Download to read offline








![How are transformers made?
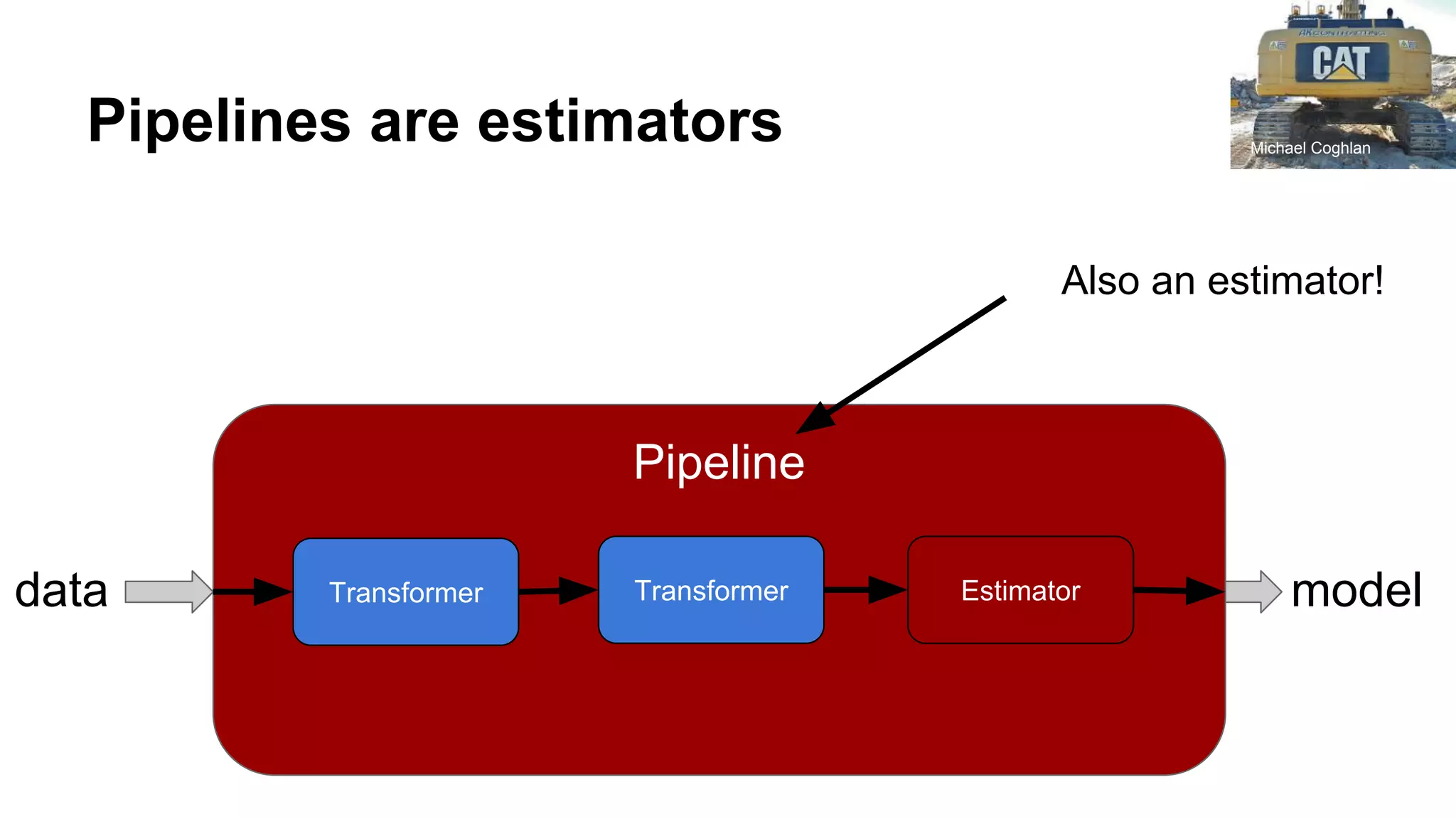
Estimator
data
class Estimator extends PipelineStage {
def fit(dataset: Dataset[_]): Transformer = {
// magic happens here
}
}
Transformer](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-15-2048.jpg)
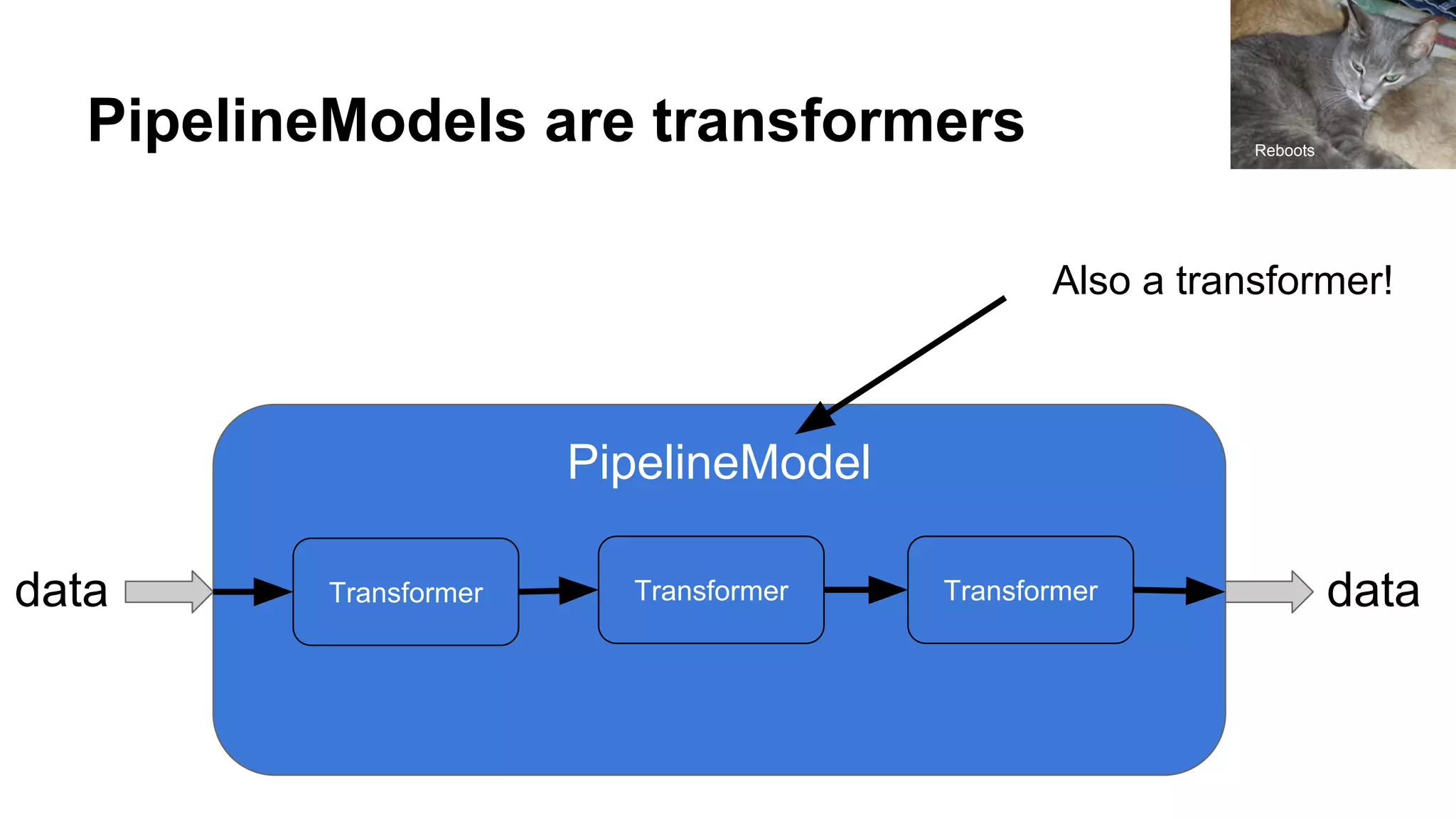
![How is new data made?
Transformer ( data )
class Transformer extends PipelineStage {
def transform(df: Dataset[_]): DataFrame
}
new data.transform](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-16-2048.jpg)
![Feature transformations
+-----+-----+----+--------+
|admit| gre| gpa|prestige|
+-----+-----+----+--------+
| no|380.0|3.61| 3.0|
| yes|660.0|3.67| 3.0|
| yes|800.0| 4.0| 1.0|
| yes|640.0|3.19| 4.0|
| no|520.0|2.93| 4.0|
+-----+-----+----+--------+
val assembler = new VectorAssembler()
.setInputCols(Array("gre", "gpa", "prestige"))
val df2 = assembler.transform(df)
VectorAssembler
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-17-2048.jpg)
![Train a classifier on the transformed data
StringIndexer
StringIndexerModel
val si = new StringIndexer().setInputCol("admit").setOutputCol("label")
val siModel = si.fit(df2)
val df3 = siModel.transform(df2)
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+
+-----+-----+----+--------+----------------+-----+
|admit| gre| gpa|prestige| features|label|
+-----+-----+----+--------+----------------+-----+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0|
+-----+-----+----+--------+----------------+-----+](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-18-2048.jpg)
![Train a classifier on the transformed data
+----------------+-----+
| features|label|
+----------------+-----+
|[380.0,3.61,3.0]| 0.0|
|[660.0,3.67,3.0]| 1.0|
| [800.0,4.0,1.0]| 1.0|
|[640.0,3.19,4.0]| 1.0|
|[520.0,2.93,4.0]| 0.0|
+----------------+-----+
DecisionTreeClassifier
DecisionTree
ClassificationModel
+----------------+-----+----------+
| features|label|prediction|
+----------------+-----+----------+
|[380.0,3.61,3.0]| 0.0| 0.0|
|[660.0,3.67,3.0]| 1.0| 0.0|
| [800.0,4.0,1.0]| 1.0| 1.0|
|[640.0,3.19,4.0]| 1.0| 1.0|
|[520.0,2.93,4.0]| 0.0| 0.0|
+----------------+-----+----------+
val dt = new DecisionTreeClassifier()
val dtModel = dt.fit(df3)
val df4 = dtModel.transform(df3)](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-19-2048.jpg)









![Do the “work” (e.g. predict labels or w/e):
def transform(df: Dataset[_]): DataFrame = {
val wordcount = udf { in: String => in.split(" ").size }
df.select(col("*"),
wordcount(df.col("happy_pandas")).as("happy_panda_counts"))
}
vic15](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-30-2048.jpg)


final val outputCol = new Param[String](this, "outputCol", "The
output column")
def setInputCol(value: String): this.type = set(inputCol, value)
def setOutputCol(value: String): this.type = set(outputCol, value)
Jason Wesley Upton](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-32-2048.jpg)




![A simple string indexer estimator
class SimpleIndexer(override val uid: String) extends
Estimator[SimpleIndexerModel] with SimpleIndexerParams {
….
override def fit(dataset: Dataset[_]): SimpleIndexerModel = {
import dataset.sparkSession.implicits._
val words = dataset.select(dataset($(inputCol)).as[String]).distinct
.collect()
new SimpleIndexerModel(uid, words)
}
}](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-37-2048.jpg)

![And our friend the transformer is back:
class SimpleIndexerModel(
override val uid: String, words: Array[String]) extends
Model[SimpleIndexerModel] with SimpleIndexerParams {
...
private val labelToIndex: Map[String, Double] = words.zipWithIndex.
map{case (x, y) => (x, y.toDouble)}.toMap
override def transform(dataset: Dataset[_]): DataFrame = {
val indexer = udf { label: String => labelToIndex(label) }
dataset.select(col("*"),
indexer(dataset($(inputCol)).cast(StringType)).as($(outputCol)))
Still not to be confused with the Transformers franchise from Hasbro and Tomy.](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-39-2048.jpg)










![Cross-validation
because saving a test set is effort & a reason to integrate
// ParamGridBuilder constructs an Array of parameter
combinations.
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(nb.smoothing, Array(0.1, 0.5, 1.0, 2.0))
.build()
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEstimatorParamMaps(paramGrid)
val cvModel = cv.fit(df)
val bestModel = cvModel.bestModel
Jonathan Kotta](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-51-2048.jpg)


![Let’s make a Classifier* :)
// Example only - not for production use.
class SimpleNaiveBayes(val uid: String)
extends Classifier[Vector, SimpleNaiveBayes, SimpleNaiveBayesModel] {
Input type Trained Model](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-54-2048.jpg)
![Let’s make a Classifier* :)
override def train(ds: Dataset[_]): SimpleNaiveBayesModel = {
import ds.sparkSession.implicits._
ds.cache()
….
…
….
}](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-55-2048.jpg)
![If you reallllly want to see inside the ...s (1/5)
// Get the number of features by peaking at the first row
val numFeatures: Integer = ds.select(col($(featuresCol))).head
.get(0).asInstanceOf[Vector].size
// Determine the number of records for each class
val groupedByLabel = ds.select(col($(labelCol)).as[Double]).groupByKey(x =>
x)
val classCounts = groupedByLabel.agg(count("*").as[Long])
.sort(col("value")).collect().toMap
// Select the labels and features so we can more easily map over them.
// Note: we do this as a DataFrame using the untyped API because the Vector
// UDT is no longer public.
val df = ds.select(col($(labelCol)).cast(DoubleType), col($(featuresCol)))](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-56-2048.jpg)

![If you reallllly want to see inside the ...s (3/5)
// Figure out the non-zero frequency of each feature for each label and
// output label index pairs using a case clas to make it easier to work
with.
val labelCounts: Dataset[LabeledToken] = df.flatMap {
case Row(label: Double, features: Vector) =>
features.toArray.zip(Stream from 1)
.filter{vIdx => vIdx._2 == 1.0}
.map{case (v, idx) => LabeledToken(label, idx)}
}
// Use the typed Dataset aggregation API to count the number of non-zero
// features for each label-feature index.
val aggregatedCounts: Array[((Double, Integer), Long)] = labelCounts
.groupByKey(x => (x.label, x.index))
.agg(count("*").as[Long]).collect()
val theta = Array.fill(numClasses)(new Array[Double](numFeatures))](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-58-2048.jpg)






![Minimal prep continued
val assembler = new VectorAssembler()
assembler.setInputCols(Array("gre", "gpa", "prestige"))
val si = new StringIndexer()
si.setInputCol("admit").setOutputCol("label")
val pipeline = new Pipeline()
pipeline.setStages(Array(assembler, si))
Huang
Yun
Chung
+-----+-----+----+--------+----------------+-----+
|admit| gre| gpa|prestige| features|label|
+-----+-----+----+--------+----------------+-----+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0|
+-----+-----+----+--------+----------------+-----+
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+
+-----+-----+----+--------+
|admit| gre| gpa|prestige|
+-----+-----+----+--------+
| no|380.0|3.61| 3.0|
| yes|660.0|3.67| 3.0|
| yes|800.0| 4.0| 1.0|
| yes|640.0|3.19| 4.0|
| no|520.0|2.93| 4.0|
+-----+-----+----+--------+](https://image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-67-2048.jpg)


















![How are transformers made?
Estimator
data
class Estimator extends PipelineStage {
def fit(dataset: Dataset[_]): Transformer = {
// magic happens here
}
}
Transformer](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-15-2048.jpg)
![How is new data made?
Transformer ( data )
class Transformer extends PipelineStage {
def transform(df: Dataset[_]): DataFrame
}
new data.transform](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-16-2048.jpg)
![Feature transformations
+-----+-----+----+--------+
|admit| gre| gpa|prestige|
+-----+-----+----+--------+
| no|380.0|3.61| 3.0|
| yes|660.0|3.67| 3.0|
| yes|800.0| 4.0| 1.0|
| yes|640.0|3.19| 4.0|
| no|520.0|2.93| 4.0|
+-----+-----+----+--------+
val assembler = new VectorAssembler()
.setInputCols(Array("gre", "gpa", "prestige"))
val df2 = assembler.transform(df)
VectorAssembler
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-17-2048.jpg)
![Train a classifier on the transformed data
StringIndexer
StringIndexerModel
val si = new StringIndexer().setInputCol("admit").setOutputCol("label")
val siModel = si.fit(df2)
val df3 = siModel.transform(df2)
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+
+-----+-----+----+--------+----------------+-----+
|admit| gre| gpa|prestige| features|label|
+-----+-----+----+--------+----------------+-----+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0|
+-----+-----+----+--------+----------------+-----+](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-18-2048.jpg)
![Train a classifier on the transformed data
+----------------+-----+
| features|label|
+----------------+-----+
|[380.0,3.61,3.0]| 0.0|
|[660.0,3.67,3.0]| 1.0|
| [800.0,4.0,1.0]| 1.0|
|[640.0,3.19,4.0]| 1.0|
|[520.0,2.93,4.0]| 0.0|
+----------------+-----+
DecisionTreeClassifier
DecisionTree
ClassificationModel
+----------------+-----+----------+
| features|label|prediction|
+----------------+-----+----------+
|[380.0,3.61,3.0]| 0.0| 0.0|
|[660.0,3.67,3.0]| 1.0| 0.0|
| [800.0,4.0,1.0]| 1.0| 1.0|
|[640.0,3.19,4.0]| 1.0| 1.0|
|[520.0,2.93,4.0]| 0.0| 0.0|
+----------------+-----+----------+
val dt = new DecisionTreeClassifier()
val dtModel = dt.fit(df3)
val df4 = dtModel.transform(df3)](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-19-2048.jpg)










![Do the “work” (e.g. predict labels or w/e):
def transform(df: Dataset[_]): DataFrame = {
val wordcount = udf { in: String => in.split(" ").size }
df.select(col("*"),
wordcount(df.col("happy_pandas")).as("happy_panda_counts"))
}
vic15](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-30-2048.jpg)


final val outputCol = new Param[String](this, "outputCol", "The
output column")
def setInputCol(value: String): this.type = set(inputCol, value)
def setOutputCol(value: String): this.type = set(outputCol, value)
Jason Wesley Upton](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-32-2048.jpg)




![A simple string indexer estimator
class SimpleIndexer(override val uid: String) extends
Estimator[SimpleIndexerModel] with SimpleIndexerParams {
….
override def fit(dataset: Dataset[_]): SimpleIndexerModel = {
import dataset.sparkSession.implicits._
val words = dataset.select(dataset($(inputCol)).as[String]).distinct
.collect()
new SimpleIndexerModel(uid, words)
}
}](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-37-2048.jpg)

![And our friend the transformer is back:
class SimpleIndexerModel(
override val uid: String, words: Array[String]) extends
Model[SimpleIndexerModel] with SimpleIndexerParams {
...
private val labelToIndex: Map[String, Double] = words.zipWithIndex.
map{case (x, y) => (x, y.toDouble)}.toMap
override def transform(dataset: Dataset[_]): DataFrame = {
val indexer = udf { label: String => labelToIndex(label) }
dataset.select(col("*"),
indexer(dataset($(inputCol)).cast(StringType)).as($(outputCol)))
Still not to be confused with the Transformers franchise from Hasbro and Tomy.](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-39-2048.jpg)











![Cross-validation
because saving a test set is effort & a reason to integrate
// ParamGridBuilder constructs an Array of parameter
combinations.
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(nb.smoothing, Array(0.1, 0.5, 1.0, 2.0))
.build()
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEstimatorParamMaps(paramGrid)
val cvModel = cv.fit(df)
val bestModel = cvModel.bestModel
Jonathan Kotta](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-51-2048.jpg)


![Let’s make a Classifier* :)
// Example only - not for production use.
class SimpleNaiveBayes(val uid: String)
extends Classifier[Vector, SimpleNaiveBayes, SimpleNaiveBayesModel] {
Input type Trained Model](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-54-2048.jpg)
![Let’s make a Classifier* :)
override def train(ds: Dataset[_]): SimpleNaiveBayesModel = {
import ds.sparkSession.implicits._
ds.cache()
….
…
….
}](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-55-2048.jpg)
![If you reallllly want to see inside the ...s (1/5)
// Get the number of features by peaking at the first row
val numFeatures: Integer = ds.select(col($(featuresCol))).head
.get(0).asInstanceOf[Vector].size
// Determine the number of records for each class
val groupedByLabel = ds.select(col($(labelCol)).as[Double]).groupByKey(x =>
x)
val classCounts = groupedByLabel.agg(count("*").as[Long])
.sort(col("value")).collect().toMap
// Select the labels and features so we can more easily map over them.
// Note: we do this as a DataFrame using the untyped API because the Vector
// UDT is no longer public.
val df = ds.select(col($(labelCol)).cast(DoubleType), col($(featuresCol)))](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-56-2048.jpg)

![If you reallllly want to see inside the ...s (3/5)
// Figure out the non-zero frequency of each feature for each label and
// output label index pairs using a case clas to make it easier to work
with.
val labelCounts: Dataset[LabeledToken] = df.flatMap {
case Row(label: Double, features: Vector) =>
features.toArray.zip(Stream from 1)
.filter{vIdx => vIdx._2 == 1.0}
.map{case (v, idx) => LabeledToken(label, idx)}
}
// Use the typed Dataset aggregation API to count the number of non-zero
// features for each label-feature index.
val aggregatedCounts: Array[((Double, Integer), Long)] = labelCounts
.groupByKey(x => (x.label, x.index))
.agg(count("*").as[Long]).collect()
val theta = Array.fill(numClasses)(new Array[Double](numFeatures))](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-58-2048.jpg)








![Minimal prep continued
val assembler = new VectorAssembler()
assembler.setInputCols(Array("gre", "gpa", "prestige"))
val si = new StringIndexer()
si.setInputCol("admit").setOutputCol("label")
val pipeline = new Pipeline()
pipeline.setStages(Array(assembler, si))
Huang
Yun
Chung
+-----+-----+----+--------+----------------+-----+
|admit| gre| gpa|prestige| features|label|
+-----+-----+----+--------+----------------+-----+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]| 0.0|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]| 1.0|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]| 1.0|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]| 1.0|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]| 0.0|
+-----+-----+----+--------+----------------+-----+
+-----+-----+----+--------+----------------+
|admit| gre| gpa|prestige| features|
+-----+-----+----+--------+----------------+
| no|380.0|3.61| 3.0|[380.0,3.61,3.0]|
| yes|660.0|3.67| 3.0|[660.0,3.67,3.0]|
| yes|800.0| 4.0| 1.0| [800.0,4.0,1.0]|
| yes|640.0|3.19| 4.0|[640.0,3.19,4.0]|
| no|520.0|2.93| 4.0|[520.0,2.93,4.0]|
+-----+-----+----+--------+----------------+
+-----+-----+----+--------+
|admit| gre| gpa|prestige|
+-----+-----+----+--------+
| no|380.0|3.61| 3.0|
| yes|660.0|3.67| 3.0|
| yes|800.0| 4.0| 1.0|
| yes|640.0|3.19| 4.0|
| no|520.0|2.93| 4.0|
+-----+-----+----+--------+](https://crownmelresort.com/image.slidesharecdn.com/extendingsparkmlforcustommodels-estimatorsandtransformers-nowwithpython-170811065657/75/Extending-spark-ML-for-custom-models-now-with-python-67-2048.jpg)





The document discusses the extension of Spark ML estimators and transformers, highlighting the role of its principal software engineer Holden Karau and the objectives of IBM's Spark Technology Center. It explains Spark ML pipelines, the structure and function of estimators and transformers, and introduces a project called SparklingML aimed at enhancing Spark ML capabilities. Additionally, it provides an overview of building custom stages within Spark ML and encourages contributions to the community.

















































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)

















