Downloaded 431 times










![Markov Decision Processes (MDPs)
14
● State transition model p(st+1
| st
, at
) where,
s - state & a - action
● Reward p(rt+1
| st
, at
)
○ Depends on the current state and the
action performed
● Discount factor ∈ [0,1]
○ Controls the importance of future rewards
A simple MDP
Image courtesy: Wikipedia](https://image.slidesharecdn.com/anintroductiontodeepreinforcementlearning-170826175742/75/An-introduction-to-deep-reinforcement-learning-14-2048.jpg)


























![References
● Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves et al.
Human-level control through deep reinforcement learning. [MnihDQN16]
In Nature 518, no. 7540 (2015): 529-533.
● Mnih, Volodymyr, Adria P. Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, & Koray Kavukcuoglu.
Asynchronous methods for deep reinforcement learning. [MnihA3C16]
In International Conference on Machine Learning, pp. 1928-1937. 2016.
● Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage and Anil Anthony Bharath.
A Brief Survey of Deep Reinforcement Learning. [KaiDeepRLSurvey17]
In IEEE Signal Processing Magazine, Special Issue on Deep Learning for Image Understanding.
● Wang, Ziyu, Victor Bapst, Nicolas Heess, Volodymyr Mnih, Remi Munos, Koray Kavukcuoglu, and Nando de Freitas.
Sample efficient actor-critic with experience replay. [WangACExpReplay17]
In arXiv preprint arXiv:1611.01224 (2016).
48](https://image.slidesharecdn.com/anintroductiontodeepreinforcementlearning-170826175742/75/An-introduction-to-deep-reinforcement-learning-48-2048.jpg)


















![Markov Decision Processes (MDPs)
14
● State transition model p(st+1
| st
, at
) where,
s - state & a - action
● Reward p(rt+1
| st
, at
)
○ Depends on the current state and the
action performed
● Discount factor ∈ [0,1]
○ Controls the importance of future rewards
A simple MDP
Image courtesy: Wikipedia](https://crownmelresort.com/image.slidesharecdn.com/anintroductiontodeepreinforcementlearning-170826175742/75/An-introduction-to-deep-reinforcement-learning-14-2048.jpg)

































![References
● Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves et al.
Human-level control through deep reinforcement learning. [MnihDQN16]
In Nature 518, no. 7540 (2015): 529-533.
● Mnih, Volodymyr, Adria P. Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, & Koray Kavukcuoglu.
Asynchronous methods for deep reinforcement learning. [MnihA3C16]
In International Conference on Machine Learning, pp. 1928-1937. 2016.
● Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage and Anil Anthony Bharath.
A Brief Survey of Deep Reinforcement Learning. [KaiDeepRLSurvey17]
In IEEE Signal Processing Magazine, Special Issue on Deep Learning for Image Understanding.
● Wang, Ziyu, Victor Bapst, Nicolas Heess, Volodymyr Mnih, Remi Munos, Koray Kavukcuoglu, and Nando de Freitas.
Sample efficient actor-critic with experience replay. [WangACExpReplay17]
In arXiv preprint arXiv:1611.01224 (2016).
48](https://crownmelresort.com/image.slidesharecdn.com/anintroductiontodeepreinforcementlearning-170826175742/75/An-introduction-to-deep-reinforcement-learning-48-2048.jpg)






The document is an introductory presentation on deep reinforcement learning given by Vishal A. Bhalla at a data science meetup. It discusses the integration of deep neural networks with reinforcement learning, applications across various domains, and key algorithms and concepts involved in the field. The document also highlights research considerations, notable contributors, and fundamental tools utilized in deep reinforcement learning.
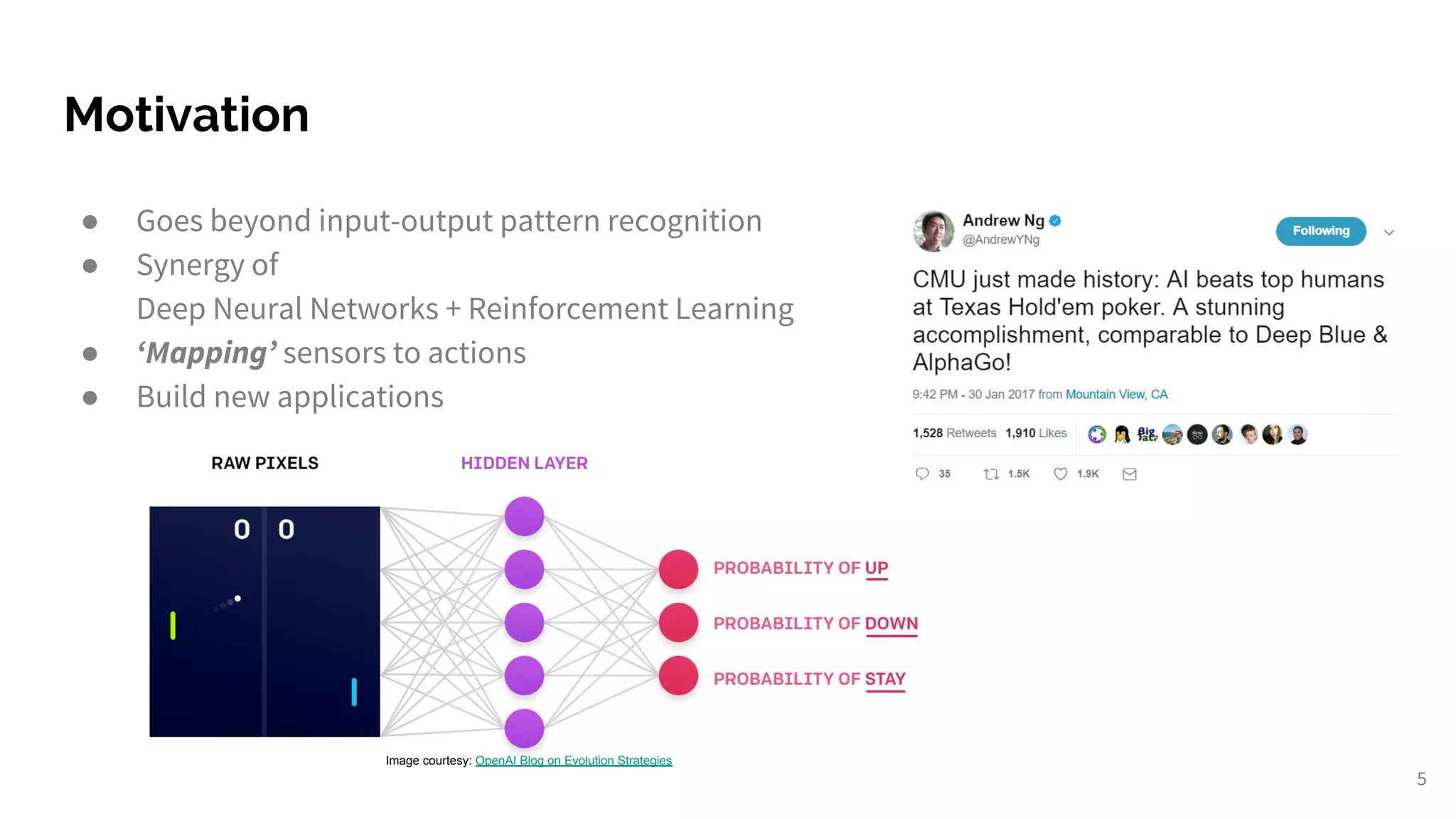
Overview of the presentation, speaker background, and introduction to deep reinforcement learning.
Outline of the presentation structure including theory, applications, and research considerations.
Introduction to Reinforcement Learning; combining Deep Neural Networks with RL for innovative applications.
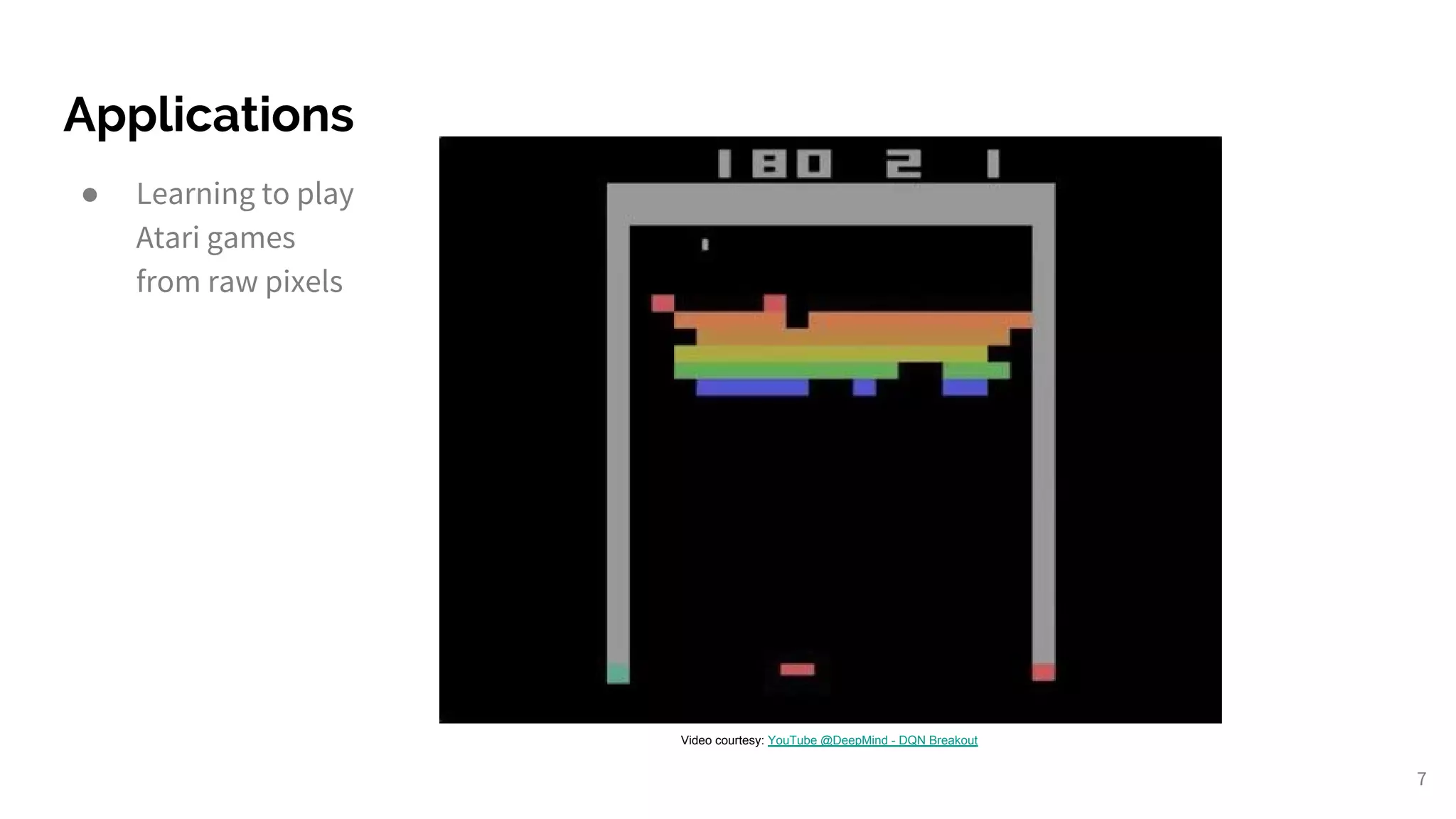
Highlighting major RL achievements including AlphaGo and applications in games like Atari and DOTA 2.
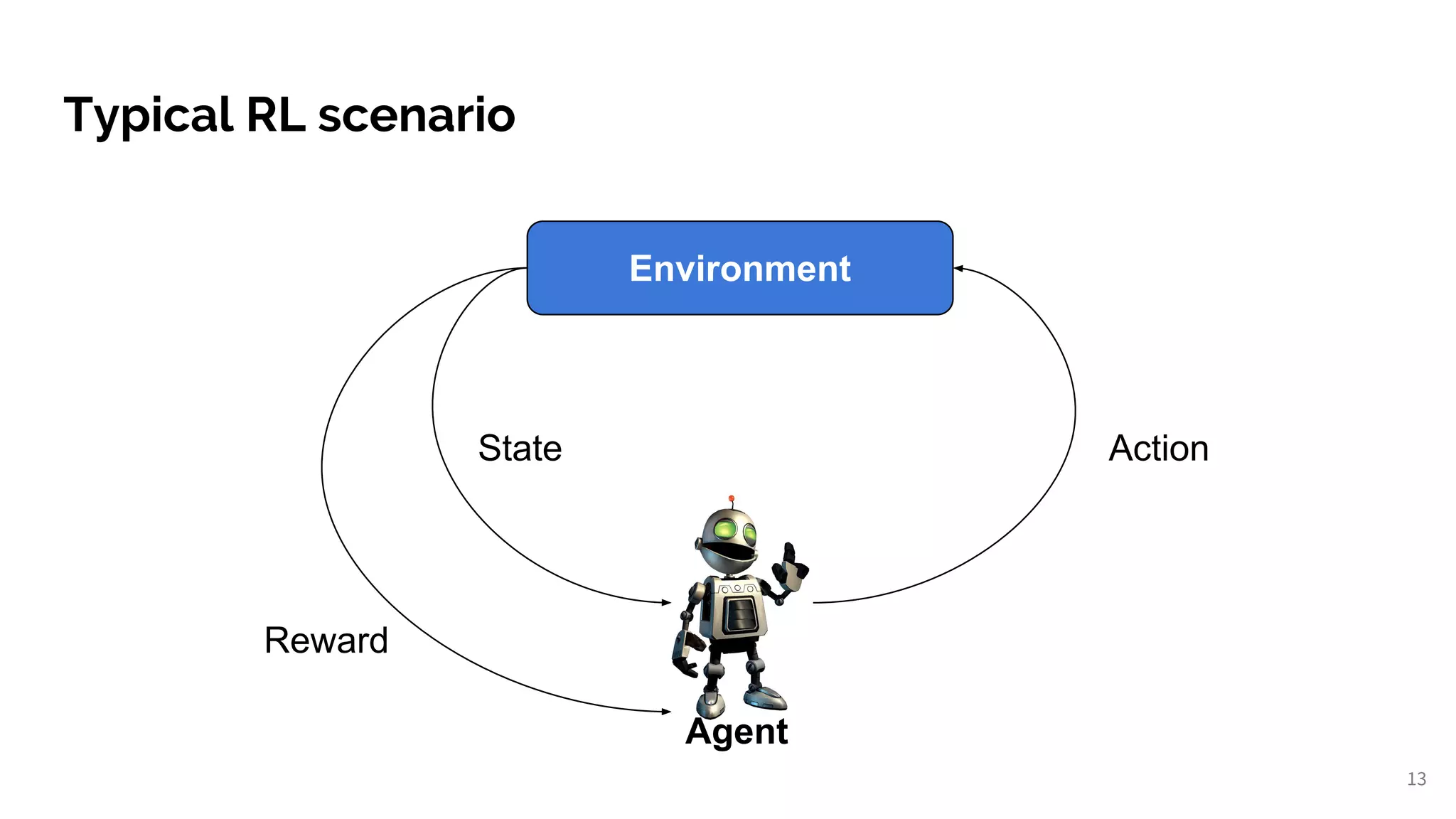
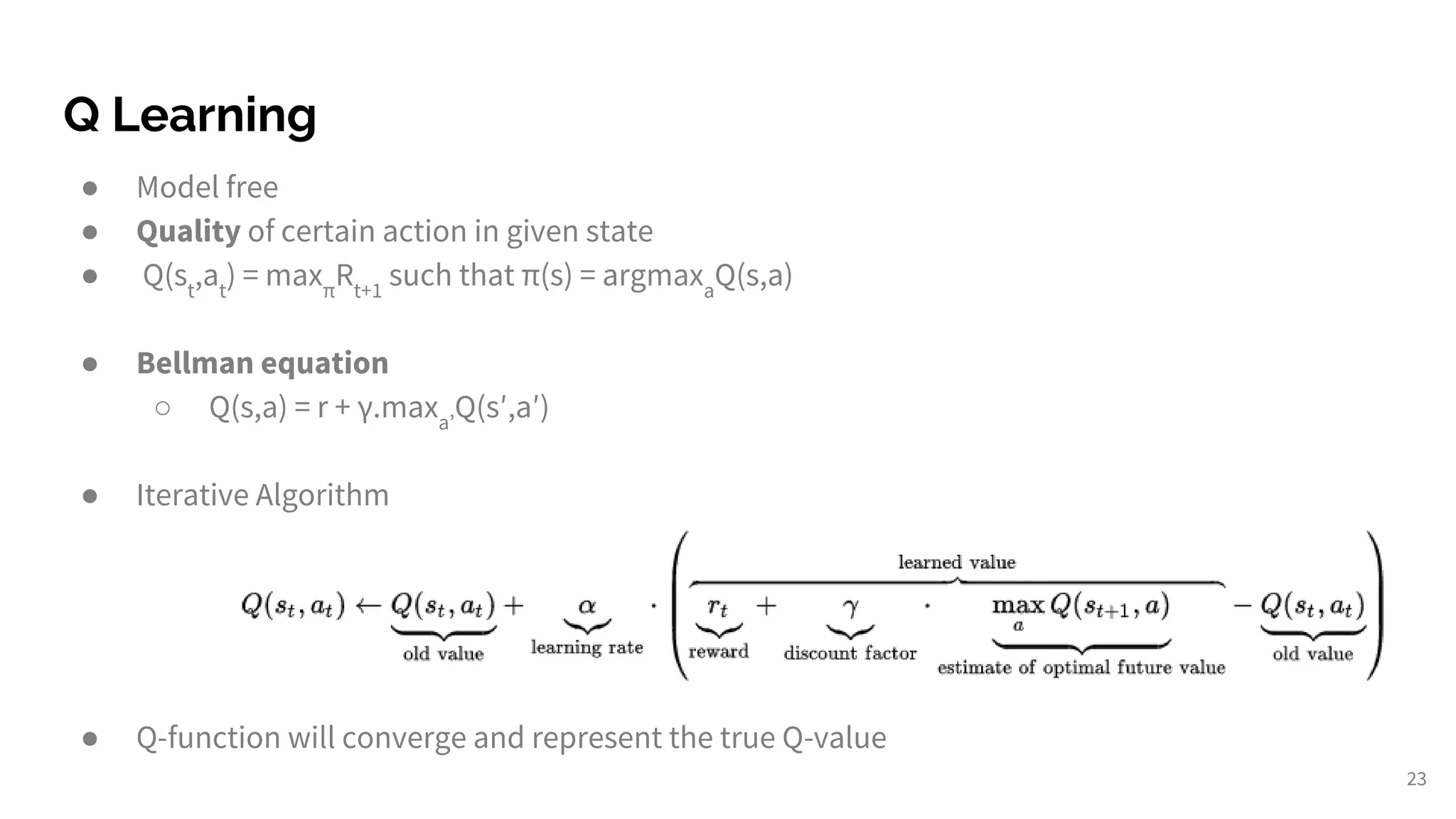
Explains RL fundamentals, MDP concepts, policies, reward systems, and explores Q-learning methodology.
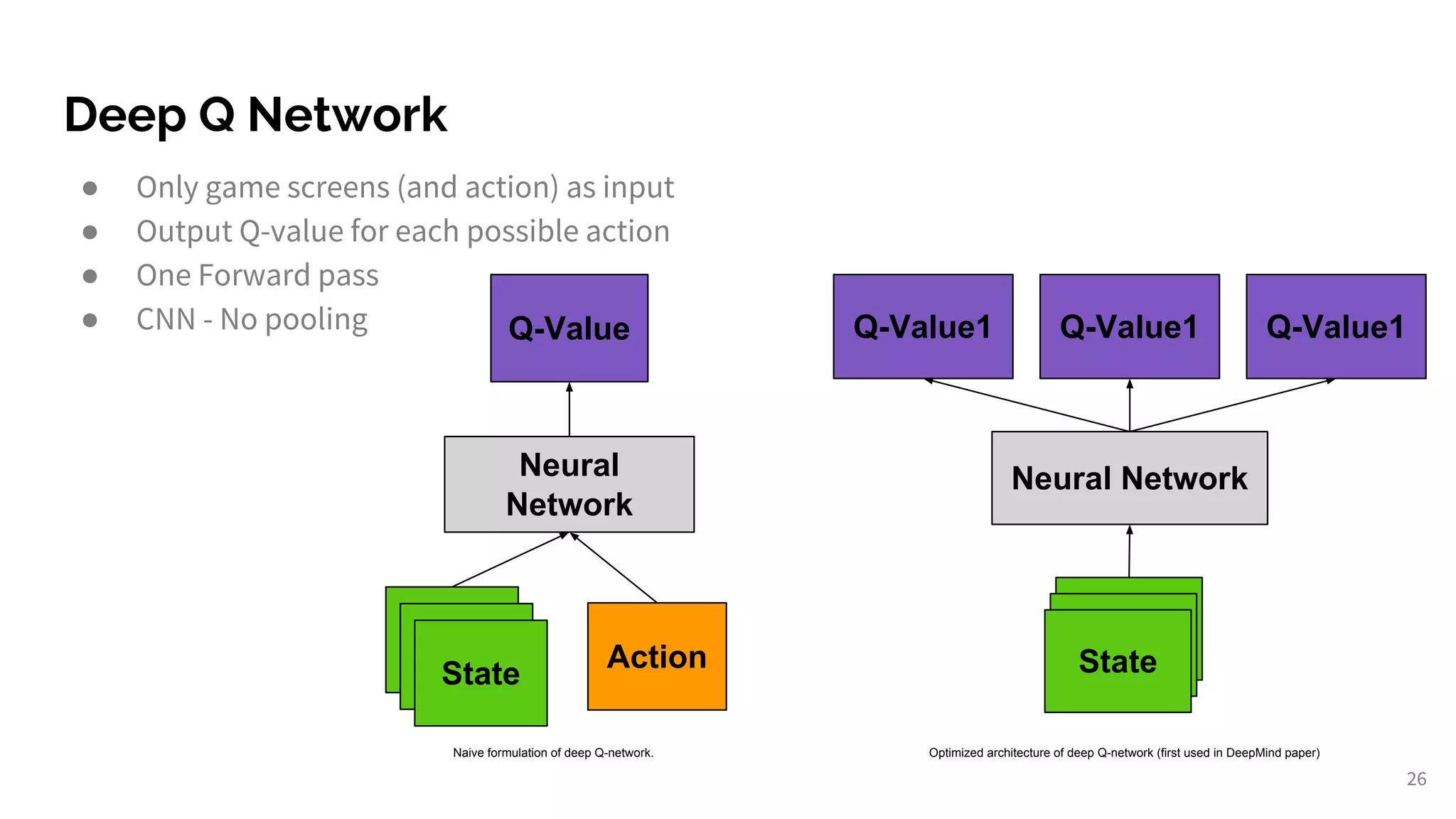
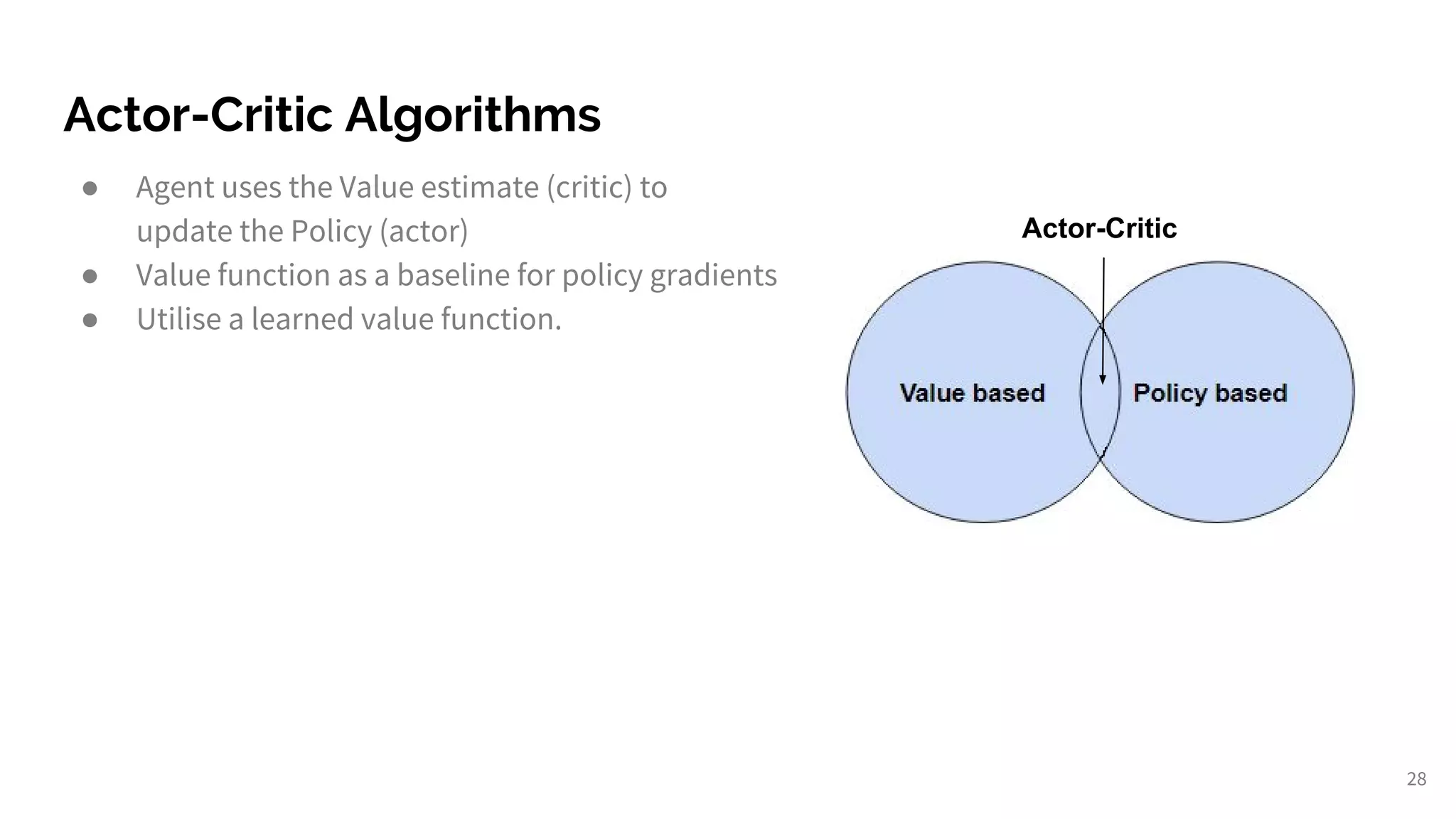
Introduction to deep RL techniques, including Deep Q-Learning and Actor-Critic methods.
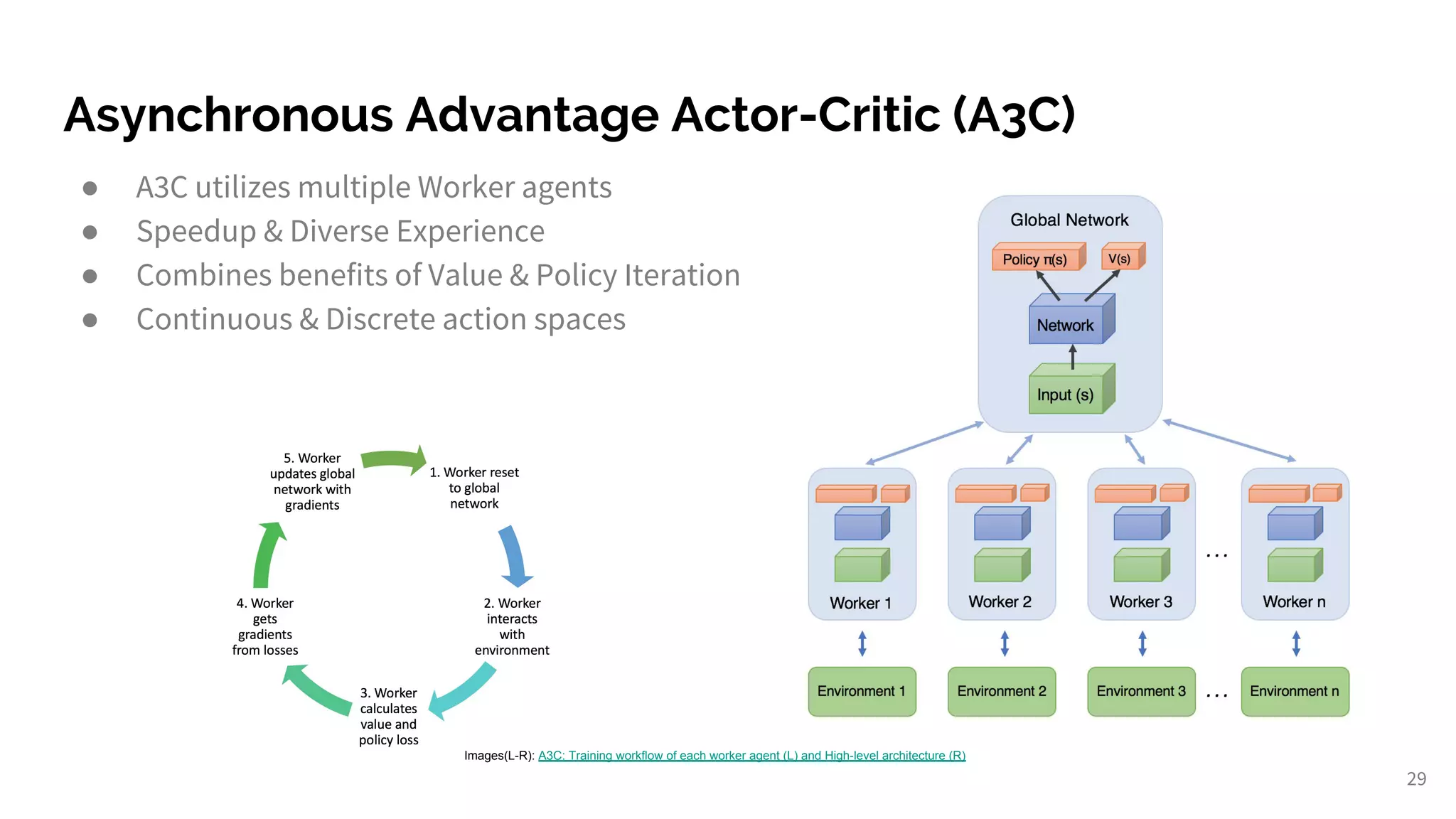
Details on A3C, which utilizes multiple agents for improved learning and efficiency in RL.
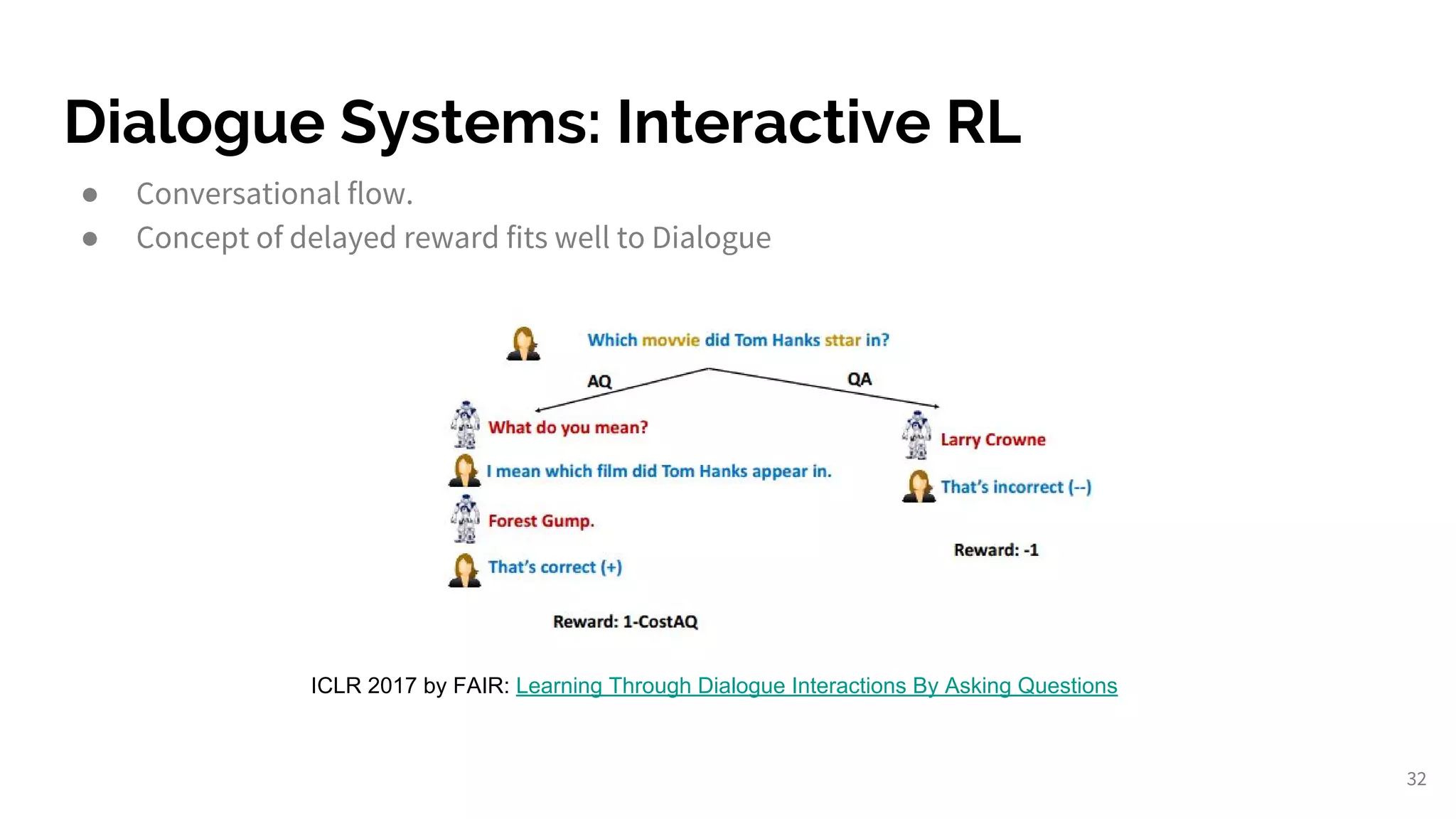
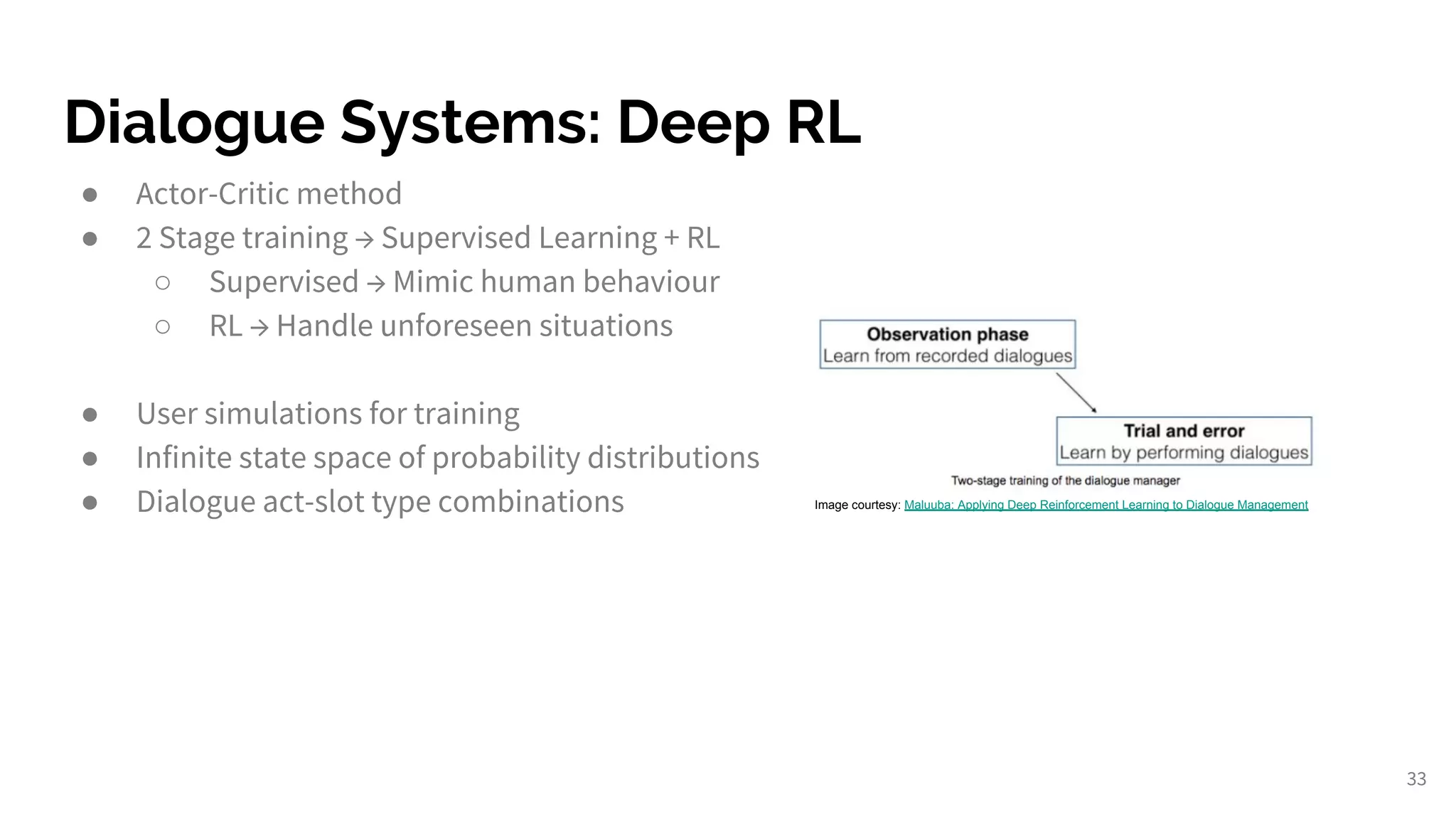
Applying RL methods to dialogue systems for enhanced user interactions and training.
Insights on important institutions, researchers, and tools available for RL algorithm development.
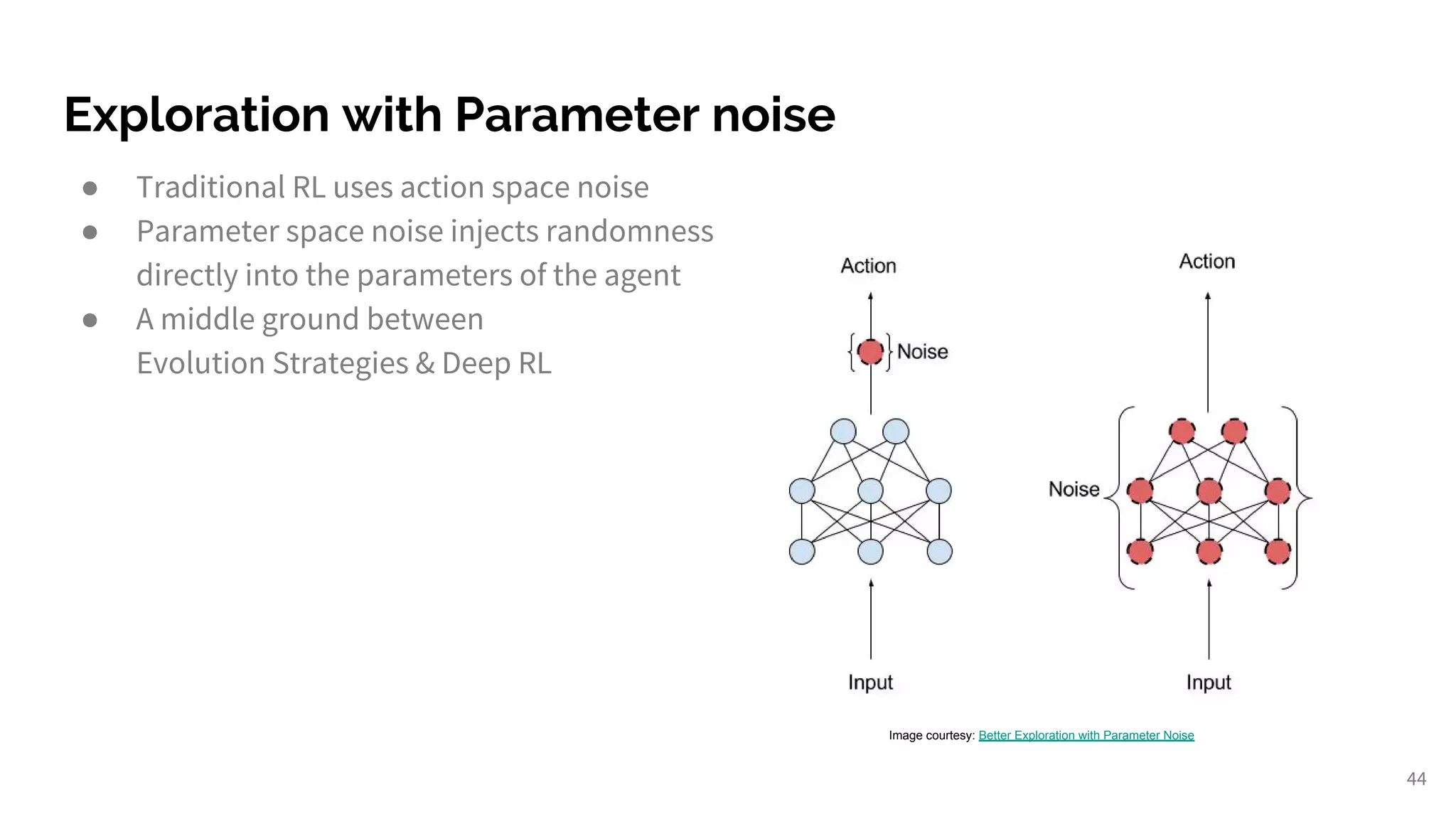
Discusses ongoing research in RL, growth challenges, and strategies for enhancing exploration.
Reinforcement learning stability and scalability; emphasizes the extensive future applications and hacks needed.
Citations for foundational and recent RL research, along with extra blogs and tutorials as learning resources.
Open floor for audience questions; provides additional insight into presentation content.
End of the presentation, signaling closure and hope for continued exploration of deep reinforcement learning.




































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)

















