Download to read offline
















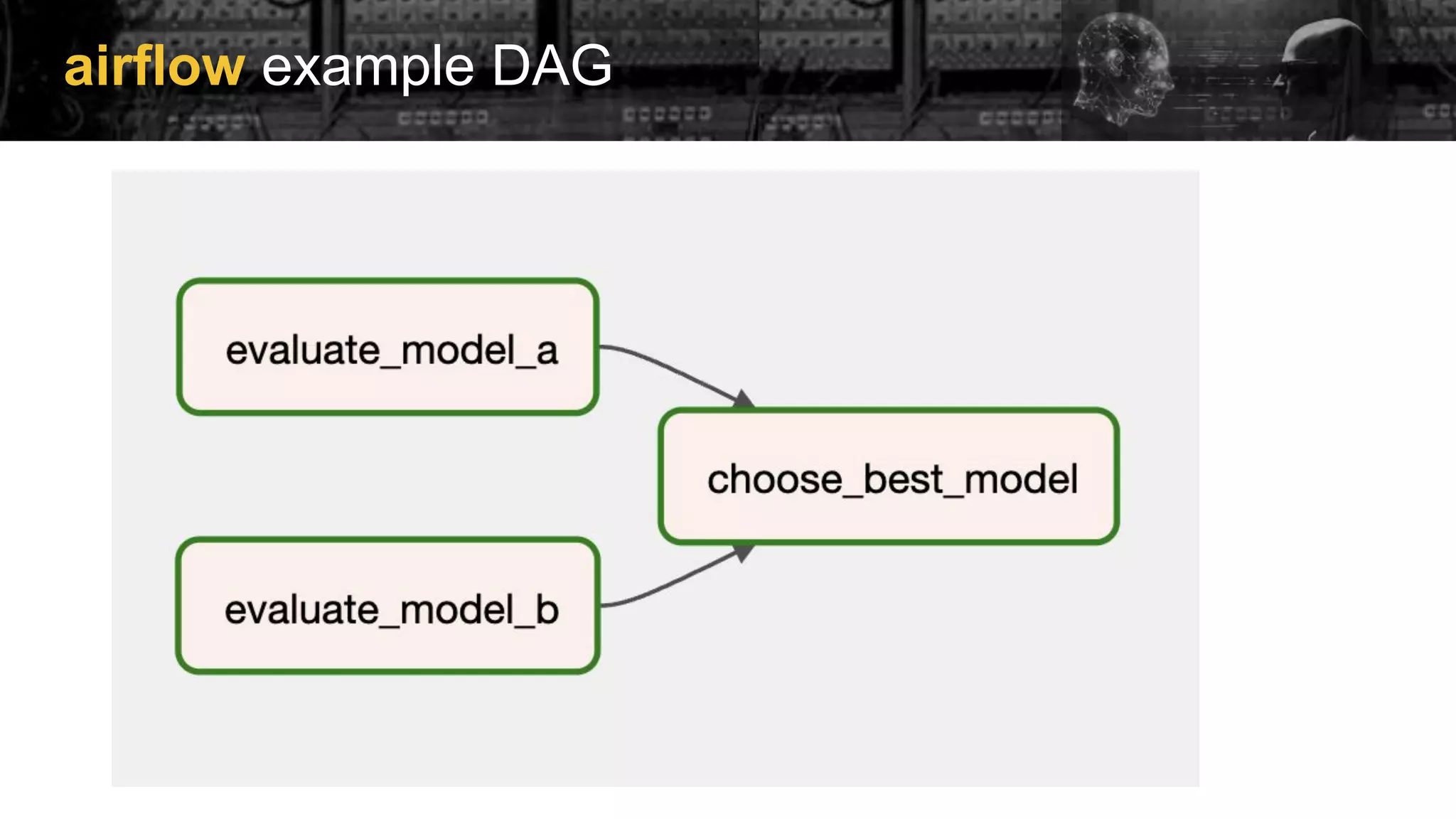
![airflow example DAG
from airflow import DAG
from airflow.operators.python import PythonOperator
from random import randint
from datetime import datetime
def _evaluate_model():
return randint(1,10)
def _choose_best(ti):
tasks = [
"evaluate_model_a",
"evaluate_model_b"
]
accuracies = [ti.xcom_pull(task_id) for task_id in
tasks]
best_accuracy = max(accuracies)
for model, model_accuracy in zip(tasks,
accuracies):
if model_accuracy == best_accuracy:
return model
with DAG(
"evaluate_models",
start_date=datetime(2023, 7, 4),
schedule="@daily") as dag:
evaluate_model_a = PythonOperator(
task_id="evaluate_model_a",
python_callable=_evaluate_model
)
evaluate_model_b = PythonOperator(
task_id="evaluate_model_b",
python_callable=_evaluate_model
)
choose_best_model = PythonOperator(
task_id="choose_best_model",
python_callable=_choose_best
)
[evaluate_model_a, evaluate_model_b] >>
choose_best_model](https://image.slidesharecdn.com/2023-07-13-creatingyourownchatgptwithapacheairflow-230713184330-672035d9/75/Integrating-ChatGPT-with-Apache-Airflow-28-2048.jpg)



![Use Dataset-aware scheduling
● Schedule when tasks (from other DAGs) complete successfully
from airflow.datasets import Dataset
with DAG(“ingest_dataset”, ...):
MyOperator(
# this task updates example.csv
outlets=[Dataset("s3://dataset-bucket/source-data.parquet")],
...,
)
with DAG(“train_model”,
# this DAG should be run when source-data.parquet is updated (by dag “ingest_dataset”)
schedule=[Dataset("s3://dataset-bucket/source_data.csv")],
...,
):
https://airflow.apache.org/docs/apache-airflow/stable/authoring-and-scheduling/datasets.html](https://image.slidesharecdn.com/2023-07-13-creatingyourownchatgptwithapacheairflow-230713184330-672035d9/75/Integrating-ChatGPT-with-Apache-Airflow-36-2048.jpg)

![Dynamic Task Mapping
from __future__ import annotations
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
with DAG(
dag_id="example_dynamic_task_mapping",
start_date=datetime(2022, 3, 4)
) as dag:
@task
def evaluate_model(model_path):
(...)
return evaluation_metrics
@task
def chose_model(metrics_by_model):
(...)
return chosen_one
models_metrics = evaluate_model.expand(
model_path=["/data/model1", "/data/model2", "/data/model3"]
)
chose_model(models_metrics)](https://image.slidesharecdn.com/2023-07-13-creatingyourownchatgptwithapacheairflow-230713184330-672035d9/75/Integrating-ChatGPT-with-Apache-Airflow-38-2048.jpg)
































![airflow example DAG
from airflow import DAG
from airflow.operators.python import PythonOperator
from random import randint
from datetime import datetime
def _evaluate_model():
return randint(1,10)
def _choose_best(ti):
tasks = [
"evaluate_model_a",
"evaluate_model_b"
]
accuracies = [ti.xcom_pull(task_id) for task_id in
tasks]
best_accuracy = max(accuracies)
for model, model_accuracy in zip(tasks,
accuracies):
if model_accuracy == best_accuracy:
return model
with DAG(
"evaluate_models",
start_date=datetime(2023, 7, 4),
schedule="@daily") as dag:
evaluate_model_a = PythonOperator(
task_id="evaluate_model_a",
python_callable=_evaluate_model
)
evaluate_model_b = PythonOperator(
task_id="evaluate_model_b",
python_callable=_evaluate_model
)
choose_best_model = PythonOperator(
task_id="choose_best_model",
python_callable=_choose_best
)
[evaluate_model_a, evaluate_model_b] >>
choose_best_model](https://crownmelresort.com/image.slidesharecdn.com/2023-07-13-creatingyourownchatgptwithapacheairflow-230713184330-672035d9/75/Integrating-ChatGPT-with-Apache-Airflow-28-2048.jpg)







![Use Dataset-aware scheduling
● Schedule when tasks (from other DAGs) complete successfully
from airflow.datasets import Dataset
with DAG(“ingest_dataset”, ...):
MyOperator(
# this task updates example.csv
outlets=[Dataset("s3://dataset-bucket/source-data.parquet")],
...,
)
with DAG(“train_model”,
# this DAG should be run when source-data.parquet is updated (by dag “ingest_dataset”)
schedule=[Dataset("s3://dataset-bucket/source_data.csv")],
...,
):
https://airflow.apache.org/docs/apache-airflow/stable/authoring-and-scheduling/datasets.html](https://crownmelresort.com/image.slidesharecdn.com/2023-07-13-creatingyourownchatgptwithapacheairflow-230713184330-672035d9/75/Integrating-ChatGPT-with-Apache-Airflow-36-2048.jpg)

![Dynamic Task Mapping
from __future__ import annotations
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
with DAG(
dag_id="example_dynamic_task_mapping",
start_date=datetime(2022, 3, 4)
) as dag:
@task
def evaluate_model(model_path):
(...)
return evaluation_metrics
@task
def chose_model(metrics_by_model):
(...)
return chosen_one
models_metrics = evaluate_model.expand(
model_path=["/data/model1", "/data/model2", "/data/model3"]
)
chose_model(models_metrics)](https://crownmelresort.com/image.slidesharecdn.com/2023-07-13-creatingyourownchatgptwithapacheairflow-230713184330-672035d9/75/Integrating-ChatGPT-with-Apache-Airflow-38-2048.jpg)






The document provides an overview of Apache Airflow, an open-source platform for developing and monitoring workflows, with a focus on its application in building AI chatbots using large language models (LLMs). It discusses the features of LLMs, the limitations of proprietary models, and the advantages of open-source alternatives. Additionally, it outlines practical examples of how Airflow can automate and manage machine learning model pipelines, including dynamic task mapping and dataset-aware scheduling.
Presentation on creating Chat GPT with Airflow. Introduction to the Turing test.
Information on ChatGPT includes it being an AI chatbot by OpenAI, utilizing LLM, with 100M users, 570GB dataset, and $3M monthly running cost.
Explanation of LLMs, their characteristics, and proprietary limitations such as data privacy and customization issues.
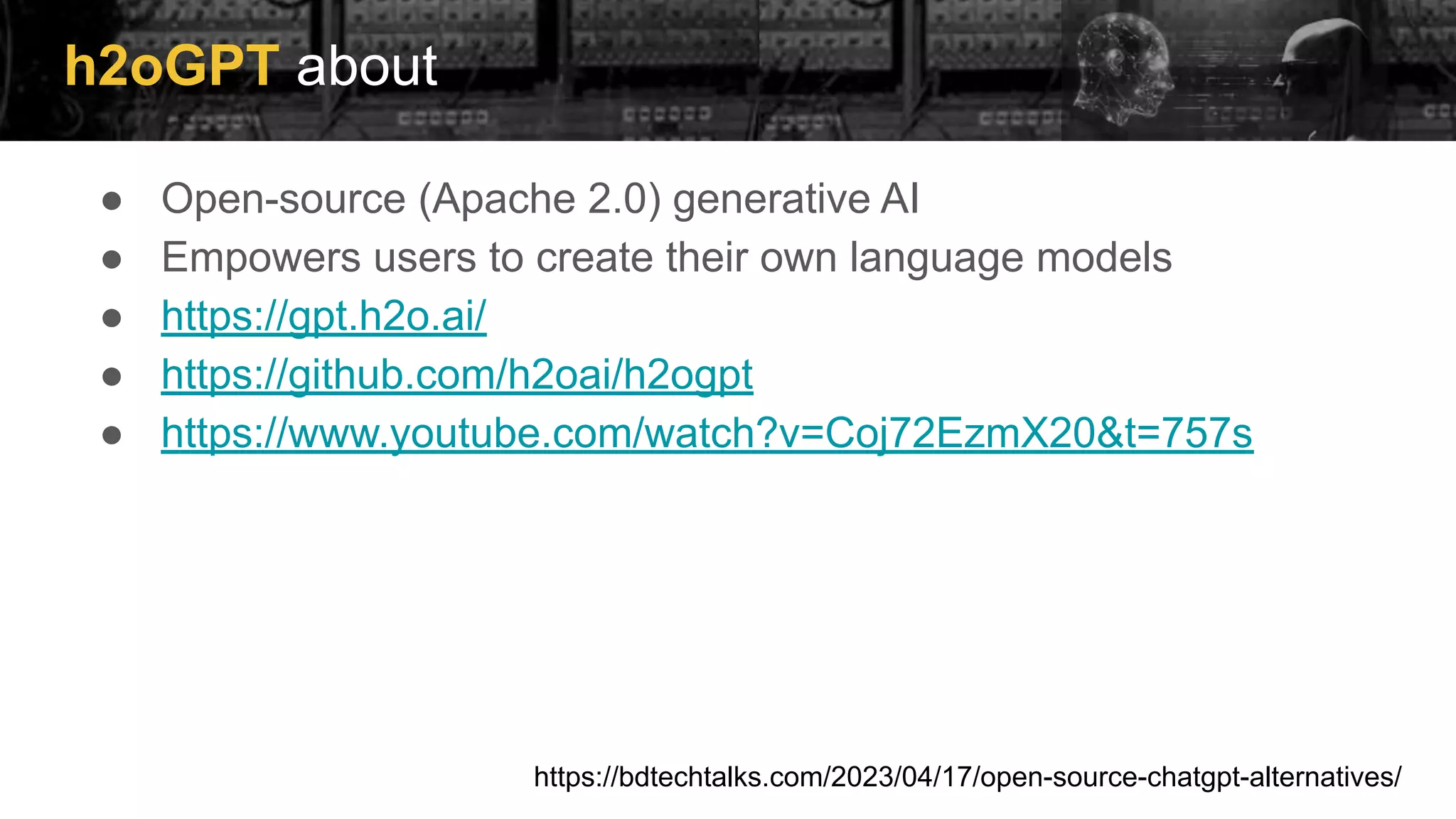
List of open-source LLM alternatives like LLaMA, Alpaca and h2oGPT, inviting exploration of their usage.
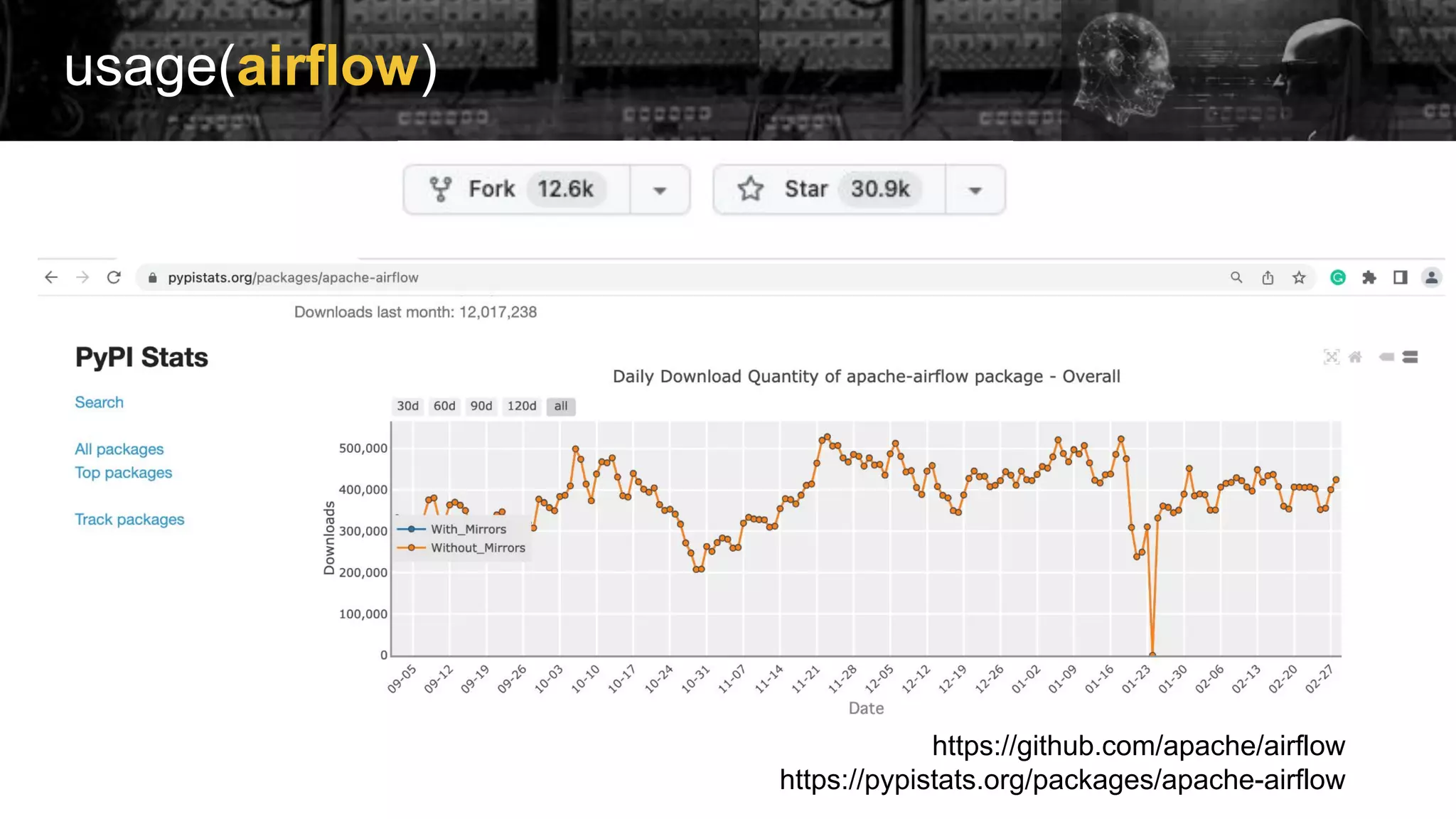
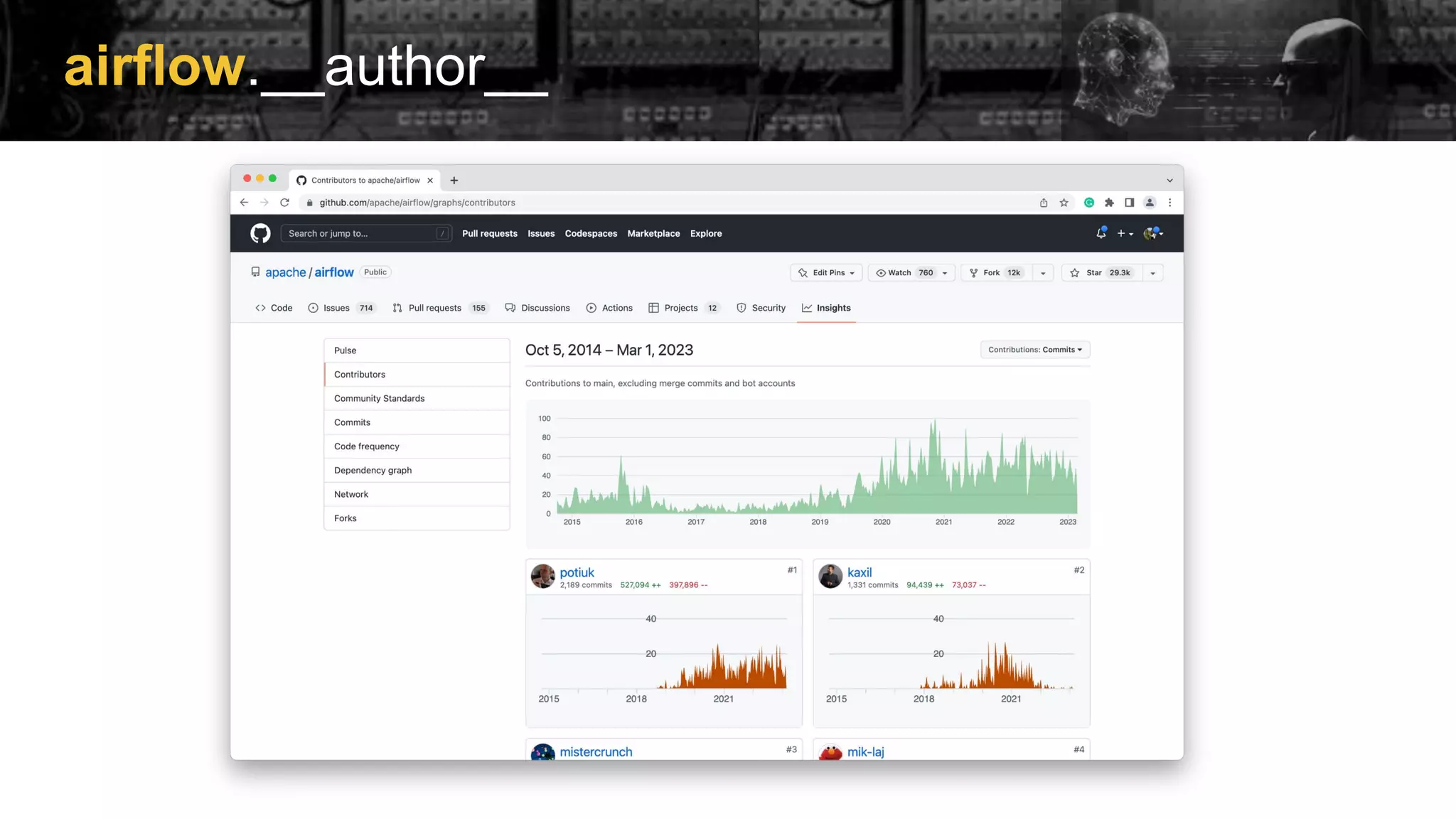
Introduction to Apache Airflow as an open-source tool for workflow management, linking to resources for installation and usage.
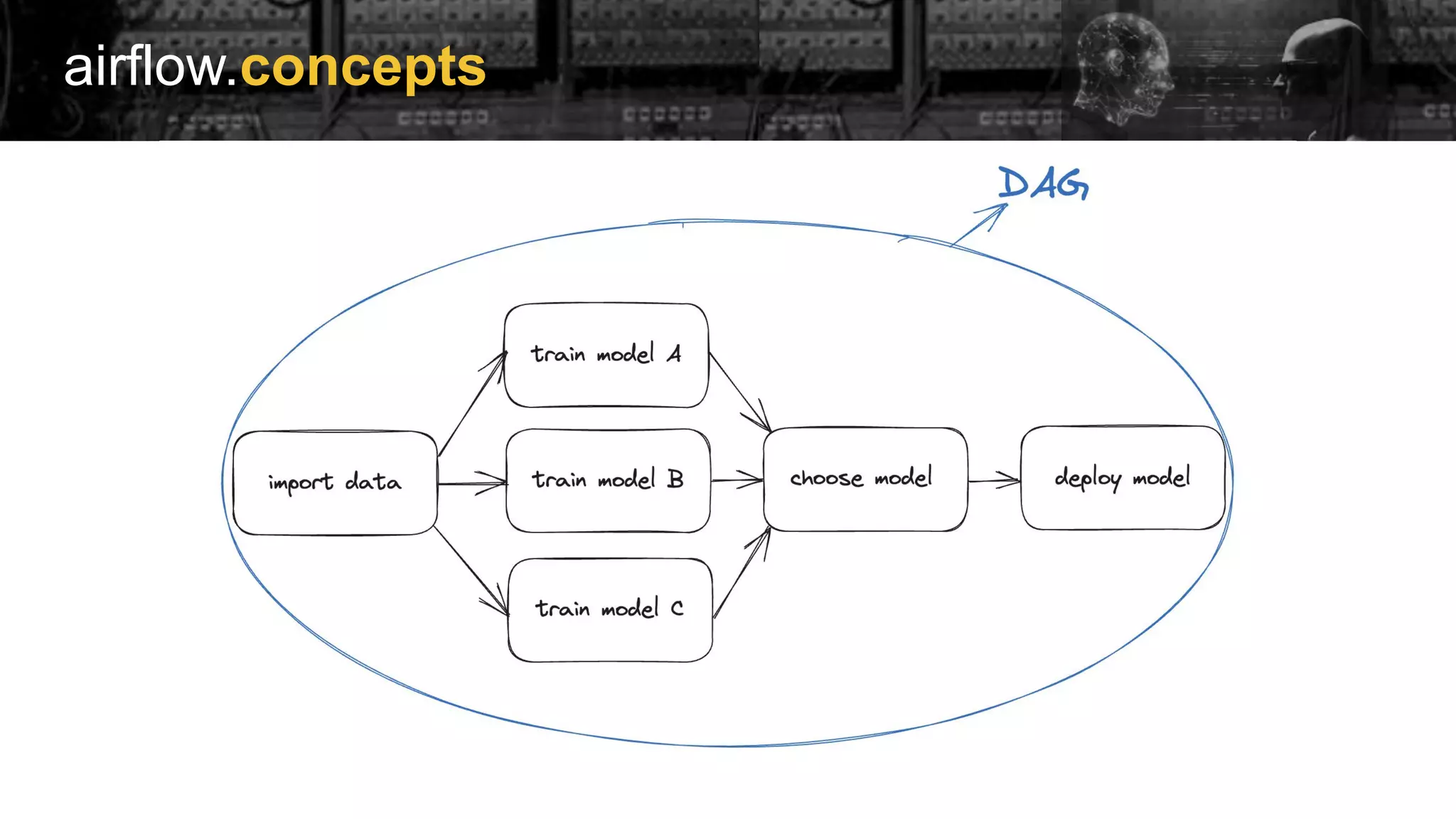
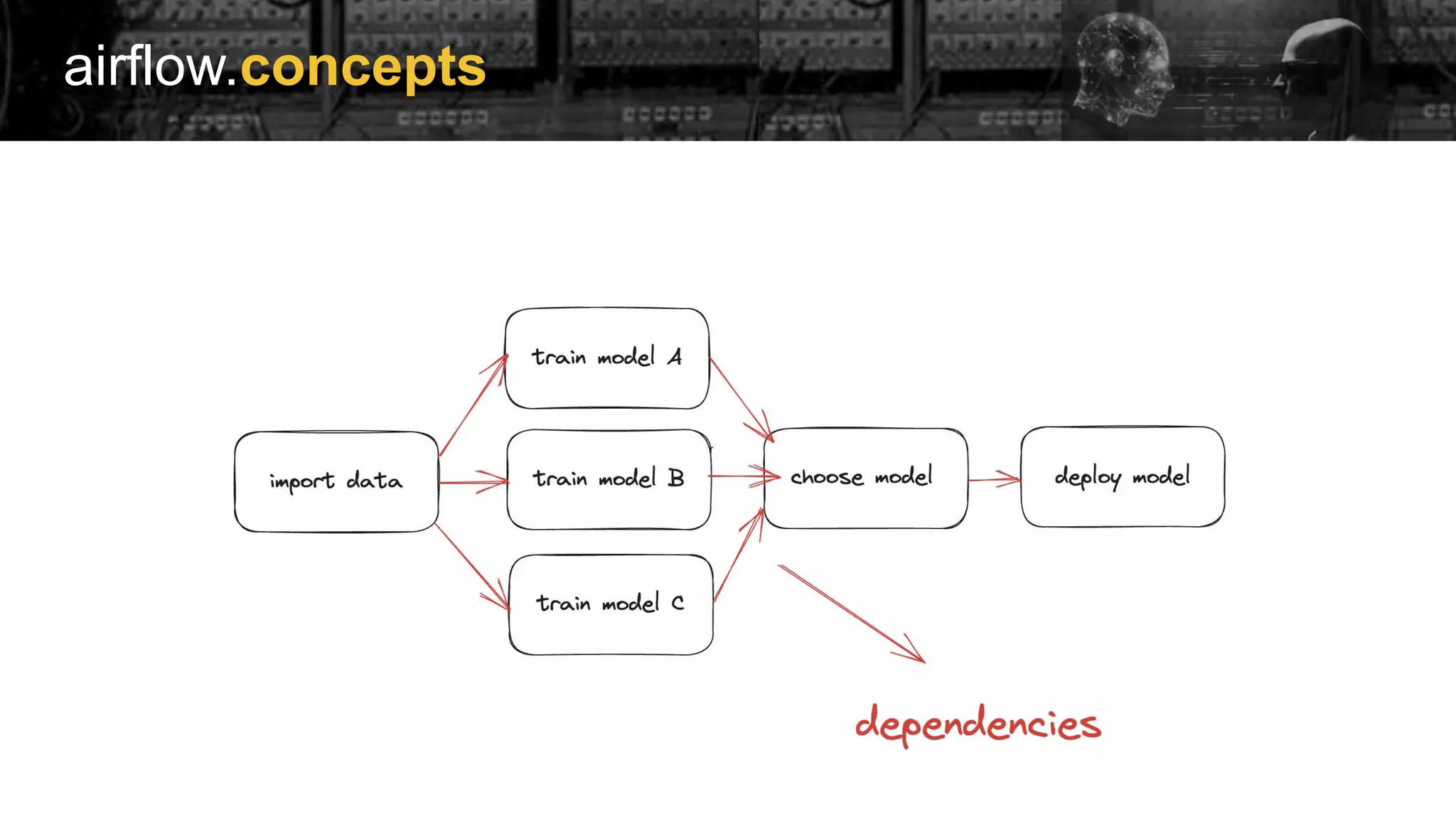
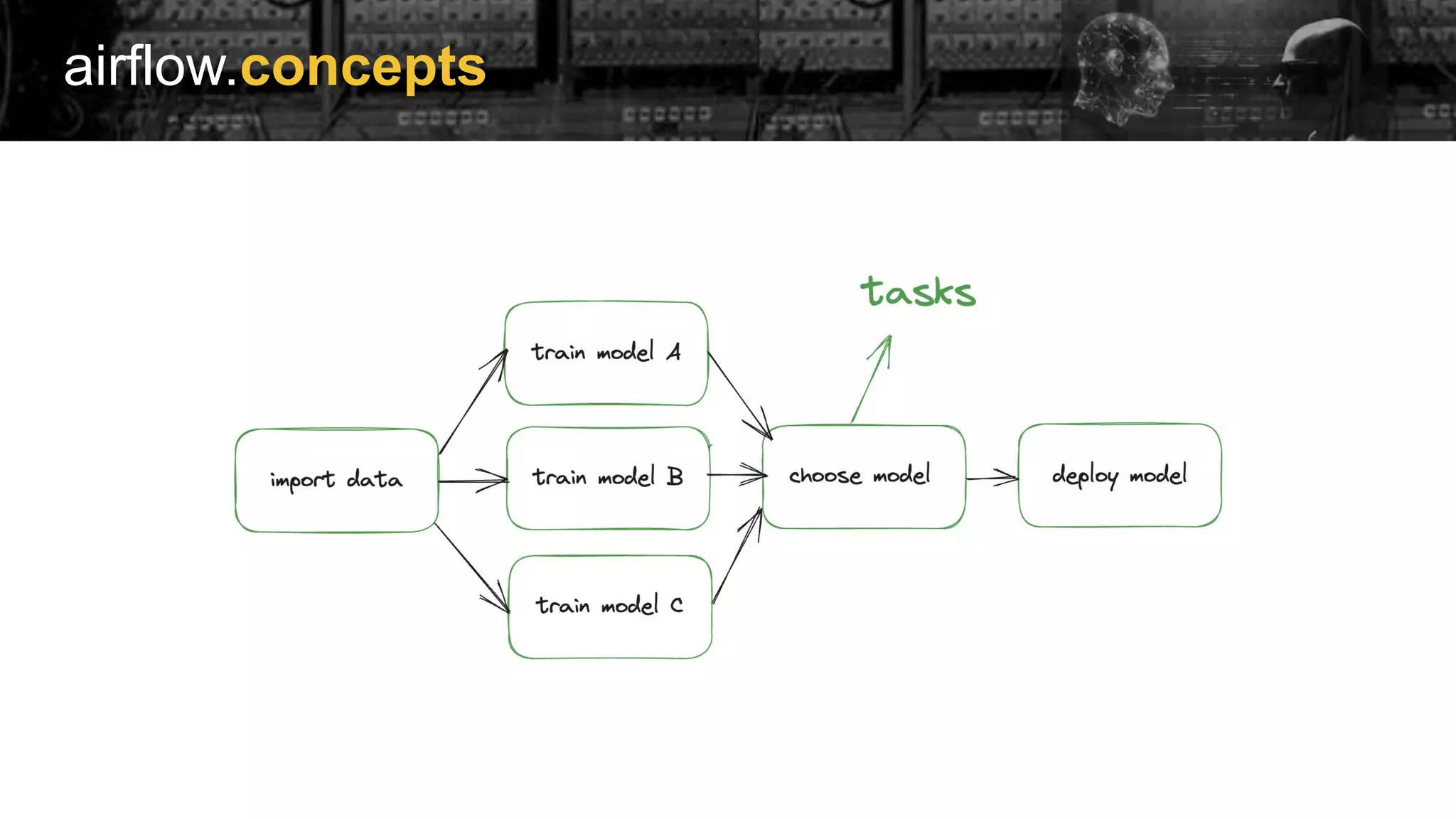
Explanation of Airflow concepts and extensive listing of its provider packages for various integrations.
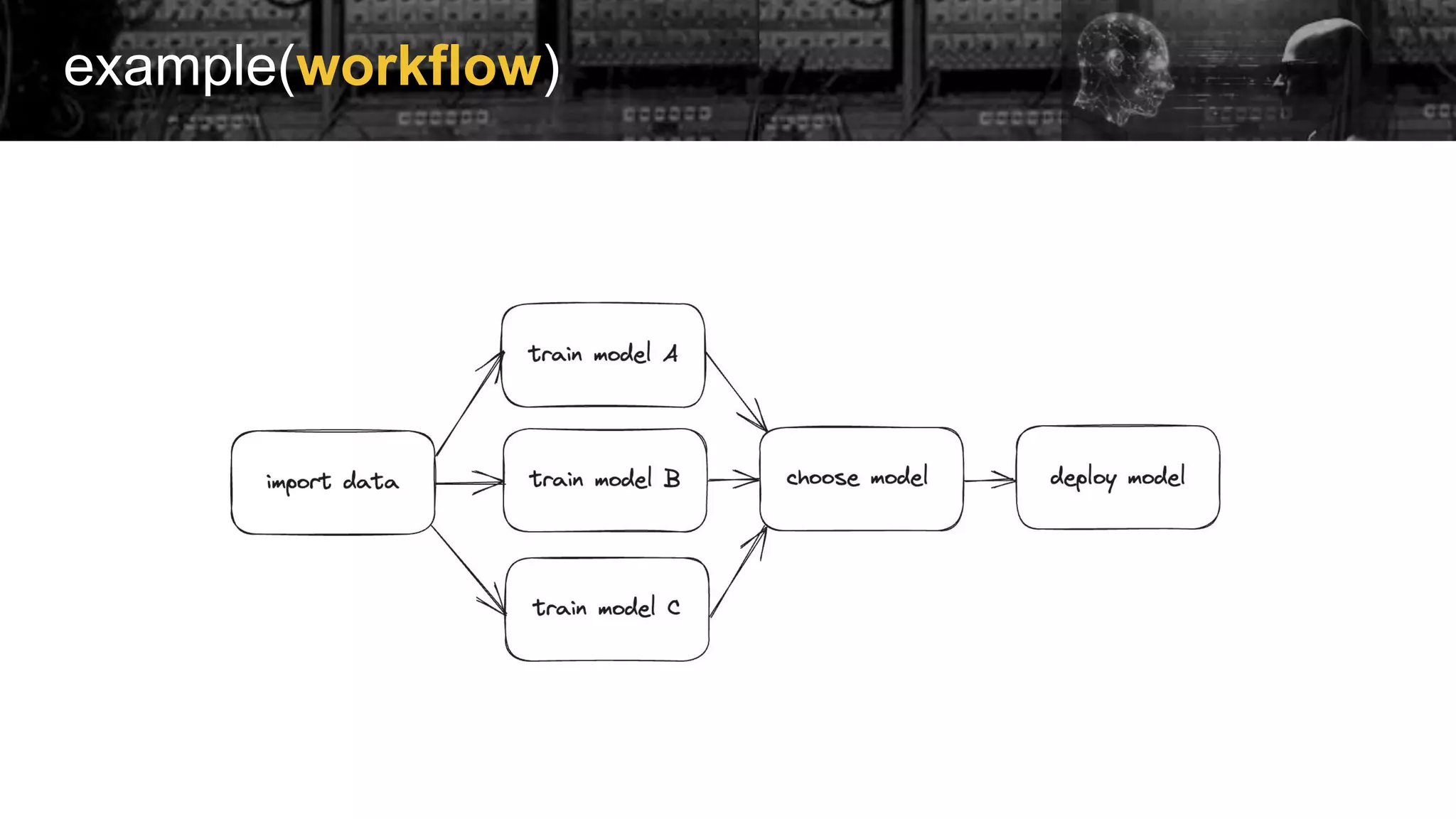
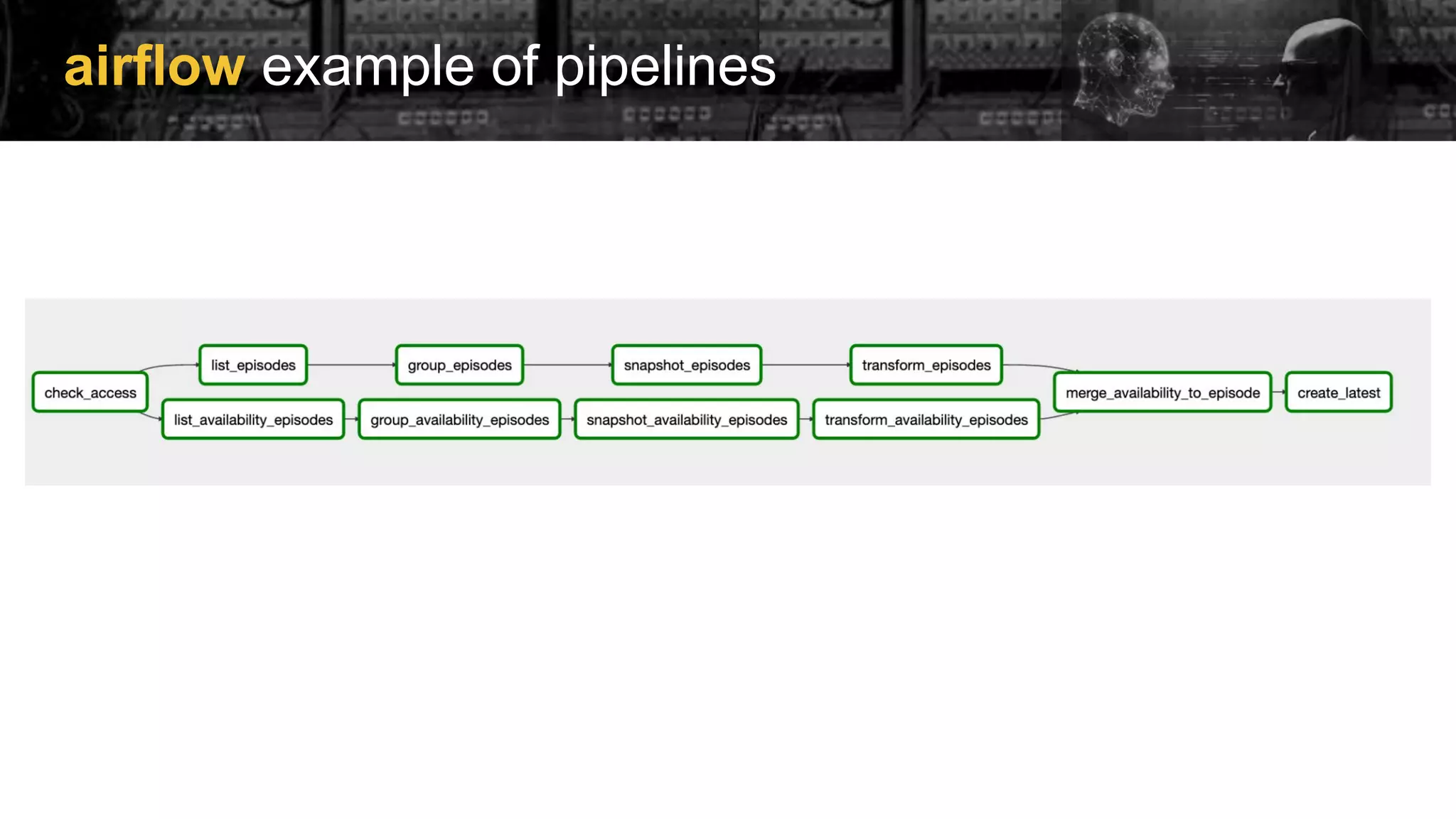
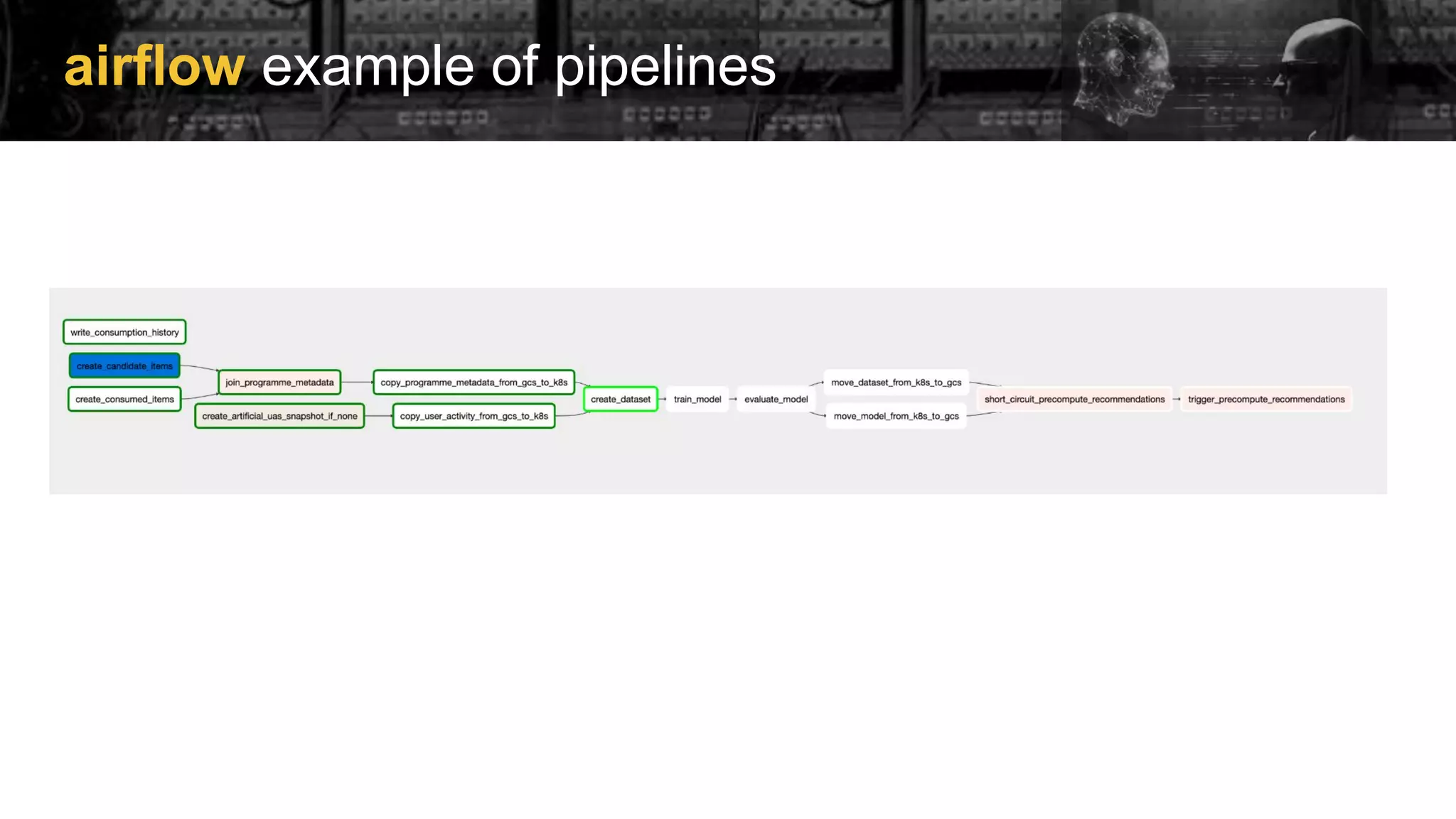
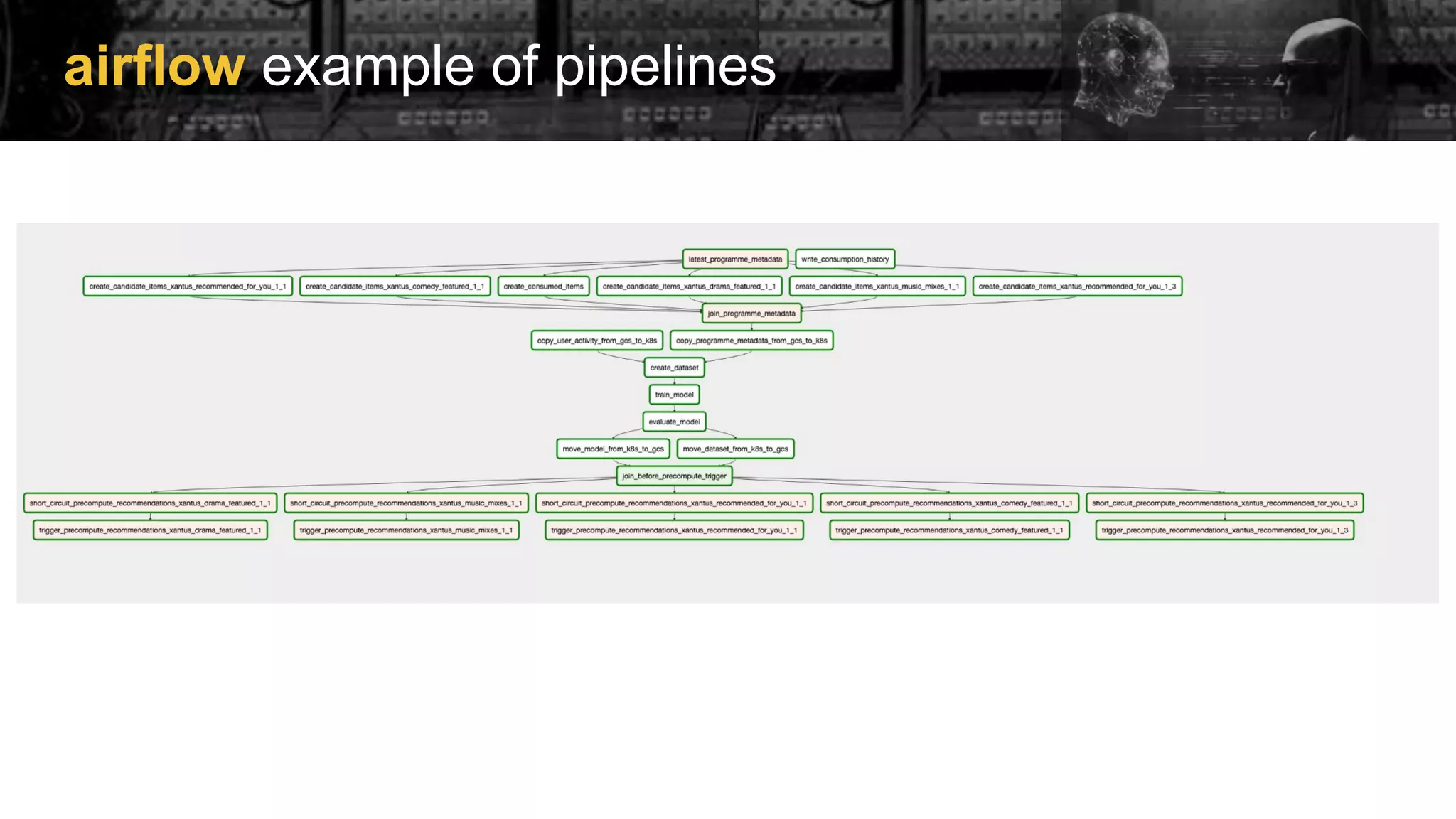
Examples of implementing Directed Acyclic Graphs (DAGs) within Airflow to manage model training and evaluation.
Outline of using Airflow to build an LLM chatbot, emphasizing orchestration for ML and automation capabilities.
Features like using KubernetesPodOperator, dataset-aware scheduling, and dynamic task mapping for efficient task management.
Information about the Apache Airflow community, linking to resources for further engagement.

















![[네이버오픈소스세미나] Pinpoint를 이용해서 서버리스 플랫폼 Apache Openwhisk 트레이싱하기 - 오승현](https://cdn.slidesharecdn.com/ss_thumbnails/apacheopenwhisktracingwithpinpoint-190716072443-thumbnail.jpg?width=640&height=640&fit=bounds)










































![PythonBrasil[8] - CPython for dummies](https://cdn.slidesharecdn.com/ss_thumbnails/cpythonfordummies-170610060108-thumbnail.jpg?width=640&height=640&fit=bounds)


























