Downloaded 112 times



















![PerpetualStream
• Provides a convenience trait to help
write streams controlled by system
lifecycle
• Minimal/no message losses
• Register PerpetualStream to make
stream start/stop
• Provides customization hooks –
especially for how to stop the stream
• Provides killSwitch (from Akka) to be
embedded into stream
• Implementers - just provide your
stream!
A non-stop stream; starts and stops with the system
class MyStream extends PerpetualStream[Future[Int]] {
def generator = Iterator.iterate(0) { p =>
if (p == Int.MaxValue) 0 else p + 1
}
val source = Source.fromIterator(generator _)
val ignoreSink = Sink.ignore[Int]
override def streamGraph = RunnableGraph.fromGraph(
GraphDSL.create(ignoreSink) { implicit builder =>
sink =>
import GraphDSL.Implicits._
source ~> killSwitch.flow[Int] ~> sink
ClosedShape
})
}](https://image.slidesharecdn.com/squbs-backpressure-webinar-161117182110/75/Lessons-Learned-From-PayPal-Implementing-Back-Pressure-With-Akka-Streams-And-Kafka-27-2048.jpg)






























![PerpetualStream
• Provides a convenience trait to help
write streams controlled by system
lifecycle
• Minimal/no message losses
• Register PerpetualStream to make
stream start/stop
• Provides customization hooks –
especially for how to stop the stream
• Provides killSwitch (from Akka) to be
embedded into stream
• Implementers - just provide your
stream!
A non-stop stream; starts and stops with the system
class MyStream extends PerpetualStream[Future[Int]] {
def generator = Iterator.iterate(0) { p =>
if (p == Int.MaxValue) 0 else p + 1
}
val source = Source.fromIterator(generator _)
val ignoreSink = Sink.ignore[Int]
override def streamGraph = RunnableGraph.fromGraph(
GraphDSL.create(ignoreSink) { implicit builder =>
sink =>
import GraphDSL.Implicits._
source ~> killSwitch.flow[Int] ~> sink
ClosedShape
})
}](https://crownmelresort.com/image.slidesharecdn.com/squbs-backpressure-webinar-161117182110/75/Lessons-Learned-From-PayPal-Implementing-Back-Pressure-With-Akka-Streams-And-Kafka-27-2048.jpg)





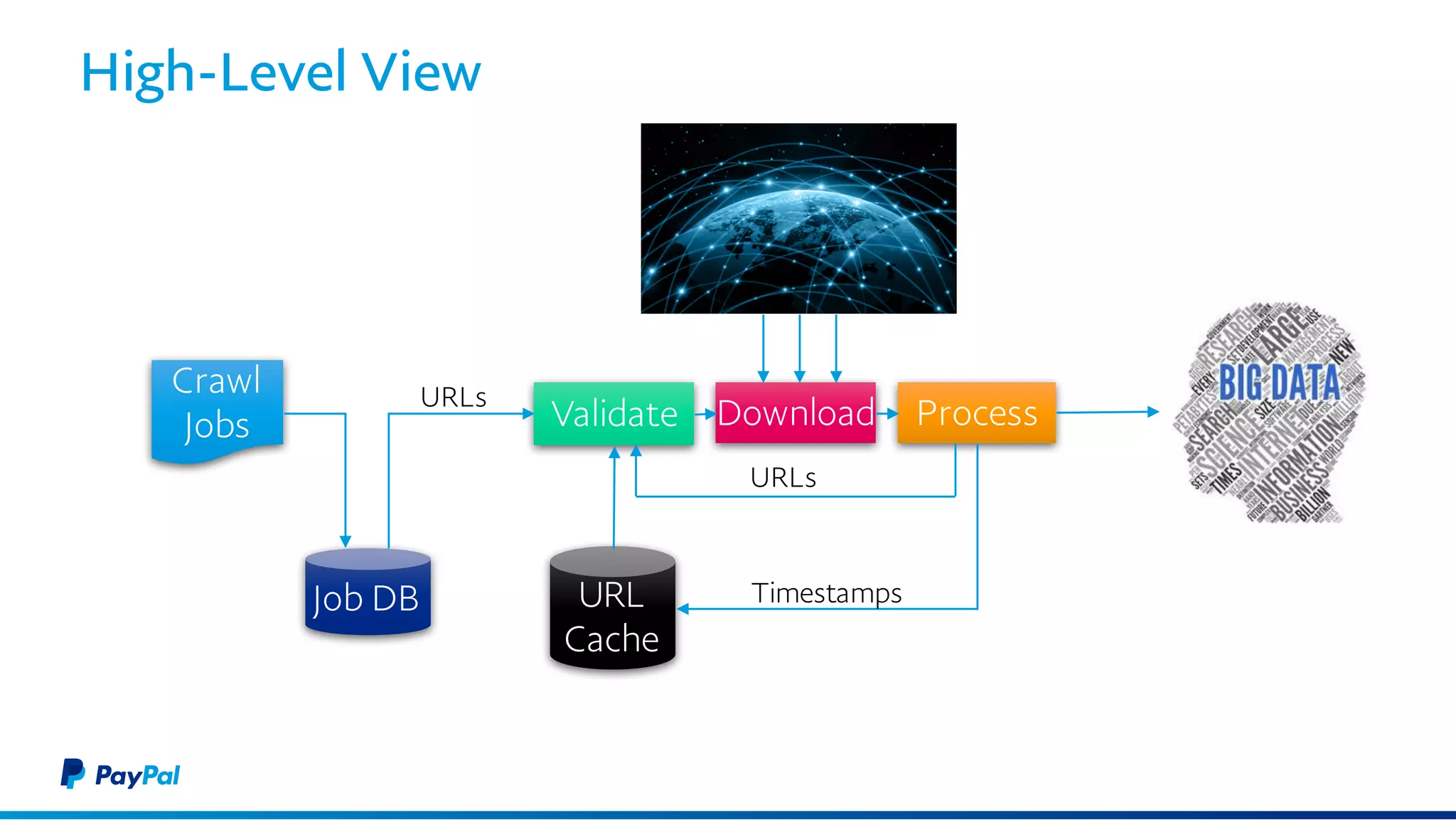
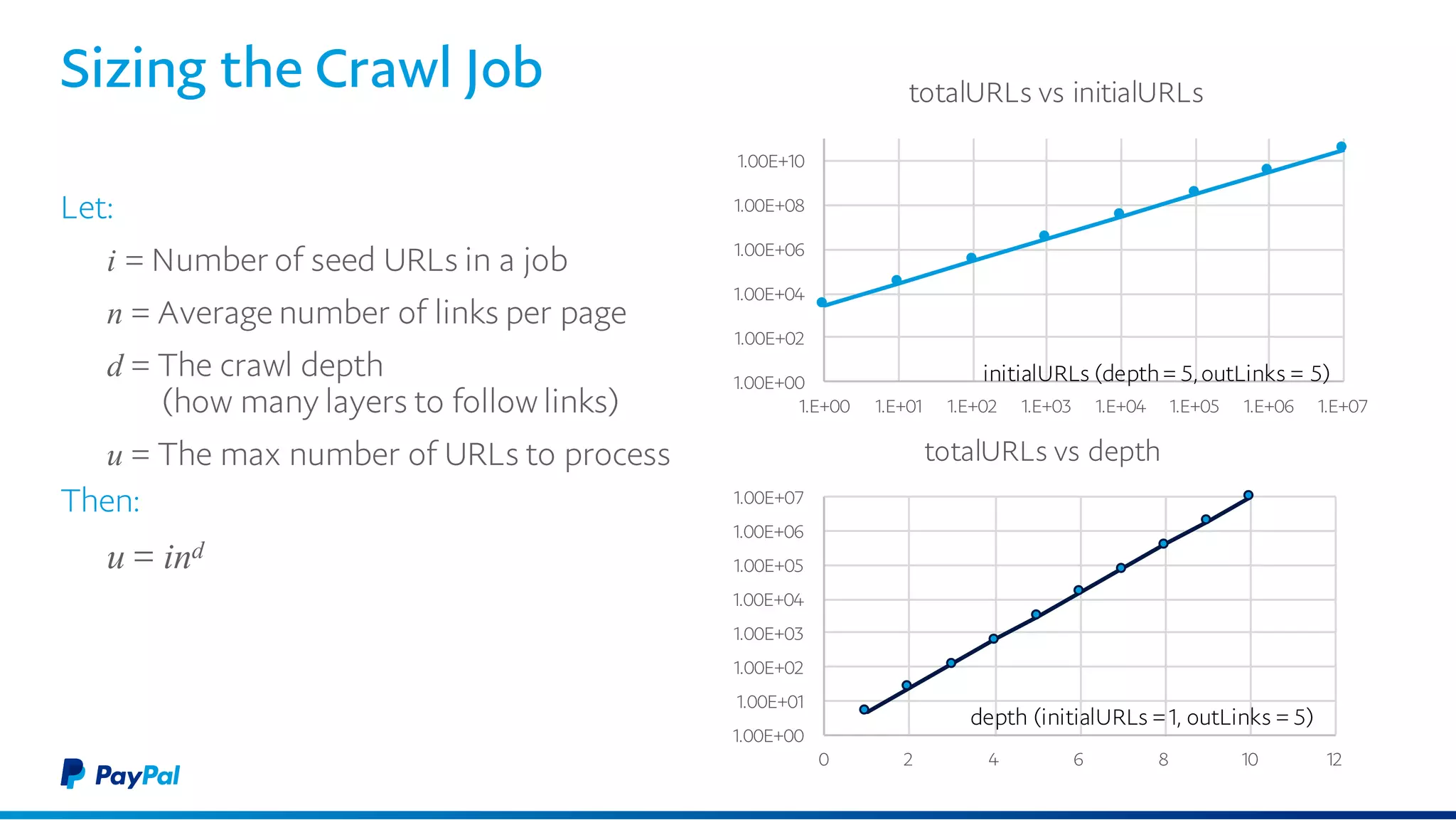
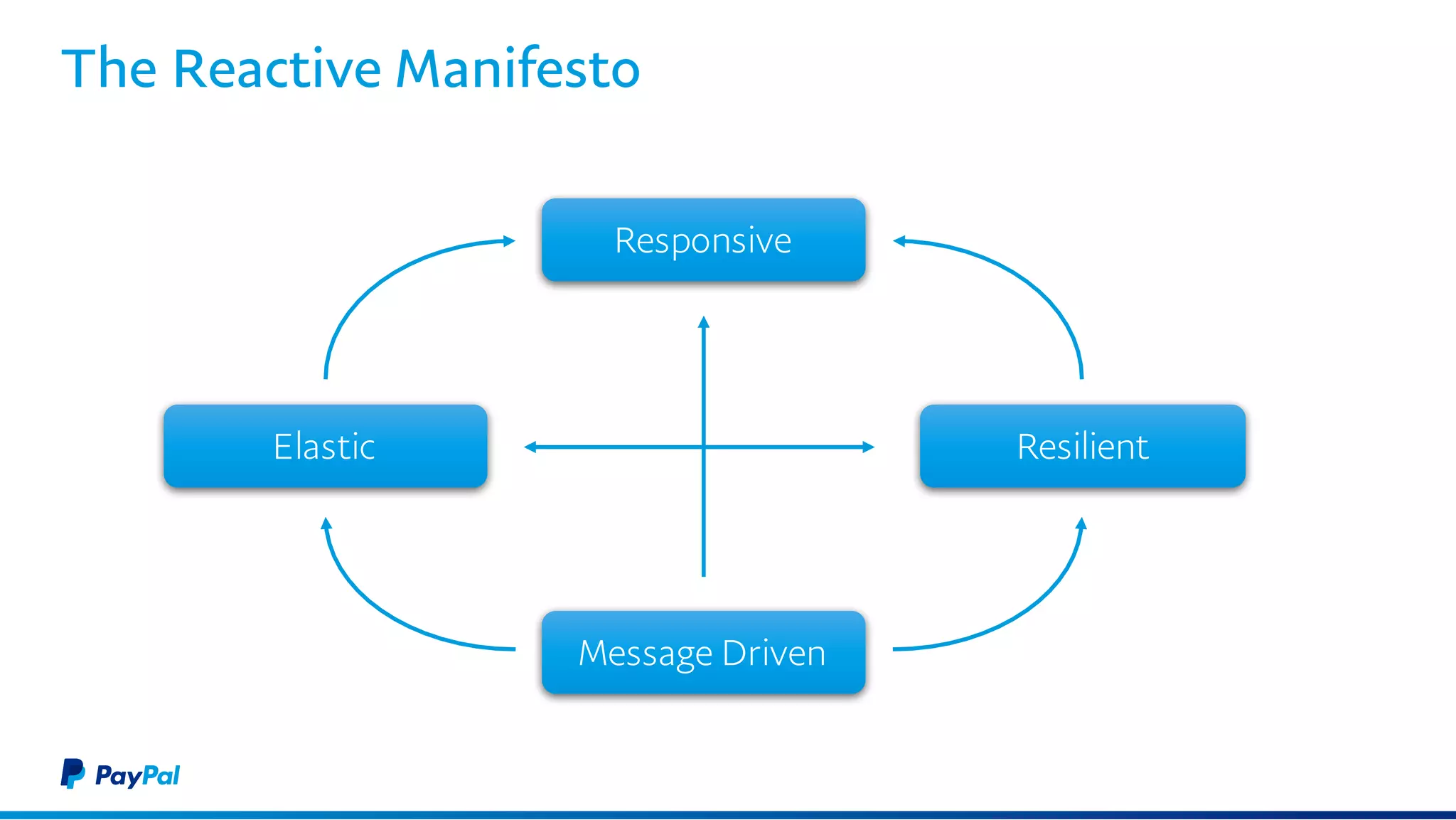
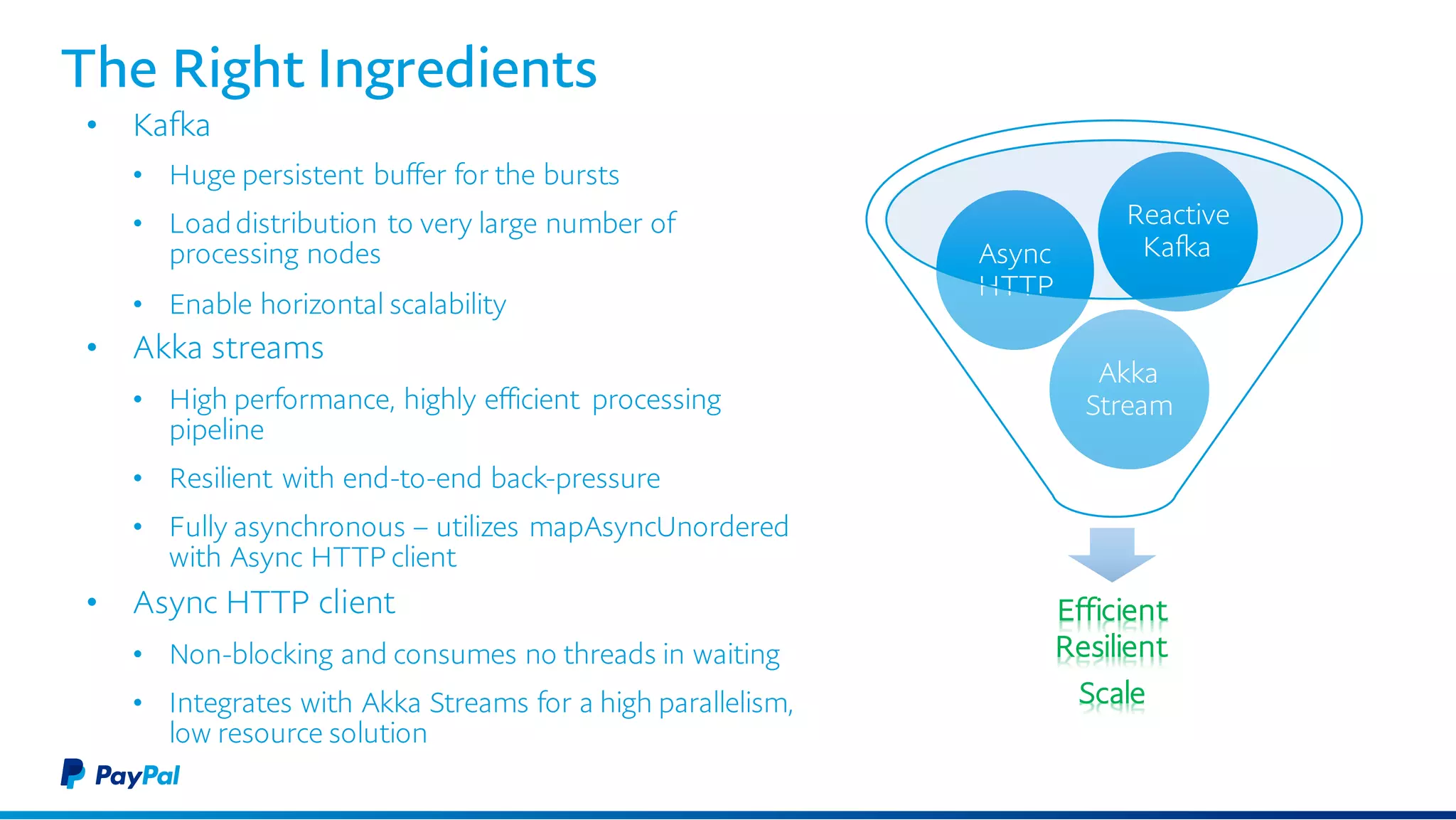
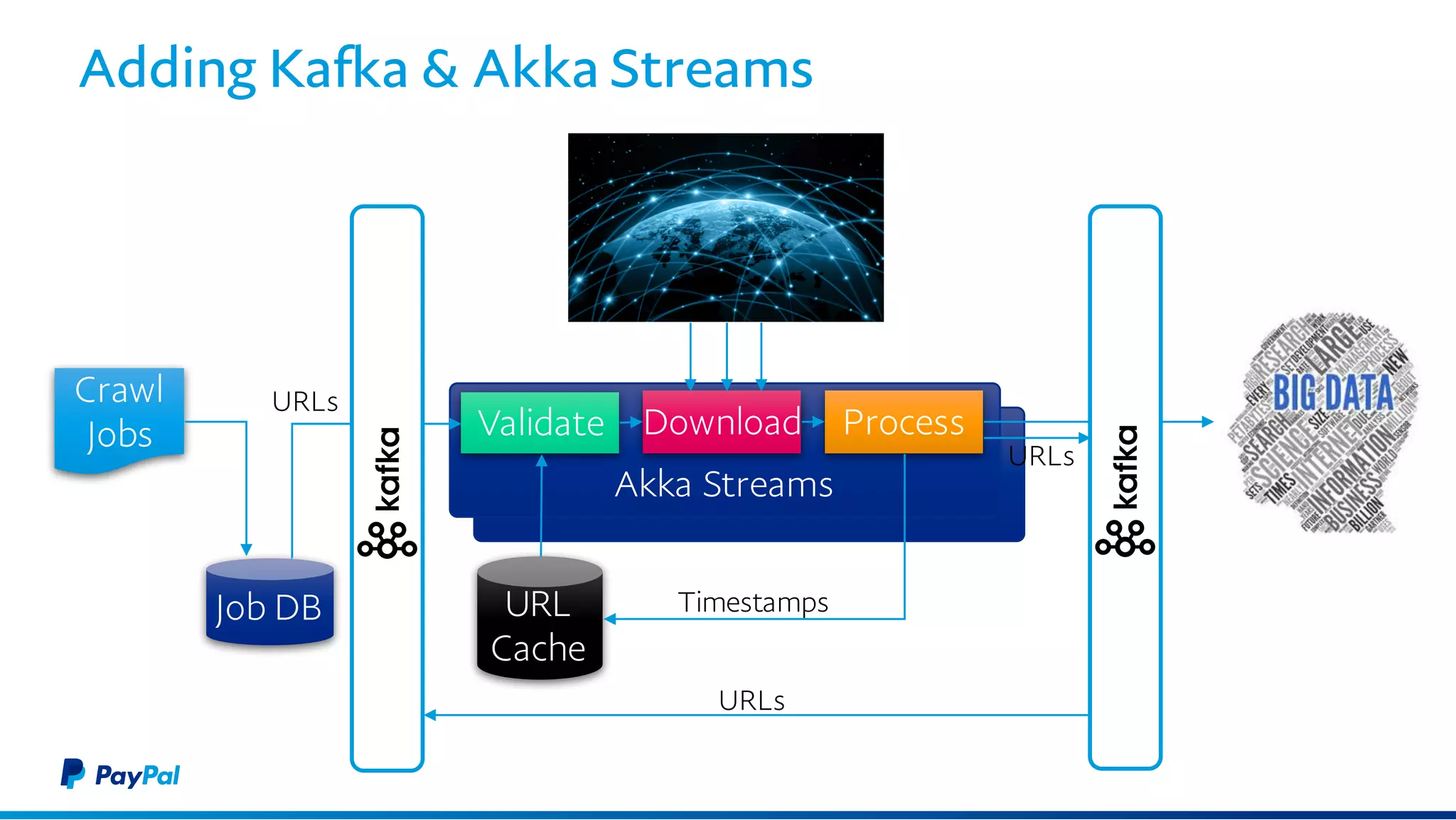
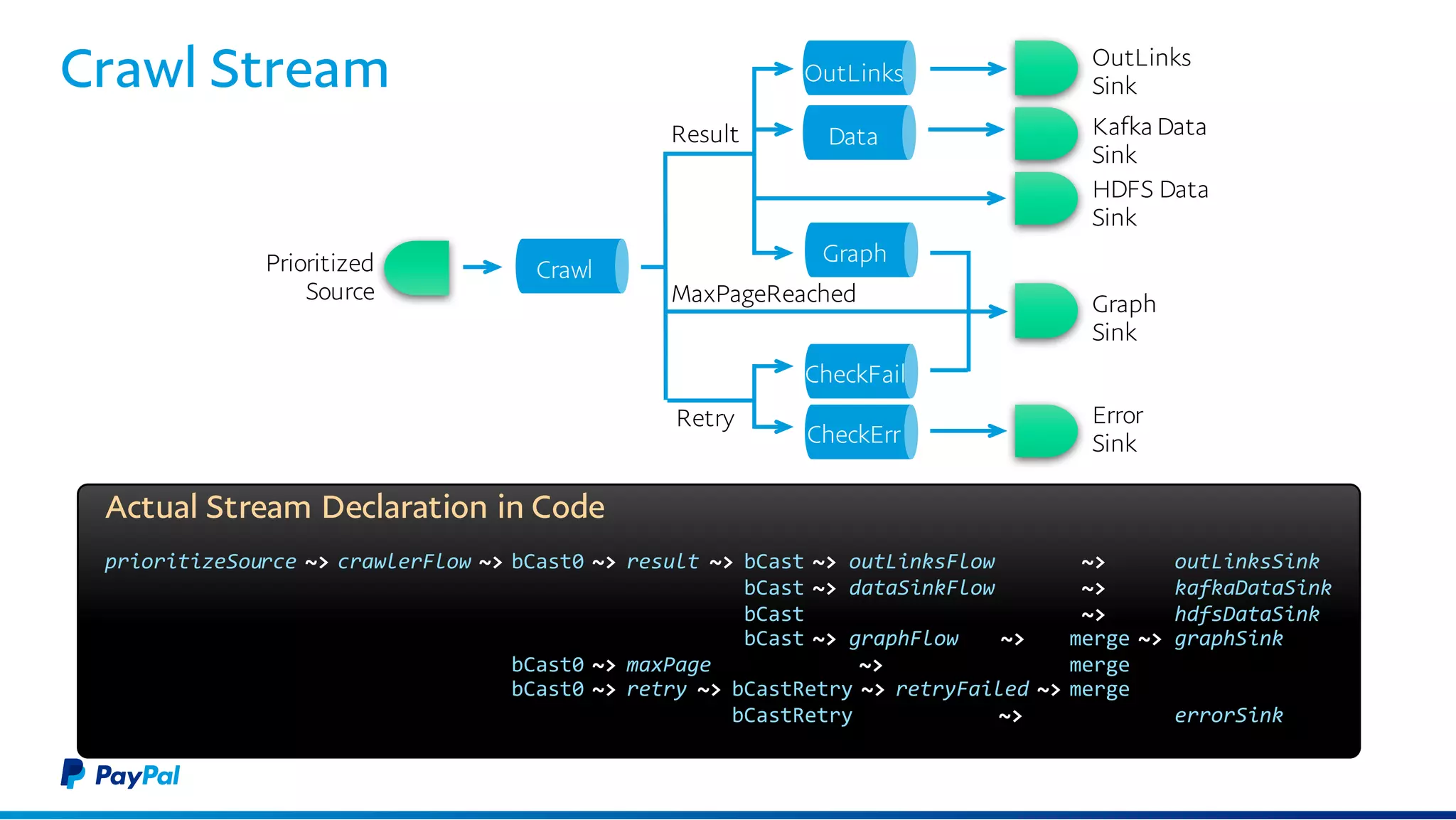
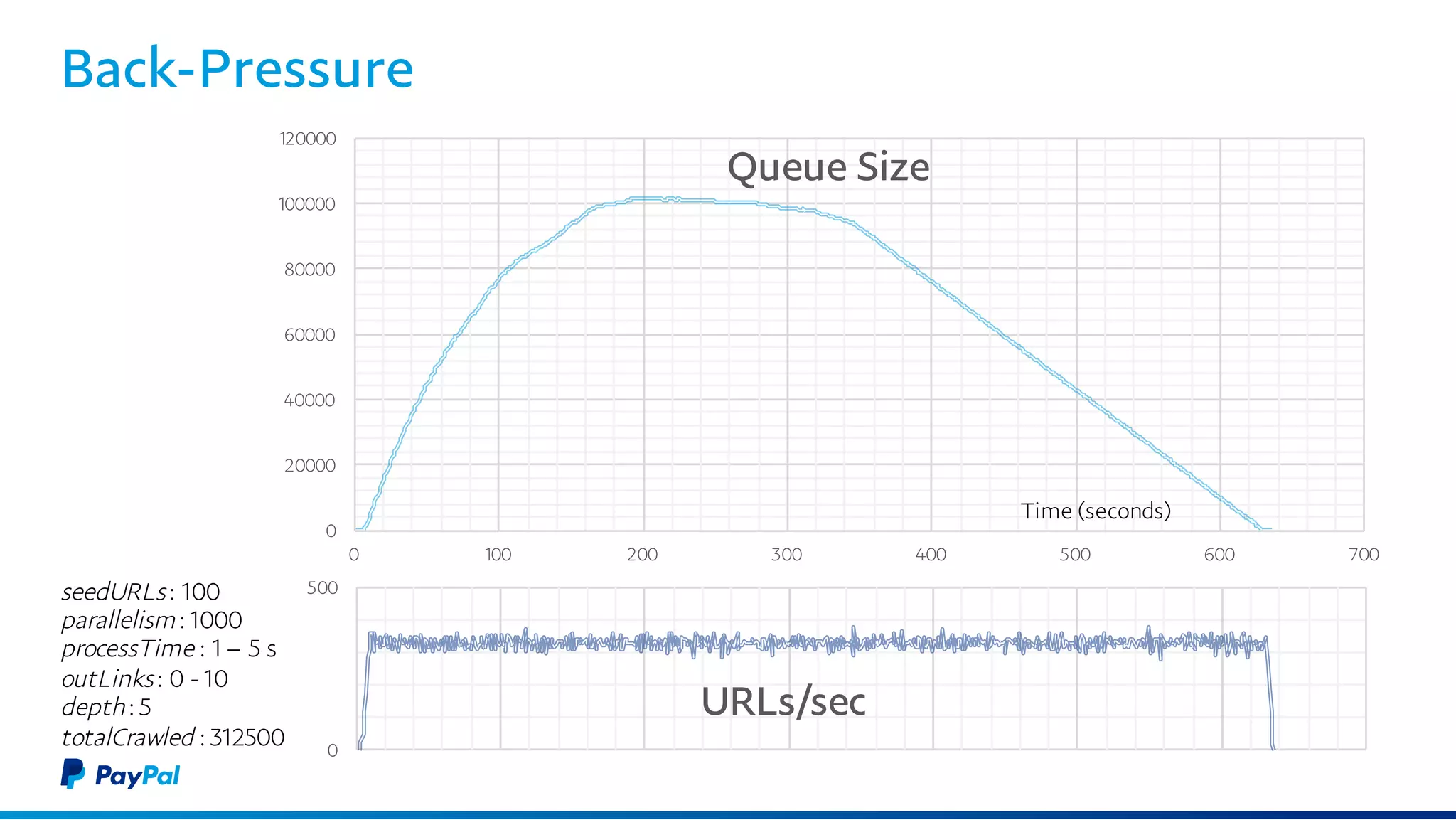
The document discusses the architecture and benefits of using Akka Streams and Kafka for efficient web crawling. It highlights the reactive manifesto principles of responsiveness, resilience, and elasticity while detailing the system's design for handling high-volume URL processing. Key features include asynchronous processing, back-pressure management, and modular components to ensure scalability and performance without compromising resource efficiency.




































![[PDF Download] Akka in Action 1st Edition Raymond Roestenburg fulll chapter](https://cdn.slidesharecdn.com/ss_thumbnails/10639-240805124441-3617891d-thumbnail.jpg?width=640&height=640&fit=bounds)





![Introduction to Akka Streams [Part-I]](https://cdn.slidesharecdn.com/ss_thumbnails/babystepsinakkastreampart-i-171117070802-thumbnail.jpg?width=640&height=640&fit=bounds)

















































