Download as PDF, PPTX










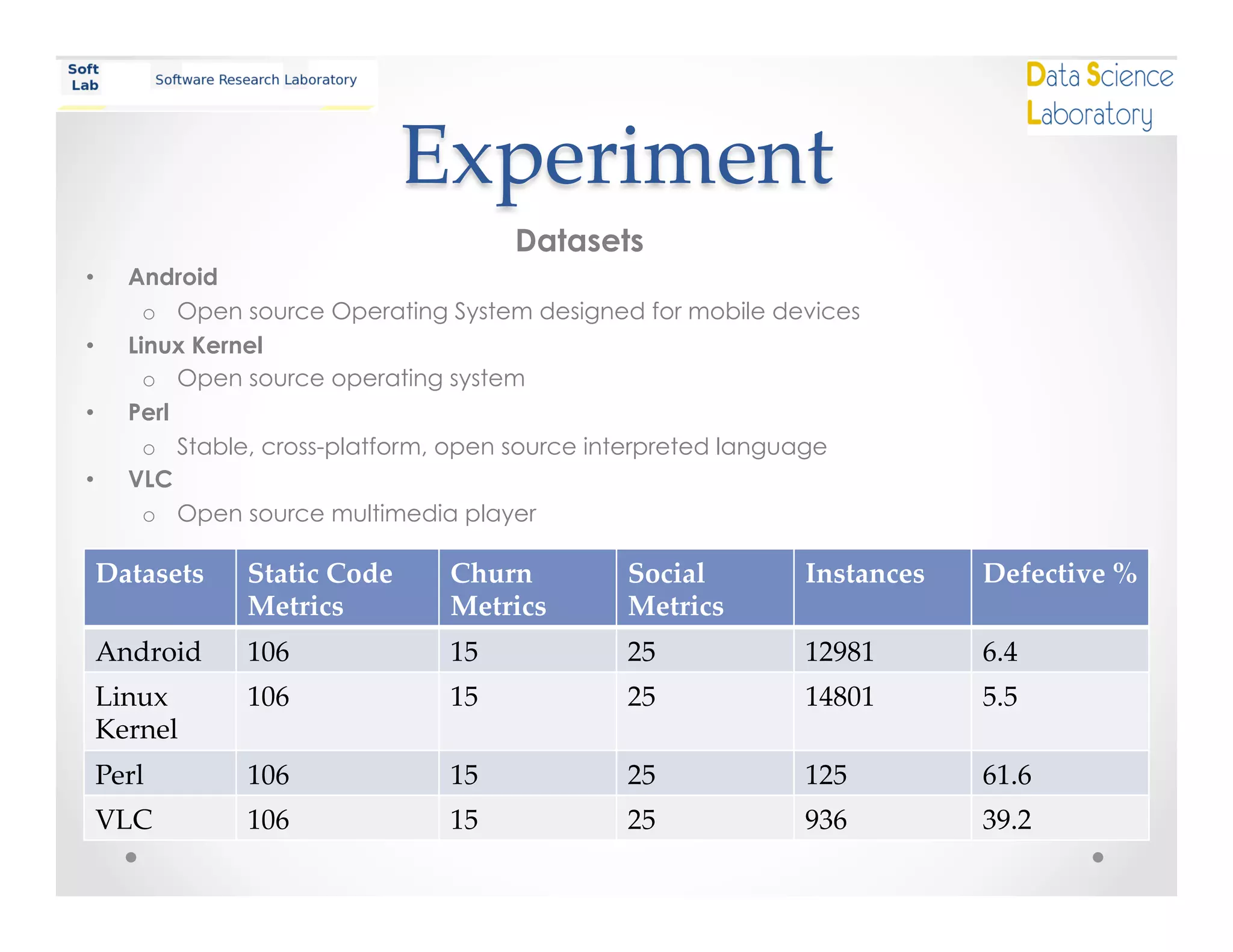


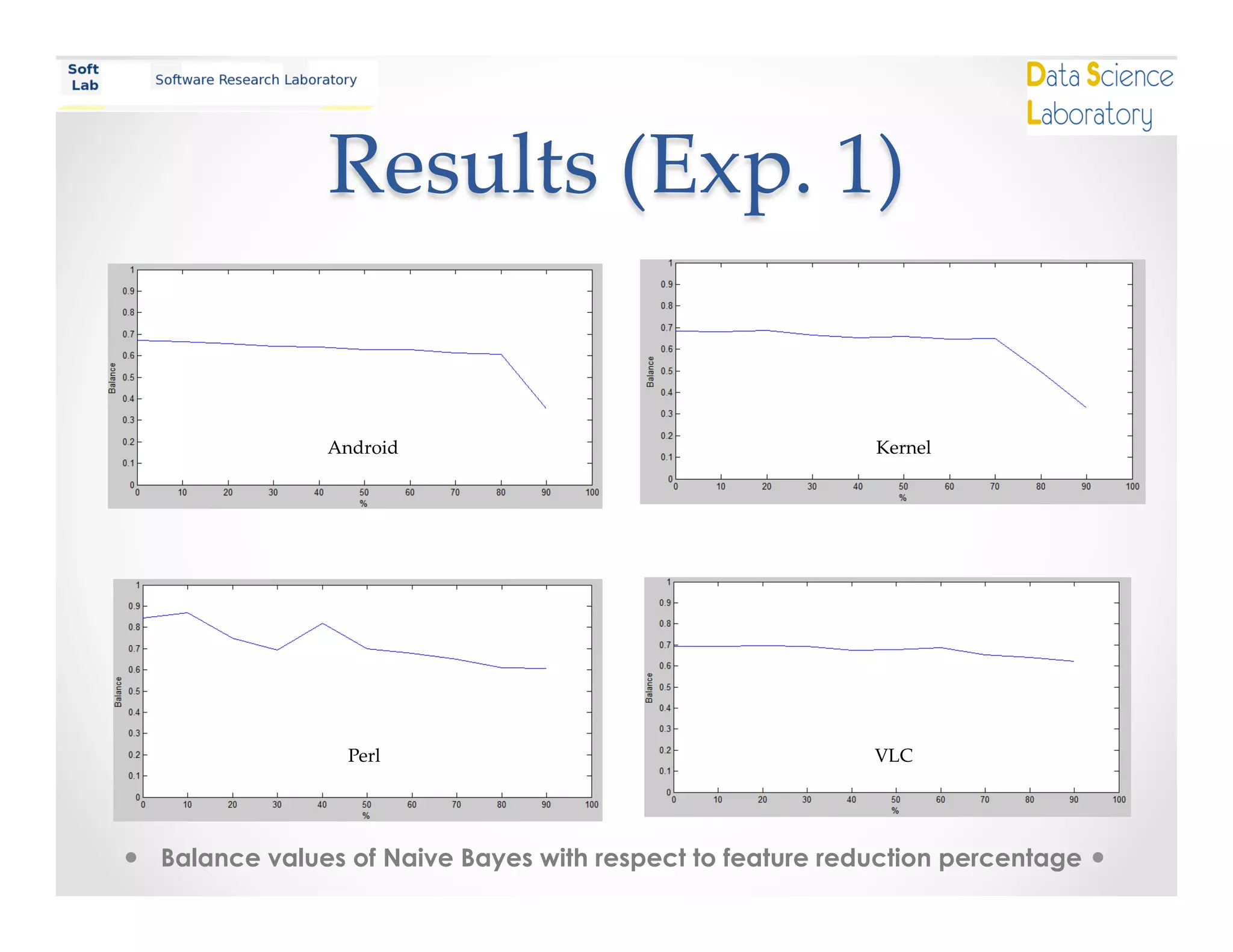
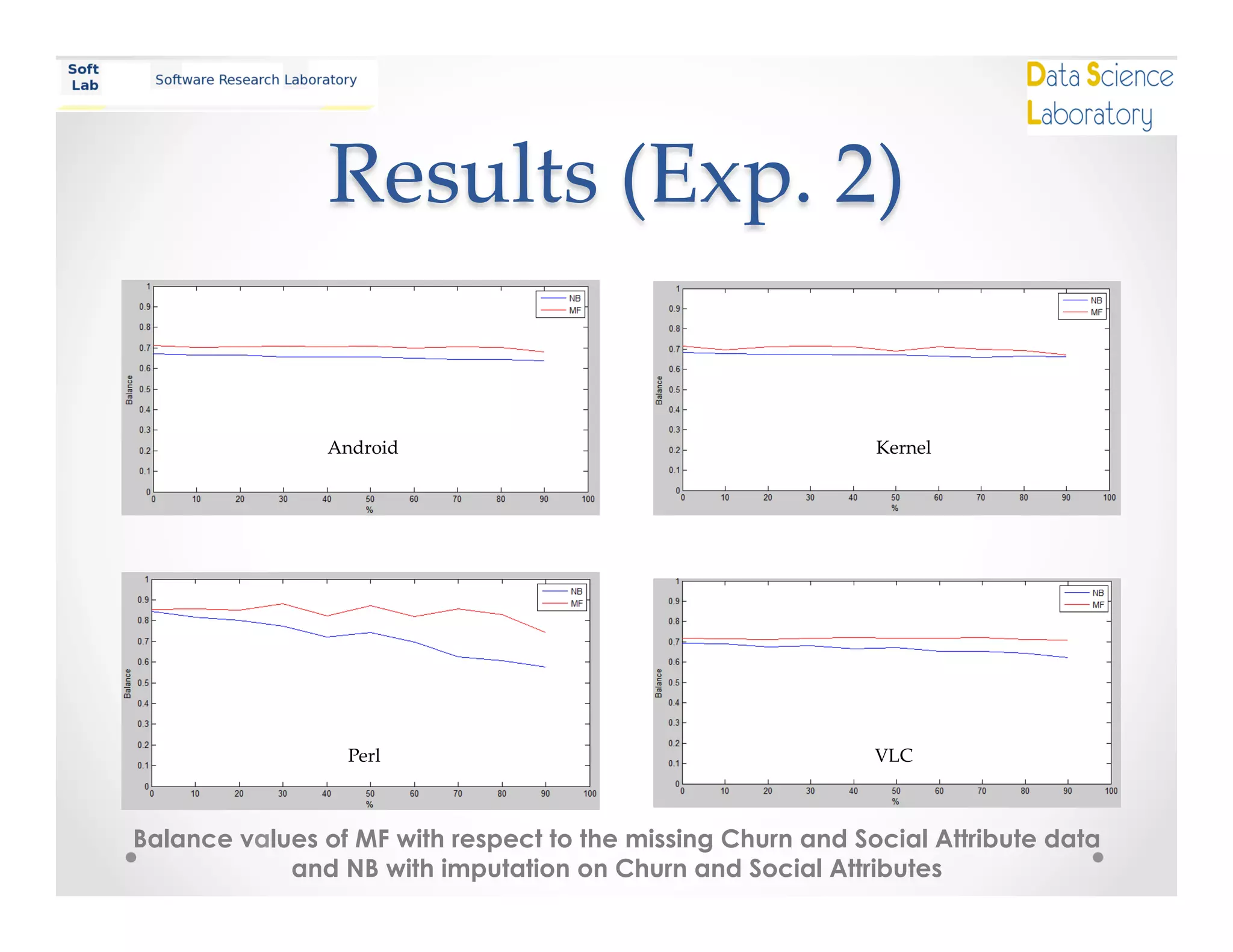






















This document summarizes a study on using matrix factorization to handle missing attributes in software defect prediction models. The study conducted two experiments: 1) evaluating the performance of a naive Bayes classifier as features were gradually removed, and 2) comparing the performance of naive Bayes with imputation versus matrix factorization on datasets with missing attributes. The results showed that naive Bayes performance decreased with fewer features, while matrix factorization performed better than naive Bayes when attributes were missing. The study concludes that matrix factorization is a promising approach for the missing data problem in defect prediction.


























![[WISE 2015] Similarity-Based Context-aware Recommendation](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2015wise-151105004039-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



























































