Download to read offline




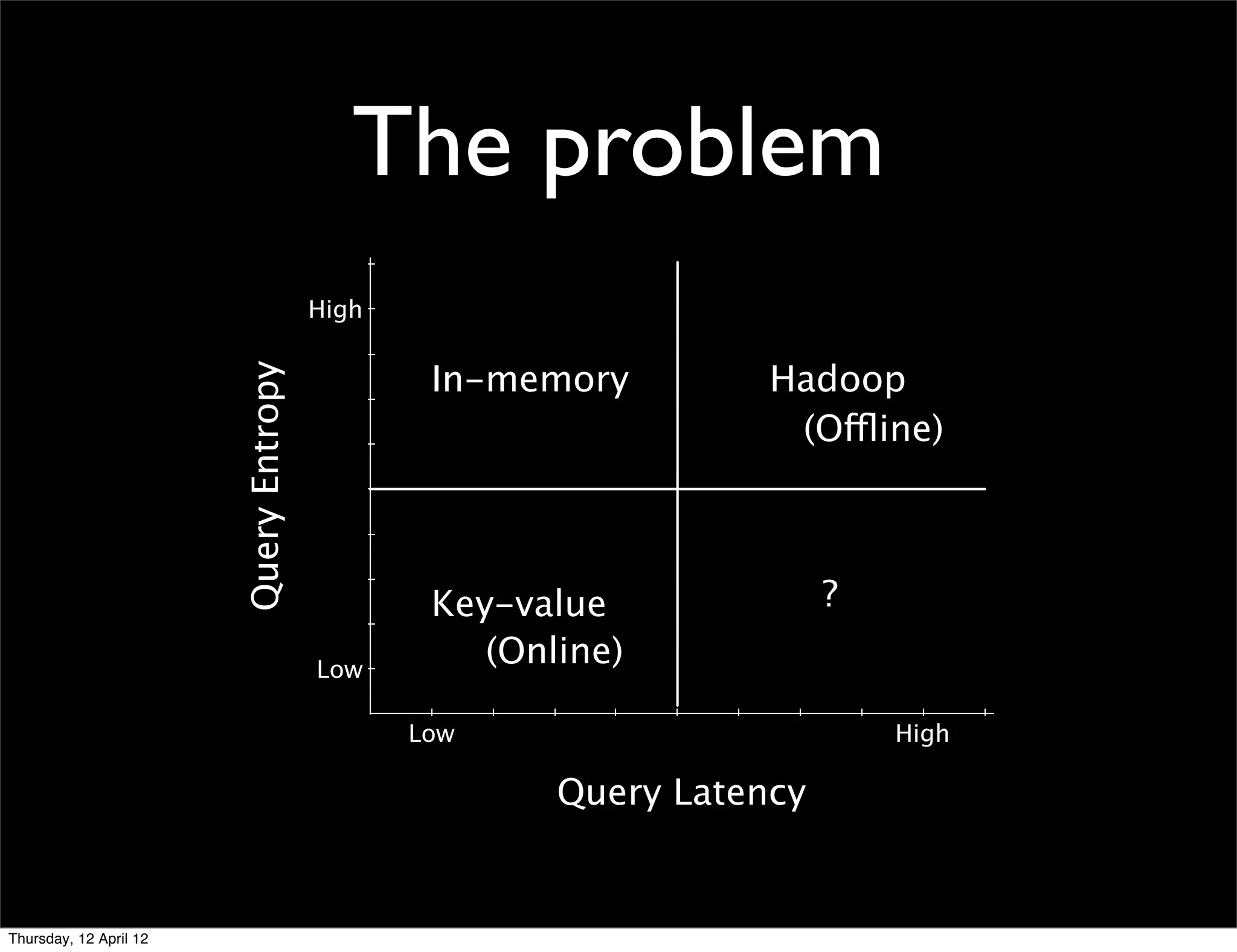


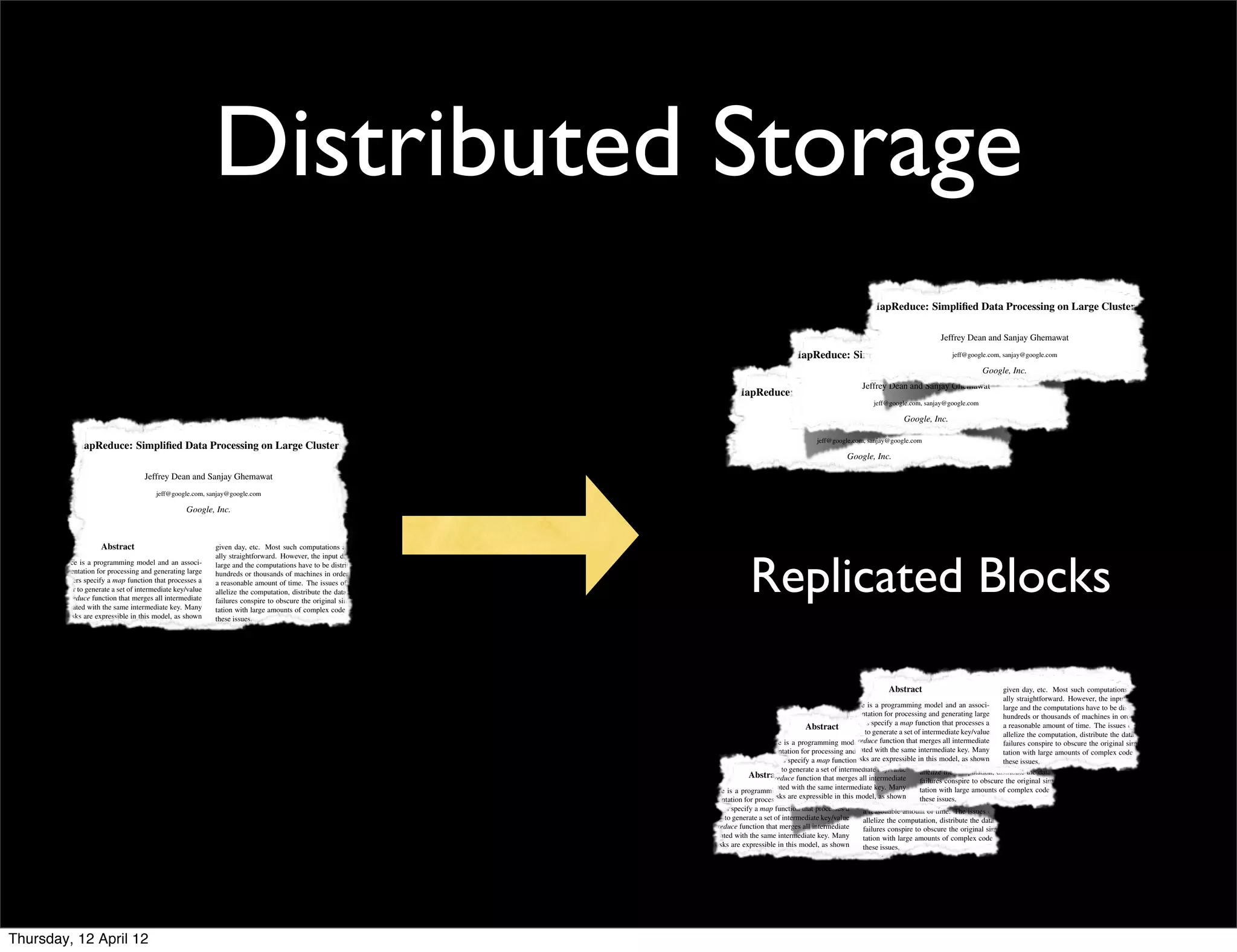
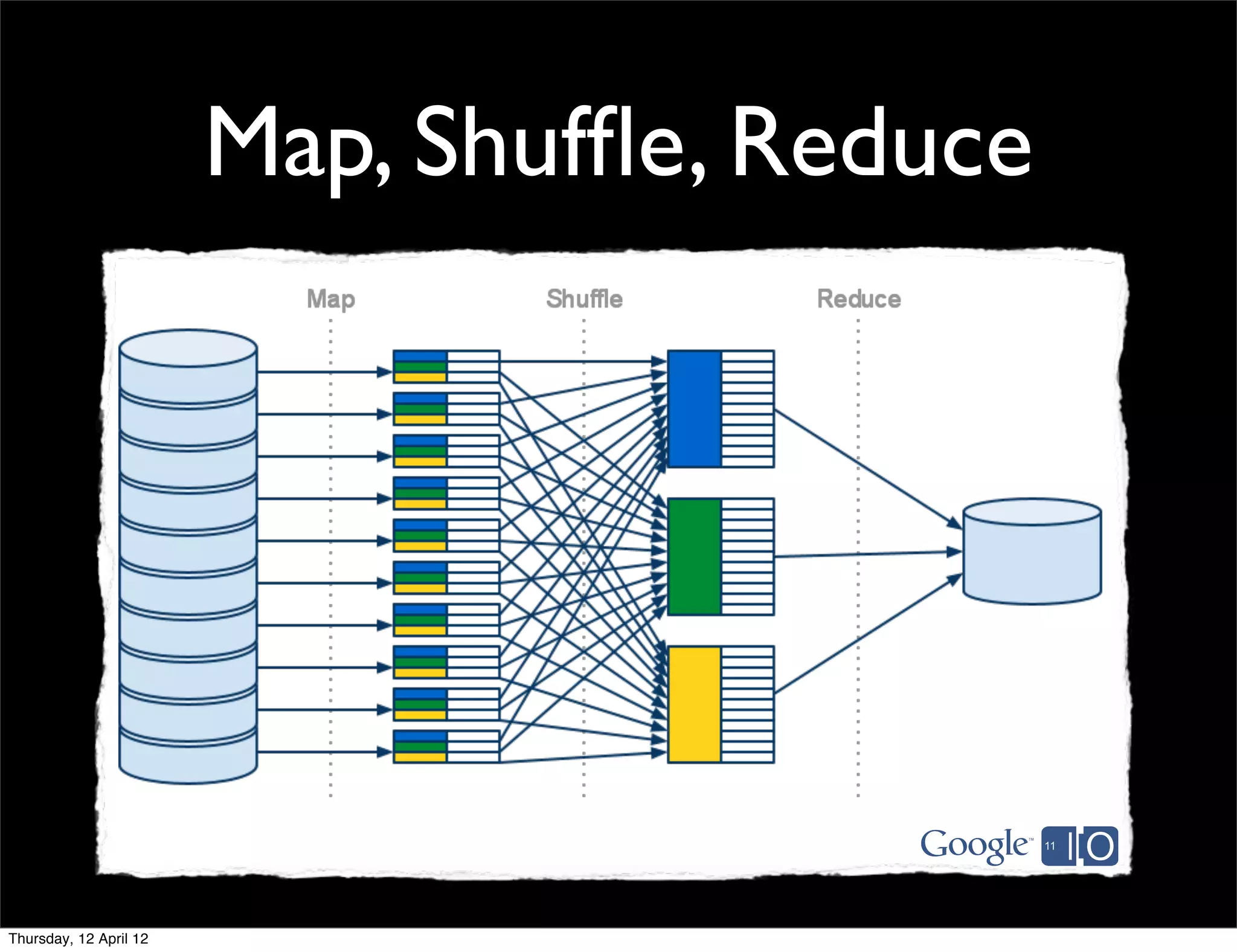
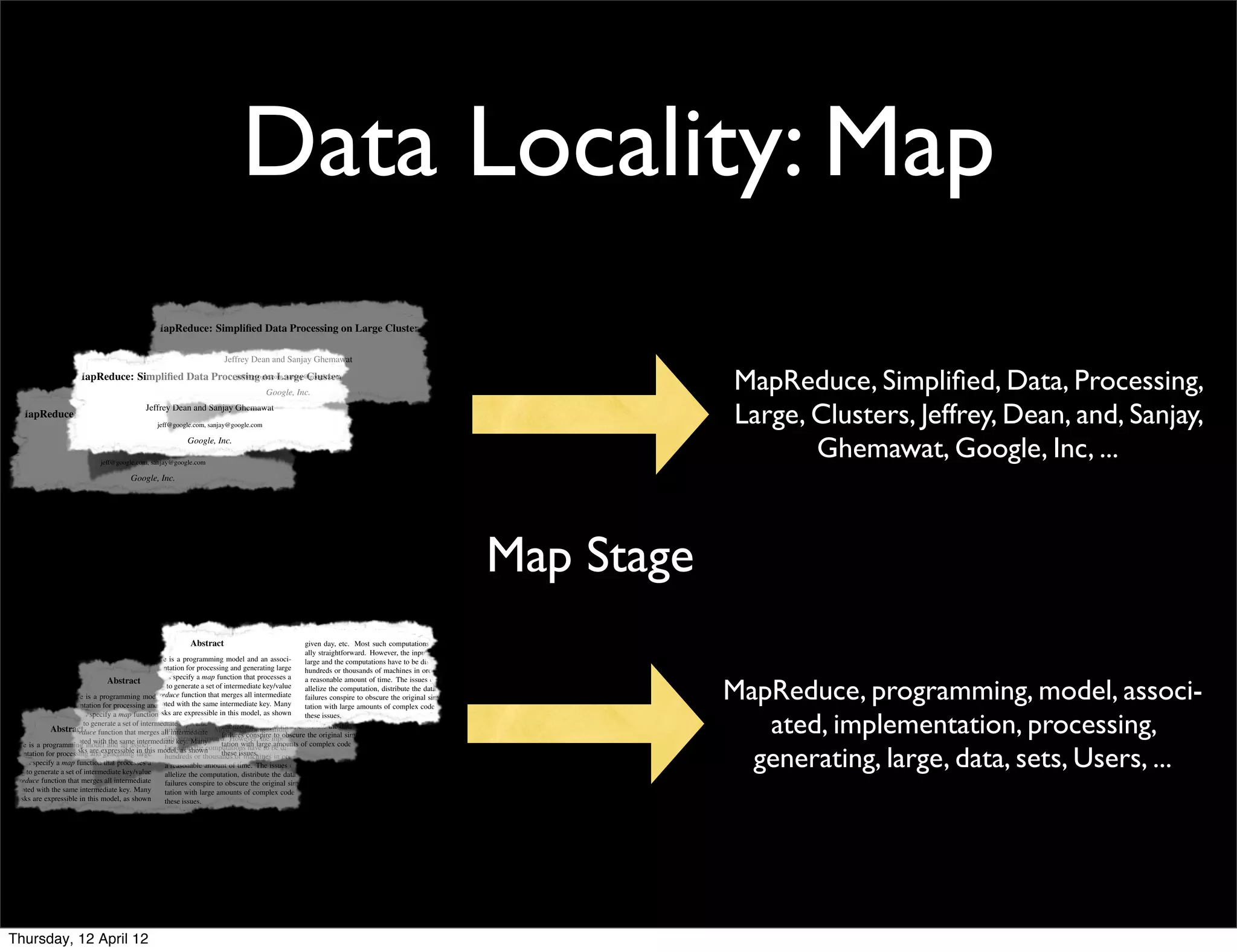

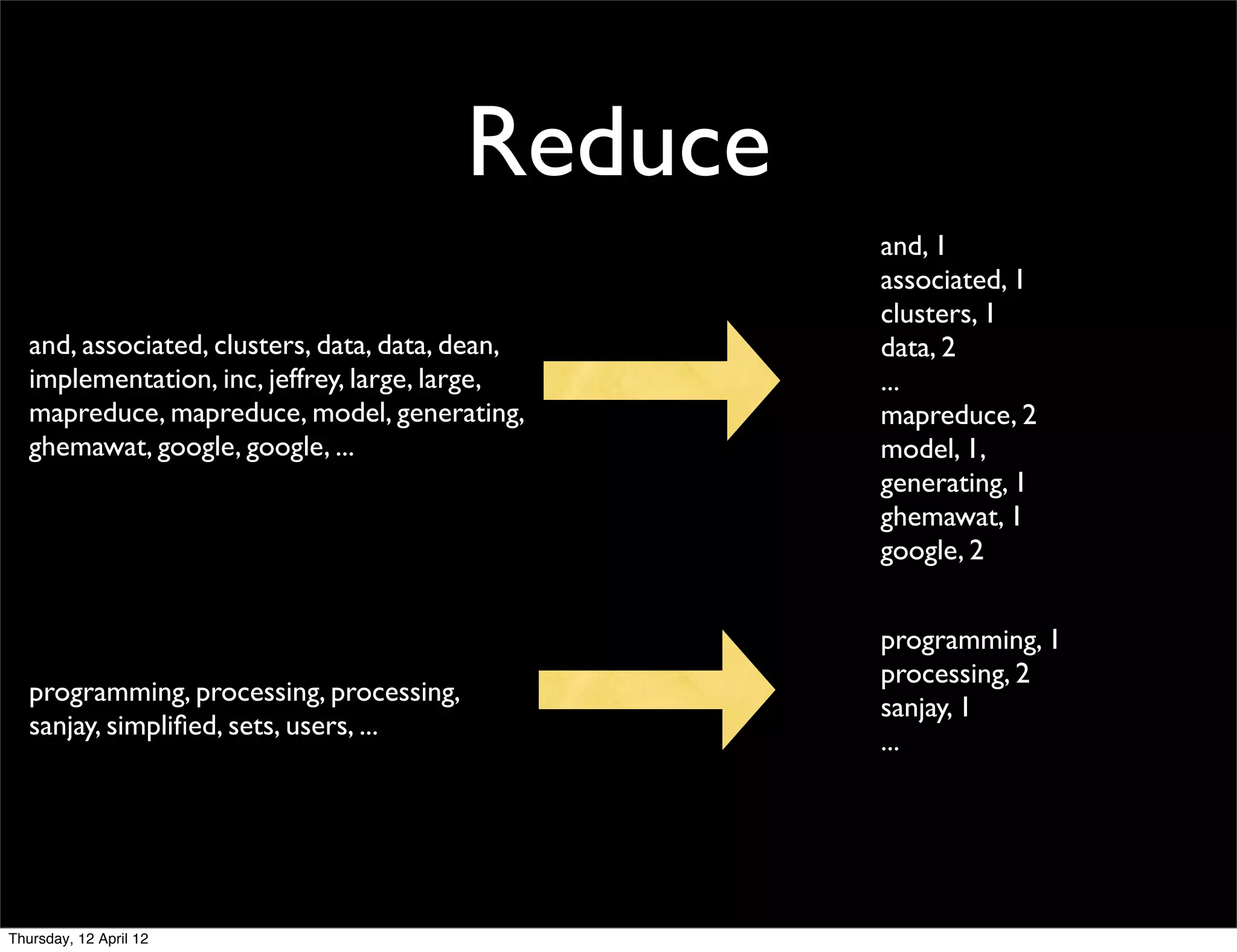

























This document provides an introduction and overview of MapReduce, a programming model for processing large datasets across distributed systems. It describes how MapReduce allows users to specify map and reduce functions to parallelize computations across large clusters. The key advantages are that it hides the complexity of parallelization, fault tolerance, and load balancing. It also provides an example implementation at Google that processes vast amounts of data across thousands of machines every day.



























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)





