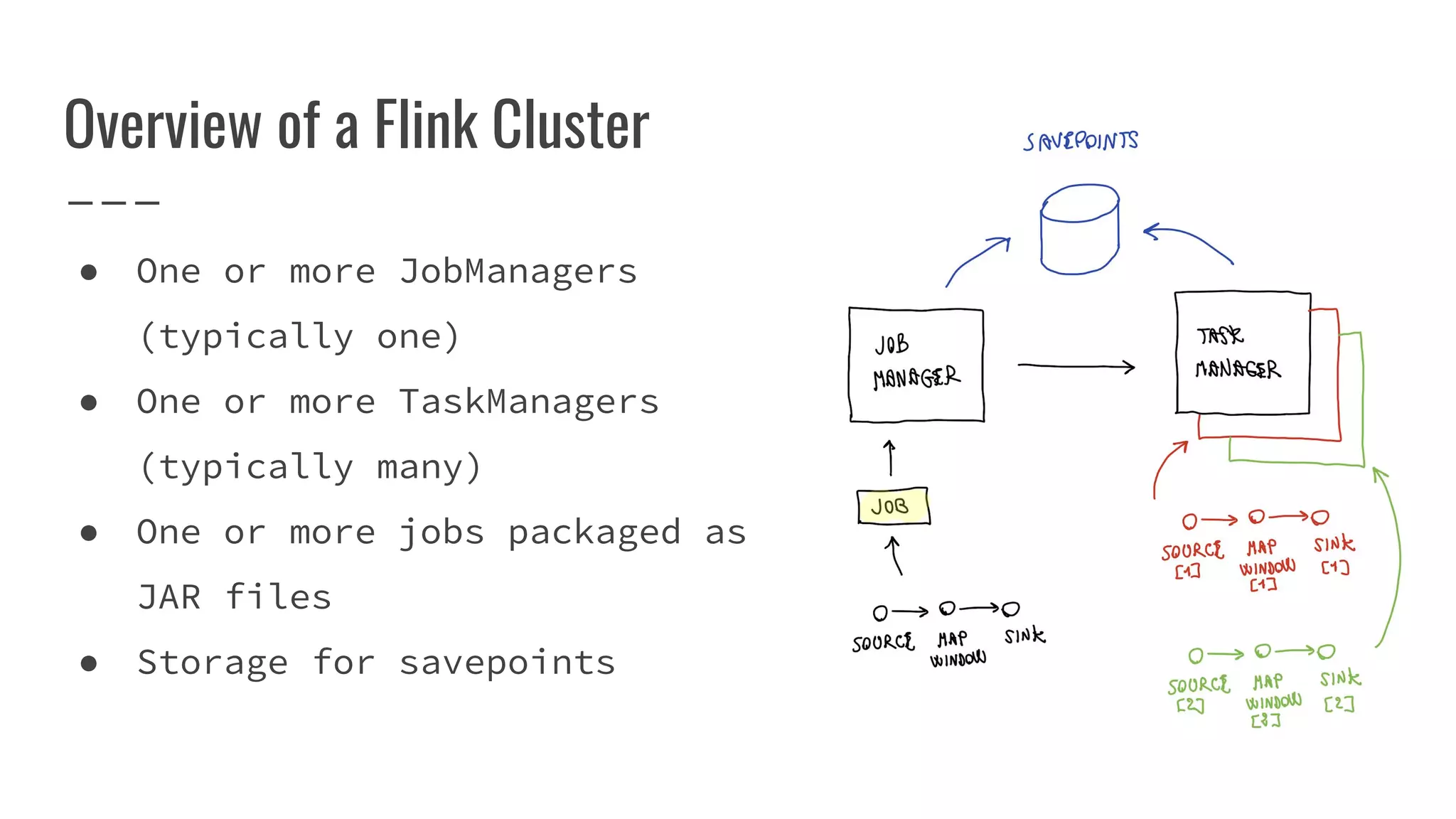
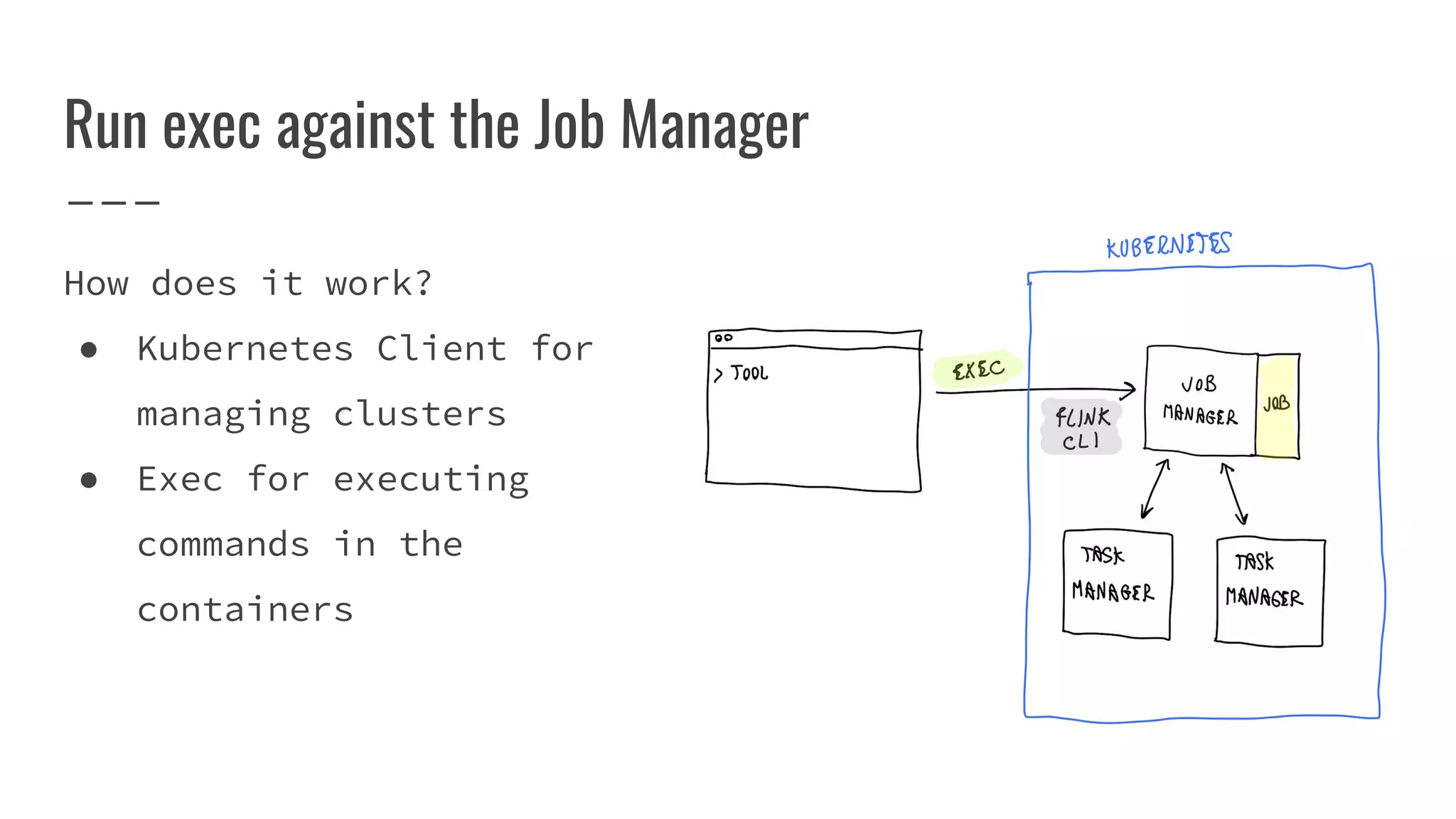
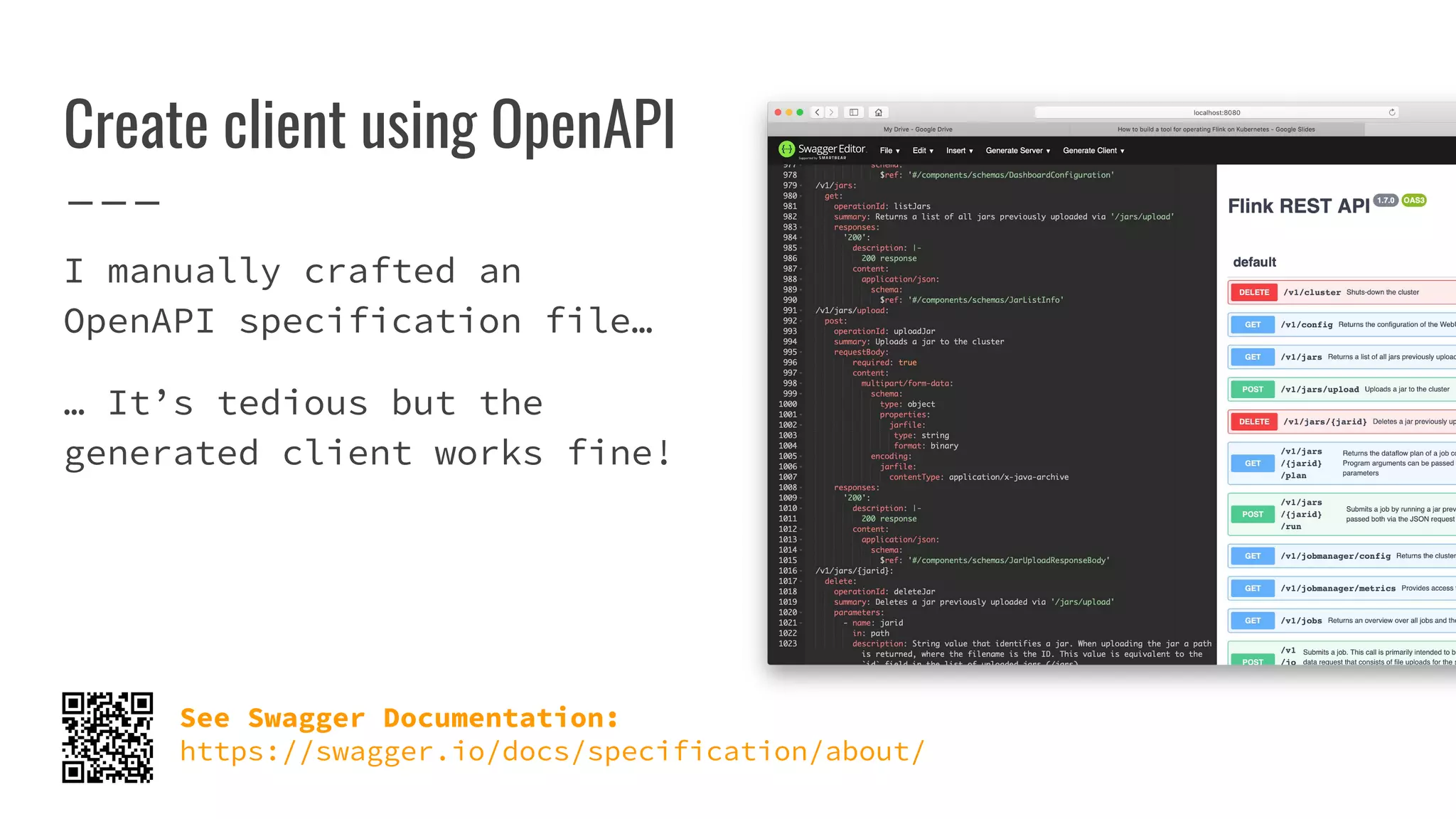
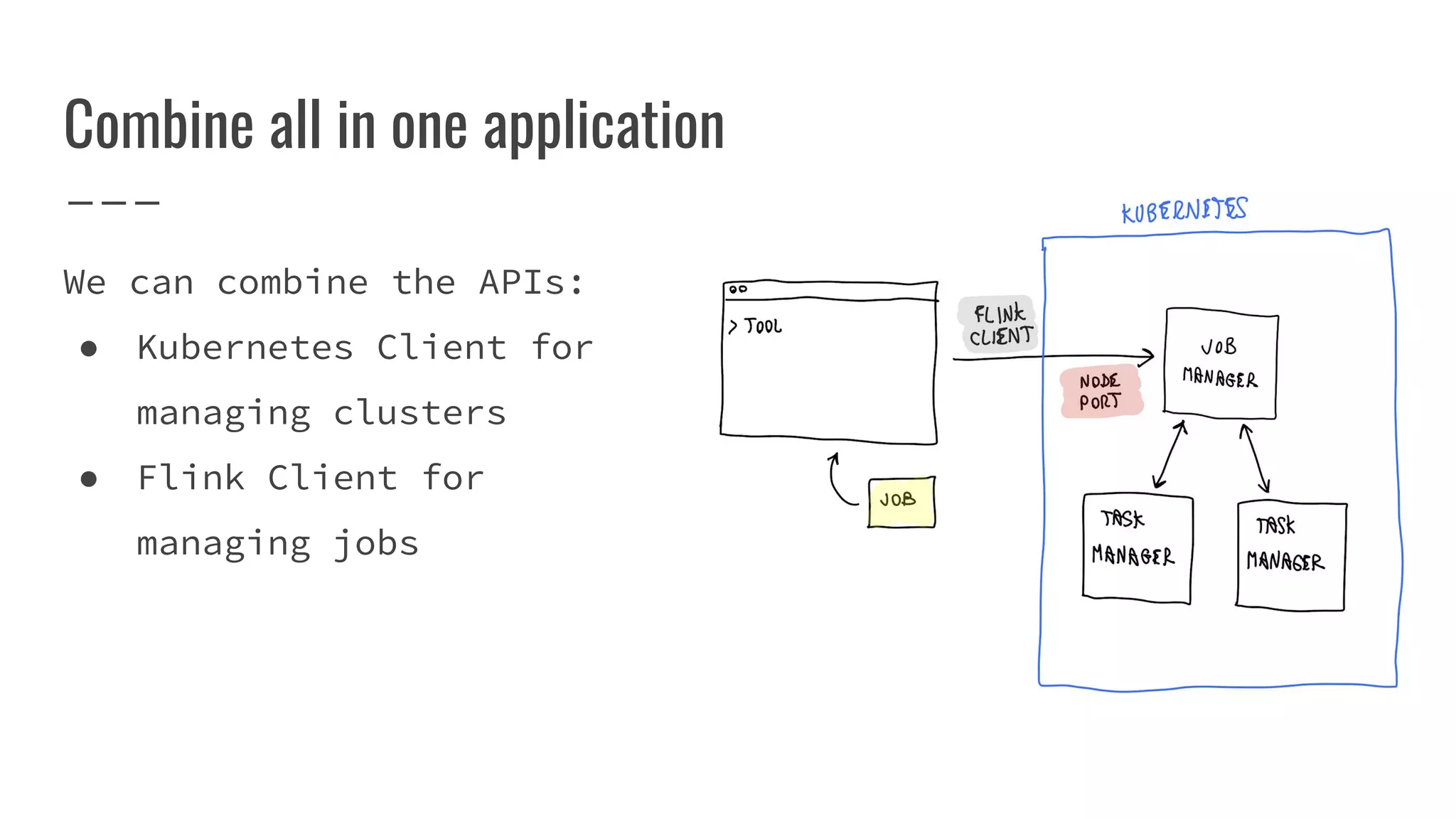
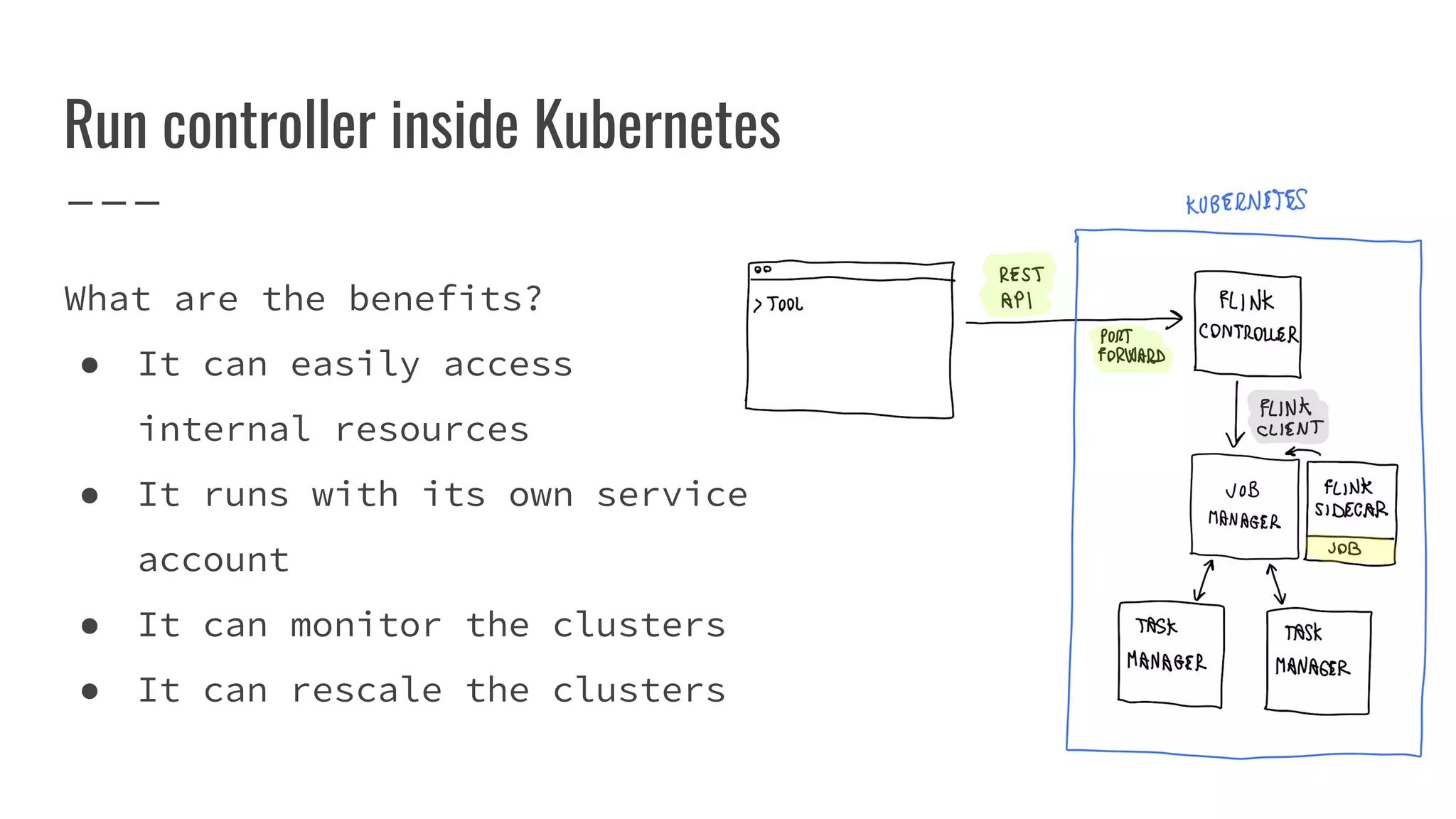
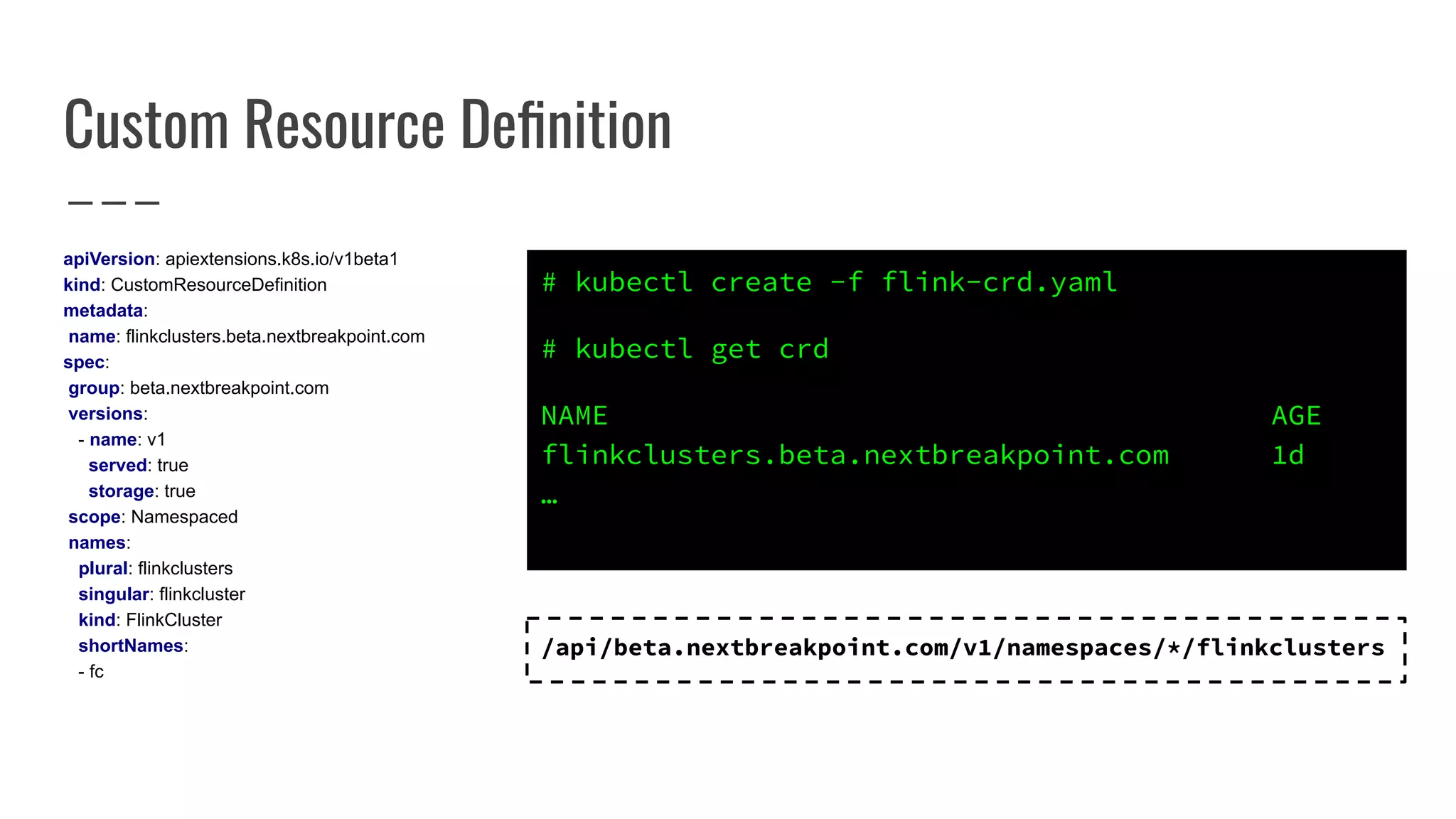
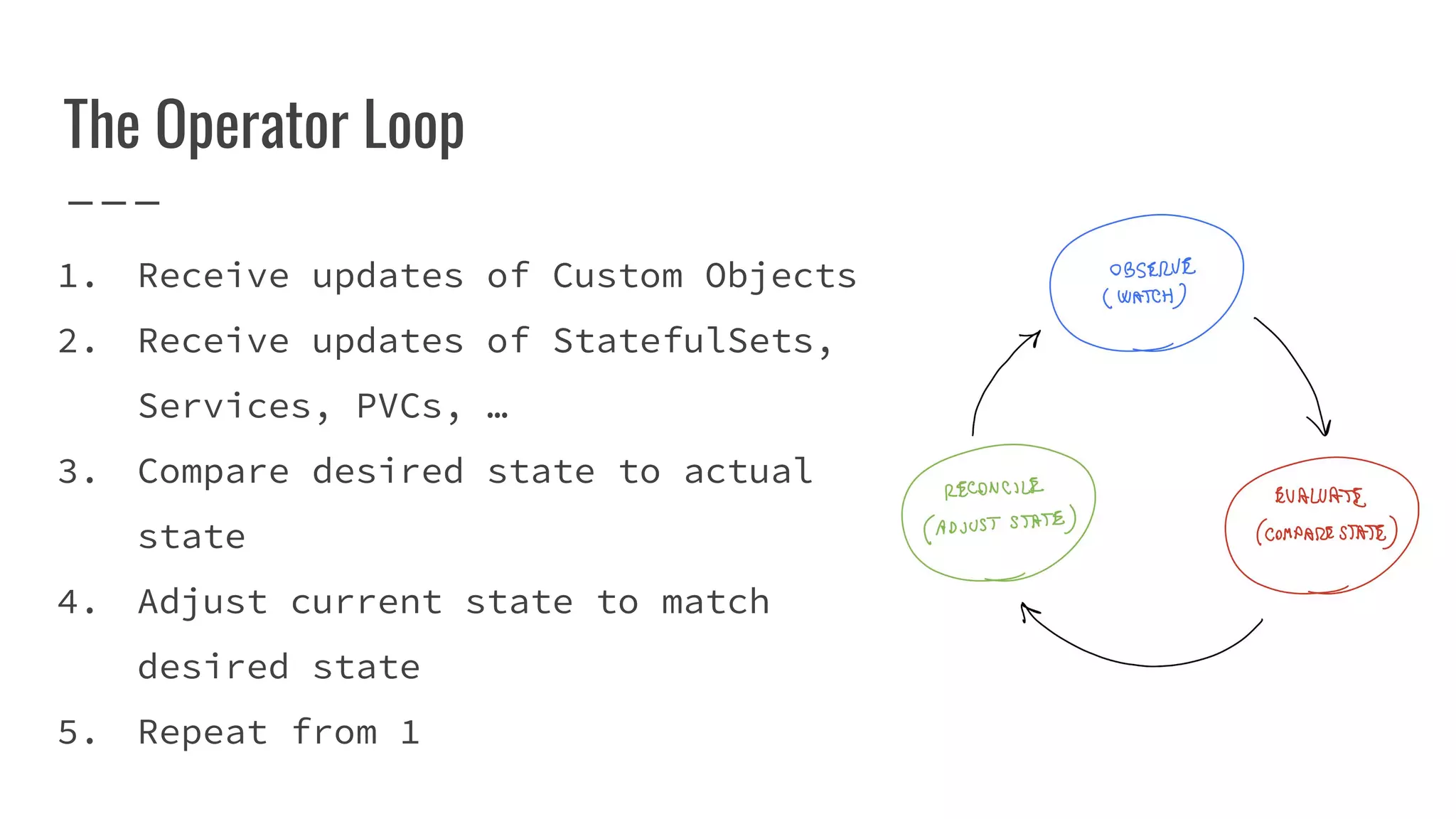
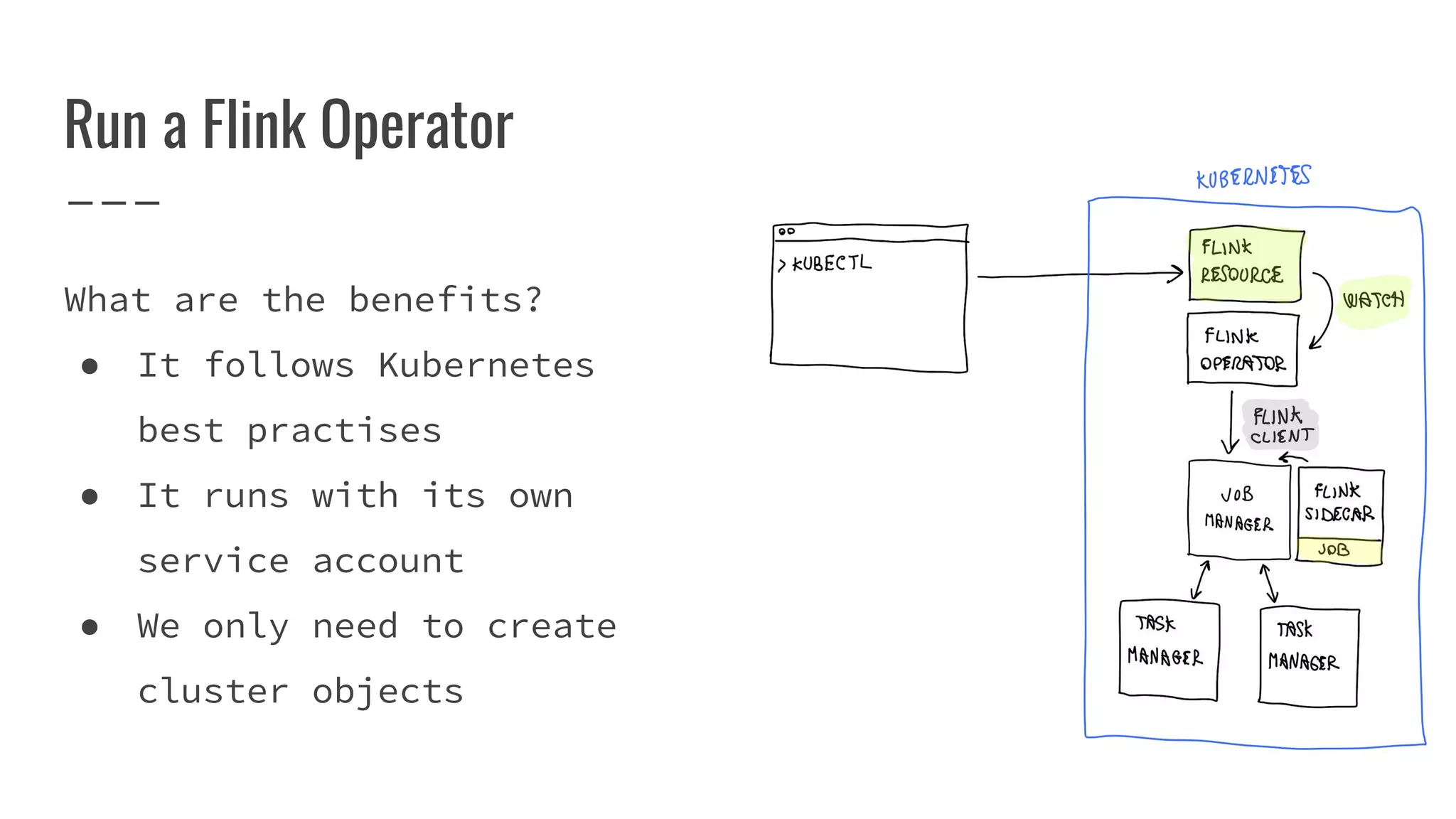
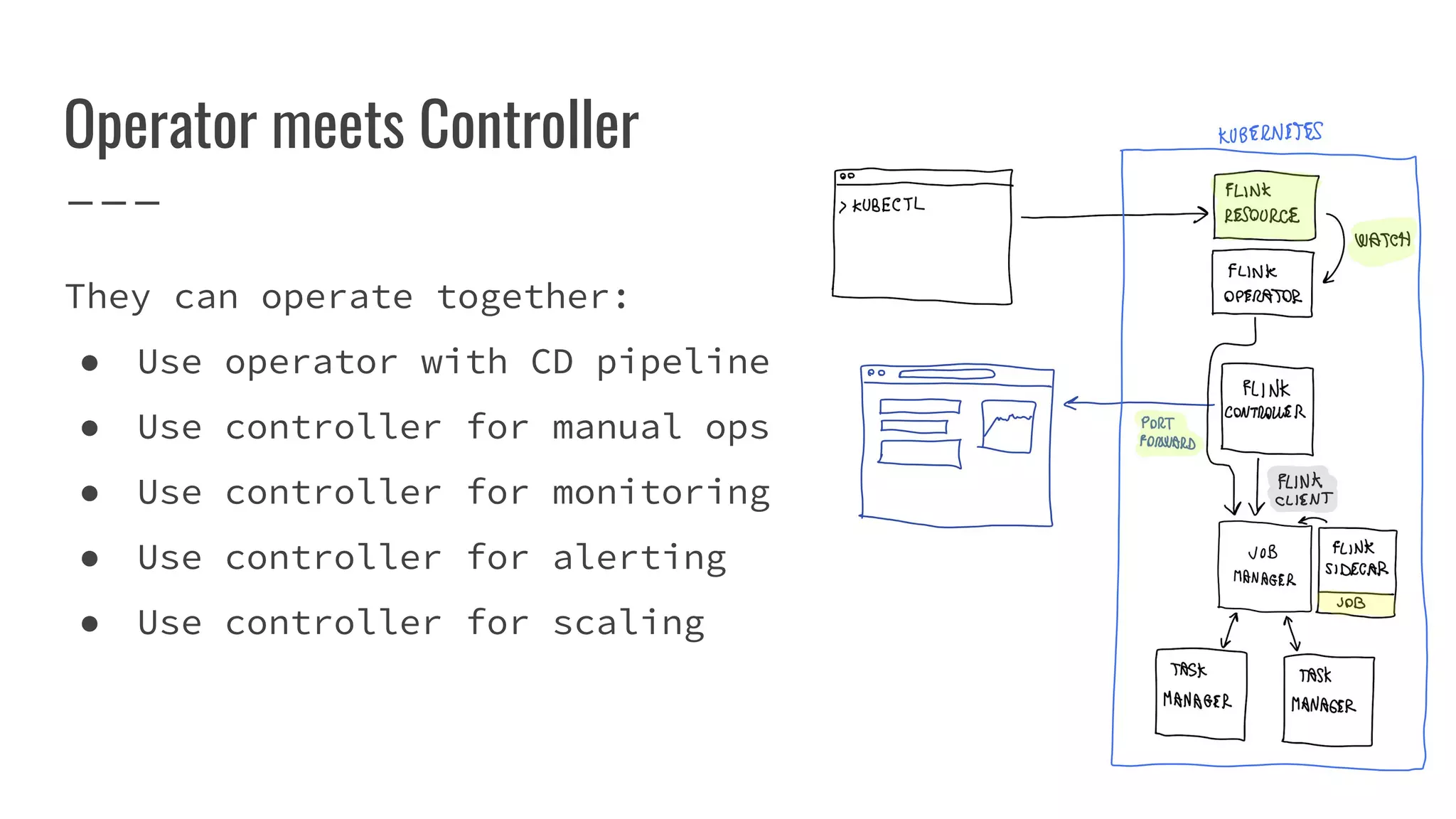
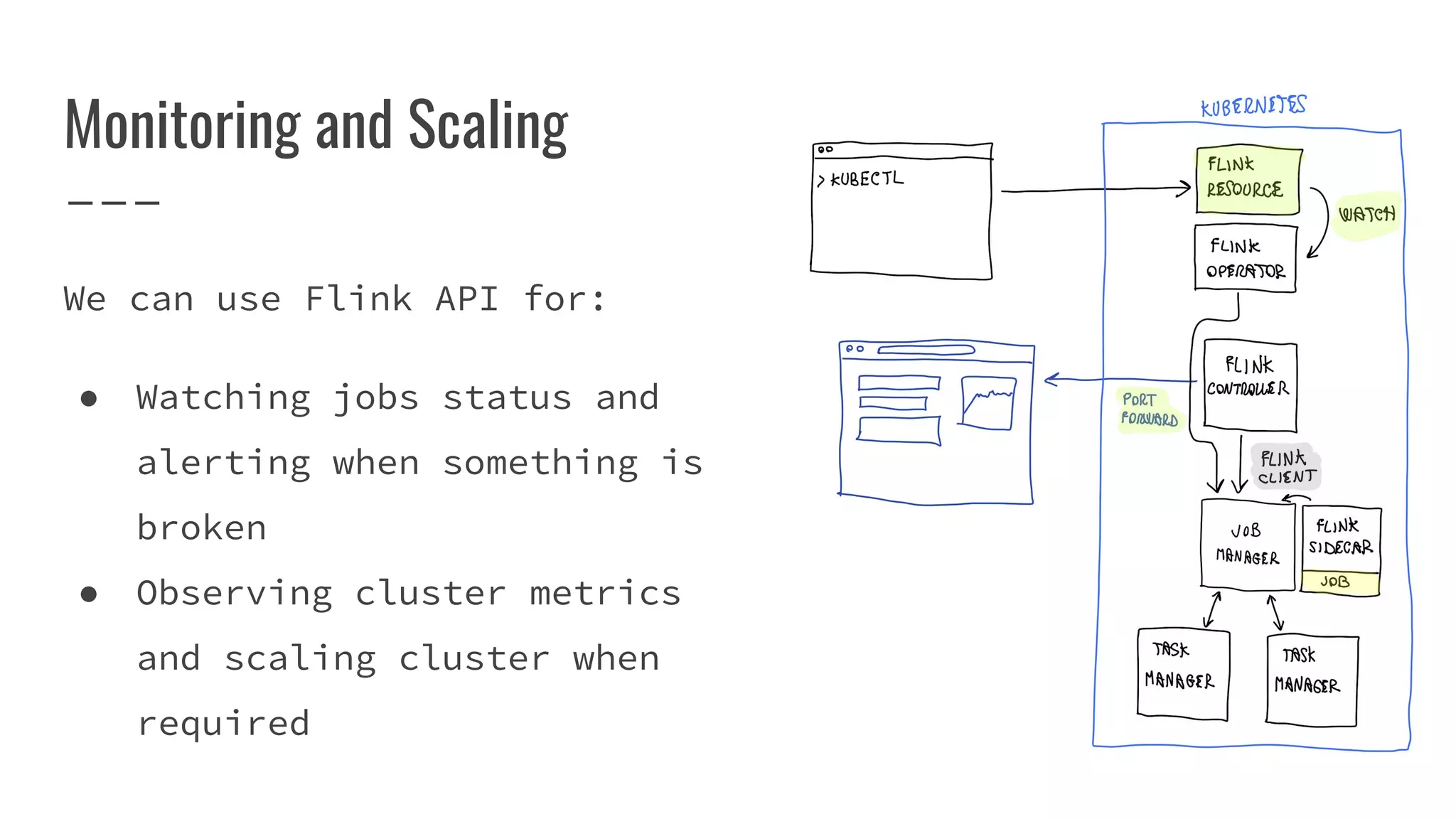
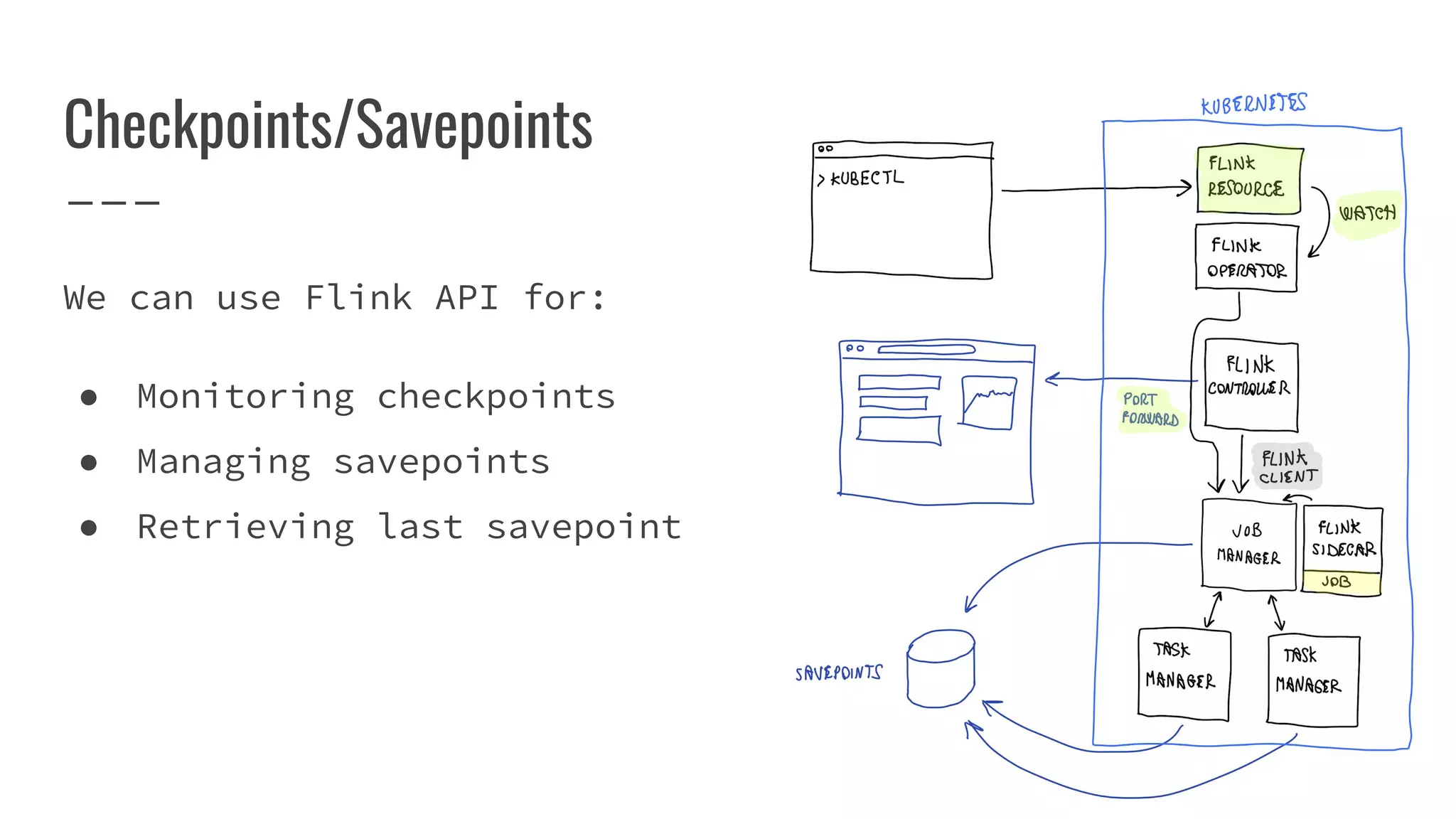
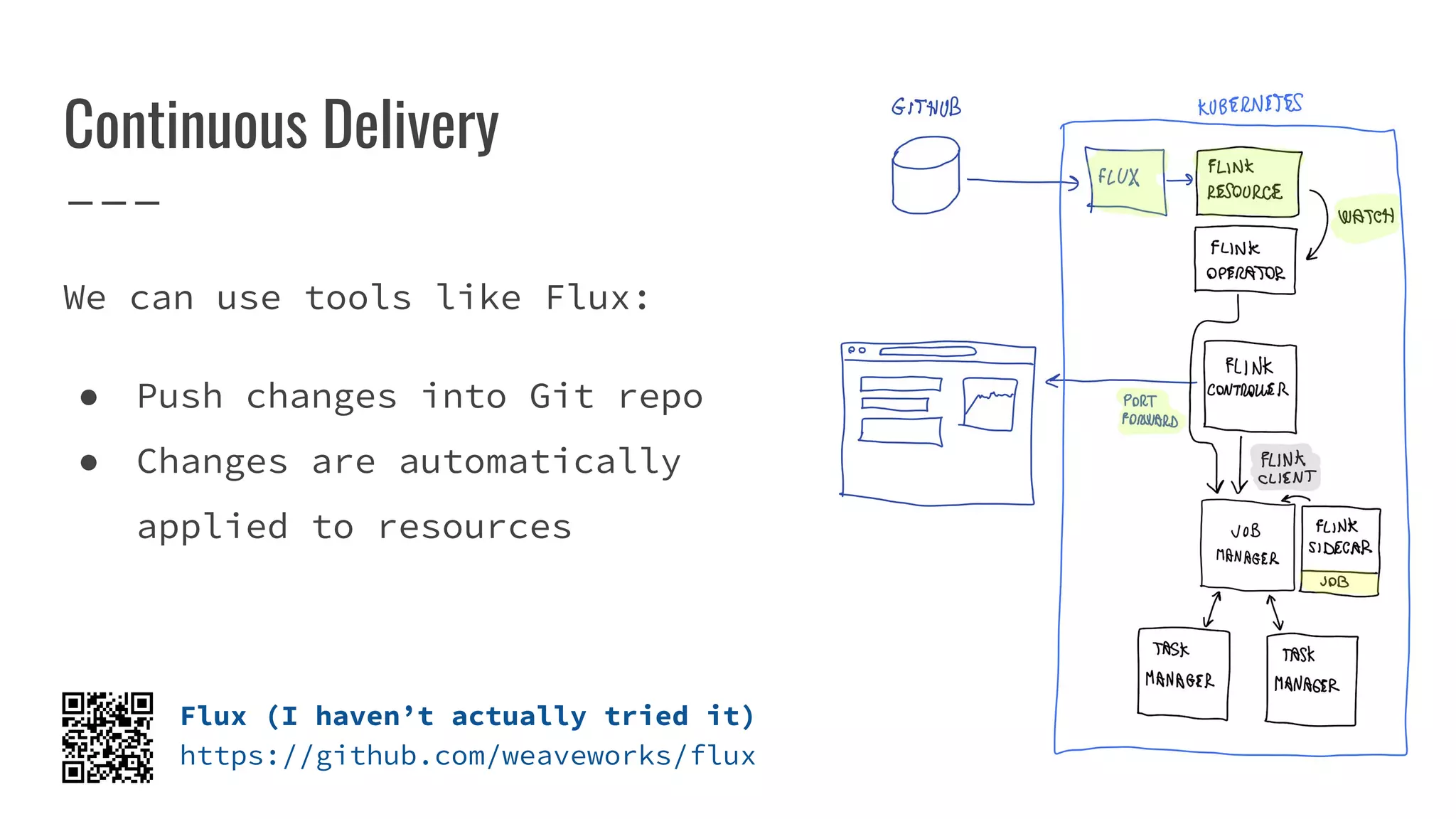
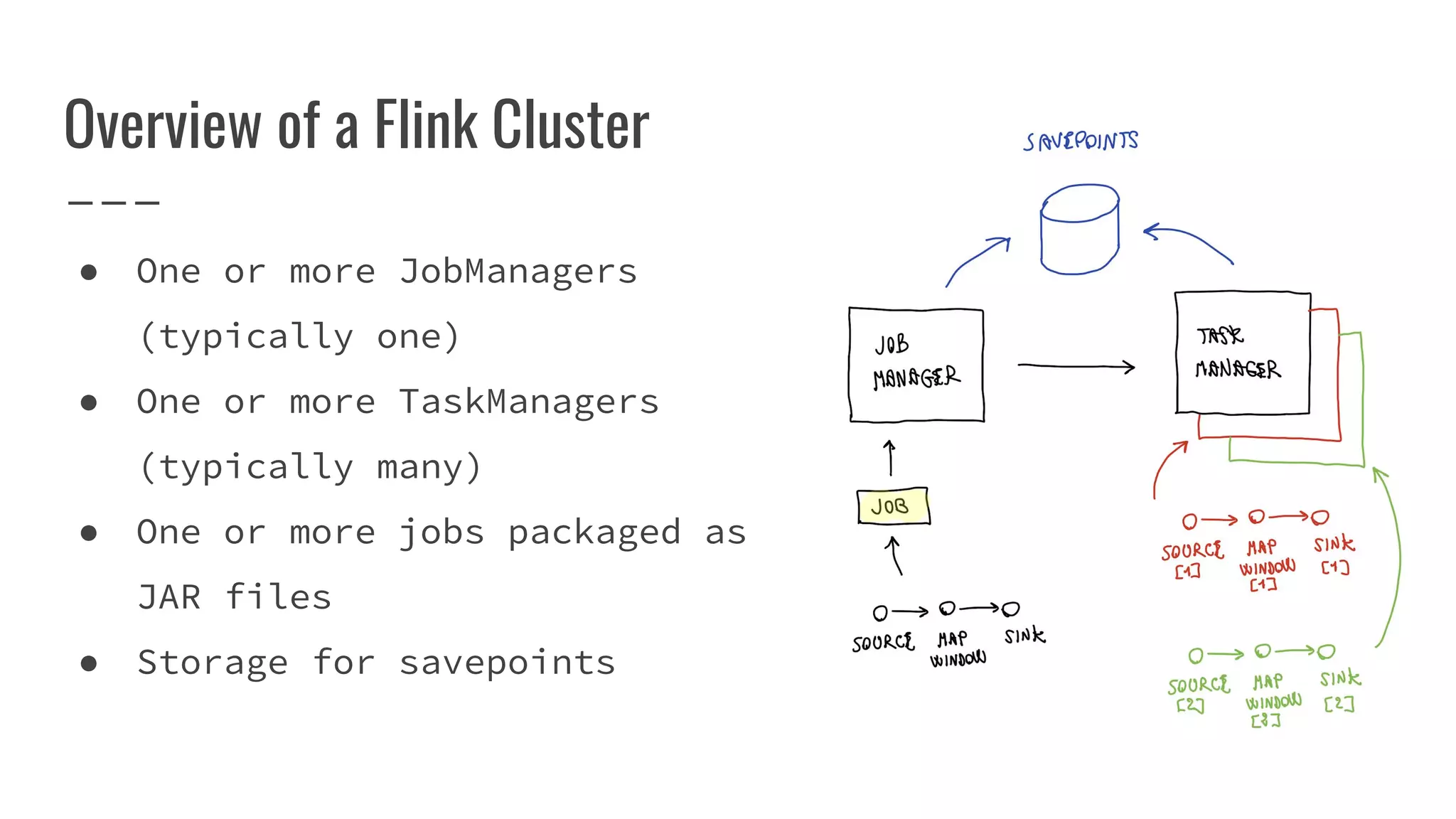
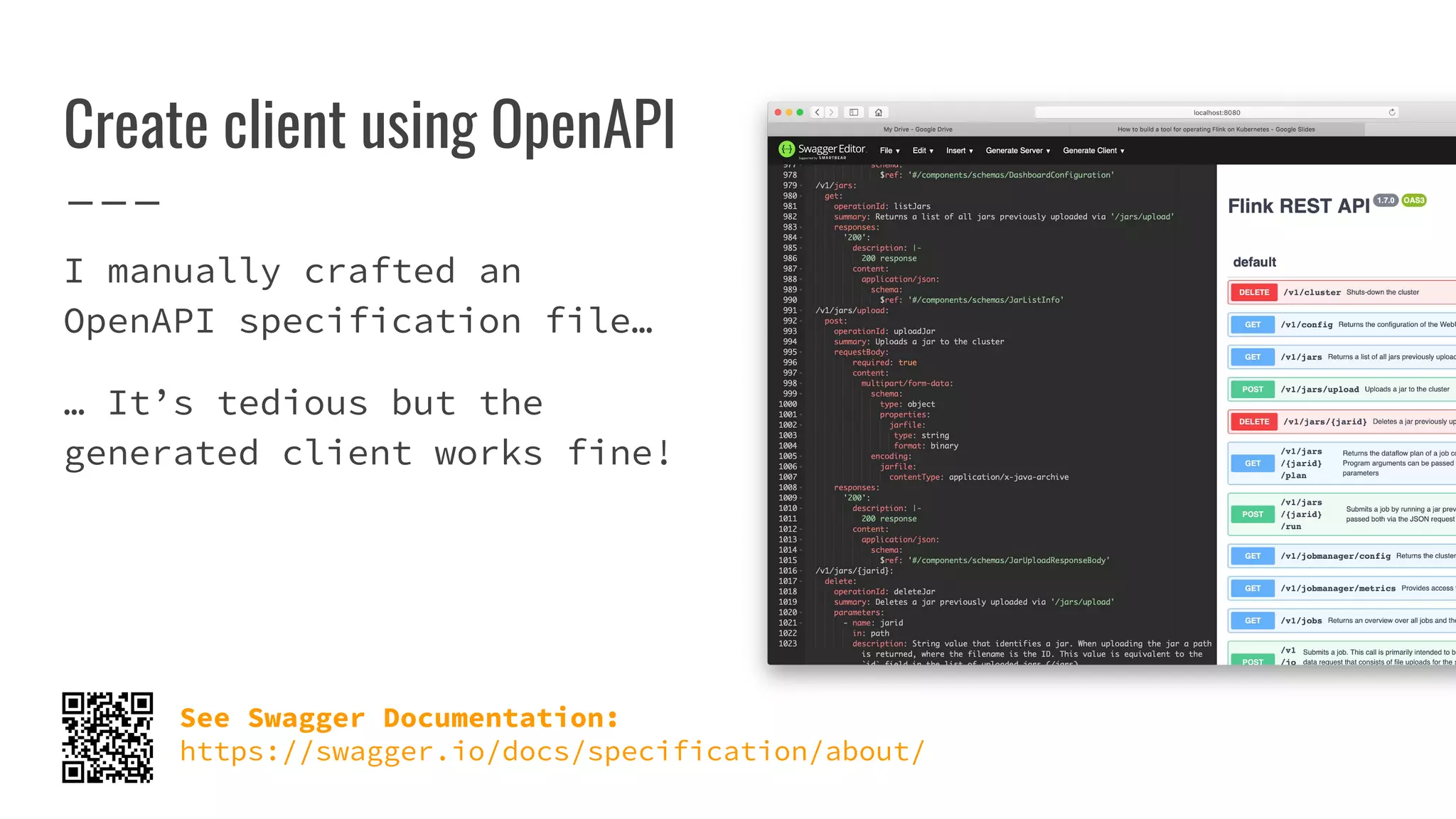
The document outlines the process of building a tool to operate Apache Flink on Kubernetes, discussing available products, challenges in developing a custom solution, and the need for an efficient open-source tool. It highlights the use of Kubernetes APIs, the creation of custom resources, and the benefits of employing a Kubernetes operator for better management of Flink clusters. Additionally, it mentions the integration of monitoring, scaling, and continuous delivery strategies to enhance Flink operations in a Kubernetes environment.