Downloaded 30 times






![Loading + Saving Data
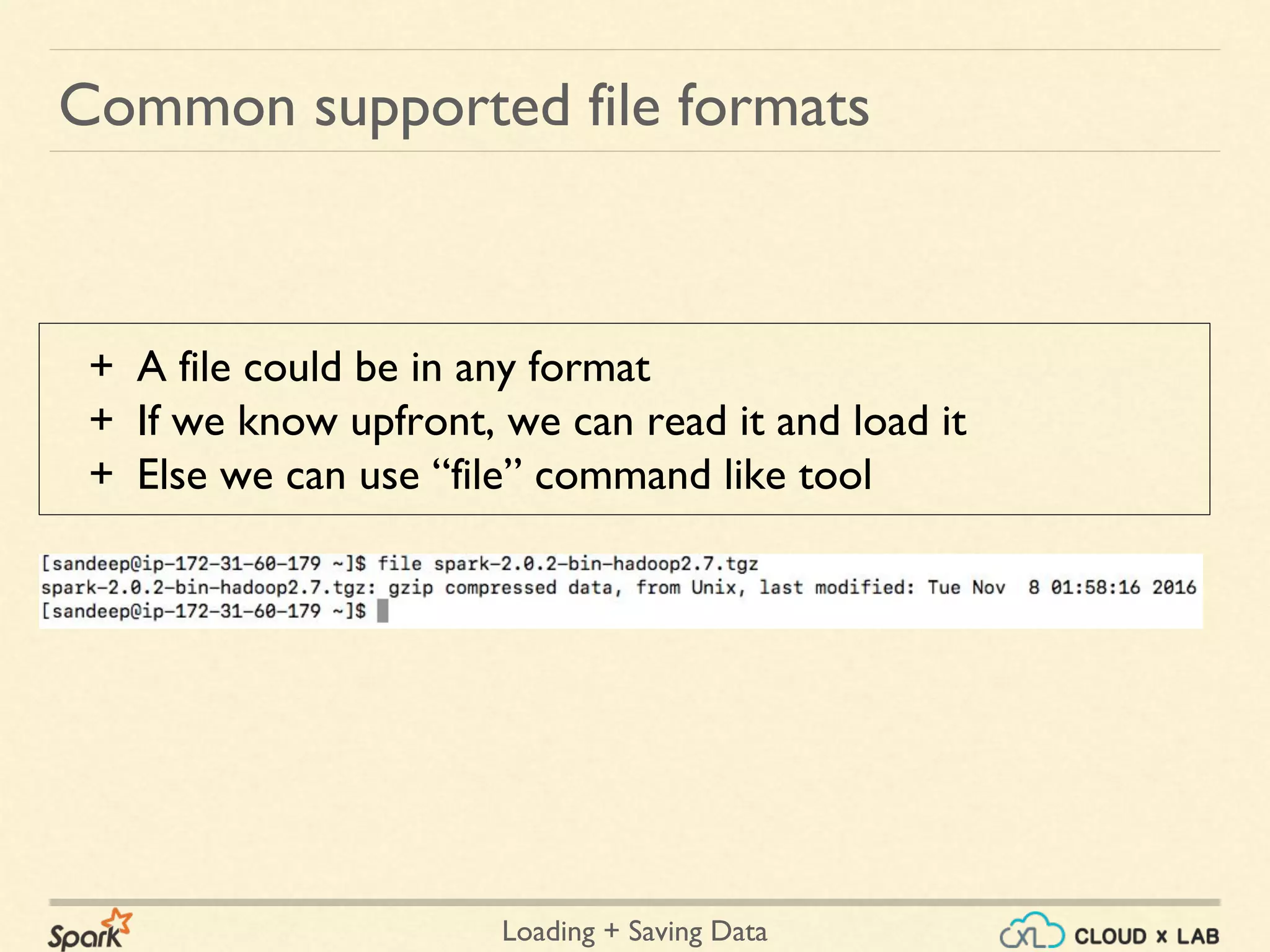
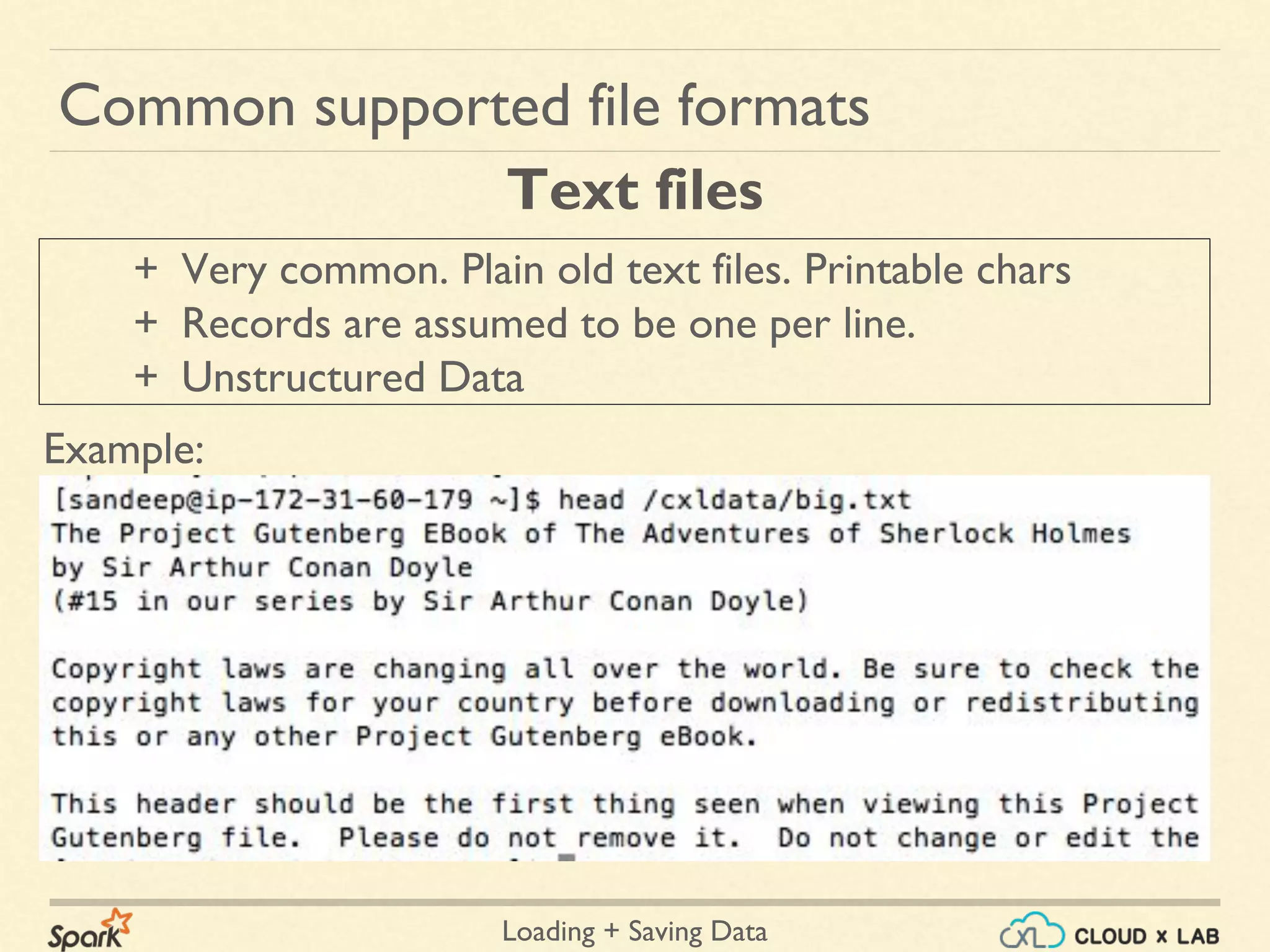
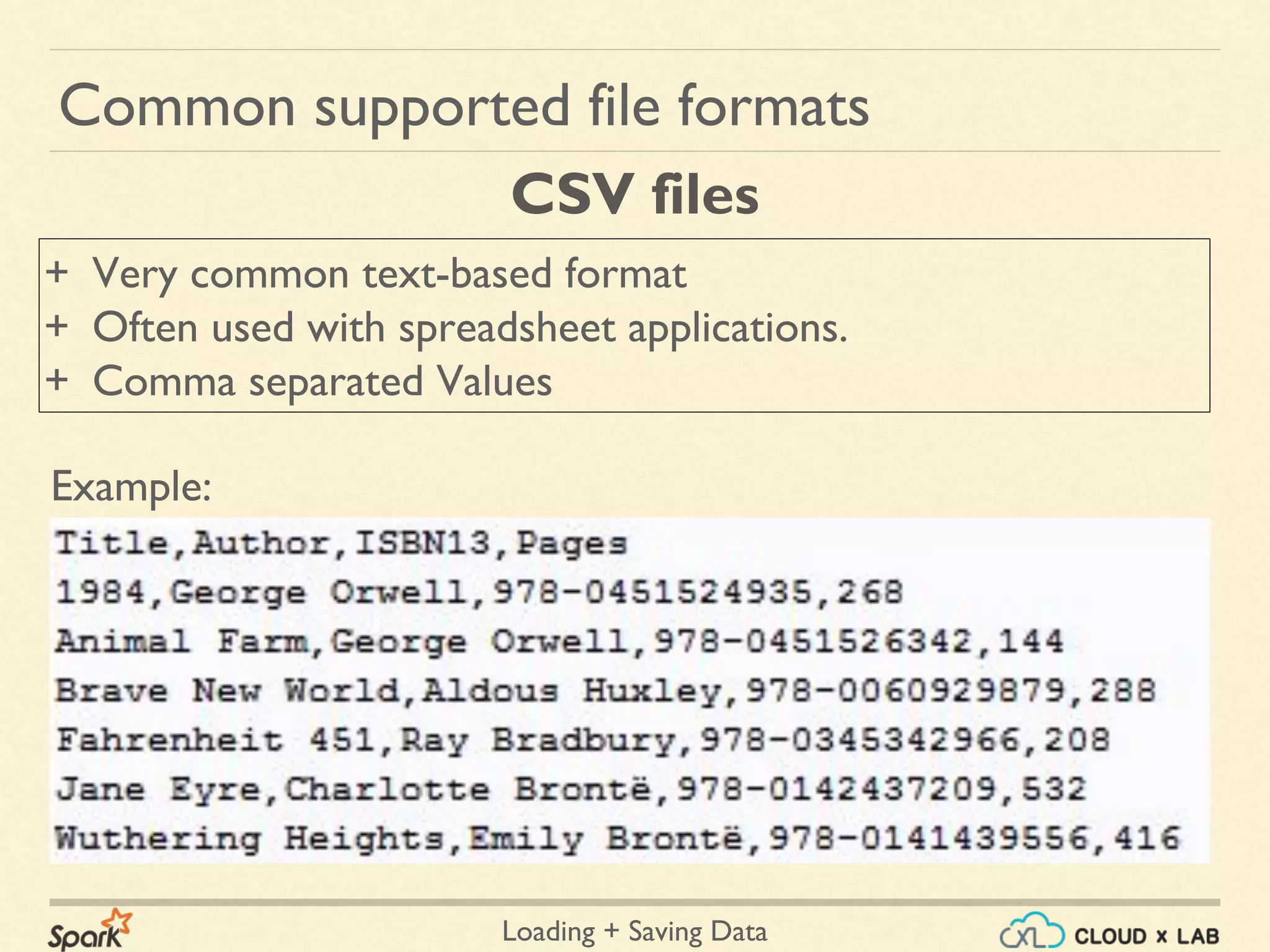
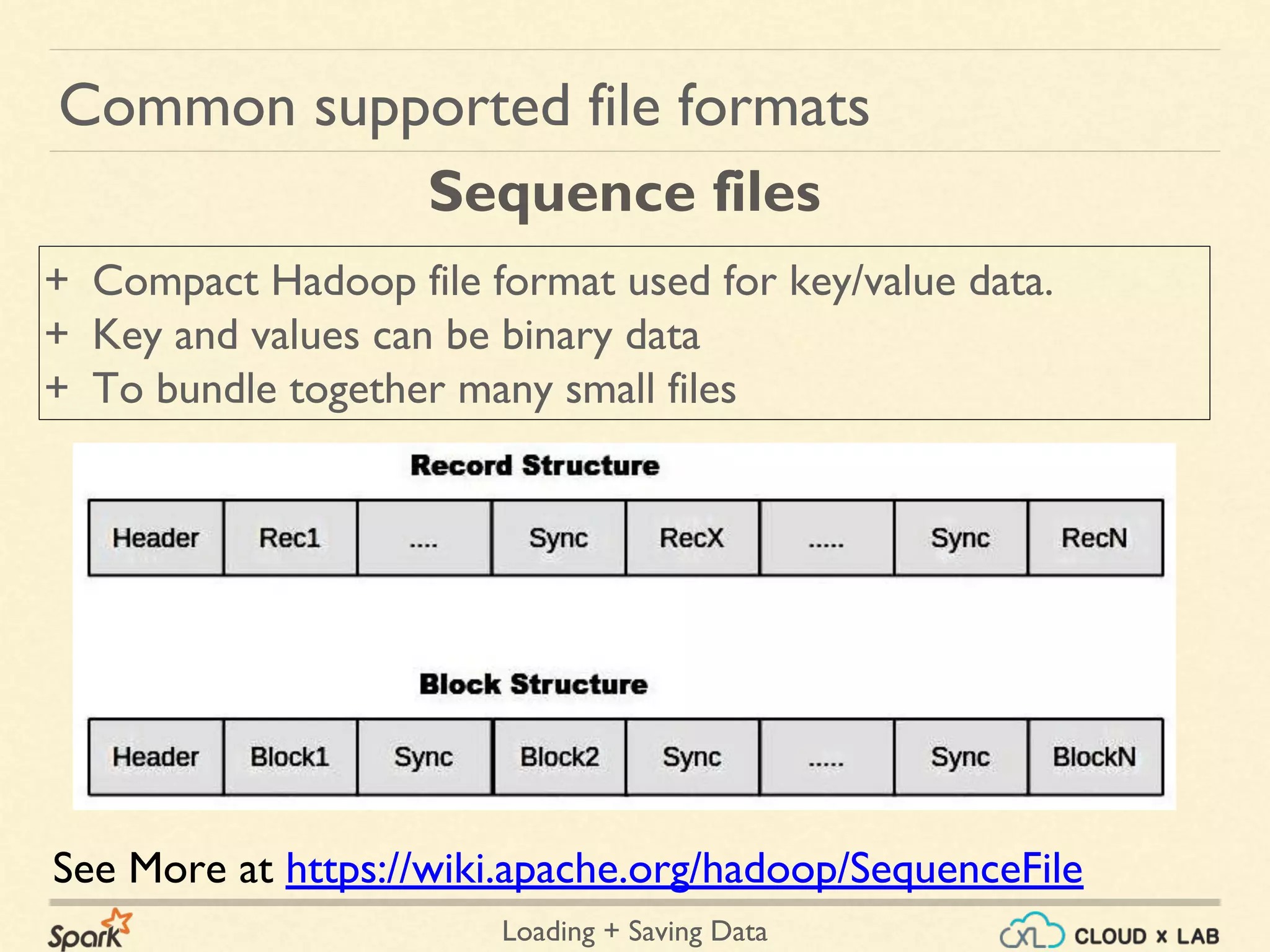
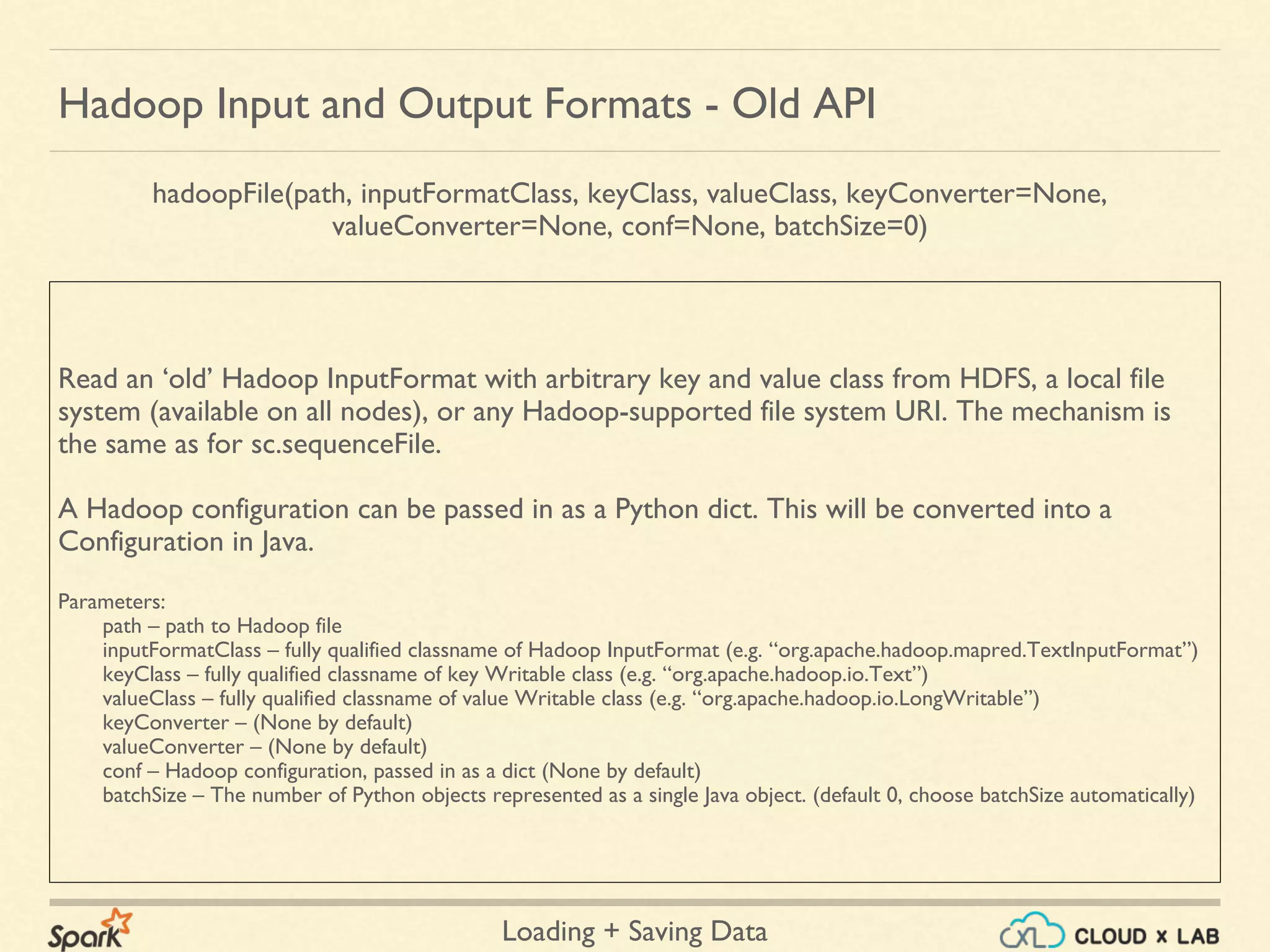
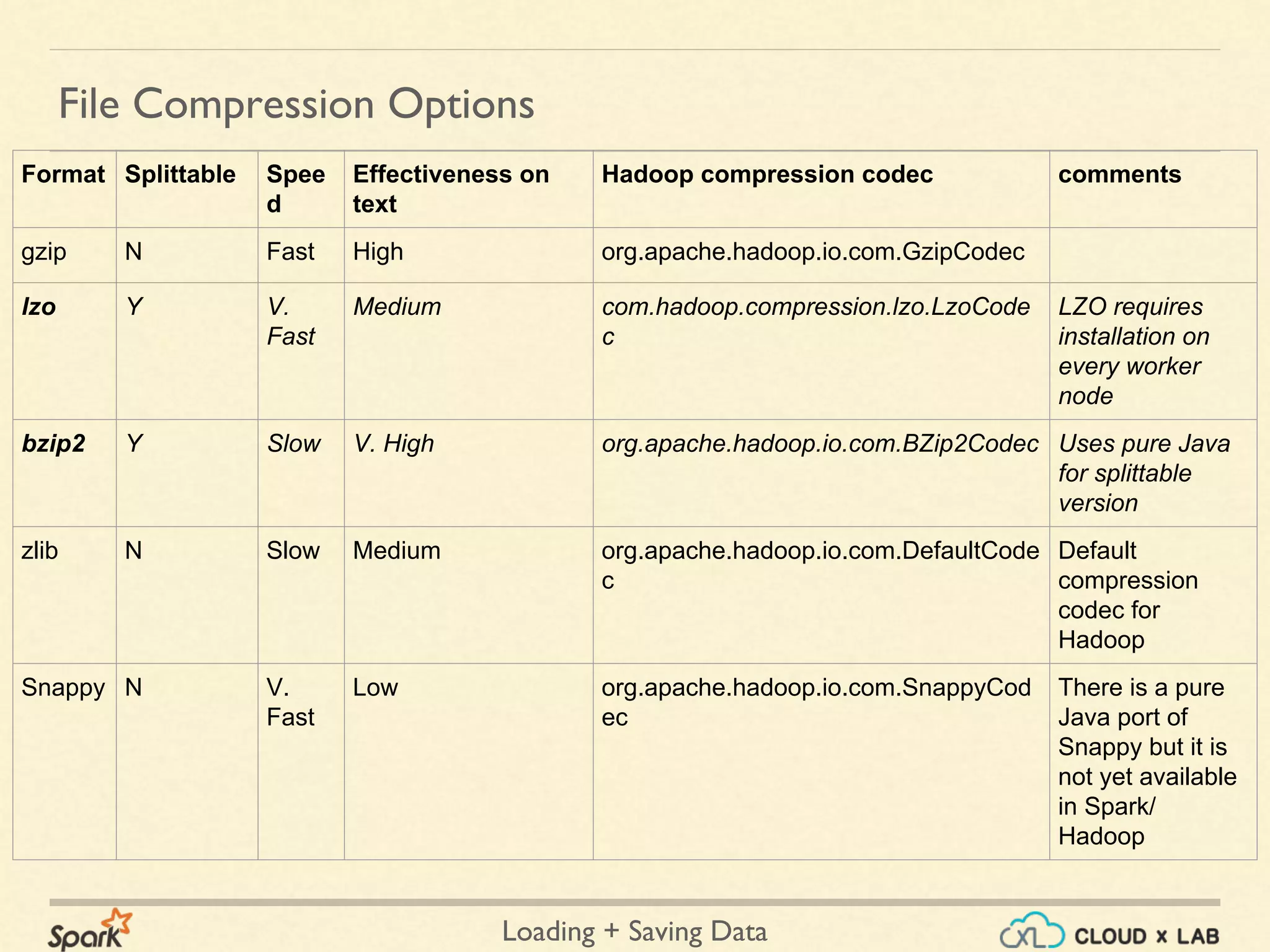
Common supported file formats
+ Javascript Object Notation
+ Common text-based format
+ Semistructured; most libraries require one record per line.
JSON files
{
"name" : "John",
"age" : 31,
"knows" : [“C”, “C++”]
}
Example:](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-10-2048.jpg)


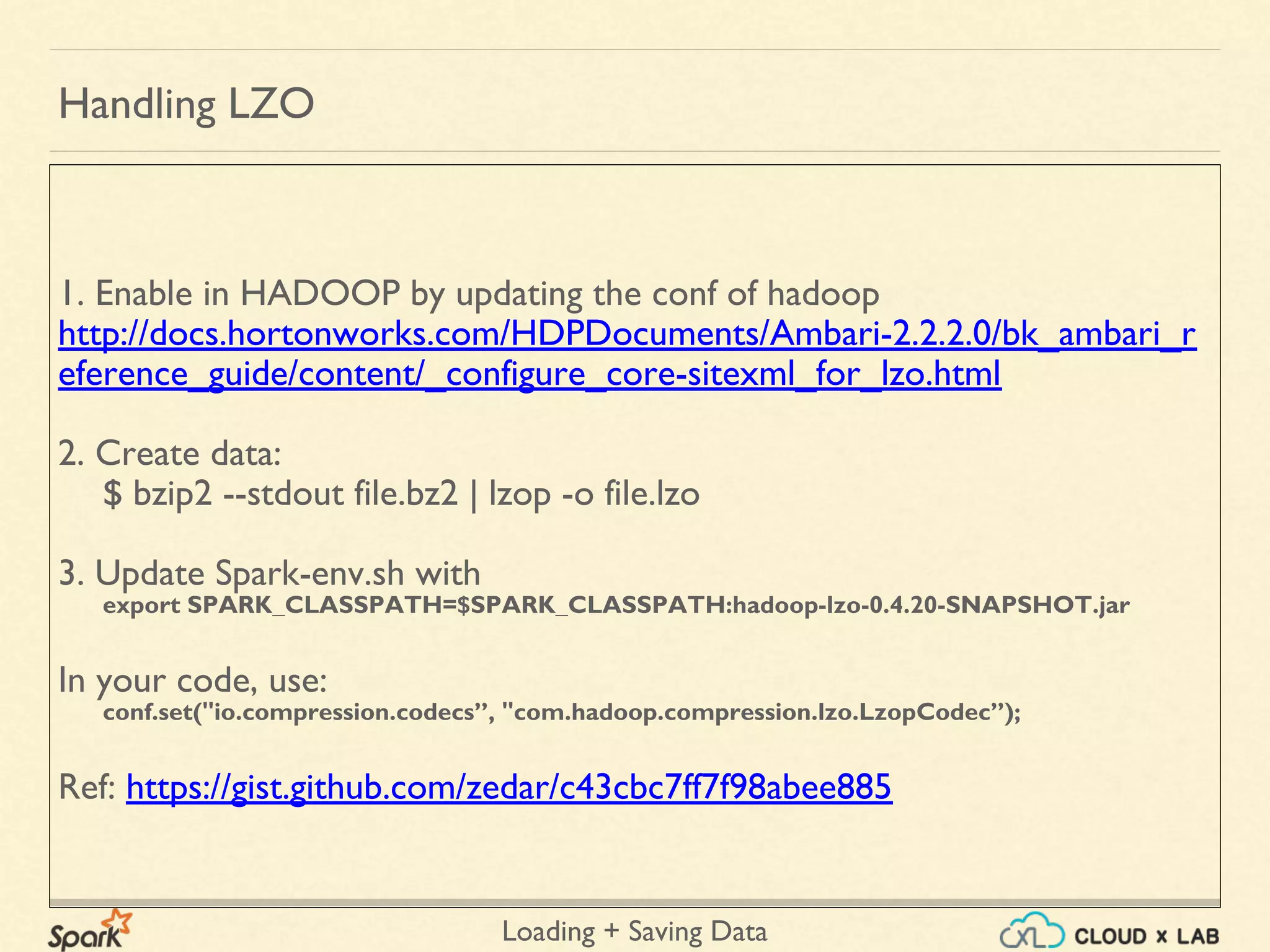
![Loading + Saving Data
Loading Files
var input = sc.textFile("/data/ml-100k/u1.test")
Loading Directories
var input = sc.wholeTextFiles("/data/ml-100k");
var lengths = input.mapValues(x => x.length);
lengths.collect();
[(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/mku.sh', 643),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.data', 1979173),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.genre', 202),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.info', 36) …]
Handling Text Files - scala](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-16-2048.jpg)
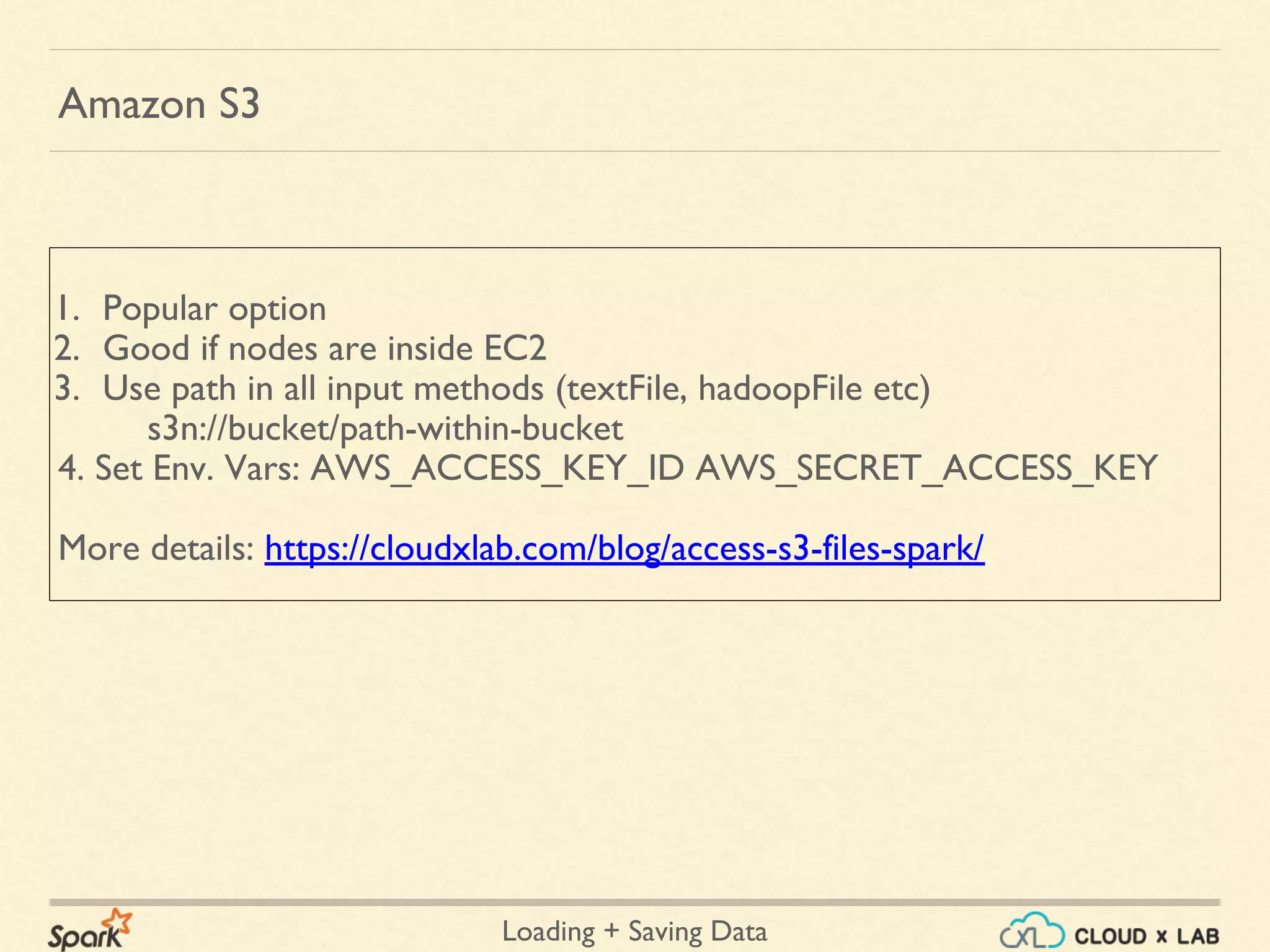
![Loading + Saving Data
Handling Text Files - scala
Loading Files
var input = sc.textFile("/data/ml-100k/u1.test")
Loading Directories
var input = sc.wholeTextFiles("/data/ml-100k");
var lengths = input.mapValues(x => x.length);
lengths.collect();
[(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/mku.sh', 643),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.data', 1979173),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.genre', 202),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.info', 36) …]
Saving Files
lengths.saveAsTextFile(outputDir)](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-17-2048.jpg)






![Loading + Saving Data
import au.com.bytecode.opencsv.CSVParser
var linesRdd = sc.textFile("/data/spark/temps.csv");
def parseCSV(itr:Iterator[String]):Iterator[Array[String]] = {
val parser = new CSVParser(',')
for(line <- itr)
yield parser.parseLine(line)
}
Loading CSV - Example Efficient
https://gist.github.com/girisandeep/fddf49ef97fde429a0d3256160b257c1](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-24-2048.jpg)
![Loading + Saving Data
import au.com.bytecode.opencsv.CSVParser
var linesRdd = sc.textFile("/data/spark/temps.csv");
def parseCSV(itr:Iterator[String]):Iterator[Array[String]] = {
val parser = new CSVParser(',')
for(line <- itr)
yield parser.parseLine(line)
}
//Check with simple example
val x = parseCSV(Array("1,2,3","a,b,c").iterator)
val result = linesRdd.mapPartitions(parseCSV)
Loading CSV - Example Efficient
https://gist.github.com/girisandeep/fddf49ef97fde429a0d3256160b257c1](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-25-2048.jpg)
![Loading + Saving Data
import au.com.bytecode.opencsv.CSVParser
var linesRdd = sc.textFile("/data/spark/temps.csv");
def parseCSV(itr:Iterator[String]):Iterator[Array[String]] = {
val parser = new CSVParser(',')
for(line <- itr)
yield parser.parseLine(line)
}
//Check with simple example
val x = parseCSV(Array("1,2,3","a,b,c").iterator)
val result = linesRdd.mapPartitions(parseCSV)
result.take(1)
//Array[Array[String]] = Array(Array(20, " NYC", " 2014-01-01"))
Loading CSV - Example Efficient
https://gist.github.com/girisandeep/fddf49ef97fde429a0d3256160b257c1](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-26-2048.jpg)





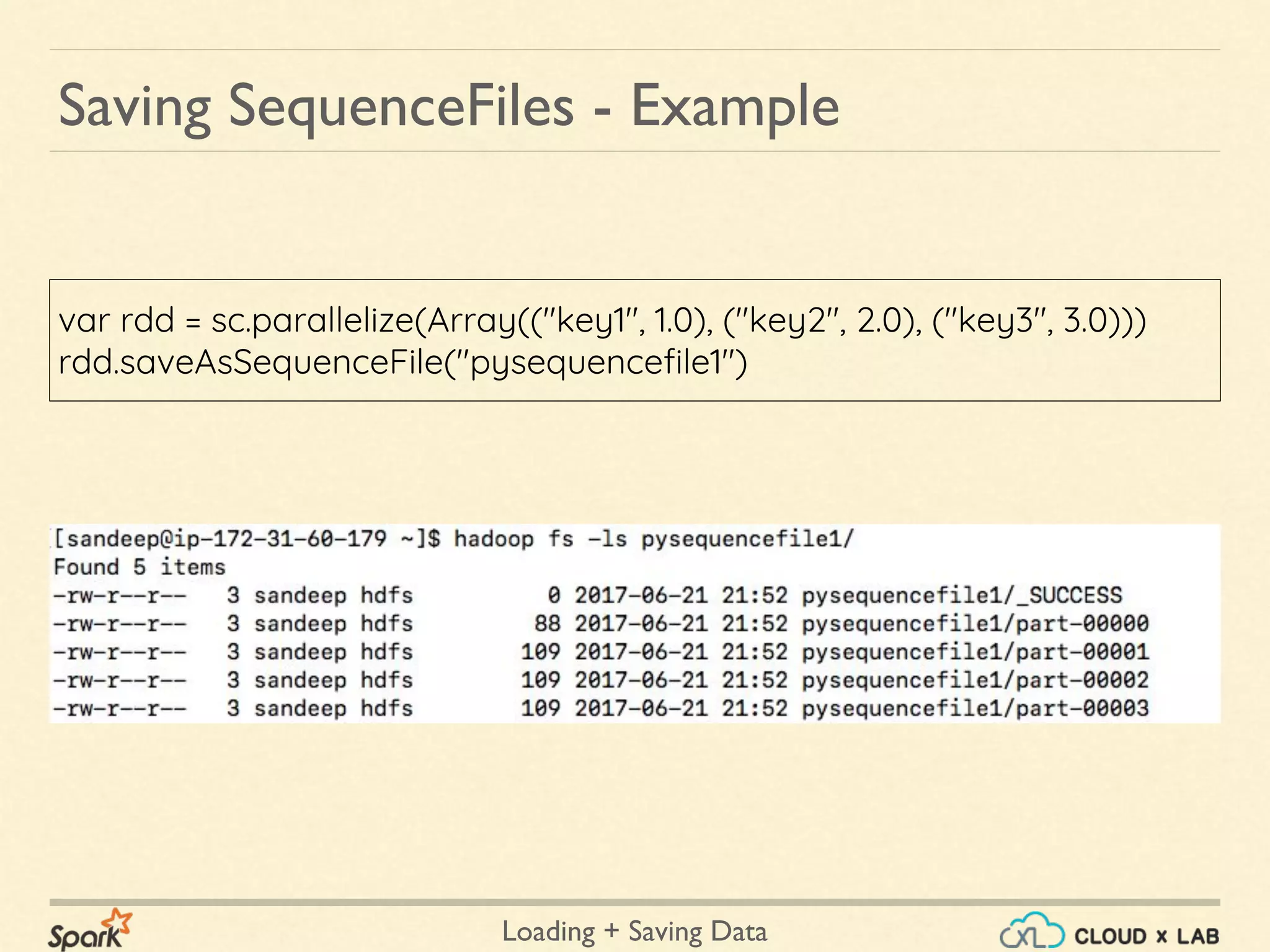

![Loading + Saving Data
import org.apache.hadoop.io.DoubleWritable
import org.apache.hadoop.io.Text
val myrdd = sc.sequenceFile(
"pysequencefile1",
classOf[Text], classOf[DoubleWritable])
Loading SequenceFiles - Example](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-34-2048.jpg)
![Loading + Saving Data
Loading SequenceFiles - Example
import org.apache.hadoop.io.DoubleWritable
import org.apache.hadoop.io.Text
val myrdd = sc.sequenceFile(
"pysequencefile1",
classOf[Text], classOf[DoubleWritable])
val result = myrdd.map{case (x, y) => (x.toString, y.get())}
result.collect()
//Array((key1,1.0), (key2,2.0), (key3,3.0))](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-35-2048.jpg)





![Loading + Saving Data
Protocol buffers - Example
package tutorial;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}](https://image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-44-2048.jpg)














![Loading + Saving Data
Common supported file formats
+ Javascript Object Notation
+ Common text-based format
+ Semistructured; most libraries require one record per line.
JSON files
{
"name" : "John",
"age" : 31,
"knows" : [“C”, “C++”]
}
Example:](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-10-2048.jpg)





![Loading + Saving Data
Loading Files
var input = sc.textFile("/data/ml-100k/u1.test")
Loading Directories
var input = sc.wholeTextFiles("/data/ml-100k");
var lengths = input.mapValues(x => x.length);
lengths.collect();
[(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/mku.sh', 643),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.data', 1979173),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.genre', 202),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.info', 36) …]
Handling Text Files - scala](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-16-2048.jpg)
![Loading + Saving Data
Handling Text Files - scala
Loading Files
var input = sc.textFile("/data/ml-100k/u1.test")
Loading Directories
var input = sc.wholeTextFiles("/data/ml-100k");
var lengths = input.mapValues(x => x.length);
lengths.collect();
[(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/mku.sh', 643),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.data', 1979173),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.genre', 202),
(u'hdfs://ip-172-31-53-48.ec2.internal:8020/data/ml-100k/u.info', 36) …]
Saving Files
lengths.saveAsTextFile(outputDir)](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-17-2048.jpg)






![Loading + Saving Data
import au.com.bytecode.opencsv.CSVParser
var linesRdd = sc.textFile("/data/spark/temps.csv");
def parseCSV(itr:Iterator[String]):Iterator[Array[String]] = {
val parser = new CSVParser(',')
for(line <- itr)
yield parser.parseLine(line)
}
Loading CSV - Example Efficient
https://gist.github.com/girisandeep/fddf49ef97fde429a0d3256160b257c1](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-24-2048.jpg)
![Loading + Saving Data
import au.com.bytecode.opencsv.CSVParser
var linesRdd = sc.textFile("/data/spark/temps.csv");
def parseCSV(itr:Iterator[String]):Iterator[Array[String]] = {
val parser = new CSVParser(',')
for(line <- itr)
yield parser.parseLine(line)
}
//Check with simple example
val x = parseCSV(Array("1,2,3","a,b,c").iterator)
val result = linesRdd.mapPartitions(parseCSV)
Loading CSV - Example Efficient
https://gist.github.com/girisandeep/fddf49ef97fde429a0d3256160b257c1](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-25-2048.jpg)
![Loading + Saving Data
import au.com.bytecode.opencsv.CSVParser
var linesRdd = sc.textFile("/data/spark/temps.csv");
def parseCSV(itr:Iterator[String]):Iterator[Array[String]] = {
val parser = new CSVParser(',')
for(line <- itr)
yield parser.parseLine(line)
}
//Check with simple example
val x = parseCSV(Array("1,2,3","a,b,c").iterator)
val result = linesRdd.mapPartitions(parseCSV)
result.take(1)
//Array[Array[String]] = Array(Array(20, " NYC", " 2014-01-01"))
Loading CSV - Example Efficient
https://gist.github.com/girisandeep/fddf49ef97fde429a0d3256160b257c1](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-26-2048.jpg)







![Loading + Saving Data
import org.apache.hadoop.io.DoubleWritable
import org.apache.hadoop.io.Text
val myrdd = sc.sequenceFile(
"pysequencefile1",
classOf[Text], classOf[DoubleWritable])
Loading SequenceFiles - Example](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-34-2048.jpg)
![Loading + Saving Data
Loading SequenceFiles - Example
import org.apache.hadoop.io.DoubleWritable
import org.apache.hadoop.io.Text
val myrdd = sc.sequenceFile(
"pysequencefile1",
classOf[Text], classOf[DoubleWritable])
val result = myrdd.map{case (x, y) => (x.toString, y.get())}
result.collect()
//Array((key1,1.0), (key2,2.0), (key3,3.0))](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-35-2048.jpg)








![Loading + Saving Data
Protocol buffers - Example
package tutorial;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}](https://crownmelresort.com/image.slidesharecdn.com/spark-loadingsavingdata-180514105500/75/Apache-Spark-Loading-Saving-data-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-44-2048.jpg)











The document discusses loading and saving data in Spark, detailing various supported file formats, storage systems, and methods for handling structured and unstructured data. It covers formats such as CSV, JSON, sequence files, and protocol buffers, explaining how to read and write these formats using Spark APIs. Additionally, it addresses data source configurations and the use of Hadoop input formats for reading from and writing to different storage systems.



















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


