Download as PDF, PPTX





![http://pralab.diee.unica.it
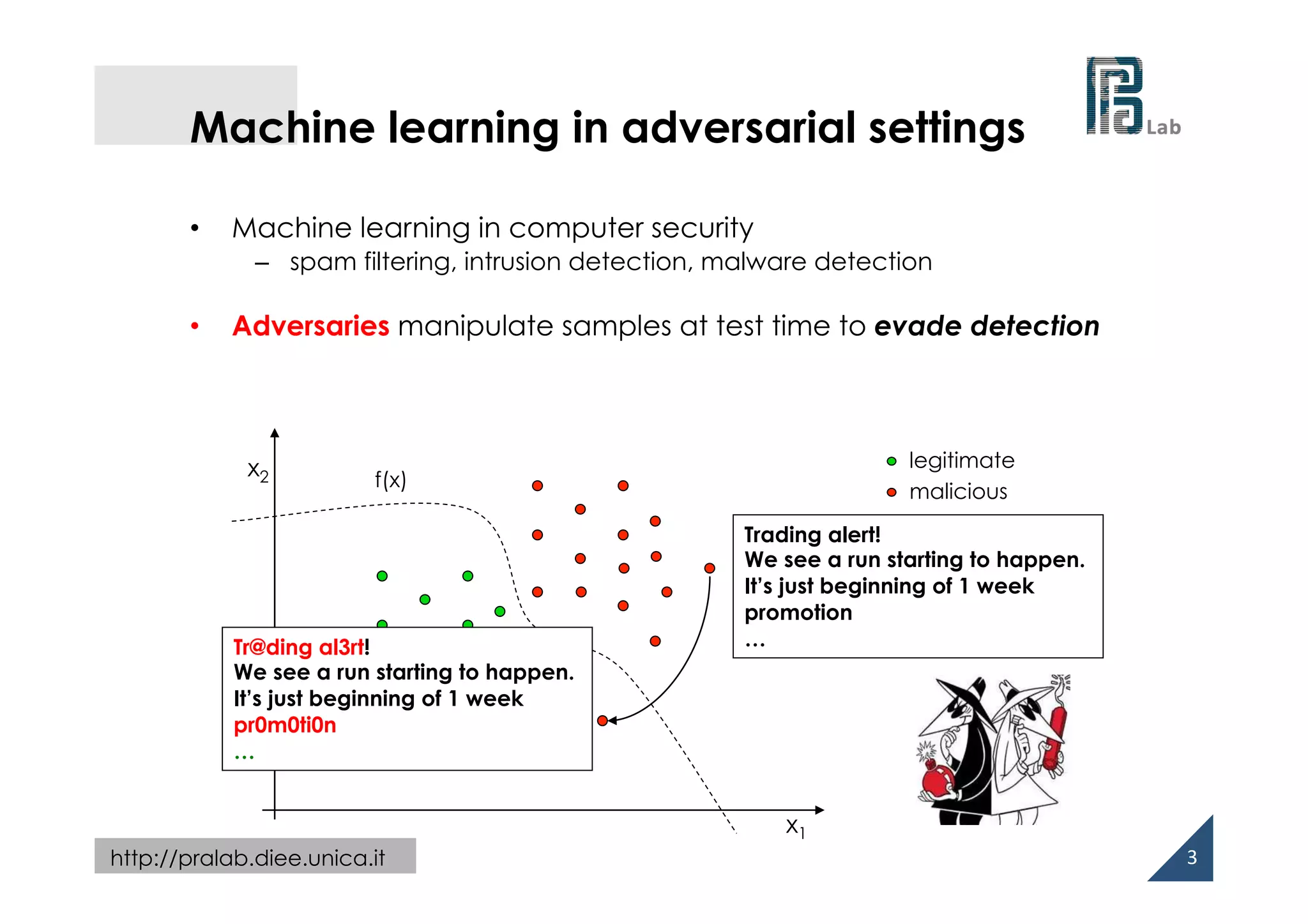
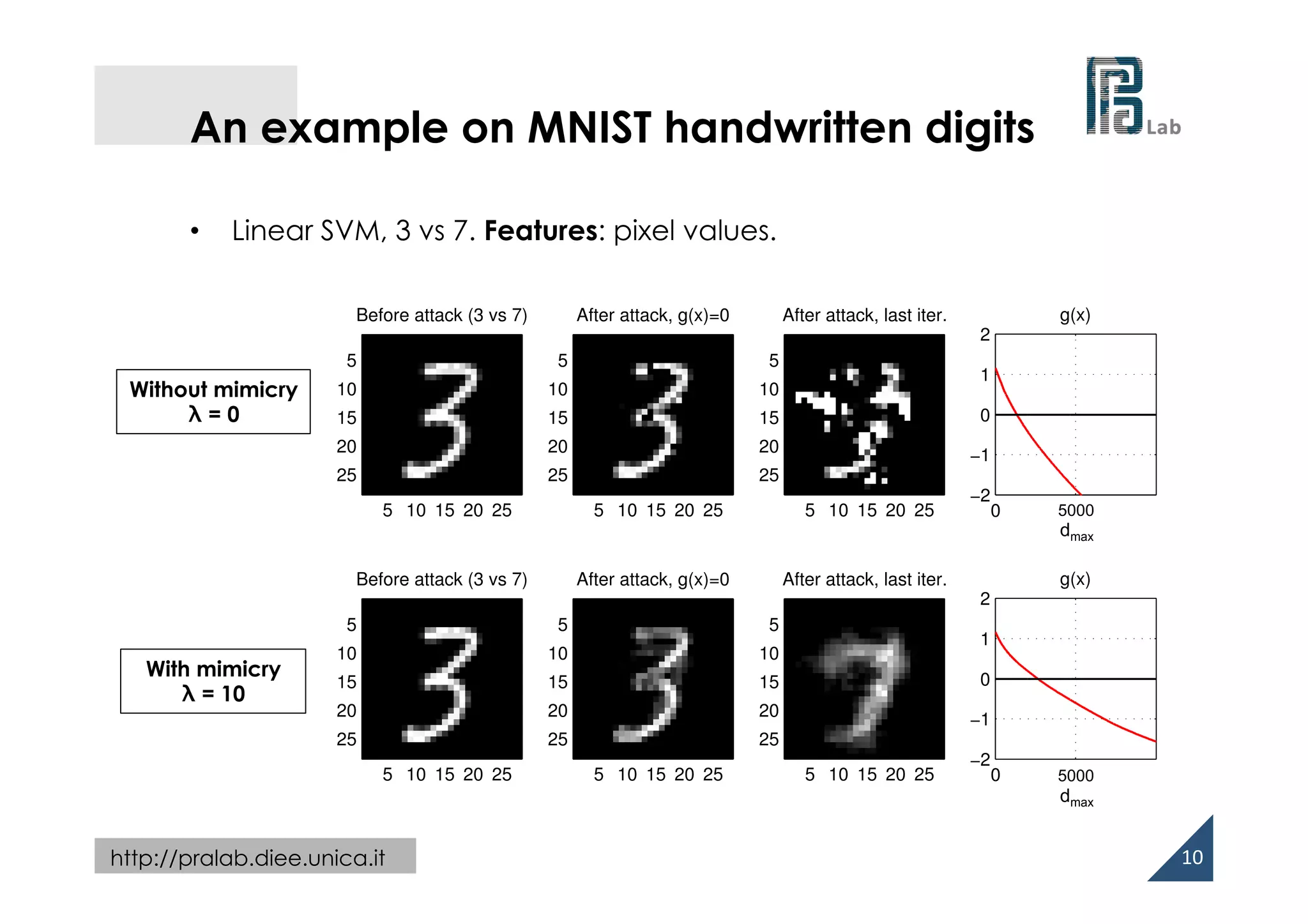
Experiments on PDF malware detection
• PDF: hierarchy of interconnected objects (keyword/value pairs)
• Adversary’s capability
– adding up to dmax objects to the PDF
– removing objects may
compromise the PDF file
(and embedded malware code)!
12
/Type
2
/Page
1
/Encoding
1
…
13
0
obj
<<
/Kids
[
1
0
R
11
0
R
]
/Type
/Page
...
>>
end
obj
17
0
obj
<<
/Type
/Encoding
/Differences
[
0
/C0032
]
>>
endobj
Features:
keyword
count
min
x'
g(x')− λp(x' | y = −1)
s.t. d(x, x') ≤ dmax
x ≤ x'](https://image.slidesharecdn.com/biggio13-ecml-slides-130925050002-phpapp02/75/Battista-Biggio-ECML-PKDD-2013-Evasion-attacks-against-machine-learning-at-test-time-12-2048.jpg)













![http://pralab.diee.unica.it
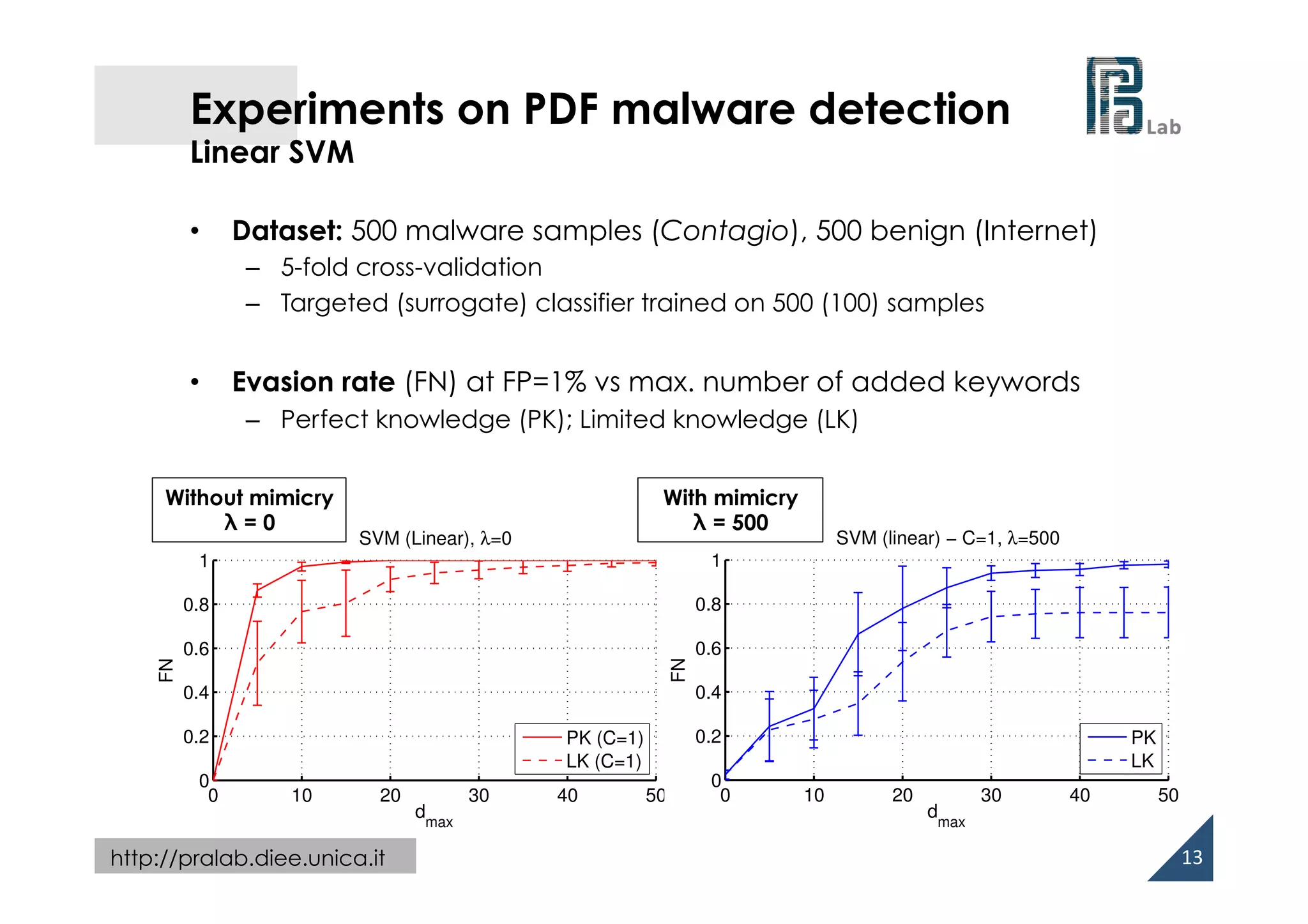
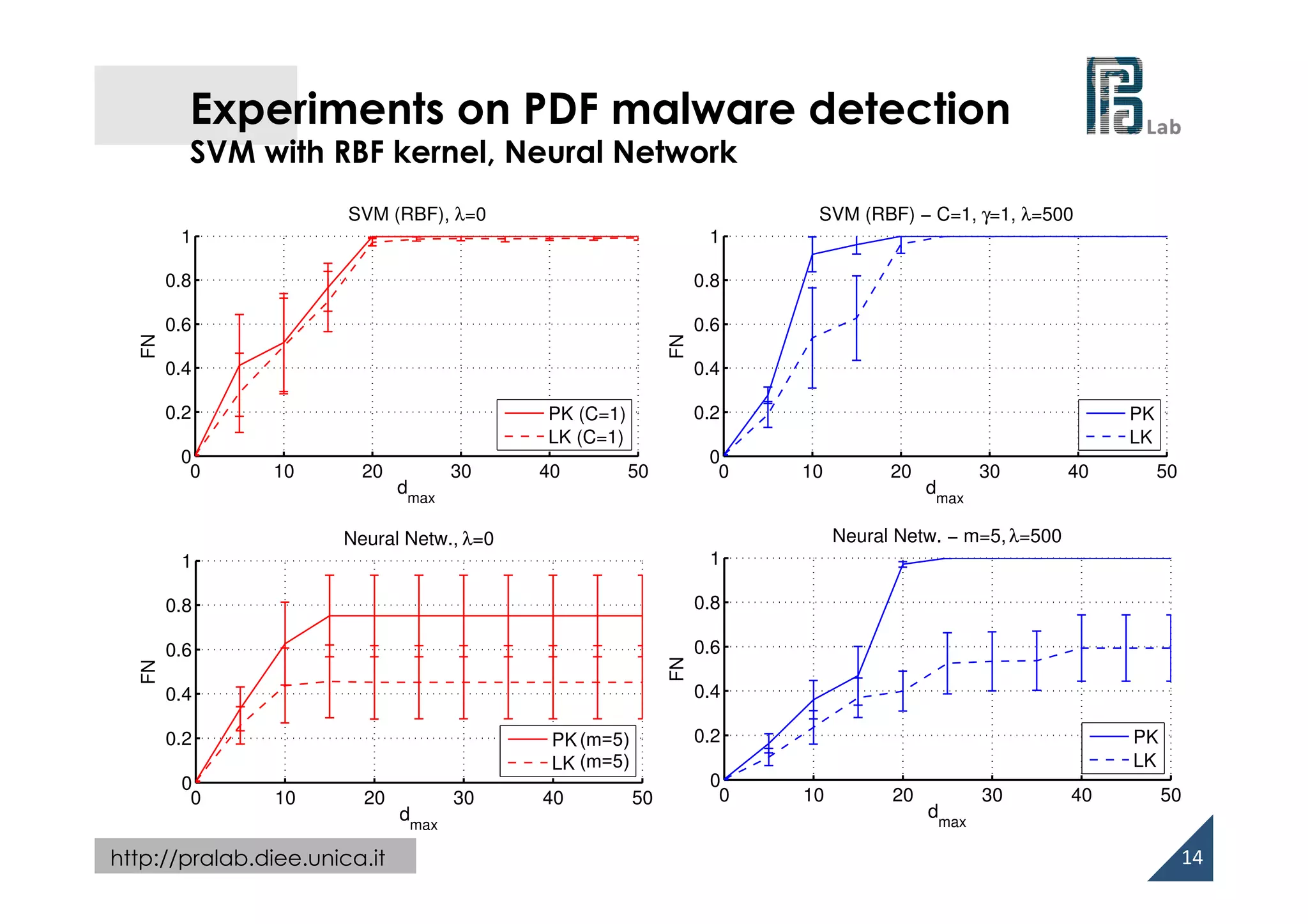
Experiments on PDF malware detection
• PDF: hierarchy of interconnected objects (keyword/value pairs)
• Adversary’s capability
– adding up to dmax objects to the PDF
– removing objects may
compromise the PDF file
(and embedded malware code)!
12
/Type
2
/Page
1
/Encoding
1
…
13
0
obj
<<
/Kids
[
1
0
R
11
0
R
]
/Type
/Page
...
>>
end
obj
17
0
obj
<<
/Type
/Encoding
/Differences
[
0
/C0032
]
>>
endobj
Features:
keyword
count
min
x'
g(x')− λp(x' | y = −1)
s.t. d(x, x') ≤ dmax
x ≤ x'](https://crownmelresort.com/image.slidesharecdn.com/biggio13-ecml-slides-130925050002-phpapp02/75/Battista-Biggio-ECML-PKDD-2013-Evasion-attacks-against-machine-learning-at-test-time-12-2048.jpg)





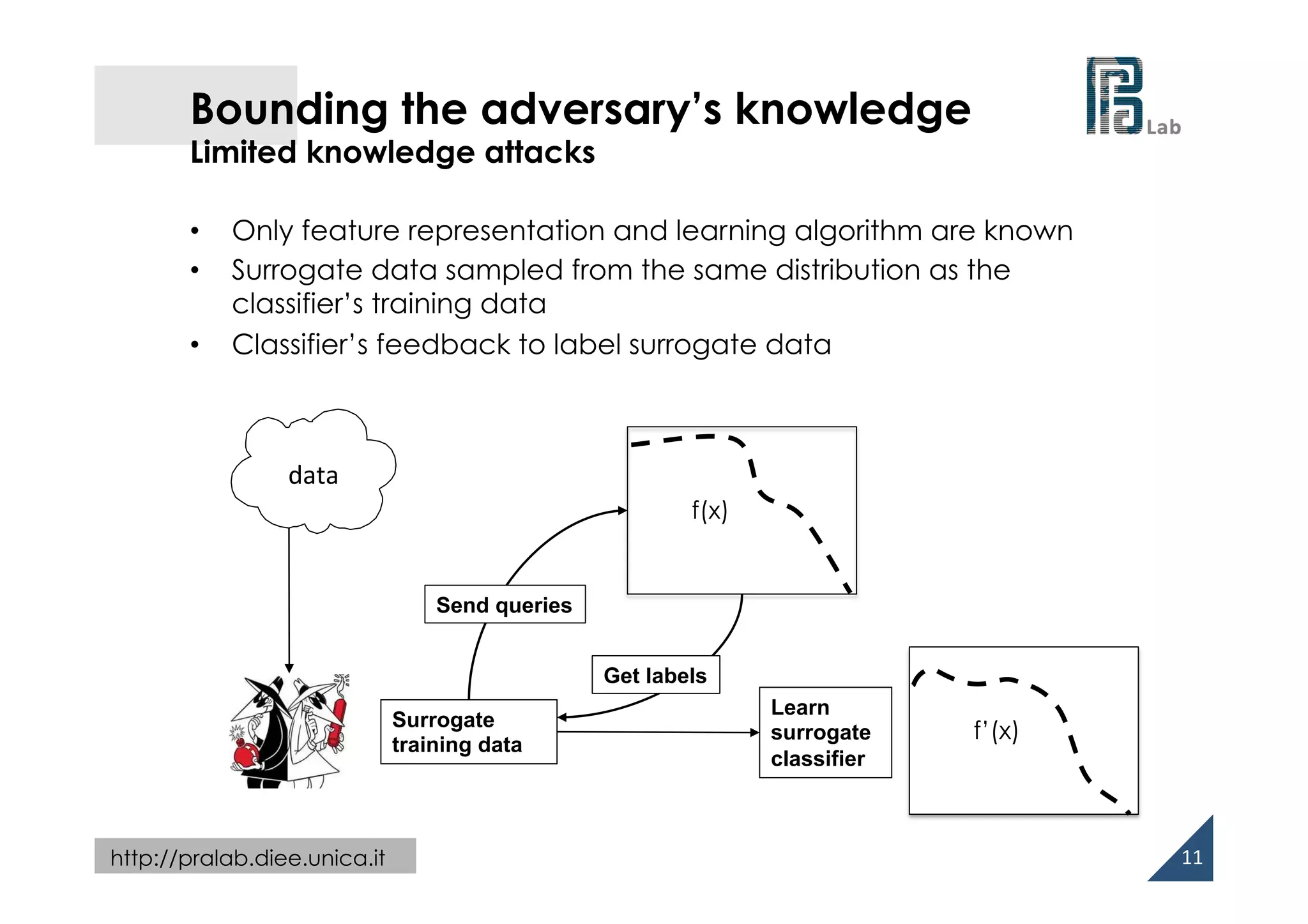
This document summarizes research on evasion attacks against machine learning systems at test time. The researchers propose a framework for evaluating the security of machine learning algorithms against evasion attacks. They model the adversary's goal, knowledge, capabilities, and attack strategy as an optimization problem. Using this framework, they evaluate gradient-descent evasion attacks against systems like spam filters and malware detectors. They show that machine learning classifiers can be vulnerable, even when the adversary has limited knowledge. The researchers explore techniques like bounding the adversary and adding a "mimicry" component to attacks to improve evasion effectiveness.





















































![[SOTIF US Conference] Introduction to Safe ML](https://cdn.slidesharecdn.com/ss_thumbnails/20190930crdcccsafemlv1-190930165846-thumbnail.jpg?width=640&height=640&fit=bounds)















































