Download as PDF, PPTX


![● Originally a research project (Tachyon) in UC Berkeley AMPLab led by by-then PHD student
Haoyuan Li (Alluxio founder CEO)
● Backed by top VCs (e.g., Andreessen Horowitz) with $70M raised in total, Series C ($50M)
announced in 2021
● Deployed in production at large scale in Facebook, Uber, Microsoft, Tencent, Tiktok and etc
● More than 1200 Contributors on Github. In 2021, more than 40% commits in Github were
contributed by the community users
● The 9th most critical Java-based Open-Source projects on Github by Google/OpenSSF[1]
Alluxio Overview
ALLUXIO 3
[1] Google Comes Up With A Metric For Gauging Critical Open-Source Projects](https://image.slidesharecdn.com/alluxio-slides-220927202640-c25cd9b5/75/Unified-Data-API-for-Distributed-Cloud-Analytics-and-AI-3-2048.jpg)











![● Originally a research project (Tachyon) in UC Berkeley AMPLab led by by-then PHD student
Haoyuan Li (Alluxio founder CEO)
● Backed by top VCs (e.g., Andreessen Horowitz) with $70M raised in total, Series C ($50M)
announced in 2021
● Deployed in production at large scale in Facebook, Uber, Microsoft, Tencent, Tiktok and etc
● More than 1200 Contributors on Github. In 2021, more than 40% commits in Github were
contributed by the community users
● The 9th most critical Java-based Open-Source projects on Github by Google/OpenSSF[1]
Alluxio Overview
ALLUXIO 3
[1] Google Comes Up With A Metric For Gauging Critical Open-Source Projects](https://crownmelresort.com/image.slidesharecdn.com/alluxio-slides-220927202640-c25cd9b5/75/Unified-Data-API-for-Distributed-Cloud-Analytics-and-AI-3-2048.jpg)































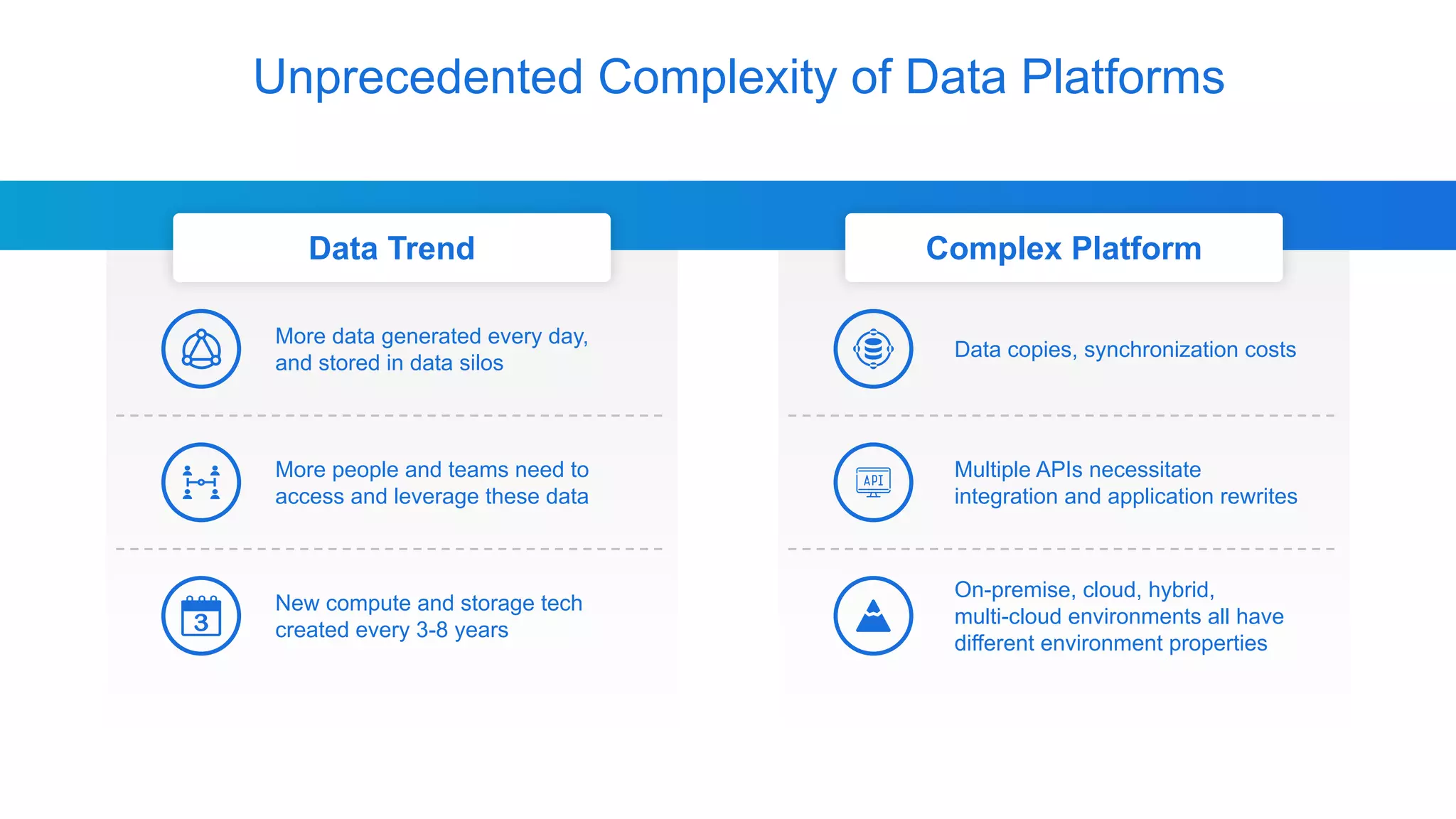
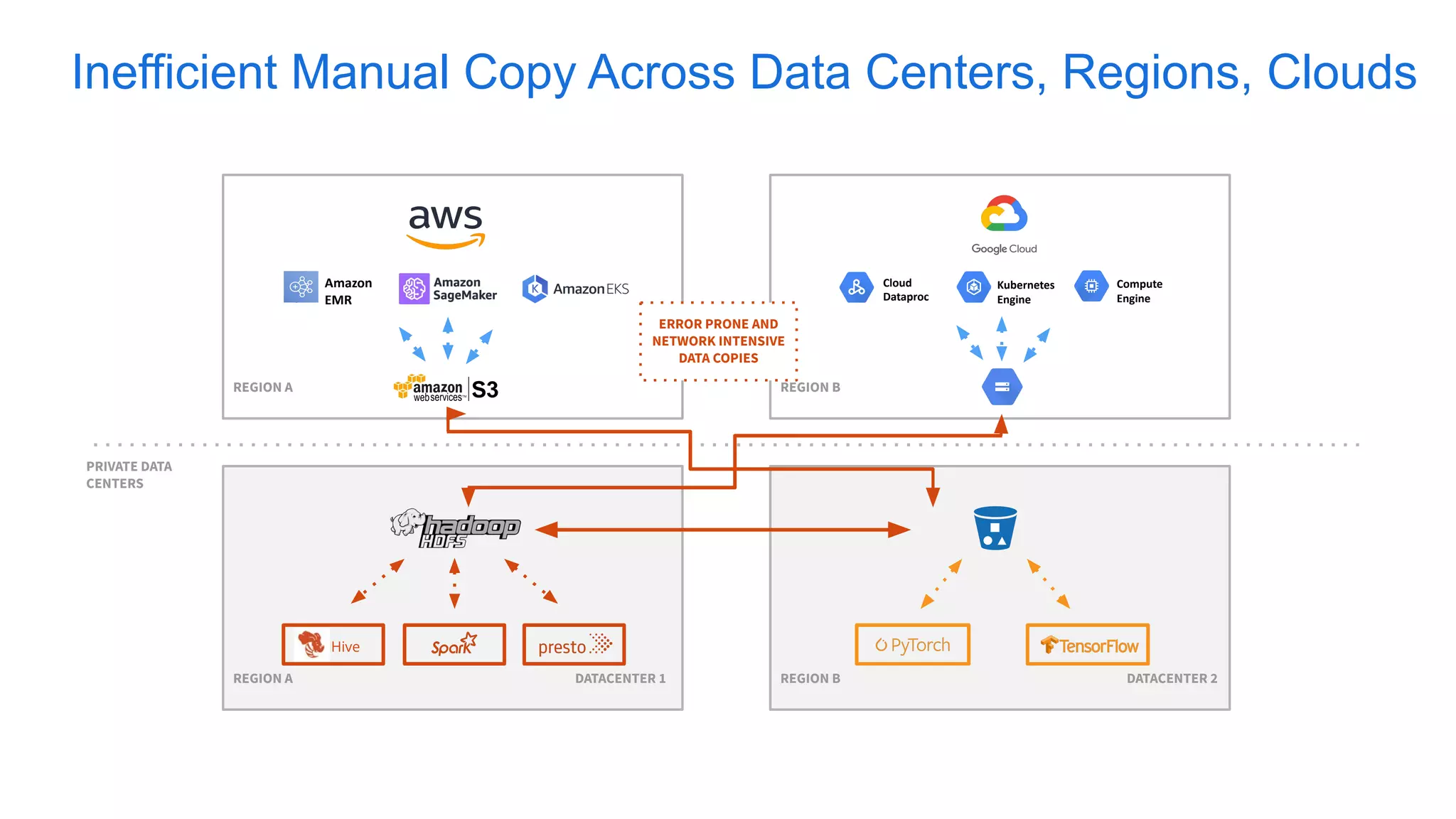
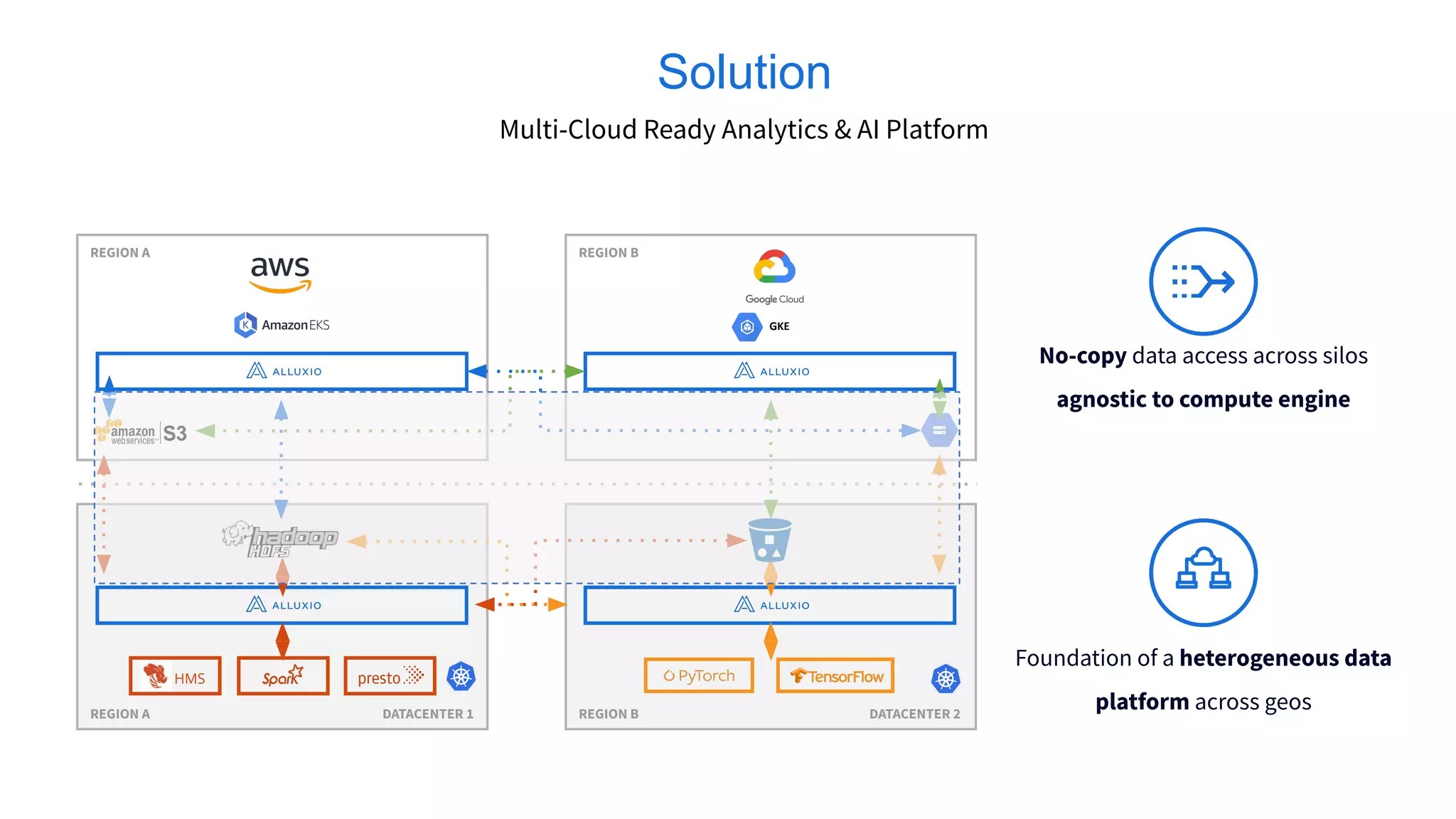
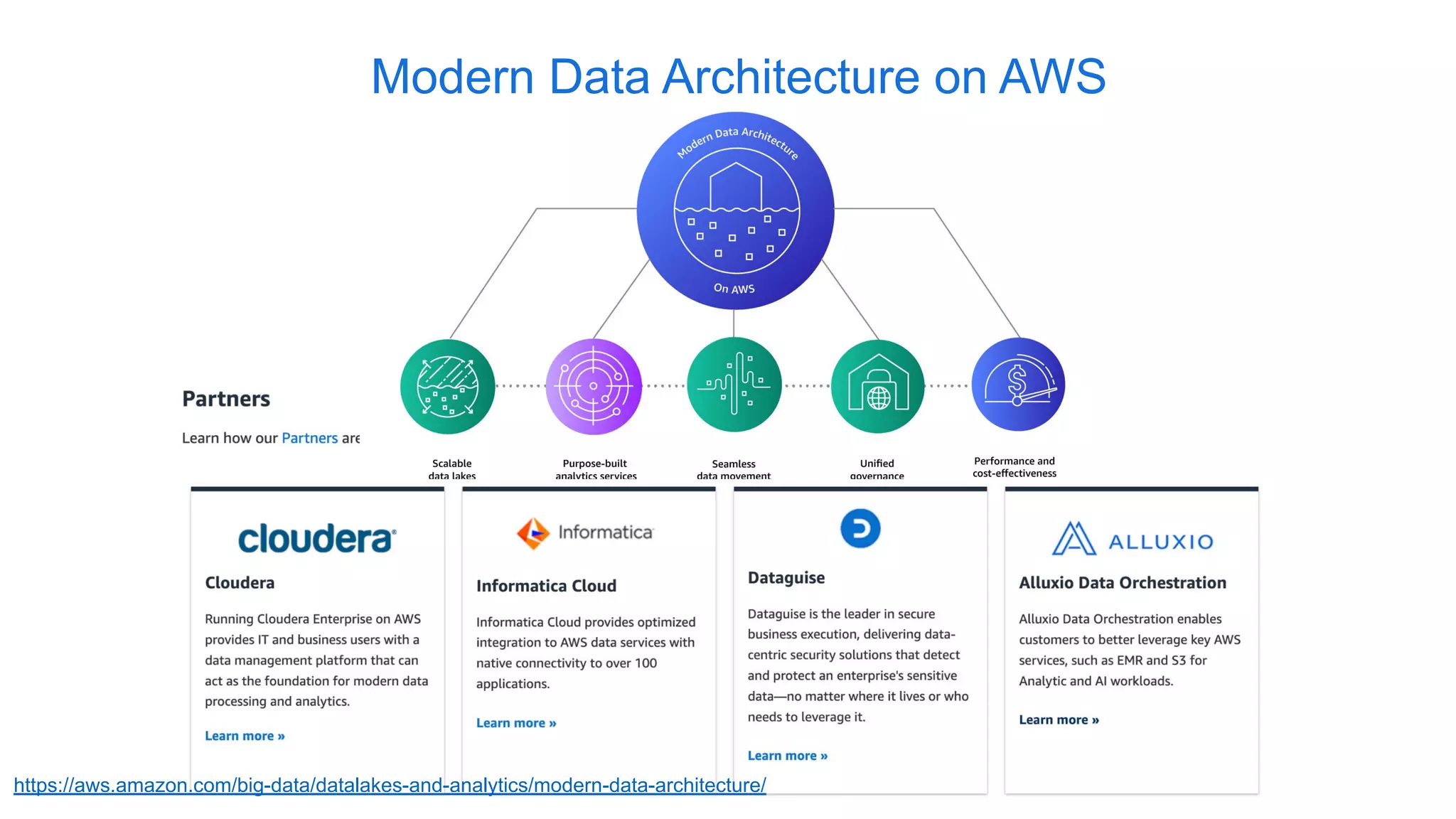
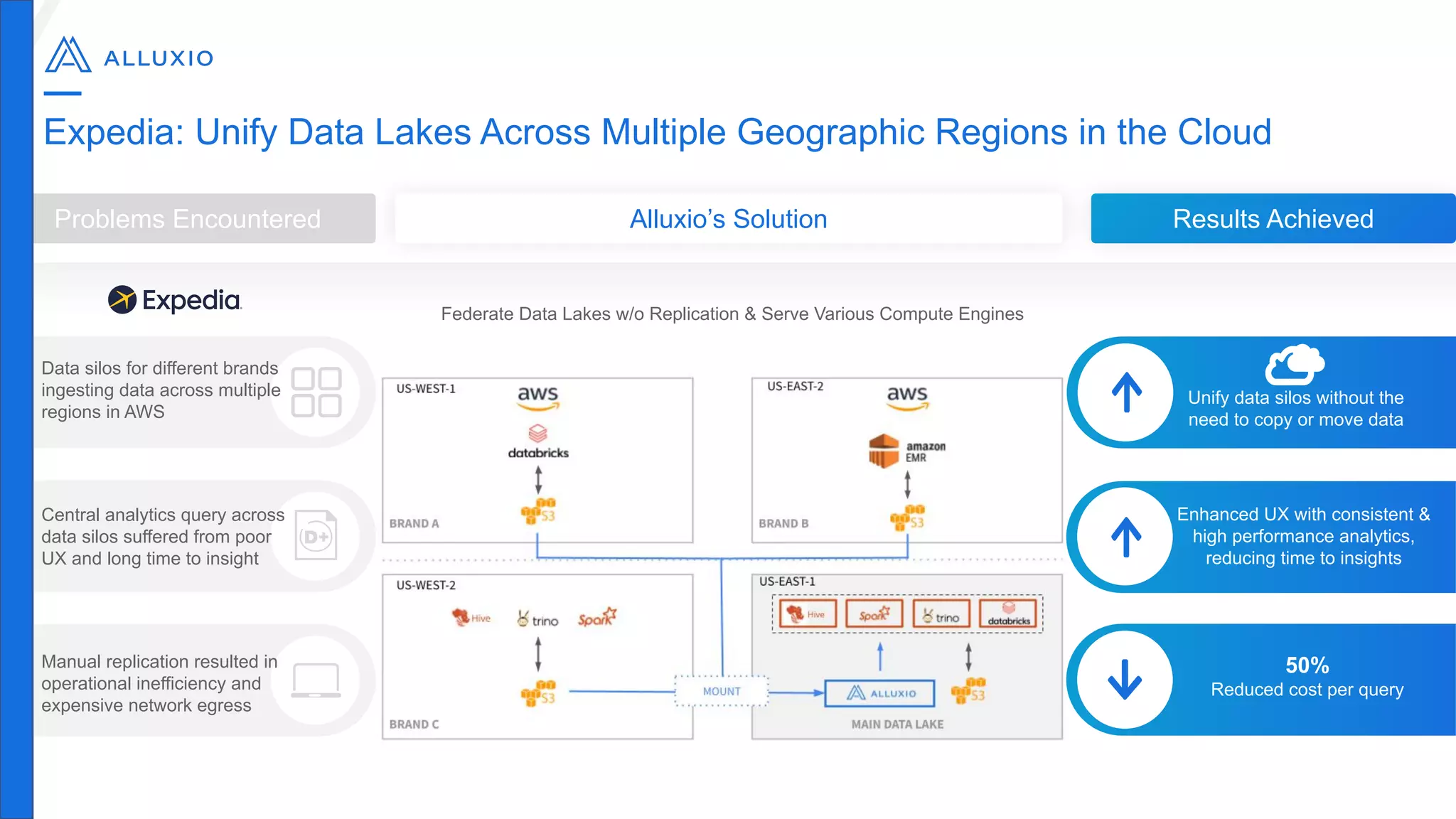
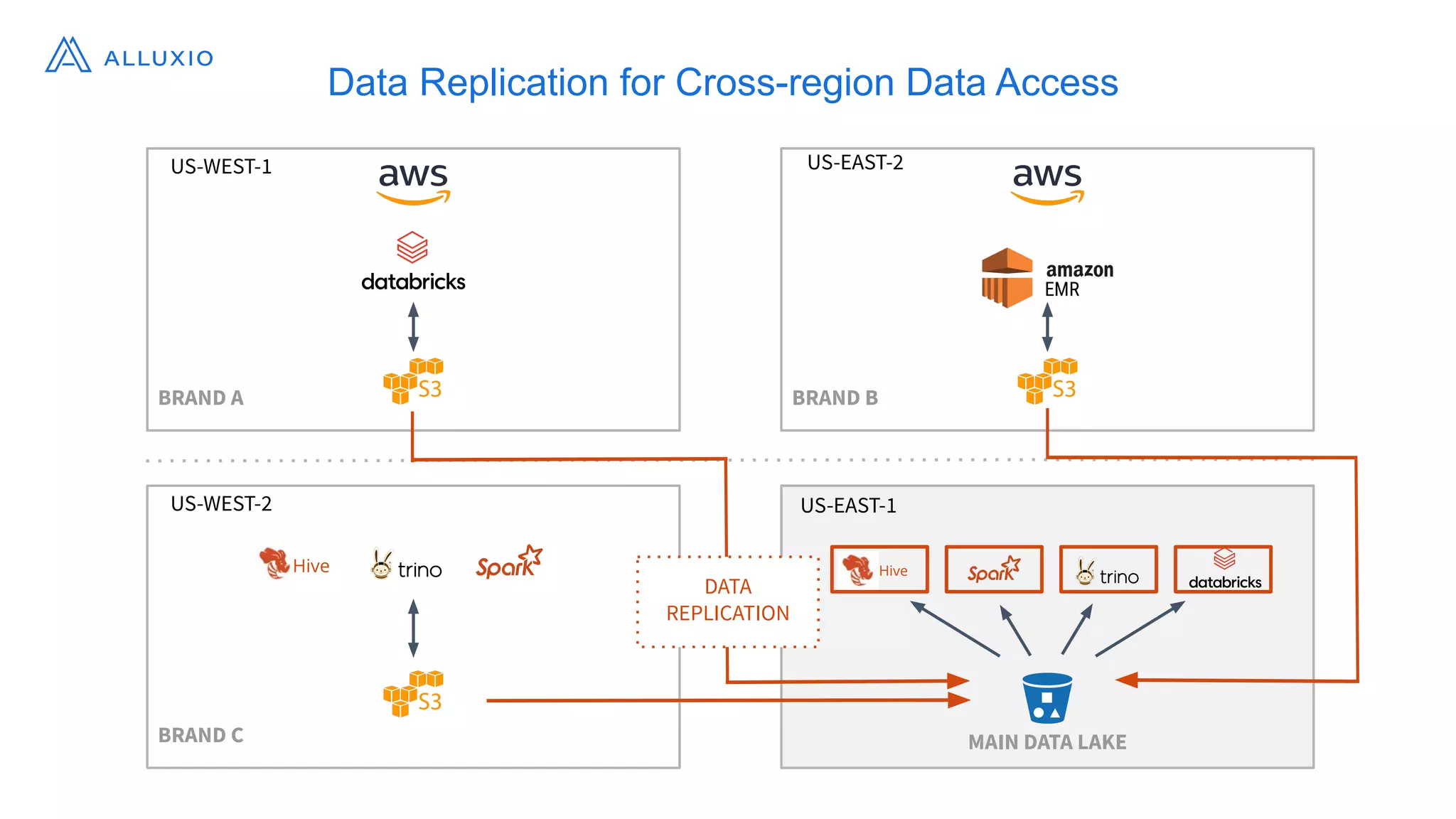
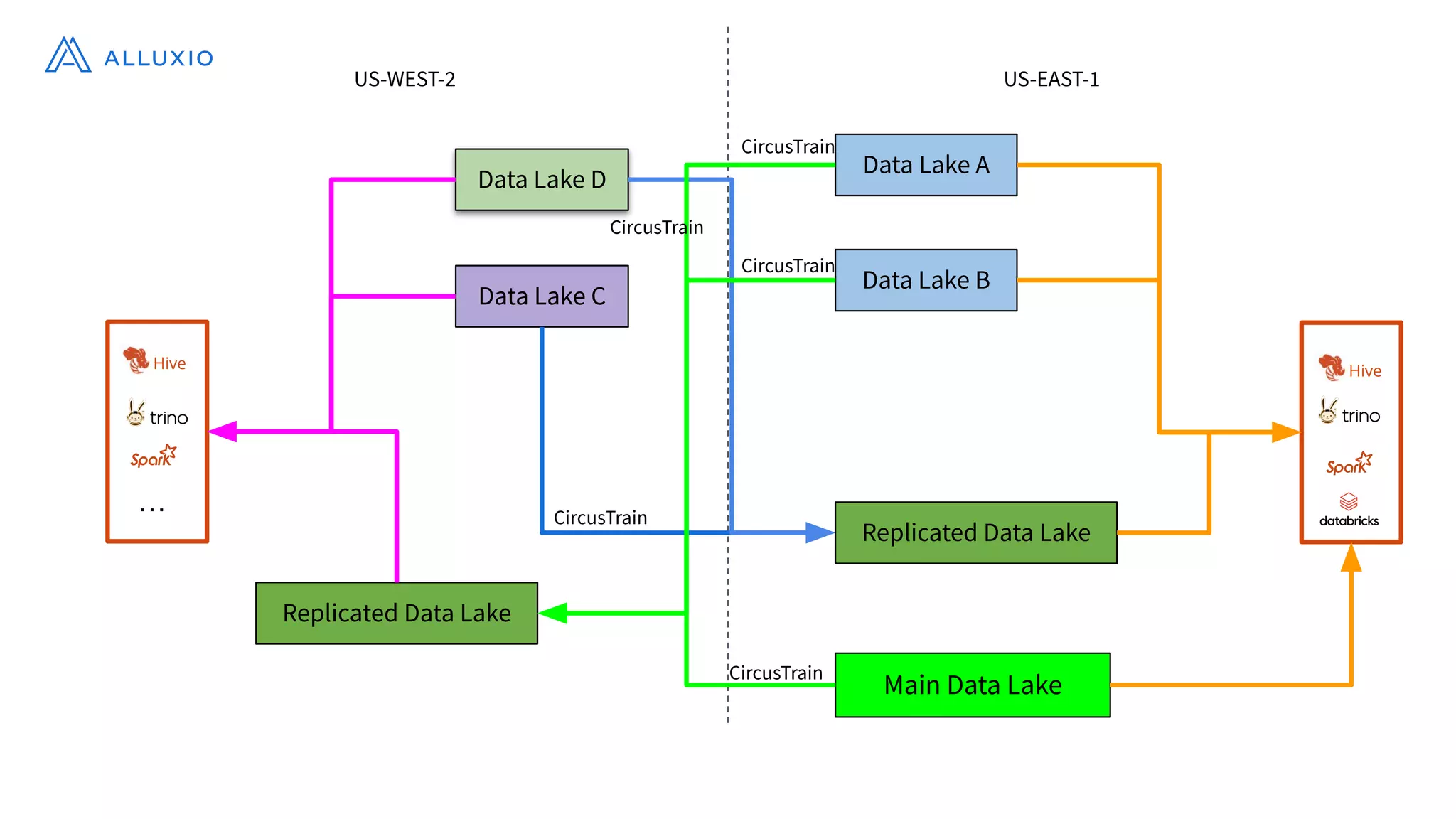
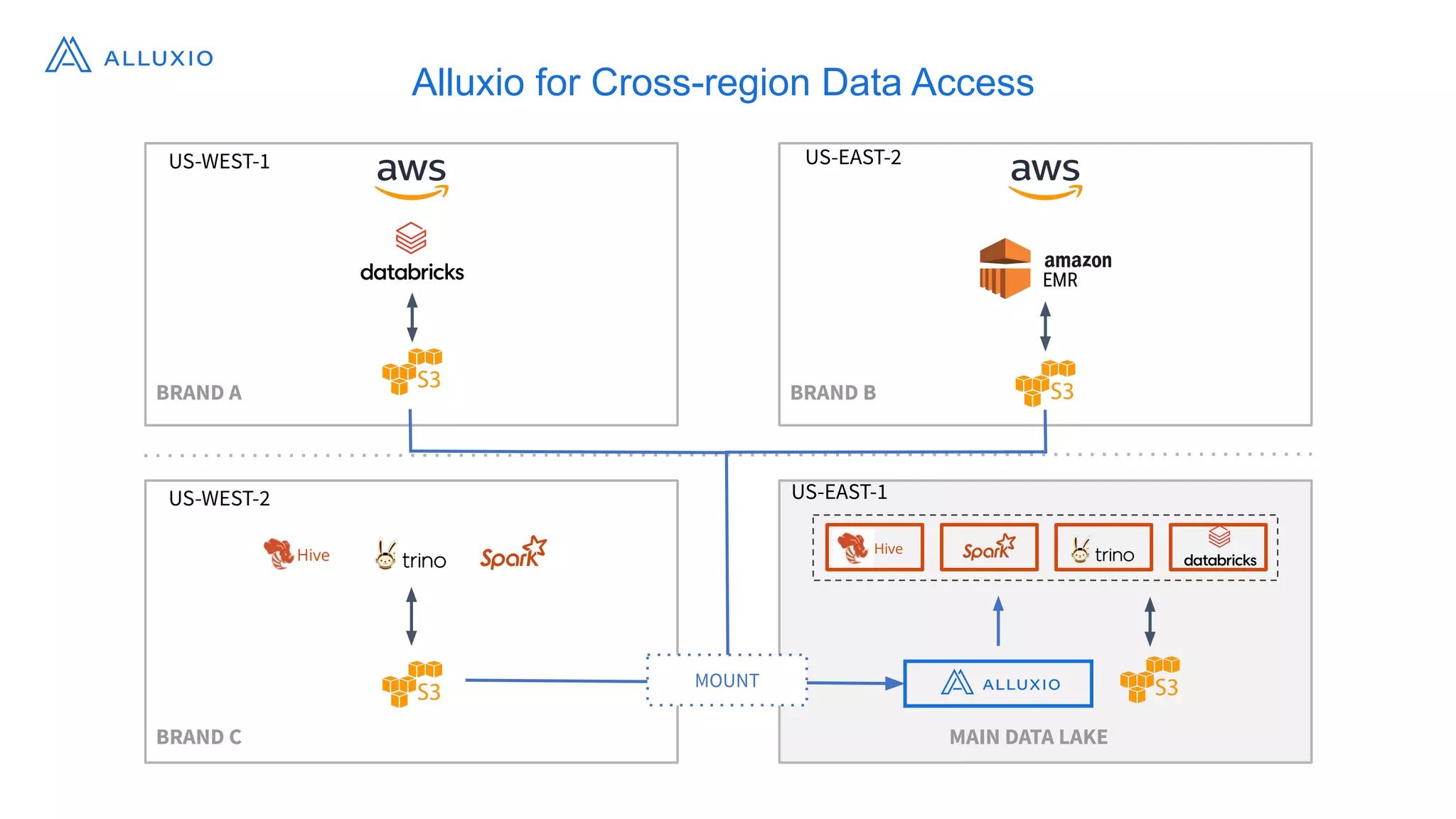
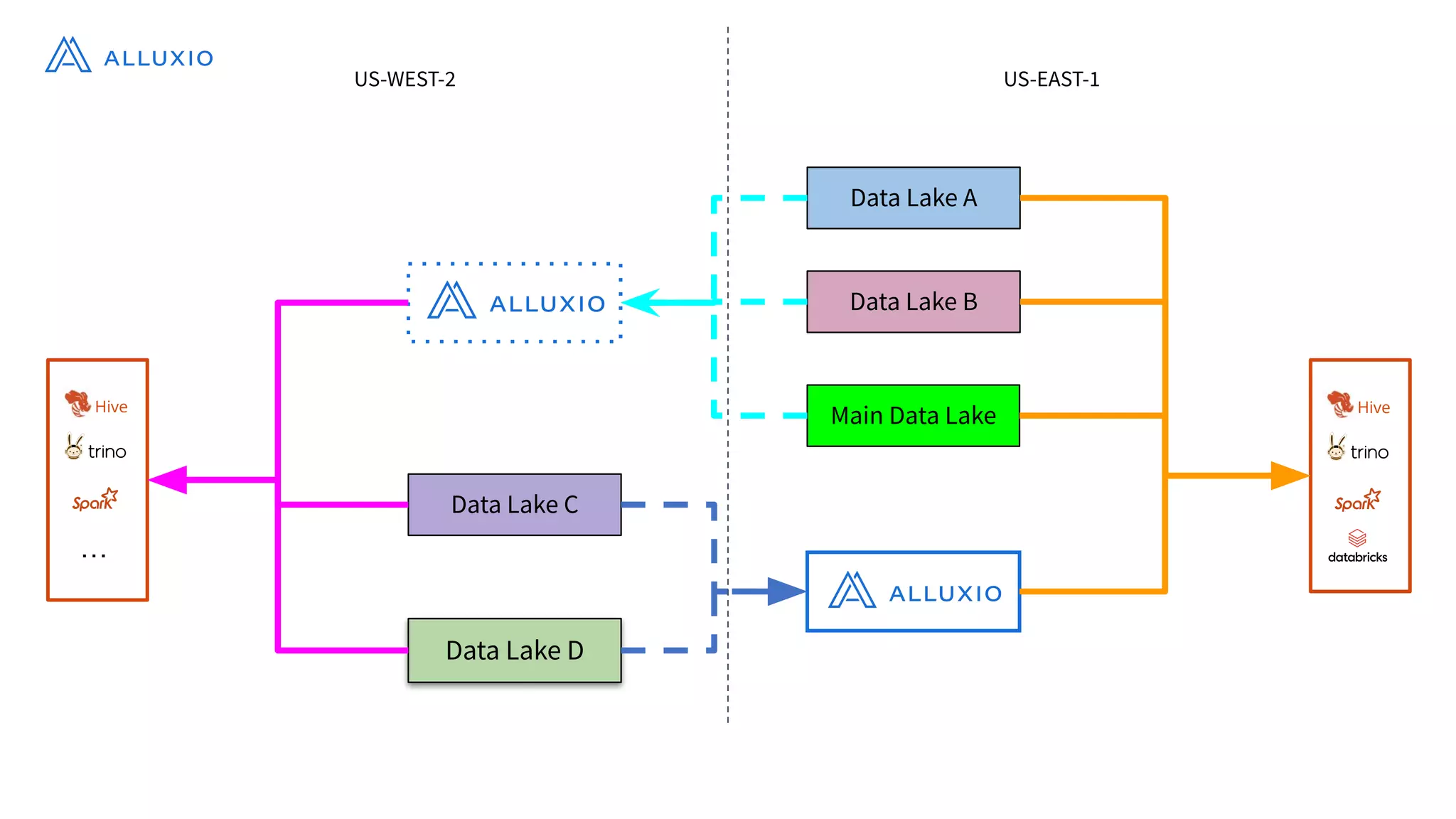
Alluxio, founded by Haoyuan Li, originated from a research project at UC Berkeley and has since raised $70 million, notably being adopted by major companies like Facebook and Uber. It serves as a unified analytics and AI platform that enables efficient data access across multi-cloud and hybrid environments, eliminating the need for data copies and replication. Alluxio addresses complex data management challenges with innovative solutions for analytics, data lakes, and machine learning workloads.


































































