Downloaded 43 times





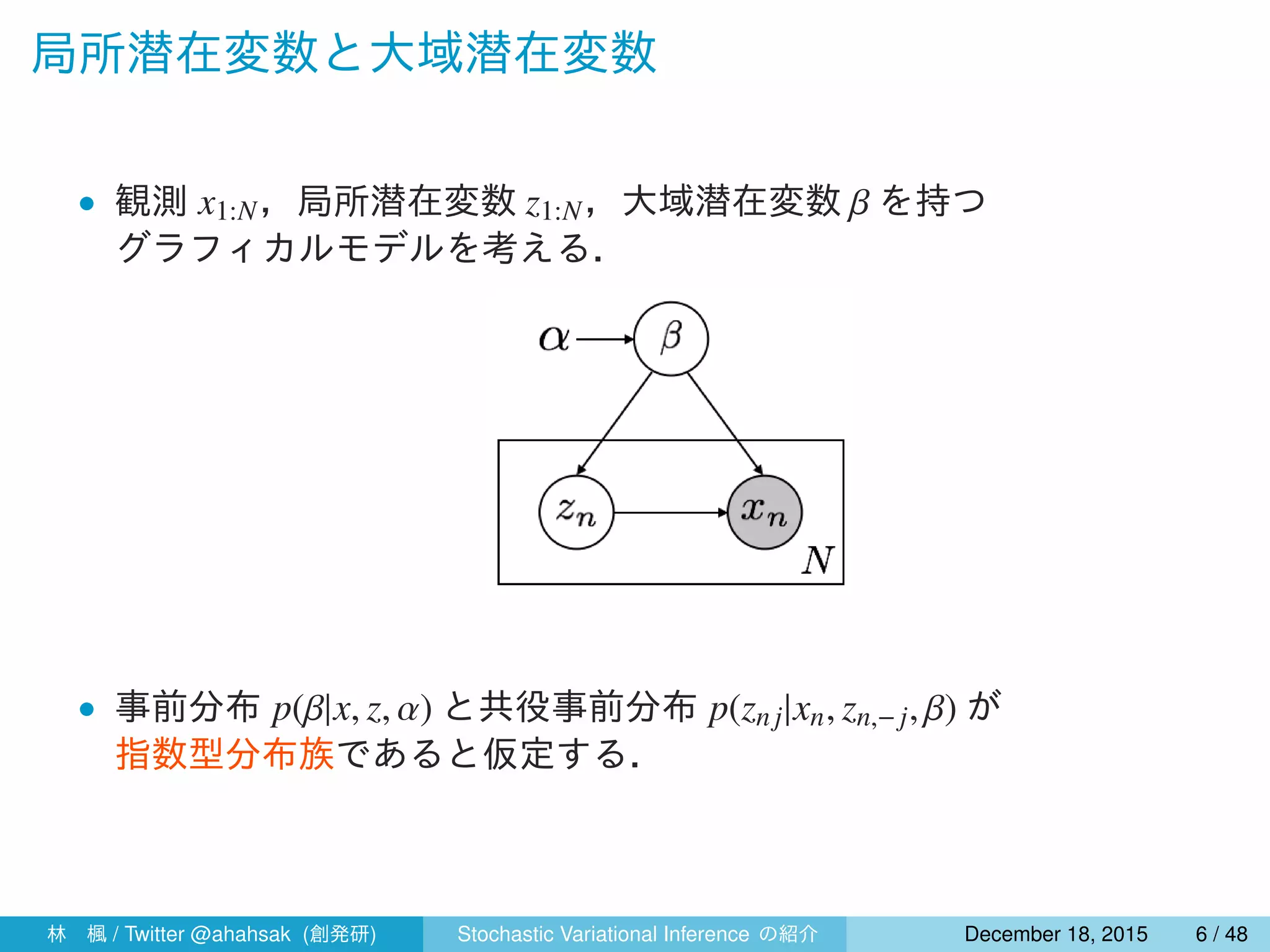



![対数周辺尤度と KL 情報量
変分ベイズ法では事後分布と変分事後分布との KL 情報量を最小化するた
めに,変分下限の最大化を行う.
p(x|α) = L[q(z, β)] + KL[q(z, β)||p(z, β|x, α)]
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 10 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-10-2048.jpg)
![対数周辺尤度と KL 情報量
変分ベイズ法では事後分布と変分事後分布との KL 情報量を最小化するた
めに,変分下限の最大化を行う.
p(x|α) = L[q(z, β)] + KL[q(z, β)||p(z, β|x, α)]
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 11 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-11-2048.jpg)
![変分下限の導出
変分下限 L は対数関数の凸性とイエンゼンの不等式を利用することで得
られる.
log p(x) = log
∫
p(x, z, β)dzdβ
= log
∫
q(z, β)
p(x, z, β)
q(z, β)
dzdβ
= log Eq
[
p(x, z, β)
q(z, β)
]
≥ Eq
[
log p(x, z, β)
]
− Eq
[
log q(z, β)
]
(6)
def
= L(q)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 12 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-12-2048.jpg)
![変分下限の導出
L(q) = Eq
[
log p(x, z, β)
]
− Eq
[
log q(z, β)
]
• 結合分布の対数の期待値 Eq
[
log p(x, z, β)
]
Eq
[
log p(x, z, β)
]
= Eq
[
log p(β|x, z)p(x, z)
]
= Eq
[
log p(β|x, z)
]
+ Eq
[
p(x, z)
]
(7)
• 変分事後分布のエントロピー −Eq
[
log q(z, β)
]
−Eq
[
log q(z, β)
]
= −Eq
[
log q(β|λ)
]
−
N∑
n=1
J∑
j=1
Eq
[
log q(znj|ϕn j)
]
(8)
※ 変分事後分布 q(z, β) は因子分解可能を仮定する.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 13 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-13-2048.jpg)
![変分下限の最大化
L(q) = Lglobal + Llocal
Lglobal = Eq
[
log p(β|x, z)
]
− Eq
[
log q(β|λ)
] def
= L(λ)
Llocal = Eq
[
log p(znj|xn, zn,− j, β)
]
− Eq
[
log q(znj)
] def
= L(ϕnj)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 14 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-14-2048.jpg)
![変分下限の最大化
変分事後分布の定義 (指数型分布族)
q(β|λ) = h(β) exp{λT
t(β) − ag(λ)} (9)
q(znj|ϕn j) = h(znj) exp{ϕT
njt(znj) − al(ϕnj)} (10)
式 (1),(9) より, L(λ) は次のように変形できる.
L(λ) = Eq
[
ηg(x, z, α)
]T
∇λag(λ) − λT
∇λag(λ) + ag(λ) + const (11)
ここで,−Eq
[
ag(ηg(x, z, α))
]
は q(β) に依らないため定数とした.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 15 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-15-2048.jpg)
![変分下限の最大化
式 (11) で λ 方向の勾配をとると以下のようになる.
∇λL(λ) = ∇2
λag(λ)(Eq
[
ηg(x, z, α)
]
− λ) (12)
この勾配が 0 になるとき,
λ = Eq
[
ηg(x, z, α)
]
(13)
L(ϕnj) についても同様で
∇ϕnj L(ϕn j) = ∇2
ϕnj
al(ϕnj)(Eq
[
ηl(xn, zn,− j, β)
]
− ϕnj) (14)
ϕnj = Eq
[
ηl(xn, zn,−j, β)
]
(15)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 16 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-16-2048.jpg)


![自然勾配
自然勾配を導入することでユークリッド空間以外の空間での解の探索が
可能になる.関数 f(λ) の自然勾配は次のように表せる.
ˆ∇λ f(λ)
def
= G(λ)−1
∇λ f(λ) (18)
ここで G(λ) は変分事後分布 q(λ) についてのフィッシャーの情報行列で
ある.
G(λ) の計算
G(λ) = Eλ
[
(∇λ log q(β|λ))(∇λ log q(β|λ))T
]
= Eλ
[
(t(β) − Eλ[t(β)])(t(β) − Eλ[t(β)])T
]
= ∇2
λag(λ) (19)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 19 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-19-2048.jpg)
![自然勾配
式 (12) と (19) より,
変分下限 L(λ) の自然勾配 ˆ∇λL(λ) は
ˆ∇λL(λ) = Eϕ
[
ηg(x, z, α)
]
− λ (20)
同様に,式 (14) と (19) より,
変分下限 L(ϕnj) の自然勾配 ˆ∇λL(ϕnj) は
ˆ∇ϕnj L(ϕnj) = Eλ,ϕn,− j
[
ηl(xn, zn, β)
]
− ϕnj (21)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 20 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-20-2048.jpg)
![SVI
SVI では,データの一部をサンプリングすることで確率的自然勾配を推
定し,確率的最適化の枠組みで変分下限 L の最大化を行う.
最適化問題 (Robbins Monro 型)
q∗
= argmax
q
L(q)
λ(t)
= λ(t−1)
+ ρ(t) ˆ∇λLi(λ) (22)
自然勾配
ˆ∇λL(λ) = Eϕ
[
ηg(x, z, α)
]
− λ
ˆ∇ϕnj L(ϕnj) = Eλ,ϕn,− j
[
ηl(xn, zn, β)
]
− ϕnj
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 21 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-21-2048.jpg)

![確率的自然勾配の導出
変分下限を大域的な部分と局所的な部分に分解する.
L(λ) = Eq
[
log p(β)
]
− Eq
[
log q(β)
]
+
N∑
n=1
max
ϕn
(Eq
[
log p(xn, zn|β)
]
− Eq
[
log q(zn)
]
)
変数が I ∼ Unif(1, ..., N) からランダムに選ばれるとすると
LI(λ)
def
= Eq
[
log p(β)
]
− Eq
[
log q(β)
]
+ max
ϕI
(Eq
[
log p(xI, zI|β)
]
− Eq
[
log q(zI)
]
) (24)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 23 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-23-2048.jpg)
![確率的自然勾配の導出
式 (20),(24) より,LI(λ) の自然勾配は次のようになる.{x(N)
i , z(N)
i } は観
測 xn,潜在変数 zn の N 個のサンプルからなるデータセット.
ˆ∇λLi(λ) = Eq
[
ηg(x(N)
i , z(N)
i , α)
]
− λ (25)
また,式 (5) と (25) から
ˆ∇λLi(λ) = α + N · (Eϕi(λ) [t(xi, zi)] , 1) − λ (26)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 24 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-24-2048.jpg)
![SVI
最適化問題 (Robbins Monro 型)
q∗
= argmax
q
L(q)
λ(t)
= λ(t−1)
+ ρ(t) ˆ∇λLi(λ) (27)
式 (26) を代入して,
λ(t)
= λ(t−1)
+ ρ(t)
(α + N · (Eϕi(λ) [t(xi, zi)] , 1) − λ(t−1)
)
= (1 − ρ(t)
)λ(t−1)
+ ρ(t)
(α + N · (Eϕi(λ) [t(xi, zi)] , 1)) (28)
忘却率 κ ∈ (0.5, 1],遅延 τ ≥ 0 とすると,
ρ(t)
= (t + τ)−κ
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 25 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-25-2048.jpg)


![ミニバッチを利用する場合
ミニバッチを利用することでアルゴリズムの安定性を改善することがで
きる.
処理の流れ
• イテレーション xt,1:S ごとに S 個の例の集合をサンプリング.
• 各データポイントでの局所変分パラメータ ϕS (λ(t−1)) を計算.
• データポイント xtS ごとについての確率的自然勾配を計算.
• 更新式は以下のようになる.
λ(t)
= (1 − ρ(t)
)λ(t−1)
+
ρ(t)
S
∑
S
(α + N · (EϕS (λ(t−1)) [t(xi, zi)] , 1))
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 28 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-28-2048.jpg)





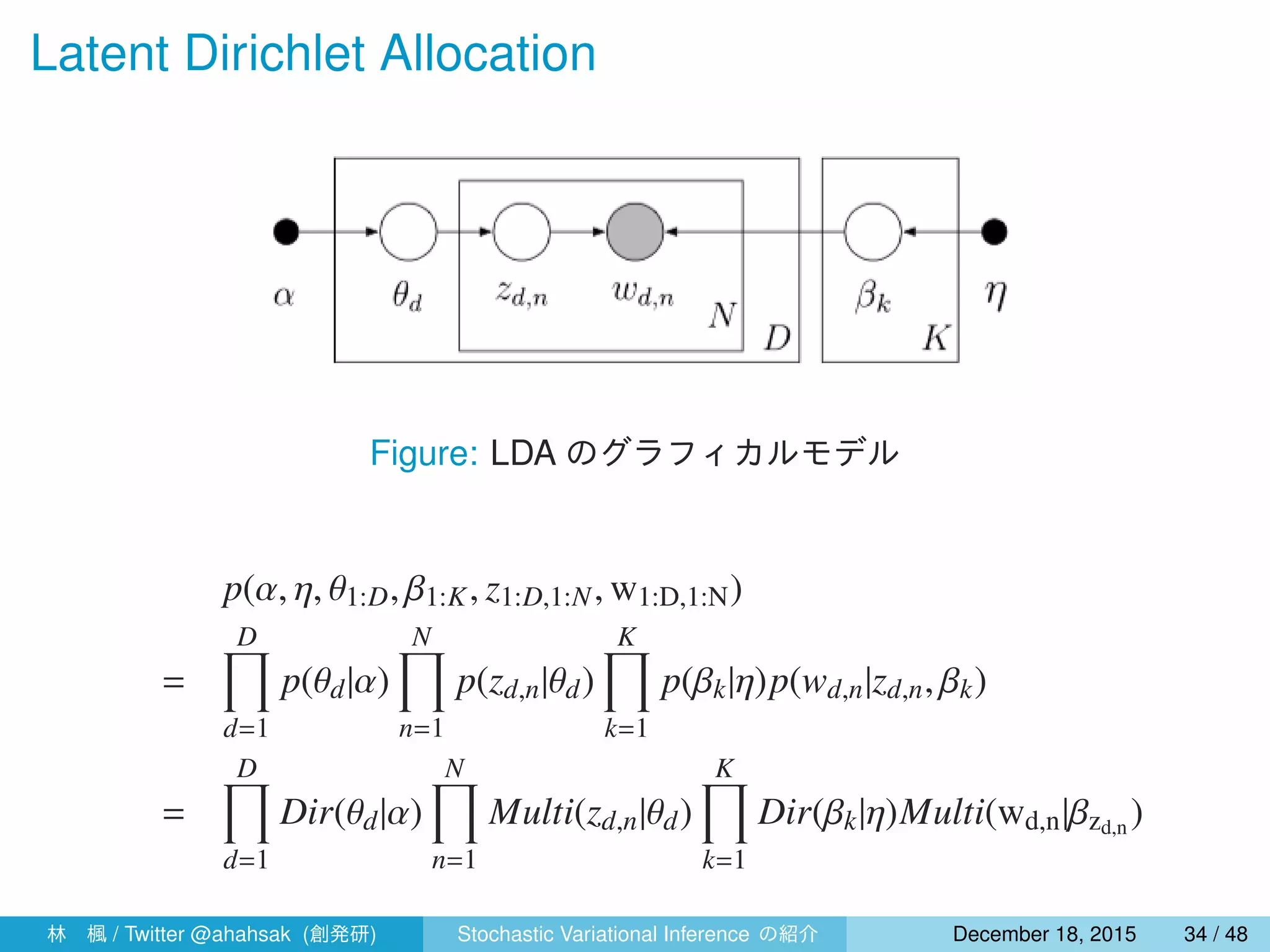



![指数型分布族でのディリクレ分布
多項分布は指数型分布族の形で表すことができる.
Dir(π|λ) =
Γ(
∑K
i=1 γi)
∏K
i=1 Γ(γi)
K∏
i=1
πγi−1
= exp
( K∑
i=1
(γi − 1) log πi
)
+ log Γ
( K∑
i=1
γi
)
−
K∑
i=1
log Γ(γi)
ディリクレ分布の特性
E[θk|γ] =
γk
∑K
i=1 γi
(29)
E[log θk|γ] = Ψ(γk) − Ψ
( K∑
i=1
γi
)
(30)
ここで,Ψ(x) =
d log Γ(x)
dx であり,Ψ(x) はディガンマ関数と呼ばれる.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 40 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-40-2048.jpg)
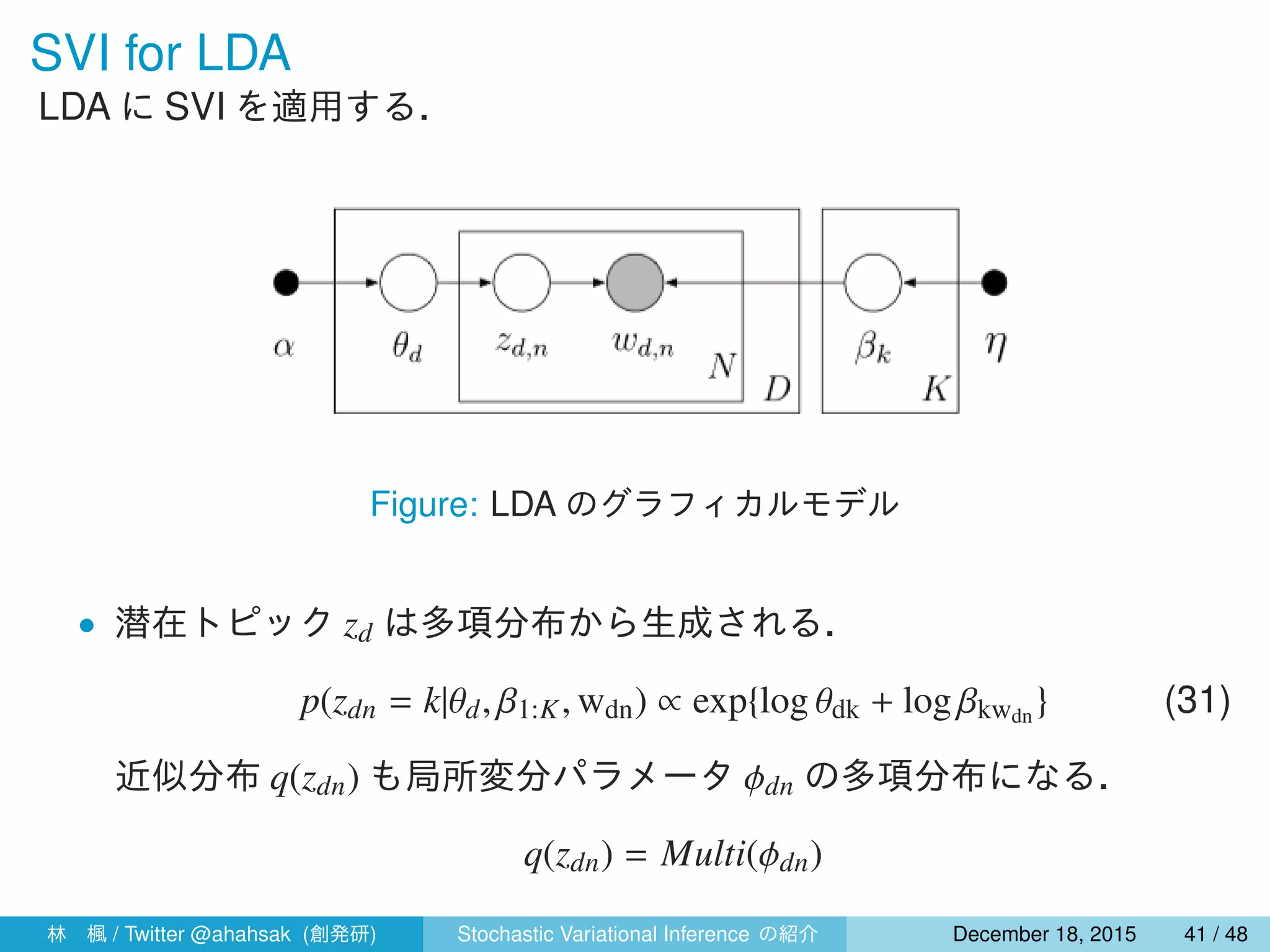
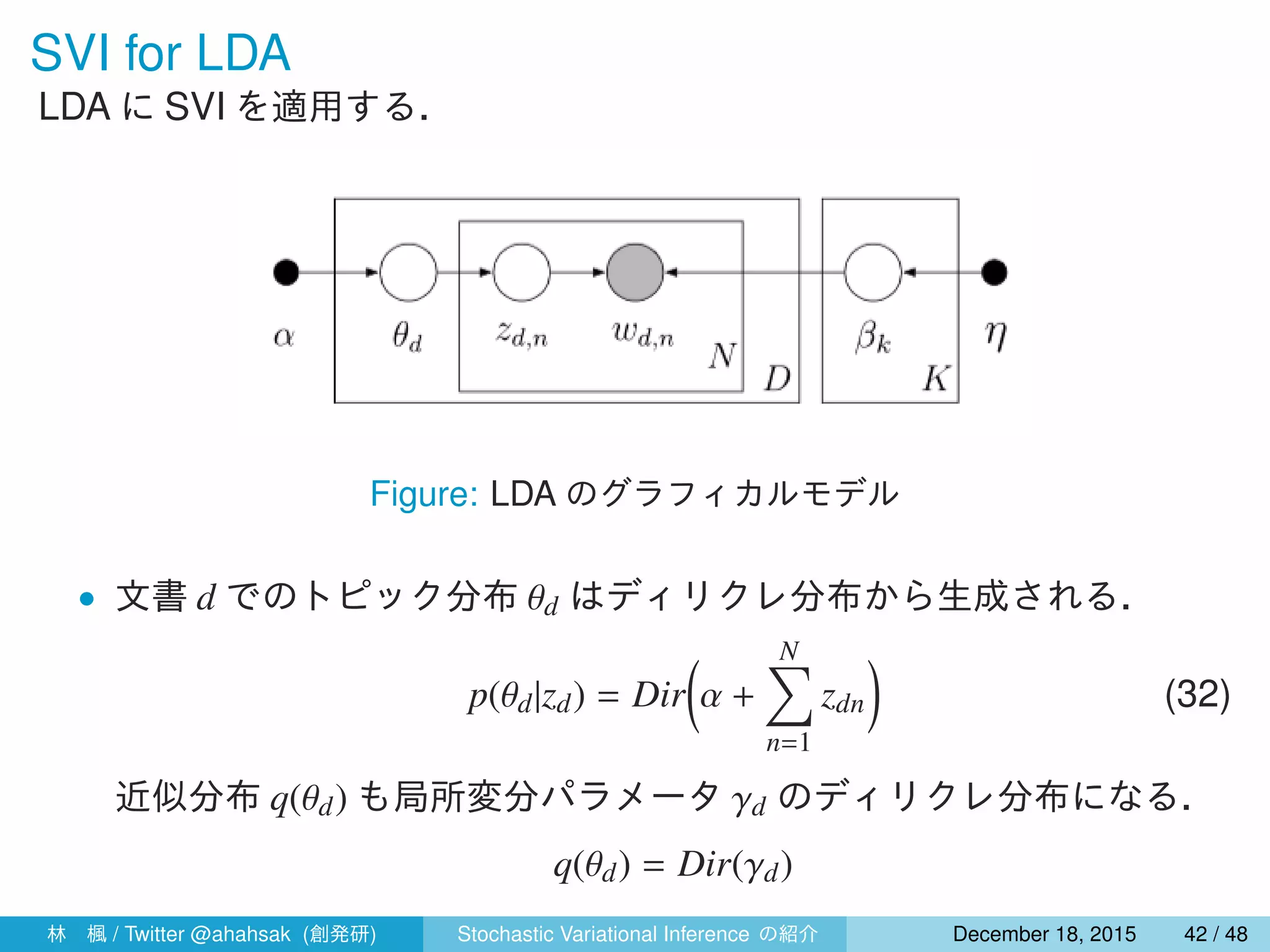
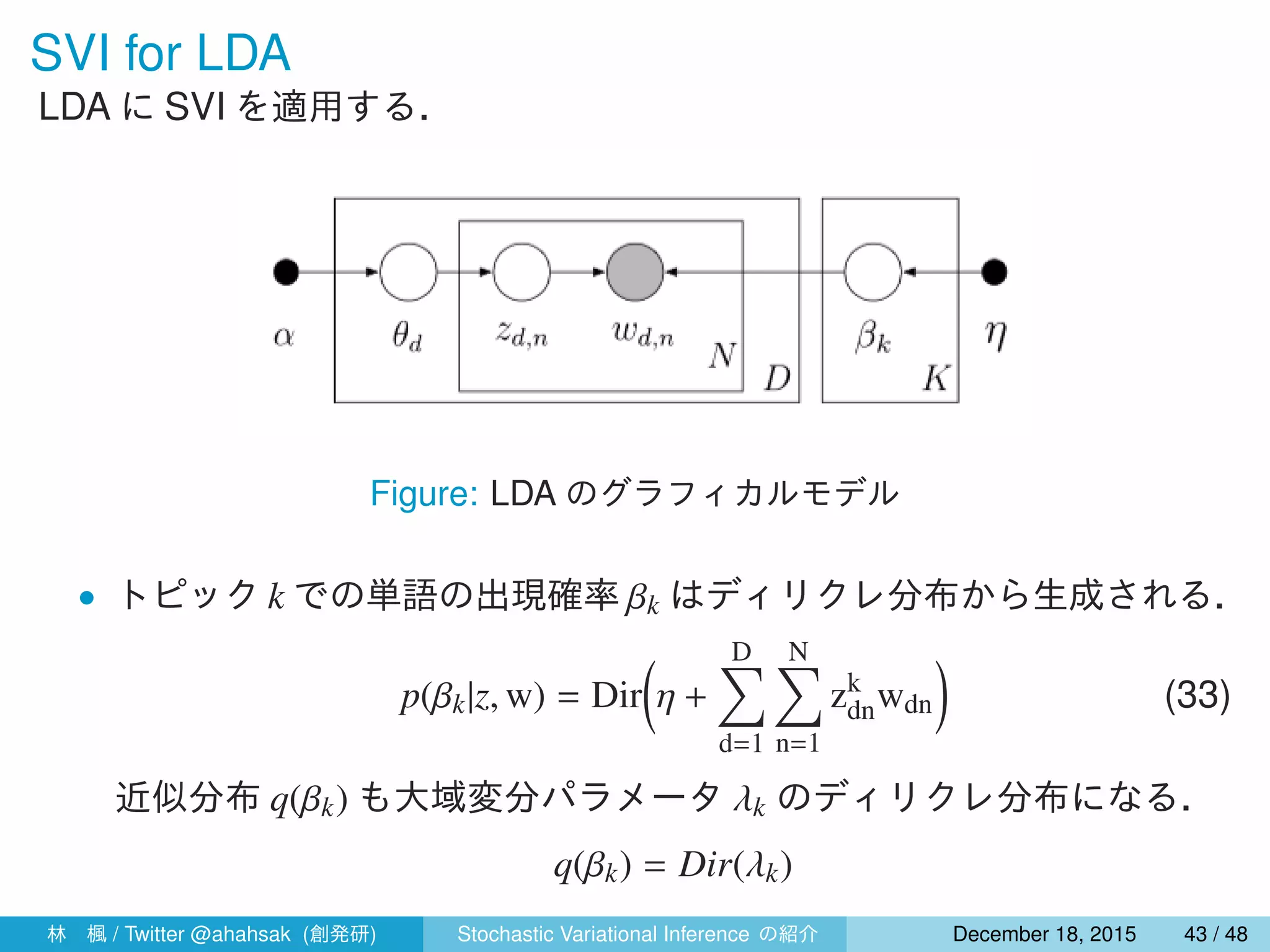
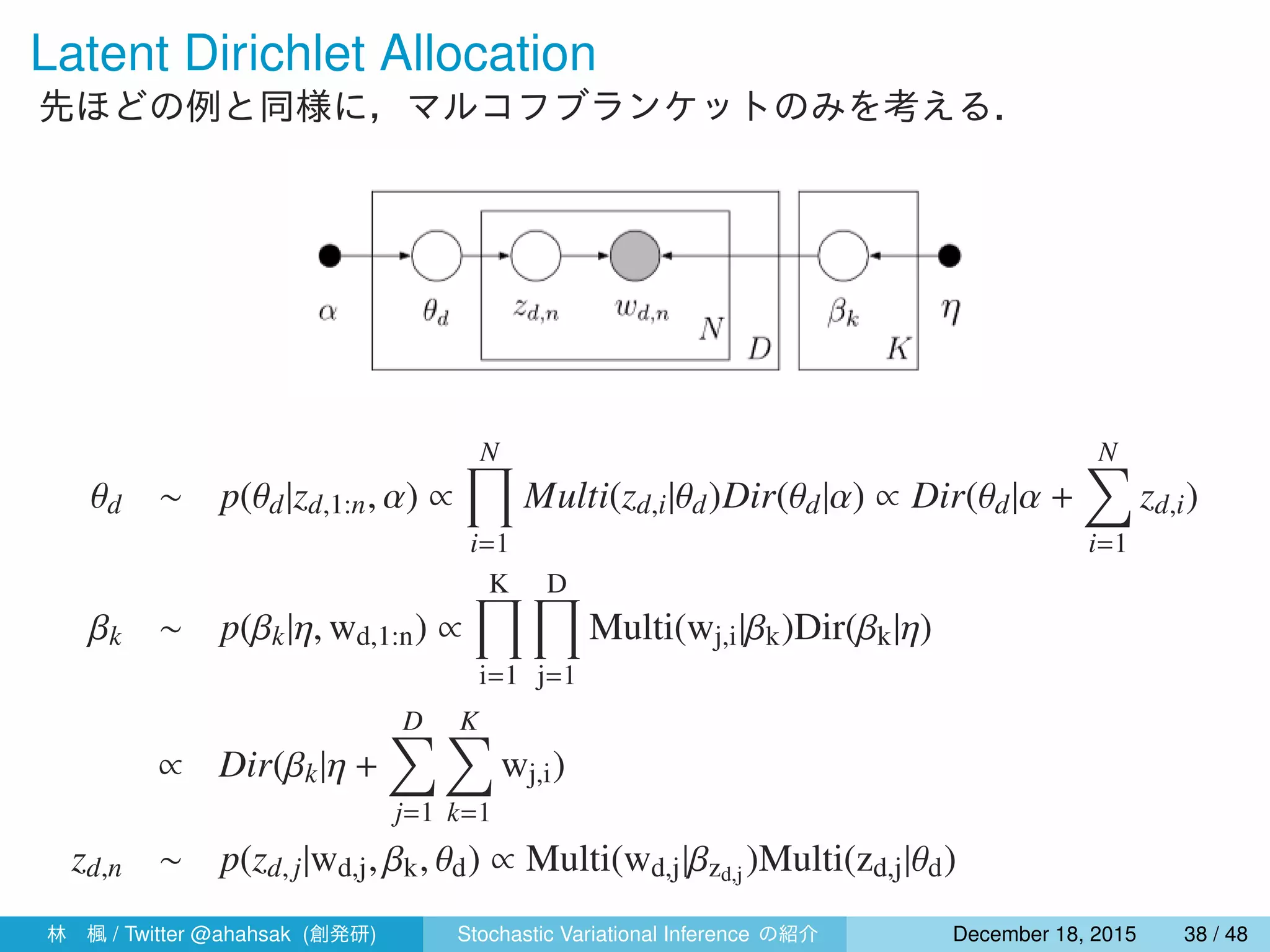
![変分ベイズでの局所変分パラメータの更新
式 (15) より,式 (31),(32) の自然パラメータの期待値をとると,
• 単語ごとのトピックの割り当てに関する更新は以下のようにできる.
ϕk
dn ∝ exp{E[log θdk] + E[log βk,wdn ]}
= exp
{
Ψ(γdk) + Ψ(γdk) + Ψ(λk,wdn ) − Ψ
(∑
ν
λkν
)}
(34)
• 文書ごとのトピックの割合に関する更新は以下のようにできる.
γd = α +
N∑
n=1
ϕdn (35)
ここで,Eq[zk
dn] = ϕk
dn を用いた.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 44 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-44-2048.jpg)






![補足: 十分統計量の期待値
式 (37) のような一般的な指数型分布族では次の式が成り立つ.
∇ηZ(η) = E[t(x)] (38)
証明.
式 (38) を示す.
∇ηZ(η) = ∇η log
∫
e⟨η,t(x)⟩
h(x)dx (39)
=
1
∫
e⟨η,t(x)⟩h(x)dx
∫
e⟨η,t(x)⟩
h(x)dx (40)
=
∫
t(x)p(x|η)dx (41)
= E[t(x)] (42)
□
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 51 / 53](https://image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-51-2048.jpg)











![対数周辺尤度と KL 情報量
変分ベイズ法では事後分布と変分事後分布との KL 情報量を最小化するた
めに,変分下限の最大化を行う.
p(x|α) = L[q(z, β)] + KL[q(z, β)||p(z, β|x, α)]
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 10 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-10-2048.jpg)
![対数周辺尤度と KL 情報量
変分ベイズ法では事後分布と変分事後分布との KL 情報量を最小化するた
めに,変分下限の最大化を行う.
p(x|α) = L[q(z, β)] + KL[q(z, β)||p(z, β|x, α)]
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 11 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-11-2048.jpg)
![変分下限の導出
変分下限 L は対数関数の凸性とイエンゼンの不等式を利用することで得
られる.
log p(x) = log
∫
p(x, z, β)dzdβ
= log
∫
q(z, β)
p(x, z, β)
q(z, β)
dzdβ
= log Eq
[
p(x, z, β)
q(z, β)
]
≥ Eq
[
log p(x, z, β)
]
− Eq
[
log q(z, β)
]
(6)
def
= L(q)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 12 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-12-2048.jpg)
![変分下限の導出
L(q) = Eq
[
log p(x, z, β)
]
− Eq
[
log q(z, β)
]
• 結合分布の対数の期待値 Eq
[
log p(x, z, β)
]
Eq
[
log p(x, z, β)
]
= Eq
[
log p(β|x, z)p(x, z)
]
= Eq
[
log p(β|x, z)
]
+ Eq
[
p(x, z)
]
(7)
• 変分事後分布のエントロピー −Eq
[
log q(z, β)
]
−Eq
[
log q(z, β)
]
= −Eq
[
log q(β|λ)
]
−
N∑
n=1
J∑
j=1
Eq
[
log q(znj|ϕn j)
]
(8)
※ 変分事後分布 q(z, β) は因子分解可能を仮定する.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 13 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-13-2048.jpg)
![変分下限の最大化
L(q) = Lglobal + Llocal
Lglobal = Eq
[
log p(β|x, z)
]
− Eq
[
log q(β|λ)
] def
= L(λ)
Llocal = Eq
[
log p(znj|xn, zn,− j, β)
]
− Eq
[
log q(znj)
] def
= L(ϕnj)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 14 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-14-2048.jpg)
![変分下限の最大化
変分事後分布の定義 (指数型分布族)
q(β|λ) = h(β) exp{λT
t(β) − ag(λ)} (9)
q(znj|ϕn j) = h(znj) exp{ϕT
njt(znj) − al(ϕnj)} (10)
式 (1),(9) より, L(λ) は次のように変形できる.
L(λ) = Eq
[
ηg(x, z, α)
]T
∇λag(λ) − λT
∇λag(λ) + ag(λ) + const (11)
ここで,−Eq
[
ag(ηg(x, z, α))
]
は q(β) に依らないため定数とした.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 15 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-15-2048.jpg)
![変分下限の最大化
式 (11) で λ 方向の勾配をとると以下のようになる.
∇λL(λ) = ∇2
λag(λ)(Eq
[
ηg(x, z, α)
]
− λ) (12)
この勾配が 0 になるとき,
λ = Eq
[
ηg(x, z, α)
]
(13)
L(ϕnj) についても同様で
∇ϕnj L(ϕn j) = ∇2
ϕnj
al(ϕnj)(Eq
[
ηl(xn, zn,− j, β)
]
− ϕnj) (14)
ϕnj = Eq
[
ηl(xn, zn,−j, β)
]
(15)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 16 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-16-2048.jpg)


![自然勾配
自然勾配を導入することでユークリッド空間以外の空間での解の探索が
可能になる.関数 f(λ) の自然勾配は次のように表せる.
ˆ∇λ f(λ)
def
= G(λ)−1
∇λ f(λ) (18)
ここで G(λ) は変分事後分布 q(λ) についてのフィッシャーの情報行列で
ある.
G(λ) の計算
G(λ) = Eλ
[
(∇λ log q(β|λ))(∇λ log q(β|λ))T
]
= Eλ
[
(t(β) − Eλ[t(β)])(t(β) − Eλ[t(β)])T
]
= ∇2
λag(λ) (19)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 19 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-19-2048.jpg)
![自然勾配
式 (12) と (19) より,
変分下限 L(λ) の自然勾配 ˆ∇λL(λ) は
ˆ∇λL(λ) = Eϕ
[
ηg(x, z, α)
]
− λ (20)
同様に,式 (14) と (19) より,
変分下限 L(ϕnj) の自然勾配 ˆ∇λL(ϕnj) は
ˆ∇ϕnj L(ϕnj) = Eλ,ϕn,− j
[
ηl(xn, zn, β)
]
− ϕnj (21)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 20 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-20-2048.jpg)
![SVI
SVI では,データの一部をサンプリングすることで確率的自然勾配を推
定し,確率的最適化の枠組みで変分下限 L の最大化を行う.
最適化問題 (Robbins Monro 型)
q∗
= argmax
q
L(q)
λ(t)
= λ(t−1)
+ ρ(t) ˆ∇λLi(λ) (22)
自然勾配
ˆ∇λL(λ) = Eϕ
[
ηg(x, z, α)
]
− λ
ˆ∇ϕnj L(ϕnj) = Eλ,ϕn,− j
[
ηl(xn, zn, β)
]
− ϕnj
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 21 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-21-2048.jpg)

![確率的自然勾配の導出
変分下限を大域的な部分と局所的な部分に分解する.
L(λ) = Eq
[
log p(β)
]
− Eq
[
log q(β)
]
+
N∑
n=1
max
ϕn
(Eq
[
log p(xn, zn|β)
]
− Eq
[
log q(zn)
]
)
変数が I ∼ Unif(1, ..., N) からランダムに選ばれるとすると
LI(λ)
def
= Eq
[
log p(β)
]
− Eq
[
log q(β)
]
+ max
ϕI
(Eq
[
log p(xI, zI|β)
]
− Eq
[
log q(zI)
]
) (24)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 23 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-23-2048.jpg)
![確率的自然勾配の導出
式 (20),(24) より,LI(λ) の自然勾配は次のようになる.{x(N)
i , z(N)
i } は観
測 xn,潜在変数 zn の N 個のサンプルからなるデータセット.
ˆ∇λLi(λ) = Eq
[
ηg(x(N)
i , z(N)
i , α)
]
− λ (25)
また,式 (5) と (25) から
ˆ∇λLi(λ) = α + N · (Eϕi(λ) [t(xi, zi)] , 1) − λ (26)
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 24 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-24-2048.jpg)
![SVI
最適化問題 (Robbins Monro 型)
q∗
= argmax
q
L(q)
λ(t)
= λ(t−1)
+ ρ(t) ˆ∇λLi(λ) (27)
式 (26) を代入して,
λ(t)
= λ(t−1)
+ ρ(t)
(α + N · (Eϕi(λ) [t(xi, zi)] , 1) − λ(t−1)
)
= (1 − ρ(t)
)λ(t−1)
+ ρ(t)
(α + N · (Eϕi(λ) [t(xi, zi)] , 1)) (28)
忘却率 κ ∈ (0.5, 1],遅延 τ ≥ 0 とすると,
ρ(t)
= (t + τ)−κ
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 25 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-25-2048.jpg)


![ミニバッチを利用する場合
ミニバッチを利用することでアルゴリズムの安定性を改善することがで
きる.
処理の流れ
• イテレーション xt,1:S ごとに S 個の例の集合をサンプリング.
• 各データポイントでの局所変分パラメータ ϕS (λ(t−1)) を計算.
• データポイント xtS ごとについての確率的自然勾配を計算.
• 更新式は以下のようになる.
λ(t)
= (1 − ρ(t)
)λ(t−1)
+
ρ(t)
S
∑
S
(α + N · (EϕS (λ(t−1)) [t(xi, zi)] , 1))
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 28 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-28-2048.jpg)











![指数型分布族でのディリクレ分布
多項分布は指数型分布族の形で表すことができる.
Dir(π|λ) =
Γ(
∑K
i=1 γi)
∏K
i=1 Γ(γi)
K∏
i=1
πγi−1
= exp
( K∑
i=1
(γi − 1) log πi
)
+ log Γ
( K∑
i=1
γi
)
−
K∑
i=1
log Γ(γi)
ディリクレ分布の特性
E[θk|γ] =
γk
∑K
i=1 γi
(29)
E[log θk|γ] = Ψ(γk) − Ψ
( K∑
i=1
γi
)
(30)
ここで,Ψ(x) =
d log Γ(x)
dx であり,Ψ(x) はディガンマ関数と呼ばれる.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 40 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-40-2048.jpg)



![変分ベイズでの局所変分パラメータの更新
式 (15) より,式 (31),(32) の自然パラメータの期待値をとると,
• 単語ごとのトピックの割り当てに関する更新は以下のようにできる.
ϕk
dn ∝ exp{E[log θdk] + E[log βk,wdn ]}
= exp
{
Ψ(γdk) + Ψ(γdk) + Ψ(λk,wdn ) − Ψ
(∑
ν
λkν
)}
(34)
• 文書ごとのトピックの割合に関する更新は以下のようにできる.
γd = α +
N∑
n=1
ϕdn (35)
ここで,Eq[zk
dn] = ϕk
dn を用いた.
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 44 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-44-2048.jpg)






![補足: 十分統計量の期待値
式 (37) のような一般的な指数型分布族では次の式が成り立つ.
∇ηZ(η) = E[t(x)] (38)
証明.
式 (38) を示す.
∇ηZ(η) = ∇η log
∫
e⟨η,t(x)⟩
h(x)dx (39)
=
1
∫
e⟨η,t(x)⟩h(x)dx
∫
e⟨η,t(x)⟩
h(x)dx (40)
=
∫
t(x)p(x|η)dx (41)
= E[t(x)] (42)
□
林 楓 / Twitter @ahahsak (創発研) Stochastic Variational Inference の紹介 January 12, 2016 51 / 53](https://crownmelresort.com/image.slidesharecdn.com/svislide-151218031048/75/Stochastic-Variational-Inference-51-2048.jpg)



大規模データセットでの推論に便利なSVIの概要をまとめました. SVIは確率的最適化の枠組みで行う変分ベイズ法です. 随時更新してます. 参考文献 [1]Matthew D Hoffman, David M Blei, Chong Wang, and John Paisley. Stochastic variational inference. The Journal of Machine Learning Research, Vol. 14, No. 1, pp. 1303–1347, 2013. [2] 佐藤一誠. トピックモデルによる統計的意味解析. コロナ社, 2015.






![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)














![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2025 Rakuten Technology Conference] Daybreak for AI Agents](https://cdn.slidesharecdn.com/ss_thumbnails/2025rakutentechnologyconferenceai-251119080407-027fe107-thumbnail.jpg?width=640&height=640&fit=bounds)





