Download as PDF, PPTX



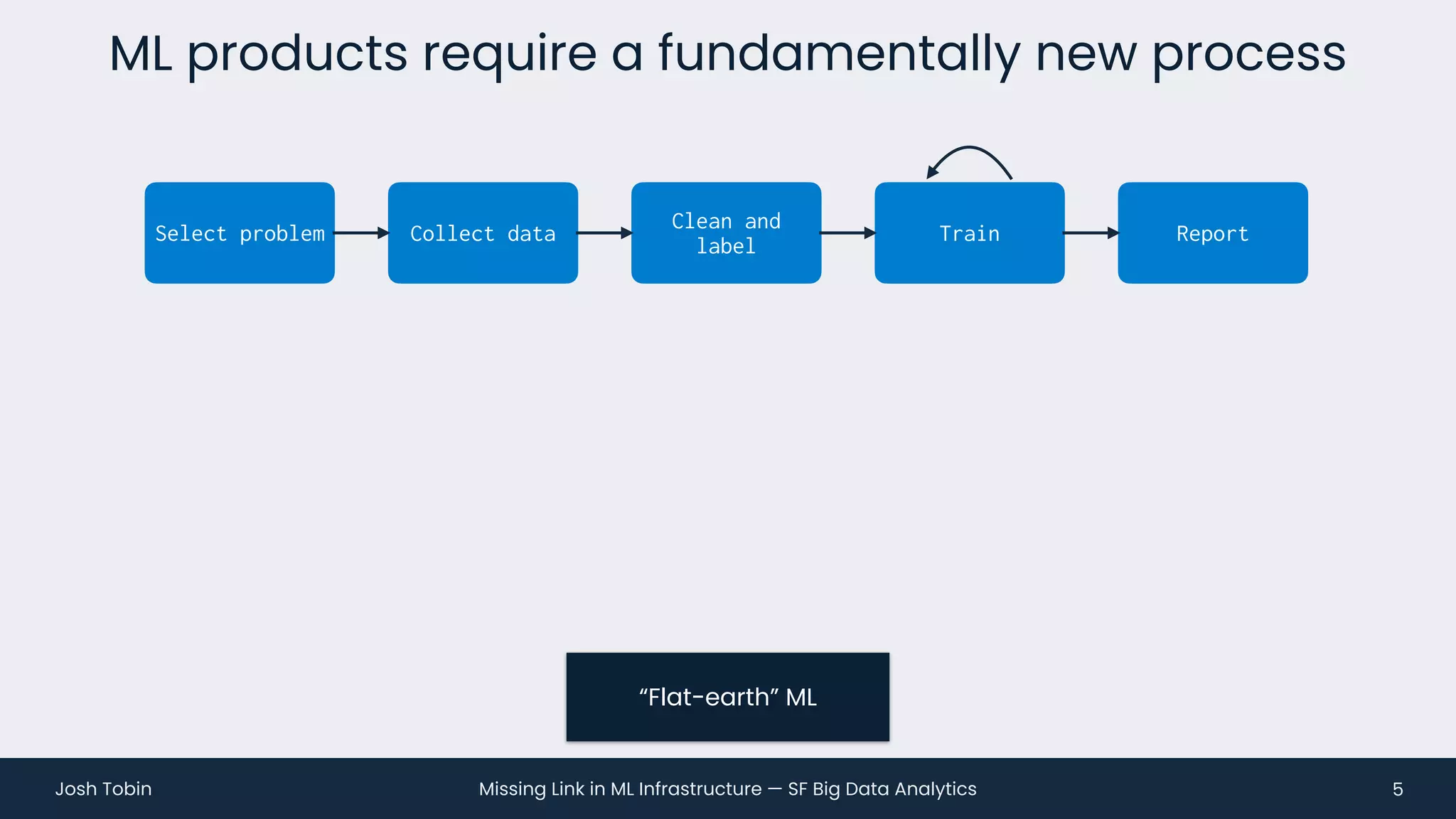
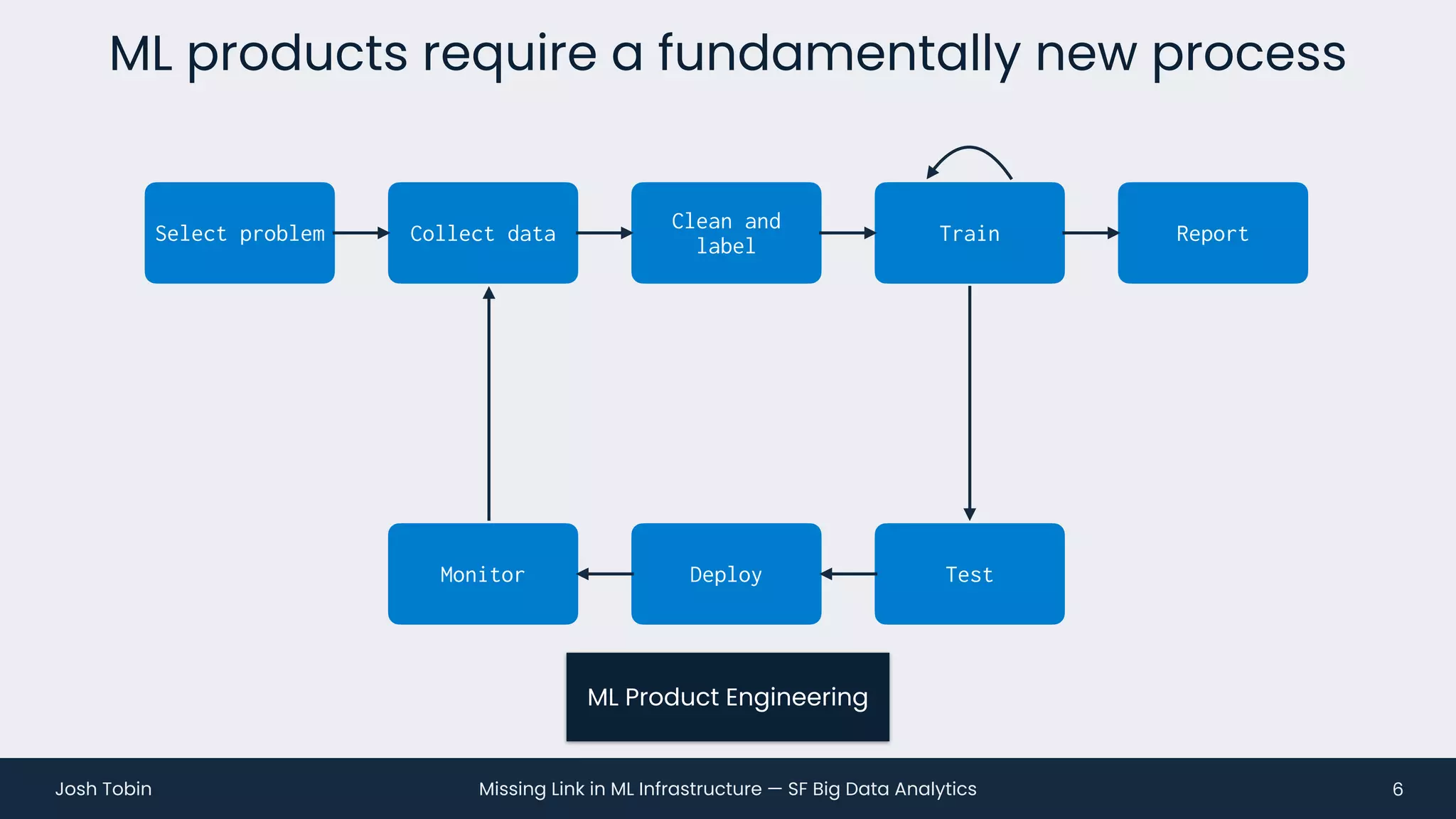


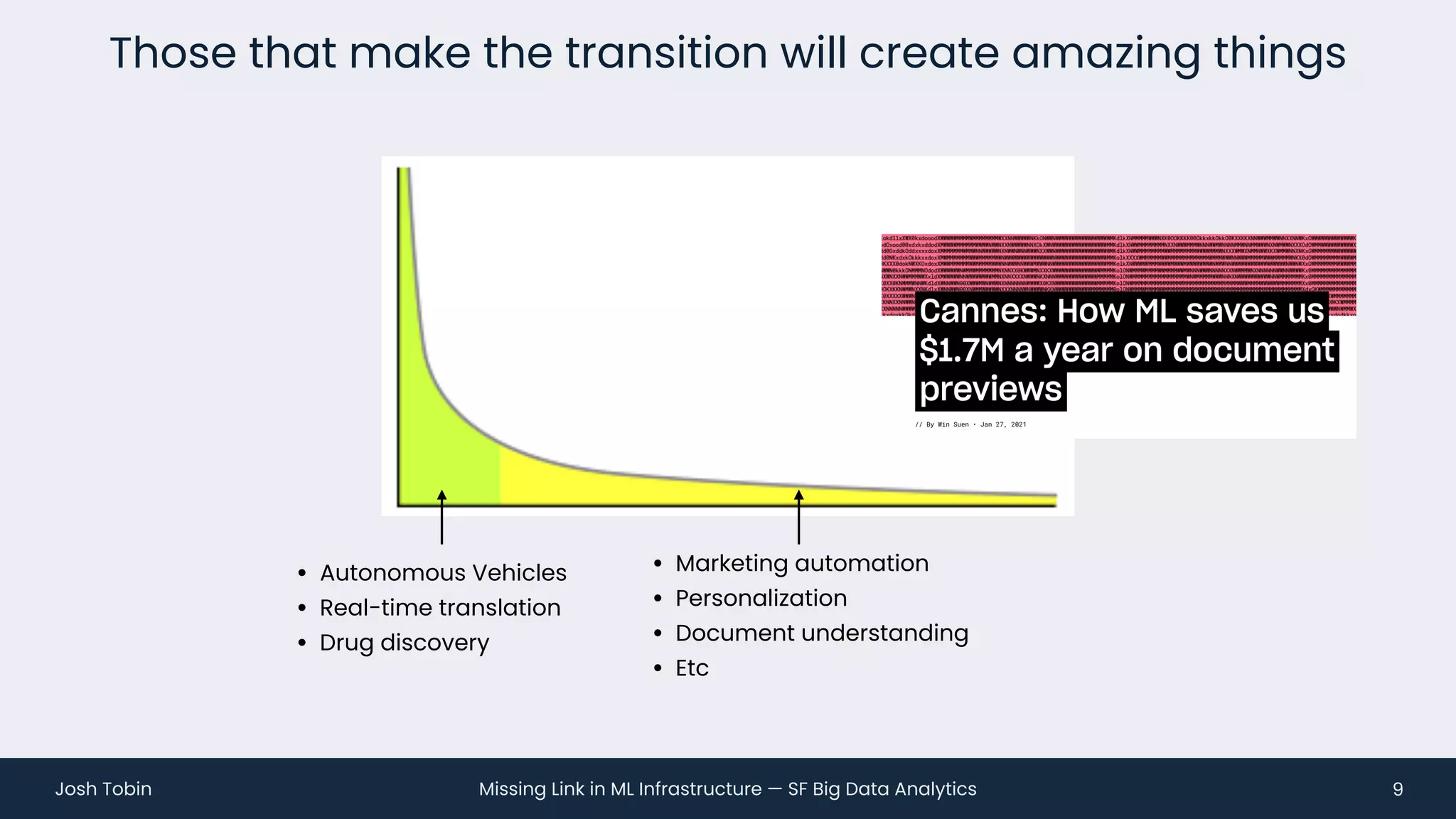


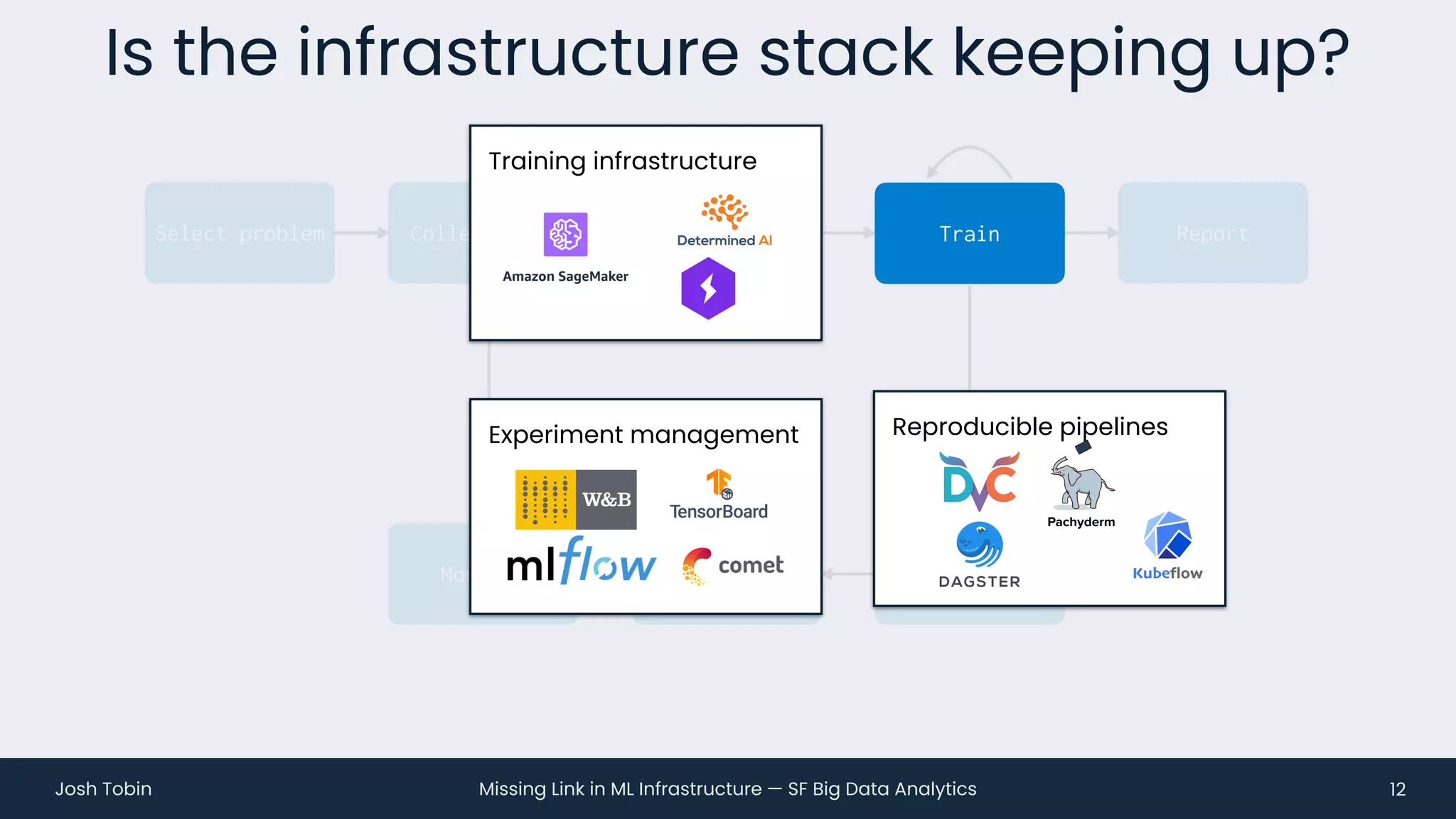
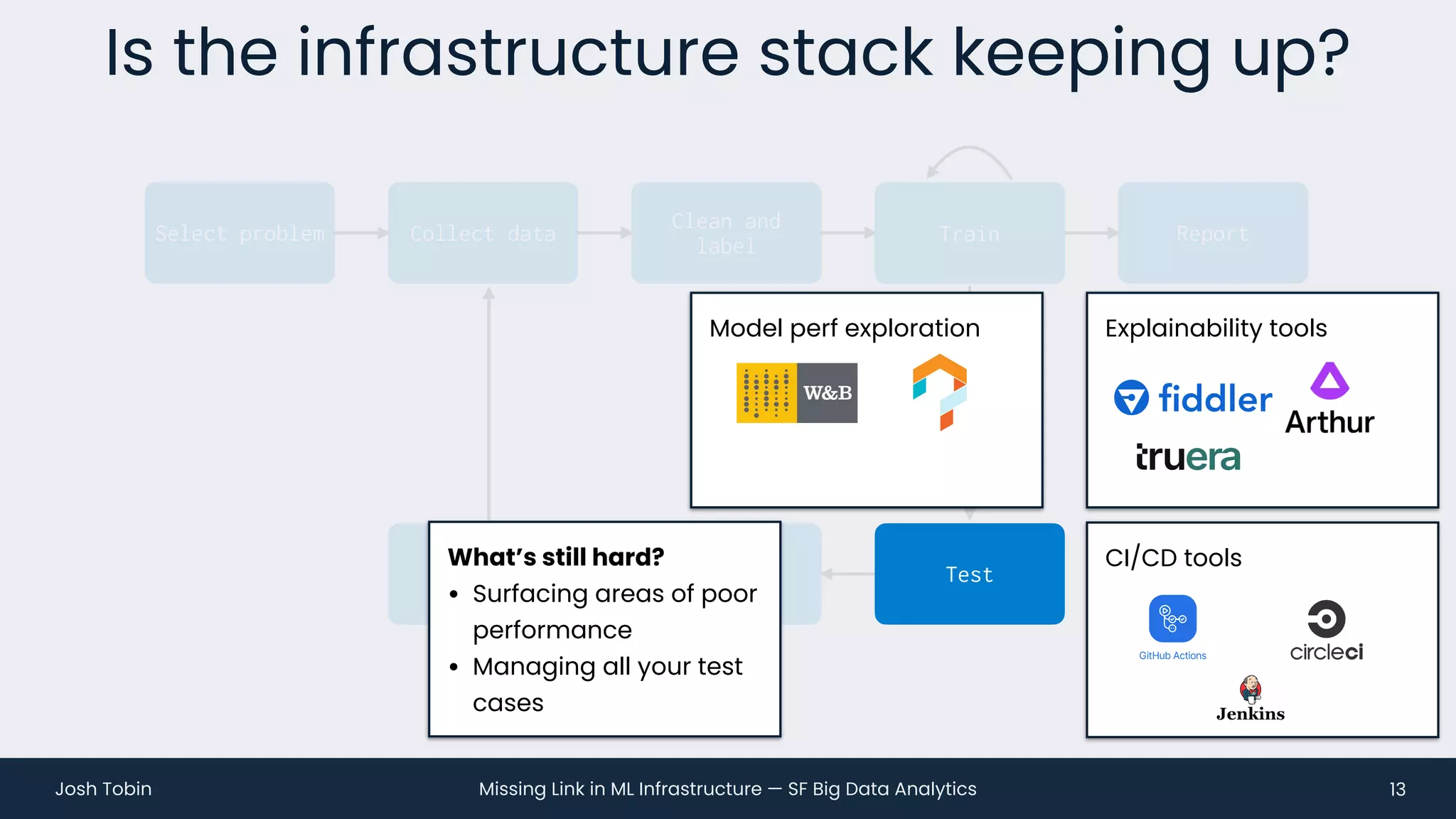
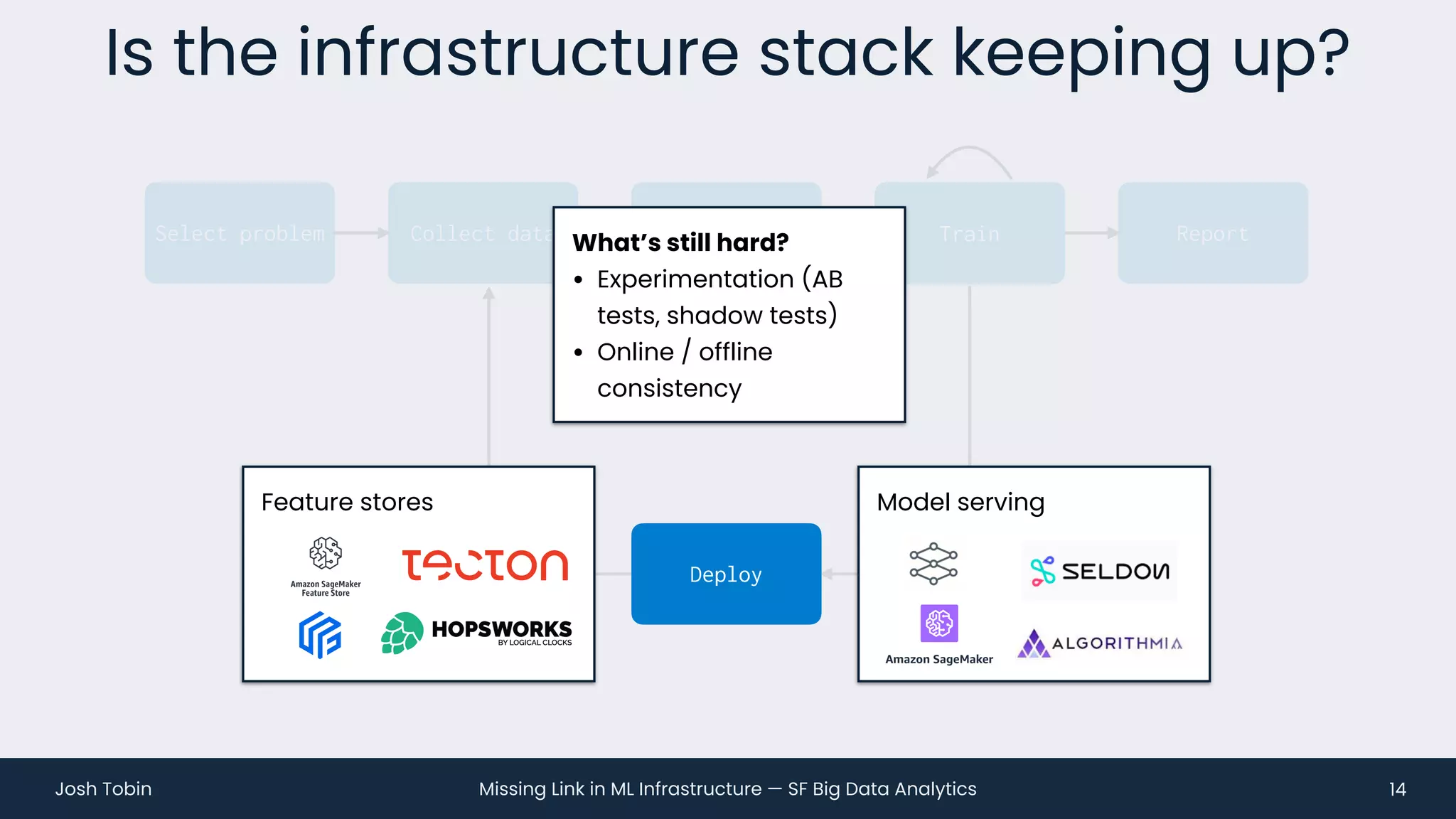
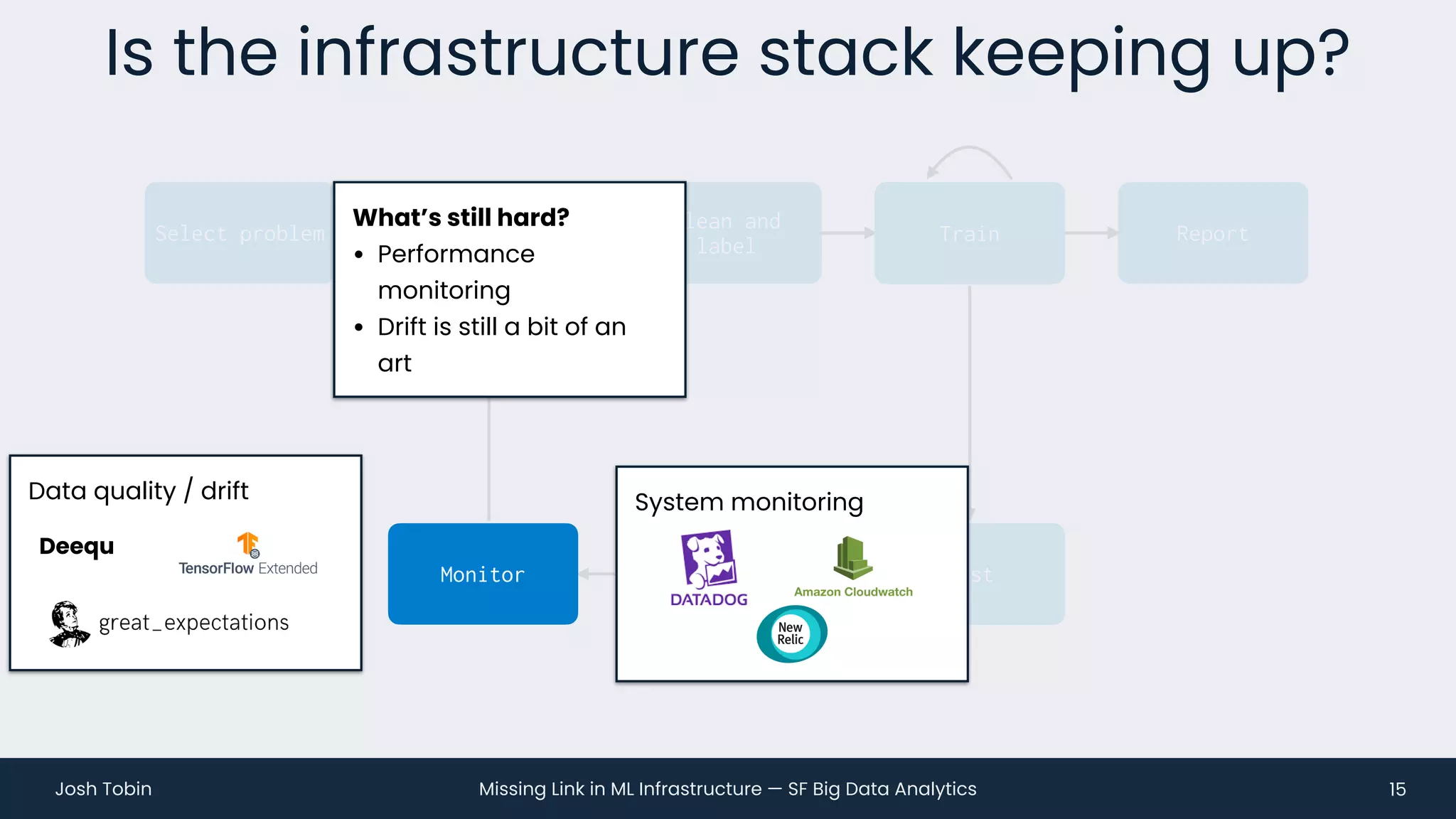
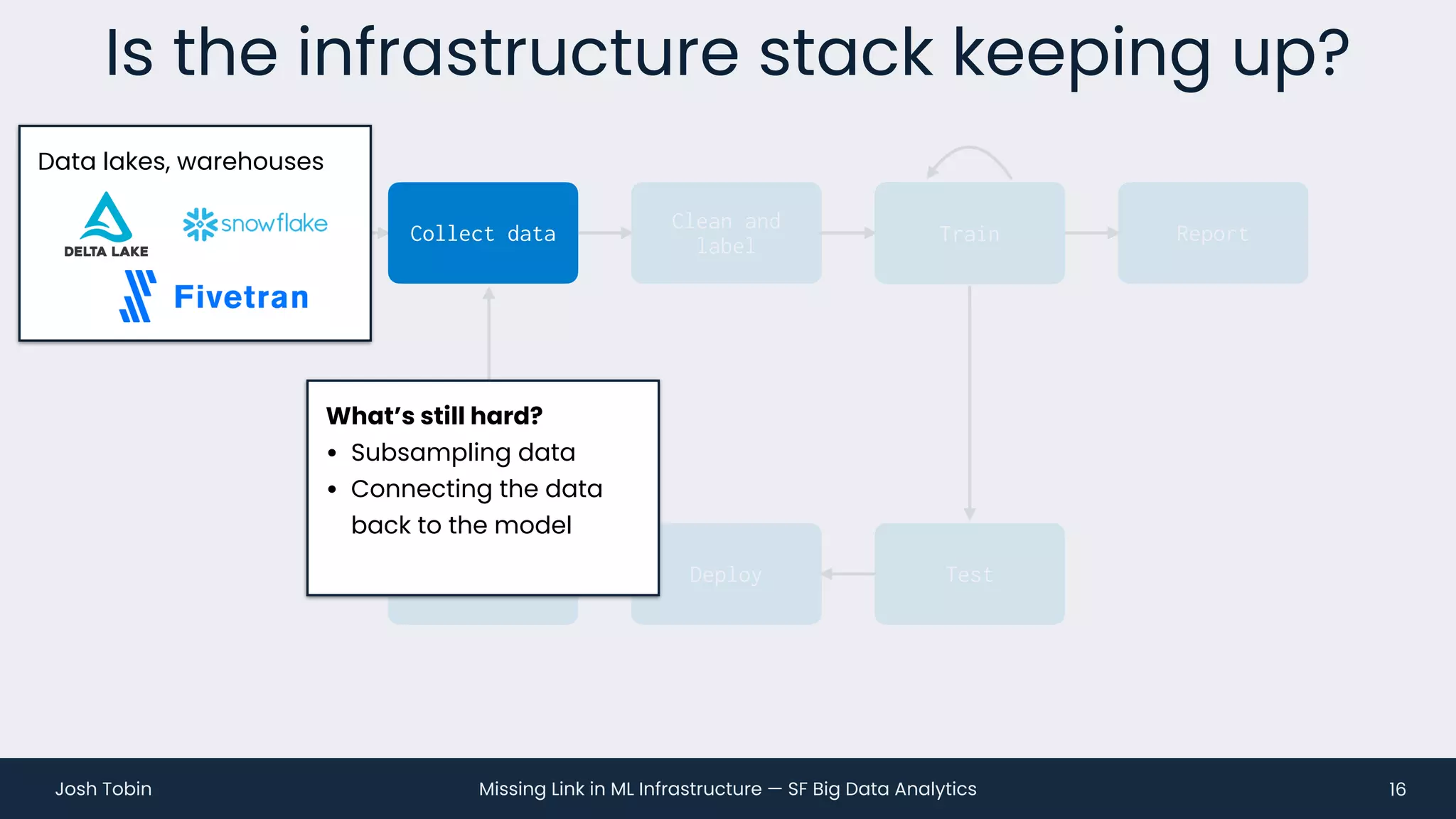
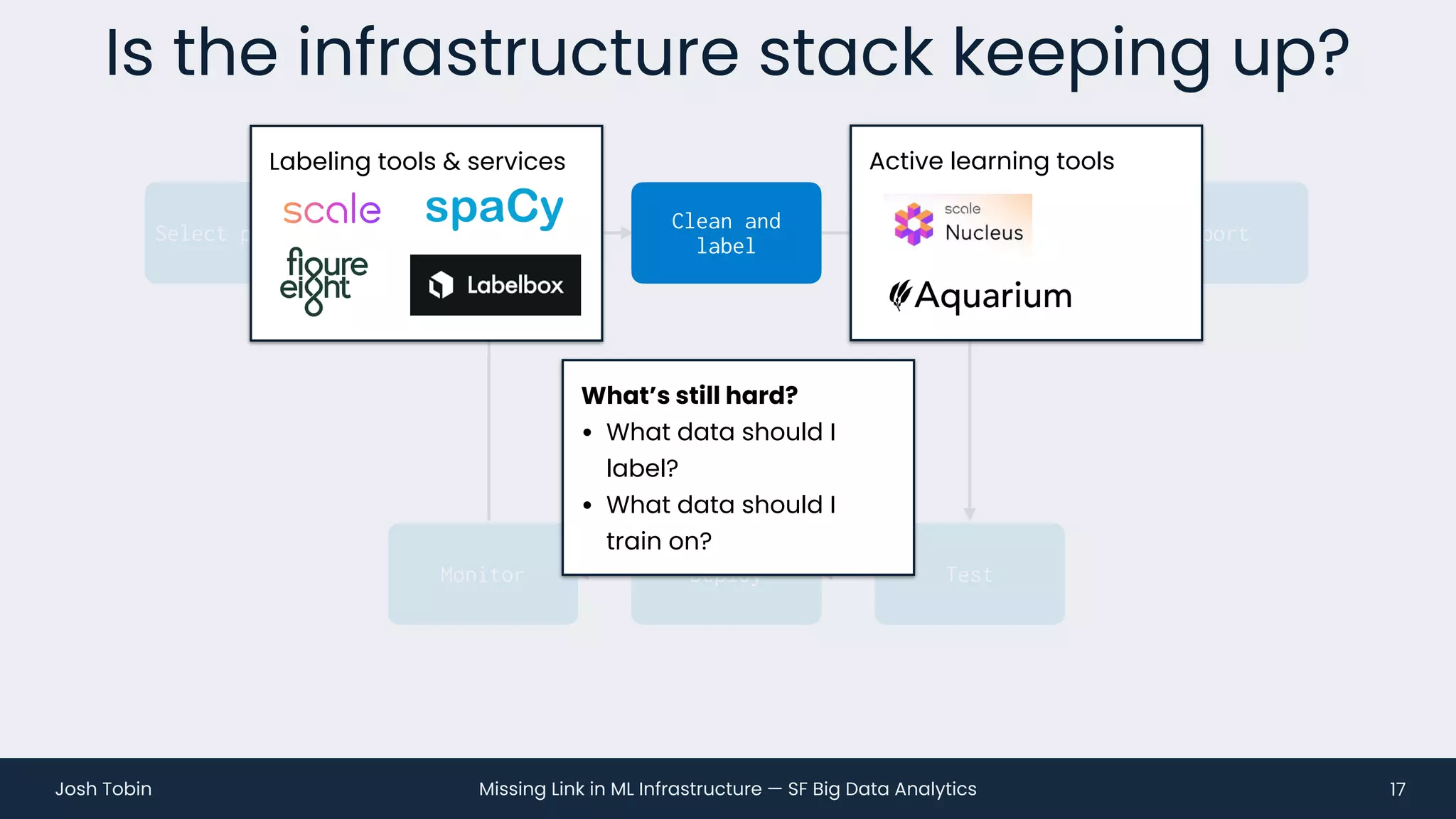
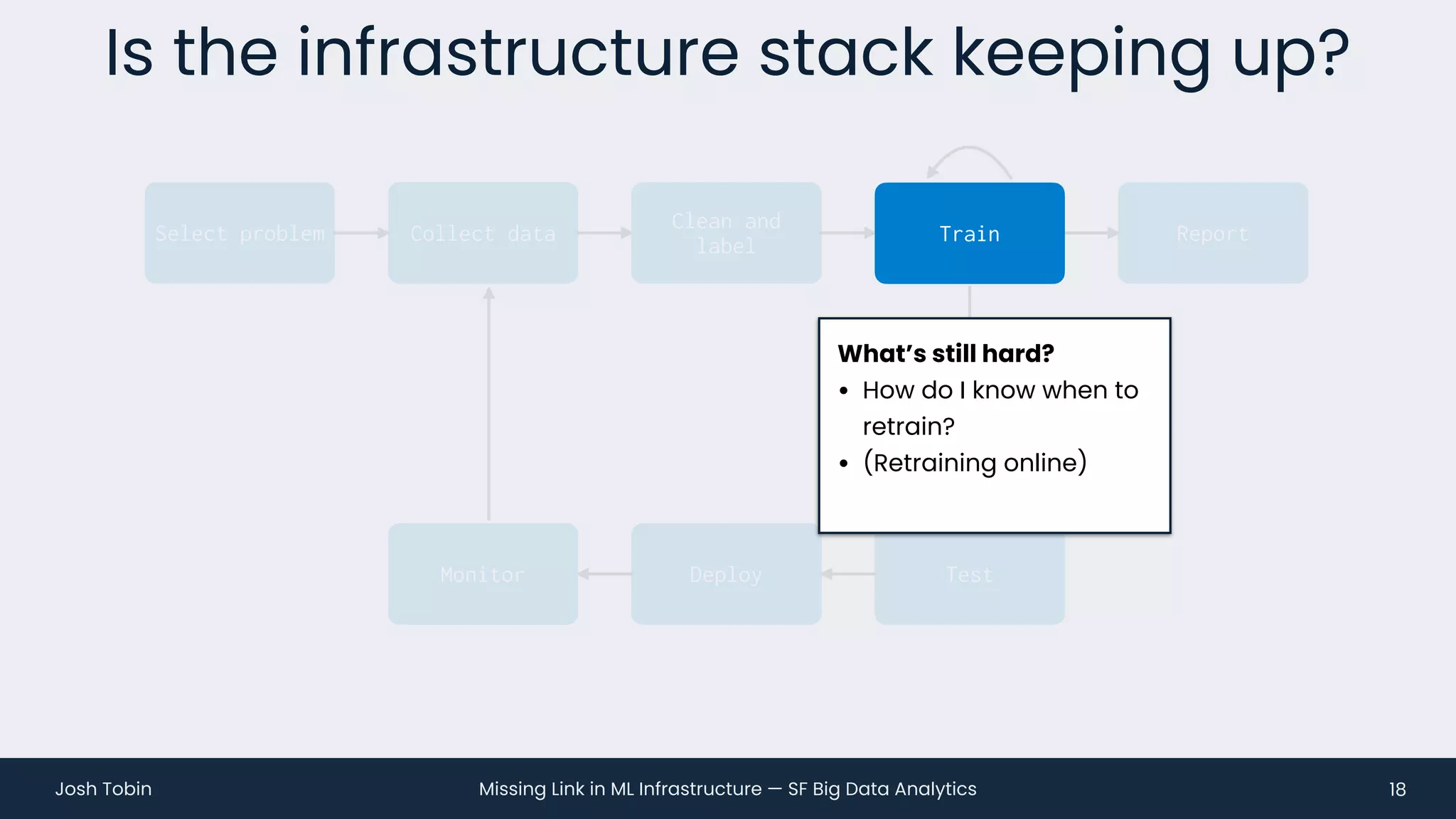


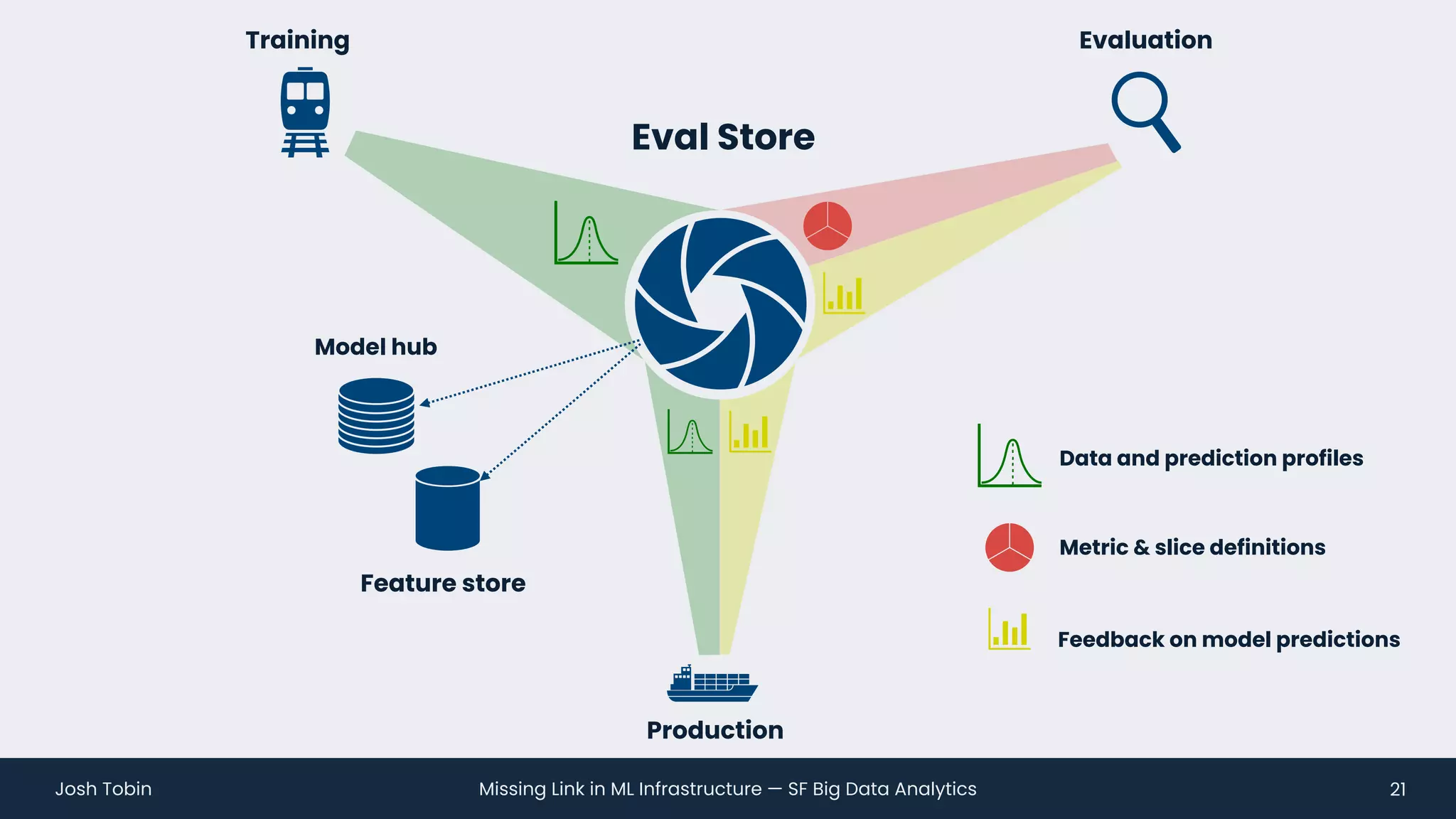






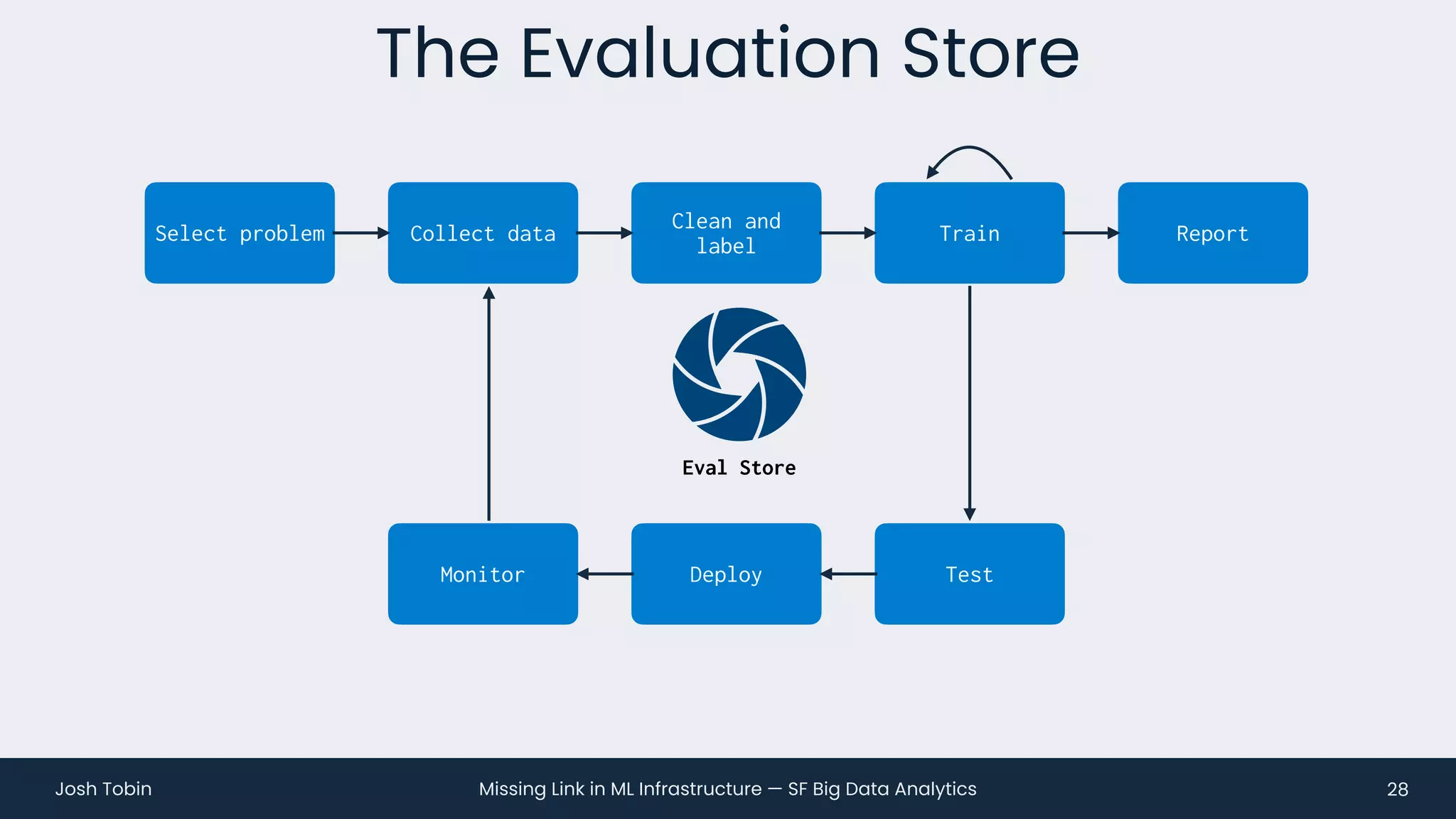
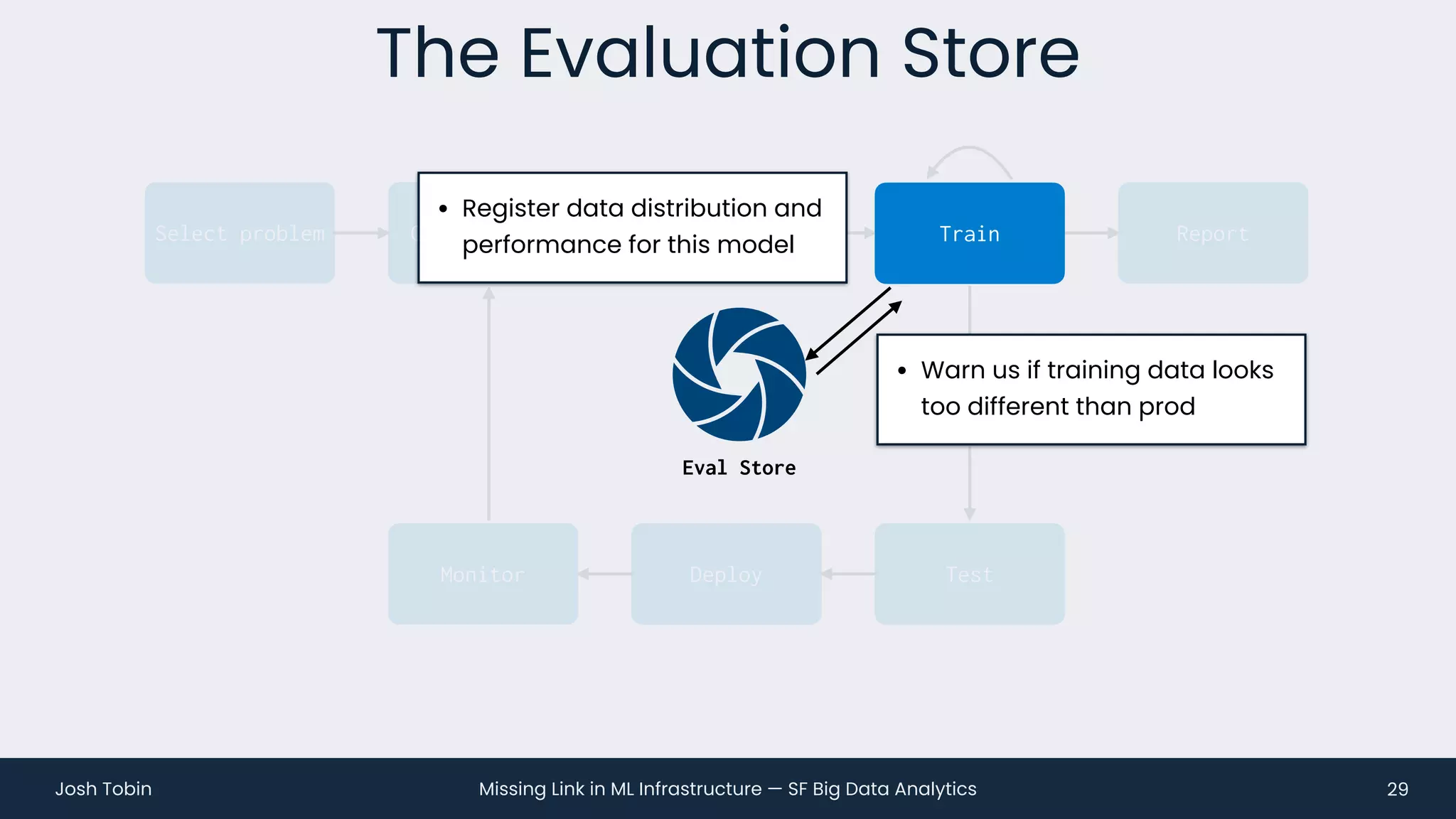
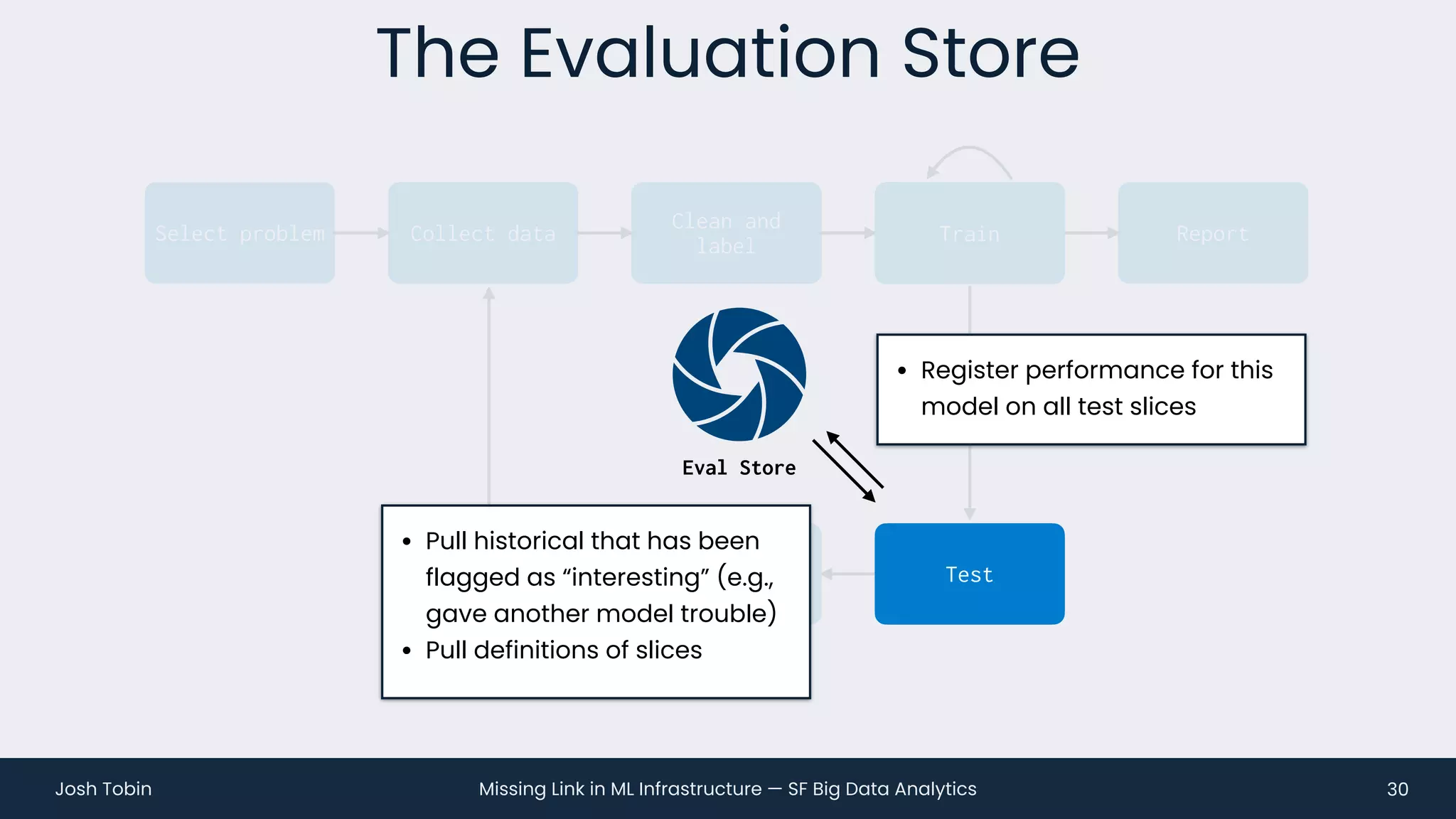
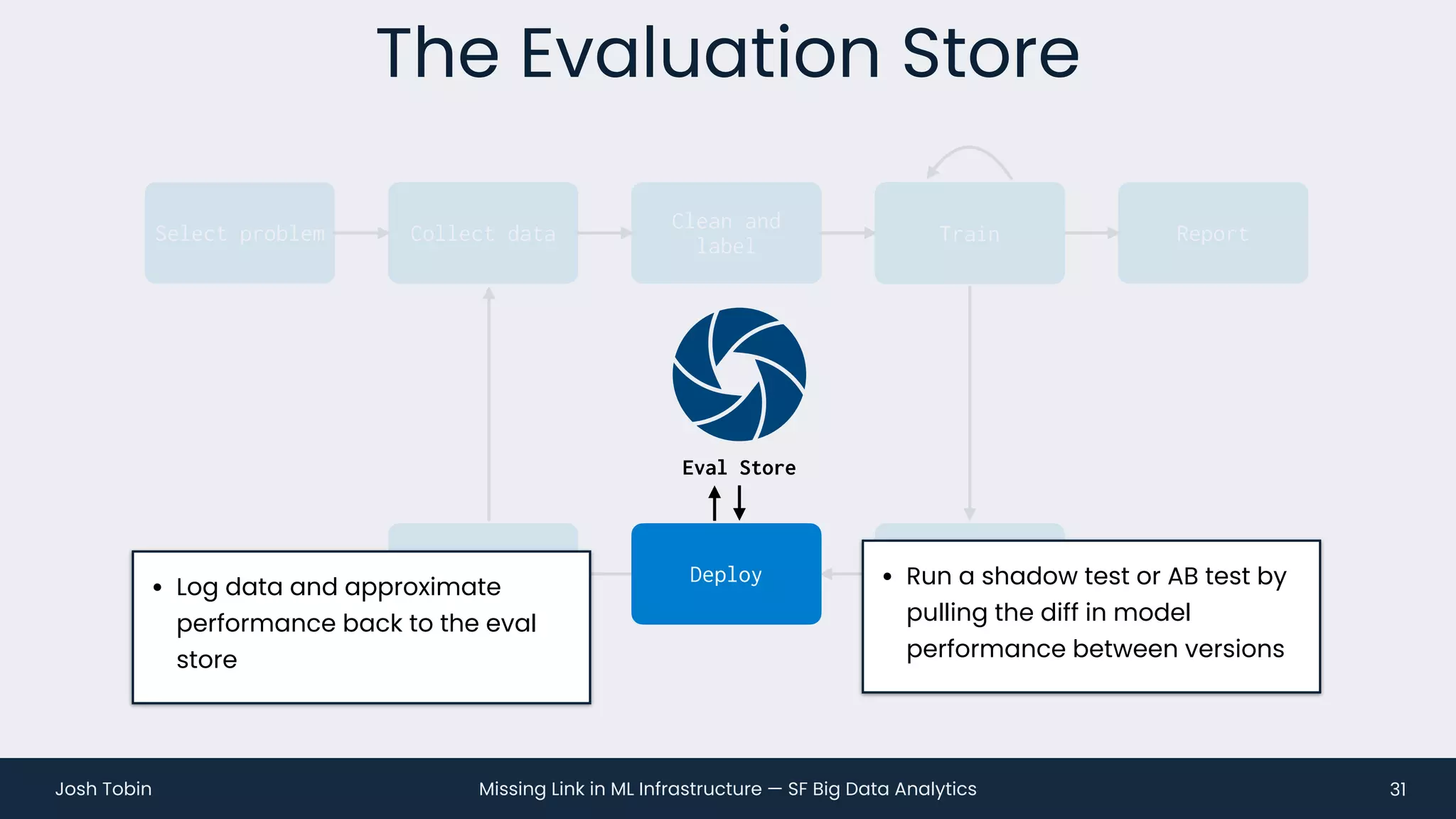
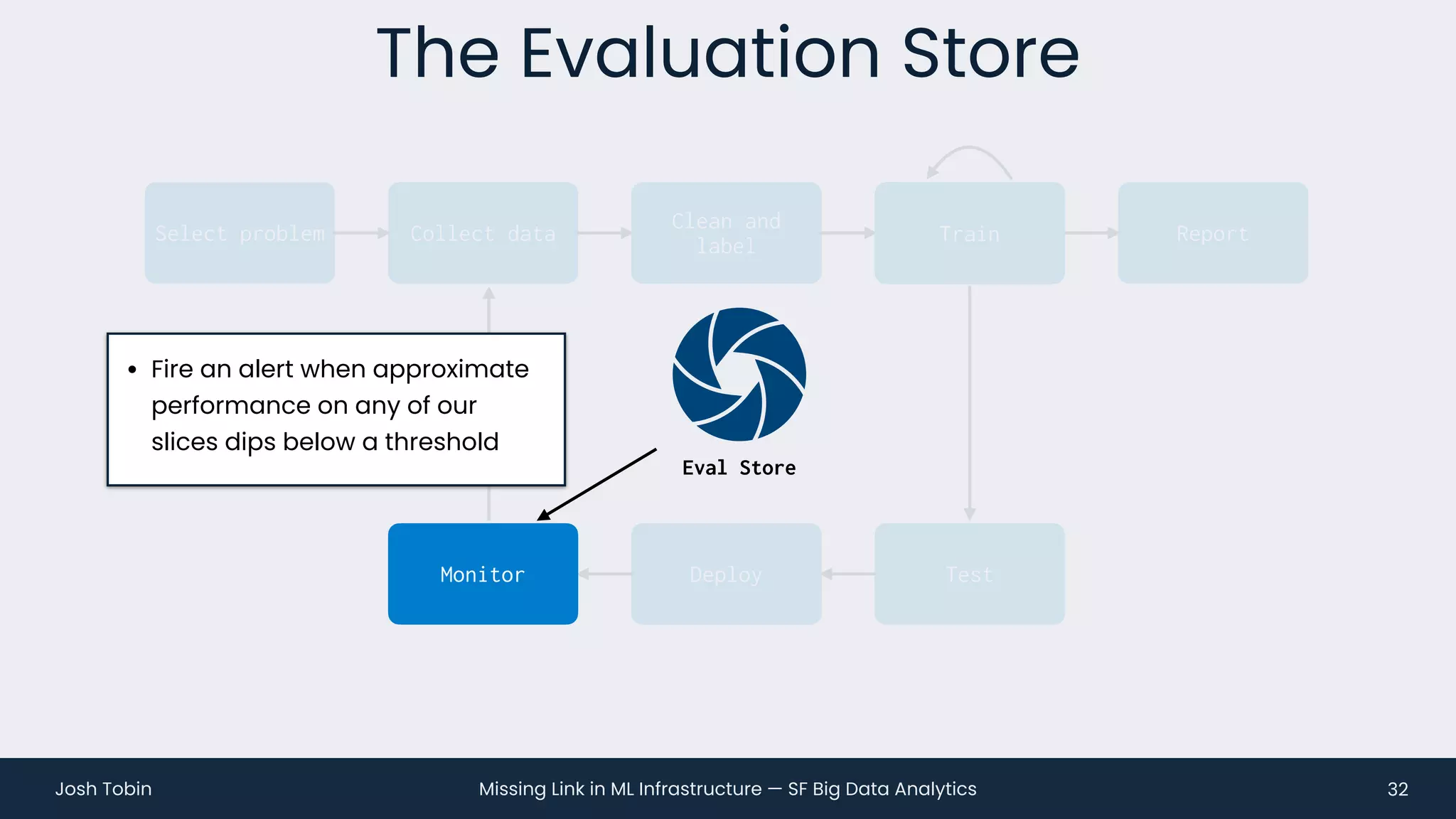
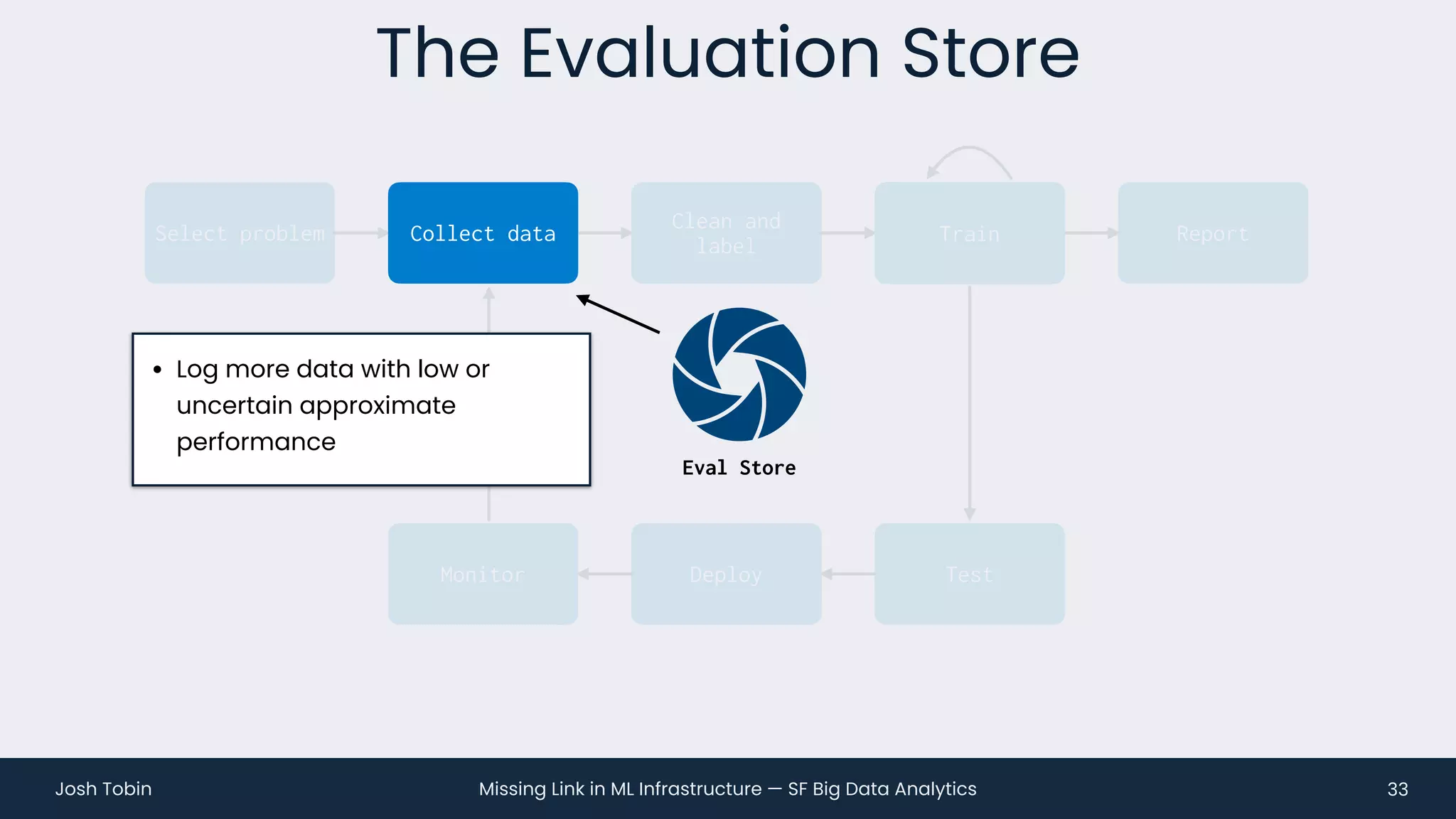
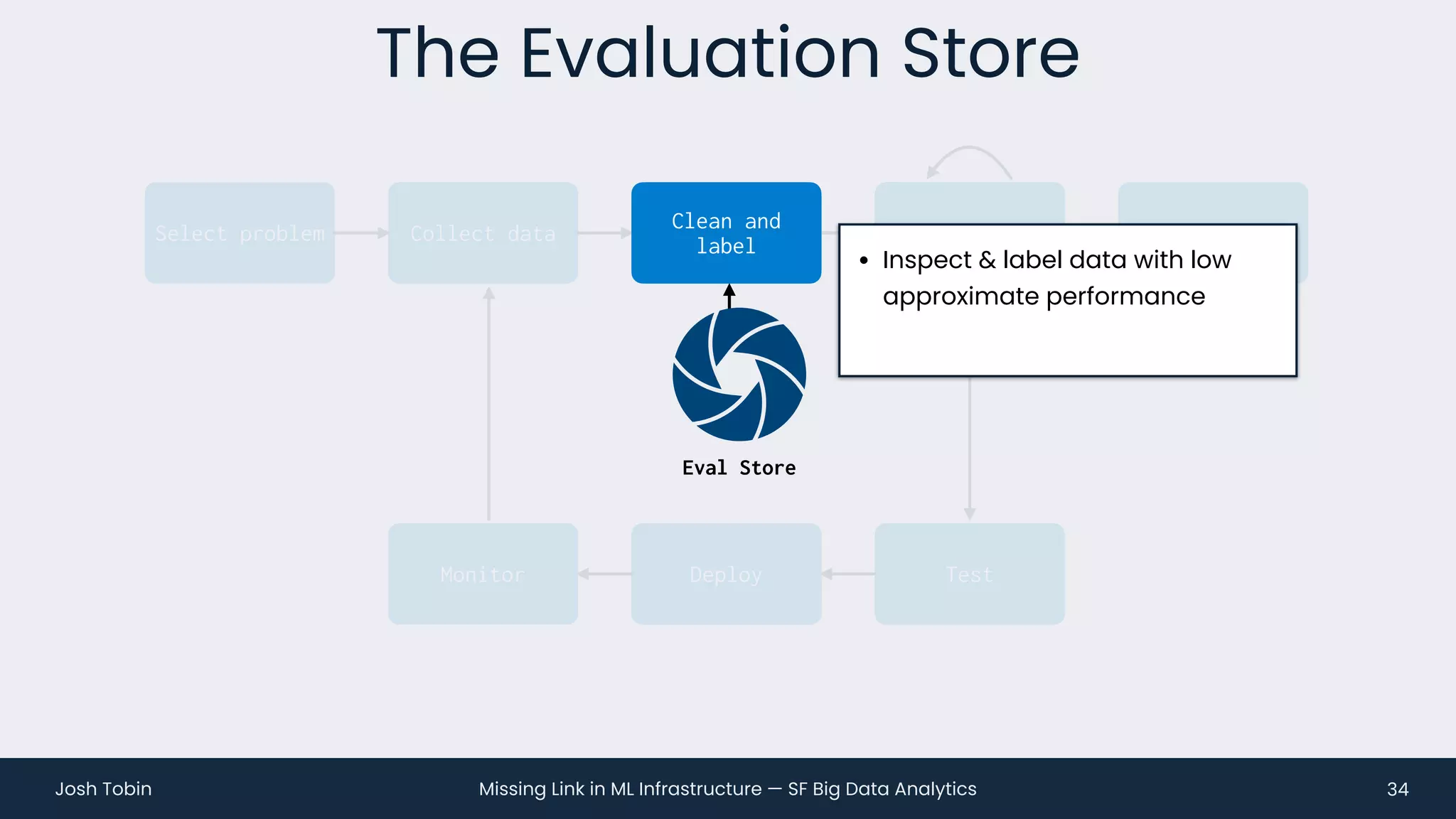
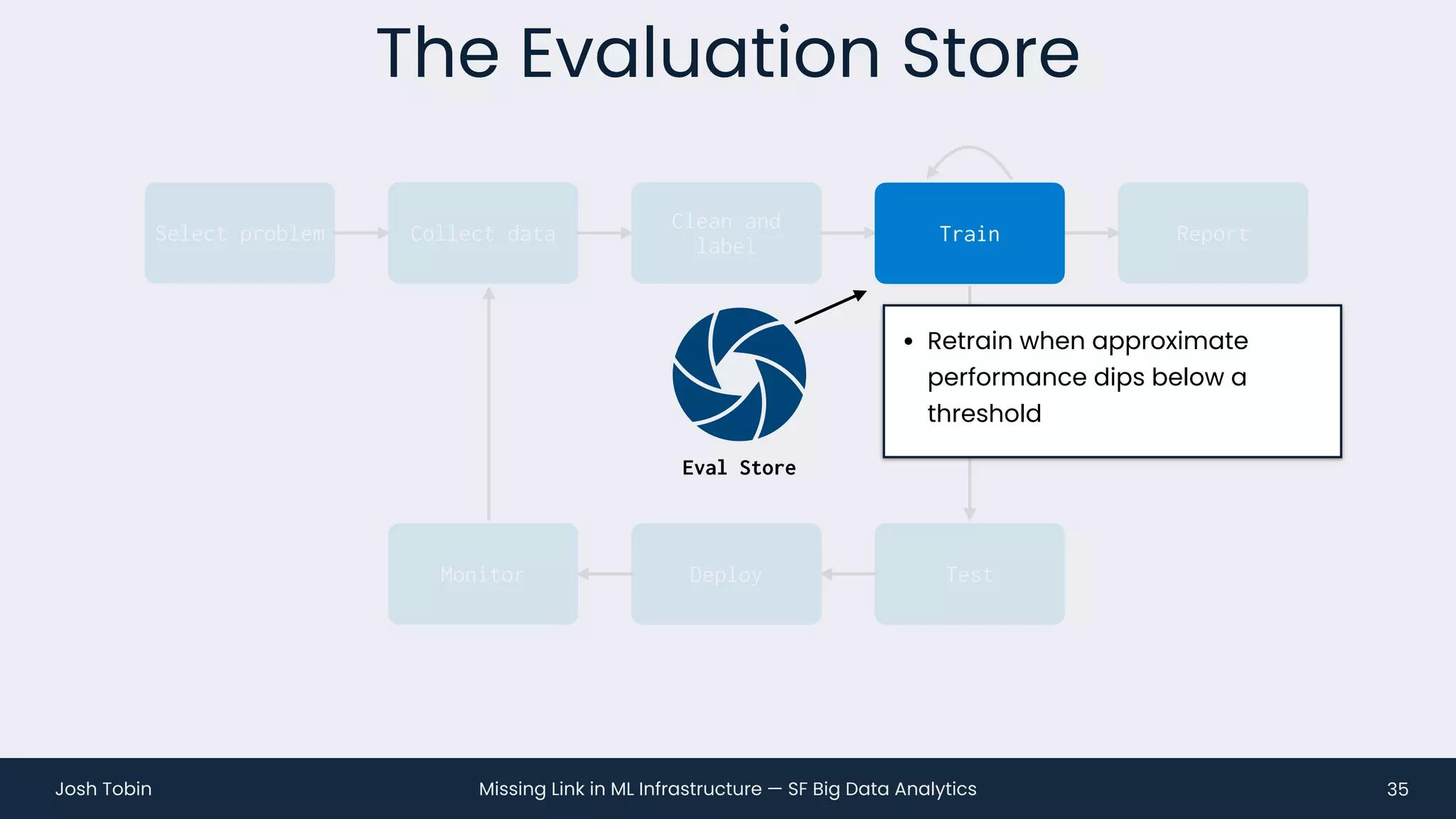




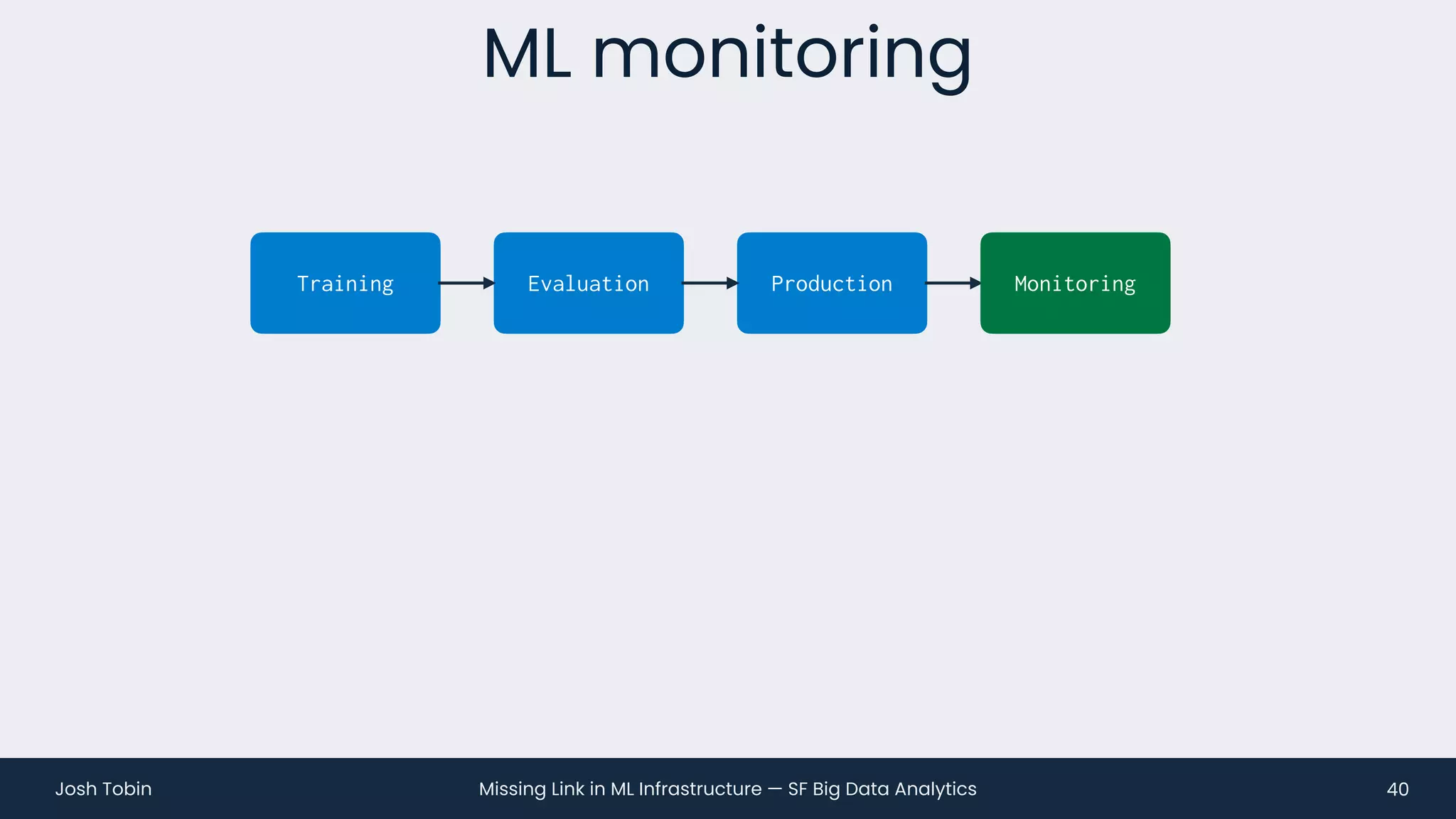
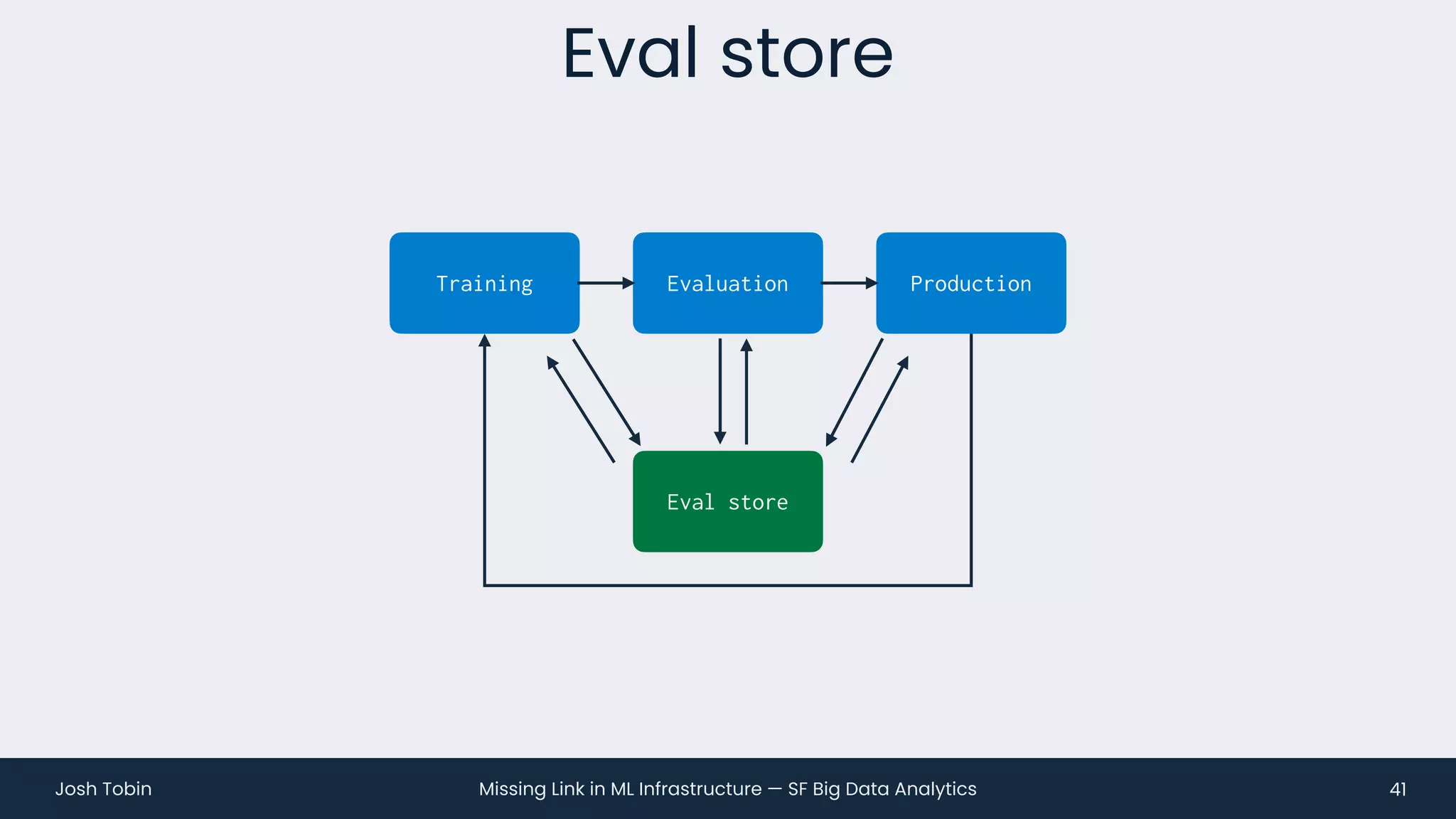
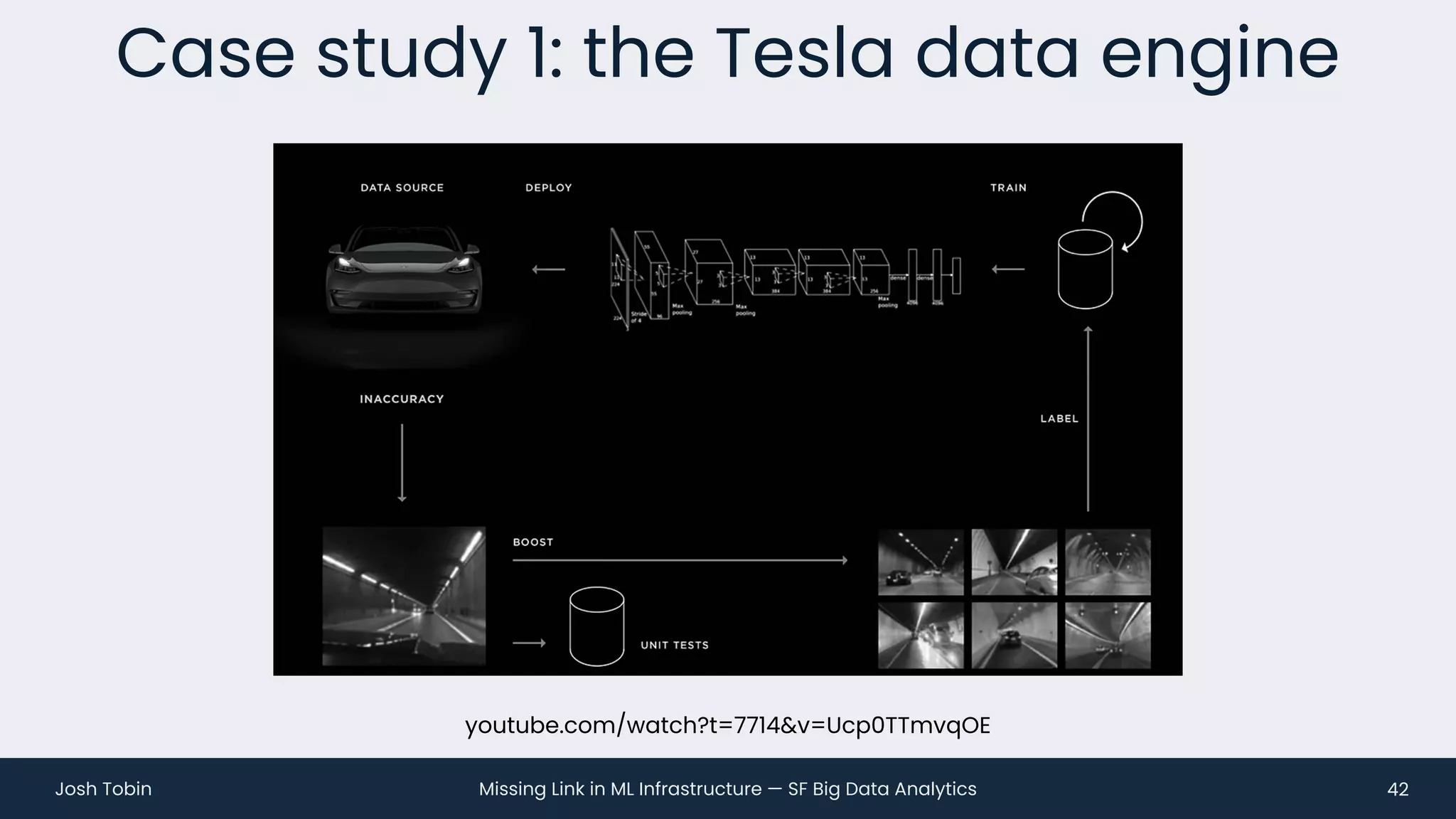
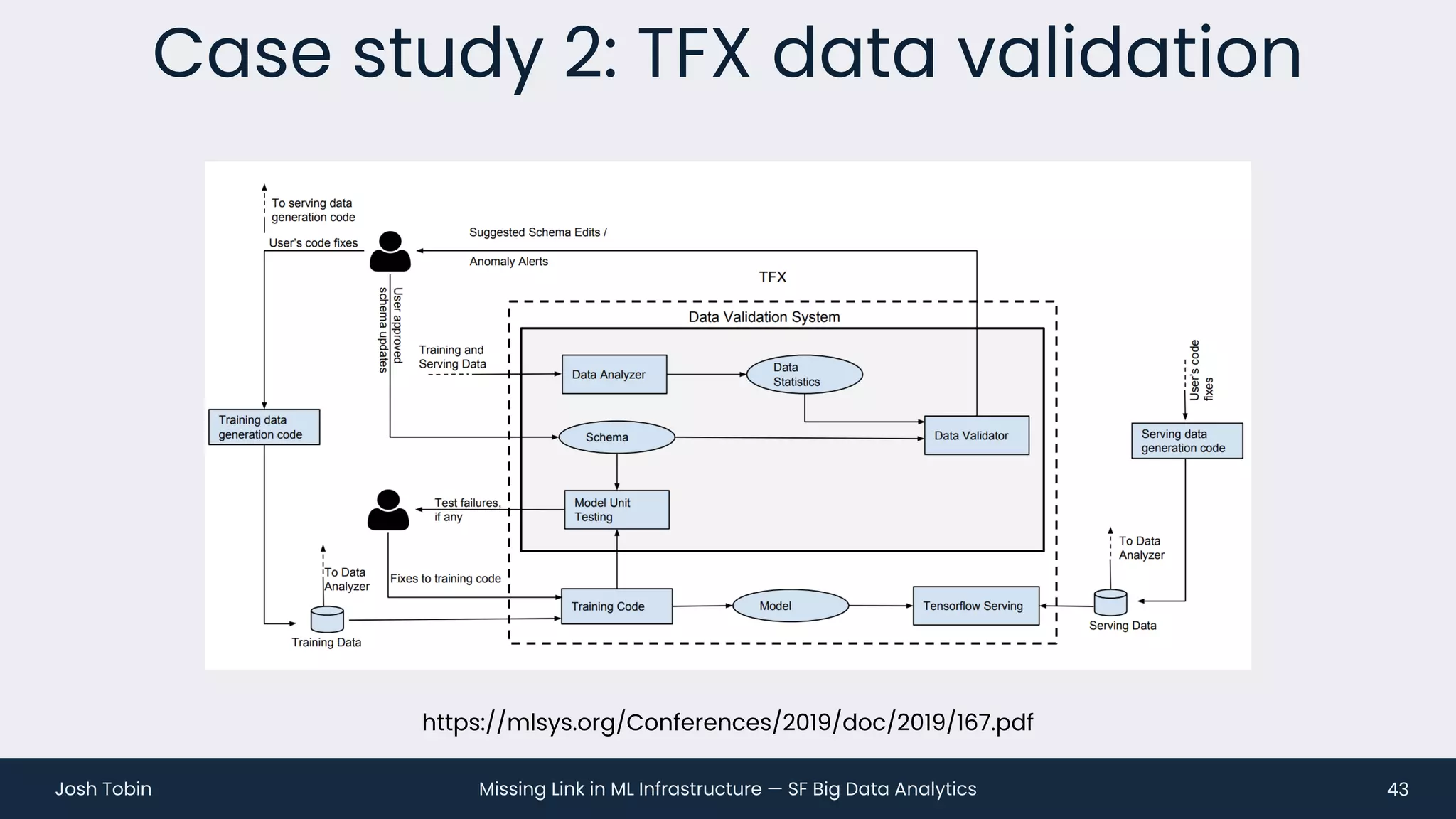















































The document discusses the evolving landscape of machine learning (ML) infrastructure, emphasizing the shift from simple offline models to the need for scalable and maintainable ML products that deliver business value. It highlights the challenges in creating effective ML products, such as performance monitoring, retraining, and handling complex data distributions, and suggests the importance of an evaluation store to track model performance and facilitate better decision-making. The document ultimately argues that an integrated ML infrastructure is crucial for fostering innovation and improving business outcomes.



































































