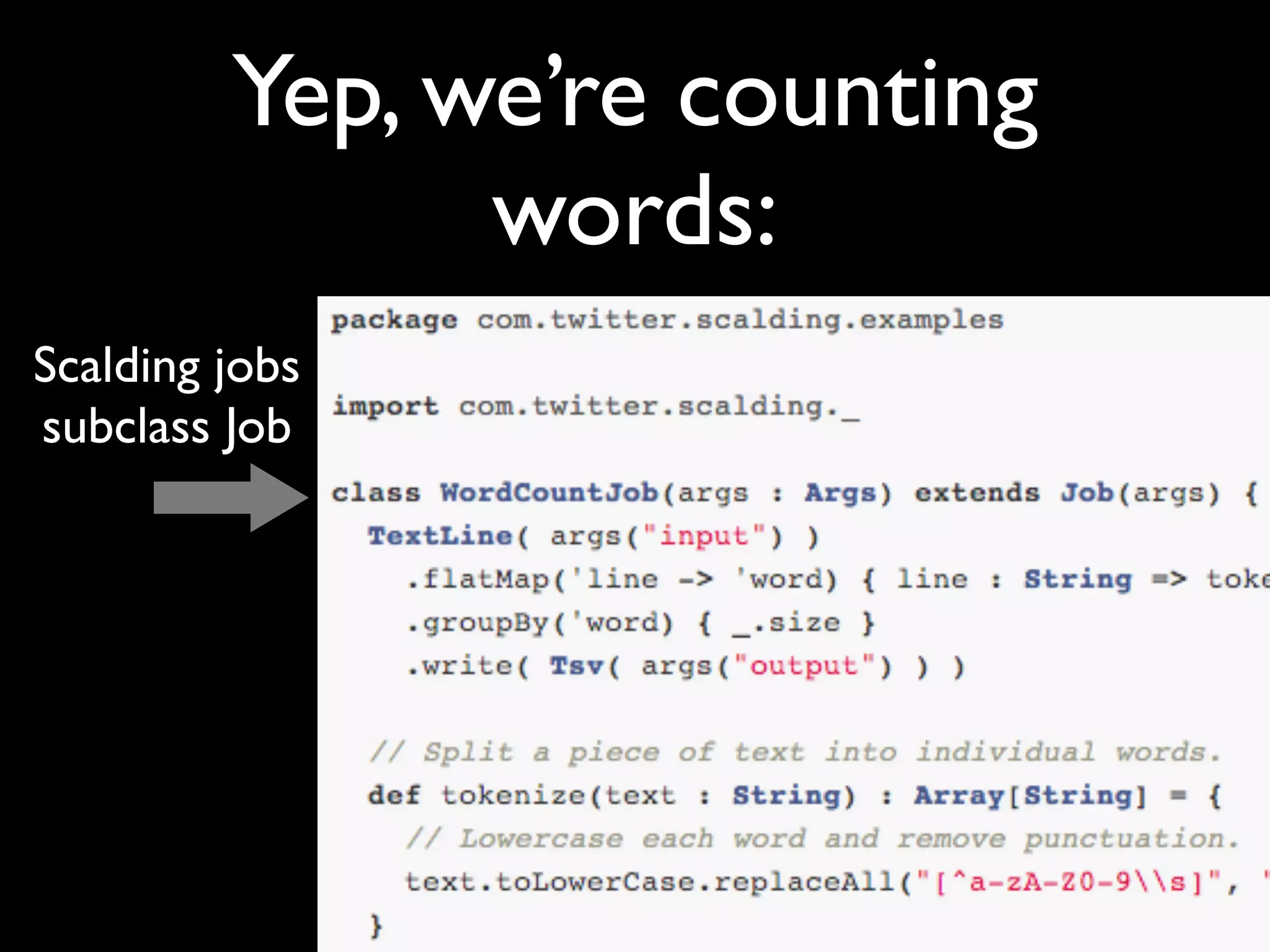
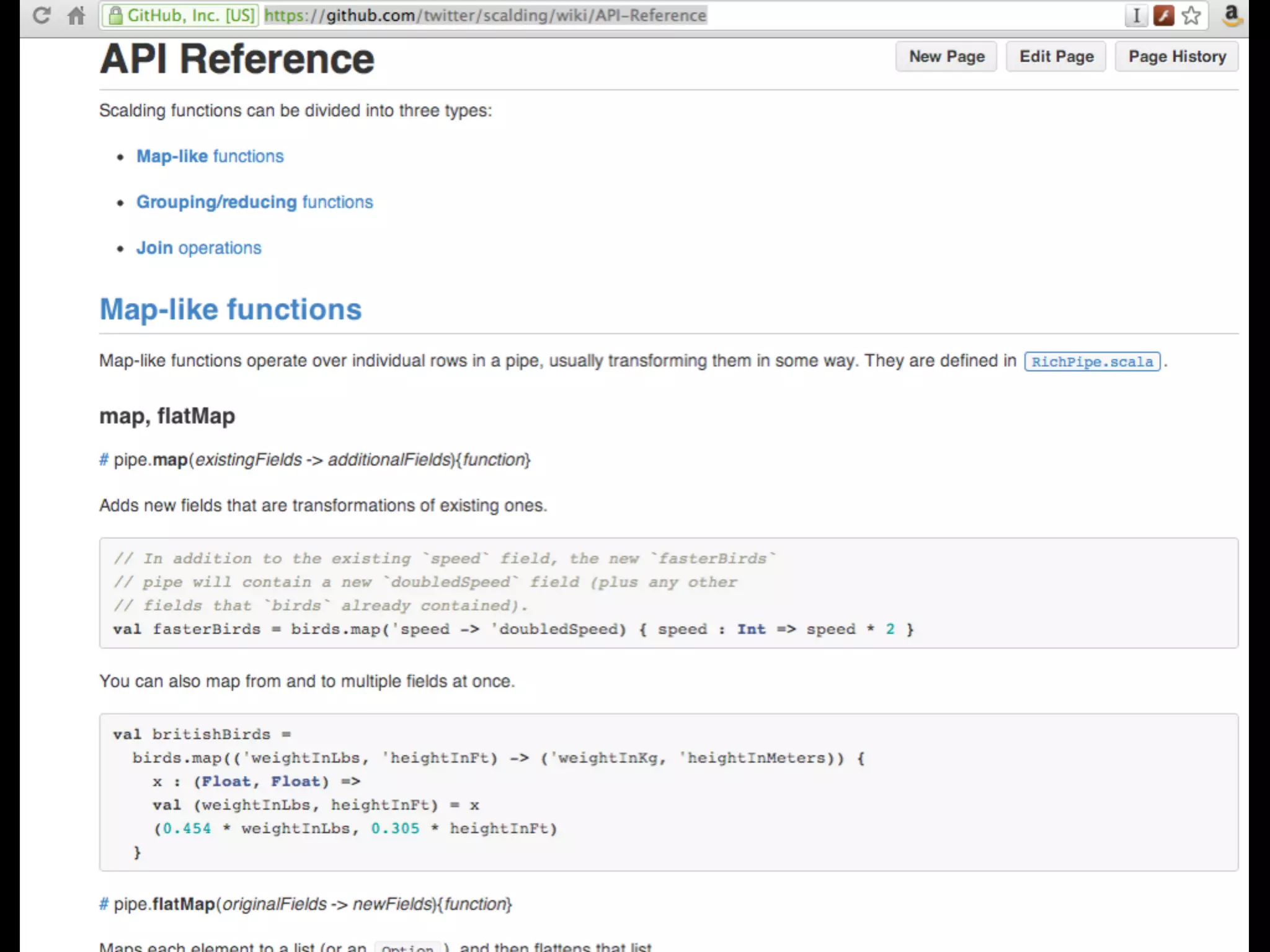
The document outlines the features and functionalities of Scalding, a Scala-based library used for map/reduce tasks at Twitter, highlighting its data flow modeling and integration with various data sources. It emphasizes the advantages of Scala for implementing domain-specific languages and the library's capabilities for complex data processing, such as parallel reductions and optimized joins. Additionally, upcoming improvements and the widespread use of Scalding within Twitter's revenue quality team are mentioned.











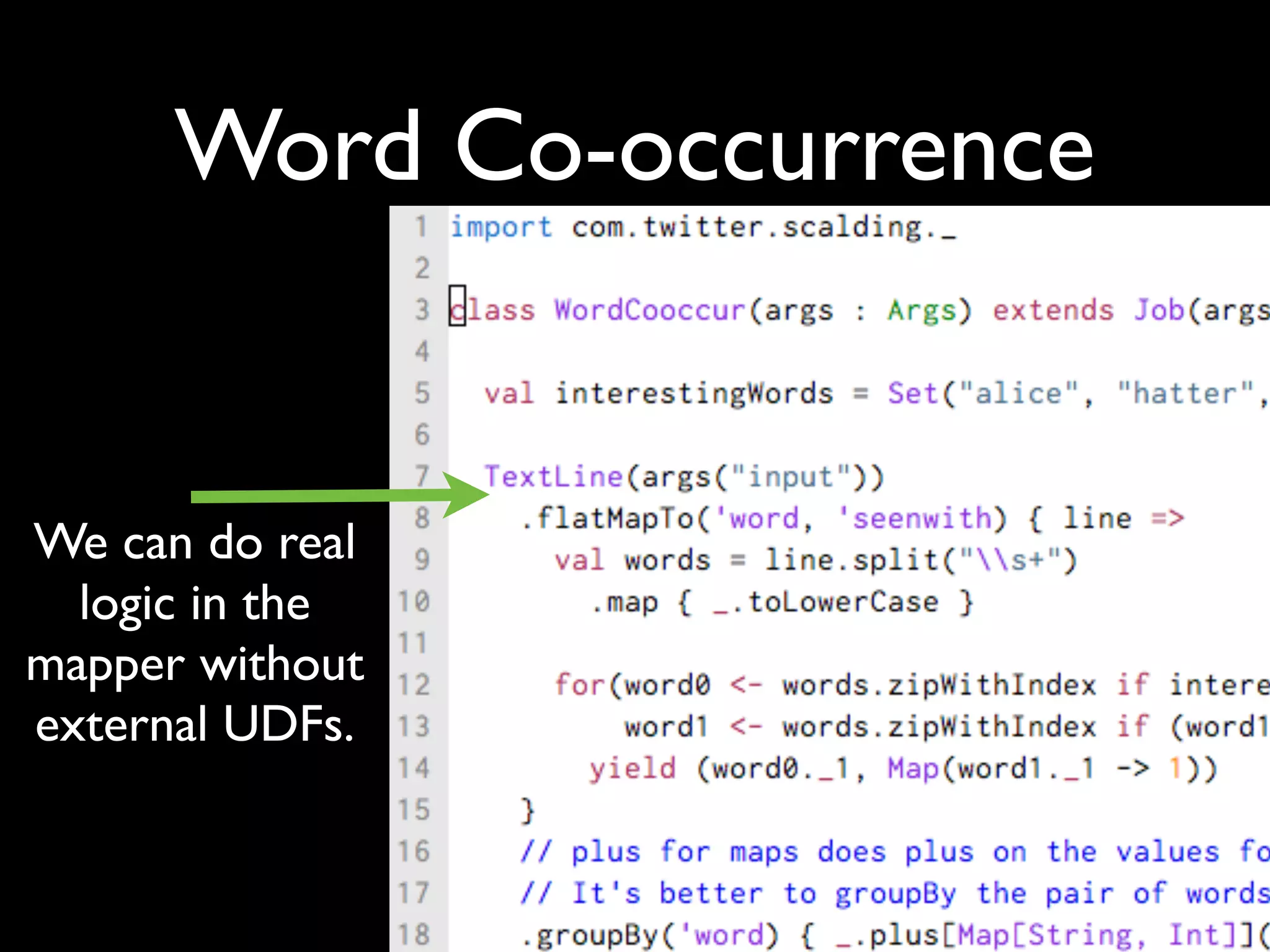
![Word Co-occurrence
Generalized
“plus” handles
lists/sets/maps
and can be
customized
(implement
Monoid[T])](https://image.slidesharecdn.com/hadoopsummittalknew-120626131633-phpapp02/75/Scalding-Twitter-s-Scala-DSL-for-Hadoop-Cascading-14-2048.jpg)






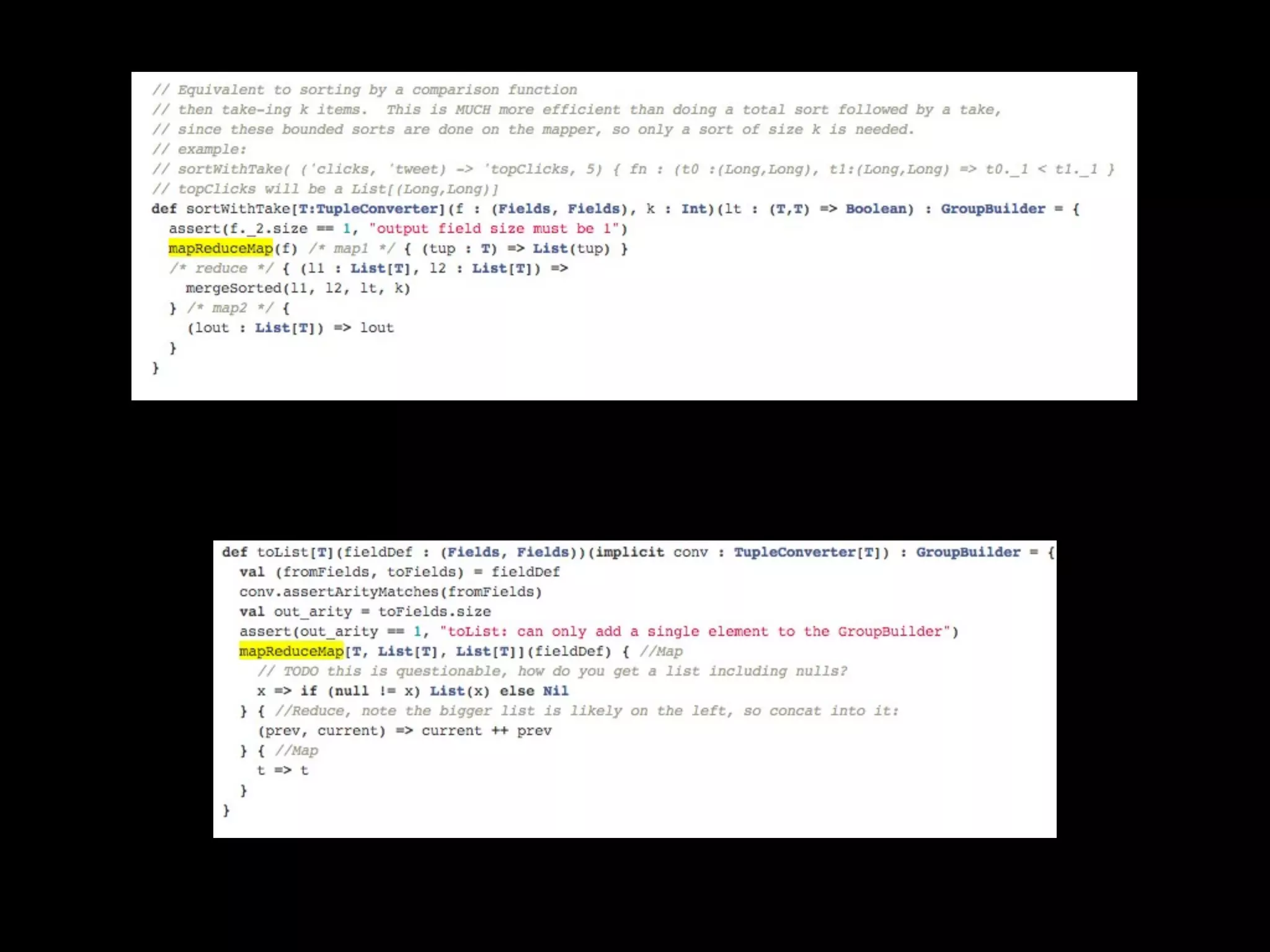





![Cosine Similarity
Value
(Double) can
be anything
with a Ring[T]
(plus/times)](https://image.slidesharecdn.com/hadoopsummittalknew-120626131633-phpapp02/75/Scalding-Twitter-s-Scala-DSL-for-Hadoop-Cascading-28-2048.jpg)



















![Word Co-occurrence
Generalized
“plus” handles
lists/sets/maps
and can be
customized
(implement
Monoid[T])](https://crownmelresort.com/image.slidesharecdn.com/hadoopsummittalknew-120626131633-phpapp02/75/Scalding-Twitter-s-Scala-DSL-for-Hadoop-Cascading-14-2048.jpg)













![Cosine Similarity
Value
(Double) can
be anything
with a Ring[T]
(plus/times)](https://crownmelresort.com/image.slidesharecdn.com/hadoopsummittalknew-120626131633-phpapp02/75/Scalding-Twitter-s-Scala-DSL-for-Hadoop-Cascading-28-2048.jpg)




























































































