Downloaded 24 times











'{'
' @DeveloperApi'
' def'compute(split:'Partition,'context:'TaskContext):'Iterator[T]'
'
' protected'def'getPartitions:'Array[Partition]'
' '
' protected'def'getPreferredLocations(split:'Partition):'Seq[String]'='Nil''''''''
}'](https://image.slidesharecdn.com/spark-cassandraintegration2016-160331161336/75/Spark-cassandra-integration-2016-20-2048.jpg)

































'{'
' @DeveloperApi'
' def'compute(split:'Partition,'context:'TaskContext):'Iterator[T]'
'
' protected'def'getPartitions:'Array[Partition]'
' '
' protected'def'getPreferredLocations(split:'Partition):'Seq[String]'='Nil''''''''
}'](https://crownmelresort.com/image.slidesharecdn.com/spark-cassandraintegration2016-160331161336/75/Spark-cassandra-integration-2016-20-2048.jpg)

















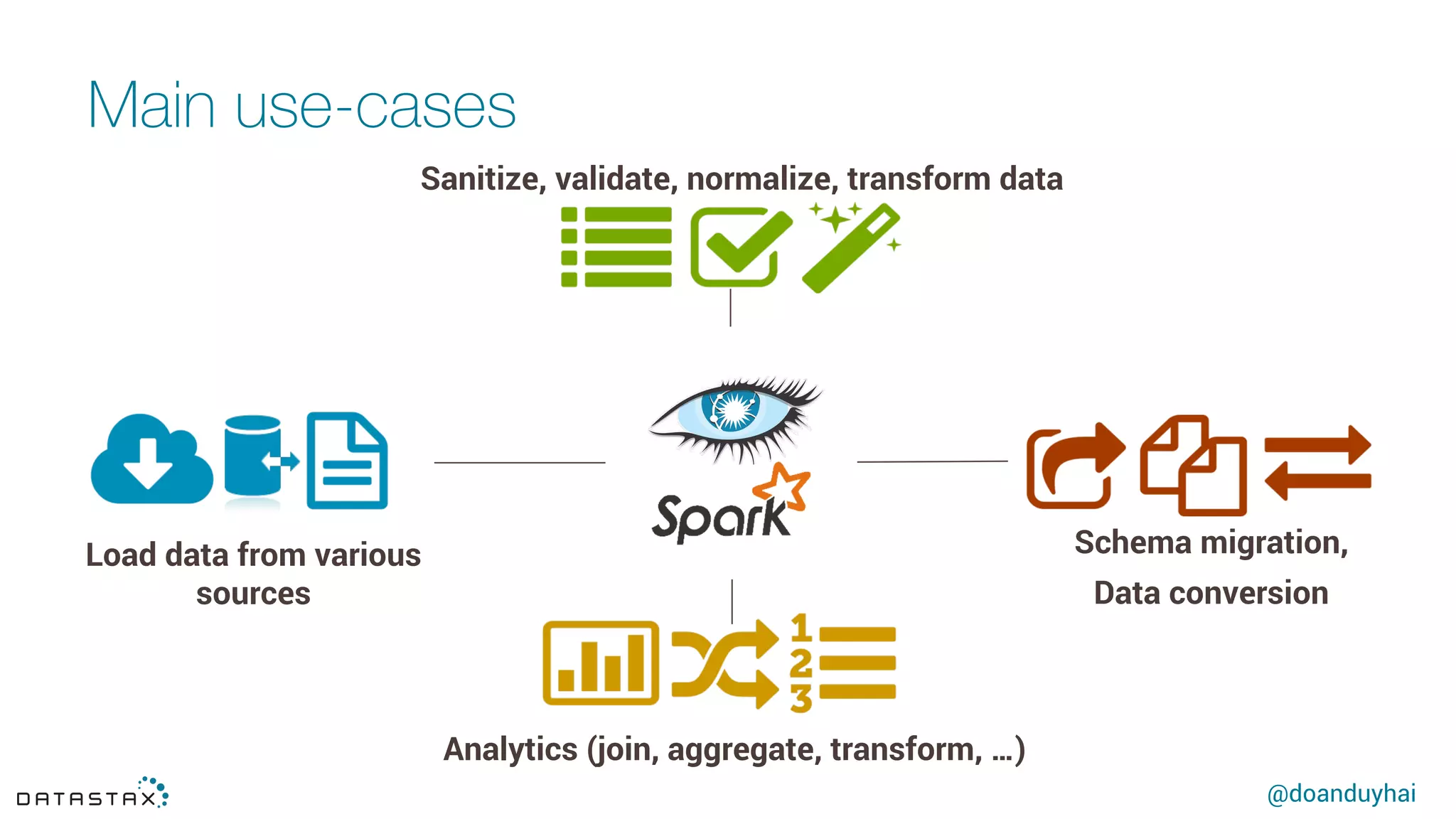
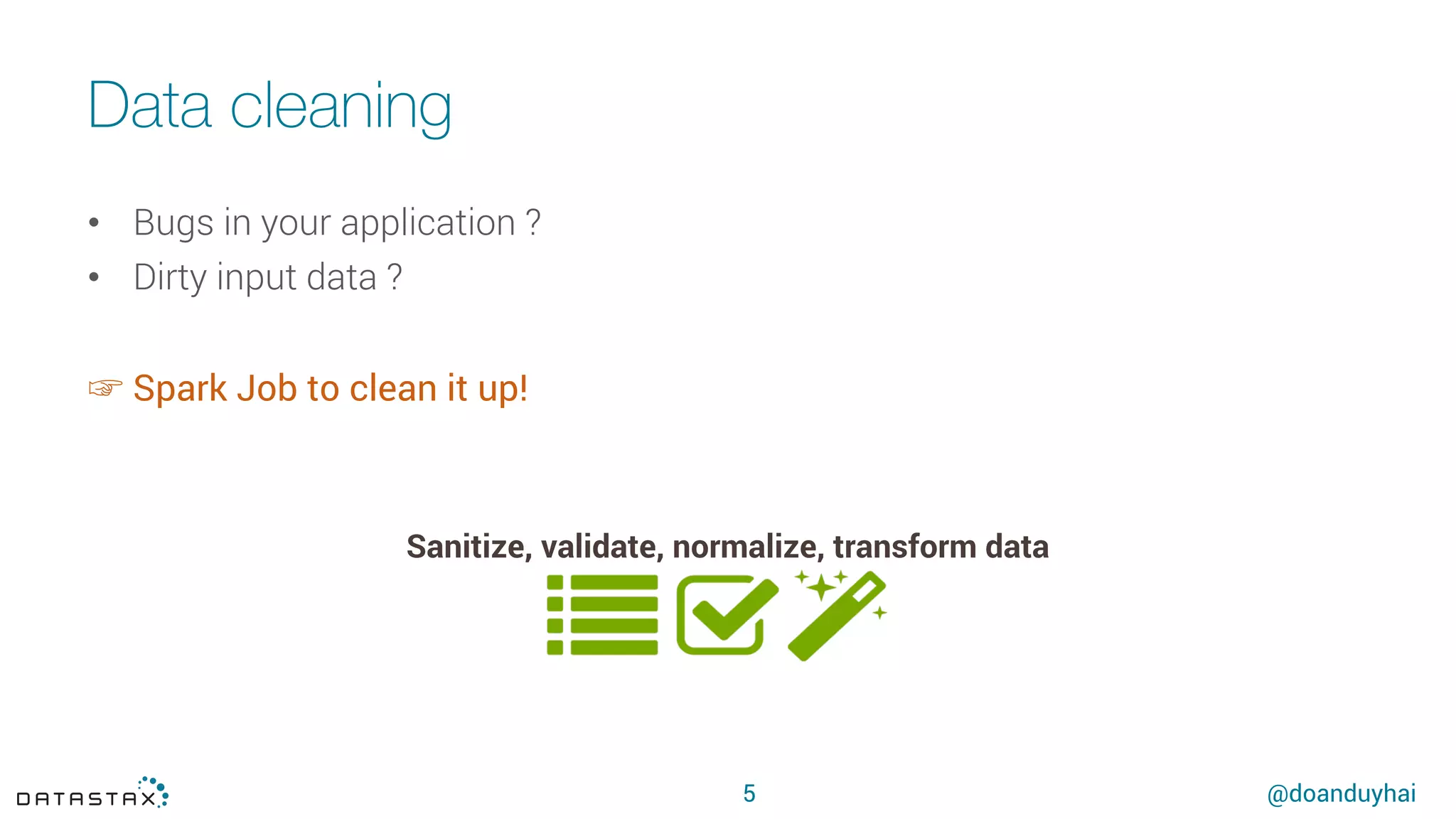
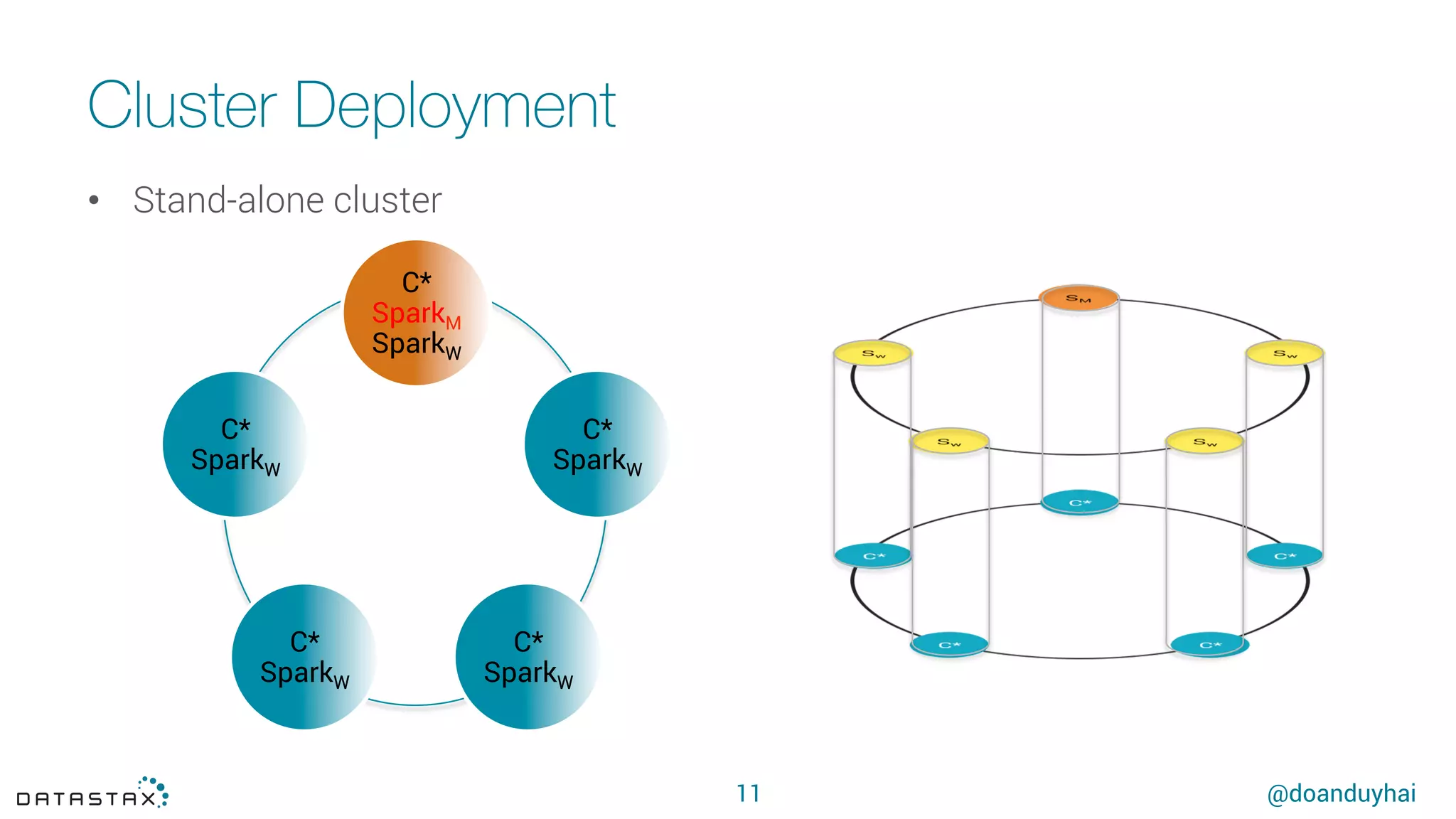
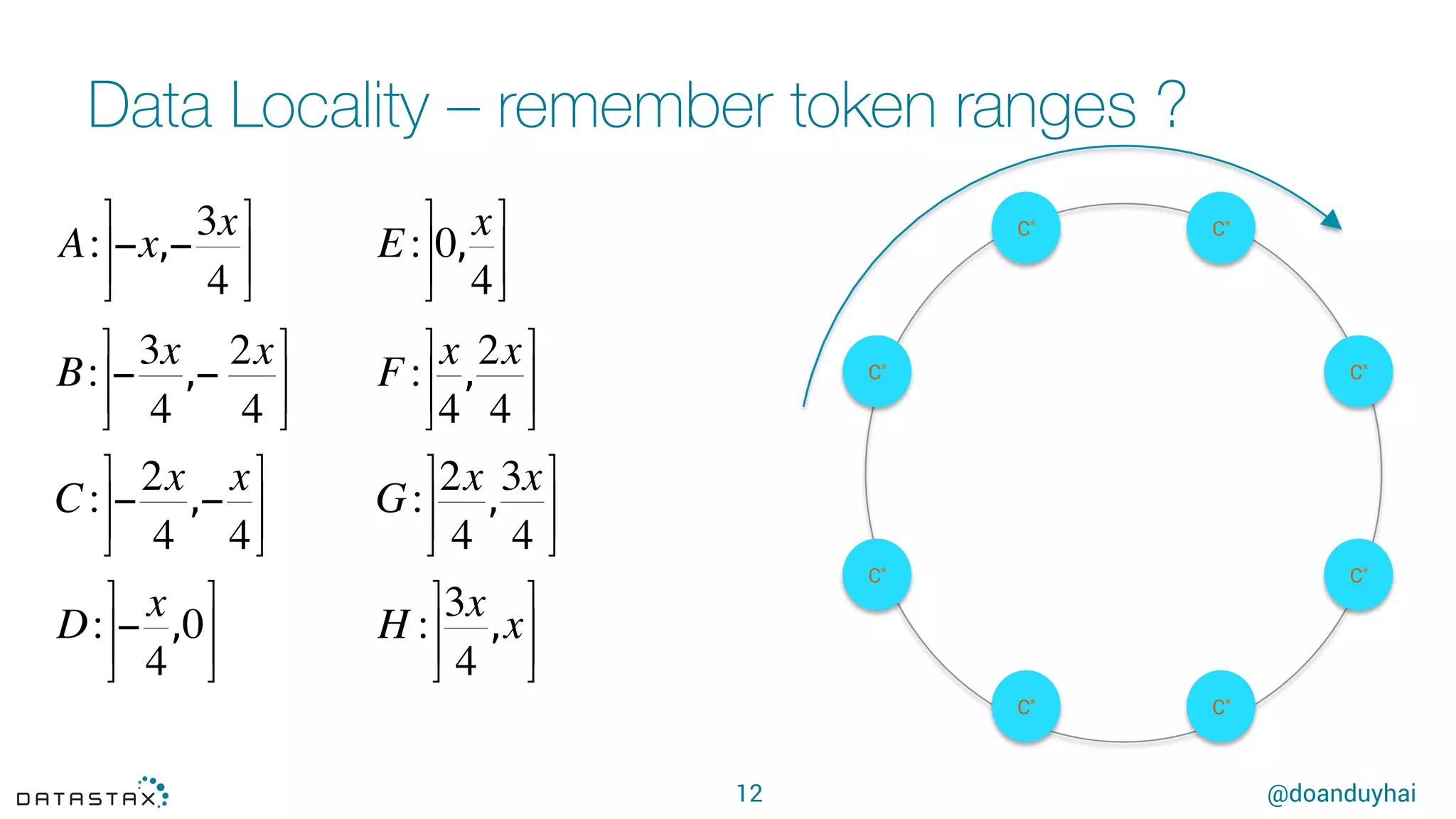
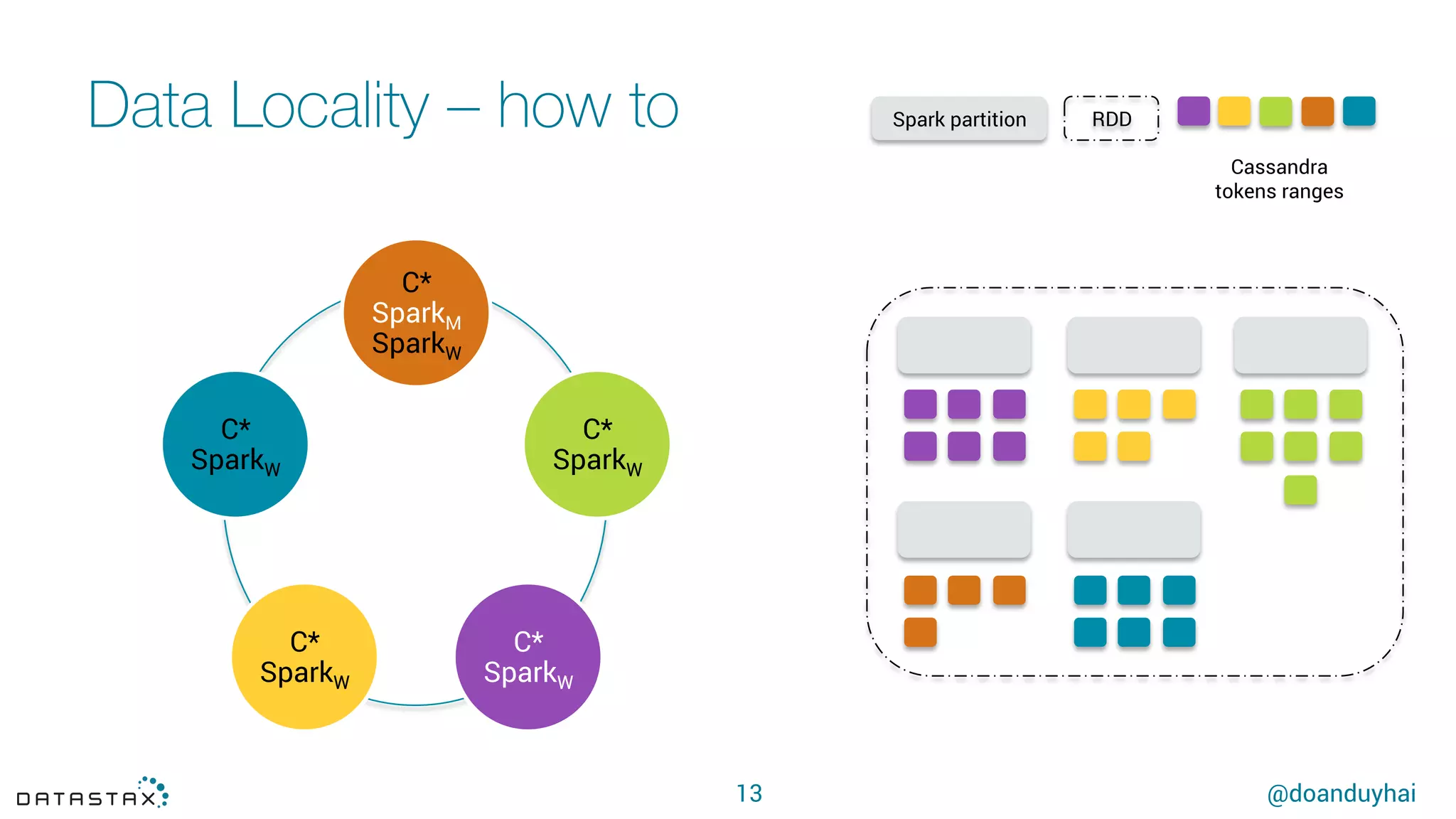
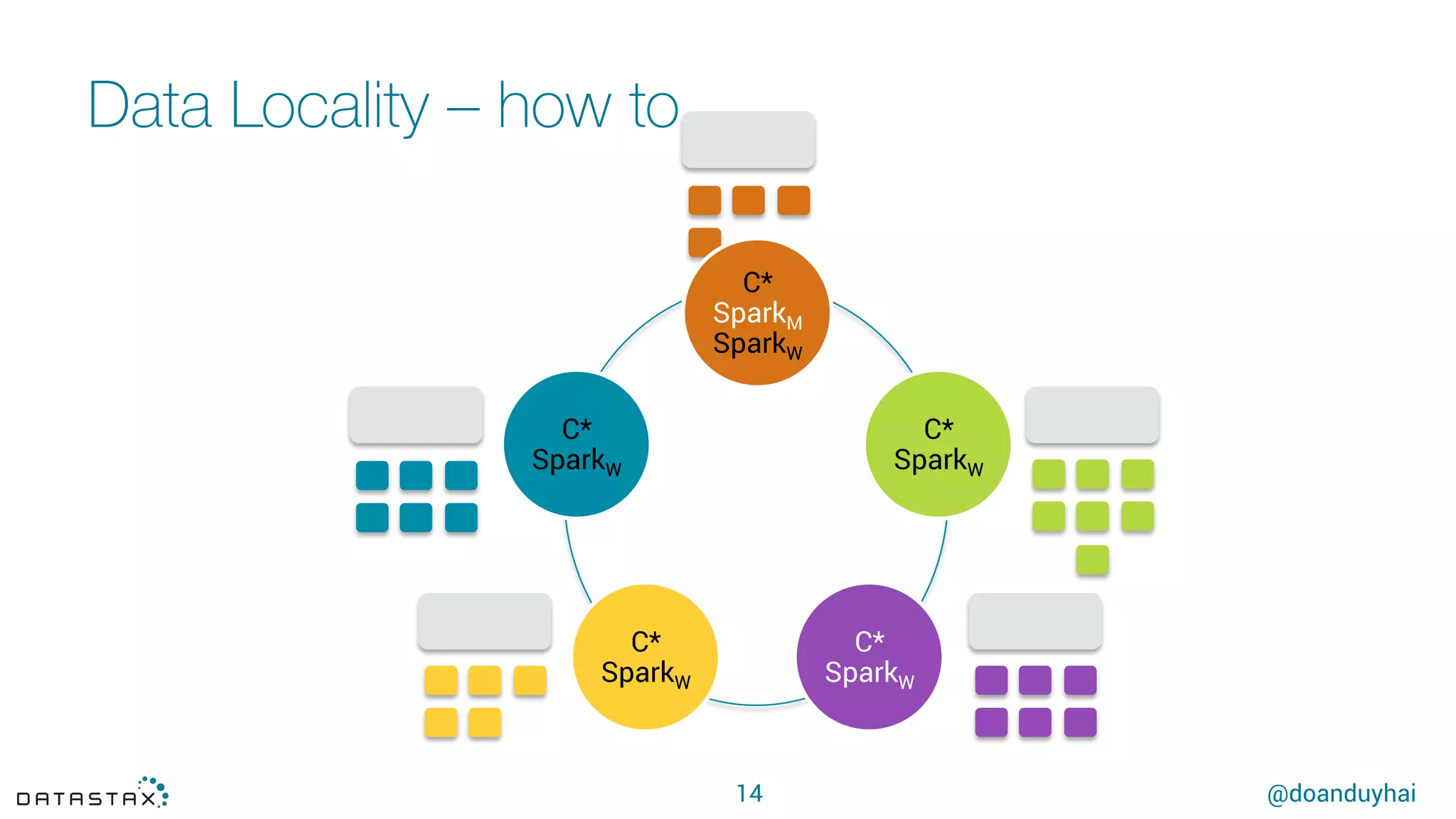
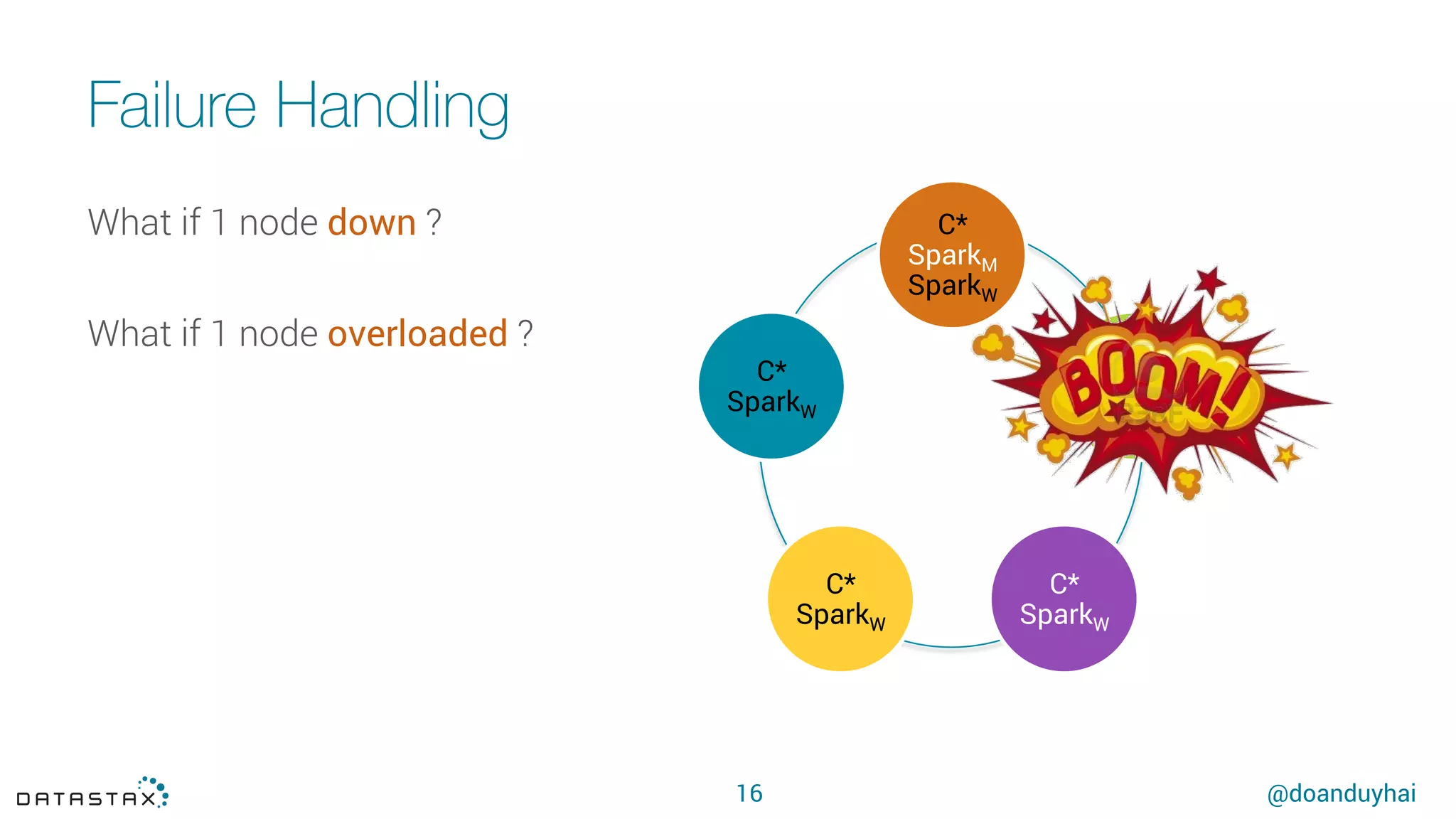
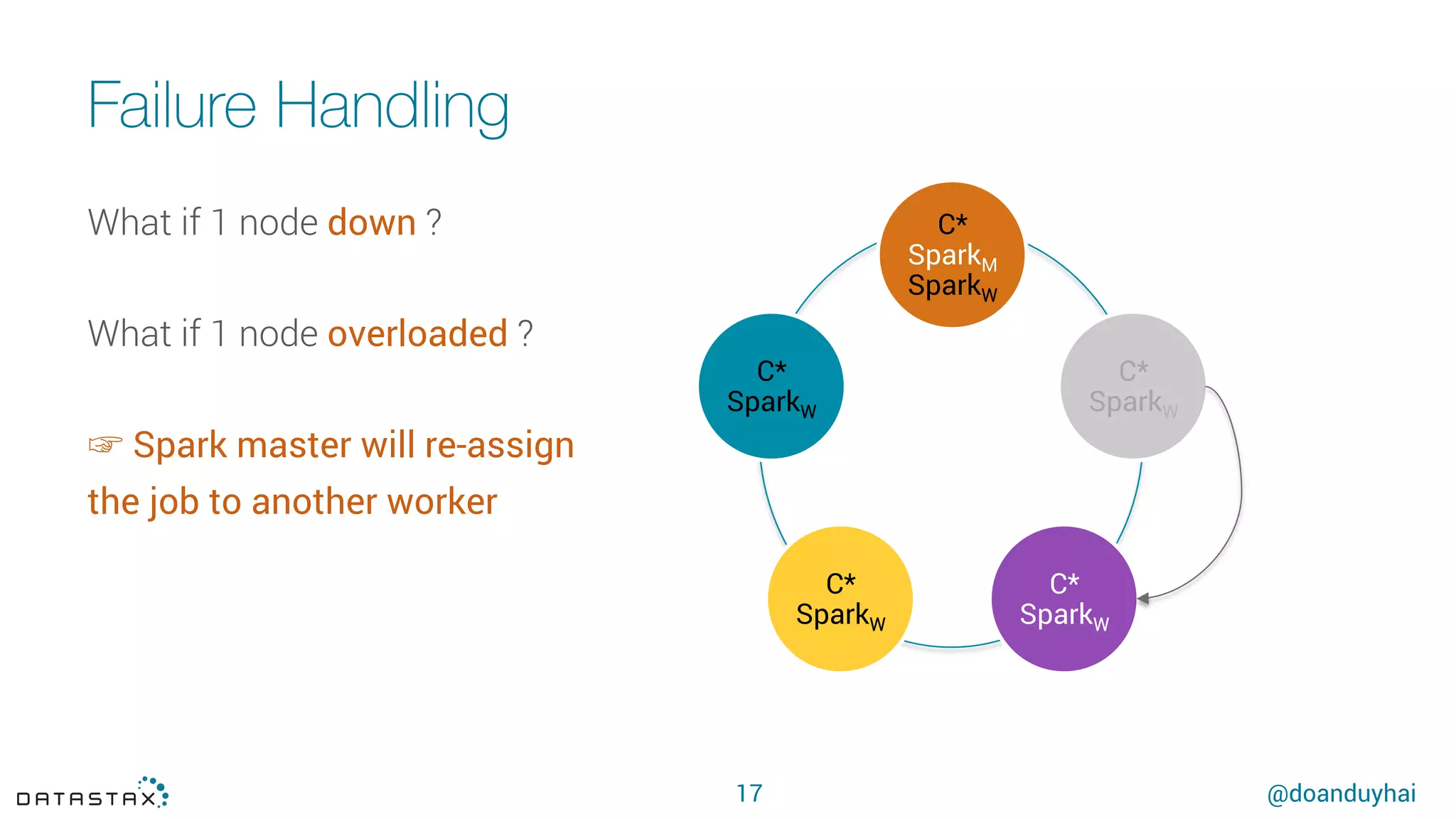
This document summarizes a presentation about using Spark with Apache Cassandra. It discusses using Spark jobs to load and transform data in Cassandra for purposes such as data import, cleaning, schema migration and analytics. It also covers aspects of the connector architecture like data locality, failure handling and cross-cluster operations. Examples are given of using Spark and Cassandra together for parallel data ingestion and top-K queries on a large dataset.



























































































