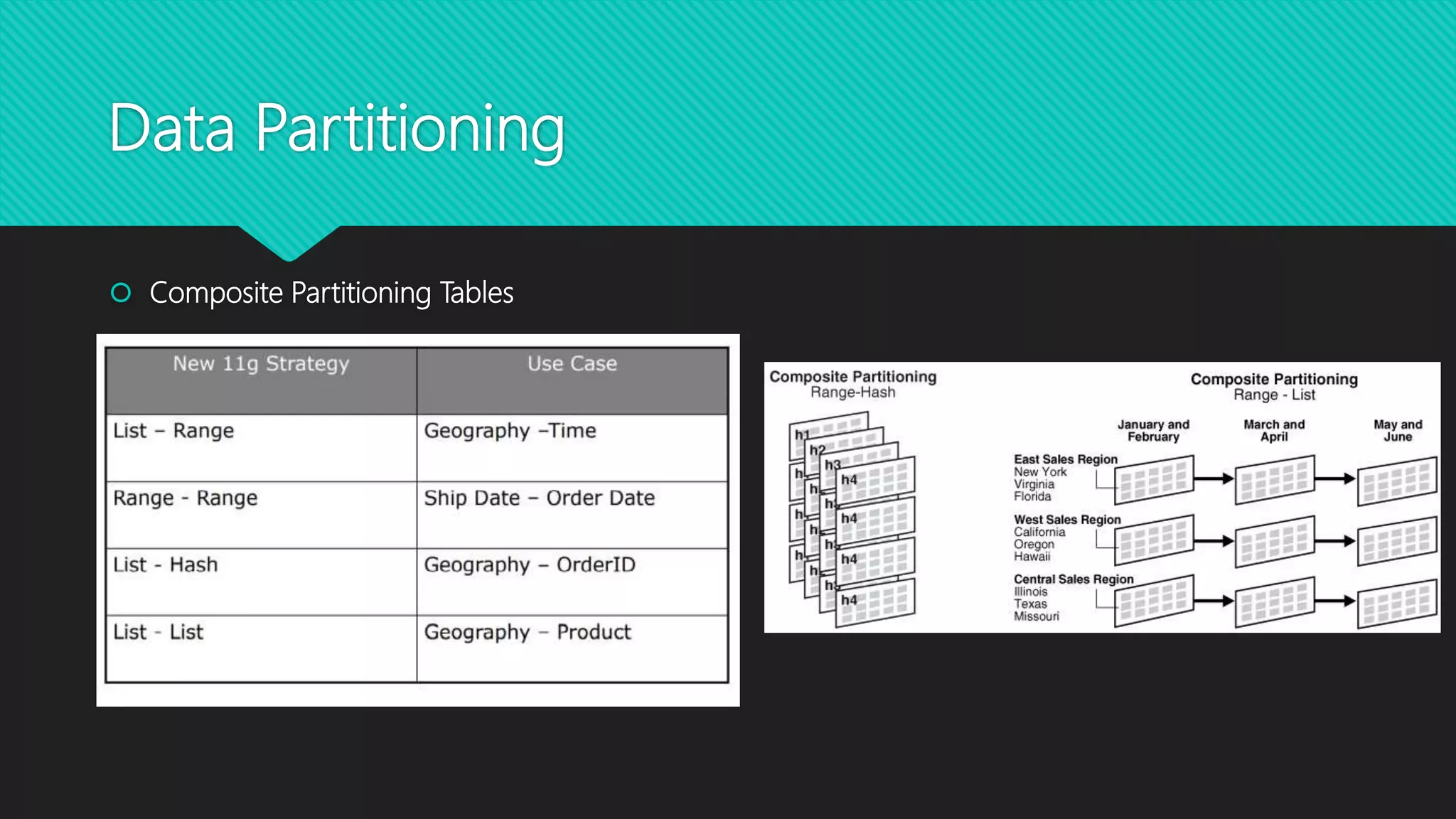
The document outlines strategies for optimizing database performance, including upgrading server hardware, optimizing SQL queries, and creating proper indexes. Key recommendations include selecting specific fields instead of using 'SELECT *', avoiding 'SELECT DISTINCT', using appropriate join methods, and implementing various index types. Additionally, it discusses data partitioning techniques to improve efficiency by subdividing large tables into smaller, manageable segments.