey images (from Palomar Observatory).
– 3000 images with 23,040 x 23,040 pixels per image.
– Approach:
◆ Segment the image.
◆ Measure image attributes (features) - 40 of them per object.
◆ Model the class based on these features.
◆ Success Story: Could find 16 new high red-shift quasars, some
of the farthest objects that are difficult to find!
26-May-24 29
From [Fayyad, et.al.] Advances in Knowledge Discovery and Data Mining, 1996](https://crownmelresort.com/image.slidesharecdn.com/introductiontodatamining-240526031235-cb221b25/75/Introduction-to-Data-Mining-and-Knowledge-DiscoveryChapter-01-29-2048.jpg)










![[Paper Presentation] EMOTIONAL STRESS DETECTION USING DEEP LEARNING](https://cdn.slidesharecdn.com/ss_thumbnails/emotnetmlds2020-200205075816-thumbnail.jpg?width=640&height=640&fit=bounds)

































































