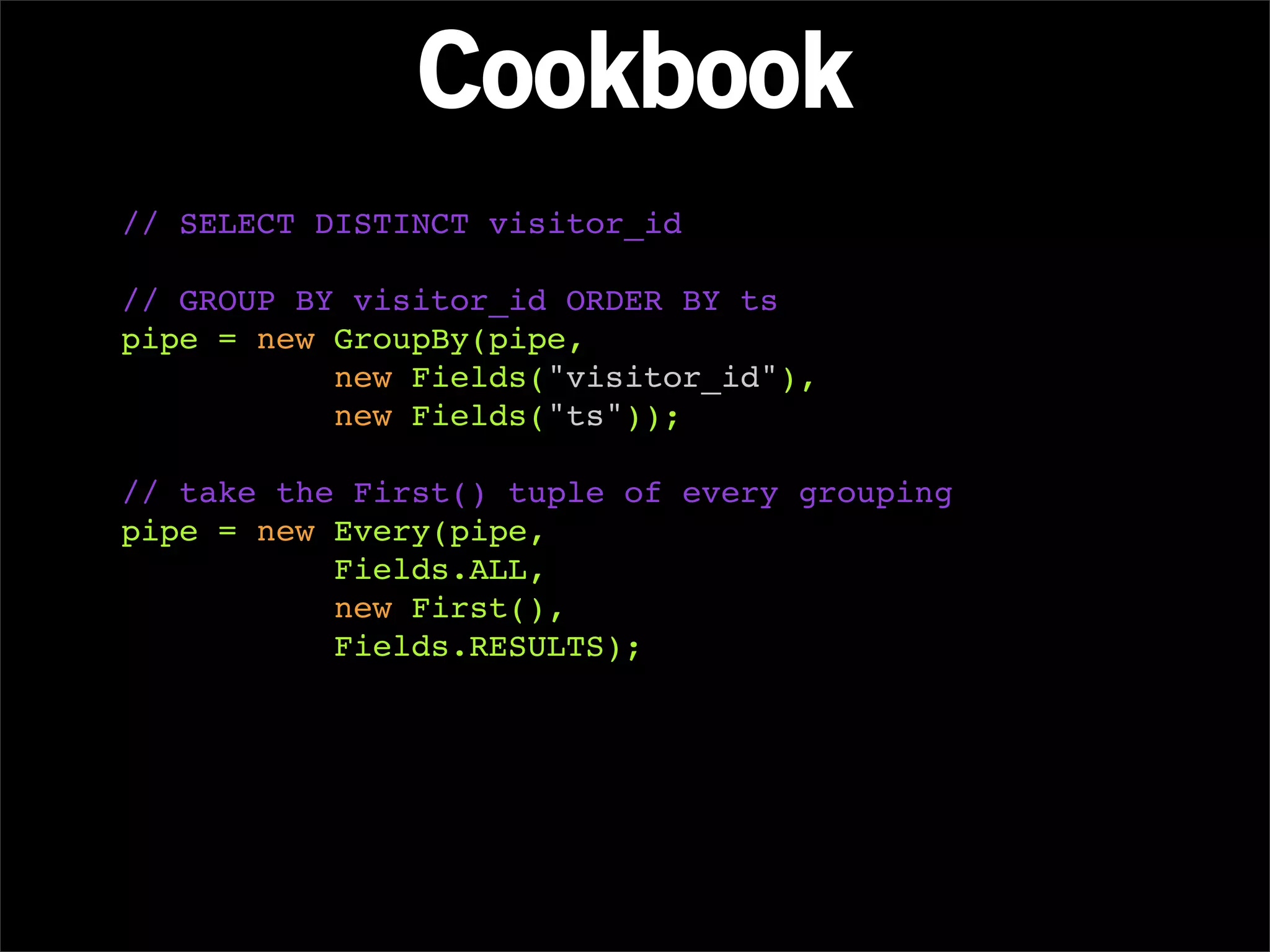
Downloaded 712 times














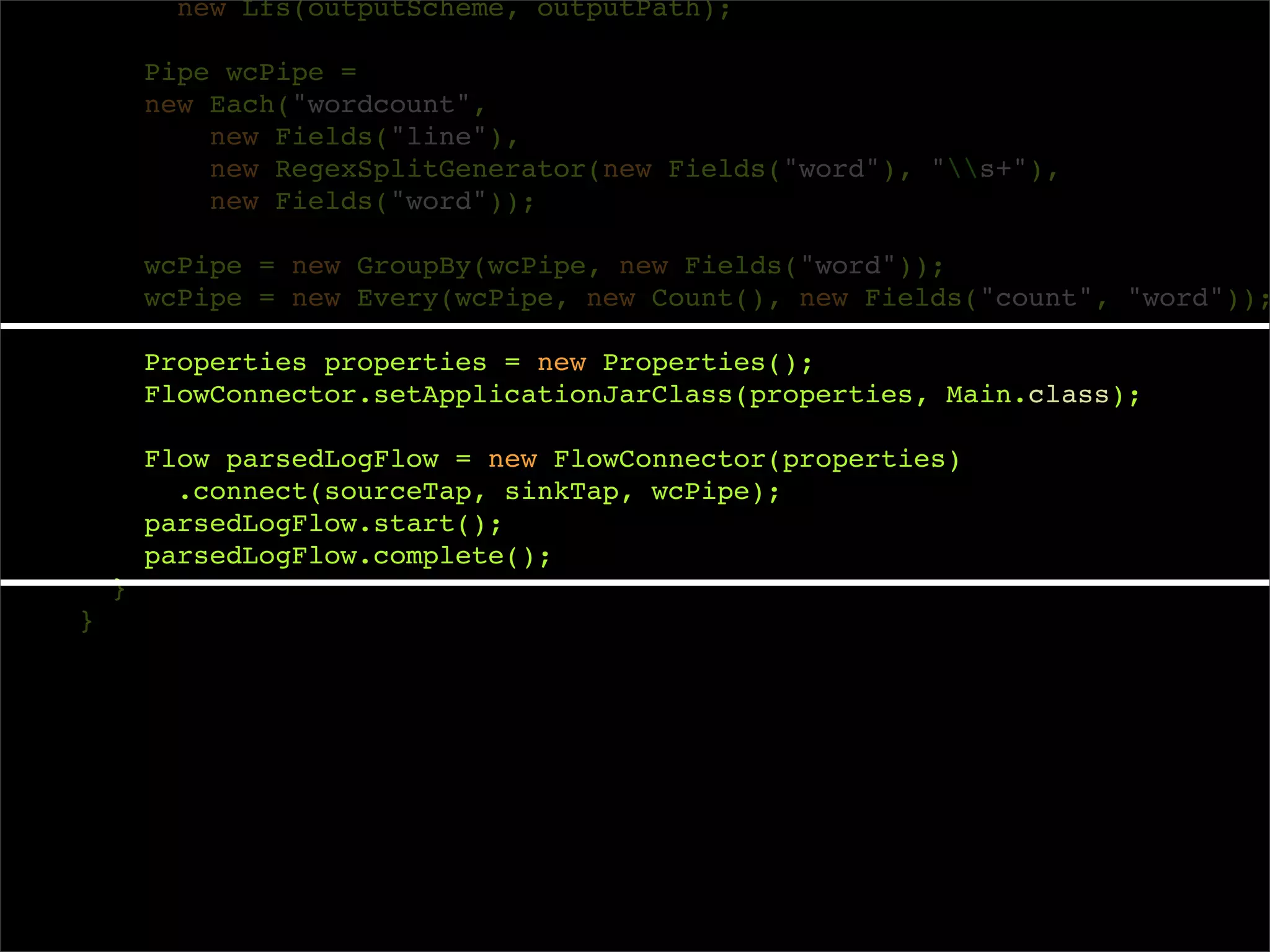
![package cascadingtutorial.wordcount;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
String inputPath = args[0];
String outputPath = args[1];
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
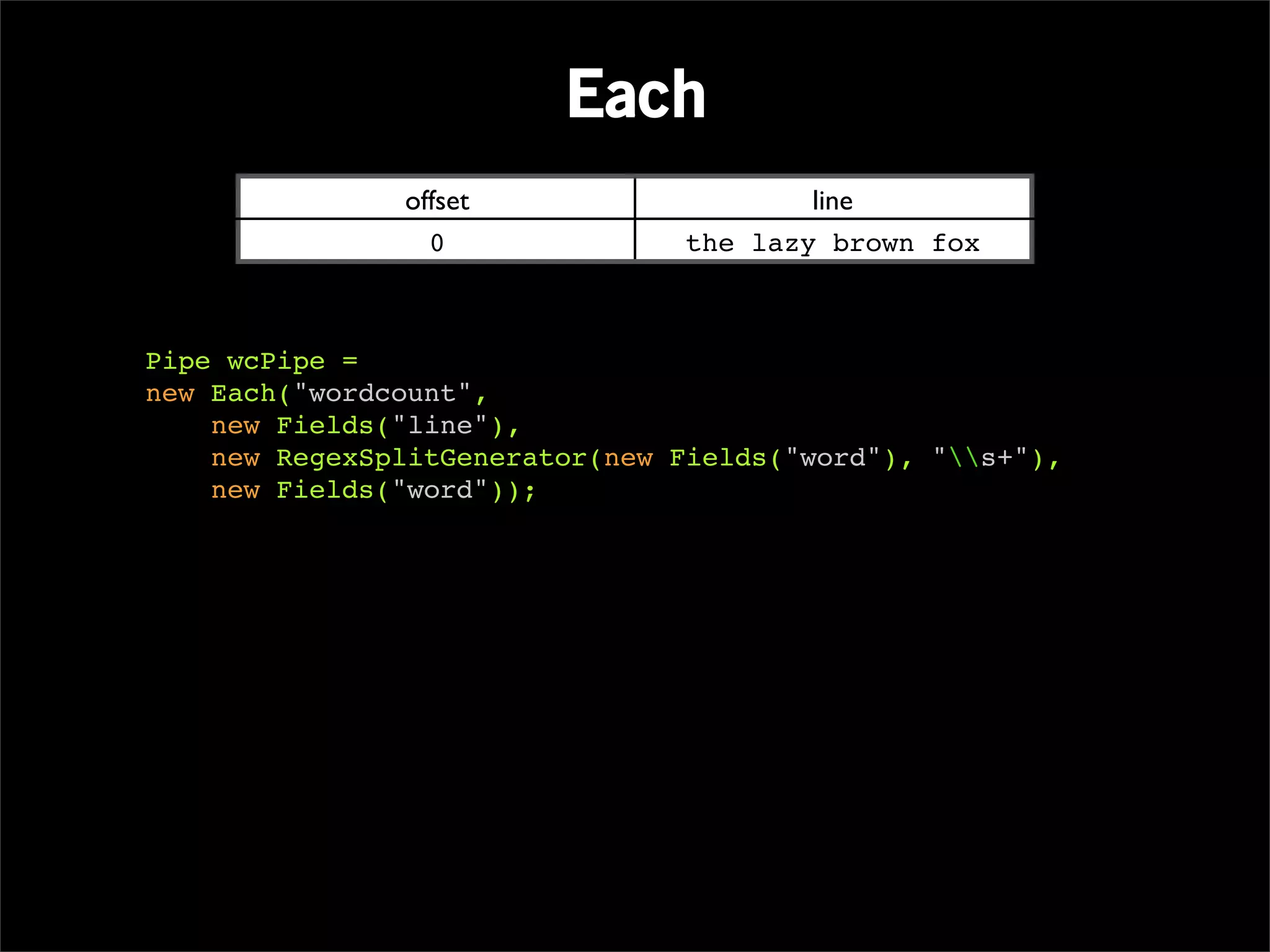
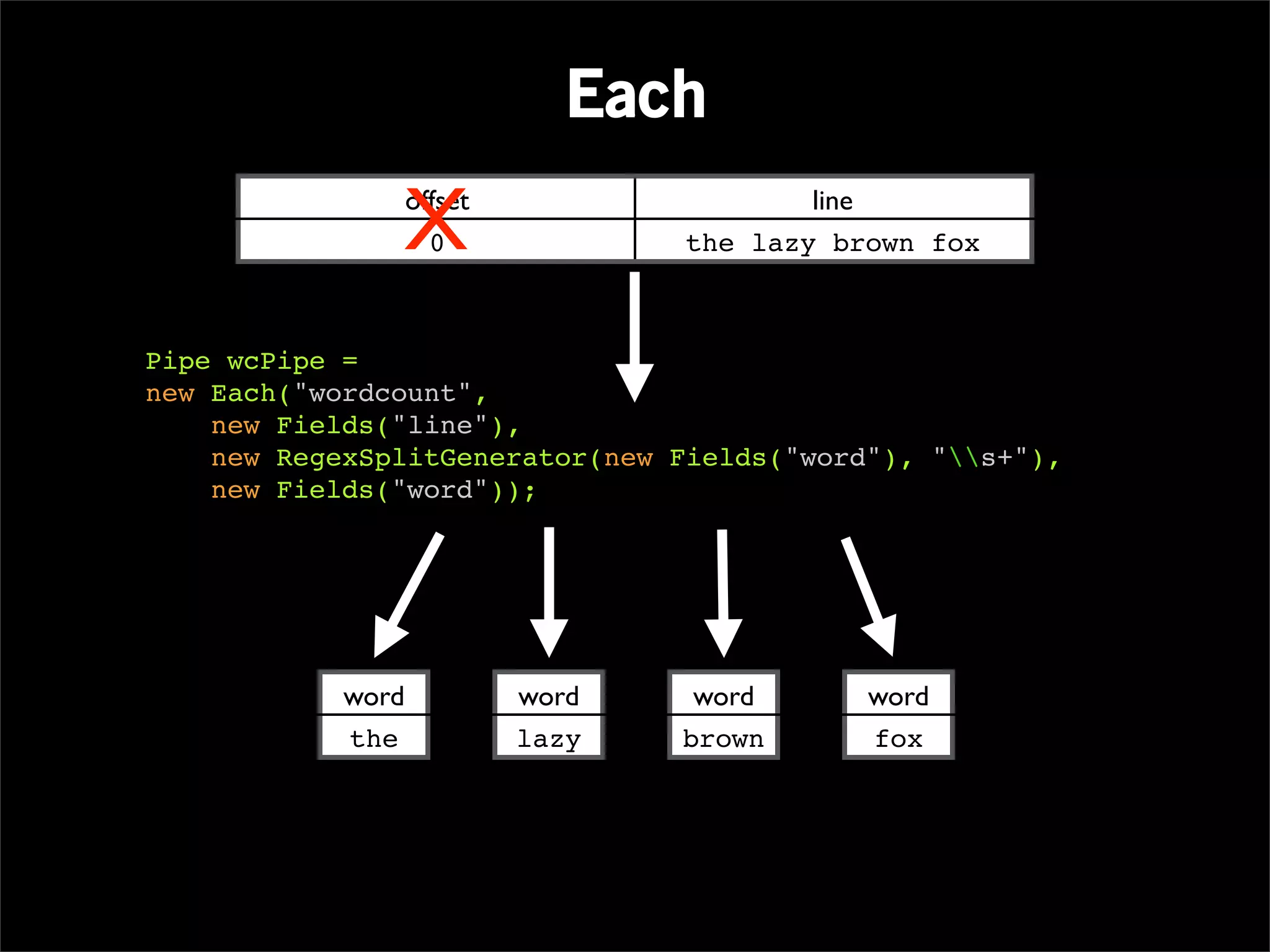
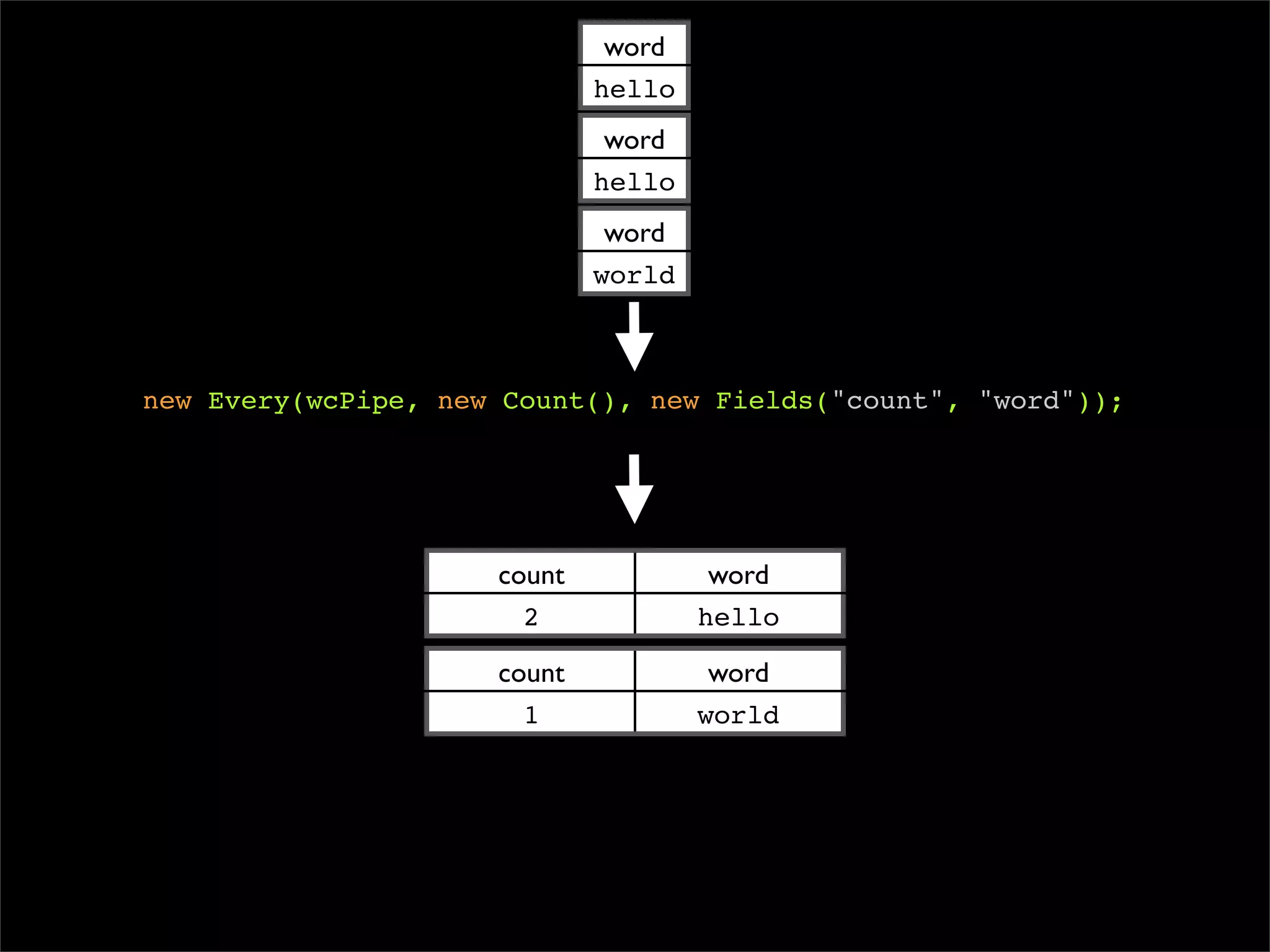
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
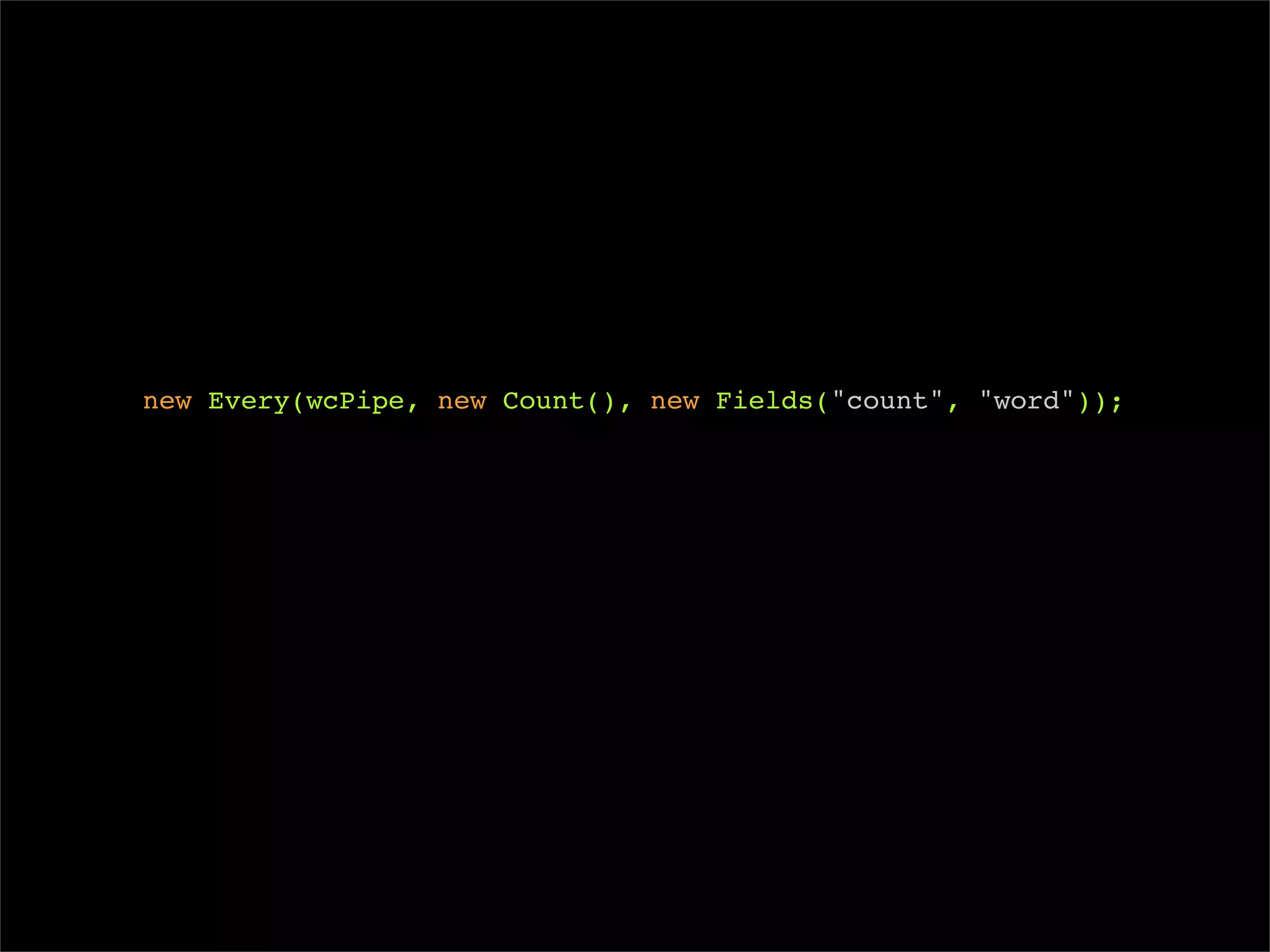
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
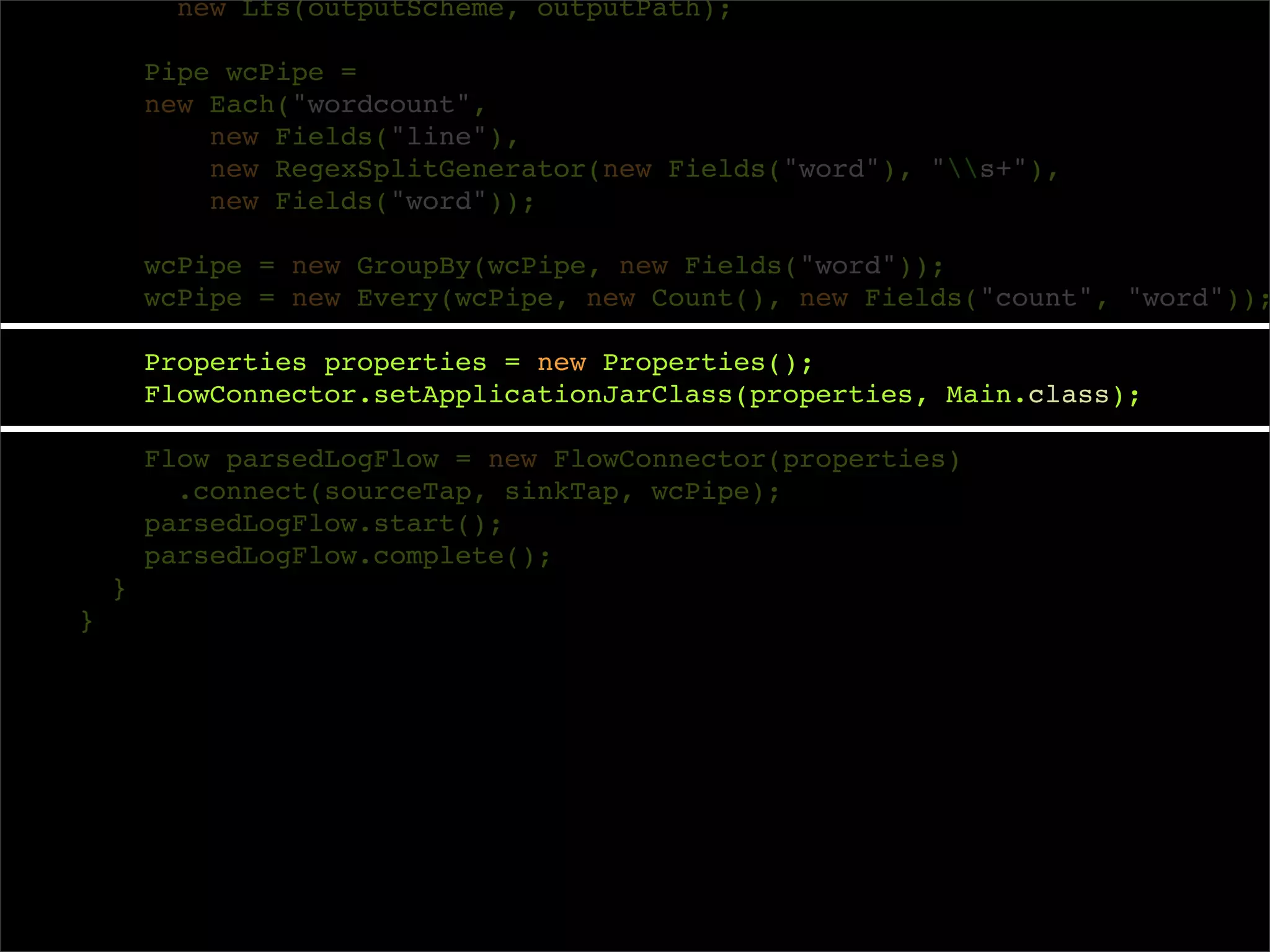
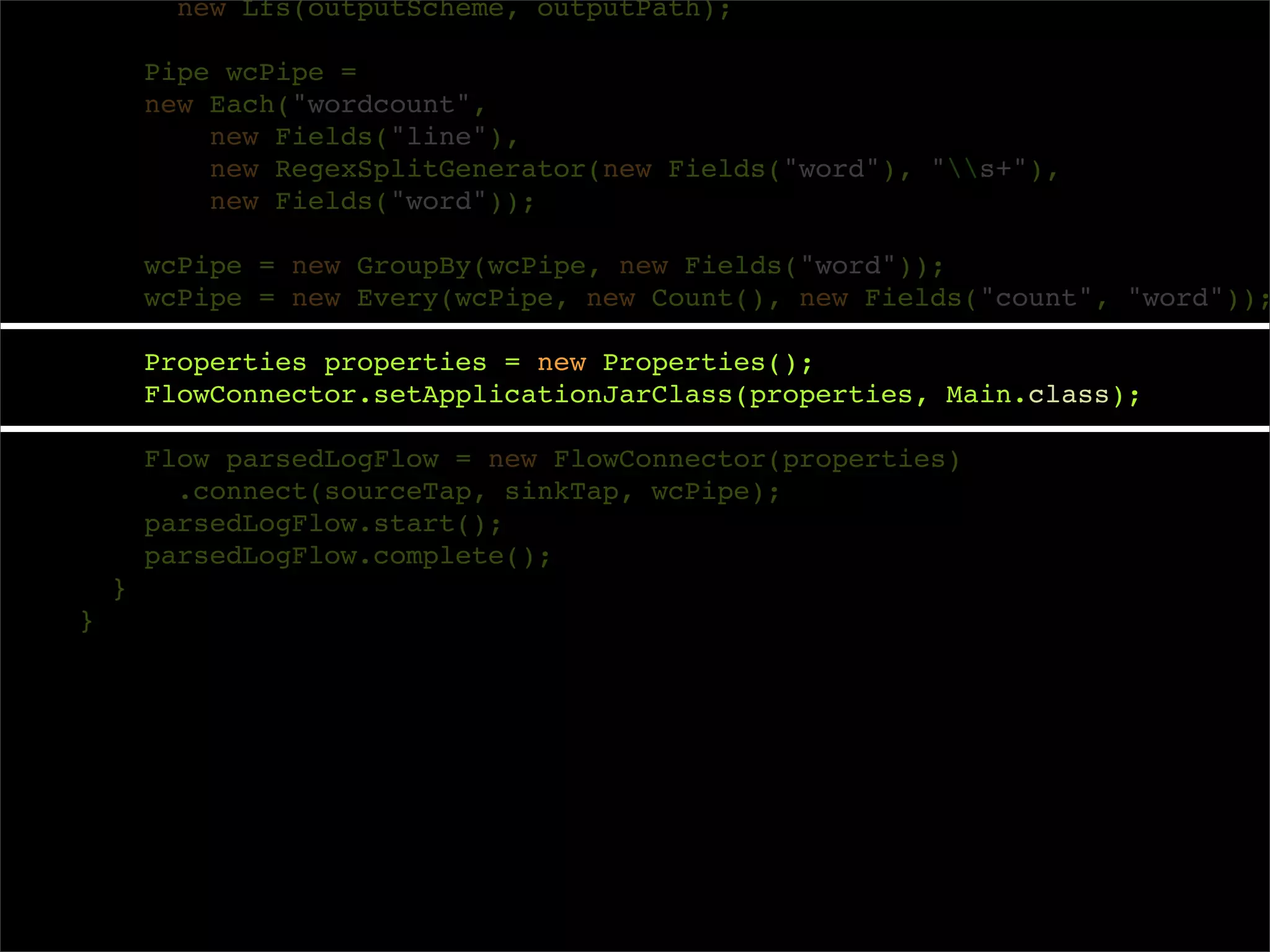
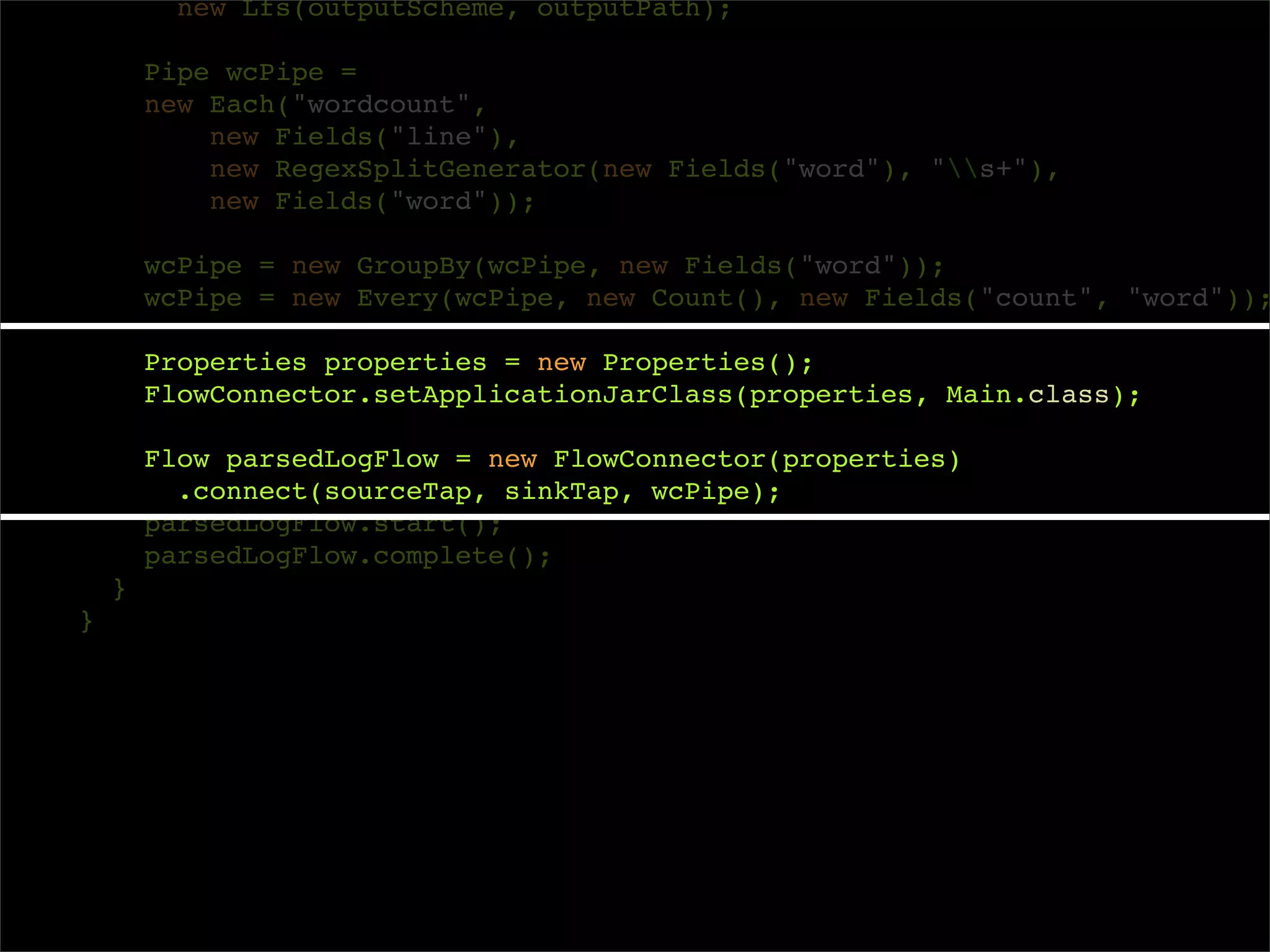
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-15-2048.jpg)





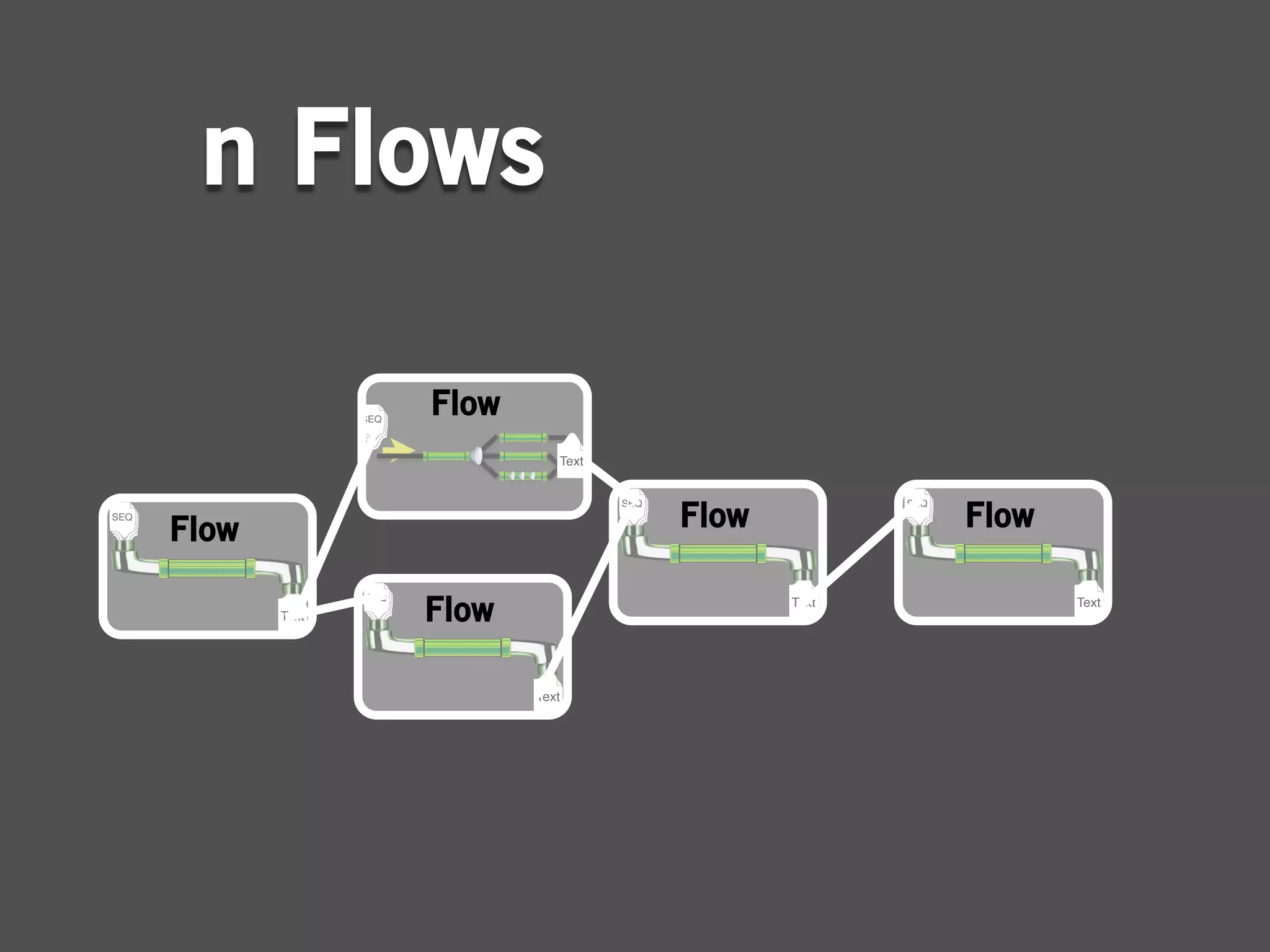
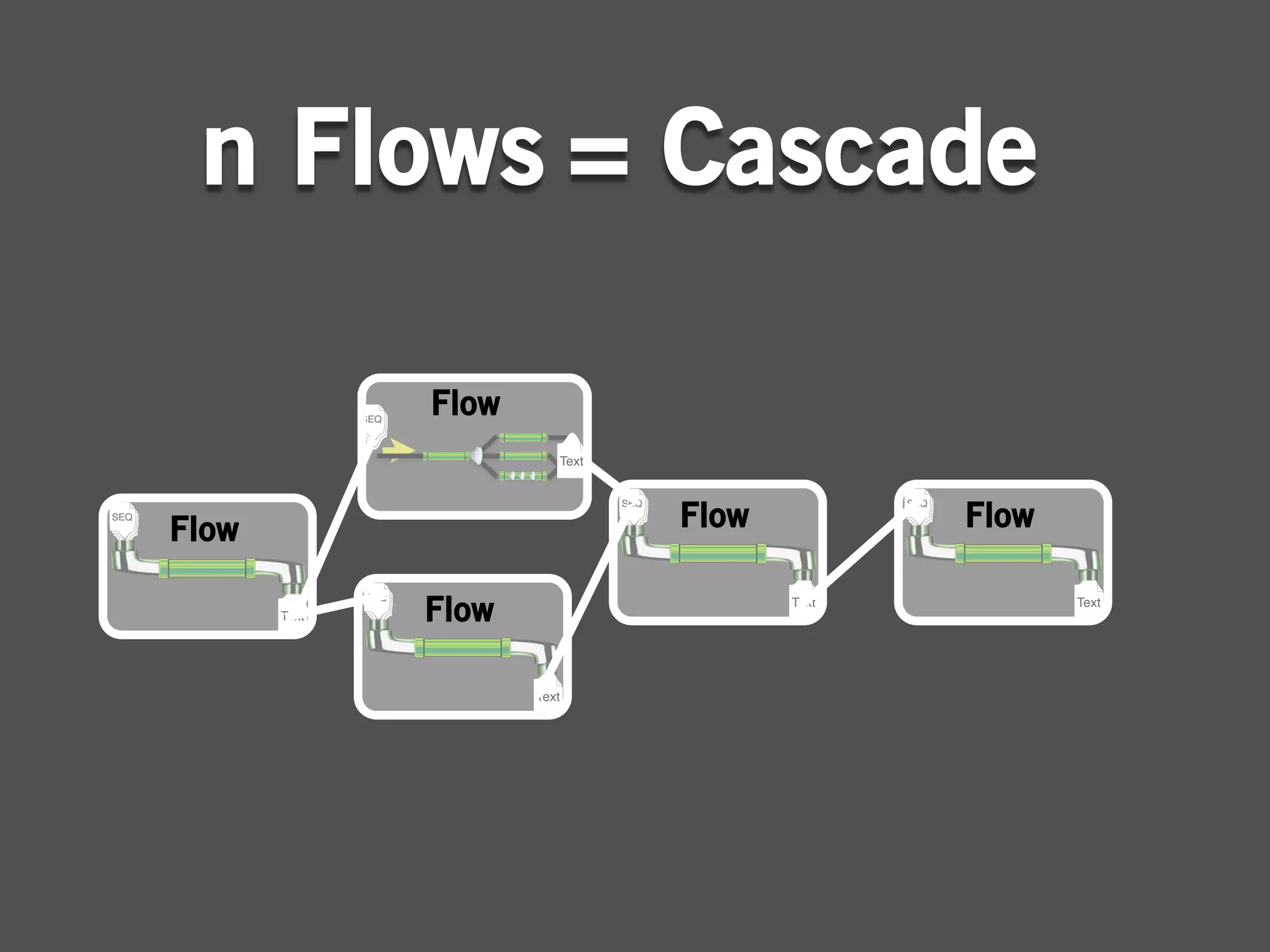
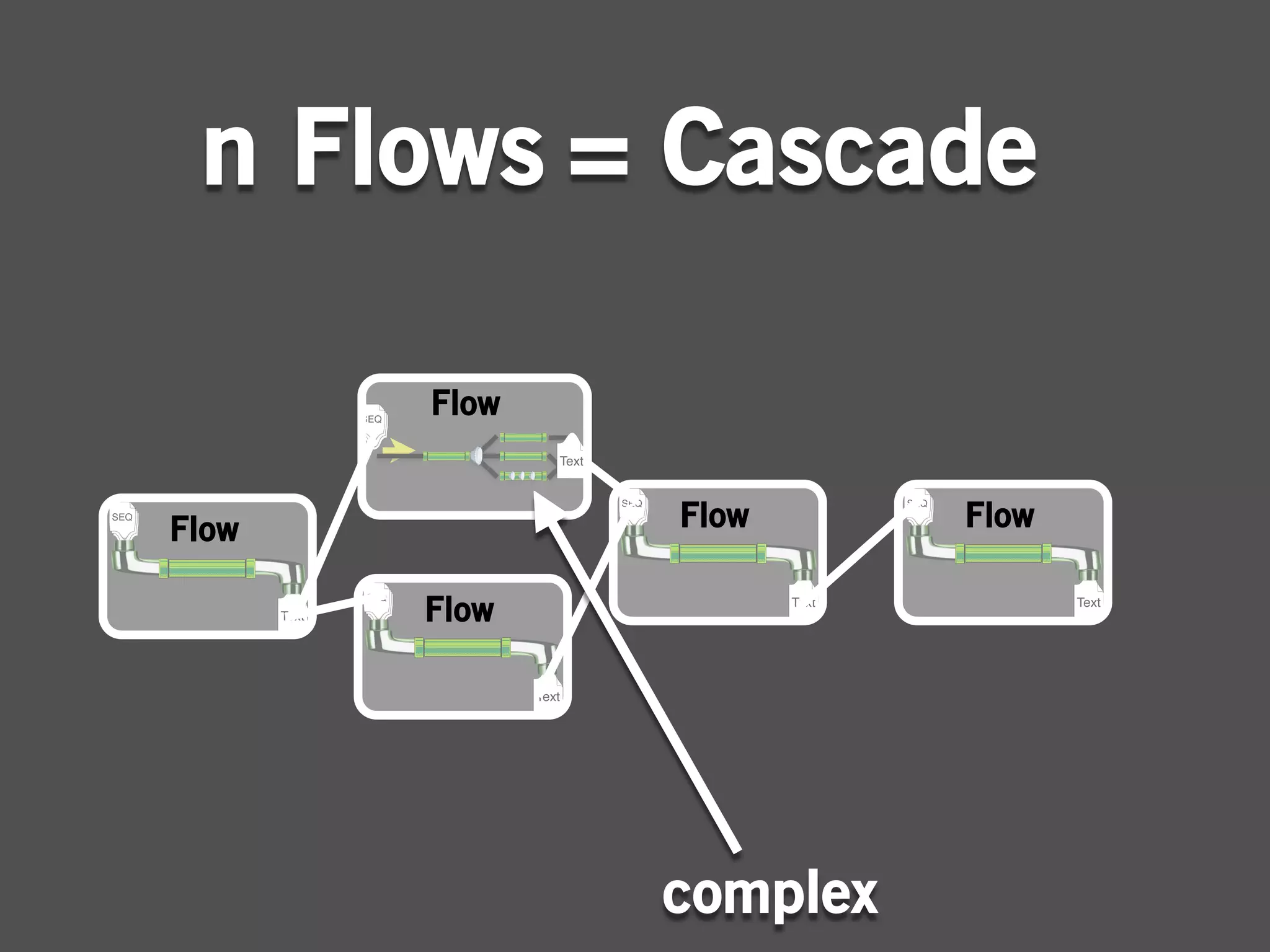

![package cascadingtutorial.wordcount;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
String inputPath = args[0];
String outputPath = args[1];
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-41-2048.jpg)
![package cascadingtutorial.wordcount;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
String inputPath = args[0];
String outputPath = args[1];
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-42-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-43-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-44-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
TextLine()
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-45-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
TextLine()
Tap sinkTap
SequenceFile()
= outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-46-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-47-2048.jpg)
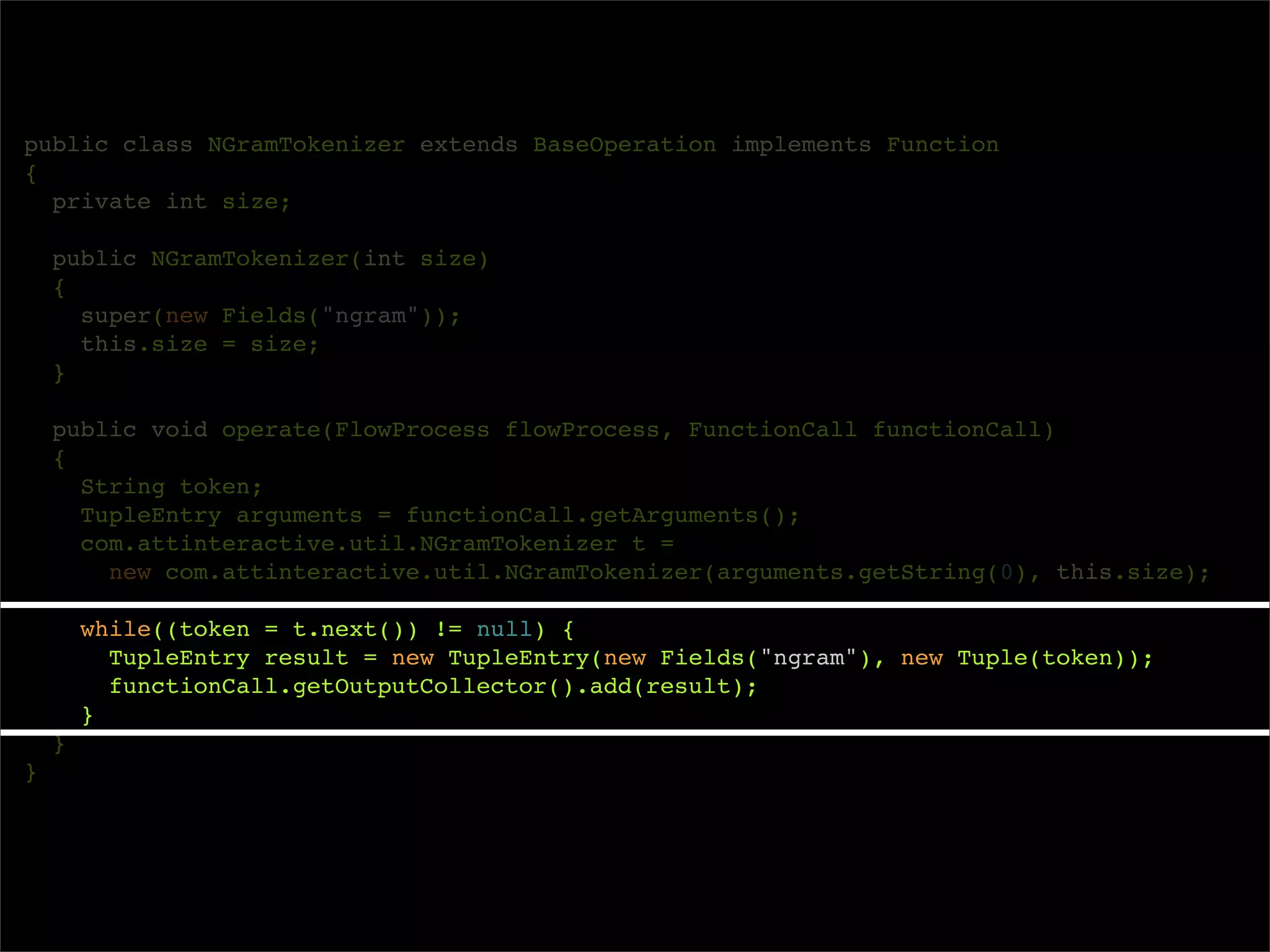
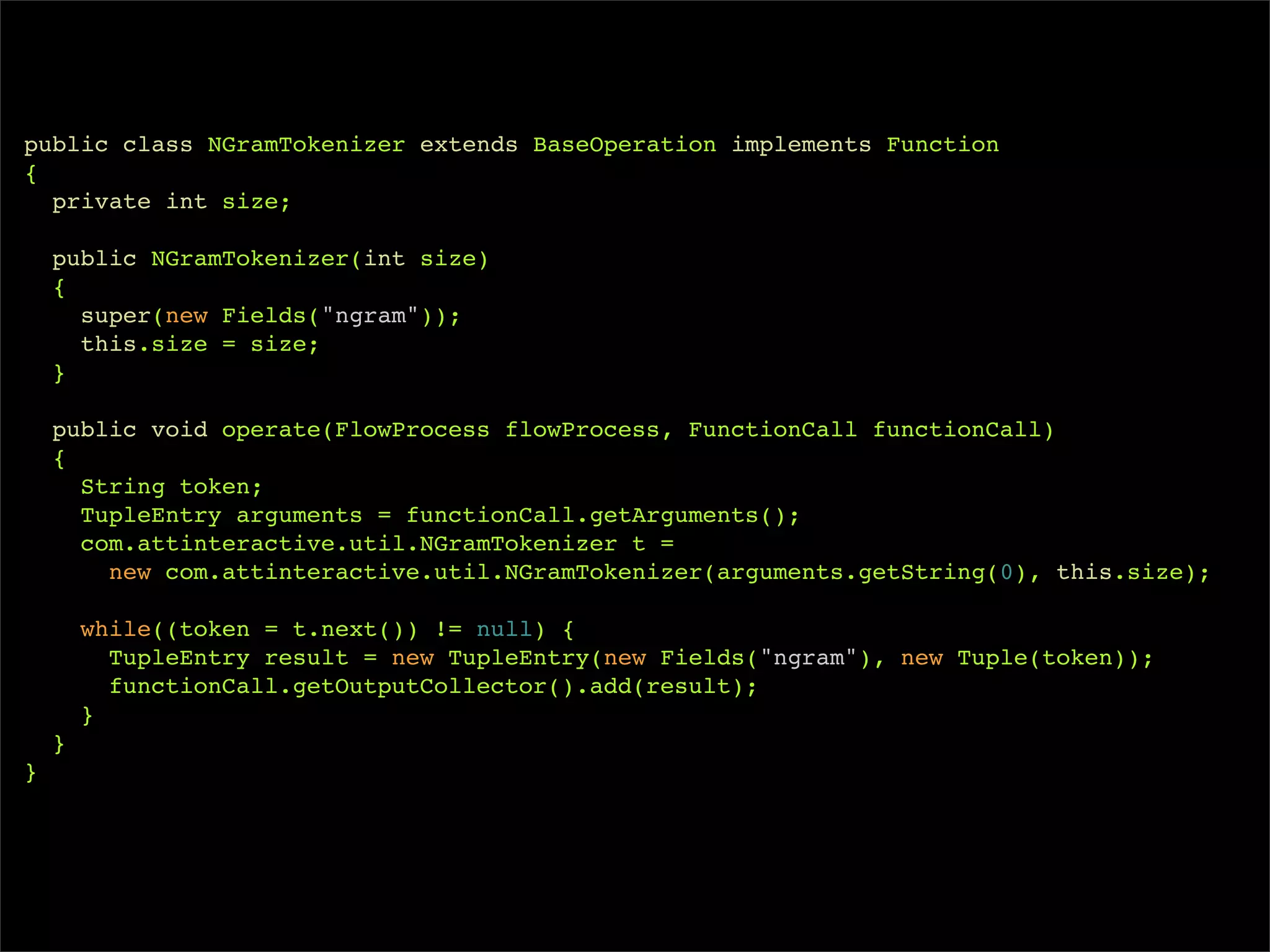
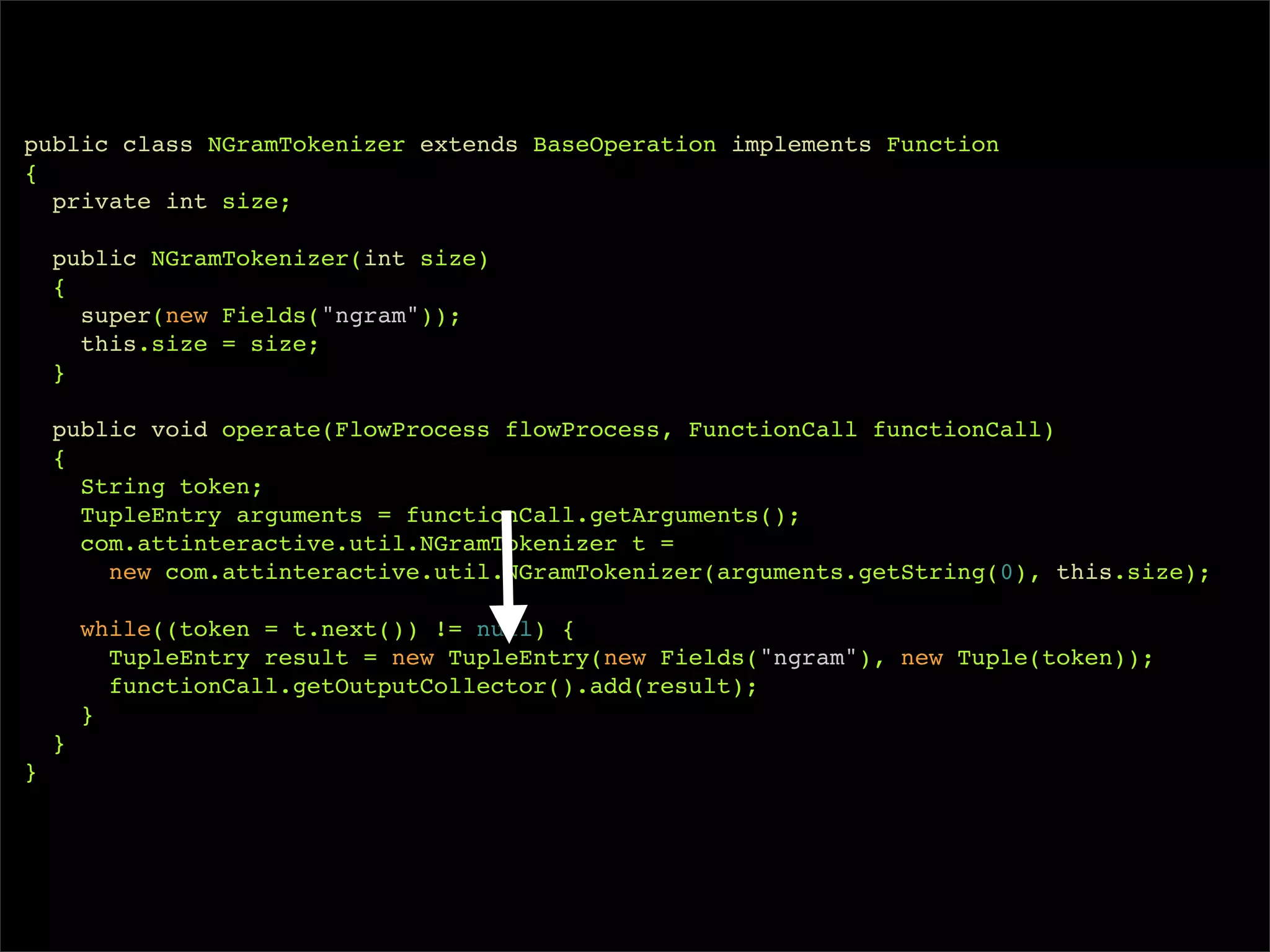
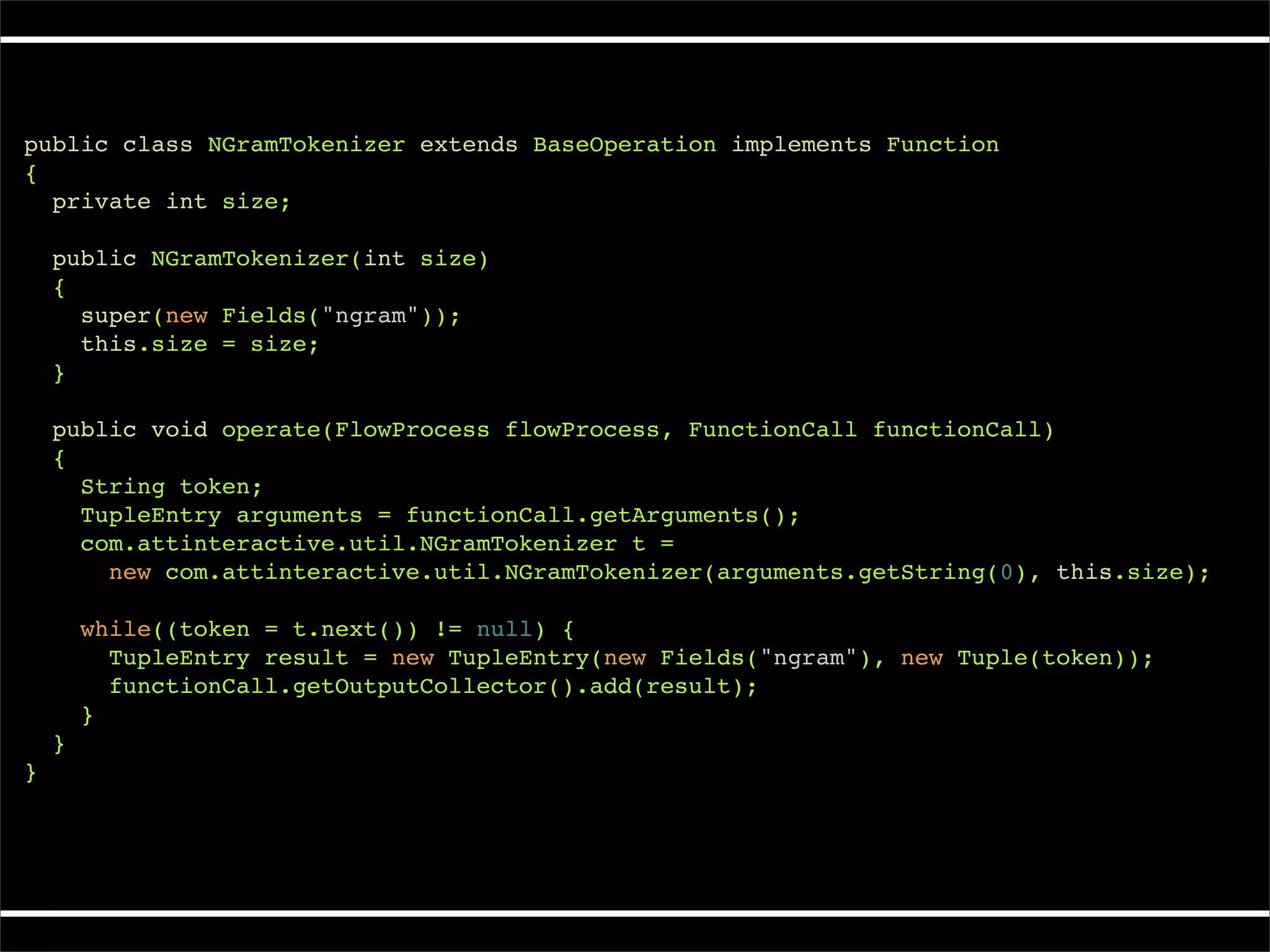
![/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-48-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-49-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-50-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-51-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
new Lfs()
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-52-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
new Lfs()
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
S3fs()
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-53-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
new Lfs()
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
S3fs()
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
GlobHfs() new Fields("count", "word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(),](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-54-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-55-2048.jpg)
![Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-56-2048.jpg)
![Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
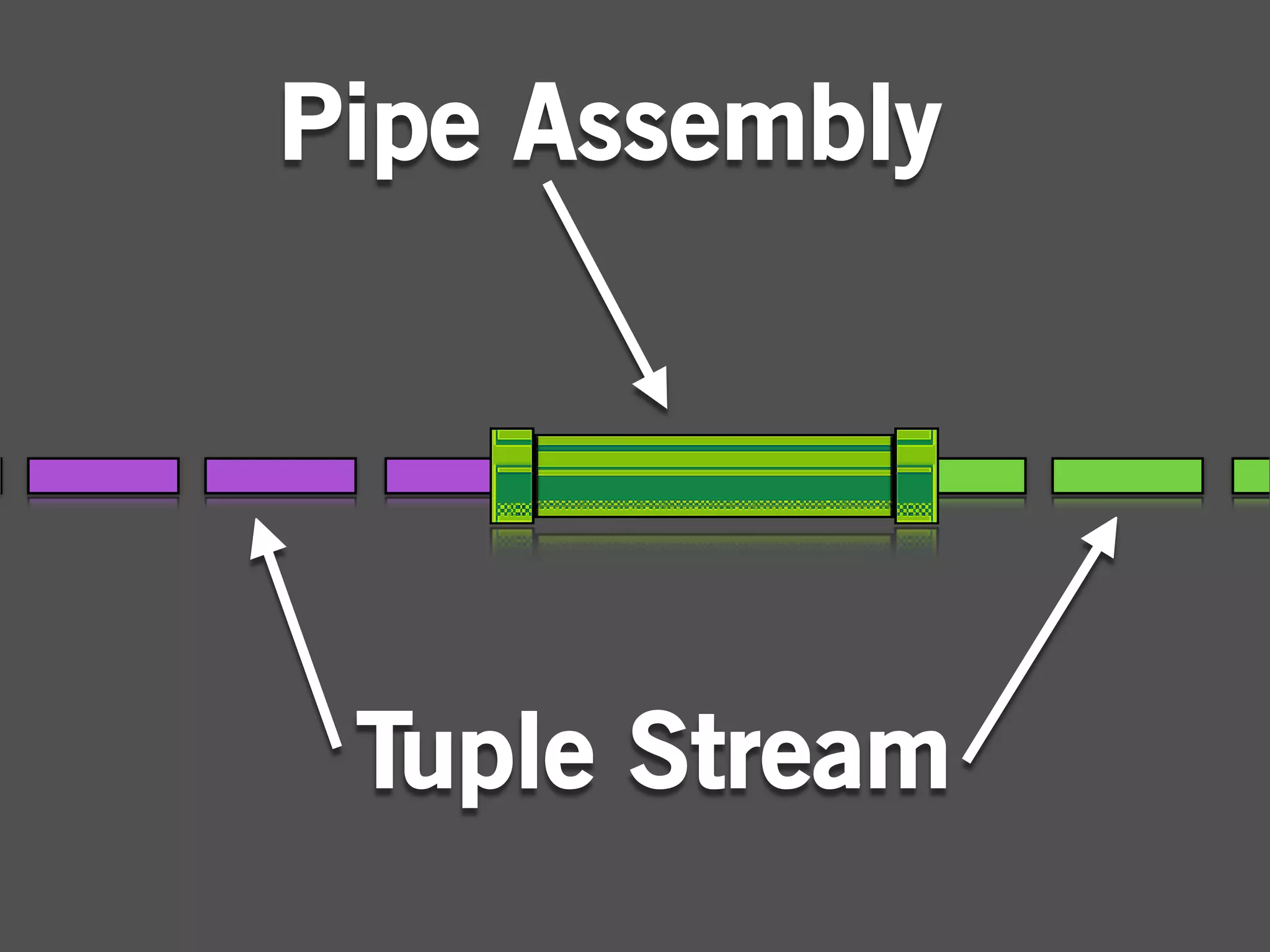
Pipe Assembly
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-57-2048.jpg)
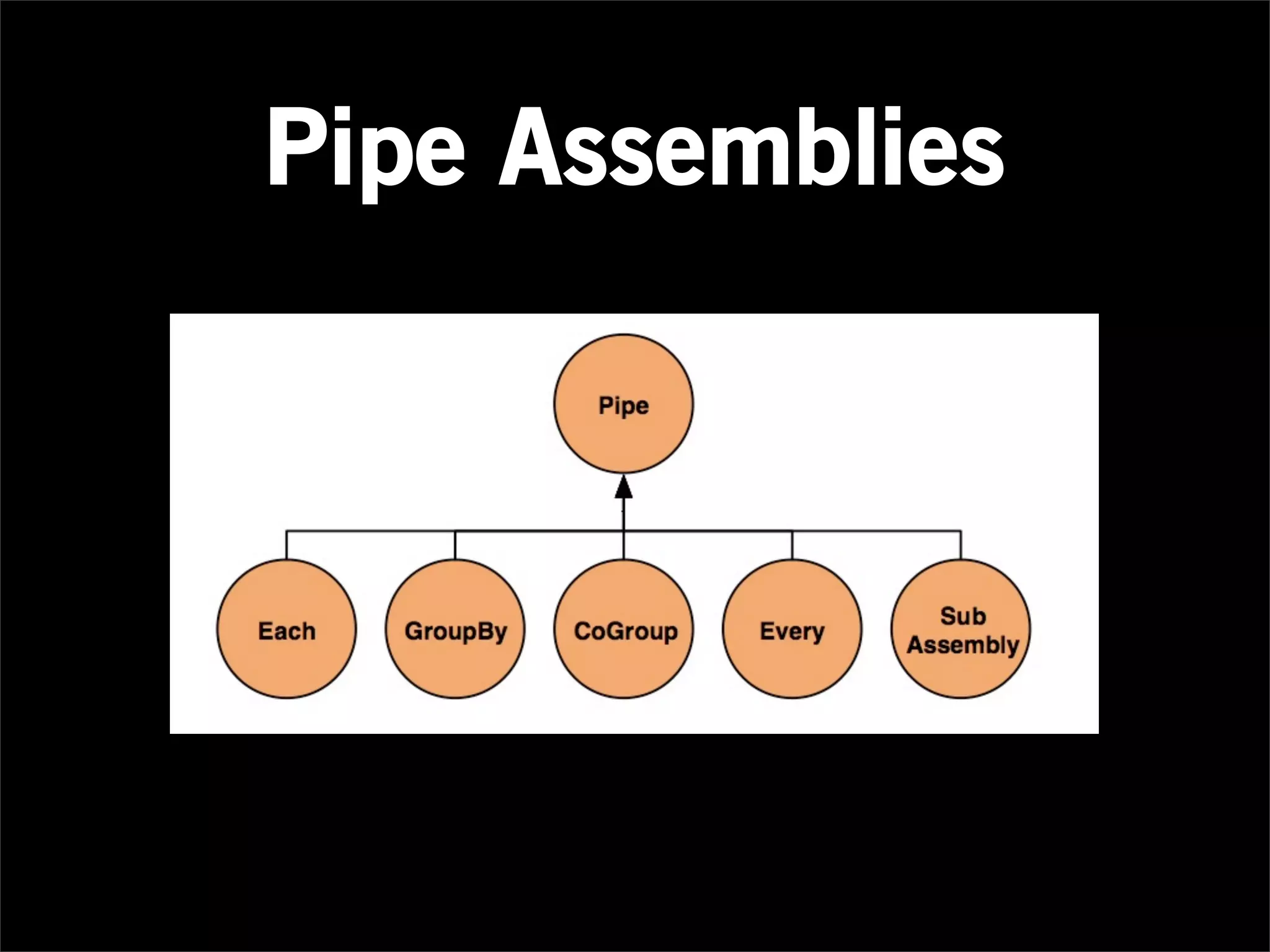

























![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-84-2048.jpg)





















![String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-108-2048.jpg)
![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-109-2048.jpg)
![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-110-2048.jpg)
![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-111-2048.jpg)


























![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-153-2048.jpg)















































![package cascadingtutorial.wordcount;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
String inputPath = args[0];
String outputPath = args[1];
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-15-2048.jpg)

























![package cascadingtutorial.wordcount;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
String inputPath = args[0];
String outputPath = args[1];
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-41-2048.jpg)
![package cascadingtutorial.wordcount;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
String inputPath = args[0];
String outputPath = args[1];
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-42-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-43-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-44-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
TextLine()
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-45-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
TextLine()
Tap sinkTap
SequenceFile()
= outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-46-2048.jpg)
![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-47-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-48-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-49-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-50-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-51-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
new Lfs()
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-52-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
new Lfs()
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
S3fs()
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-53-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{ hdfs://master0:54310/user/nmurray/data.txt new Hfs()
data/sources/obama-inaugural-address.txt
public static void main( String[] args )
new Lfs()
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
S3fs()
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
GlobHfs() new Fields("count", "word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(),](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-54-2048.jpg)
![/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-55-2048.jpg)
![Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-56-2048.jpg)
![Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Pipe Assembly
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-57-2048.jpg)


























![import cascading.tap.Tap;
import cascading.tuple.Fields;
import java.util.Properties;
/**
* Wordcount example in Cascading
*/
public class Main
{
public static void main( String[] args )
{
Scheme inputScheme = new TextLine(new Fields("offset", "line"));
Scheme outputScheme = new TextLine();
String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe = new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-84-2048.jpg)























![String inputPath = args[0];
String outputPath = args[1];
Tap sourceTap = inputPath.matches( "^[^:]+://.*") ?
new Hfs(inputScheme, inputPath) :
new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-108-2048.jpg)
![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-109-2048.jpg)
![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-110-2048.jpg)
![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-111-2048.jpg)









































![new Lfs(inputScheme, inputPath);
Tap sinkTap = outputPath.matches("^[^:]+://.*") ?
new Hfs(outputScheme, outputPath) :
new Lfs(outputScheme, outputPath);
Pipe wcPipe =
new Each("wordcount",
new Fields("line"),
new RegexSplitGenerator(new Fields("word"), "s+"),
new Fields("word"));
wcPipe = new GroupBy(wcPipe, new Fields("word"));
wcPipe = new Every(wcPipe, new Count(), new Fields("count", "word"));
Properties properties = new Properties();
FlowConnector.setApplicationJarClass(properties, Main.class);
Flow parsedLogFlow = new FlowConnector(properties)
.connect(sourceTap, sinkTap, wcPipe);
parsedLogFlow.start();
parsedLogFlow.complete();
}
}](https://crownmelresort.com/image.slidesharecdn.com/intro-to-cascading-091112163237-phpapp01/75/Intro-To-Cascading-153-2048.jpg)

























































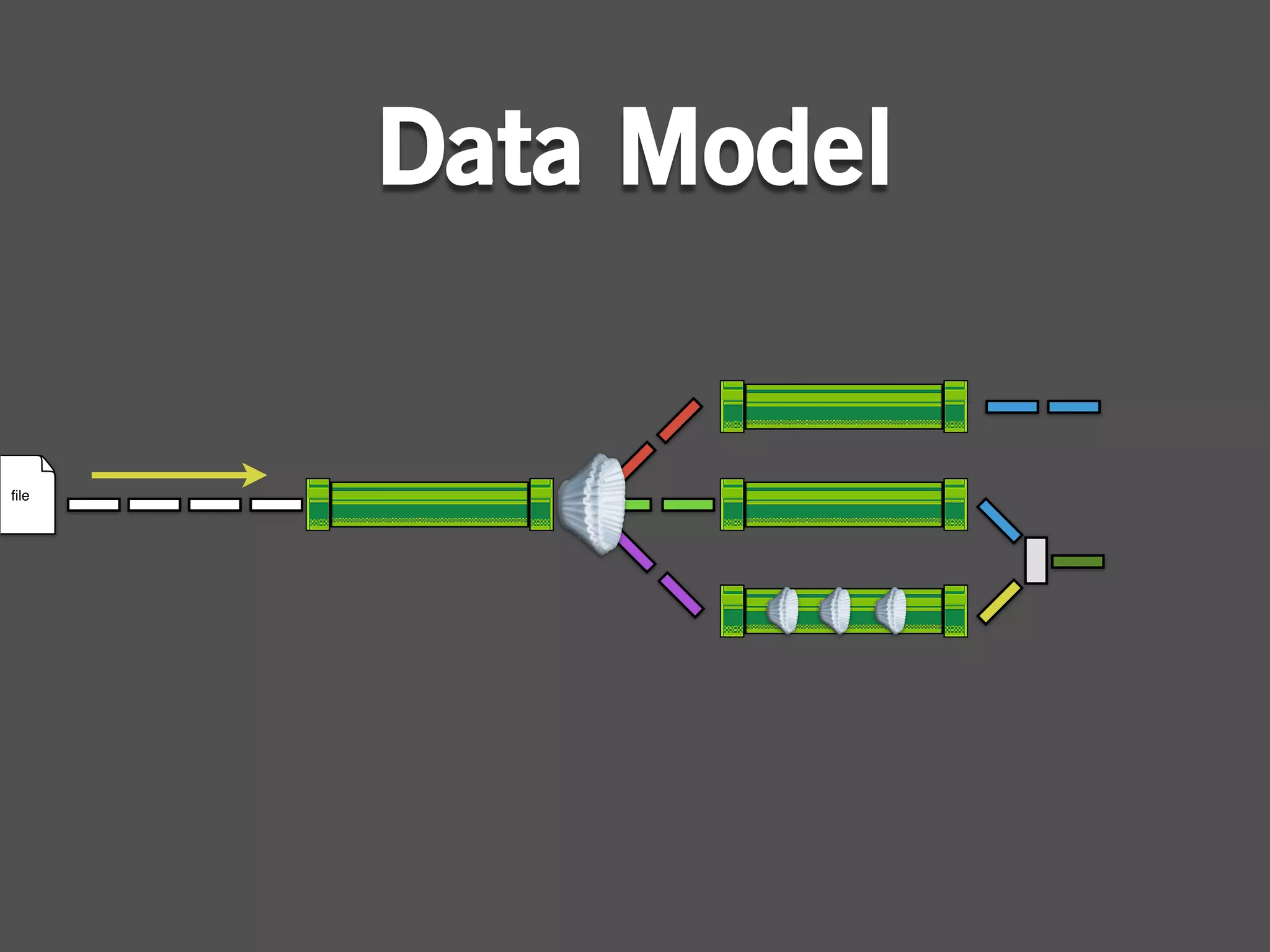
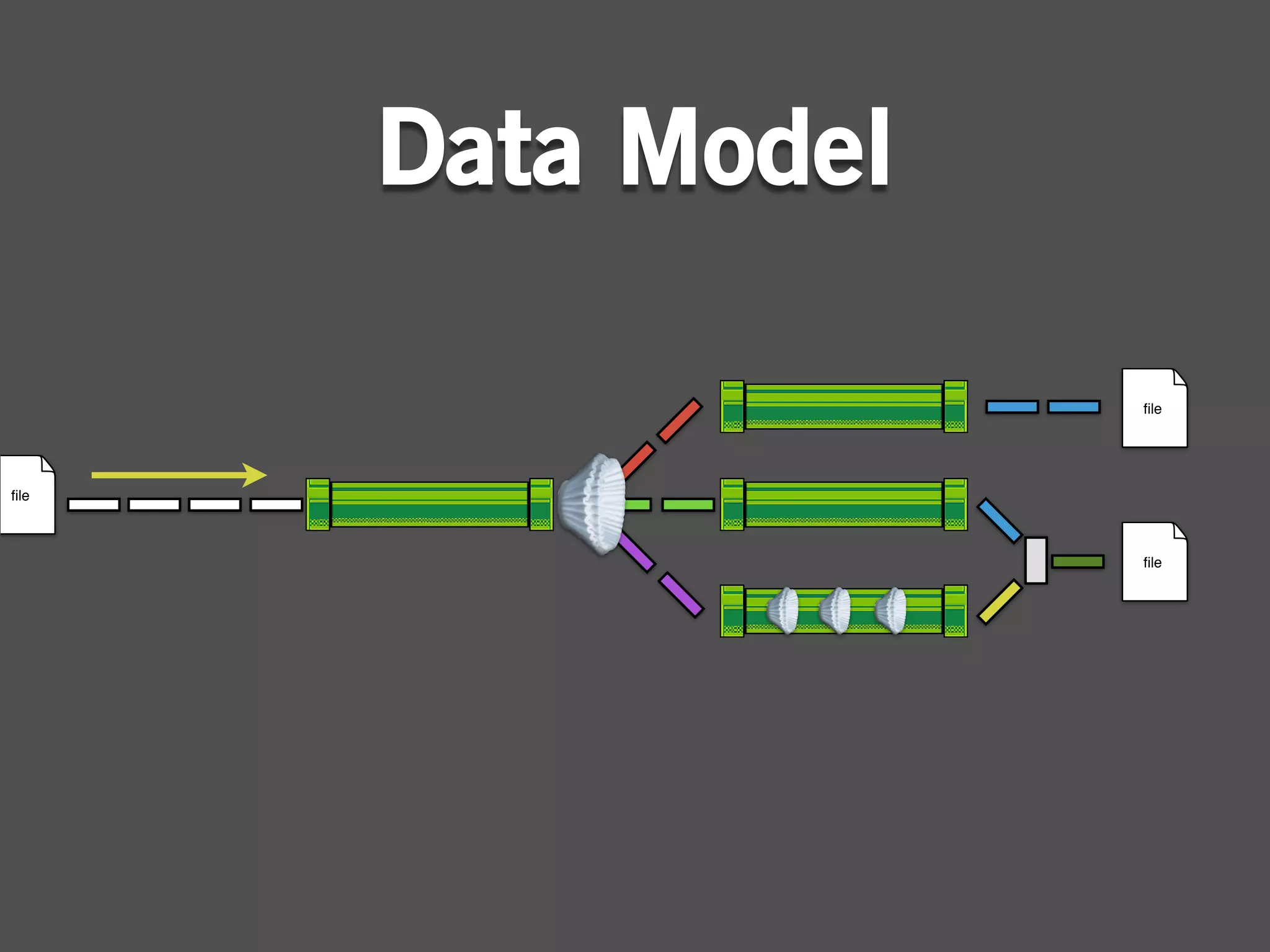
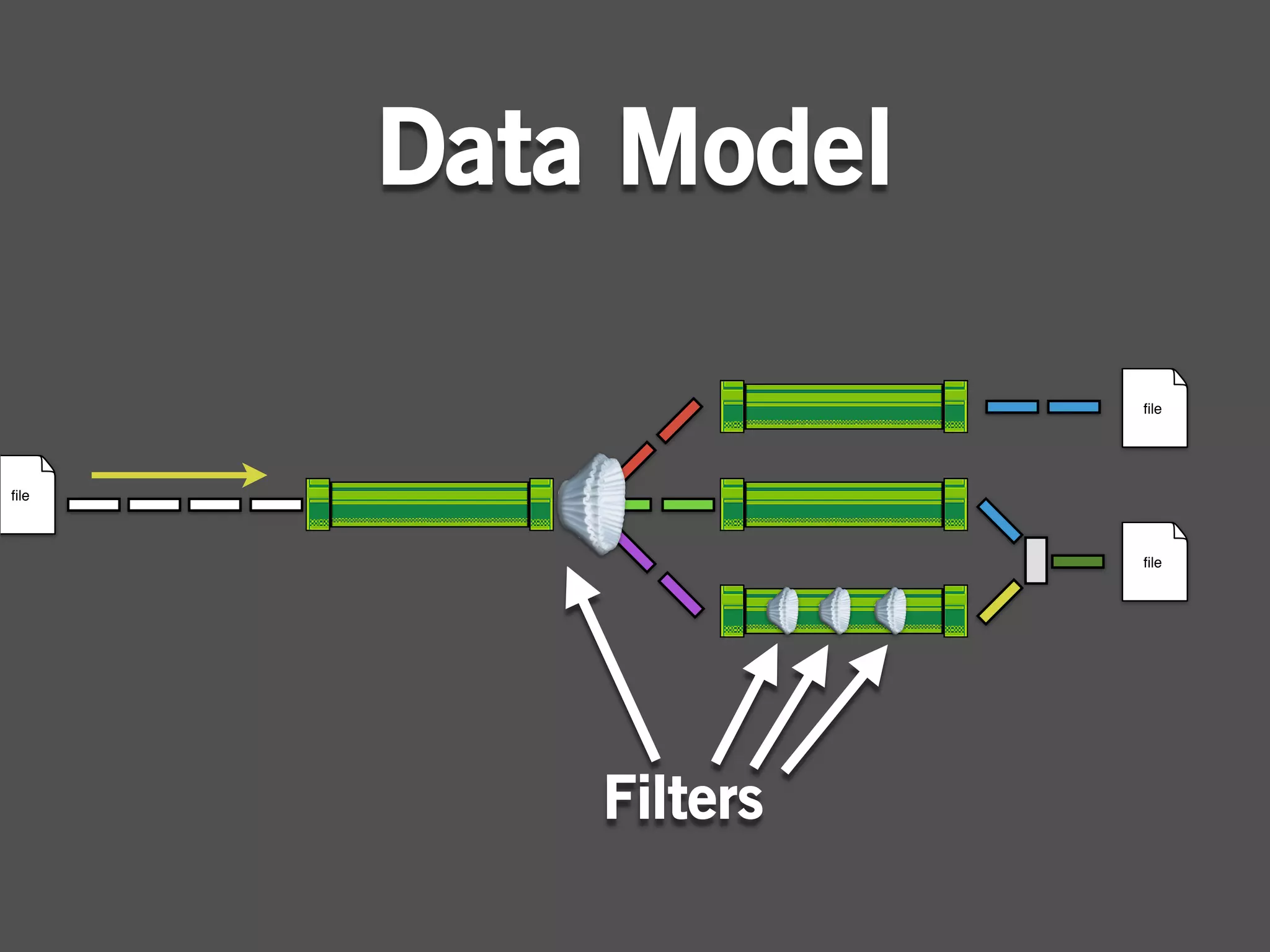
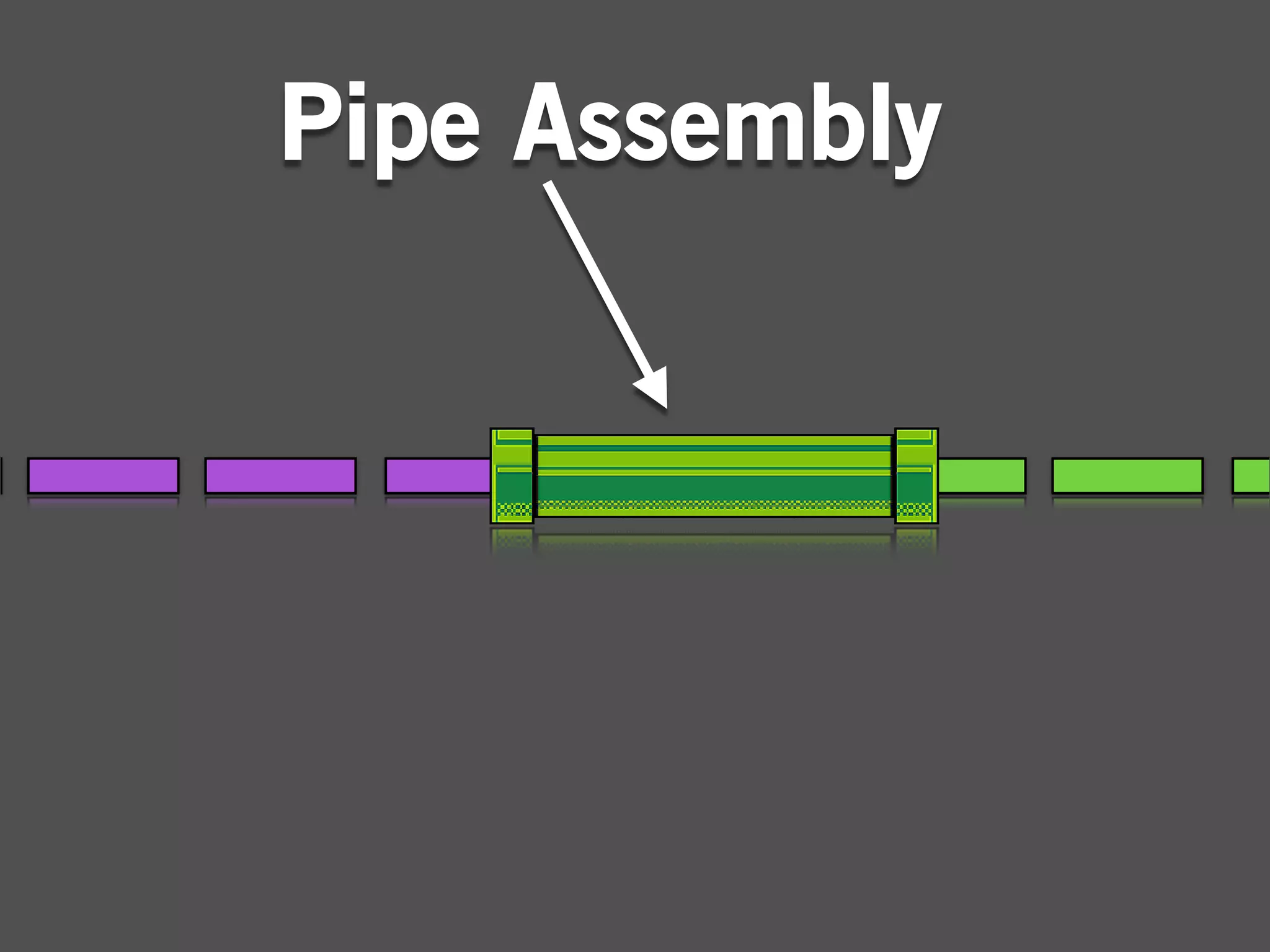
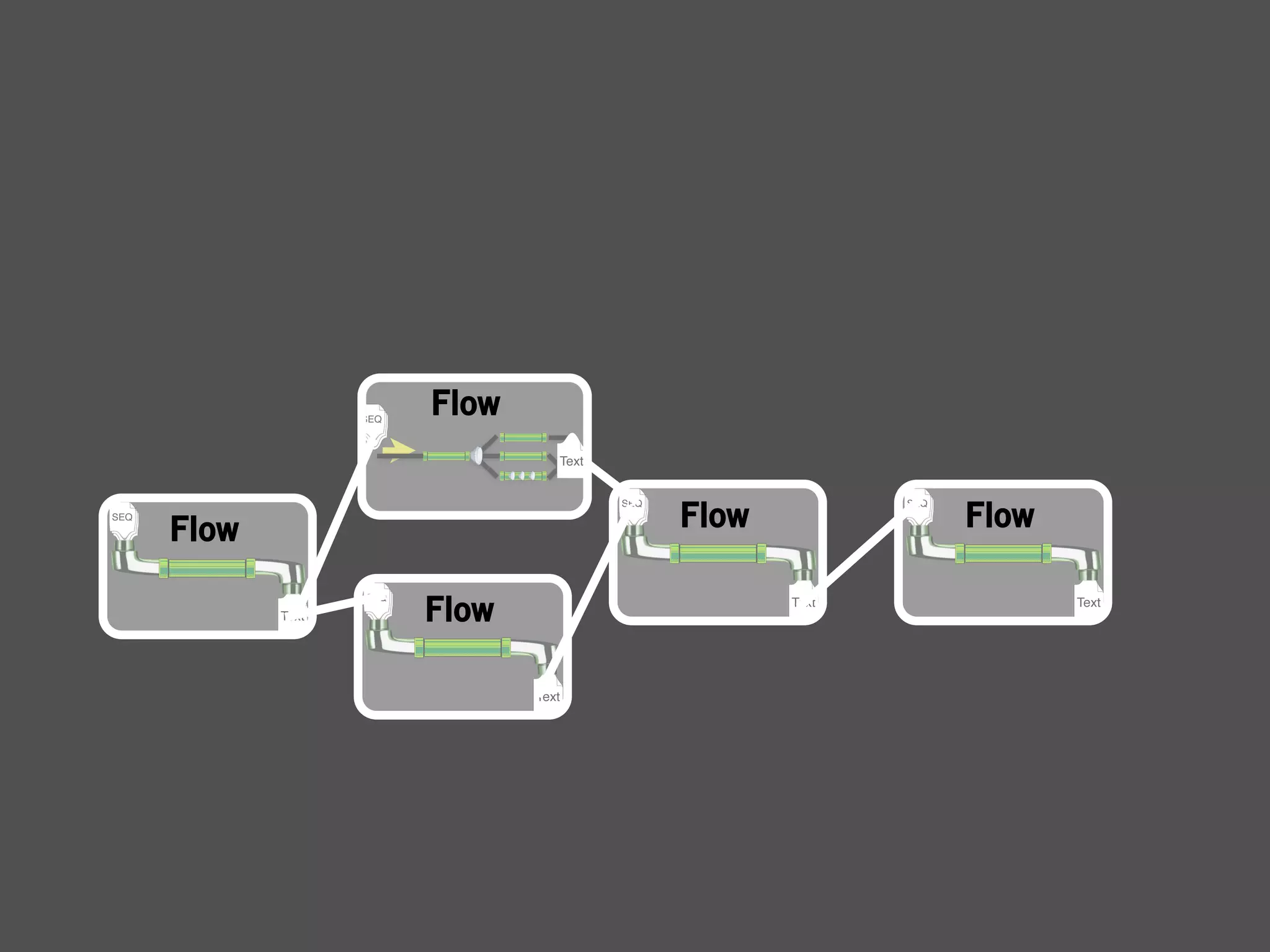
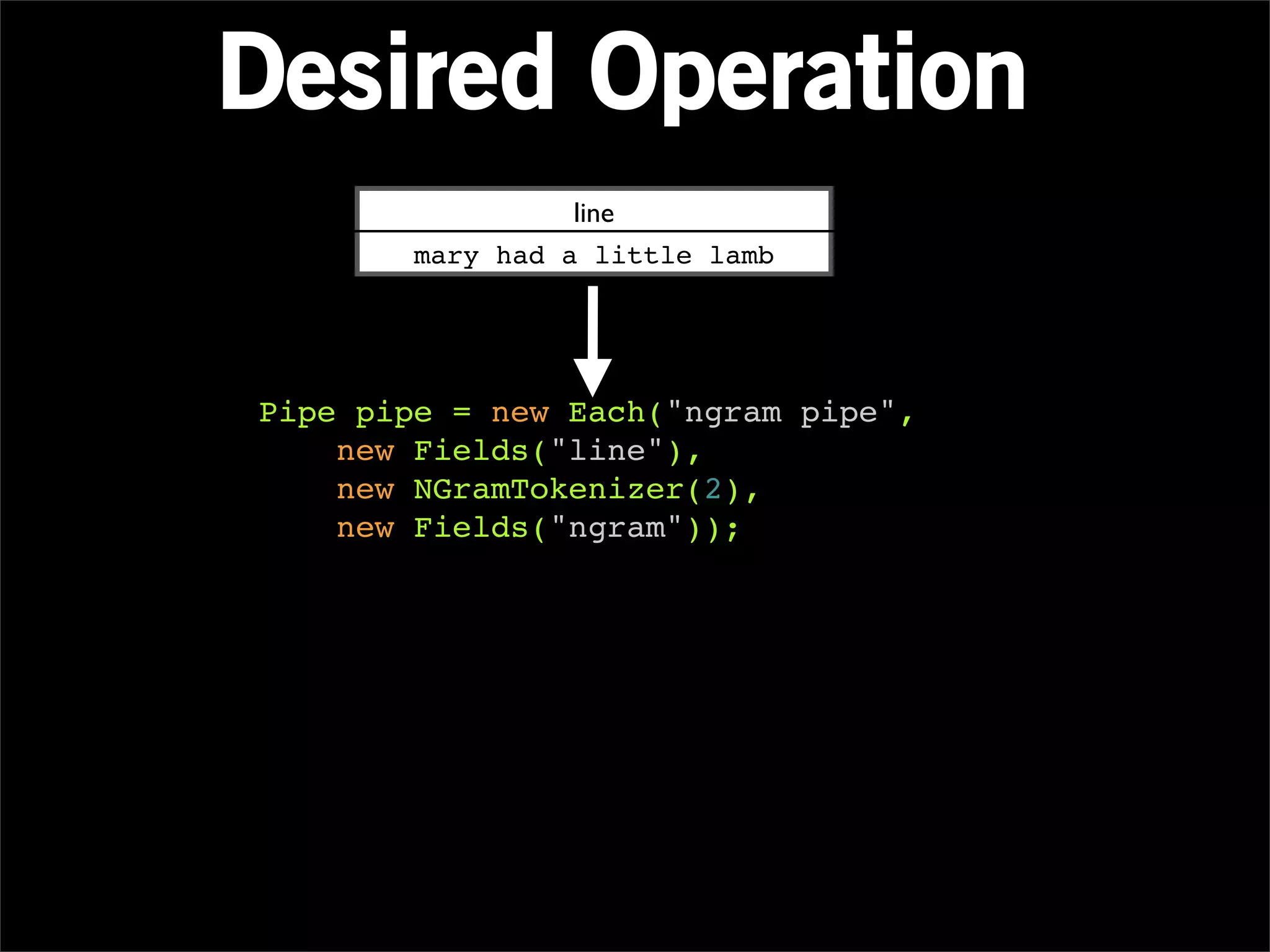
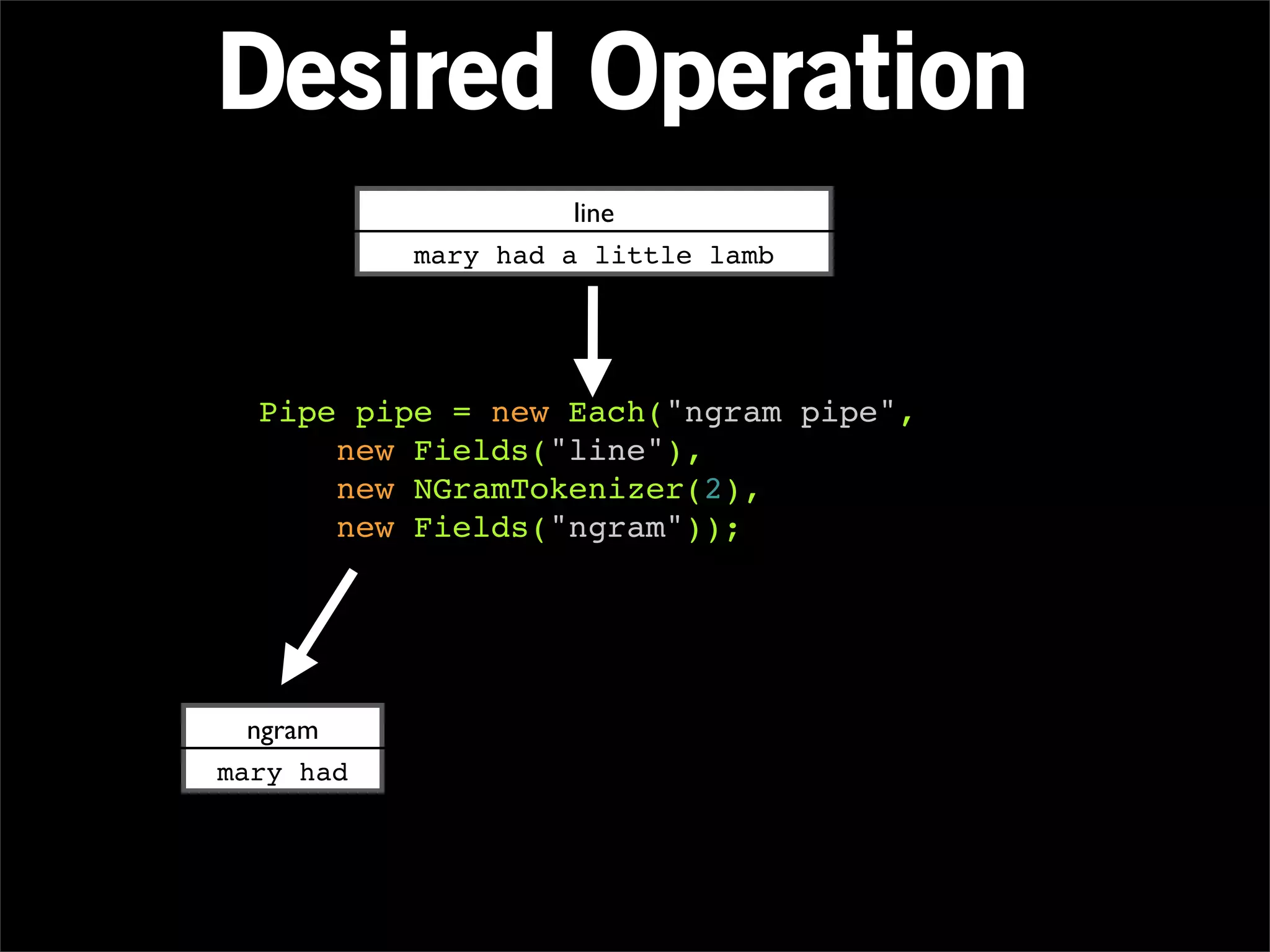
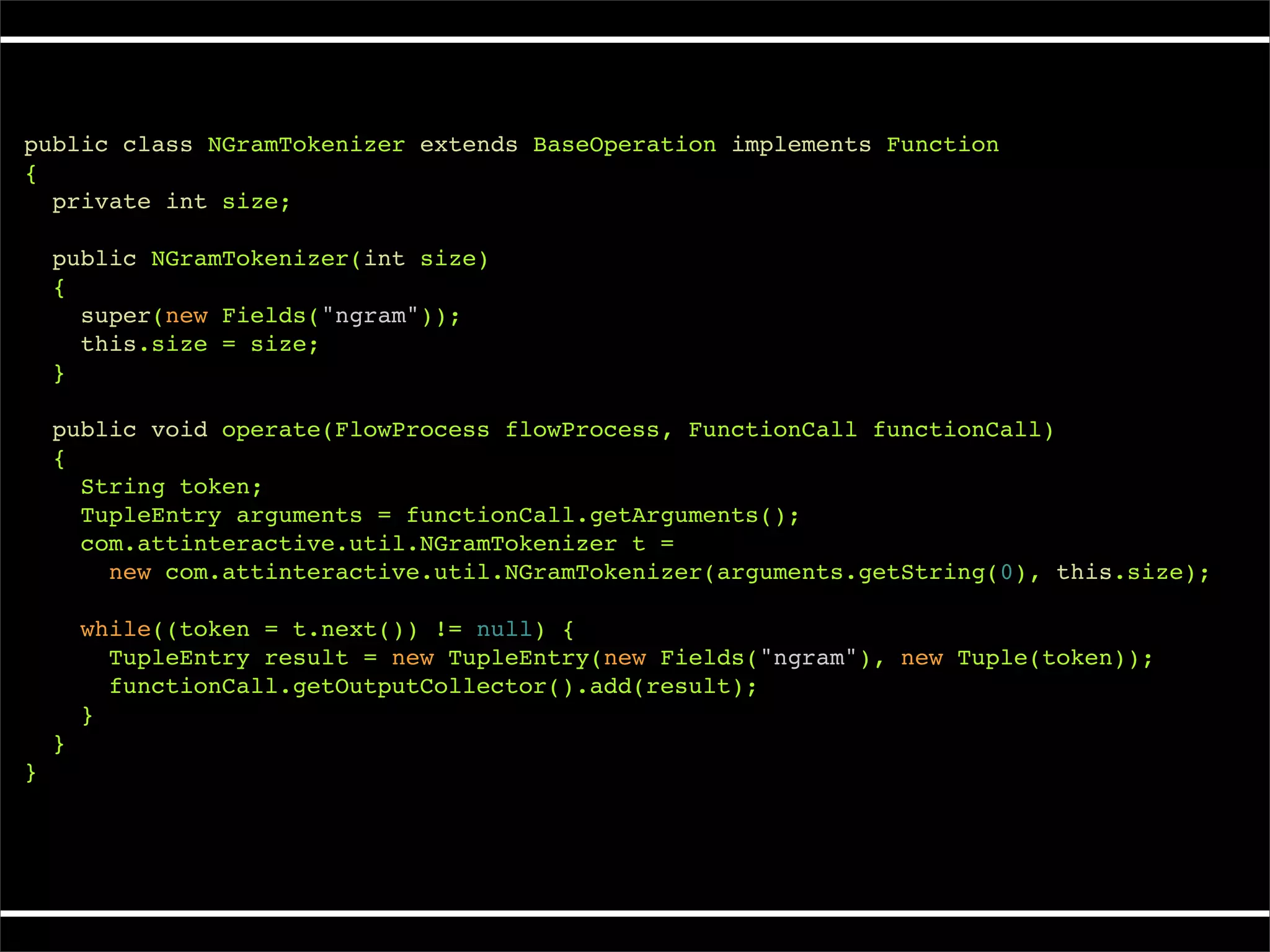
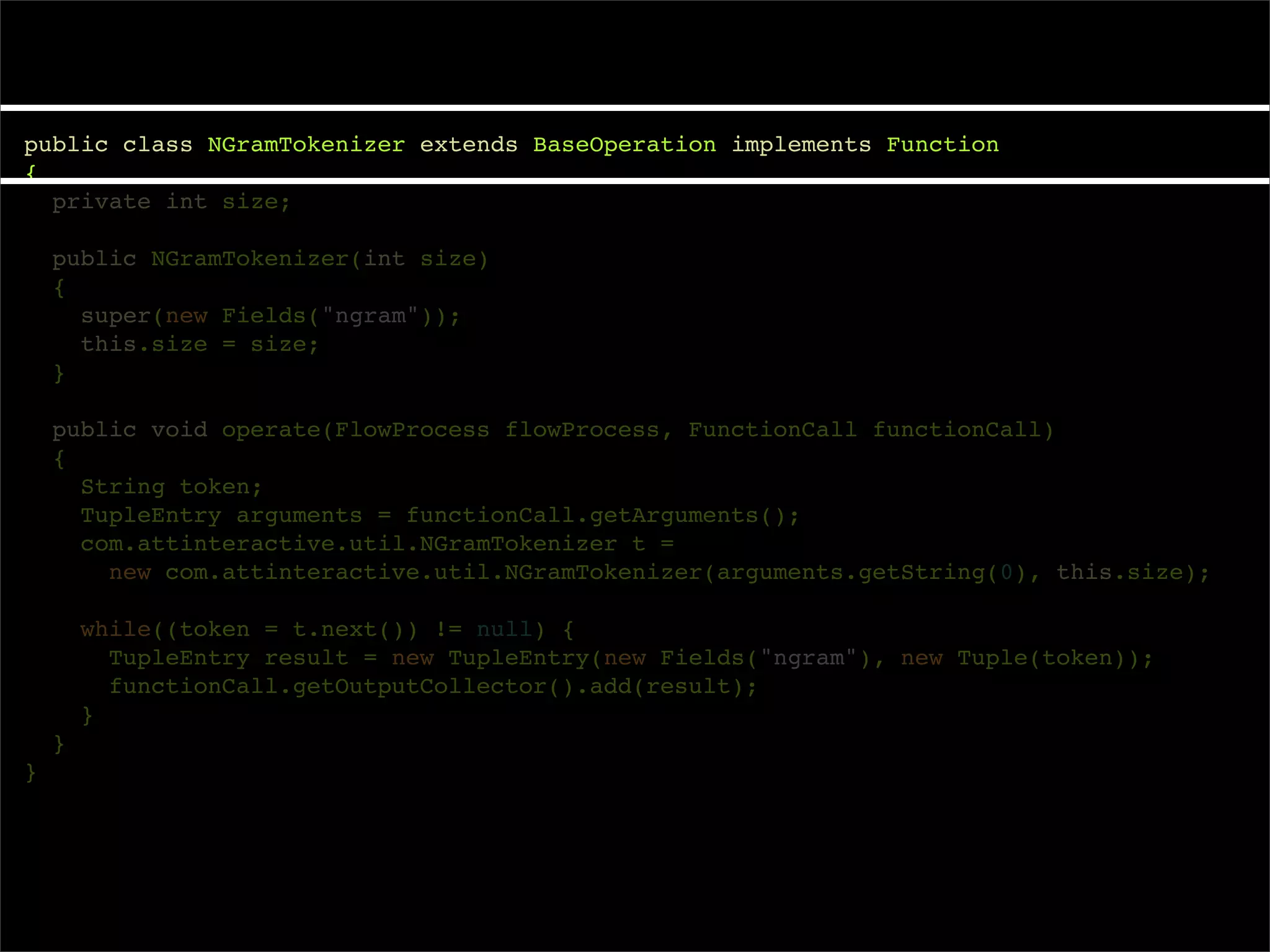
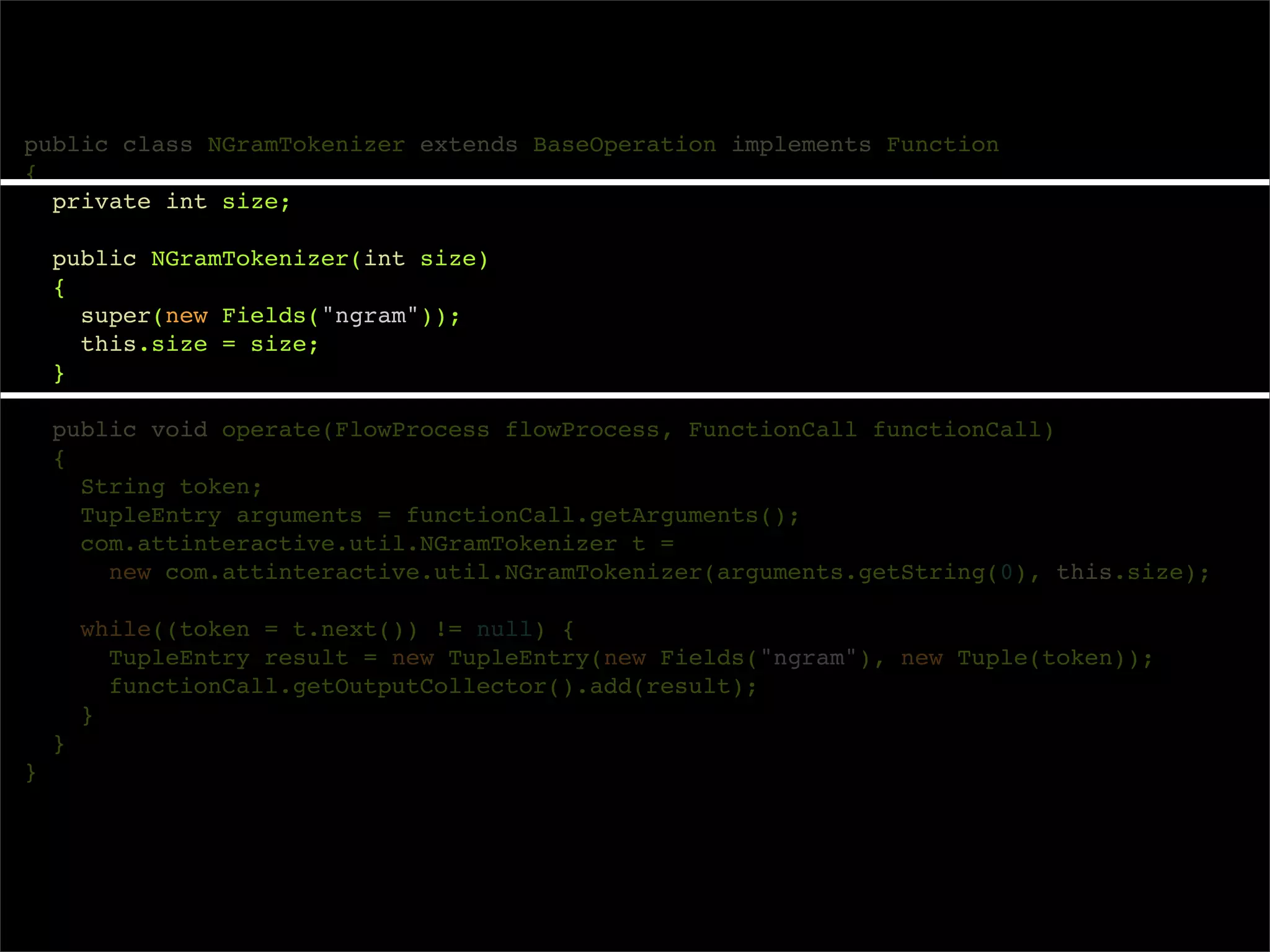
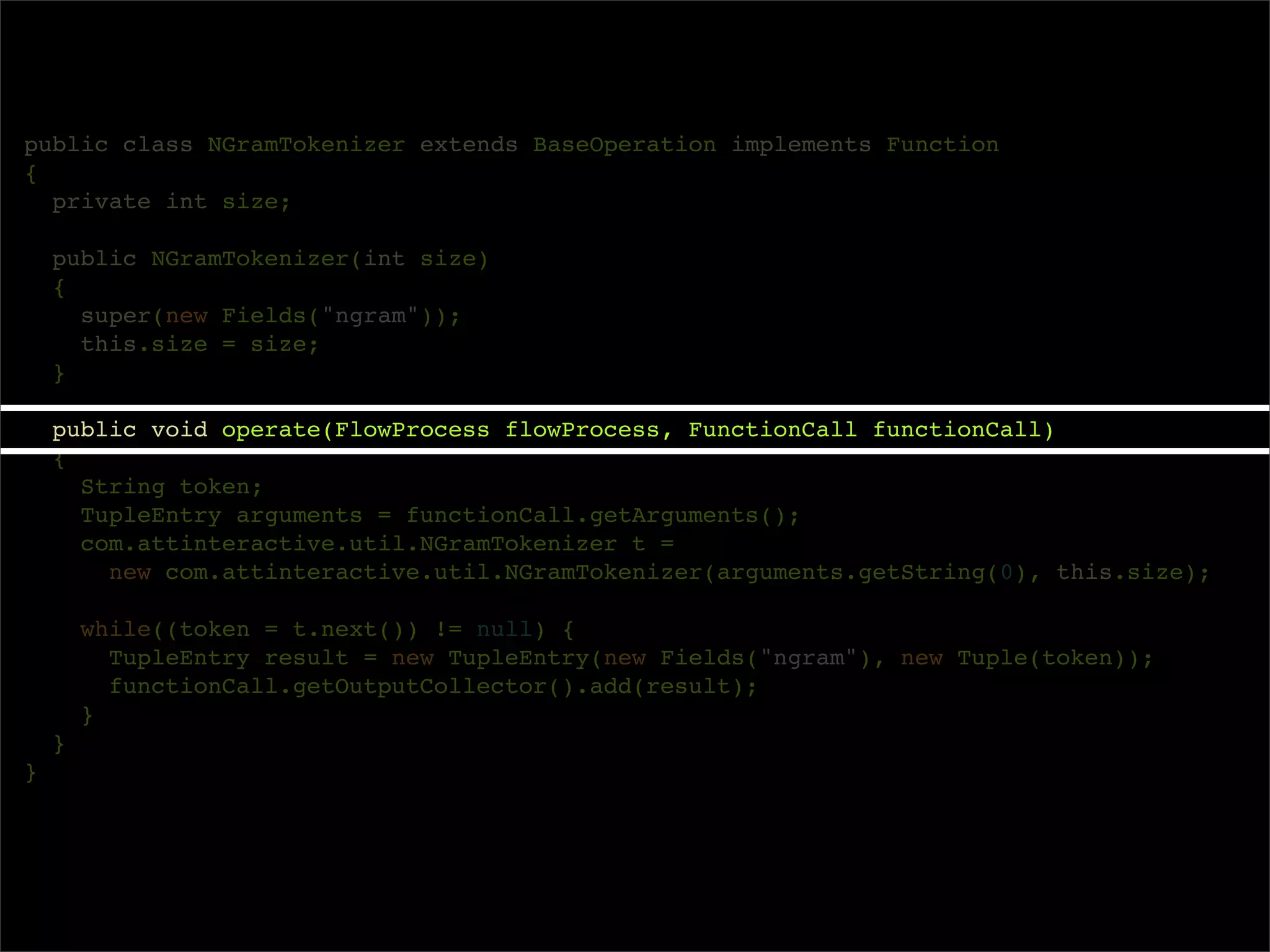
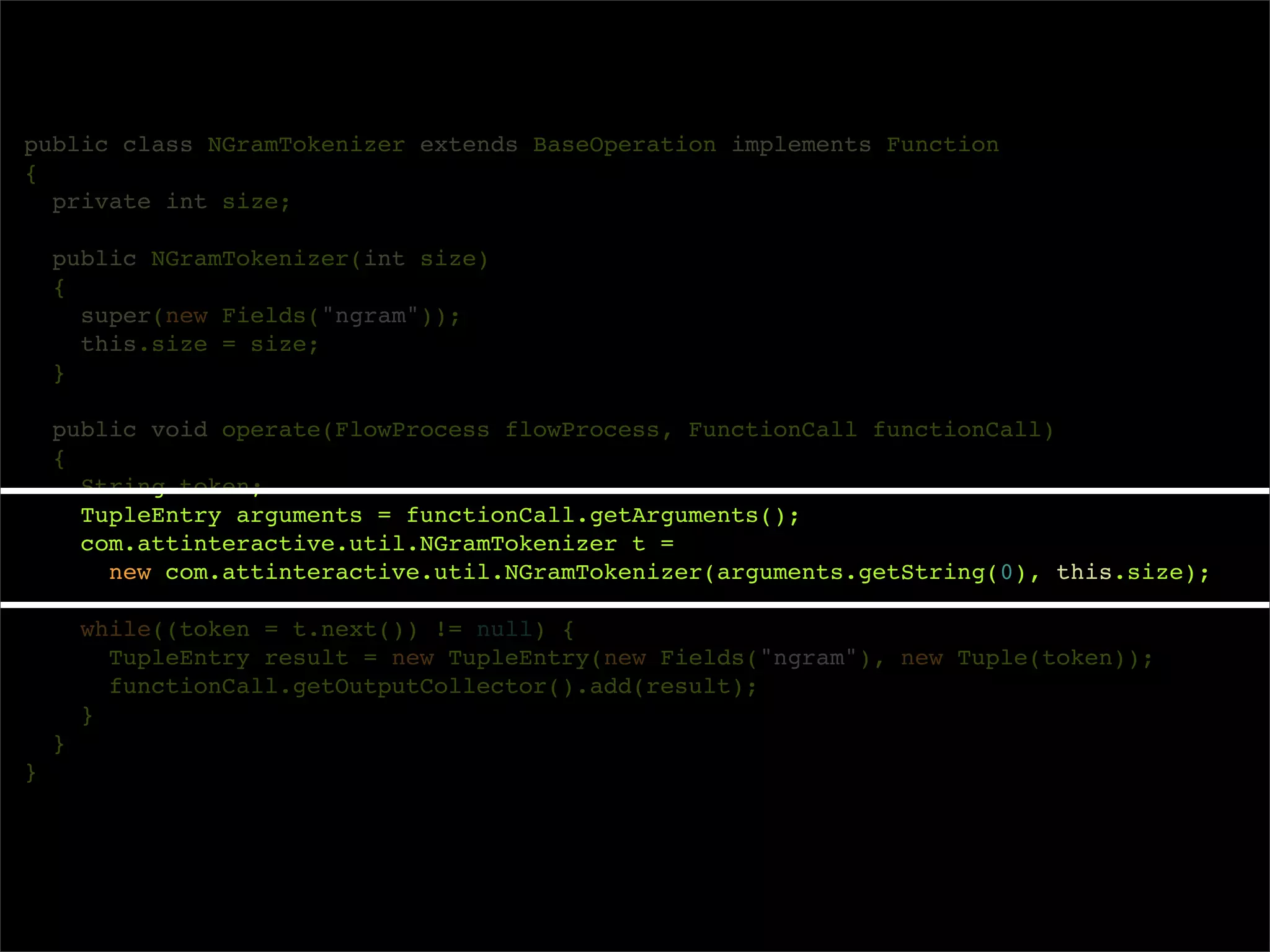
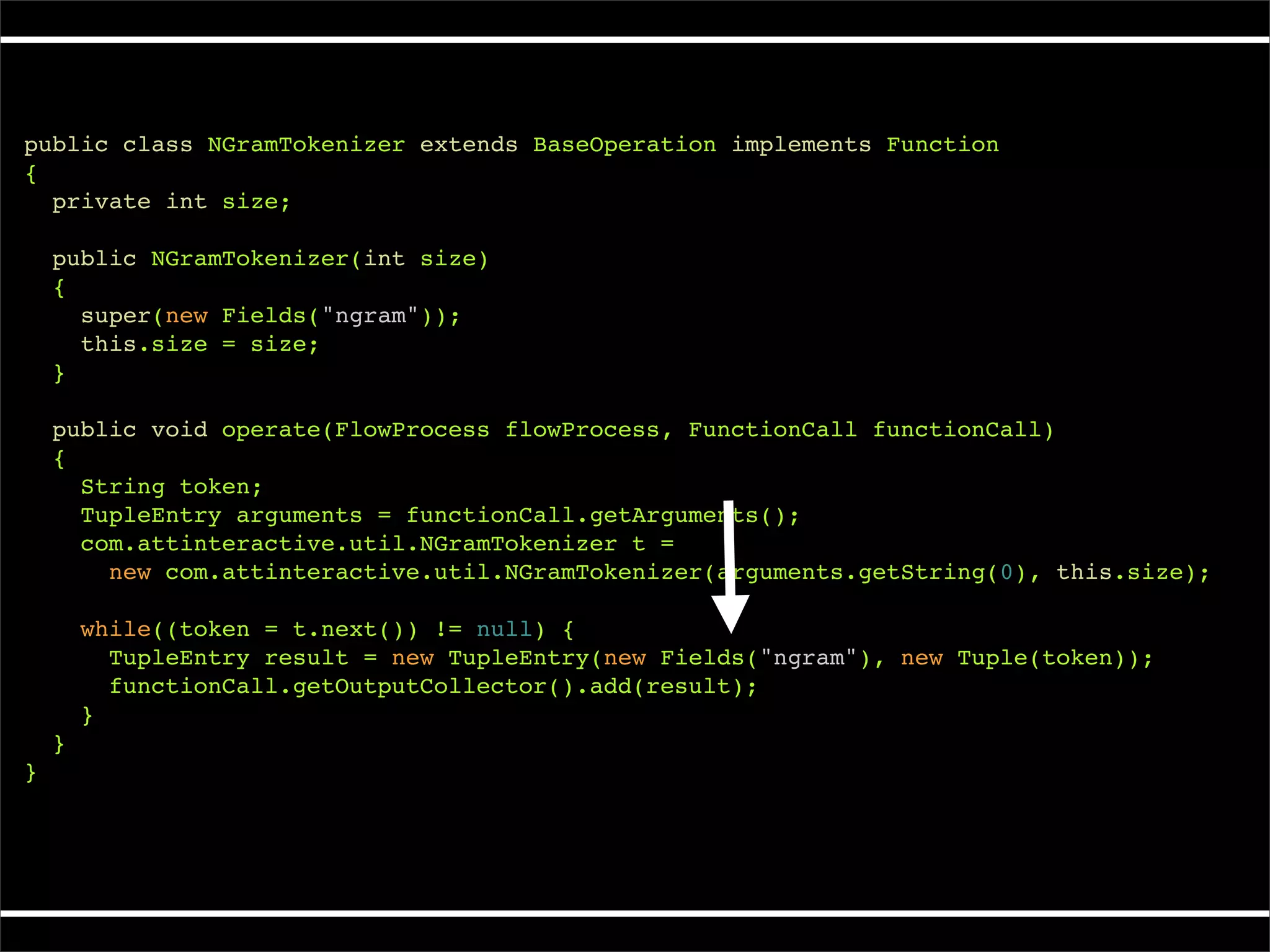
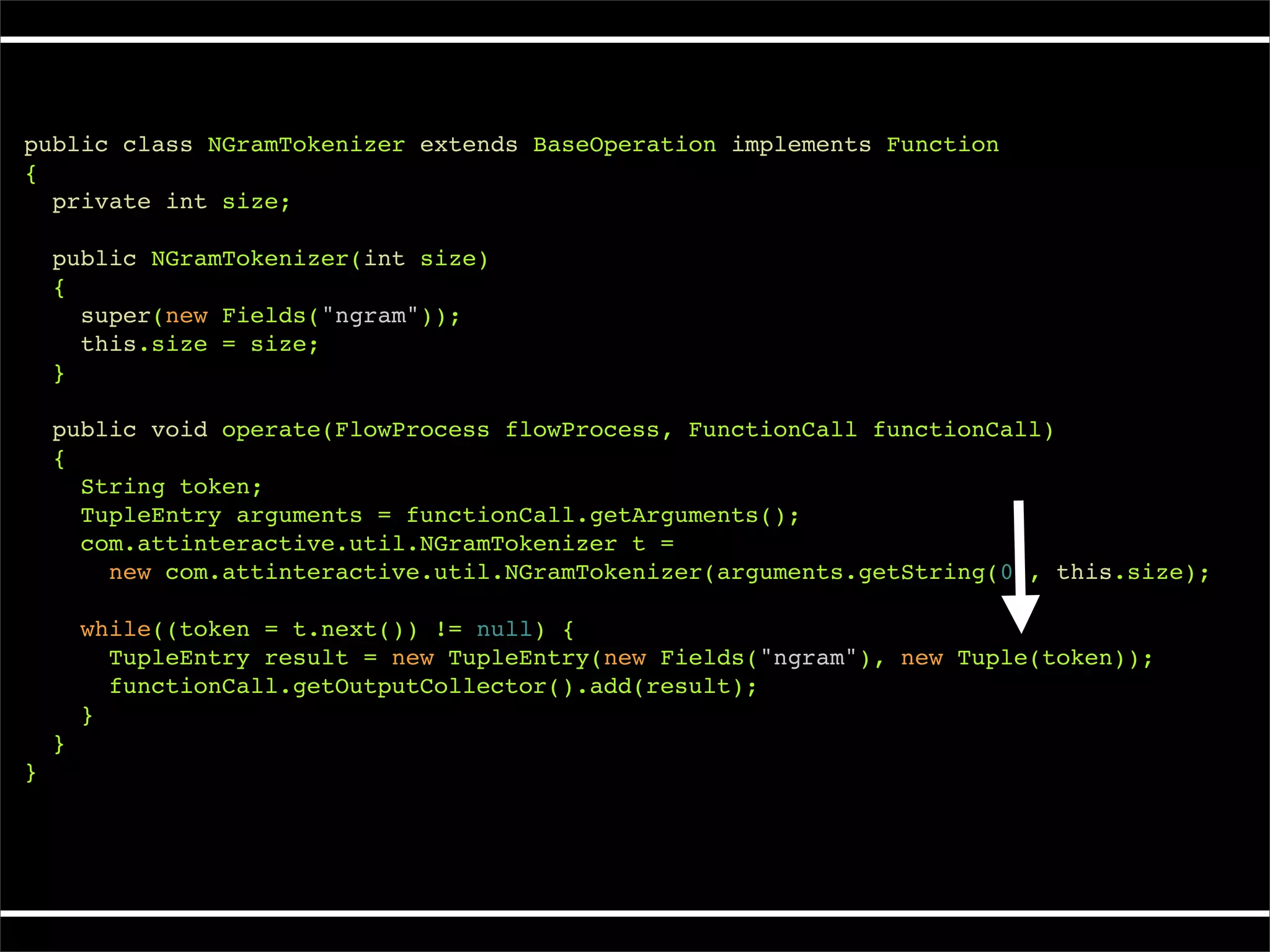
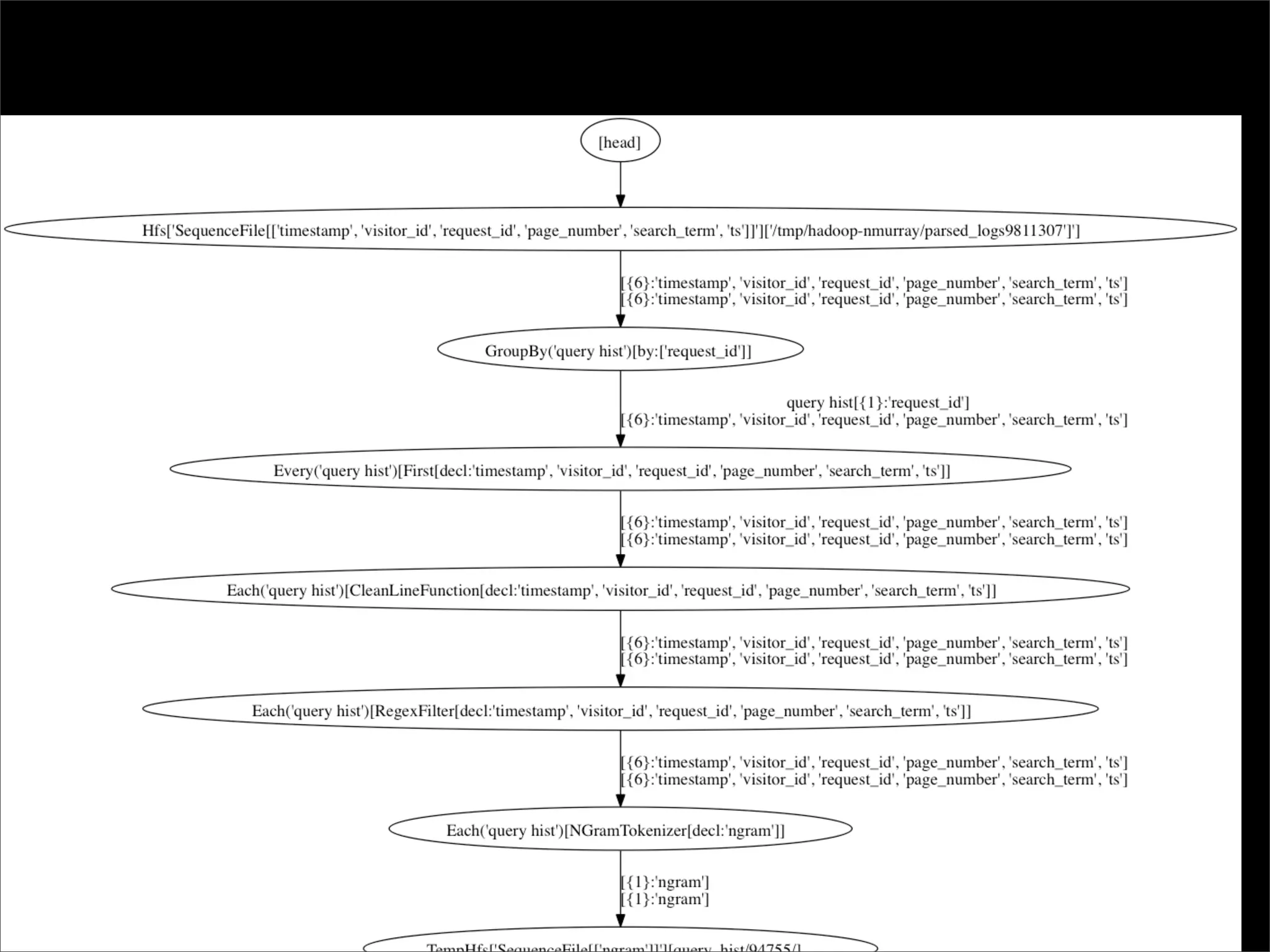
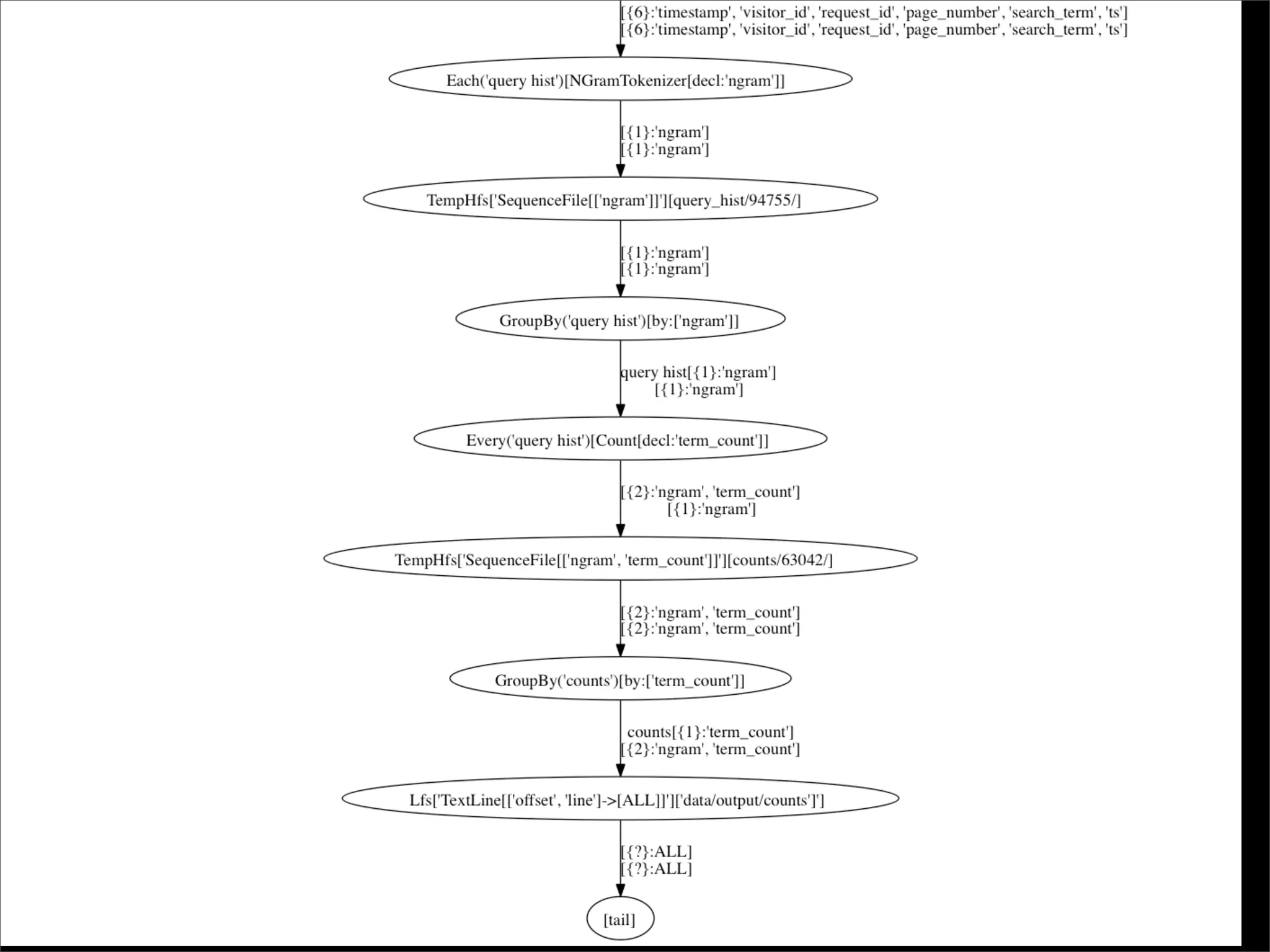
The document describes Cascading, an abstraction layer over MapReduce that allows for the creation of complex data processing workflows and reusable components. It provides higher-level abstractions than MapReduce by allowing multiple MapReduce jobs to be chained together into a single data pipeline. The document includes an example of a word count application implemented in Cascading to demonstrate how Cascading assembles pipes and taps to define data flows.



















































































