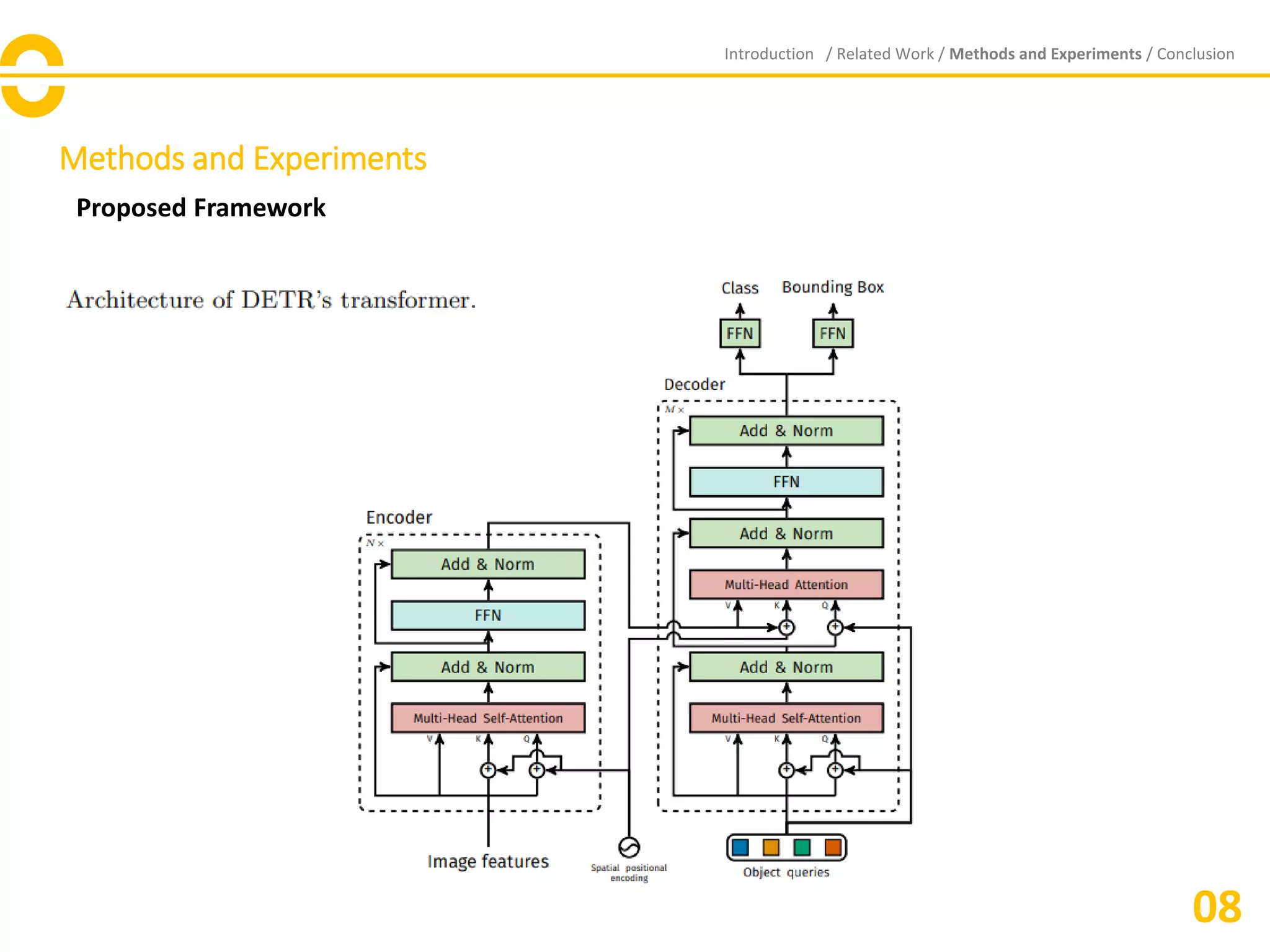
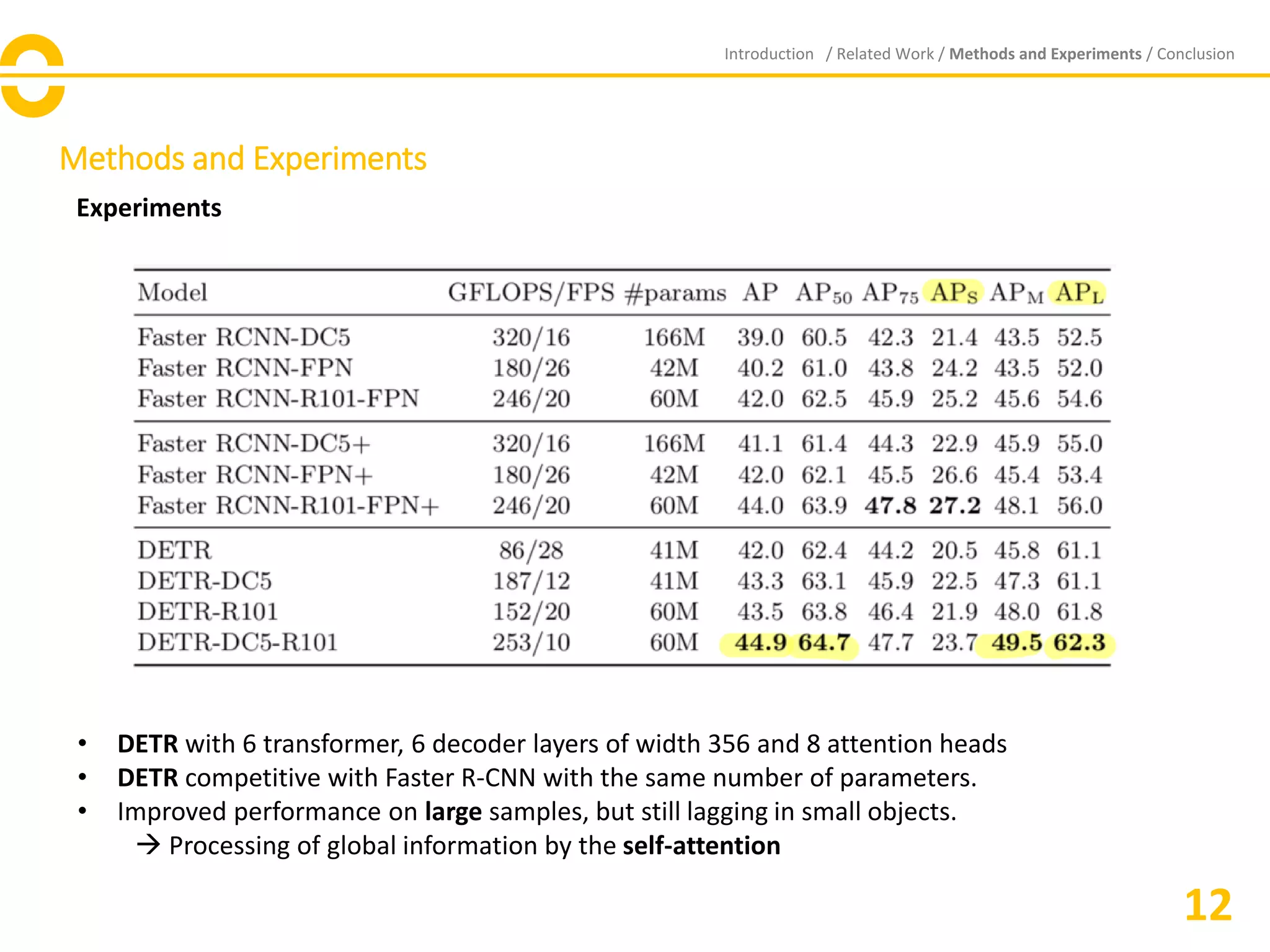
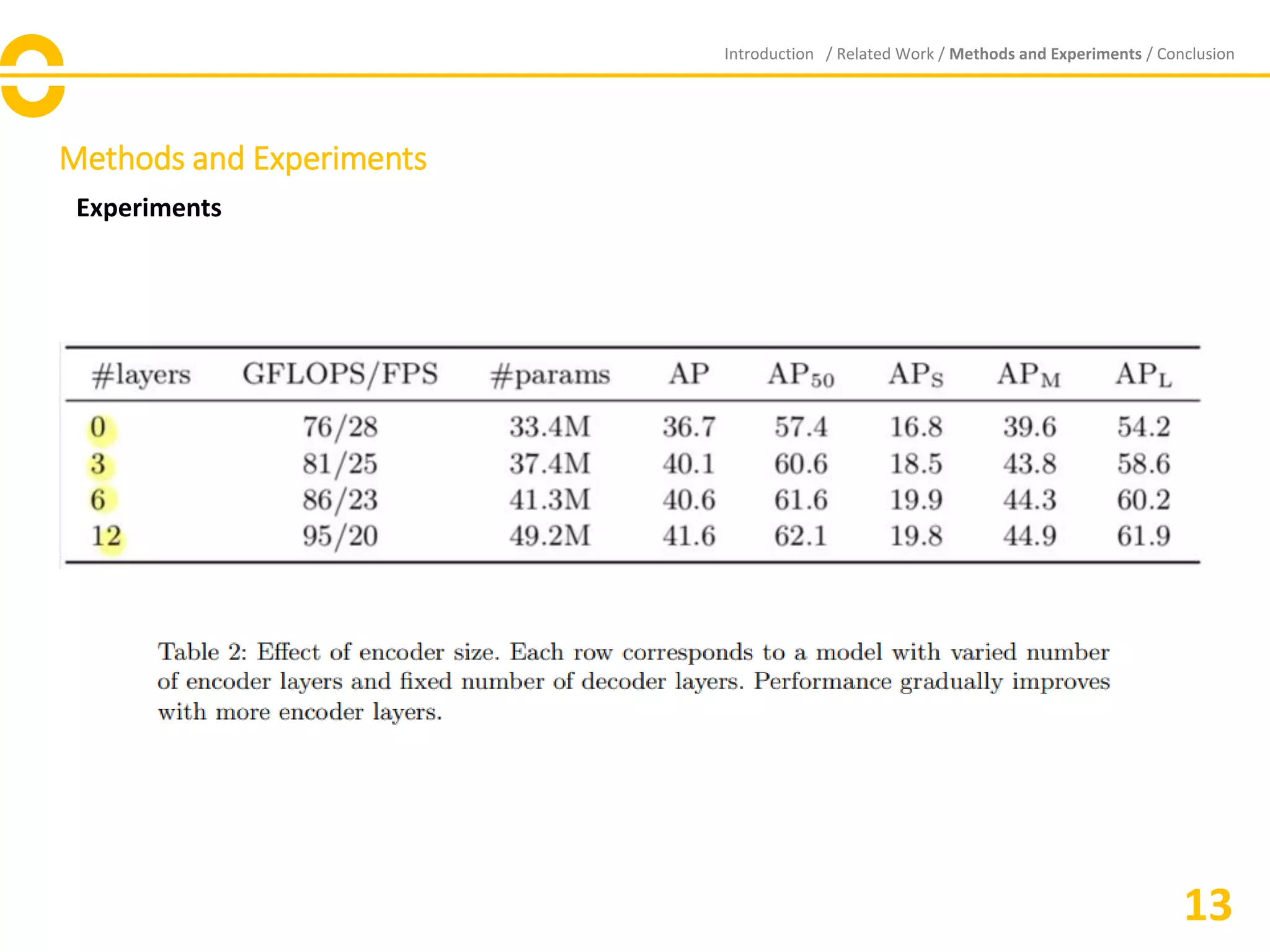
The document presents the Detection Transformer (DETR), an innovative end-to-end object detection framework that utilizes transformers and a bipartite matching loss for direct set prediction. DETR simplifies traditional detection processes by eliminating components like spatial anchors and non-maximum suppression, demonstrating competitive accuracy and performance compared to Faster R-CNN on the COCO dataset. While it excels at detecting large objects, DETR faces challenges with small object detection and necessitates further optimization and training refinements.



![Introduction – Proposal
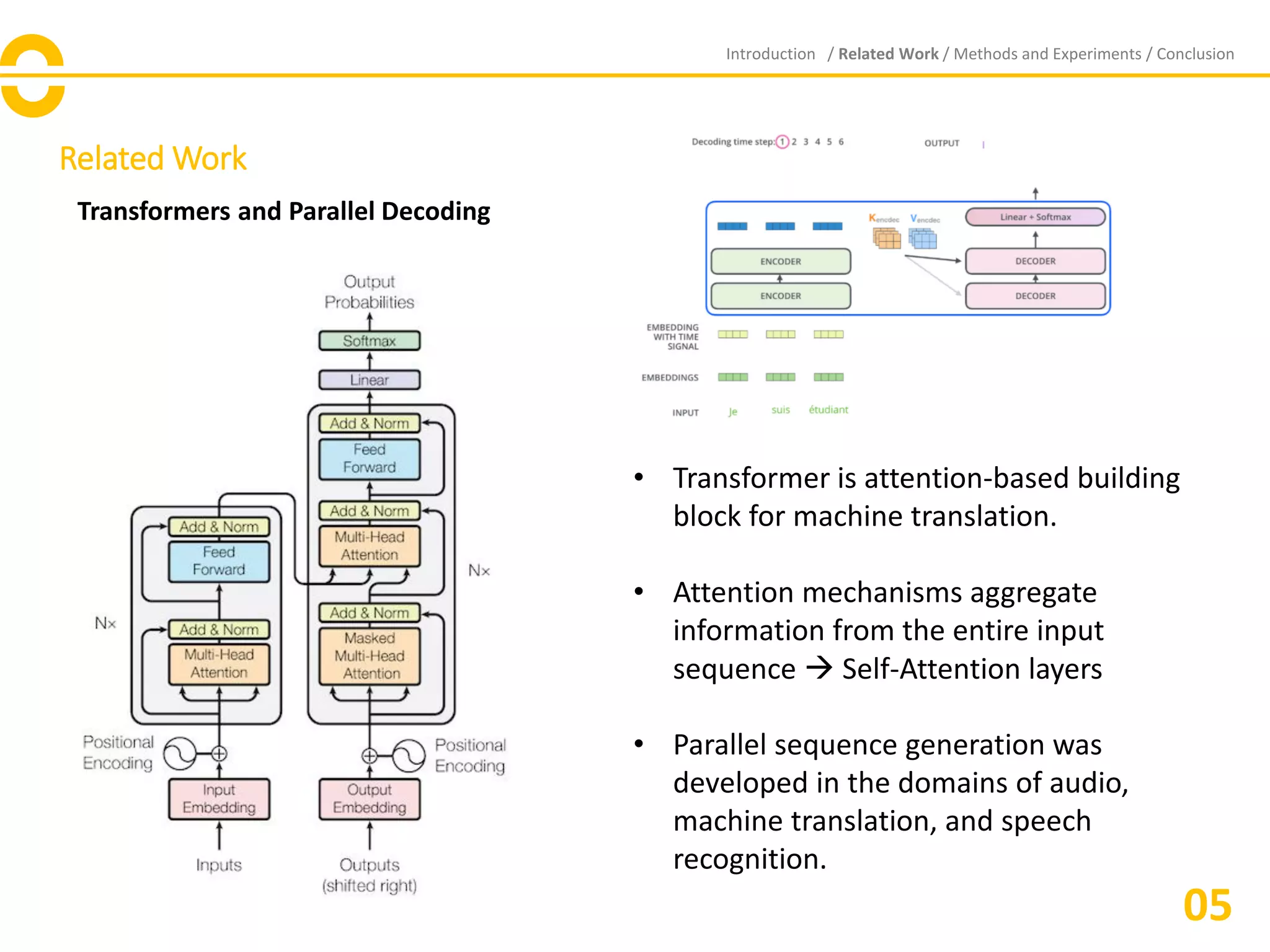
• Propose a direct set prediction approach to bypass the surrogate tasks.
• Adopt an encoder-decoder architecture based on transformers.
• Self-attention mechanisms of transformers, which model all pairwise interactions
between elements in a sequence, helps remove duplicate predictions.
• DEtection TRansformer (DETR) predicts all objects at once in end-to-end manner, with a
set loss function which performs bipartite matching between predicted and GT objects.
• DETR are the conjunction of the bipartite matching loss, transformers, with parallel
decoding.
Introduction / Related Work / Methods and Experiments / Conclusion
02
[Overview of proposed framework]
DETR](https://image.slidesharecdn.com/detrreview-201025124505/75/End-to-End-Object-Detection-with-Transformers-4-2048.jpg)


![Related Work
Introduction / Related Work / Methods and Experiments / Conclusion
06
Object Detection
• Two-stage detectors that predict boxes
w.r.t proposals
• Single-stage methods make predictions
w.r.t anchors or a grid of possible
object centers.
• DETR remove this hand-crafted process
by directly predicting the set of
detections with absolute box prediction
w.r.t the input image.
[YOLO]
[R-CNN]](https://image.slidesharecdn.com/detrreview-201025124505/75/End-to-End-Object-Detection-with-Transformers-8-2048.jpg)











![Introduction – Proposal
• Propose a direct set prediction approach to bypass the surrogate tasks.
• Adopt an encoder-decoder architecture based on transformers.
• Self-attention mechanisms of transformers, which model all pairwise interactions
between elements in a sequence, helps remove duplicate predictions.
• DEtection TRansformer (DETR) predicts all objects at once in end-to-end manner, with a
set loss function which performs bipartite matching between predicted and GT objects.
• DETR are the conjunction of the bipartite matching loss, transformers, with parallel
decoding.
Introduction / Related Work / Methods and Experiments / Conclusion
02
[Overview of proposed framework]
DETR](https://crownmelresort.com/image.slidesharecdn.com/detrreview-201025124505/75/End-to-End-Object-Detection-with-Transformers-4-2048.jpg)



![Related Work
Introduction / Related Work / Methods and Experiments / Conclusion
06
Object Detection
• Two-stage detectors that predict boxes
w.r.t proposals
• Single-stage methods make predictions
w.r.t anchors or a grid of possible
object centers.
• DETR remove this hand-crafted process
by directly predicting the set of
detections with absolute box prediction
w.r.t the input image.
[YOLO]
[R-CNN]](https://crownmelresort.com/image.slidesharecdn.com/detrreview-201025124505/75/End-to-End-Object-Detection-with-Transformers-8-2048.jpg)

















![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)

![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)









































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
