






































































The document discusses the zero-shot learning capabilities of the CLIP model from OpenAI, including applications in zero-shot classification, image ranking, and search. It highlights the model's training process, limitations, and performance metrics, particularly in context with datasets like FairFace. Additionally, it touches on concepts like knowledge distillation, generative adversarial networks, and alternatives for object detection and segmentation.
Overview of CLIP model's zero-shot learning capabilities and presenter's background.
Definition of Zero-Shot Learning, its motivation linked to costly datasets, and its connection between text and images.
Details on CLIP pre-training, featuring 400 million image-text pairs, and specifications of training resources.
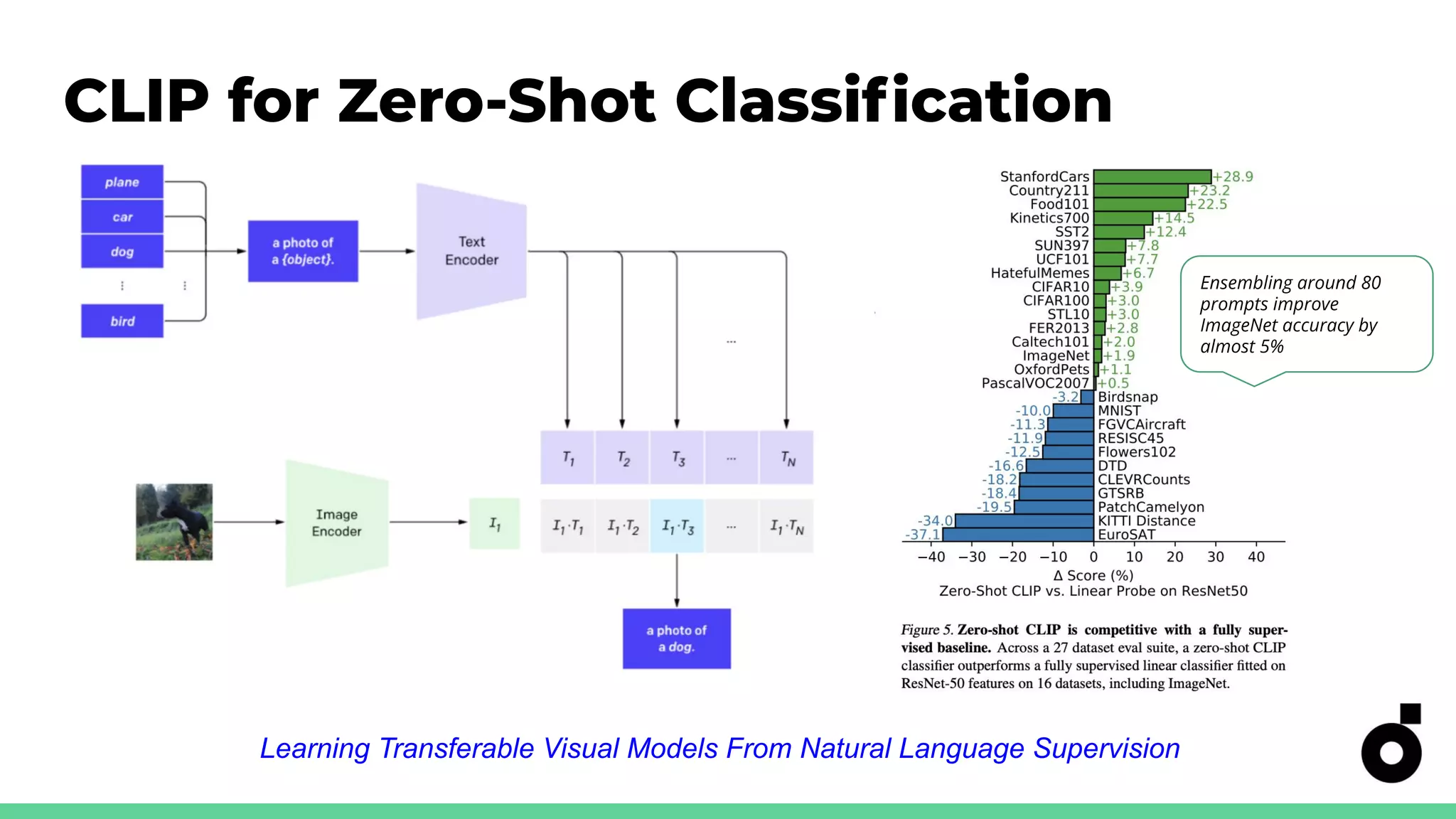
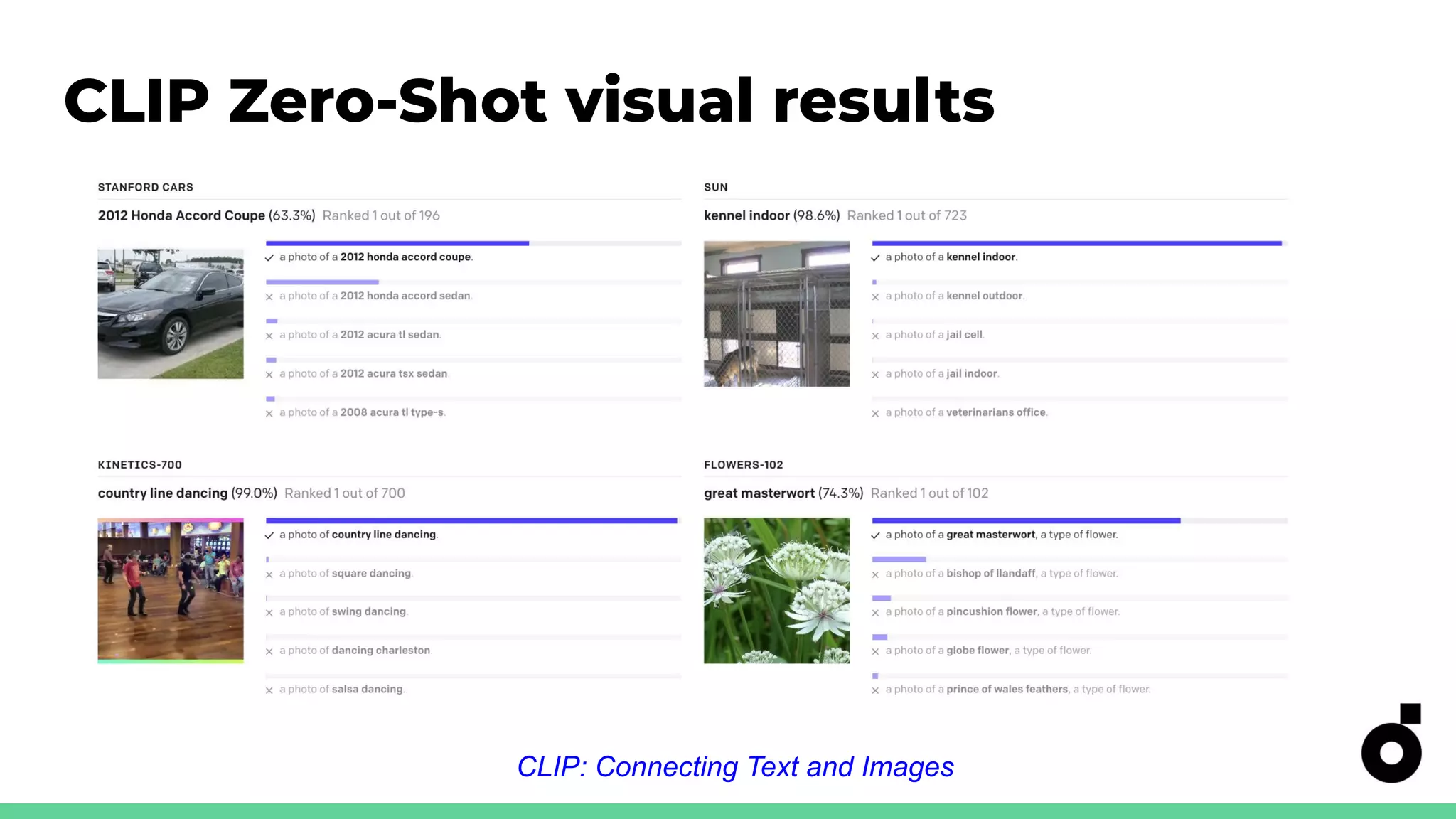
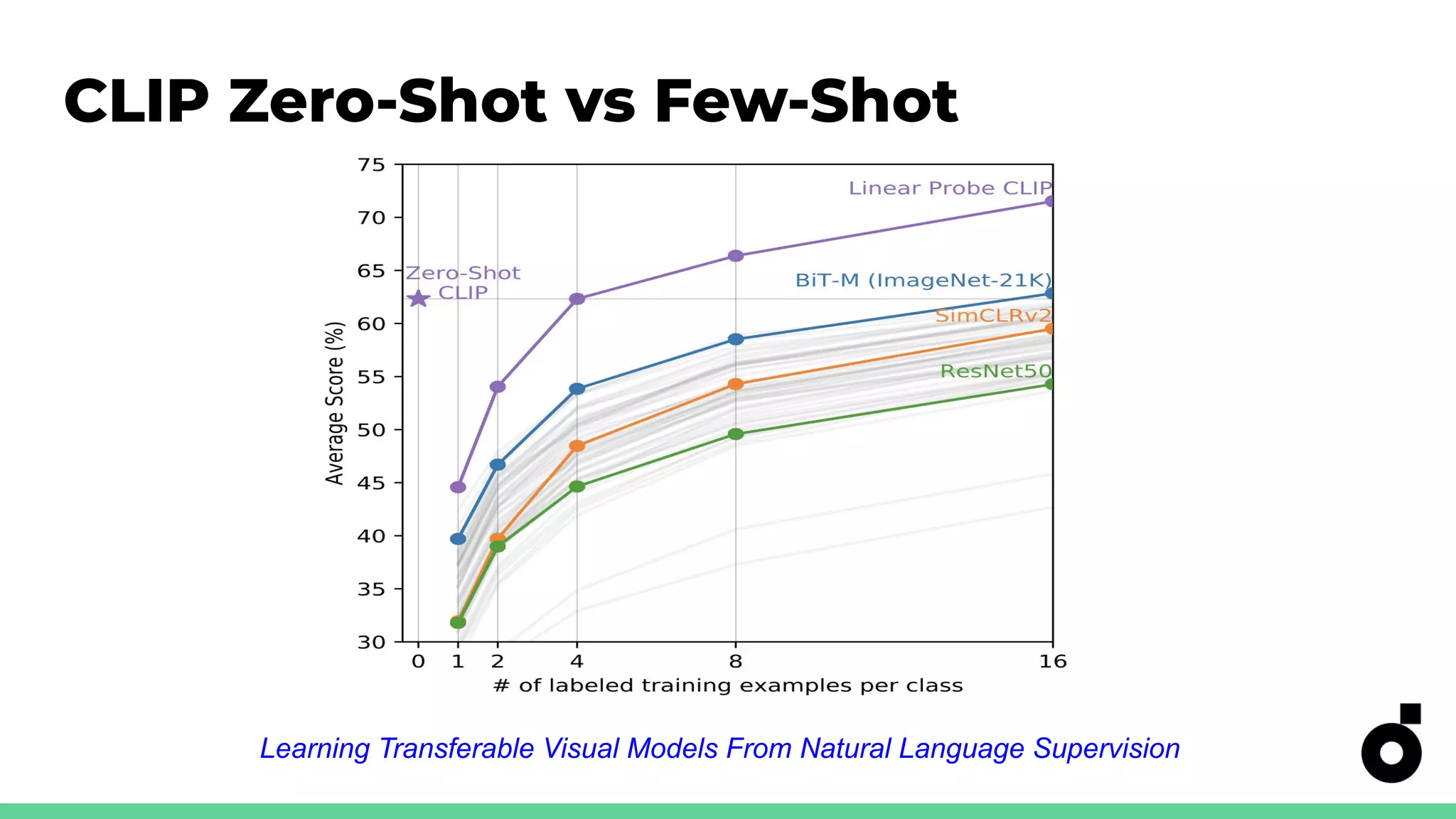
CLIP's capabilities in zero-shot classification and its accuracy metrics for real-world applications.
CLIP's capabilities in zero-shot classification and its accuracy metrics for real-world applications.
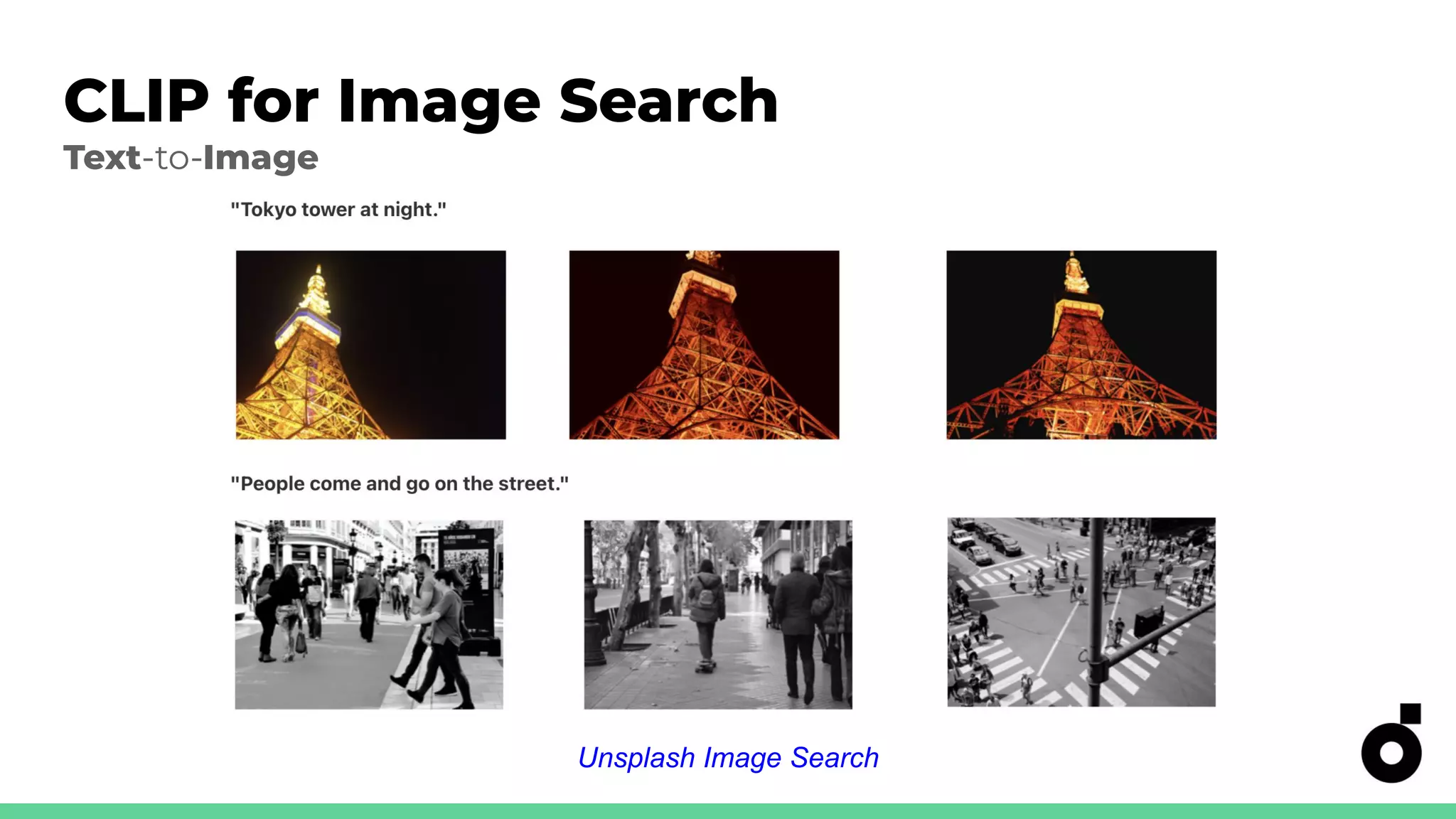
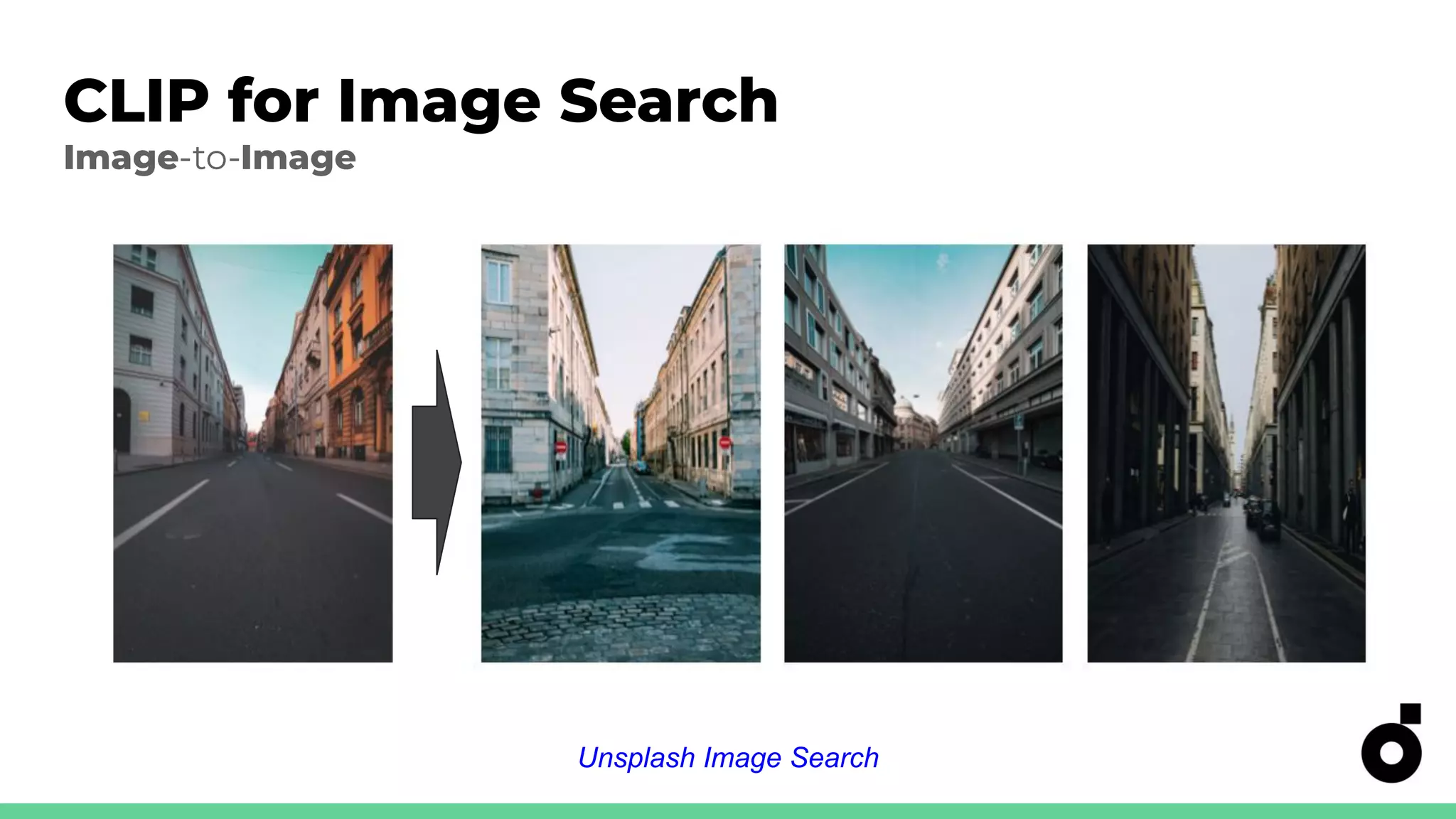
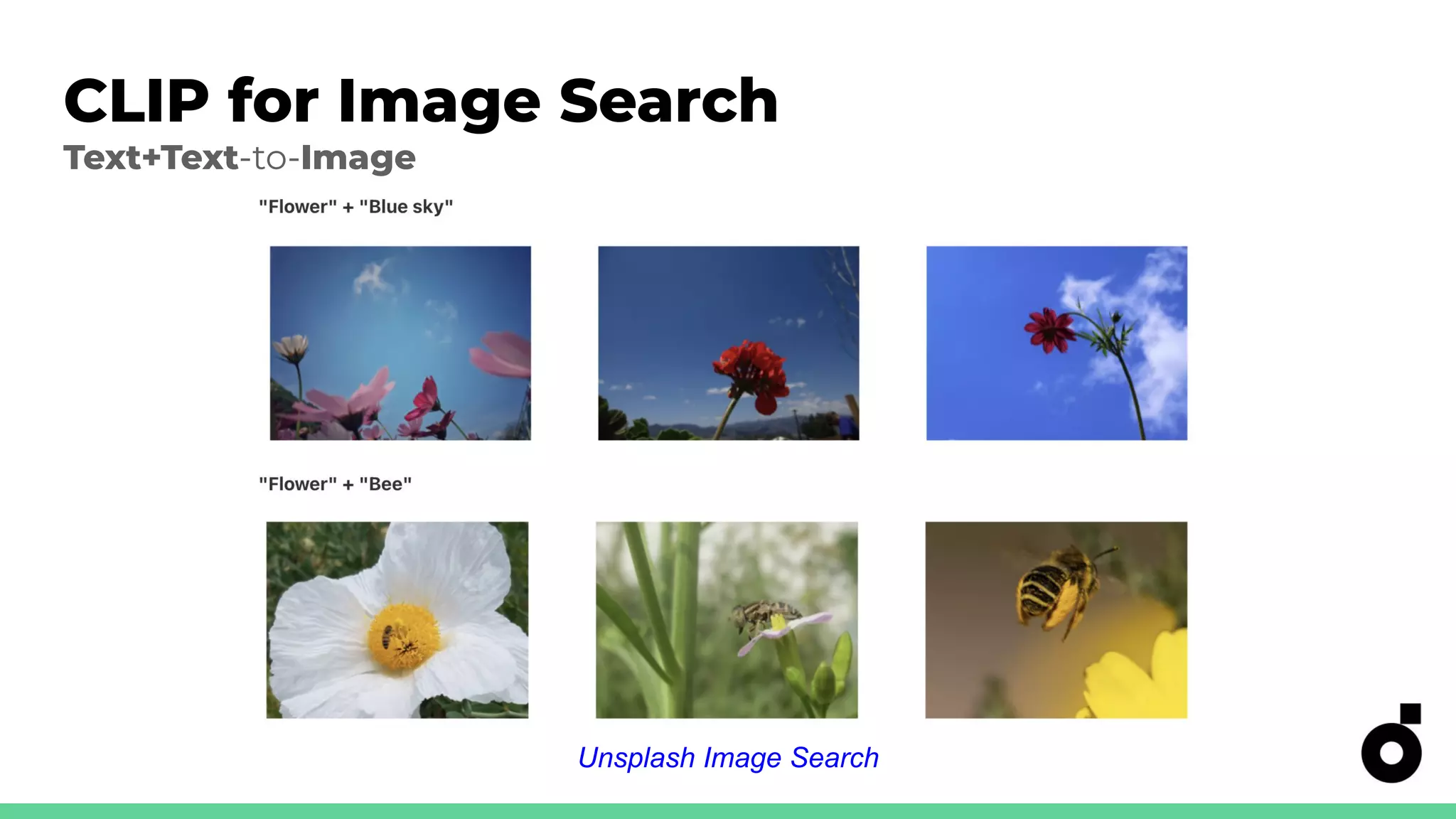
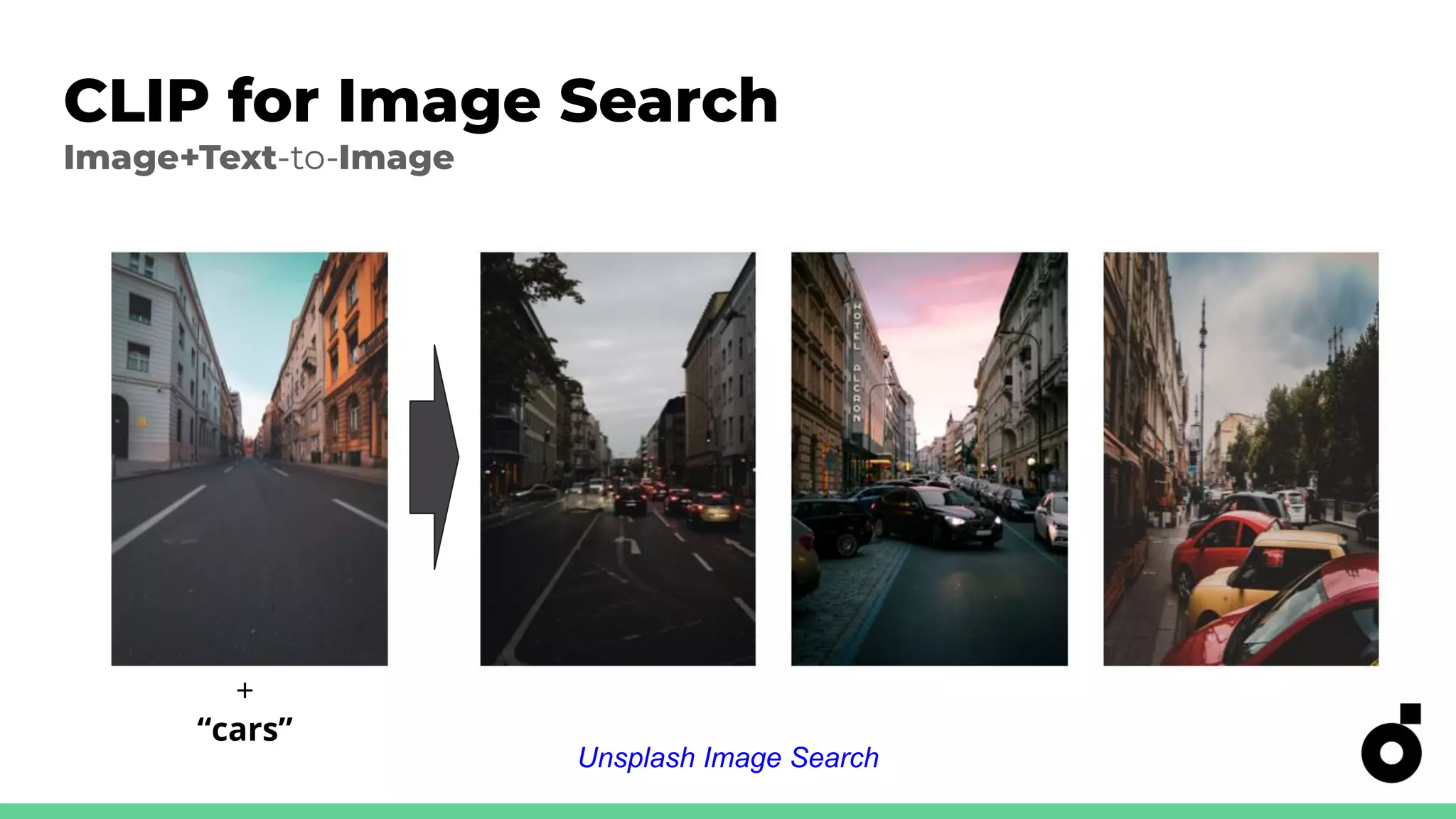
Applications of CLIP in image ranking and search using various text inputs.
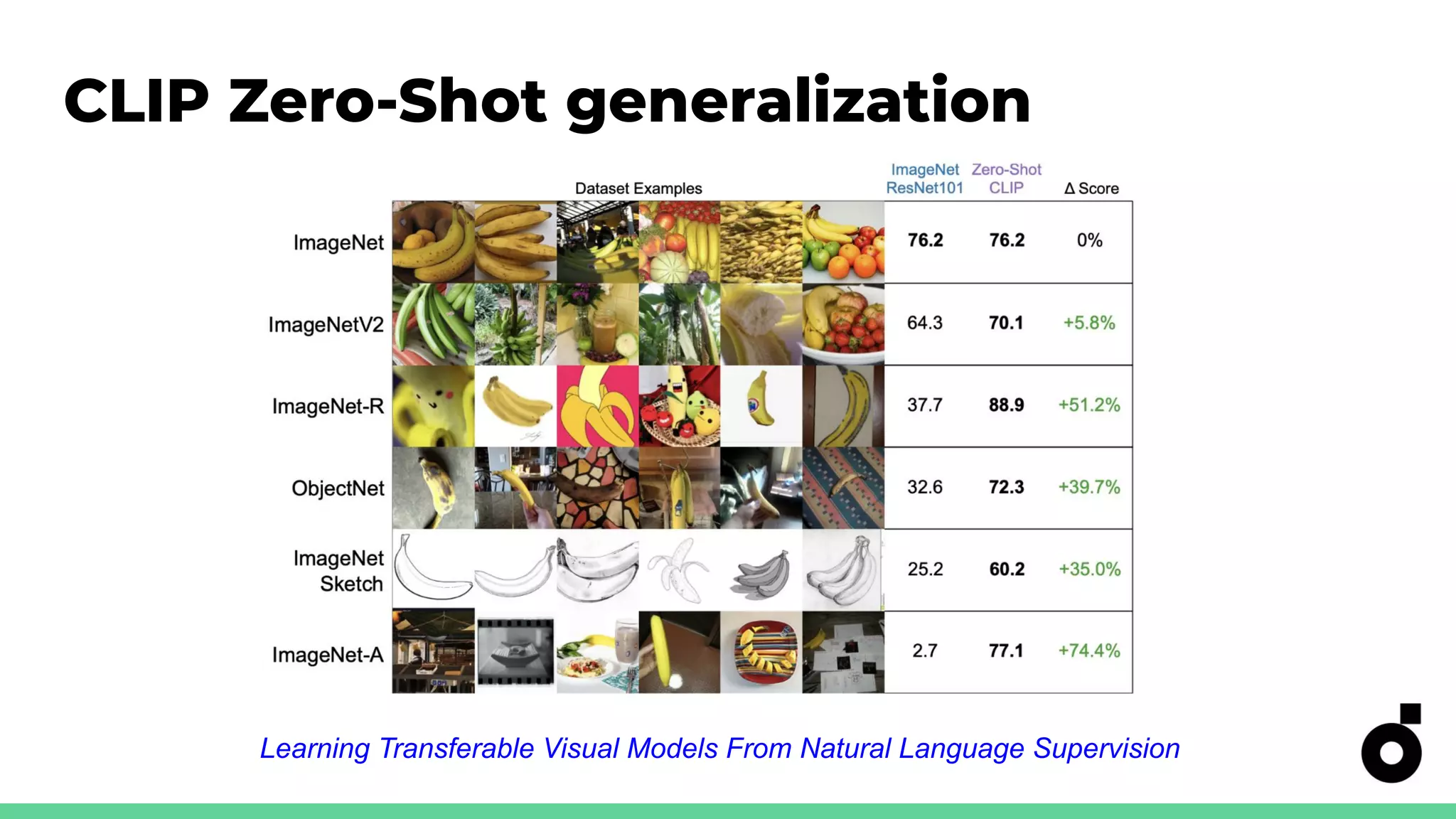
Challenges with CLIP, including poor generalization and sensitivity to wording in zero-shot classification.
Challenges with CLIP, including poor generalization and sensitivity to wording in zero-shot classification.
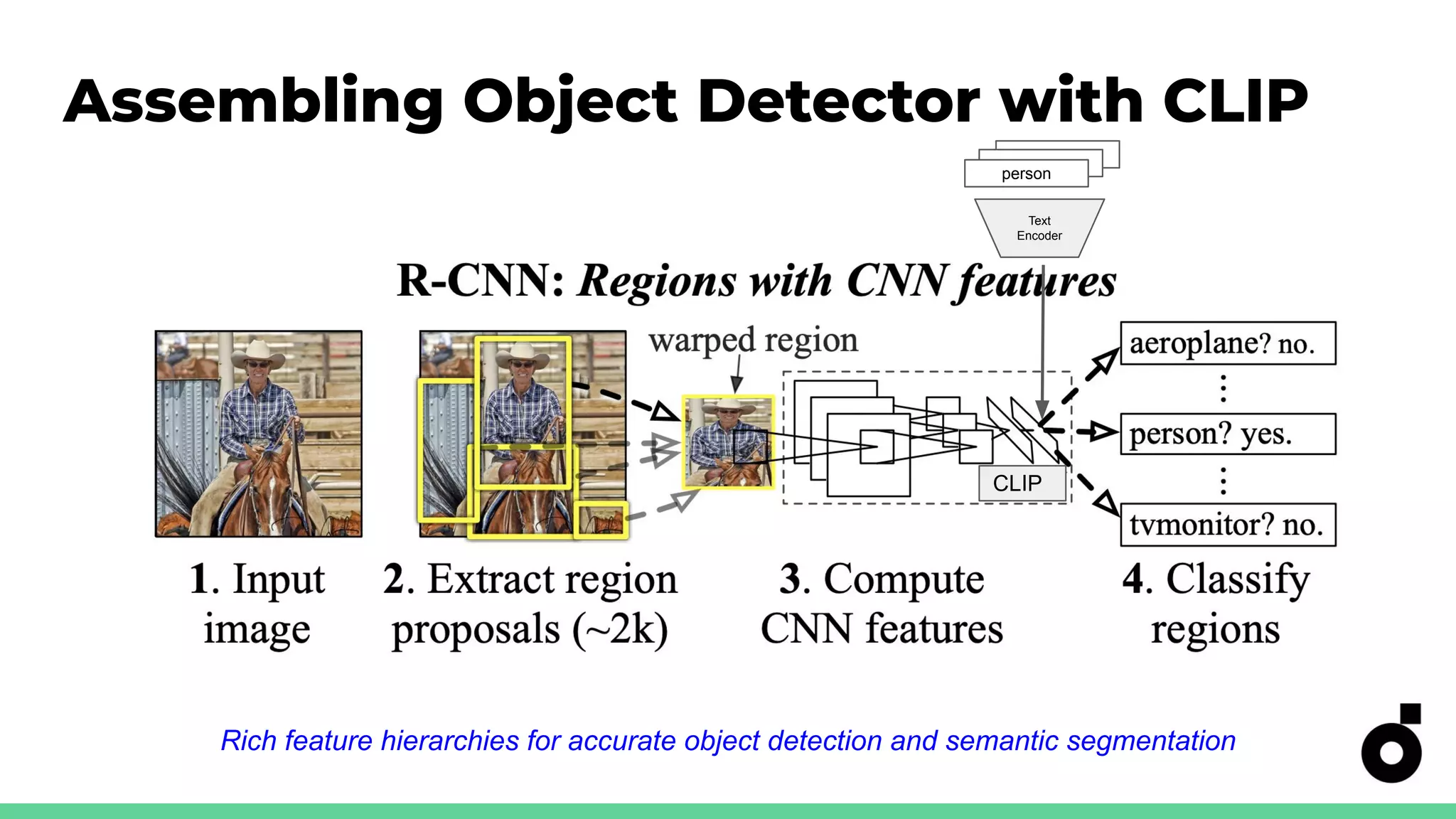
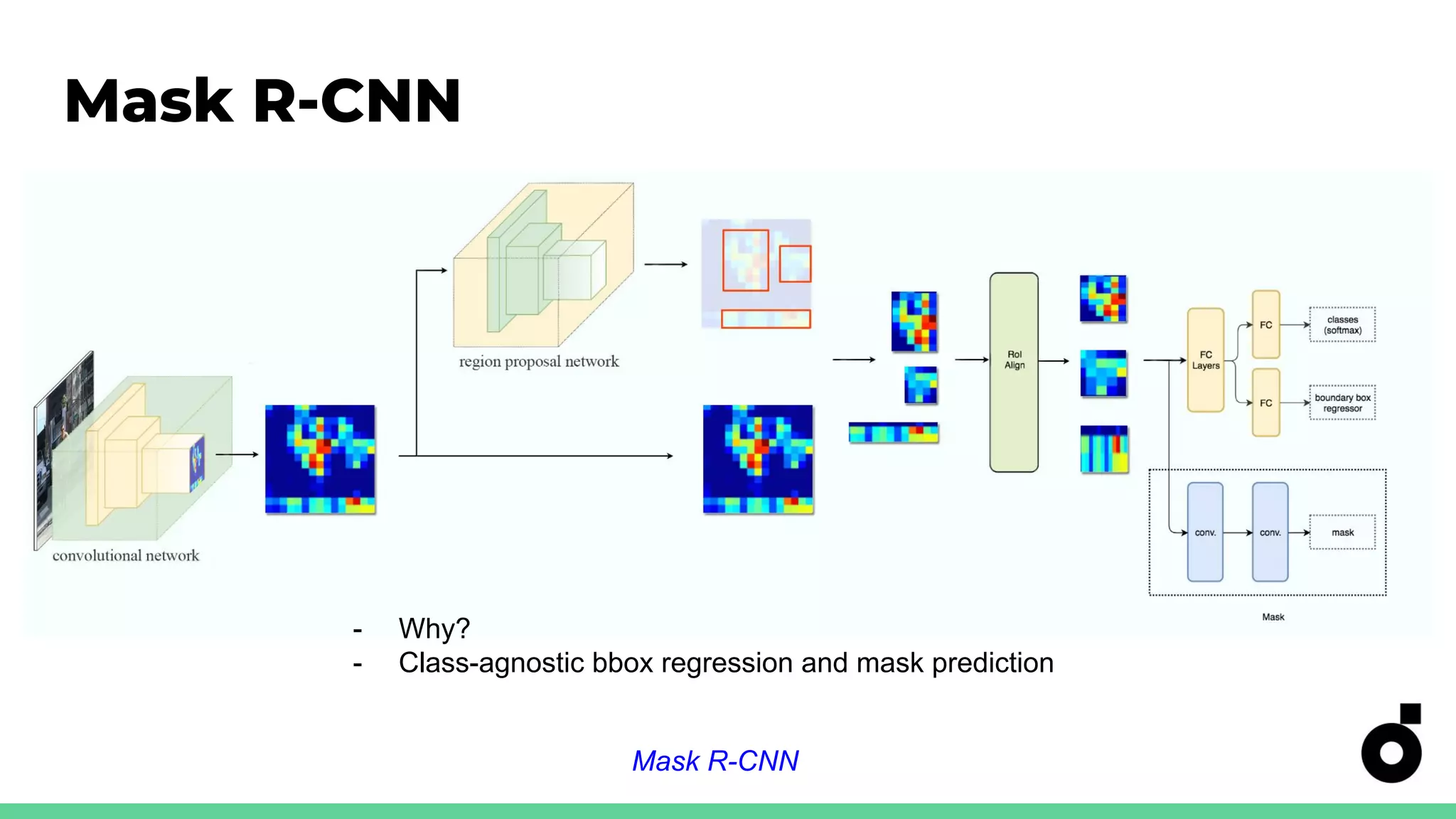
Strategies for utilizing CLIP in object detection tasks, highlighting importance of feature hierarchies.
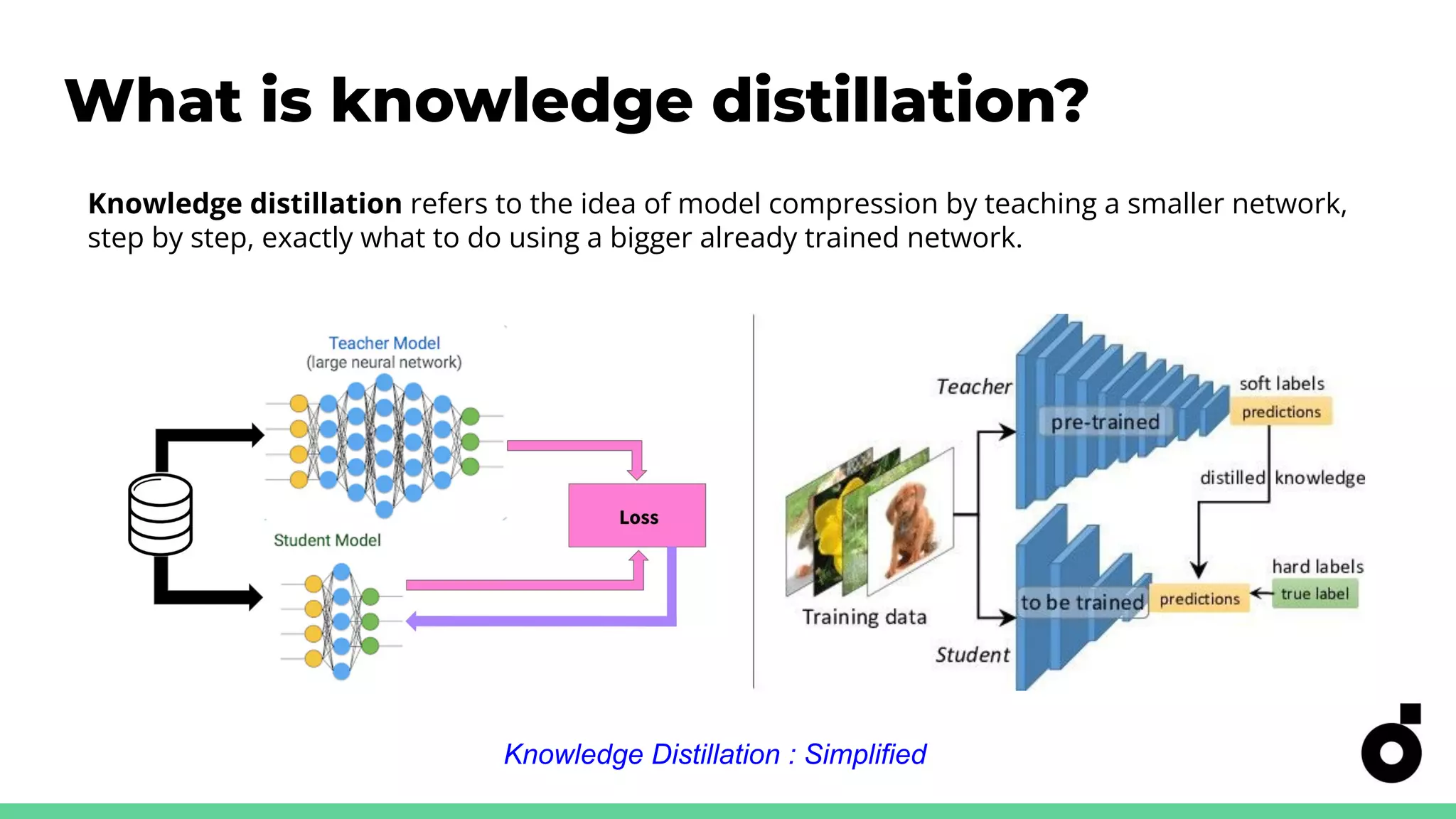
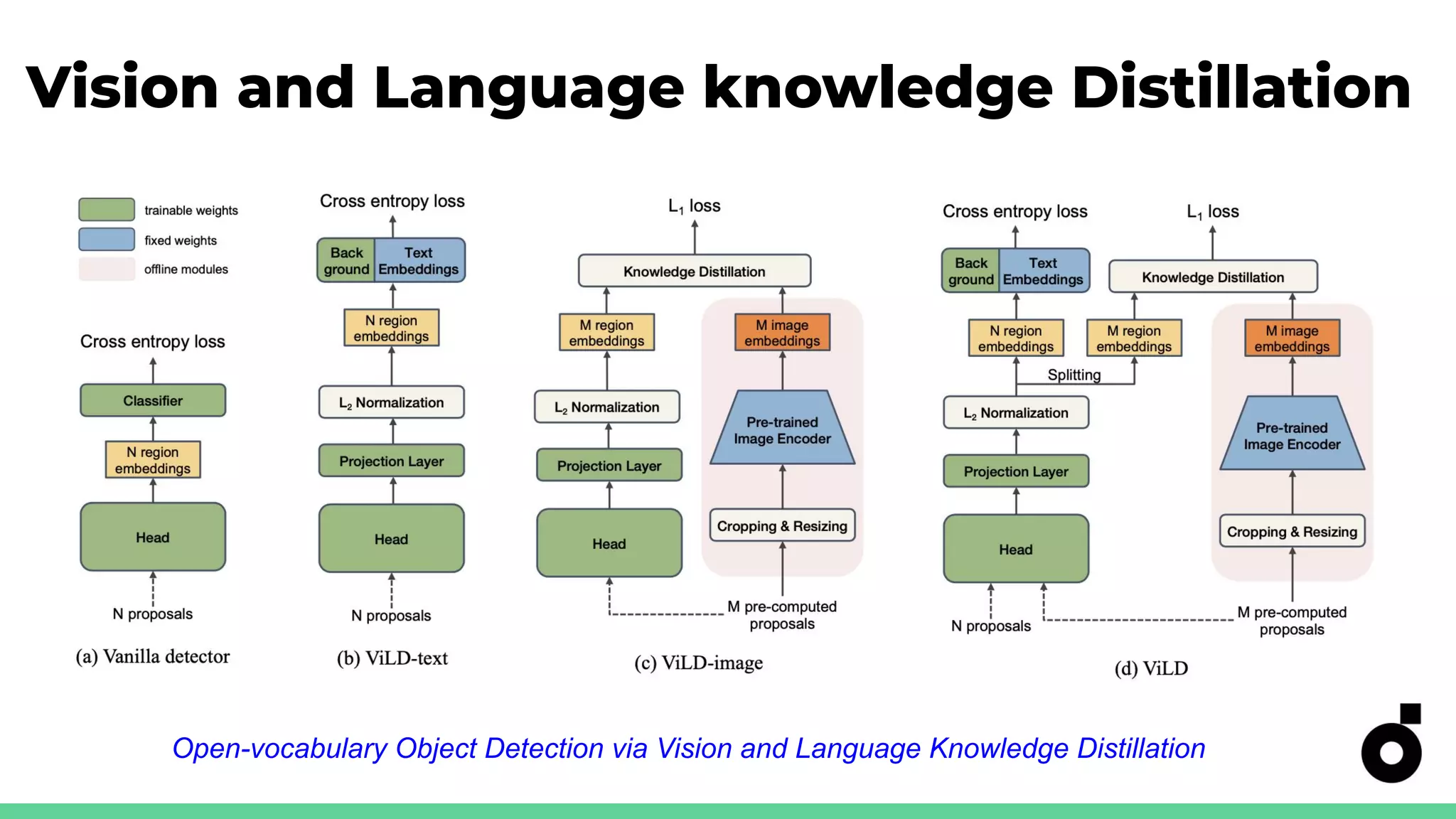
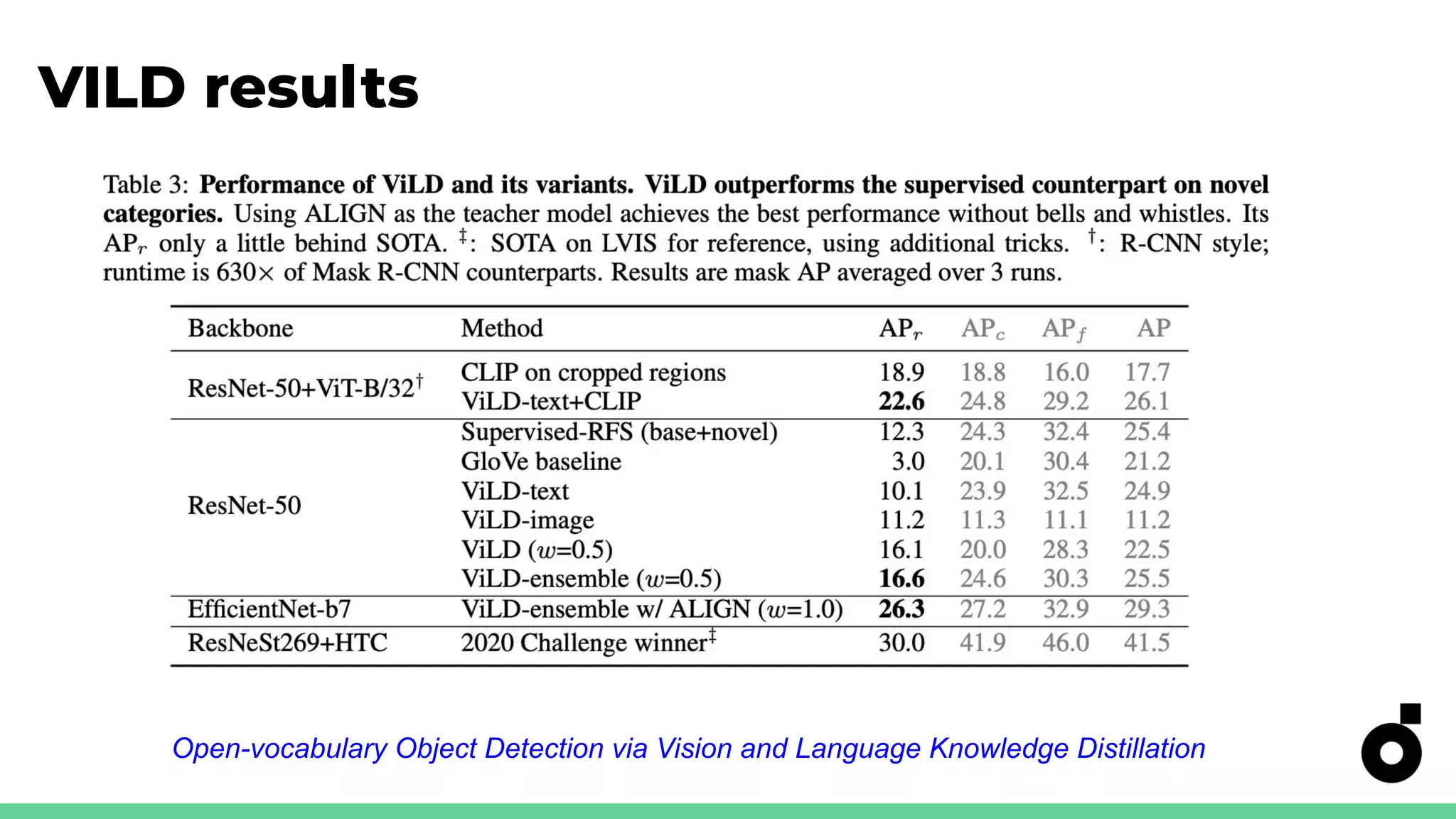
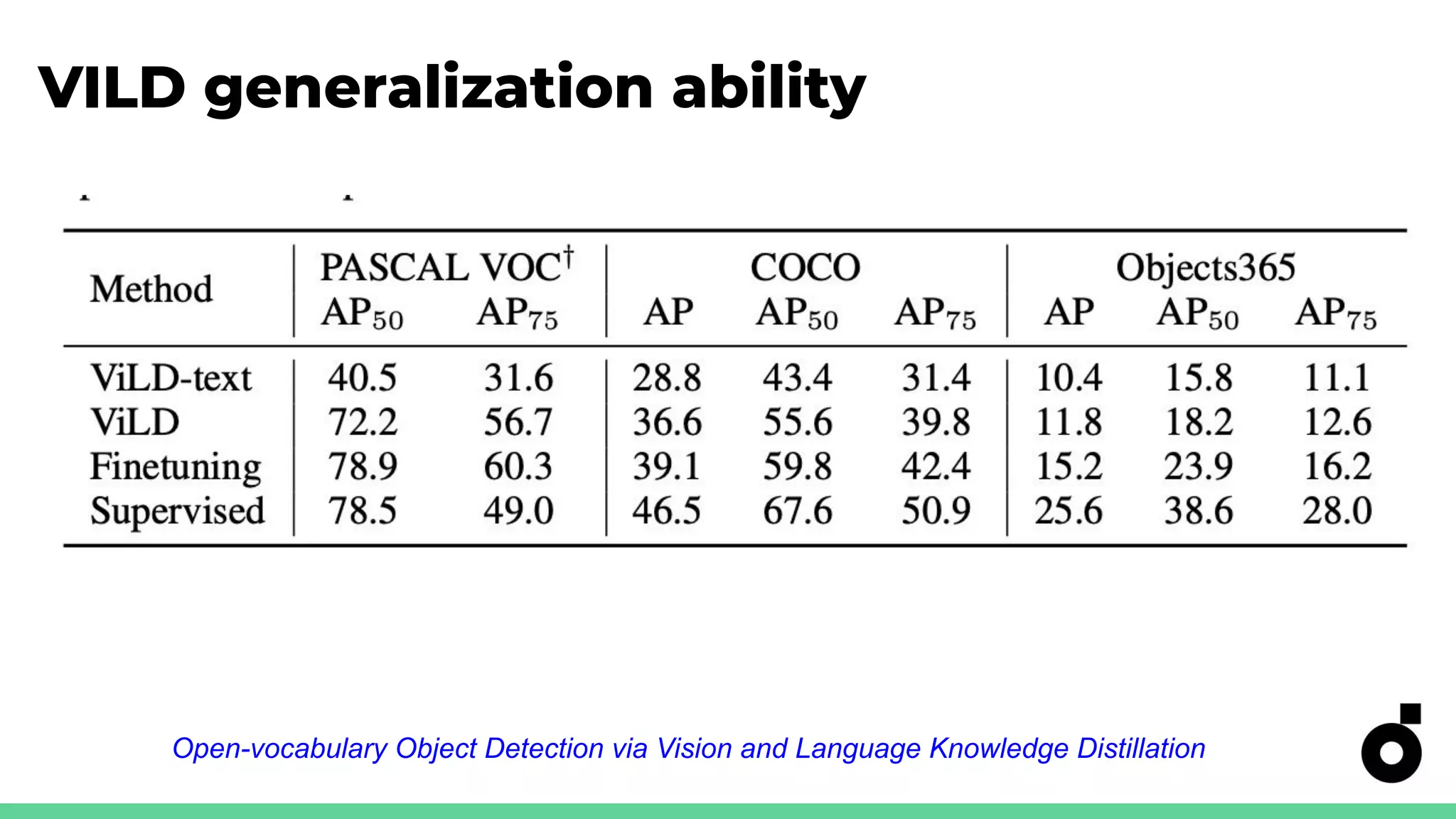
Explains knowledge distillation for model compression, focusing on open-vocabulary object detection.
Explains knowledge distillation for model compression, focusing on open-vocabulary object detection.
Explains knowledge distillation for model compression, focusing on open-vocabulary object detection.
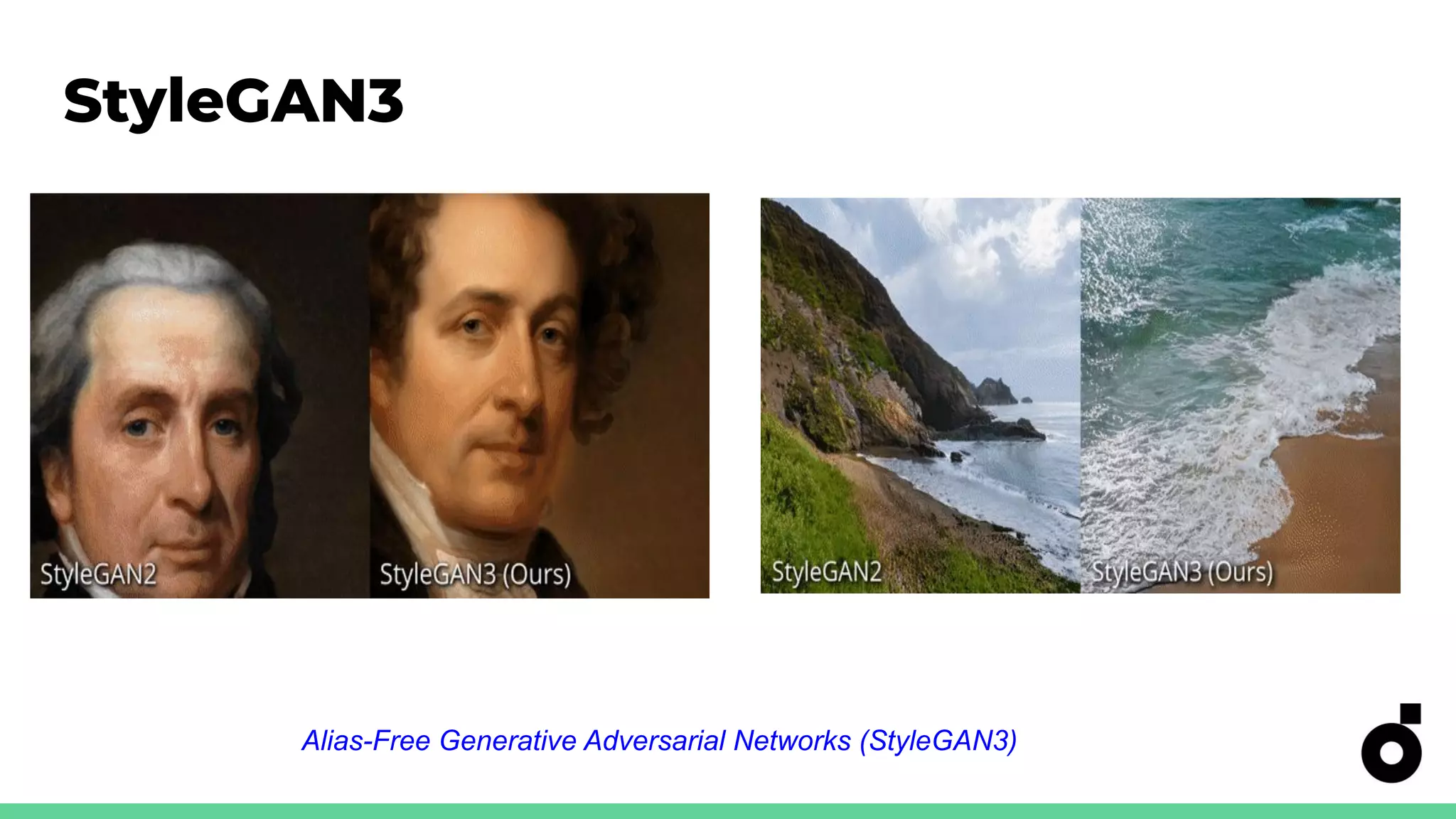
Integration of VQGAN, StyleCLIP, and StyleGAN3 with CLIP for varied generative tasks.
Closing remarks by the presenter, thanking the audience and providing contact info.
















![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 24] Nemanja Milosevic - Beyond Supervised Learning with Zero-Shot...](https://cdn.slidesharecdn.com/ss_thumbnails/nemanjamilosevic-241219150756-b1cc16e6-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)

















