Download as PDF, PPTX





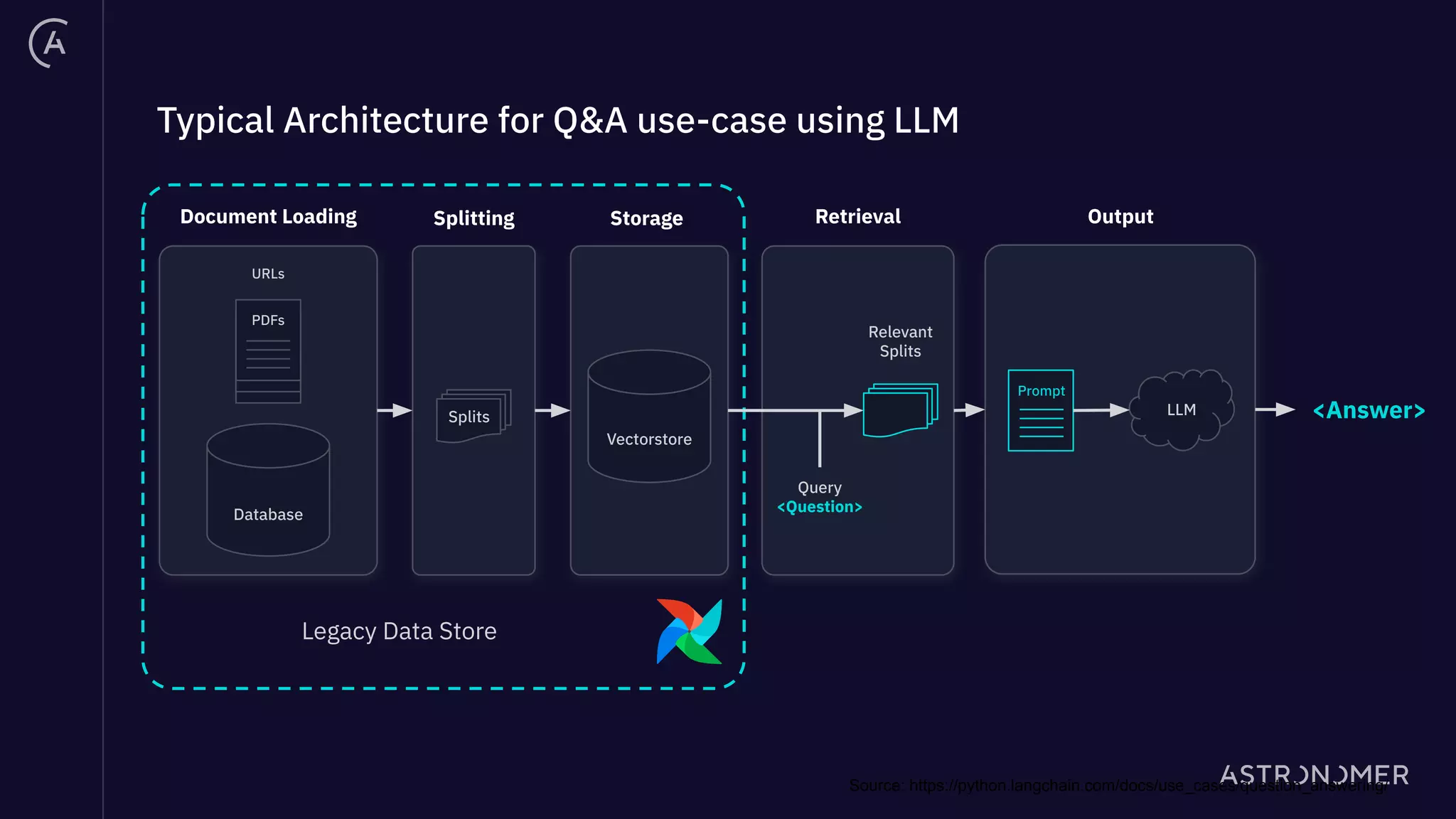




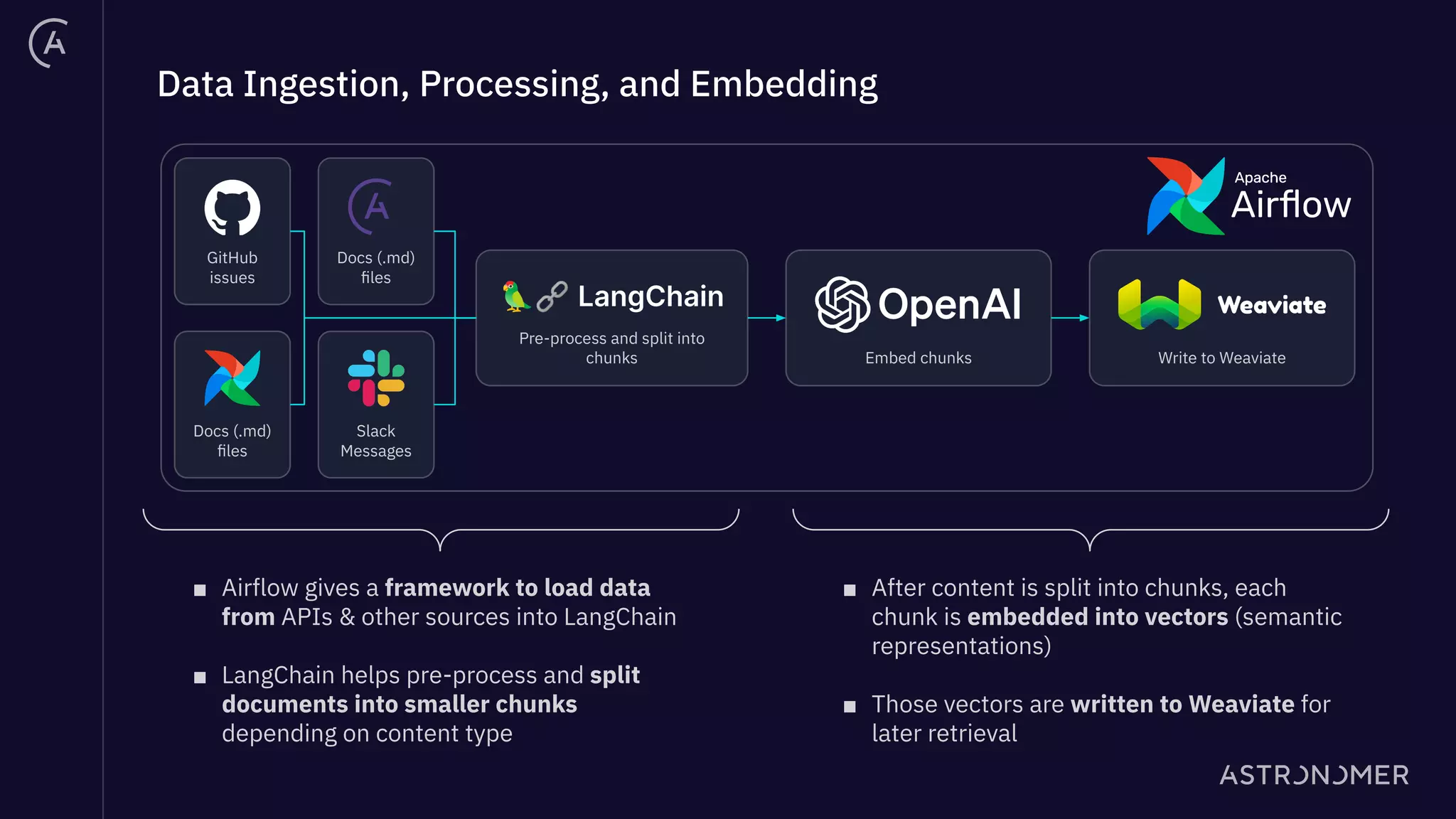
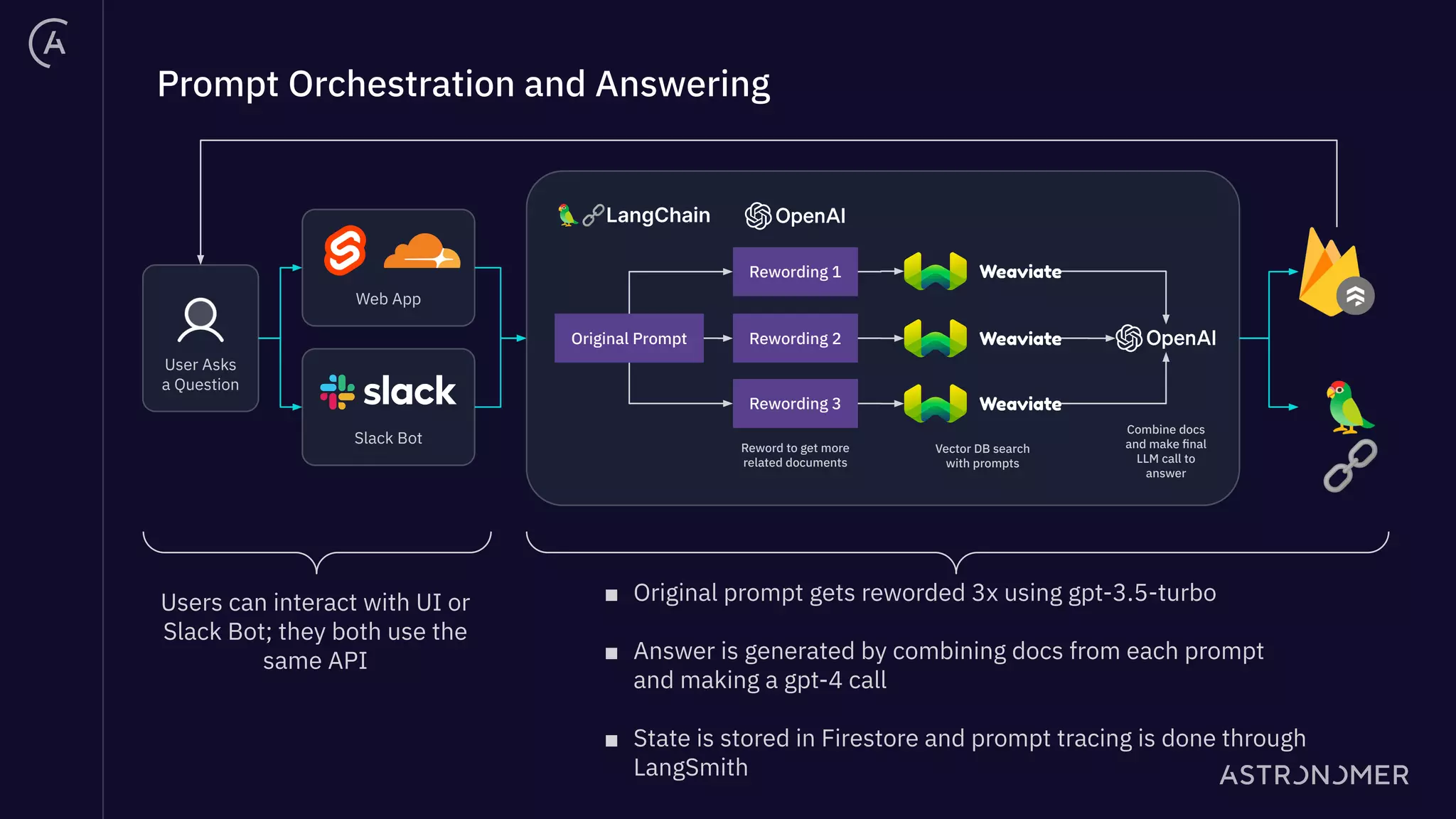
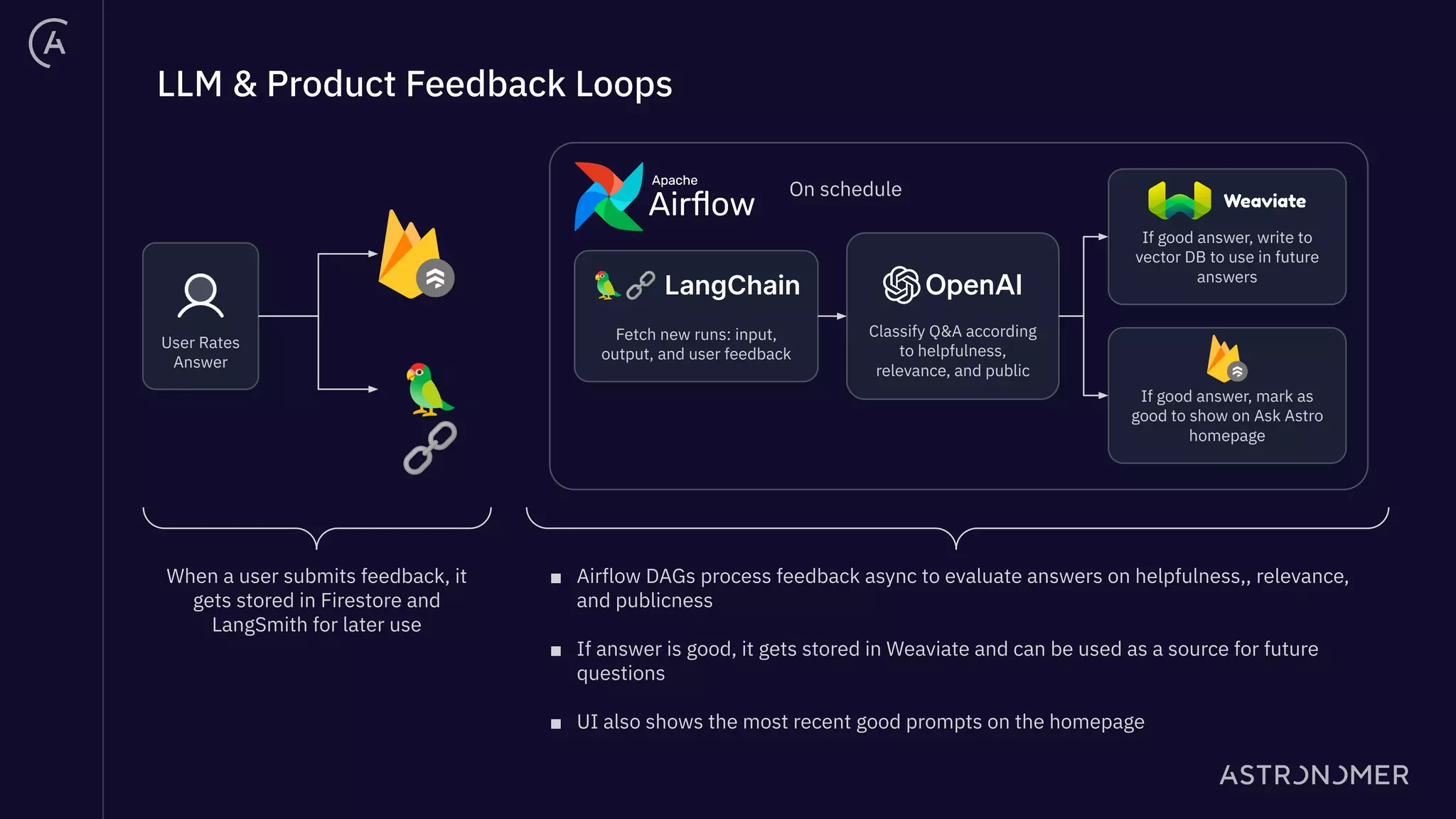



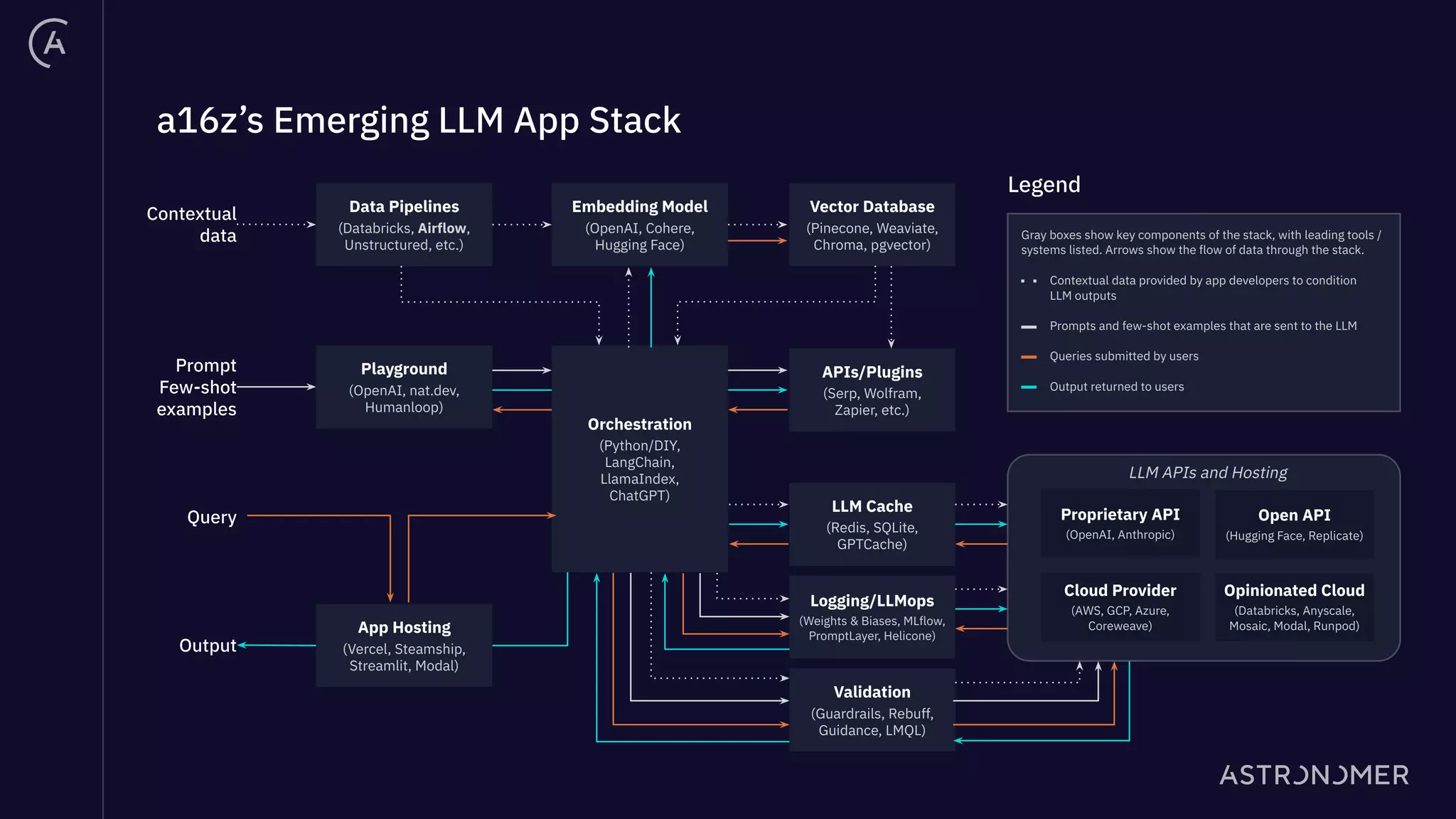
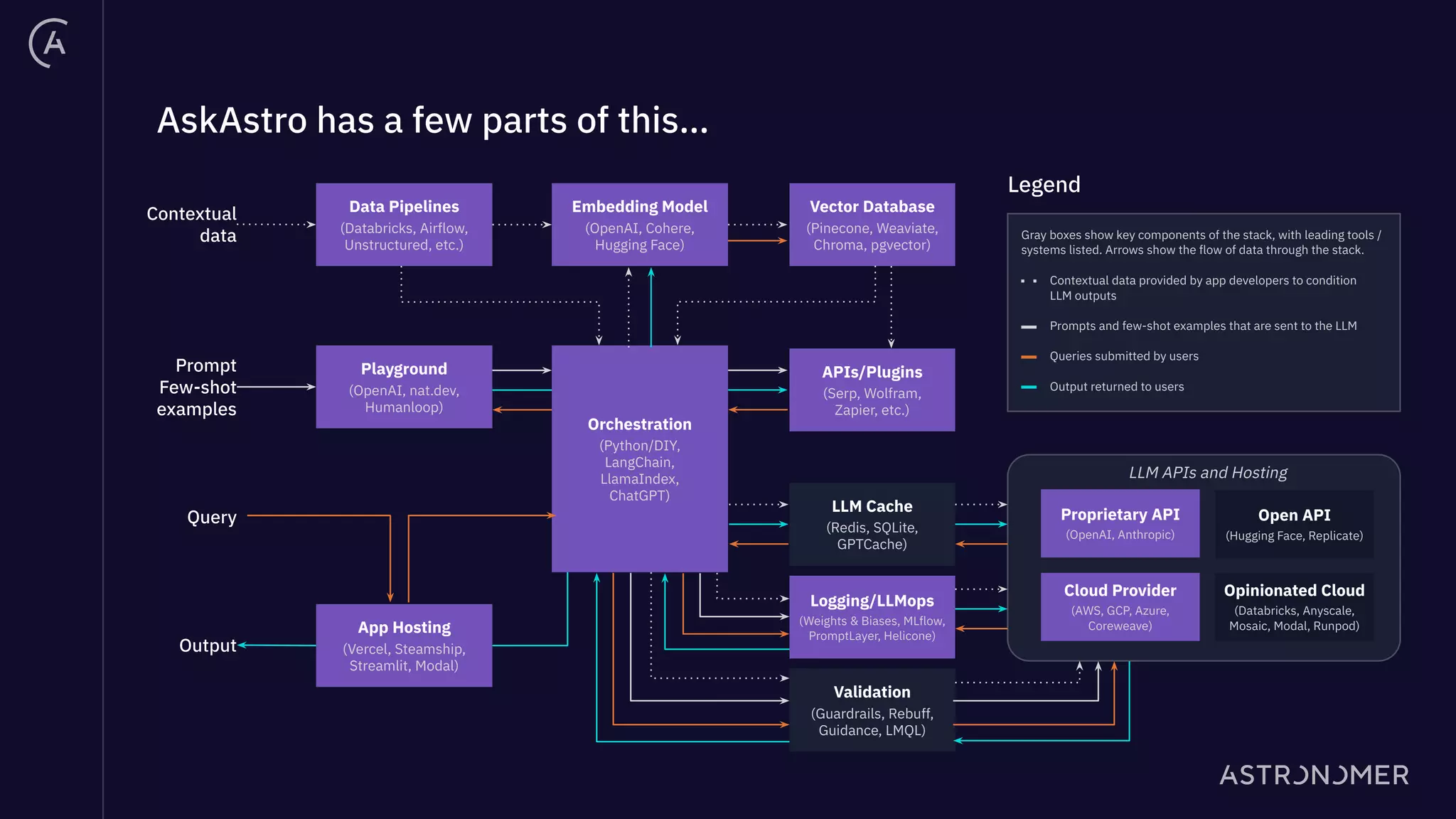




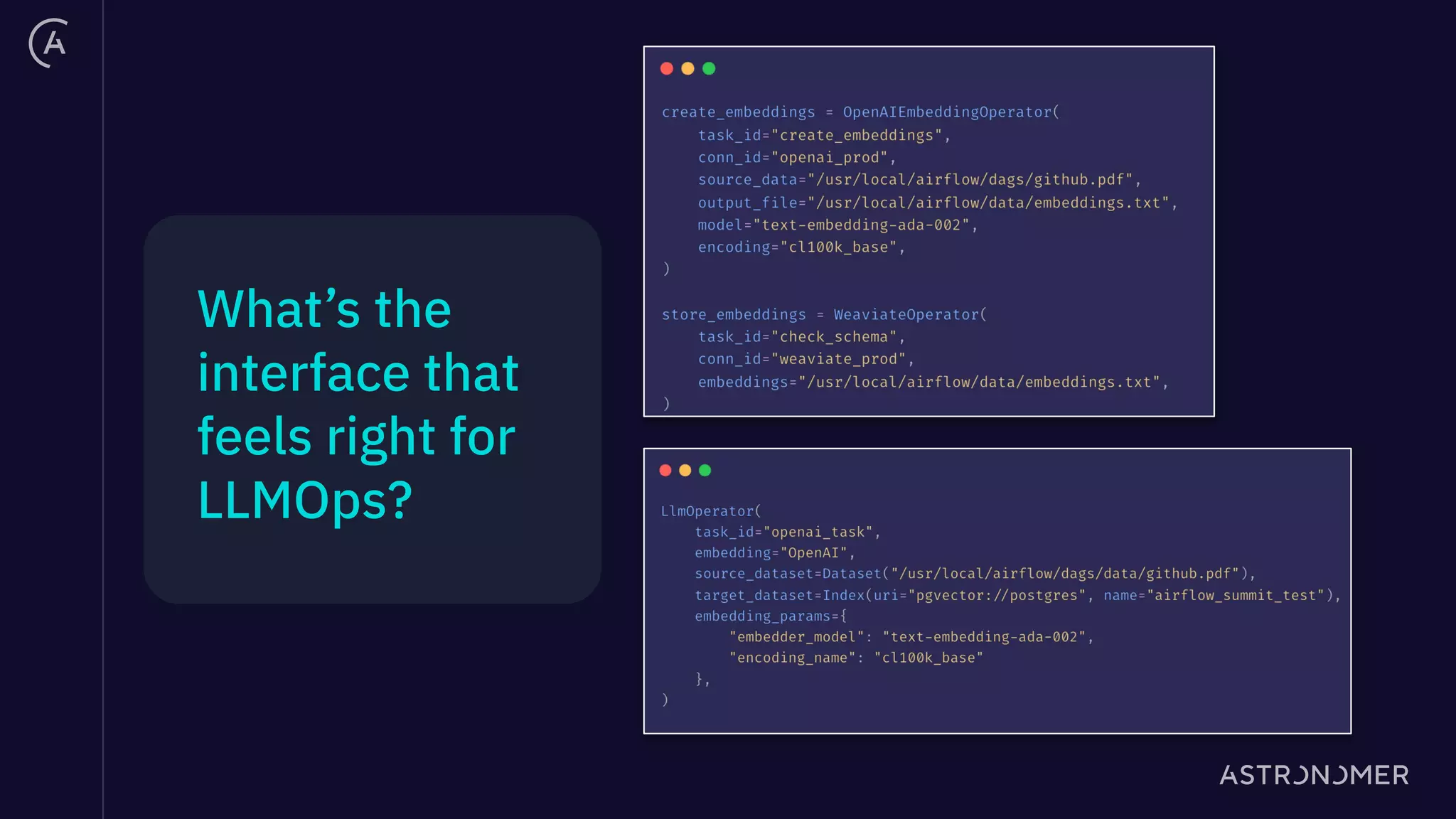

































The document discusses the integration of Apache Airflow in building and deploying large language model (LLM) applications, emphasizing data engineering challenges and the need for orchestration in LLM operations (LLMOps). It outlines a real use case involving a Q&A system that utilizes Langchain to manage data ingestion, processing, and retrieval effectively while implementing feedback loops and monitoring. The document also highlights best practices for creating pipelines in LLM applications, ensuring governance, transparency, and efficiency in data handling.














































































