Download as PDF, PPTX


















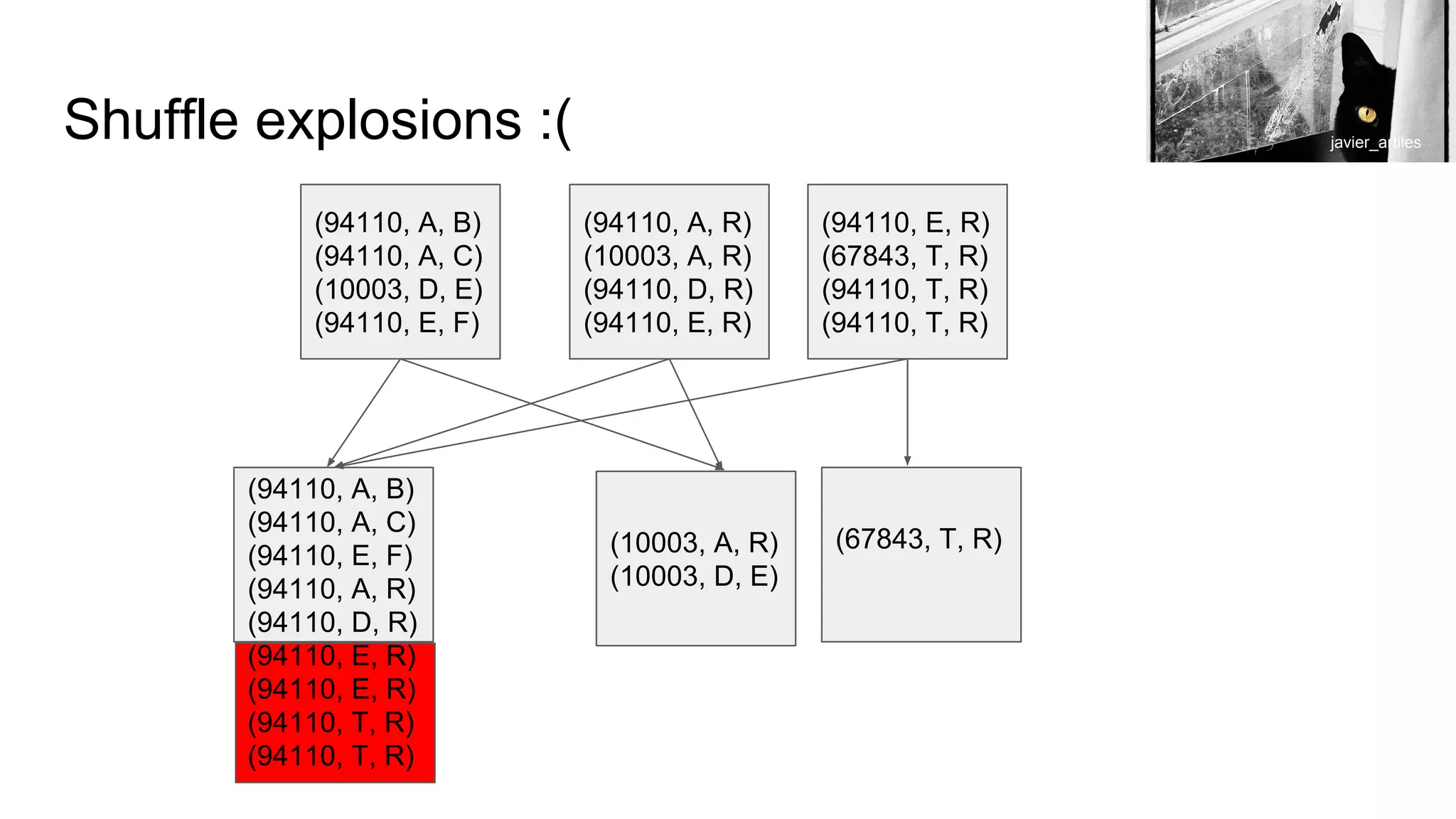
![So what does groupByKey look like?
(94110, A, B)
(94110, A, C)
(10003, D, E)
(94110, E, F)
(94110, A, R)
(10003, A, R)
(94110, D, R)
(94110, E, R)
(94110, E, R)
(67843, T, R)
(94110, T, R)
(94110, T, R)
(67843, T, R)(10003, A, R)
(94110, [(A, B), (A, C), (E, F), (A, R), (D, R), (E, R), (E, R), (T, R) (T, R)]
Tomomi](https://image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-23-2048.jpg)







![Using Datasets to mix functional & relational style
val ds: Dataset[RawPanda] = ...
val happiness = ds.filter($"happy" === true).
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)](https://image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-35-2048.jpg)
![So what was that?
ds.filter($"happy" === true).
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)
A typed query (specifies the
return type). Without the as[]
will return a DataFrame
(Dataset[Row])
Traditional functional
reduction:
arbitrary scala code :)
Robert Couse-Baker](https://image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-36-2048.jpg)
![And functional style maps:
/**
* Functional map + Dataset, sums the positive attributes for the
pandas
*/
def funMap(ds: Dataset[RawPanda]): Dataset[Double] = {
ds.map{rp => rp.attributes.filter(_ > 0).sum}
}](https://image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-37-2048.jpg)

































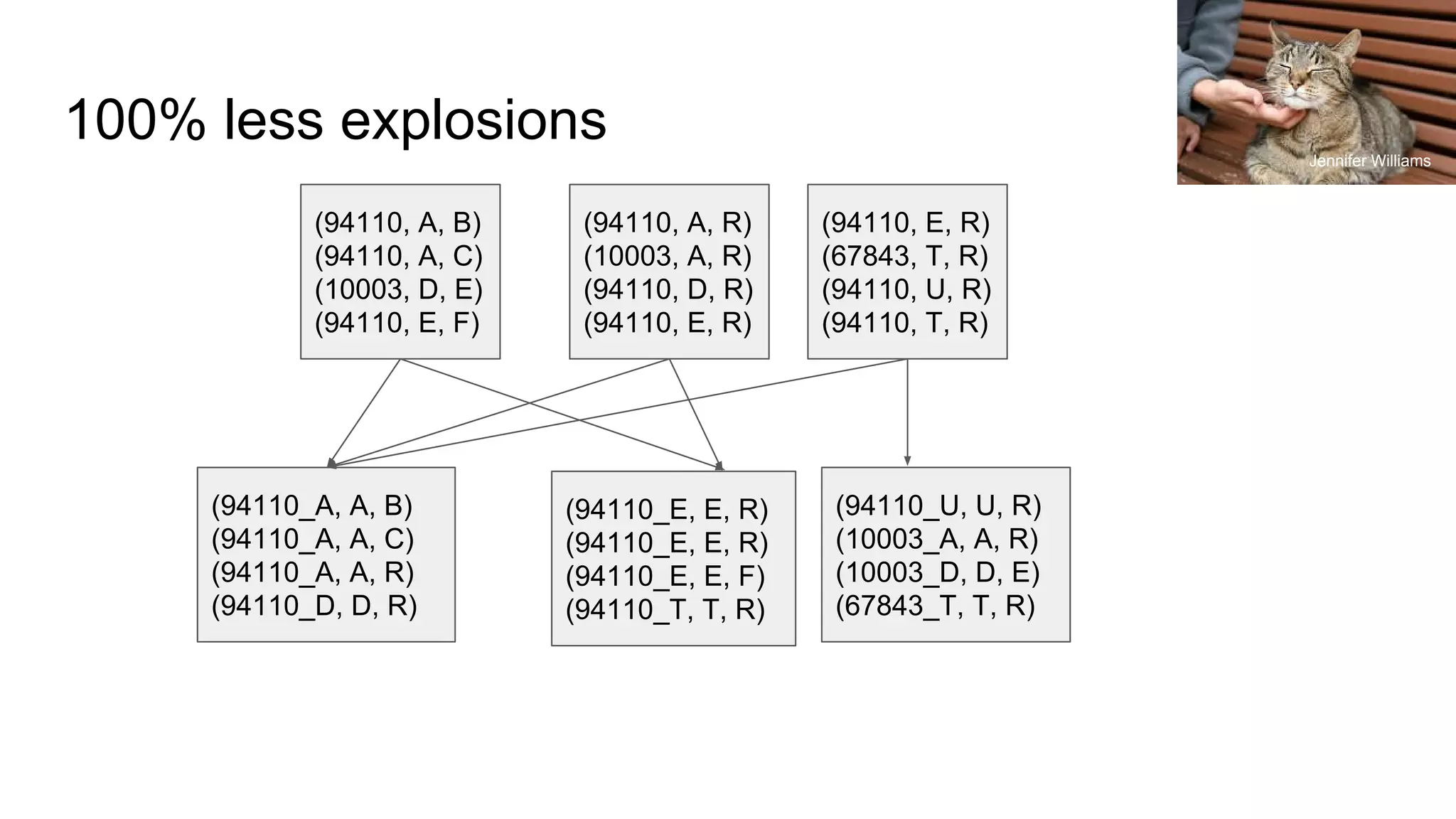
![So what does groupByKey look like?
(94110, A, B)
(94110, A, C)
(10003, D, E)
(94110, E, F)
(94110, A, R)
(10003, A, R)
(94110, D, R)
(94110, E, R)
(94110, E, R)
(67843, T, R)
(94110, T, R)
(94110, T, R)
(67843, T, R)(10003, A, R)
(94110, [(A, B), (A, C), (E, F), (A, R), (D, R), (E, R), (E, R), (T, R) (T, R)]
Tomomi](https://crownmelresort.com/image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-23-2048.jpg)











![Using Datasets to mix functional & relational style
val ds: Dataset[RawPanda] = ...
val happiness = ds.filter($"happy" === true).
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)](https://crownmelresort.com/image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-35-2048.jpg)
![So what was that?
ds.filter($"happy" === true).
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)
A typed query (specifies the
return type). Without the as[]
will return a DataFrame
(Dataset[Row])
Traditional functional
reduction:
arbitrary scala code :)
Robert Couse-Baker](https://crownmelresort.com/image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-36-2048.jpg)
![And functional style maps:
/**
* Functional map + Dataset, sums the positive attributes for the
pandas
*/
def funMap(ds: Dataset[RawPanda]): Dataset[Double] = {
ds.map{rp => rp.attributes.filter(_ > 0).sum}
}](https://crownmelresort.com/image.slidesharecdn.com/scalingwithapachesparkalessoninunintendedconsequences-strangeloop20171-171001055626/75/Scaling-with-apache-spark-a-lesson-in-unintended-consequences-strange-loop-2017-1-37-2048.jpg)

















This document discusses scaling Apache Spark applications and some of the unintended consequences that can arise. It covers Spark's core abstractions of RDDs and DataFrames for distributed data and computation. It explains how Spark's lazy evaluation model and use of deterministic partitioning can impact reusing data and operations like groupByKey. It also discusses challenges that can arise from Spark's support for arbitrary functions and working with non-JVM languages like Python.





























































