Download as PDF, PPTX














![primes.sample(0.1, seed=0).explain(true)
== Analyzed Logical Plan ==
ordinal: int, prime: int, delta: int
Sample 0.0, 0.1, false, 0
+- SubqueryAlias primes
+- Relation[ordinal#2034,prime#2035,delta#2036] parquet
== Optimized Logical Plan ==
Sample 0.0, 0.1, false, 0
+- Relation[ordinal#2034,prime#2035,delta#2036] parquet
== Physical Plan ==
*(1) Sample 0.0, 0.1, false, 0
+- *(1) FileScan parquet default.primes[ordinal#2034,prime#2035,delta#2036]
Format: Parquet, Location: InMemoryFileIndex[dbfs:/user/hive/warehouse/primes]](https://image.slidesharecdn.com/01simsimeonov-181010202719/75/Unafraid-of-Change-Optimizing-ETL-ML-and-AI-in-Fast-Paced-Environments-with-Sim-Simeonov-20-2048.jpg)
![ordinal: int, prime: int, delta: int
Sample 0.0, 0.1, false, 0
+- Relation[ordinal#2034,prime#2035,delta#2036] parquet
+- InMemoryFileIndex[dbfs:/user/hive/warehouse/primes]
ordinal: int, prime: int, delta: int
Sample 0.0, 0.1, false, 0
+- Relation[ordinal#0,prime#1,delta#2] parquet
+- InMemoryFileIndex[dbfs:/user/hive/warehouse/primes]
CAP (hash: 4bb0070bd5f50bec95dd95f76130f55cd2d0c6bc)
ALM (createdAt: {now}, expiresAt: {based on TTL})
JDR (dependencies: ["table:default.primes"])
cross-cluster canonicalization](https://image.slidesharecdn.com/01simsimeonov-181010202719/75/Unafraid-of-Change-Optimizing-ETL-ML-and-AI-in-Fast-Paced-Environments-with-Sim-Simeonov-21-2048.jpg)




![Spark offers no ability to inject behaviors into reading/writing.
We added reading & writing interceptors.
Dependency management works via an interceptor.
trait InterceptorSupport[In, Out] {
def intercept(f: In => Out): (In => Out)
}](https://image.slidesharecdn.com/01simsimeonov-181010202719/75/Unafraid-of-Change-Optimizing-ETL-ML-and-AI-in-Fast-Paced-Environments-with-Sim-Simeonov-26-2048.jpg)





















![primes.sample(0.1, seed=0).explain(true)
== Analyzed Logical Plan ==
ordinal: int, prime: int, delta: int
Sample 0.0, 0.1, false, 0
+- SubqueryAlias primes
+- Relation[ordinal#2034,prime#2035,delta#2036] parquet
== Optimized Logical Plan ==
Sample 0.0, 0.1, false, 0
+- Relation[ordinal#2034,prime#2035,delta#2036] parquet
== Physical Plan ==
*(1) Sample 0.0, 0.1, false, 0
+- *(1) FileScan parquet default.primes[ordinal#2034,prime#2035,delta#2036]
Format: Parquet, Location: InMemoryFileIndex[dbfs:/user/hive/warehouse/primes]](https://crownmelresort.com/image.slidesharecdn.com/01simsimeonov-181010202719/75/Unafraid-of-Change-Optimizing-ETL-ML-and-AI-in-Fast-Paced-Environments-with-Sim-Simeonov-20-2048.jpg)
![ordinal: int, prime: int, delta: int
Sample 0.0, 0.1, false, 0
+- Relation[ordinal#2034,prime#2035,delta#2036] parquet
+- InMemoryFileIndex[dbfs:/user/hive/warehouse/primes]
ordinal: int, prime: int, delta: int
Sample 0.0, 0.1, false, 0
+- Relation[ordinal#0,prime#1,delta#2] parquet
+- InMemoryFileIndex[dbfs:/user/hive/warehouse/primes]
CAP (hash: 4bb0070bd5f50bec95dd95f76130f55cd2d0c6bc)
ALM (createdAt: {now}, expiresAt: {based on TTL})
JDR (dependencies: ["table:default.primes"])
cross-cluster canonicalization](https://crownmelresort.com/image.slidesharecdn.com/01simsimeonov-181010202719/75/Unafraid-of-Change-Optimizing-ETL-ML-and-AI-in-Fast-Paced-Environments-with-Sim-Simeonov-21-2048.jpg)




![Spark offers no ability to inject behaviors into reading/writing.
We added reading & writing interceptors.
Dependency management works via an interceptor.
trait InterceptorSupport[In, Out] {
def intercept(f: In => Out): (In => Out)
}](https://crownmelresort.com/image.slidesharecdn.com/01simsimeonov-181010202719/75/Unafraid-of-Change-Optimizing-ETL-ML-and-AI-in-Fast-Paced-Environments-with-Sim-Simeonov-26-2048.jpg)



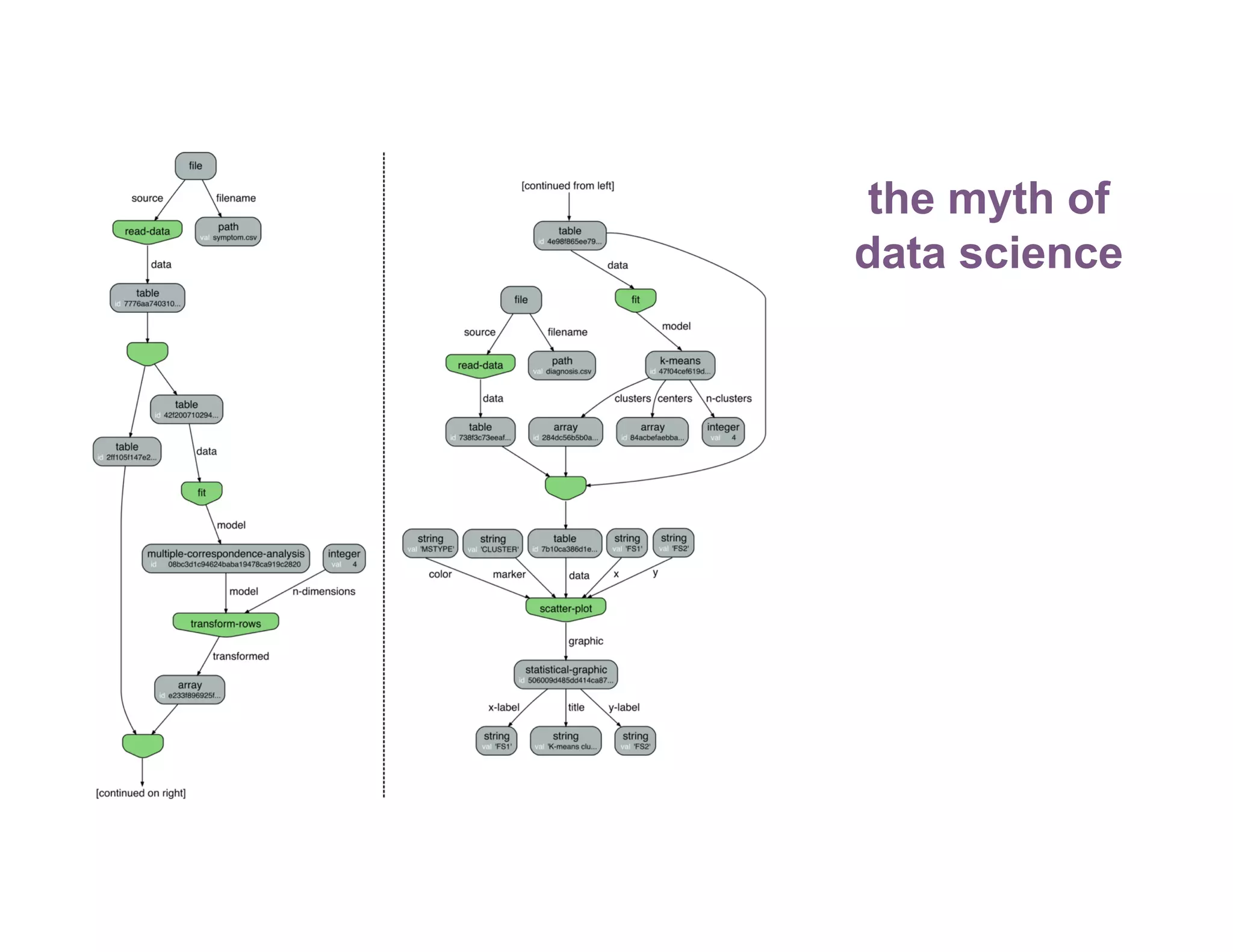
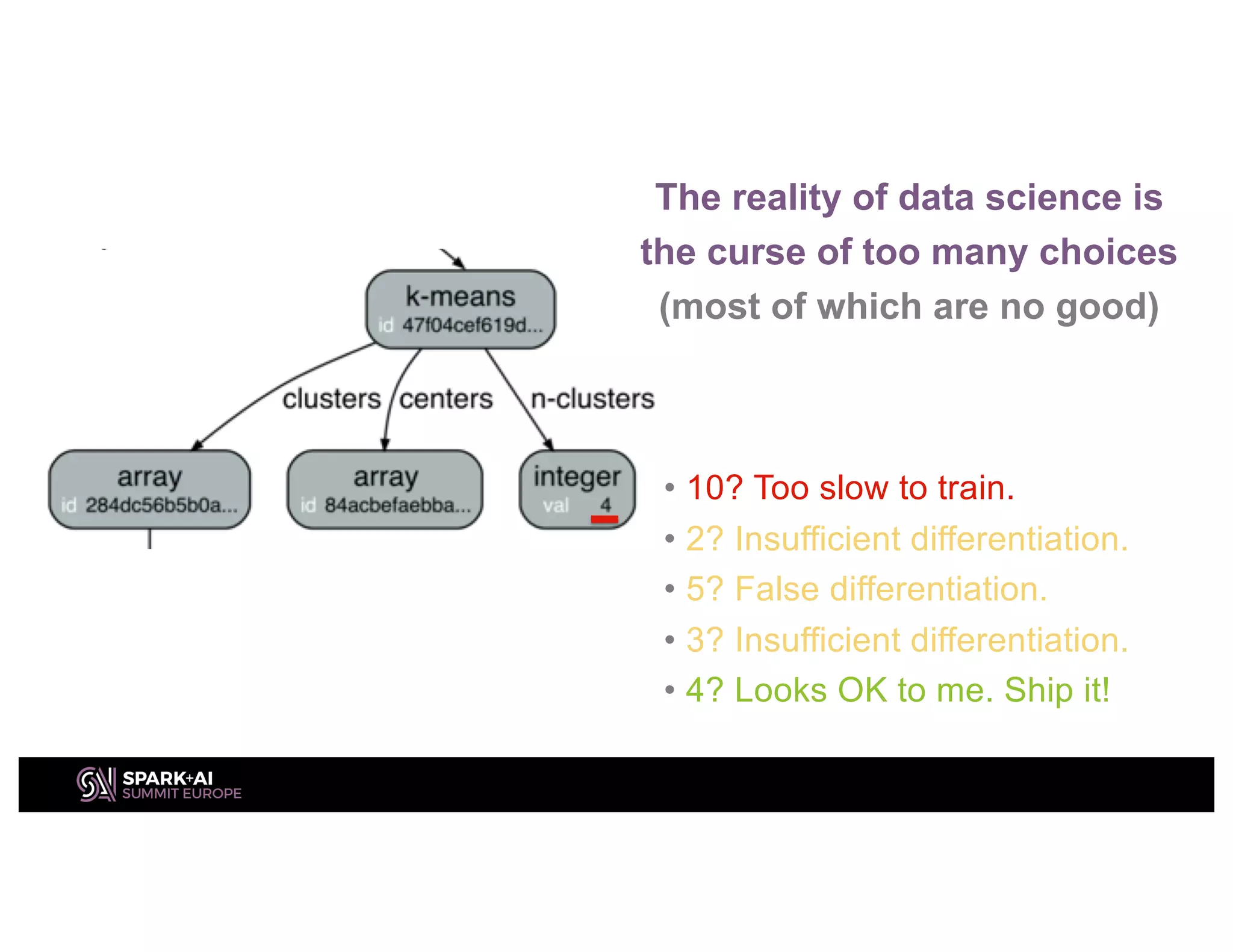
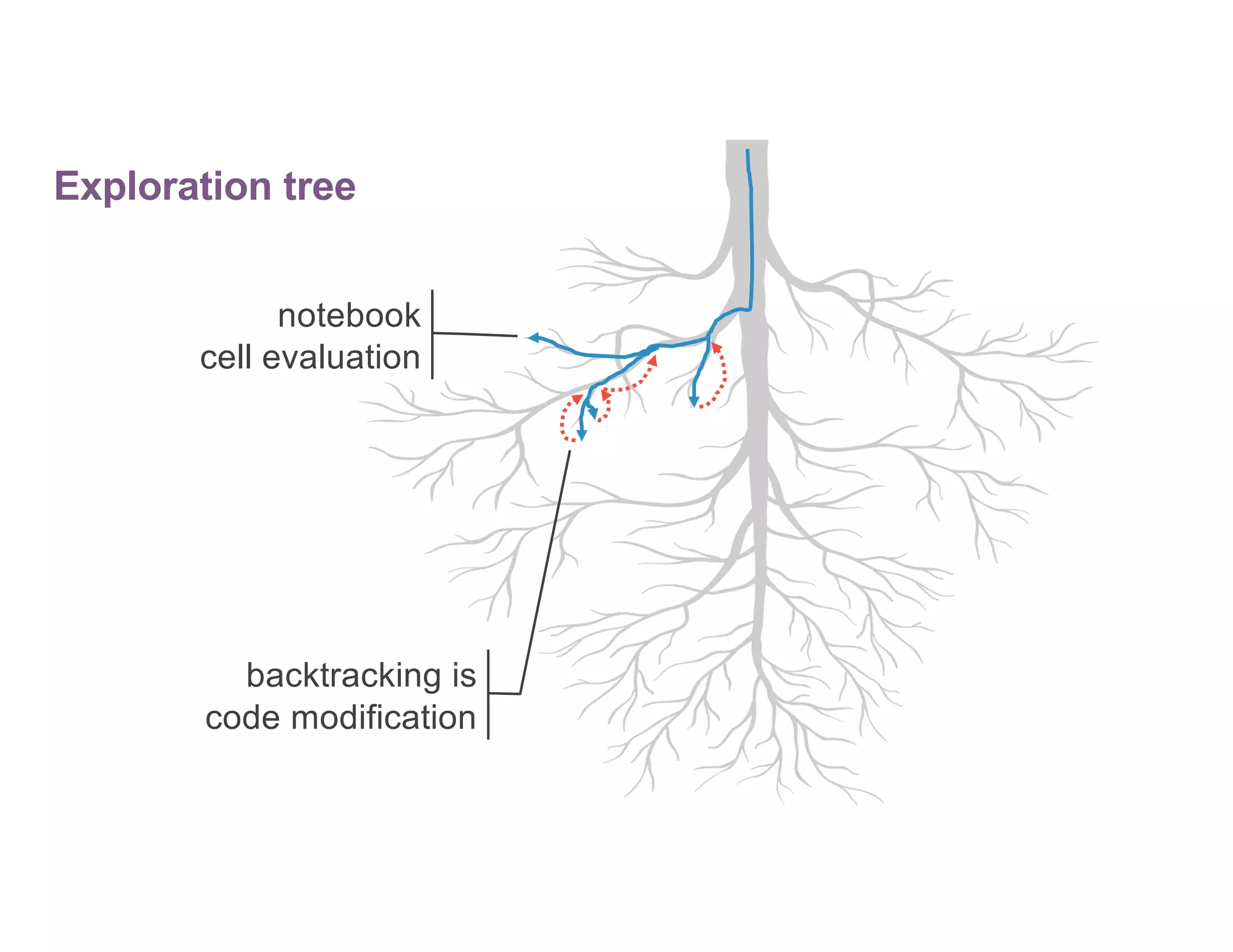
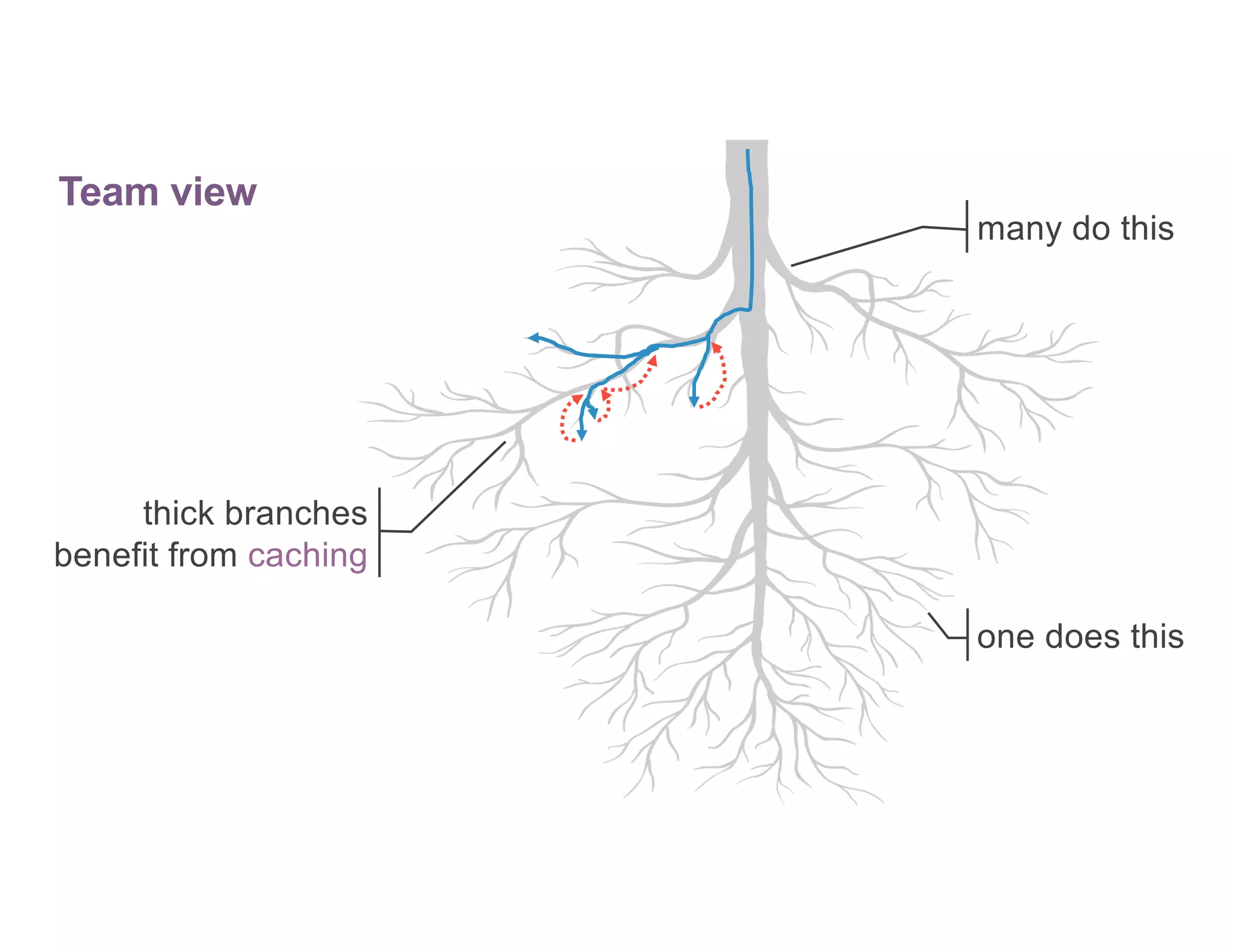
The document discusses optimizing ETL, machine learning (ML), and artificial intelligence (AI) in complex environments, emphasizing the need for privacy-preserving methods and efficient data management. It highlights the challenges of exploratory data science, particularly with Spark's limitations on caching and data consistency, and proposes advanced solutions like cross-cluster reuse and automated lifecycle management. Additionally, it critiques Spark's user-level APIs for reading and writing data, advocating for more consistent and extensible alternatives.


















![Introduction to Pandas and Time Series Analysis [PyCon DE]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysispyconde-170617163724-thumbnail.jpg?width=640&height=640&fit=bounds)




































































