Ontologies for Semantic Interoperability in the Age of AI
1.
Ontologies for Semantic
Interoperabilityin the Age of AI
Michel Dumontier, PhD
Distinguished Professor of Data Science
Founder and Director, Institute of Data Science
Department of Advanced Computing Sciences
Maastricht University
ICBO 2025 :: Virtual :: 11-11-2025
2.
Semantic Interoperability
Semantic interoperabilityis the ability of different systems, organizations, or agents to exchange
data with unambiguous, shared meaning, so that the information received is interpreted and used in
exactly the same way as intended by the sender.
Semantic interoperability is crucial to:
• FAIR data (Findable, Accessible, Interoperable, Reusable)
• data integration and query answering over knowledge graphs
• Scientific reproducibility and data reuse
• Healthcare data exchange (e.g., FHIR, OMOP, EHDS)
Moreover, information that are represented in different formats and terminologies are
considered to be equivalent
Example:
Dataset A: “BP = 120/80 mmHg”
Dataset B: “SystolicPressure = 120, DiastolicPressure = 80, Unit = mmHg”
Semantic interoperability requires that both datasets are mapped to the same concepts in a
shared ontology which allows for integration, reasoning, and inference of data and knowledge.
3.
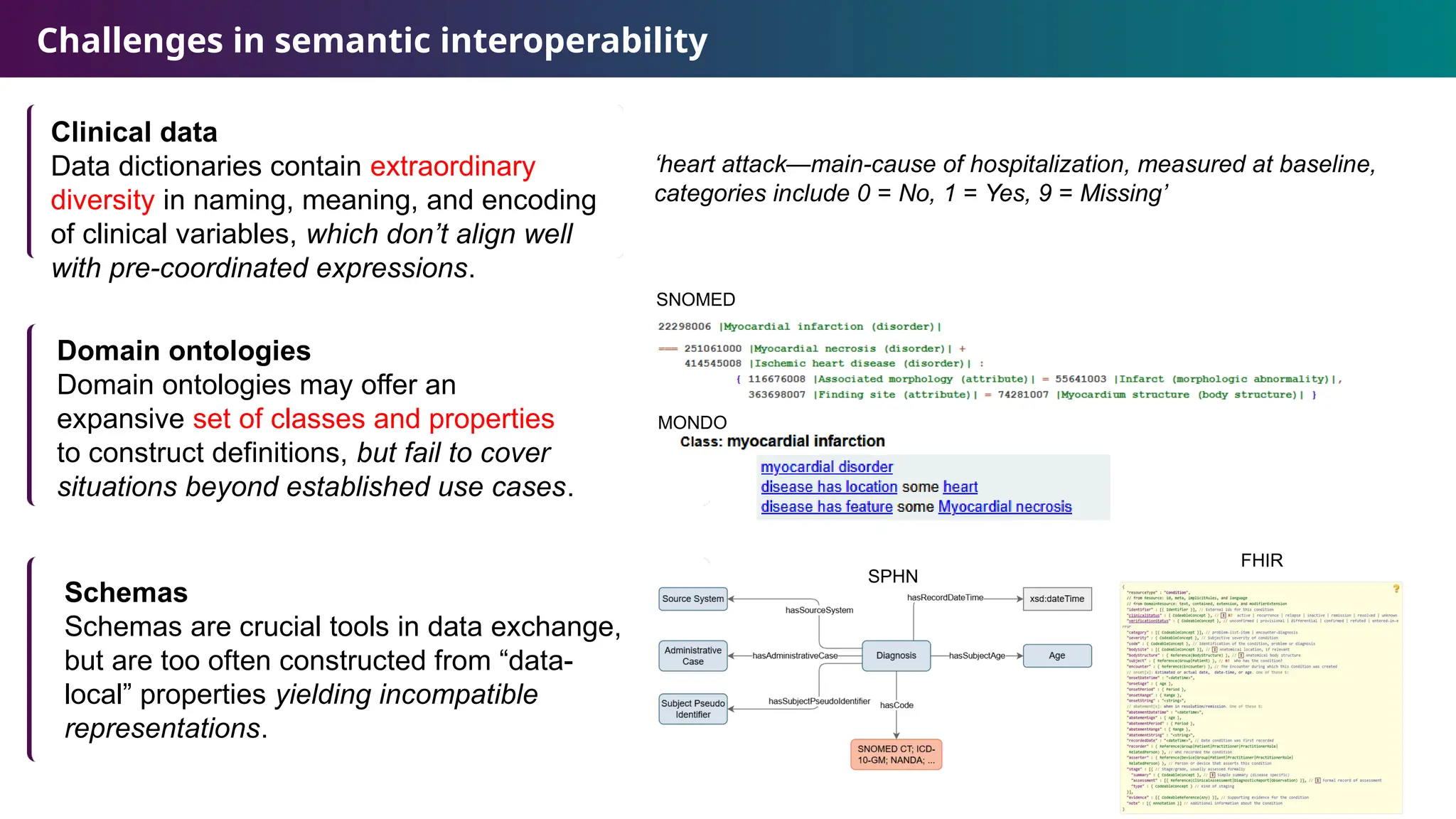
Challenges in semanticinteroperability
‘heart attack—main-cause of hospitalization, measured at baseline,
categories include 0 = No, 1 = Yes, 9 = Missing’
Clinical data
Data dictionaries contain extraordinary
diversity in naming, meaning, and encoding
of clinical variables, which don’t align well
with pre-coordinated expressions.
Domain ontologies
Domain ontologies may offer an
expansive set of classes and properties
to construct definitions, but fail to cover
situations beyond established use cases.
Schemas
Schemas are crucial tools in data exchange,
but are too often constructed from “data-
local” properties yielding incompatible
representations.
SNOMED
MONDO
SPHN
FHIR
4.
Ontologies for SemanticInteroperability in the Age of AI
LLM-Assisted Concept Mapping
Mapping data dictionaries to standard codes is a challenging task
that can made easier with AI
A simpler foundation ontology
We introduce the Simplified Upper Level Ontology (SULO) with a set
of basic ontology design patterns to guide end users to provide good
foundation for domain ontologies and schemas.
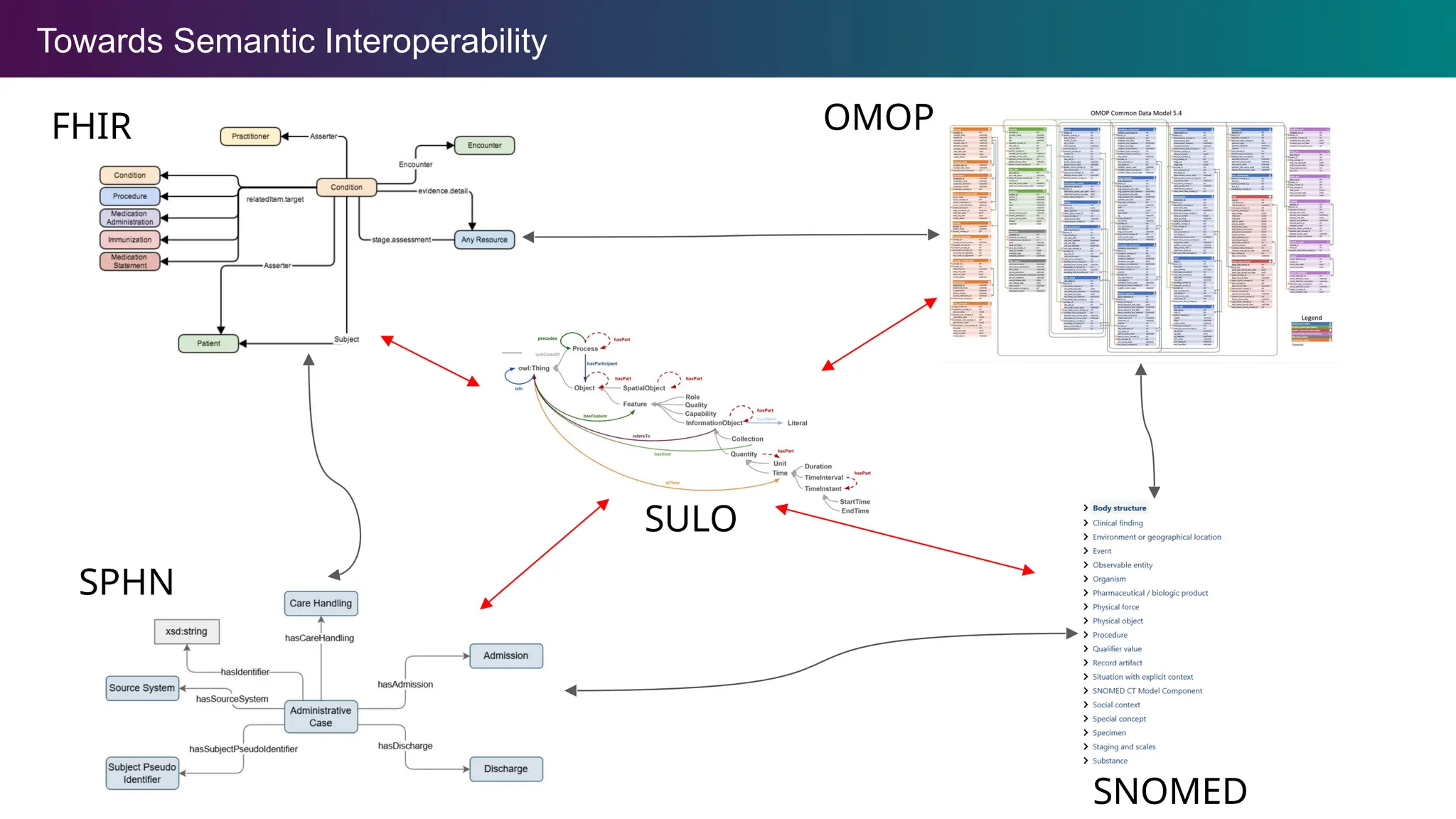
Towards Semantic Interoperability
A vision for the future that combines FAIR, ontologies,
and data interoperability technologies.
The Standardization Challengein Healthcare
Modern clinical research captures and makes use of a variety of
data stemming from prospective clinical trials to observational
studies.
Analysis of individual data is facilitated by standardization to a
particular data model, but analysis of aggregate data faces a
considerable number of challenges.
Different Data Models
Clinical trials typically follow CDISC standards, while observational
studies use OMOP, FHIR. These differ in table structures, variable
naming, value normalization, and concept assignment.
Terminology Misalignment
Different terminology/coding systems are used and mappings
between these are incomplete, ambiguous, or erroneous.
Impact of Poor Standardization
Research Reproducibility
Inconsistent data makes it difficult to reproduce findings across
studies.
Clinical Decision Support
Inaccurate data integration undermines clinical decision-making
systems.
Lower productivity
Incompatible data s essential for seamless data exchange
between systems.
7.
Concept Mapping ofClinical Data Elements (CDEs)
Case I: Precise Units
pmol/L
Case II: Composite CDEs
heart rate measured in the recumbent
position
Case III: Severity Gradients
mild to moderate asthma exacerbation
pmol/L : SNOMED-CT (258819003). Qualifier Value.
pmol/L : CDISC (C67434). Unit
picomole per liter : UCUM (p/mol/L). Unit
Heart rate taken in specific position (LOINC: LP135721-1)
Recumbent body position (SNOMED:102538003)
mild-to-moderate equine asthma (SNOMED:359871000009104)
Moderate acute exacerbation of asthma (SNOMED:734905008)
Exacerbation of mild persistent asthma (SNOMED:707445000)
acute asthma (SNOMED:304527002).
mild-to-moderate (LOINC:LA15008-8)
8.
Limitations of CurrentMethods for Concept Mapping
Existing approaches to CDE standardization face several critical limitations:
Ineffectiveness with Composite CDEs
Many methods optimized for atomic CDEs:
• Rule-based systems (QuickUMLS, MetaMapLite, cTAKES)
• Fine-tuned language models (BERT)
Struggle with complex composite CDEs that require
understanding context and relationships between multiple
attributes.
Scalability Issues
Current approaches face challenges with:
• Processing large controlled vocabularies
• Handling overlapping and granular concepts
• Must align to a predefined schema.
Efficient scaling remains a critical challenge for real-world
healthcare applications.
Lack of Intrinsic Domain Knowledge
Large Language Models generally lack specialized medical
domain knowledge unless:
• Fine-tuned on medical data
• Augmented with domain-specific resources
Specialized terminologies and evolving vocabularies require
deeper domain understanding.
Generalization & Limited Training Data
Most concept linking methods struggle with:
• Generalizing to unseen data
• Exhibiting decreased accuracy due to limited training
datasets
Clinical concepts require robust models that can handle the
complexity and variability of medical language.
9.
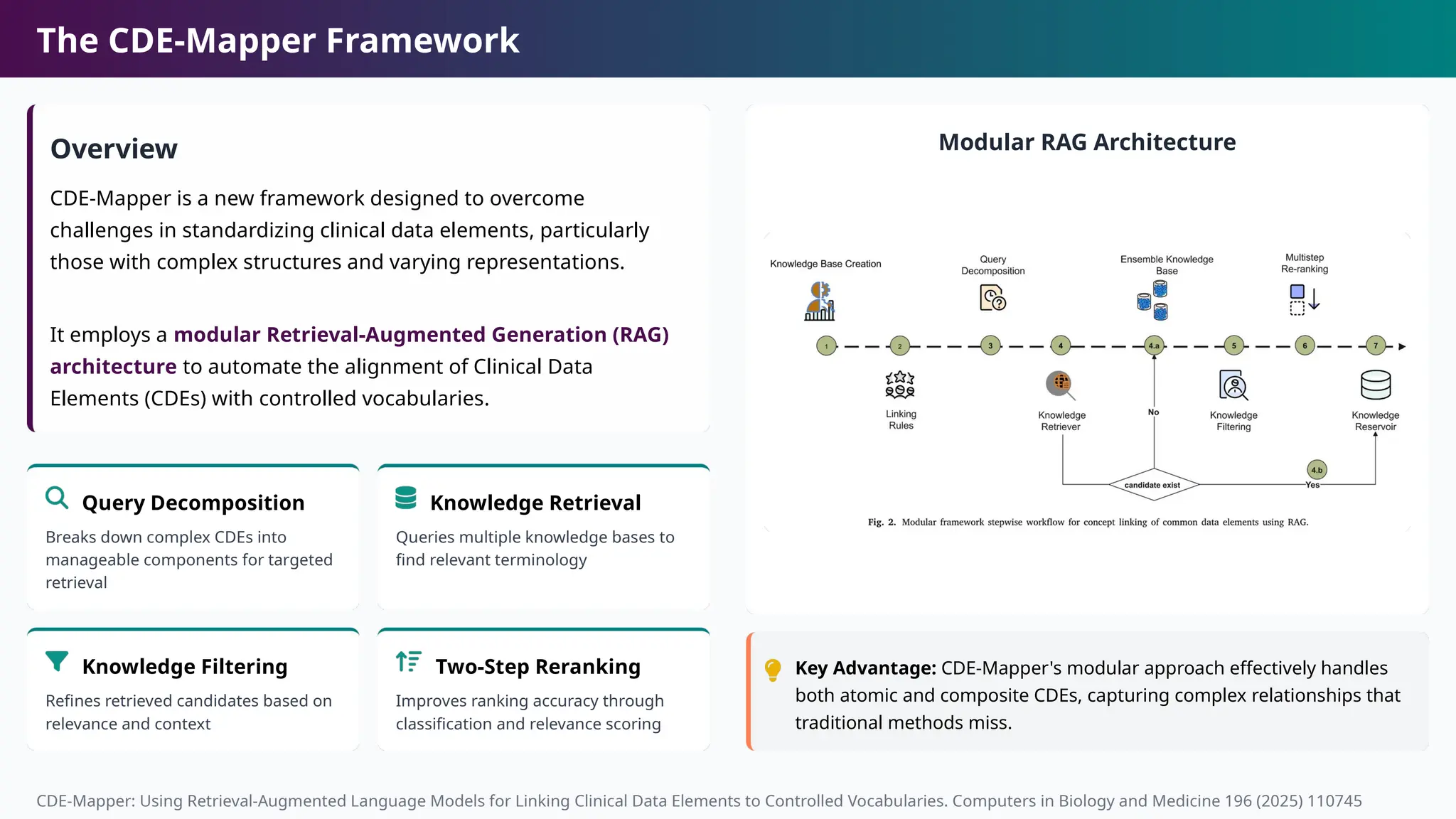
The CDE-Mapper Framework
Overview
CDE-Mapperis a new framework designed to overcome
challenges in standardizing clinical data elements, particularly
those with complex structures and varying representations.
It employs a modular Retrieval-Augmented Generation (RAG)
architecture to automate the alignment of Clinical Data
Elements (CDEs) with controlled vocabularies.
Query Decomposition
Breaks down complex CDEs into
manageable components for targeted
retrieval
Knowledge Retrieval
Queries multiple knowledge bases to
find relevant terminology
Knowledge Filtering
Refines retrieved candidates based on
relevance and context
Two-Step Reranking
Improves ranking accuracy through
classification and relevance scoring
Modular RAG Architecture
Key Advantage: CDE-Mapper's modular approach effectively handles
both atomic and composite CDEs, capturing complex relationships that
traditional methods miss.
CDE-Mapper: Using Retrieval-Augmented Language Models for Linking Clinical Data Elements to Controlled Vocabularies. Computers in Biology and Medicine 196 (2025) 110745
10.
Query Decomposition
The querydecomposition (qd) step involves using
an LLM to decompose the query into a structured
output upon which individual concept mappings
will be performed. In-context learning with the
original query, a task description, and relevant
examples.
{
base_entity: "heart attack",
associated_entities: ["Hospitalization Reason"],
categories: ["Yes", "No", "Missing"],
visit: "baseline"
}
QD format
{
base_entity: <>
associated_entities: <>
categories: <>
unit: <>
visit: <>
method: <>
}
‘heart attack—main-cause of hospitalization,
measured at baseline, categories
include 0 = No, 1 = Yes, 9 = Missing’
11.
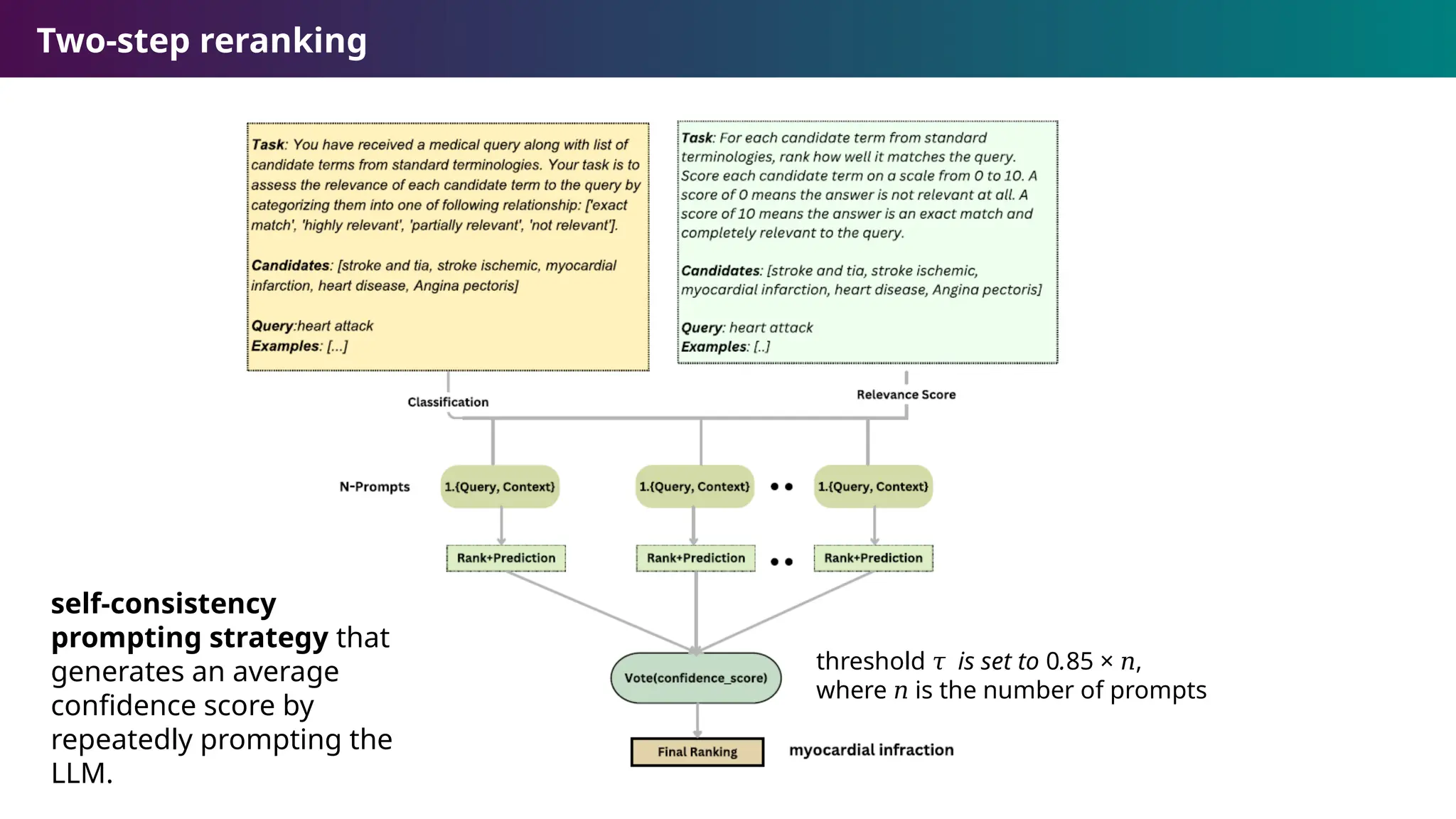
Knowledge retriever, filtering,and reranking
For each decomposed query, the knowledge retriever checks the
knowledge reservoir for an exact match. The knowledge reservoir is
human validated database of LLM-generated concept mappings.
If the component is not found, then knowledge retrieval occurs using an
ensemble embedding retrieval strategy.
a) SPLADE for sparse representations towards exact concept matches
b) SapBERT for dense representations towards to discriminate between
subtle variations
Concept embeddings are generated from the concept label, its synonyms,
along with hierarchical information and semantic type. Searching the query
against the embedded concepts generates a ranked list.
The knowledge filter uses a similarity threshold + metadata-based filtering
rules to enhance accuracy and precision by discarding noisy, irrelevant, or
semantically misaligned candidates
Two step reranking is the applied to obtain final candidates.
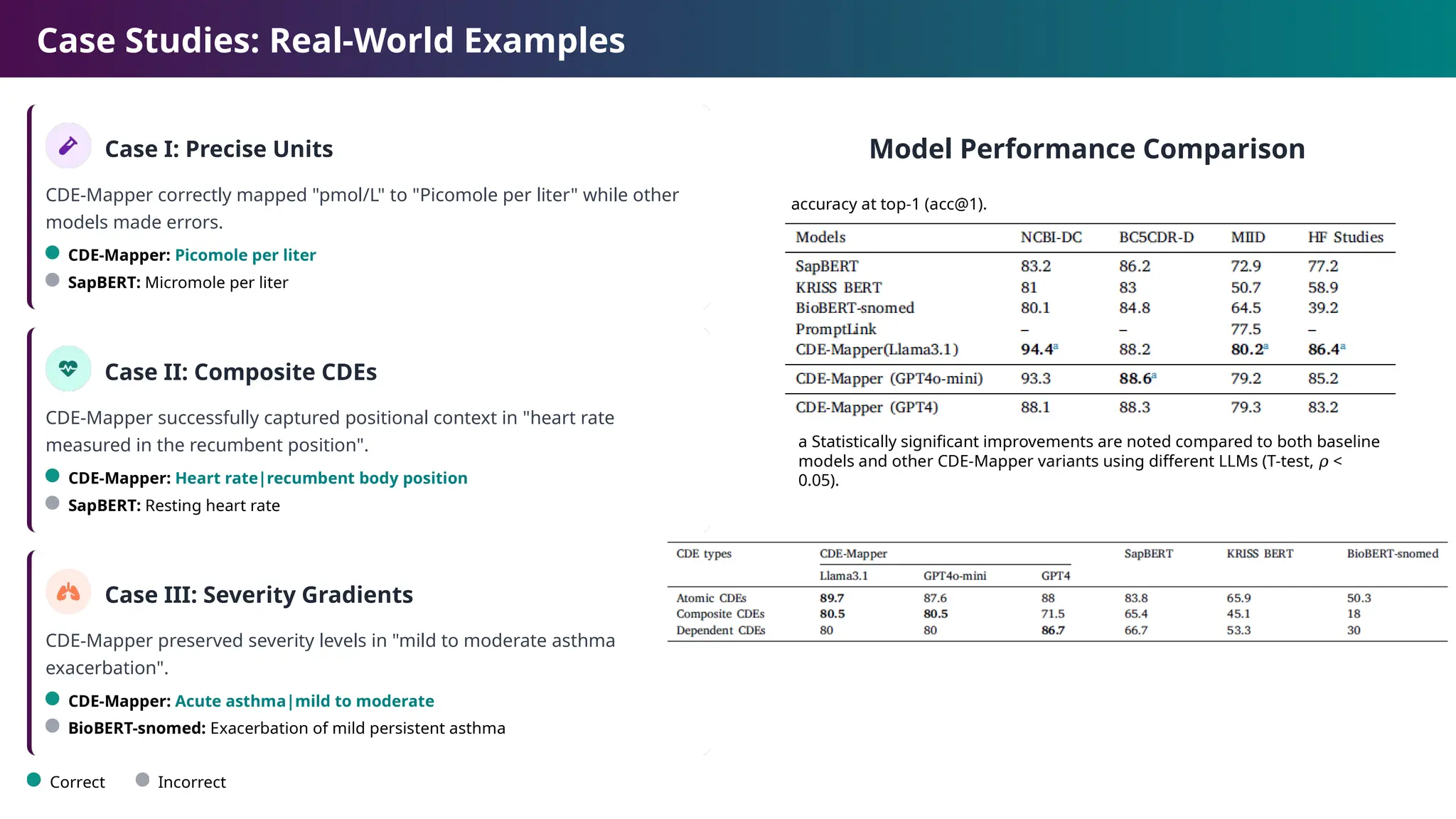
Case Studies: Real-WorldExamples
Case I: Precise Units
CDE-Mapper correctly mapped "pmol/L" to "Picomole per liter" while other
models made errors.
CDE-Mapper: Picomole per liter
SapBERT: Micromole per liter
Case II: Composite CDEs
CDE-Mapper successfully captured positional context in "heart rate
measured in the recumbent position".
CDE-Mapper: Heart rate|recumbent body position
SapBERT: Resting heart rate
Case III: Severity Gradients
CDE-Mapper preserved severity levels in "mild to moderate asthma
exacerbation".
CDE-Mapper: Acute asthma|mild to moderate
BioBERT-snomed: Exacerbation of mild persistent asthma
Model Performance Comparison
Correct Incorrect
accuracy at top-1 (acc@1).
a Statistically significant improvements are noted compared to both baseline
models and other CDE-Mapper variants using different LLMs (T-test, <
𝜌
0.05).
14.
Conclusion and Impact
KeyContributions & Impact
Novel RAG Framework
CDE-Mapper introduces a modular Retrieval-Augmented
Generation framework specifically designed for clinical data
standardization.
Superior Performance
Consistently outperforms baseline models across diverse
datasets, particularly with complex composite CDEs.
Enhanced Interoperability
Improves data integration and interoperability, supporting
more robust clinical decision-making and research.
Conclusion
CDE-Mapper represents a significant step forward in clinical data
standardization, but ongoing work is needed to address remaining
challenges and further enhance interoperability across healthcare systems
Foundation Ontologies
Ontologies area formalization of a shared conceptualization of a
domain. They provide machine interpretable descriptions of entities,
their attributes, and their relations.
Upper Level Ontologies (ULOs), aka foundation ontologies, offer
an overarching axiomatic framework for domain ontologies (DOs) so
as to constrain the conceptualization and lead to a consistent
formalization.
Many ontologies and schemas don’t use ULOs
Domain ontologies (e.g. SNOMED) and data schemas (e.g. SPHN) are
often driven by immediate, pragmatic needs and ULOs are not typically
used to guide their development.
Inefficient representations
The lack of adherence to an ULO leads to inefficient representations:
● Inability to extend the domain ontology or schema by reusing
domain and/or application-specific relations
● a proliferation of semantically ungrounded relations
● non-interoperable schemas around each target class
17.
SNOMED
SNOMED CT (SystematizedNomenclature of Medicine –
Clinical Terms) is a comprehensive, multilingual clinical
terminology designed to represent medical knowledge in a
computable form.
SNOMED CT covers diseases, symptoms, procedures, body
structures, organisms, substances, pharmaceuticals, devices,
findings, and other clinical concepts.
SNOMED CT comprises 375,783 classes with 19 top level
classes and 246 properties that can be used to compose
expressions:
Observations
Top level classes such as Body structure, Organism,
Pharmaceutical/biologic product, Specimen are all
kinds of physical entities of interest now, but what if
something new comes around in the future?
Object properties such as Associated morphology or
Finding Site are used to constrain data expressions to
a particular value range, but what if we need to
construct different kinds of descriptions?
18.
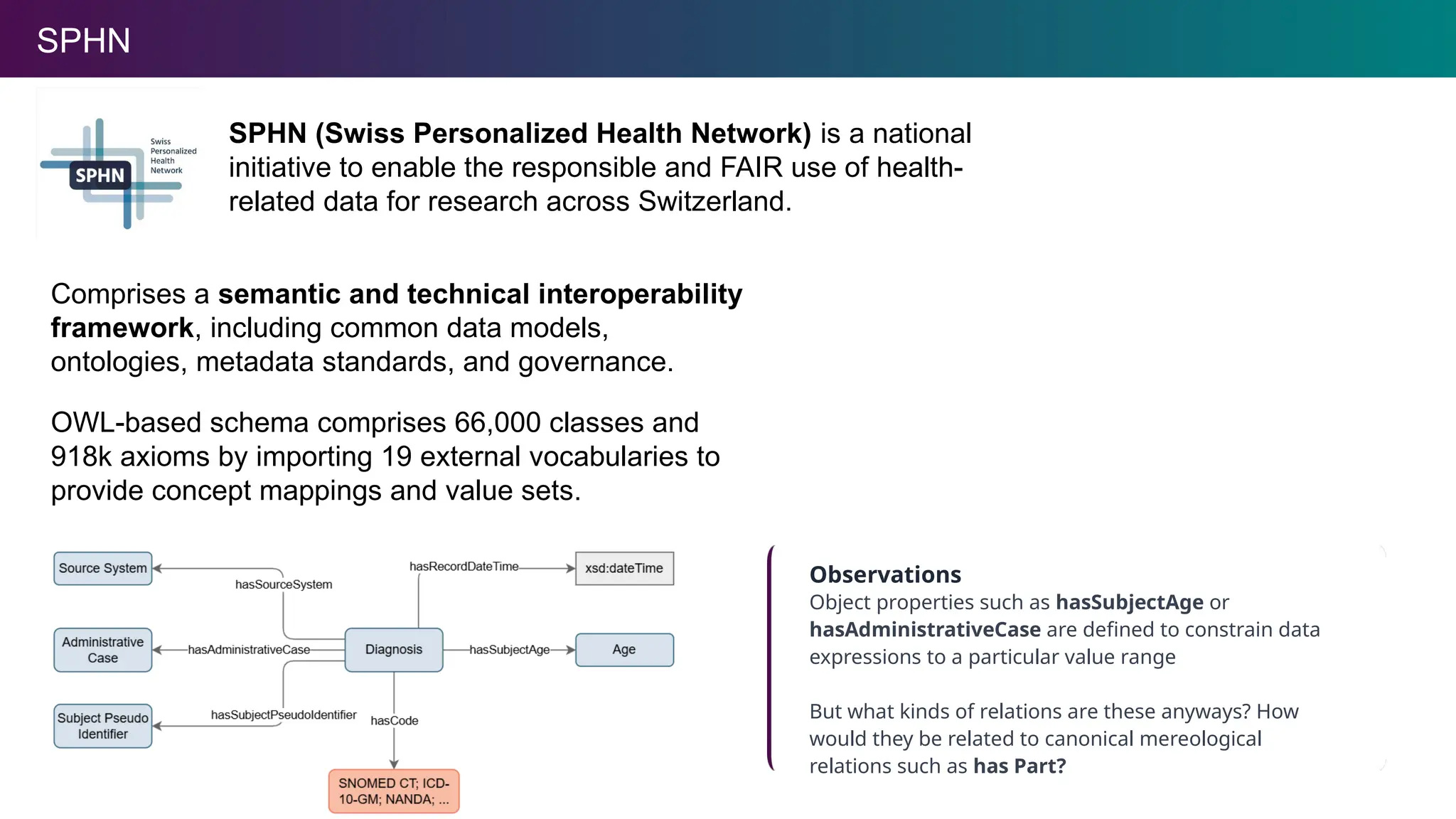
SPHN
SPHN (Swiss PersonalizedHealth Network) is a national
initiative to enable the responsible and FAIR use of health-
related data for research across Switzerland.
OWL-based schema comprises 66,000 classes and
918k axioms by importing 19 external vocabularies to
provide concept mappings and value sets.
Observations
Object properties such as hasSubjectAge or
hasAdministrativeCase are defined to constrain data
expressions to a particular value range
But what kinds of relations are these anyways? How
would they be related to canonical mereological
relations such as has Part?
Comprises a semantic and technical interoperability
framework, including common data models,
ontologies, metadata standards, and governance.
19.
Foundation Ontologies
Ontologies area formalization of a shared conceptualization of a
domain. They provide machine interpretable descriptions of entities,
their attributes, and their relations.
Upper Level Ontologies (ULOs), aka foundation ontologies, offer
an overarching axiomatic framework for domain ontologies (DOs) so
as to constrain the conceptualization and lead to a consistent
formalization.
Many ontologies and schemas don’t use ULOs
Domain ontologies (e.g. SNOMED) and data schemas (e.g. SPHN) are
often driven by immediate, pragmatic needs and ULOs are not typically
used to guide their development.
Inefficient representations
The lack of adherence to an ULO leads to inefficient representations:
● Inability to extend the domain ontology or schema by reusing
domain and/or application-specific relations
● leading to a proliferation of semantically ungrounded relations
● leading to non-interoperable schemas around each target class
Challenges in (re)using Foundation Ontologies
Need background in Logic and Philosophy
Most ULOs feature nuanced philosophical considerations
and familiarity with logic.
Unfamiliar labels
ULOs adopt unfamiliar or technical labels: continuant,
endurant, perdurant, specifically dependent continuant,
which avoids meaning overload, but are difficult to grasp
and correctly apply by non experts
Variable coverage
ULOs have distinct, missing, underrepresented, or
overconstrained areas. BFO and DOLCE focus on
particulars, only BFO has time indexed relations (only in
their common logic), immaterial bearers are not possible in
BFO, BFO/GFO/DOLCE do not offer any data relations.
20.
Surprisingly high levelsof disagreement even among trained experts
0.52 inter-rater agreement
degree of classification consistency is
correlated with the frequency the respective
BFO classes are used in practice
8 BFO experts asked to classify 46
commonly known entities from the
domain of travel with BFO entities.
21.
Desirable features ofan upper level ontology
• Minimalism: A small taxonomy of disjoint classes and a minimal set of constrained
relations to ensure broad applicability for domain knowledge representation.
• Compatibility: Maintain compatibility with core components of well-known ULOs while
remaining accessible to domain experts.
• Accessibility: Be accessible to users with no or little training in formal ontology through
friendly labeling and minimalist design.
• Composability: Provide building blocks to construct complex, machine-readable class
expressions.
• Interoperability: Foster interoperability by providing a common semantic foundation,
strengthened by ontology design patterns that help domain experts adhere to intended
semantics.
• Data validation: Constrains real-world knowledge graphs through automated reasoning
and schema validation.
22.
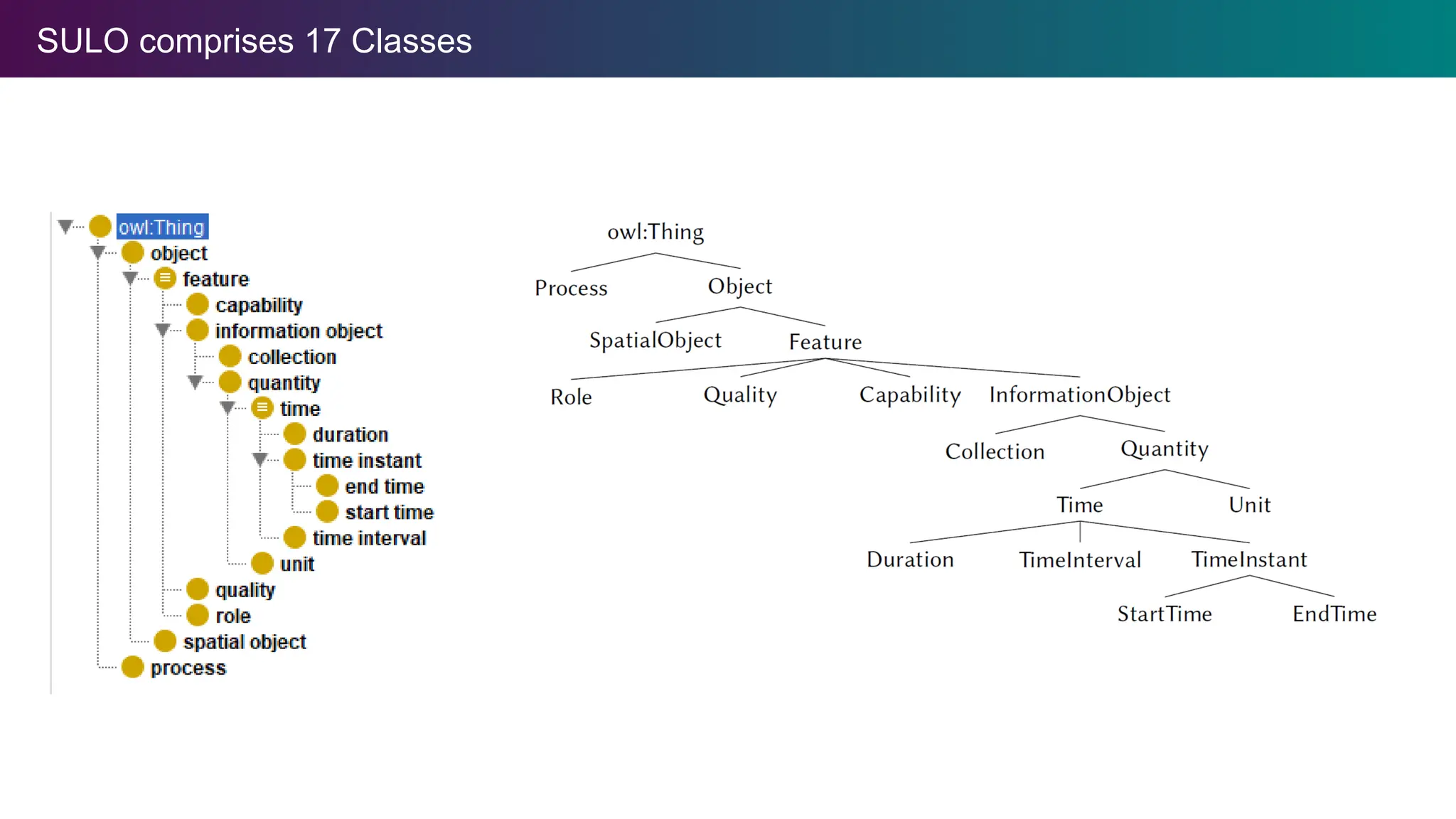
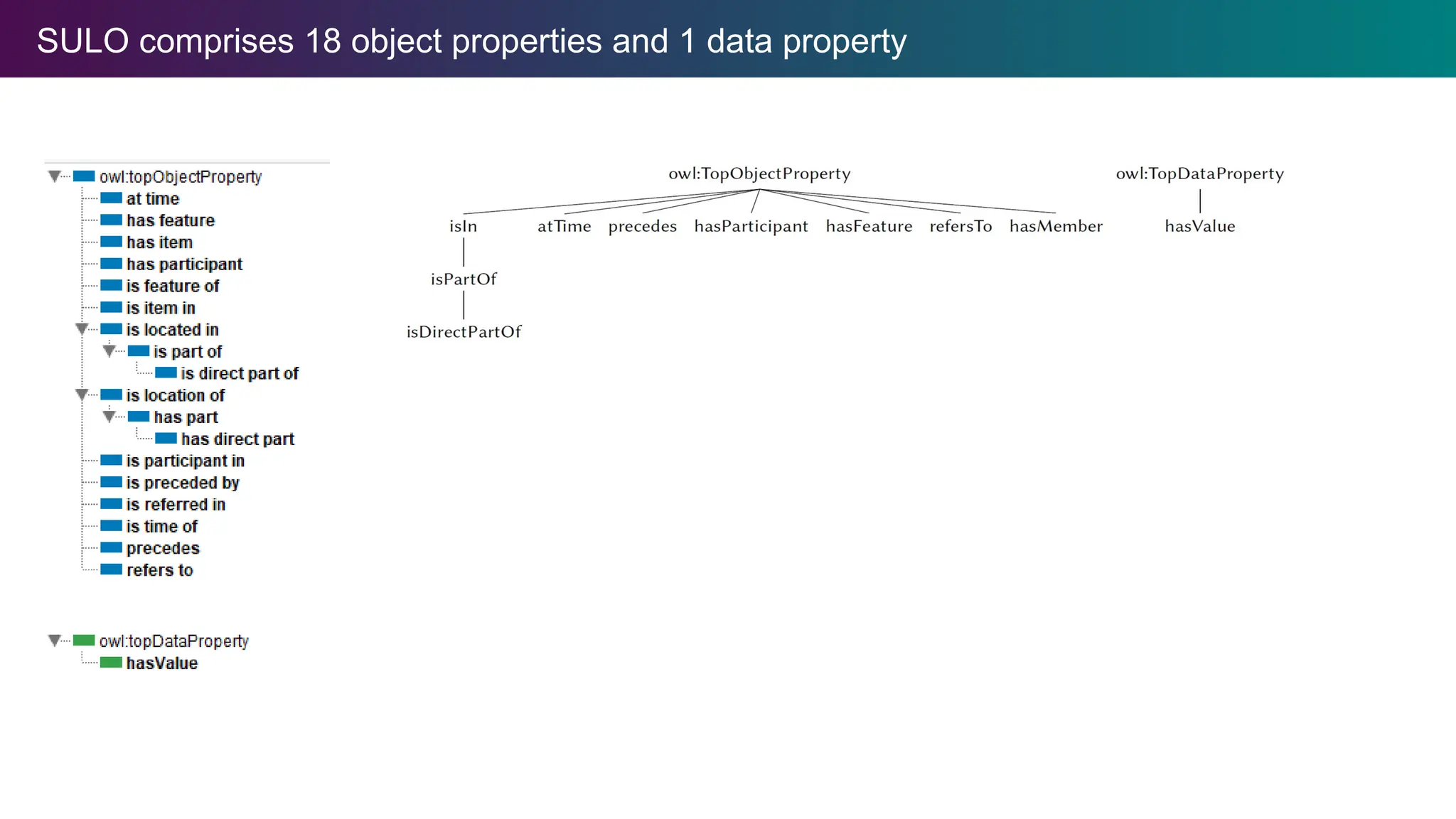
Simplified Upper LevelOntology (SULO)
We propose the Simplified Upper Level
Ontology (SULO) take a minimalistic
approach to guide the alignment,
formalization, and reusability of (upper level
and domain) ontologies and schemas.
SULO attempts to balance formal rigor with
simplicity and practical usability.
NEON methodology:
1. domain analysis
2. gathering requirements
3. development of modular and
pattern-based designs
4. alignment with standards and
existing ontologies
5. iterative development and
validation
6. integration and maintenance
SULO reduces thecomplexity of choosing relations to compose expressions
SULO BFO GFO gUFO DOLCE
27.
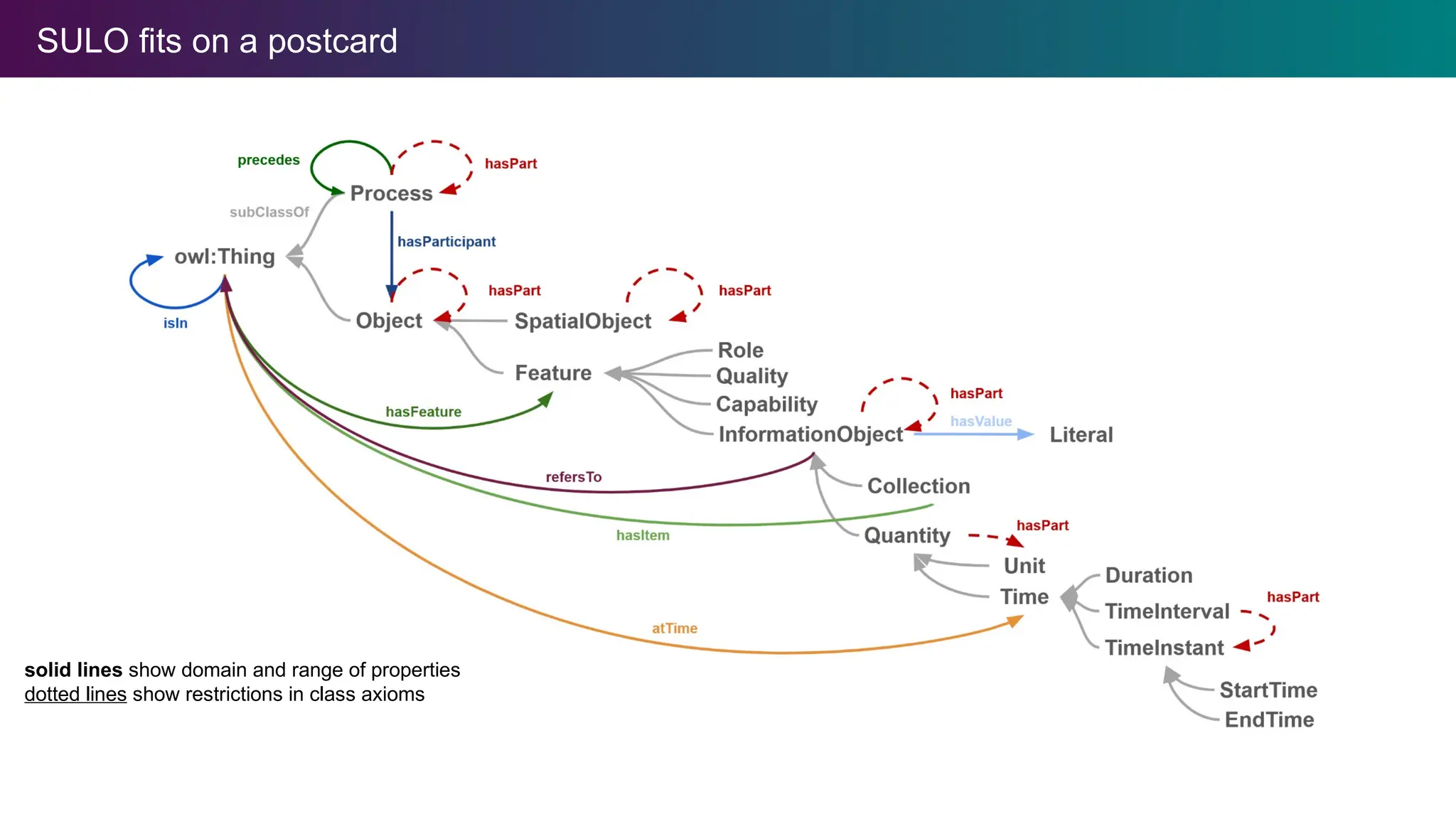
SULO fits ona postcard
solid lines show domain and range of properties
dotted lines show restrictions in class axioms
28.
Ontology Design Patterns
OntologyDesign Patterns (ODPs) can help to structure
data graphs that strengthens semantic interoperability
across domain-specific knowledge representations
We propose two key ODPs to reduce the proliferation
of data and object properties
SOLID focuses on describing literal values
PRO focuses on describing role-based relations
29.
SULO Ontology DesignPatterns – SOLID
The SOLID pattern uses SULO’s single functional data property, hasValue, to assign a literal
value to an InformationObject.
Example: Instead of using arbitrary relations such as hasTemperature or
hasTemperatureInCelcius, the design pattern reuses SULO’s hasValue, hasFeature, refersTo,
and hasPart properties in conjunction with two externally defined classes, namely Temperature
from PATO and Celcius from the Unit Ontology
Hence, developing an ontology of InformationObject is encouraged, rather than focusing on a
proliferation of data properties.
30.
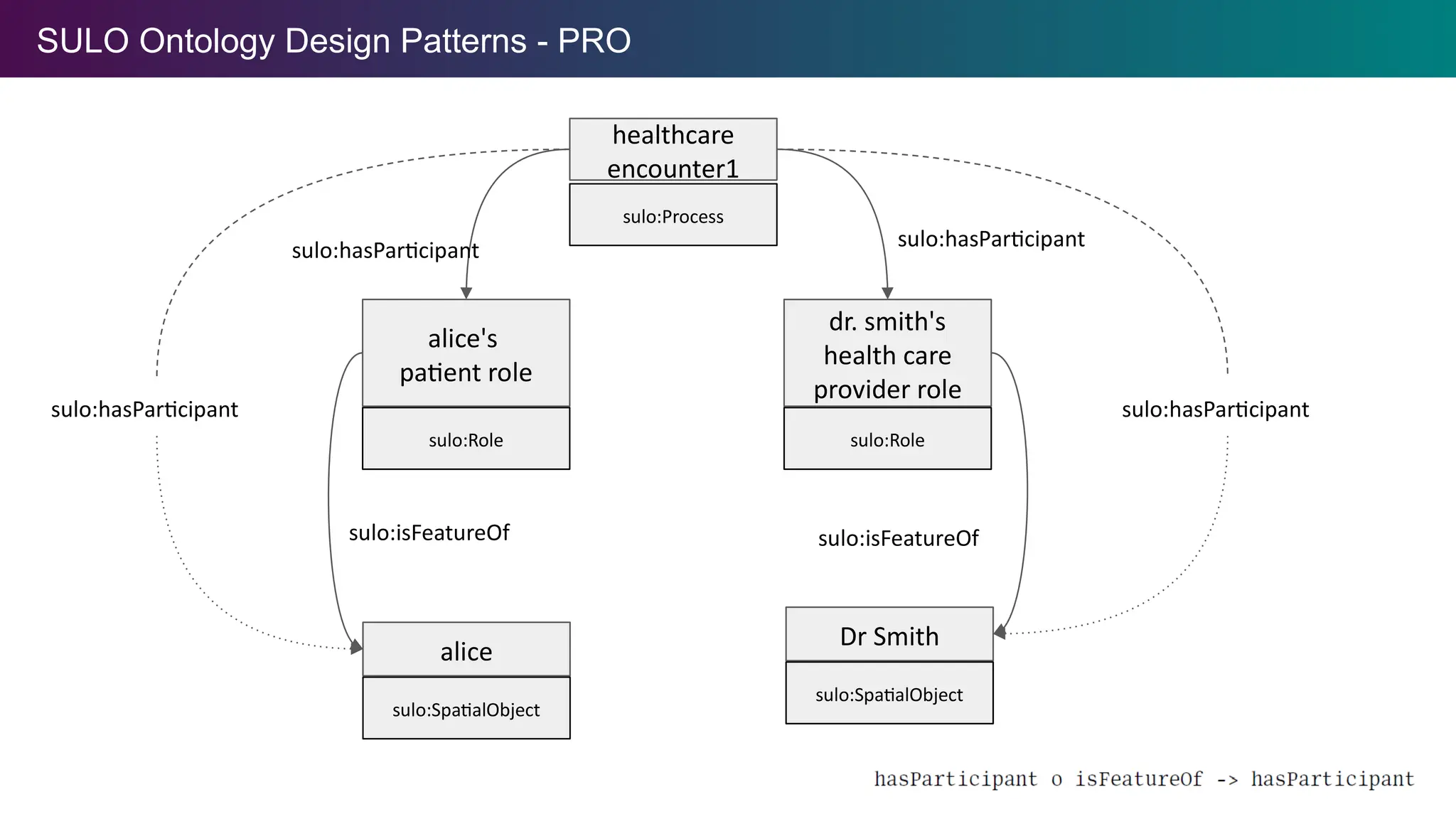
SULO Ontology DesignPatterns - PRO
The Process-Role-Object (PRO) ODP provides a way to represent the manner in which
objects participate in processes through specified roles.
Applies to spatial objects and information objects!
Role chain to infer participation of role holding object
The pattern makes explicit the semantics for role-aligned object relations such as
hasPatient, hasCareProvider. Hence, this pattern reduces the impulse to create and
proliferate such relations.
31.
SULO Ontology DesignPatterns - PRO
sulo:Process
healthcare
encounter1
sulo:SpatialObject
alice
sulo:SpatialObject
Dr Smith
sulo:Role
dr. smith's
health care
provider role
sulo:Role
alice's
patient role
sulo:hasParticipant
sulo:isFeatureOf
sulo:hasParticipant
sulo:hasParticipant
sulo:isFeatureOf
sulo:hasParticipant
32.
Grounding SNOMED CTto SULO
Most SNOMED classes and
relations can be directly mapped to
SULO classes and relations.
Other SNOMED relations map to a
SULO class expression
SNOMED SULO
SNOMED expressions can then be rewritten into a standard form, with no new relations
33.
Grounding SPHN withSULO
SPHN uses hasX (object and data) properties, which are
brittle when the schema is refactored. A SULO-based
formalization ensures predicate semantics are put into
classes, whose instances are connected with domain-
independent relations.
34.
SULO to BFO
SULOmore compact than BFO in both classes
and properties
● Share a top level binary division of Process
(Occurrent) and Object (Continuant)
● SULO's Object simplifies GDC + SDC + IC
● SULO includes key information objects
including Quantity, Collection and Time
(measurements), while BFO doesn't
● SULO contains a data property, BFO
doesn't.
● BFO has spatial / temporal regions and
boundaries, SULO doesn't.
SULO BFO
35.
Limitations & FutureWork
• SULO is a work in progress
• We have focused foremost on biomedical use cases
• We have not made a full comparison of ULO classes, relations, and their application.
• SULO does not put forward elaborate theories of ontology (e.g. the nature of space and
time), but rather on pragmatic KR needs. However, other ULOs may provide finer
grained, and likely compatible KR
• Revision/extension/refinement of SULO towards a robust theory across application
spaces.
• We plan studies on the usability of SULO and other ULOs.
SULO takes a minimalistic approach to an ULO formulation that balances formal rigor with
simplicity and practical usability.
https://w3id.org/sulo/github
36.
If only wecould map health data standards
to upper level ontologies...
- Michel Dumontier
The future of Health AI: Is our knowledge
infrastructure up to the task?
FOIS 2024 Keynote
Enschede, Netherlands
Realizing Semantic Interoperability
Differentconceptualizations and formalisations lead to (directly) incompatible knowledge graphs.
Mappings have largely been limited to pairs (classes, predicates). Graph-based
transformations are needed to correctly restructure/transform data in a bidirectional manner
Build a framework and community for semantic interoperability through the use of upper
level ontologies combined with bidirectional ontology/schema graph transformations
● Use SULO as a semantic foundation
● Use ShExMap to represent and execute bidirectional graph mappings
● Create a FAIR repository of ShExMaps
○ w3id persistent IDs
○ (CEDAR) metadata templates
● Gather together healthcare standards developers to discuss the role of SULO for semantic
interoperability (Dec 2 Workshop @ i~HD Annual Conference in Ghent, Belgium)
● Develop AI systems to use these knowledge resources to semantically annotate data, as we
have shown, and to perform data transformations
40.
Relevance
What can wedo to quell these concerns?
• Acknowledge that ontology engineering is hard, but that good tools
can make it easier
• Accept that OWL may not be the “one ring to rule them all”
• Educate people about the importance of standards for data
management
• Accept that important standards come in forms that are not
ontological
Mark Musen
from ICBO 2025 keynote
Conspiracy theories: Are
ontologies really under attack?
• We must continue our work of aligning standards to semantically
interoperable representations
41.
Summary
MD supported byHorizon Europe Framework Program under Grant Agreement Nos. 101057062 (AIDAVA), 101112022 (iCare4CVD),
101095435 (REALM); 101181300 (Ambrosia); ARPA-H BDF CHARM project; NWO LTP ROBUST (GENIUS Lab).
Language models are powerful technologies that can
assist us in the work of structuring and standardizing
scientific data.
Simpler Upper Level Ontologies, such as SULO, may
be able to help standards developers to construct
compatible representations, which will, in turn, keep
maintenance and new development costs low while
maintaining interoperability with other knowledge
sources.
New efforts are needed to capture and share these
complex (graph-based) mappings in a FAIR manner.
Michel Dumontier
Michel.Dumontier@maastrichtuniversity.nl







![Query Decomposition
The query decomposition (qd) step involves using
an LLM to decompose the query into a structured
output upon which individual concept mappings
will be performed. In-context learning with the
original query, a task description, and relevant
examples.
{
base_entity: "heart attack",
associated_entities: ["Hospitalization Reason"],
categories: ["Yes", "No", "Missing"],
visit: "baseline"
}
QD format
{
base_entity: <>
associated_entities: <>
categories: <>
unit: <>
visit: <>
method: <>
}
‘heart attack—main-cause of hospitalization,
measured at baseline, categories
include 0 = No, 1 = Yes, 9 = Missing’](https://image.slidesharecdn.com/dumontiericbo2025-keynote-251120141905-c0662f99/75/Ontologies-for-Semantic-Interoperability-in-the-Age-of-AI-10-2048.jpg)
































![Query Decomposition
The query decomposition (qd) step involves using
an LLM to decompose the query into a structured
output upon which individual concept mappings
will be performed. In-context learning with the
original query, a task description, and relevant
examples.
{
base_entity: "heart attack",
associated_entities: ["Hospitalization Reason"],
categories: ["Yes", "No", "Missing"],
visit: "baseline"
}
QD format
{
base_entity: <>
associated_entities: <>
categories: <>
unit: <>
visit: <>
method: <>
}
‘heart attack—main-cause of hospitalization,
measured at baseline, categories
include 0 = No, 1 = Yes, 9 = Missing’](https://crownmelresort.com/image.slidesharecdn.com/dumontiericbo2025-keynote-251120141905-c0662f99/75/Ontologies-for-Semantic-Interoperability-in-the-Age-of-AI-10-2048.jpg)



































































































