Download as PDF, PPTX



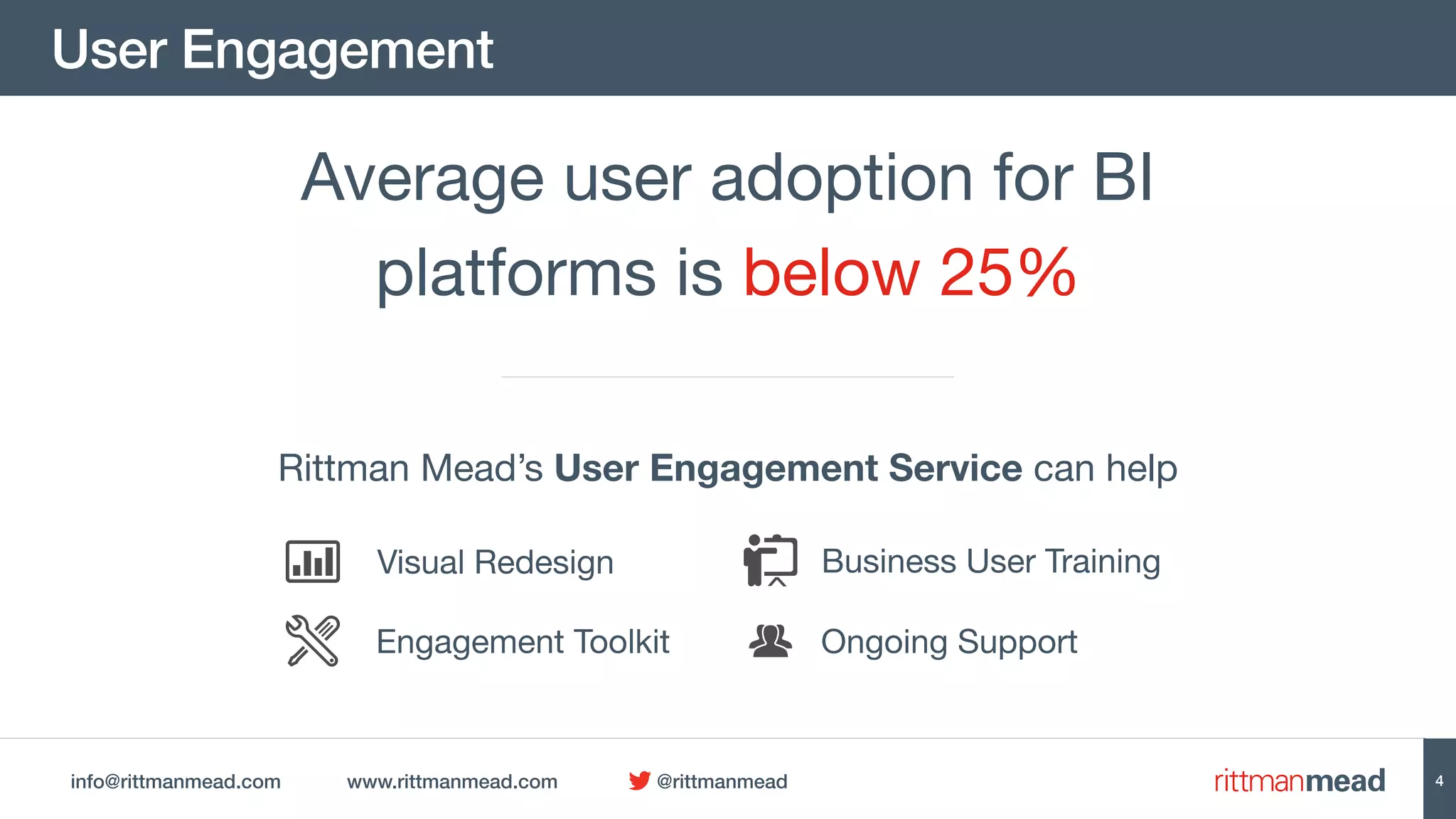

![info@rittmanmead.com www.rittmanmead.com @rittmanmead
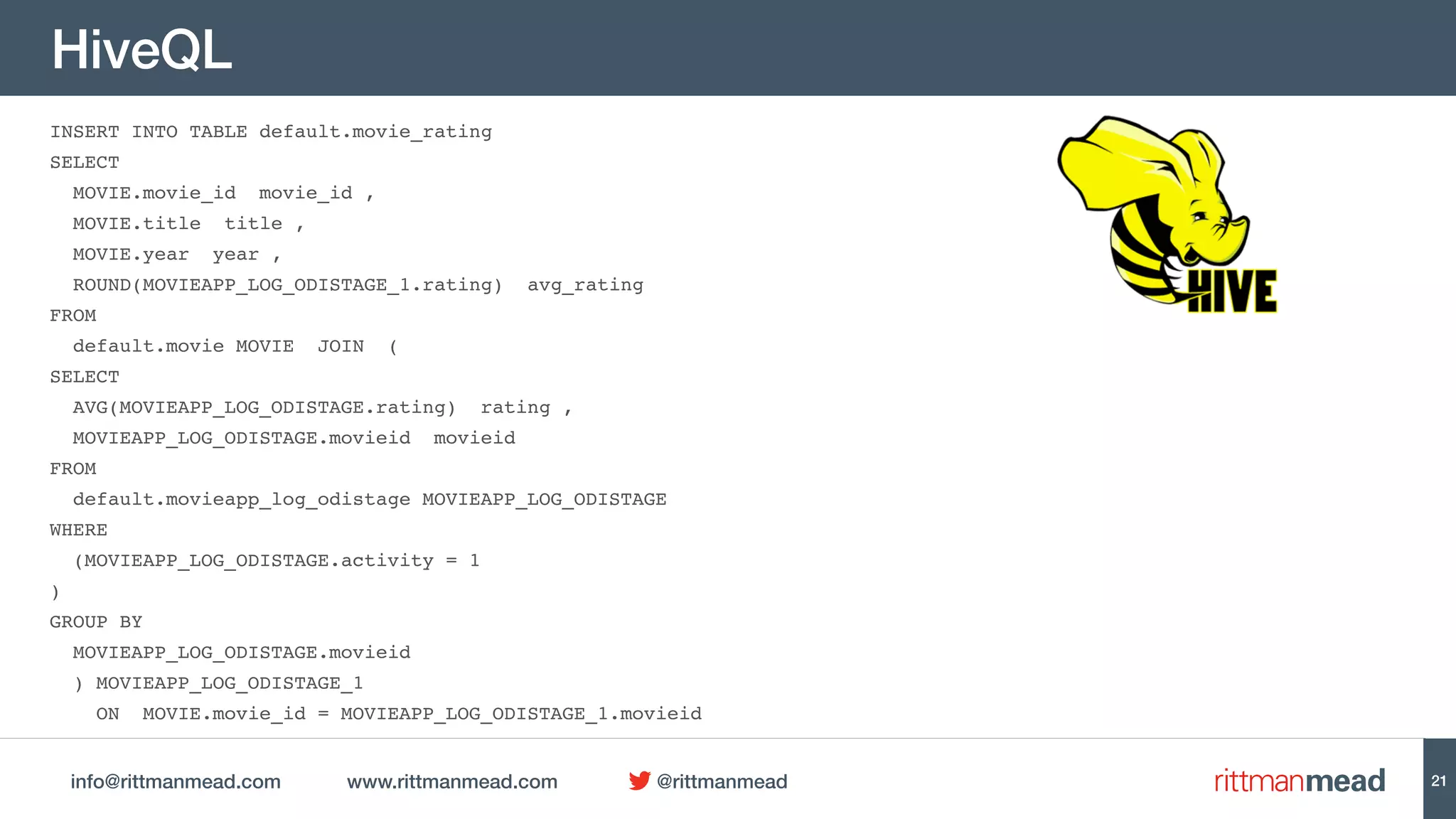
HiveQL
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|[[^]]*]) ([^ "]*|"[^"]*") (-|[0-9]*) (-|[0-9]*)(?: ([^ "]*|
"[^"]*") ([^ "]*|"[^"]*"))?",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)
STORED AS TEXTFILE;
LOAD DATA INPATH '/user/jfrancoi/apache_data/FlumeData.1412752921353' OVERWRITE INTO TABLE apachelog;
8](https://image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-8-2048.jpg)

![info@rittmanmead.com www.rittmanmead.com @rittmanmead
Pig Latin
register /opt/cloudera/parcels/CDH/lib/pig/piggybank.jar
raw_logs = LOAD '/user/mrittman/rm_logs' USING TextLoader AS (line:chararray);
logs_base = FOREACH raw_logs
GENERATE FLATTEN
(REGEX_EXTRACT_ALL(line,'^(S+) (S+) (S+) [([w:/]+s[+-]d{4})] "(.+?)" (S+) (S+) "([^"]*)"
"([^"]*)"')
)AS
(remoteAddr: chararray, remoteLogname: chararray, user: chararray,time: chararray, request: chararray, status:
chararray, bytes_string: chararray,referrer:chararray,browser: chararray);
logs_base_nobots = FILTER logs_base BY NOT (browser matches '.*(spider|robot|bot|slurp|bot|monitis|Baiduspider|
AhrefsBot|EasouSpider|HTTrack|Uptime|FeedFetcher|dummy).*');
logs_base_page = FOREACH logs_base_nobots GENERATE SUBSTRING(time,0,2) as day, SUBSTRING(time,3,6) as month,
SUBSTRING(time,7,11) as year, FLATTEN(STRSPLIT(request,' ',5)) AS (method:chararray, request_page:chararray,
protocol:chararray), remoteAddr, status;
logs_base_page_cleaned = FILTER logs_base_page BY NOT (SUBSTRING(request_page,0,3) == '/wp' or request_page == '/'
or SUBSTRING(request_page,0,7) == '/files/' or SUBSTRING(request_page,0,12) == '/favicon.ico');
logs_base_page_cleaned_by_page = GROUP logs_base_page_cleaned BY request_page;
page_count = FOREACH logs_base_page_cleaned_by_page GENERATE FLATTEN(group) as request_page,
COUNT(logs_base_page_cleaned) as hits;
page_count_sorted = ORDER page_count BY hits DESC;
page_count_top_10 = LIMIT page_count_sorted 10;
10](https://image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-10-2048.jpg)

![info@rittmanmead.com www.rittmanmead.com @rittmanmead
Spark
package com.cloudera.analyzeblog
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql.SQLContext
(…)
def main(args: Array[String]) {
val sc = new SparkContext(new
SparkConf().setAppName("analyzeBlog"))
val sqlContext = new SQLContext(sc)
import sqlContext._
val raw_logs = "/user/mrittman/rm_logs"
//val rowRegex = """^([0-9.]+)s([w.-]+)
s([w.-]+)s([[^[]]+])s"((?:[^"]|")
+)"s(d{3})s(d+|-)s"((?:[^"]|")+)"s"((?:
[^"]|")+)"$""".r
val rowRegex = """^([d.]+) (S+) (S+) [([w
d:/]+s[+-]d{4})] "(.+?)" (d{3}) ([d-]+)
"([^"]+)" "([^"]+)".*""".r
val logs_base = sc.textFile(raw_logs) flatMap {
case rowRegex(host,
identity, user, time, request, status, size,
referer, agent) =>
Seq(accessLogRow(host, identity, user, time,
request, status, size, referer, agent))
case _ => Nil
}
val logs_base_nobots = logs_base.filter( r => !
r.request.matches(".*(spider|robot|bot|slurp|
bot|monitis|Baiduspider|AhrefsBot|EasouSpider|
HTTrack|Uptime|FeedFetcher|dummy).*"))
val logs_base_page = logs_base_nobots.map { r
=>
val request = getRequestUrl(r.request)
val request_formatted = if
(request.charAt(request.length-1).toString ==
"/") request else request.concat("/")
(r.host, request_formatted, r.status,
r.agent)
}
val logs_base_page_schemaRDD =
logs_base_page.map(p => pageRow(p._1, p._2,
p._3, p._4))
logs_base_page_schemaRDD.registerAsTable("logs_
base_page")
val page_count = sql("SELECT request_page,
count(*) as hits FROM logs_base_page GROUP BY
request_page").registerAsTable("page_count")
val postsLocation = "/user/mrittman/posts.psv"
val posts =
sc.textFile(postsLocation).map{ line =>
val cols=line.split('|')
postRow(cols(0),cols(1),cols(2),cols(3),cols(4)
,cols(5),cols(6).concat("/"))
}
posts.registerAsTable("posts")
val pages_and_posts_details = sql("SELECT
p.request_page, p.hits, ps.title, ps.author
FROM page_count p JOIN posts ps ON
p.request_page = ps.generated_url ORDER BY hits
DESC LIMIT 10")
pages_and_posts_details.saveAsTextFile("/user/
mrittman/top_10_pages_and_author4")
}
}
12](https://image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-12-2048.jpg)


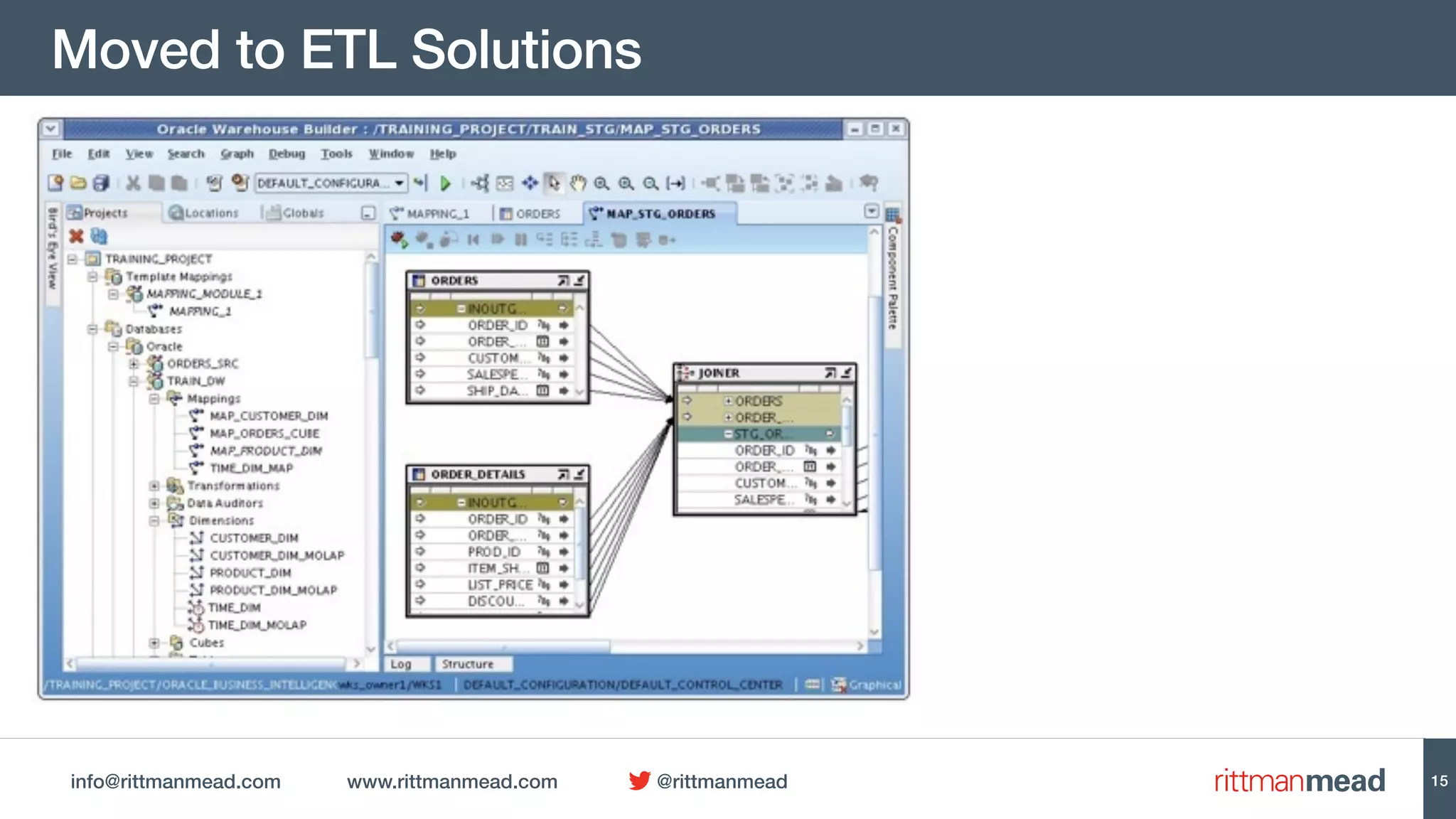





![info@rittmanmead.com www.rittmanmead.com @rittmanmead
pySpark
OdiOutFile -FILE=/tmp/
C___Calc_Ratings__Hive___Pig___Spark_.py -
CHARSET_ENCODING=UTF-8
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
from pyspark.sql import *
config =
SparkConf().setAppName("C___Calc_Ratings__Hive_
__Pig___Spark_").setMaster("yarn-client")
sc = SparkContext(conf = config)
sqlContext = SQLContext(sc)
sparkVersion = reduce(lambda sum, elem: sum*10
+ elem, map(lambda x: int(x) if x.isdigit()
else 0, sc.version.strip().split('.')), 0)
import sys
from datetime import *
hiveCtx = HiveContext(sc)
def convertRowToDict(row):
ret = {}
for num in range(0, len(row.__FIELDS__)) :
ret[row.__FIELDS__[num]] = row[num]
return ret
from pyspark_ext import *
#Local defs
#Replace None RDD element to new defined
'NoneRddElement' object, which overload the []
operator.
#For example, MOV["MOVIE_ID"] return None
rather than TypeError: 'NoneType' object is
unsubscriptable when MOV is none RDD element.
def convert_to_none(x):
return NoneRddElement() if x is None else x
#Transform RDD element from dict to tuple to
support RDD subtraction.
#For example (MOV, (RAT, LAN)) transform to
(tuple(sorted(MOV.items())),
(tuple(sorted(RAT.items())),tuple(sorted(LAN.it
ems())))
def dict2Tuple(t):
return tuple(map(dict2Tuple, t)) if
isinstance(t, (list, tuple)) else
tuple(sorted(t.items()))
#reverse dict2Tuple(t)
def tuple2Dict(t):
return dict((x,y) for x,y in t) if not
isinstance(t[0][0], (list, tuple)) else
tuple(map(tuple2Dict, t))
from operator import is_not
from functools import partial
def SUM(x): return sum(filter(None,x));
def MAX(x): return max(x);
def MIN(x): return min(x);
def AVG(x): return None if COUNT(x) == 0 else
SUM(x)/COUNT(x);
def COUNT(x): return len(filter(partial(is_not,
None),x));
def safeAggregate(x,y): return None if not y
else x(y);
def getValue(type,value,format='%Y-%m-%d'):
try:
if type is date:
return
datetime.strptime(value,format).date()
else: return type(value)
except ValueError:return None;
def getScaledValue(scale, value):
try: return '' if value is None else
('%0.'+ str(scale) +'f')%float(value);
except ValueError:return '';
def getStrValue(value, format='%Y-%m-%d'):
if value is None : return ''
if isinstance(value, date): return
value.strftime(format)
if isinstance(value, str): return
unicode(value, 'utf-8')
if isinstance(value, unicode) : return value
try: return unicode(value)
25](https://image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-29-2048.jpg)







![info@rittmanmead.com www.rittmanmead.com @rittmanmead
Rittman Mead Sessions
39
No Big Data Hacking—Time for a Complete ETL
Solution with Oracle Data Integrator 12c
[UGF5827]
Jérôme Françoisse | Sunday, Oct 25, 8:00am |
Moscone South 301
Empowering Users: Oracle Business Intelligence
Enterprise Edition 12c Visual Analyzer [UGF5481]
Edelweiss Kammermann | Sunday, Oct 25, 10:00am
| Moscone West 3011
A Walk Through the Kimball ETL Subsystems
with Oracle Data Integration Solutions [UGF6311]
Michael Rainey | Sunday, Oct 25, 12:00pm |
Moscone South 301
Oracle Business Intelligence Cloud Service—
Moving Your Complete BI Platform to the Cloud
[UGF4906]
Mark Rittman | Sunday, Oct 25, 2:30pm | Moscone
South 301
Oracle Data Integration Product Family: a
Cornerstone for Big Data [CON9609]
Mark Rittman | Wednesday, Oct 28, 12:15pm |
Moscone West 2022
Developer Best Practices for Oracle Data
Integrator Lifecycle Management [CON9611]
Jérôme Françoisse | Thursday, Oct 29, 2:30 pm |
Moscone West 2022](https://image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-48-2048.jpg)







![info@rittmanmead.com www.rittmanmead.com @rittmanmead
HiveQL
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|[[^]]*]) ([^ "]*|"[^"]*") (-|[0-9]*) (-|[0-9]*)(?: ([^ "]*|
"[^"]*") ([^ "]*|"[^"]*"))?",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)
STORED AS TEXTFILE;
LOAD DATA INPATH '/user/jfrancoi/apache_data/FlumeData.1412752921353' OVERWRITE INTO TABLE apachelog;
8](https://crownmelresort.com/image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-8-2048.jpg)

![info@rittmanmead.com www.rittmanmead.com @rittmanmead
Pig Latin
register /opt/cloudera/parcels/CDH/lib/pig/piggybank.jar
raw_logs = LOAD '/user/mrittman/rm_logs' USING TextLoader AS (line:chararray);
logs_base = FOREACH raw_logs
GENERATE FLATTEN
(REGEX_EXTRACT_ALL(line,'^(S+) (S+) (S+) [([w:/]+s[+-]d{4})] "(.+?)" (S+) (S+) "([^"]*)"
"([^"]*)"')
)AS
(remoteAddr: chararray, remoteLogname: chararray, user: chararray,time: chararray, request: chararray, status:
chararray, bytes_string: chararray,referrer:chararray,browser: chararray);
logs_base_nobots = FILTER logs_base BY NOT (browser matches '.*(spider|robot|bot|slurp|bot|monitis|Baiduspider|
AhrefsBot|EasouSpider|HTTrack|Uptime|FeedFetcher|dummy).*');
logs_base_page = FOREACH logs_base_nobots GENERATE SUBSTRING(time,0,2) as day, SUBSTRING(time,3,6) as month,
SUBSTRING(time,7,11) as year, FLATTEN(STRSPLIT(request,' ',5)) AS (method:chararray, request_page:chararray,
protocol:chararray), remoteAddr, status;
logs_base_page_cleaned = FILTER logs_base_page BY NOT (SUBSTRING(request_page,0,3) == '/wp' or request_page == '/'
or SUBSTRING(request_page,0,7) == '/files/' or SUBSTRING(request_page,0,12) == '/favicon.ico');
logs_base_page_cleaned_by_page = GROUP logs_base_page_cleaned BY request_page;
page_count = FOREACH logs_base_page_cleaned_by_page GENERATE FLATTEN(group) as request_page,
COUNT(logs_base_page_cleaned) as hits;
page_count_sorted = ORDER page_count BY hits DESC;
page_count_top_10 = LIMIT page_count_sorted 10;
10](https://crownmelresort.com/image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-10-2048.jpg)

![info@rittmanmead.com www.rittmanmead.com @rittmanmead
Spark
package com.cloudera.analyzeblog
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql.SQLContext
(…)
def main(args: Array[String]) {
val sc = new SparkContext(new
SparkConf().setAppName("analyzeBlog"))
val sqlContext = new SQLContext(sc)
import sqlContext._
val raw_logs = "/user/mrittman/rm_logs"
//val rowRegex = """^([0-9.]+)s([w.-]+)
s([w.-]+)s([[^[]]+])s"((?:[^"]|")
+)"s(d{3})s(d+|-)s"((?:[^"]|")+)"s"((?:
[^"]|")+)"$""".r
val rowRegex = """^([d.]+) (S+) (S+) [([w
d:/]+s[+-]d{4})] "(.+?)" (d{3}) ([d-]+)
"([^"]+)" "([^"]+)".*""".r
val logs_base = sc.textFile(raw_logs) flatMap {
case rowRegex(host,
identity, user, time, request, status, size,
referer, agent) =>
Seq(accessLogRow(host, identity, user, time,
request, status, size, referer, agent))
case _ => Nil
}
val logs_base_nobots = logs_base.filter( r => !
r.request.matches(".*(spider|robot|bot|slurp|
bot|monitis|Baiduspider|AhrefsBot|EasouSpider|
HTTrack|Uptime|FeedFetcher|dummy).*"))
val logs_base_page = logs_base_nobots.map { r
=>
val request = getRequestUrl(r.request)
val request_formatted = if
(request.charAt(request.length-1).toString ==
"/") request else request.concat("/")
(r.host, request_formatted, r.status,
r.agent)
}
val logs_base_page_schemaRDD =
logs_base_page.map(p => pageRow(p._1, p._2,
p._3, p._4))
logs_base_page_schemaRDD.registerAsTable("logs_
base_page")
val page_count = sql("SELECT request_page,
count(*) as hits FROM logs_base_page GROUP BY
request_page").registerAsTable("page_count")
val postsLocation = "/user/mrittman/posts.psv"
val posts =
sc.textFile(postsLocation).map{ line =>
val cols=line.split('|')
postRow(cols(0),cols(1),cols(2),cols(3),cols(4)
,cols(5),cols(6).concat("/"))
}
posts.registerAsTable("posts")
val pages_and_posts_details = sql("SELECT
p.request_page, p.hits, ps.title, ps.author
FROM page_count p JOIN posts ps ON
p.request_page = ps.generated_url ORDER BY hits
DESC LIMIT 10")
pages_and_posts_details.saveAsTextFile("/user/
mrittman/top_10_pages_and_author4")
}
}
12](https://crownmelresort.com/image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-12-2048.jpg)
















![info@rittmanmead.com www.rittmanmead.com @rittmanmead
pySpark
OdiOutFile -FILE=/tmp/
C___Calc_Ratings__Hive___Pig___Spark_.py -
CHARSET_ENCODING=UTF-8
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
from pyspark.sql import *
config =
SparkConf().setAppName("C___Calc_Ratings__Hive_
__Pig___Spark_").setMaster("yarn-client")
sc = SparkContext(conf = config)
sqlContext = SQLContext(sc)
sparkVersion = reduce(lambda sum, elem: sum*10
+ elem, map(lambda x: int(x) if x.isdigit()
else 0, sc.version.strip().split('.')), 0)
import sys
from datetime import *
hiveCtx = HiveContext(sc)
def convertRowToDict(row):
ret = {}
for num in range(0, len(row.__FIELDS__)) :
ret[row.__FIELDS__[num]] = row[num]
return ret
from pyspark_ext import *
#Local defs
#Replace None RDD element to new defined
'NoneRddElement' object, which overload the []
operator.
#For example, MOV["MOVIE_ID"] return None
rather than TypeError: 'NoneType' object is
unsubscriptable when MOV is none RDD element.
def convert_to_none(x):
return NoneRddElement() if x is None else x
#Transform RDD element from dict to tuple to
support RDD subtraction.
#For example (MOV, (RAT, LAN)) transform to
(tuple(sorted(MOV.items())),
(tuple(sorted(RAT.items())),tuple(sorted(LAN.it
ems())))
def dict2Tuple(t):
return tuple(map(dict2Tuple, t)) if
isinstance(t, (list, tuple)) else
tuple(sorted(t.items()))
#reverse dict2Tuple(t)
def tuple2Dict(t):
return dict((x,y) for x,y in t) if not
isinstance(t[0][0], (list, tuple)) else
tuple(map(tuple2Dict, t))
from operator import is_not
from functools import partial
def SUM(x): return sum(filter(None,x));
def MAX(x): return max(x);
def MIN(x): return min(x);
def AVG(x): return None if COUNT(x) == 0 else
SUM(x)/COUNT(x);
def COUNT(x): return len(filter(partial(is_not,
None),x));
def safeAggregate(x,y): return None if not y
else x(y);
def getValue(type,value,format='%Y-%m-%d'):
try:
if type is date:
return
datetime.strptime(value,format).date()
else: return type(value)
except ValueError:return None;
def getScaledValue(scale, value):
try: return '' if value is None else
('%0.'+ str(scale) +'f')%float(value);
except ValueError:return '';
def getStrValue(value, format='%Y-%m-%d'):
if value is None : return ''
if isinstance(value, date): return
value.strftime(format)
if isinstance(value, str): return
unicode(value, 'utf-8')
if isinstance(value, unicode) : return value
try: return unicode(value)
25](https://crownmelresort.com/image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-29-2048.jpg)


















![info@rittmanmead.com www.rittmanmead.com @rittmanmead
Rittman Mead Sessions
39
No Big Data Hacking—Time for a Complete ETL
Solution with Oracle Data Integrator 12c
[UGF5827]
Jérôme Françoisse | Sunday, Oct 25, 8:00am |
Moscone South 301
Empowering Users: Oracle Business Intelligence
Enterprise Edition 12c Visual Analyzer [UGF5481]
Edelweiss Kammermann | Sunday, Oct 25, 10:00am
| Moscone West 3011
A Walk Through the Kimball ETL Subsystems
with Oracle Data Integration Solutions [UGF6311]
Michael Rainey | Sunday, Oct 25, 12:00pm |
Moscone South 301
Oracle Business Intelligence Cloud Service—
Moving Your Complete BI Platform to the Cloud
[UGF4906]
Mark Rittman | Sunday, Oct 25, 2:30pm | Moscone
South 301
Oracle Data Integration Product Family: a
Cornerstone for Big Data [CON9609]
Mark Rittman | Wednesday, Oct 28, 12:15pm |
Moscone West 2022
Developer Best Practices for Oracle Data
Integrator Lifecycle Management [CON9611]
Jérôme Françoisse | Thursday, Oct 29, 2:30 pm |
Moscone West 2022](https://crownmelresort.com/image.slidesharecdn.com/ugf5827-nobigdatahacking-151025193911-lva1-app6891/75/No-more-Big-Data-Hacking-Time-for-a-Complete-ETL-Solution-with-Oracle-Data-Integrator-12c-48-2048.jpg)

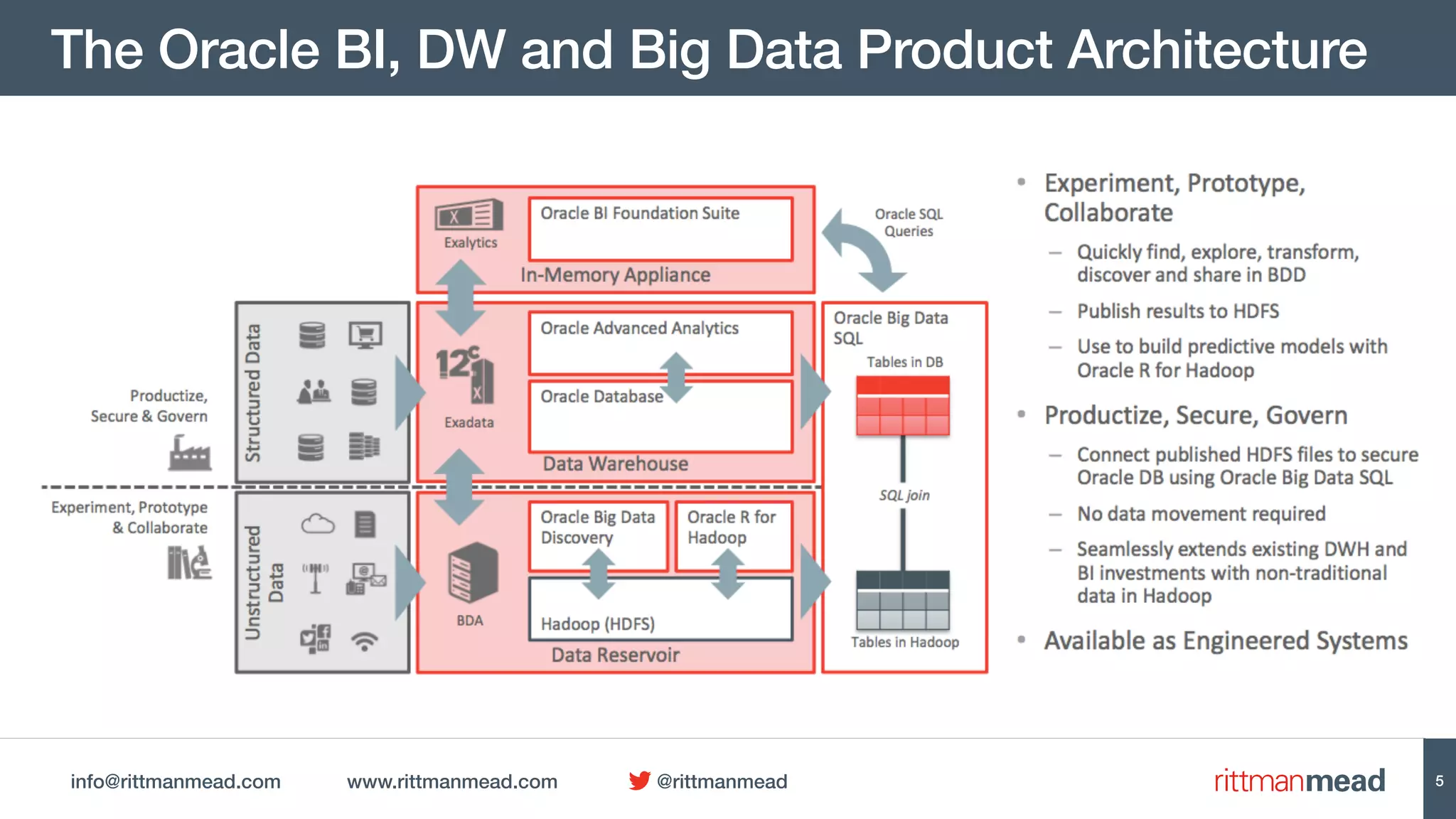
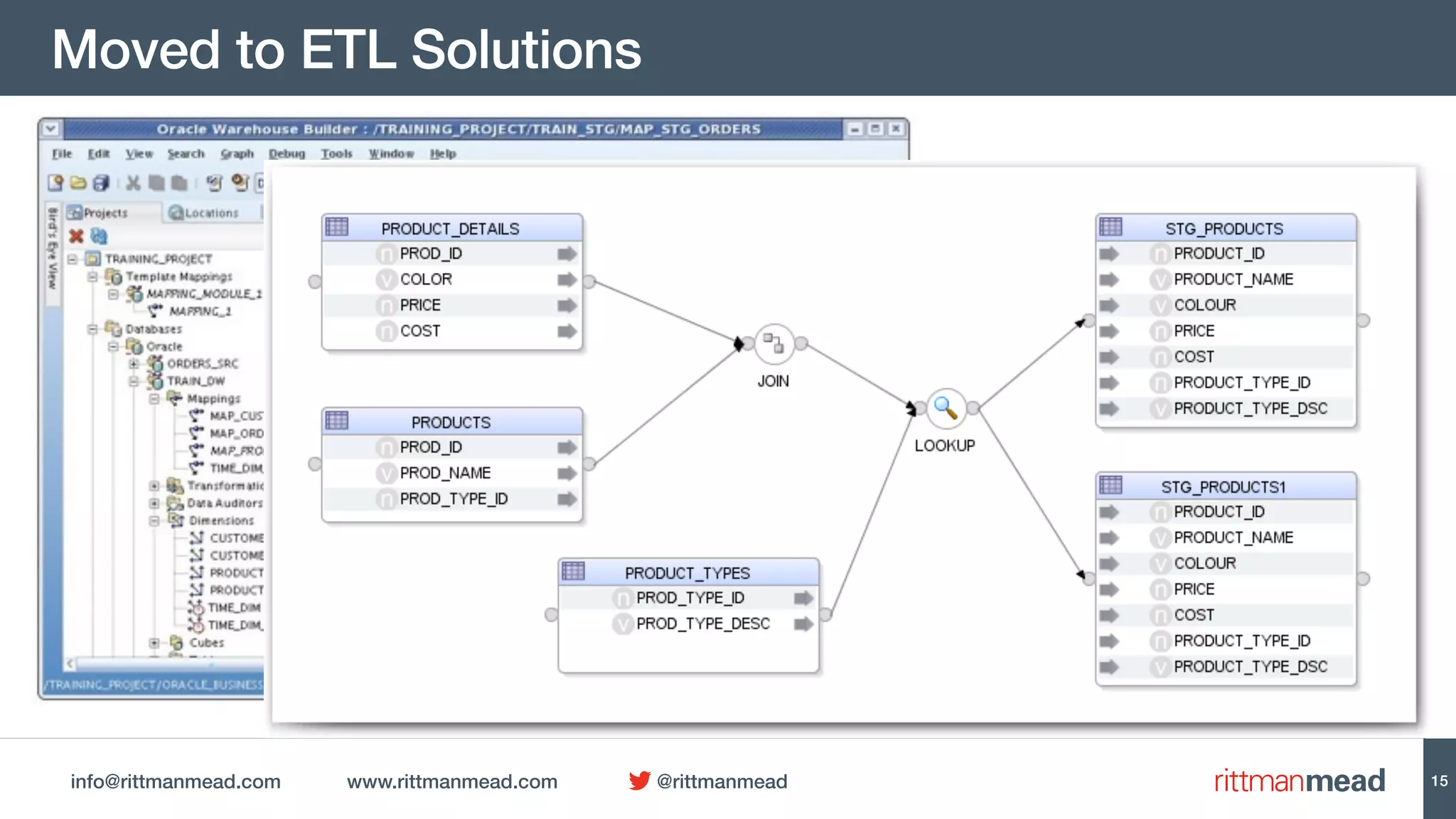
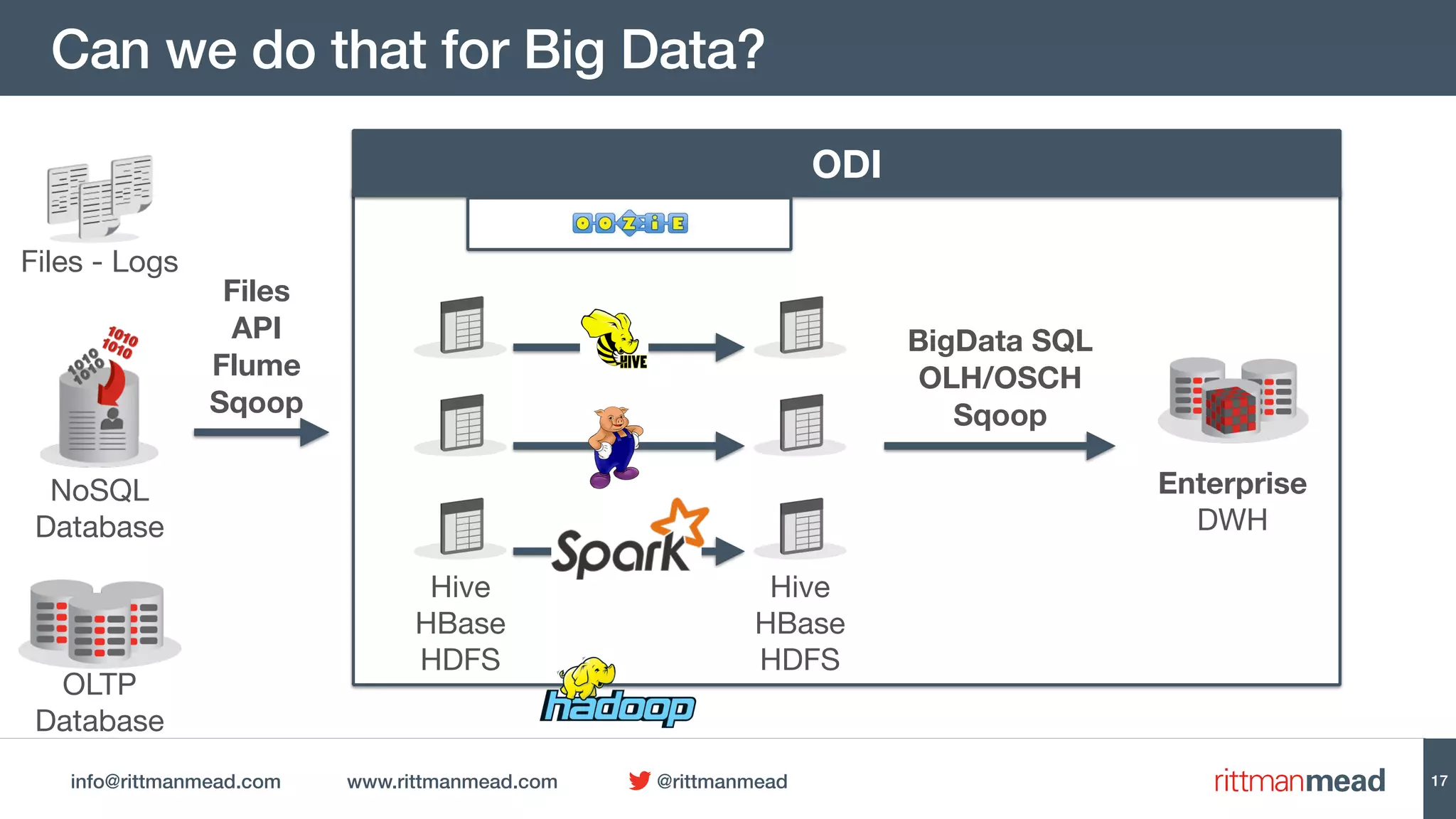
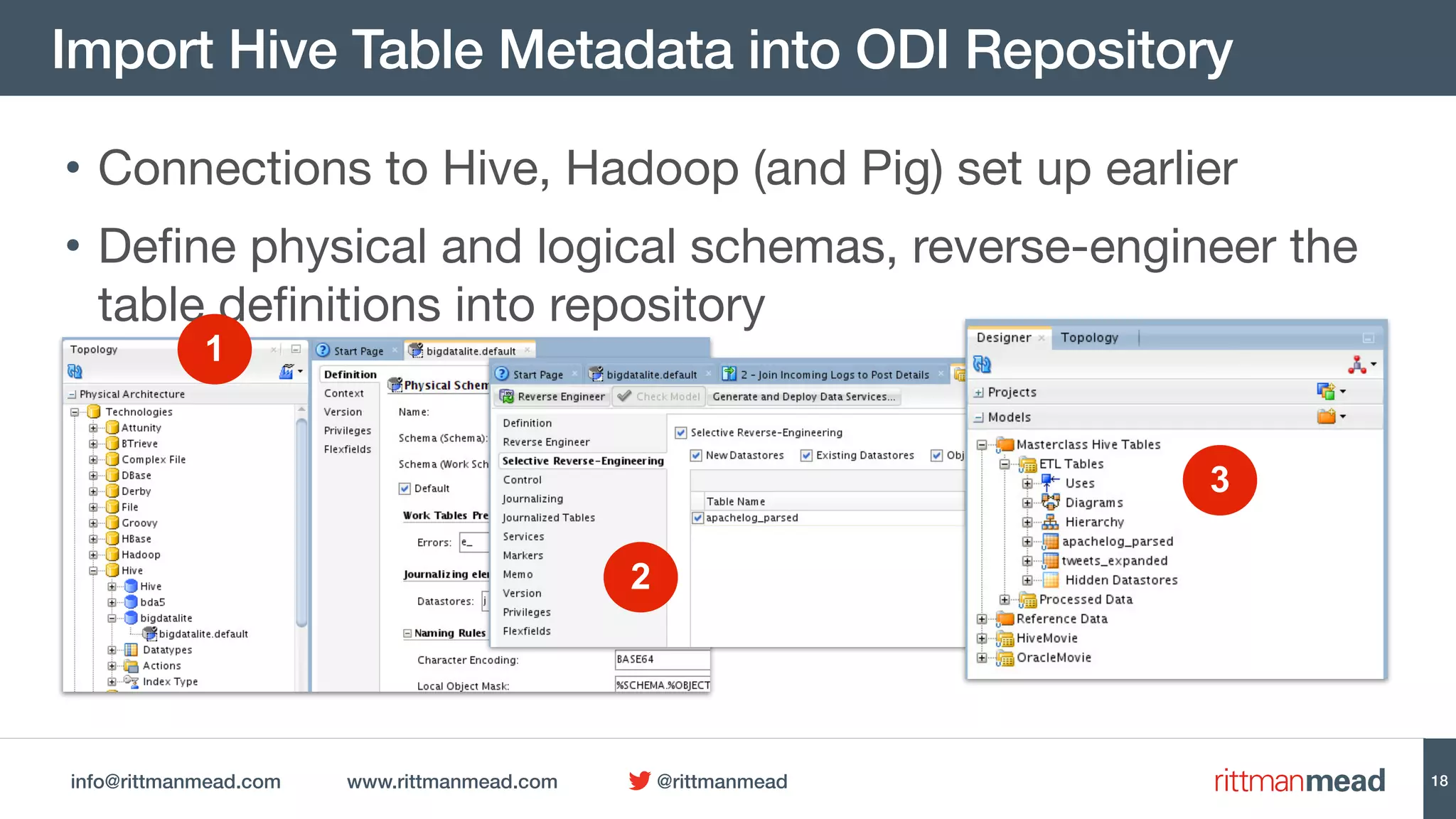
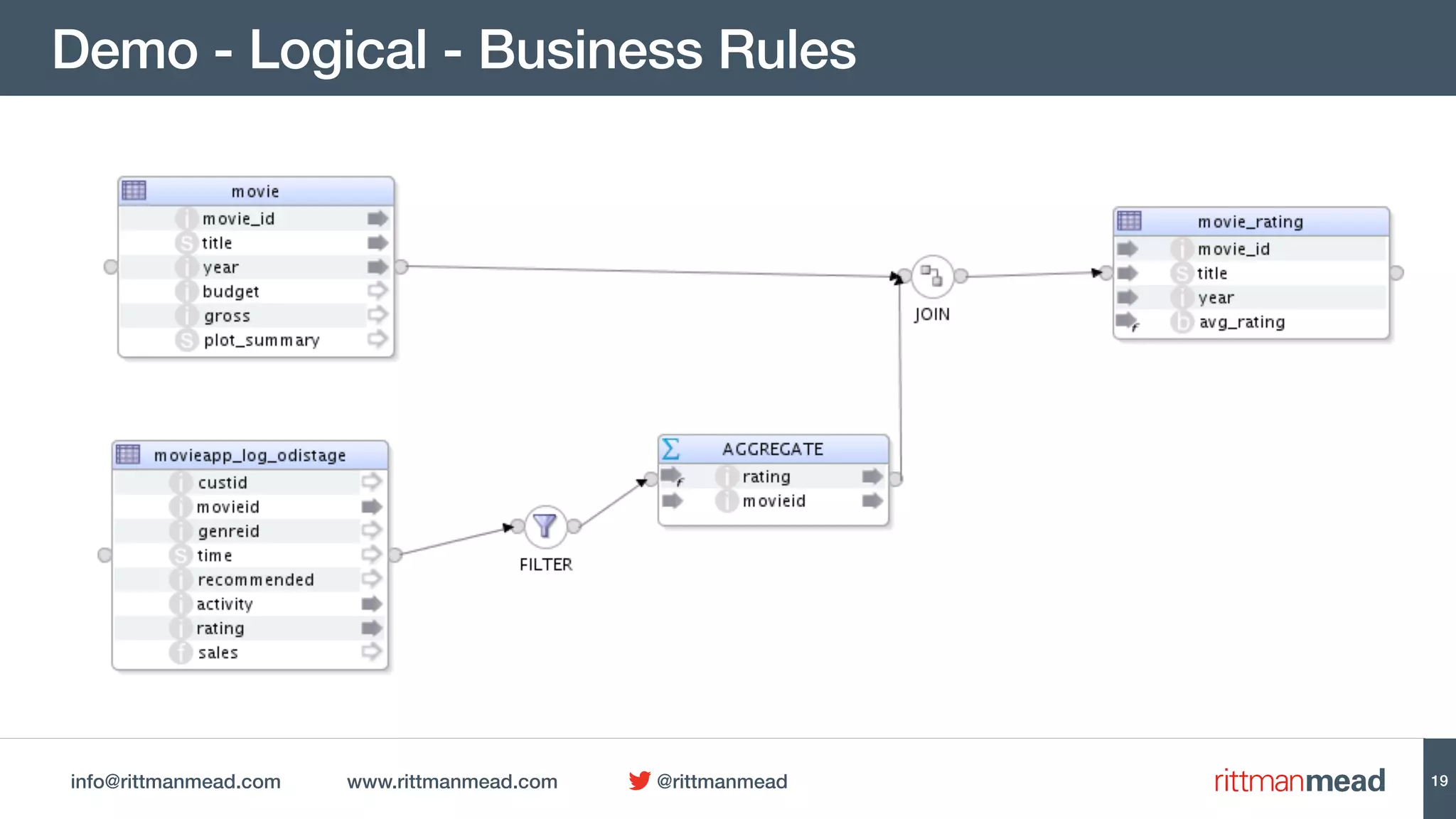
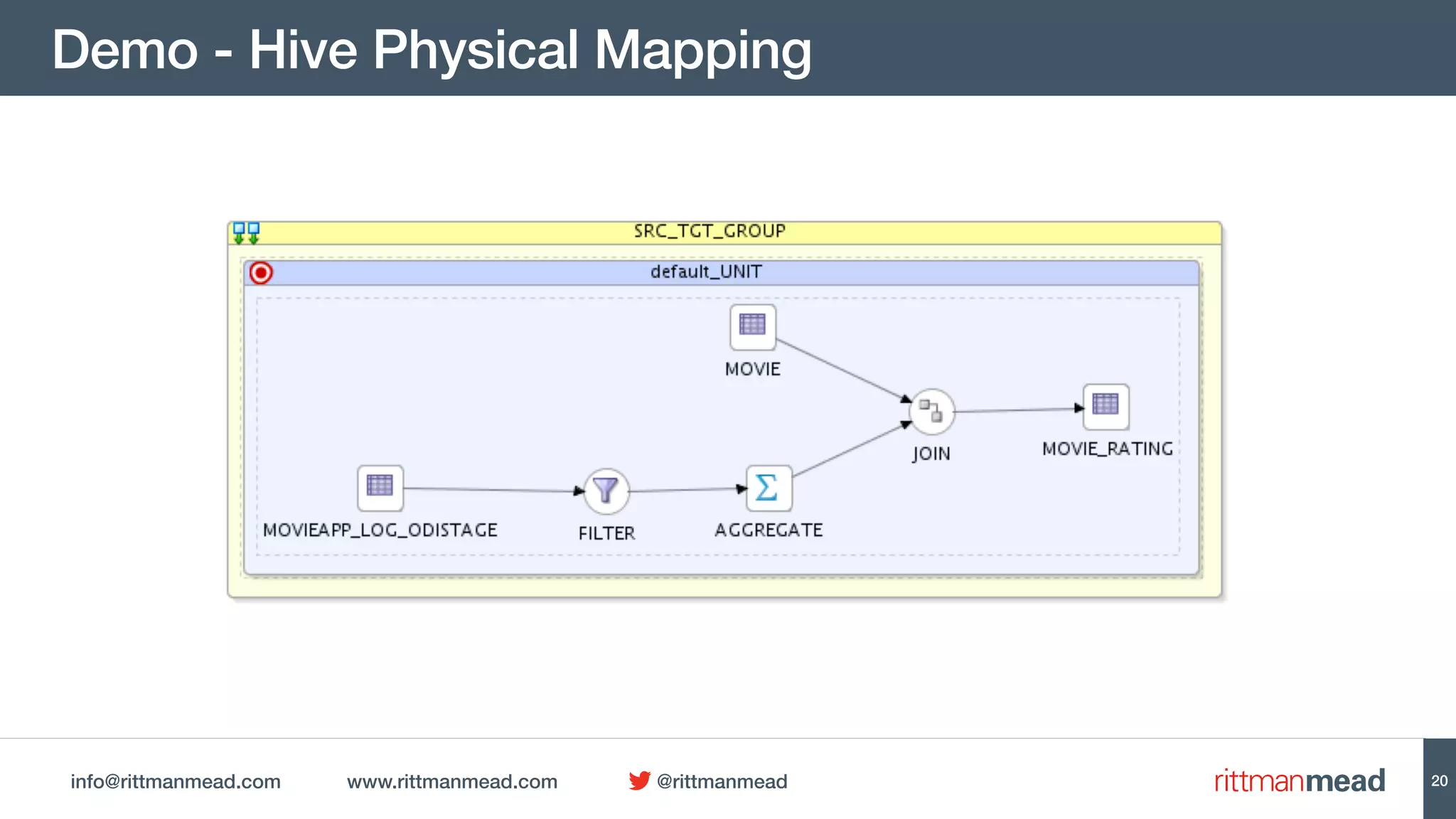
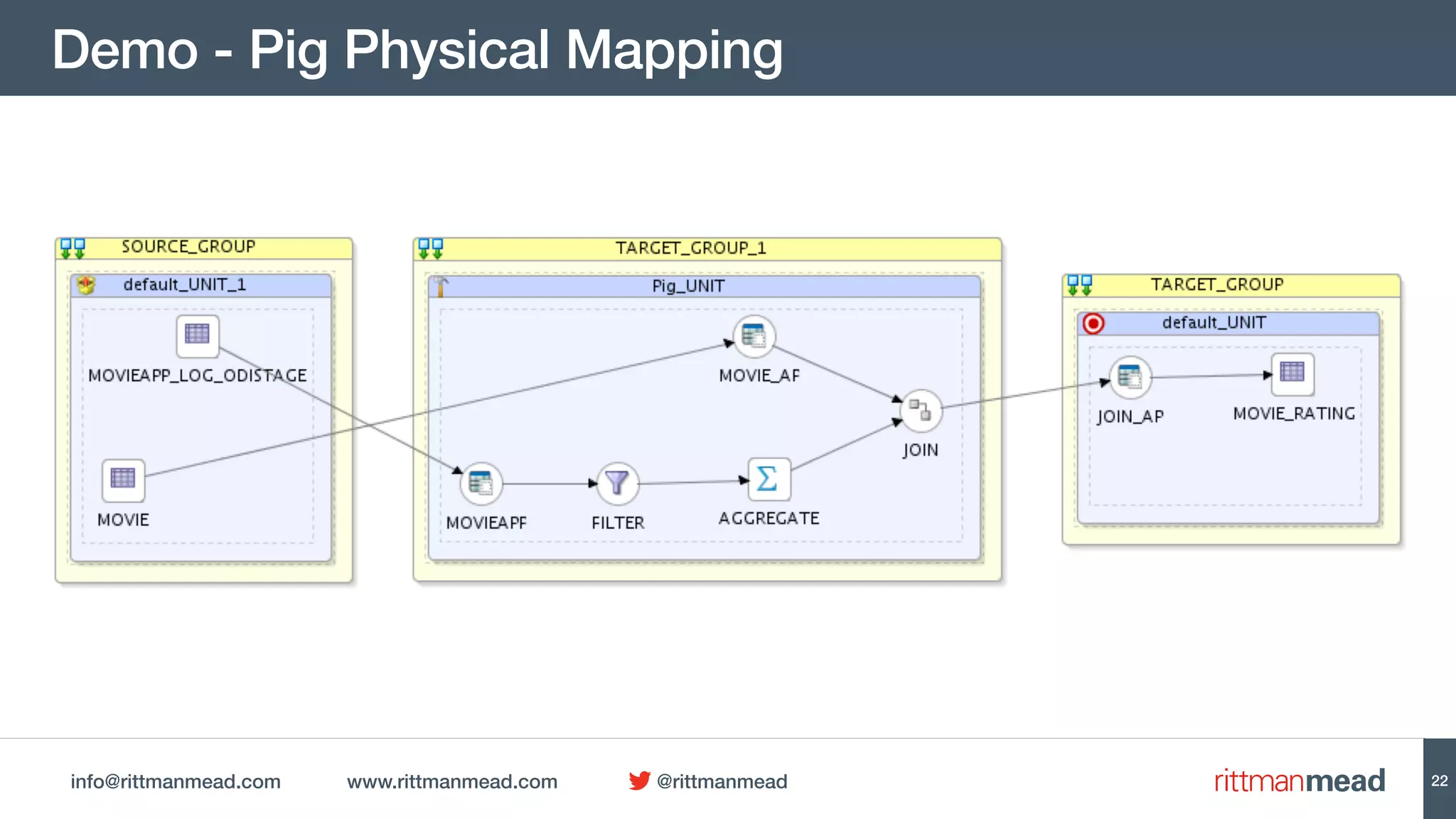
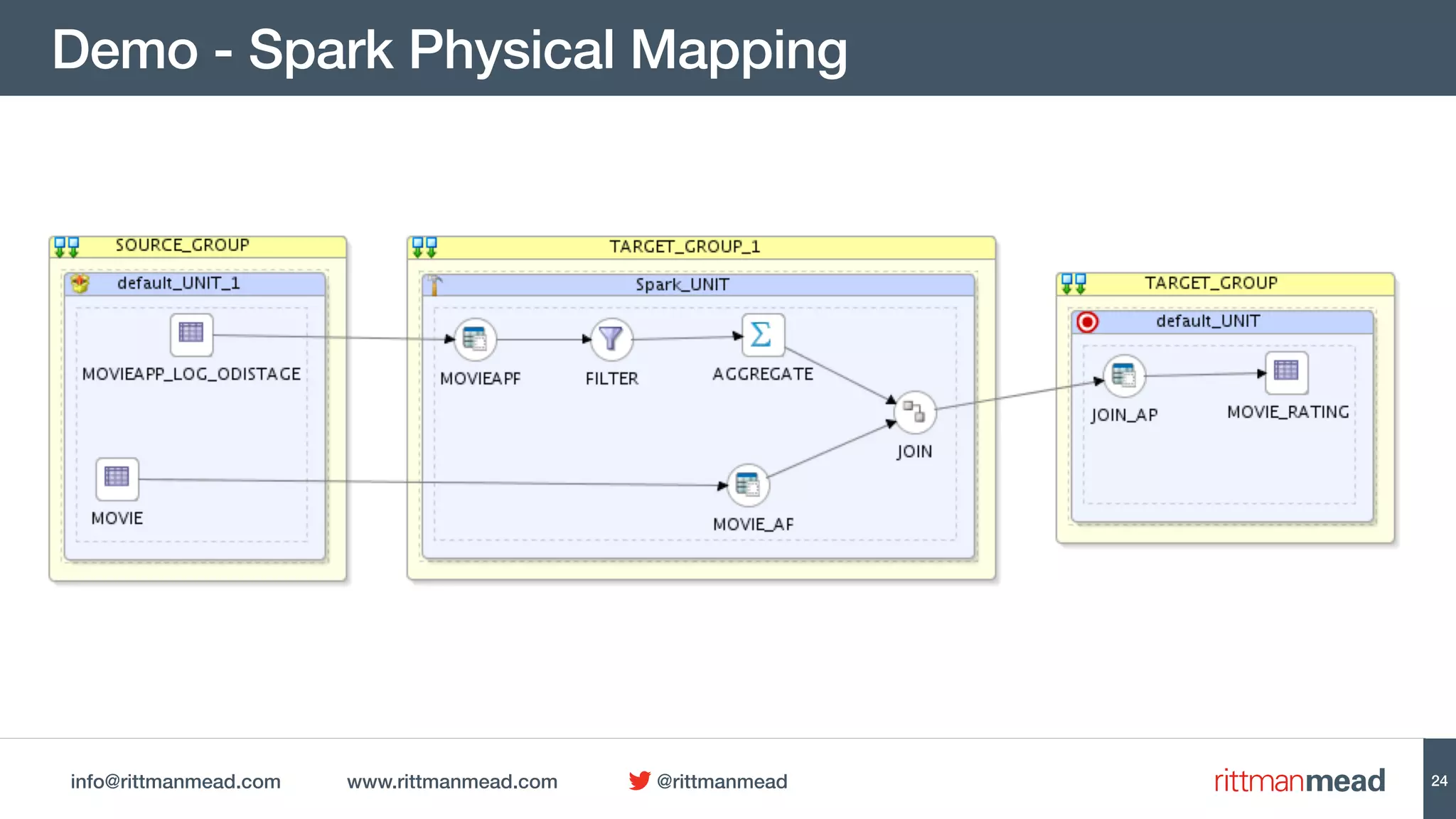
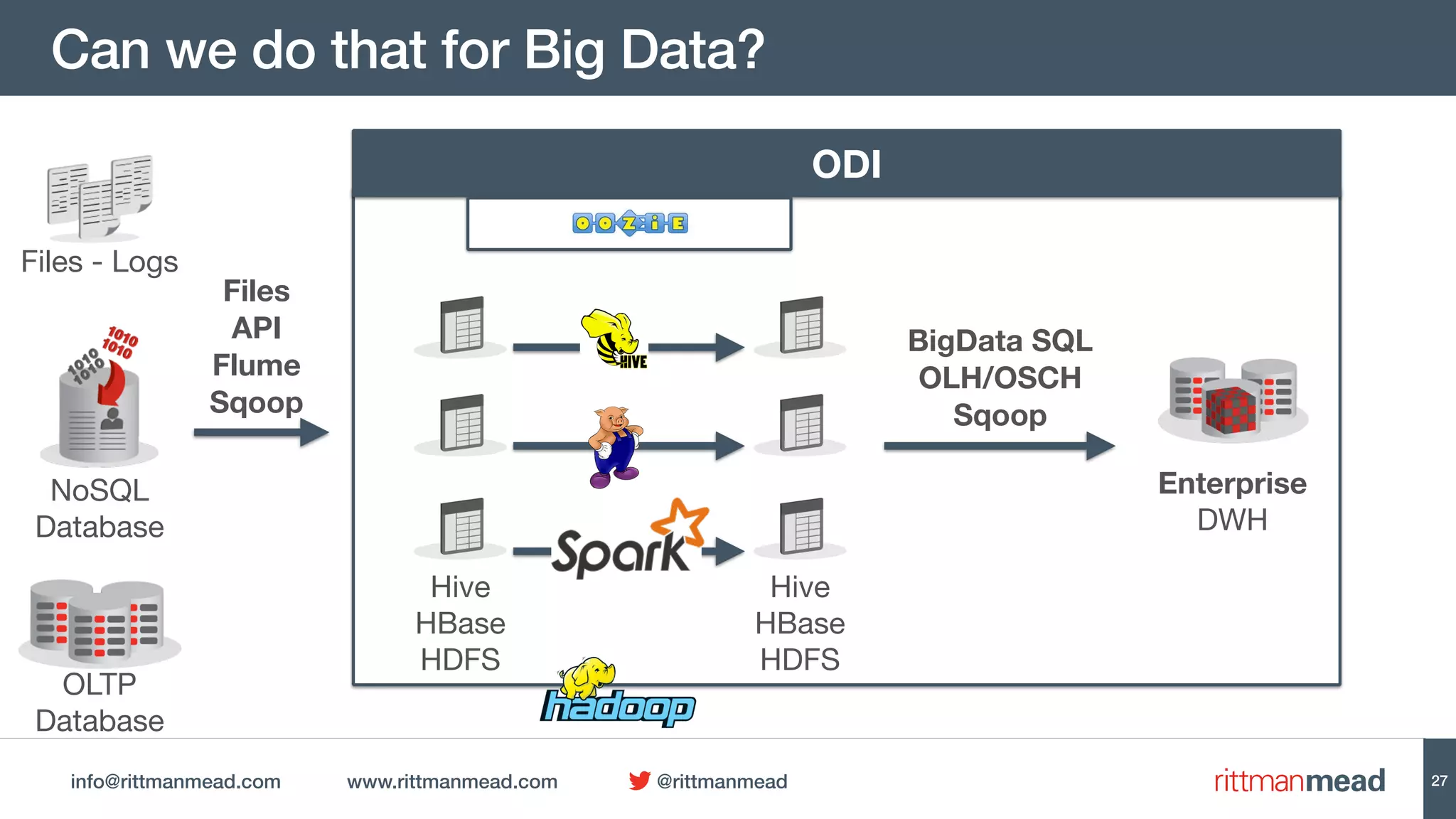
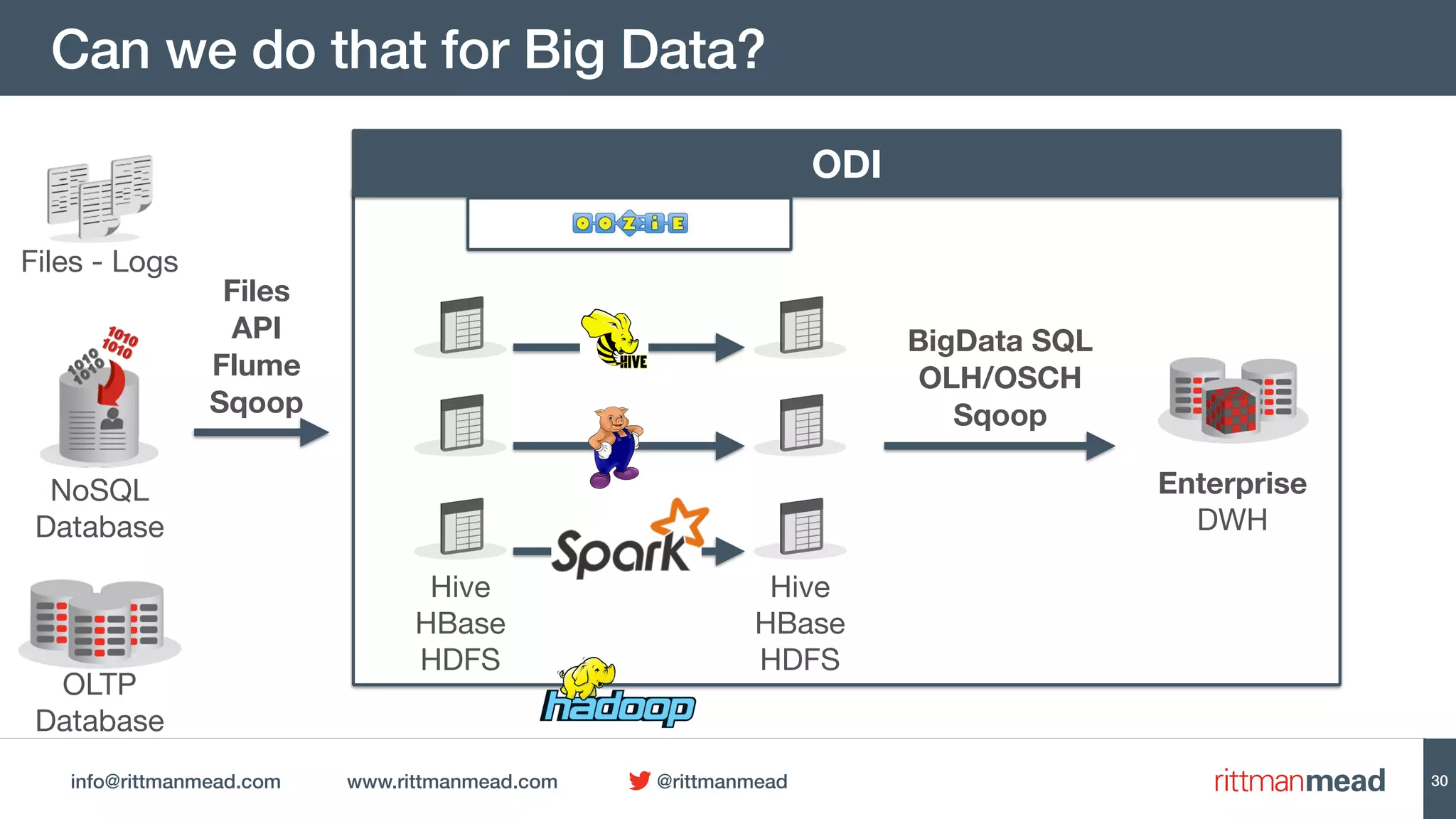
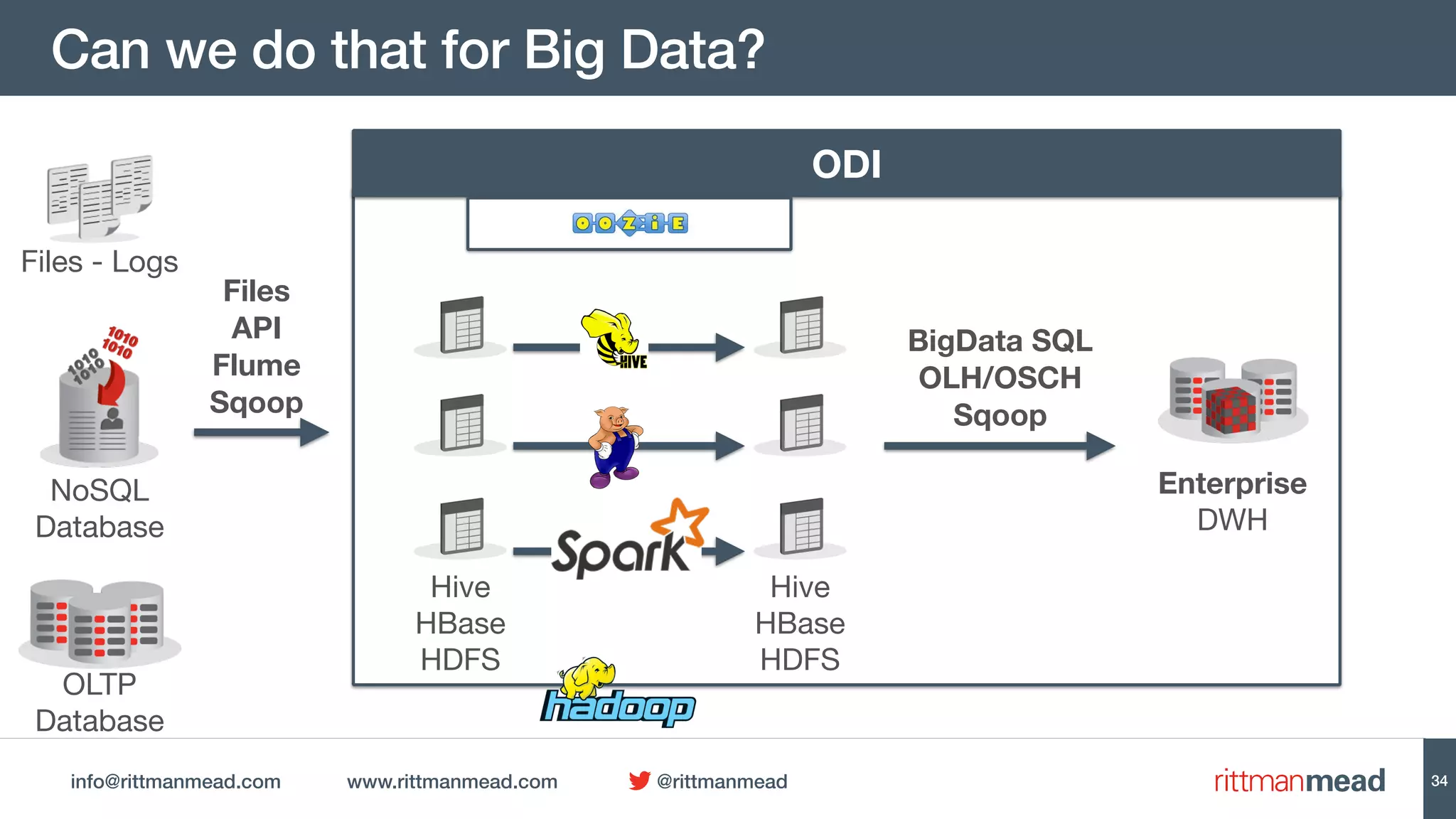
This document discusses using Oracle Data Integrator (ODI) for Extract, Transform, Load (ETL) processes involving big data. It demonstrates how ODI can be used to run ETL jobs on Hadoop technologies like Hive, Pig, and Spark. The document shows examples of importing Hive table metadata into the ODI repository and creating physical mappings for Hive, Pig, and Spark transformations. It emphasizes that ODI provides governance, orchestration, and monitoring for big data ETL processes while leveraging native Hadoop technologies.





![[db tech showcase Tokyo 2018] #dbts2018 #B31 『1,2,3 and Done! 3 easy ways to ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018b31123done3easywaystothecloud-181004231948-thumbnail.jpg?width=640&height=640&fit=bounds)











































































