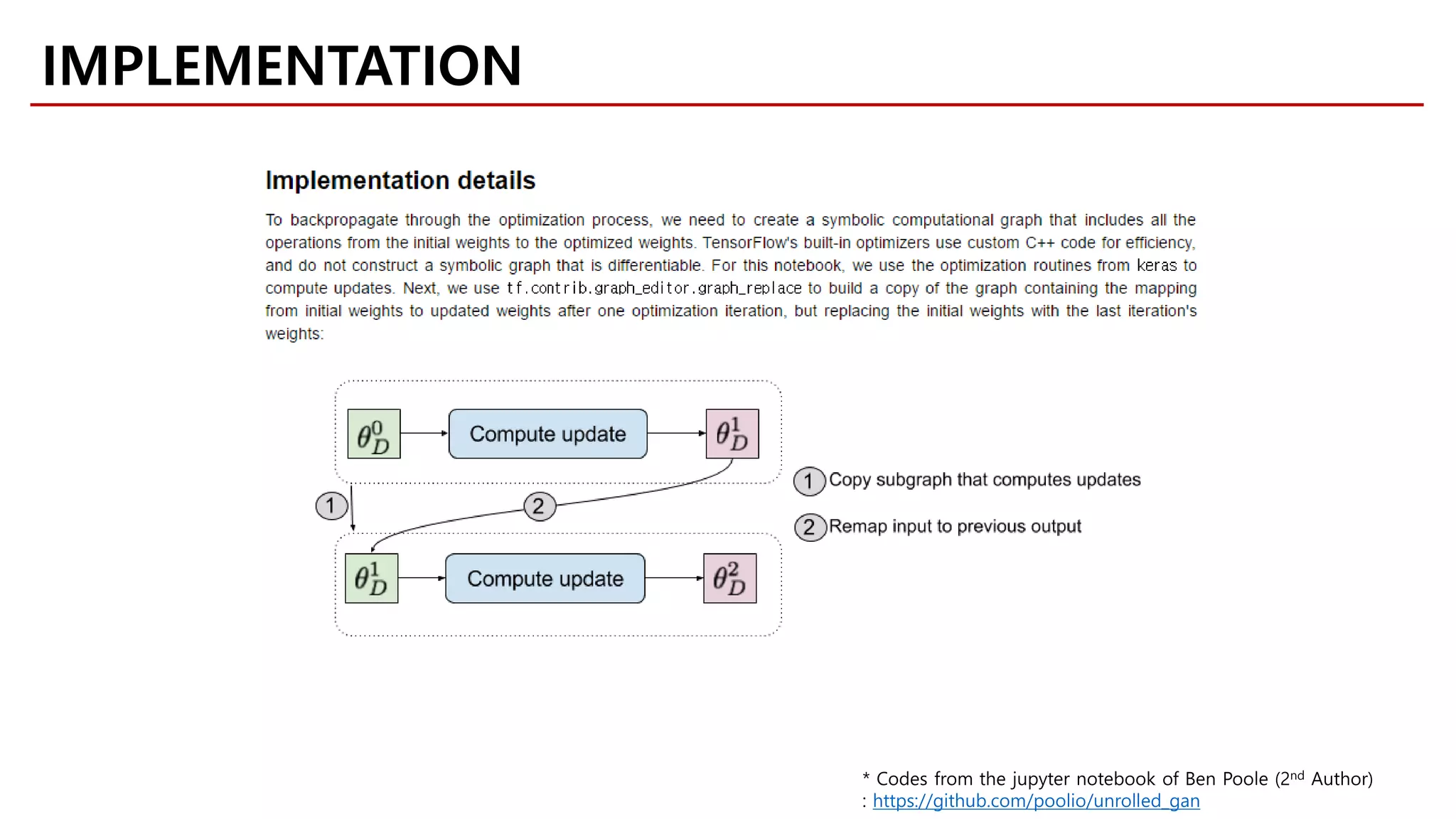
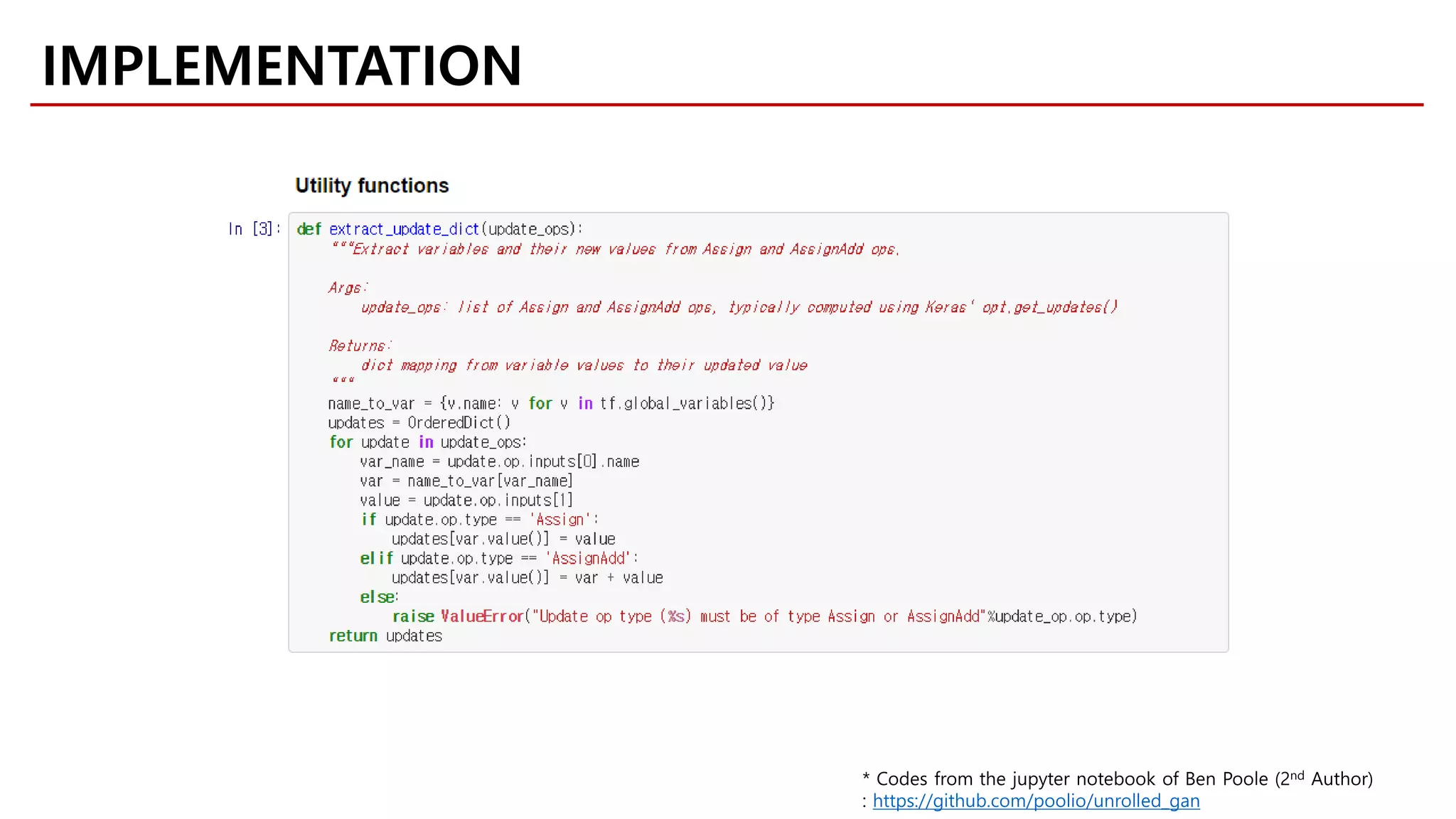
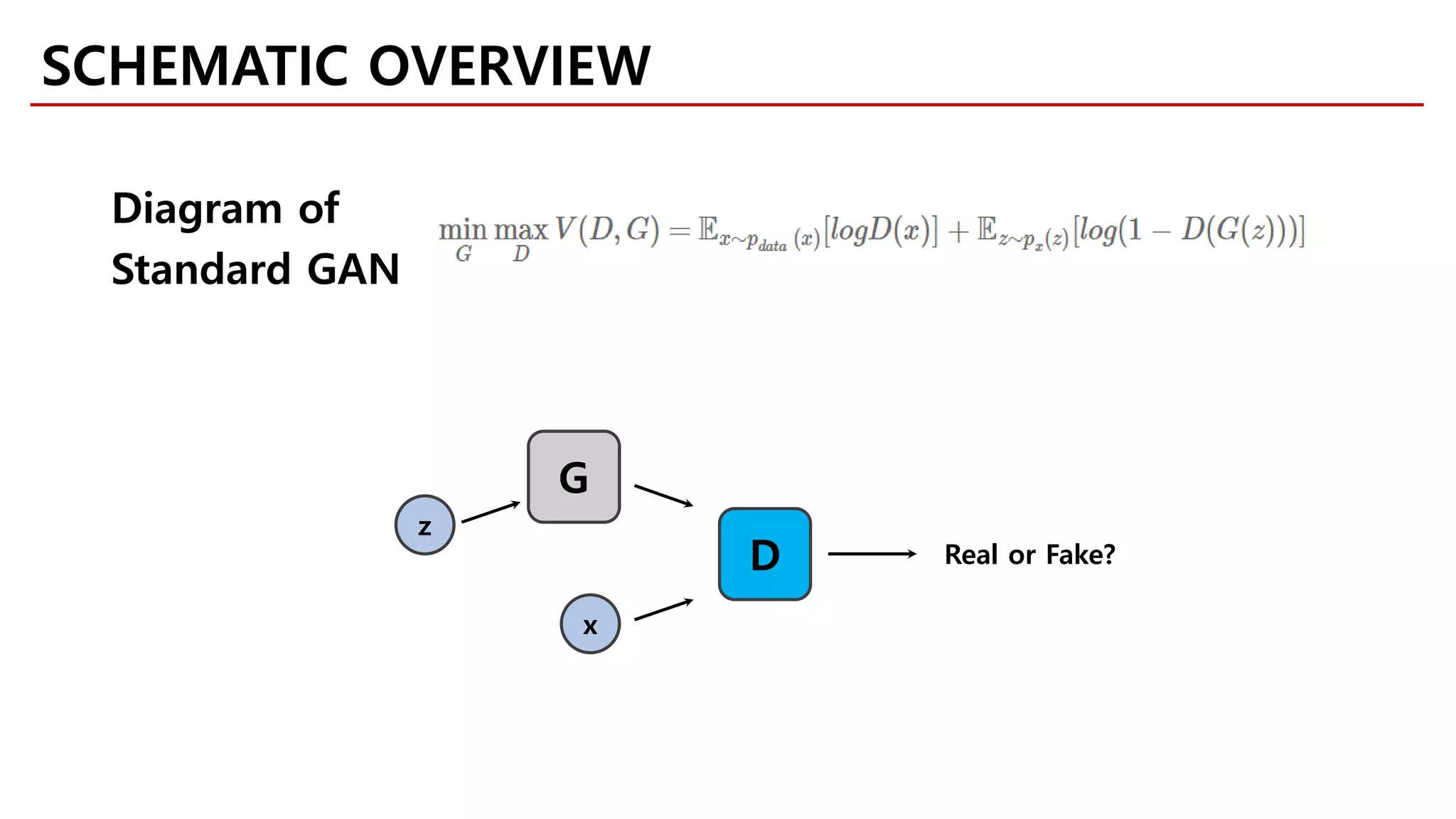
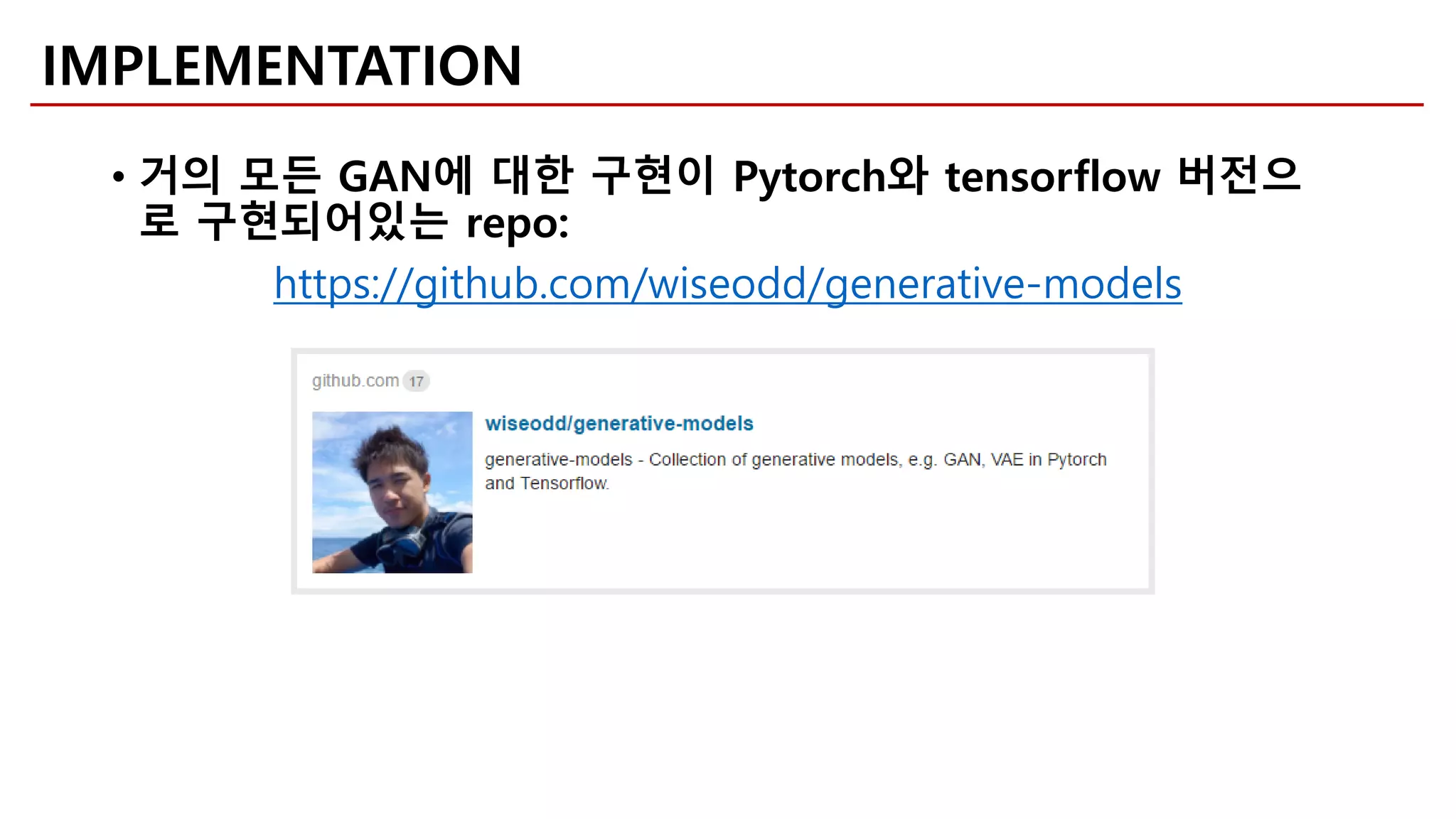
Download as PDF, PPTX


















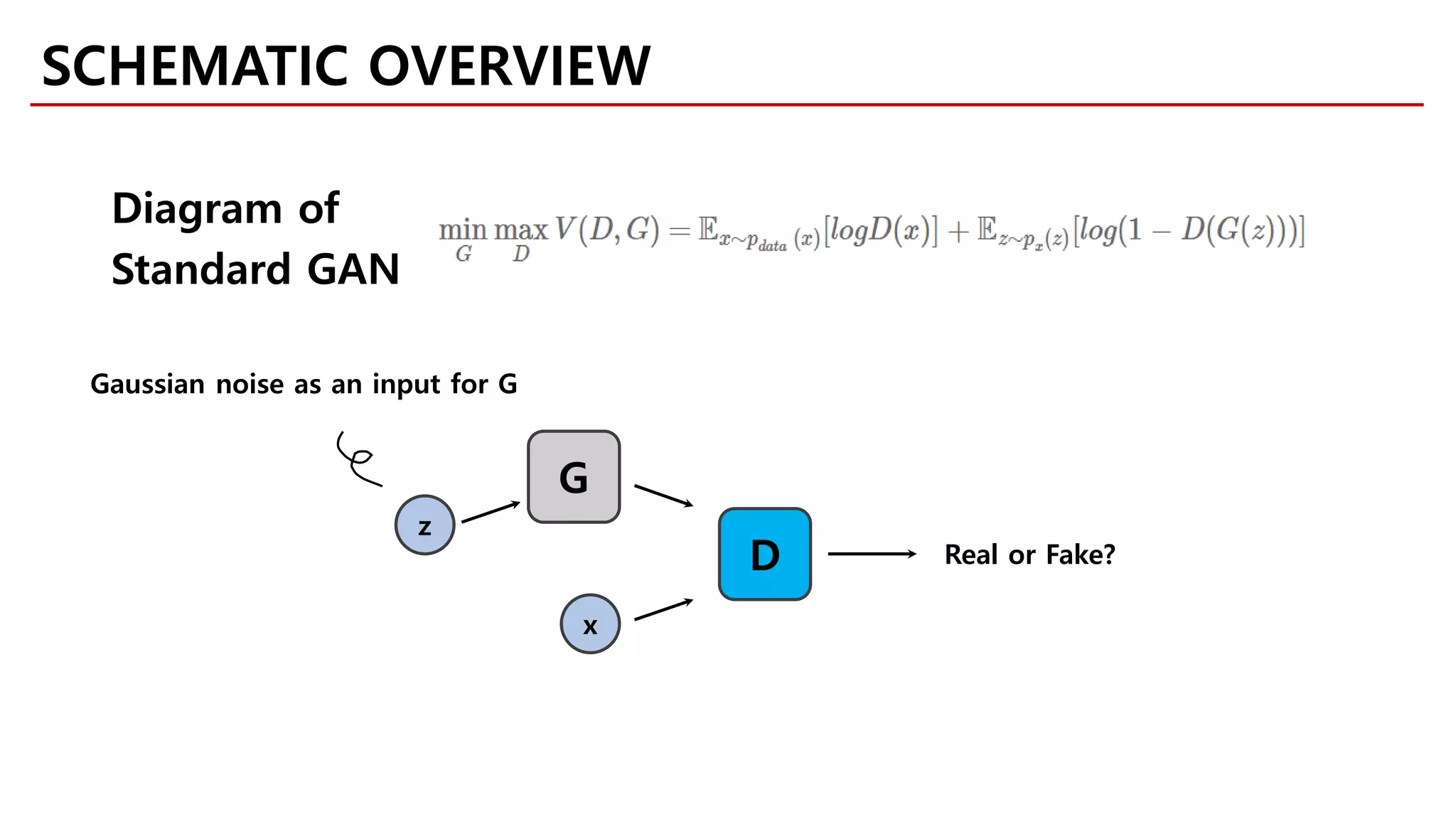
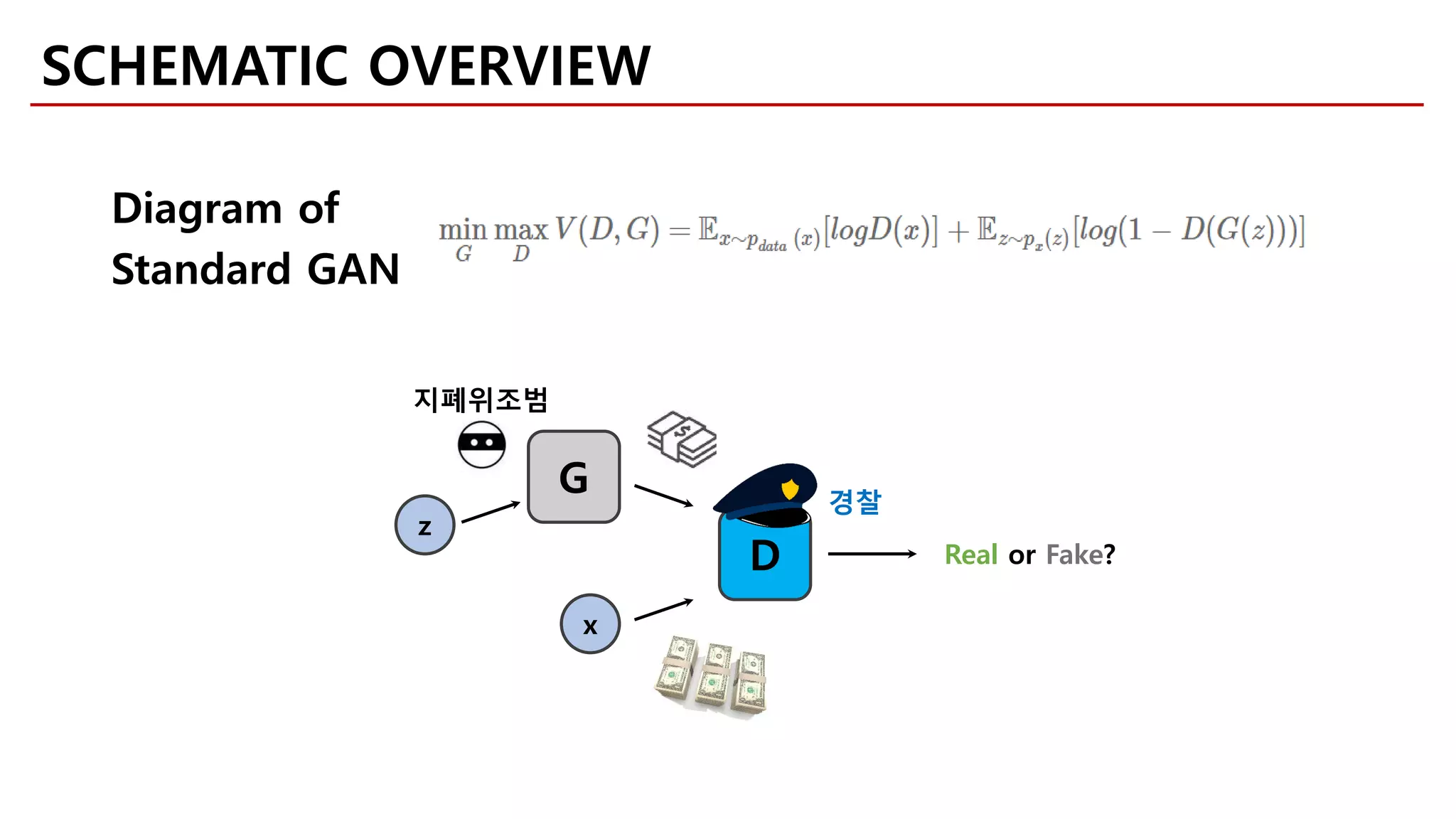
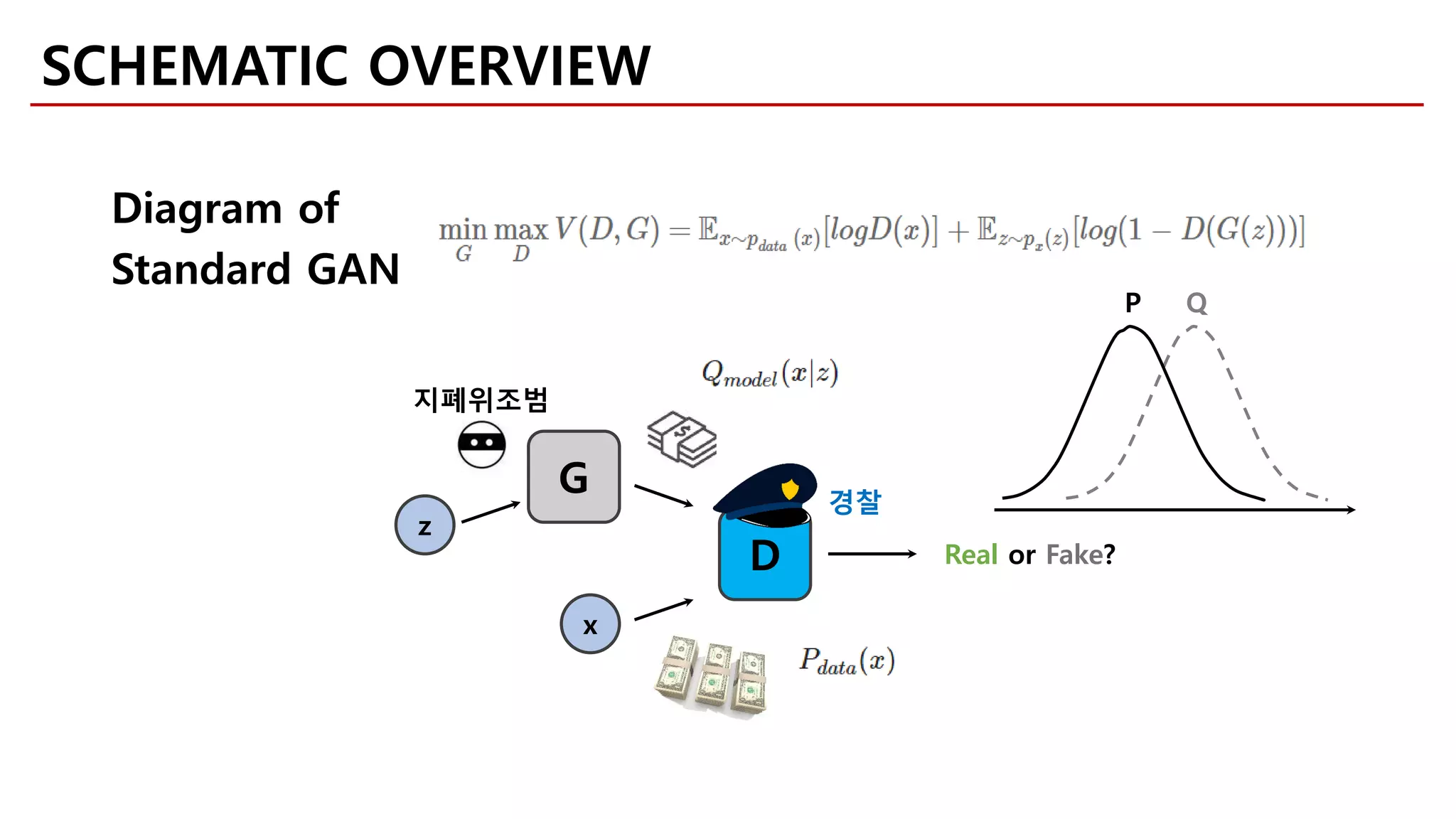
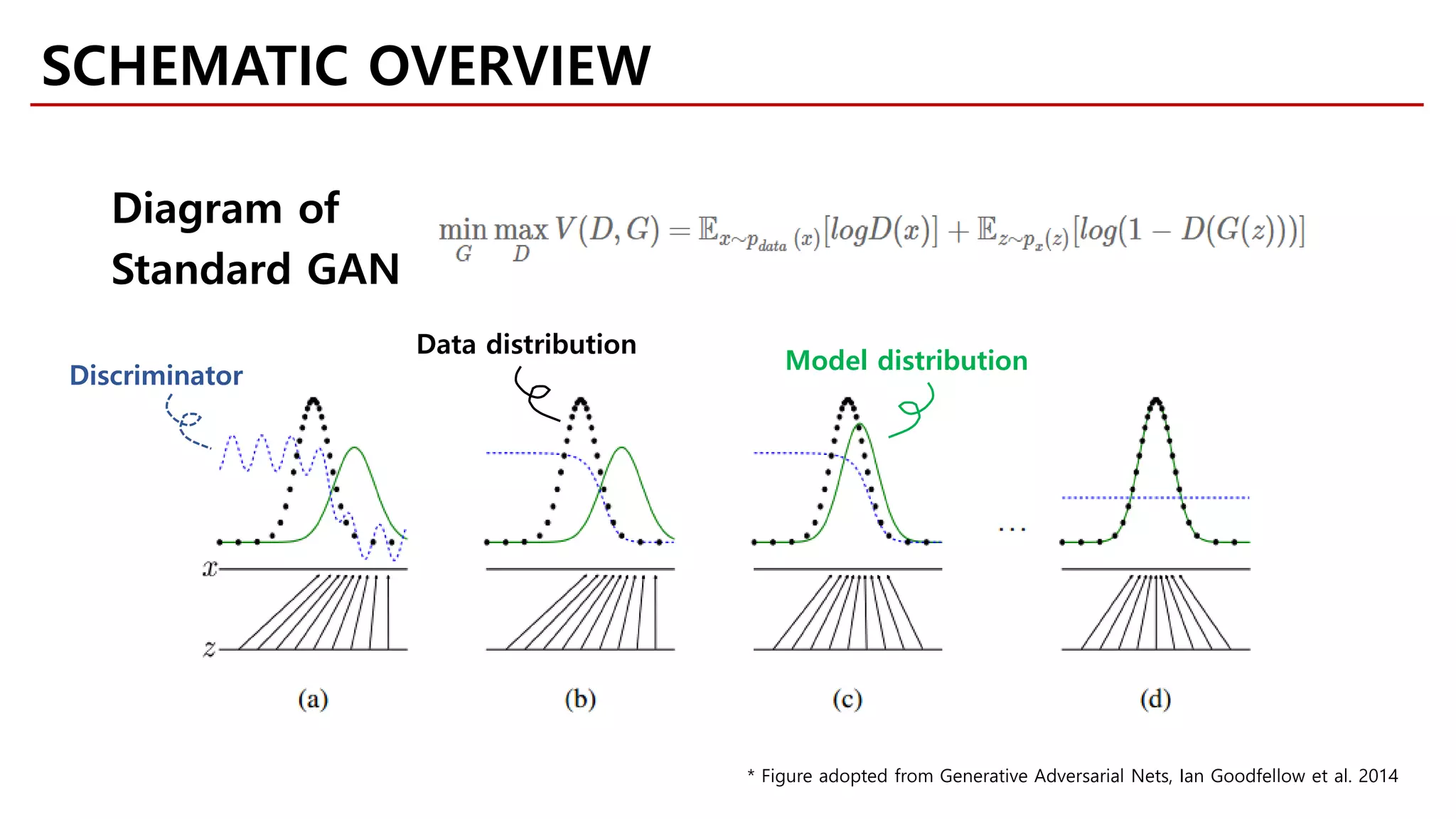






























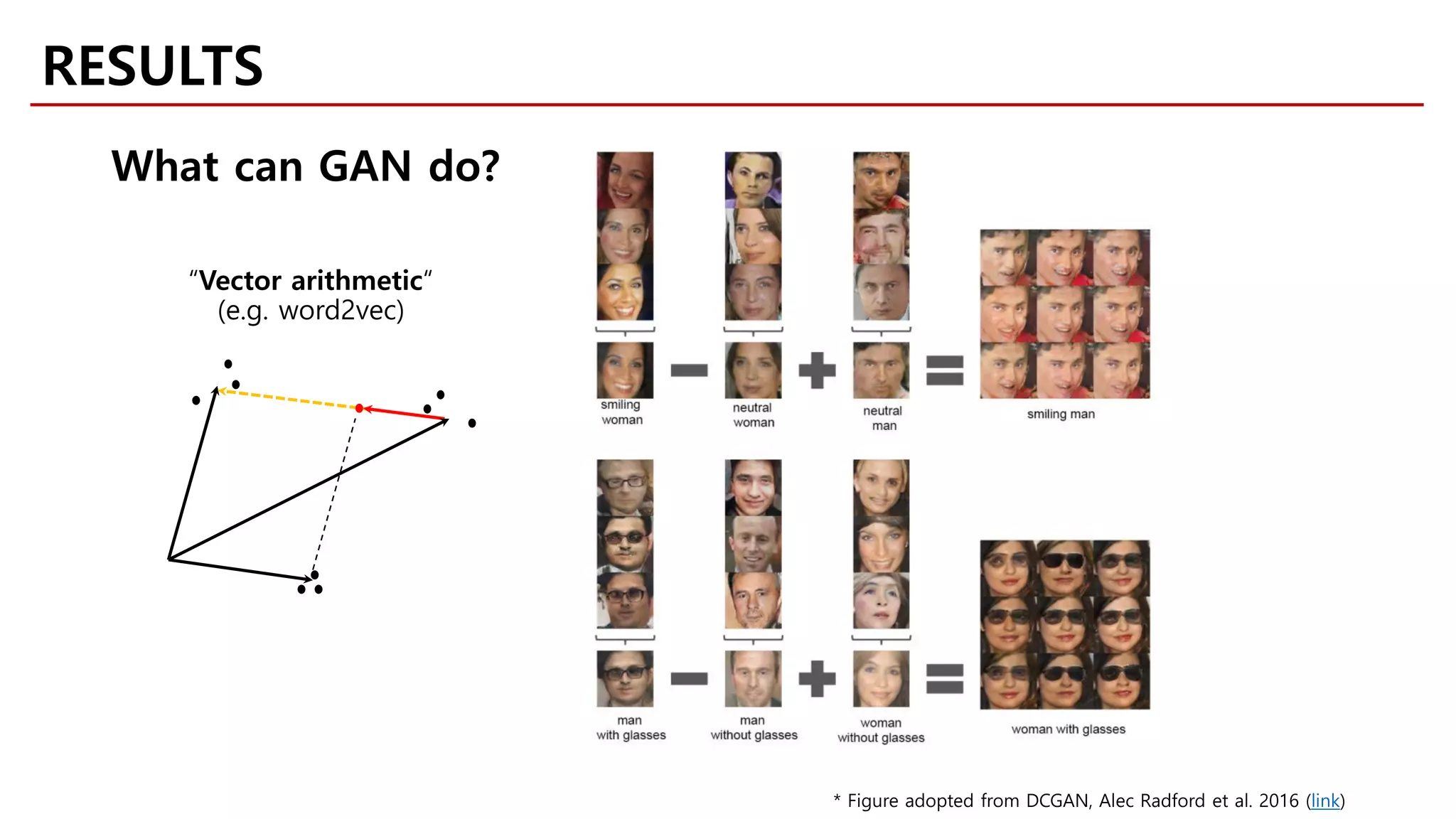







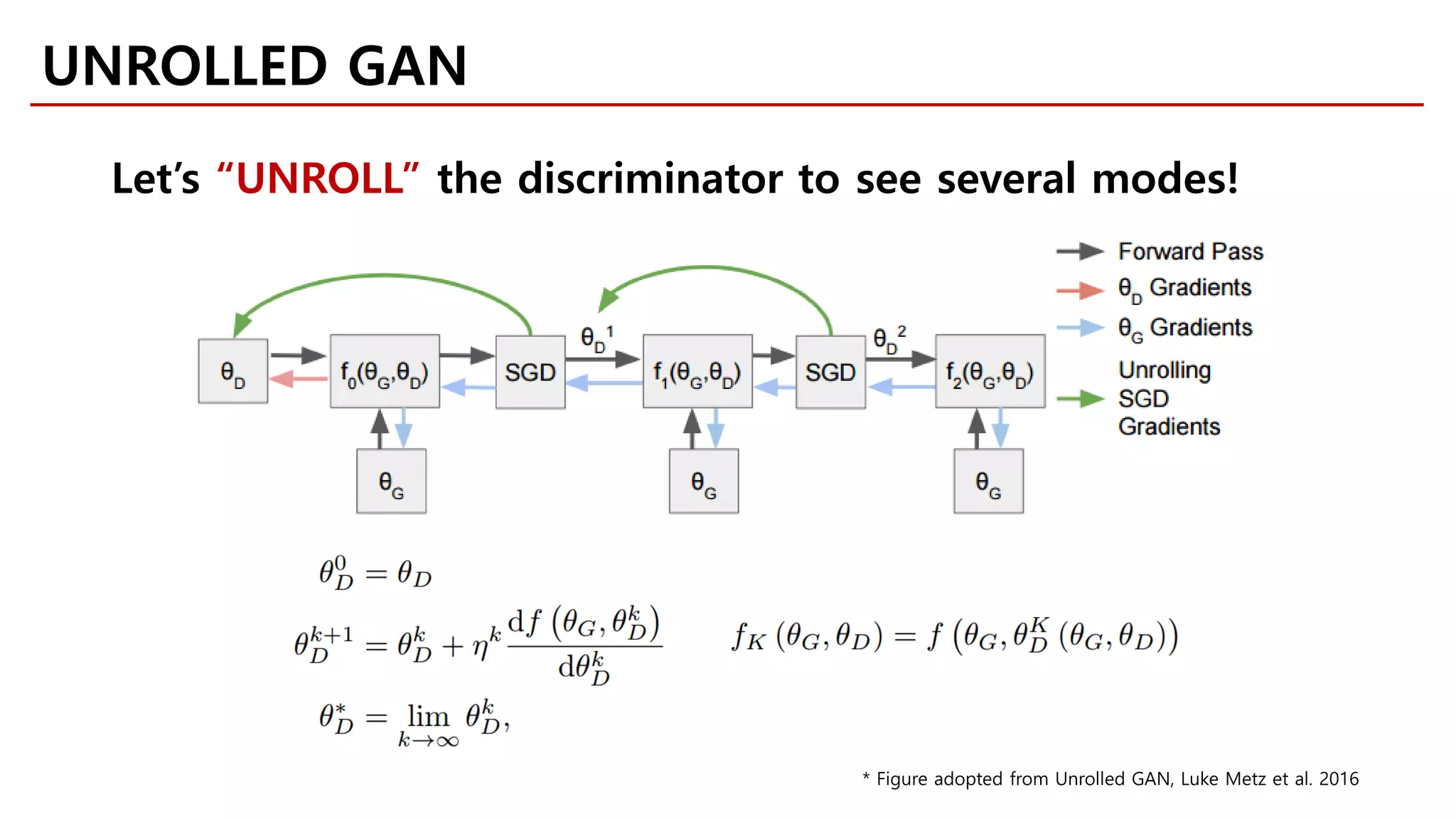























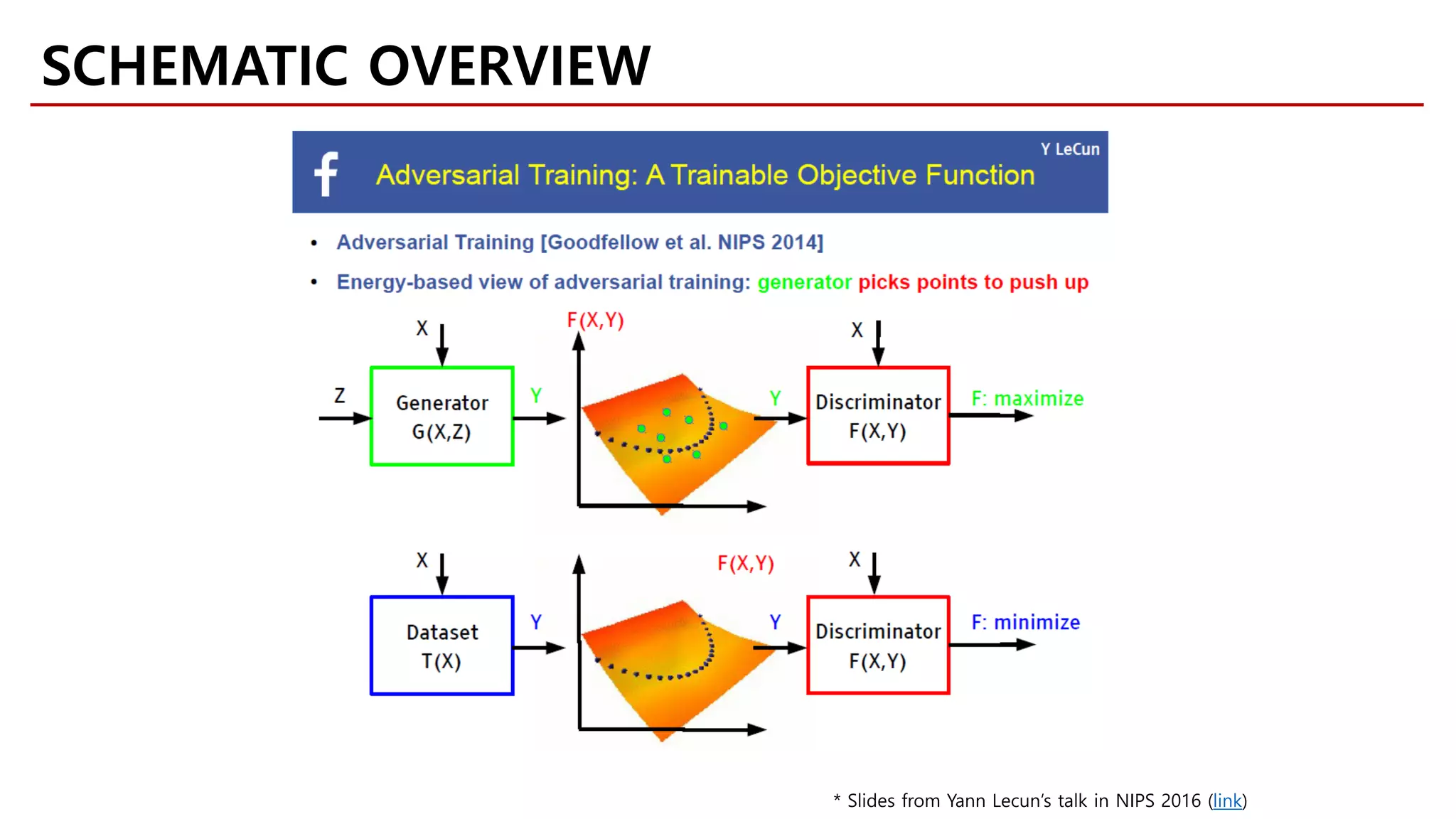
![[Goodfellow et al., 2014]
𝑧𝑧 → Lin 100,1200 → ReLU
→ Lin 1200,1200 → ReLU
→ Lin(1200,784) → Sigmoid
Random input Generator Output
𝑧𝑧 ~ Uniform100
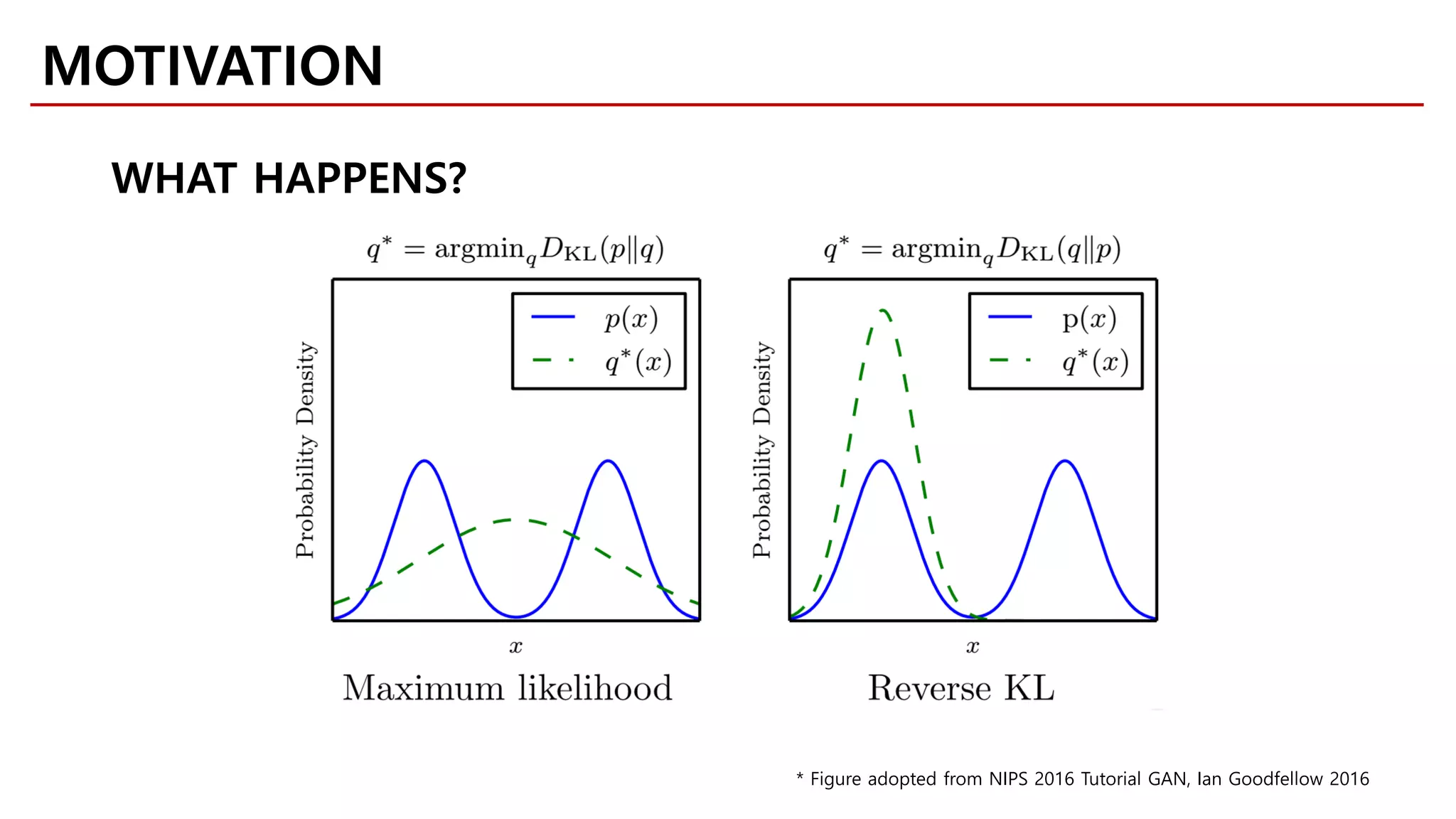
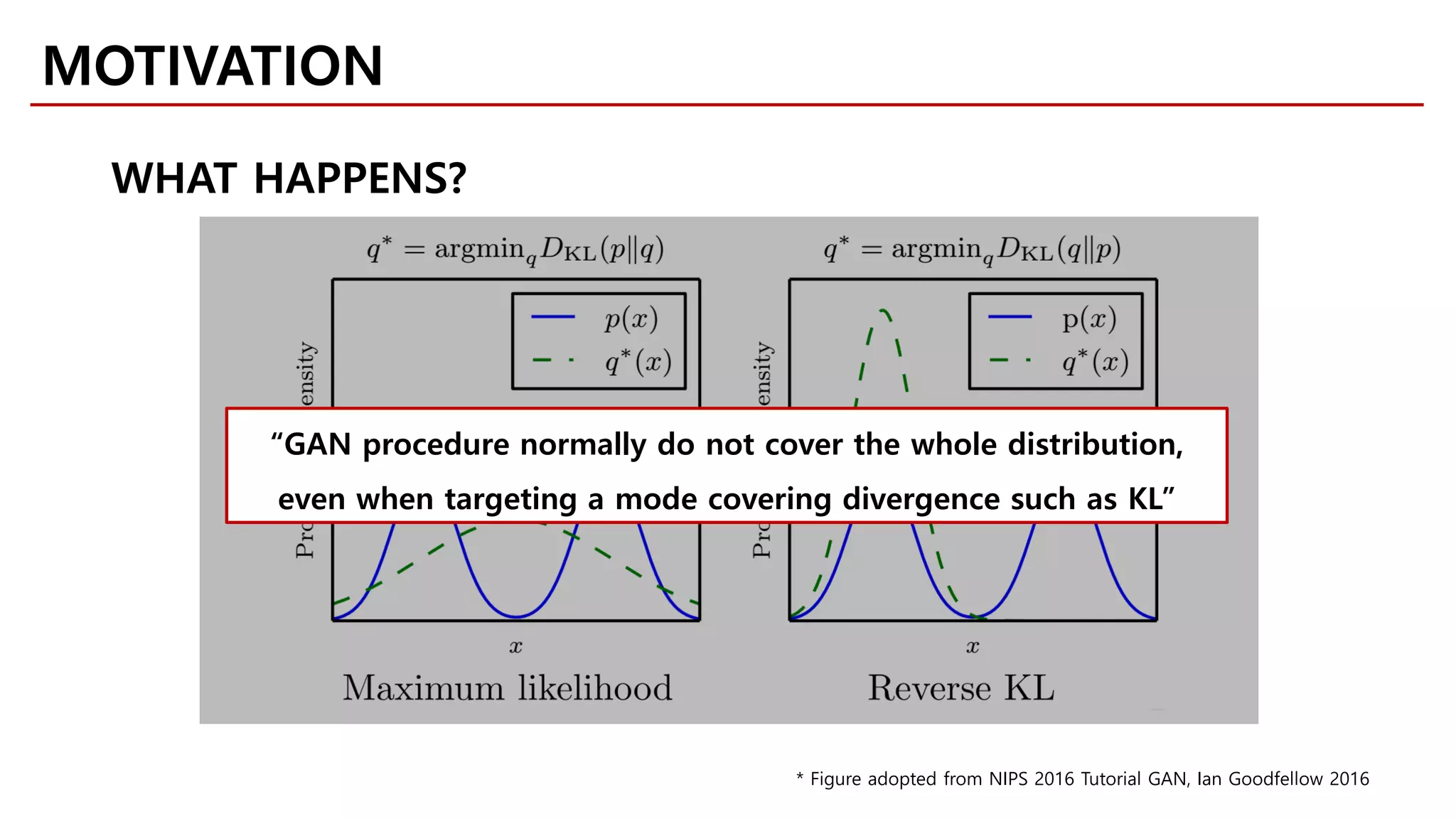
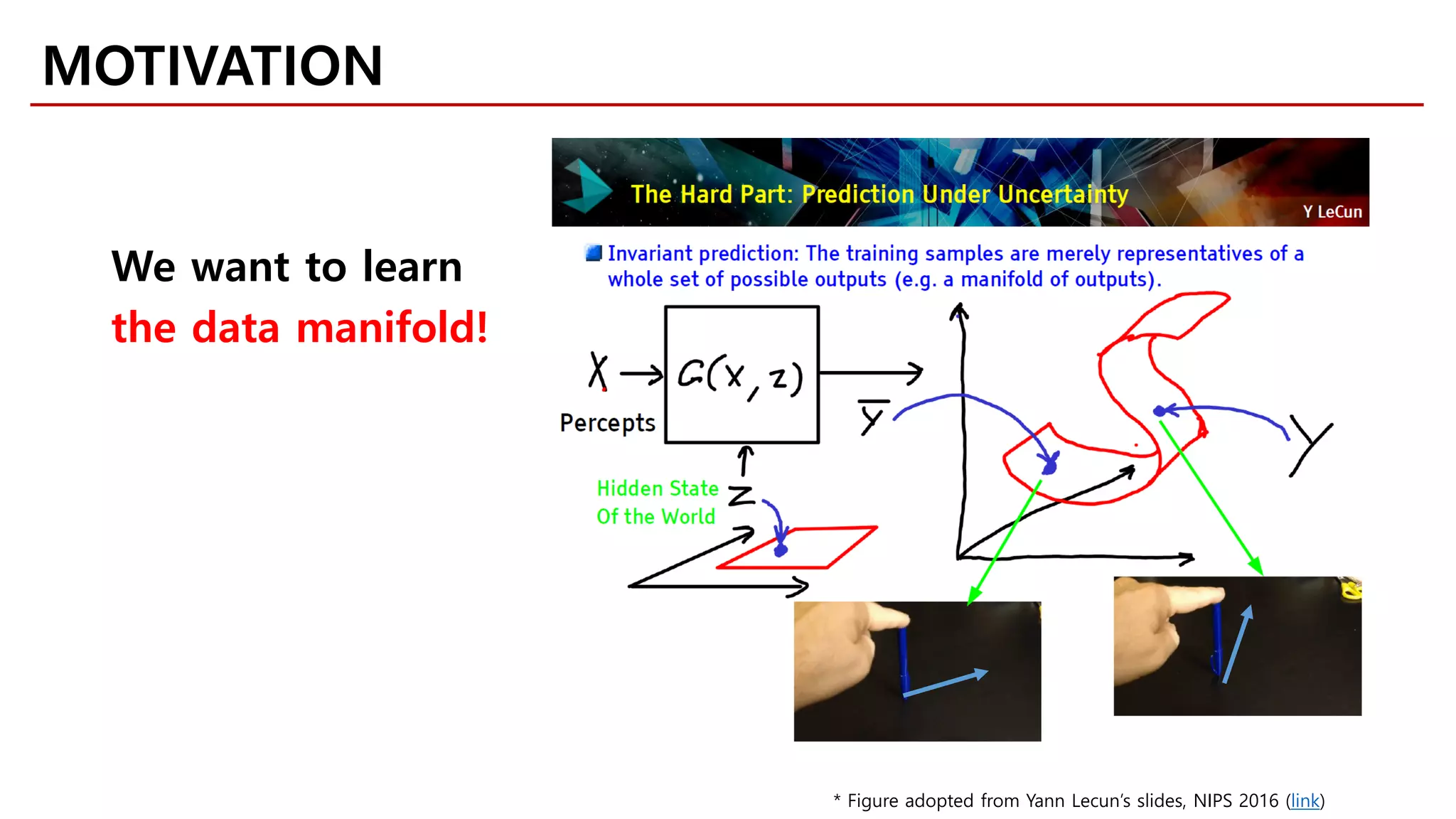
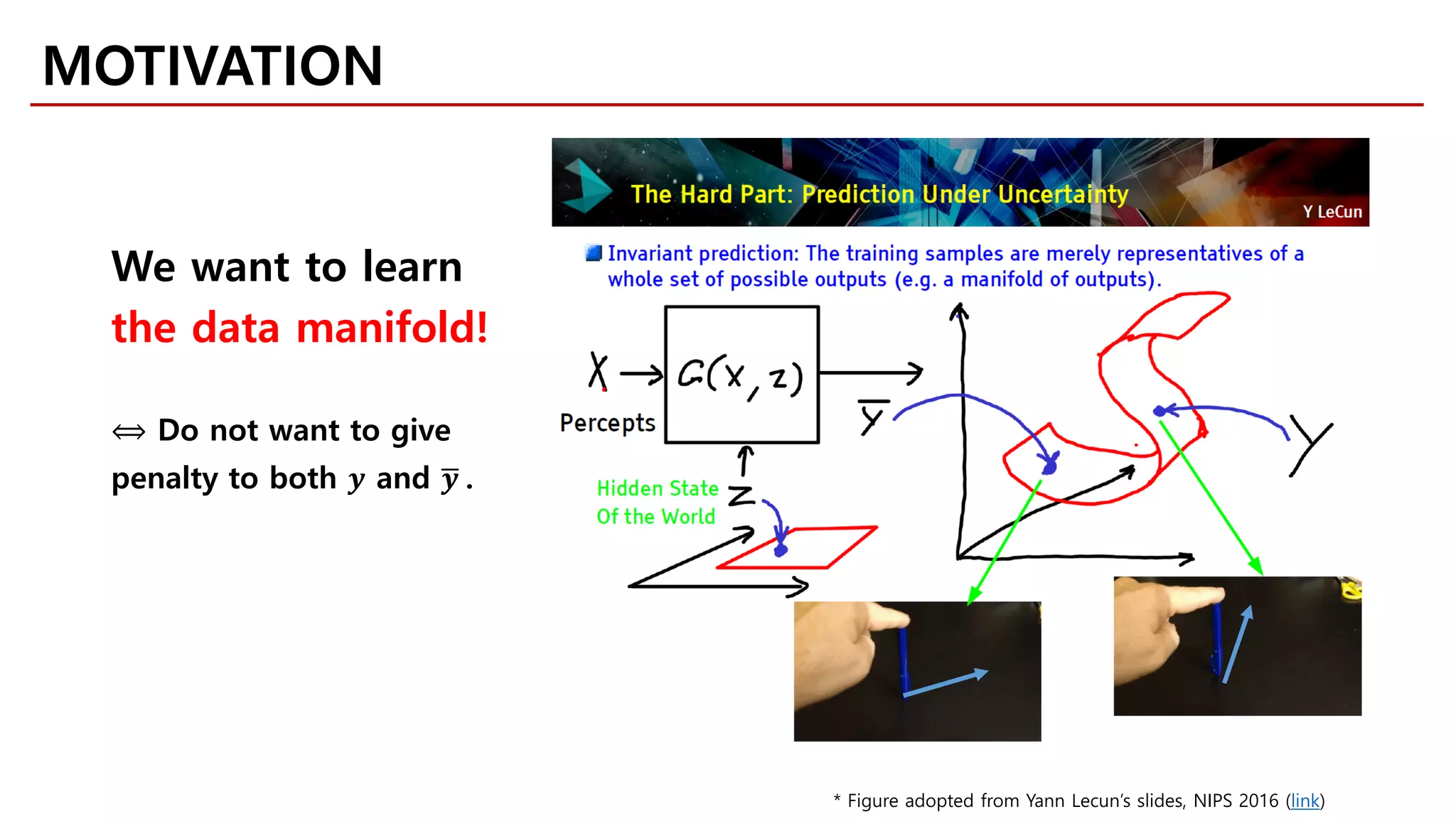
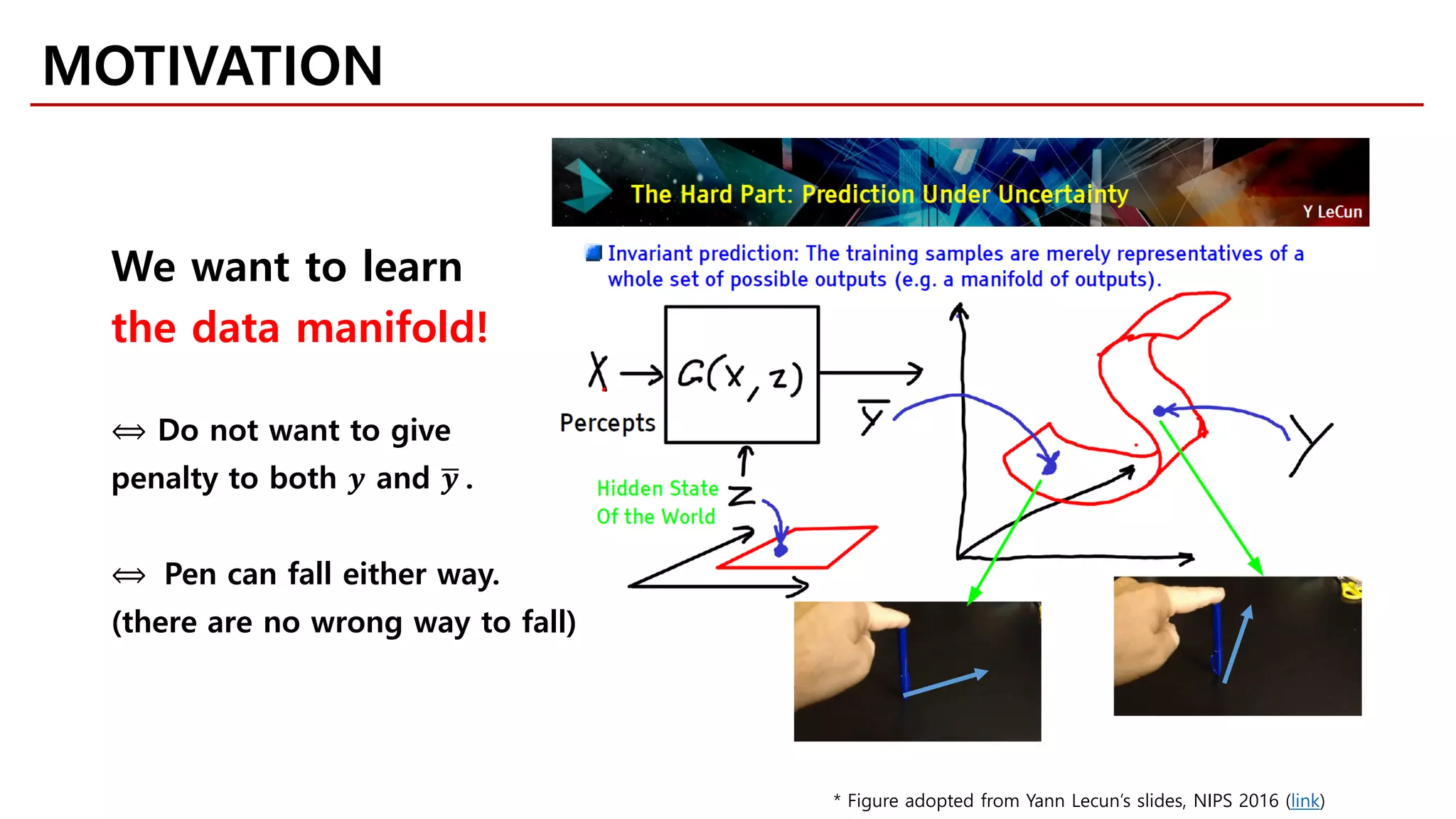
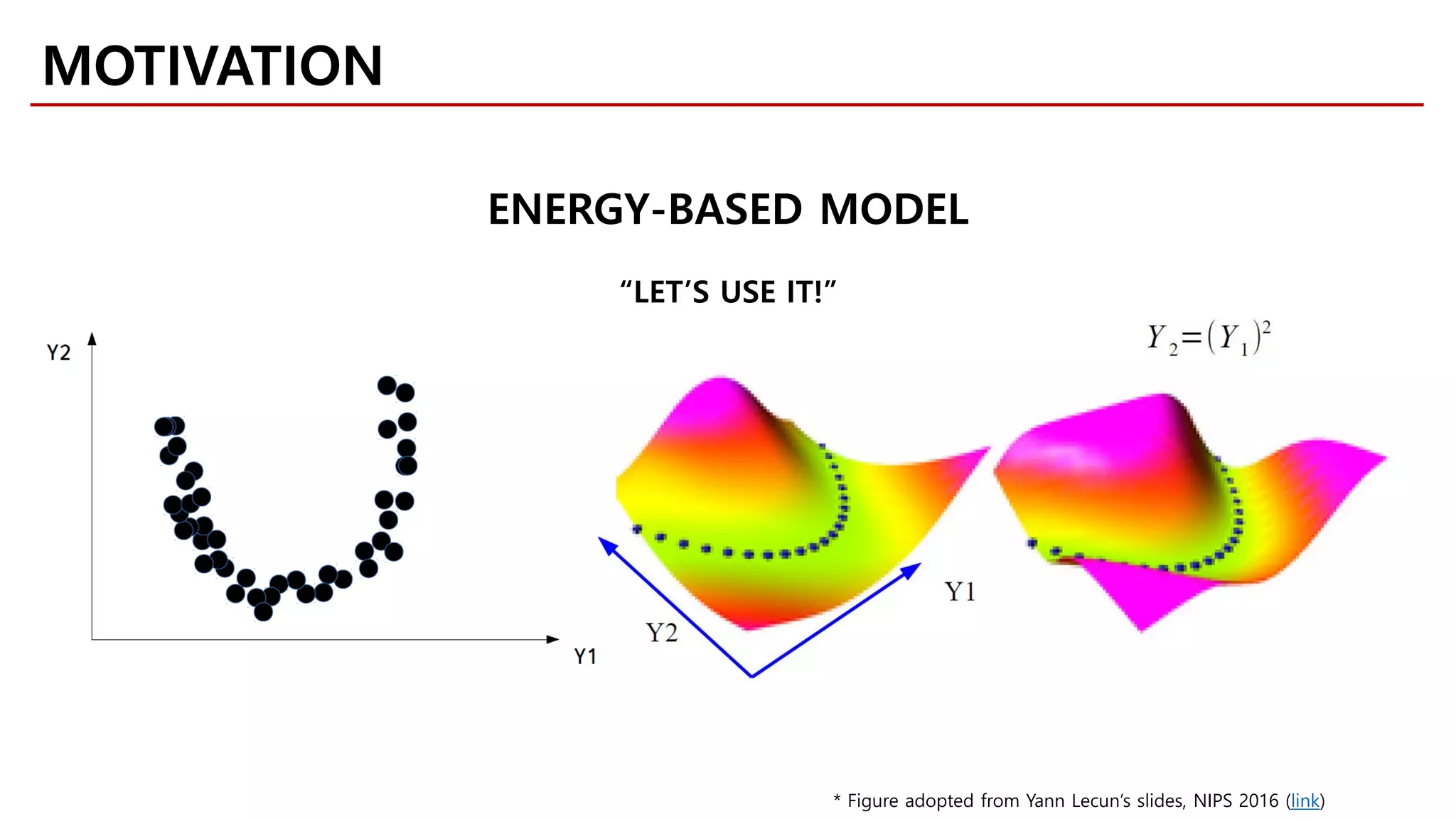
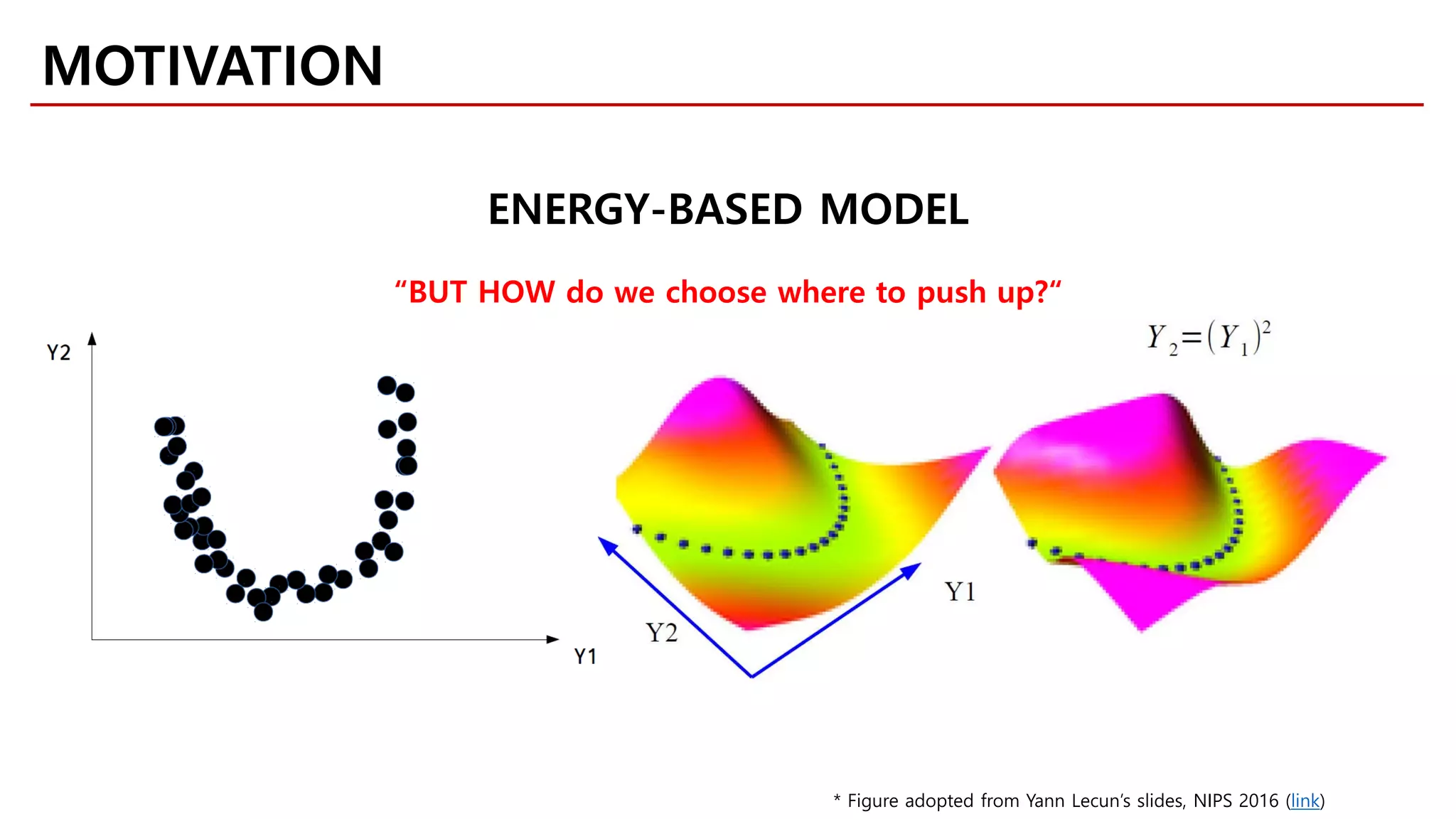
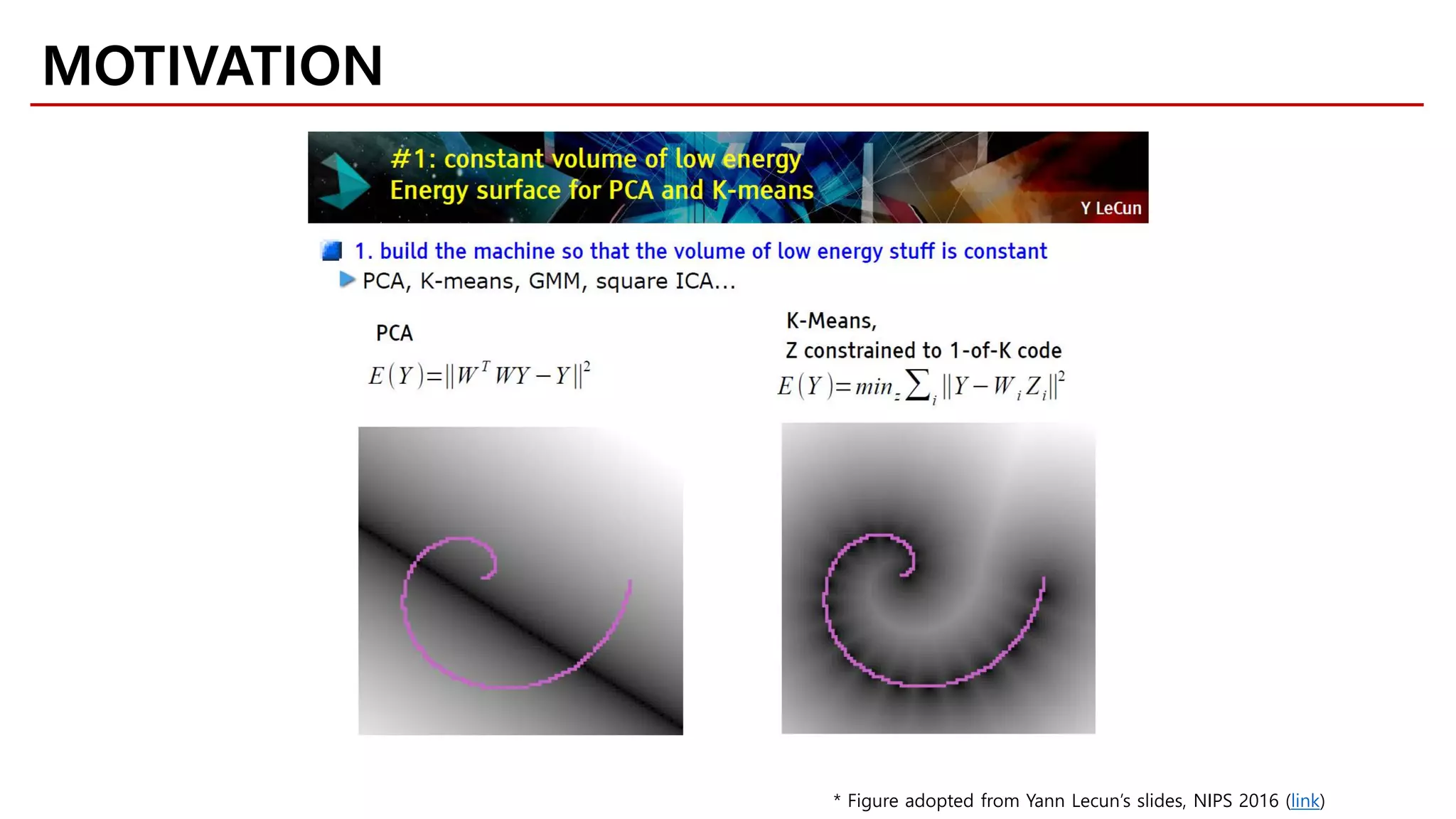
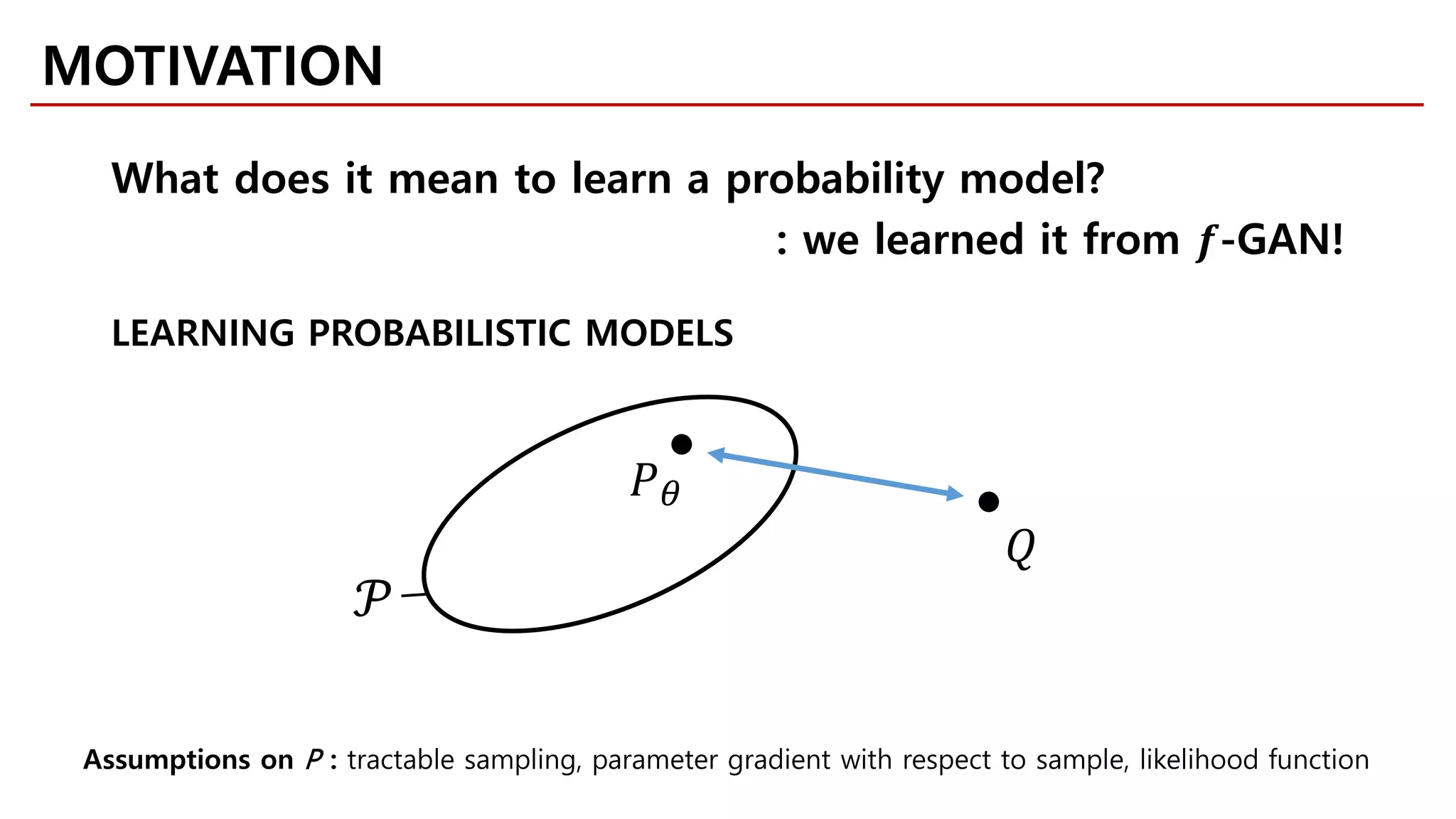
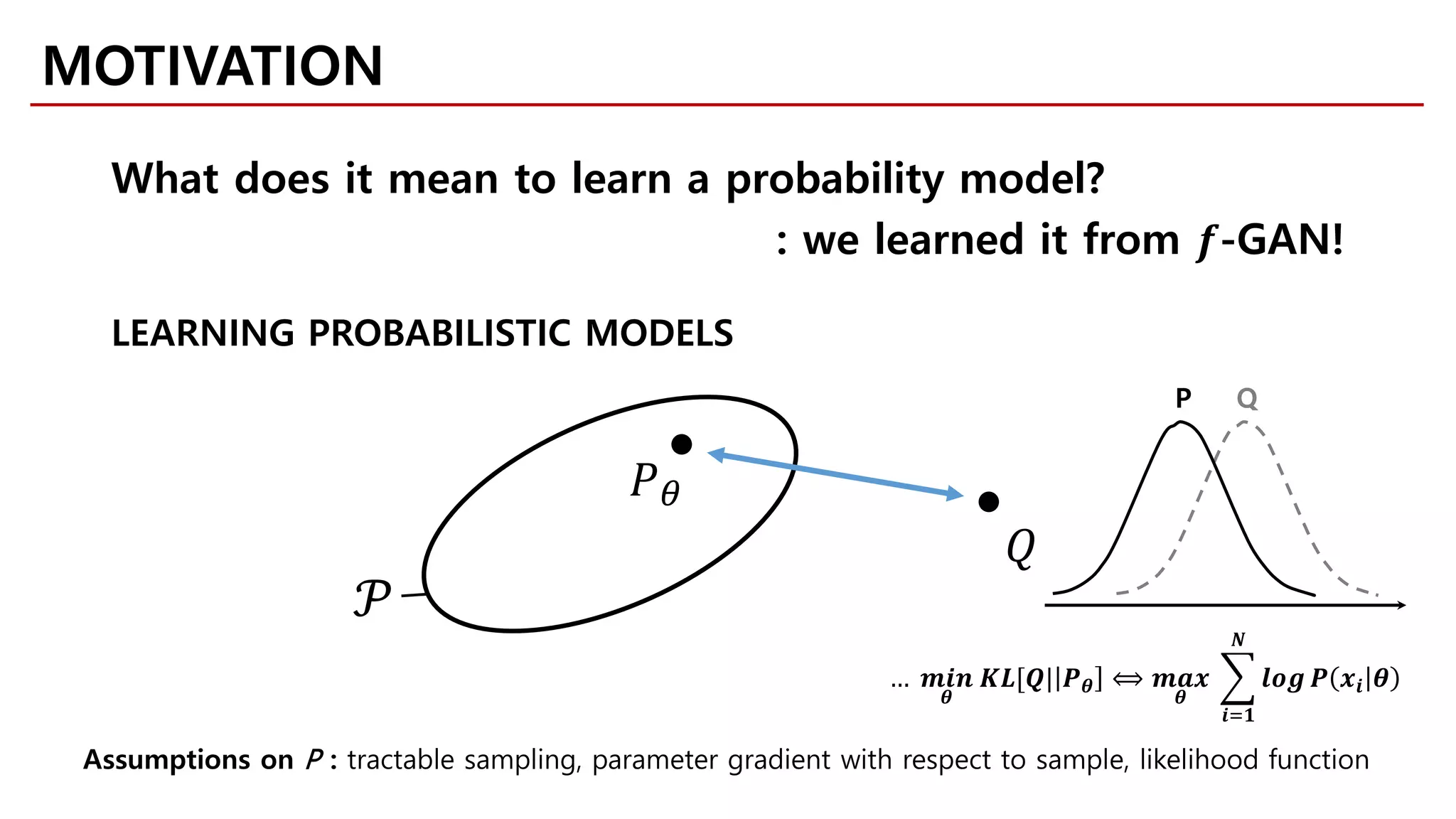
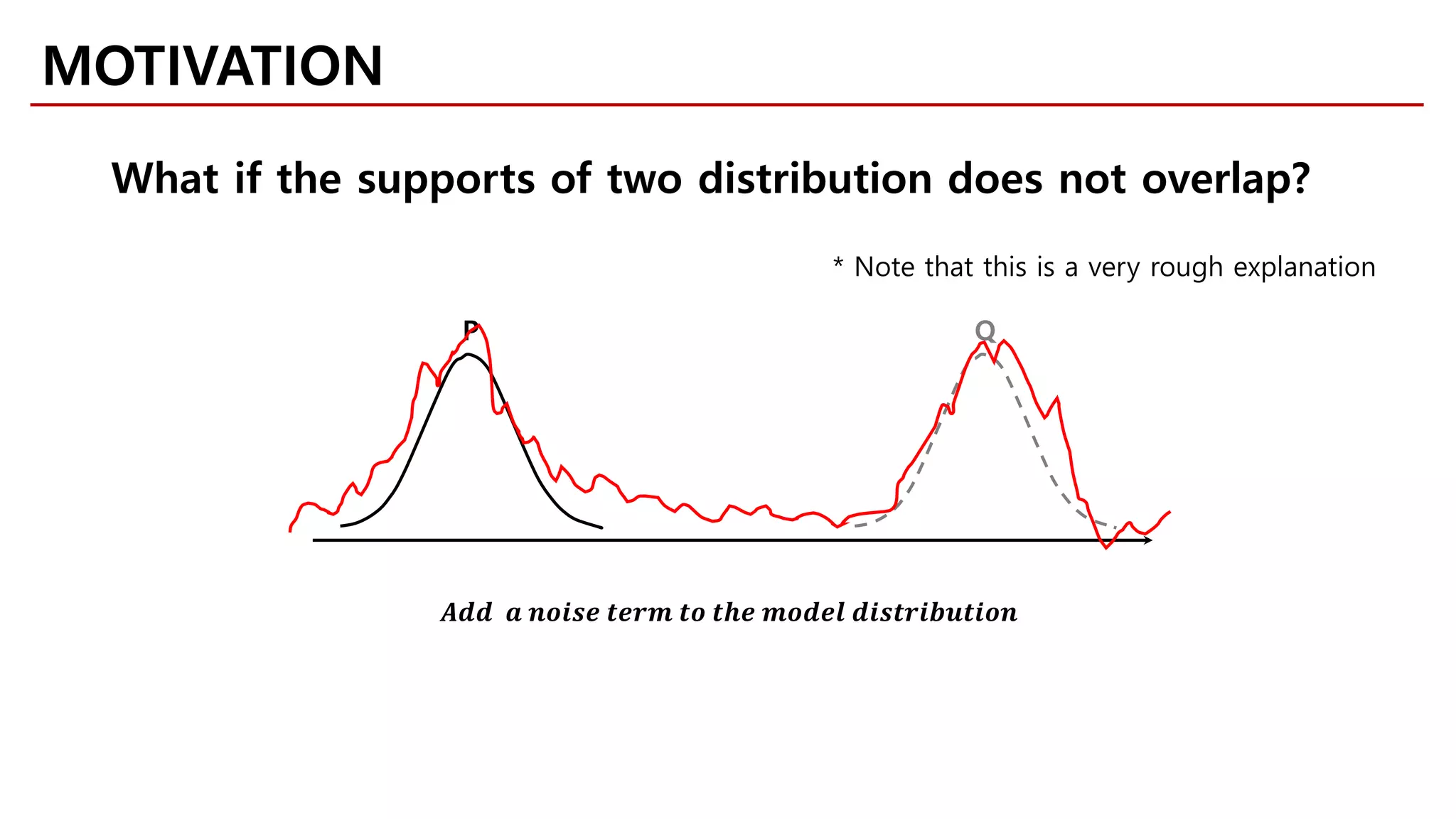
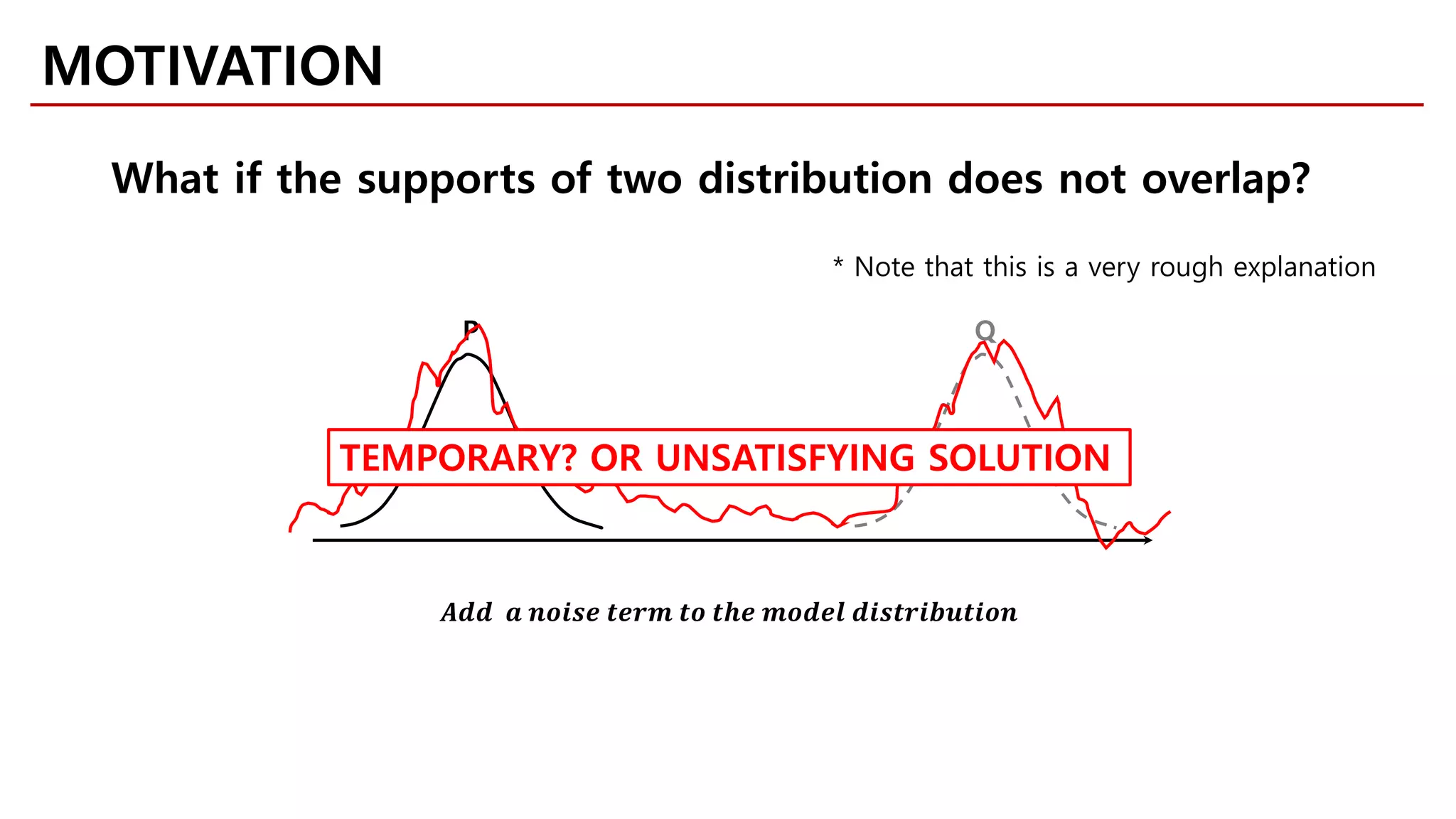
MOTIVATION
Likelihood-free Model](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-103-2048.jpg)
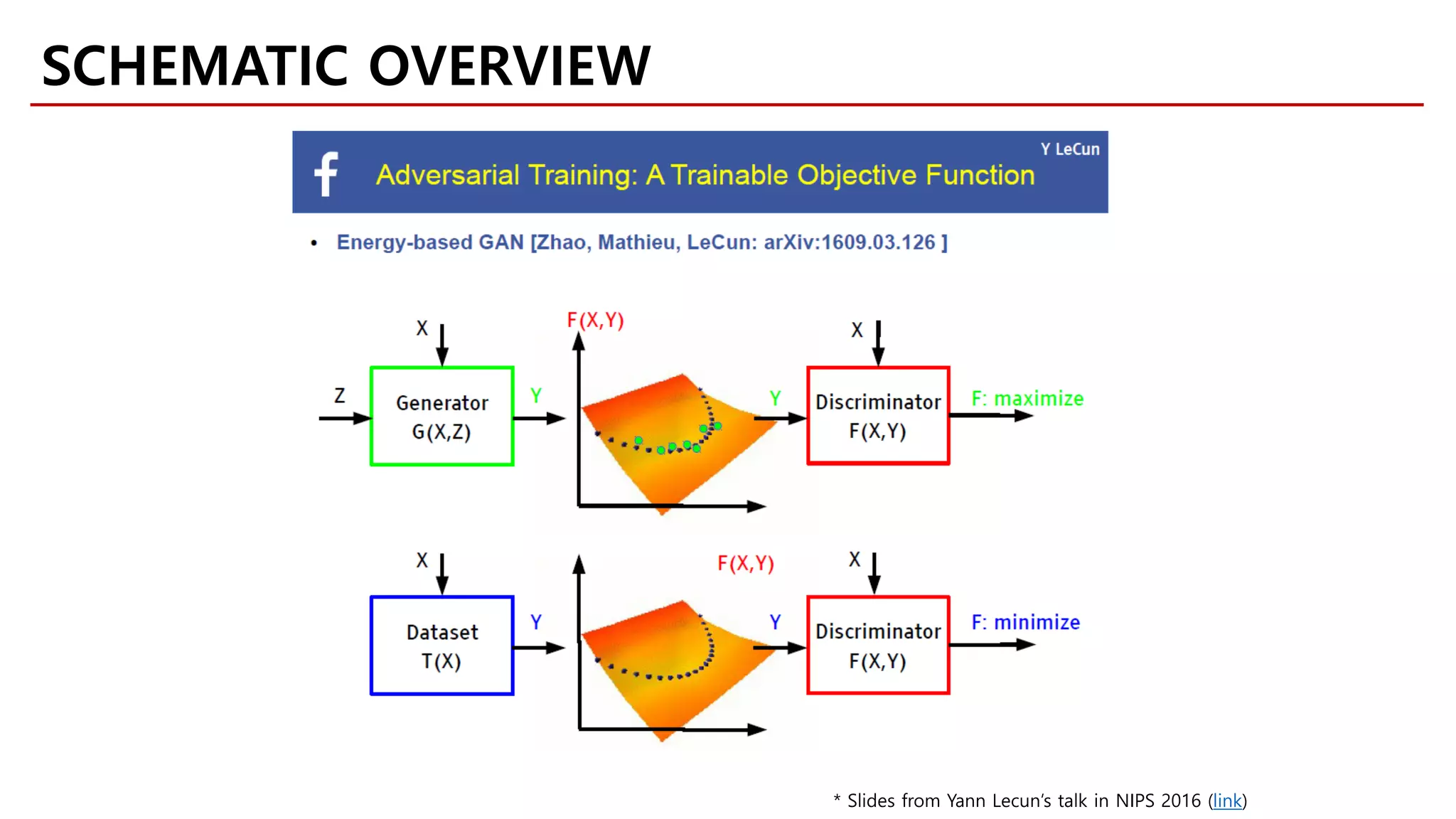
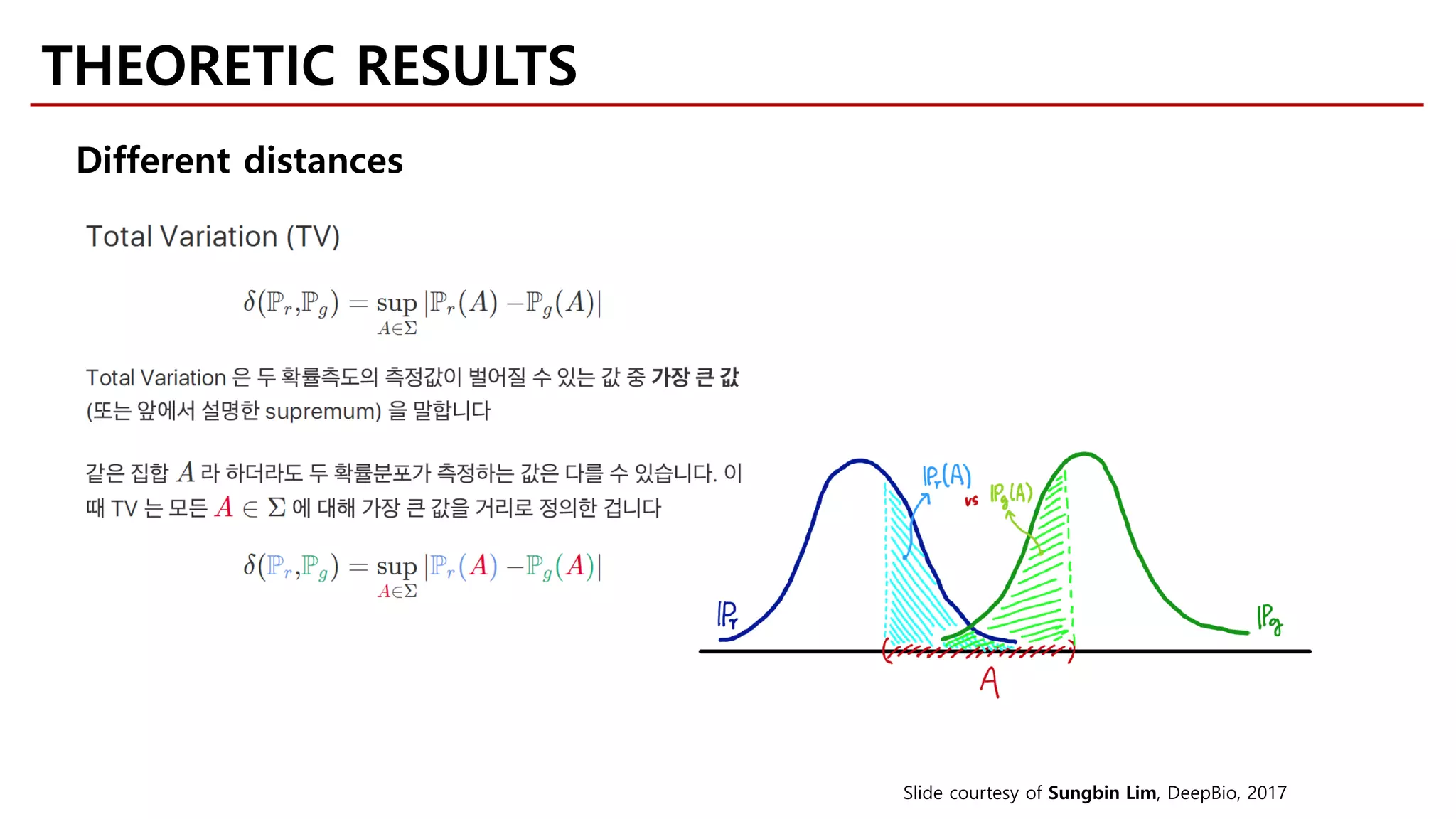
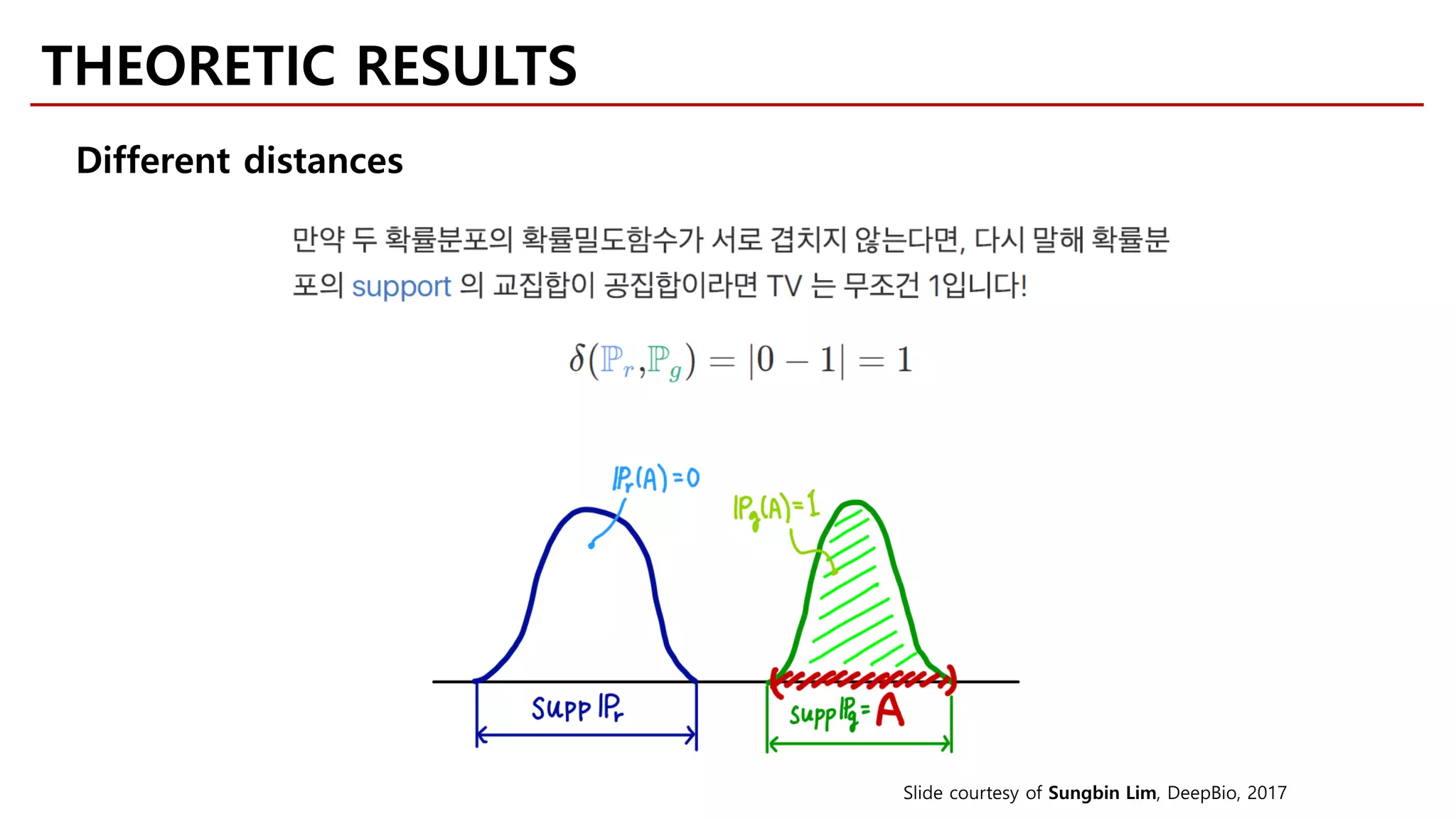
![• P: Expectation
• Q: Expectation
• Structure in ℱ
• Examples:
• Energy statistic [Szekely, 1997]
• Kernel MMD [Gretton et al., 20
12],
[Smola et al., 2007]
• Wasserstein distance [Cuturi, 20
13]
• DISCO Nets
[Bouchacourt et al., 2016]
Integral Probability Metrics
[Müller, 1997]
[Sriperumbudur et al., 2010]
𝛾𝛾ℱ 𝑃𝑃, 𝑄𝑄 = sup
𝑓𝑓∈ℱ
� 𝑓𝑓d𝑃𝑃 − � 𝑓𝑓d𝑄𝑄
Proper scoring rules
[Gneiting and Raftery, 2007]
𝑆𝑆 𝑃𝑃, 𝑄𝑄 = � 𝑆𝑆 𝑃𝑃, 𝑥𝑥 d𝑄𝑄(𝑥𝑥)
• P: Distribution
• Q: Expectation
• Examples:
• Log-likelihood
[Fisher, 1922], [Good, 1952]
• Quadratic score
[Bernardo, 1979]
f-divergences
[Ali and Silvey, 1966]
𝐷𝐷𝑓𝑓 𝑃𝑃 ∥ 𝑄𝑄 = � 𝑞𝑞 𝑥𝑥 𝑓𝑓
𝑝𝑝(𝑥𝑥)
𝑞𝑞(𝑥𝑥)
d𝑥𝑥
• P: Distribution
• Q: Distribution
• Examples:
• Kullback-Leibler divergence
[Kullback and Leibler, 1952]
• Jensen-Shannon divergence
• Total variation
• Pearson 𝜒𝜒2
LEARNING PROBABILISTIC MODELS
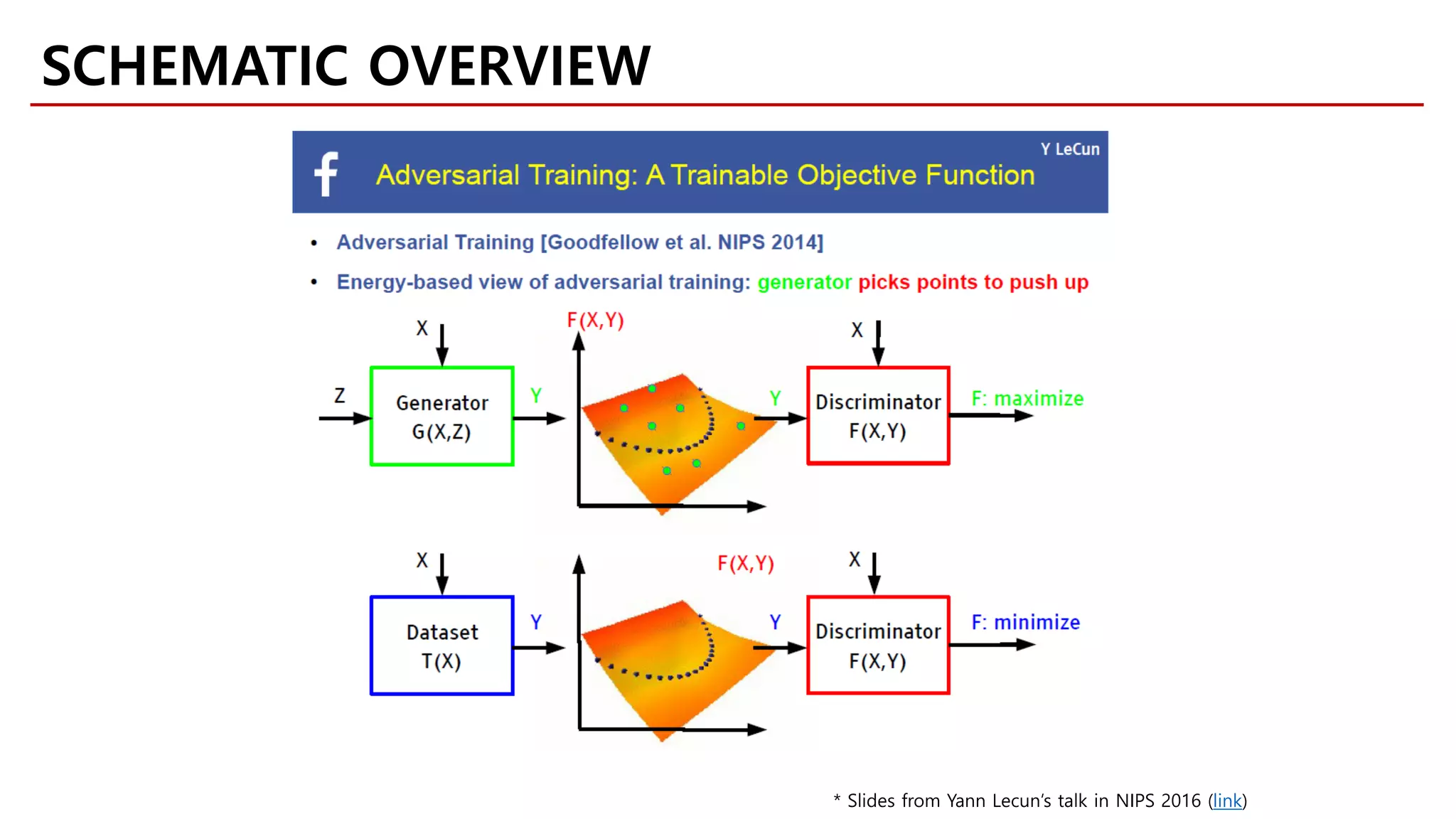
SCHEMATIC OVERVIEW](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-104-2048.jpg)
![• P: Distribution
• Q: Expectation
• P: Expectation
• Q: Expectation
• P: Distribution
• Q: Distribution
[Nguyen et al., 2010], [Reid and Williamson, 2011], [Goodfellow et a
l., 2014]
Variational representation of divergences
LEARNING PROBABILISTIC MODELS
SCHEMATIC OVERVIEW](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-105-2048.jpg)


![• Divergence between two distributions
𝑫𝑫𝒇𝒇 𝑸𝑸 ∥ 𝑷𝑷 = �
𝓧𝓧
𝒑𝒑 𝒙𝒙 𝒇𝒇
𝒒𝒒(𝒙𝒙)
𝒑𝒑(𝒙𝒙)
𝒅𝒅𝒅𝒅
• f : generator function, convex, f (1) = 0
[Ali and Silvey, 1966]
𝑓𝑓-DIVERGENCE](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-109-2048.jpg)

![• Divergence between two distributions
𝐷𝐷𝑓𝑓 𝑄𝑄 ∥ 𝑃𝑃 = �
𝒳𝒳
𝑝𝑝 𝑥𝑥 𝑓𝑓
𝑞𝑞(𝑥𝑥)
𝑝𝑝(𝑥𝑥)
d𝑥𝑥
• Every convex function 𝑓𝑓 has a Fenchel conjugate 𝑓𝑓∗
so that
𝑓𝑓 𝑢𝑢 = sup
𝑡𝑡∈dom𝑓𝑓∗
𝑡𝑡𝑢𝑢 − 𝑓𝑓∗
(𝑡𝑡)
[Nguyen, Wainwright, Jordan, 2010]
“Any convex f can be represented as point-wise max of linear functions”
Estimating 𝑓𝑓-divergences from samples
𝑓𝑓-DIVERGENCE](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-111-2048.jpg)

![𝐷𝐷𝑓𝑓 𝑄𝑄 ∥ 𝑃𝑃 = �
𝒳𝒳
𝑝𝑝 𝑥𝑥 𝑓𝑓
𝑞𝑞(𝑥𝑥)
𝑝𝑝(𝑥𝑥)
d𝑥𝑥
= �
𝒳𝒳
𝑝𝑝 𝑥𝑥 sup
𝑡𝑡∈dom𝑓𝑓∗
𝑡𝑡
𝑞𝑞(𝑥𝑥)
𝑝𝑝(𝑥𝑥)
− 𝑓𝑓∗(𝑡𝑡) d𝑥𝑥
≥ sup
𝑇𝑇∈𝒯𝒯
�
𝒳𝒳
𝑞𝑞 𝑥𝑥 𝑇𝑇 𝑥𝑥 d𝑥𝑥 − �
𝒳𝒳
𝑝𝑝 𝑥𝑥 𝑓𝑓∗ 𝑇𝑇 𝑥𝑥 d𝑥𝑥
= sup
𝑇𝑇∈𝒯𝒯
𝔼𝔼𝑥𝑥~𝑄𝑄 𝑇𝑇(𝑥𝑥) − 𝔼𝔼𝑥𝑥~𝑃𝑃[𝑓𝑓∗(𝑇𝑇(𝑥𝑥))]
Approximate using: samples from Q samples from P
Estimating 𝑓𝑓-divergences from samples (cont)
𝑓𝑓-DIVERGENCE
* Please note that in S. Nowozin’s slides, Q represents the real distribution and P stands for the parametric model we set.](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-113-2048.jpg)
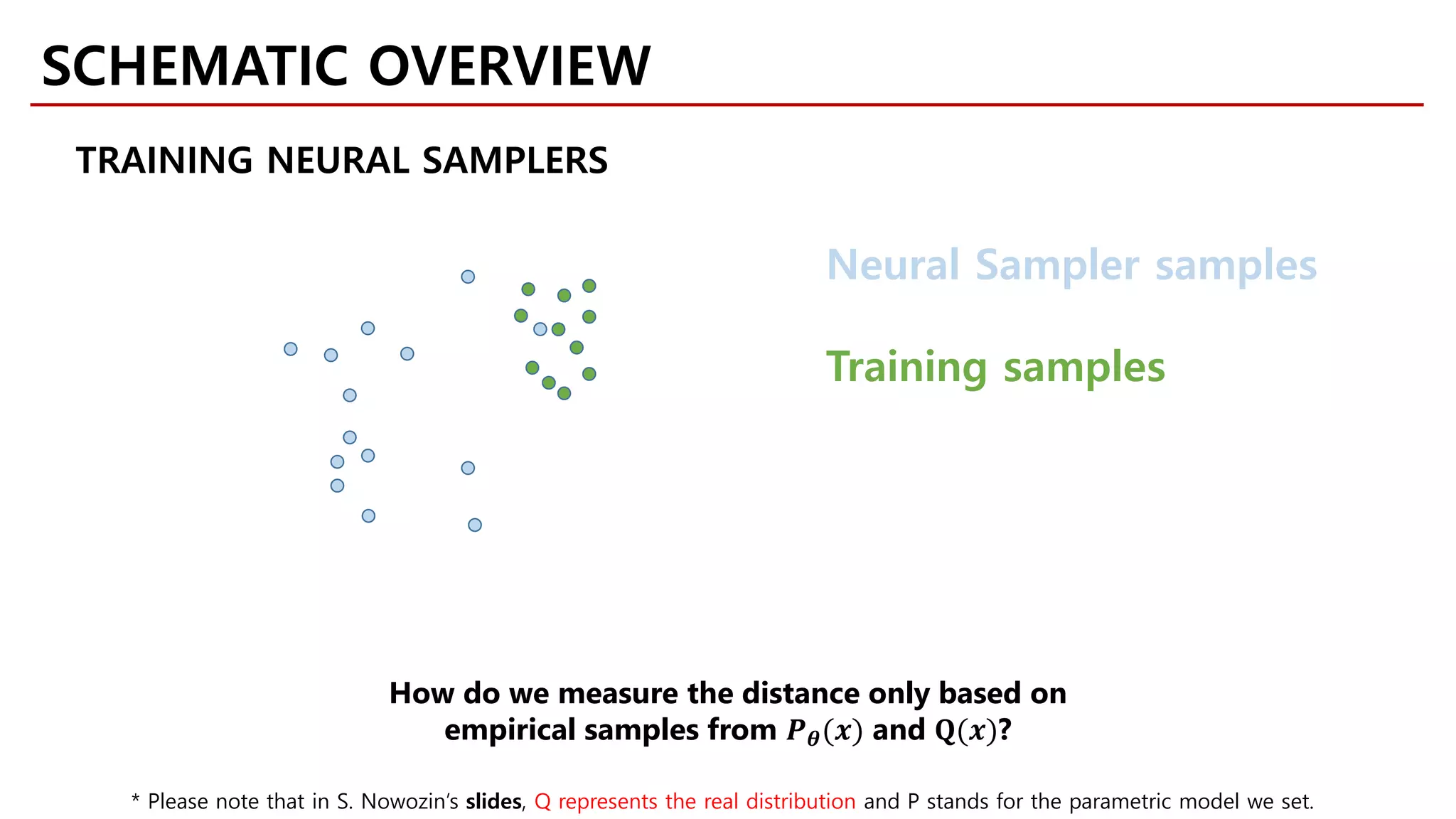
![• GAN
min
𝜃𝜃
max
𝜔𝜔
𝔼𝔼𝑥𝑥~𝑄𝑄[log 𝐷𝐷𝜔𝜔 𝑥𝑥 ] + 𝔼𝔼𝑥𝑥~𝑃𝑃𝜃𝜃
[log(1 − 𝐷𝐷𝜔𝜔(𝑥𝑥))]
• 𝑓𝑓-GAN
min
𝜃𝜃
max
𝜔𝜔
𝔼𝔼𝑥𝑥~𝑄𝑄 𝑇𝑇𝜔𝜔 (𝑥𝑥) − 𝔼𝔼𝑥𝑥~𝑃𝑃𝜃𝜃
[𝑓𝑓∗
(𝑇𝑇𝜔𝜔(𝑥𝑥))]
• GAN discriminator-variational function correspondence: log𝐷𝐷𝜔𝜔 𝑥𝑥 =
𝑇𝑇𝜔𝜔 𝑥𝑥
• GAN minimizes the Jensen-Shannon divergence (which was also pointed
out in Goodfellow et al., 2014)
𝑓𝑓-GAN and GAN objectives
𝑓𝑓-GAN
* Please note that in S. Nowozin’s slides, Q represents the real distribution and P stands for the parametric model we set.](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-114-2048.jpg)
![• Double-loop algorithm [Goodfellow et al., 2014]
• Algorithm:
• Inner loop: tighten divergence lower bound
• Outer loop: minimize generator loss
• In practice the inner loop is run only for one step (two backprops)
• Missing justification for this practice
• Single-step algorithm (proposed)
• Algorithm: simultaneously take (one backprop)
• a positive gradient step w.r.t. variational function 𝑇𝑇𝜔𝜔(𝑥𝑥)
• a negative gradient step w.r.t. generator function 𝑃𝑃𝜃𝜃 𝑥𝑥
• Does this converge?
THEORETICAL RESULTS
Algorithm: Double-Loop versus Single-Step](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-116-2048.jpg)



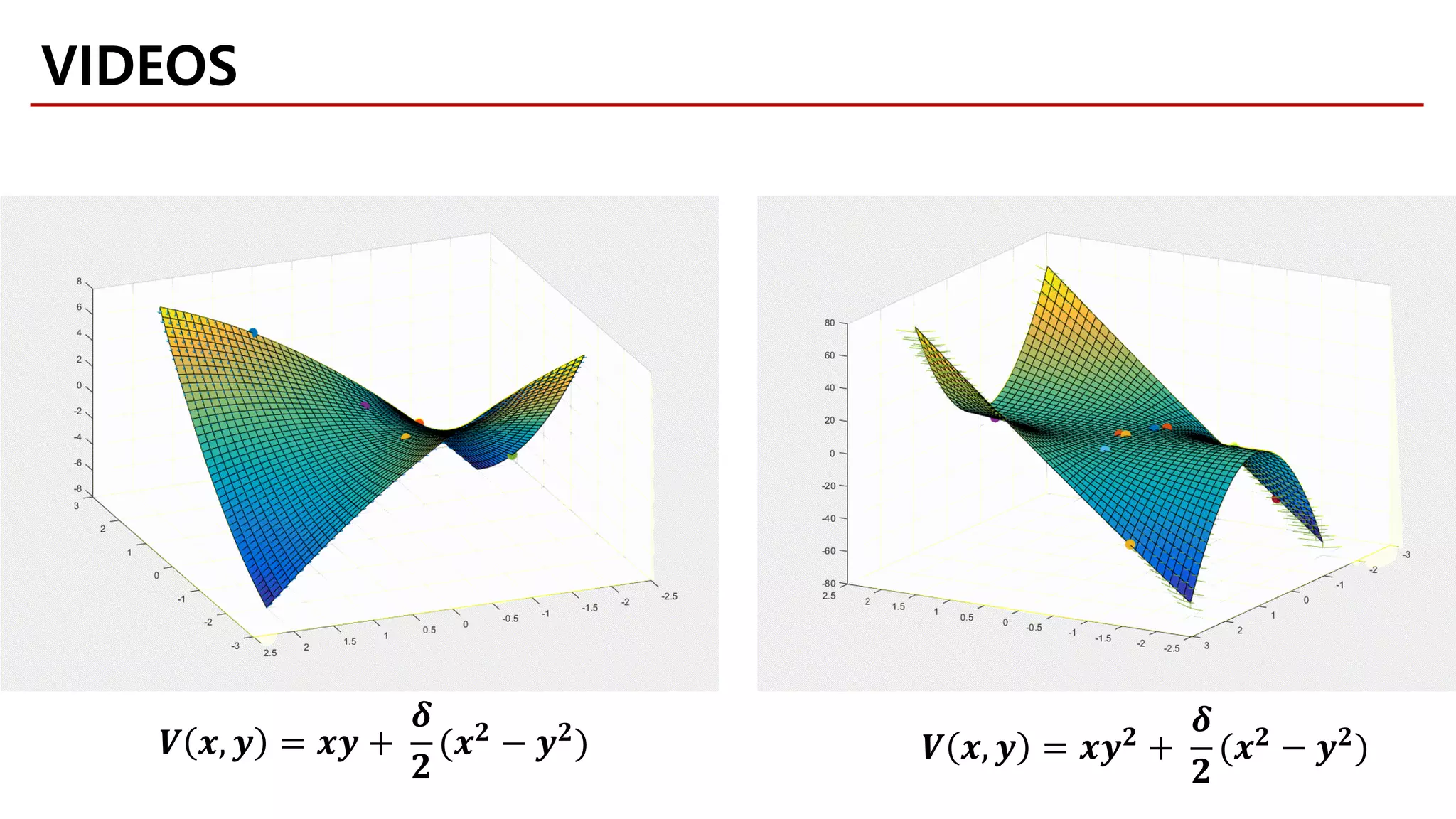
![RESULTS
Synthetic 1D Univariate
Approximate a mixture of Gaussians by a Gaussian to
• Validate the approach
• Demonstrate the properties of different divergences [Minka, 2005]
Compare the exact optimization of the divergence with the GAN approach
* Please note that in S. Nowozin’s paper, P represents the real distribution and 𝑄𝑄𝜃𝜃 stands for the parametric model we set.](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-121-2048.jpg)




![• LSUN experiment: No (visually)
• Empirical contradiction to intuition from [Theis et al., 2015],
[Huszar, 2015]
• Why?
• Intuition: strong inductive bias of model class
Q
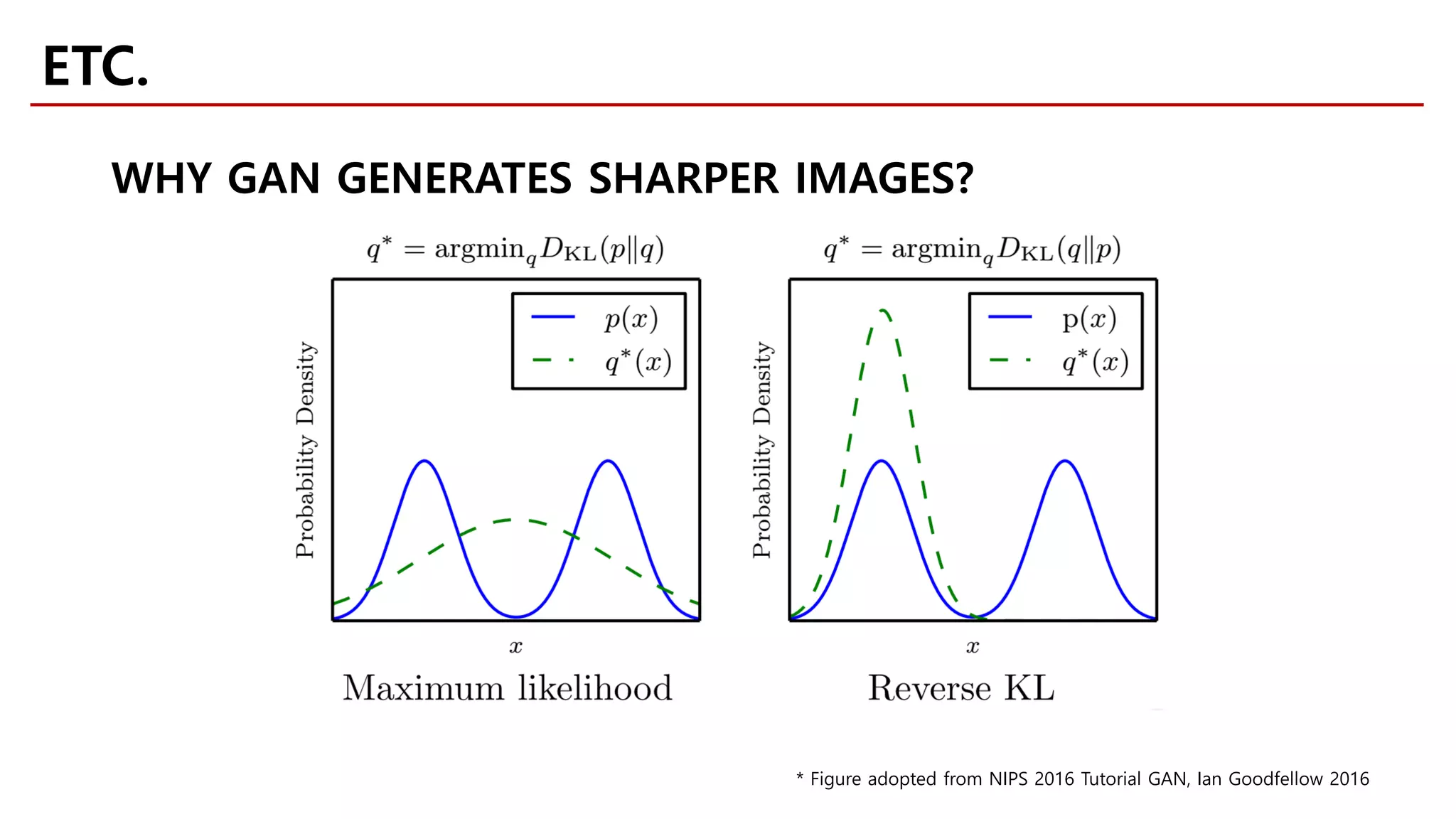
ETC.
DOES THE DIVERGENCE MATTER?](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-128-2048.jpg)










![• P: Expectation
• Q: Expectation
• Structure in ℱ
• Examples:
• Energy statistic [Szekely, 1997]
• Kernel MMD [Gretton et al., 20
12],
[Smola et al., 2007]
• Wasserstein distance [Cuturi, 20
13]
• DISCO Nets
[Bouchacourt et al., 2016]
Integral Probability Metrics
[Müller, 1997]
[Sriperumbudur et al., 2010]
𝛾𝛾ℱ 𝑃𝑃, 𝑄𝑄 = sup
𝑓𝑓∈ℱ
� 𝑓𝑓d𝑃𝑃 − � 𝑓𝑓d𝑄𝑄
Proper scoring rules
[Gneiting and Raftery, 2007]
𝑆𝑆 𝑃𝑃, 𝑄𝑄 = � 𝑆𝑆 𝑃𝑃, 𝑥𝑥 d𝑄𝑄(𝑥𝑥)
• P: Distribution
• Q: Expectation
• Examples:
• Log-likelihood
[Fisher, 1922], [Good, 1952]
• Quadratic score
[Bernardo, 1979]
f-divergences
[Ali and Silvey, 1966]
𝐷𝐷𝑓𝑓 𝑃𝑃 ∥ 𝑄𝑄 = � 𝑞𝑞 𝑥𝑥 𝑓𝑓
𝑝𝑝(𝑥𝑥)
𝑞𝑞(𝑥𝑥)
d𝑥𝑥
• P: Distribution
• Q: Distribution
• Examples:
• Kullback-Leibler divergence
[Kullback and Leibler, 1952]
• Jensen-Shannon divergence
• Total variation
• Pearson 𝜒𝜒2
LEARNING PROBABILISTIC MODELS
REVIEW!](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-156-2048.jpg)
![[Goodfellow et al., 2014]
𝑧𝑧 → Lin 100,1200 → ReLU
→ Lin 1200,1200 → ReLU
→ Lin(1200,784) → Sigmoid
Random input Generator Output
𝑧𝑧 ~ Uniform100
REVIEW!
Likelihood-free Model](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-157-2048.jpg)
![[Goodfellow et al., 2014]
𝑧𝑧 → Lin 100,1200 → ReLU
→ Lin 1200,1200 → ReLU
→ Lin(1200,784) → Sigmoid
Random input Generator Output
𝑧𝑧 ~ Uniform100
REVIEW!
WELL KNOWN FOR BEING DELICATE AND UNSTABLE FOR TRAINING
Likelihood-free Model](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-158-2048.jpg)
![• P: Expectation
• Q: Expectation
• Structure in ℱ
• Examples:
• Energy statistic [Szekely, 1997]
• Kernel MMD [Gretton et al., 20
12],
[Smola et al., 2007]
• Wasserstein distance [Cuturi, 20
13]
• DISCO Nets
[Bouchacourt et al., 2016]
Integral Probability Metrics
[Müller, 1997]
[Sriperumbudur et al., 2010]
𝛾𝛾ℱ 𝑃𝑃, 𝑄𝑄 = sup
𝑓𝑓∈ℱ
� 𝑓𝑓d𝑃𝑃 − � 𝑓𝑓d𝑄𝑄
Proper scoring rules
[Gneiting and Raftery, 2007]
𝑆𝑆 𝑃𝑃, 𝑄𝑄 = � 𝑆𝑆 𝑃𝑃, 𝑥𝑥 d𝑄𝑄(𝑥𝑥)
• P: Distribution
• Q: Expectation
• Examples:
• Log-likelihood
[Fisher, 1922], [Good, 1952]
• Quadratic score
[Bernardo, 1979]
f-divergences
[Ali and Silvey, 1966]
𝐷𝐷𝑓𝑓 𝑃𝑃 ∥ 𝑄𝑄 = � 𝑞𝑞 𝑥𝑥 𝑓𝑓
𝑝𝑝(𝑥𝑥)
𝑞𝑞(𝑥𝑥)
d𝑥𝑥
• P: Distribution
• Q: Distribution
• Examples:
• Kullback-Leibler divergence
[Kullback and Leibler, 1952]
• Jensen-Shannon divergence
• Total variation
• Pearson 𝜒𝜒2
LEARNING PROBABILISTIC MODELS
REVIEW!](https://image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-159-2048.jpg)































































































































![[Goodfellow et al., 2014]
𝑧𝑧 → Lin 100,1200 → ReLU
→ Lin 1200,1200 → ReLU
→ Lin(1200,784) → Sigmoid
Random input Generator Output
𝑧𝑧 ~ Uniform100
MOTIVATION
Likelihood-free Model](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-103-2048.jpg)
![• P: Expectation
• Q: Expectation
• Structure in ℱ
• Examples:
• Energy statistic [Szekely, 1997]
• Kernel MMD [Gretton et al., 20
12],
[Smola et al., 2007]
• Wasserstein distance [Cuturi, 20
13]
• DISCO Nets
[Bouchacourt et al., 2016]
Integral Probability Metrics
[Müller, 1997]
[Sriperumbudur et al., 2010]
𝛾𝛾ℱ 𝑃𝑃, 𝑄𝑄 = sup
𝑓𝑓∈ℱ
� 𝑓𝑓d𝑃𝑃 − � 𝑓𝑓d𝑄𝑄
Proper scoring rules
[Gneiting and Raftery, 2007]
𝑆𝑆 𝑃𝑃, 𝑄𝑄 = � 𝑆𝑆 𝑃𝑃, 𝑥𝑥 d𝑄𝑄(𝑥𝑥)
• P: Distribution
• Q: Expectation
• Examples:
• Log-likelihood
[Fisher, 1922], [Good, 1952]
• Quadratic score
[Bernardo, 1979]
f-divergences
[Ali and Silvey, 1966]
𝐷𝐷𝑓𝑓 𝑃𝑃 ∥ 𝑄𝑄 = � 𝑞𝑞 𝑥𝑥 𝑓𝑓
𝑝𝑝(𝑥𝑥)
𝑞𝑞(𝑥𝑥)
d𝑥𝑥
• P: Distribution
• Q: Distribution
• Examples:
• Kullback-Leibler divergence
[Kullback and Leibler, 1952]
• Jensen-Shannon divergence
• Total variation
• Pearson 𝜒𝜒2
LEARNING PROBABILISTIC MODELS
SCHEMATIC OVERVIEW](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-104-2048.jpg)
![• P: Distribution
• Q: Expectation
• P: Expectation
• Q: Expectation
• P: Distribution
• Q: Distribution
[Nguyen et al., 2010], [Reid and Williamson, 2011], [Goodfellow et a
l., 2014]
Variational representation of divergences
LEARNING PROBABILISTIC MODELS
SCHEMATIC OVERVIEW](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-105-2048.jpg)



![• Divergence between two distributions
𝑫𝑫𝒇𝒇 𝑸𝑸 ∥ 𝑷𝑷 = �
𝓧𝓧
𝒑𝒑 𝒙𝒙 𝒇𝒇
𝒒𝒒(𝒙𝒙)
𝒑𝒑(𝒙𝒙)
𝒅𝒅𝒅𝒅
• f : generator function, convex, f (1) = 0
[Ali and Silvey, 1966]
𝑓𝑓-DIVERGENCE](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-109-2048.jpg)

![• Divergence between two distributions
𝐷𝐷𝑓𝑓 𝑄𝑄 ∥ 𝑃𝑃 = �
𝒳𝒳
𝑝𝑝 𝑥𝑥 𝑓𝑓
𝑞𝑞(𝑥𝑥)
𝑝𝑝(𝑥𝑥)
d𝑥𝑥
• Every convex function 𝑓𝑓 has a Fenchel conjugate 𝑓𝑓∗
so that
𝑓𝑓 𝑢𝑢 = sup
𝑡𝑡∈dom𝑓𝑓∗
𝑡𝑡𝑢𝑢 − 𝑓𝑓∗
(𝑡𝑡)
[Nguyen, Wainwright, Jordan, 2010]
“Any convex f can be represented as point-wise max of linear functions”
Estimating 𝑓𝑓-divergences from samples
𝑓𝑓-DIVERGENCE](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-111-2048.jpg)

![𝐷𝐷𝑓𝑓 𝑄𝑄 ∥ 𝑃𝑃 = �
𝒳𝒳
𝑝𝑝 𝑥𝑥 𝑓𝑓
𝑞𝑞(𝑥𝑥)
𝑝𝑝(𝑥𝑥)
d𝑥𝑥
= �
𝒳𝒳
𝑝𝑝 𝑥𝑥 sup
𝑡𝑡∈dom𝑓𝑓∗
𝑡𝑡
𝑞𝑞(𝑥𝑥)
𝑝𝑝(𝑥𝑥)
− 𝑓𝑓∗(𝑡𝑡) d𝑥𝑥
≥ sup
𝑇𝑇∈𝒯𝒯
�
𝒳𝒳
𝑞𝑞 𝑥𝑥 𝑇𝑇 𝑥𝑥 d𝑥𝑥 − �
𝒳𝒳
𝑝𝑝 𝑥𝑥 𝑓𝑓∗ 𝑇𝑇 𝑥𝑥 d𝑥𝑥
= sup
𝑇𝑇∈𝒯𝒯
𝔼𝔼𝑥𝑥~𝑄𝑄 𝑇𝑇(𝑥𝑥) − 𝔼𝔼𝑥𝑥~𝑃𝑃[𝑓𝑓∗(𝑇𝑇(𝑥𝑥))]
Approximate using: samples from Q samples from P
Estimating 𝑓𝑓-divergences from samples (cont)
𝑓𝑓-DIVERGENCE
* Please note that in S. Nowozin’s slides, Q represents the real distribution and P stands for the parametric model we set.](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-113-2048.jpg)
![• GAN
min
𝜃𝜃
max
𝜔𝜔
𝔼𝔼𝑥𝑥~𝑄𝑄[log 𝐷𝐷𝜔𝜔 𝑥𝑥 ] + 𝔼𝔼𝑥𝑥~𝑃𝑃𝜃𝜃
[log(1 − 𝐷𝐷𝜔𝜔(𝑥𝑥))]
• 𝑓𝑓-GAN
min
𝜃𝜃
max
𝜔𝜔
𝔼𝔼𝑥𝑥~𝑄𝑄 𝑇𝑇𝜔𝜔 (𝑥𝑥) − 𝔼𝔼𝑥𝑥~𝑃𝑃𝜃𝜃
[𝑓𝑓∗
(𝑇𝑇𝜔𝜔(𝑥𝑥))]
• GAN discriminator-variational function correspondence: log𝐷𝐷𝜔𝜔 𝑥𝑥 =
𝑇𝑇𝜔𝜔 𝑥𝑥
• GAN minimizes the Jensen-Shannon divergence (which was also pointed
out in Goodfellow et al., 2014)
𝑓𝑓-GAN and GAN objectives
𝑓𝑓-GAN
* Please note that in S. Nowozin’s slides, Q represents the real distribution and P stands for the parametric model we set.](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-114-2048.jpg)

![• Double-loop algorithm [Goodfellow et al., 2014]
• Algorithm:
• Inner loop: tighten divergence lower bound
• Outer loop: minimize generator loss
• In practice the inner loop is run only for one step (two backprops)
• Missing justification for this practice
• Single-step algorithm (proposed)
• Algorithm: simultaneously take (one backprop)
• a positive gradient step w.r.t. variational function 𝑇𝑇𝜔𝜔(𝑥𝑥)
• a negative gradient step w.r.t. generator function 𝑃𝑃𝜃𝜃 𝑥𝑥
• Does this converge?
THEORETICAL RESULTS
Algorithm: Double-Loop versus Single-Step](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-116-2048.jpg)




![RESULTS
Synthetic 1D Univariate
Approximate a mixture of Gaussians by a Gaussian to
• Validate the approach
• Demonstrate the properties of different divergences [Minka, 2005]
Compare the exact optimization of the divergence with the GAN approach
* Please note that in S. Nowozin’s paper, P represents the real distribution and 𝑄𝑄𝜃𝜃 stands for the parametric model we set.](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-121-2048.jpg)






![• LSUN experiment: No (visually)
• Empirical contradiction to intuition from [Theis et al., 2015],
[Huszar, 2015]
• Why?
• Intuition: strong inductive bias of model class
Q
ETC.
DOES THE DIVERGENCE MATTER?](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-128-2048.jpg)



























![• P: Expectation
• Q: Expectation
• Structure in ℱ
• Examples:
• Energy statistic [Szekely, 1997]
• Kernel MMD [Gretton et al., 20
12],
[Smola et al., 2007]
• Wasserstein distance [Cuturi, 20
13]
• DISCO Nets
[Bouchacourt et al., 2016]
Integral Probability Metrics
[Müller, 1997]
[Sriperumbudur et al., 2010]
𝛾𝛾ℱ 𝑃𝑃, 𝑄𝑄 = sup
𝑓𝑓∈ℱ
� 𝑓𝑓d𝑃𝑃 − � 𝑓𝑓d𝑄𝑄
Proper scoring rules
[Gneiting and Raftery, 2007]
𝑆𝑆 𝑃𝑃, 𝑄𝑄 = � 𝑆𝑆 𝑃𝑃, 𝑥𝑥 d𝑄𝑄(𝑥𝑥)
• P: Distribution
• Q: Expectation
• Examples:
• Log-likelihood
[Fisher, 1922], [Good, 1952]
• Quadratic score
[Bernardo, 1979]
f-divergences
[Ali and Silvey, 1966]
𝐷𝐷𝑓𝑓 𝑃𝑃 ∥ 𝑄𝑄 = � 𝑞𝑞 𝑥𝑥 𝑓𝑓
𝑝𝑝(𝑥𝑥)
𝑞𝑞(𝑥𝑥)
d𝑥𝑥
• P: Distribution
• Q: Distribution
• Examples:
• Kullback-Leibler divergence
[Kullback and Leibler, 1952]
• Jensen-Shannon divergence
• Total variation
• Pearson 𝜒𝜒2
LEARNING PROBABILISTIC MODELS
REVIEW!](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-156-2048.jpg)
![[Goodfellow et al., 2014]
𝑧𝑧 → Lin 100,1200 → ReLU
→ Lin 1200,1200 → ReLU
→ Lin(1200,784) → Sigmoid
Random input Generator Output
𝑧𝑧 ~ Uniform100
REVIEW!
Likelihood-free Model](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-157-2048.jpg)
![[Goodfellow et al., 2014]
𝑧𝑧 → Lin 100,1200 → ReLU
→ Lin 1200,1200 → ReLU
→ Lin(1200,784) → Sigmoid
Random input Generator Output
𝑧𝑧 ~ Uniform100
REVIEW!
WELL KNOWN FOR BEING DELICATE AND UNSTABLE FOR TRAINING
Likelihood-free Model](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-158-2048.jpg)
![• P: Expectation
• Q: Expectation
• Structure in ℱ
• Examples:
• Energy statistic [Szekely, 1997]
• Kernel MMD [Gretton et al., 20
12],
[Smola et al., 2007]
• Wasserstein distance [Cuturi, 20
13]
• DISCO Nets
[Bouchacourt et al., 2016]
Integral Probability Metrics
[Müller, 1997]
[Sriperumbudur et al., 2010]
𝛾𝛾ℱ 𝑃𝑃, 𝑄𝑄 = sup
𝑓𝑓∈ℱ
� 𝑓𝑓d𝑃𝑃 − � 𝑓𝑓d𝑄𝑄
Proper scoring rules
[Gneiting and Raftery, 2007]
𝑆𝑆 𝑃𝑃, 𝑄𝑄 = � 𝑆𝑆 𝑃𝑃, 𝑥𝑥 d𝑄𝑄(𝑥𝑥)
• P: Distribution
• Q: Expectation
• Examples:
• Log-likelihood
[Fisher, 1922], [Good, 1952]
• Quadratic score
[Bernardo, 1979]
f-divergences
[Ali and Silvey, 1966]
𝐷𝐷𝑓𝑓 𝑃𝑃 ∥ 𝑄𝑄 = � 𝑞𝑞 𝑥𝑥 𝑓𝑓
𝑝𝑝(𝑥𝑥)
𝑞𝑞(𝑥𝑥)
d𝑥𝑥
• P: Distribution
• Q: Distribution
• Examples:
• Kullback-Leibler divergence
[Kullback and Leibler, 1952]
• Jensen-Shannon divergence
• Total variation
• Pearson 𝜒𝜒2
LEARNING PROBABILISTIC MODELS
REVIEW!](https://crownmelresort.com/image.slidesharecdn.com/fastcampusvariantsofgans-jaejunyoo-170516010153/75/Variants-of-GANs-Jaejun-Yoo-159-2048.jpg)

































The document discusses various aspects and developments in Generative Adversarial Networks (GANs), with a focus on their challenges and improvements. It covers different variants of GANs, their theoretical underpinnings, and practical solutions to common issues such as mode collapse and convergence difficulties. Key concepts such as the unrolled GAN and InfoGAN are also explored to enhance the model's performance and feature representation.


![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL Hacks 実装]Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/transformer1-180219072816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)













![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)









![[PR12] Inception and Xception - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12inceptionandxception-jaejunyoo-170910140157-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] categorical reparameterization with gumbel softmax](https://cdn.slidesharecdn.com/ss_thumbnails/pr12categoricalreparameterizationwithgumbel-softmax-180304131005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pr12] dann jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12dann-jaejunyoo-170604150015-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] Capsule Networks - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12capsulenetworks-jaejunyoo-171217144319-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] Spectral Normalization for Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12spectralnormalizationforgans-180513142600-thumbnail.jpg?width=640&height=640&fit=bounds)

![[CVPR2020] Simple but effective image enhancement techniques](https://cdn.slidesharecdn.com/ss_thumbnails/simplebuteffectiveimageenhancementtechniques-200617034047-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] Generative Models as Distributions of Functions](https://cdn.slidesharecdn.com/ss_thumbnails/pr12generativemodelsasdistributionsoffunctions-jaejunyoo-210411152822-thumbnail.jpg?width=640&height=640&fit=bounds)



















