Downloaded 73 times


![Challenges
• Small amount of supervised training data
- Language specific features and knowledge resources are required
- Costly to develop in new languages or domain
• Unsupervised learning offers an alternative
- Existing systems [1,2] rely on unsupervised features to augment hand-
engineered features
4](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-4-2048.jpg)


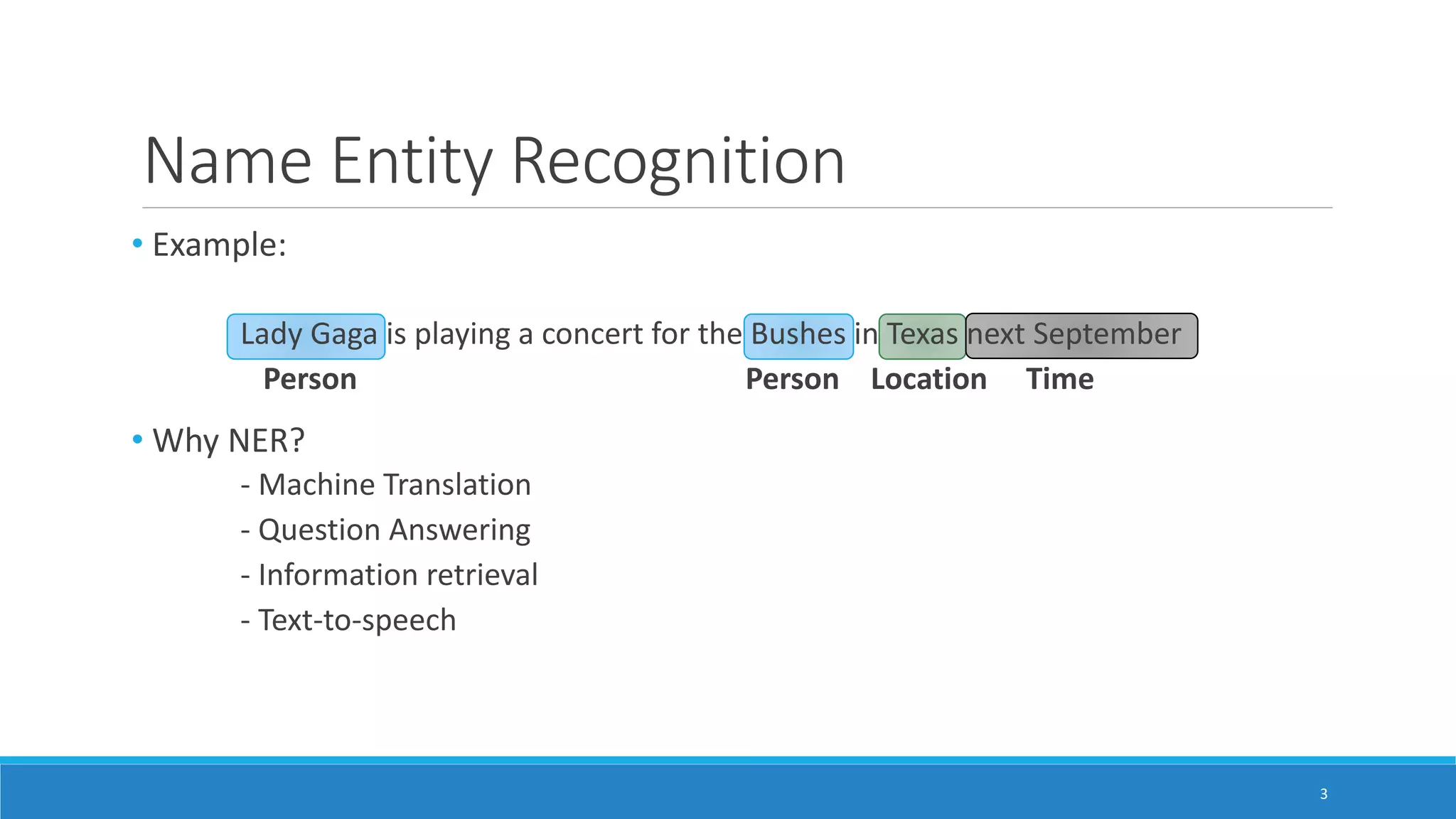
![Word Representation
• Character based representation + Word embedding
• Character based model
- Proposed by Ling et al. [3]
- Randomly initialized character embedding matrix
- Bidirectional LSTM captures orthographic information of a word
• Word embedding
- Pretrained embedding using skip-ngram [4]
• Dropout to encourage the model to depend on both representation
7](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-7-2048.jpg)
![Why not a CNN?
• Existing approaches [5, 6] use CNN for character based word representation
• CNN is designed to discover position-invariant features
• In a word, important information are position dependent
- e.g. Prefix and Suffix
9](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-9-2048.jpg)
![LSTM-CRF Model
• Bidirectional LSTM transforms a word representation to context representation
10
it = σ(Wi[xt, ht-1, ct-1] + bi)
ot = σ(Wo[xt, ht-1, ct-1] + bo)
ct = (1- it)*ct-1 + it*tanh(Wc[xt, ht-1, ct-1] + bc)
ht = ot*tanh(ct)
h't = [ht ; ht]
X +
X
-1
X
σ σtanh
ct-1
ht-1
ct
ht
xt
ht
it
ot](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-10-2048.jpg)




![Tagging scheme
• General tagging scheme – IOB format
- B-label : Beginning of a named entity
- I-label : Inside a named entity
- O-label : Outside a named entity
• Dai et al. [7] have showed that more expressive tagging scheme improves the
performance
• No significant performance improvement is observed with IOBES
- S : Singleton entities
- E : End of named entities
15](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-15-2048.jpg)
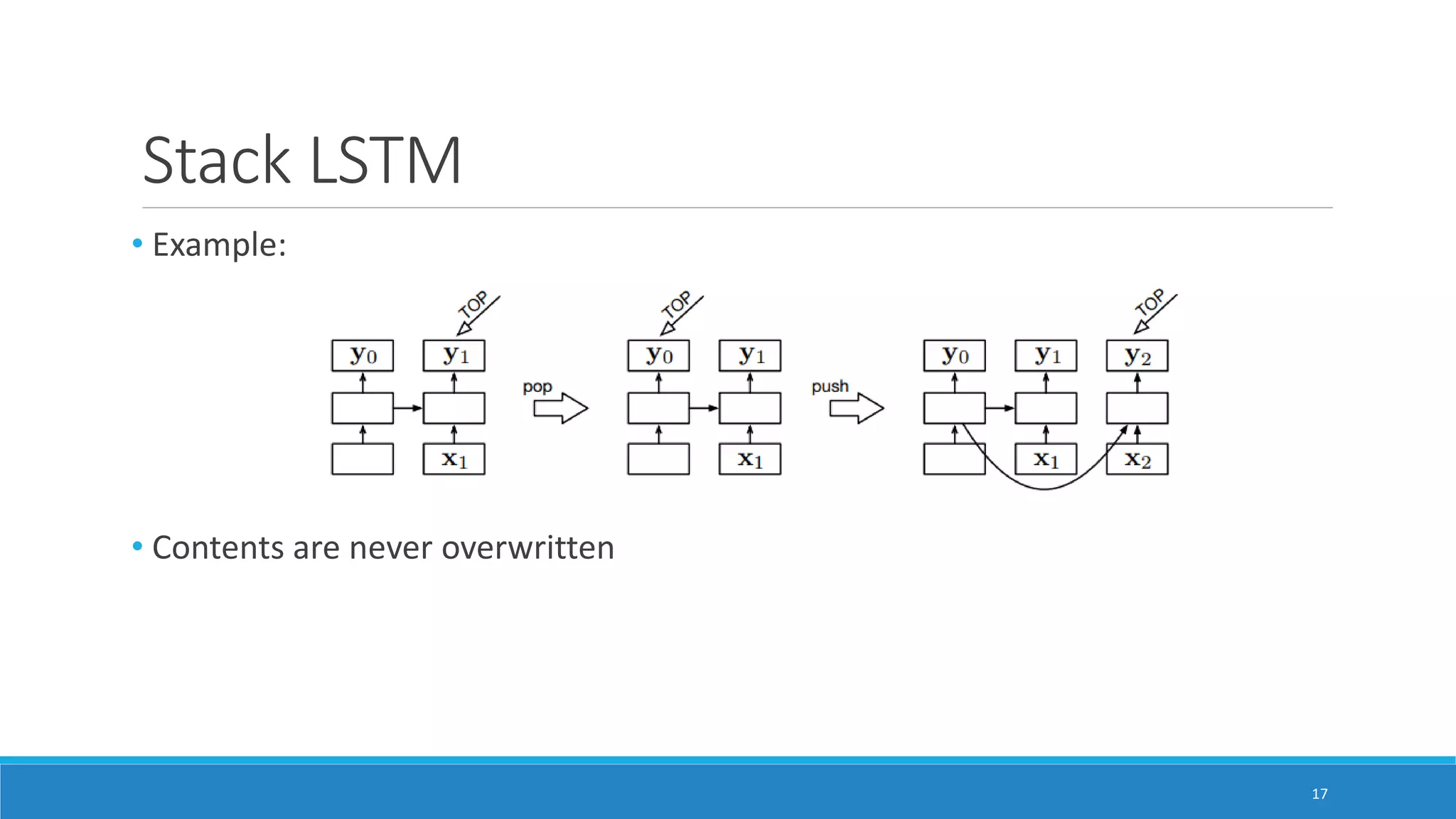
![Stack LSTM
• Proposed by Dyer at al. [8] for dependency parsing
• LSTM is augmented with a stack pointer
- Output cell of stack point gives stack summary
- Used to deicde ct-1 and ht-1 for the new input
• Stack operations are simulated using the pointer
- Push : Add a new input to LSTM
- Pop : Moves stack pointer to previous element
16](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-16-2048.jpg)






![Novelty
• LSTM-CRF
- Word representation proposed by Ling et al. [3] has been experimented
for language independent NER
• Stack-LSTM
- Stack LSTM Dyer at al. [8] has been experimented for language independent
NER
24](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-24-2048.jpg)







![Related Work
• Neural Architectures
1. CNN-CRF [1]
2. LSTM-CRF [9]
• Language independent NER
1. Bayesian approach [10]
• NER with character-based representation
1. Byte level processing of strings [11]
2. CNN-LSTM [12]
37](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-37-2048.jpg)


![Future Work
• Extend CRF layer to higher order CRF [13]
• Experiment the model performance by jointly learning NER and other NLP task
[14]
40](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-40-2048.jpg)
![Reference
[1] Ronan Collobert, Jason Weston, Leon Bottou, Michael ´Karlen, Koray Kavukcuoglu, and Pavel Kuksa.
2011. Natural language processing (almost) from scratch. The Journal of Machine Learning Research,
12:2493–2537.
[2] Joseph Turian, Lev Ratinov, and Yoshua Bengio. 2010. Word representations: A simple and general
method for semi-supervised learning. In Proc. ACL.
[3] Wang Ling, Tiago Lu´ıs, Lu´ıs Marujo, Ramon Fernandez ´Astudillo, Silvio Amir, Chris Dyer, Alan W Black,
and Isabel Trancoso. 2015b. Finding function in form: Compositional character models for open vocabulary
word representation. In Proceedings of the Conference on Empirical Methods in Natural Language
Processing (EMNLP).
[4] Wang Ling, Lin Chu-Cheng, Yulia Tsvetkov, Silvio Amir, Ramon Fernandez Astudillo, Chris Dyer, Alan W
´Black, and Isabel Trancoso. 2015a. Not all contexts are created equal: Better word representations with
variable attention. In Proc. EMNLP.
[5] Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text
classification.
In Advances in Neural Information Processing Systems, pages 649–657.
[6] Yoon Kim, Yacine Jernite, David Sontag, and Alexander M. Rush. 2015. Character-aware neural language
models. CoRR, abs/1508.06615
[7] Hong-Jie Dai, Po-Ting Lai, Yung-Chun Chang, and Richard Tzong-Han Tsai. 2015. Enhancing of chemical
compound and drug name recognition using representative tag scheme and fine-grained tokenization.
Journal of cheminformatics, 7(Suppl 1):S14.
41](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-41-2048.jpg)
![Reference
[8] Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, and Noah A. Smith. 2015. Transitionbased
dependency parsing with stack long short-term memory. In Proc. ACL
[9] Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF models for sequence tagging. CoRR,
abs/1508.01991. Yoon Kim, Yacine Jernite, David Sontag, and Alexander M. Rush. 2015. Character-aware
neural language models. CoRR, abs/1508.06615.
[10] Jacob Eisenstein, Tae Yano, William W Cohen, Noah A Smith, and Eric P Xing. 2011. Structured
databases of named entities from bayesian nonparametrics. In Proceedings of the First Workshop on
Unsupervised Learning in NLP, pages 2–12. Association for Computational Linguistics.
[11] Dan Gillick, Cliff Brunk, Oriol Vinyals, and Amarnag Subramanya. 2015. Multilingual language processing
from bytes. arXiv preprint arXiv:1512.00103
[12] Jason PC Chiu and Eric Nichols. 2015. Named entity recognition with bidirectional lstm-cnns. arXiv
preprint arXiv:1511.08308.
[13] S. Sarawagi, W. W. Cohen. Semi-Markov conditional random fields for information extraction. NIPS,
2004
[14] Gang Luo, Xiaojiang Huang, Chin-Yew Lin, and Zaiqing Nie. 2015. Joint named entity recognition and
disambiguation. In Proc. EMNLP.
42](https://image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-42-2048.jpg)





![Challenges
• Small amount of supervised training data
- Language specific features and knowledge resources are required
- Costly to develop in new languages or domain
• Unsupervised learning offers an alternative
- Existing systems [1,2] rely on unsupervised features to augment hand-
engineered features
4](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-4-2048.jpg)


![Word Representation
• Character based representation + Word embedding
• Character based model
- Proposed by Ling et al. [3]
- Randomly initialized character embedding matrix
- Bidirectional LSTM captures orthographic information of a word
• Word embedding
- Pretrained embedding using skip-ngram [4]
• Dropout to encourage the model to depend on both representation
7](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-7-2048.jpg)

![Why not a CNN?
• Existing approaches [5, 6] use CNN for character based word representation
• CNN is designed to discover position-invariant features
• In a word, important information are position dependent
- e.g. Prefix and Suffix
9](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-9-2048.jpg)
![LSTM-CRF Model
• Bidirectional LSTM transforms a word representation to context representation
10
it = σ(Wi[xt, ht-1, ct-1] + bi)
ot = σ(Wo[xt, ht-1, ct-1] + bo)
ct = (1- it)*ct-1 + it*tanh(Wc[xt, ht-1, ct-1] + bc)
ht = ot*tanh(ct)
h't = [ht ; ht]
X +
X
-1
X
σ σtanh
ct-1
ht-1
ct
ht
xt
ht
it
ot](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-10-2048.jpg)




![Tagging scheme
• General tagging scheme – IOB format
- B-label : Beginning of a named entity
- I-label : Inside a named entity
- O-label : Outside a named entity
• Dai et al. [7] have showed that more expressive tagging scheme improves the
performance
• No significant performance improvement is observed with IOBES
- S : Singleton entities
- E : End of named entities
15](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-15-2048.jpg)
![Stack LSTM
• Proposed by Dyer at al. [8] for dependency parsing
• LSTM is augmented with a stack pointer
- Output cell of stack point gives stack summary
- Used to deicde ct-1 and ht-1 for the new input
• Stack operations are simulated using the pointer
- Push : Add a new input to LSTM
- Pop : Moves stack pointer to previous element
16](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-16-2048.jpg)







![Novelty
• LSTM-CRF
- Word representation proposed by Ling et al. [3] has been experimented
for language independent NER
• Stack-LSTM
- Stack LSTM Dyer at al. [8] has been experimented for language independent
NER
24](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-24-2048.jpg)












![Related Work
• Neural Architectures
1. CNN-CRF [1]
2. LSTM-CRF [9]
• Language independent NER
1. Bayesian approach [10]
• NER with character-based representation
1. Byte level processing of strings [11]
2. CNN-LSTM [12]
37](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-37-2048.jpg)


![Future Work
• Extend CRF layer to higher order CRF [13]
• Experiment the model performance by jointly learning NER and other NLP task
[14]
40](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-40-2048.jpg)
![Reference
[1] Ronan Collobert, Jason Weston, Leon Bottou, Michael ´Karlen, Koray Kavukcuoglu, and Pavel Kuksa.
2011. Natural language processing (almost) from scratch. The Journal of Machine Learning Research,
12:2493–2537.
[2] Joseph Turian, Lev Ratinov, and Yoshua Bengio. 2010. Word representations: A simple and general
method for semi-supervised learning. In Proc. ACL.
[3] Wang Ling, Tiago Lu´ıs, Lu´ıs Marujo, Ramon Fernandez ´Astudillo, Silvio Amir, Chris Dyer, Alan W Black,
and Isabel Trancoso. 2015b. Finding function in form: Compositional character models for open vocabulary
word representation. In Proceedings of the Conference on Empirical Methods in Natural Language
Processing (EMNLP).
[4] Wang Ling, Lin Chu-Cheng, Yulia Tsvetkov, Silvio Amir, Ramon Fernandez Astudillo, Chris Dyer, Alan W
´Black, and Isabel Trancoso. 2015a. Not all contexts are created equal: Better word representations with
variable attention. In Proc. EMNLP.
[5] Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text
classification.
In Advances in Neural Information Processing Systems, pages 649–657.
[6] Yoon Kim, Yacine Jernite, David Sontag, and Alexander M. Rush. 2015. Character-aware neural language
models. CoRR, abs/1508.06615
[7] Hong-Jie Dai, Po-Ting Lai, Yung-Chun Chang, and Richard Tzong-Han Tsai. 2015. Enhancing of chemical
compound and drug name recognition using representative tag scheme and fine-grained tokenization.
Journal of cheminformatics, 7(Suppl 1):S14.
41](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-41-2048.jpg)
![Reference
[8] Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, and Noah A. Smith. 2015. Transitionbased
dependency parsing with stack long short-term memory. In Proc. ACL
[9] Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF models for sequence tagging. CoRR,
abs/1508.01991. Yoon Kim, Yacine Jernite, David Sontag, and Alexander M. Rush. 2015. Character-aware
neural language models. CoRR, abs/1508.06615.
[10] Jacob Eisenstein, Tae Yano, William W Cohen, Noah A Smith, and Eric P Xing. 2011. Structured
databases of named entities from bayesian nonparametrics. In Proceedings of the First Workshop on
Unsupervised Learning in NLP, pages 2–12. Association for Computational Linguistics.
[11] Dan Gillick, Cliff Brunk, Oriol Vinyals, and Amarnag Subramanya. 2015. Multilingual language processing
from bytes. arXiv preprint arXiv:1512.00103
[12] Jason PC Chiu and Eric Nichols. 2015. Named entity recognition with bidirectional lstm-cnns. arXiv
preprint arXiv:1511.08308.
[13] S. Sarawagi, W. W. Cohen. Semi-Markov conditional random fields for information extraction. NIPS,
2004
[14] Gang Luo, Xiaojiang Huang, Chin-Yew Lin, and Zaiqing Nie. 2015. Joint named entity recognition and
disambiguation. In Proc. EMNLP.
42](https://crownmelresort.com/image.slidesharecdn.com/s07rrubaapanchendrarajan-180406073011/75/Neural-Architectures-for-Named-Entity-Recognition-42-2048.jpg)



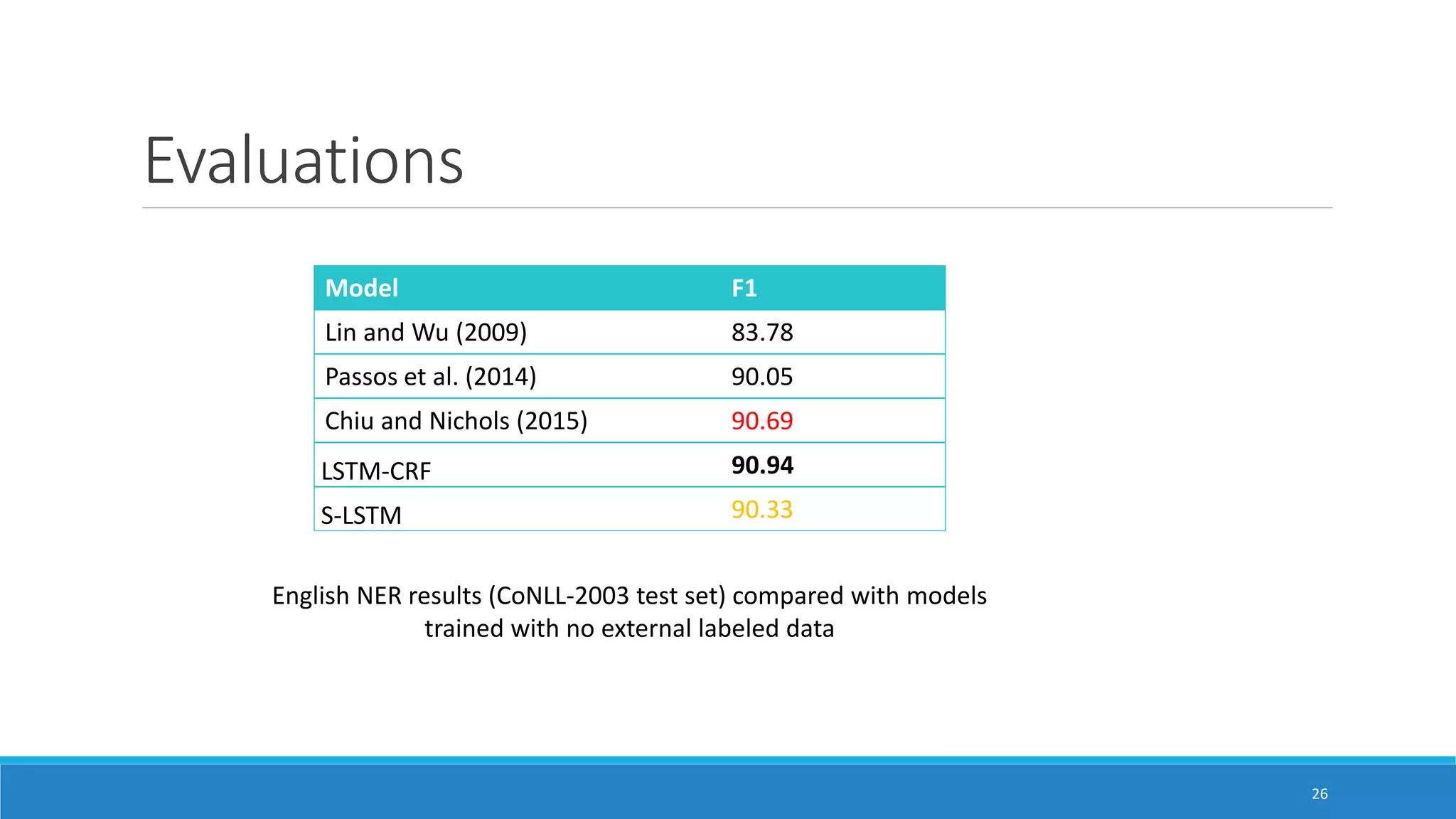
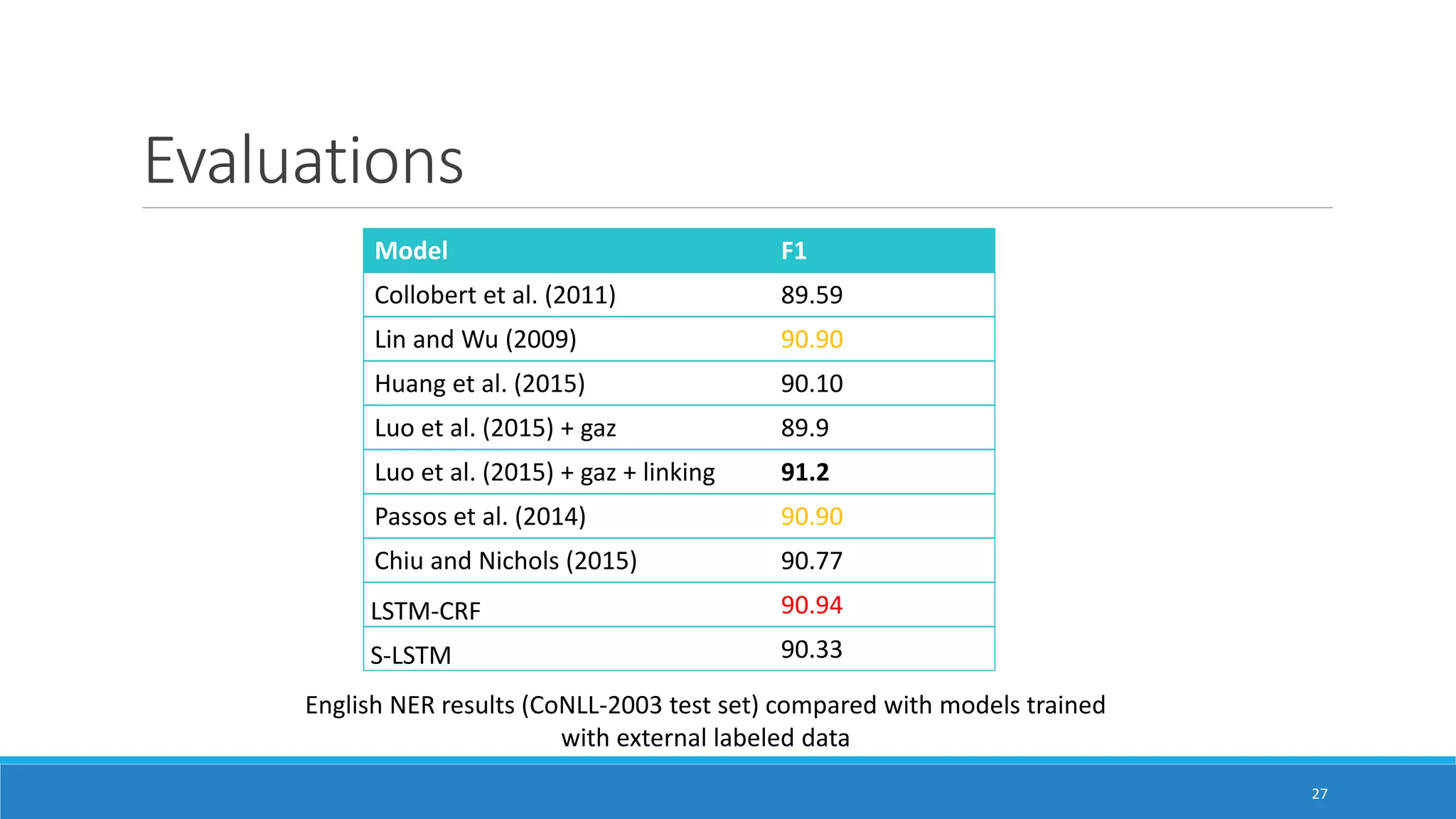
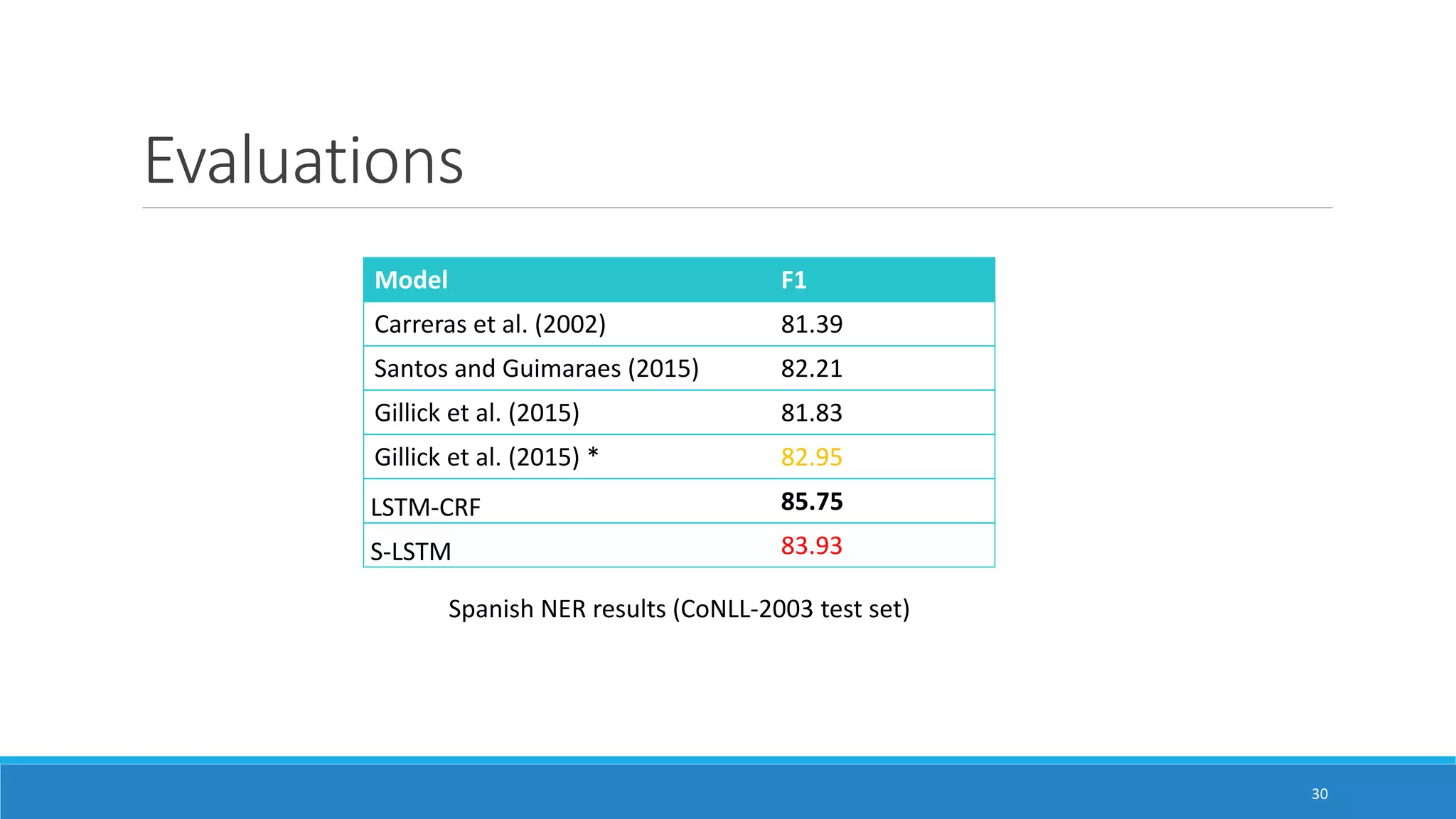
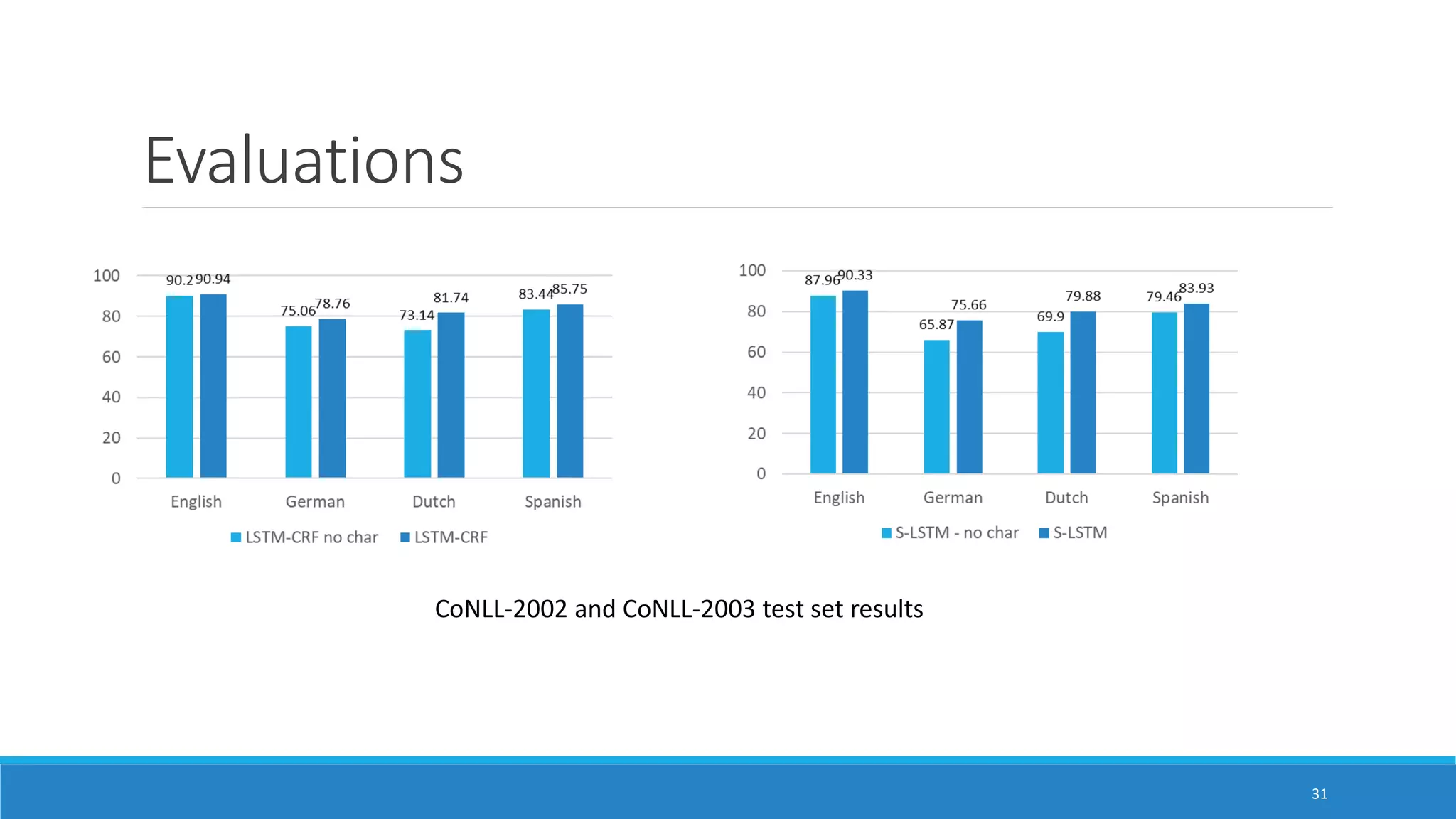
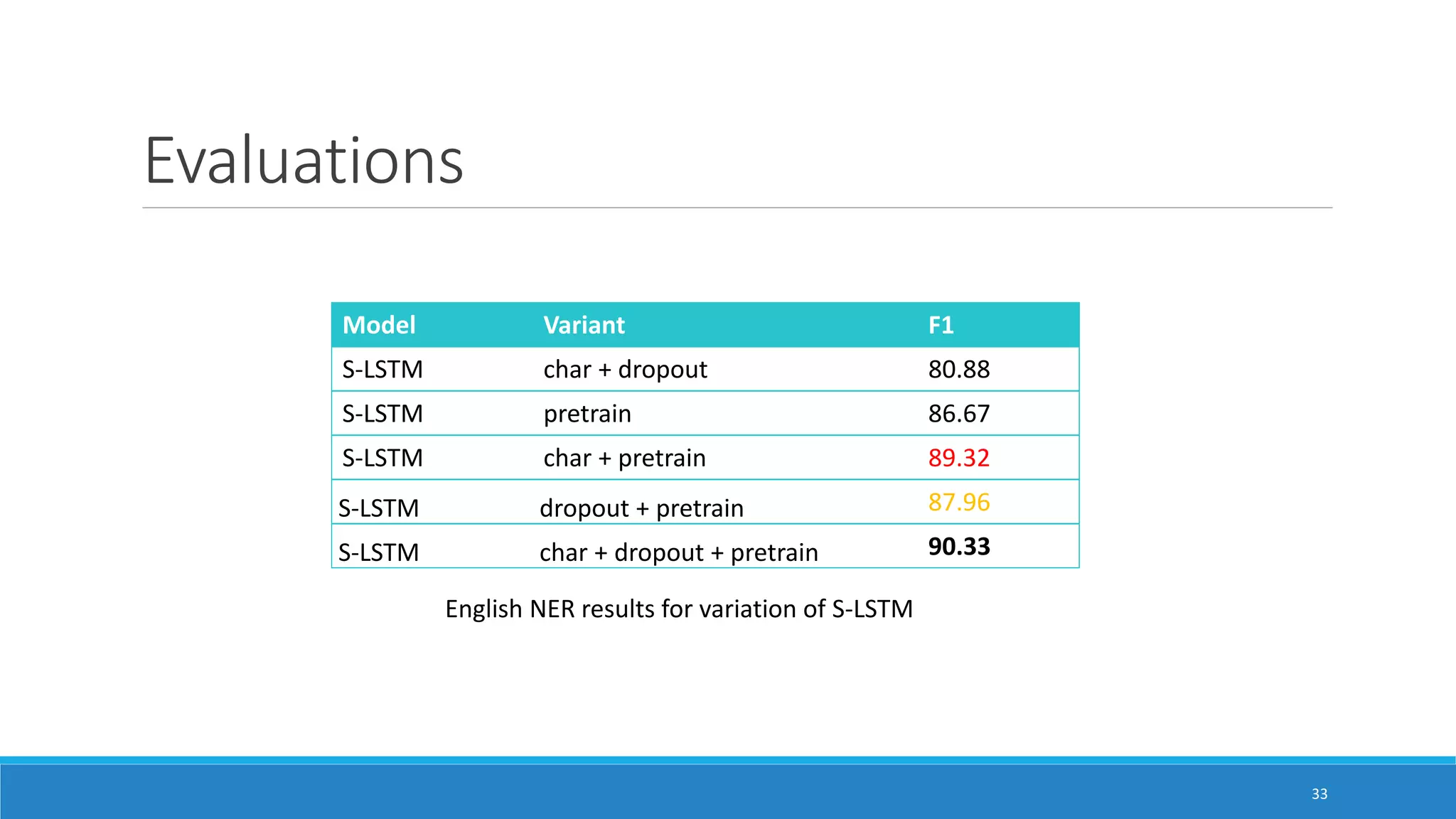
The document presents two neural network models for named entity recognition (NER) without language-specific resources: an LSTM-CRF model and a transition-based stack LSTM (S-LSTM) model. The LSTM-CRF model uses a bidirectional LSTM layer followed by a CRF layer to label input sequences, while the S-LSTM model directly constructs labeled entity chunks. Both models represent words as character-level representations from a bidirectional LSTM combined with word embeddings. The models are evaluated on four languages and achieve state-of-the-art performance on three of the languages without external labeled data.



































































