
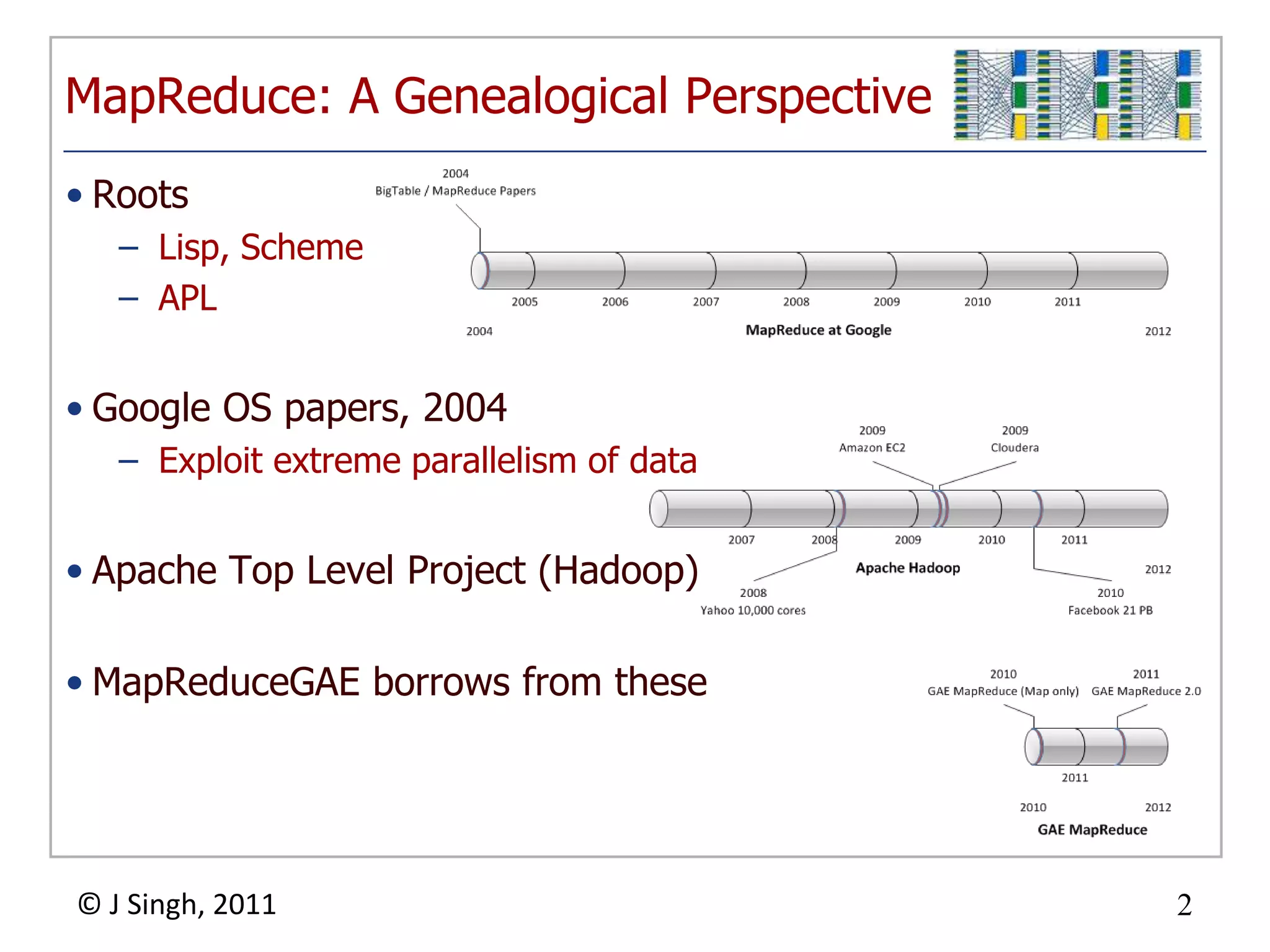





![Pipeline API Example Code
Split and Merge example
class aPipe(pipeline.Pipeline):
def run(self, e_kind, prop_name, *value_list):
all_bs = []
for v in value_list:
stage = yield bPipe(e_kind, prop_name, v)
all_bs.append(stage)
yield common.Append(*all_bs)
© J Singh, 2011 10
10](https://image.slidesharecdn.com/mapreducegae-111019150041-phpapp02/75/Social-Media-Mining-using-GAE-Map-Reduce-10-2048.jpg)












![Pipeline API Example Code
Split and Merge example
class aPipe(pipeline.Pipeline):
def run(self, e_kind, prop_name, *value_list):
all_bs = []
for v in value_list:
stage = yield bPipe(e_kind, prop_name, v)
all_bs.append(stage)
yield common.Append(*all_bs)
© J Singh, 2011 10
10](https://crownmelresort.com/image.slidesharecdn.com/mapreducegae-111019150041-phpapp02/75/Social-Media-Mining-using-GAE-Map-Reduce-10-2048.jpg)




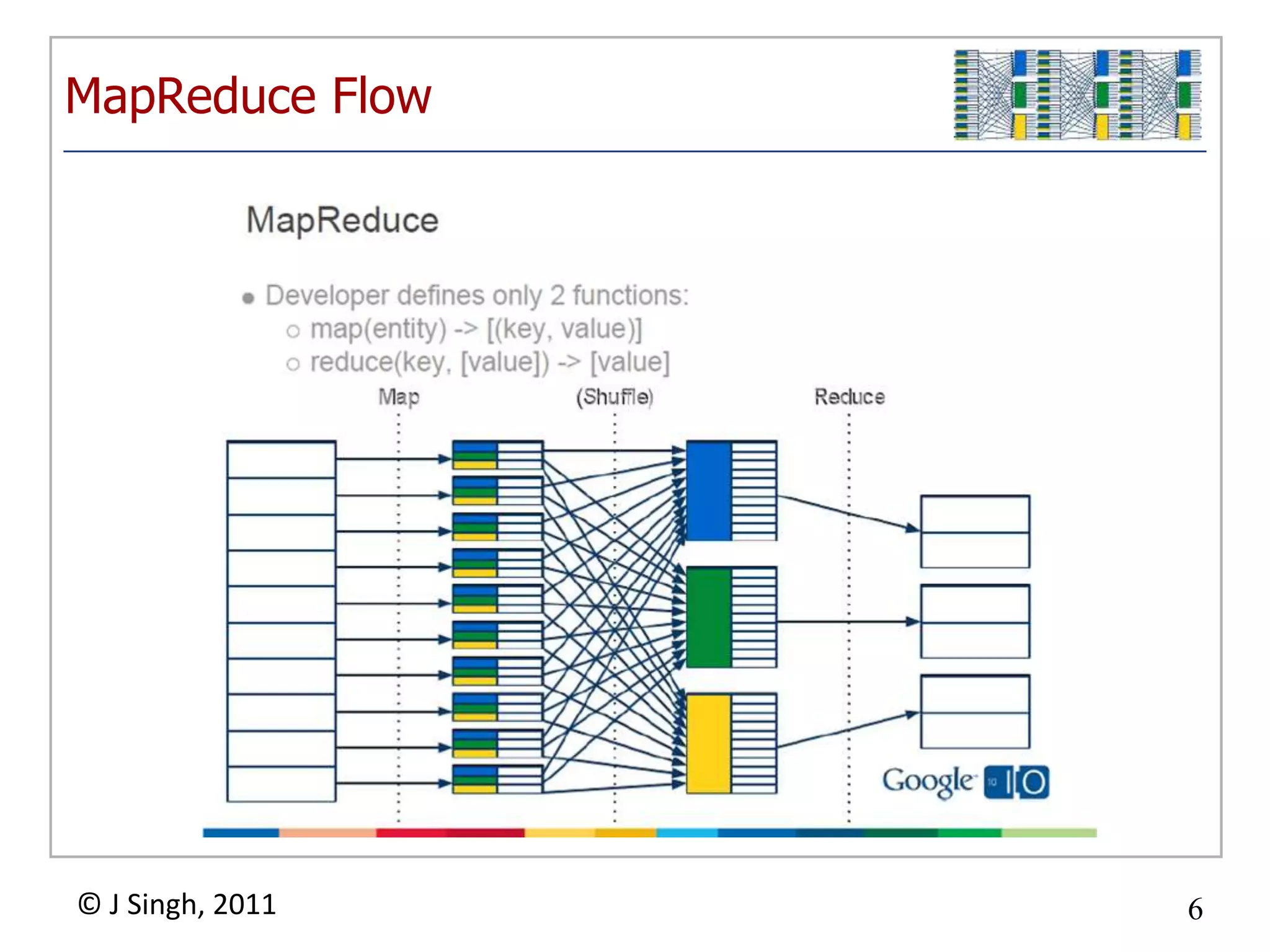
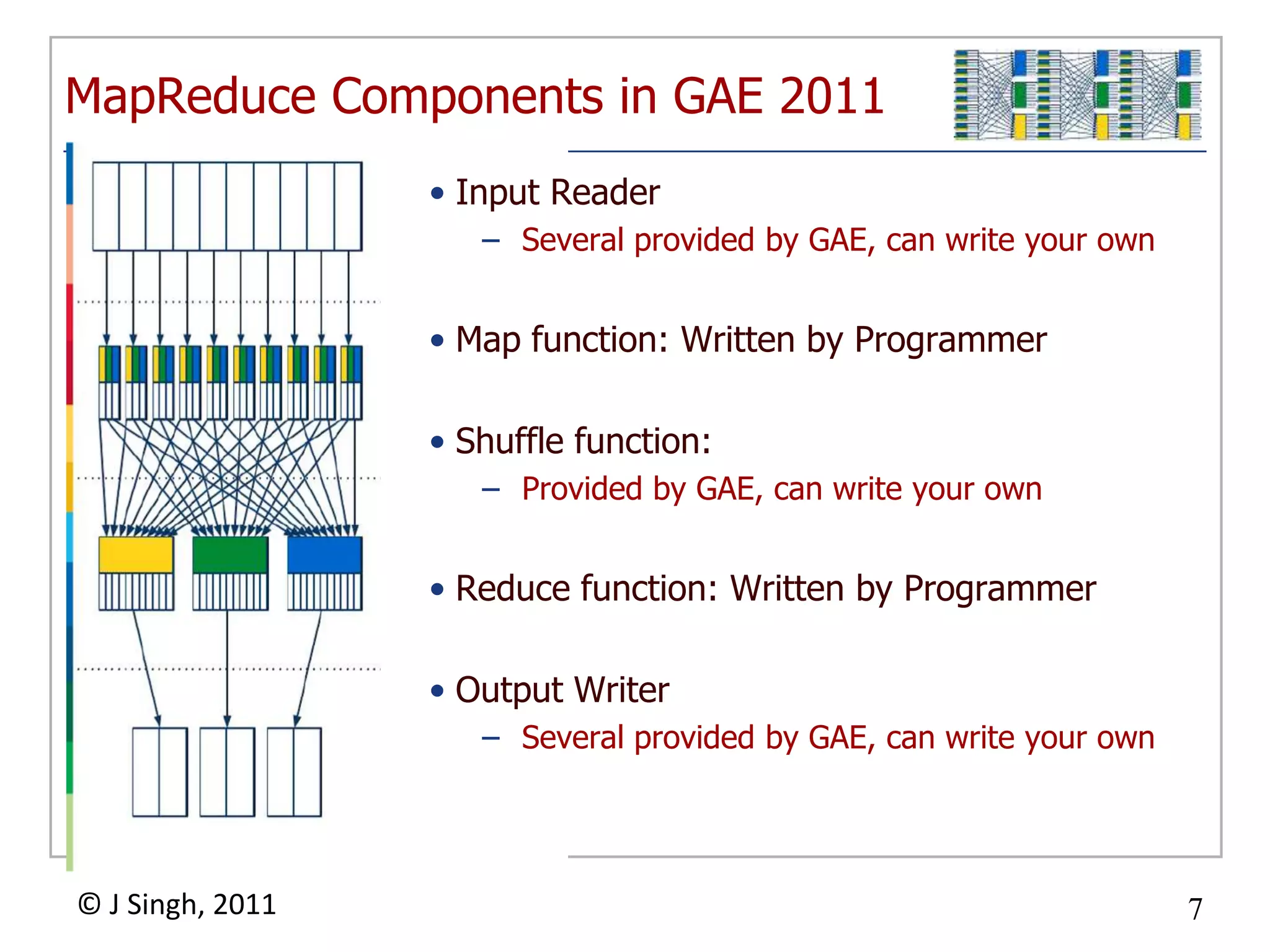
The document discusses social network mining solutions utilizing Google App Engine's MapReduce framework, highlighting its capabilities for clustering and data analysis. It illustrates the components and operational flow of MapReduce and asserts that the framework effectively scales for social network data analysis. The author plans to report on performance and scalability based on ongoing proof-of-concept tests in the near future.



![[2020 CVPR Efficient DET paper review]](https://cdn.slidesharecdn.com/ss_thumbnails/efficientdetleechanhyuk-210615060443-thumbnail.jpg?width=640&height=640&fit=bounds)











































