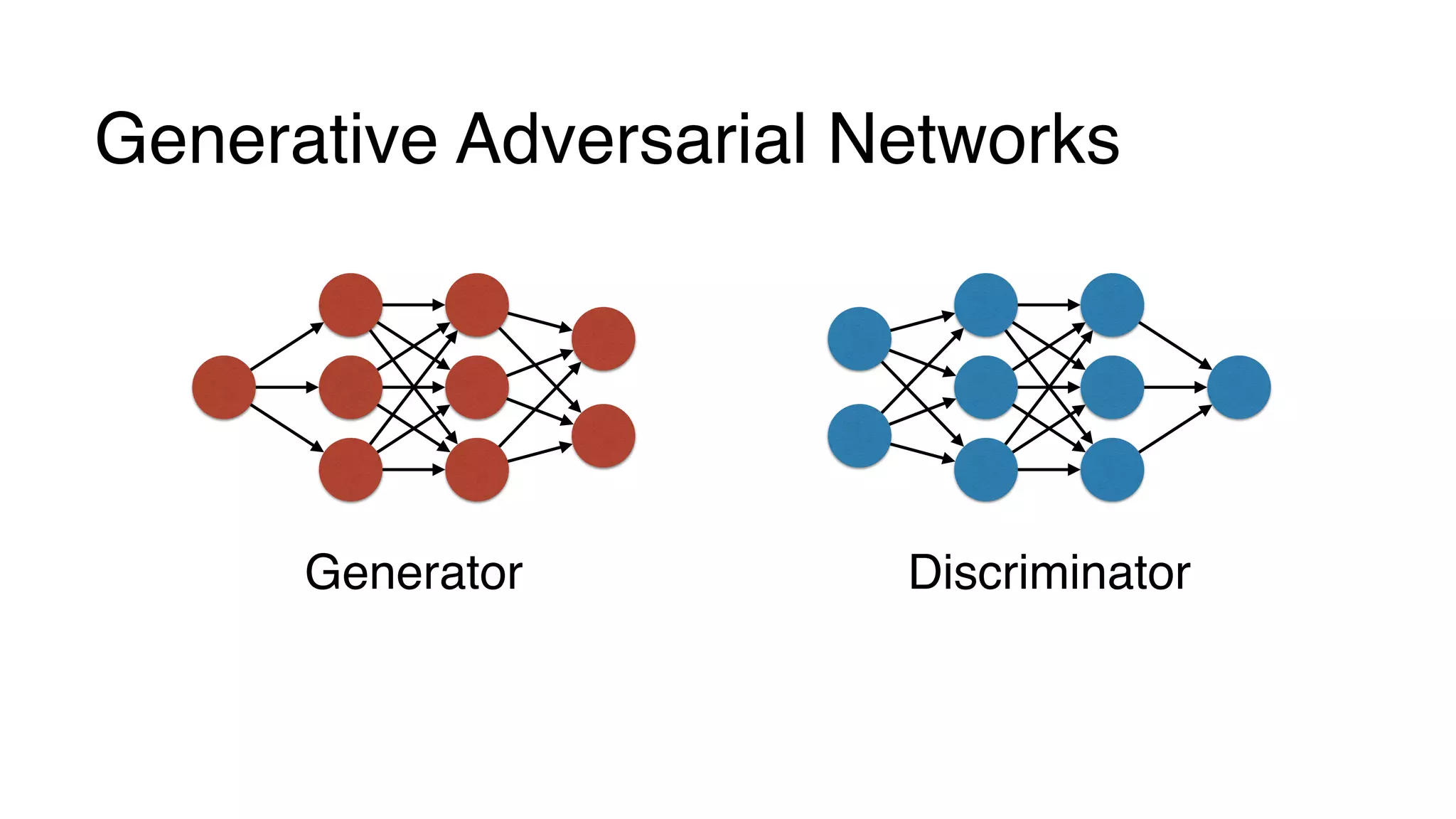
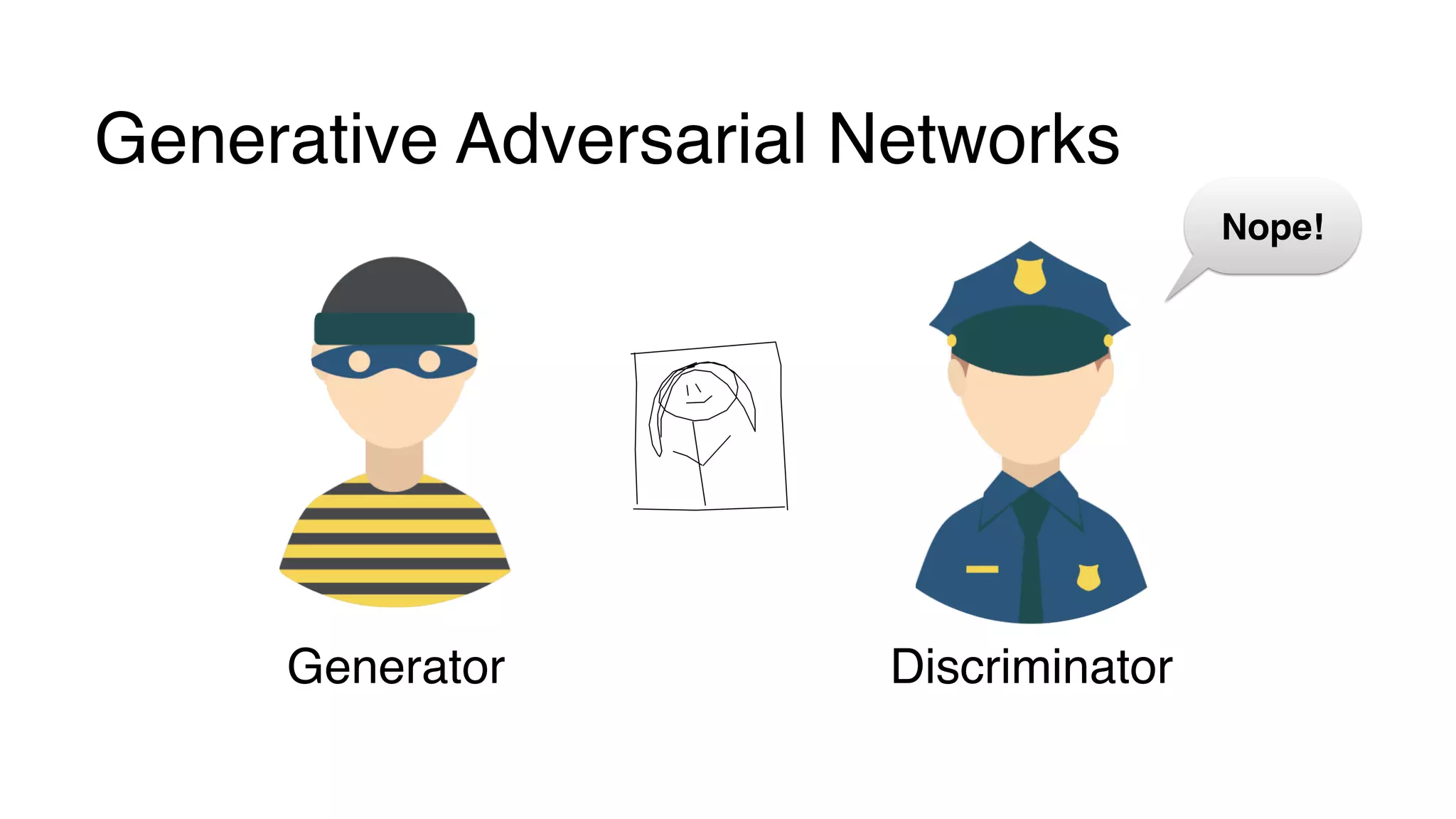
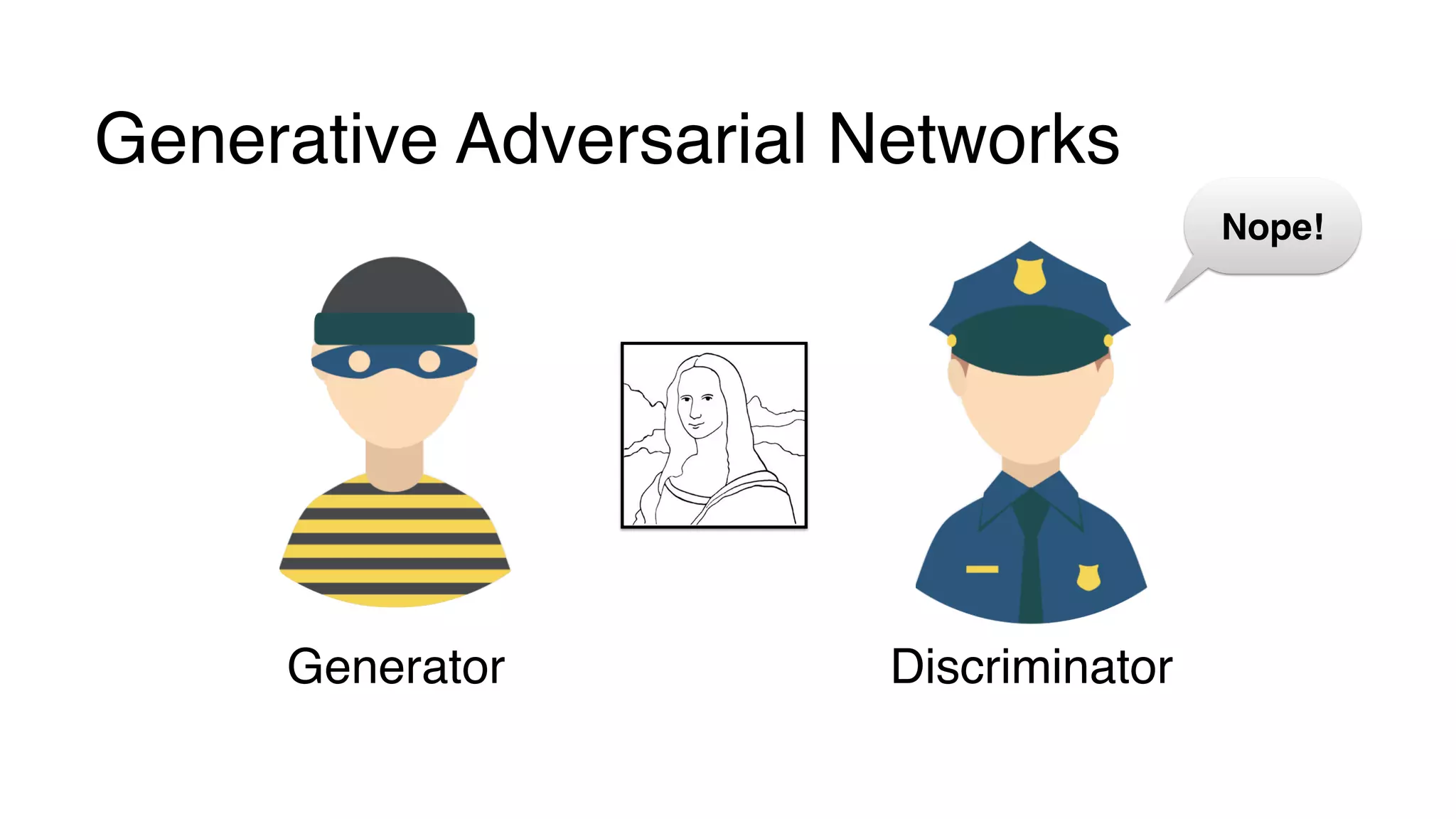
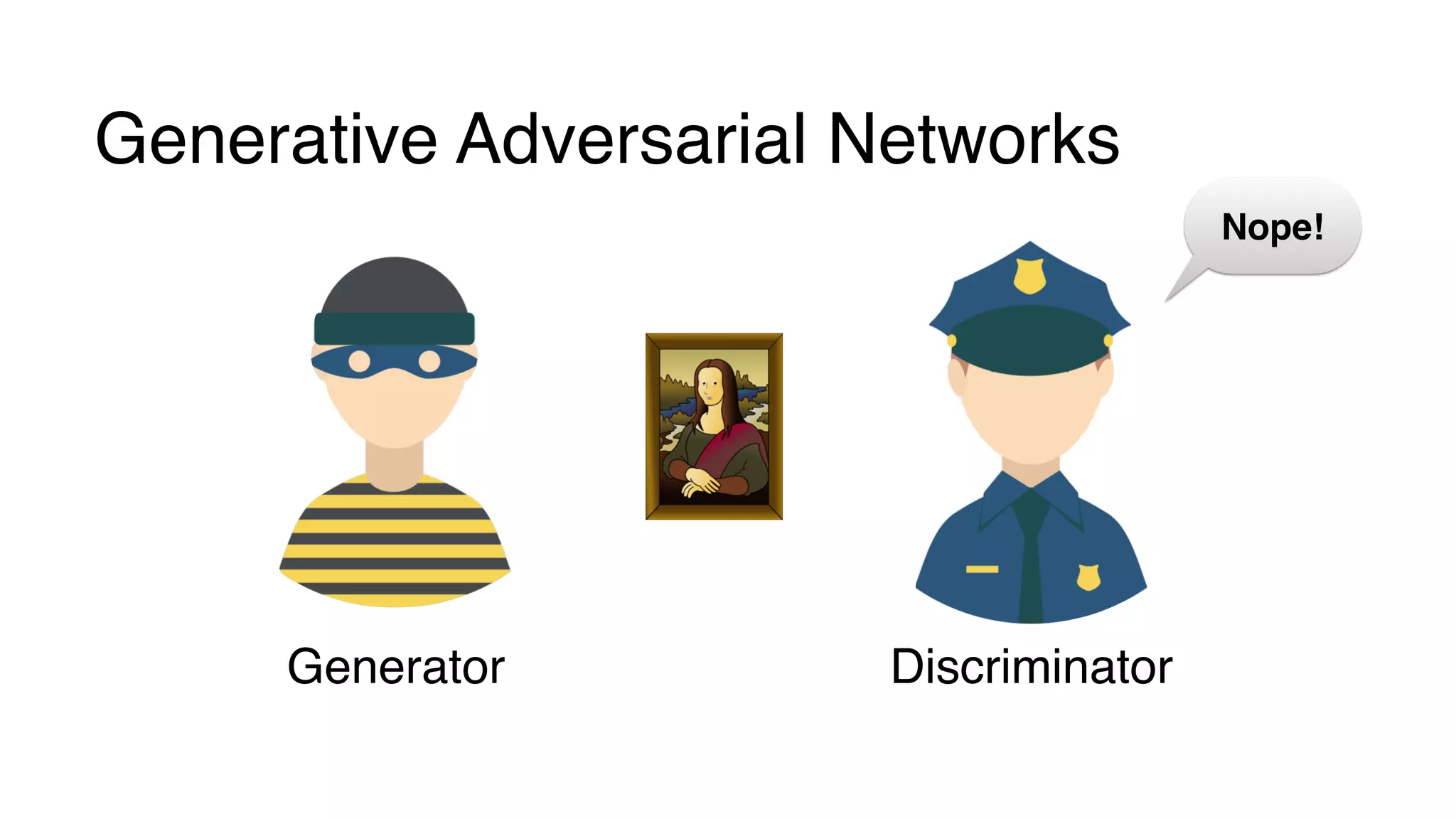
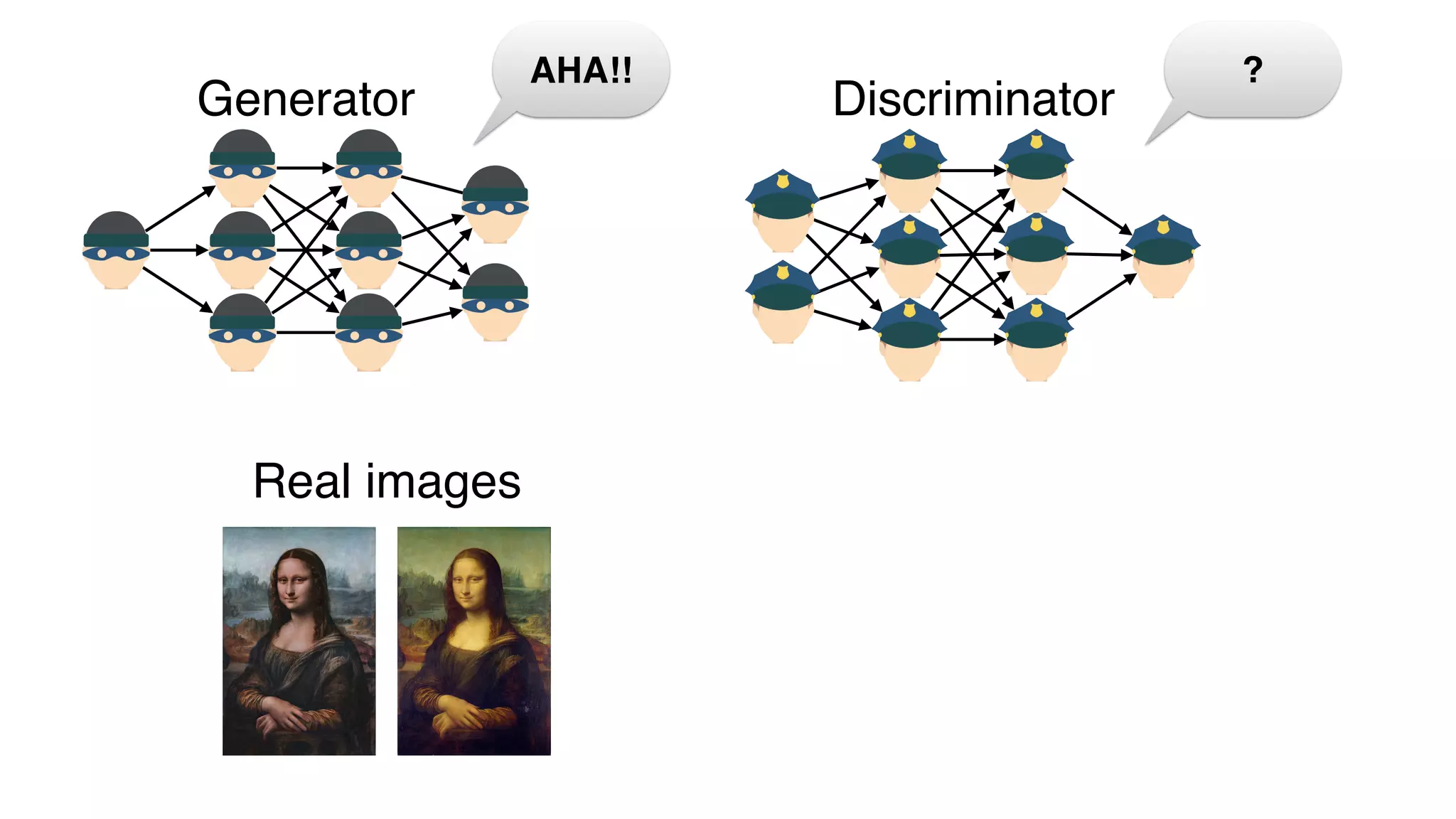
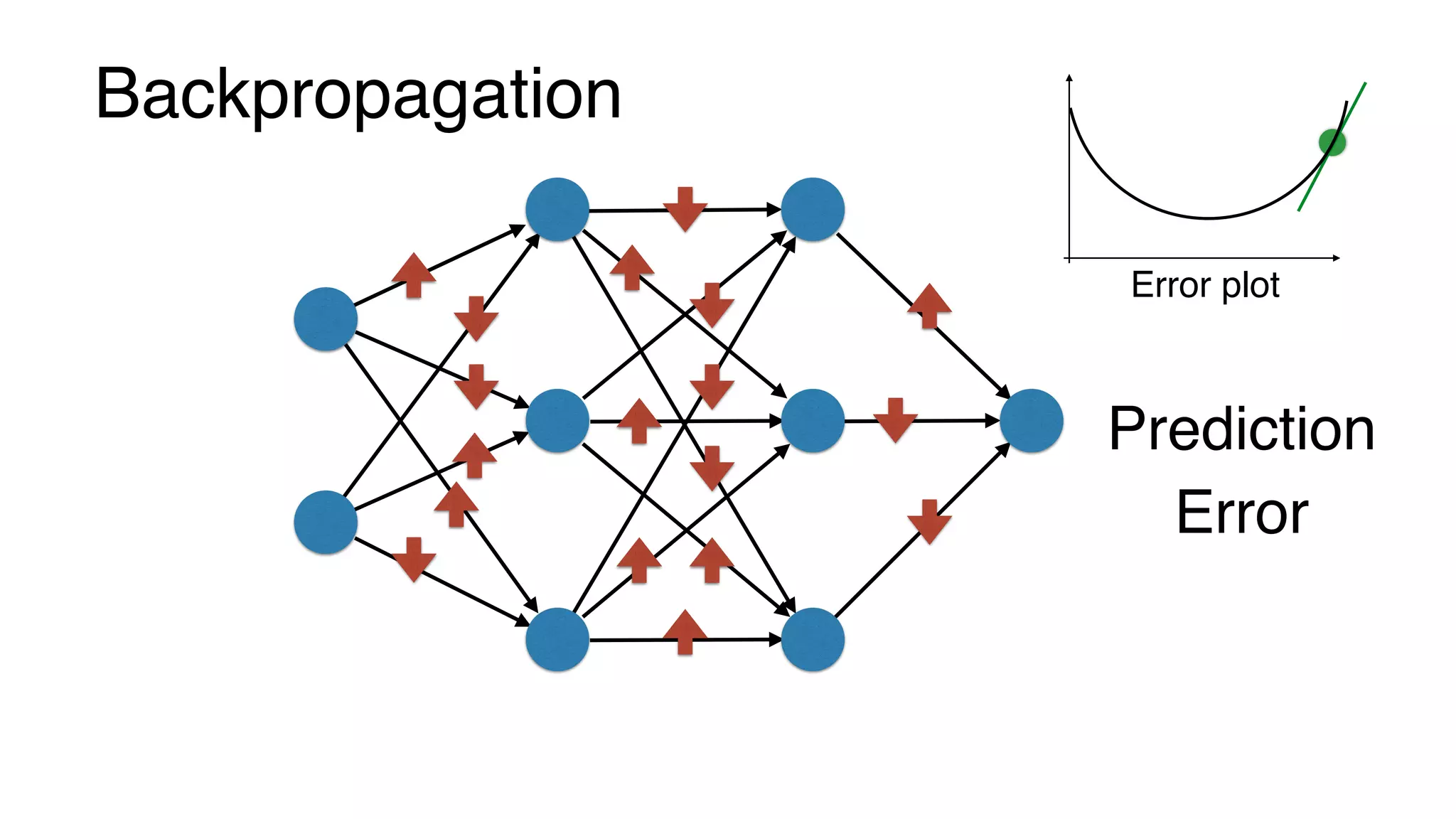
This document provides a friendly introduction to generative adversarial networks (GANs). It explains the general idea of GANs which involve a discriminator and generator playing a game, with the goal of the generator being to generate fake images that cannot be distinguished from real images by the discriminator. The document then walks through building the simplest GAN with a 1-layer neural network discriminator and generator. It explains how to train the GAN by having the discriminator and generator update through backpropagation to minimize their loss functions. Code examples are provided to demonstrate how to implement the GAN.

















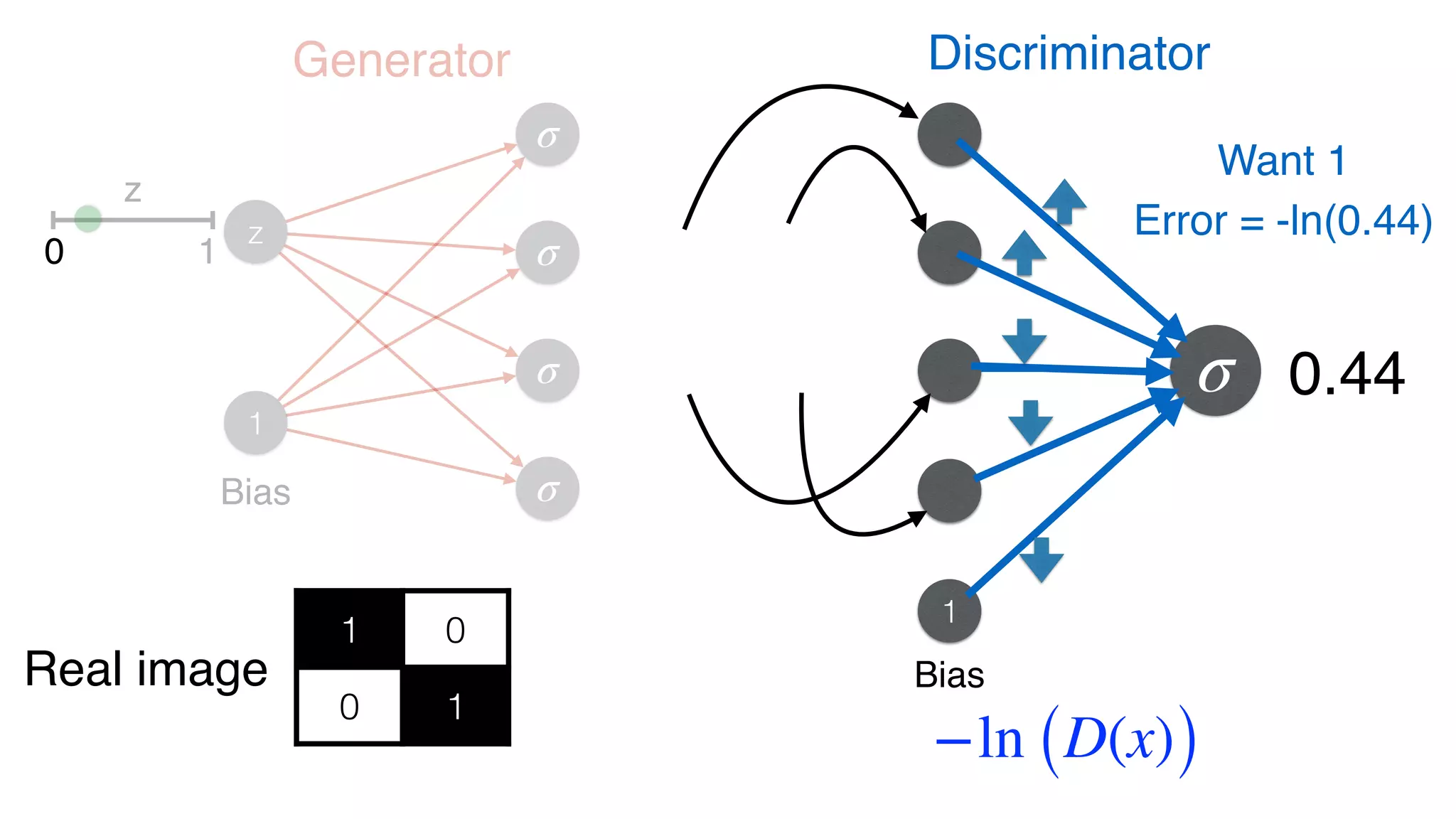

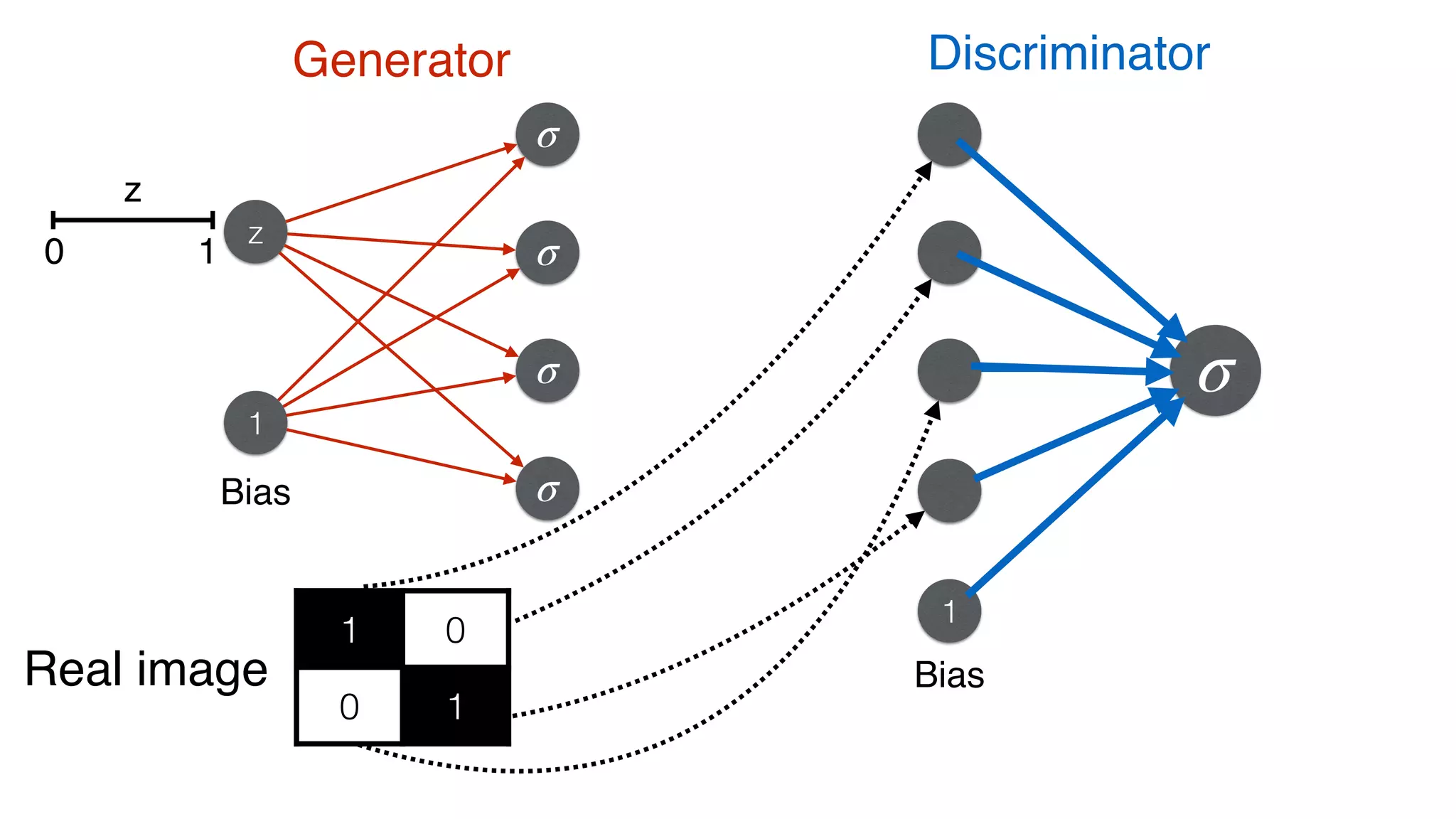

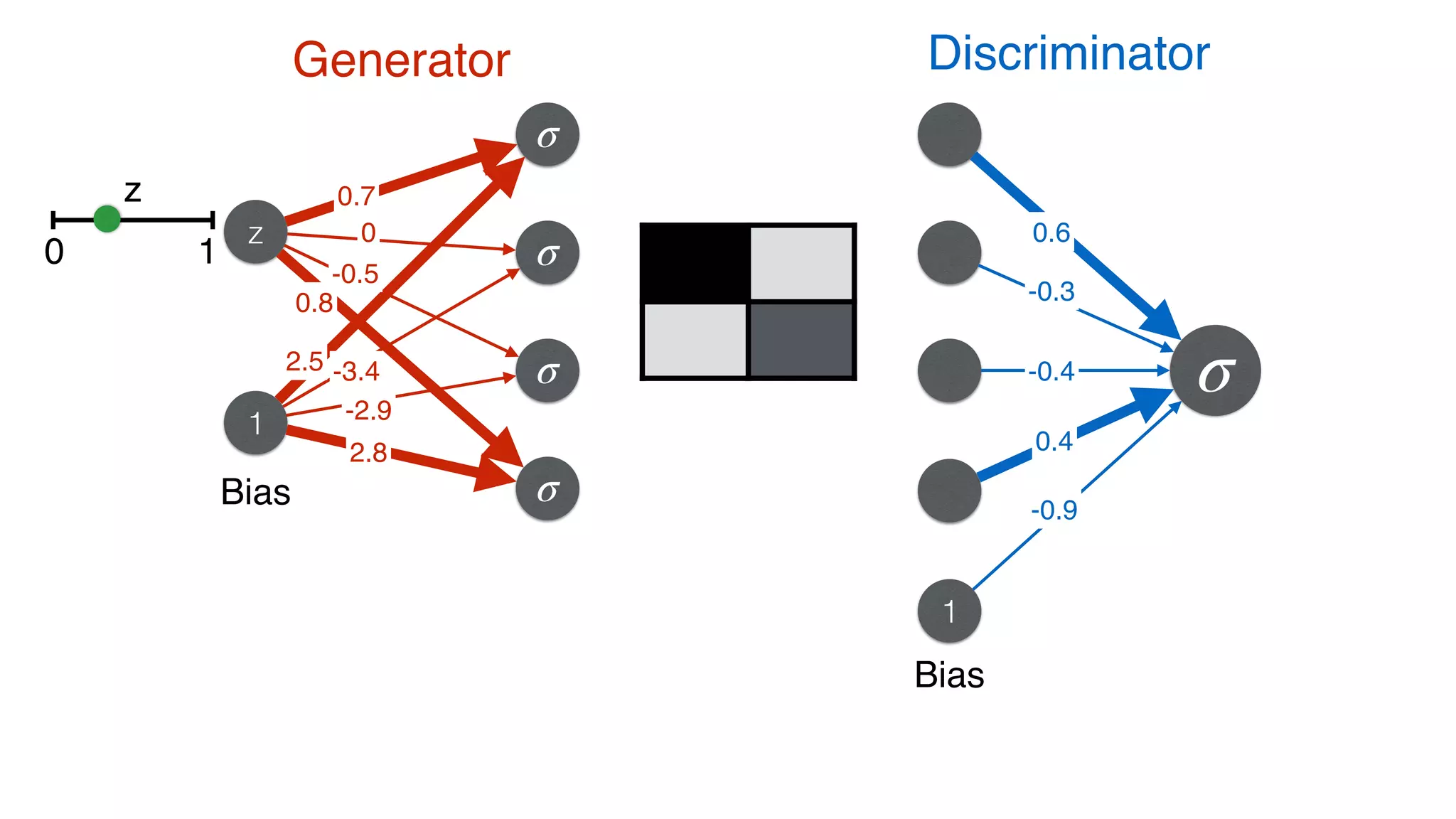

![Discriminator
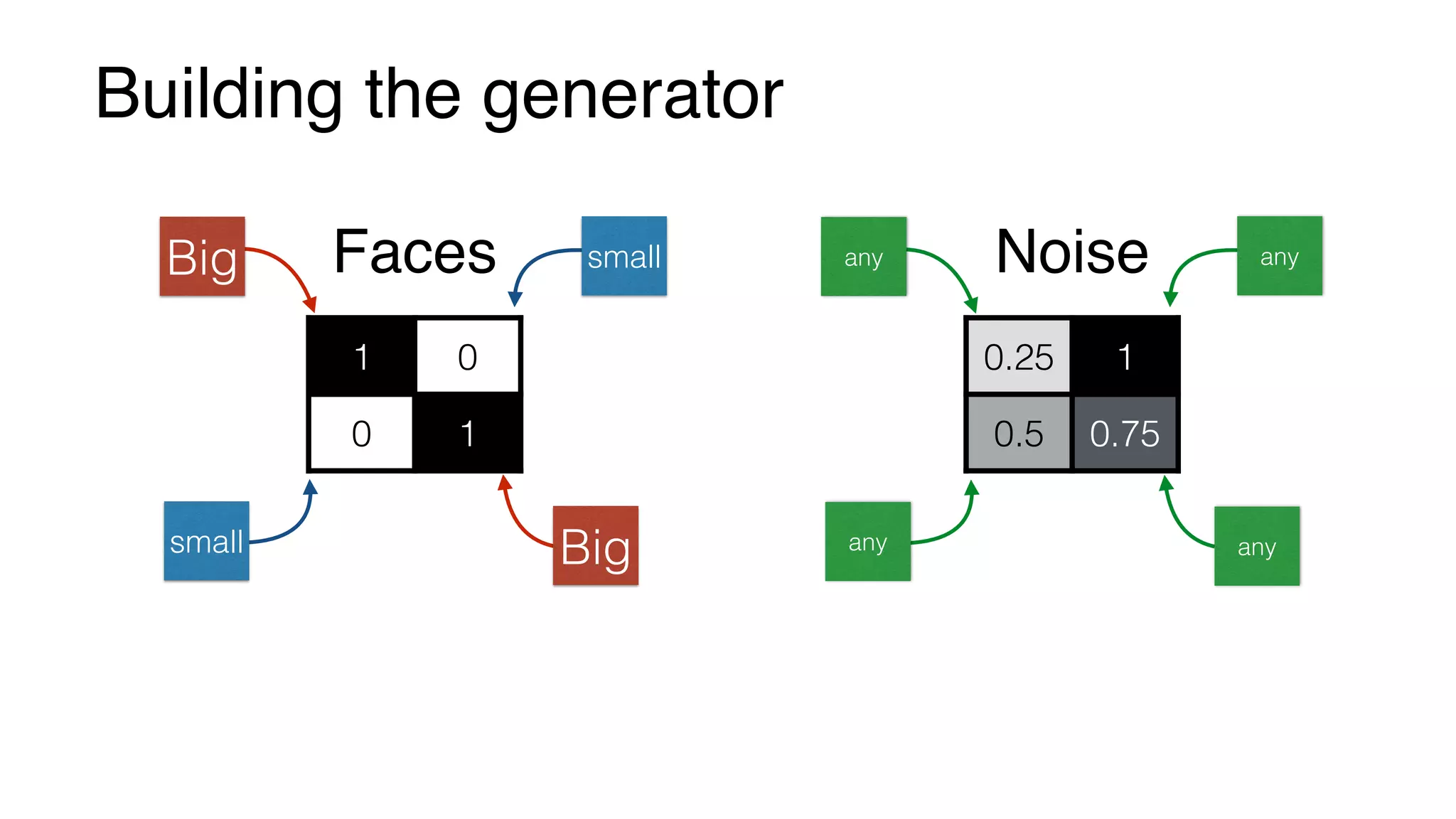
1 0
0 1
w1
w2
w4
w3
1
b
Bias
σ
x1
x2
x3
x4
Prediction
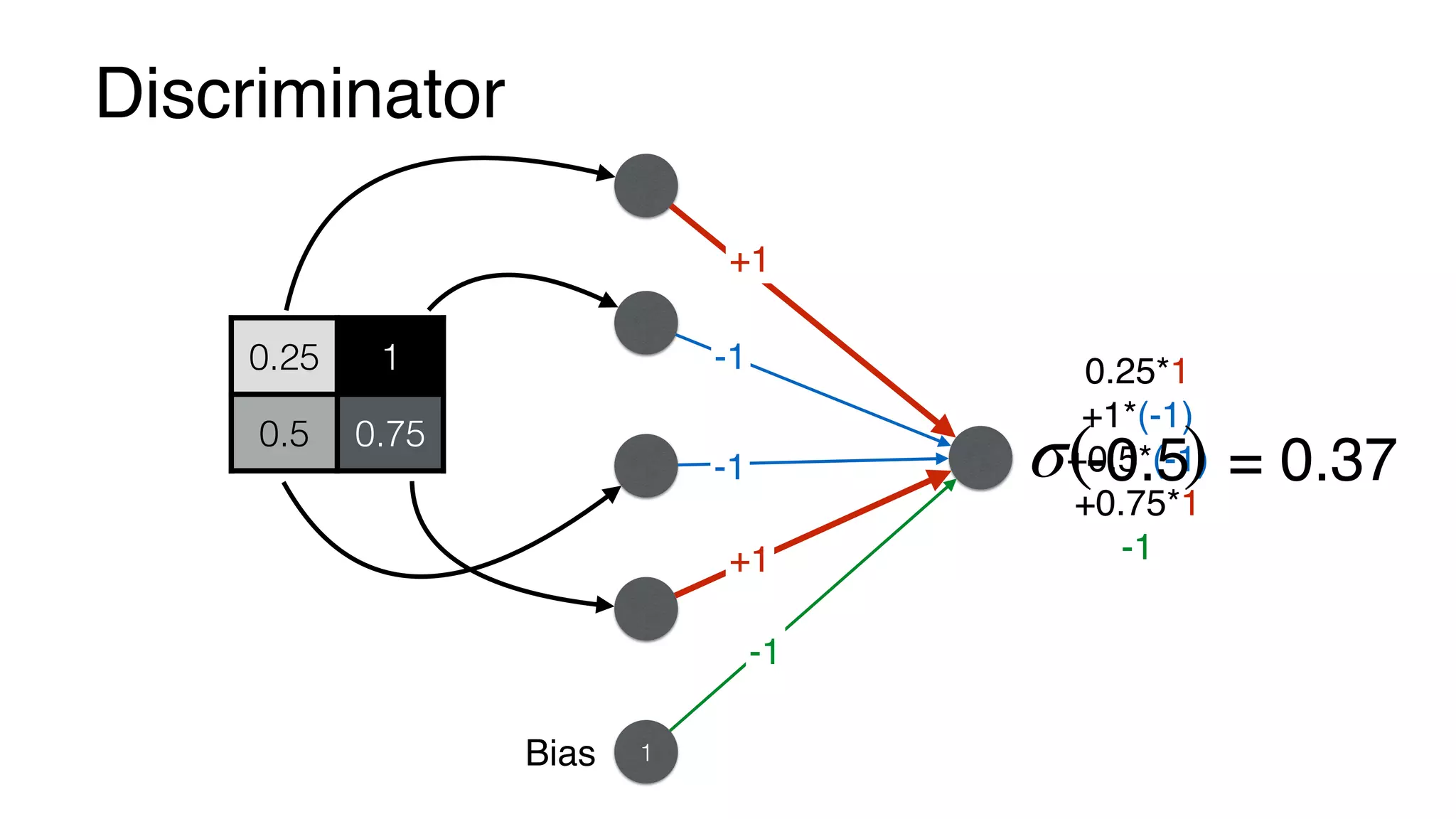
D(x) = σ(x1w1+x2w2+x3w3+x4w4 + b)
∂E
∂wi
=
∂E
∂D
⋅
∂D
∂wi
Loss function (error) from images
E = − ln(D(x))
=
−1
D(x)
⋅ σ(
4
∑
j=1
xjwj + b)[1 − σ(
4
∑
j=1
xjwj + b)]xi
=
−1
D(x)
⋅ D(x)[1 − D(x)]xi
Derivatives
∂E
∂b
=
∂E
∂D
⋅
∂D
∂b
= − [1 − D(x)]
= − [1 − D(x)]xi](https://image.slidesharecdn.com/gans-201013014510/75/Generative-Adversarial-Networks-GANs-45-2048.jpg)
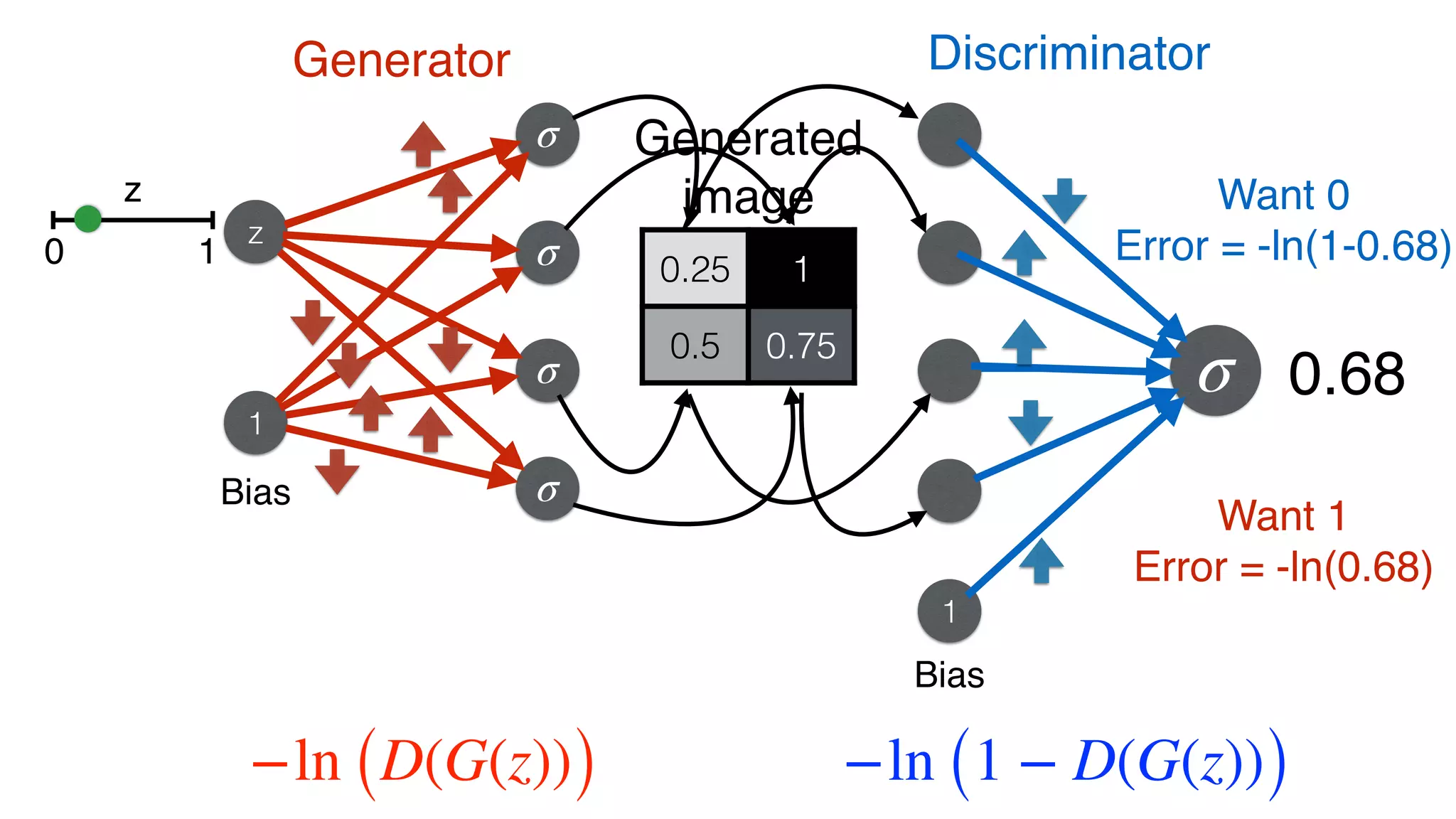
![Discriminator
0.25 1
0.5 0.75
w1
w2
w4
w3
1
b
Bias
σ
x1
x2
x3
x4
∂E
∂wi
=
∂E
∂D
⋅
∂D
∂wi
Loss function (error) from noise
E = − ln(1 − D(x))
=
1
1 − D(x)
⋅ σ(
4
∑
j=1
xjwj + b)[1 − σ(
4
∑
j=1
xjwj + b)]xi
=
1
1 − D(x)
⋅ D(x)[1 − D(x)]xi
Derivatives
∂E
∂b
=
∂E
∂D
⋅
∂D
∂b
= D(x)
Prediction
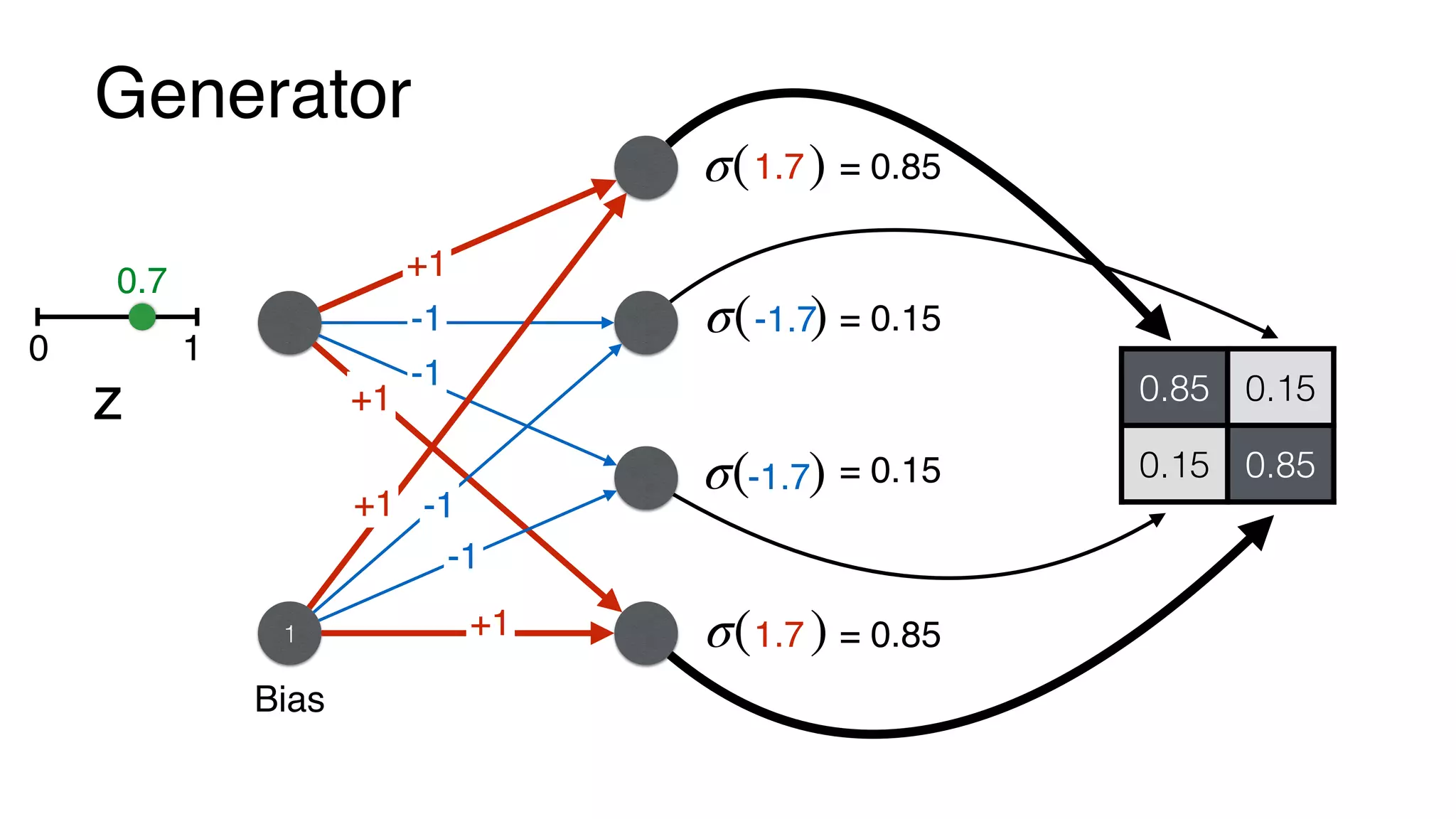
D(x) = σ(x1w1+x2w2+x3w3+x4w4 + b)
= D(x)xi](https://image.slidesharecdn.com/gans-201013014510/75/Generative-Adversarial-Networks-GANs-46-2048.jpg)
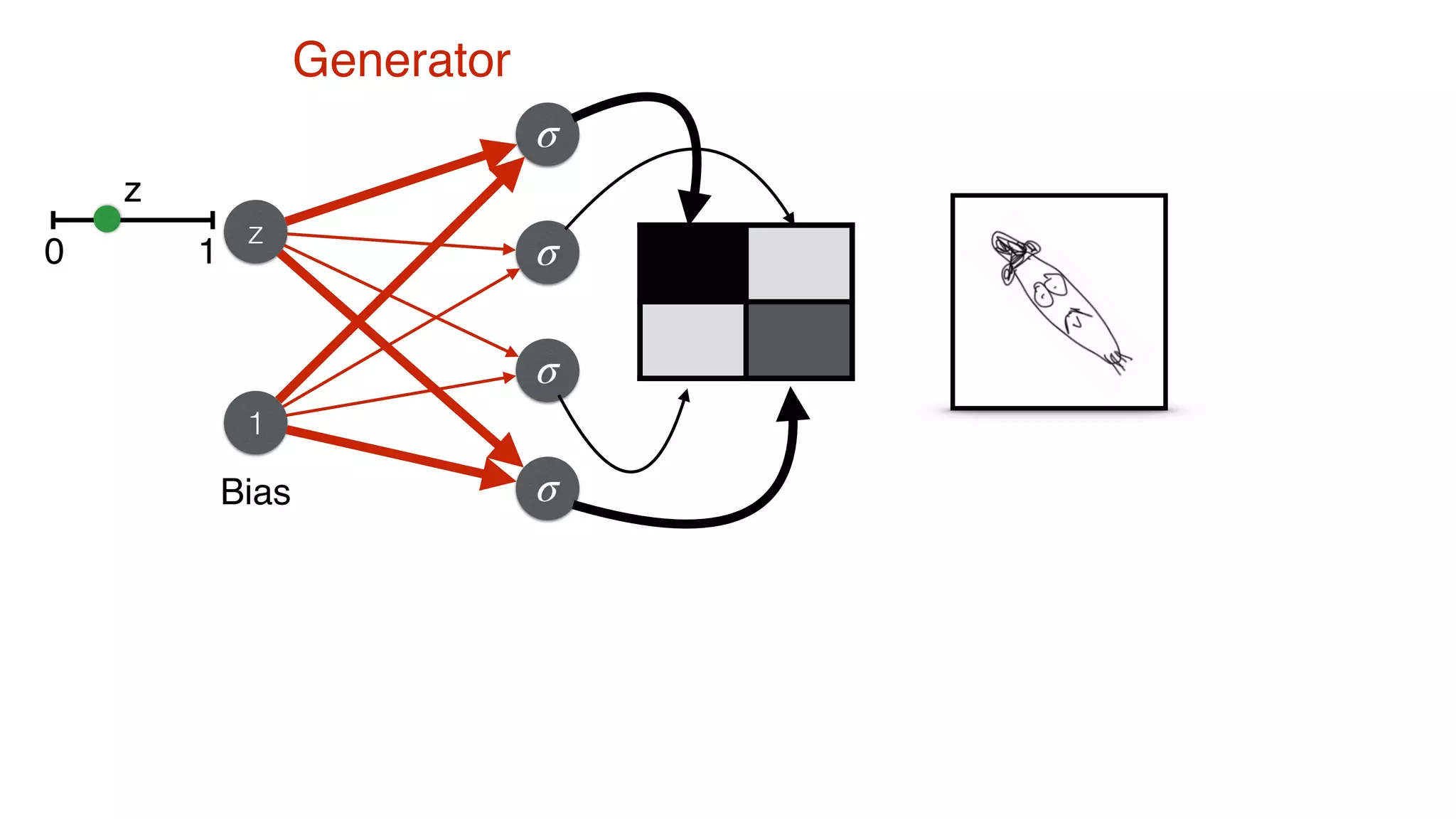
![Generator Predictions
G(z) = (G1, G2, G3, G4)
∂E
∂wi
=
∂E
∂D
⋅
∂D
∂G
⋅
∂G
∂z
Loss function (error)
E = − ln(D(G(z))
Derivatives
=
−1
D(G(z))
⋅ σ(
4
∑
j=1
Giwi + b)[1 − σ(
4
∑
j=1
Giwi + b)]G(z) ⋅ σ(wiz + bi)[1 − σ(wiz + bi]z
=
−1
D(G(z))
⋅ D(G(z))[1 − D(G(z))] ⋅ Gi(1 − Gi)z
= (σ(v1z+c1), σ(v2z+c2), σ(v3z+c3), σ(v4z+c4))
D(G(z)) = σ(G1w1 + G2w2 + G3w3 + G4w4 + b)
= − [1 − D(G(z))] ⋅ Gi(1 − Gi)z
Biases
1
z
v1
v2
v4
v3
c1
c2
c4
c3
σ
σ
σ
σ
G1 G2
G3 G4
∂E
∂b
= − [1 − D(G(z))] ⋅ Gi(1 − Gi)](https://image.slidesharecdn.com/gans-201013014510/75/Generative-Adversarial-Networks-GANs-48-2048.jpg)




















































![Discriminator
1 0
0 1
w1
w2
w4
w3
1
b
Bias
σ
x1
x2
x3
x4
Prediction
D(x) = σ(x1w1+x2w2+x3w3+x4w4 + b)
∂E
∂wi
=
∂E
∂D
⋅
∂D
∂wi
Loss function (error) from images
E = − ln(D(x))
=
−1
D(x)
⋅ σ(
4
∑
j=1
xjwj + b)[1 − σ(
4
∑
j=1
xjwj + b)]xi
=
−1
D(x)
⋅ D(x)[1 − D(x)]xi
Derivatives
∂E
∂b
=
∂E
∂D
⋅
∂D
∂b
= − [1 − D(x)]
= − [1 − D(x)]xi](https://crownmelresort.com/image.slidesharecdn.com/gans-201013014510/75/Generative-Adversarial-Networks-GANs-45-2048.jpg)
![Discriminator
0.25 1
0.5 0.75
w1
w2
w4
w3
1
b
Bias
σ
x1
x2
x3
x4
∂E
∂wi
=
∂E
∂D
⋅
∂D
∂wi
Loss function (error) from noise
E = − ln(1 − D(x))
=
1
1 − D(x)
⋅ σ(
4
∑
j=1
xjwj + b)[1 − σ(
4
∑
j=1
xjwj + b)]xi
=
1
1 − D(x)
⋅ D(x)[1 − D(x)]xi
Derivatives
∂E
∂b
=
∂E
∂D
⋅
∂D
∂b
= D(x)
Prediction
D(x) = σ(x1w1+x2w2+x3w3+x4w4 + b)
= D(x)xi](https://crownmelresort.com/image.slidesharecdn.com/gans-201013014510/75/Generative-Adversarial-Networks-GANs-46-2048.jpg)

![Generator Predictions
G(z) = (G1, G2, G3, G4)
∂E
∂wi
=
∂E
∂D
⋅
∂D
∂G
⋅
∂G
∂z
Loss function (error)
E = − ln(D(G(z))
Derivatives
=
−1
D(G(z))
⋅ σ(
4
∑
j=1
Giwi + b)[1 − σ(
4
∑
j=1
Giwi + b)]G(z) ⋅ σ(wiz + bi)[1 − σ(wiz + bi]z
=
−1
D(G(z))
⋅ D(G(z))[1 − D(G(z))] ⋅ Gi(1 − Gi)z
= (σ(v1z+c1), σ(v2z+c2), σ(v3z+c3), σ(v4z+c4))
D(G(z)) = σ(G1w1 + G2w2 + G3w3 + G4w4 + b)
= − [1 − D(G(z))] ⋅ Gi(1 − Gi)z
Biases
1
z
v1
v2
v4
v3
c1
c2
c4
c3
σ
σ
σ
σ
G1 G2
G3 G4
∂E
∂b
= − [1 − D(G(z))] ⋅ Gi(1 − Gi)](https://crownmelresort.com/image.slidesharecdn.com/gans-201013014510/75/Generative-Adversarial-Networks-GANs-48-2048.jpg)













































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)





