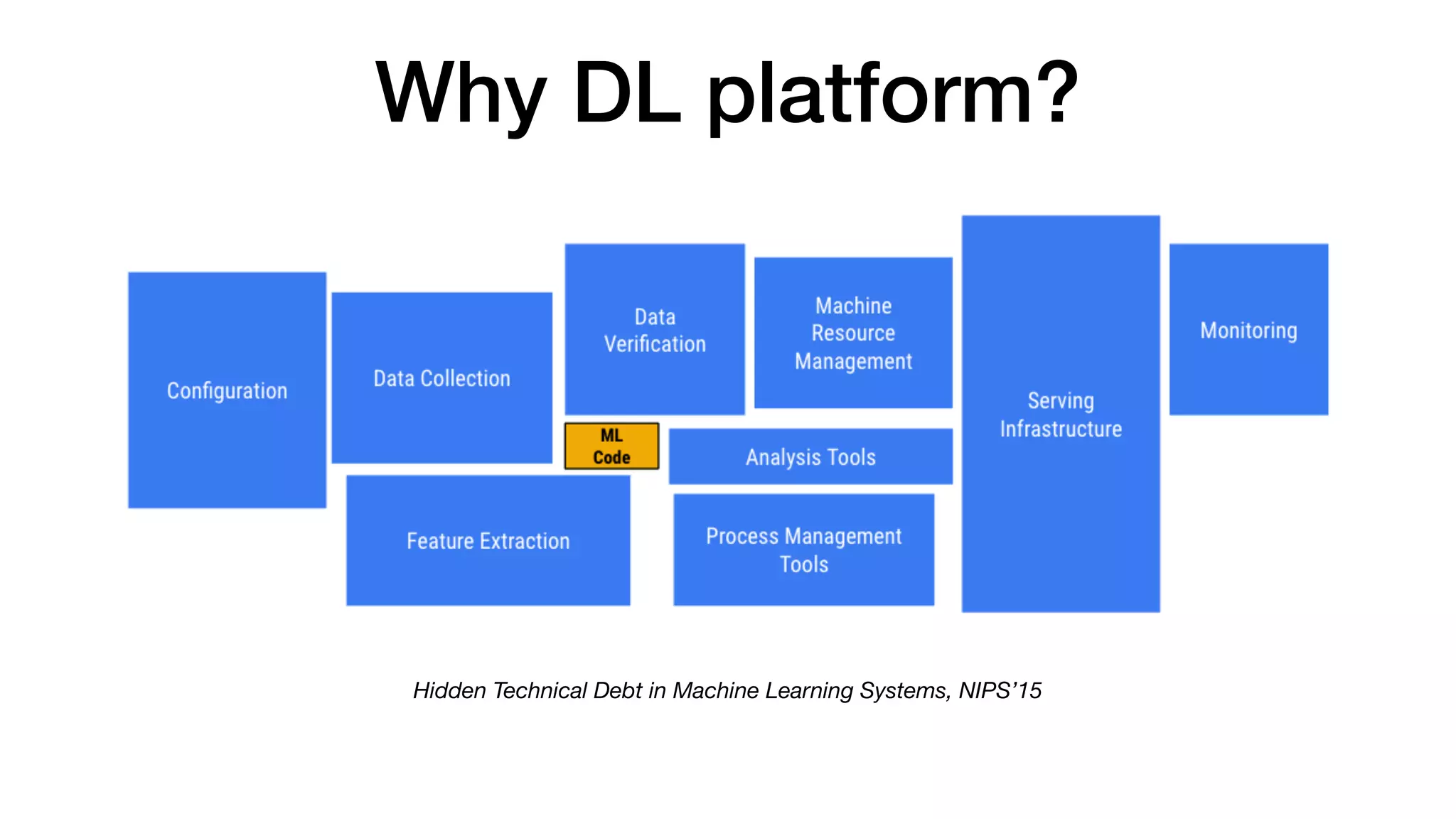
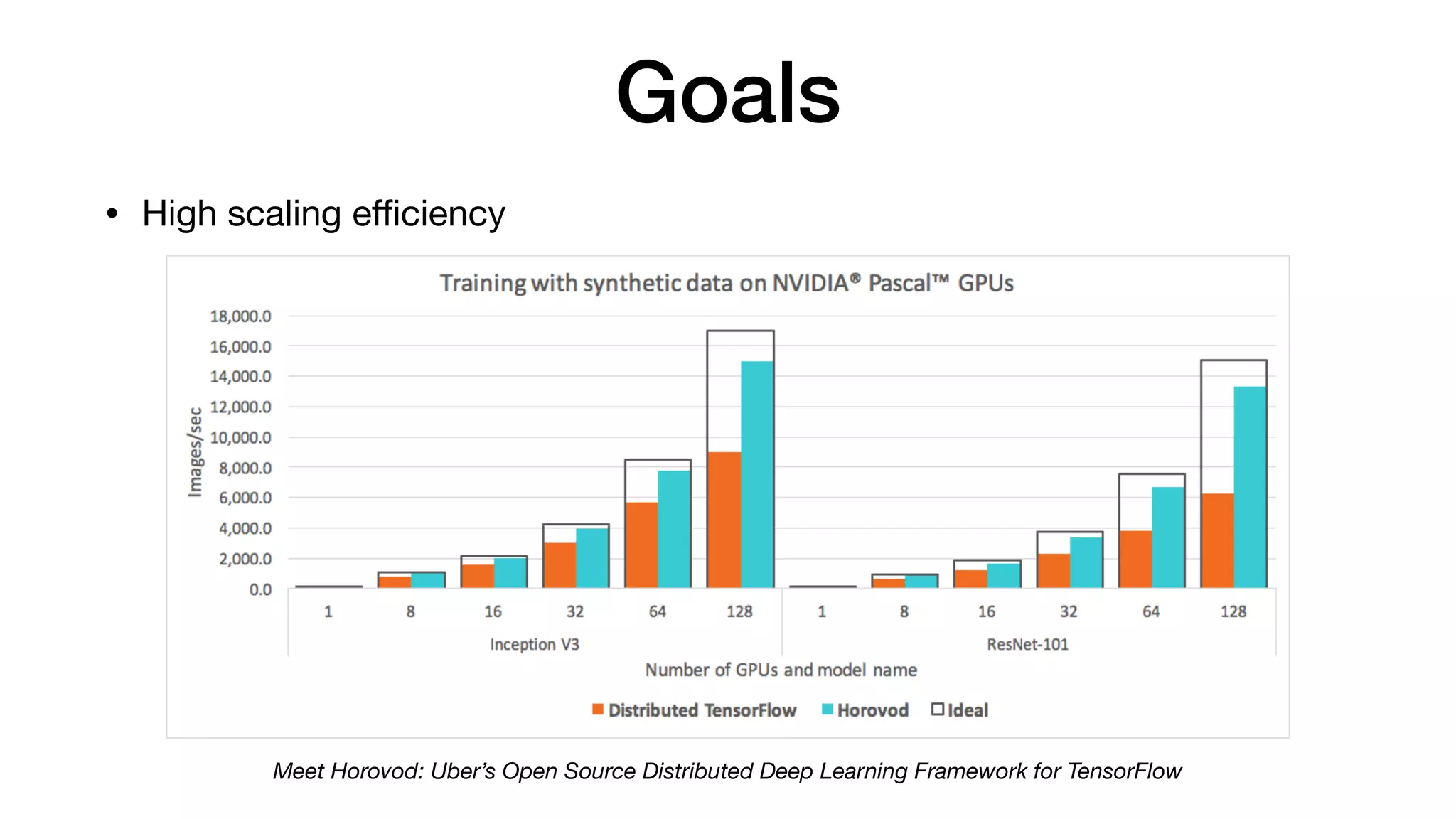
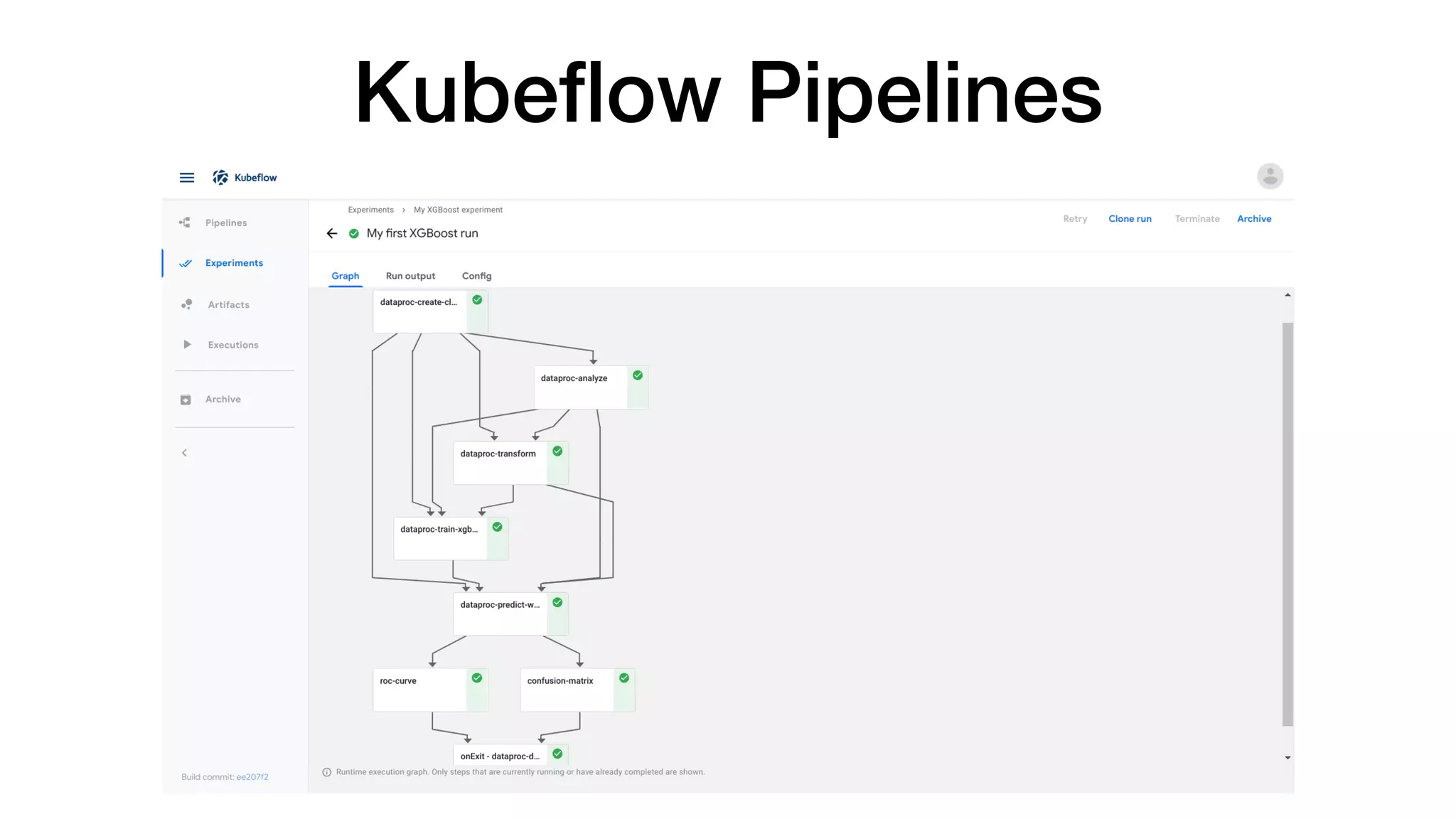
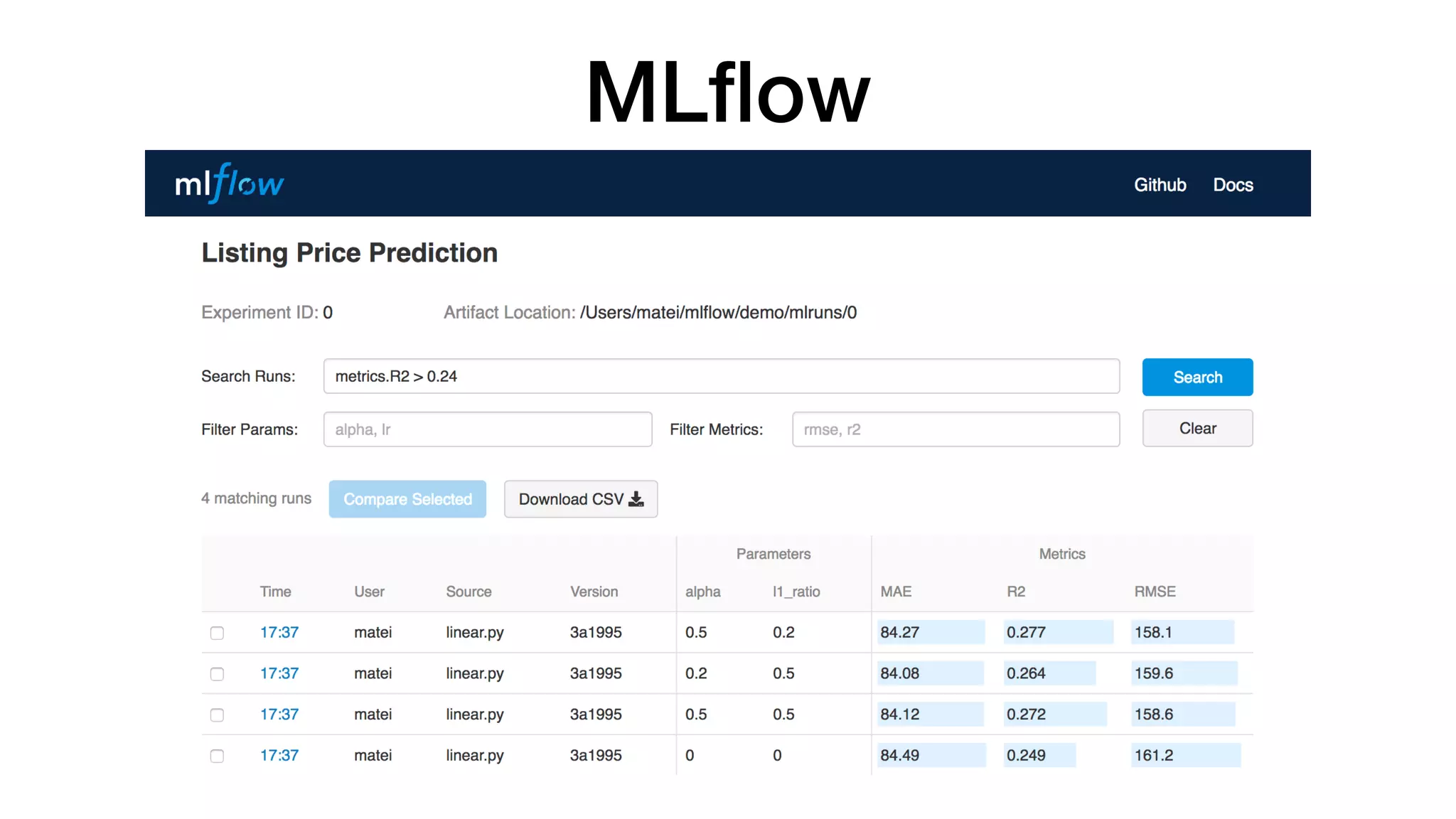
This document introduces a deep learning platform that aims to:
1) Manage heterogeneous computing resources like CPUs and GPUs and allow for multi-tenant usage and isolation of resources.
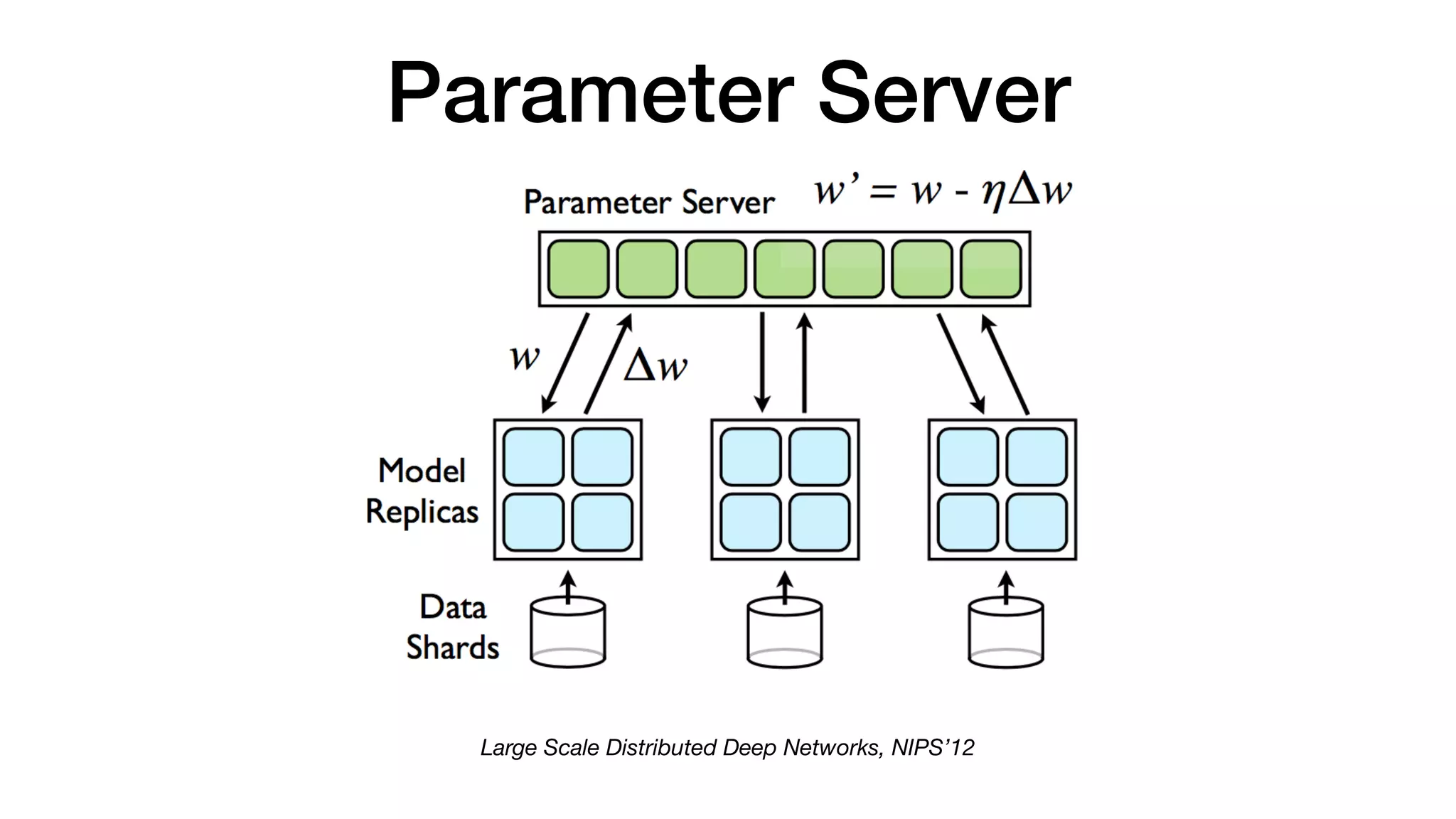
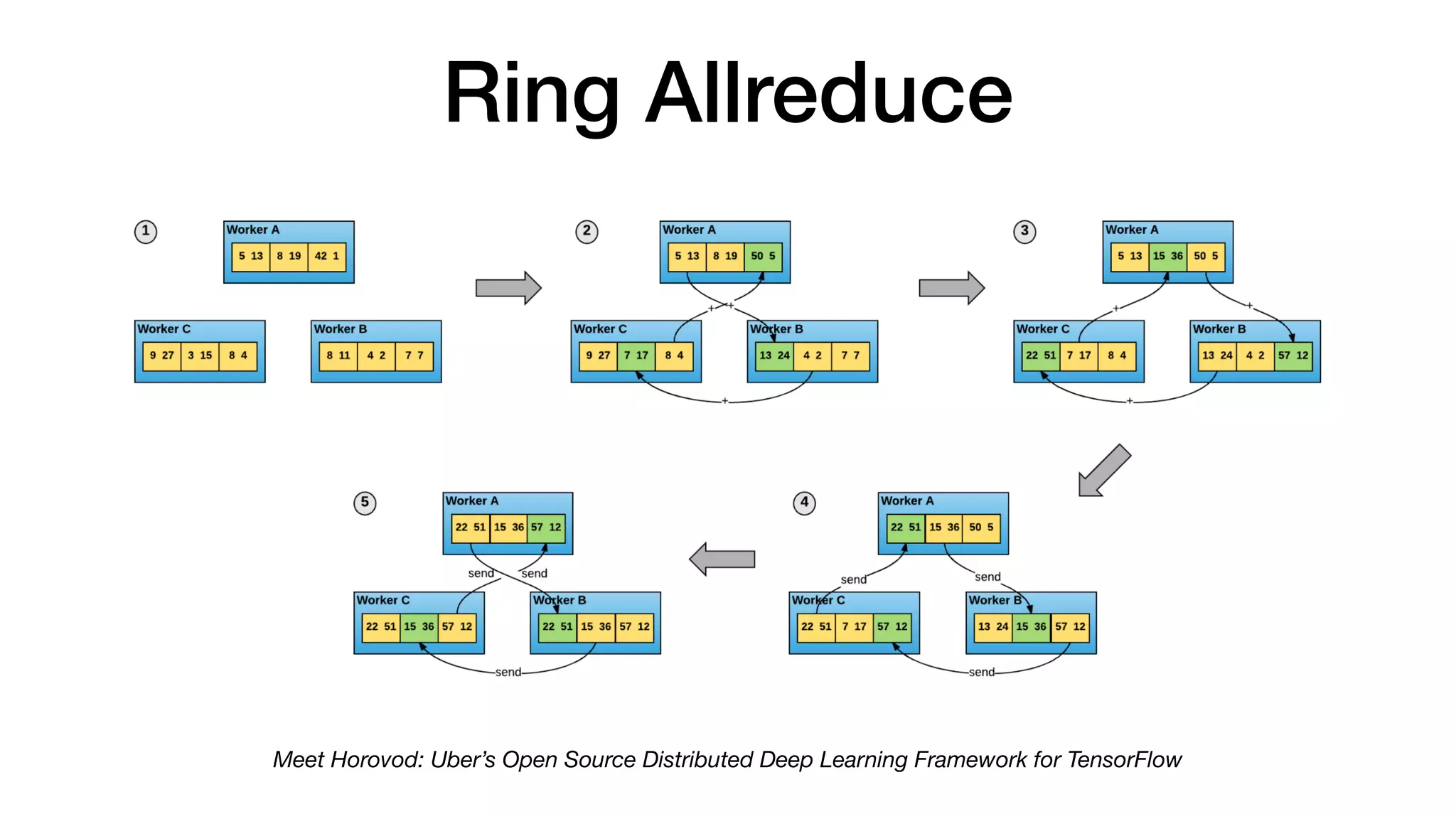
2) Enable distributed deep learning training through frameworks like Kubernetes operators, Horovod, and parameter servers.
3) Apply software engineering practices to deep learning through continuous integration/deployment (CI/CD), logging, metrics, and reusable workflows.