Download as PDF, PPTX



![SQL in Apex
SQL support is part of Malhar
(malhar-sql) [1]
Disclaimer: Not everything I
describe today is in Apex
Operators: Scan, Filter, Project
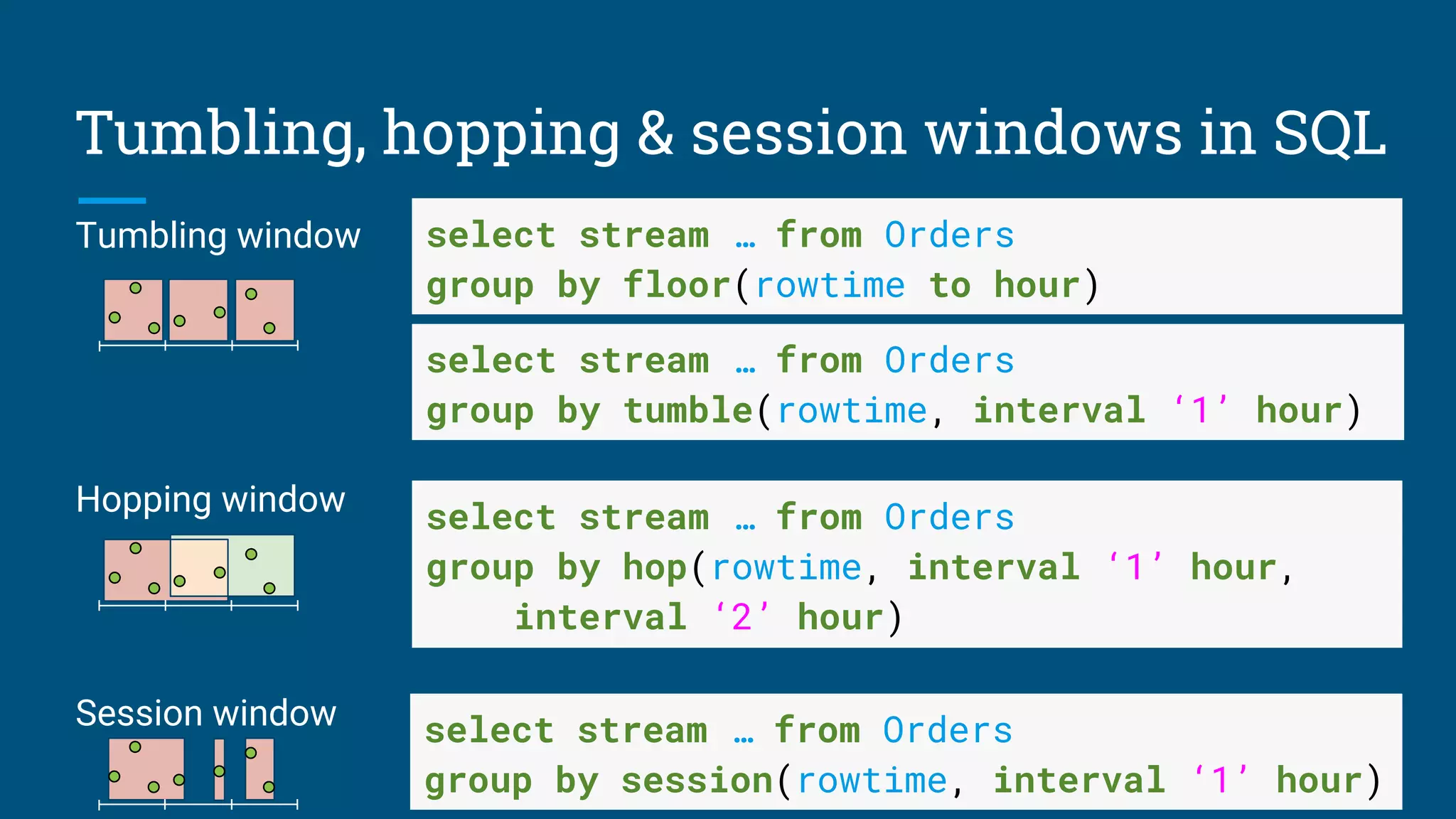
Coming soon: Window operators
[1] https://www.datatorrent.com/blog/sql-apache-apex/](https://image.slidesharecdn.com/calcite-streaming-sql-apex-2017-170404191828/75/Streaming-SQL-5-2048.jpg)













![Thank you!
@julianhyde
@ApacheCalcite
http://calcite.apache.org
http://calcite.apache.org/docs/stream.html
References
● Hyde, Julian. "Data in flight." Communications of the ACM 53.1
(2010): 48-52. [pdf]
● Akidau, Tyler, et al. "The dataflow model: a practical approach to
balancing correctness, latency, and cost in massive-scale,
unbounded, out-of-order data processing." Proceedings of the
VLDB Endowment 8.12 (2015): 1792-1803. [pdf]
● Arasu, Arvind, Shivnath Babu, and Jennifer Widom. "The CQL
continuous query language: semantic foundations and query
execution." The VLDB Journal—The International Journal on Very
Large Data Bases 15.2 (2006): 121-142. [pdf]](https://image.slidesharecdn.com/calcite-streaming-sql-apex-2017-170404191828/75/Streaming-SQL-21-2048.jpg)












![SQL in Apex
SQL support is part of Malhar
(malhar-sql) [1]
Disclaimer: Not everything I
describe today is in Apex
Operators: Scan, Filter, Project
Coming soon: Window operators
[1] https://www.datatorrent.com/blog/sql-apache-apex/](https://crownmelresort.com/image.slidesharecdn.com/calcite-streaming-sql-apex-2017-170404191828/75/Streaming-SQL-5-2048.jpg)















![Thank you!
@julianhyde
@ApacheCalcite
http://calcite.apache.org
http://calcite.apache.org/docs/stream.html
References
● Hyde, Julian. "Data in flight." Communications of the ACM 53.1
(2010): 48-52. [pdf]
● Akidau, Tyler, et al. "The dataflow model: a practical approach to
balancing correctness, latency, and cost in massive-scale,
unbounded, out-of-order data processing." Proceedings of the
VLDB Endowment 8.12 (2015): 1792-1803. [pdf]
● Arasu, Arvind, Shivnath Babu, and Jennifer Widom. "The CQL
continuous query language: semantic foundations and query
execution." The VLDB Journal—The International Journal on Very
Large Data Bases 15.2 (2006): 121-142. [pdf]](https://crownmelresort.com/image.slidesharecdn.com/calcite-streaming-sql-apex-2017-170404191828/75/Streaming-SQL-21-2048.jpg)










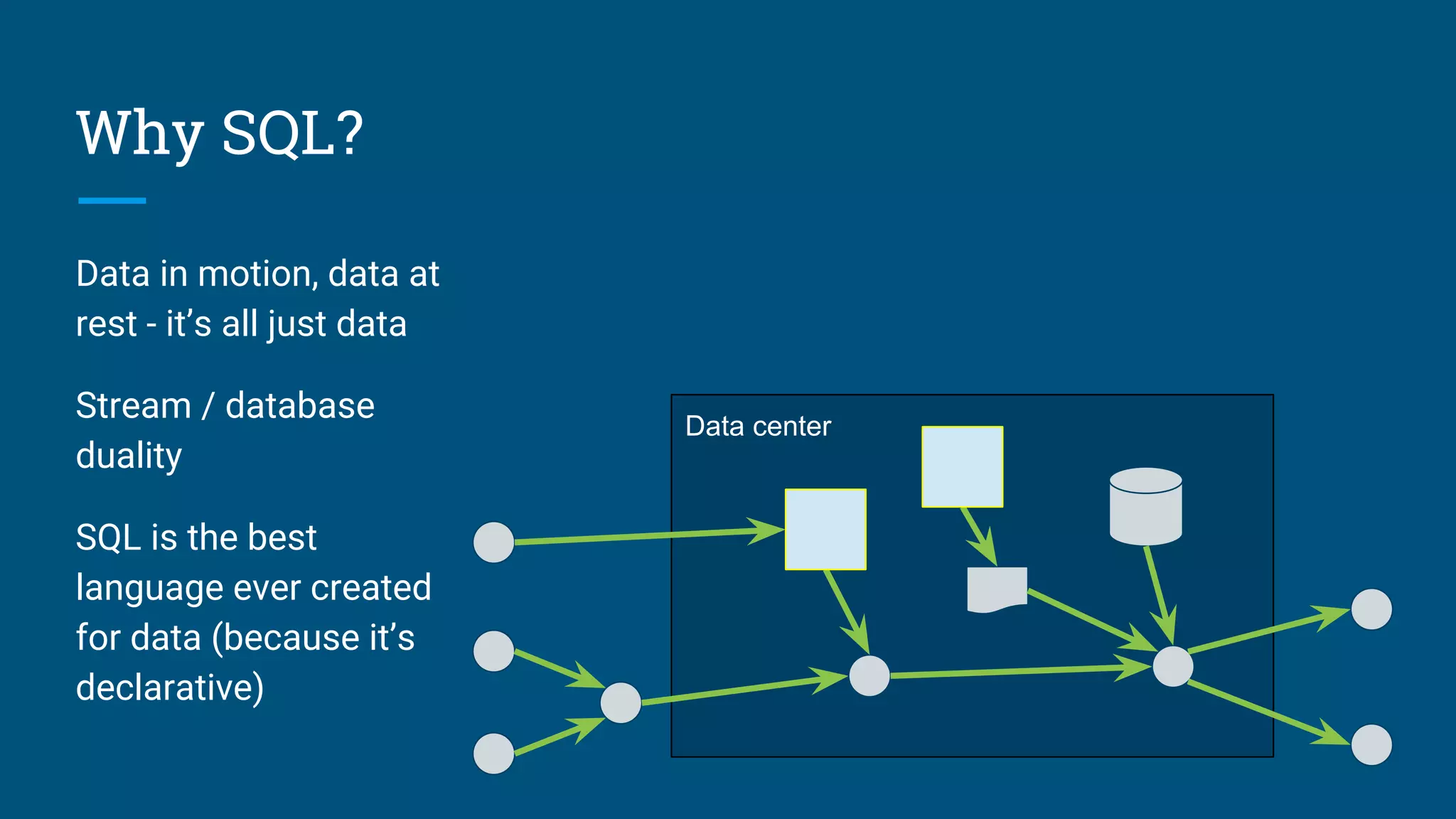
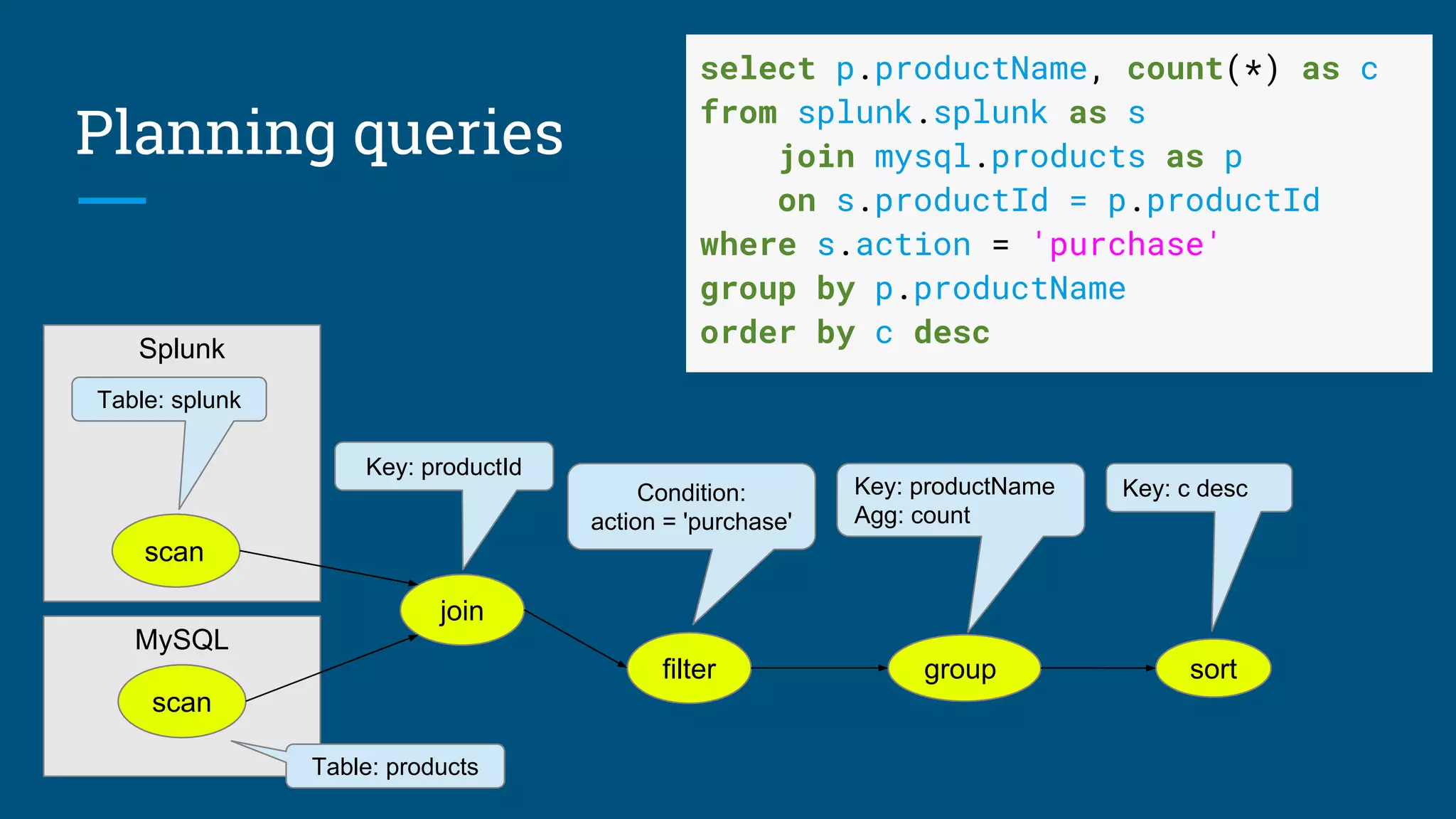
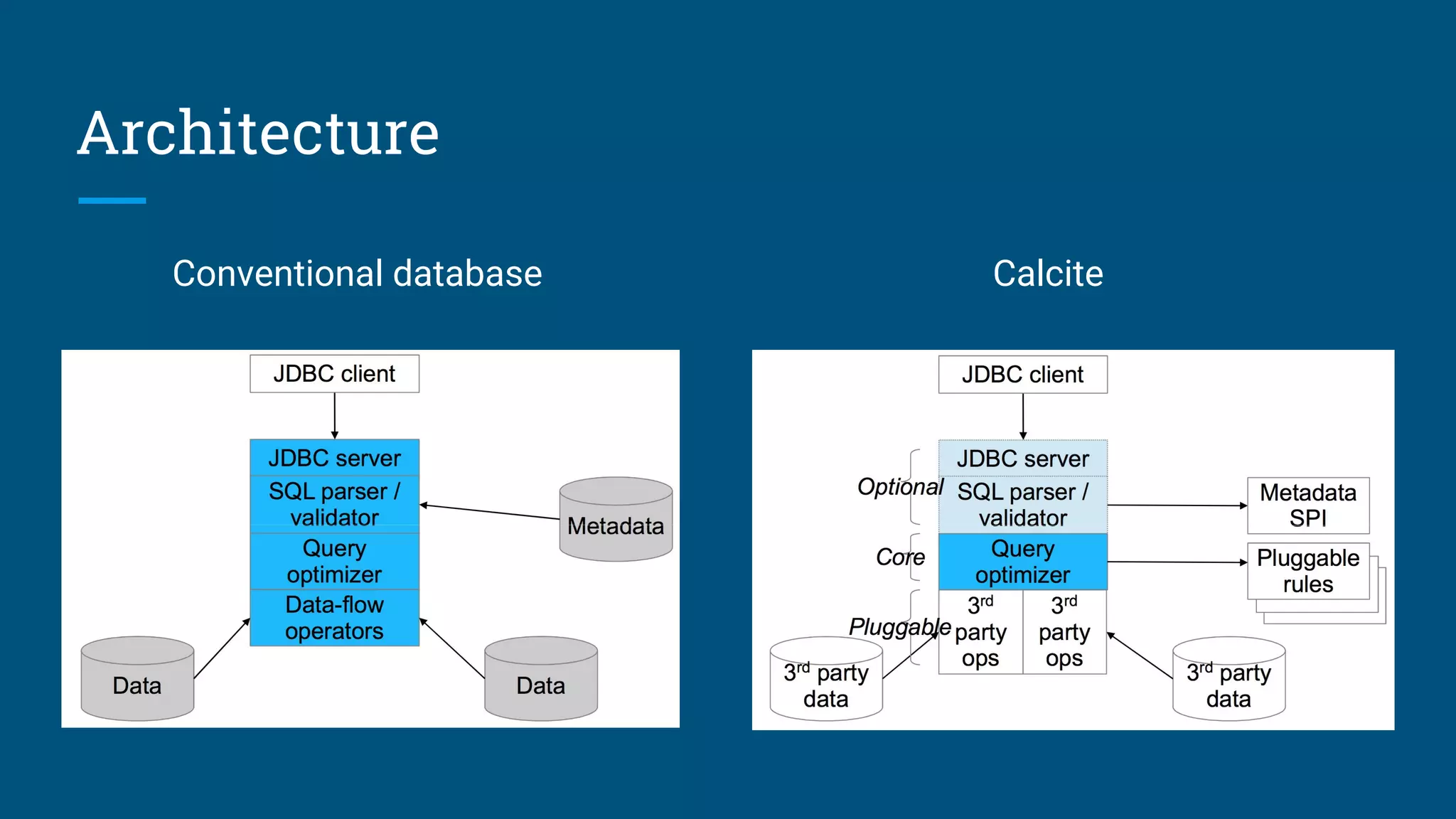
The document discusses the development of a streaming SQL standard, emphasizing the importance of SQL as a declarative language for managing both streaming and relational data. It highlights key features such as query planning, window functions, and various streaming operations supported by projects like Apache Calcite and Apex. The document advocates for a unified approach to streaming SQL without the need for 'SQL-like' languages, while also inviting community involvement in the ongoing development of this framework.










































![[WSO2Con EU 2018] Streaming SQL in the Real World](https://cdn.slidesharecdn.com/ss_thumbnails/wso2coneu2018streamingsqlintherealworld-181113090808-thumbnail.jpg?width=640&height=640&fit=bounds)







































