Download as PDF, PPTX




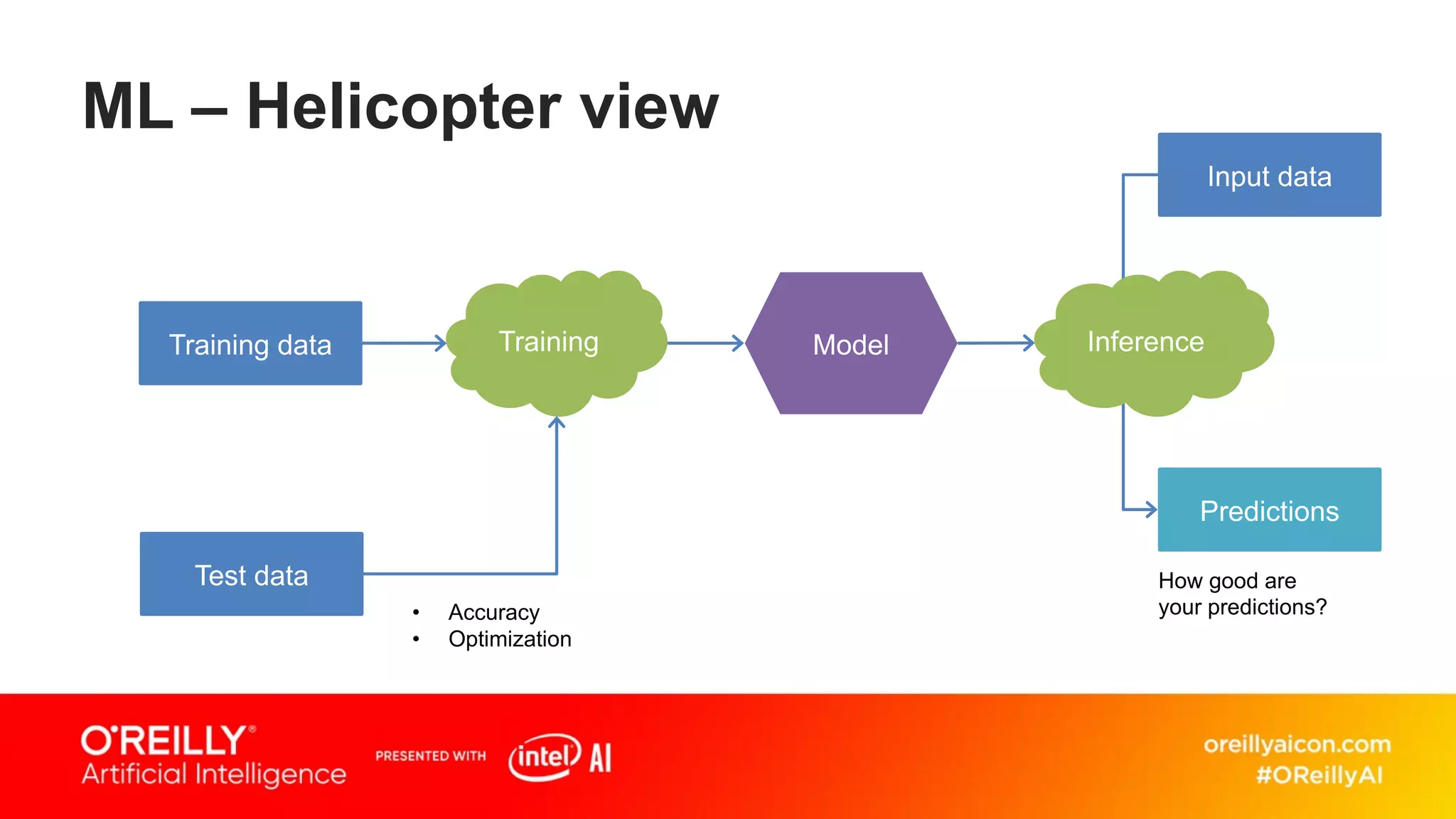

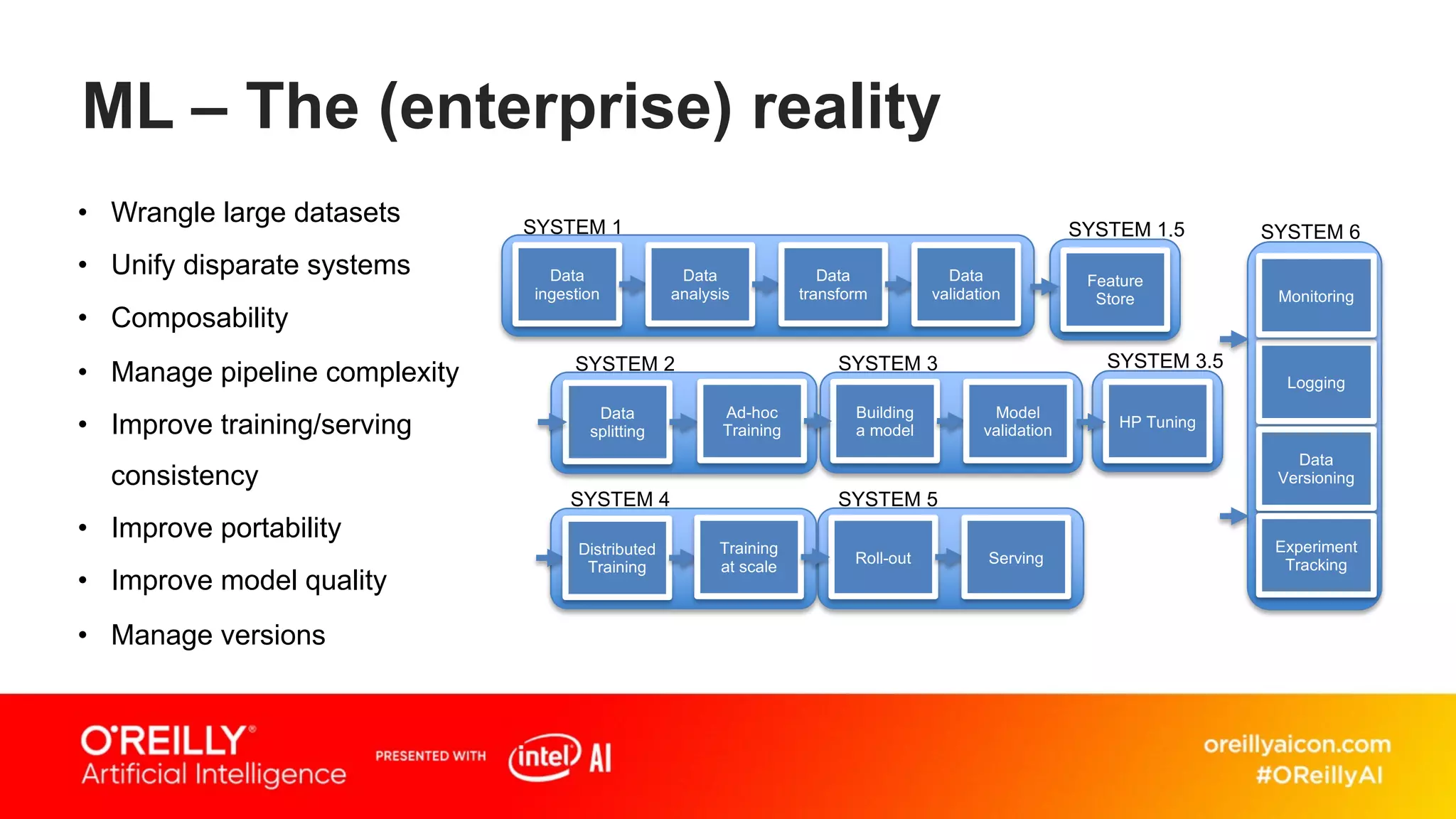

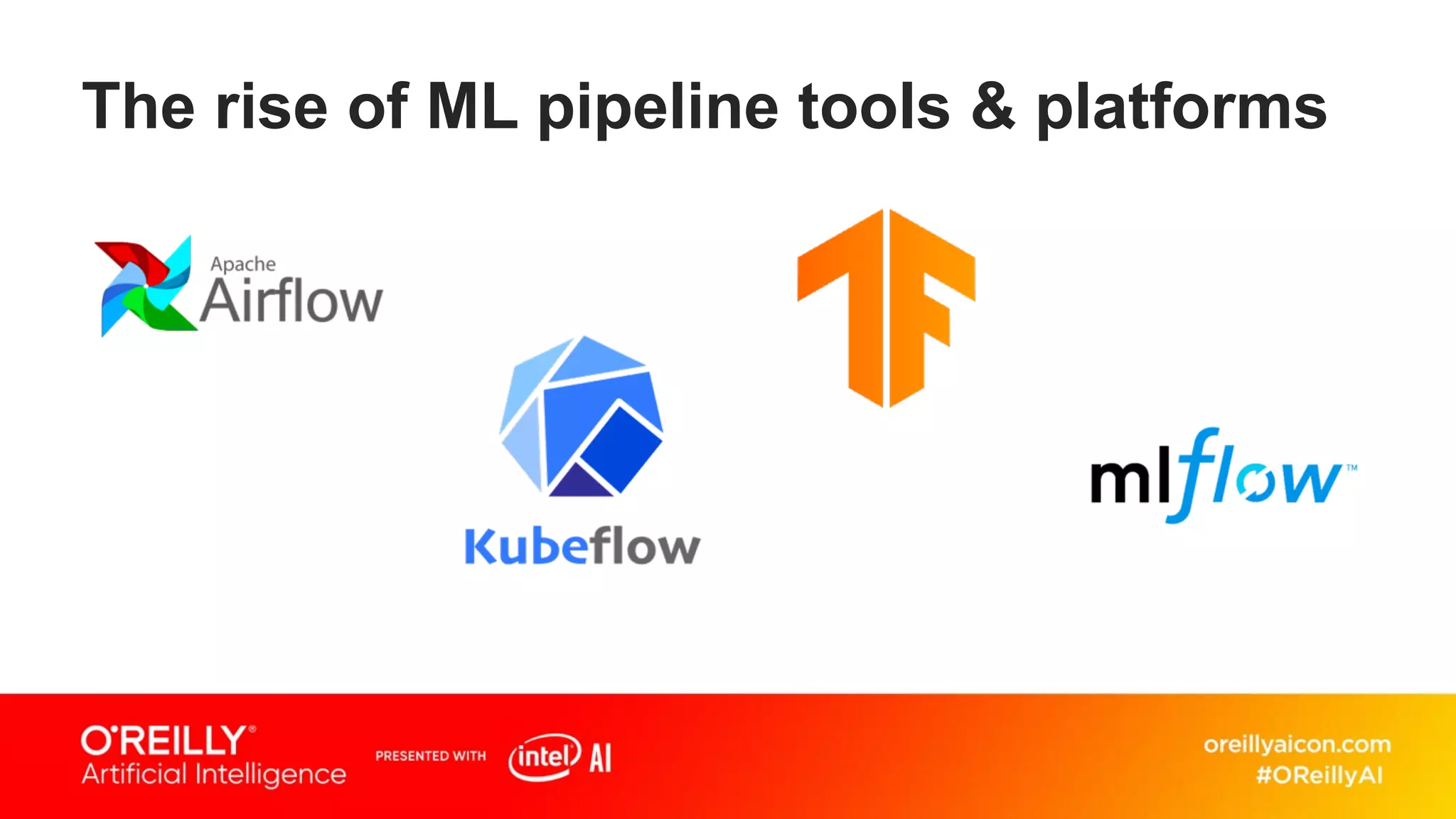












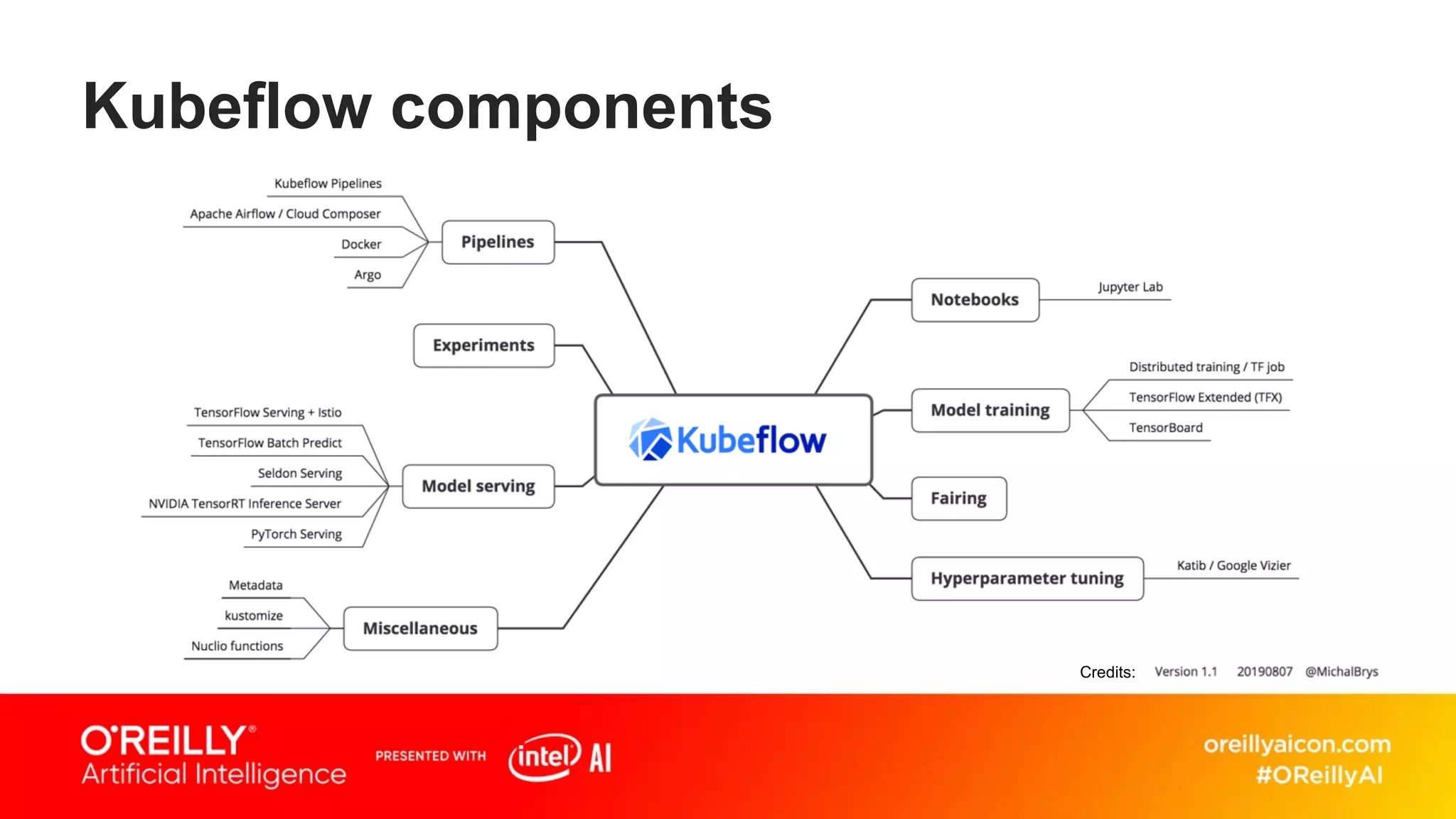

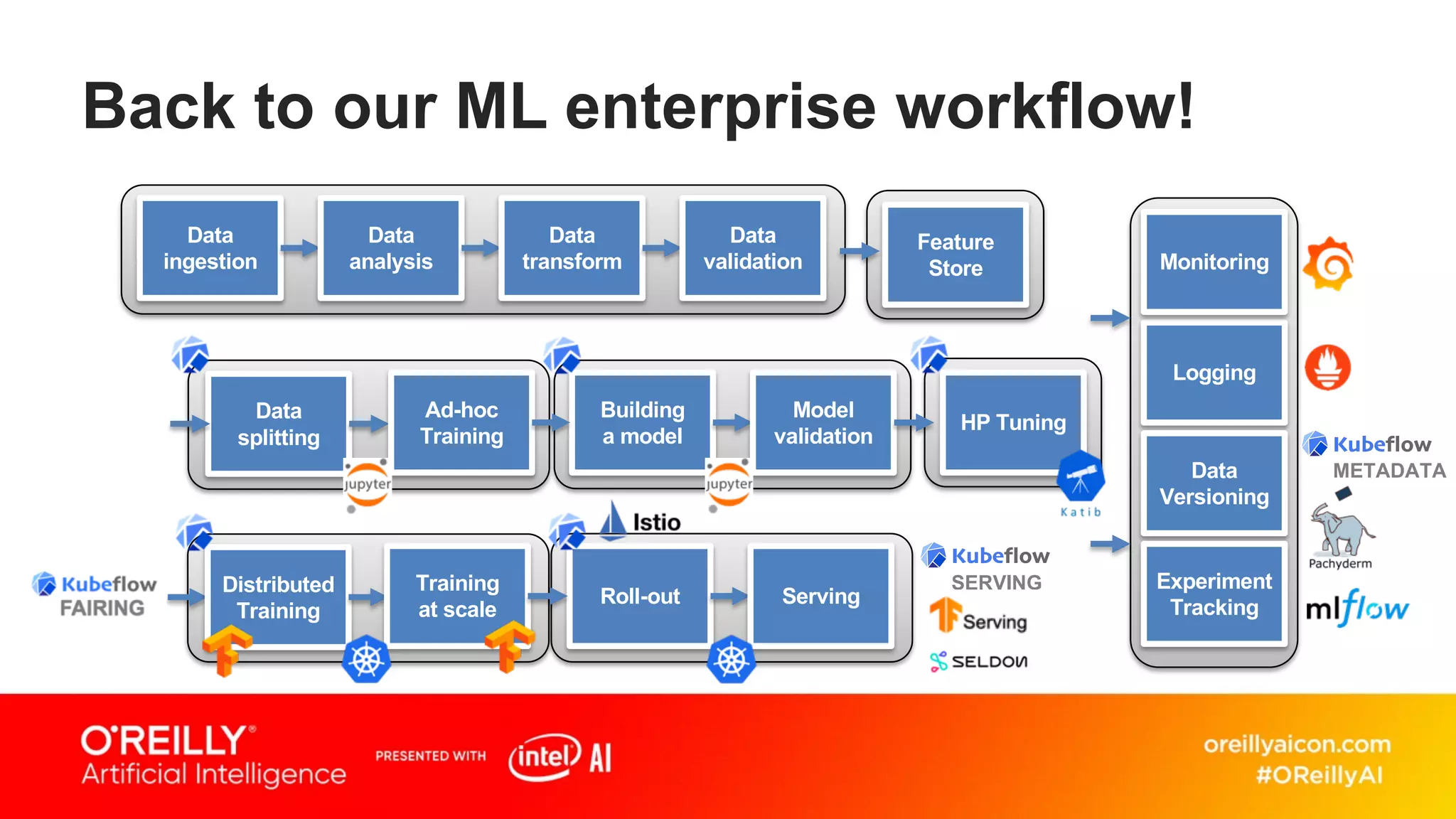
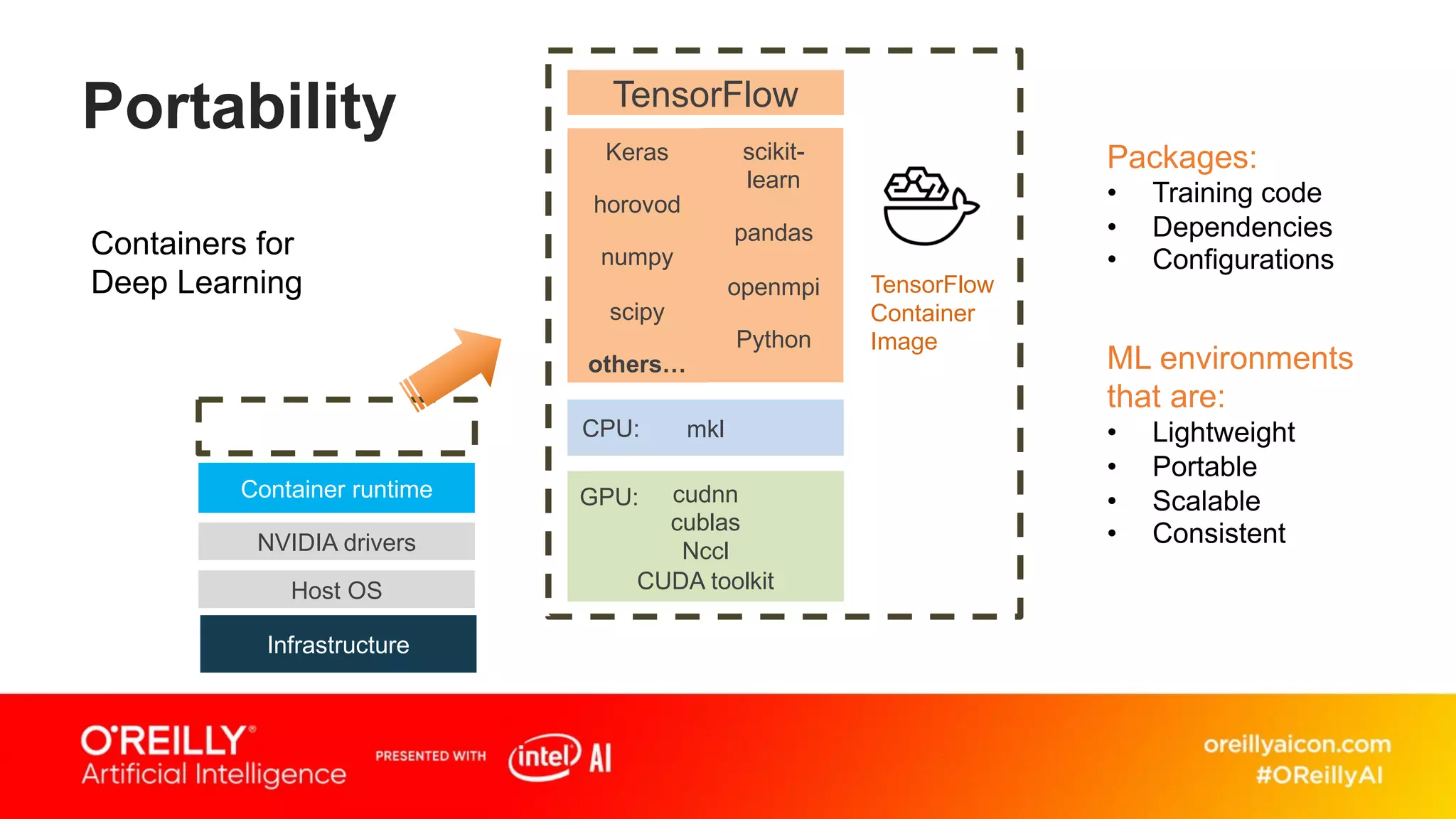
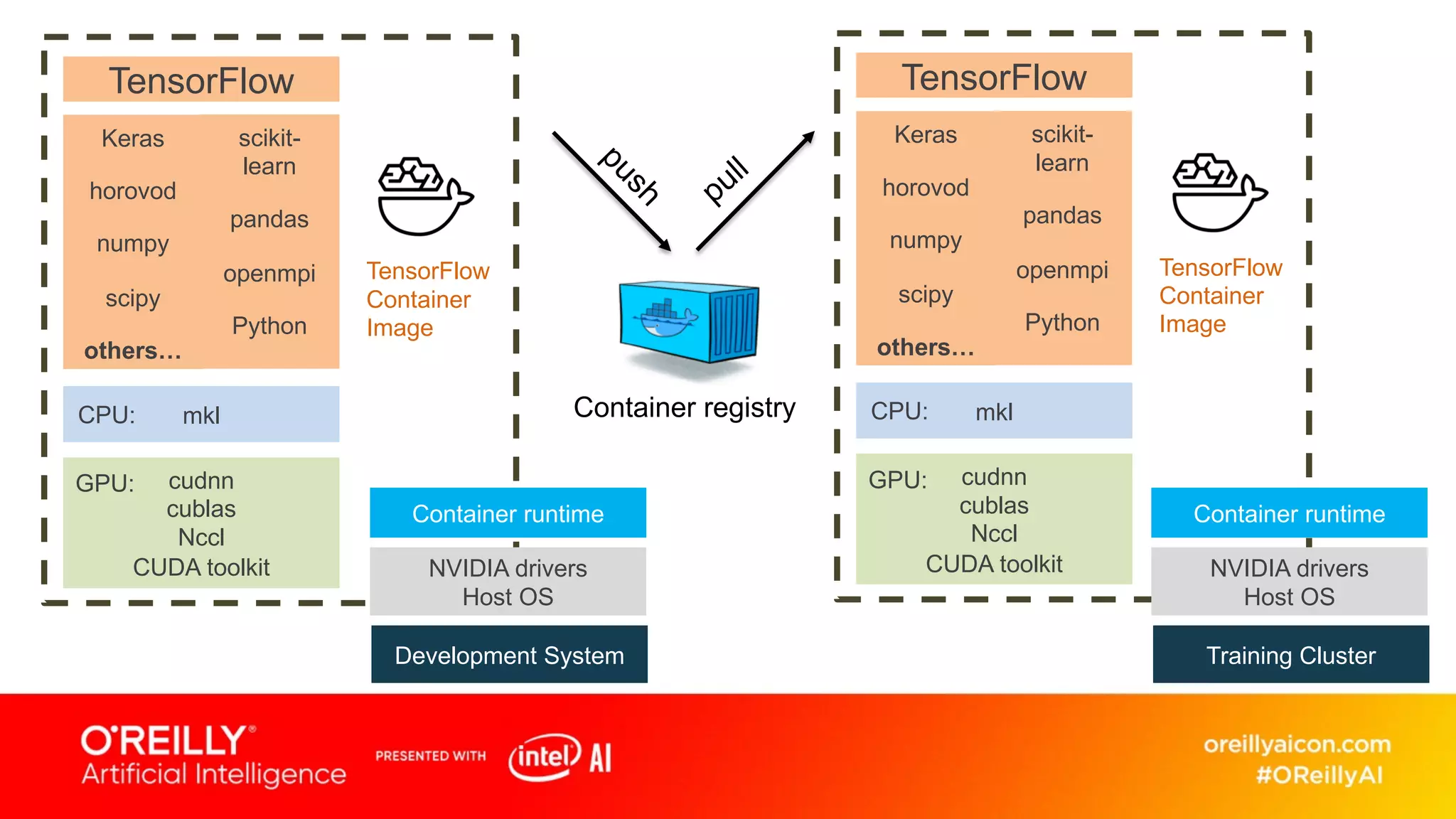


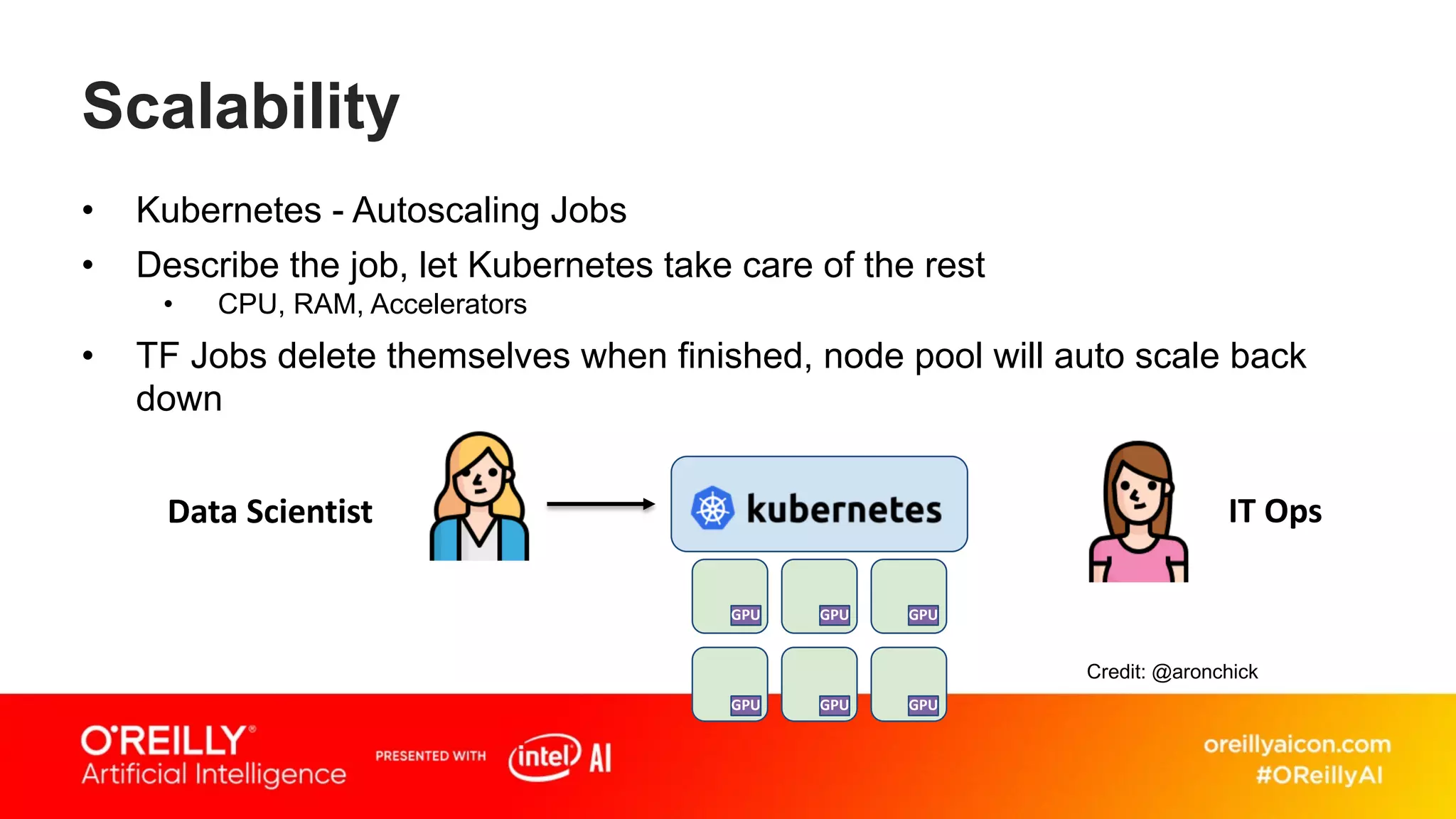



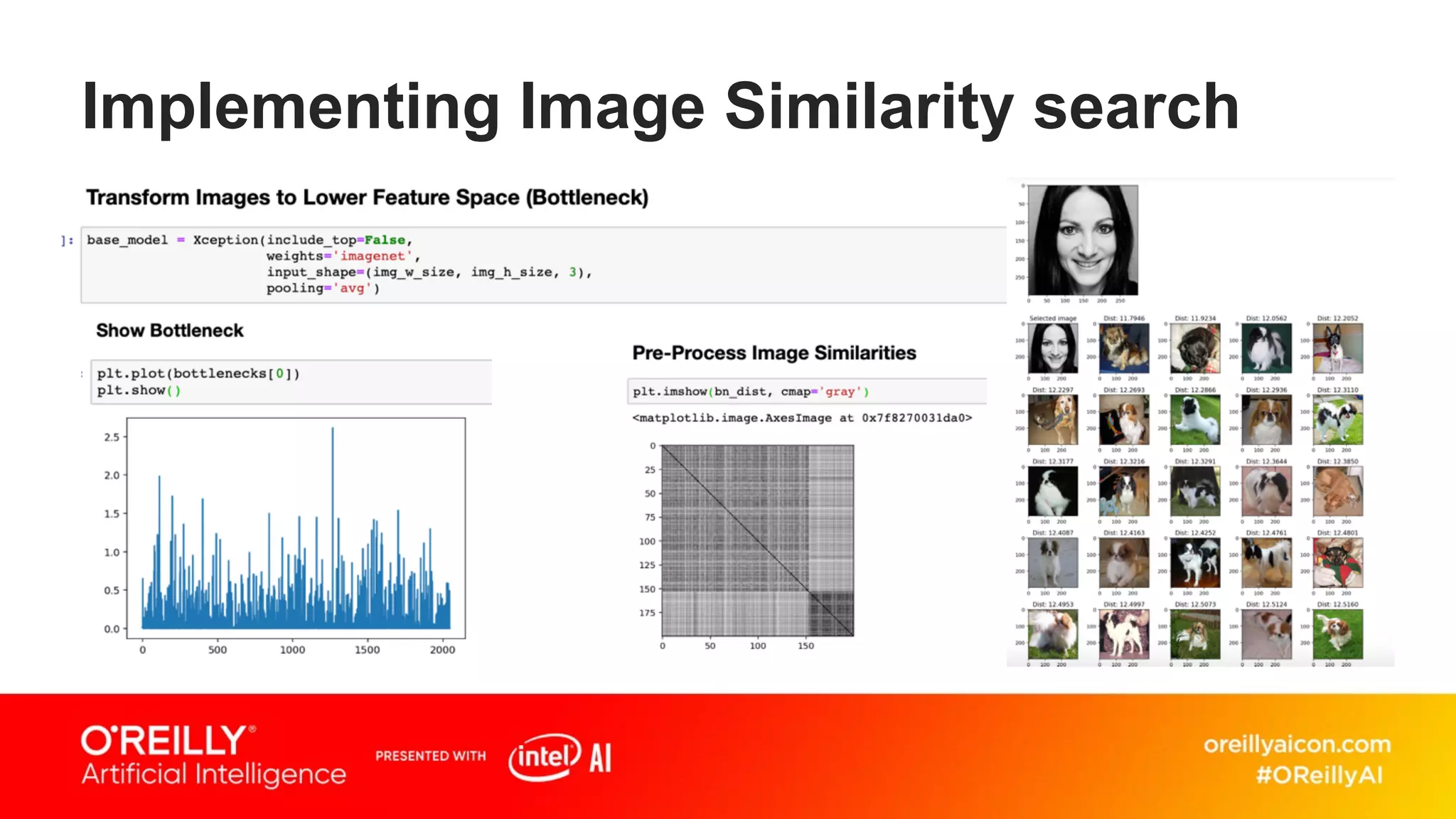
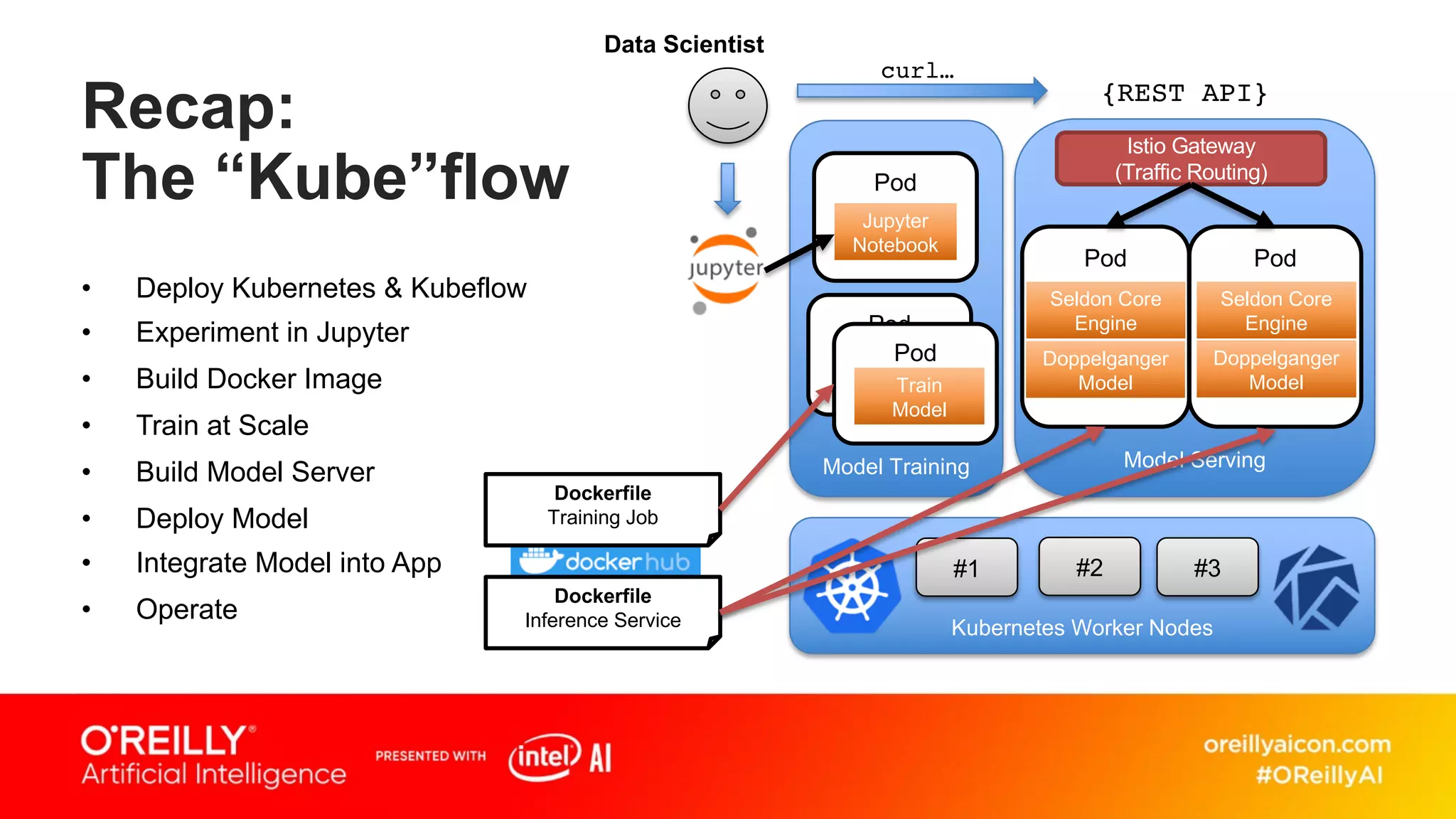













































This document discusses containerized architectures for deep learning using Kubernetes and Kubeflow. It motivates the use of machine learning pipelines for improving data wrangling, system unification, composability, complexity management, portability, and model quality. It then summarizes popular machine learning pipeline tools like Apache Airflow, Kubeflow, TensorFlow Extended, and MLflow. It introduces Kubernetes and containers, and argues that Kubernetes and Kubeflow can provide composability, portability, and scalability for machine learning workloads. It demonstrates a deep learning model deployed on Kubernetes with Kubeflow through a doppelganger image similarity search app.



























![Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]](https://cdn.slidesharecdn.com/ss_thumbnails/tfx-kfp-191031073013-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[AWS Tech Talk] Using containers for deep learning workflows](https://cdn.slidesharecdn.com/ss_thumbnails/webinarusingcontainersfordeeplearningworkflows-190930224433-thumbnail.jpg?width=640&height=640&fit=bounds)



















