Download as PDF, PPTX

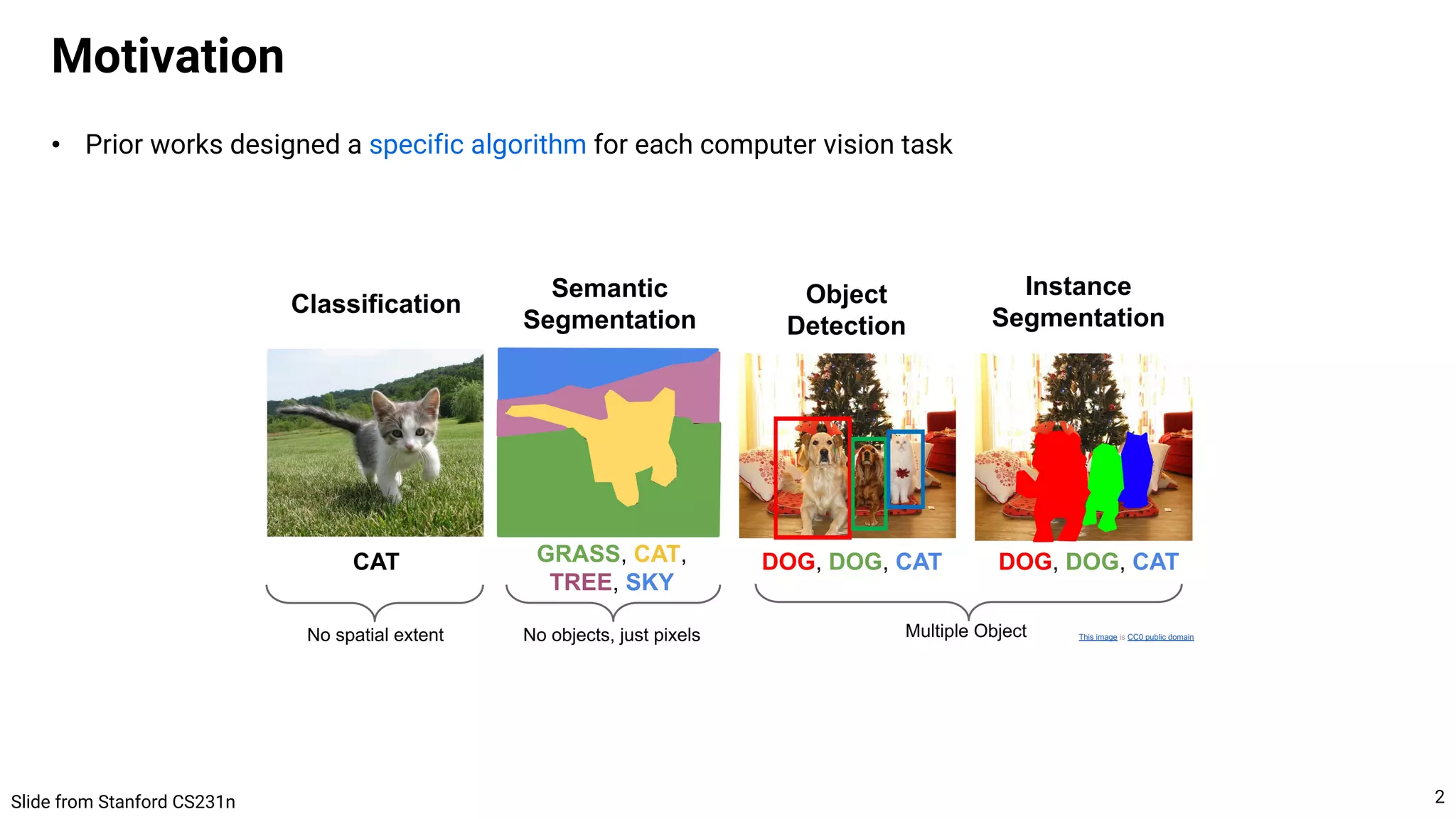



![• Pix2Seq
• Cast object descriptions as a sequence of discrete tokens (bboxes and class labels)
• Training and inference are done as LM (MLE training, stochastic decoding)
• Each object = {4 bbox coordinates + 1 class label}
• The coordinate is quantized to 𝑛!"#$ values, hence the vocab size = 𝑛!"#$ + 𝑛%&'$$ + 1 for [EOS] token
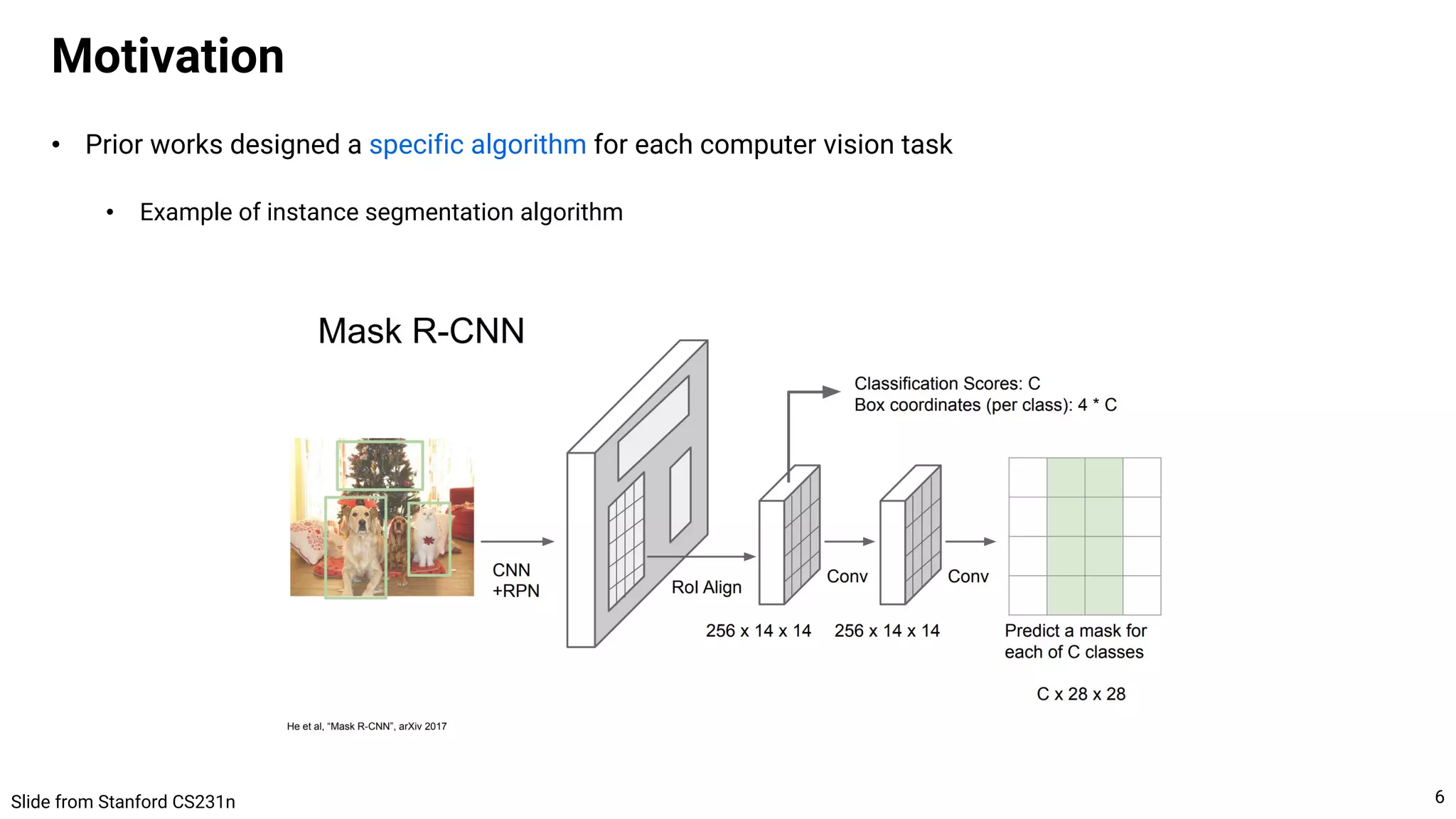
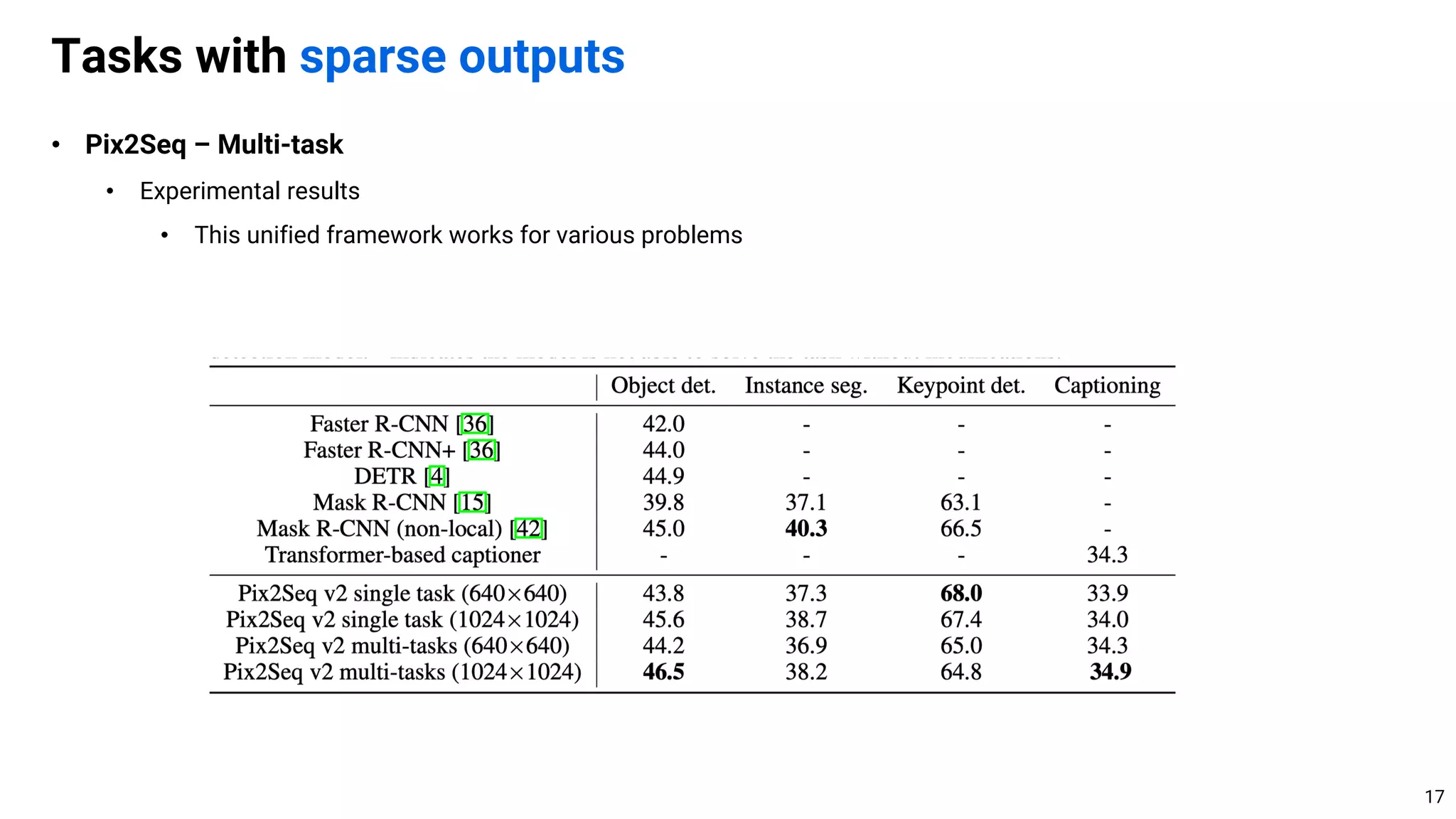
Tasks with sparse outputs
10
CNN encoder + Transformer decoder](https://image.slidesharecdn.com/221017visionbygen-221017213905-7e62b51d/75/A-Unified-Framework-for-Computer-Vision-Tasks-Conditional-Generative-Model-is-All-You-Need-10-2048.jpg)

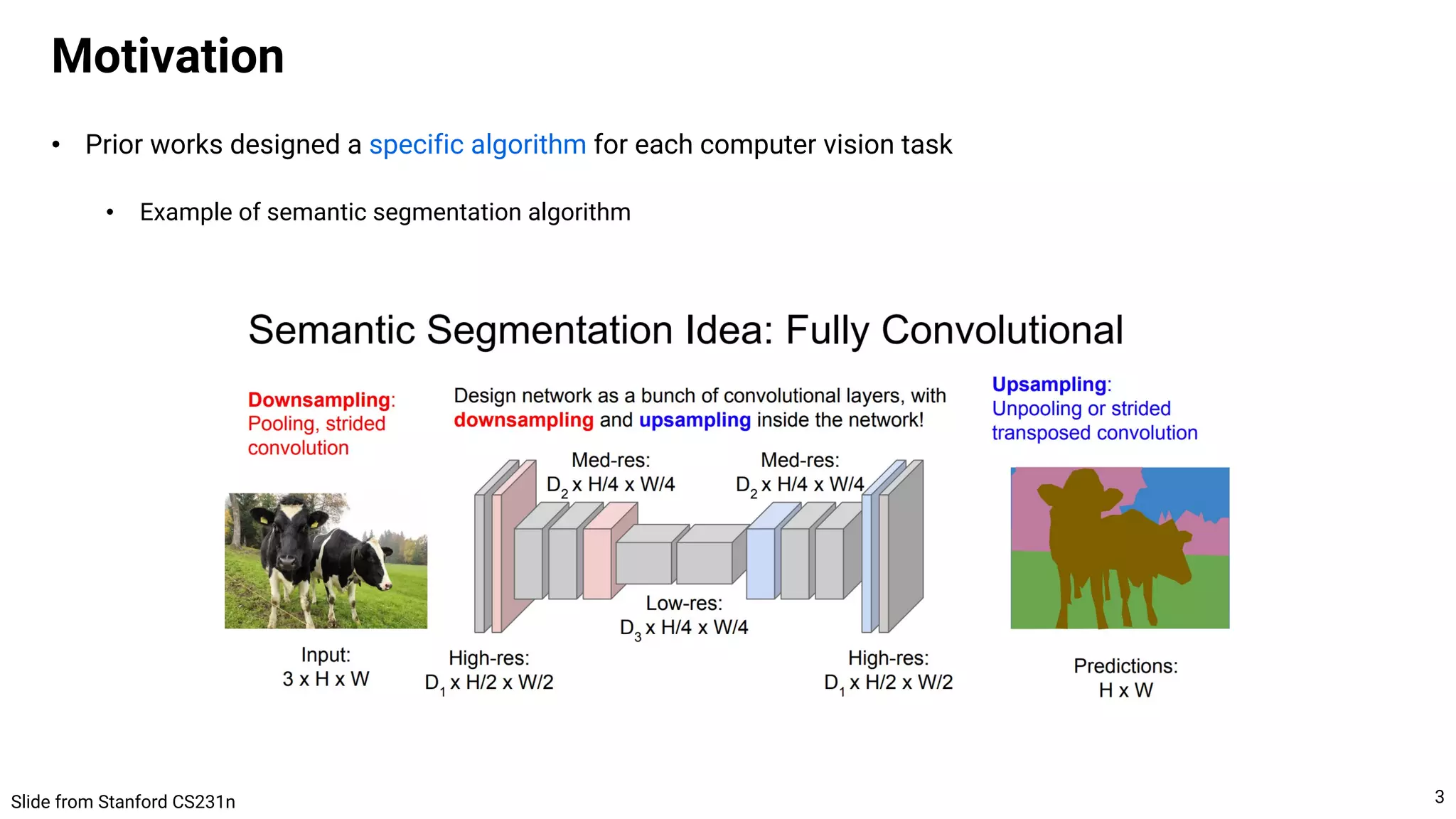
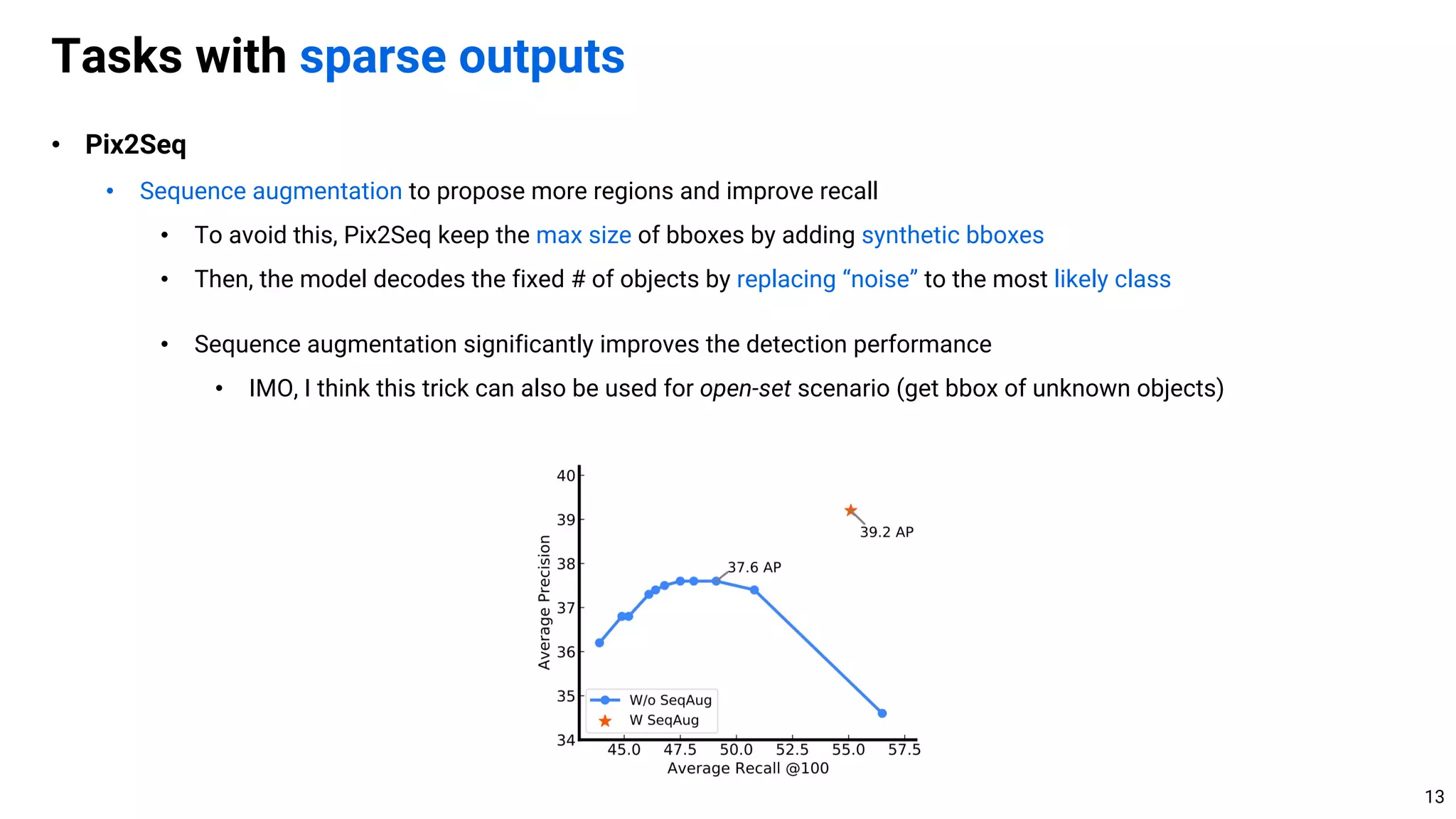
![• Pix2Seq
• Sequence augmentation to propose more regions and improve recall
• Pix2Seq misses some objects due to early stopping of decoding ([EOS] comes quickly)
• To avoid this, Pix2Seq keep the max size of bboxes by adding synthetic bboxes
• Specially, get the 4 coordinates of a random rectangle and assign “noise” class
Tasks with sparse outputs
12](https://image.slidesharecdn.com/221017visionbygen-221017213905-7e62b51d/75/A-Unified-Framework-for-Computer-Vision-Tasks-Conditional-Generative-Model-is-All-You-Need-12-2048.jpg)
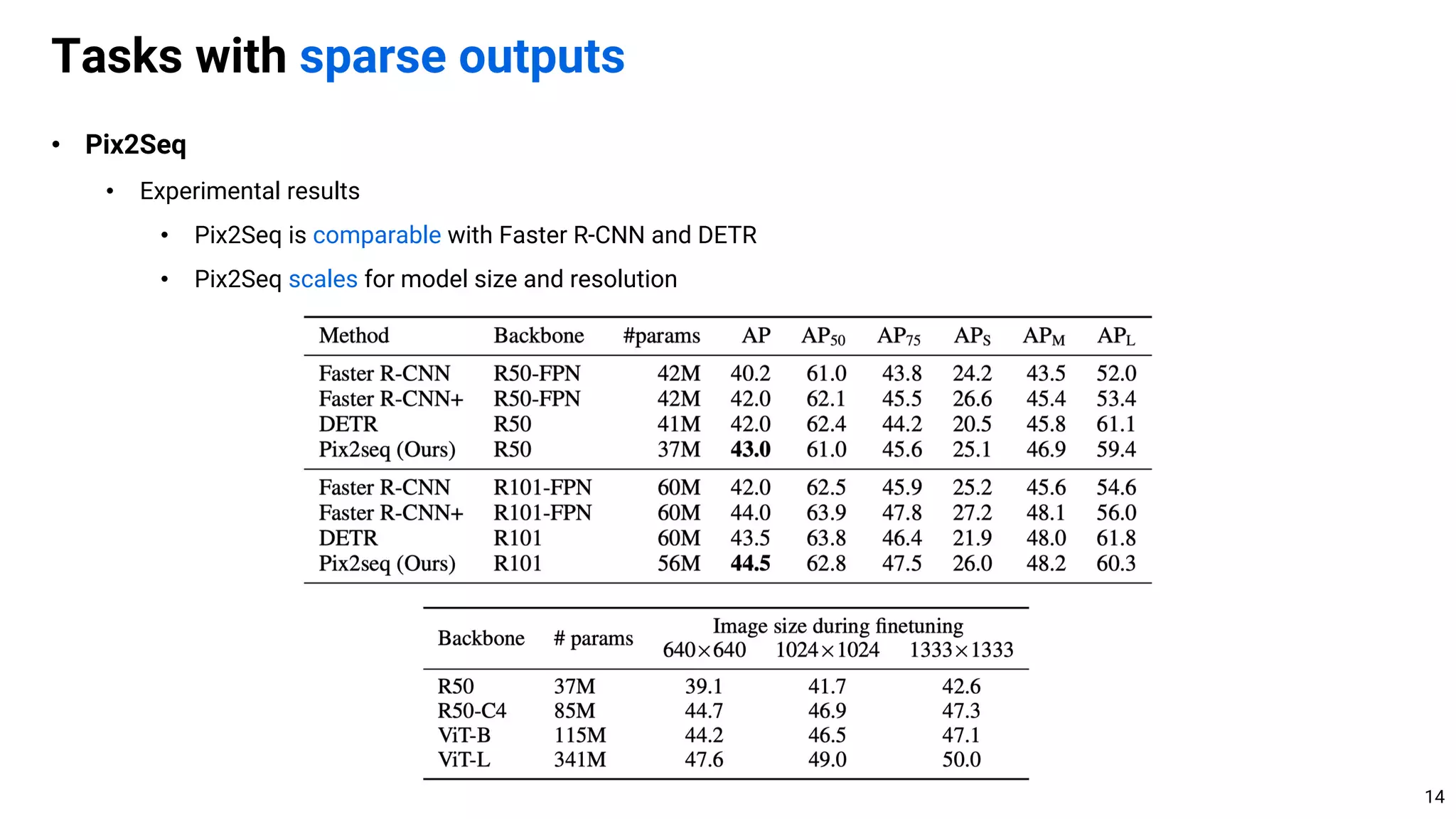
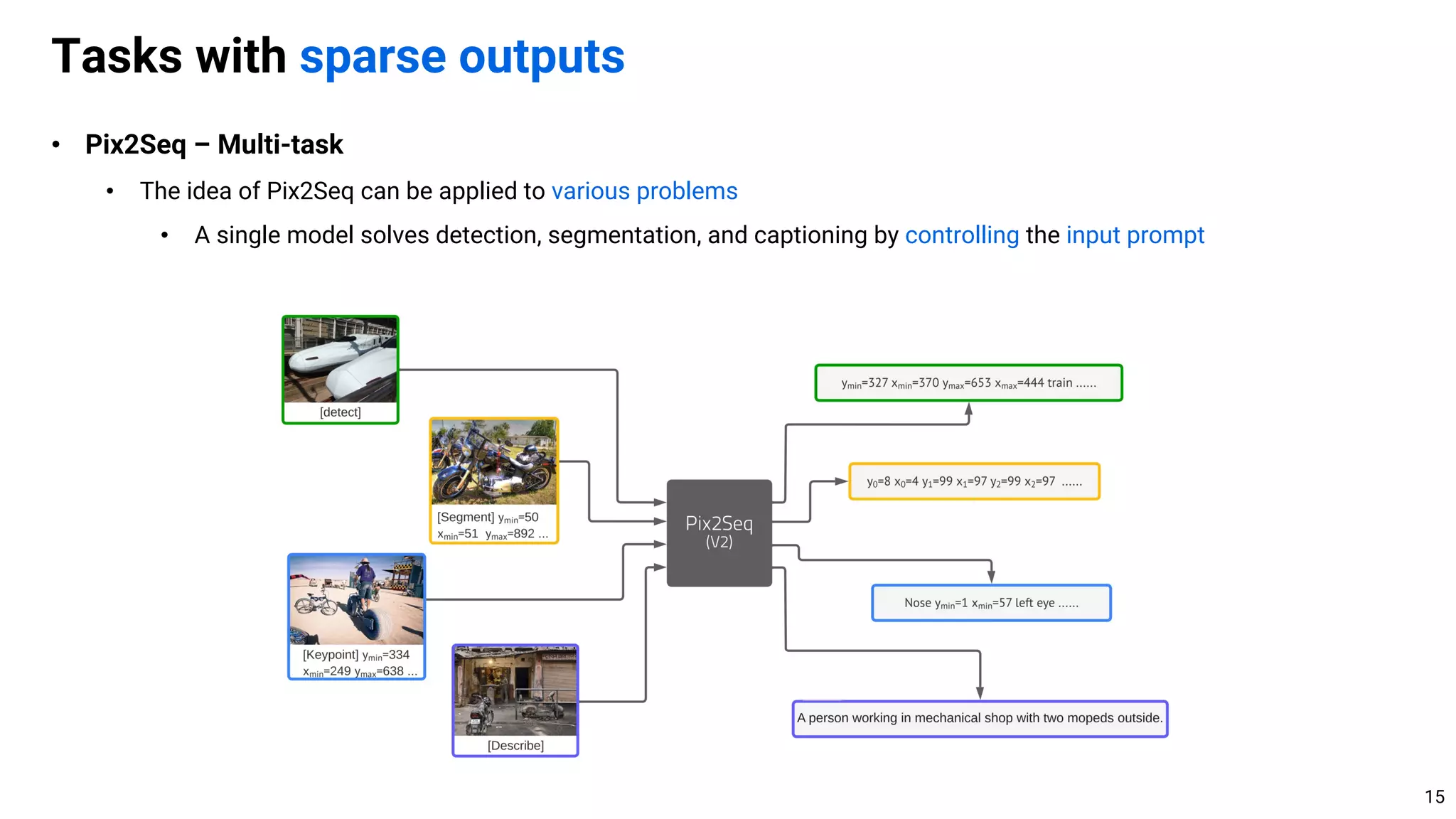


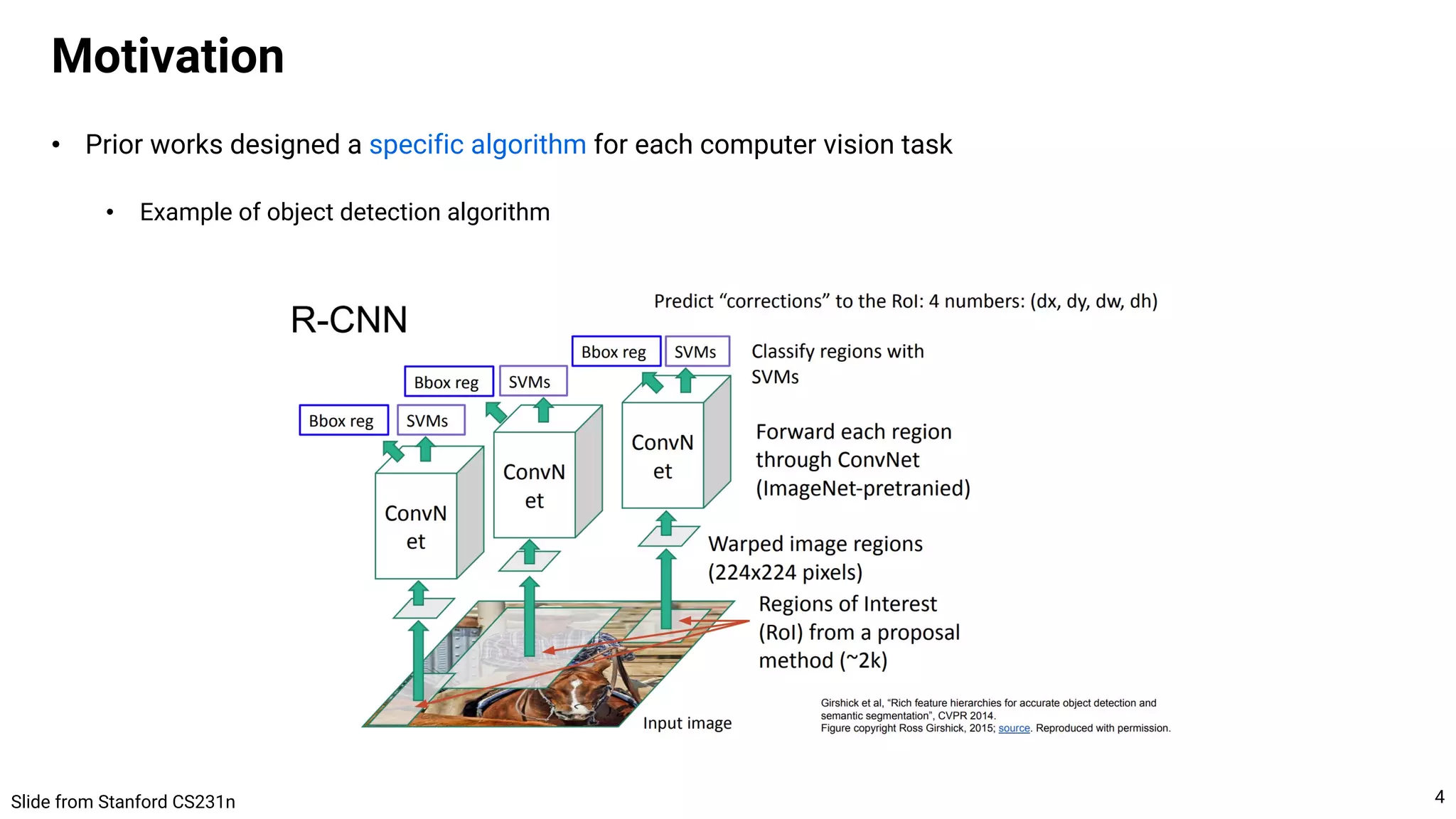
![• TL;DR. Simple autoregressive or diffusion models can solve a large class of computer vision problems
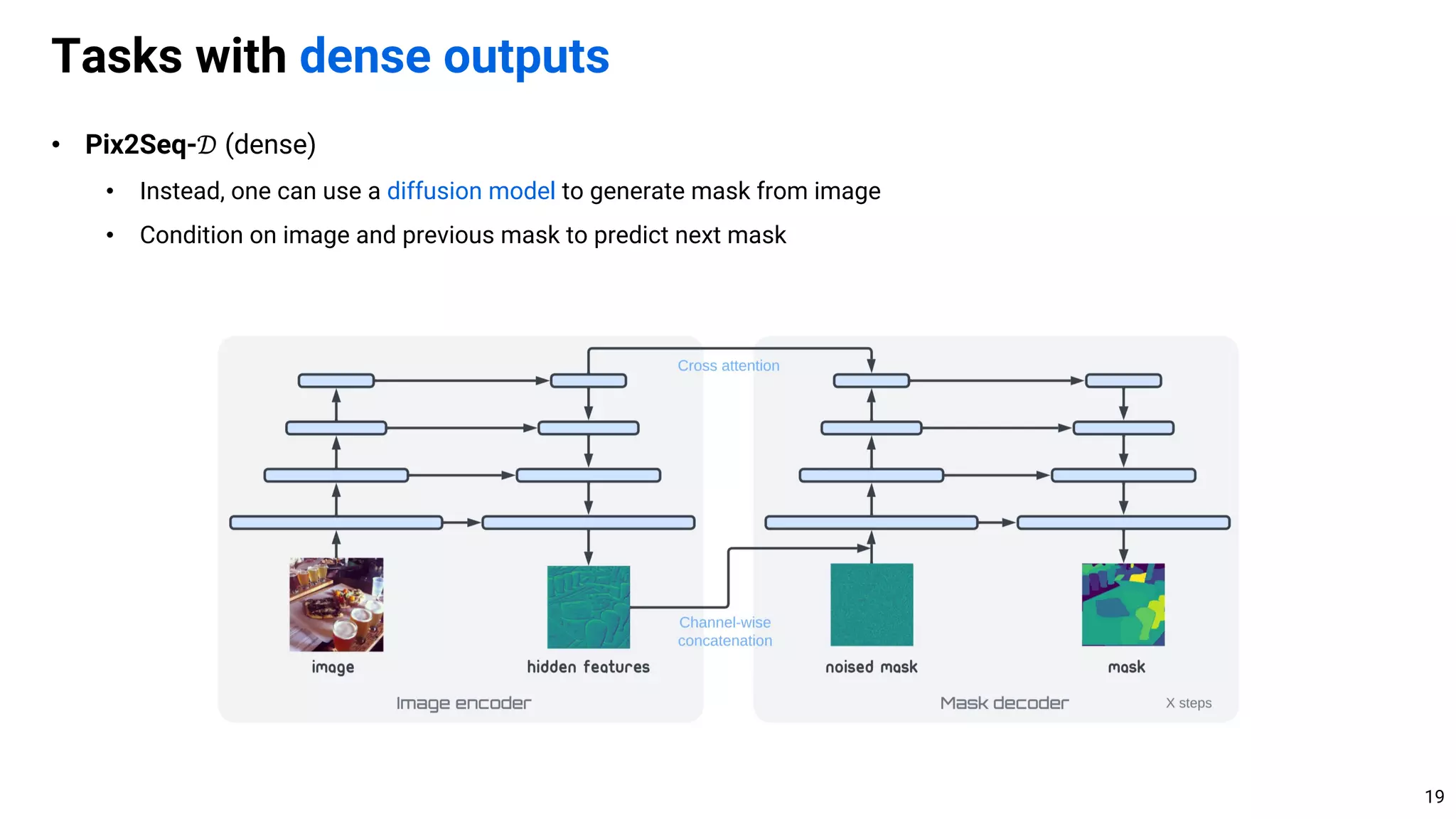
• Discussion. General vs. task-specific algorithm design
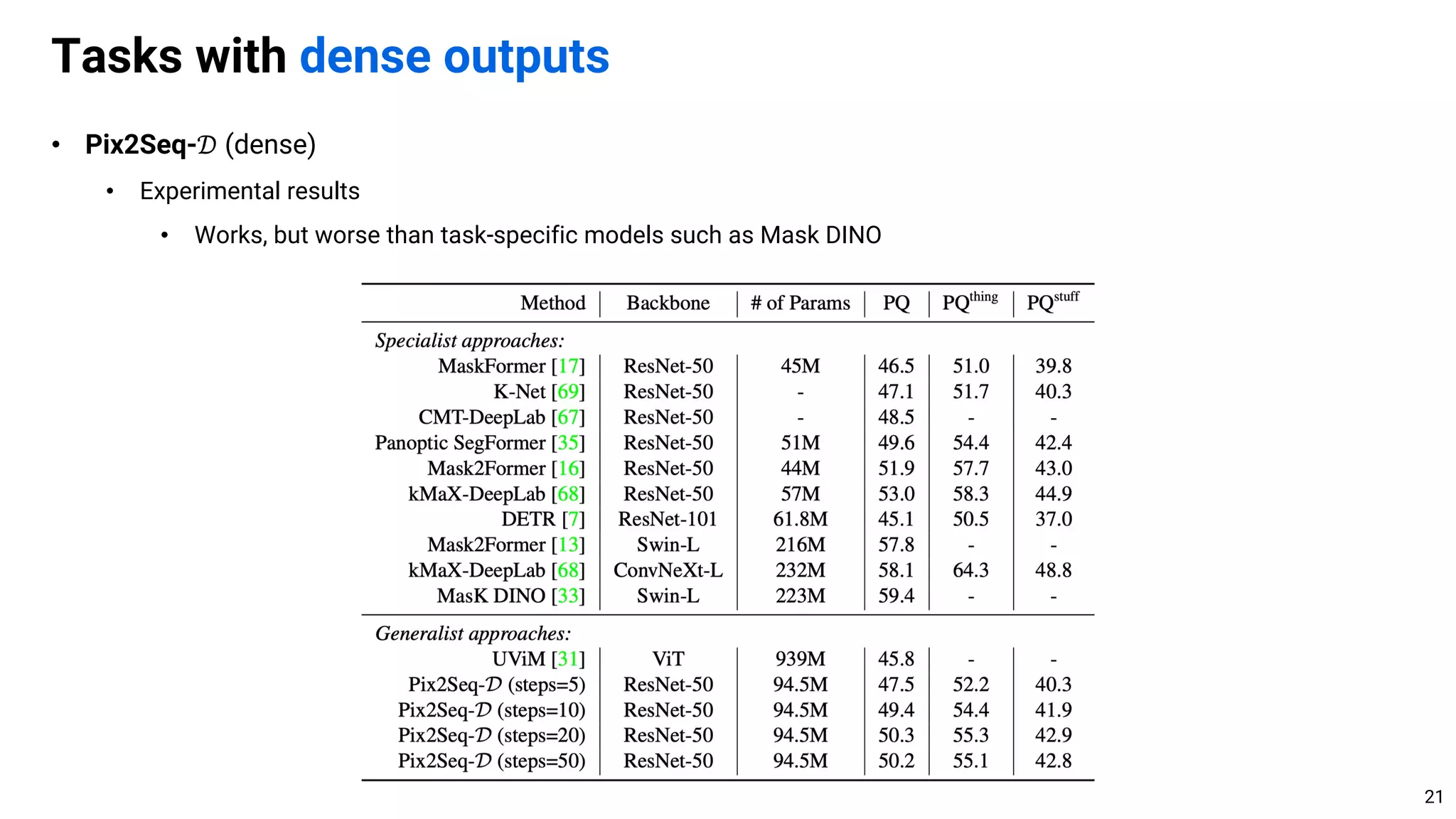
• Currently, task-specific algorithm usually performs better by leveraging the structures of task
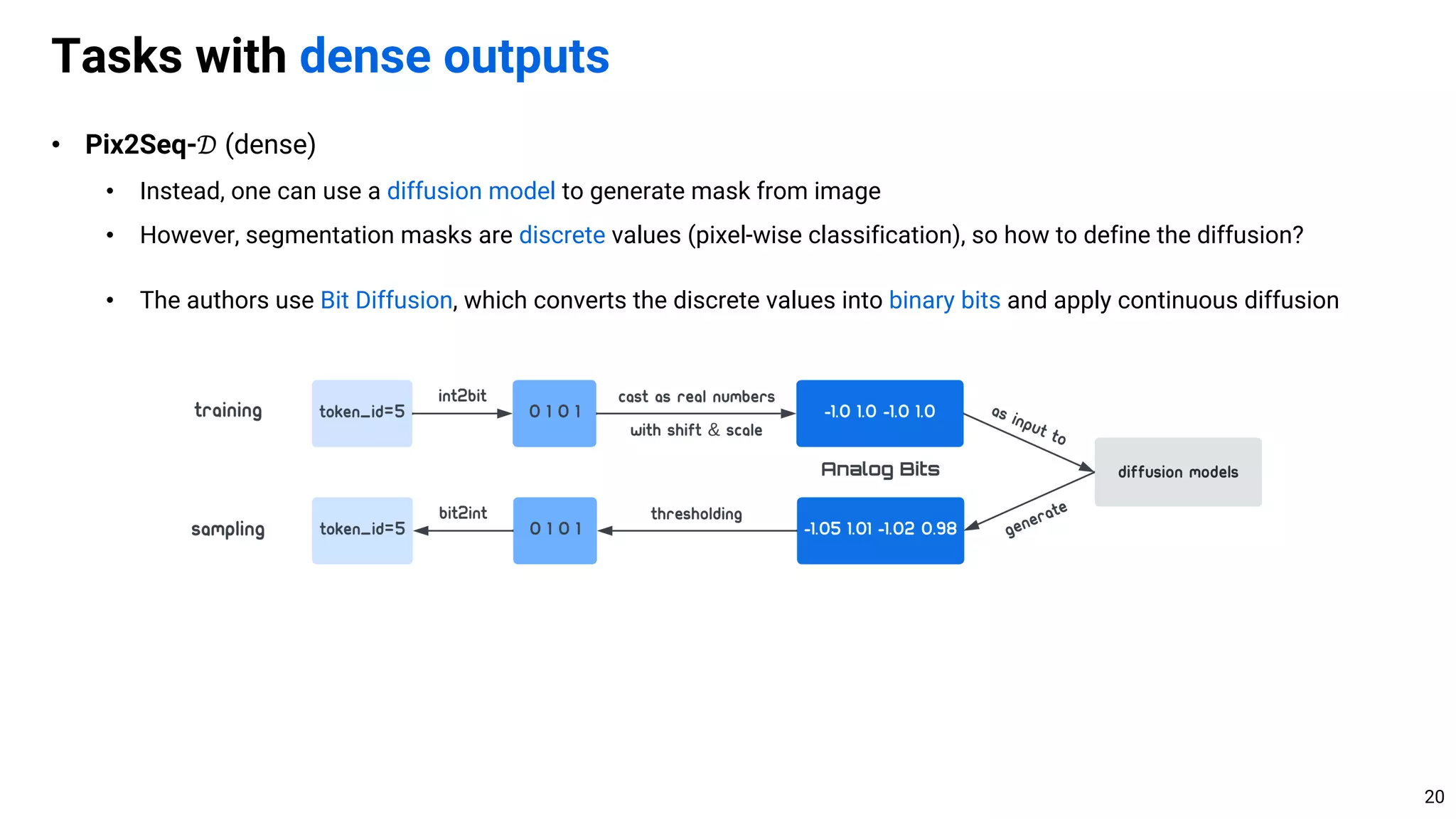
• However, the general-purpose algorithm may implicitly learn the structure of task from data
• E.g., ViT learns the spatial structure of images, e.g., translation equivariance
• I believe the model should reflect the task structures in some way, either explicitly or implicitly
• In this perspective, I think there are three directions for designing algorithms:
1. Keep design a task-specific algorithm (short-term goal before AGI comes)
2. Make the general-purpose model to better learn the task structures (e.g., SeqAug)
3. Analysis the structure learned by the general-purpose model (e.g., [1])
Discussion
22
[1] The Lie Derivative for Measuring Learned Equivariance → Analyze the equivariance learned by ViT](https://image.slidesharecdn.com/221017visionbygen-221017213905-7e62b51d/75/A-Unified-Framework-for-Computer-Vision-Tasks-Conditional-Generative-Model-is-All-You-Need-22-2048.jpg)










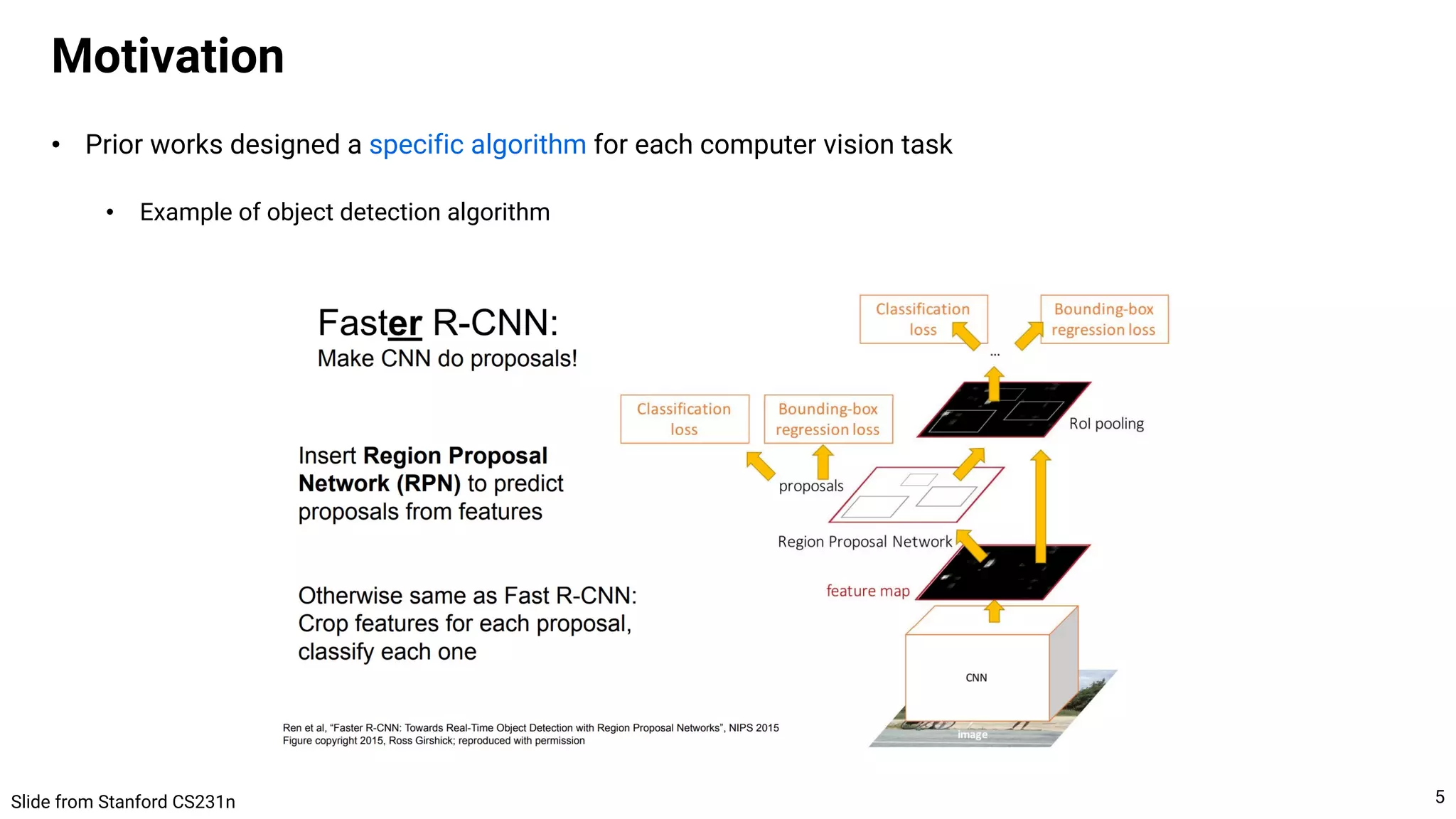
![• Pix2Seq
• Cast object descriptions as a sequence of discrete tokens (bboxes and class labels)
• Training and inference are done as LM (MLE training, stochastic decoding)
• Each object = {4 bbox coordinates + 1 class label}
• The coordinate is quantized to 𝑛!"#$ values, hence the vocab size = 𝑛!"#$ + 𝑛%&'$$ + 1 for [EOS] token
Tasks with sparse outputs
10
CNN encoder + Transformer decoder](https://crownmelresort.com/image.slidesharecdn.com/221017visionbygen-221017213905-7e62b51d/75/A-Unified-Framework-for-Computer-Vision-Tasks-Conditional-Generative-Model-is-All-You-Need-10-2048.jpg)

![• Pix2Seq
• Sequence augmentation to propose more regions and improve recall
• Pix2Seq misses some objects due to early stopping of decoding ([EOS] comes quickly)
• To avoid this, Pix2Seq keep the max size of bboxes by adding synthetic bboxes
• Specially, get the 4 coordinates of a random rectangle and assign “noise” class
Tasks with sparse outputs
12](https://crownmelresort.com/image.slidesharecdn.com/221017visionbygen-221017213905-7e62b51d/75/A-Unified-Framework-for-Computer-Vision-Tasks-Conditional-Generative-Model-is-All-You-Need-12-2048.jpg)









![• TL;DR. Simple autoregressive or diffusion models can solve a large class of computer vision problems
• Discussion. General vs. task-specific algorithm design
• Currently, task-specific algorithm usually performs better by leveraging the structures of task
• However, the general-purpose algorithm may implicitly learn the structure of task from data
• E.g., ViT learns the spatial structure of images, e.g., translation equivariance
• I believe the model should reflect the task structures in some way, either explicitly or implicitly
• In this perspective, I think there are three directions for designing algorithms:
1. Keep design a task-specific algorithm (short-term goal before AGI comes)
2. Make the general-purpose model to better learn the task structures (e.g., SeqAug)
3. Analysis the structure learned by the general-purpose model (e.g., [1])
Discussion
22
[1] The Lie Derivative for Measuring Learned Equivariance → Analyze the equivariance learned by ViT](https://crownmelresort.com/image.slidesharecdn.com/221017visionbygen-221017213905-7e62b51d/75/A-Unified-Framework-for-Computer-Vision-Tasks-Conditional-Generative-Model-is-All-You-Need-22-2048.jpg)


The document discusses the development of a unified framework using conditional generative models to address various computer vision tasks, such as detection, segmentation, and keypoint detection, which have traditionally required task-specific algorithms. It highlights the pix2seq model, which formulates outputs as sequences of discrete tokens for tasks with sparse outputs, and the use of diffusion models for tasks with dense outputs like segmentation. The authors conclude that while general algorithms may learn task structures from data, task-specific models currently perform better.
![[DL輪読会]DIVERSE TRAJECTORY FORECASTING WITH DETERMINANTAL POINT PROCESSES](https://cdn.slidesharecdn.com/ss_thumbnails/kimura20200821dlseminarv1-200821021249-thumbnail.jpg?width=640&height=640&fit=bounds)









































![[CVPR 2018] Utilizing unlabeled or noisy labeled data (classification, detect...](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr18detectionclassification-180817015950-thumbnail.jpg?width=640&height=640&fit=bounds)












































