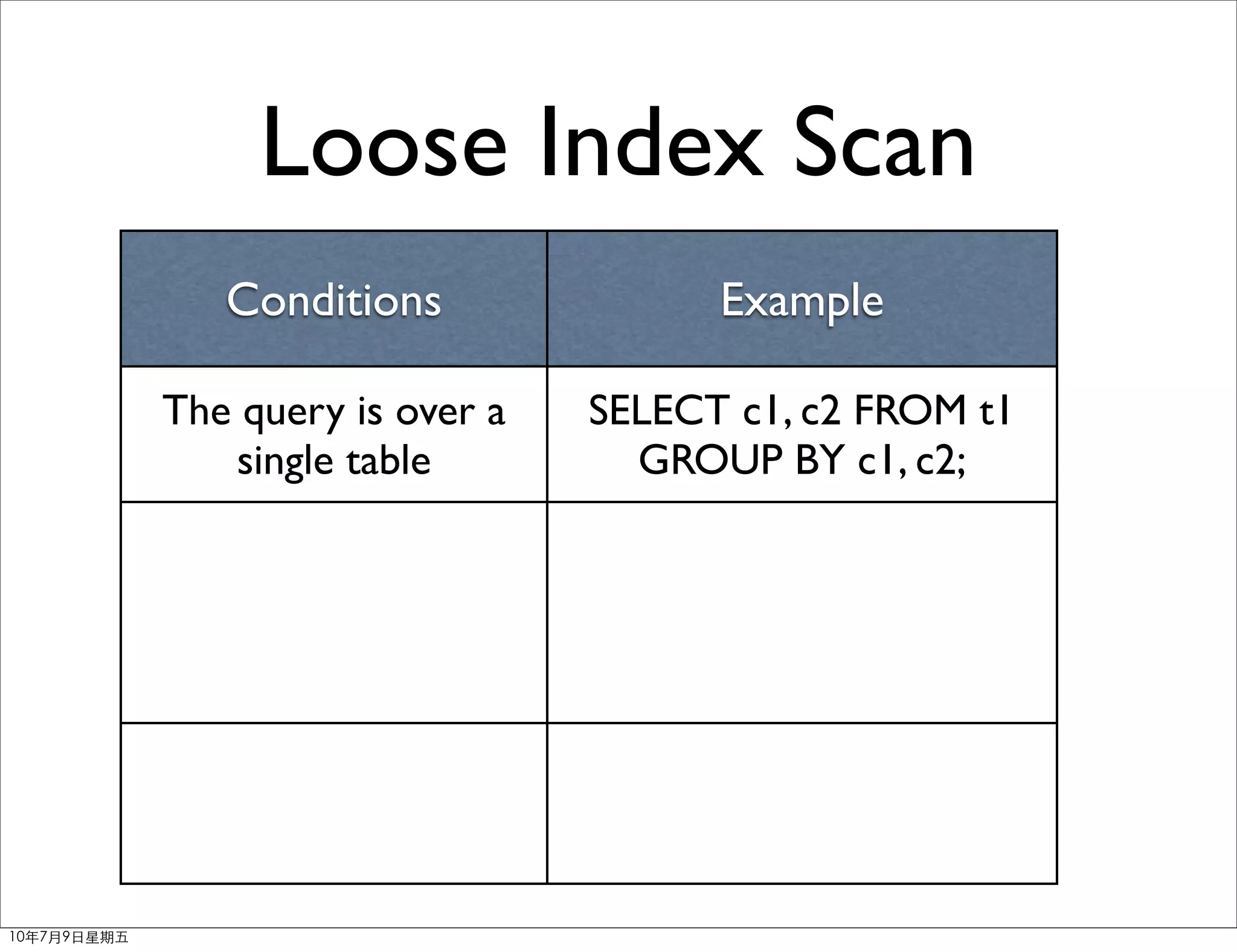
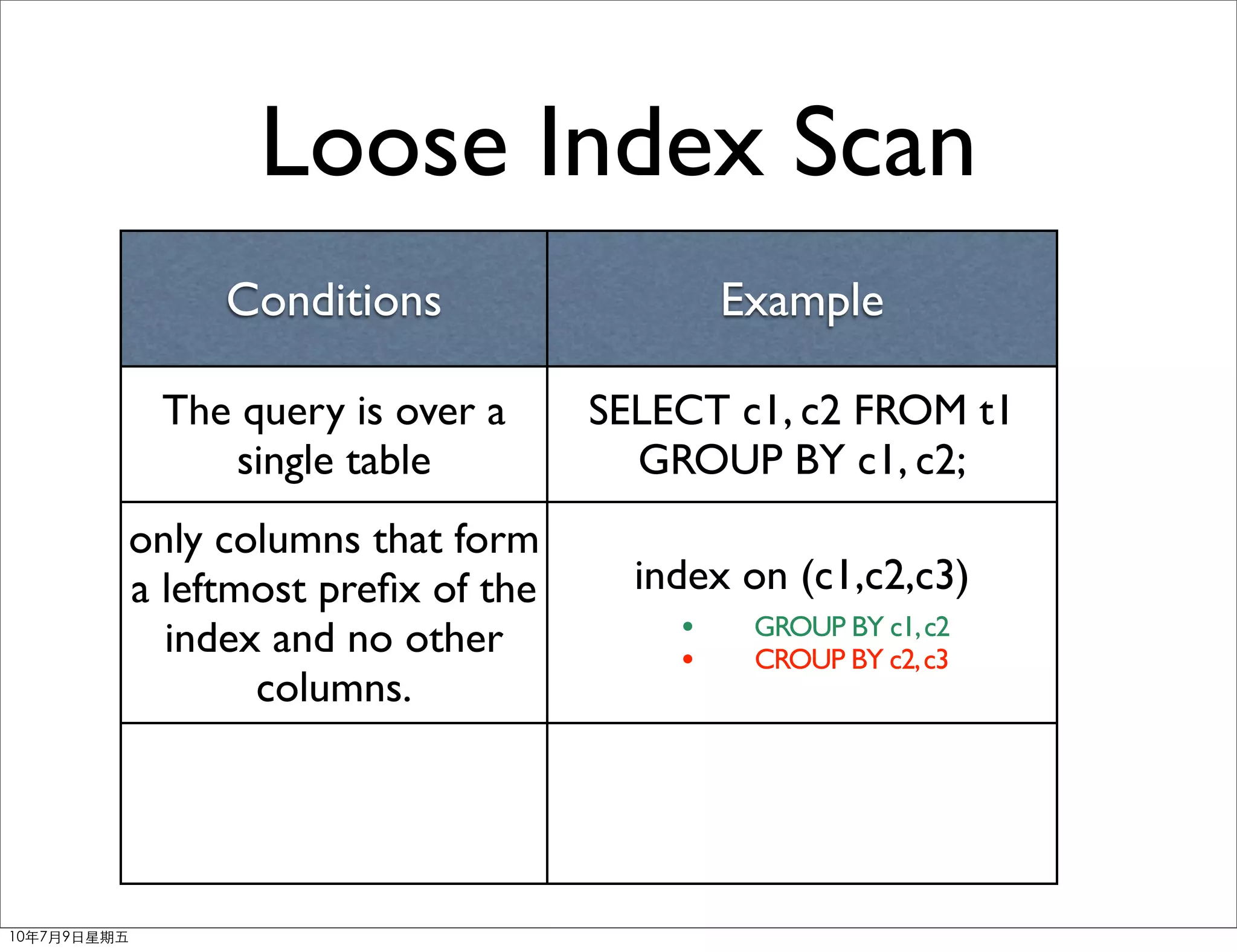
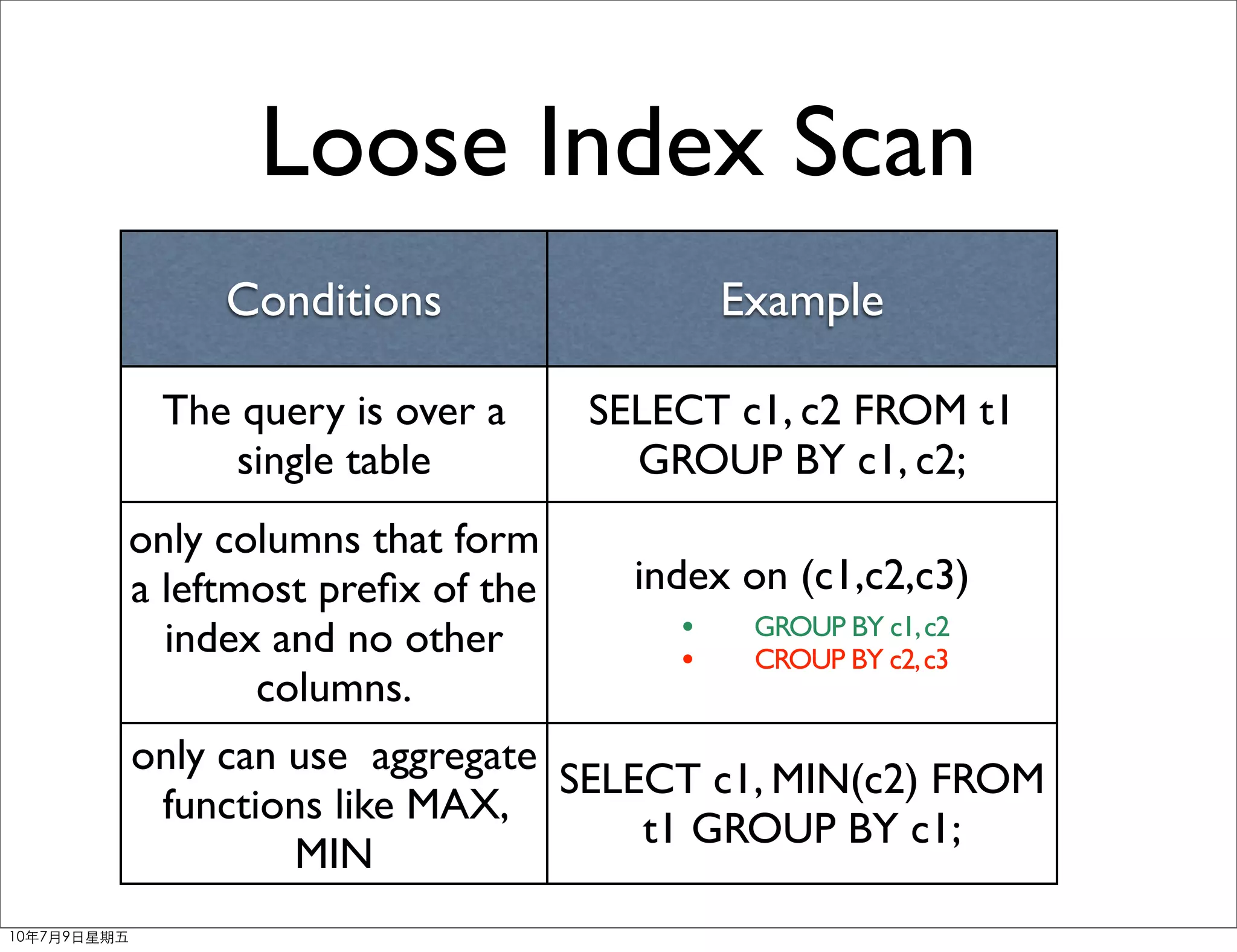
Download as PDF, PPTX






























































![Use Index
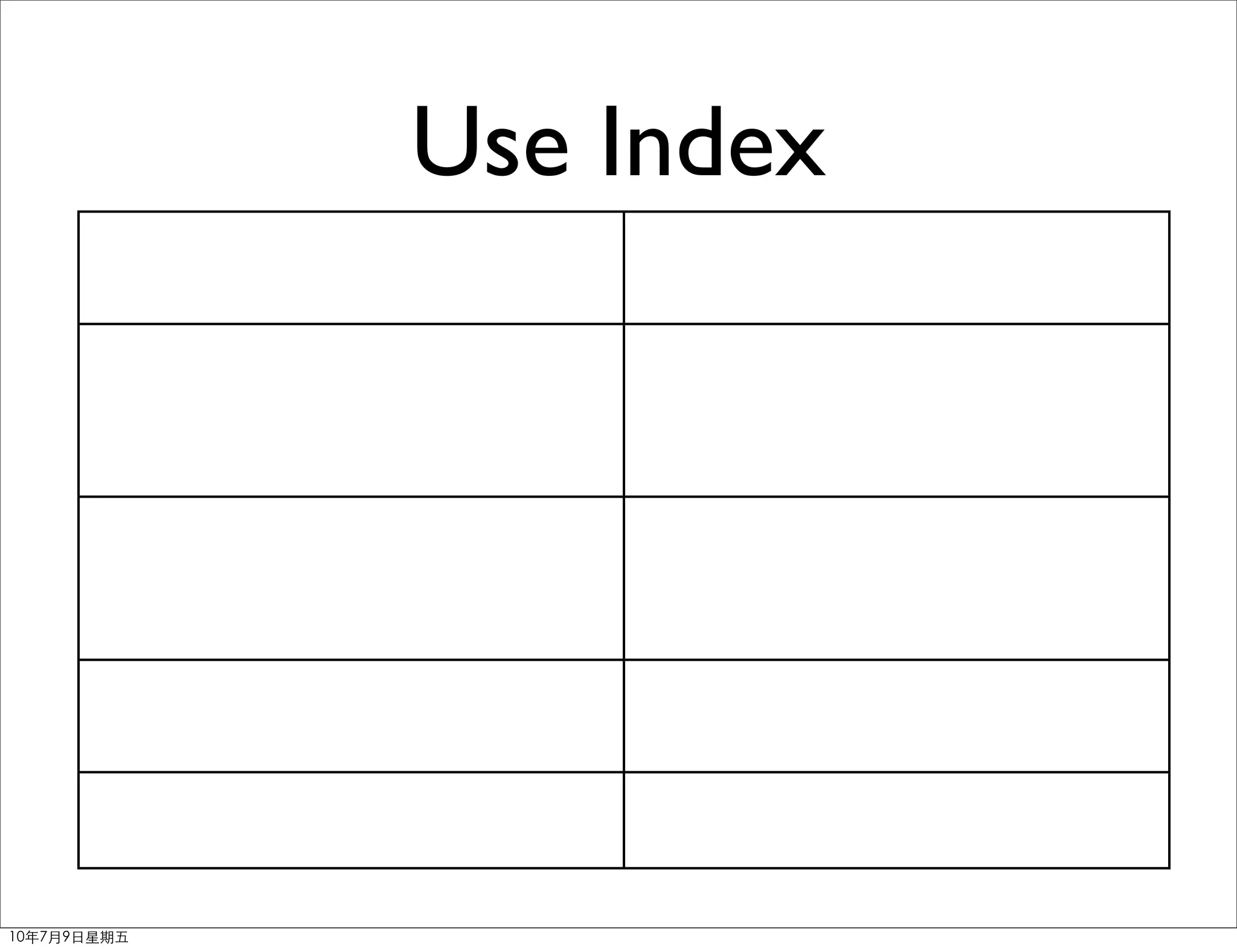
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-69-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-70-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-71-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-72-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-73-2048.jpg)







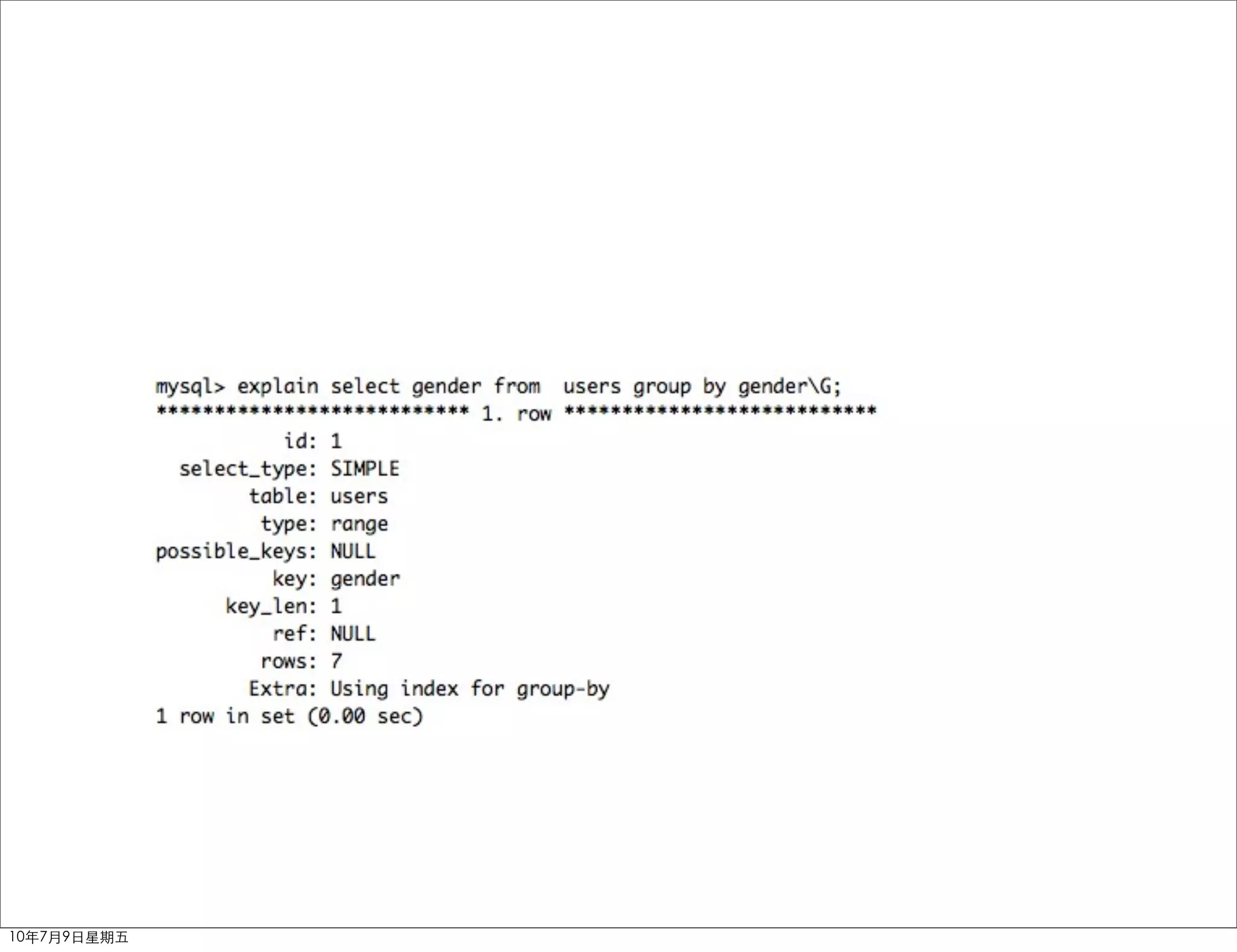











































































![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://crownmelresort.com/image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-69-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://crownmelresort.com/image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-70-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://crownmelresort.com/image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-71-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://crownmelresort.com/image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-72-2048.jpg)
![Use Index
SELECT col1, col2 FROM
sort
a ORDER BY [sort]
SELECT col1, col2 FROM
a WHERE colX=value (colx, sort)
ORDER BY [sort]
SELECT * FROM a
WHERE uid=1 ORDER BY (uid, x, y)
x, y
SELECT * FROM a
won’t use index
ORDER BY YEAR(date)
...... ......](https://crownmelresort.com/image.slidesharecdn.com/mysqlqueryoptimization-100709050517-phpapp01/75/Mysql-query-optimization-73-2048.jpg)






















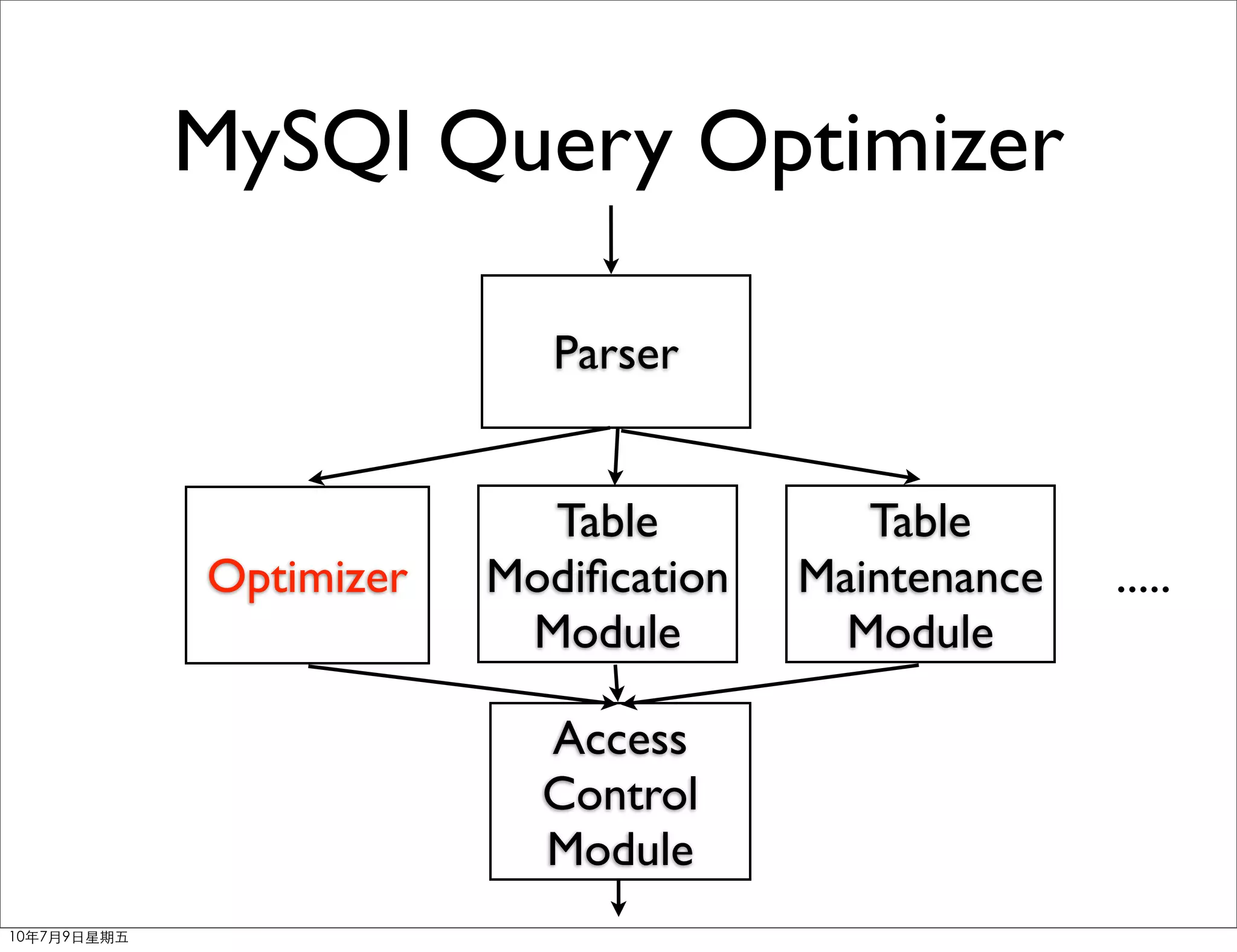
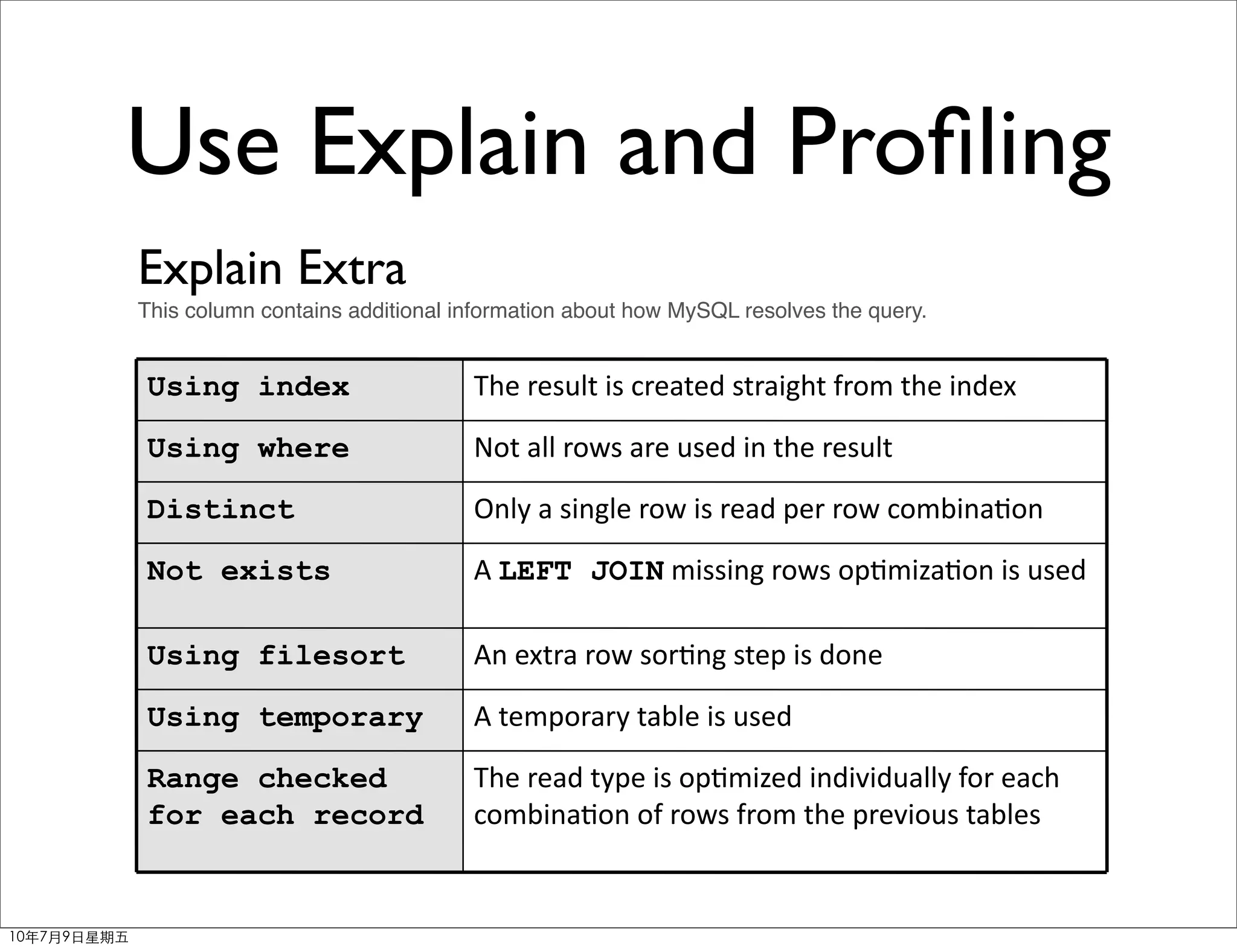
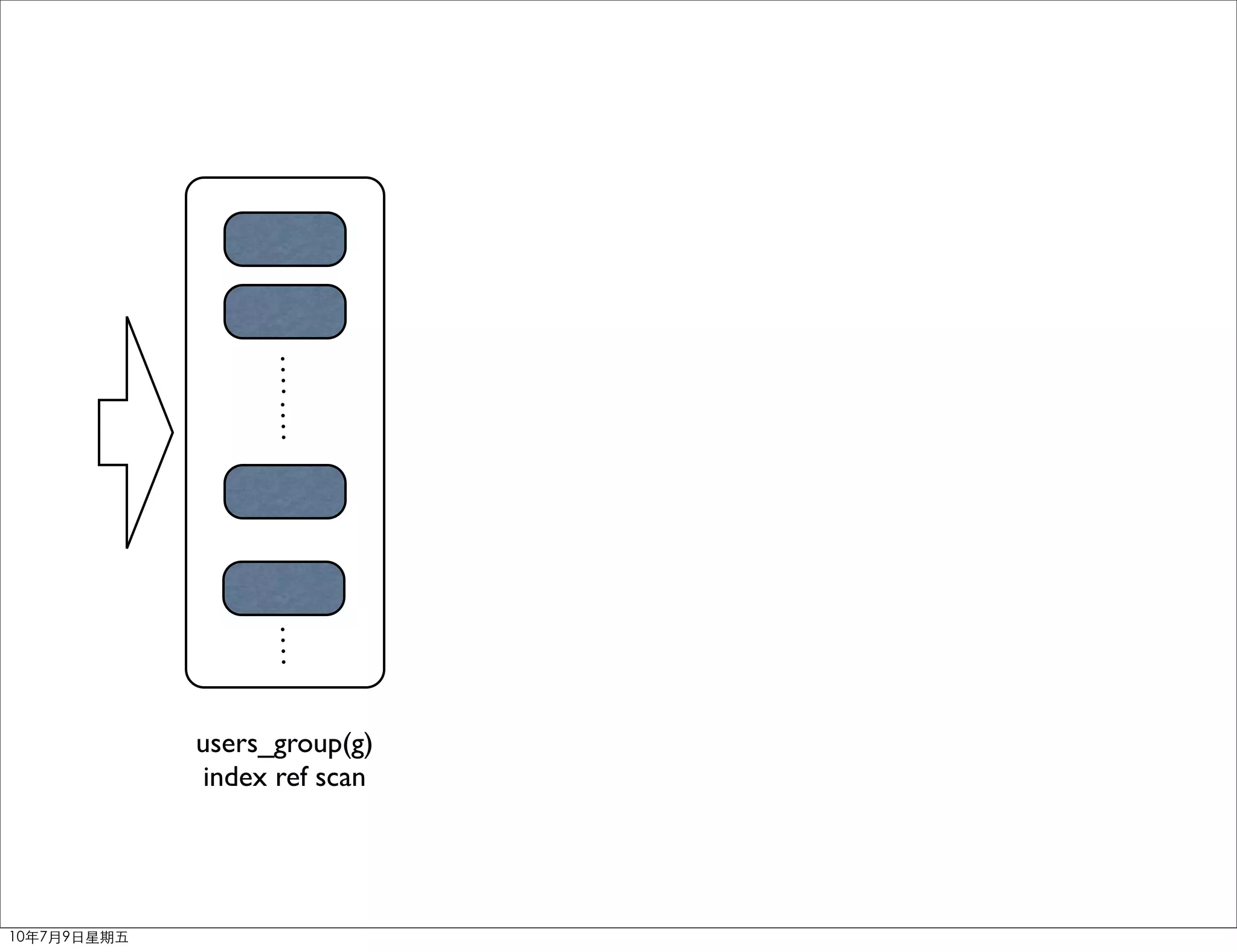
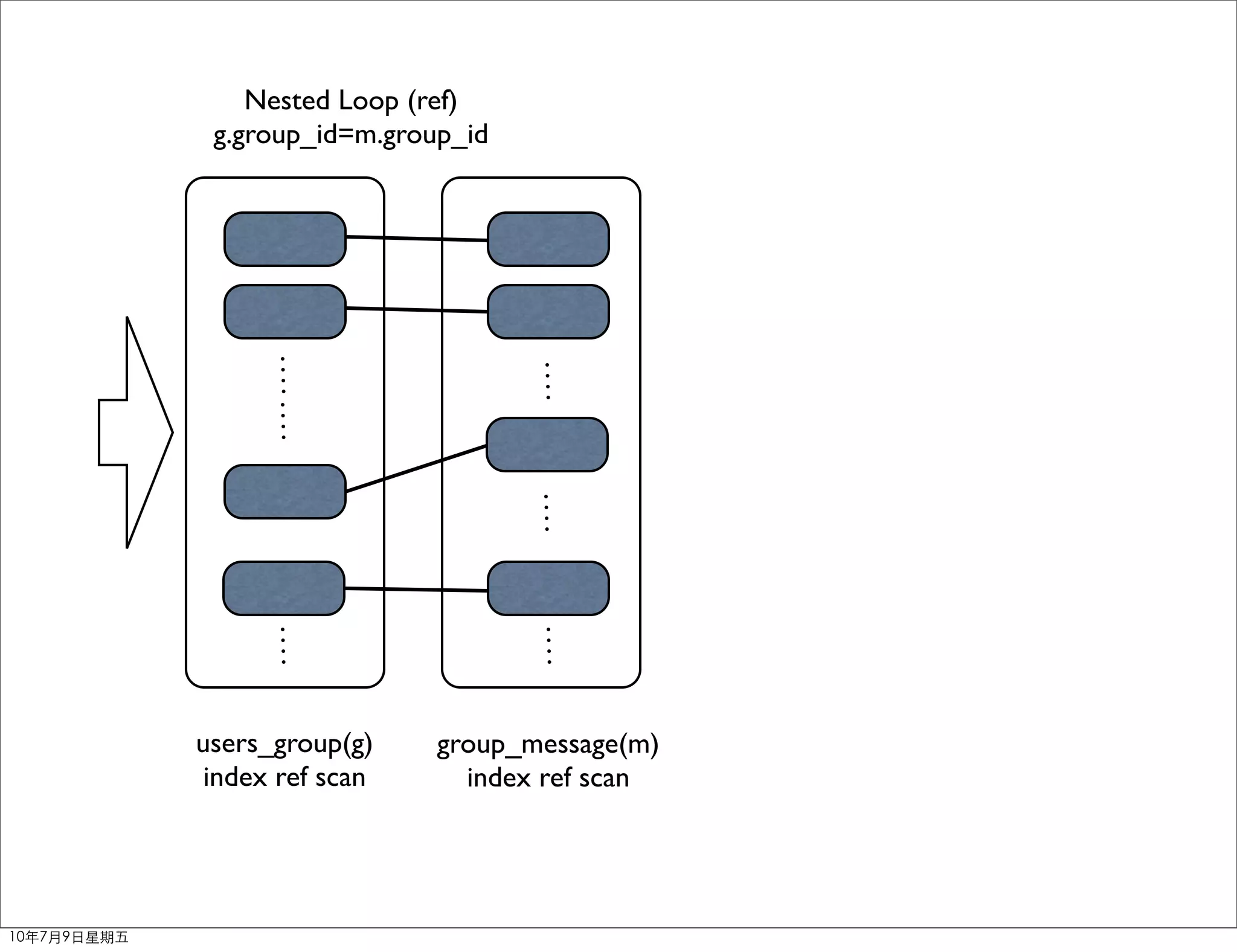
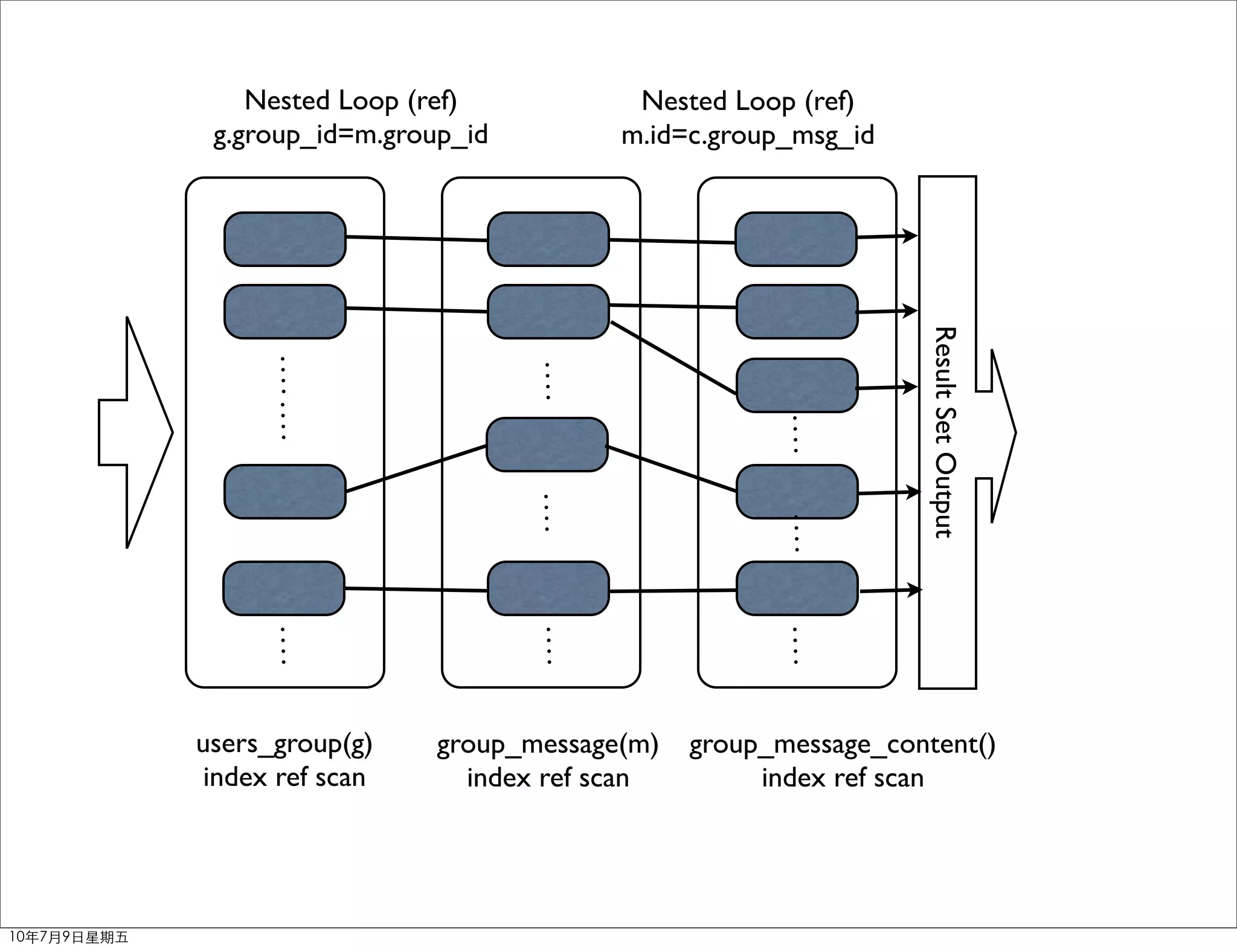
The document discusses MySQL query optimization. It covers the query optimizer, principles of optimization like using EXPLAIN and profiling, indexes, JOIN optimization, and ORDER BY/GROUP BY optimization. The key points are to identify bottlenecks, use indexes on frequently filtered fields, avoid indexes on fields that change often or contain many duplicates, and consider composite indexes to cover multiple queries.























































































