Download as PDF, PPTX







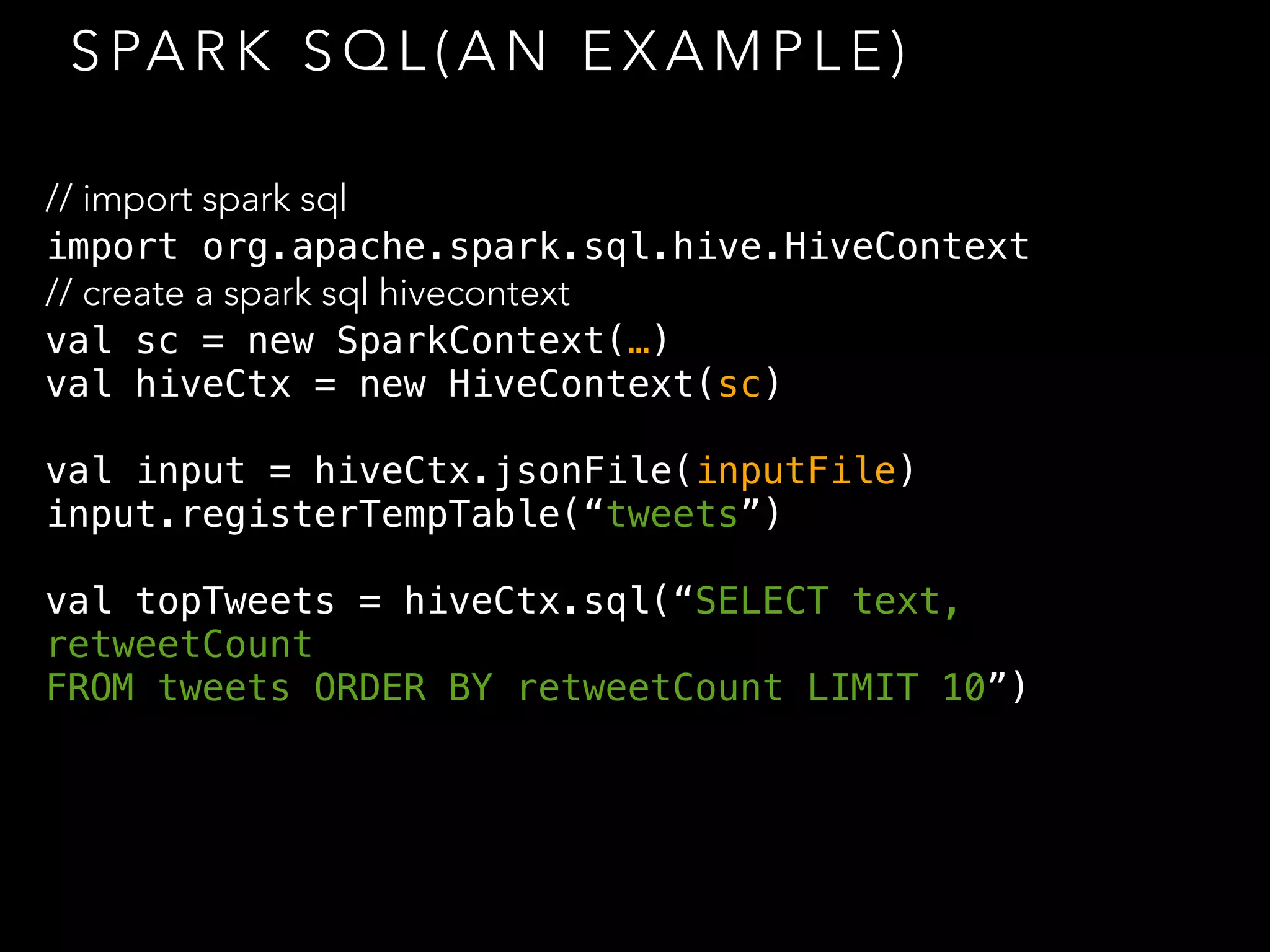
![“ C O G R O U P ” I N S PA R K
> val x = sc.parallelize(List(1, 2, 1, 3), 1)
> val y = x.map((_, "y"))
> val z = x.map((_, "z"))
> y.cogroup(z).collect
res72: Array[(Int, (Iterable[String], Iterable[String]))] = Array((1,
(Array(y, y),Array(z, z))), (3,(Array(y),Array(z))), (2,
(Array(y),Array(z))))
def cogroup[W1, W2, W3]
(other1: RDD[(K, W1)],
other2: RDD[(K, W2)],
other3: RDD[(K, W3)], numPartitions: Int):
RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2],
Iterable[W3]))]](https://image.slidesharecdn.com/of7k26ferbxxphmdxtxs-signature-d5550dee2270b62762432a9add88c4ac614c5898bdf2293a88820e0e4f43ab57-poli-150113221024-conversion-gate02/75/Toying-with-spark-9-2048.jpg)

![H O W “ C O G R O U P ” W O R K S I N S PA R K
Arraycombined
Array[(k1,[va,vc,ve,vf,vh]),
(k2,[vb,vg]),
(k3,[vd])]
RDDx.cogroup(RDDy) = *see below*](https://image.slidesharecdn.com/of7k26ferbxxphmdxtxs-signature-d5550dee2270b62762432a9add88c4ac614c5898bdf2293a88820e0e4f43ab57-poli-150113221024-conversion-gate02/75/Toying-with-spark-11-2048.jpg)
![“ C O G R O U P ” I N S PA R K
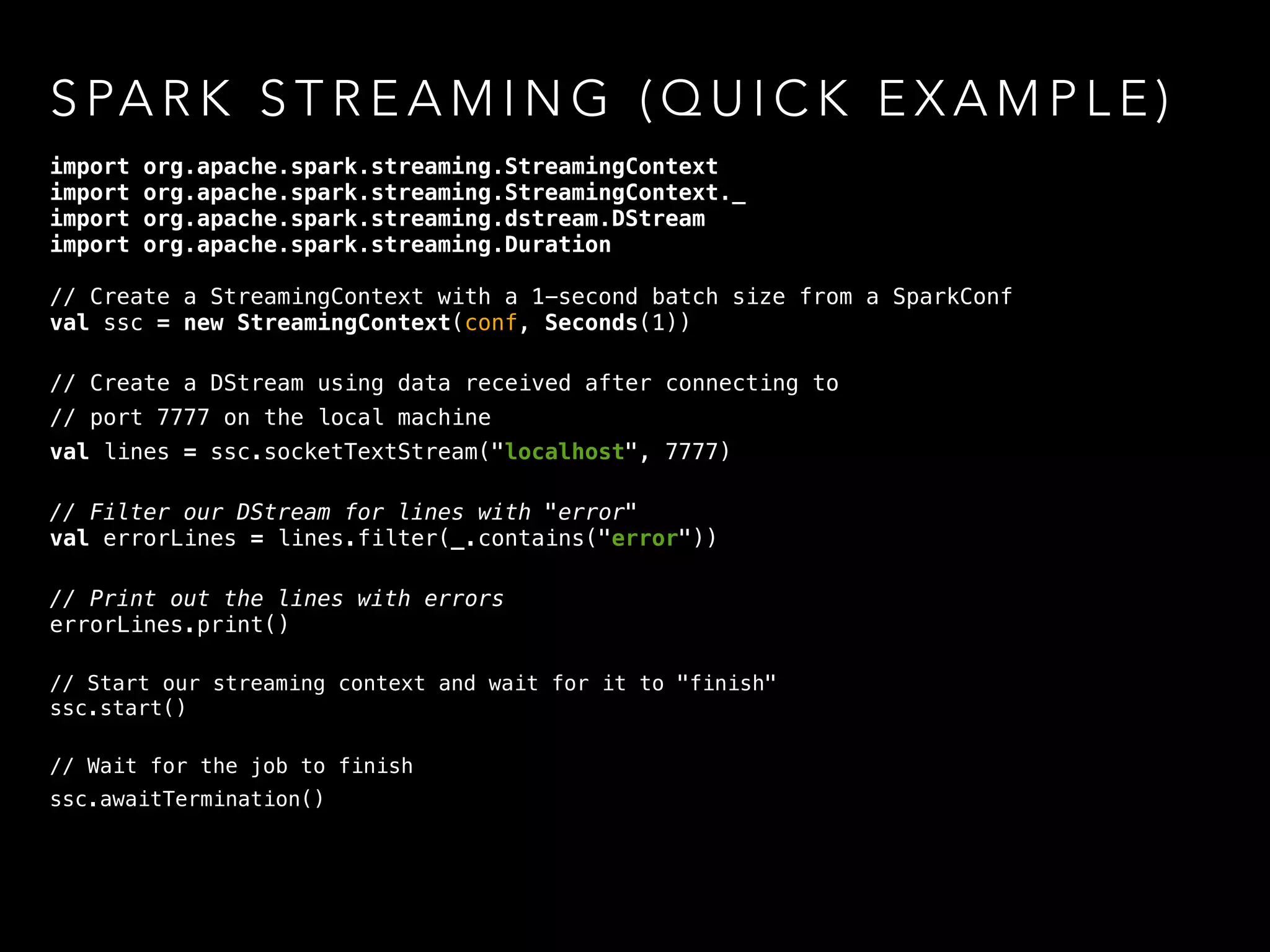
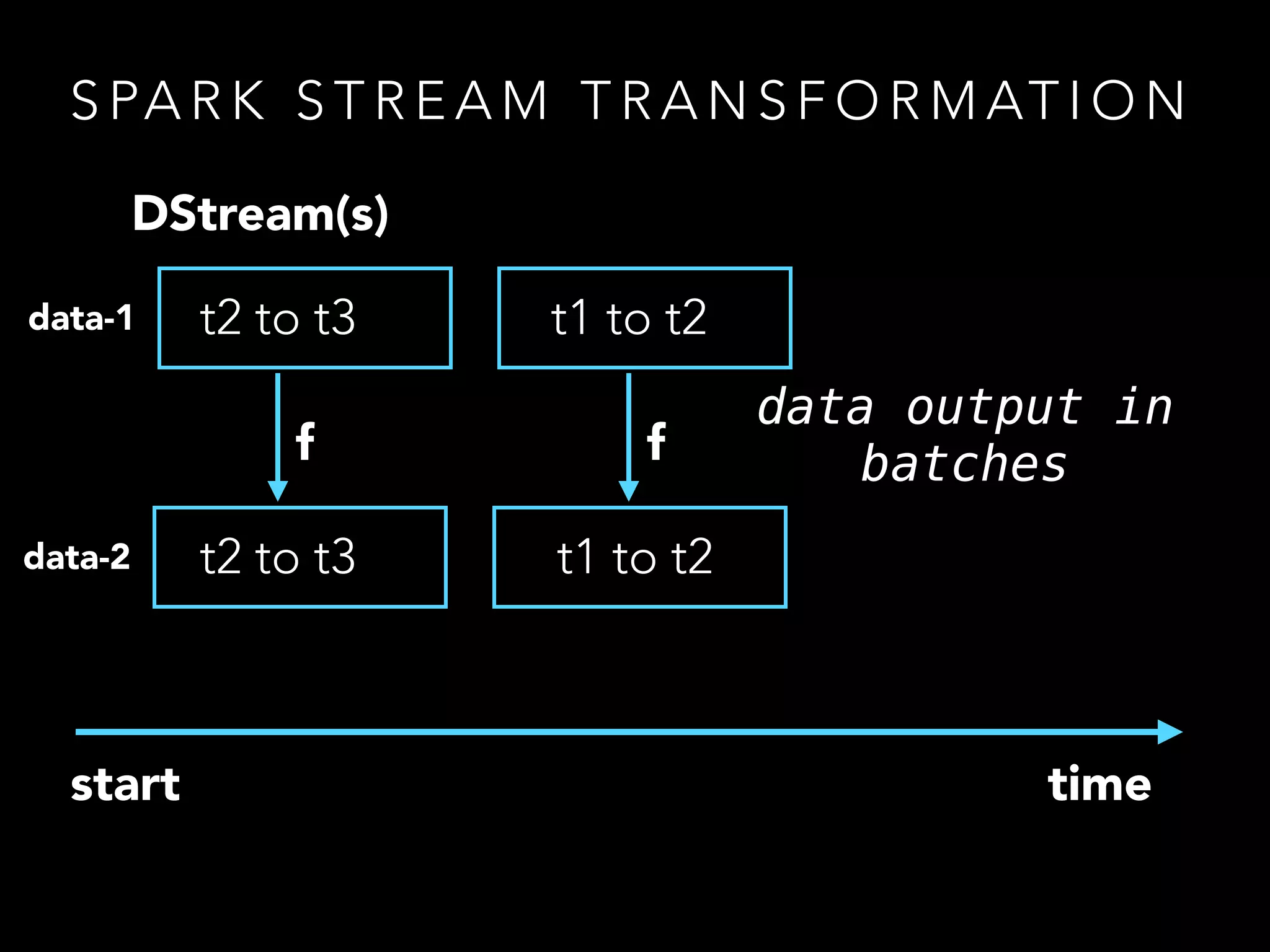
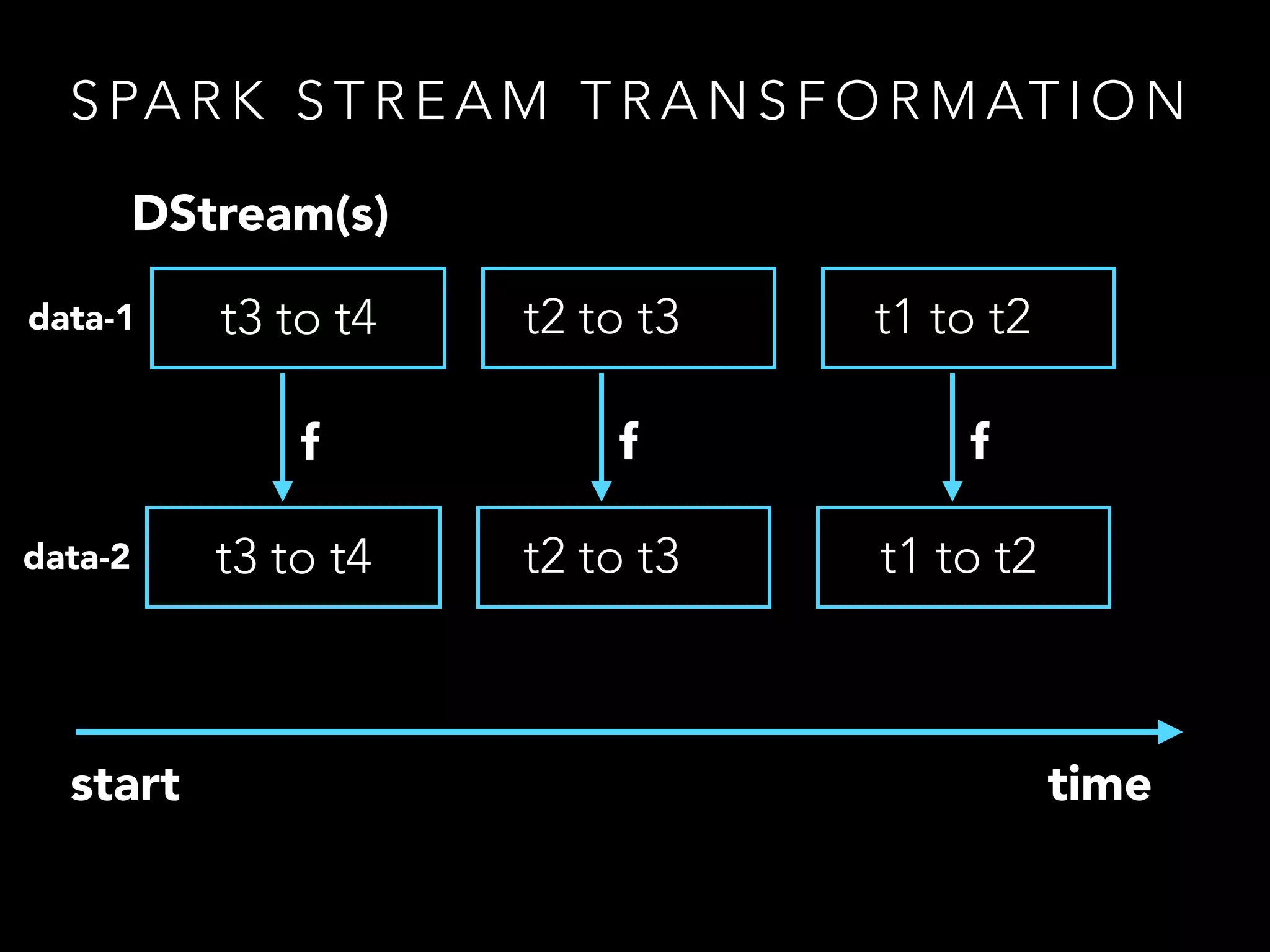
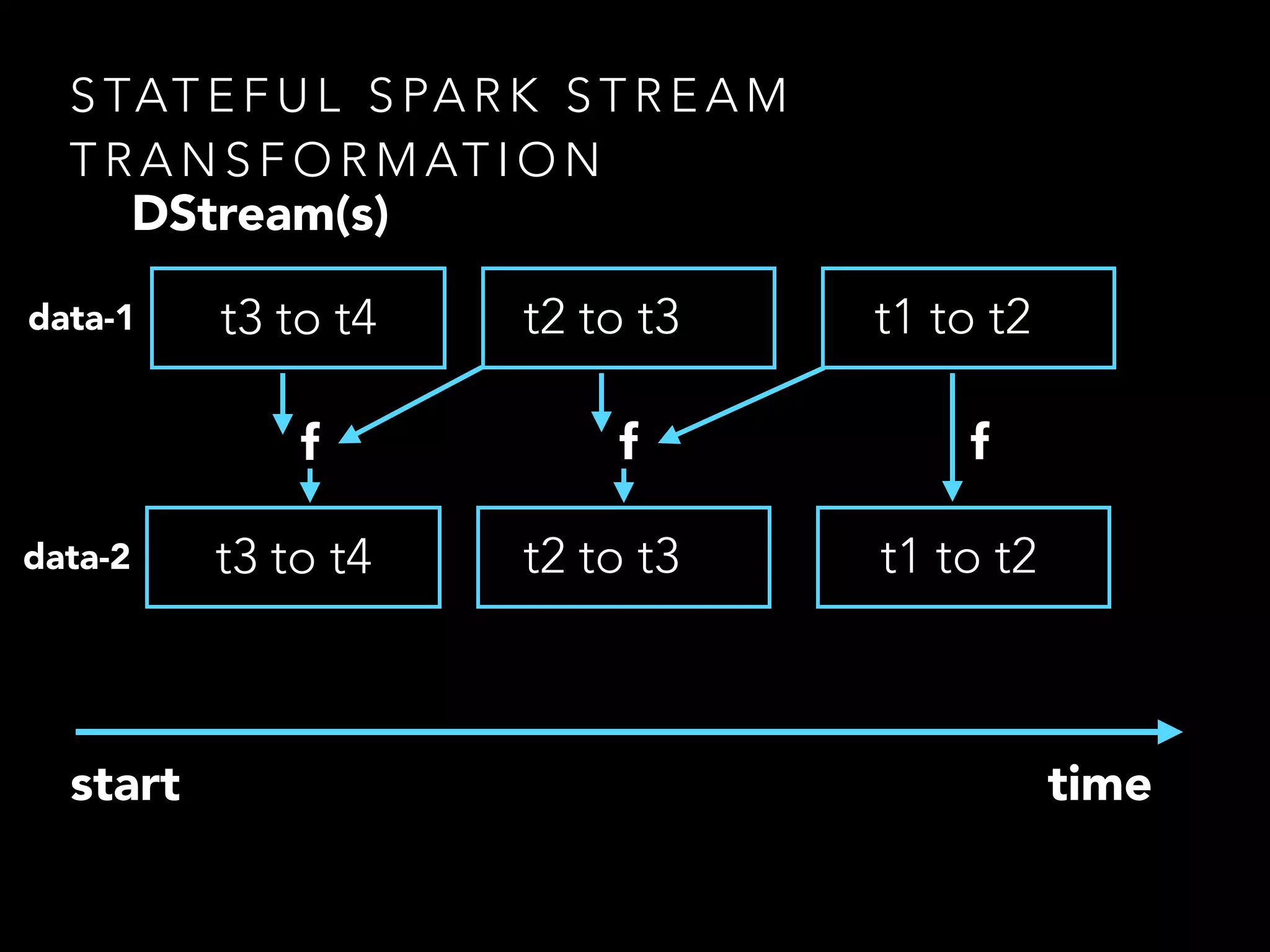
• CoGroup works in both RDD and Spark Streams
• the ability to combine multiple RDDs allows higher
abstractions to be constructed
• A Stream in Spark is just a list of (Time,RDD[U])](https://image.slidesharecdn.com/of7k26ferbxxphmdxtxs-signature-d5550dee2270b62762432a9add88c4ac614c5898bdf2293a88820e0e4f43ab57-poli-150113221024-conversion-gate02/75/Toying-with-spark-12-2048.jpg)



















![“ C O G R O U P ” I N S PA R K
> val x = sc.parallelize(List(1, 2, 1, 3), 1)
> val y = x.map((_, "y"))
> val z = x.map((_, "z"))
> y.cogroup(z).collect
res72: Array[(Int, (Iterable[String], Iterable[String]))] = Array((1,
(Array(y, y),Array(z, z))), (3,(Array(y),Array(z))), (2,
(Array(y),Array(z))))
def cogroup[W1, W2, W3]
(other1: RDD[(K, W1)],
other2: RDD[(K, W2)],
other3: RDD[(K, W3)], numPartitions: Int):
RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2],
Iterable[W3]))]](https://crownmelresort.com/image.slidesharecdn.com/of7k26ferbxxphmdxtxs-signature-d5550dee2270b62762432a9add88c4ac614c5898bdf2293a88820e0e4f43ab57-poli-150113221024-conversion-gate02/75/Toying-with-spark-9-2048.jpg)

![H O W “ C O G R O U P ” W O R K S I N S PA R K
Arraycombined
Array[(k1,[va,vc,ve,vf,vh]),
(k2,[vb,vg]),
(k3,[vd])]
RDDx.cogroup(RDDy) = *see below*](https://crownmelresort.com/image.slidesharecdn.com/of7k26ferbxxphmdxtxs-signature-d5550dee2270b62762432a9add88c4ac614c5898bdf2293a88820e0e4f43ab57-poli-150113221024-conversion-gate02/75/Toying-with-spark-11-2048.jpg)
![“ C O G R O U P ” I N S PA R K
• CoGroup works in both RDD and Spark Streams
• the ability to combine multiple RDDs allows higher
abstractions to be constructed
• A Stream in Spark is just a list of (Time,RDD[U])](https://crownmelresort.com/image.slidesharecdn.com/of7k26ferbxxphmdxtxs-signature-d5550dee2270b62762432a9add88c4ac614c5898bdf2293a88820e0e4f43ab57-poli-150113221024-conversion-gate02/75/Toying-with-spark-12-2048.jpg)




















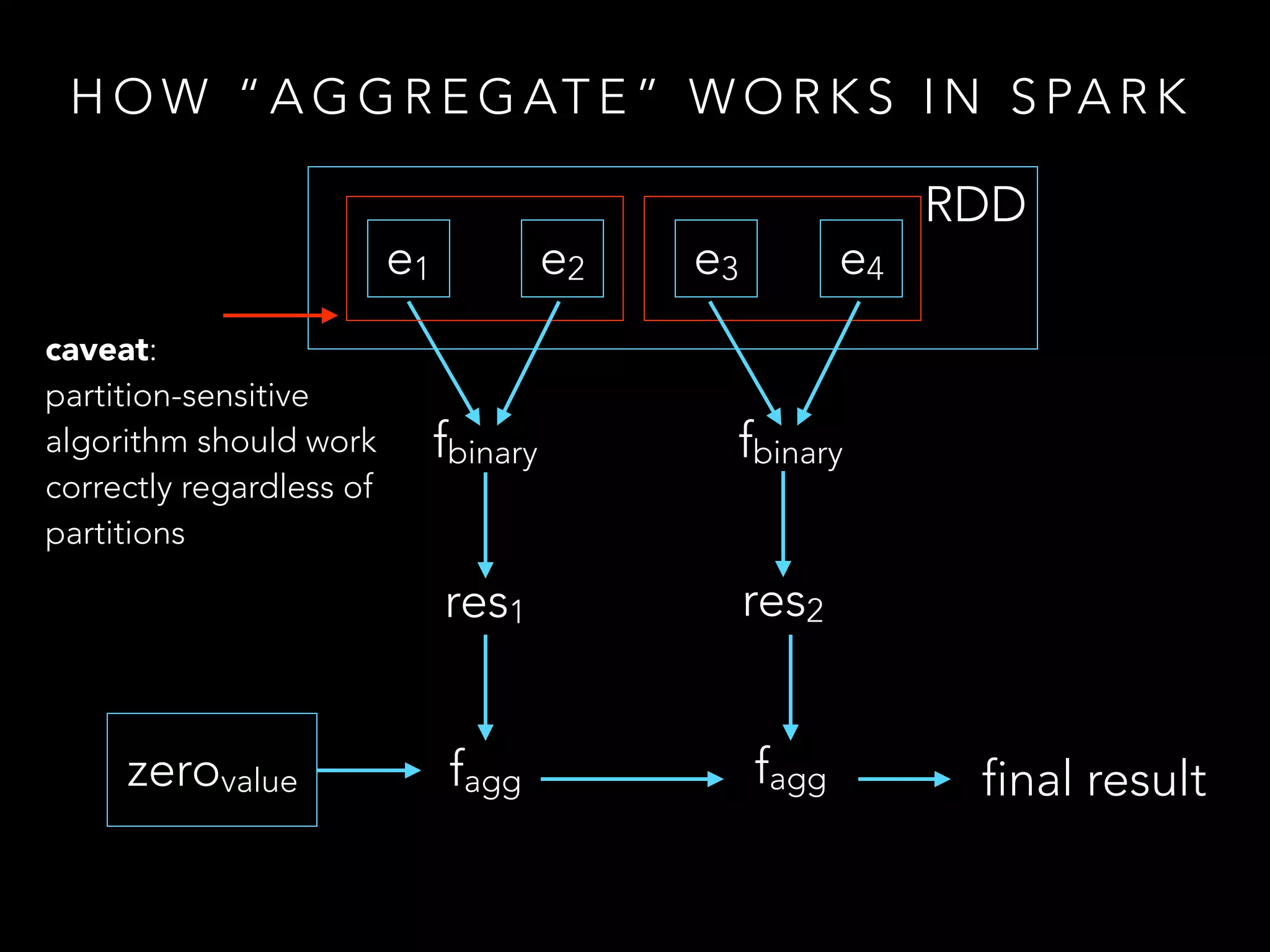
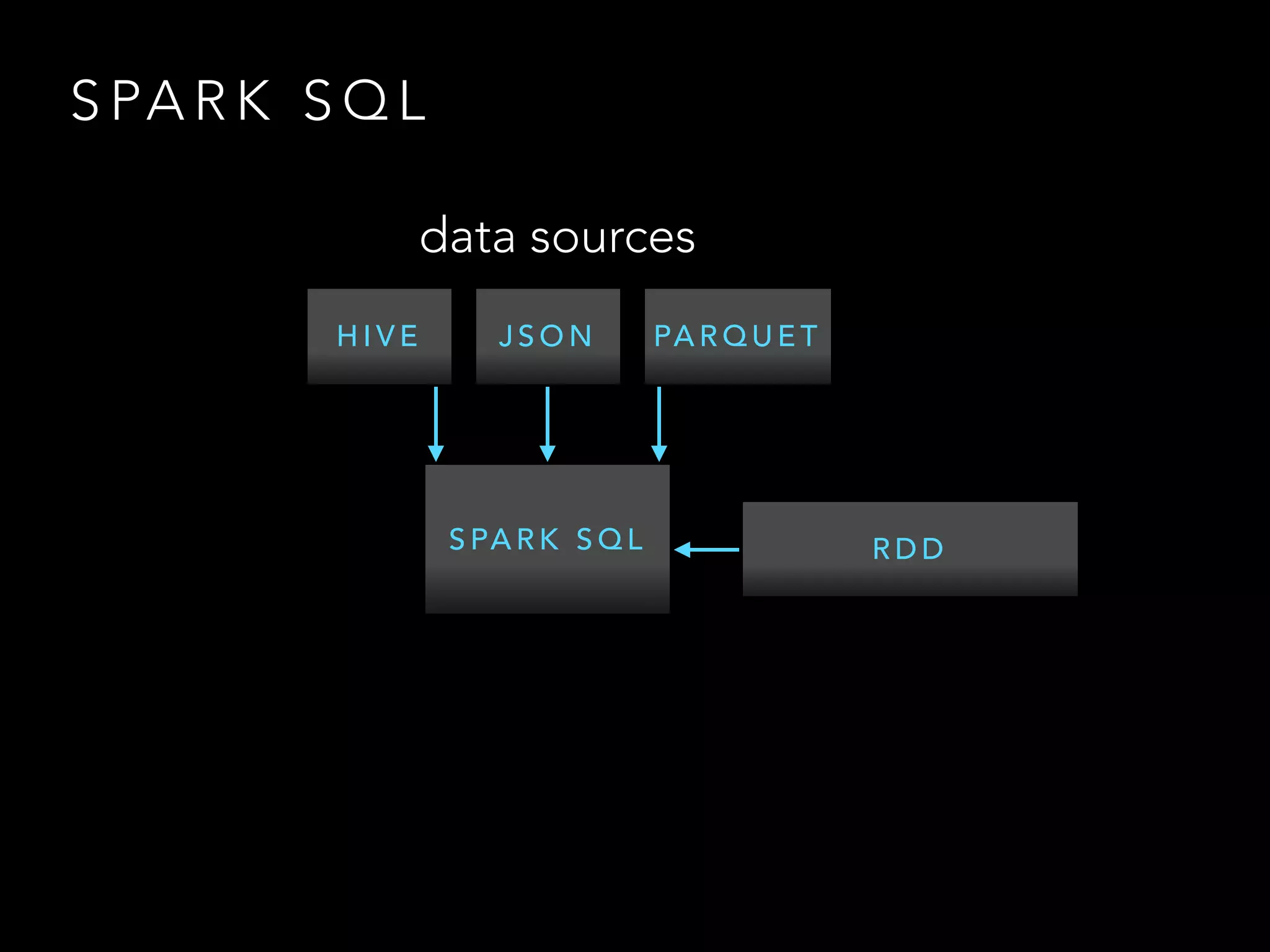
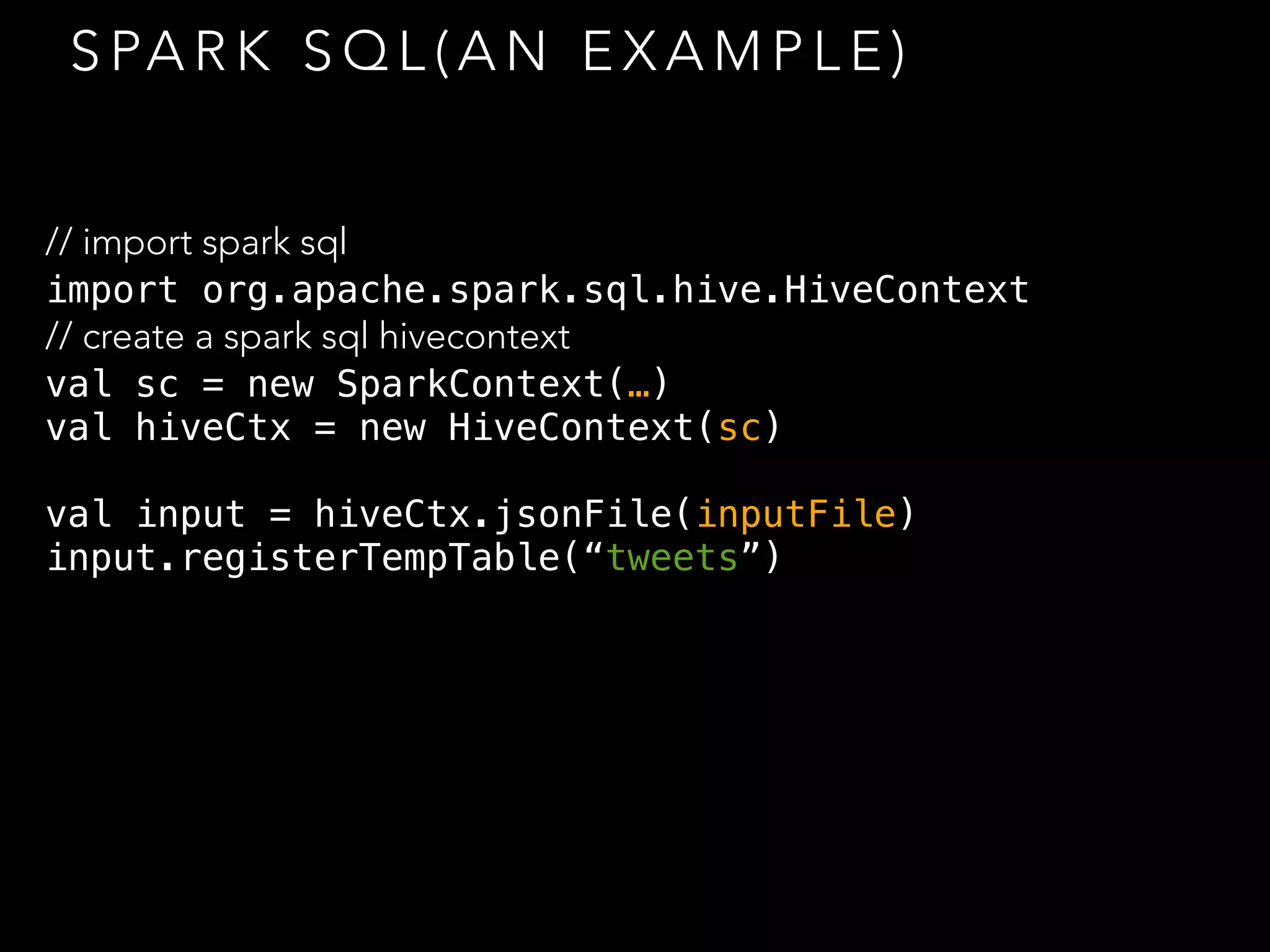
The document covers Apache Spark, including its components like RDDs, Spark SQL, and Spark Streaming, along with their functionalities and lifecycle management. It presents coding examples to illustrate operations such as aggregation and cogrouping within Spark, and discusses fault tolerance in streaming processes. Additionally, it provides references and resources for further learning about Spark and big data analytics.




















































































