Downloaded 23 times


![6/26
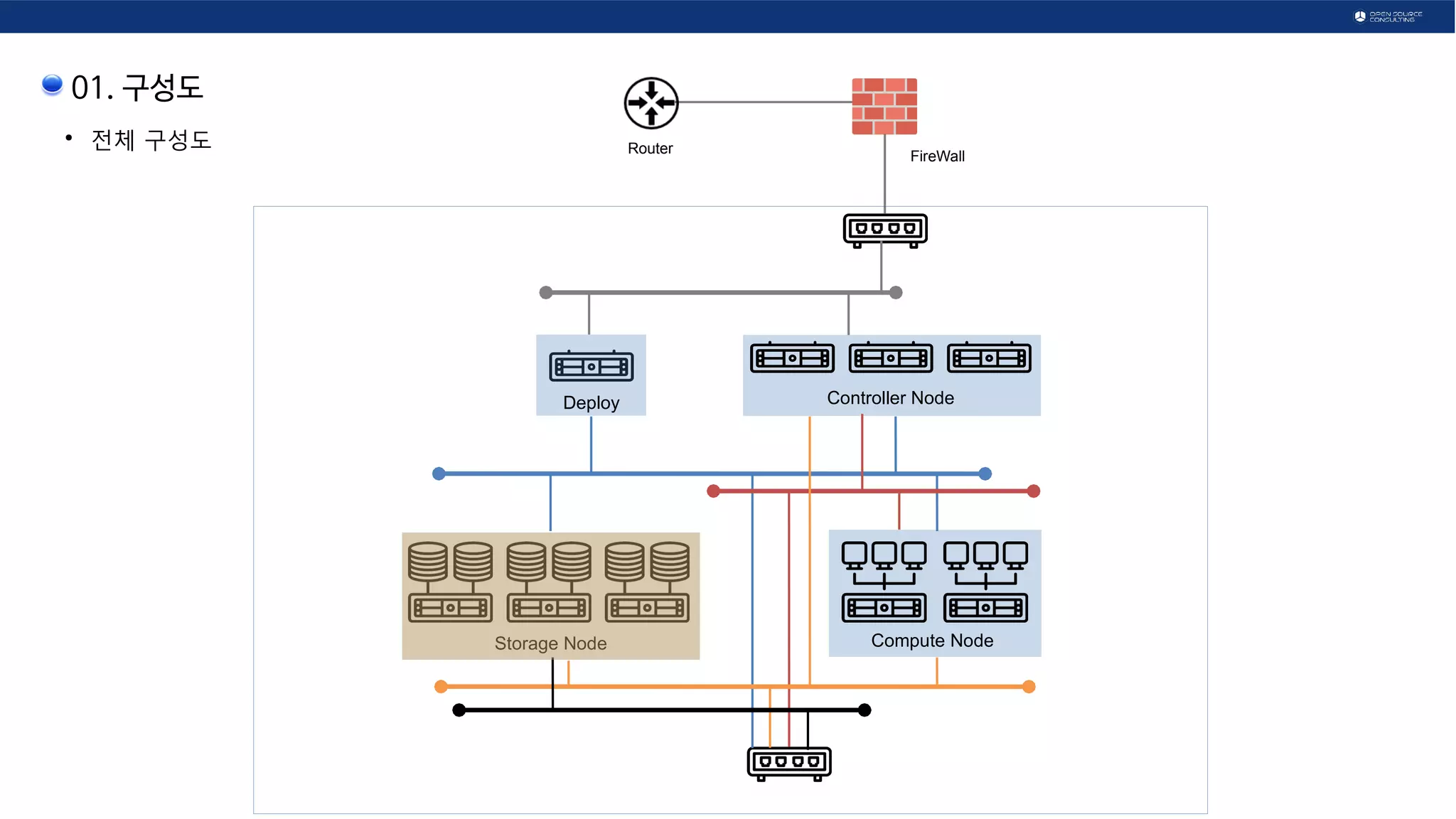
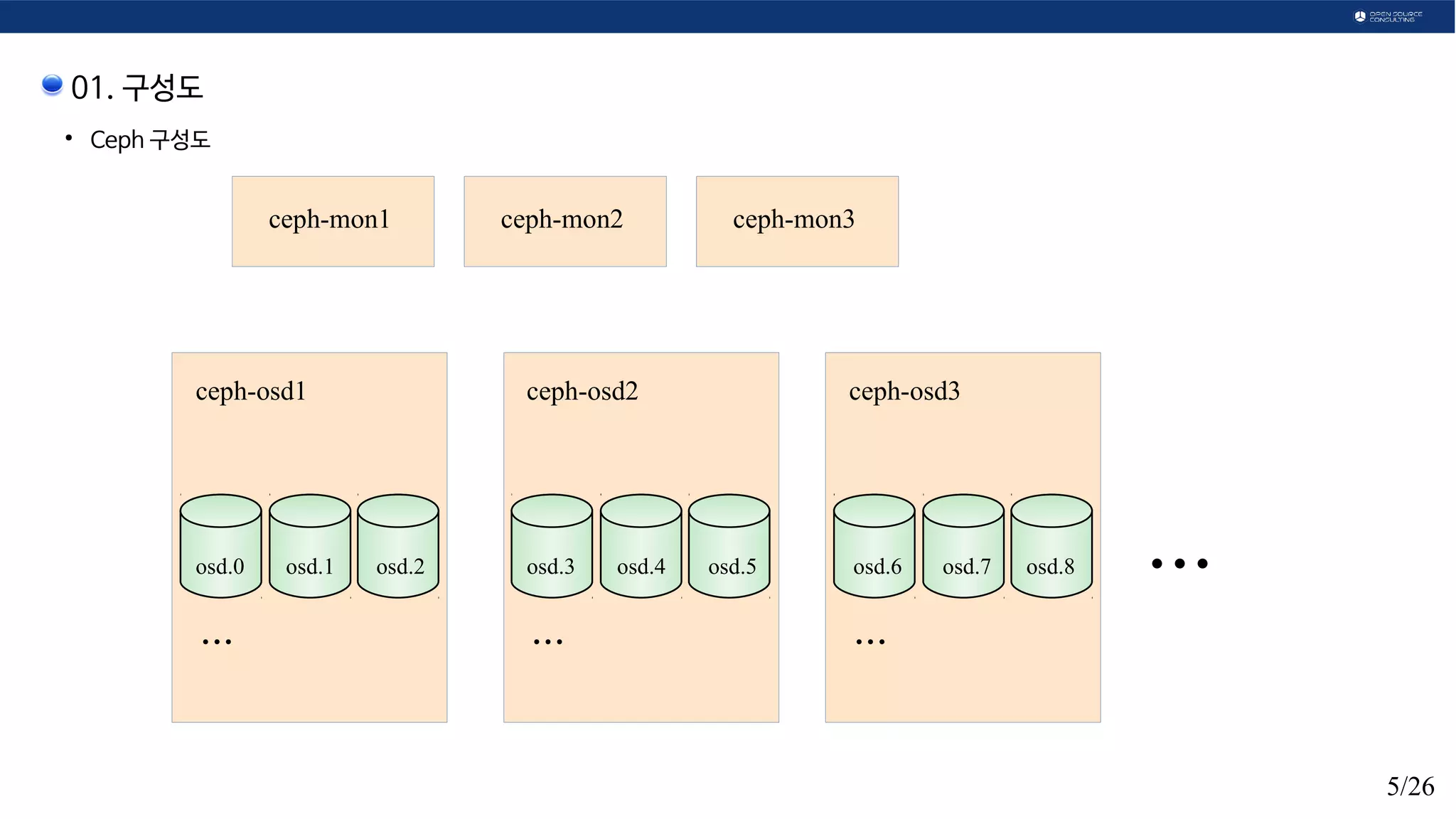
01. 구성도
●
Ceph OBJ 흐름
PG: Placement Group
Object를 저장하기 위한 OSD의 group.
복제본 수에 맞춰 member의 수가 달라짐.
OSD: Object Storage Daemon
object를 최종 저장하는 곳
Monitor: ceph OSD의
변화를 monitoring
하여 crush map을
만드는 주체 주체.
[root@ceph-osd01 ~]# rados ls -p vms
rbd_data.1735e637a64d5.0000000000000000
rbd_header.1735e637a64d5
rbd_directory
rbd_children
rbd_info
rbd_data.1735e637a64d5.0000000000000003
rbd_data.1735e637a64d5.0000000000000002
rbd_id.893f4f3d-f6d9-4521-997c-72caa861ac24_disk
rbd_data.1735e637a64d5.0000000000000001
rbd_object_map.1735e637a64d5
[root@ceph-osd01 ~]#
OBJ의 기본 크기는 크기는 주체4MBMB
CRUSH: Controlled Replication Under
Scalable Hashing
Object를 분산 저장하기위한 알고리즘.](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-6-2048.jpg)

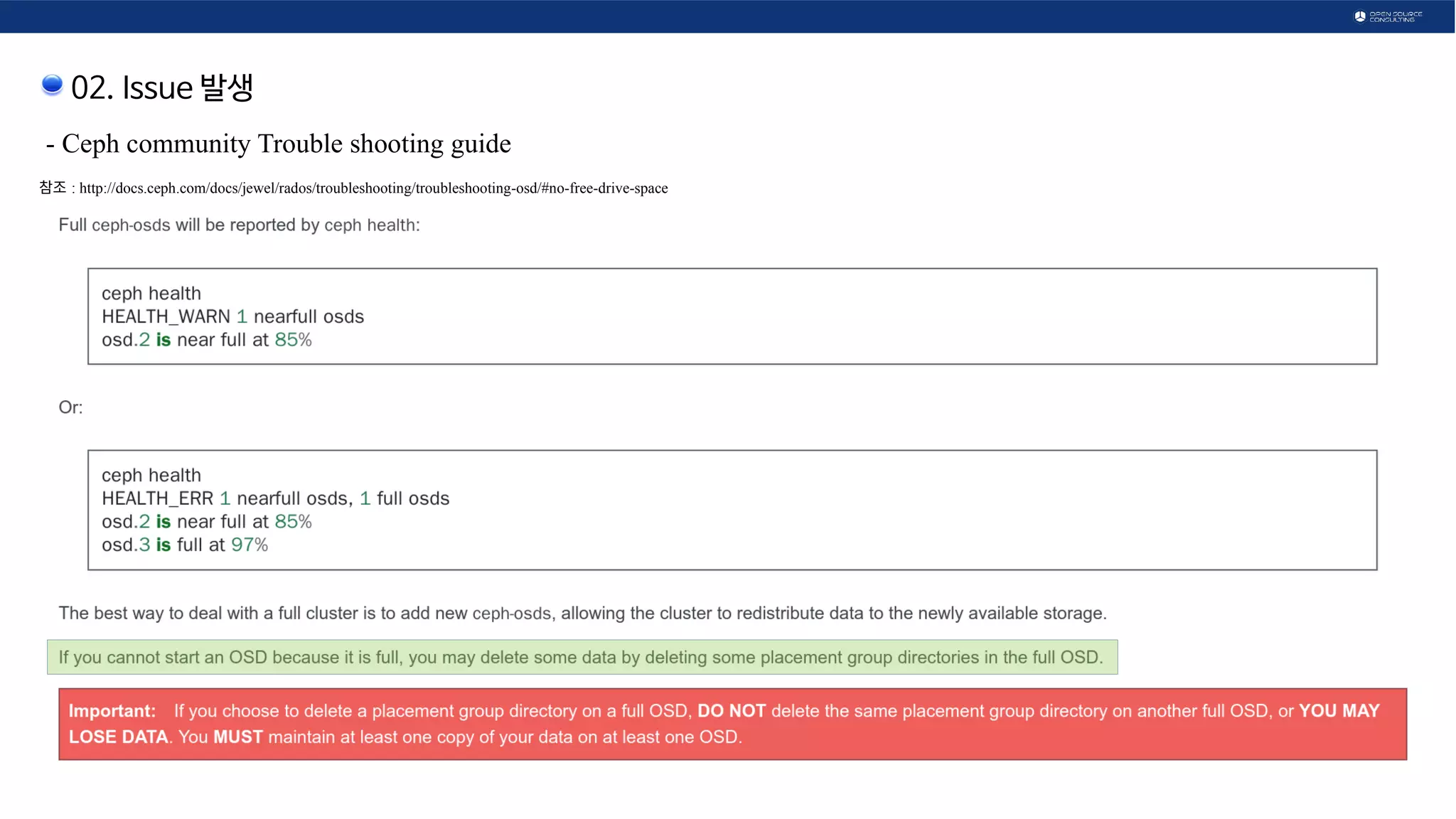
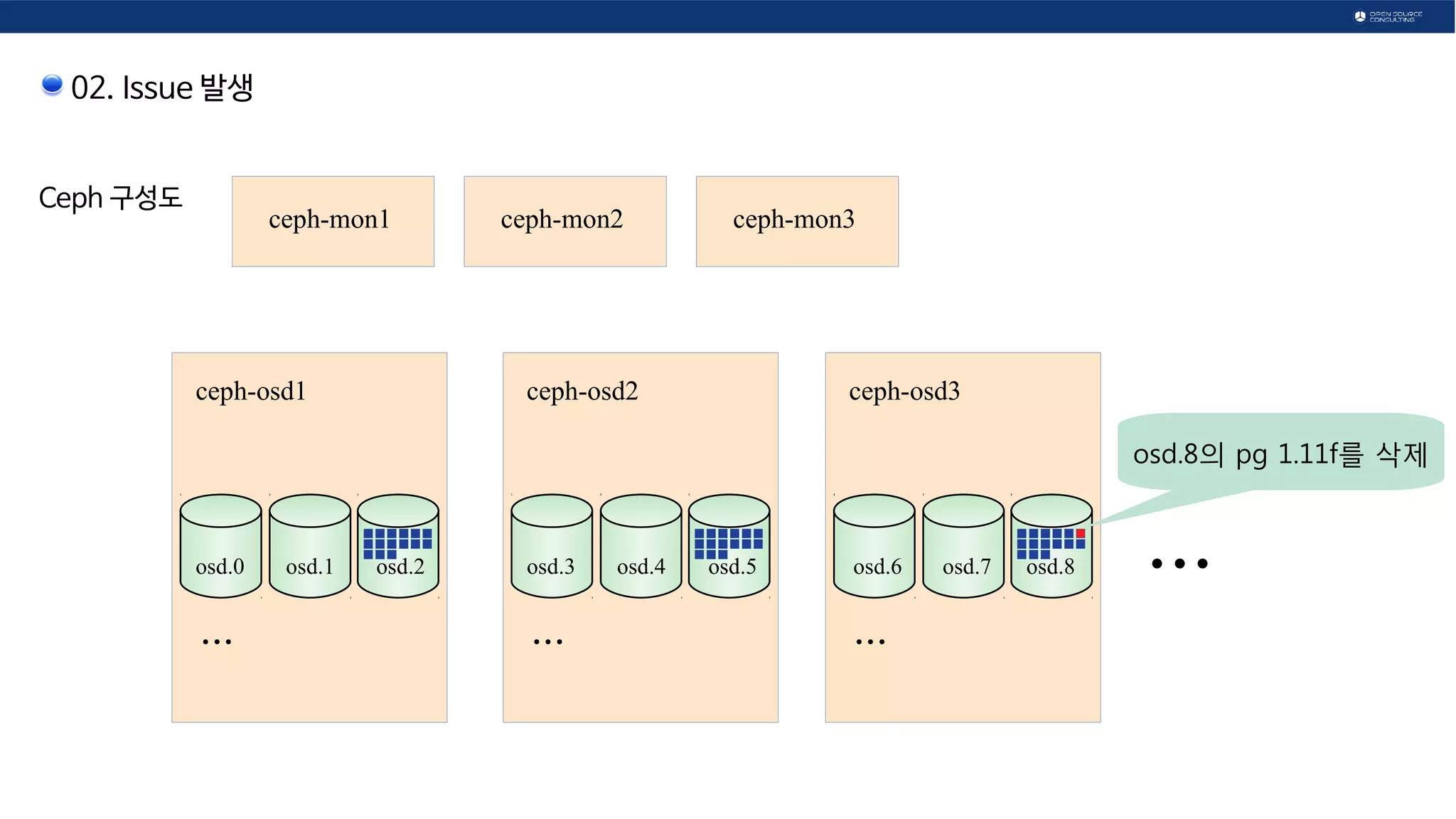
![02. Issue 발생
Ceph 구성도
ceph-osd1
...
ceph-osd2
...
ceph-osd3
...
...osd.0 osd.1 osd.2 osd.3 osd.4 osd.5 osd.6 osd.7 osd.8
ceph-mon1 ceph-mon2 ceph-mon3
OSD 중 1개가 90%가 되어
Read/Write가 안되는 주체 상태
[root@osc-ceph01 ~]# ceph pg dump |grep -i full_ratio
dumped all in format plain
full_ratio 0.9
nearfull_ratio 0.8
[root@osc-ceph01 ~]# ceph daemon mon.`hostname` config show |grep -i osd_full_ratio
"mon_osd_full_ratio": "0.9",
[root@osc-ceph01 ~]#](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-8-2048.jpg)
![02. Issue 발생
[root@ceph-mon02 ~]# ceph -s
cluster f5078395-0236-47fd-ad02-8a6daadc7475
health HEALTH_ERR
1 pgs are stuck inactive for more than 300 seconds
162 pgs backfill_wait
37 pgs backfilling
322 pgs degraded
1 pgs down
2 pgs peering
4 pgs recovering
119 pgs recovery_wait
1 pgs stuck inactive
322 pgs stuck unclean
199 pgs undersized
recovery 592647/43243812 objects degraded (1.370%)
recovery 488046/43243812 objects misplaced (1.129%)
1 mons down, quorum 0,2 ceph-mon01,ceph-mon03
monmap e1: 3 mons at {ceph-mon01=10.10.50.201:6789/0,ceph-mon02=10.10.50.202:6789/0,ceph-mon03=10.10.50.203:6789/0}
election epoch 480, quorum 0,2 ceph-mon01,ceph-mon03
osdmap e27606: 128 osds: 125 up, 125 in; 198 remapped pgs
flags sortbitwise
pgmap v58287759: 10240 pgs, 4 pools, 54316 GB data, 14076 kobjects
157 TB used, 71440 GB / 227 TB avail
592647/43243812 objects degraded (1.370%)
488046/43243812 objects misplaced (1.129%)
9916 active+clean
162 active+undersized+degraded+remapped+wait_backfill
119 active+recovery_wait+degraded
37 active+undersized+degraded+remapped+backfilling
4 active+recovering+degraded
1 down+peering
1 peering
300초 넘게 통신이 안되는 pg가 1개 (1.11f) ...
osd가 down되어 backfill을 기다리고 있는 pg가 162개
pglog의 범위를 벗어나
backfill을 진행 하고 있는 pg가 37개
3copy를 채우지 못해 성능이 떨어진 pg가 322개
문제의 down된 pg 1개... (1.11f) )
상태를 결정중인 pg 2개
(recovery, backfill)
recovery를 기다리고 있는 pg 119개
pglog를 보고 복구중인 pg 4개
(해당 pg I/O block됨)
up상태의 osd가 없어서 inactive 된 pg 1개
(1.11f)
3벌 복제에 못미치는 pg가 322개
pool의 복제본 수에 못미치는 pg가 199개
Monitor 1개 죽음
pg 1.11f를 갖고 있는
OSD 3개 죽음](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-11-2048.jpg)
![02. Issue 발생
구성도
ceph-osd1
...
ceph-osd2
...
ceph-osd3
...
...osd.0 osd.1 osd.2 osd.3 osd.4 osd.5 osd.6 osd.7 osd.8
ceph-mon1 ceph-mon2 ceph-mon3
Images Pool
Openstack image들이
들어가 있음.
Volumes Pool
pg 1.11f는 모든 openstack
volume들의 정보를
조금씩 갖고 있음.
pg 1개가 down되면 해당 pool의
모든 data들을 쓸 수가 없다.
[root@osc-ceph01 ~]# ceph pg dump |head
dumped all in format plain
...
pg_stat objects mip degr misp unf bytes log disklog state state_stamp v reported up up_primary acting acting_primary
last_scrub scrub_stamp last_deep_scrub deep_scrub_stamp
1.11f 0 0 0 0 0 0 3080 3080 active+clean 2019-07-10 08:12:46.623592 921'8580 10763:10591 [8,4,7] 8 [8,4,7] 8
921'8580 2019-07-10 08:12:46.623572 921'8580 2019-07-07 19:44:32.652377
...
Primary pg가
모든 I/O를 책임진다.](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-12-2048.jpg)

![03. 해결 과정
ceph-osd1
...
ceph-osd2
...
ceph-osd3
...
...osd.0 osd.1 osd.2 osd.3 osd.4 osd.5 osd.6 osd.7 osd.8
vms Pool
Nova에 의해 생성되는
vm image를 저장
12345_disk 기존 vm rbd
67890_disk 신규 vm rbd
신규 VM1
ID=67890
기존 VM1
ID=12345
복구 과정
- 신규 vm생성 (ID 67890)
- vms pool에 있는 rbd 67890_disk삭제
- 12345_disk를 67890_disk로 이름변경
- 이걸 모든vm에 적용...
[root@ceph01 ~]# rbd list -p vms
12345_disk
67890_disk
[root@ceph01 ~]# rbd rm -p vms 67890_disk
Removing image: 100% complete...done.
[root@ceph01 ~]#
[root@ceph01 ~]# rbd mv -p vms 12345_disk 67890_disk
[root@ceph01 ~]# rbd ls -p vms
67890_disk](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-16-2048.jpg)
![03. 해결 과정
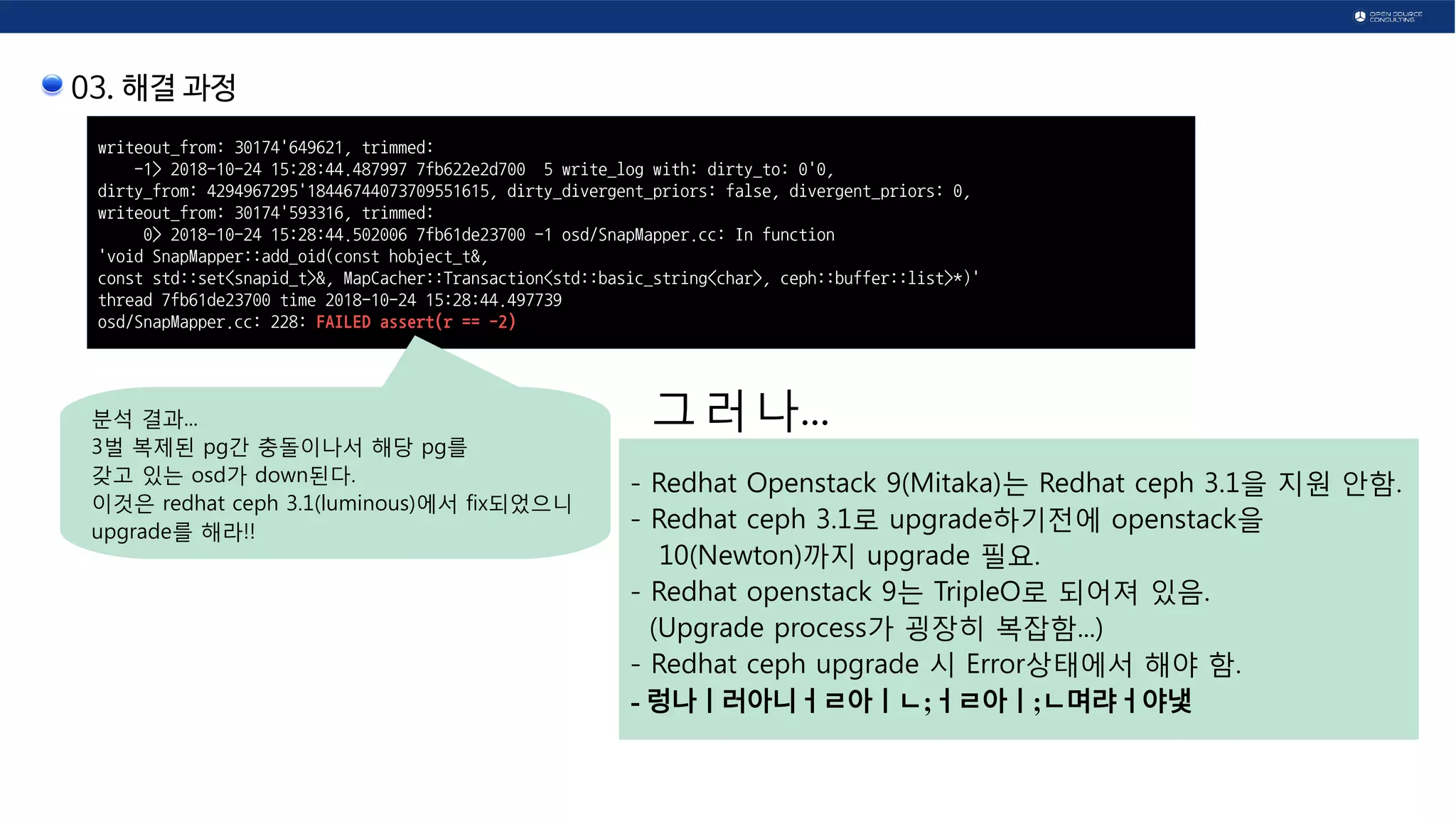
Redhat Ceph 3.1 upgrade 후 ...
- 비슷한 문제 발생
- pg 1.11f 를 갖고 있는 osd들이 up down을 반복 함.
[root@ceph-mon01 osc]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_ERR
noscrub,nodeep-scrub flag(s) set
5 scrub errors
Possible data damage: 1 pg inconsistent
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
flags noscrub,nodeep-scrub
data:
pools: 4 pools, 10240 pgs
objects: 12200k objects, 46865 GB
usage: 137 TB used, 97628 GB / 232 TB avail
pgs: 10239 active+clean
1 active+clean+inconsistent
io:
client: 0 B/s rd, 1232 kB/s wr, 19 op/s rd, 59 op/s wr
[root@ceph-mon01 osc]# ceph health detail
HEALTH_ERR noscrub,nodeep-scrub flag(s) set; 5 scrub errors; Possible data
damage: 1 pg inconsistent
OSDMAP_FLAGS noscrub,nodeep-scrub flag(s) set
OSD_SCRUB_ERRORS 5 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent
pg 1.11f is active+clean+inconsistent, acting [113,105,10]
[root@ceph-mon01 osc]#
OTL...](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-17-2048.jpg)
![03. 해결 과정
하지만 문제되는 Object를 특정지을 수 있었음.
[root@ceph-mon01 ~]# rados list-inconsistent-obj 1.11f --format=json-pretty
{
"epoch": 34376,
"inconsistents": [
{
"object": {
"name": "rbd_data.39edab651c7b53.0000000000003600",
"nspace": "",
"locator": "",](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-18-2048.jpg)
![03. 해결 과정
Object rbd_data.39edab651c7b53.0000000000003600는 고객 DB Service vm의 root filesystem volume이었음.
다행이도 DB data에는 문제가 없었고...
문제가 된 DB vm의 root filesystem을 담고 있는 RBD image를 삭제 함. 하지만 여전히 상태는 HEALTH_ERR ...
[root@ceph-mon01 osc]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_ERR
4 scrub errors
Possible data damage: 1 pg inconsistent, 1 pg snaptrim_error
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
data:
pools: 4 pools, 10240 pgs
objects: 12166k objects, 46731 GB
usage: 136 TB used, 98038 GB / 232 TB avail
pgs: 10239 active+clean
1 active+clean+inconsistent+snaptrim_error
io:
client: 0 B/s rd, 351 kB/s wr, 15 op/s rd, 51 op/s wr
[root@ceph-mon01 osc]# ceph health detail
HEALTH_ERR 4 scrub errors; Possible data damage: 1 pg inconsistent, 1 pg
snaptrim_error
OSD_SCRUB_ERRORS 4 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent, 1 pg snaptrim_error
pg 1.11f is active+clean+inconsistent+snaptrim_error, acting [113,105,10]
[root@ceph-mon01 osc]#](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-19-2048.jpg)
![03. 해결 과정
- 문제되는 object의 snapshot id 54(0x36)이 문제가 되어서 error가 발생중임.
- ??? 이미 지웠는데??
2018-11-16 18:45:00.163319 7fb827aca700 -1 log_channel(cluster) log [ERR] : 1.11f shard 10: soid 1:f886c0a3:::rbd_data.39edab651c7b53.0000000000003600:36
data_digest 0x43d61c5d != data_digest 0x86baff34 from auth oi 1:f886c0a3::: rbd_data.39edab651c7b53.0000000000003600:36(14027'236814 osd.113.0:29524 [36]
dirty|data_digest|omap_digest s 4194304 uv 235954 dd 86baff34 od ffffffff alloc_hint [0 0 0])
2018-11-16 18:45:00.163330 7fb827aca700 -1 log_channel(cluster) log [ERR] : 1.11f shard 105: soid 1:f886c0a3:::rbd_data.39edab651c7b53.0000000000003600:36
data_digest 0x43d61c5d != data_digest 0x86baff34 from auth oi 1:f886c0a3::: rbd_data.39edab651c7b53.0000000000003600:36(14027'236814 osd.113.0:29524 [36]
dirty|data_digest|omap_digest s 4194304 uv 235954 dd 86baff34 od ffffffff alloc_hint [0 0 0])
2018-11-16 18:45:00.163333 7fb827aca700 -1 log_channel(cluster) log [ERR] : 1.11f shard 113: soid 1:f886c0a3:::rbd_data.39edab651c7b53.0000000000003600:36
data_digest 0x43d61c5d != data_digest 0x86baff34 from auth oi 1:f886c0a3::: rbd_data.39edab651c7b53.0000000000003600:36(14027'236814 osd.113.0:29524 [36]
dirty|data_digest|omap_digest s 4194304 uv 235954 dd 86baff34 od ffffffff alloc_hint [0 0 0])
$ printf "%dn" 0x36
54
[root@ceph-osd08 ~]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-113 --pgid 1.11f --op list | grep 39edab651c7b53
Error getting attr on : 1.11f_head,#-3:f8800000:::scrub_1.11f:head#, (61) No data available
["1.11f",{"oid":"rbd_data.39edab651c7b53.0000000000003600","key":"","snapid":54,"hash":3305333023,"max":0,"pool":1,"namespace":"","max":0}]
["1.11f",{"oid":"rbd_data.39edab651c7b53.0000000000003600","key":"","snapid":63,"hash":3305333023,"max":0,"pool":1,"namespace":"","max":0}]
["1.11f",{"oid":"rbd_data.39edab651c7b53.0000000000003600","key":"","snapid":-2,"hash":3305333023,"max":0,"pool":1,"namespace":"","max":0}]](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-20-2048.jpg)
![03. 해결 과정
- 문제되는 object를 갖고 있는 rbd image를 찾아보자!
[root@ceph-mon01 osc]# rbd info volume-13076ffc-6520-4db8-b238-1ba6108bfe52 -p volumes
rbd image 'volume-13076ffc-6520-4db8-b238-1ba6108bfe52':
size 53248 MB in 13312 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.62cb510d494de
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
[root@ceph-mon01 osc]#
[root@ceph-mon01 osc]# cat rbd-info.sh
#!/bin/bash
for i in `rbd list -p volumes`
do
rbd info volumes/$i |grep rbd_data.39edab651c7b53
echo --- $i done ----
done
[root@ceph-mon01 osc]# bash rbd-info.sh
rbd info에서 object의
prefix를 볼 수 있다.
모든 rbd image에서
문제되는 object를
찾는 script
[root@ceph-mon01 osc]# bash rbd-info.sh
--- rbdtest done ----
--- volume-00b0de1a-bfab-40e0-a444-b6c2d0de3905 done ----
--- volume-02d9c884-fc30-4700-87fd-950855ae361d done ----
...
[root@ceph-mon01 osc]# 결과는 ...
역시나 없음...](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-21-2048.jpg)
![03. 해결 과정
- 해당 snapshot을 갖고 있는 volume이 삭제 되었으니 오류에 대한 조건이 더이상 존재하지 않음.
- repair를 다시 해보라고 함.
[root@ceph-mon01 ~]# date ; ceph pg repair 1.11f
Wed Nov 28 18:16:25 KST 2018
instructing pg 1.11f on osd.113 to repair
[root@ceph-mon01 ~]# ceph health detail
HEALTH_ERR noscrub,nodeep-scrub flag(s) set; Possible data damage: 1 pg repair
OSDMAP_FLAGS noscrub,nodeep-scrub flag(s) set
PG_DAMAGED Possible data damage: 1 pg repair
pg 1.11f is active+clean+scrubbing+deep+repair, acting [113,105,10]
[root@ceph-mon01 ~]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_ERR
noscrub,nodeep-scrub flag(s) set
Possible data damage: 1 pg repair
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
flags noscrub,nodeep-scrub
data:
pools: 4 pools, 10240 pgs
objects: 12321k objects, 47365 GB
usage: 138 TB used, 96138 GB / 232 TB avail
pgs: 10239 active+clean
1 active+clean+scrubbing+deep+repair
io:
client: 598 kB/s rd, 1145 kB/s wr, 18 op/s rd, 63 op/s wr
pg 1.11f를 repair중](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-22-2048.jpg)
![03. 해결 과정
- ceph log를 확인.
[root@ceph-mon01 ~]# ceph -w
...
2018-11-28 18:21:26.654955 osd.113 [ERR] 1.11f repair stat mismatch, got 3310/3312 objects, 91/92 clones, 3243/3245
dirty, 0/0 omap, 0/0 pinned, 0/0 hit_set_archive, 67/68 whiteouts, 13579894784/13584089088 bytes, 0/0 hit_set_archive bytes.
2018-11-28 18:21:26.655657 osd.113 [ERR] 1.11f repair 1 errors, 1 fixed
2018-11-28 18:19:28.979704 mon.ceph-mon01 [INF] Health check cleared: PG_DAMAGED (was: Possible data damage: 1 pg repair)
2018-11-28 18:20:30.652593 mon.ceph-mon01 [WRN] Health check update: nodeep-scrub flag(s) set (OSDMAP_FLAGS)
2018-11-28 18:20:35.394445 mon.ceph-mon01 [INF] Health check cleared: OSDMAP_FLAGS (was: nodeep-scrub flag(s) set)
2018-11-28 18:20:35.394457 mon.ceph-mon01 [INF] Cluster is now healthy
어..?! fixed???](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-23-2048.jpg)
![03. 해결 과정
- HEALTH_OK
[root@ceph-mon01 ~]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
data:
pools: 4 pools, 10240 pgs
objects: 12321k objects, 47366 GB
usage: 138 TB used, 96138 GB / 232 TB avail
pgs: 10216 active+clean
24 active+clean+scrubbing+deep
io:
client: 424 kB/s rd, 766 kB/s wr, 18 op/s rd, 72 op/s wr](https://image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-24-2048.jpg)







![6/26
01. 구성도
●
Ceph OBJ 흐름
PG: Placement Group
Object를 저장하기 위한 OSD의 group.
복제본 수에 맞춰 member의 수가 달라짐.
OSD: Object Storage Daemon
object를 최종 저장하는 곳
Monitor: ceph OSD의
변화를 monitoring
하여 crush map을
만드는 주체 주체.
[root@ceph-osd01 ~]# rados ls -p vms
rbd_data.1735e637a64d5.0000000000000000
rbd_header.1735e637a64d5
rbd_directory
rbd_children
rbd_info
rbd_data.1735e637a64d5.0000000000000003
rbd_data.1735e637a64d5.0000000000000002
rbd_id.893f4f3d-f6d9-4521-997c-72caa861ac24_disk
rbd_data.1735e637a64d5.0000000000000001
rbd_object_map.1735e637a64d5
[root@ceph-osd01 ~]#
OBJ의 기본 크기는 크기는 주체4MBMB
CRUSH: Controlled Replication Under
Scalable Hashing
Object를 분산 저장하기위한 알고리즘.](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-6-2048.jpg)

![02. Issue 발생
Ceph 구성도
ceph-osd1
...
ceph-osd2
...
ceph-osd3
...
...osd.0 osd.1 osd.2 osd.3 osd.4 osd.5 osd.6 osd.7 osd.8
ceph-mon1 ceph-mon2 ceph-mon3
OSD 중 1개가 90%가 되어
Read/Write가 안되는 주체 상태
[root@osc-ceph01 ~]# ceph pg dump |grep -i full_ratio
dumped all in format plain
full_ratio 0.9
nearfull_ratio 0.8
[root@osc-ceph01 ~]# ceph daemon mon.`hostname` config show |grep -i osd_full_ratio
"mon_osd_full_ratio": "0.9",
[root@osc-ceph01 ~]#](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-8-2048.jpg)


![02. Issue 발생
[root@ceph-mon02 ~]# ceph -s
cluster f5078395-0236-47fd-ad02-8a6daadc7475
health HEALTH_ERR
1 pgs are stuck inactive for more than 300 seconds
162 pgs backfill_wait
37 pgs backfilling
322 pgs degraded
1 pgs down
2 pgs peering
4 pgs recovering
119 pgs recovery_wait
1 pgs stuck inactive
322 pgs stuck unclean
199 pgs undersized
recovery 592647/43243812 objects degraded (1.370%)
recovery 488046/43243812 objects misplaced (1.129%)
1 mons down, quorum 0,2 ceph-mon01,ceph-mon03
monmap e1: 3 mons at {ceph-mon01=10.10.50.201:6789/0,ceph-mon02=10.10.50.202:6789/0,ceph-mon03=10.10.50.203:6789/0}
election epoch 480, quorum 0,2 ceph-mon01,ceph-mon03
osdmap e27606: 128 osds: 125 up, 125 in; 198 remapped pgs
flags sortbitwise
pgmap v58287759: 10240 pgs, 4 pools, 54316 GB data, 14076 kobjects
157 TB used, 71440 GB / 227 TB avail
592647/43243812 objects degraded (1.370%)
488046/43243812 objects misplaced (1.129%)
9916 active+clean
162 active+undersized+degraded+remapped+wait_backfill
119 active+recovery_wait+degraded
37 active+undersized+degraded+remapped+backfilling
4 active+recovering+degraded
1 down+peering
1 peering
300초 넘게 통신이 안되는 pg가 1개 (1.11f) ...
osd가 down되어 backfill을 기다리고 있는 pg가 162개
pglog의 범위를 벗어나
backfill을 진행 하고 있는 pg가 37개
3copy를 채우지 못해 성능이 떨어진 pg가 322개
문제의 down된 pg 1개... (1.11f) )
상태를 결정중인 pg 2개
(recovery, backfill)
recovery를 기다리고 있는 pg 119개
pglog를 보고 복구중인 pg 4개
(해당 pg I/O block됨)
up상태의 osd가 없어서 inactive 된 pg 1개
(1.11f)
3벌 복제에 못미치는 pg가 322개
pool의 복제본 수에 못미치는 pg가 199개
Monitor 1개 죽음
pg 1.11f를 갖고 있는
OSD 3개 죽음](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-11-2048.jpg)
![02. Issue 발생
구성도
ceph-osd1
...
ceph-osd2
...
ceph-osd3
...
...osd.0 osd.1 osd.2 osd.3 osd.4 osd.5 osd.6 osd.7 osd.8
ceph-mon1 ceph-mon2 ceph-mon3
Images Pool
Openstack image들이
들어가 있음.
Volumes Pool
pg 1.11f는 모든 openstack
volume들의 정보를
조금씩 갖고 있음.
pg 1개가 down되면 해당 pool의
모든 data들을 쓸 수가 없다.
[root@osc-ceph01 ~]# ceph pg dump |head
dumped all in format plain
...
pg_stat objects mip degr misp unf bytes log disklog state state_stamp v reported up up_primary acting acting_primary
last_scrub scrub_stamp last_deep_scrub deep_scrub_stamp
1.11f 0 0 0 0 0 0 3080 3080 active+clean 2019-07-10 08:12:46.623592 921'8580 10763:10591 [8,4,7] 8 [8,4,7] 8
921'8580 2019-07-10 08:12:46.623572 921'8580 2019-07-07 19:44:32.652377
...
Primary pg가
모든 I/O를 책임진다.](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-12-2048.jpg)



![03. 해결 과정
ceph-osd1
...
ceph-osd2
...
ceph-osd3
...
...osd.0 osd.1 osd.2 osd.3 osd.4 osd.5 osd.6 osd.7 osd.8
vms Pool
Nova에 의해 생성되는
vm image를 저장
12345_disk 기존 vm rbd
67890_disk 신규 vm rbd
신규 VM1
ID=67890
기존 VM1
ID=12345
복구 과정
- 신규 vm생성 (ID 67890)
- vms pool에 있는 rbd 67890_disk삭제
- 12345_disk를 67890_disk로 이름변경
- 이걸 모든vm에 적용...
[root@ceph01 ~]# rbd list -p vms
12345_disk
67890_disk
[root@ceph01 ~]# rbd rm -p vms 67890_disk
Removing image: 100% complete...done.
[root@ceph01 ~]#
[root@ceph01 ~]# rbd mv -p vms 12345_disk 67890_disk
[root@ceph01 ~]# rbd ls -p vms
67890_disk](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-16-2048.jpg)
![03. 해결 과정
Redhat Ceph 3.1 upgrade 후 ...
- 비슷한 문제 발생
- pg 1.11f 를 갖고 있는 osd들이 up down을 반복 함.
[root@ceph-mon01 osc]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_ERR
noscrub,nodeep-scrub flag(s) set
5 scrub errors
Possible data damage: 1 pg inconsistent
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
flags noscrub,nodeep-scrub
data:
pools: 4 pools, 10240 pgs
objects: 12200k objects, 46865 GB
usage: 137 TB used, 97628 GB / 232 TB avail
pgs: 10239 active+clean
1 active+clean+inconsistent
io:
client: 0 B/s rd, 1232 kB/s wr, 19 op/s rd, 59 op/s wr
[root@ceph-mon01 osc]# ceph health detail
HEALTH_ERR noscrub,nodeep-scrub flag(s) set; 5 scrub errors; Possible data
damage: 1 pg inconsistent
OSDMAP_FLAGS noscrub,nodeep-scrub flag(s) set
OSD_SCRUB_ERRORS 5 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent
pg 1.11f is active+clean+inconsistent, acting [113,105,10]
[root@ceph-mon01 osc]#
OTL...](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-17-2048.jpg)
![03. 해결 과정
하지만 문제되는 Object를 특정지을 수 있었음.
[root@ceph-mon01 ~]# rados list-inconsistent-obj 1.11f --format=json-pretty
{
"epoch": 34376,
"inconsistents": [
{
"object": {
"name": "rbd_data.39edab651c7b53.0000000000003600",
"nspace": "",
"locator": "",](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-18-2048.jpg)
![03. 해결 과정
Object rbd_data.39edab651c7b53.0000000000003600는 고객 DB Service vm의 root filesystem volume이었음.
다행이도 DB data에는 문제가 없었고...
문제가 된 DB vm의 root filesystem을 담고 있는 RBD image를 삭제 함. 하지만 여전히 상태는 HEALTH_ERR ...
[root@ceph-mon01 osc]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_ERR
4 scrub errors
Possible data damage: 1 pg inconsistent, 1 pg snaptrim_error
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
data:
pools: 4 pools, 10240 pgs
objects: 12166k objects, 46731 GB
usage: 136 TB used, 98038 GB / 232 TB avail
pgs: 10239 active+clean
1 active+clean+inconsistent+snaptrim_error
io:
client: 0 B/s rd, 351 kB/s wr, 15 op/s rd, 51 op/s wr
[root@ceph-mon01 osc]# ceph health detail
HEALTH_ERR 4 scrub errors; Possible data damage: 1 pg inconsistent, 1 pg
snaptrim_error
OSD_SCRUB_ERRORS 4 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent, 1 pg snaptrim_error
pg 1.11f is active+clean+inconsistent+snaptrim_error, acting [113,105,10]
[root@ceph-mon01 osc]#](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-19-2048.jpg)
![03. 해결 과정
- 문제되는 object의 snapshot id 54(0x36)이 문제가 되어서 error가 발생중임.
- ??? 이미 지웠는데??
2018-11-16 18:45:00.163319 7fb827aca700 -1 log_channel(cluster) log [ERR] : 1.11f shard 10: soid 1:f886c0a3:::rbd_data.39edab651c7b53.0000000000003600:36
data_digest 0x43d61c5d != data_digest 0x86baff34 from auth oi 1:f886c0a3::: rbd_data.39edab651c7b53.0000000000003600:36(14027'236814 osd.113.0:29524 [36]
dirty|data_digest|omap_digest s 4194304 uv 235954 dd 86baff34 od ffffffff alloc_hint [0 0 0])
2018-11-16 18:45:00.163330 7fb827aca700 -1 log_channel(cluster) log [ERR] : 1.11f shard 105: soid 1:f886c0a3:::rbd_data.39edab651c7b53.0000000000003600:36
data_digest 0x43d61c5d != data_digest 0x86baff34 from auth oi 1:f886c0a3::: rbd_data.39edab651c7b53.0000000000003600:36(14027'236814 osd.113.0:29524 [36]
dirty|data_digest|omap_digest s 4194304 uv 235954 dd 86baff34 od ffffffff alloc_hint [0 0 0])
2018-11-16 18:45:00.163333 7fb827aca700 -1 log_channel(cluster) log [ERR] : 1.11f shard 113: soid 1:f886c0a3:::rbd_data.39edab651c7b53.0000000000003600:36
data_digest 0x43d61c5d != data_digest 0x86baff34 from auth oi 1:f886c0a3::: rbd_data.39edab651c7b53.0000000000003600:36(14027'236814 osd.113.0:29524 [36]
dirty|data_digest|omap_digest s 4194304 uv 235954 dd 86baff34 od ffffffff alloc_hint [0 0 0])
$ printf "%dn" 0x36
54
[root@ceph-osd08 ~]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-113 --pgid 1.11f --op list | grep 39edab651c7b53
Error getting attr on : 1.11f_head,#-3:f8800000:::scrub_1.11f:head#, (61) No data available
["1.11f",{"oid":"rbd_data.39edab651c7b53.0000000000003600","key":"","snapid":54,"hash":3305333023,"max":0,"pool":1,"namespace":"","max":0}]
["1.11f",{"oid":"rbd_data.39edab651c7b53.0000000000003600","key":"","snapid":63,"hash":3305333023,"max":0,"pool":1,"namespace":"","max":0}]
["1.11f",{"oid":"rbd_data.39edab651c7b53.0000000000003600","key":"","snapid":-2,"hash":3305333023,"max":0,"pool":1,"namespace":"","max":0}]](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-20-2048.jpg)
![03. 해결 과정
- 문제되는 object를 갖고 있는 rbd image를 찾아보자!
[root@ceph-mon01 osc]# rbd info volume-13076ffc-6520-4db8-b238-1ba6108bfe52 -p volumes
rbd image 'volume-13076ffc-6520-4db8-b238-1ba6108bfe52':
size 53248 MB in 13312 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.62cb510d494de
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
[root@ceph-mon01 osc]#
[root@ceph-mon01 osc]# cat rbd-info.sh
#!/bin/bash
for i in `rbd list -p volumes`
do
rbd info volumes/$i |grep rbd_data.39edab651c7b53
echo --- $i done ----
done
[root@ceph-mon01 osc]# bash rbd-info.sh
rbd info에서 object의
prefix를 볼 수 있다.
모든 rbd image에서
문제되는 object를
찾는 script
[root@ceph-mon01 osc]# bash rbd-info.sh
--- rbdtest done ----
--- volume-00b0de1a-bfab-40e0-a444-b6c2d0de3905 done ----
--- volume-02d9c884-fc30-4700-87fd-950855ae361d done ----
...
[root@ceph-mon01 osc]# 결과는 ...
역시나 없음...](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-21-2048.jpg)
![03. 해결 과정
- 해당 snapshot을 갖고 있는 volume이 삭제 되었으니 오류에 대한 조건이 더이상 존재하지 않음.
- repair를 다시 해보라고 함.
[root@ceph-mon01 ~]# date ; ceph pg repair 1.11f
Wed Nov 28 18:16:25 KST 2018
instructing pg 1.11f on osd.113 to repair
[root@ceph-mon01 ~]# ceph health detail
HEALTH_ERR noscrub,nodeep-scrub flag(s) set; Possible data damage: 1 pg repair
OSDMAP_FLAGS noscrub,nodeep-scrub flag(s) set
PG_DAMAGED Possible data damage: 1 pg repair
pg 1.11f is active+clean+scrubbing+deep+repair, acting [113,105,10]
[root@ceph-mon01 ~]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_ERR
noscrub,nodeep-scrub flag(s) set
Possible data damage: 1 pg repair
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
flags noscrub,nodeep-scrub
data:
pools: 4 pools, 10240 pgs
objects: 12321k objects, 47365 GB
usage: 138 TB used, 96138 GB / 232 TB avail
pgs: 10239 active+clean
1 active+clean+scrubbing+deep+repair
io:
client: 598 kB/s rd, 1145 kB/s wr, 18 op/s rd, 63 op/s wr
pg 1.11f를 repair중](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-22-2048.jpg)
![03. 해결 과정
- ceph log를 확인.
[root@ceph-mon01 ~]# ceph -w
...
2018-11-28 18:21:26.654955 osd.113 [ERR] 1.11f repair stat mismatch, got 3310/3312 objects, 91/92 clones, 3243/3245
dirty, 0/0 omap, 0/0 pinned, 0/0 hit_set_archive, 67/68 whiteouts, 13579894784/13584089088 bytes, 0/0 hit_set_archive bytes.
2018-11-28 18:21:26.655657 osd.113 [ERR] 1.11f repair 1 errors, 1 fixed
2018-11-28 18:19:28.979704 mon.ceph-mon01 [INF] Health check cleared: PG_DAMAGED (was: Possible data damage: 1 pg repair)
2018-11-28 18:20:30.652593 mon.ceph-mon01 [WRN] Health check update: nodeep-scrub flag(s) set (OSDMAP_FLAGS)
2018-11-28 18:20:35.394445 mon.ceph-mon01 [INF] Health check cleared: OSDMAP_FLAGS (was: nodeep-scrub flag(s) set)
2018-11-28 18:20:35.394457 mon.ceph-mon01 [INF] Cluster is now healthy
어..?! fixed???](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-23-2048.jpg)
![03. 해결 과정
- HEALTH_OK
[root@ceph-mon01 ~]# ceph -s
cluster:
id: f5078395-0236-47fd-ad02-8a6daadc7475
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon01,ceph-mon02,ceph-mon03
mgr: ceph-mon01(active), standbys: ceph-mon02, ceph-mon03
osd: 128 osds: 128 up, 128 in
data:
pools: 4 pools, 10240 pgs
objects: 12321k objects, 47366 GB
usage: 138 TB used, 96138 GB / 232 TB avail
pgs: 10216 active+clean
24 active+clean+scrubbing+deep
io:
client: 424 kB/s rd, 766 kB/s wr, 18 op/s rd, 72 op/s wr](https://crownmelresort.com/image.slidesharecdn.com/openinfrastructurecloudnativedayskoreacephissue-190910045209/75/Ceph-issue-24-2048.jpg)



The document discusses an incident involving Ceph, an open-source distributed storage system, where an OSD (Object Storage Daemon) reached 90% capacity, causing read/write issues. It details the troubleshooting steps taken to resolve the problem, including monitoring the Ceph cluster health and eventually upgrading to Ceph 3.1 to fix underlying bugs. The recovery process involved reconfiguring virtual machines and addressing data inconsistencies.
![[오픈소스컨설팅]RHEL7/CentOS7 Pacemaker기반-HA시스템구성-v1.0](https://cdn.slidesharecdn.com/ss_thumbnails/rhel-centos7-pacemaker-based-ha-admin-guidev1-151215000535-thumbnail.jpg?width=640&height=640&fit=bounds)

![[발표자료] 오픈소스 기반 클라우드 네이티브 애플리케이션 구축 방안 (feat. Kubernetes)](https://cdn.slidesharecdn.com/ss_thumbnails/kubernetes-241219083038-3bd08c9d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]레드햇계열리눅스7 운영자가이드 - 기초편](https://cdn.slidesharecdn.com/ss_thumbnails/rhel7-160406045643-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)




![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)




![[오픈소스컨설팅] Open Stack Ceph, Neutron, HA, Multi-Region](https://cdn.slidesharecdn.com/ss_thumbnails/openstackoscv0-160718105826-thumbnail.jpg?width=640&height=640&fit=bounds)






![[OpenInfra Days Korea 2018] Day 1 - T4-7: "Ceph 스토리지, PaaS로 서비스 운영하기"](https://cdn.slidesharecdn.com/ss_thumbnails/47openinfradaykorea2018hyun-ha-180705032301-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Demo session] 관리형 Kafka 서비스 - Oracle Event Hub Service](https://cdn.slidesharecdn.com/ss_thumbnails/oraclouddevmeetupeventhubpublic-180521084803-thumbnail.jpg?width=640&height=640&fit=bounds)


![[The Future of IT] 1. AI 시대의 일하는 방법_김대일 고문](https://cdn.slidesharecdn.com/ss_thumbnails/thefutureofit1-250220022454-d0add770-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Atlassian System of Work] 모든 협업을 연결하는 아틀라시안의 프레임워크](https://cdn.slidesharecdn.com/ss_thumbnails/20250626atlassianwebinar-250630022710-fa7d49dd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[The Future of IT] 3. AI 시대의 인프라_오픈소스를 활용한 인프라 구축 및 GPU as a Service 구현사례_김호진 상무](https://cdn.slidesharecdn.com/ss_thumbnails/thefutureofit3-250220022449-a54710f8-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅] 오픈소스로 확장하는 NKP 기반 Kubernetes 환경](https://cdn.slidesharecdn.com/ss_thumbnails/nkpkubernetes-250422073333-d6a4d9a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] 먼데이닷컴 소개서](https://cdn.slidesharecdn.com/ss_thumbnails/v6-250321075427-1572d8ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Next-Gen ITSM | Atlassian이 제시하는 ITSM 혁신] 04. Rovo가 적용된 ITSM 시스템 ᄃ...](https://cdn.slidesharecdn.com/ss_thumbnails/04-250312015436-b9d45ef6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Recap] Atlassian Team25 - Progress is impossible alone](https://cdn.slidesharecdn.com/ss_thumbnails/20250430atlassianteam25recap1-250513144746-46e57942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[The Future of IT] 2. 조직 목표 Align 및 전사 협업 확장_한진규 부사장](https://cdn.slidesharecdn.com/ss_thumbnails/thefutureofit2-250220022449-75b8019c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Team on Tour 2025] Atlassian의 System of Work](https://cdn.slidesharecdn.com/ss_thumbnails/teamontour20253-250619062039-1f576989-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Next-Gen ITSM | Atlassian이 제시하는 ITSM 혁신] 02. 클라우드 기반 ITSM 최적화를...](https://cdn.slidesharecdn.com/ss_thumbnails/02-250312015118-f0da9222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[워크숍] Get to know AI, Meet your new teammate!](https://cdn.slidesharecdn.com/ss_thumbnails/gettoknowaimeetyournewteammate-241209073551-a677c30c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[202412 SAFe Meetup] SAFe Transfomration Journey](https://cdn.slidesharecdn.com/ss_thumbnails/safemeetupsafetransfomrationjourney1-241211084519-c8df01a2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Next-Gen ITSM | Atlassian이 제시하는 ITSM 혁신] 01. Gen Next ITSM_김윤희.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/01-250312014844-1ad6f3bc-thumbnail.jpg?width=640&height=640&fit=bounds)
![[발표 자료] 시각화로 전략을 실현하는 스마트 워크플로우 with 먼데이닷컴.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/with-250221001921-64176825-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Next-Gen ITSM | Atlassian이 제시하는 ITSM 혁신] 03. ITSM 구현과 고객 사례_신철ᄆ...](https://cdn.slidesharecdn.com/ss_thumbnails/03-250312015303-28a20020-thumbnail.jpg?width=640&height=640&fit=bounds)


















