Download as PDF, PPTX












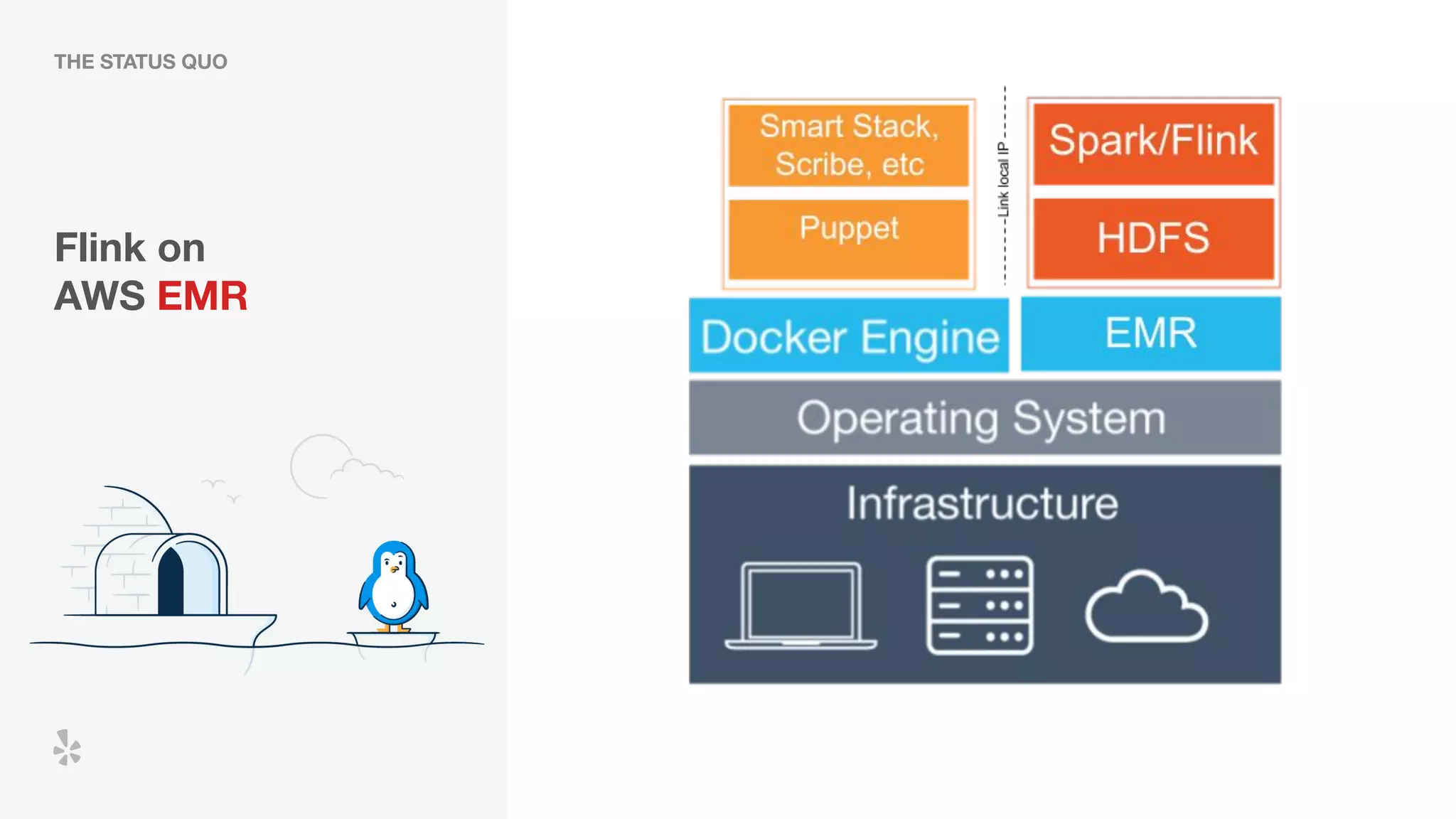







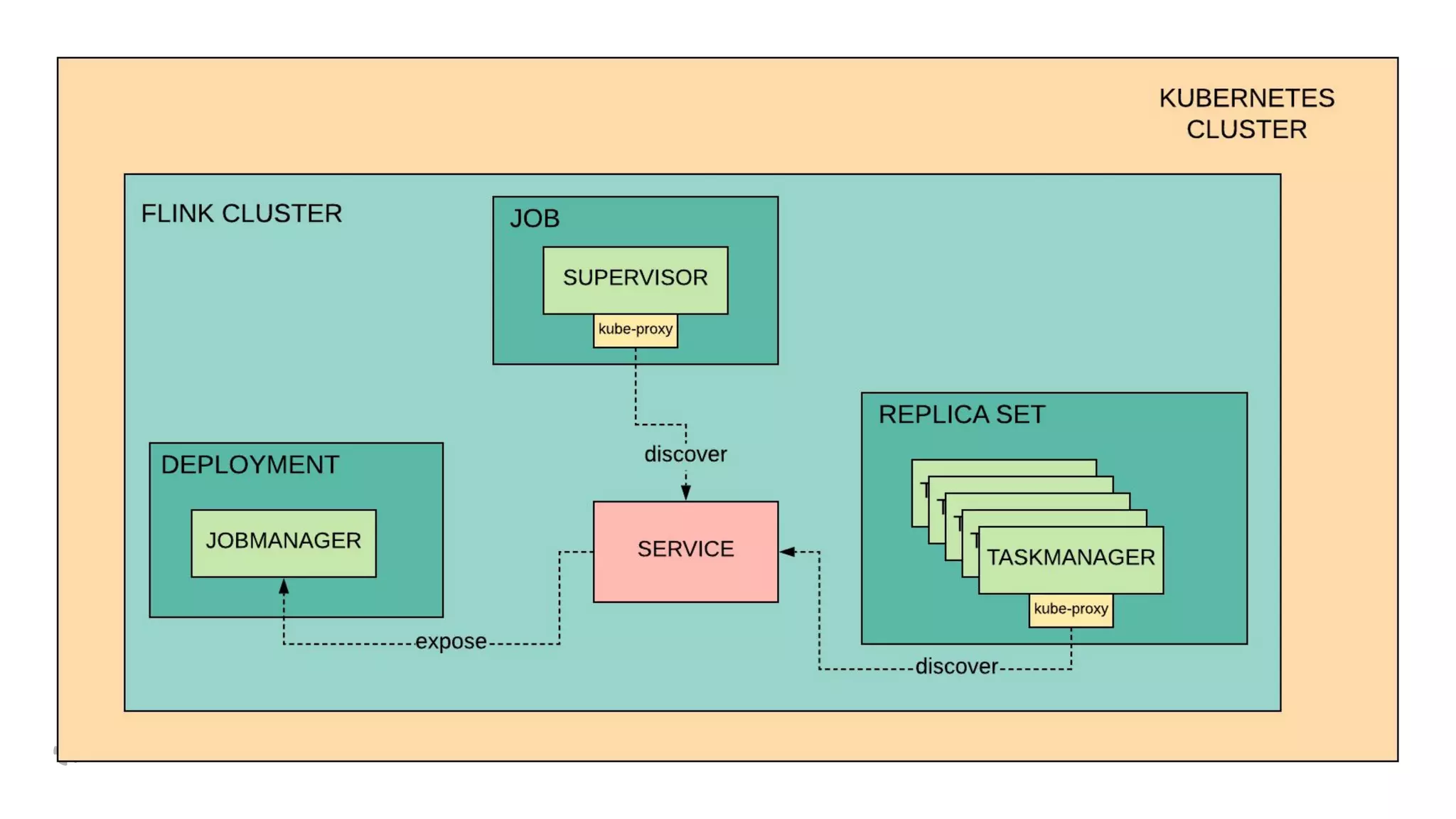
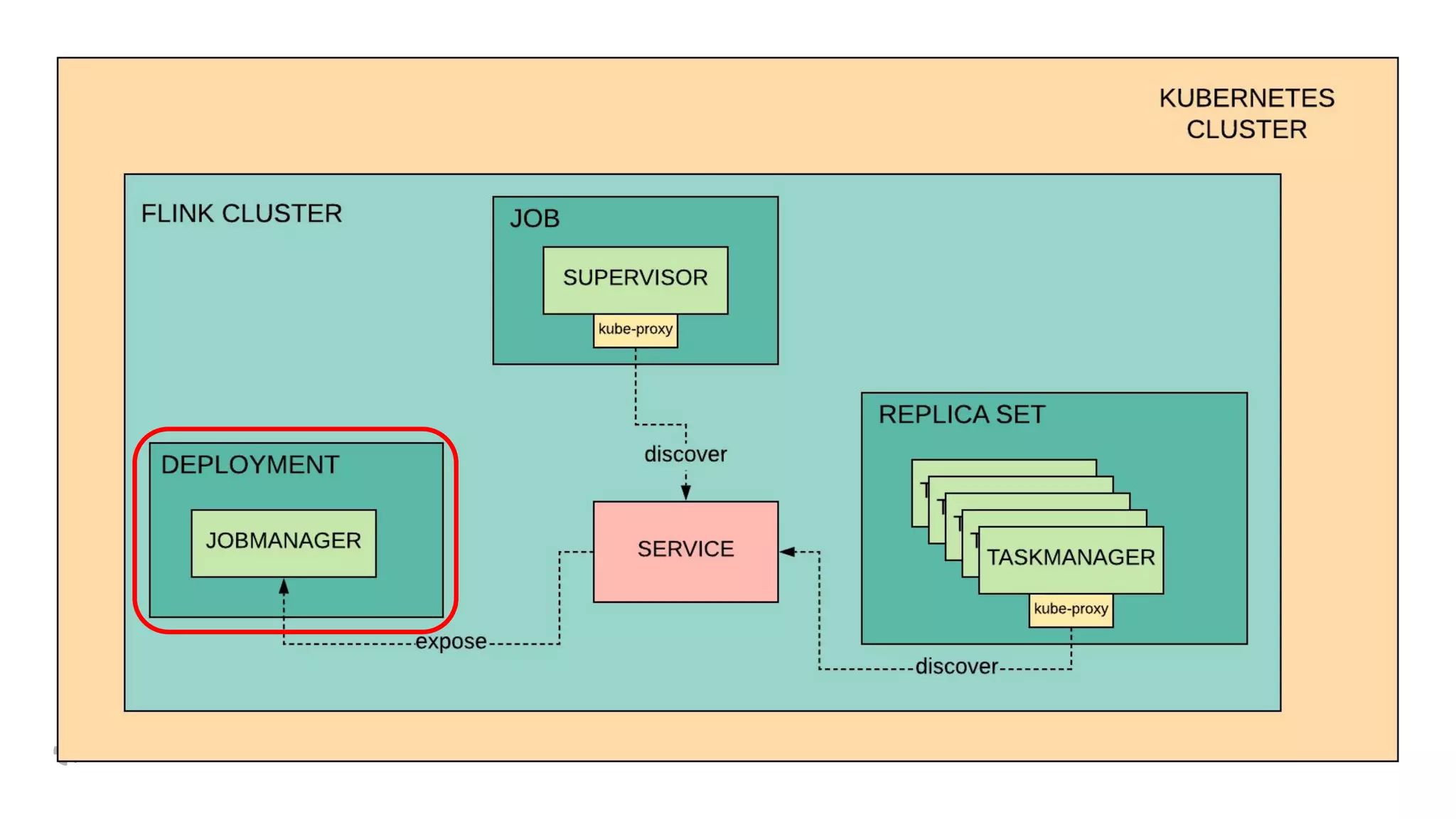



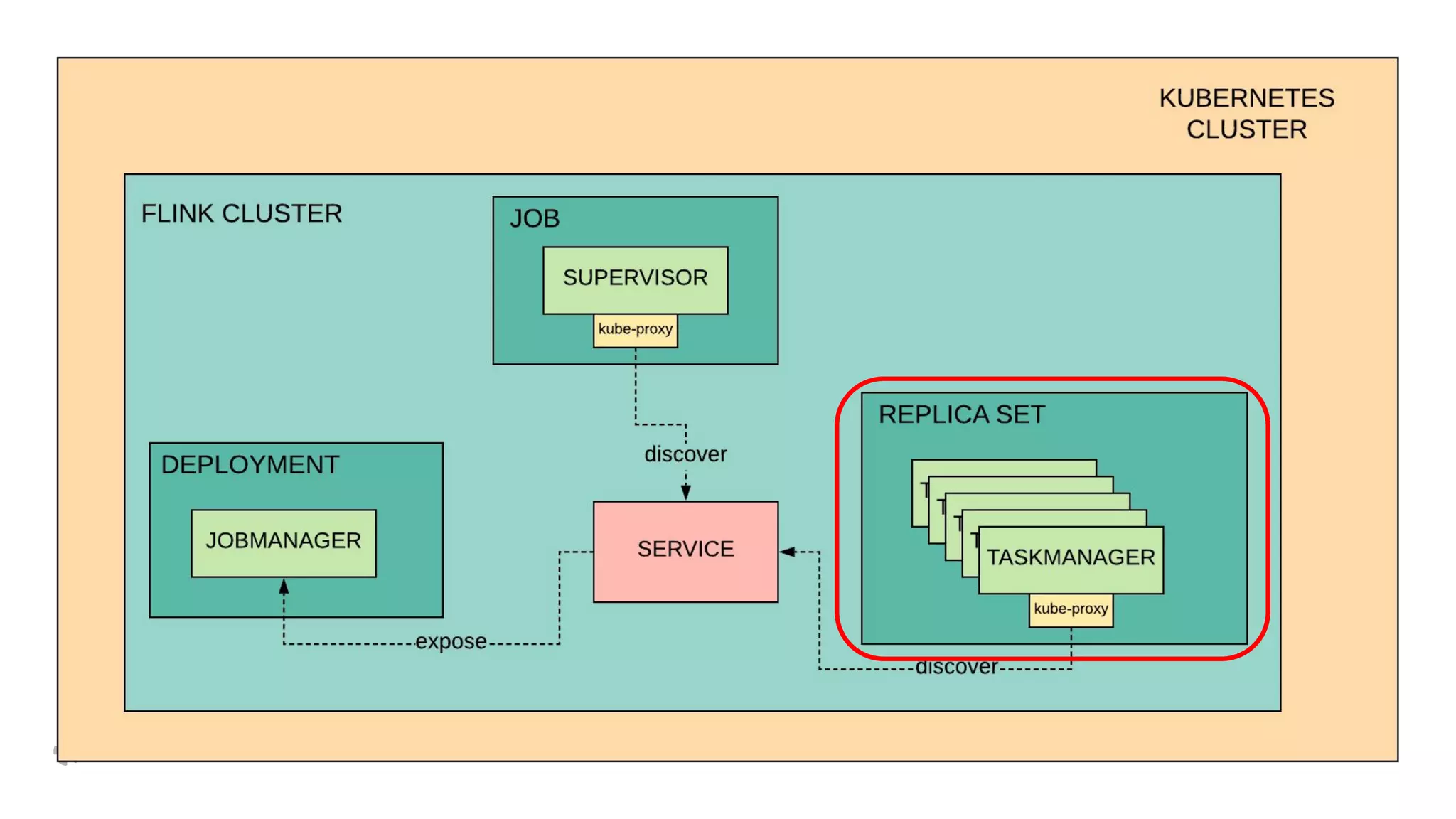


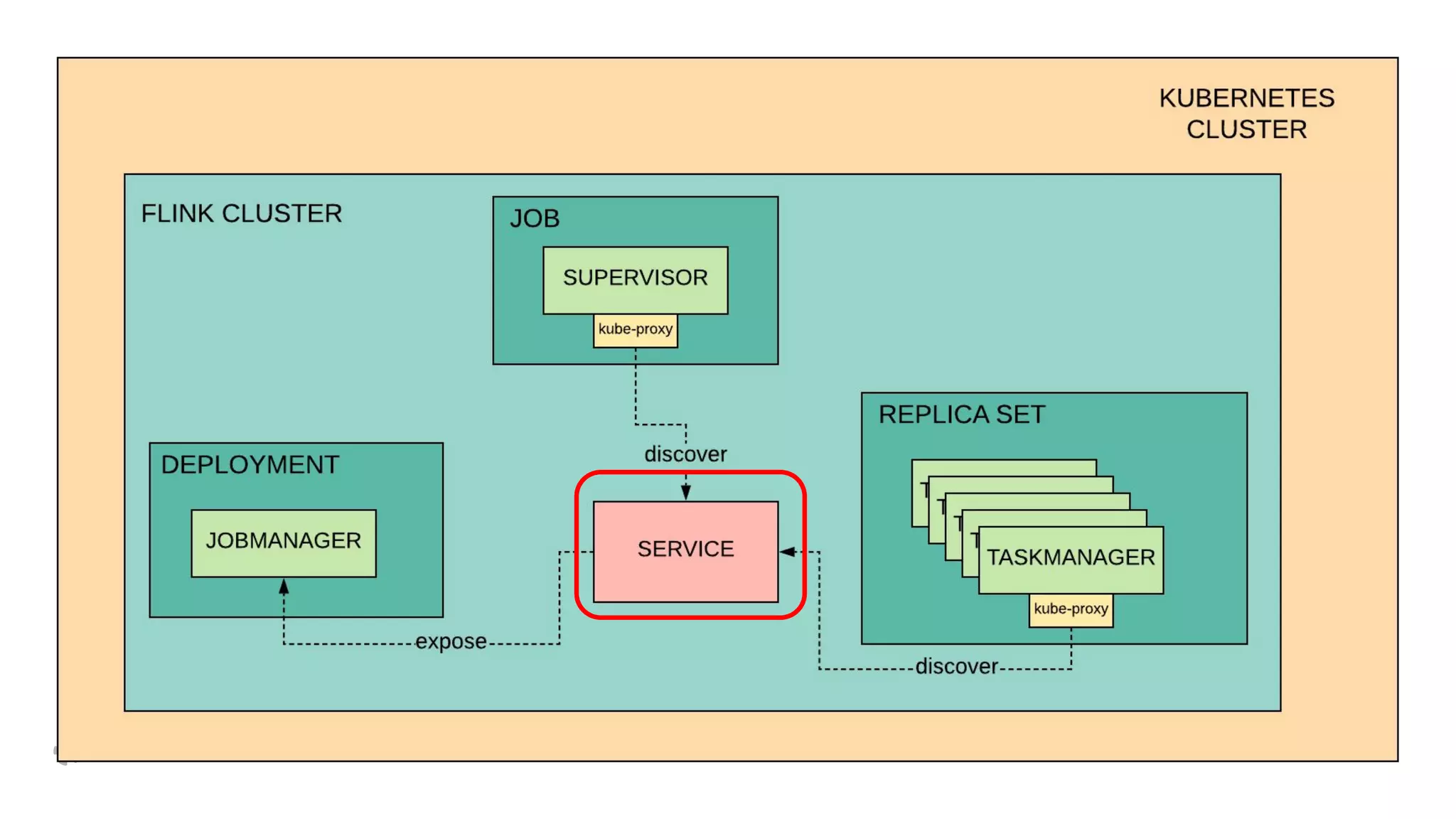
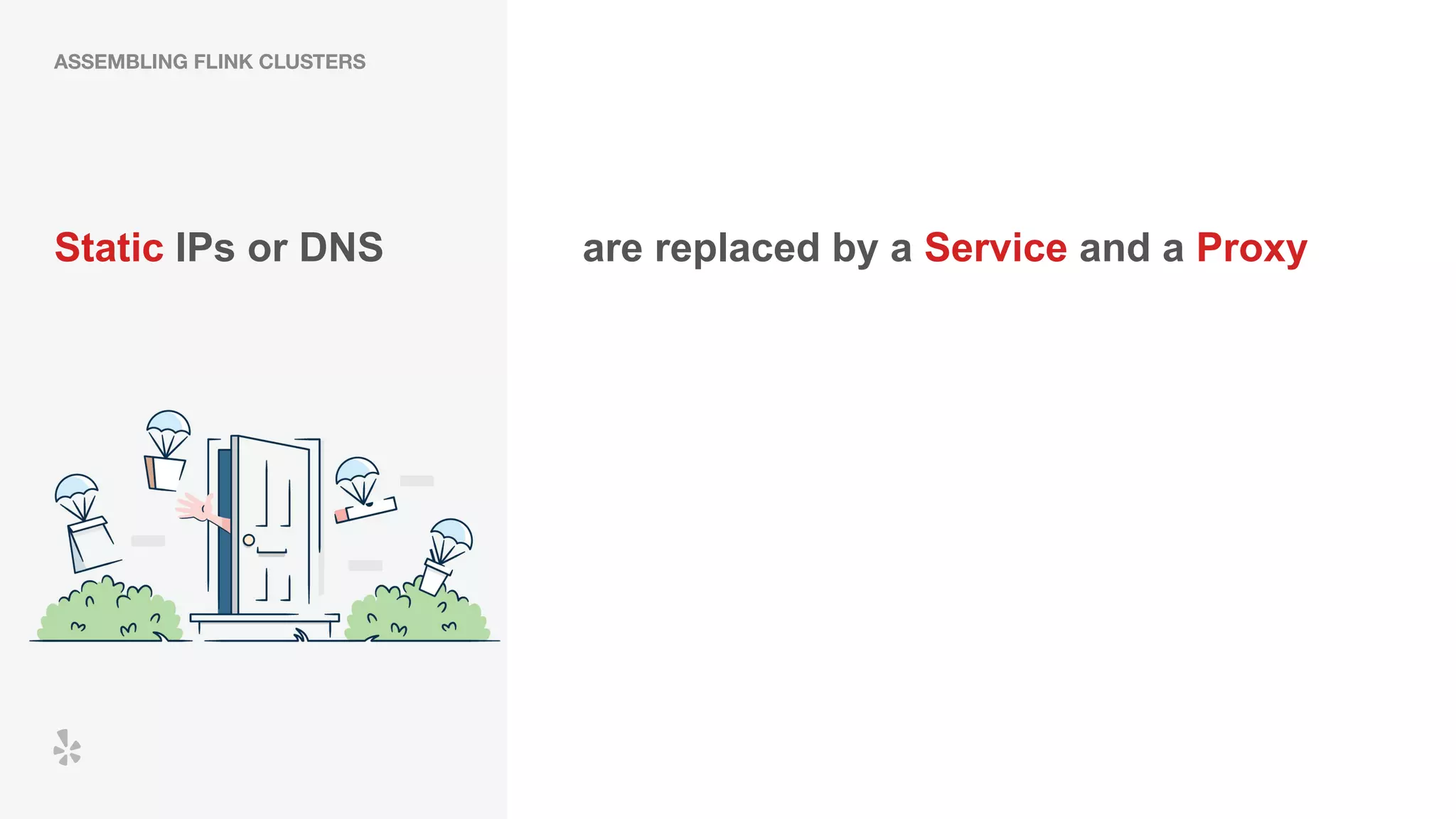


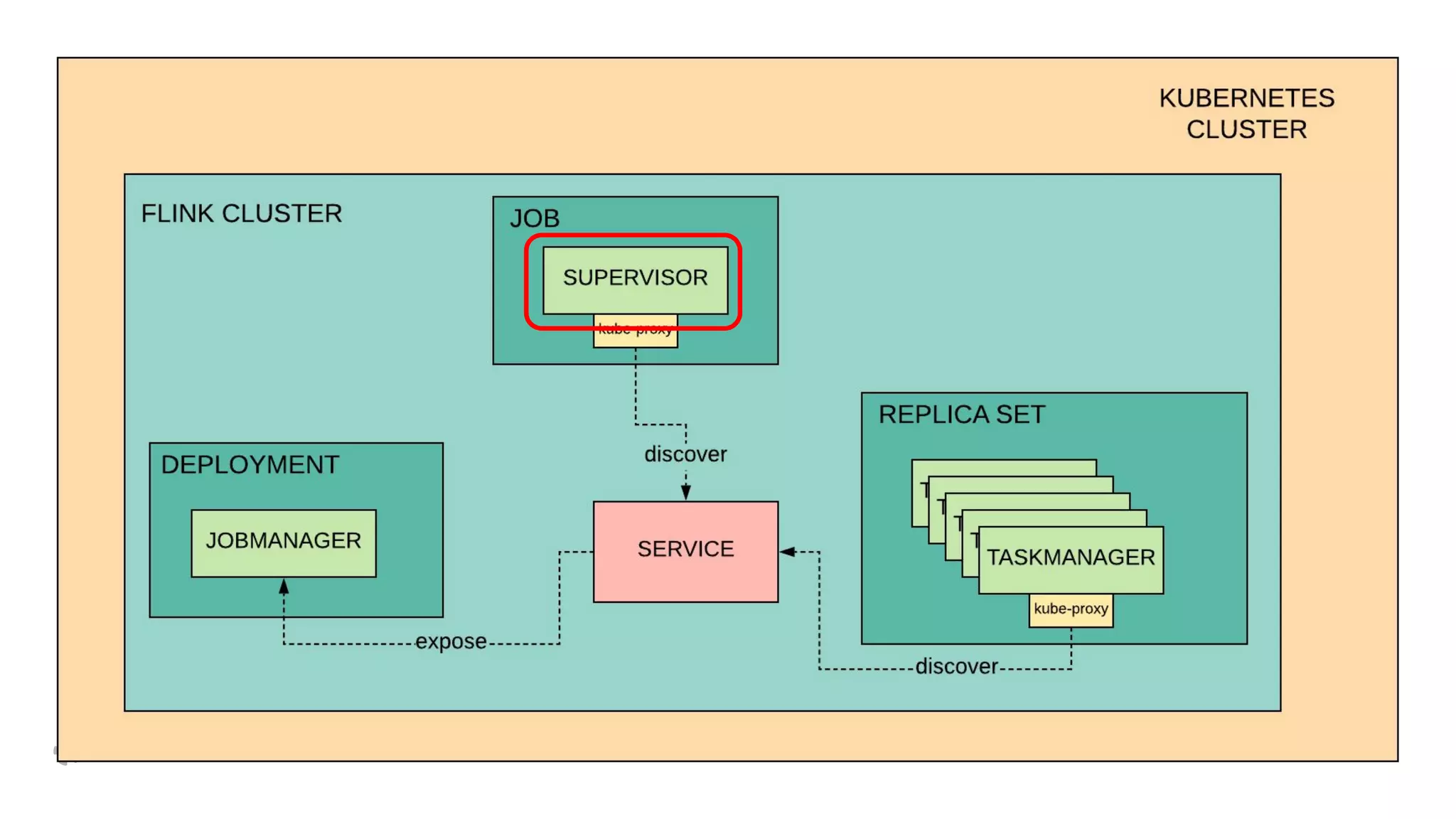

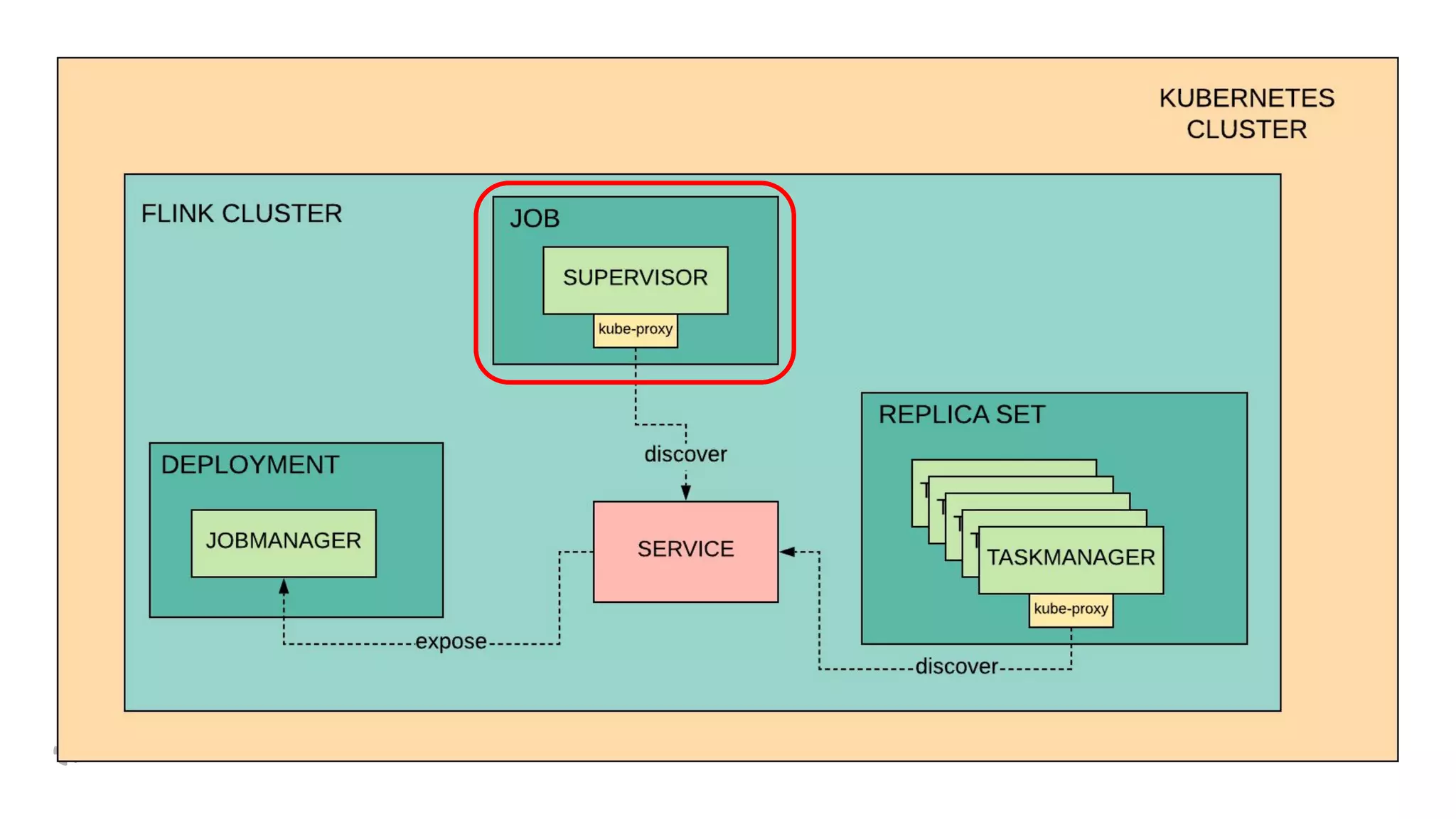


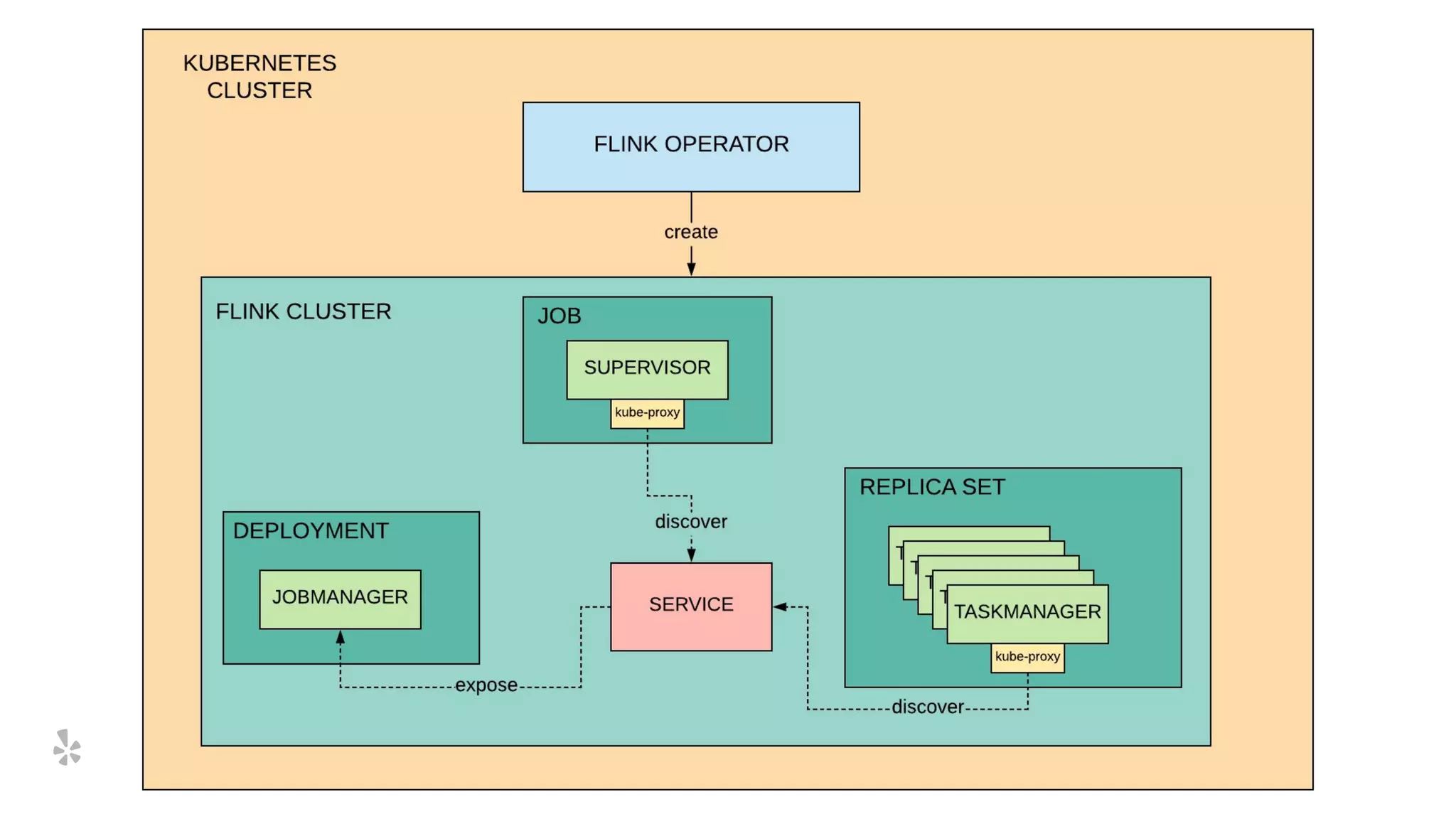
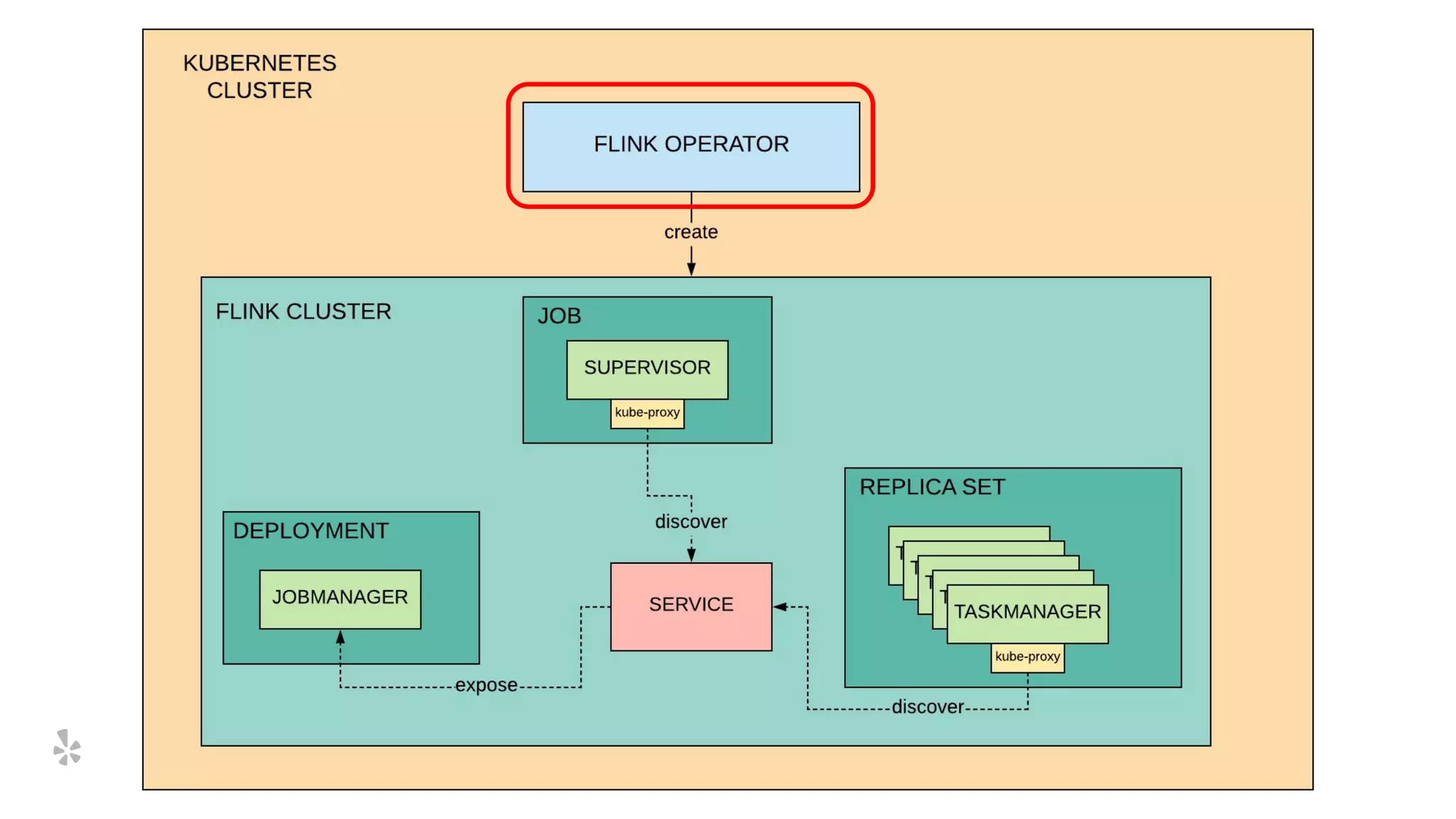
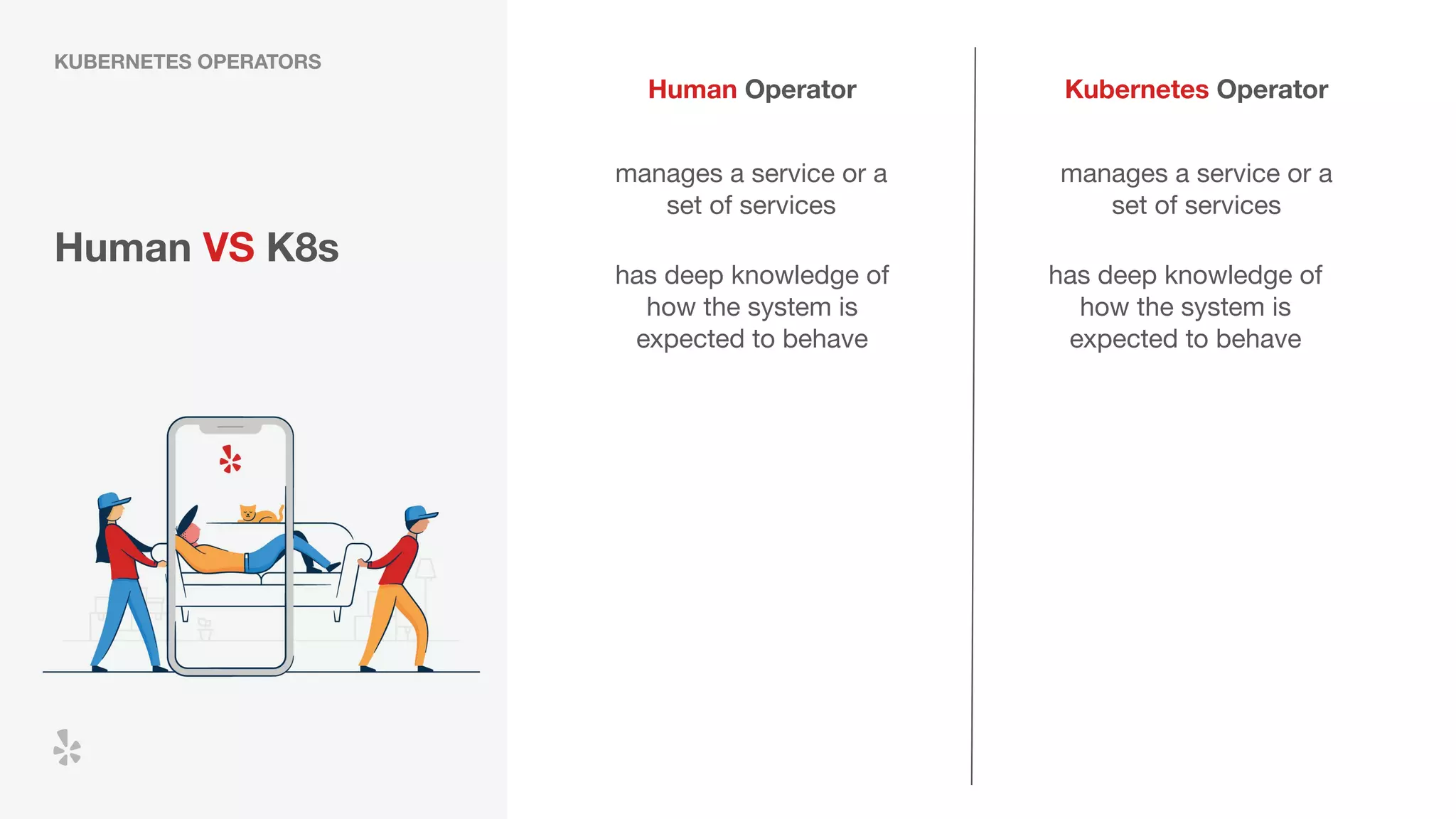
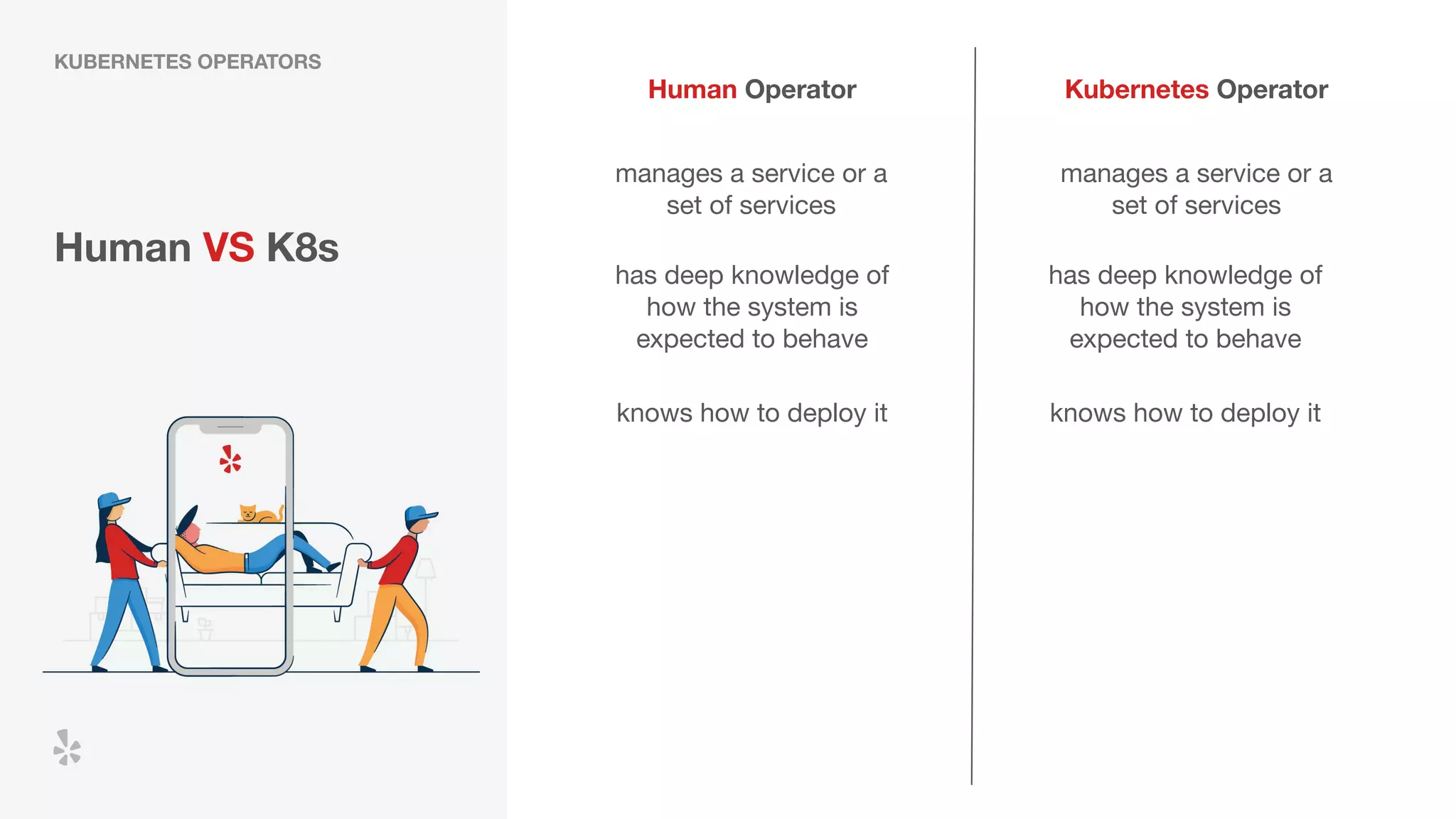
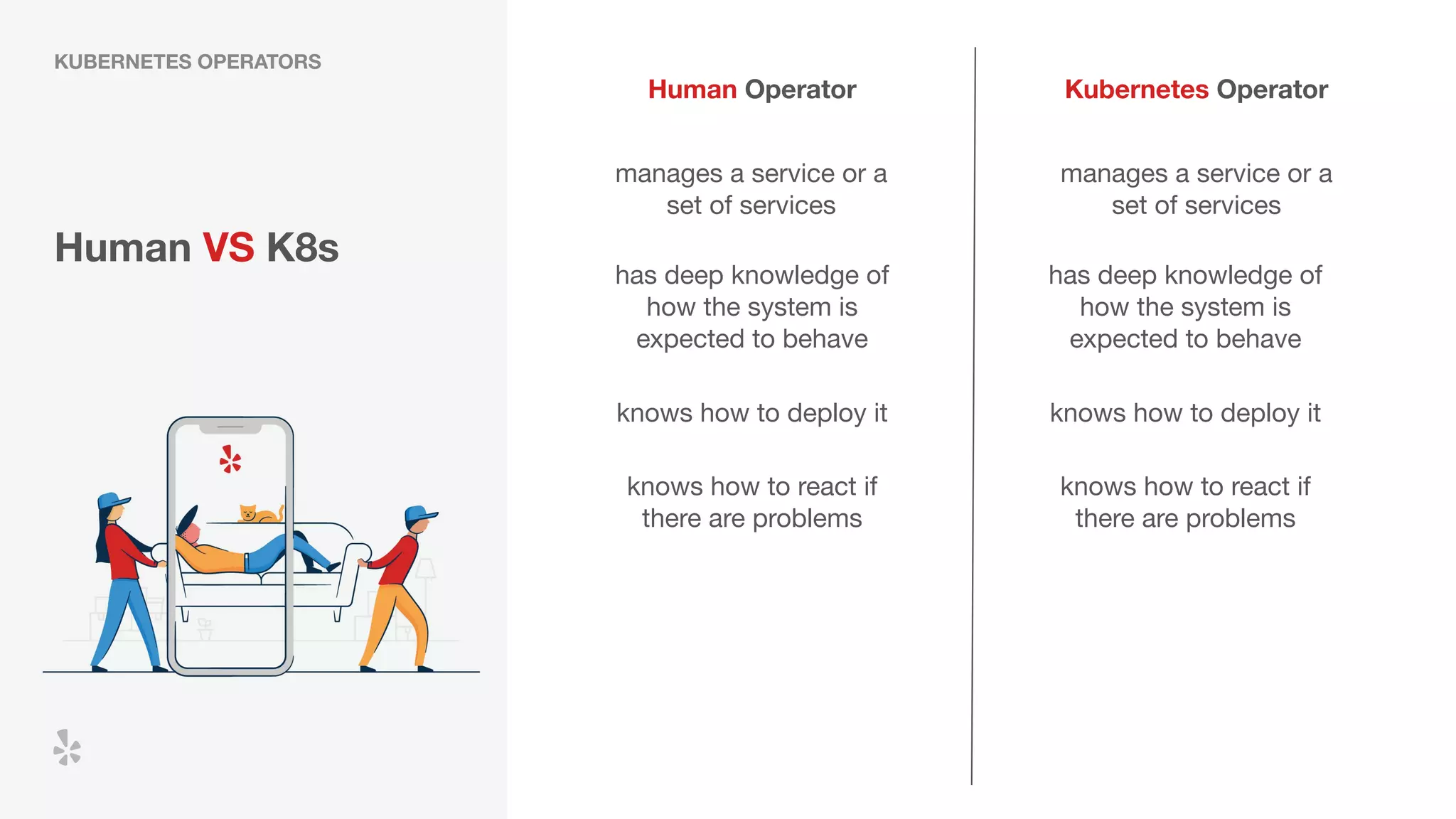
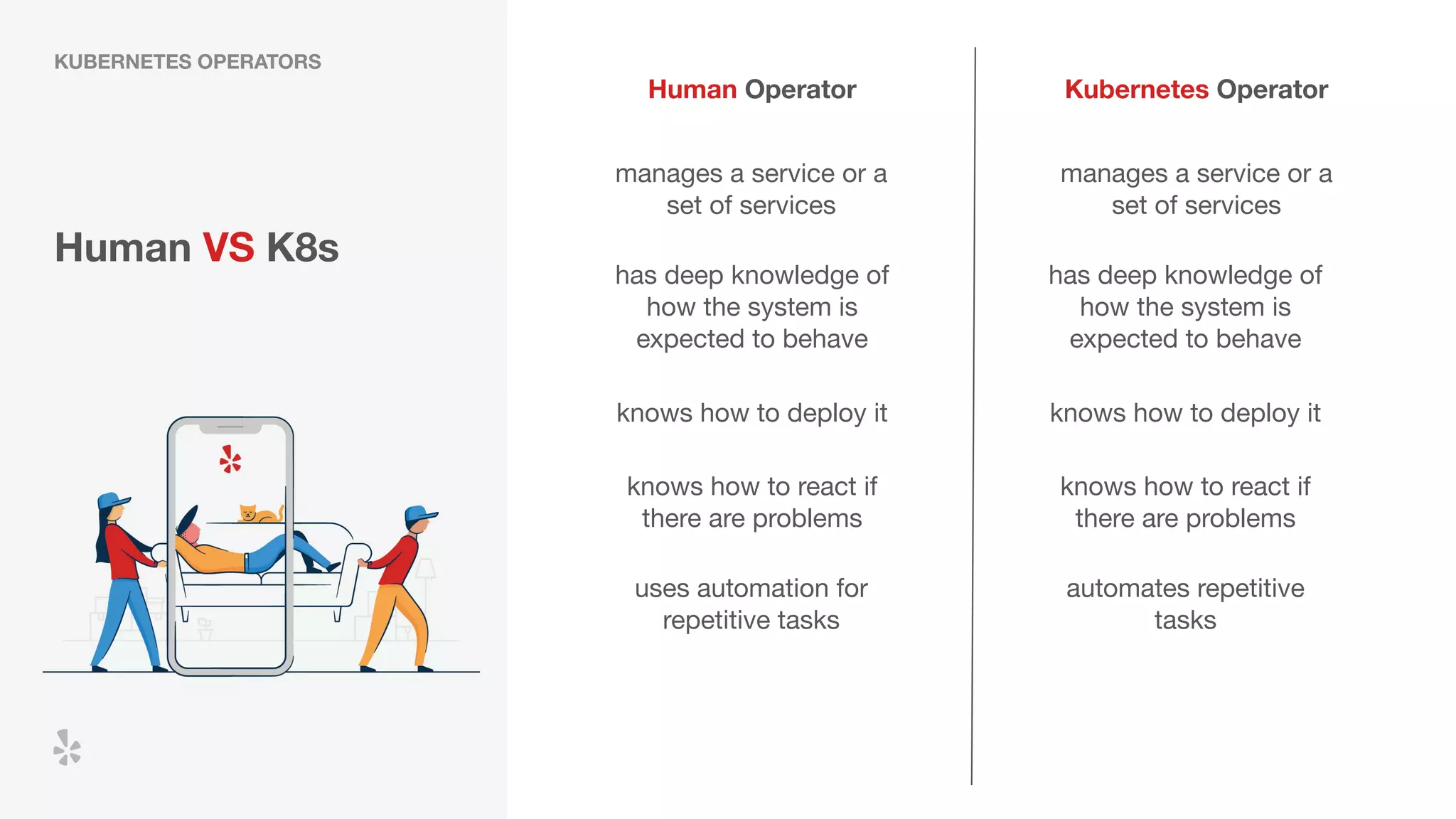
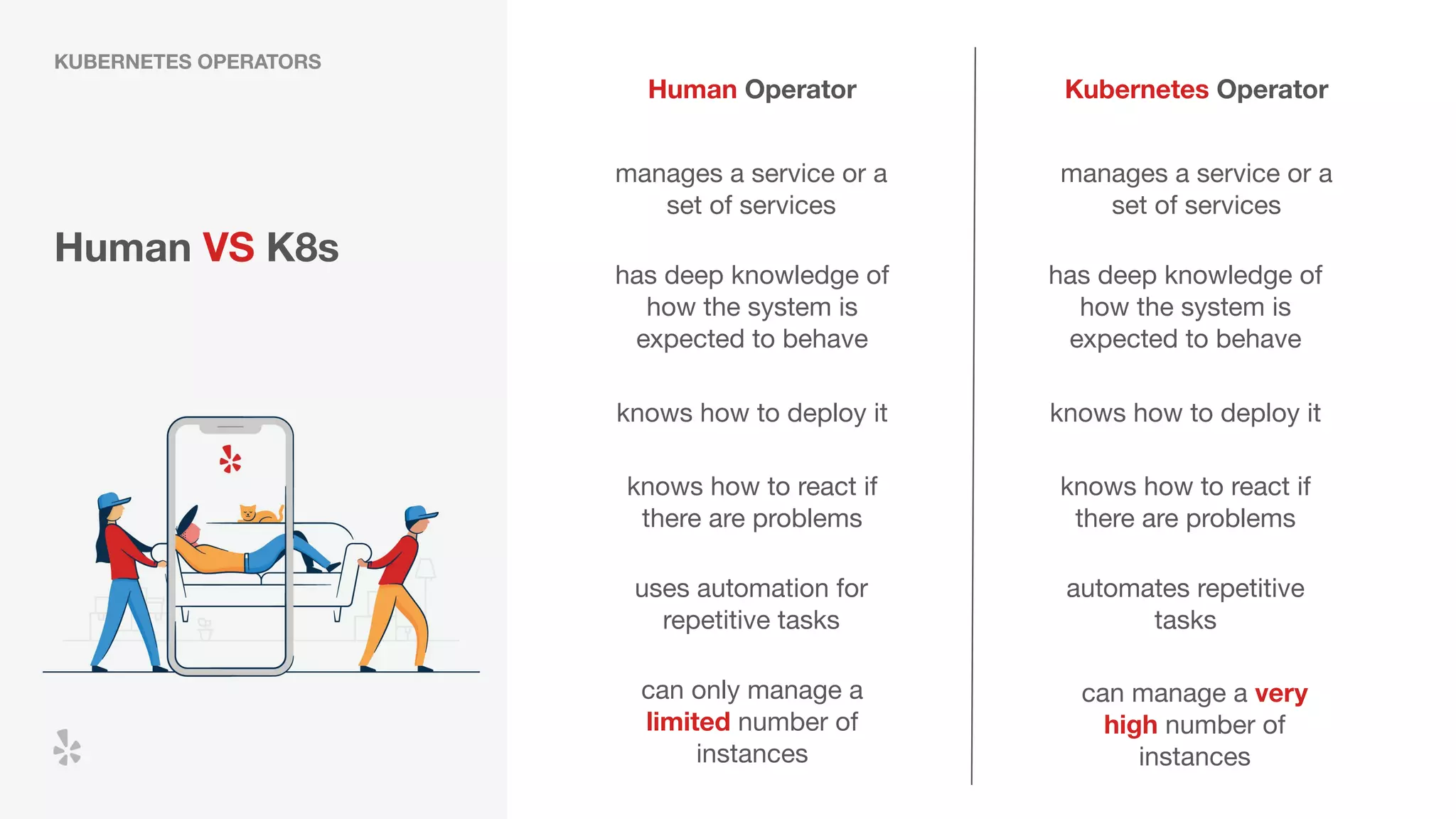
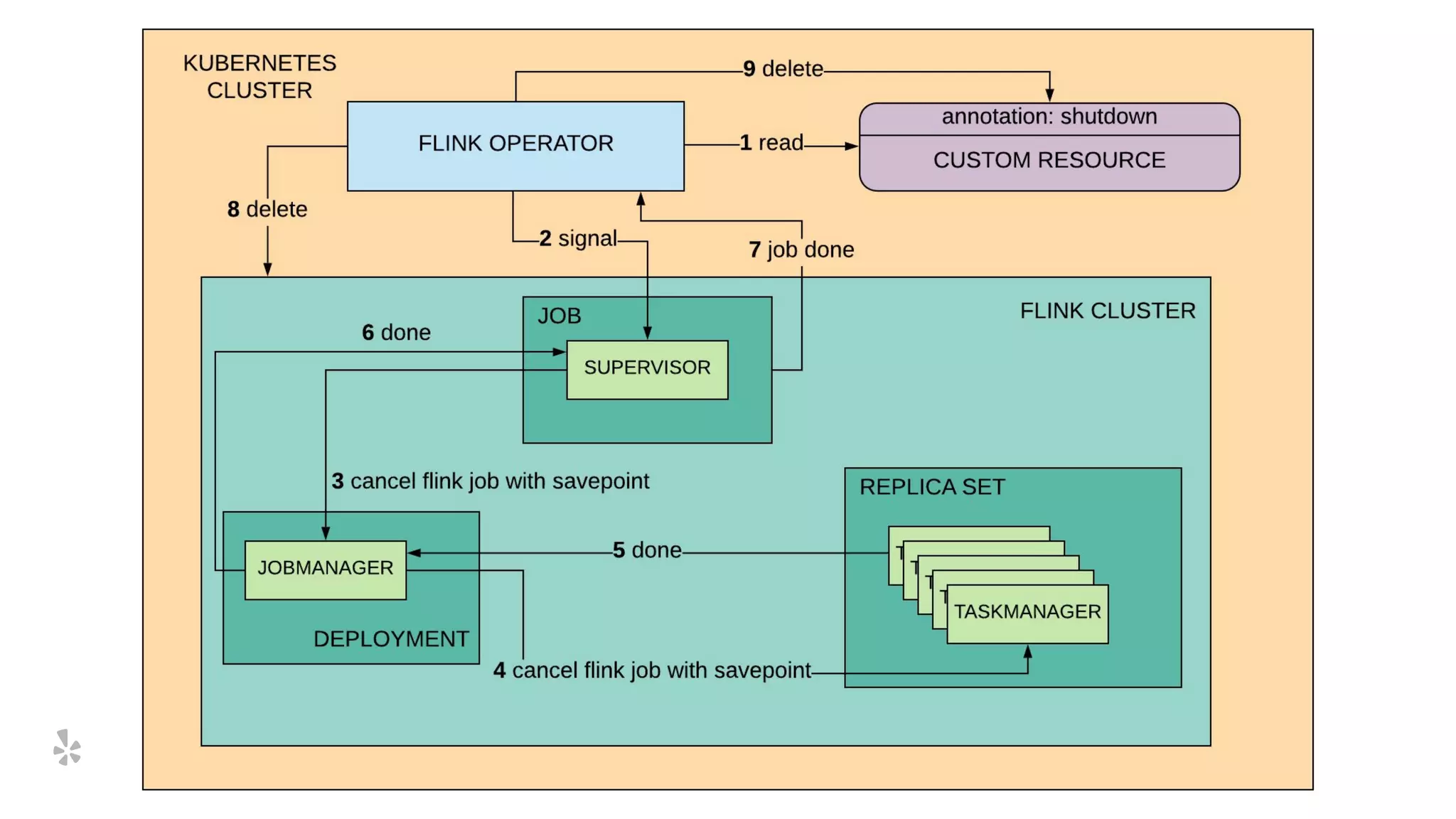
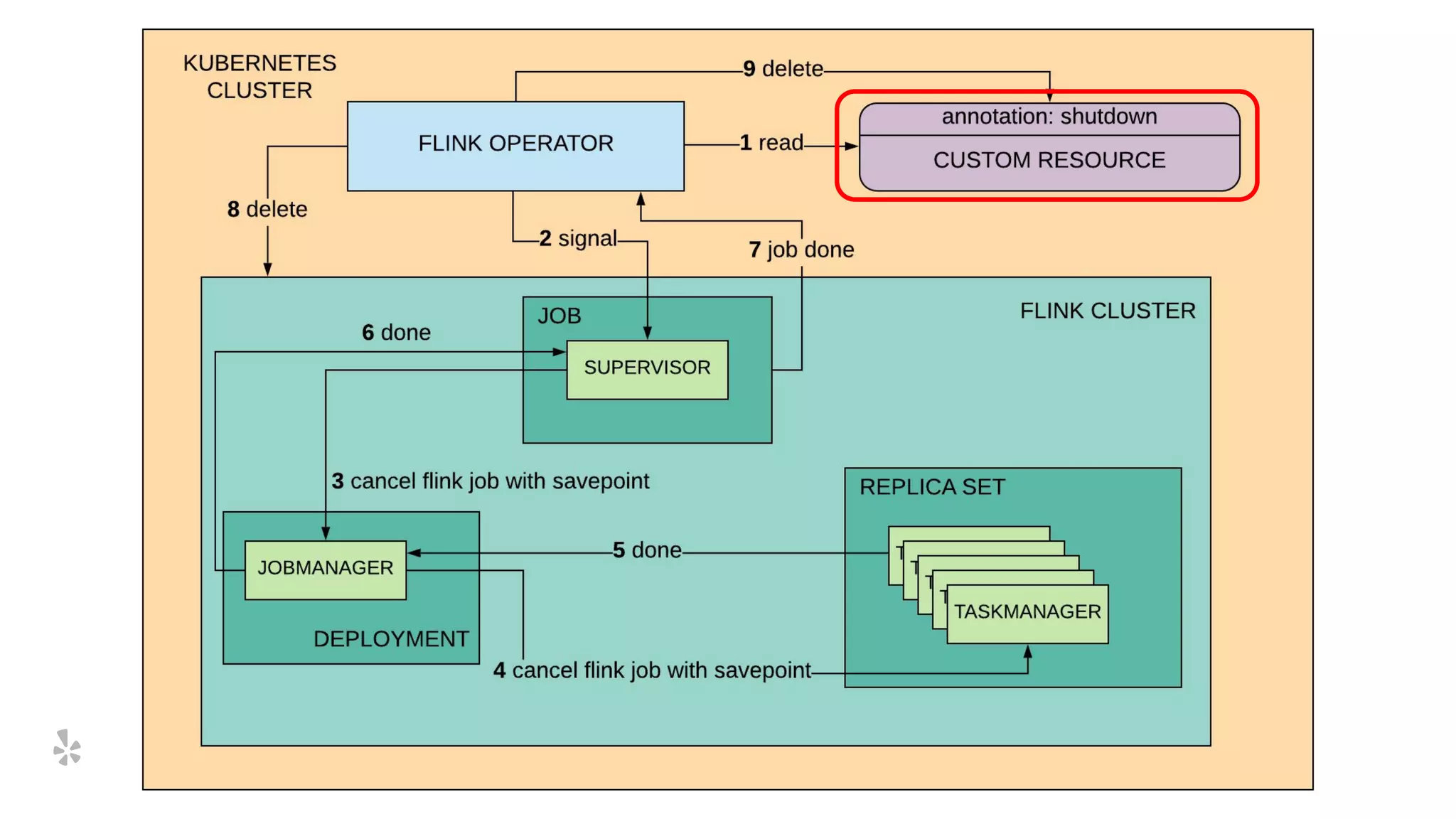

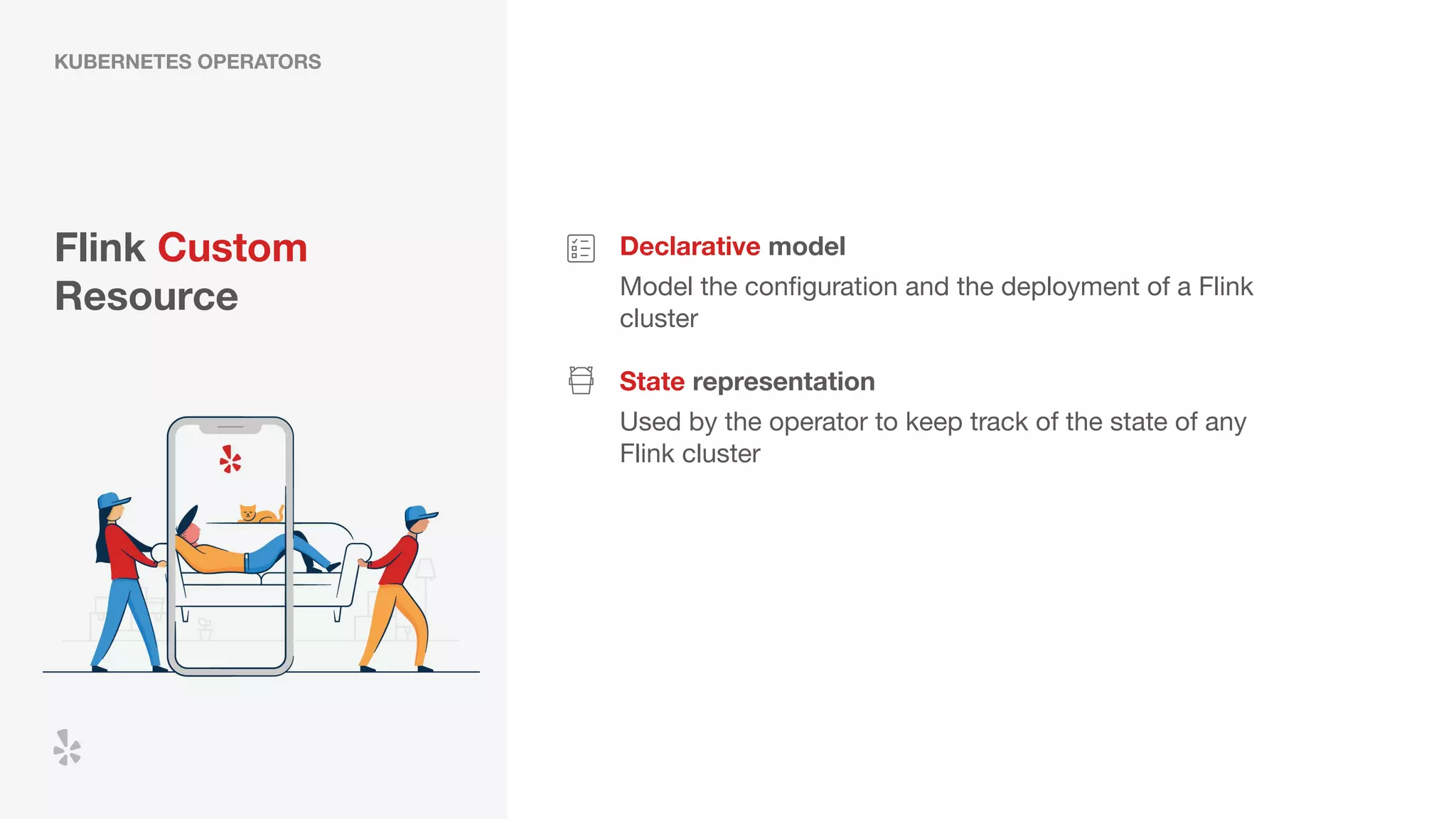
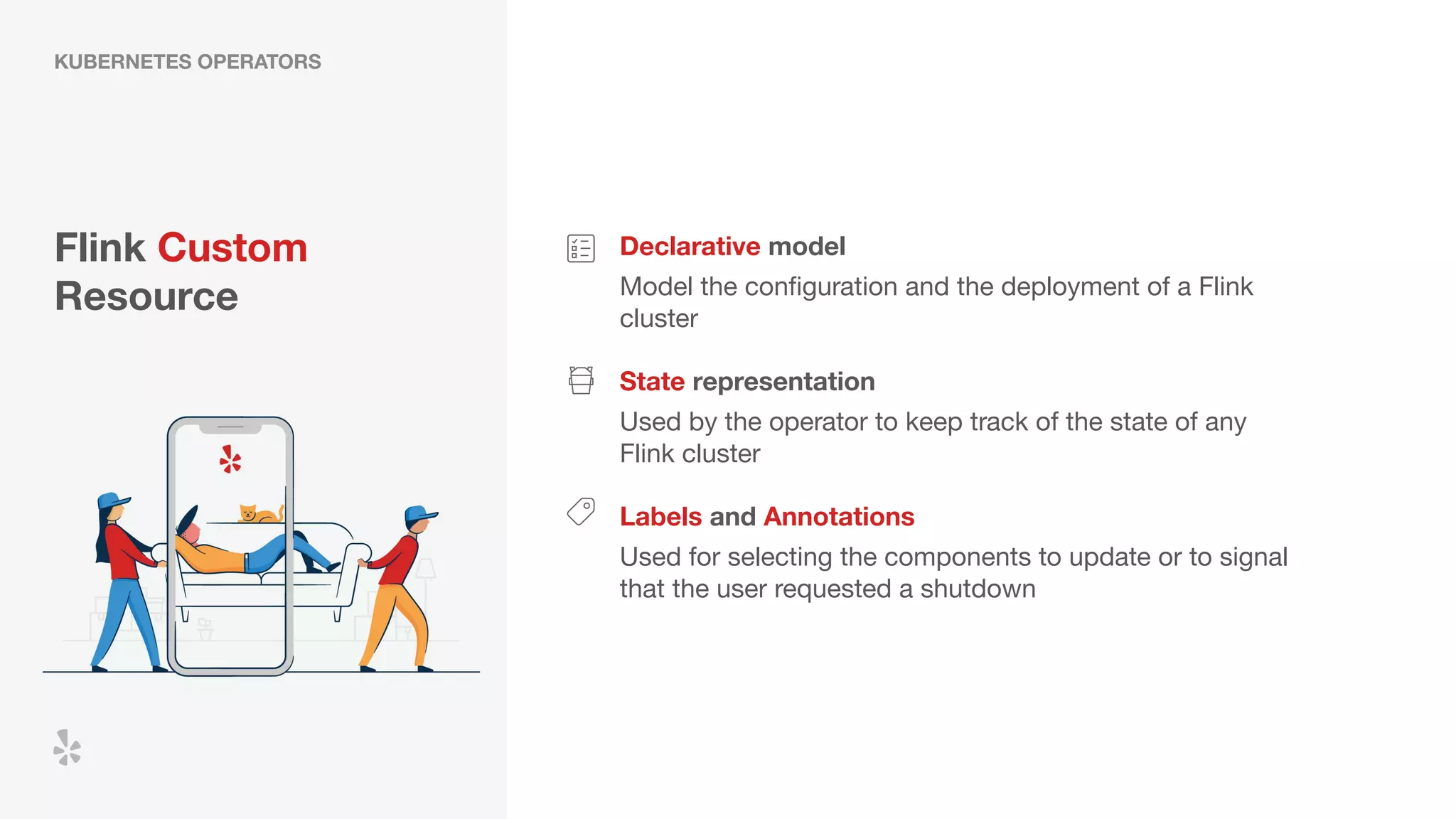
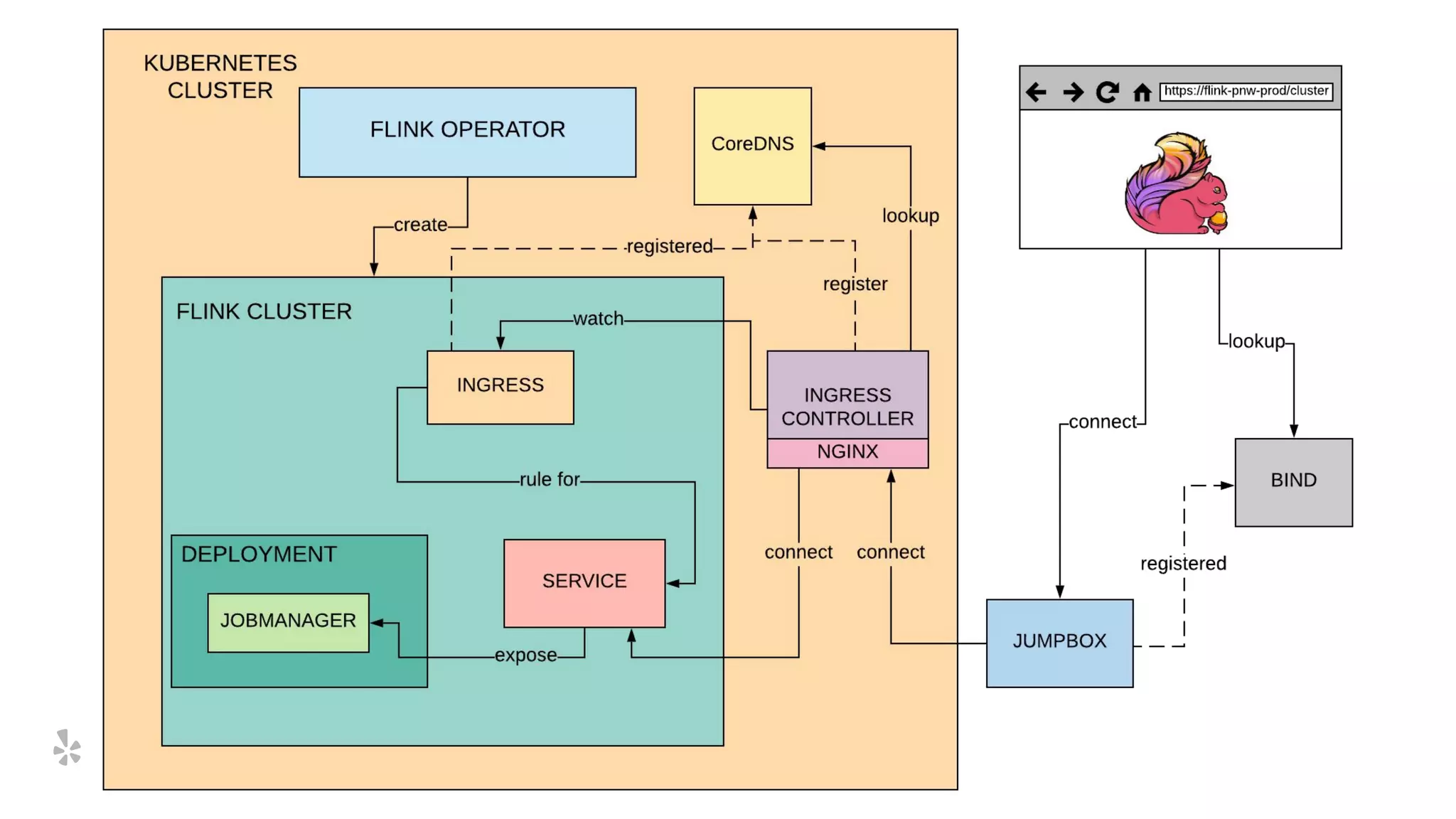
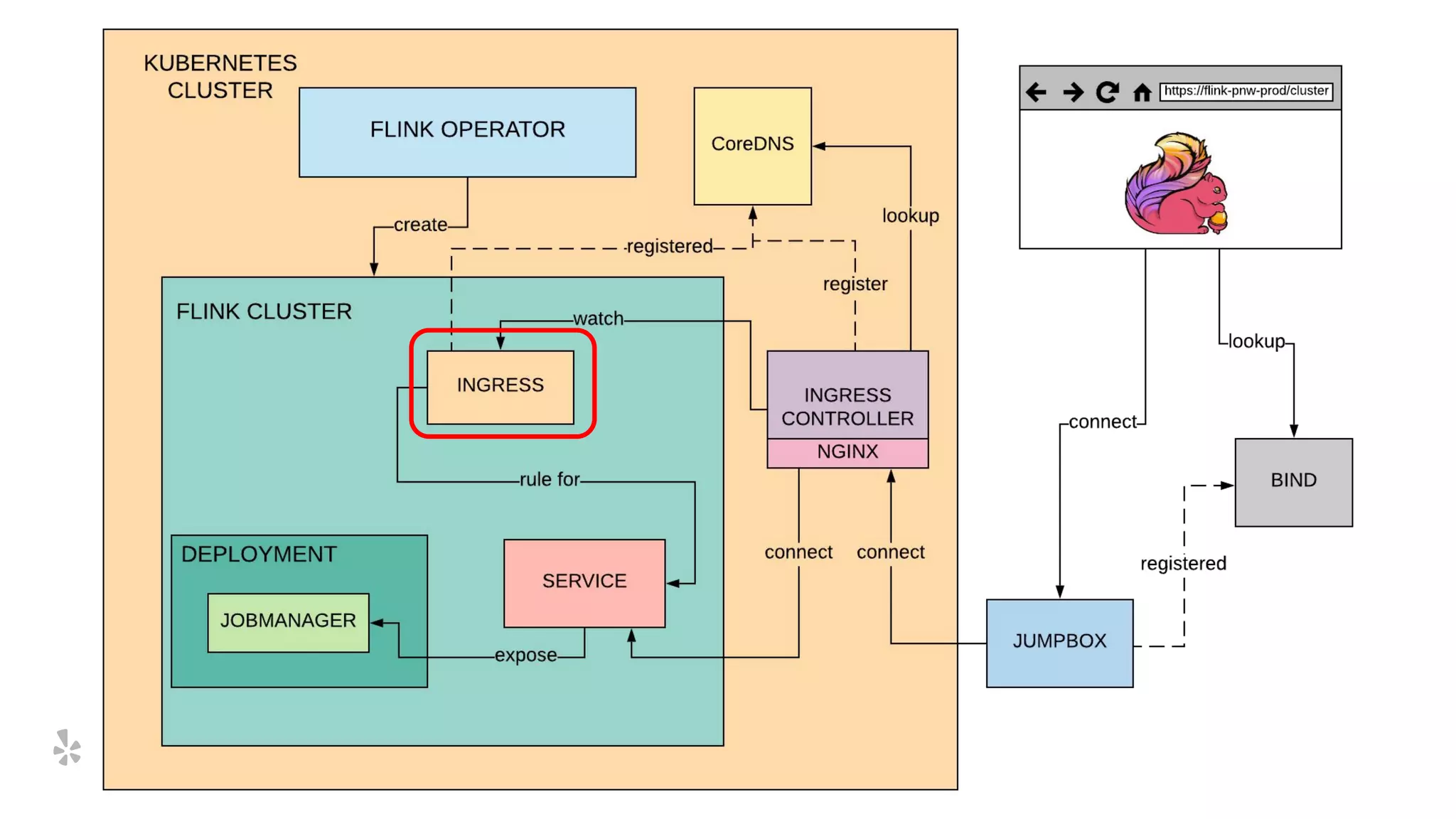



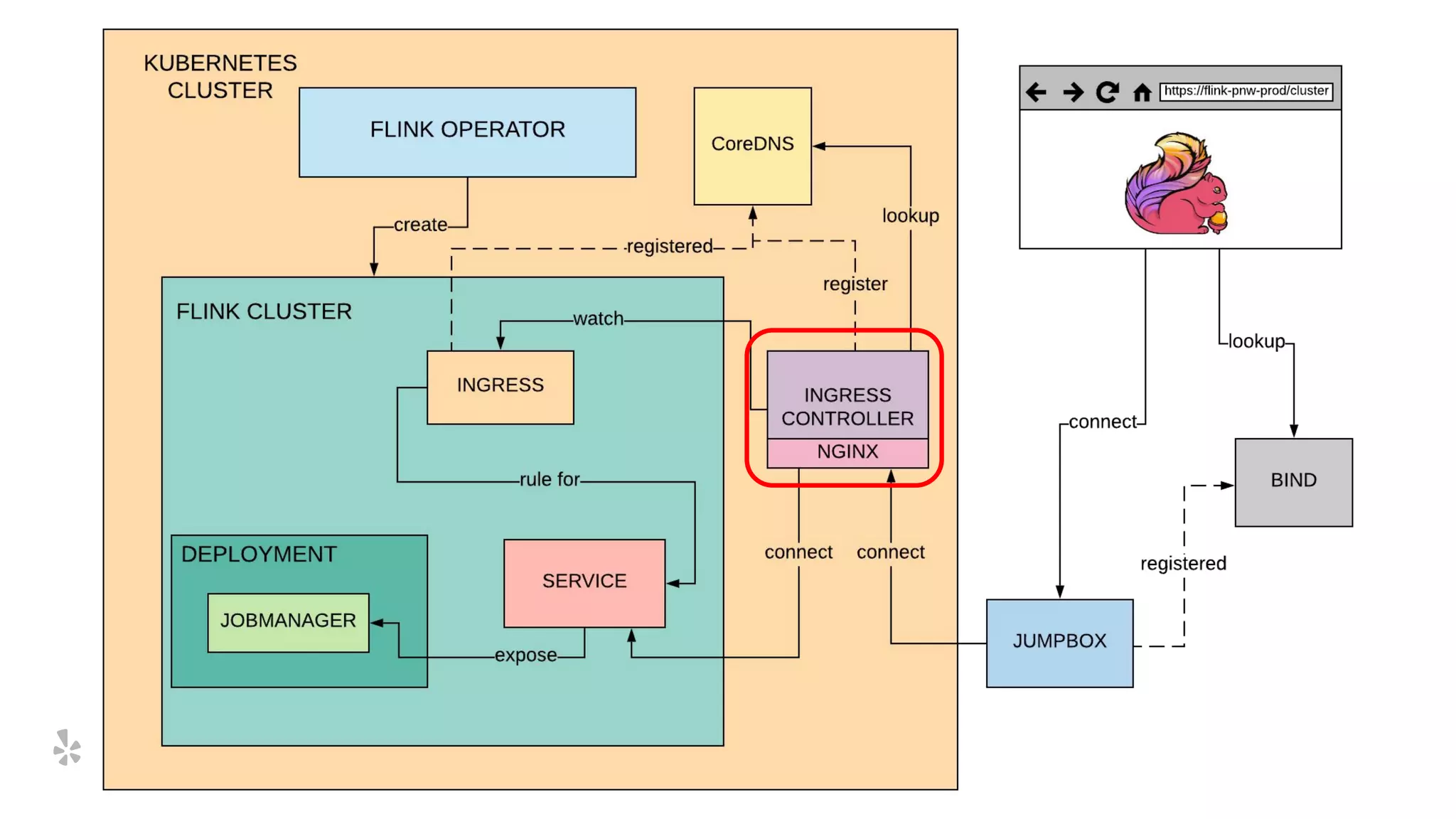


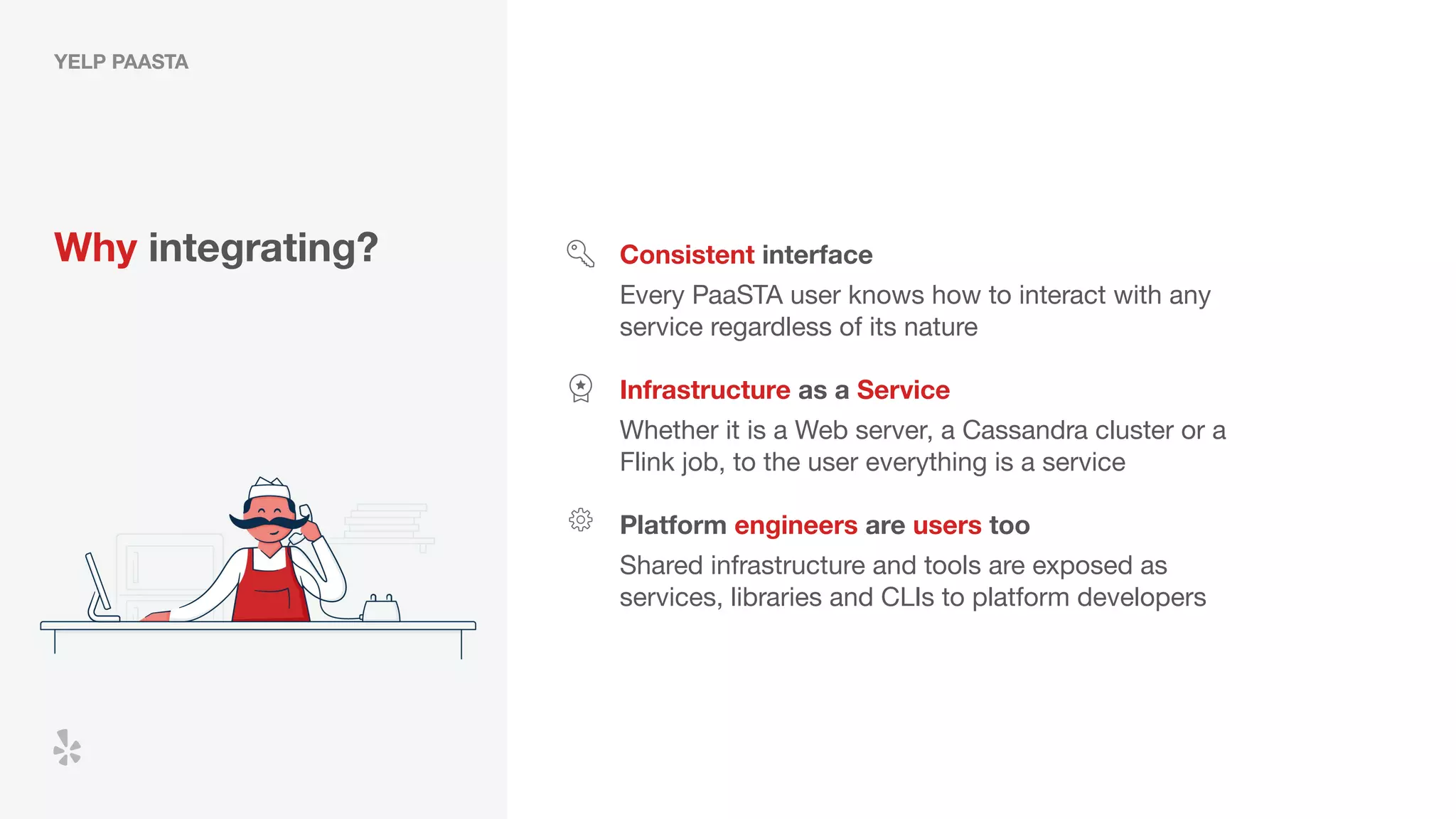
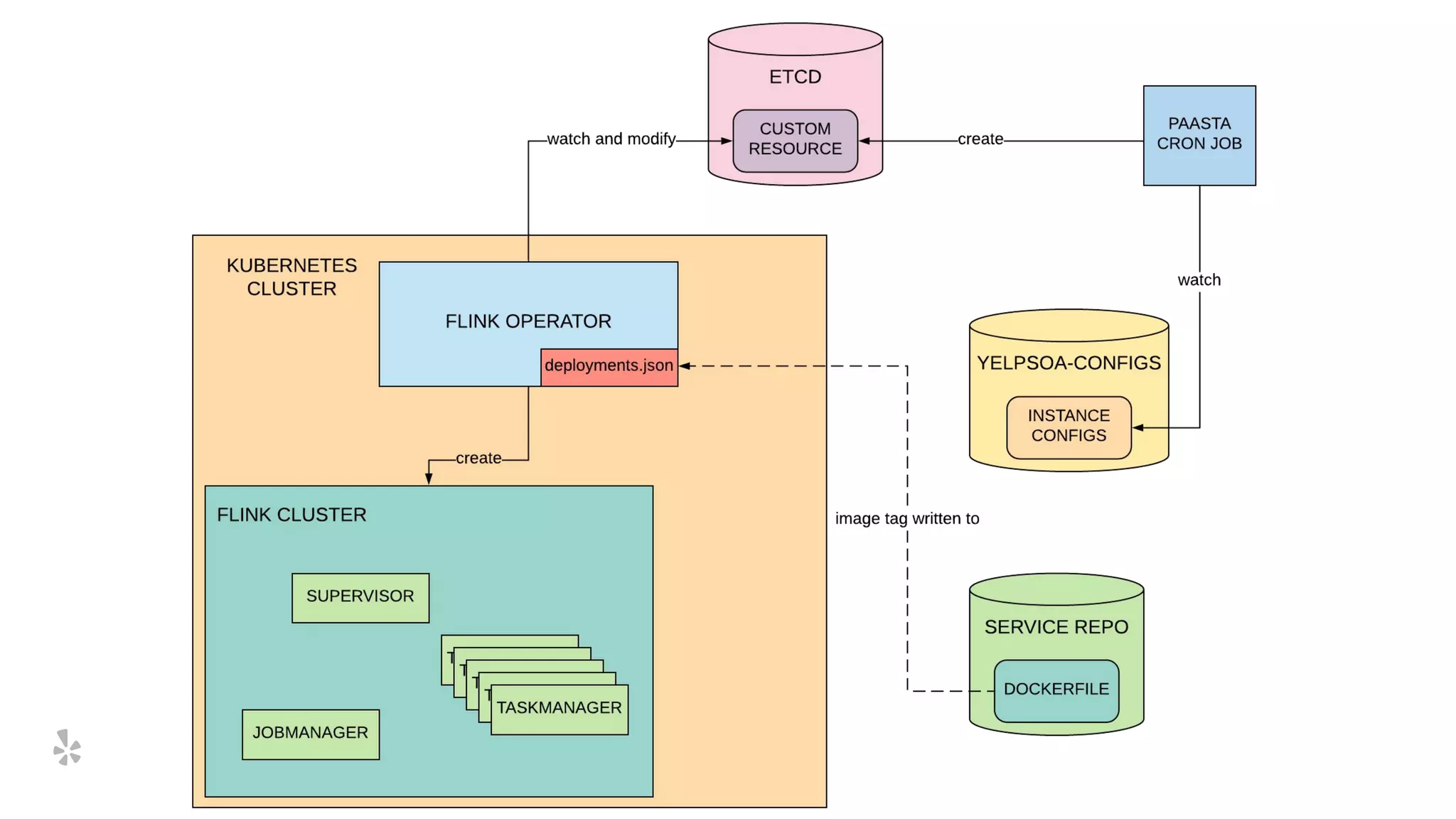
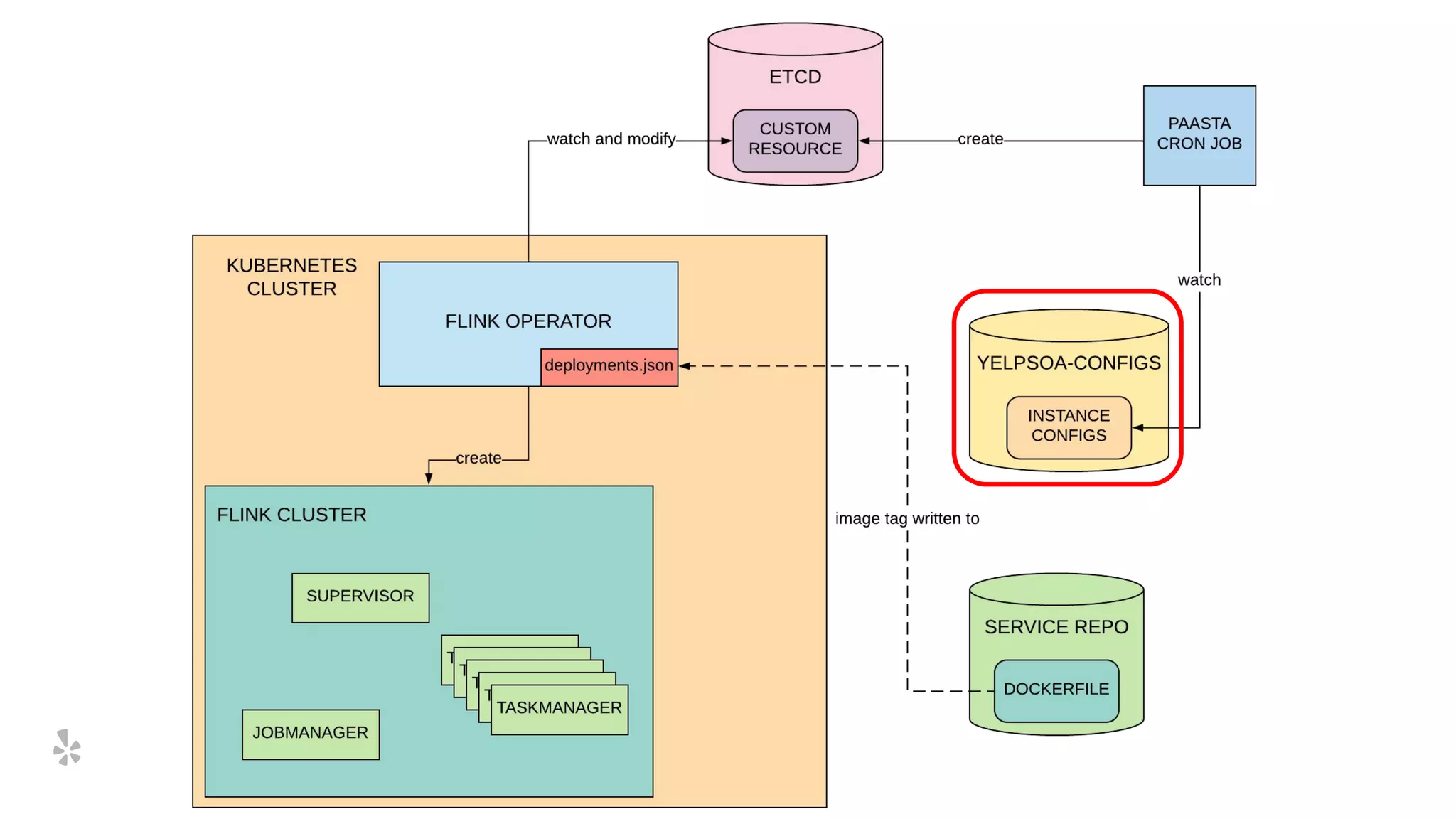


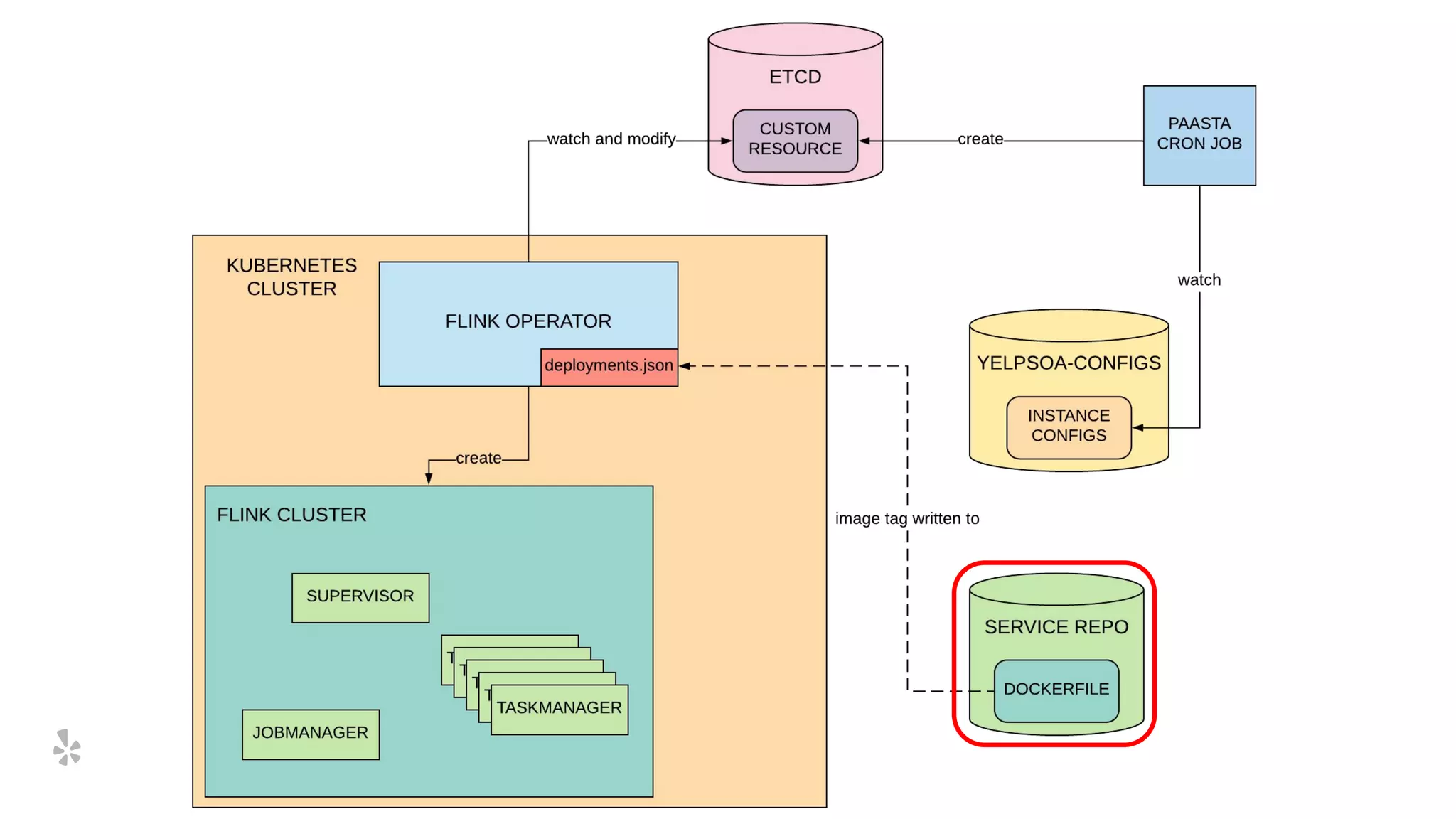
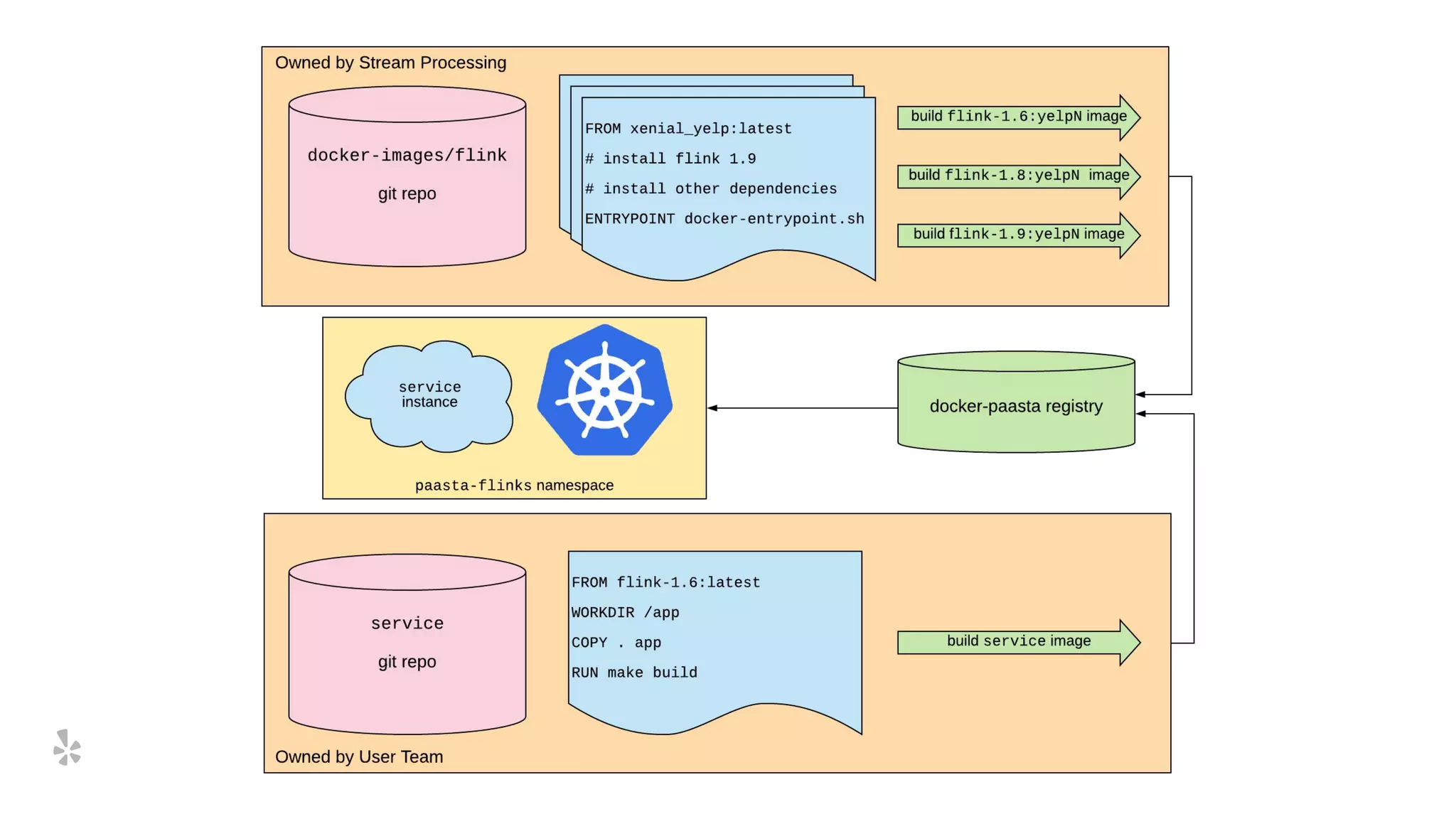
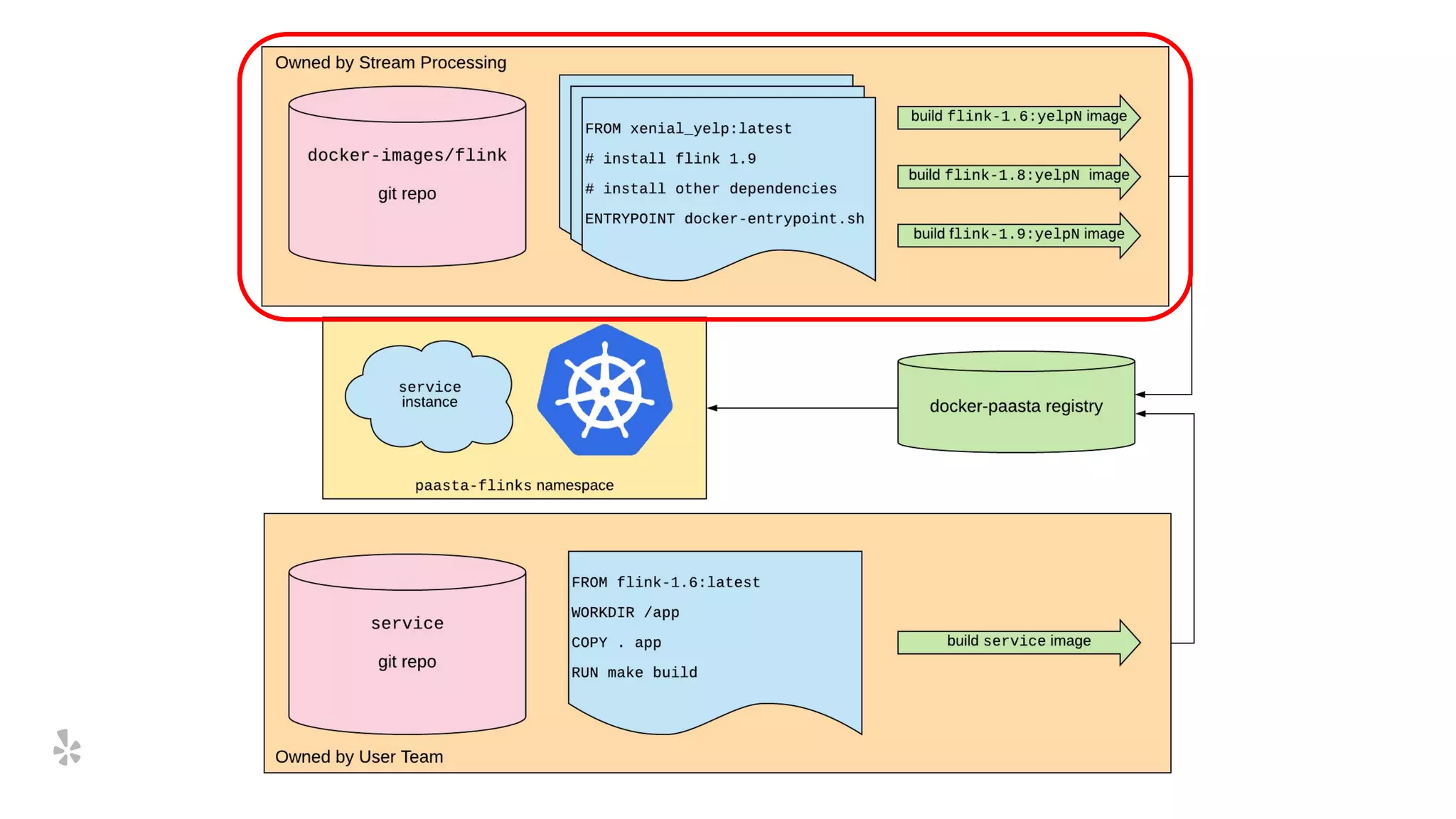
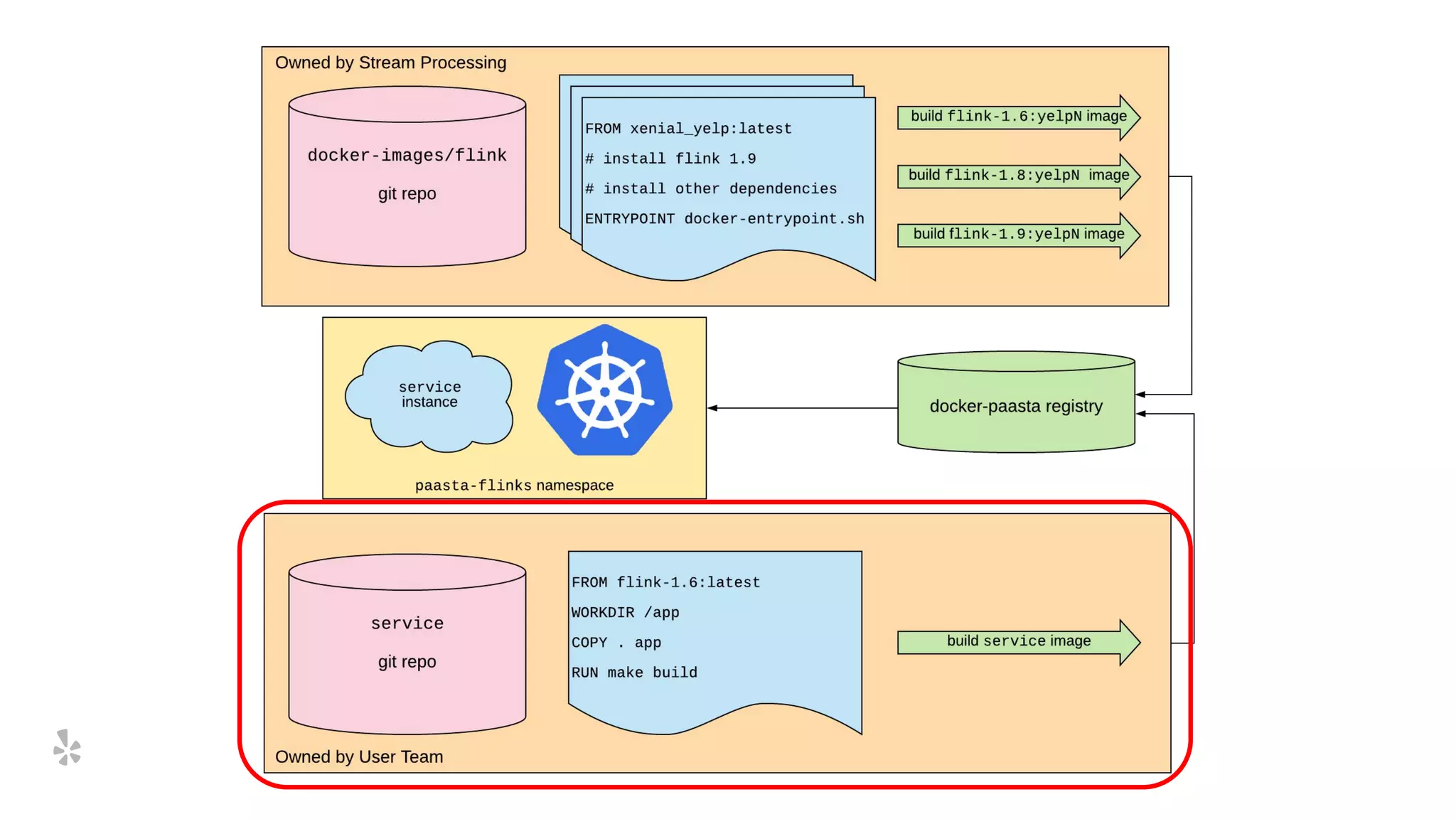
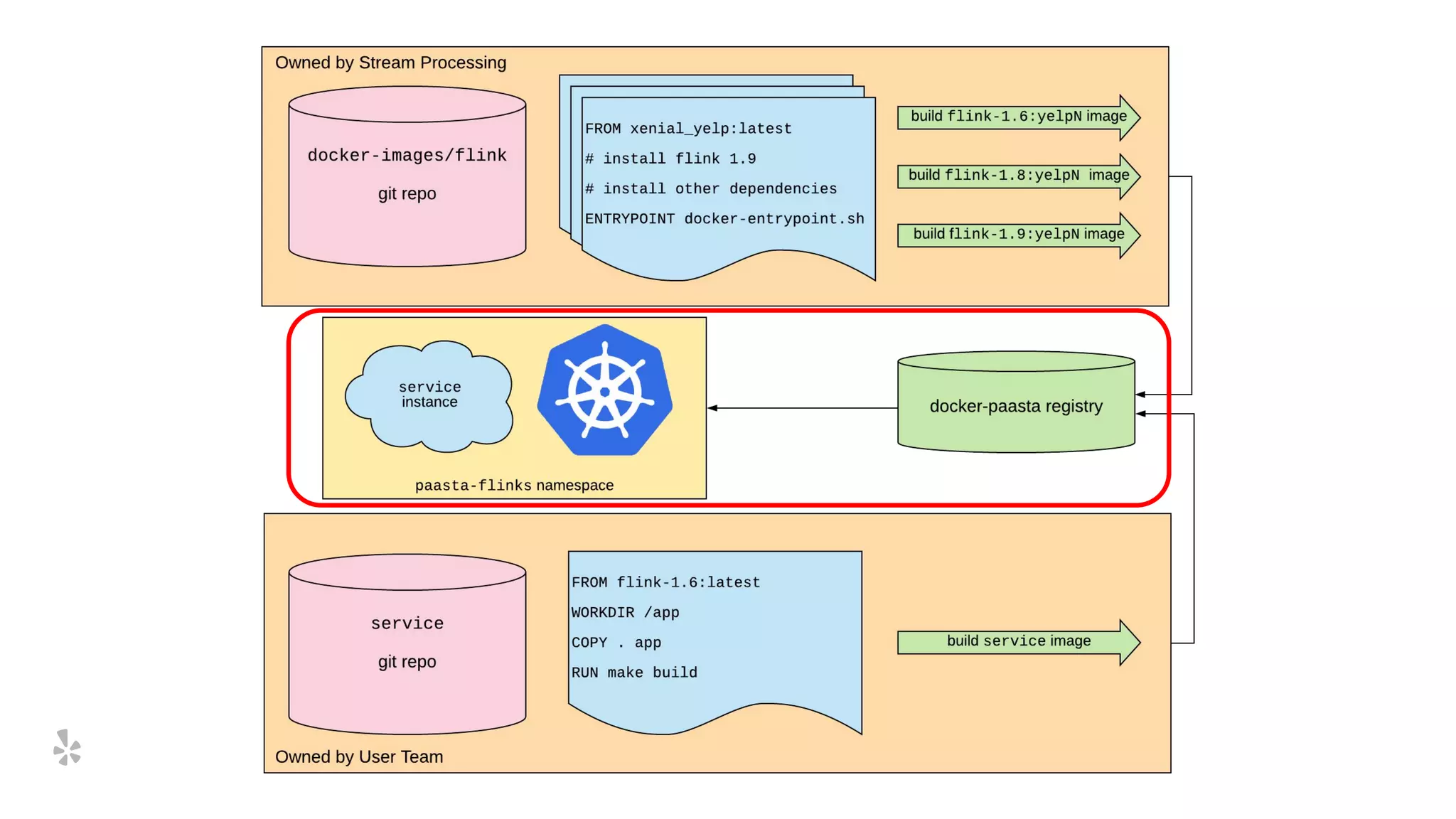
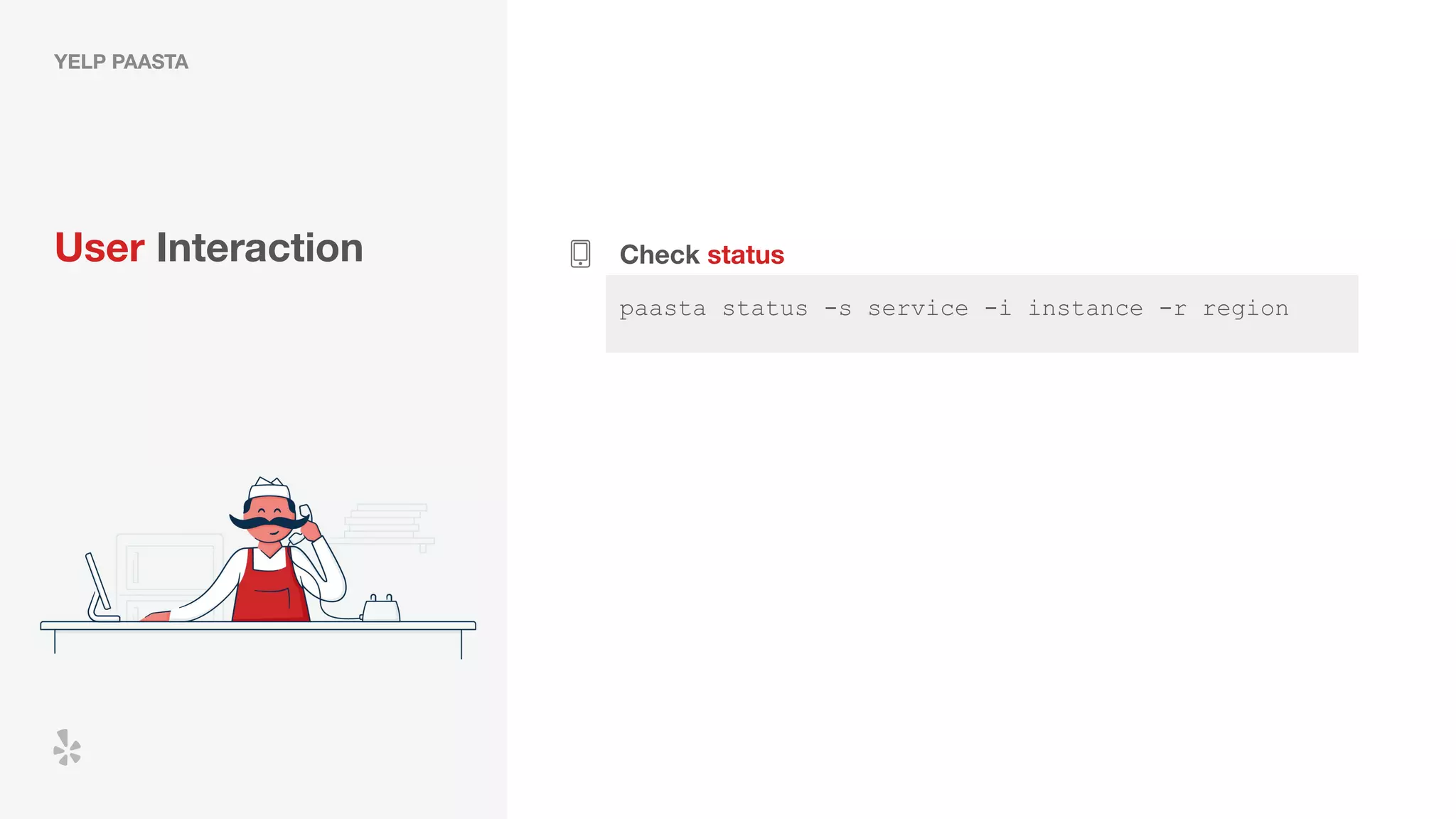
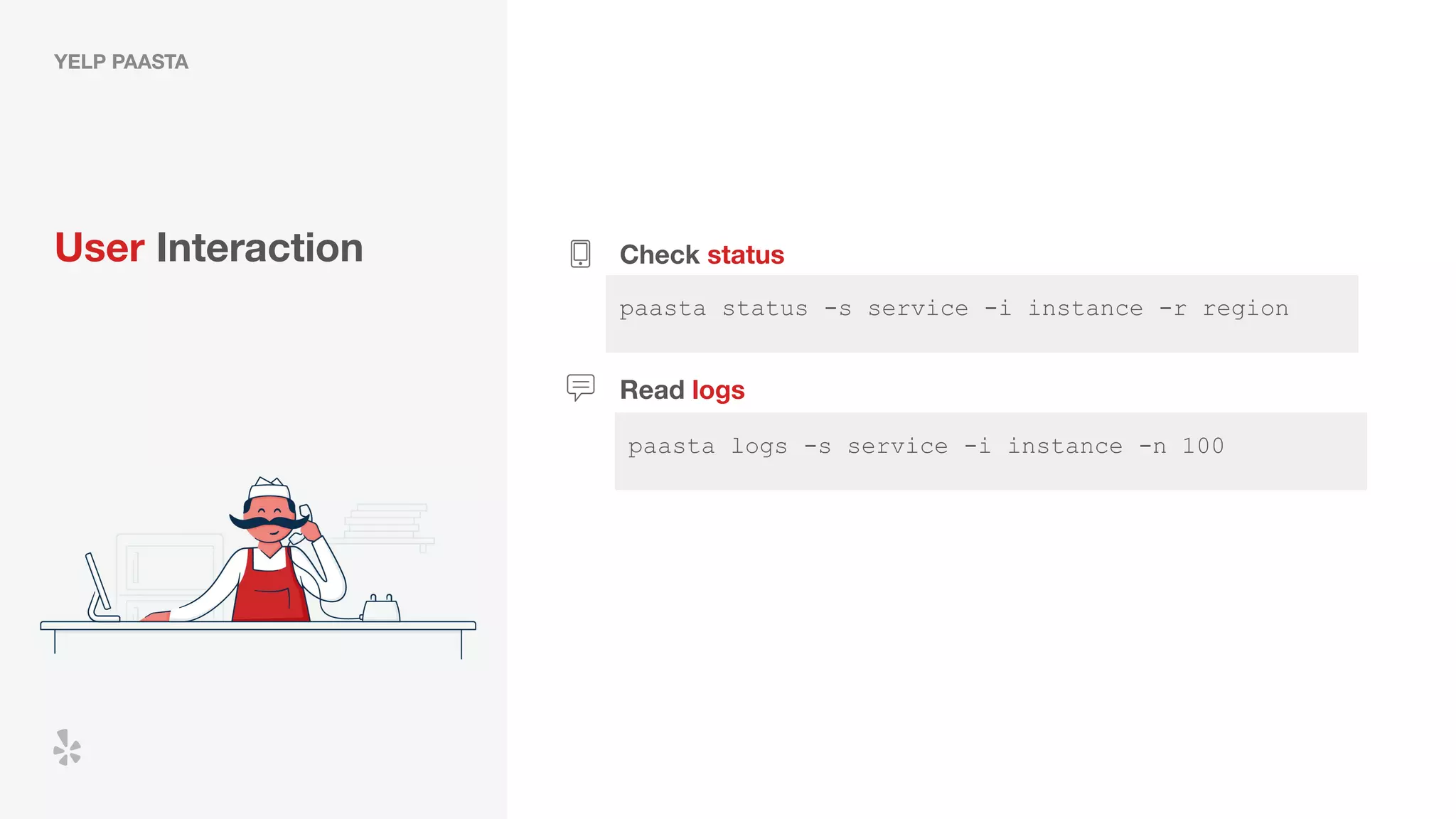
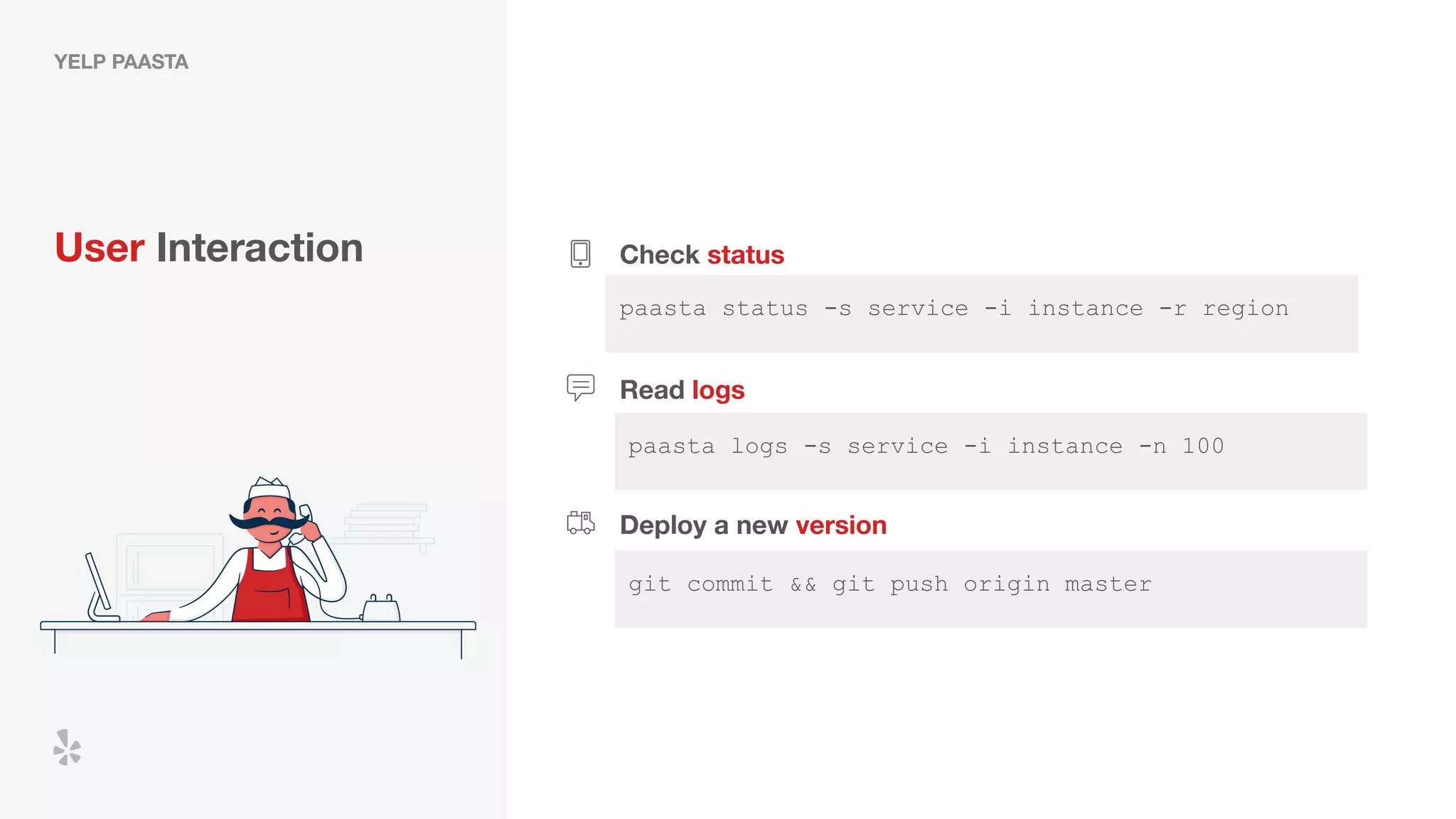





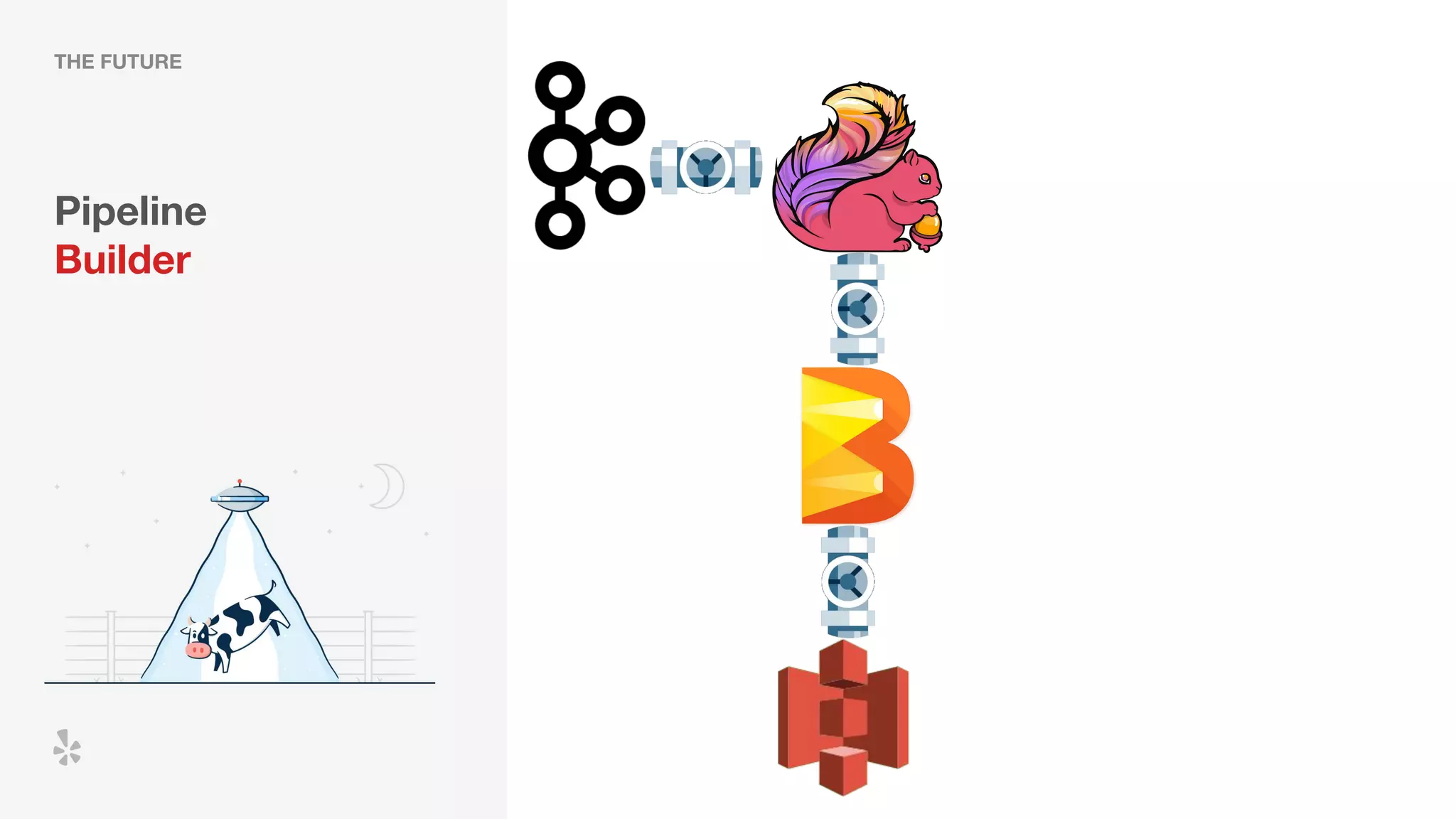
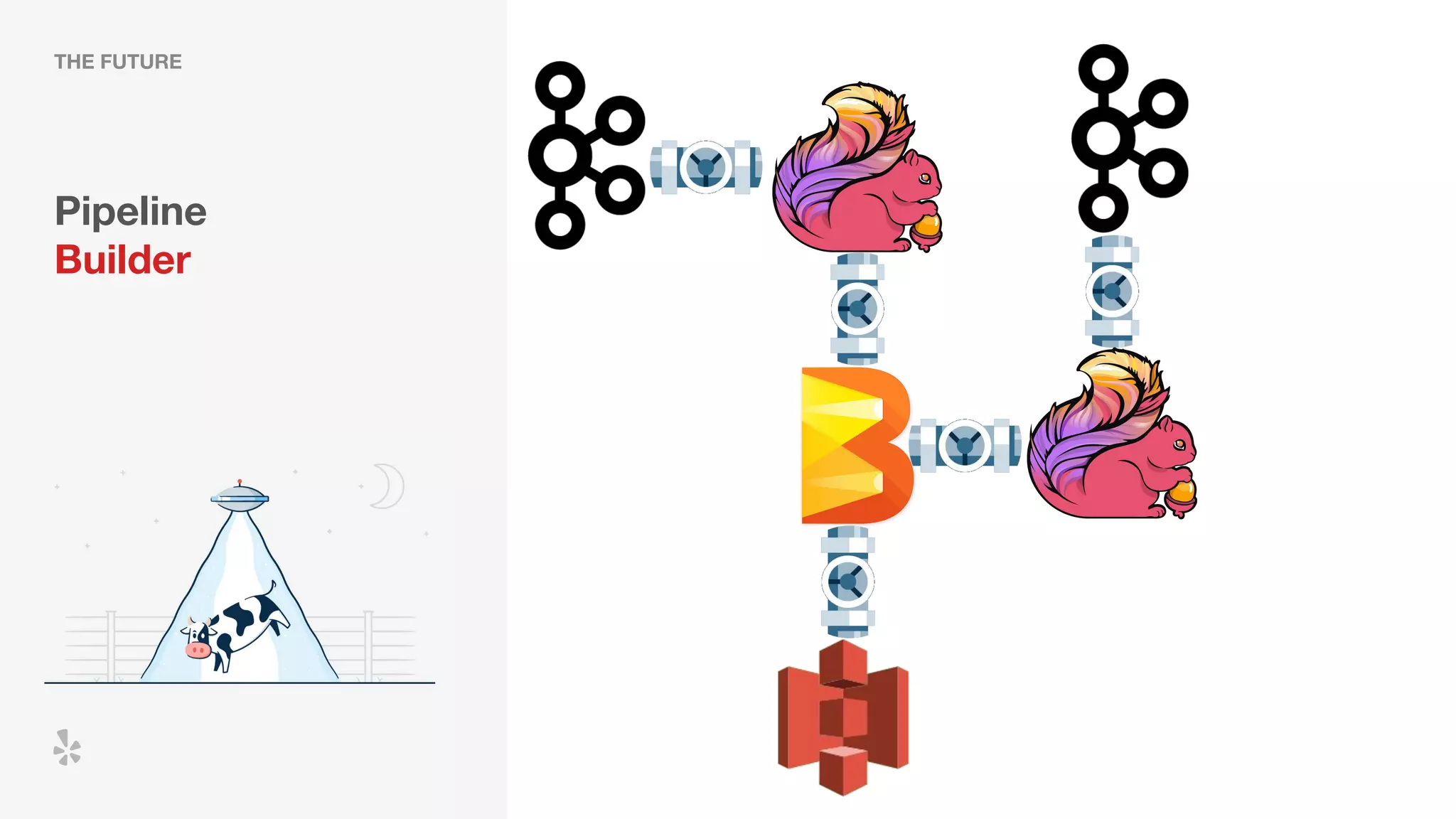
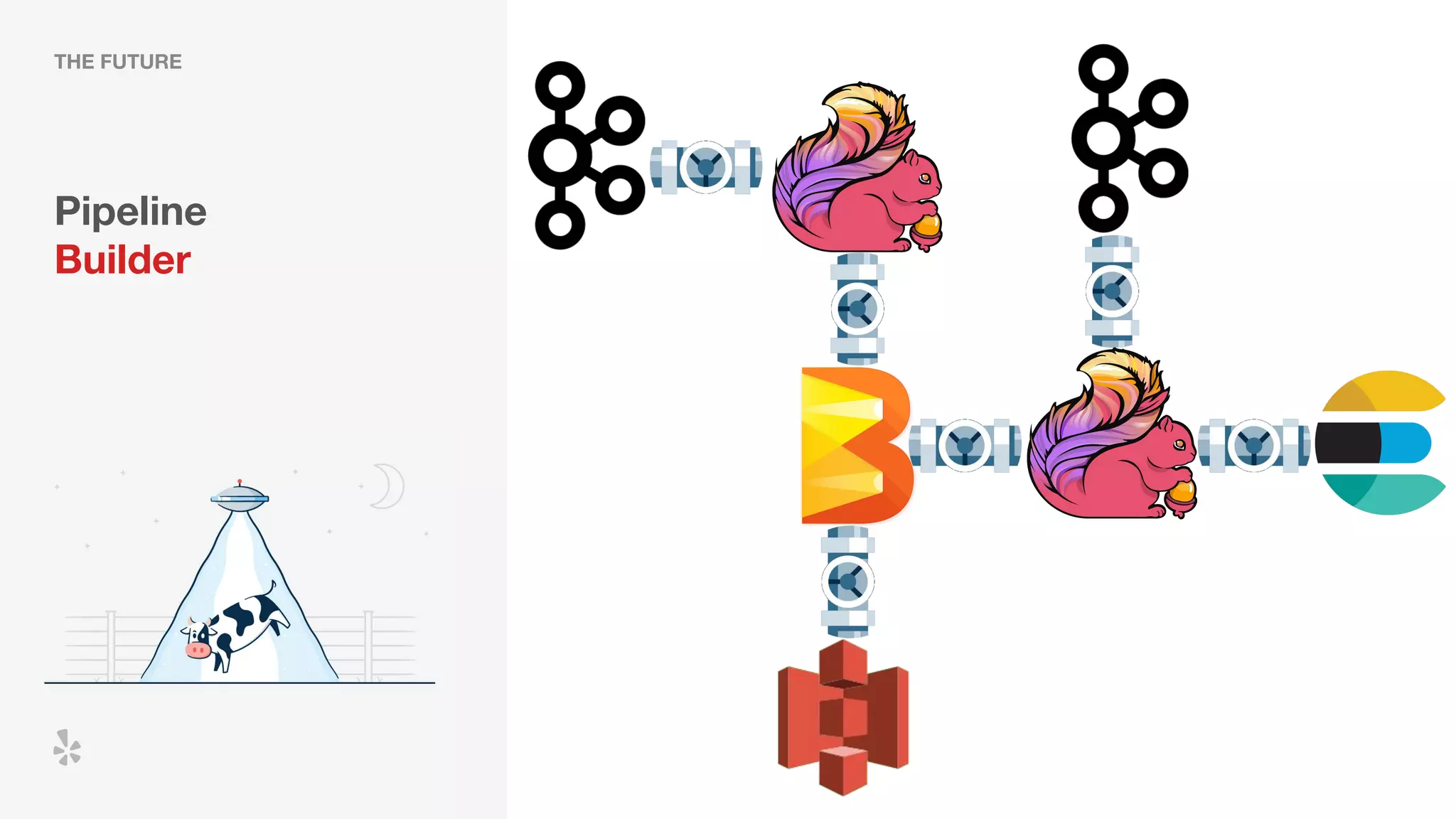








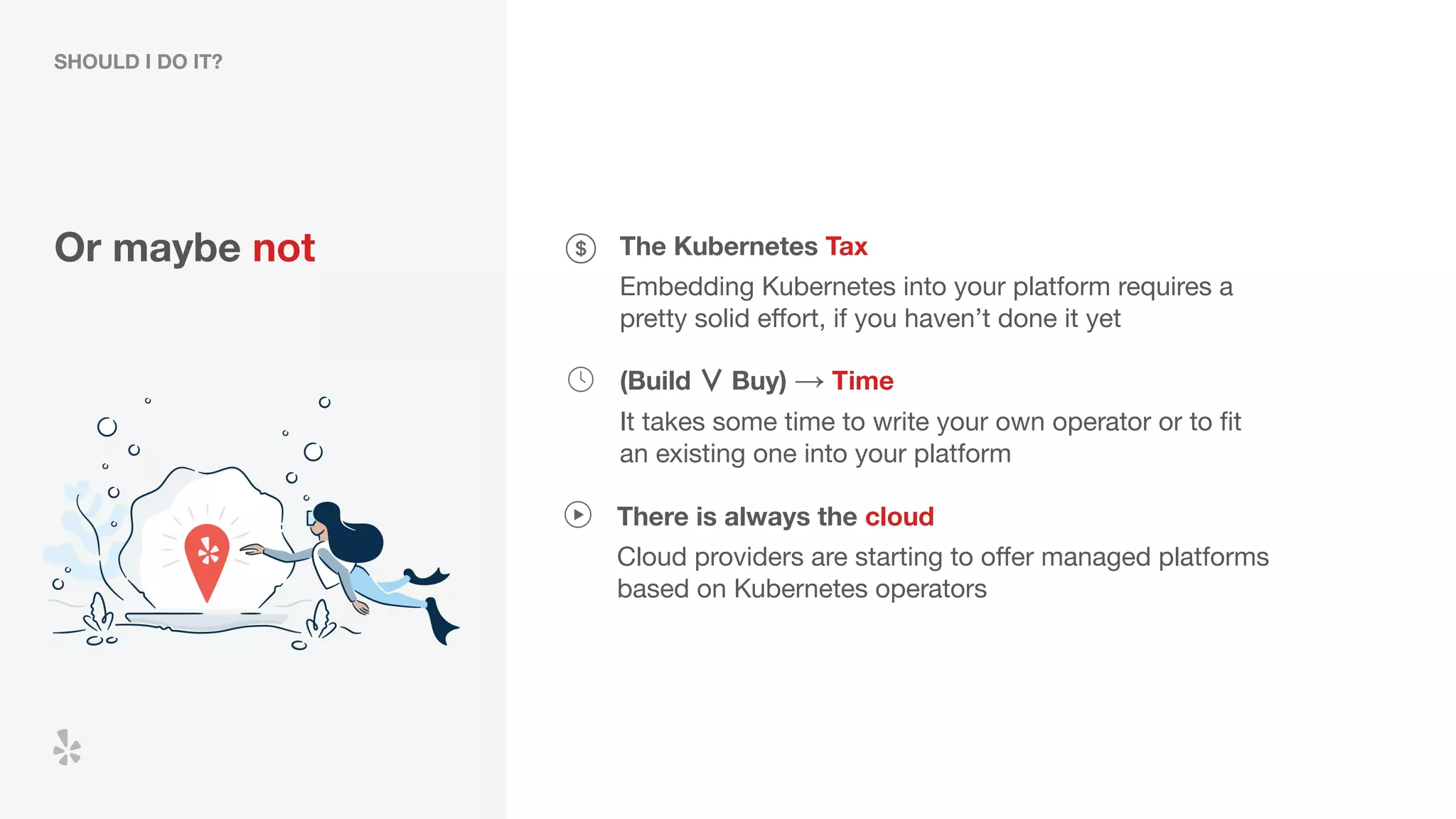





















































































































The document discusses how Yelp integrates Apache Flink with Kubernetes and its platform as a service (PaaSTA) to enhance data processing capabilities. It details the benefits of using Kubernetes for deployment, scaling, and management of Flink clusters, addressing challenges with existing setups and emphasizing the importance of a consistent service interface. The future outlook includes job-oriented deployment and better scalability through Kubernetes operators, reducing operational complexities.




















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

