Download as PDF, PPTX



![Atari[Nature,2015]
4](https://image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-4-2048.jpg)
![AlphaGo[Nature,2016]
5](https://image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-5-2048.jpg)








![Expectedfuturerewards
Any goal can be represented as a sum of intermediate rewards.
[ ∣ ] = [ + γ + + … ∣ ]∑
∞
t=0
γ
t
Rt St R0 R1 γ
2
R2 St
15](https://image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-16-2048.jpg)











![Updaterule
In rabbits, humans and machines we get the same algorithm:
while True:
Q[t] = Q[t-1] + alpha * (Q_target - Q[t-1])
27](https://image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-28-2048.jpg)
![Q-Learning[Watkins,1989]
The agent does not have a model of the environment.
Perform actions following a standard policy.
Predict using the target policy.
Which makes it an "o -policy", model-free method.
28](https://image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-29-2048.jpg)






![Network
Input: an image of shape [None, 42, 42, 4]
4 Conv2D 32 lters, 4x4 kernel
1 Hidden layer of size 256
1 Fully connected layer of size action_size
35](https://image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-36-2048.jpg)









![Atari[Nature,2015]
4](https://crownmelresort.com/image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-4-2048.jpg)
![AlphaGo[Nature,2016]
5](https://crownmelresort.com/image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-5-2048.jpg)










![Expectedfuturerewards
Any goal can be represented as a sum of intermediate rewards.
[ ∣ ] = [ + γ + + … ∣ ]∑
∞
t=0
γ
t
Rt St R0 R1 γ
2
R2 St
15](https://crownmelresort.com/image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-16-2048.jpg)











![Updaterule
In rabbits, humans and machines we get the same algorithm:
while True:
Q[t] = Q[t-1] + alpha * (Q_target - Q[t-1])
27](https://crownmelresort.com/image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-28-2048.jpg)
![Q-Learning[Watkins,1989]
The agent does not have a model of the environment.
Perform actions following a standard policy.
Predict using the target policy.
Which makes it an "o -policy", model-free method.
28](https://crownmelresort.com/image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-29-2048.jpg)






![Network
Input: an image of shape [None, 42, 42, 4]
4 Conv2D 32 lters, 4x4 kernel
1 Hidden layer of size 256
1 Fully connected layer of size action_size
35](https://crownmelresort.com/image.slidesharecdn.com/rlbasic-170706155846/75/Deep-Reinforcement-Learning-36-2048.jpg)







The document provides an overview of deep reinforcement learning (DRL), outlining its fundamental concepts such as Q-learning, policy, value functions, and the role of agents in decision-making. It discusses various aspects including the significance of delayed feedback, the use of neural networks, and methods for improving stability in learning processes. Additionally, it highlights tools, challenges, and resources available for further exploration in the field of DRL.
Overview of Deep Reinforcement Learning (RL) and its significance in Machine Learning (ML). Outlined topics include framework, Q-Learning, and a demo.
Examples of RL applications: Atari games (Nature, 2015) and AlphaGo (Nature, 2016), showcasing RL's effectiveness.
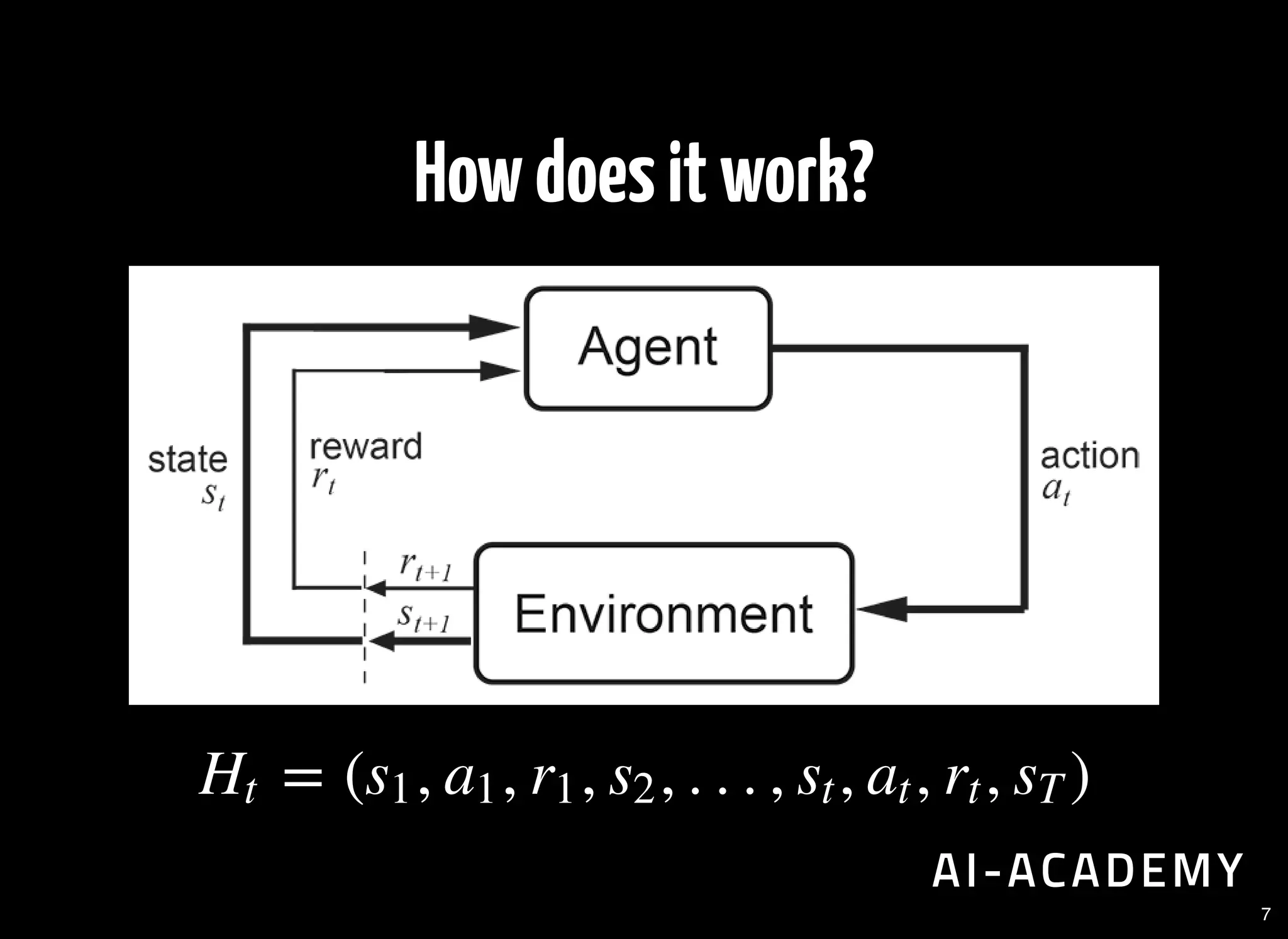
Description of RL's decision-making process and its unique aspects: no supervisor, delayed feedback, context dependence.
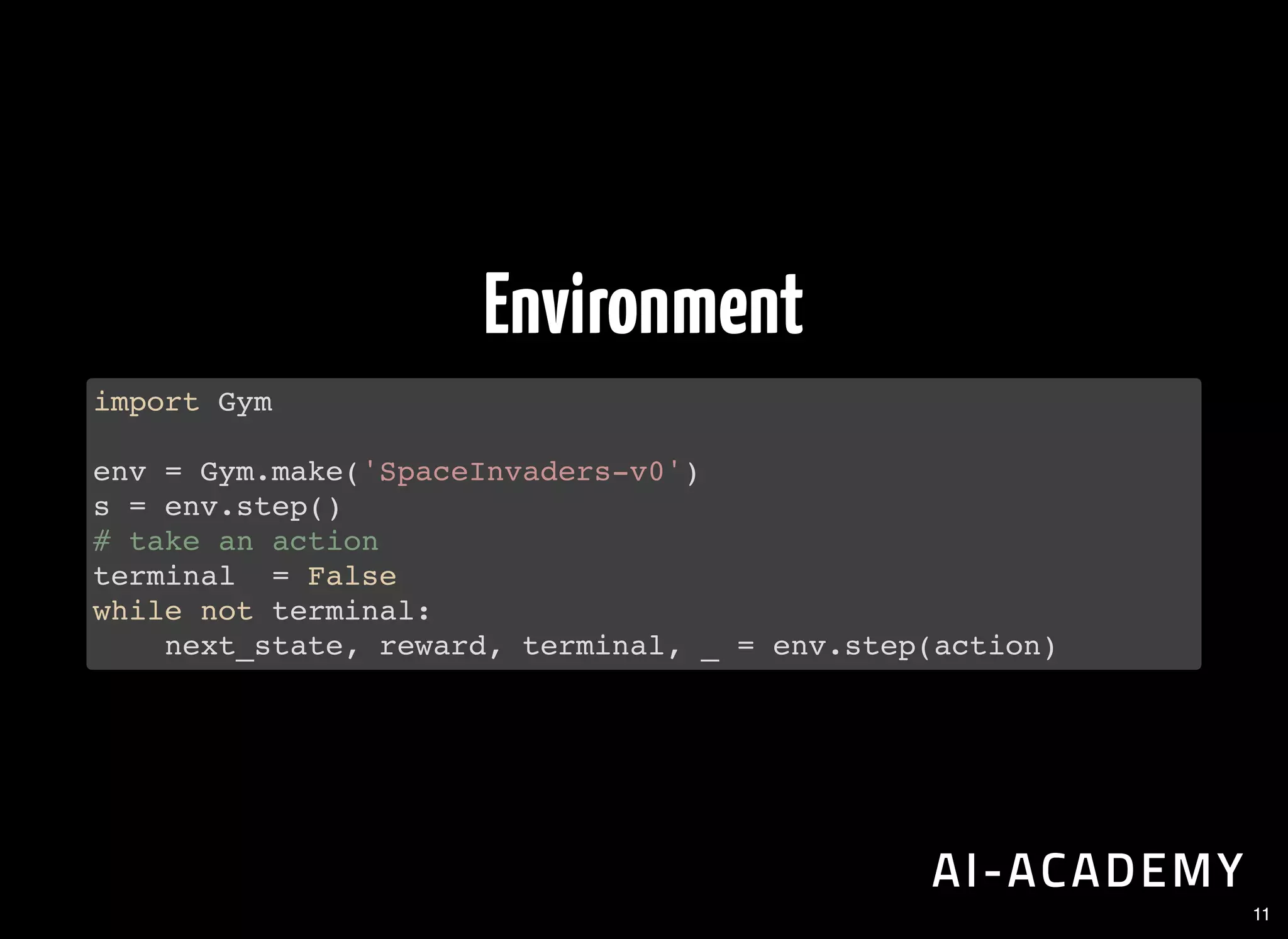
Defining the environment and agent in RL, including example code for interaction with an environment using Gym.
Discusses assumptions regarding state transitions in RL, emphasizing the importance of current state info.
Concept of expected future rewards in RL where goals are described as a sum of intermediate rewards.
The three main tools in RL: Policy, Value function, and Model; defining agent behavior and environment representation.
Key design choices like balancing exploration and exploitation and finding the optimal policy to maximize rewards.
Different methods to approximate the value function in RL: Monte Carlo and Temporal Difference learning.
Introduction of Deep Q-Learning using neural networks, addressing issues such as data correlation and reward stability.
Innovative strategies from DeepMind for stable Q-learning, including neural network architecture for input images.
Key hyperparameters for RL models such as learning rate, reward clipping, and optimizer choice.
Various resources to learn more about RL and acknowledgment to the audience, concluding the presentation.
























































![[Sponsored] C3.ai description](https://cdn.slidesharecdn.com/ss_thumbnails/c3deckmeetupnovember252019v2-191128092146-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)







