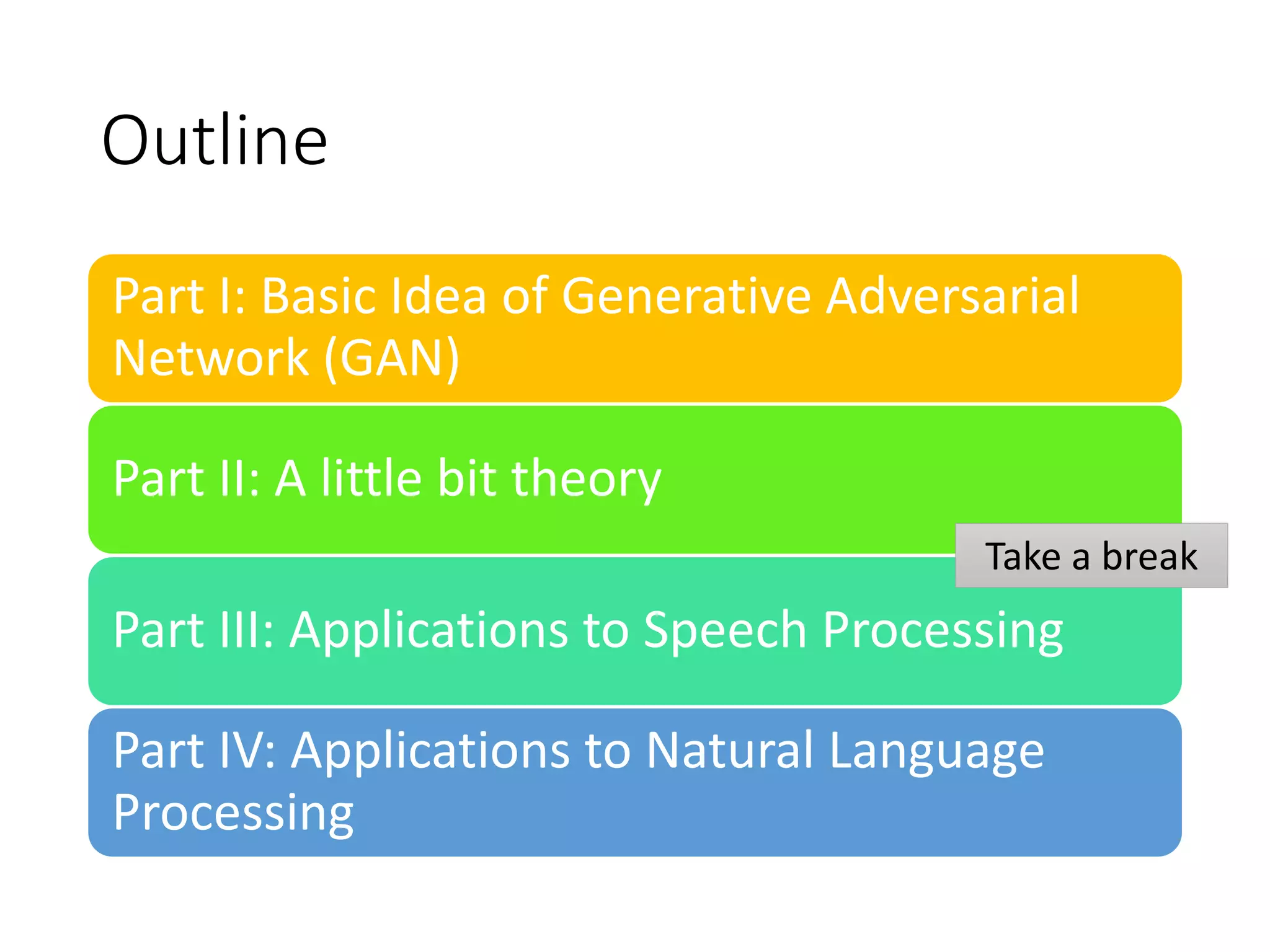
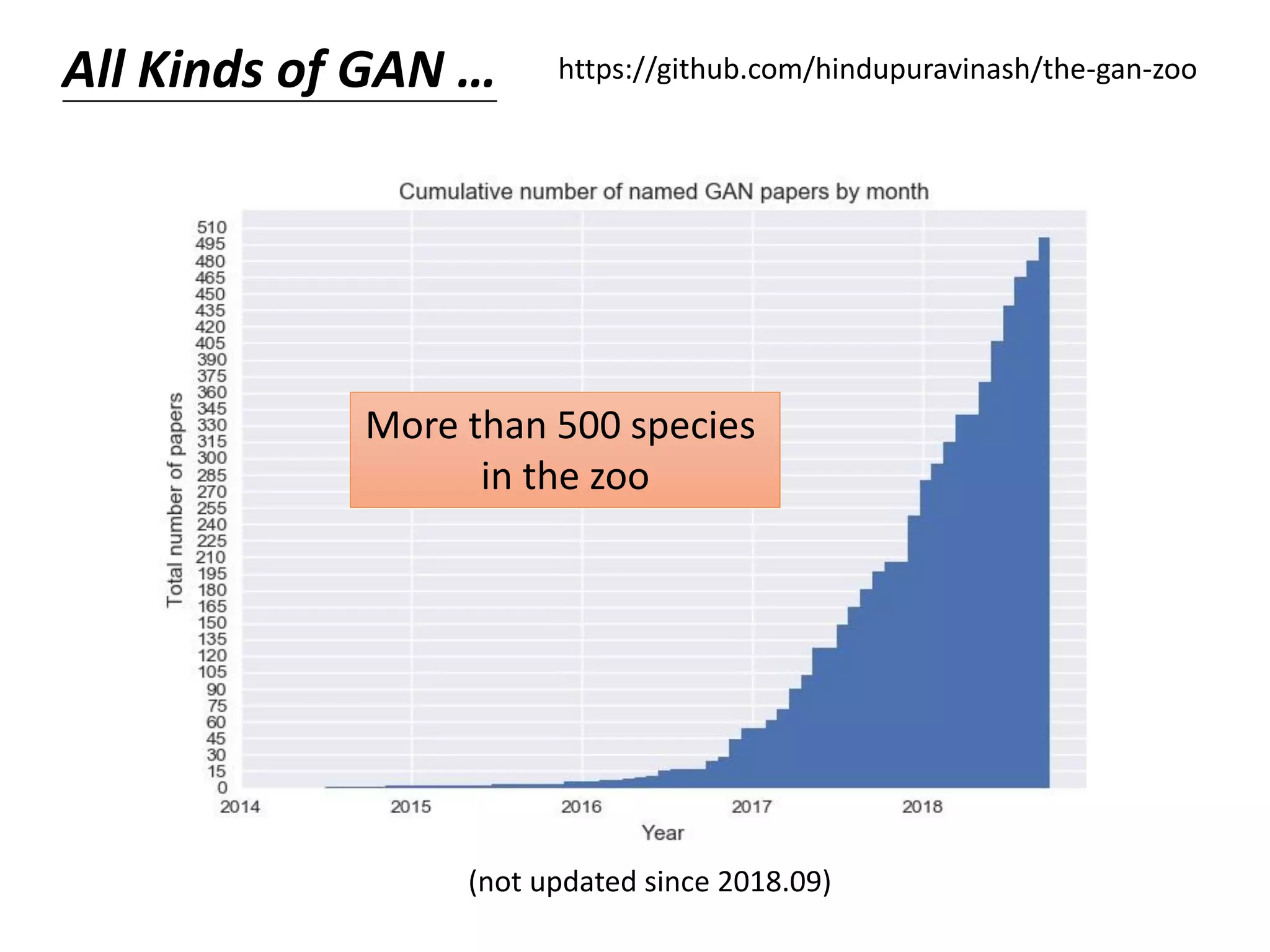
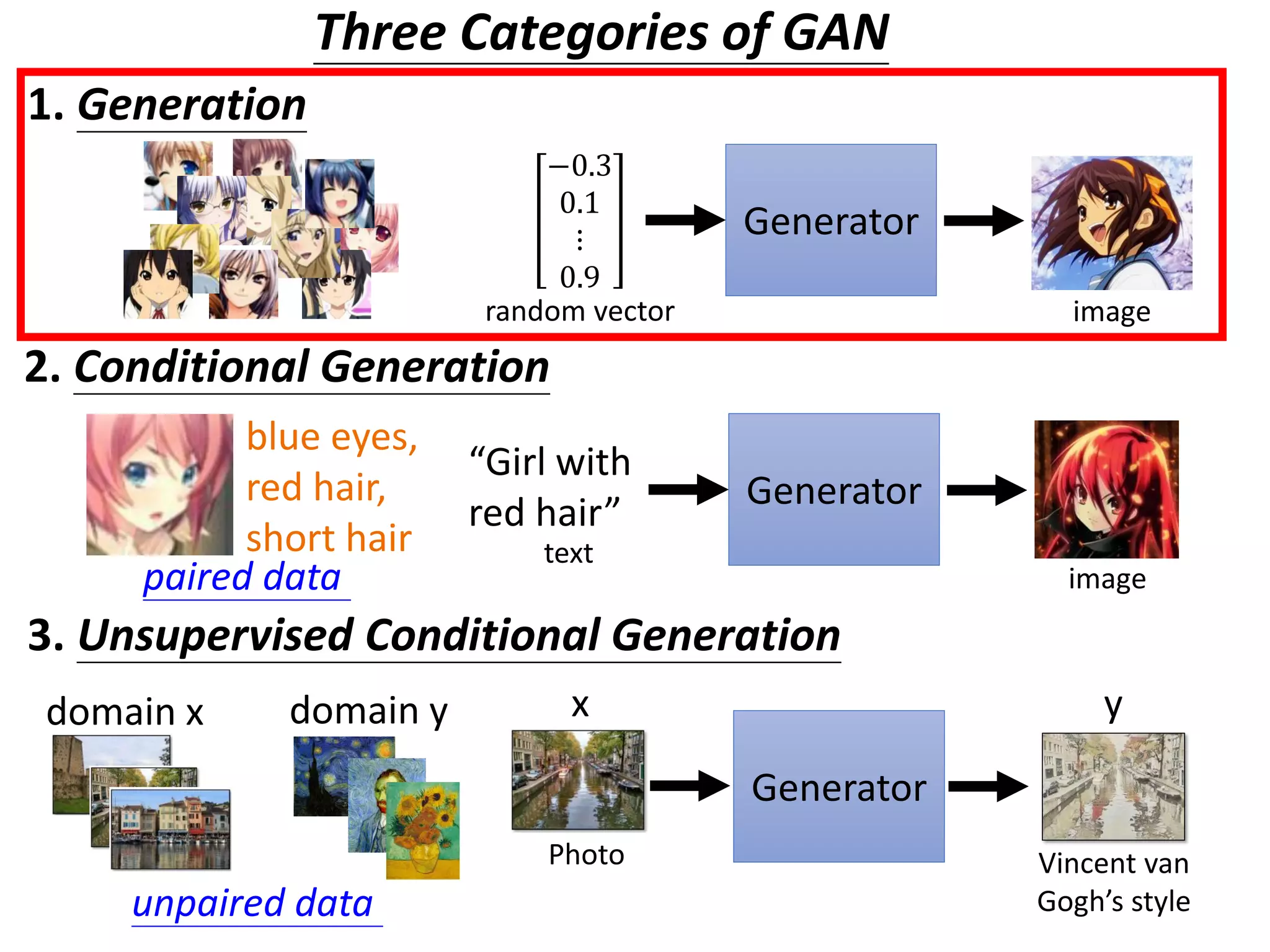
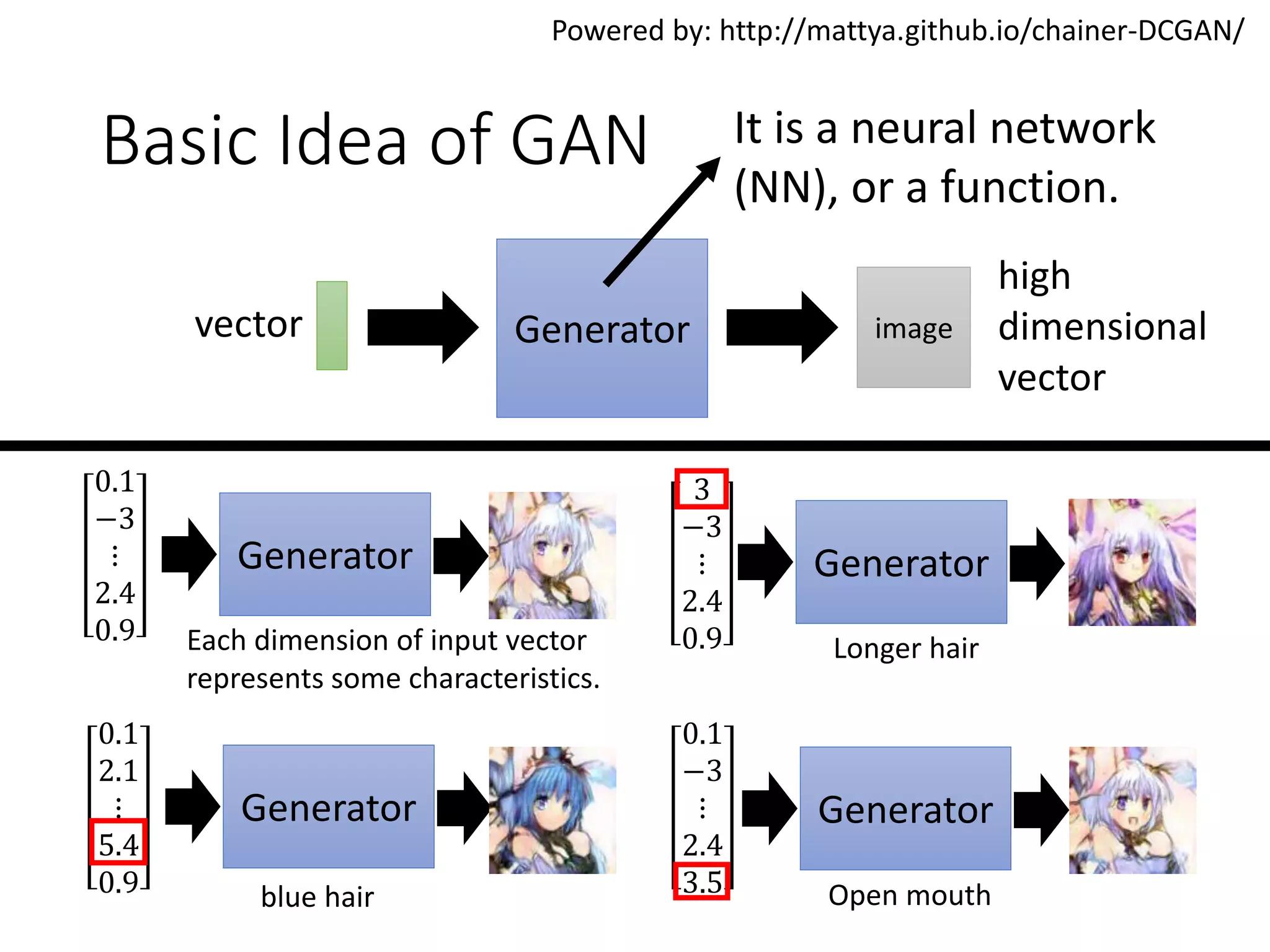
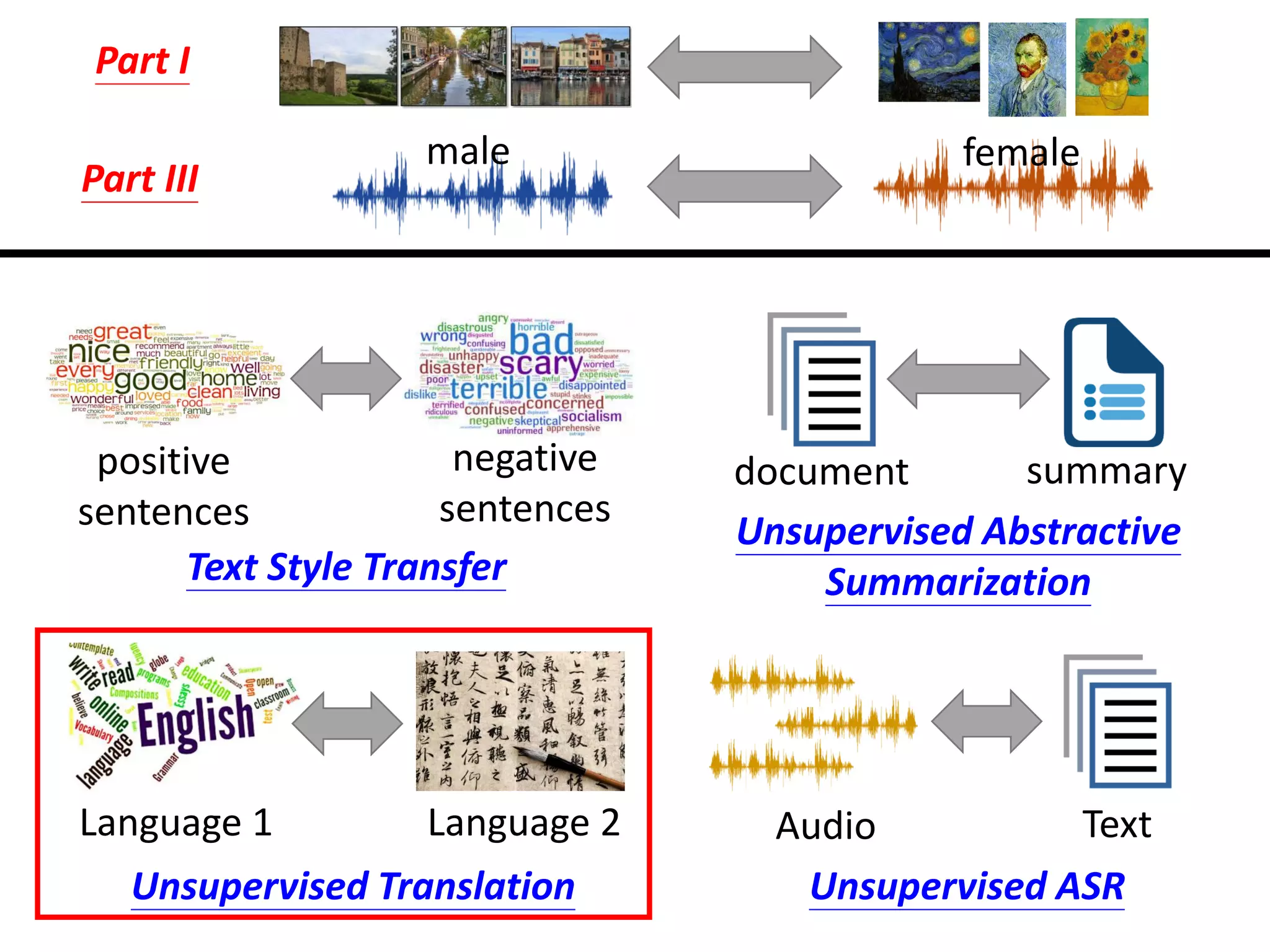
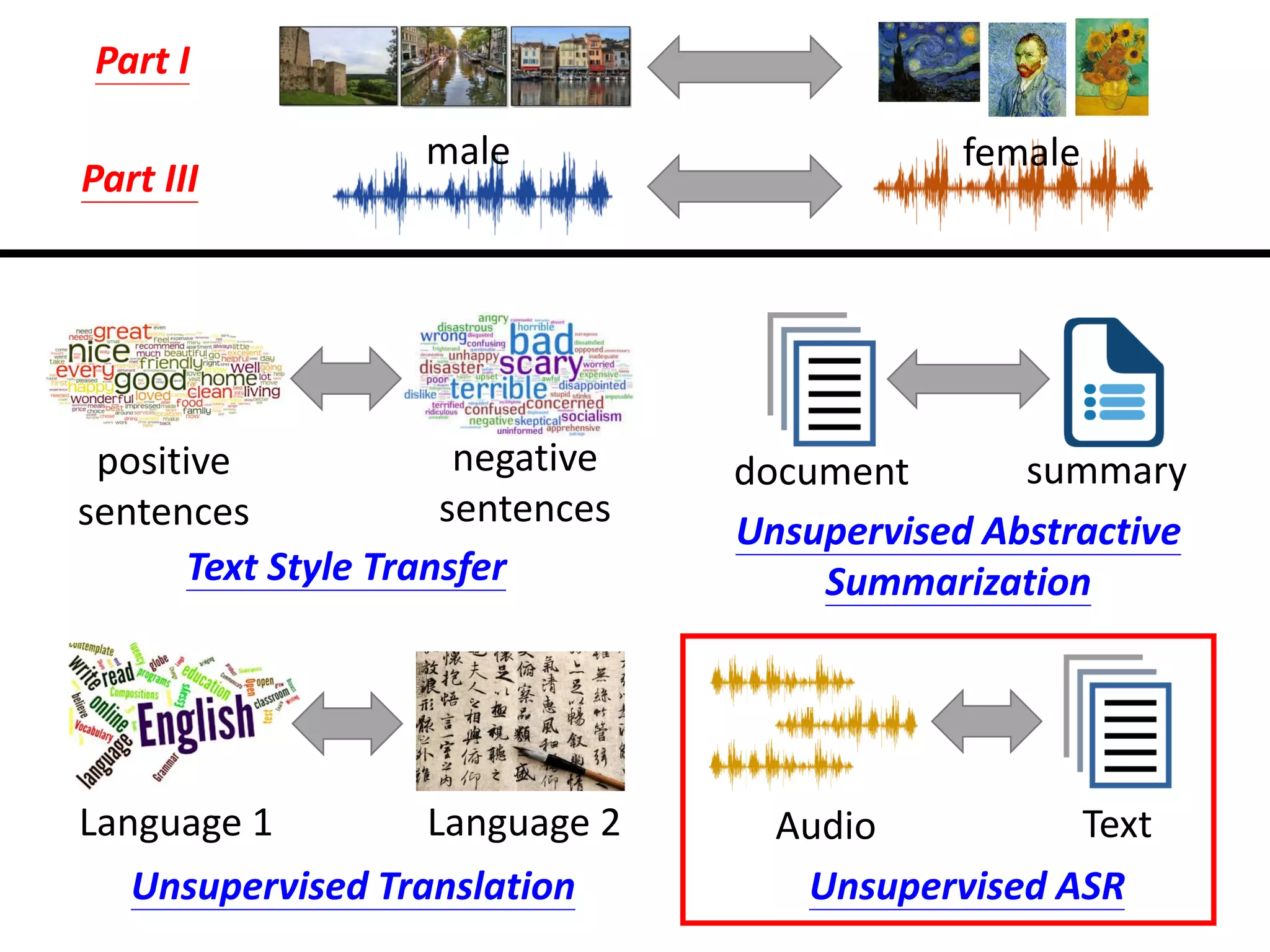
Download as PDF, PPTX












![Progressive GAN
[Tero Karras, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-23-2048.jpg)
![The first GAN
[Ian J. Goodfellow, et al., NIPS, 2014]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-24-2048.jpg)
![Today ……
[Andrew Brock, et al., arXiv, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-25-2048.jpg)
![[David Bau, et al., ICLR 2019]
Does the generator have the concept
of objects?
Some neurons correspond to specific
objects, for example, tree](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-26-2048.jpg)
![Remove the neurons for tree
[David Bau, et al., ICLR 2019]
Activate the neurons for tree](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-27-2048.jpg)
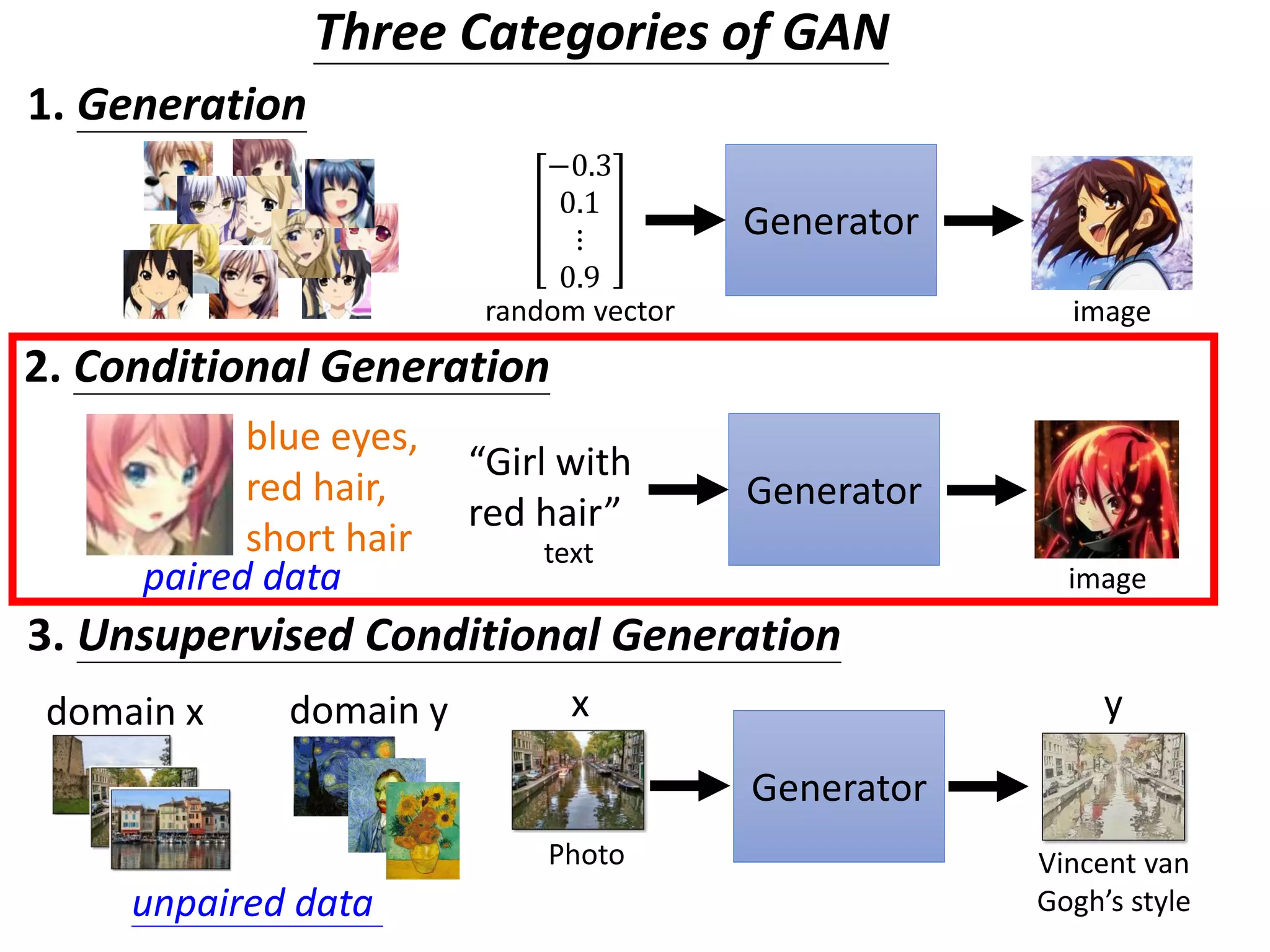
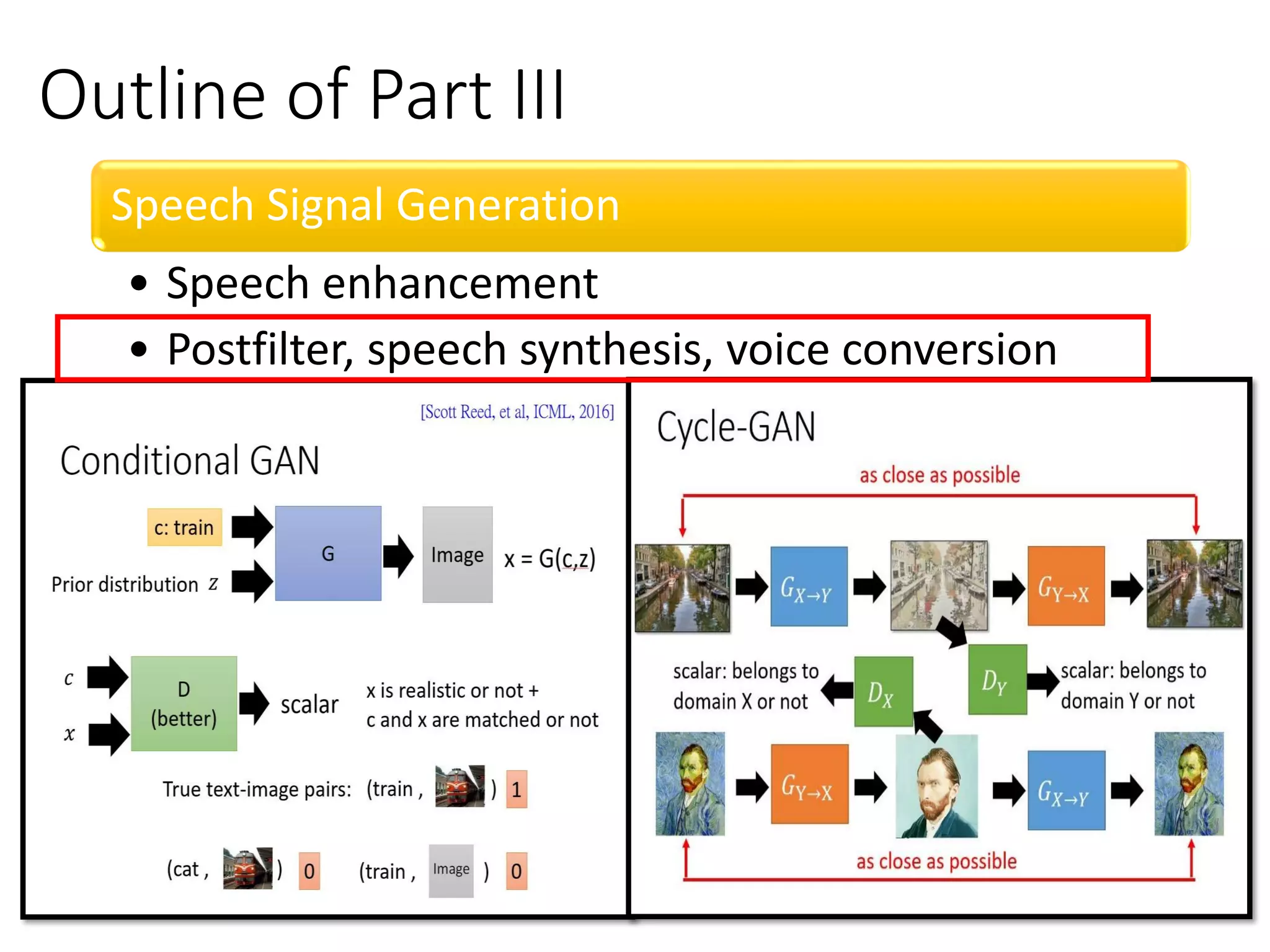
![Conditional GAN
D
(original)
scalar𝑥
G
𝑧Normal distribution
x = G(c,z)
c: train
x is real image or not
Image
Real images:
Generated images:
1
0
Generator will learn to
generate realistic images ….
But completely ignore the
input conditions.
[Scott Reed, et al, ICML, 2016]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-30-2048.jpg)
![Conditional GAN
D
(better)
scalar
𝑐
𝑥
True text-image pairs:
G
𝑧Normal distribution
x = G(c,z)
c: train
Image
x is realistic or not +
c and x are matched or not
(train , )
(train , )(cat , )
[Scott Reed, et al, ICML, 2016]
1
00](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-31-2048.jpg)
![x is realistic or not +
c and x are matched
or not
Conditional GAN - Discriminator
[Takeru Miyato, et al., ICLR, 2018]
[Han Zhang, et al., arXiv, 2017]
[Augustus Odena et al., ICML, 2017]
condition c
object x
Network
Network
Network
score
Network
Network
(almost every paper)
condition c
object x
c and x are matched
or not
x is realistic or not
+](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-32-2048.jpg)

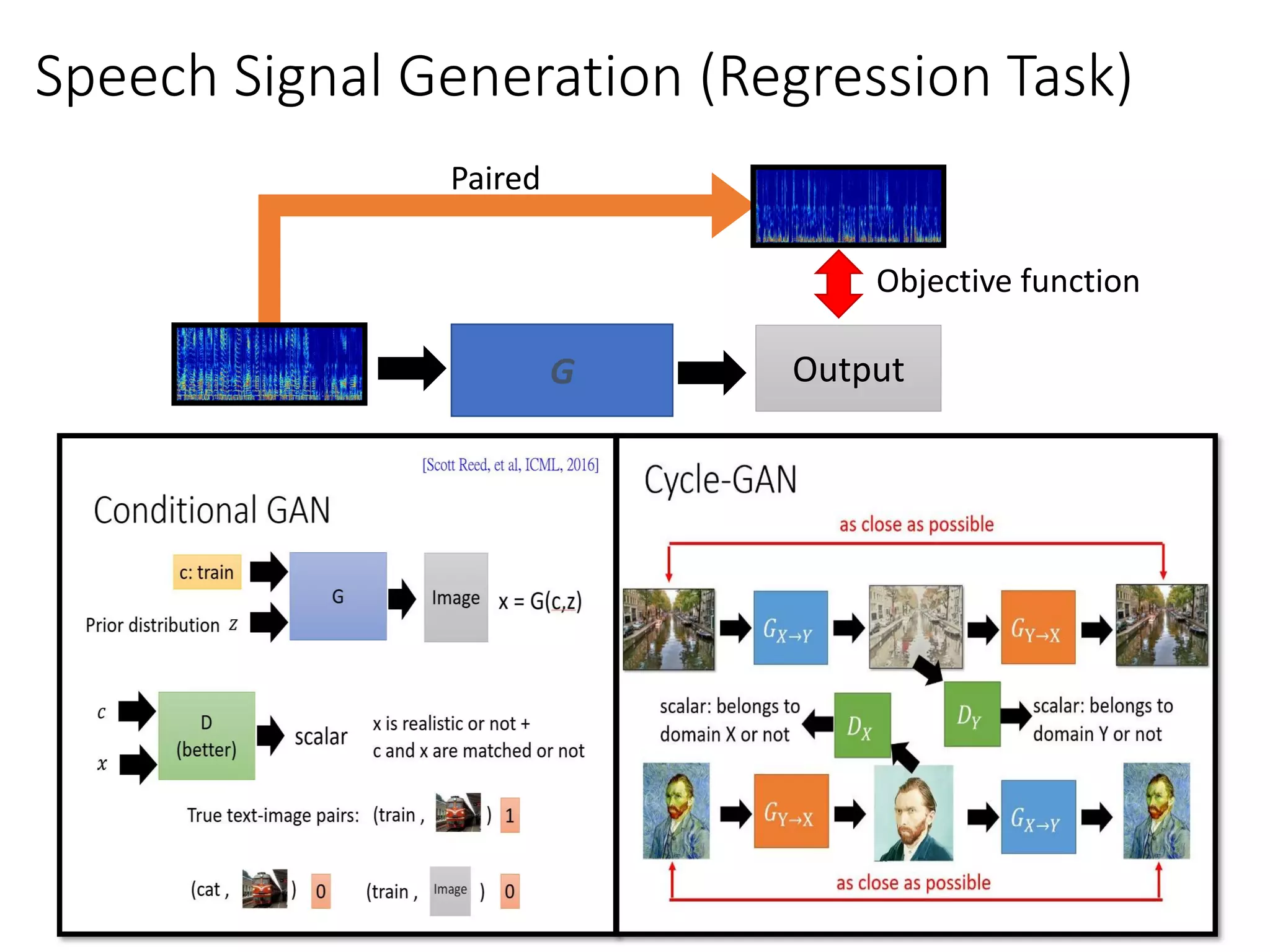
![Conditional GAN - Image-to-image
G
𝑧
x = G(c,z)
𝑐
[Phillip Isola, et al., CVPR, 2017]
Image translation, or pix2pix](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-34-2048.jpg)
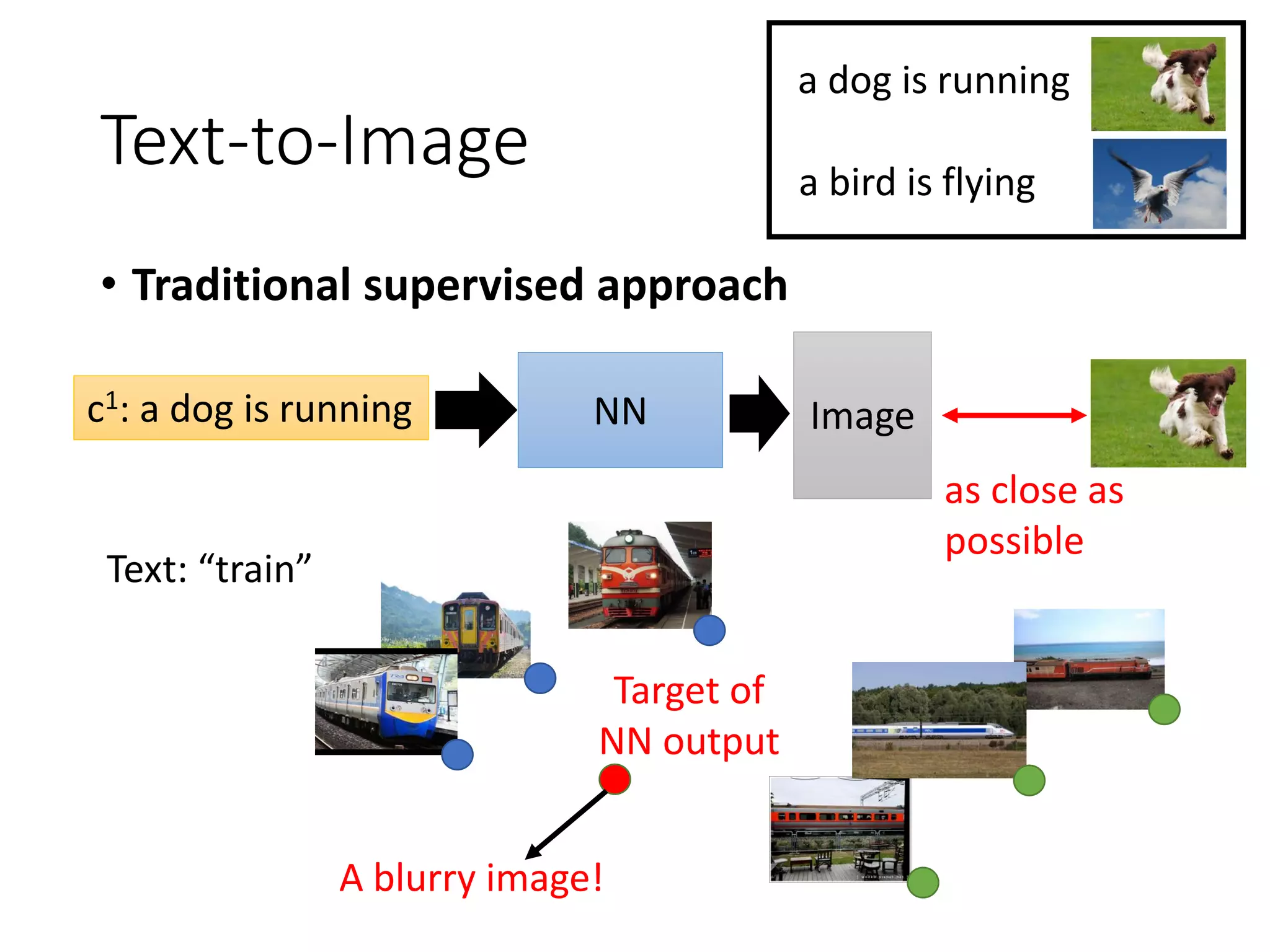
![as close as
possible
Conditional GAN - Image-to-image
• Traditional supervised approach
NN Image
It is blurry.
Testing:
input L1
e.g. L1
[Phillip Isola, et al., CVPR, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-35-2048.jpg)
![Conditional GAN - Image-to-image
Testing:
input L1 GAN
G
𝑧
Image D scalar
GAN + L1
L1
[Phillip Isola, et al., CVPR, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-36-2048.jpg)
![Conditional GAN
- Sound-to-image
Gc: sound Image
"a dog barking sound"
Training Data
Collection
video
[Wan, et al., ICASSP 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-37-2048.jpg)

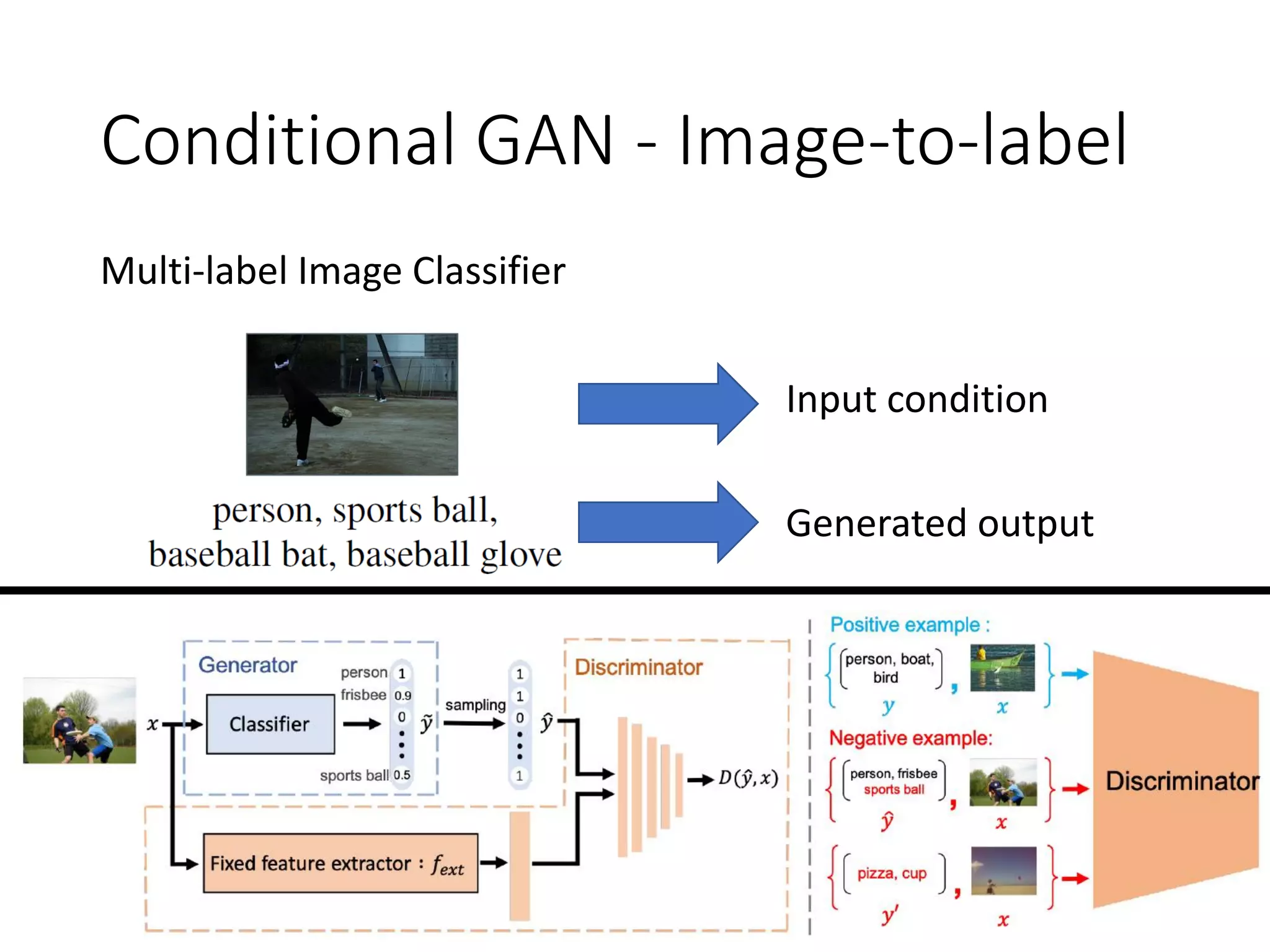
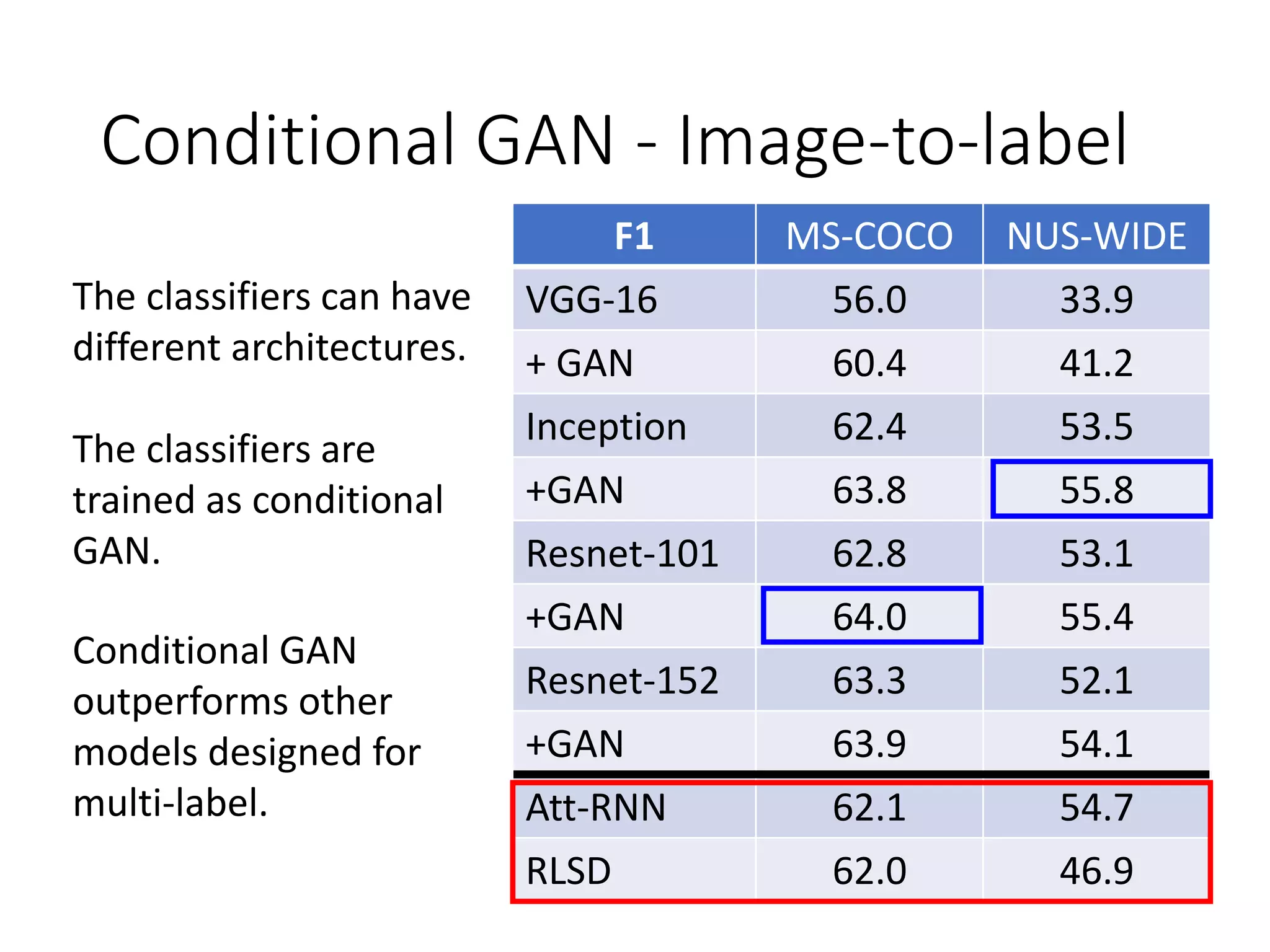
![Conditional GAN - Image-to-label
F1 MS-COCO NUS-WIDE
VGG-16 56.0 33.9
+ GAN 60.4 41.2
Inception 62.4 53.5
+GAN 63.8 55.8
Resnet-101 62.8 53.1
+GAN 64.0 55.4
Resnet-152 63.3 52.1
+GAN 63.9 54.1
Att-RNN 62.1 54.7
RLSD 62.0 46.9
The classifiers can have
different architectures.
The classifiers are
trained as conditional
GAN.
[Tsai, et al., ICASSP 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-40-2048.jpg)
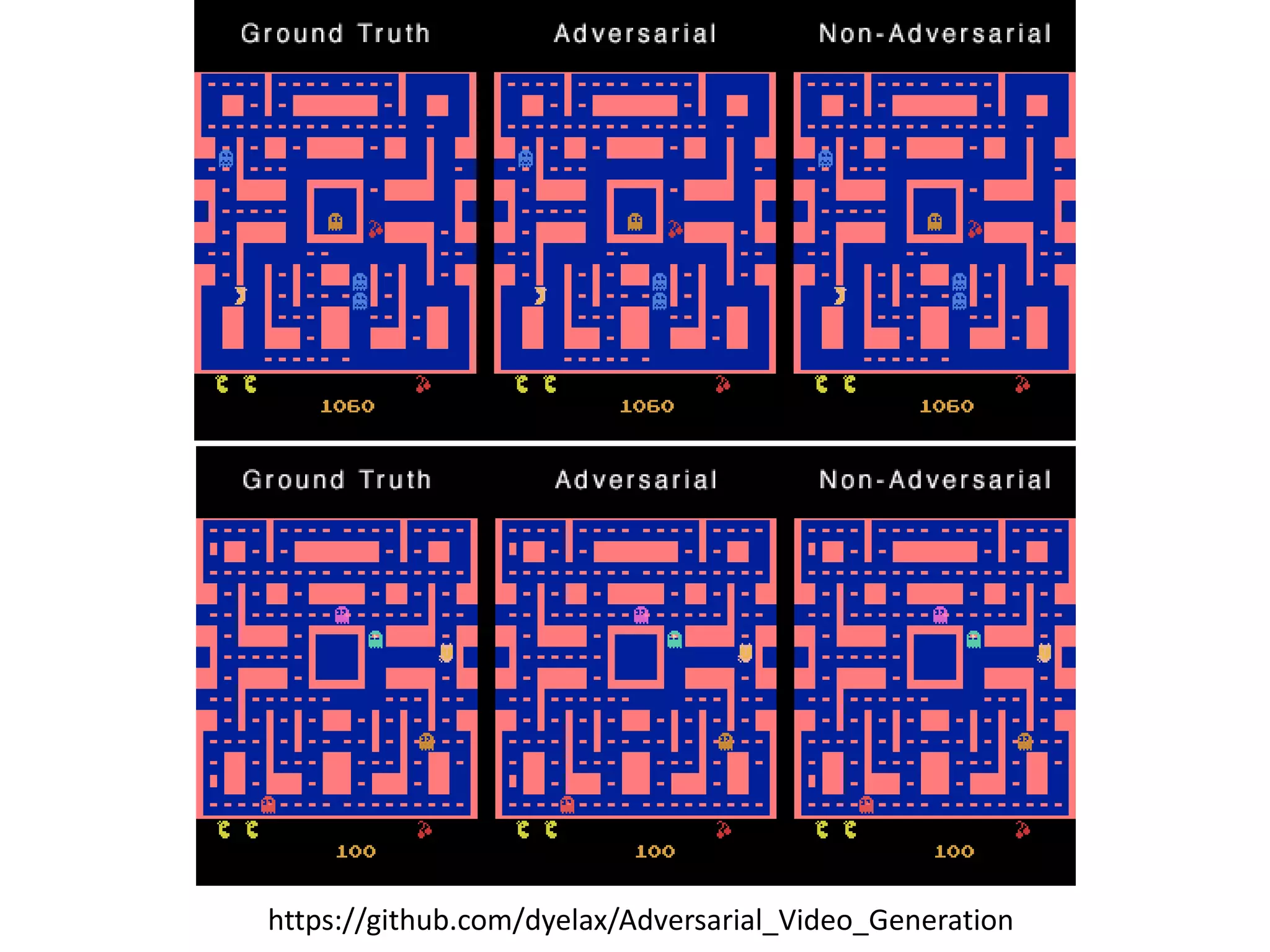
![Conditional GAN
- Video Generation
Generator
Discrimi
nator
Last frame is real
or generated
Discriminator thinks it is real
[Michael Mathieu, et al., arXiv, 2015]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-42-2048.jpg)
![More about Video Generation
https://arxiv.org/abs/1905.08233
[Egor Zakharov, et al., arXiv, 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-44-2048.jpg)
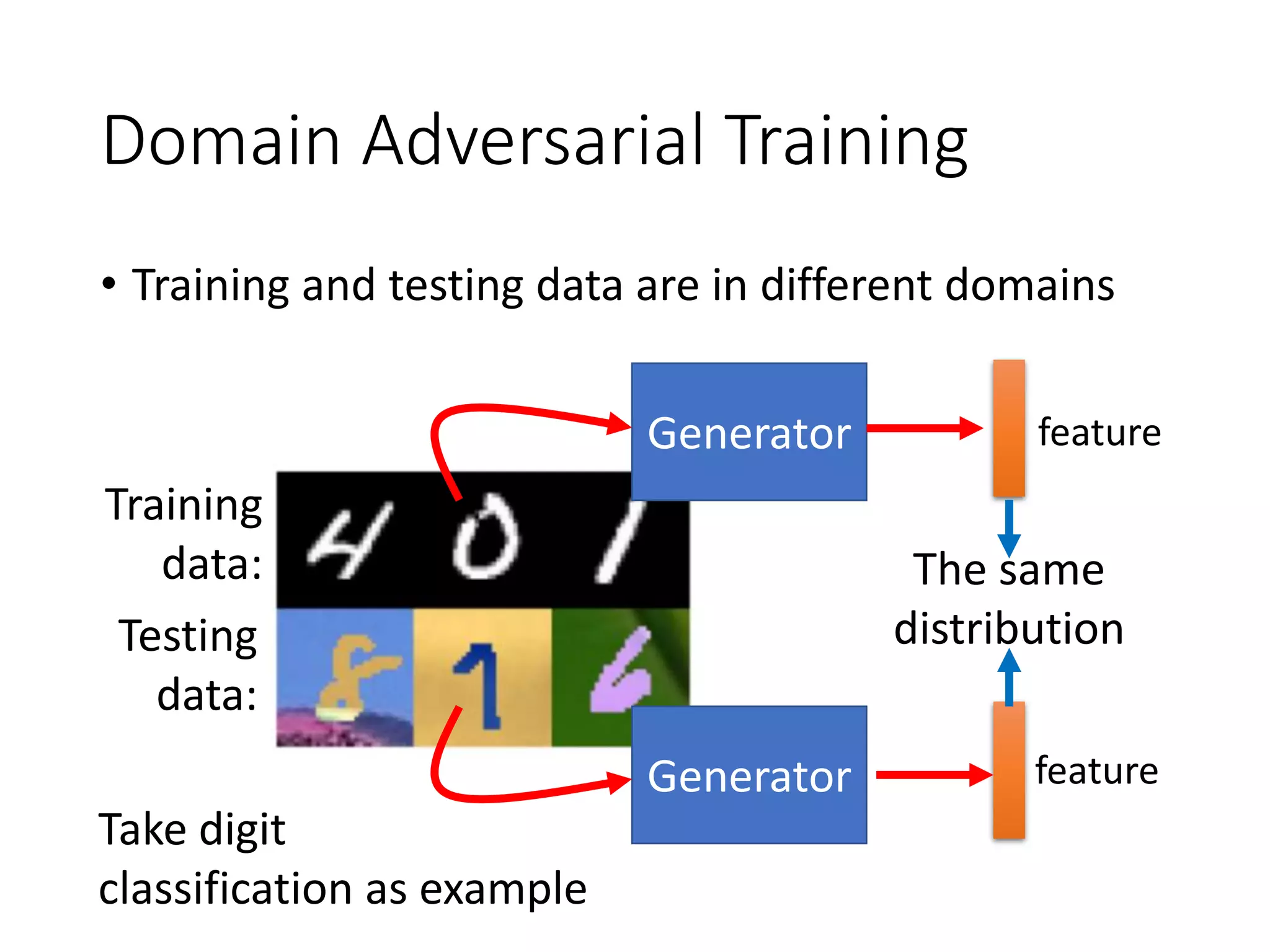
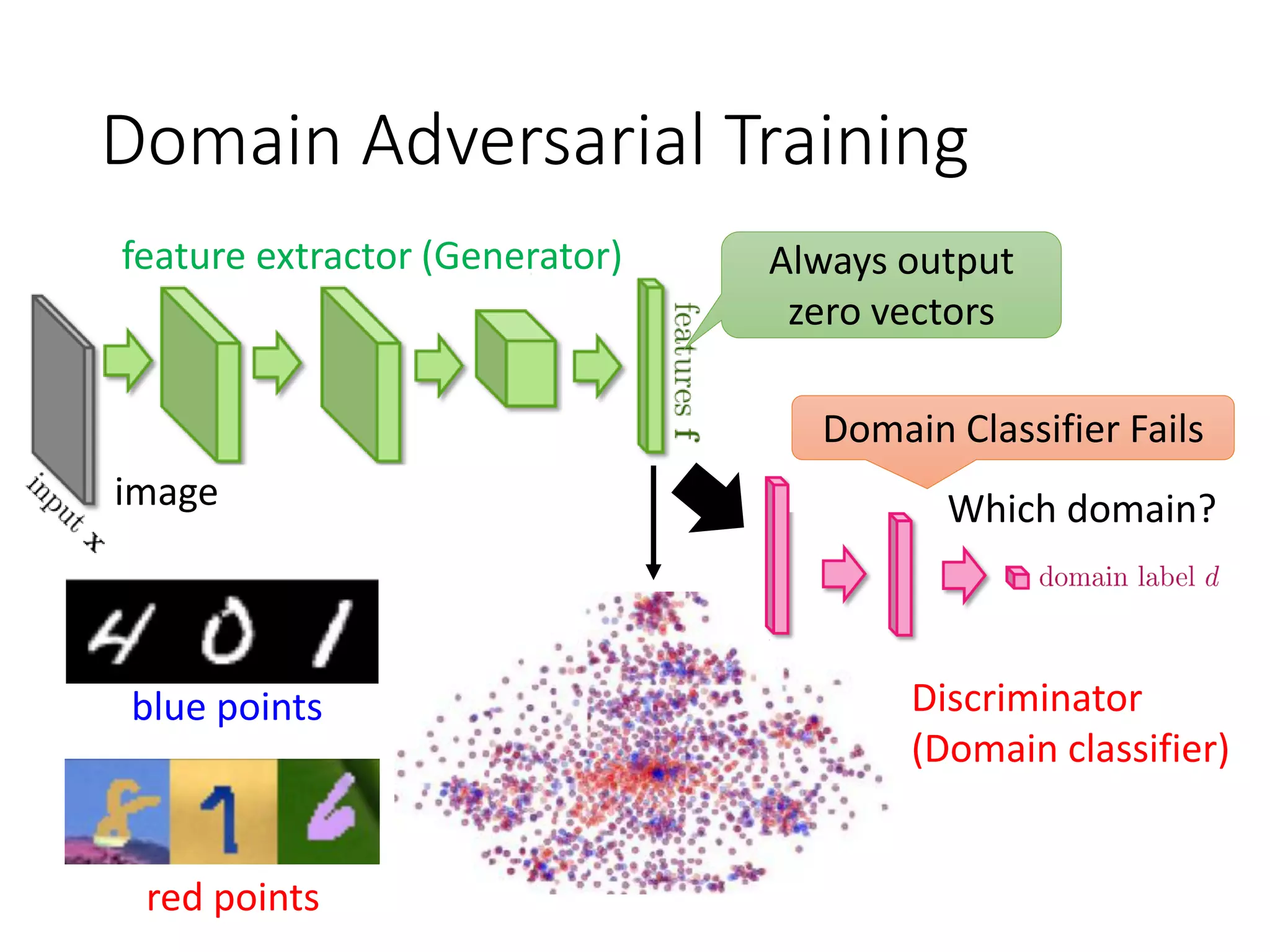
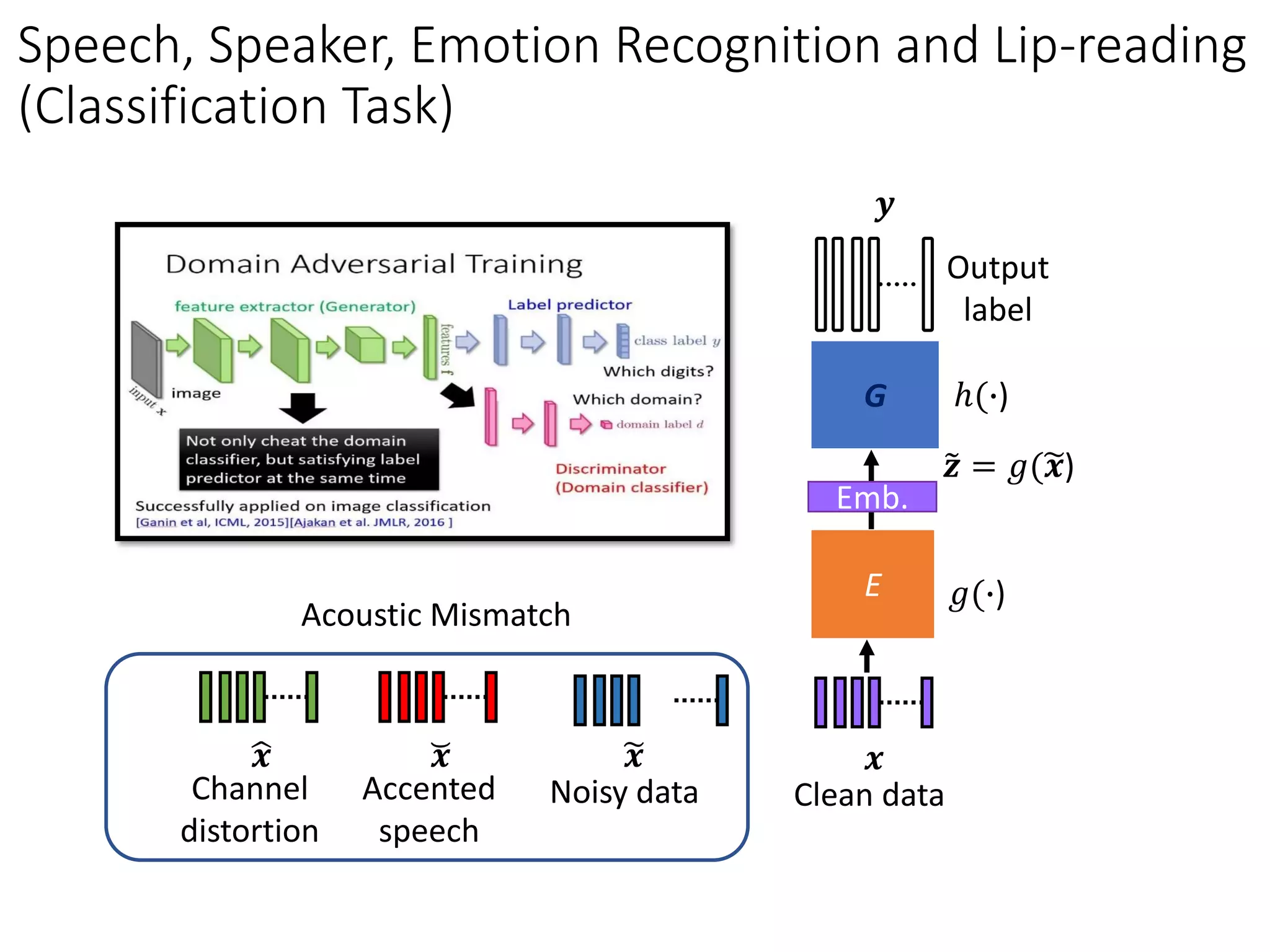
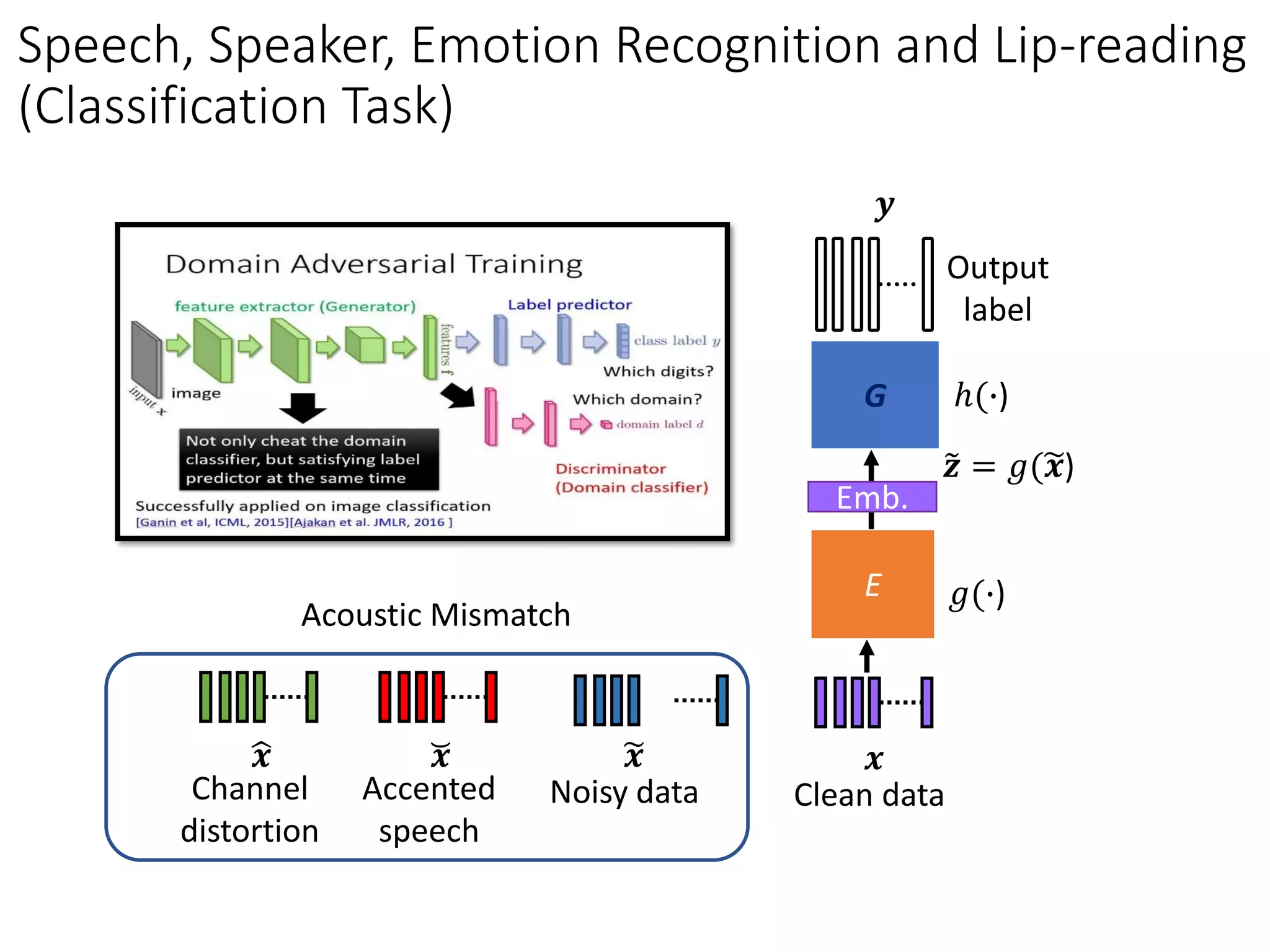
![Domain Adversarial Training
feature extractor (Generator)
Discriminator
(Domain classifier)
image
Label predictor
Which digits?
Not only cheat the domain
classifier, but satisfying label
predictor at the same time
More speech-related applications in Part III.
Successfully applied on image classification
[Ganin et al, ICML, 2015][Ajakan et al. JMLR, 2016 ]
Which domain?](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-47-2048.jpg)
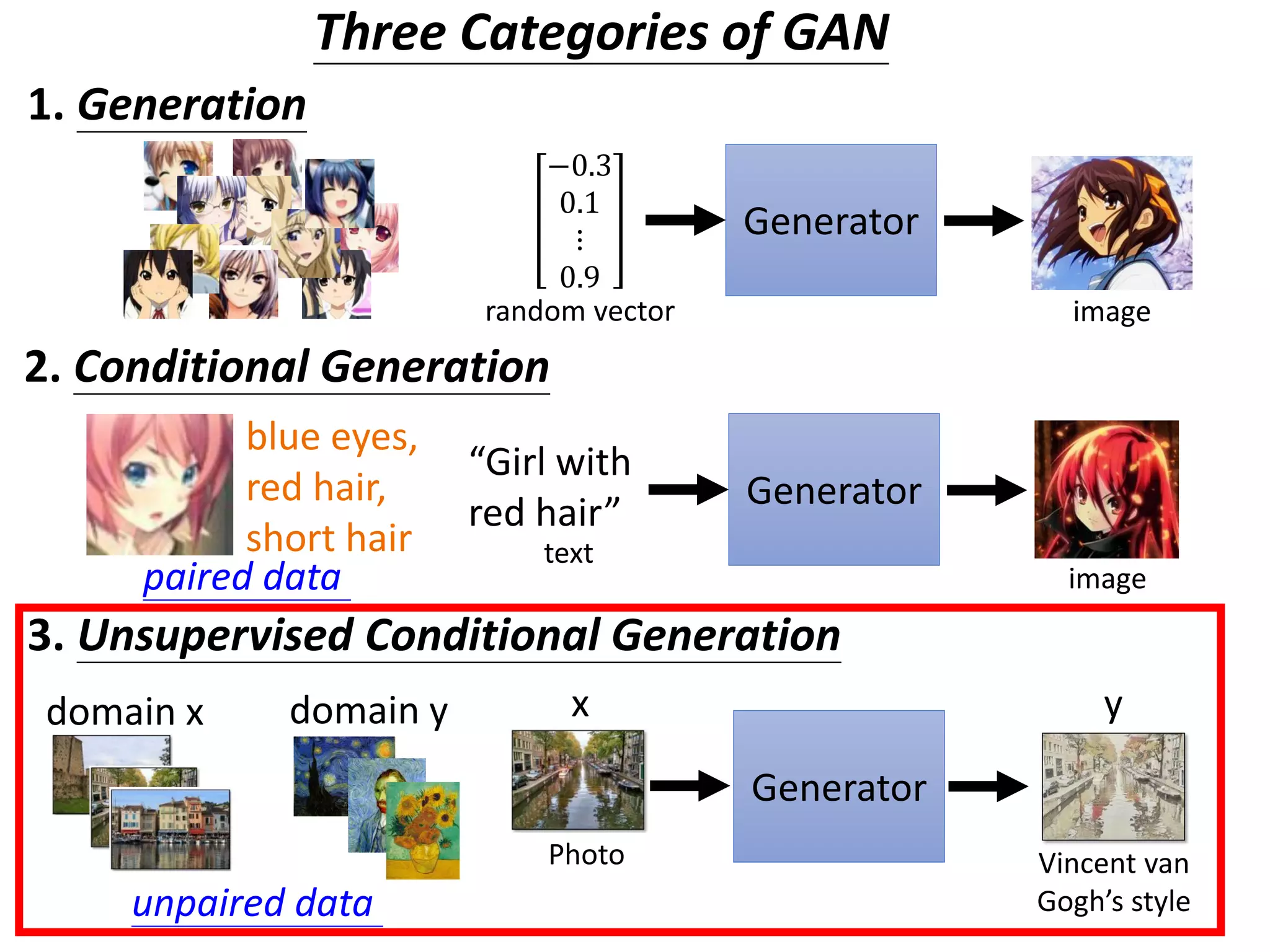
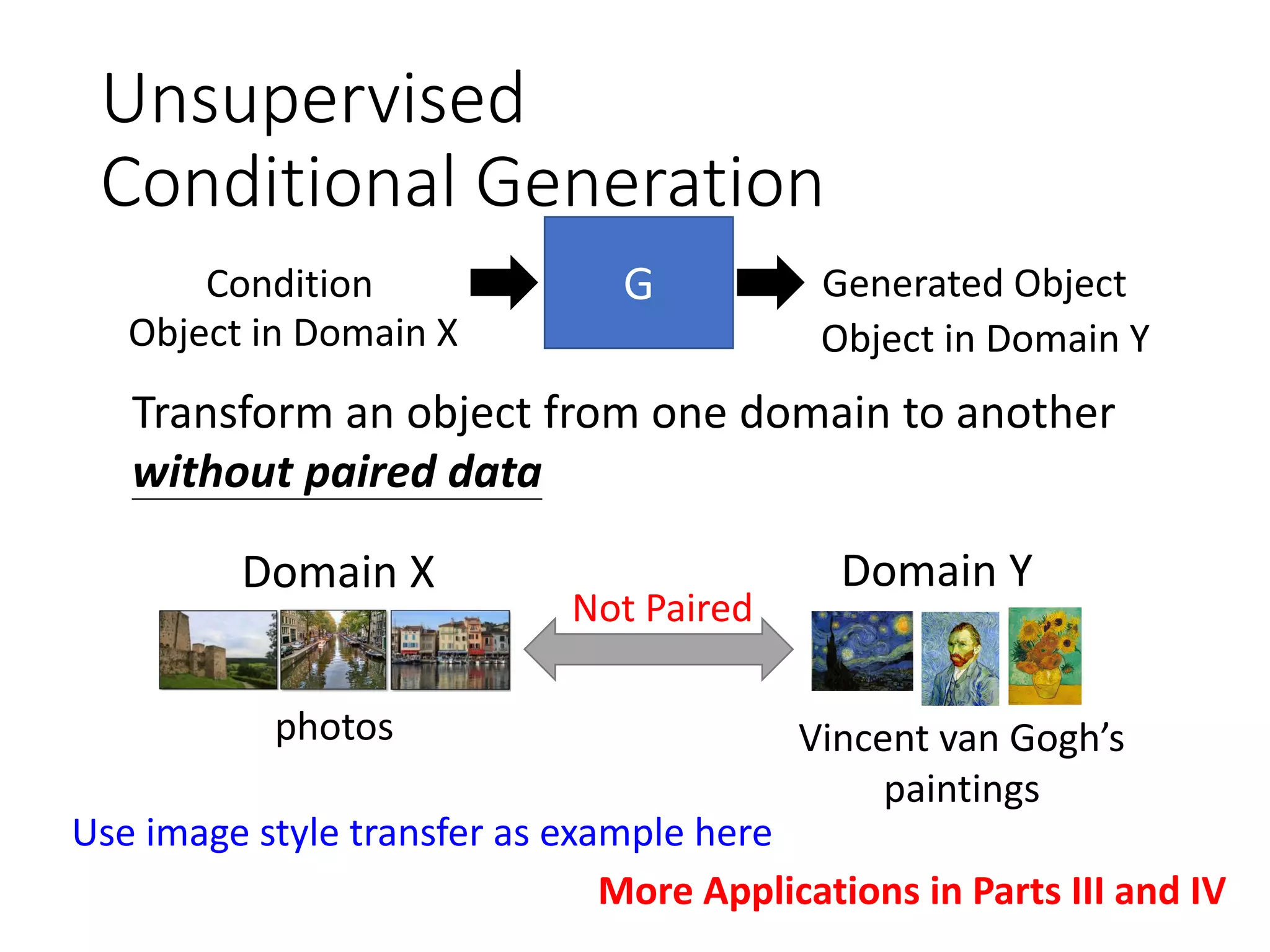
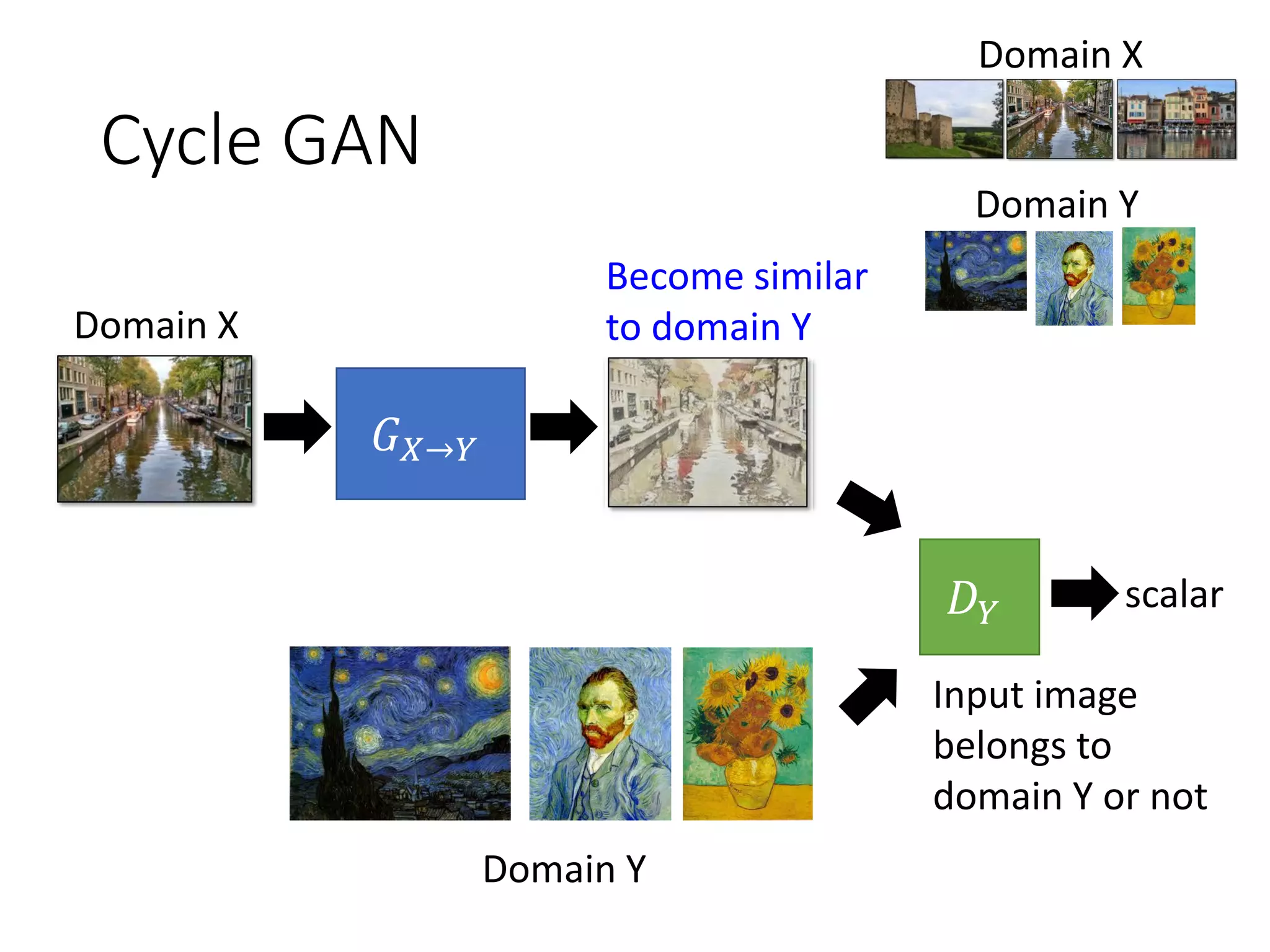
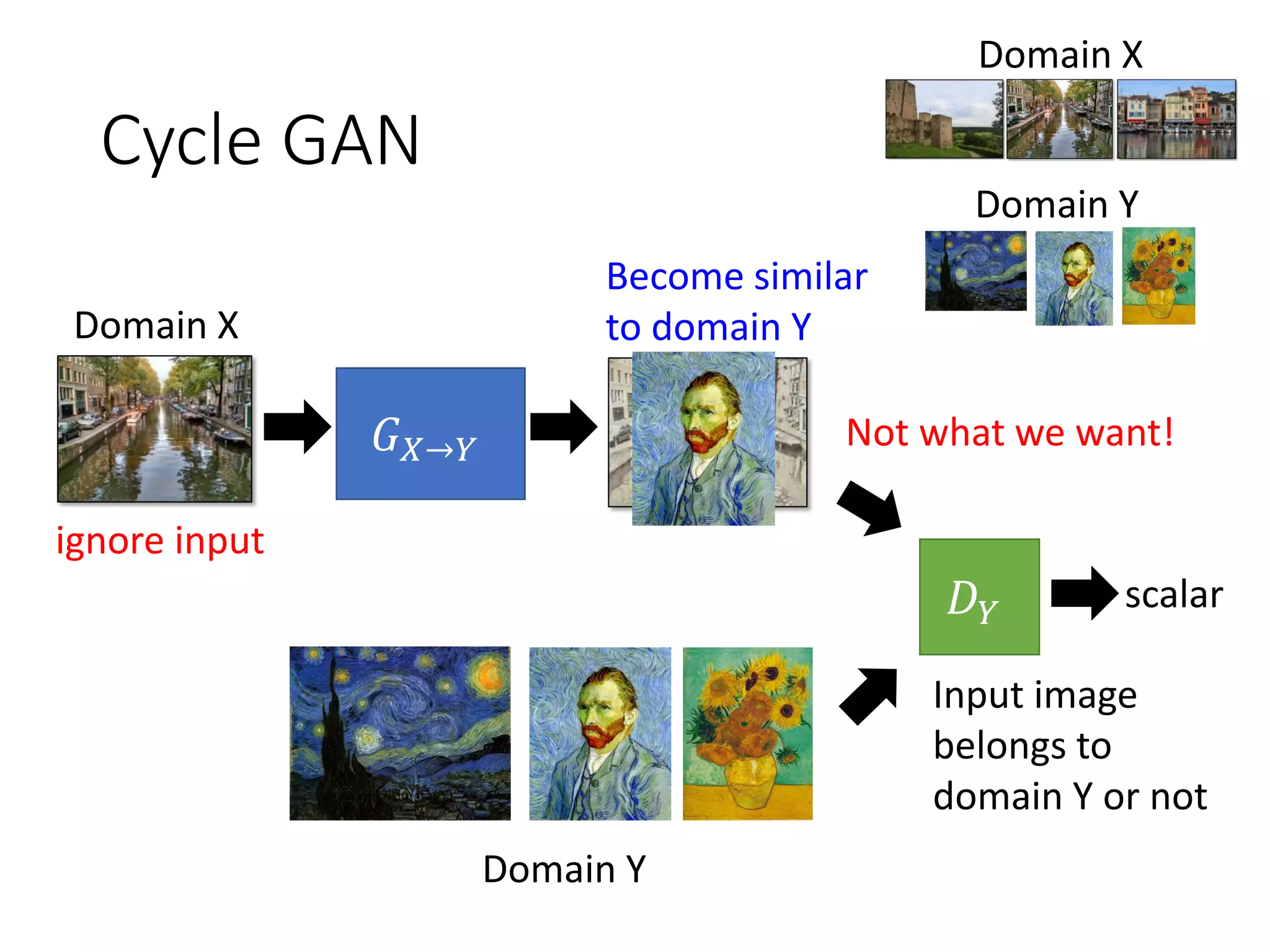
![Cycle GAN
𝐺 𝑋→𝑌
Domain X
Domain Y
𝐷 𝑌
Domain X
scalar
Input image
belongs to
domain Y or not
Become similar
to domain Y
Not what we want!
ignore input
[Tomer Galanti, et al. ICLR, 2018]
The issue can be avoided by network design.
Simpler generator makes the input and
output more closely related.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-53-2048.jpg)
![Cycle GAN
𝐺 𝑋→𝑌
Domain X
Domain Y
𝐷 𝑌
Domain X
scalar
Input image
belongs to
domain Y or not
Become similar
to domain Y
Encoder
Network
Encoder
Network
pre-trained
as close as
possible
Baseline of DTN [Yaniv Taigman, et al., ICLR, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-54-2048.jpg)
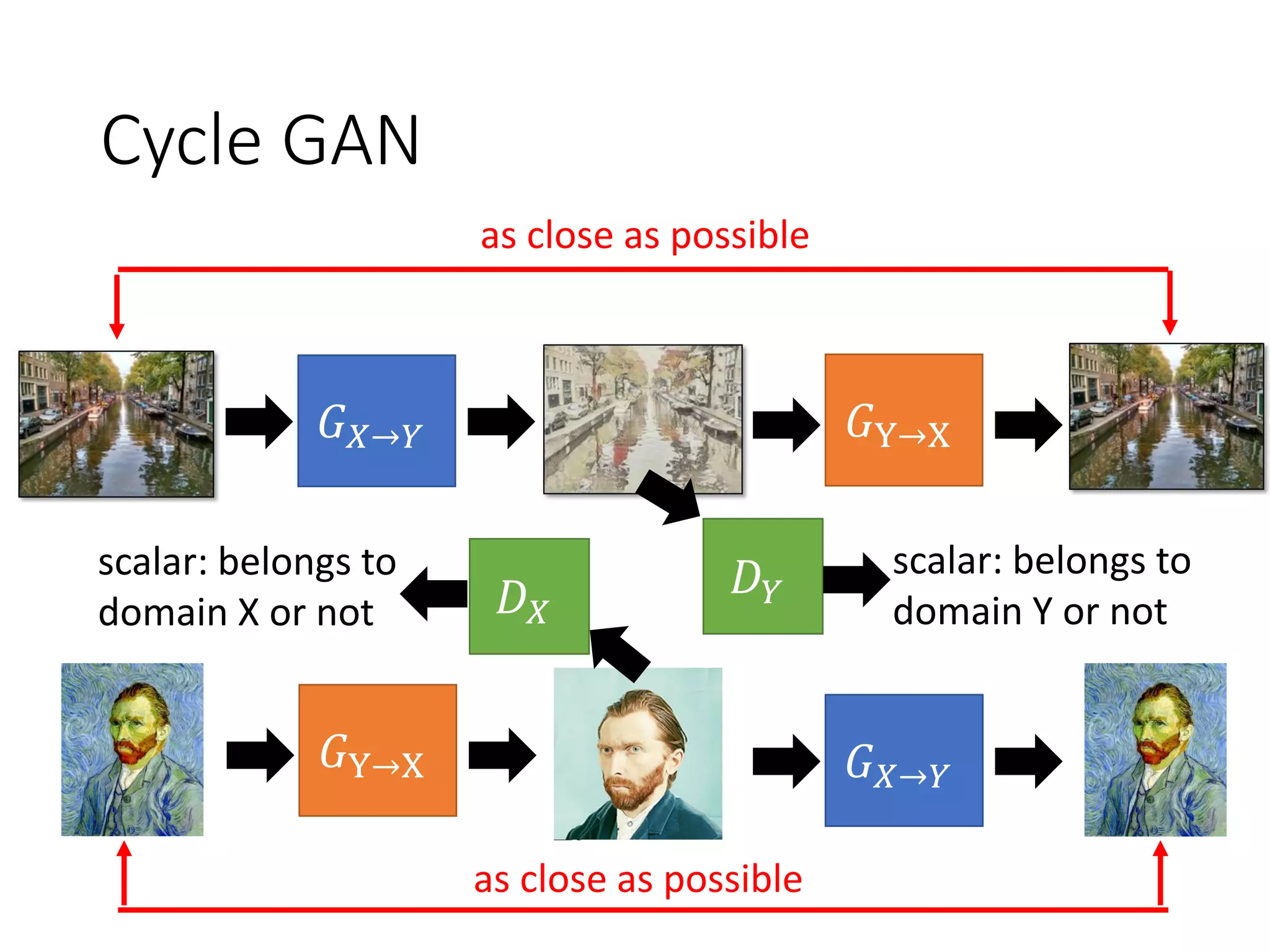
![Cycle GAN
𝐺 𝑋→𝑌
𝐷 𝑌
Domain Y
scalar
Input image
belongs to
domain Y or not
𝐺Y→X
as close as possible
Lack of information
for reconstruction
[Jun-Yan Zhu, et al., ICCV, 2017]
Cycle consistency](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-55-2048.jpg)
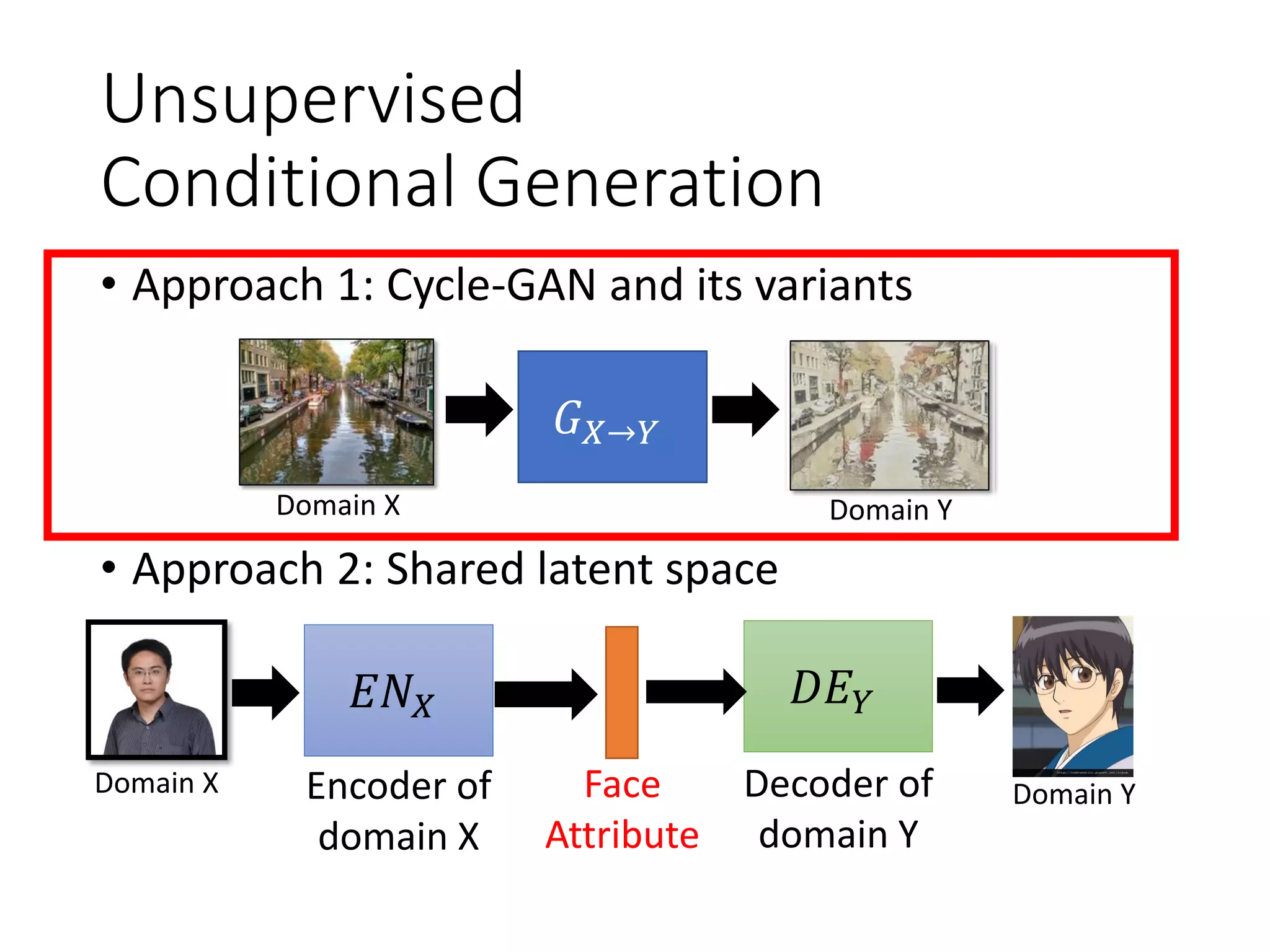
![Cycle GAN
Dual GAN
Disco GAN
[Jun-Yan Zhu, et al., ICCV, 2017]
[Zili Yi, et al., ICCV, 2017]
[Taeksoo Kim, et
al., ICML, 2017]
For multiple domains,
considering starGAN
[Yunjey Choi, arXiv, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-57-2048.jpg)
![Issue of Cycle Consistency
• CycleGAN: a Master of Steganography
[Casey Chu, et al., NIPS workshop, 2017]
𝐺Y→X𝐺 𝑋→𝑌
The information is hidden.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-58-2048.jpg)
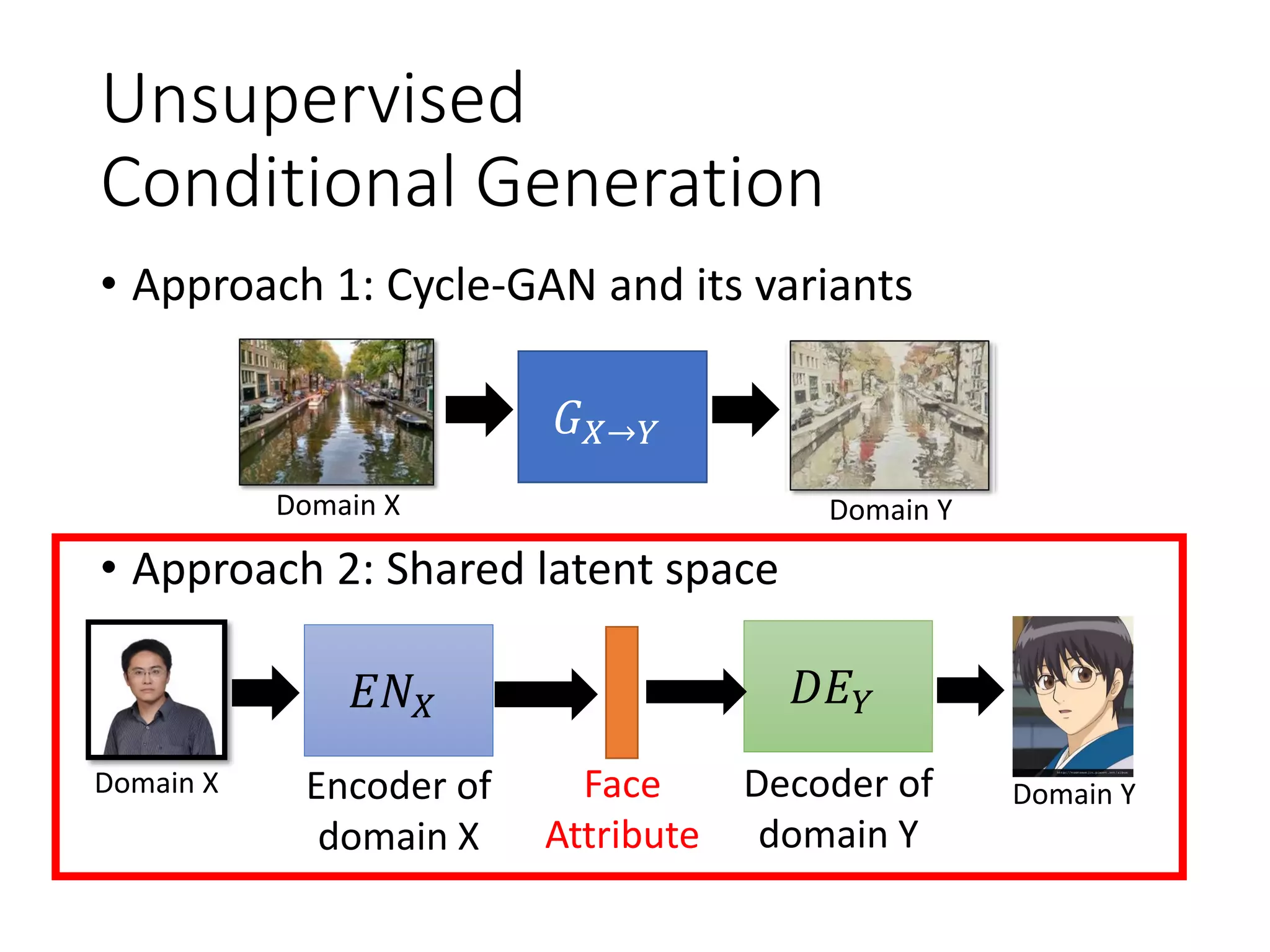
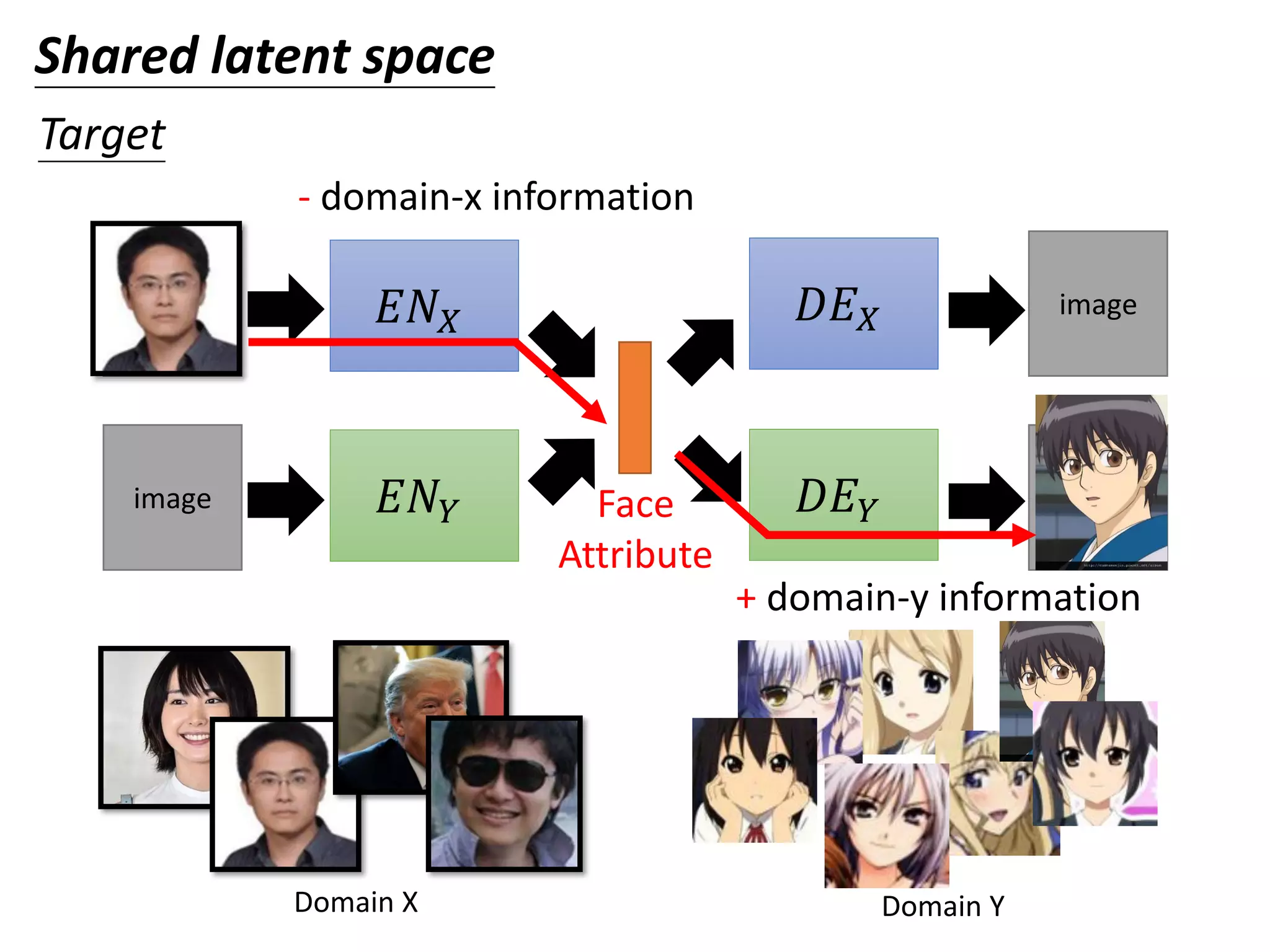
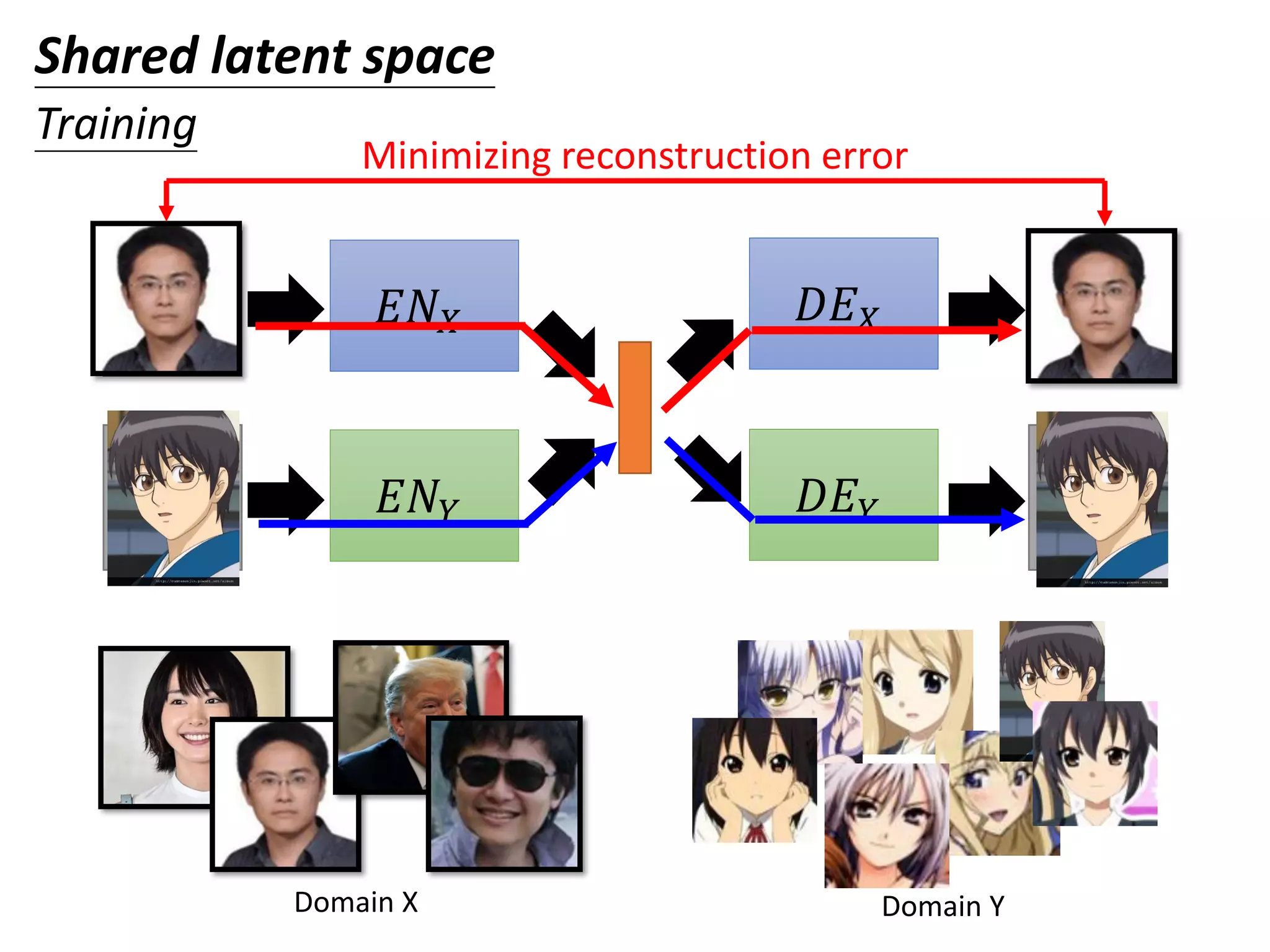
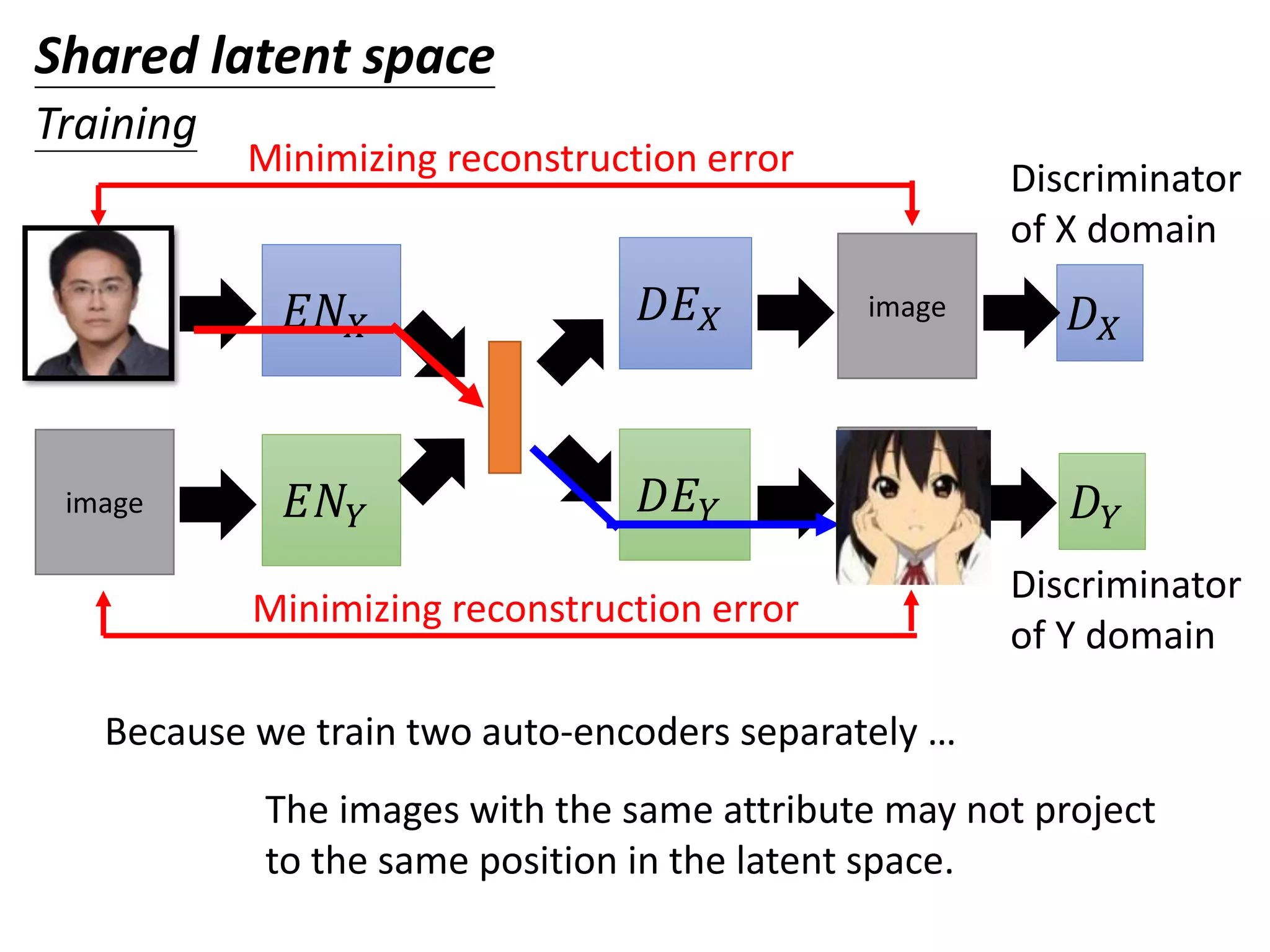
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋image
image
image
image
Minimizing reconstruction error
The domain discriminator forces the output of 𝐸𝑁𝑋 and
𝐸𝑁𝑌 have the same distribution.
From 𝐸𝑁𝑋 or 𝐸𝑁𝑌
𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared latent space
Training
Domain
Discriminator
𝐸𝑁𝑋 and 𝐸𝑁𝑌 fool the
domain discriminator
[Guillaume Lample, et al., NIPS, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-63-2048.jpg)
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋image
image
image
image
𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared latent space
Training
Cycle Consistency:
Used in ComboGAN [Asha Anoosheh, et al., arXiv, 017]
Minimizing reconstruction error](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-64-2048.jpg)
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋image
image
image
image
𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared latent space
Training
Semantic Consistency:
Used in DTN [Yaniv Taigman, et al., ICLR, 2017] and
XGAN [Amélie Royer, et al., arXiv, 2017]
To the same
latent space](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-65-2048.jpg)
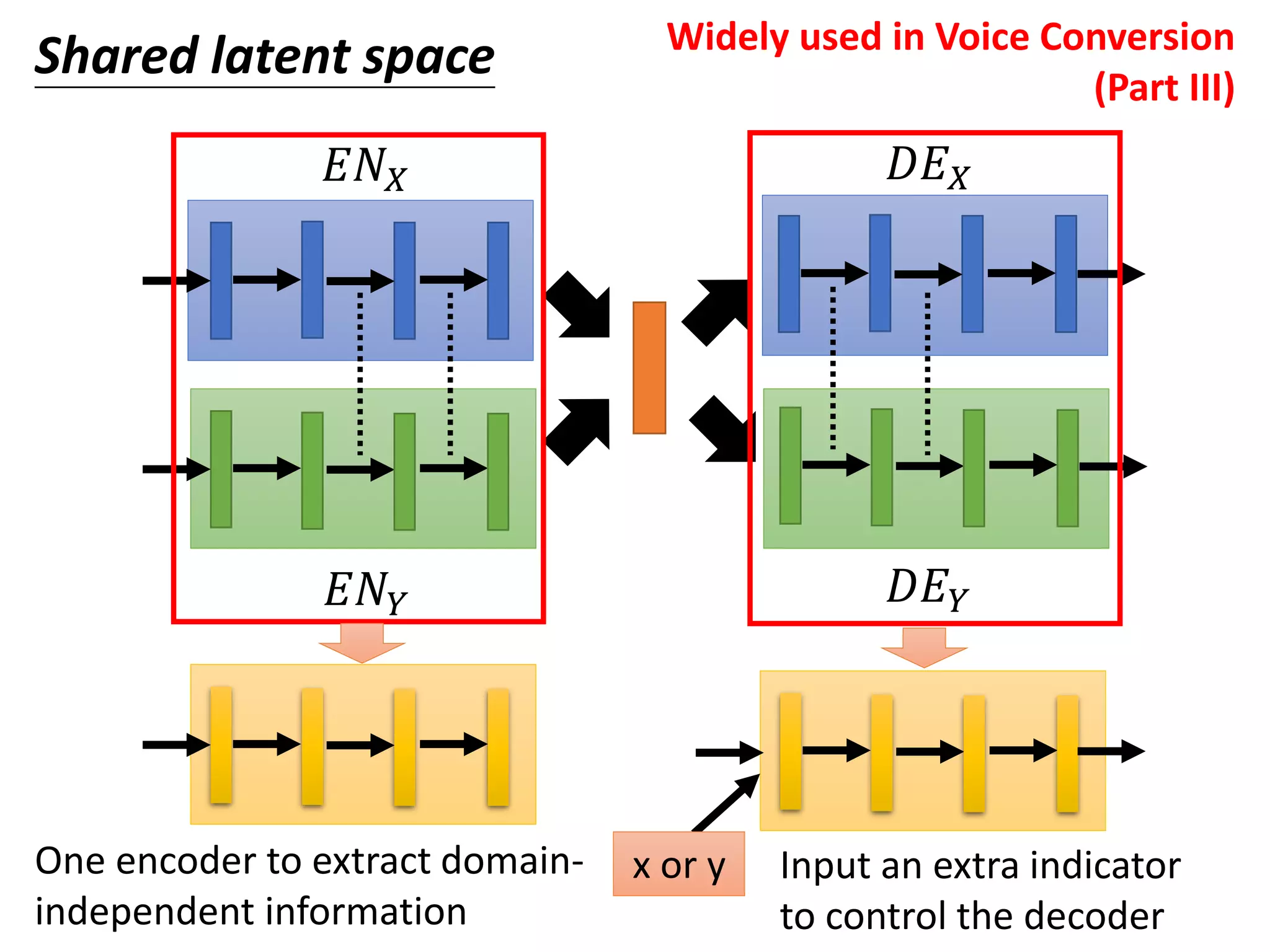
![Sharing the parameters of encoders and decoders
Shared latent space
𝐸𝑁 𝑋
𝐸𝑁𝑌
𝐷𝐸 𝑋
𝐷𝐸 𝑌
Couple GAN[Ming-Yu Liu, et al., NIPS, 2016]
UNIT[Ming-Yu Liu, et al., NIPS, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-66-2048.jpg)








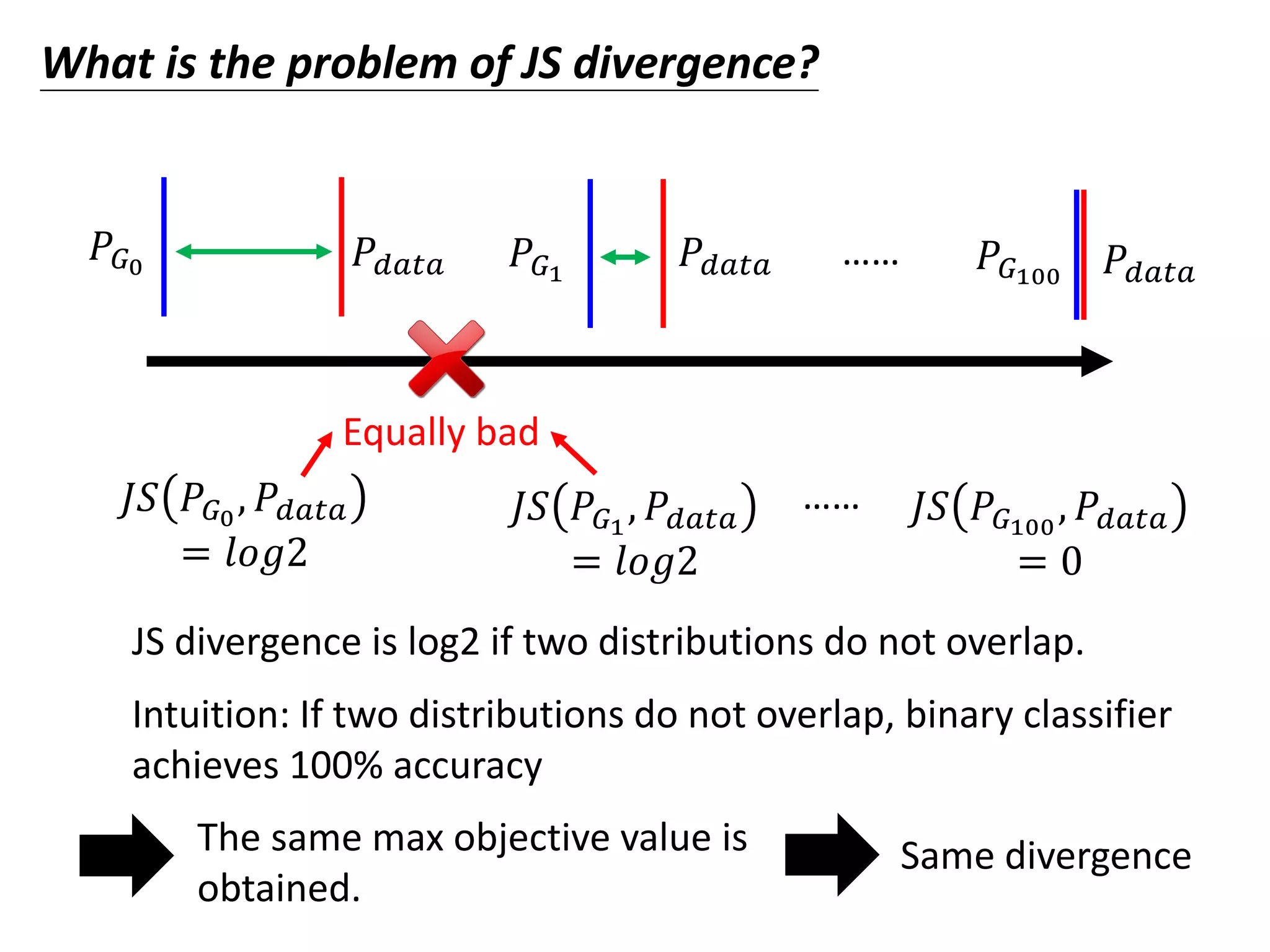
![Discriminator 𝐺∗
= 𝑎𝑟𝑔 min
𝐺
𝐷𝑖𝑣 𝑃𝐺, 𝑃𝑑𝑎𝑡𝑎
Discriminator
: data sampled from 𝑃𝑑𝑎𝑡𝑎
: data sampled from 𝑃𝐺
train
𝑉 𝐺, 𝐷 = 𝐸 𝑥∼𝑃 𝑑𝑎𝑡𝑎
𝑙𝑜𝑔𝐷 𝑥 + 𝐸 𝑥∼𝑃 𝐺
𝑙𝑜𝑔 1 − 𝐷 𝑥
Example Objective Function for D
(G is fixed)
𝐷∗ = 𝑎𝑟𝑔 max
𝐷
𝑉 𝐷, 𝐺Training:
Using the example objective
function is exactly the same as
training a binary classifier.
[Goodfellow, et al., NIPS, 2014]
The maximum objective value
is related to JS divergence.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-79-2048.jpg)

![𝐺∗
= 𝑎𝑟𝑔 min
𝐺
𝐷𝑖𝑣 𝑃𝐺, 𝑃𝑑𝑎𝑡𝑎max
𝐷
𝑉 𝐺, 𝐷
The maximum objective value
is related to JS divergence.
• Initialize generator and discriminator
• In each training iteration:
Step 1: Fix generator G, and update discriminator D
Step 2: Fix discriminator D, and update generator G
𝐷∗ = 𝑎𝑟𝑔 max
𝐷
𝑉 𝐷, 𝐺
[Goodfellow, et al., NIPS, 2014]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-81-2048.jpg)
![Using the divergence
you like ☺
[Sebastian Nowozin, et al., NIPS, 2016]
Can we use other divergence?](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-82-2048.jpg)



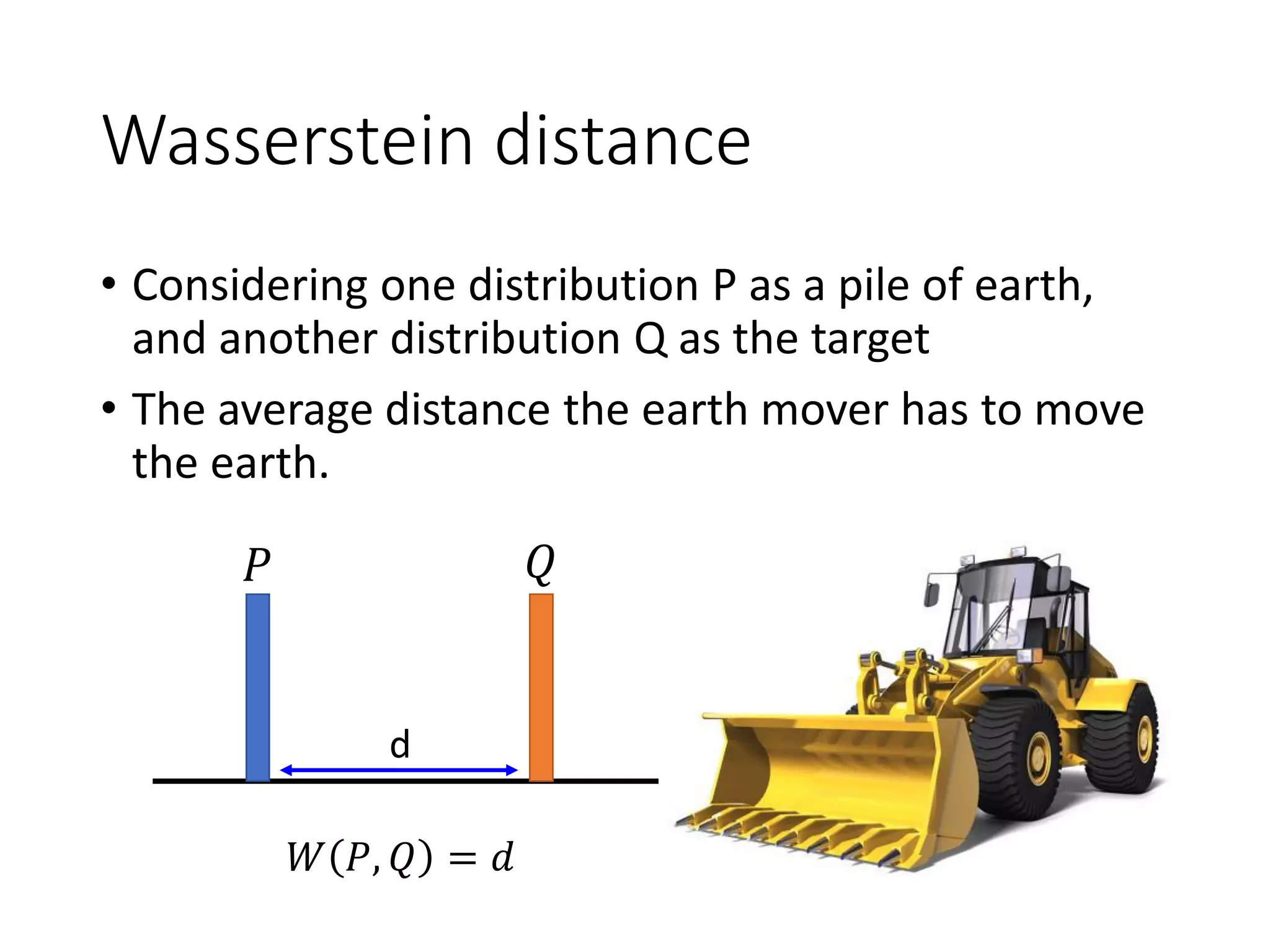
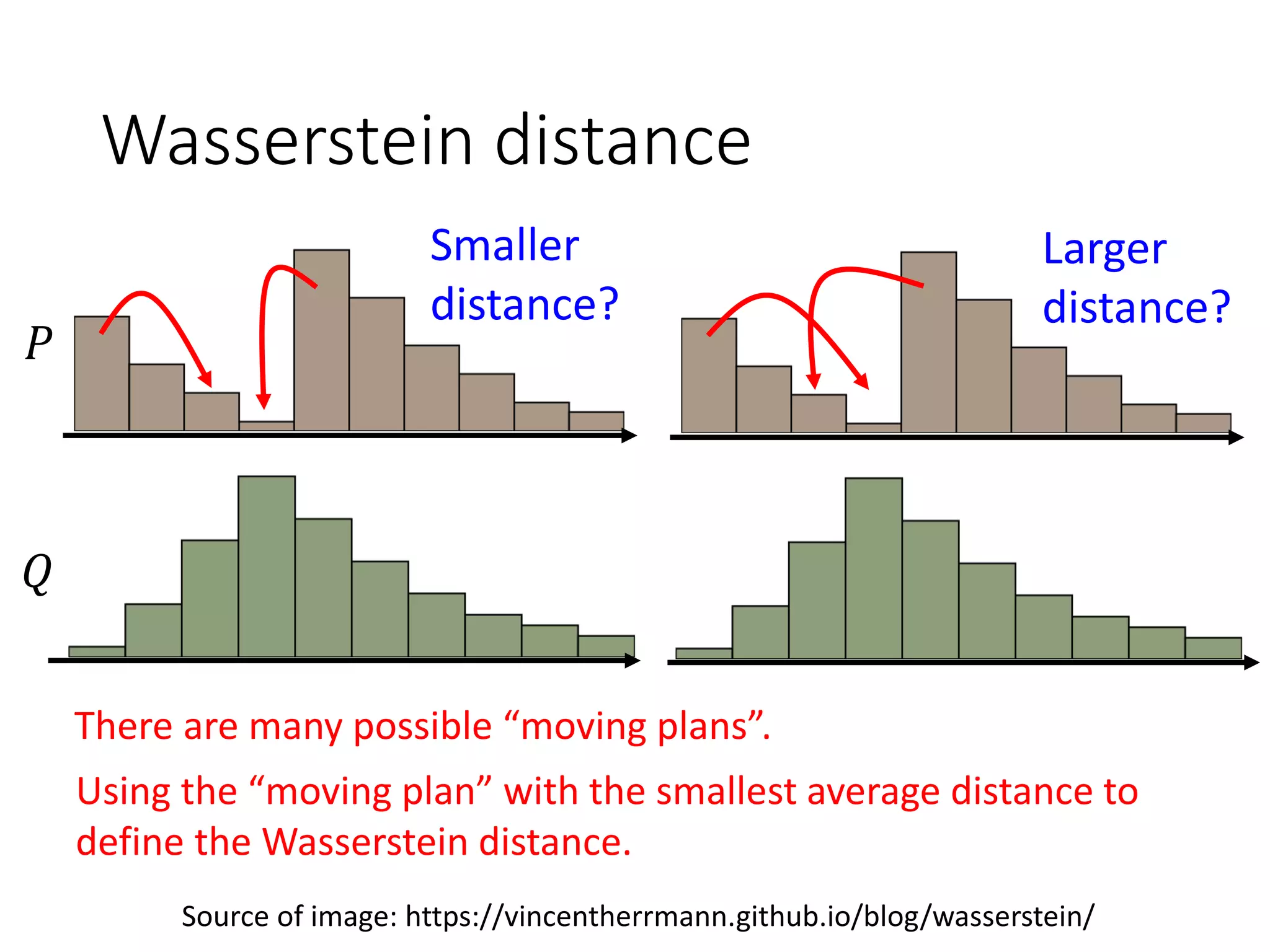

![WGAN
max
𝐷∈1−𝐿𝑖𝑝𝑠𝑐ℎ𝑖𝑡𝑧
𝐸 𝑥~𝑃 𝑑𝑎𝑡𝑎
𝐷 𝑥 − 𝐸 𝑥~𝑃 𝐺
𝐷 𝑥
Evaluate Wasserstein distance between 𝑃𝑑𝑎𝑡𝑎 and 𝑃𝐺
[Martin Arjovsky, et al., arXiv, 2017]
How to fulfill this constraint?D has to be smooth enough.
real
−∞
generated
D
∞
Without the constraint, the
training of D will not converge.
Keeping the D smooth forces
D(x) become ∞ and −∞](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-91-2048.jpg)
![• Original WGAN → Weight Clipping [Martin Arjovsky, et al.,
arXiv, 2017]
• Improved WGAN → Gradient Penalty [Ishaan Gulrajani,
NIPS, 2017]
• Spectral Normalization → Keep gradient norm
smaller than 1 everywhere [Miyato, et al., ICLR, 2018]
Force the parameters w between c and -c
After parameter update, if w > c, w = c; if w < -c, w = -c
Keep the gradient close to 1
max
𝐷∈1−𝐿𝑖𝑝𝑠𝑐ℎ𝑖𝑡𝑧
𝐸 𝑥~𝑃 𝑑𝑎𝑡𝑎
𝐷 𝑥 − 𝐸 𝑥~𝑃 𝐺
𝐷 𝑥
real
samples
Keep the gradient
close to 1
[Kodali, et al., arXiv, 2017]
[Wei, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-92-2048.jpg)
![More Tips
• Improved techniques for training GANs
• Tips in DCGAN [Alec Radford, et al., ICLR 2016]
• Guideline for network architecture design for
image generation
• Tips from Soumith
• https://github.com/soumith/ganhacks
• Tips from BigGAN [Andrew Brock, et al., arXiv, 2018]
[Tim Salimans, et al., NIPS, 2016]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-93-2048.jpg)
![Inception Score
Off-the-shelf
Image Classifier
𝑥 𝑃 𝑦|𝑥
Concentrated distribution
means higher visual quality
CNN𝑥1
𝑃 𝑦1|𝑥1
Uniform distribution
means higher variety
CNN𝑥2
𝑃 𝑦2|𝑥2
CNN𝑥3
𝑃 𝑦3|𝑥3
…
𝑃 𝑦 =
1
𝑁
𝑛
𝑃 𝑦 𝑛|𝑥 𝑛
[Tim Salimans, et al., NIPS, 2016]
𝑥: image
𝑦: class (output of CNN)
e.g. Inception net,
VGG, etc.
class 1
class 2
class 3](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-95-2048.jpg)
![Inception Score
=
𝑥
𝑦
𝑃 𝑦|𝑥 𝑙𝑜𝑔𝑃 𝑦|𝑥
−
𝑦
𝑃 𝑦 𝑙𝑜𝑔𝑃 𝑦
Negative entropy of P(y|x)
Entropy of P(y)
Inception Score
𝑃 𝑦 =
1
𝑁
𝑛
𝑃 𝑦 𝑛|𝑥 𝑛
𝑃 𝑦|𝑥
class 1
class 2
class 3
[Tim Salimans, et al., NIPS 2016]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-96-2048.jpg)
![Fréchet Inception Distance (FID)
blue points: latent representation of Inception net for
the generated images
red points: latent representation of Inception net for
the read images
FID =
Fréchet distance
between the two
Gaussians
[Martin Heusel, et al., NIPS, 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-97-2048.jpg)
![To learn more about evaluation …
Pros and cons of GAN evaluation measures
https://arxiv.org/abs/1802.03446
[Ali Borji, 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-98-2048.jpg)



![Speech Enhancement
• Neural network models for spectral mapping
• Typical objective function
➢ Mean square error (MSE) [Xu et al., TASLP 2015], L1 [Pascual et al., Interspeech
2017], likelihood [Chai et al., MLSP 2017], STOI [Fu et al., TASLP 2018].
Enhancing
➢ GAN is used as a new objective function to estimate the parameters in G.
➢Model structures of G: DNN [Wang et al. NIPS 2012; Xu et al., SPL 2014], DDAE
[Lu et al., Interspeech 2013], RNN (LSTM) [Chen et al., Interspeech 2015;
Weninger et al., LVA/ICA 2015], CNN [Fu et al., Interspeech 2016].
G Output
Objective function](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-115-2048.jpg)
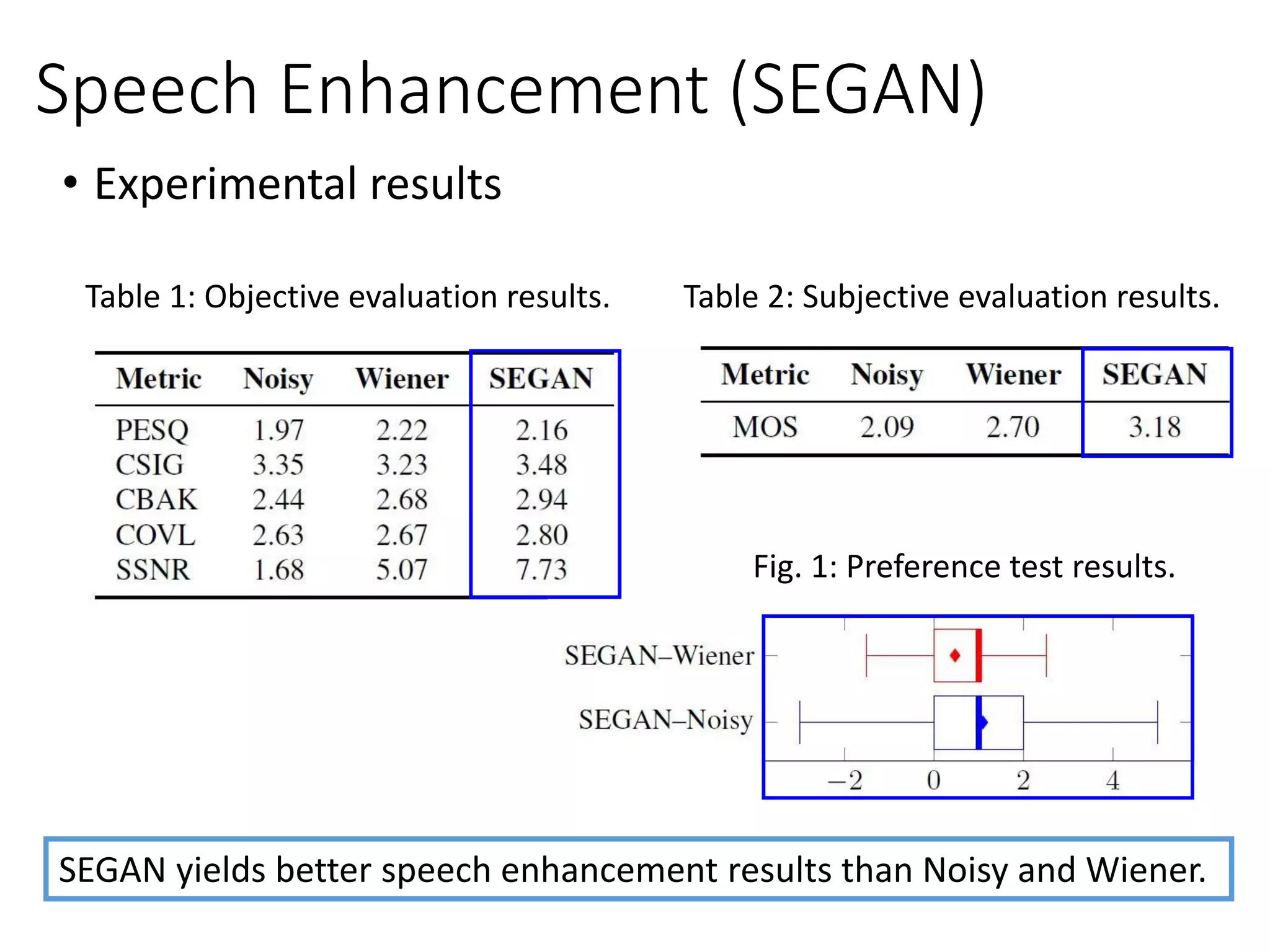
![Speech Enhancement
• Speech enhancement GAN (SEGAN) [Pascual et al., Interspeech 2017]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-116-2048.jpg)
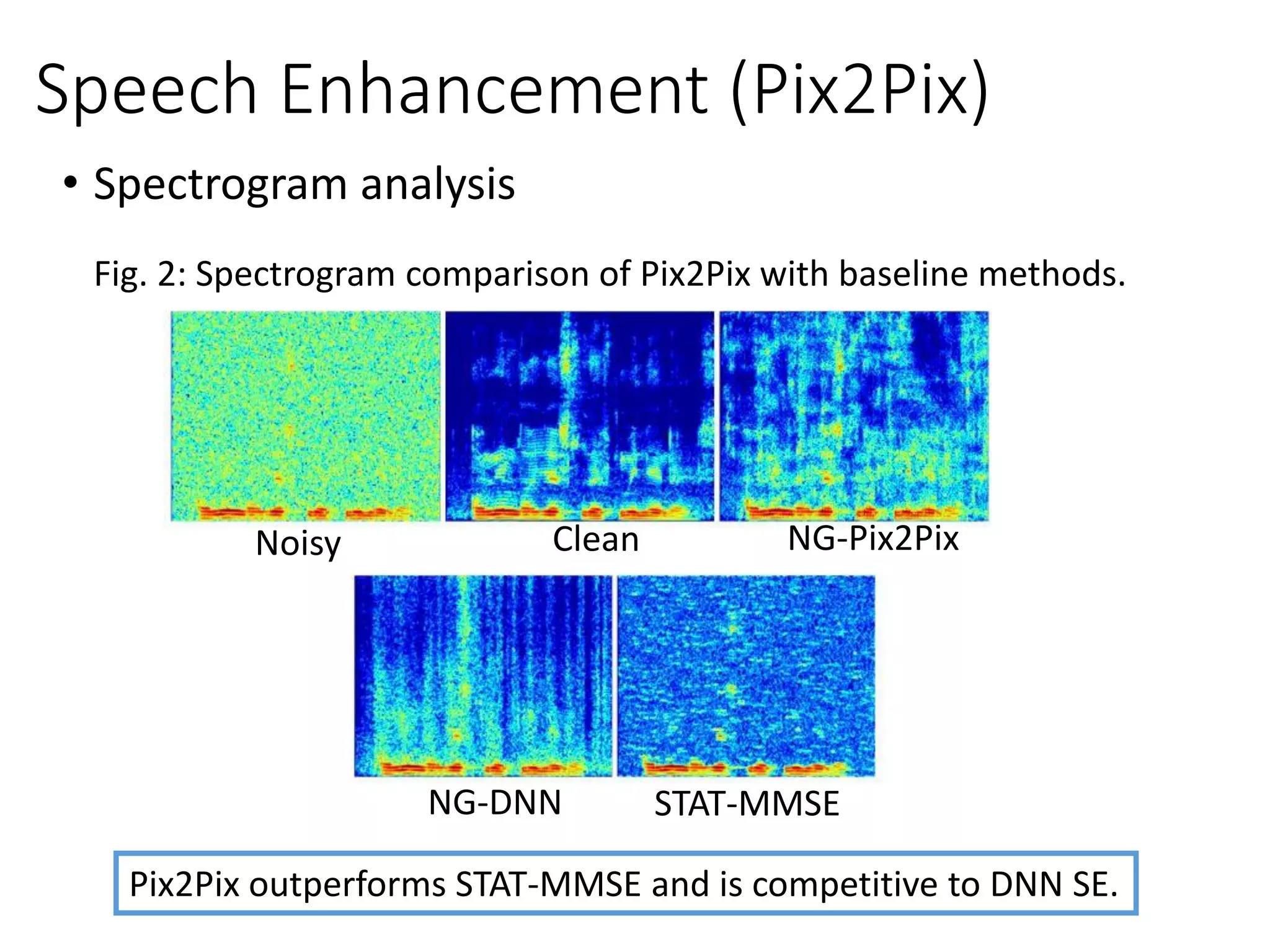
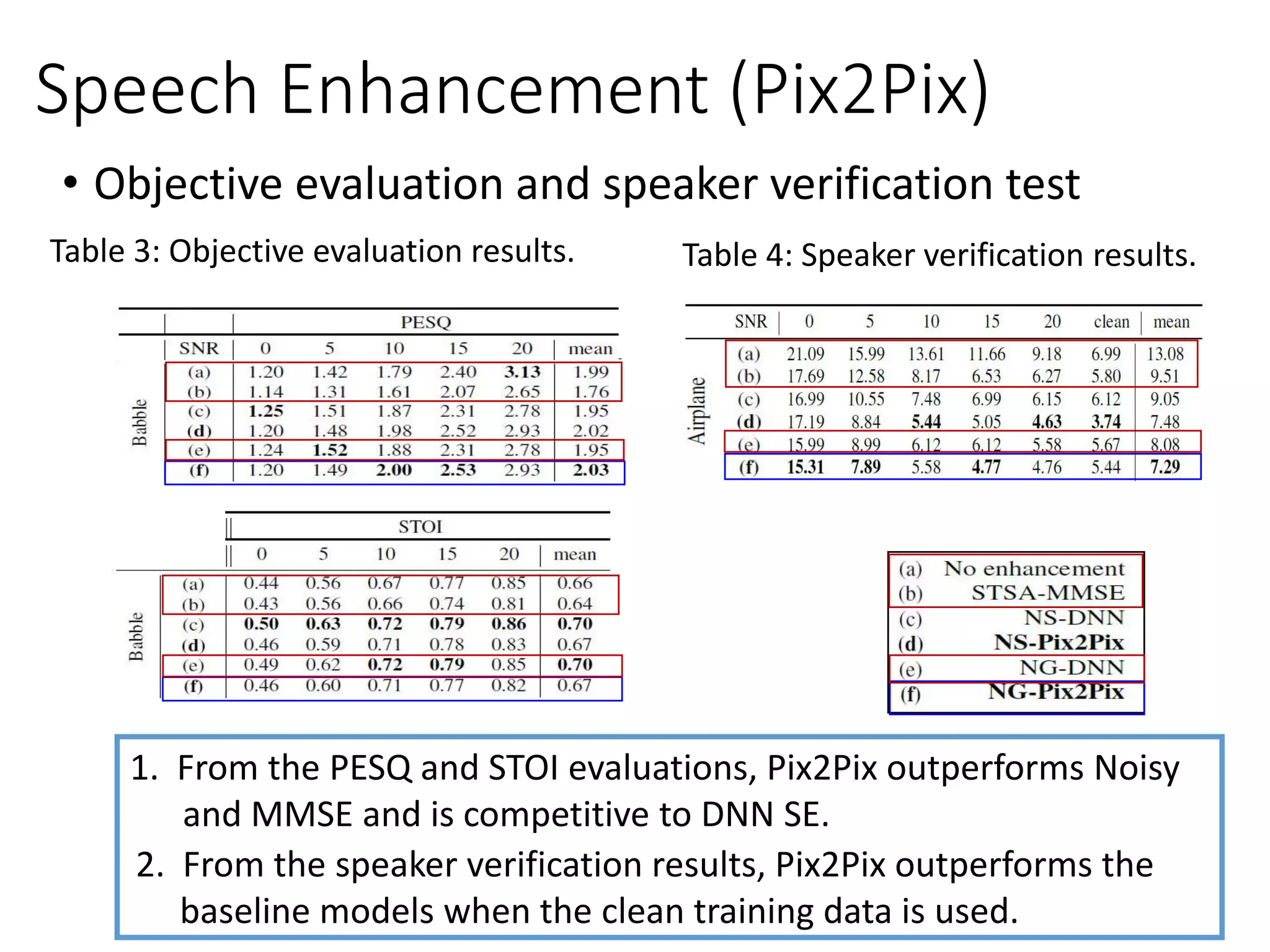
![• Pix2Pix [Michelsanti et al., Interpsech 2017]
D Scalar
Clean
Noisy
(Fake/Real)
Output
Noisy
G
Noisy Output Clean
Speech Enhancement](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-118-2048.jpg)
![• Frequency-domain SEGAN (FSEGAN) [Donahue et al., ICASSP 2018]
D Scalar
Clean
Noisy
(Fake/Real)
Output
Noisy
G
Noisy Output Clean
Speech Enhancement](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-121-2048.jpg)

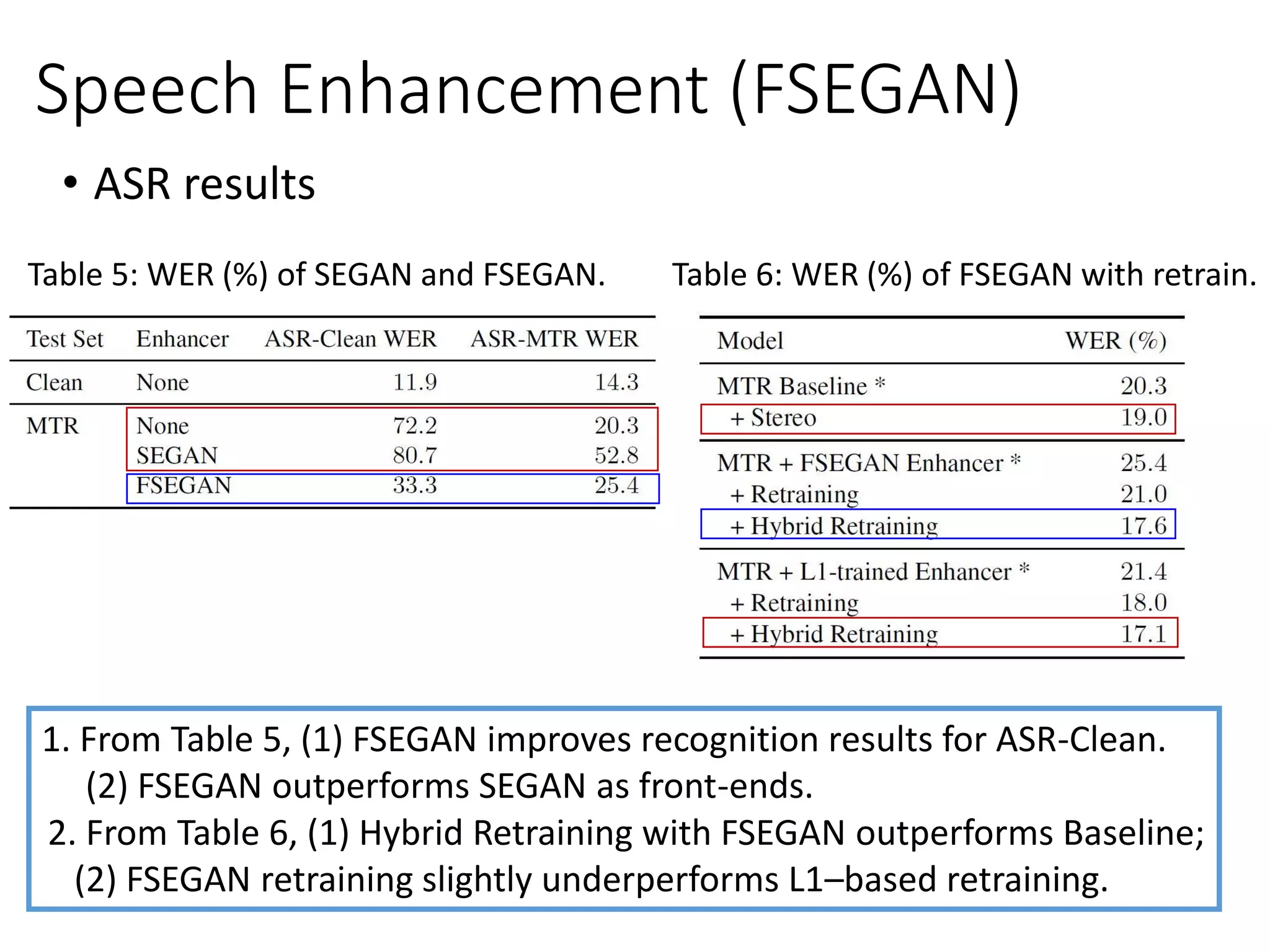
![• GAN for spectral magnitude mask estimation (MMS-GAN)
[Ashutosh Pandey and Deliang Wang, ICASSP 2018]
D Scalar
Ref.
mask
Noisy
(Fake/Real)
Output
mask
Noisy
G
Noisy Output mask Ref. mask
Speech Enhancement
We don’t know exactly what D functions.
Our ICML 2019 paper shed some lights on a potential future direction.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-125-2048.jpg)
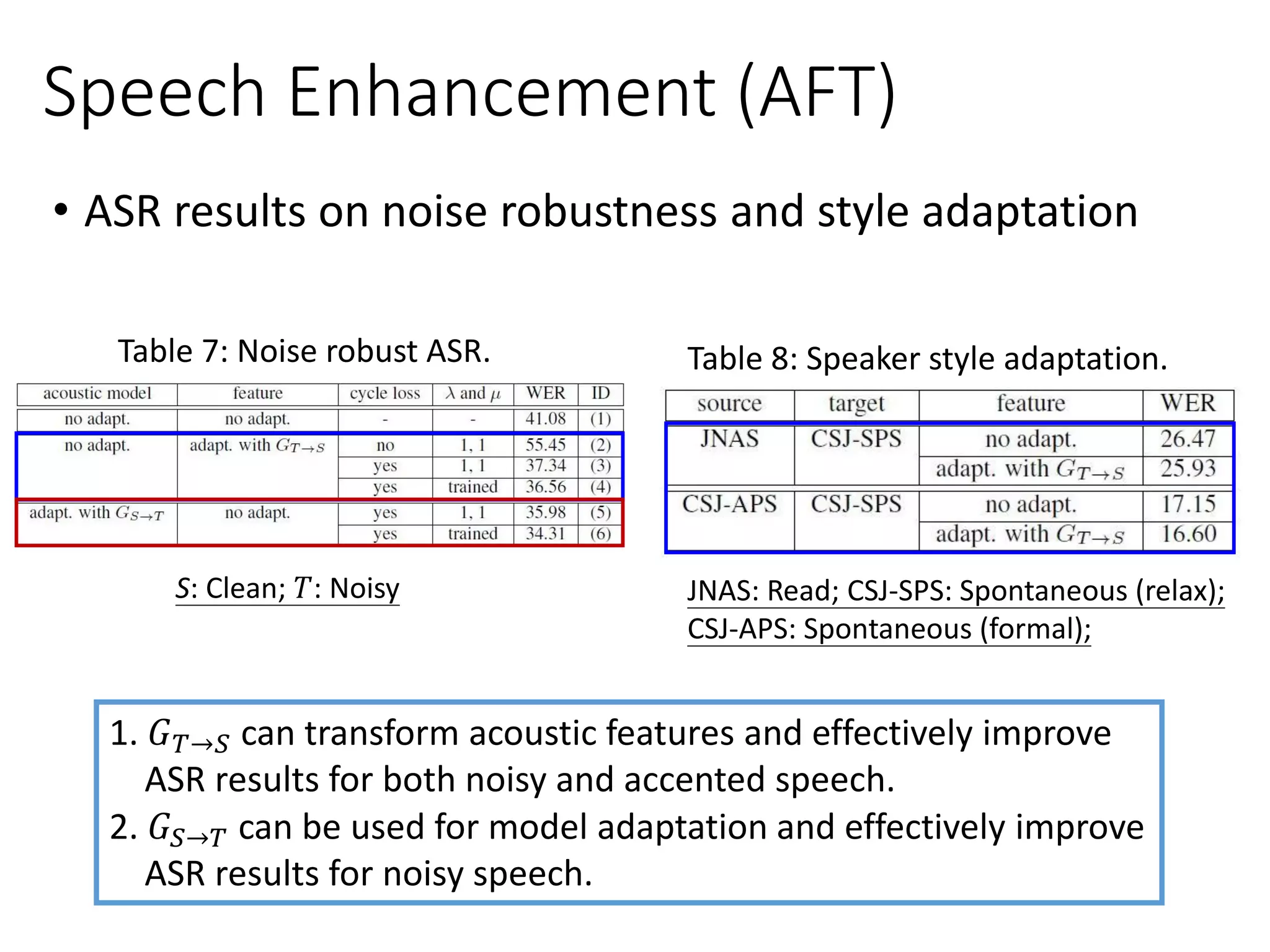
![𝐺𝑆→𝑇 𝐺 𝑇→𝑆
as close as possible
𝐷 𝑇
Scalar: belongs to
domain T or not
𝐺 𝑇→𝑆 𝐺𝑆→𝑇
as close as possible
𝐷𝑆
Scalar: belongs to
domain S or not
Speech Enhancement (AFT)
• Cycle-GAN-based acoustic feature transformation (AFT)
[Mimura et al., ASRU 2017]
𝑉𝐹𝑢𝑙𝑙 = 𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌 +𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌
+𝜆 𝑉𝐶𝑦𝑐(𝐺 𝑋→𝑌, 𝐺 𝑌→𝑋)
Noisy Enhanced Noisy
Clean Syn. Noisy Clean](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-126-2048.jpg)
![• Postfilter for synthesized or transformed speech
➢ Conventional postfilter approaches for G estimation include global variance
(GV) [Toda et al., IEICE 2007], variance scaling (VS) [Sil’en et al., Interpseech
2012], modulation spectrum (MS) [Takamichi et al., ICASSP 2014],DNN with
MSE criterion [Chen et al., Interspeech 2014; Chen et al., TASLP 2015].
➢ GAN is used a new objective function to estimate the parameters in G.
Postfilter
Synthesized
spectral texture
Natural
spectral texture
G Output
Objective function
Speech
synthesizer
Voice
conversion
Speech
enhancement](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-129-2048.jpg)
![• GAN postfilter [Kaneko et al., ICASSP 2017]
➢ Traditional MMSE criterion results in statistical averaging.
➢ GAN is used as a new objective function to estimate the parameters in G.
➢ The proposed work intends to further improve the naturalness of
synthesized speech or parameters from a synthesizer.
Postfilter
Synthesized
Mel cepst. coef.
Natural
Mel cepst. coef.
D
Nature
or
Generated
Generated
Mel cepst. coef.
G](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-130-2048.jpg)
![Speech Synthesis
• Input: linguistic features; Output: speech parameters
𝒄ො𝒄
𝑮 𝑺𝑺
Natural
speech
parameters
Generated
speech
parameters
Linguistic
features
sp sp
Objective function
Minimum
generation error
(MGE), MSE
• Speech synthesis with anti-spoofing verification (ASV)
[Saito et al., ICASSP 2017]
𝐿 𝐷 𝒄, ො𝒄 = 𝐿 𝐷,1 𝒄 + 𝐿 𝐷,0 ො𝒄
𝐿 𝐷,1 𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log( 𝐷 𝒄 𝑡 )…NAT
𝐿 𝐷,0 ො𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log(1 − 𝐷 ො𝒄 𝑡 )…SYN
𝐿 𝒄, ො𝒄 = 𝐿 𝐺 𝒄, ො𝒄 + 𝜔 𝐷
𝐸 𝐿 𝐺
𝐸 𝐿 𝐷
𝐿 𝐷,1 ො𝒄
Minimum generation error (MGE)
with adversarial loss.
𝒄ො𝒄
𝑮 𝑺𝑺
Natural
speech
parameters
Generated
speech
parameters
Gen.
Nature
𝑫 𝑨𝑺𝑽𝝓(∙)
Linguistic
features
sp sp
MGE](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-134-2048.jpg)
![• Speech synthesis with GAN (SS-GAN) [Saito et al., TASLP 2018]
𝐿 𝐷 𝒄, ො𝒄 = 𝐿 𝐷,1 𝒄 + 𝐿 𝐷,0 ො𝒄
𝐿 𝐷,1 𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log( 𝐷 𝒄 𝑡 )…NAT
𝐿 𝐷,0 ො𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log(1 − 𝐷 ො𝒄 𝑡 )…SYN
𝐿 𝒄, ො𝒄 = 𝐿 𝐺 𝒄, ො𝒄 + 𝜔 𝐷
𝐸 𝐿 𝐺
𝐸 𝐿 𝐷
𝐿 𝐷,1 ො𝒄
Minimum generation error (MGE)
with adversarial loss.
𝒄ො𝒄
Speech Synthesis
𝑮 𝑺𝑺
Natural
speech
parameters
Generated
speech
parameters
Gen.
Nature
𝑫𝝓(∙)
Linguistic
features
𝑫 𝑨𝑺𝑽
sp, f0, duration sp, f0, duration
MGE](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-136-2048.jpg)

![• Convert (transform) speech from source to target
➢ Conventional VC approaches include Gaussian mixture model (GMM) [Toda
et al., TASLP 2007], non-negative matrix factorization (NMF) [Wu et al., TASLP
2014; Fu et al., TBME 2017], locally linear embedding (LLE) [Wu et al.,
Interspeech 2016], variational autoencoder (VAE) [Hsu et al., APSIPA
2016], restricted Boltzmann machine (RBM) [Chen et al., TASLP
2014], feed forward NN [Desai et al., TASLP 2010], recurrent NN (RNN)
[Nakashika et al., Interspeech 2014].
Voice Conversion
G Output
Objective function
Target
speaker
Source
speaker](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-138-2048.jpg)
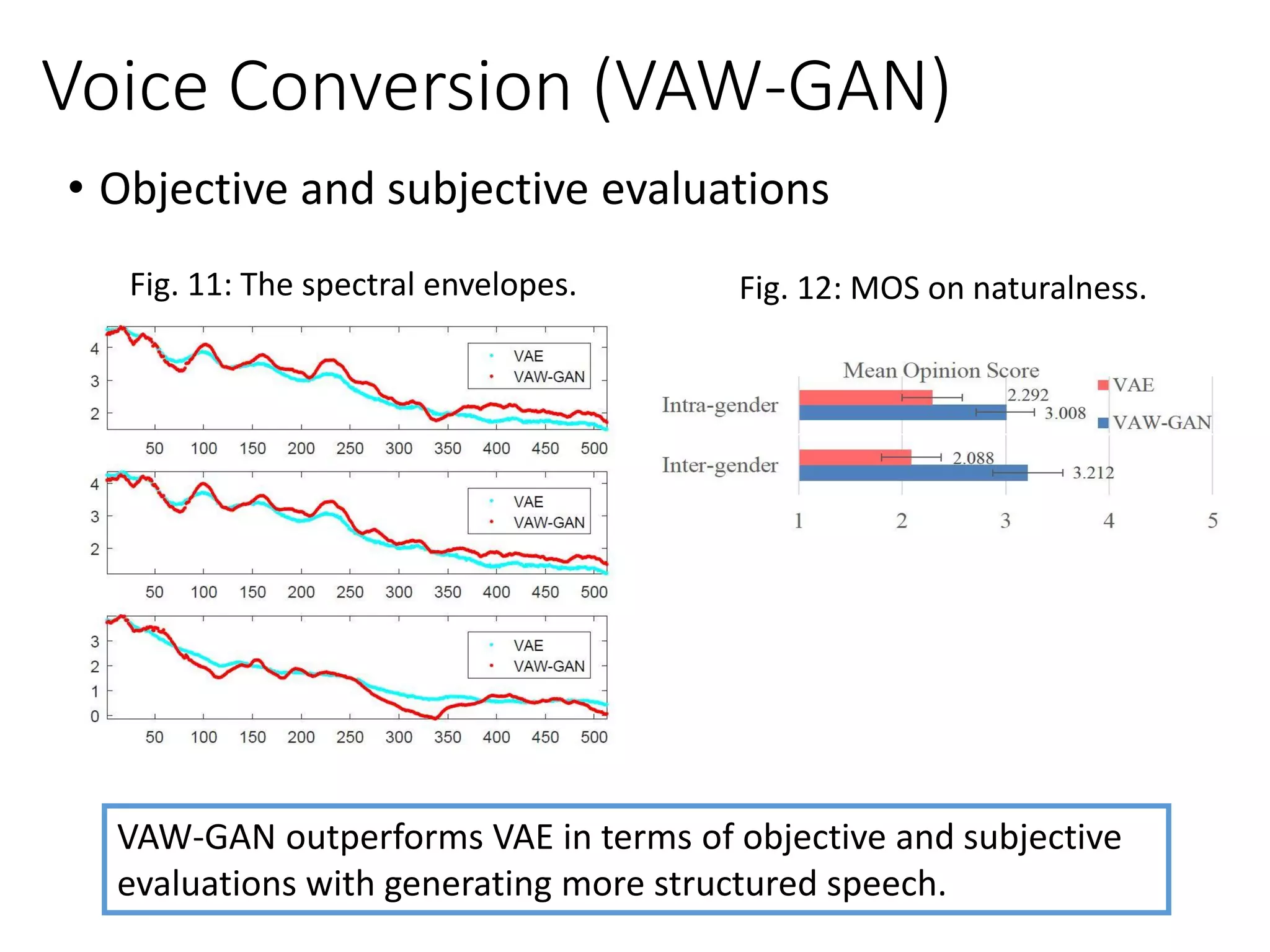
![• VAW-GAN [Hsu et al., Interspeech 2017]
➢Conventional MMSE approaches often encounter the “over-smoothing” issue.
➢ GAN is used a new objective function to estimate G.
➢ The goal is to increase the naturalness, clarity, similarity of converted speech.
Voice Conversion
D
Real
or
Fake
G
Target
speaker
Source
speaker
𝑉 𝐺, 𝐷 = 𝑉𝐺𝐴𝑁 𝐺, 𝐷 + 𝜆 𝑉𝑉𝐴𝐸 𝒙|𝒚](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-139-2048.jpg)
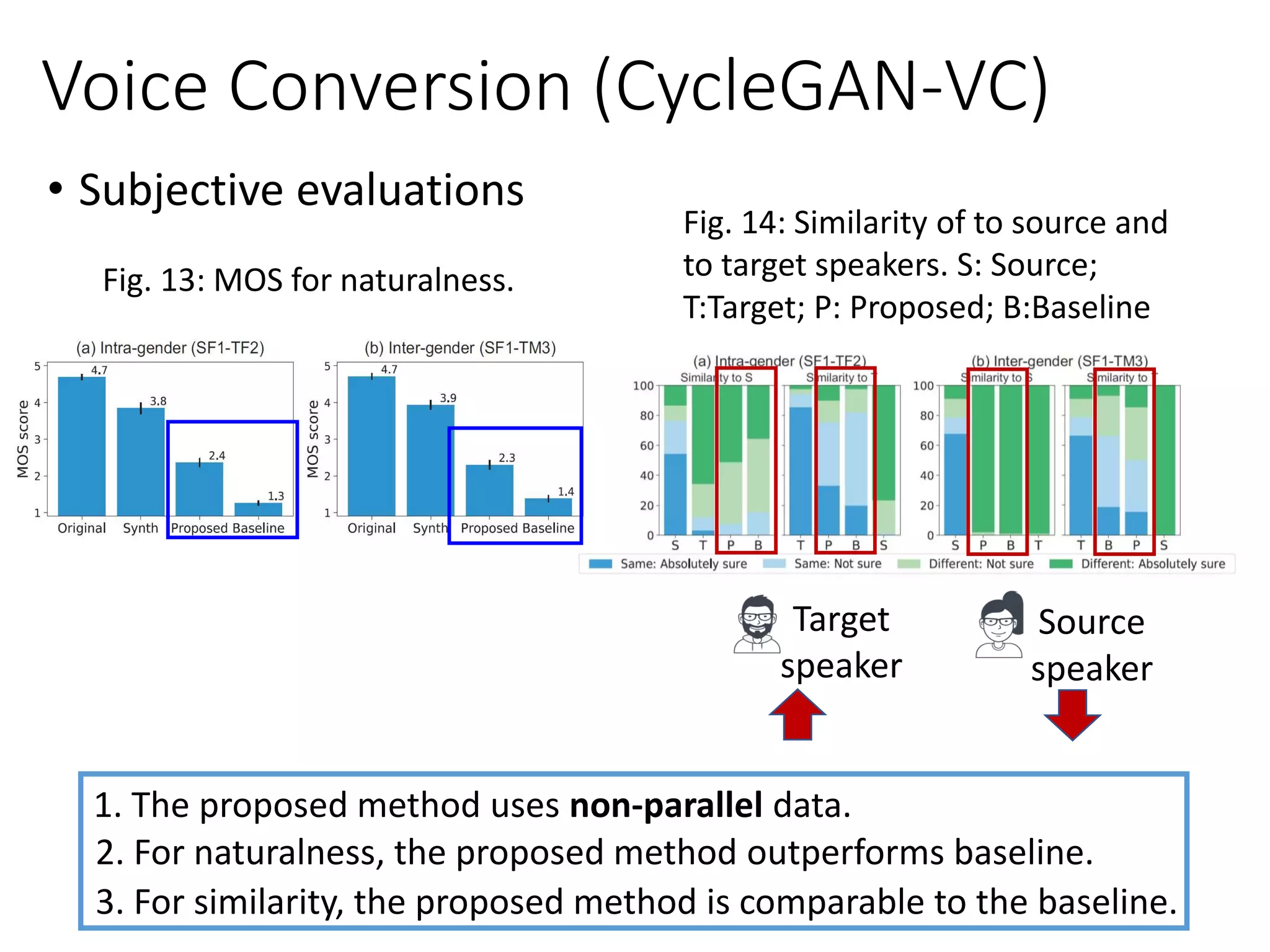
![• CycleGAN-VC [Kaneko et al., Eusipco 2018]
• used a new objective function to estimate G
𝑉𝐹𝑢𝑙𝑙 = 𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌 +𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌
+𝜆 𝑉𝐶𝑦𝑐(𝐺 𝑋→𝑌, 𝐺 𝑌→𝑋)
Voice Conversion
𝑮 𝑺→𝑻 𝐺 𝑇→𝑆
as close as possible
𝑫 𝑻
Scalar: belongs to
domain T or not
Scalar: belongs to
domain S or not
𝐺 𝑇→𝑆 𝑮 𝑺→𝑻
as close as possible
𝑫 𝑺
Target Syn. Source Target
Source Syn. Target Source](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-141-2048.jpg)

![Speech Recognition
• Adversarial multi-task learning (AMT)
[Shinohara Interspeech 2016]
Output 1
Senone
Input
Acoustic feature
E
G𝑉𝑦
Output 2
Domain
D 𝑉𝑧
𝒛
𝒚
𝒙
GRL
𝑉𝑦=− σ𝑖 log 𝑃(𝑦𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐺)
𝑉𝑧=− σ𝑖 log 𝑃(𝑧𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐷)
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺
𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
𝜃 𝐷 ← 𝜃 𝐷 − ϵ
𝜕𝑉𝑧
𝜕𝜃 𝐷
Model update
Max
classification
accuracy
Max domain
accuracy
Max classification accuracy
Objective function
+𝛼
𝜕𝑉𝑧
𝜕𝜃 𝐸
and Min domain accuracy](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-145-2048.jpg)

![Speech Recognition
• Domain adversarial training for accented ASR (DAT)
[Sun et al., ICASSP2018]
Output 2
Domain
Output 1
Senone
Input
Acoustic feature
E
G D
GRL
𝑉𝑧𝑉𝑦
𝒛
𝒚
𝒙
𝑉𝑦=− σ𝑖 log 𝑃(𝑦𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐺)
𝑉𝑧=− σ𝑖 log 𝑃(𝑧𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐷)
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺
𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
𝜃 𝐷 ← 𝜃 𝐷 − ϵ
𝜕𝑉𝑧
𝜕𝜃 𝐷
Model update
Max
classification
accuracy
Max domain
accuracy
Max classification accuracy
Objective function
+𝛼
𝜕𝑉𝑧
𝜕𝜃 𝐸
and Min domain accuracy](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-147-2048.jpg)

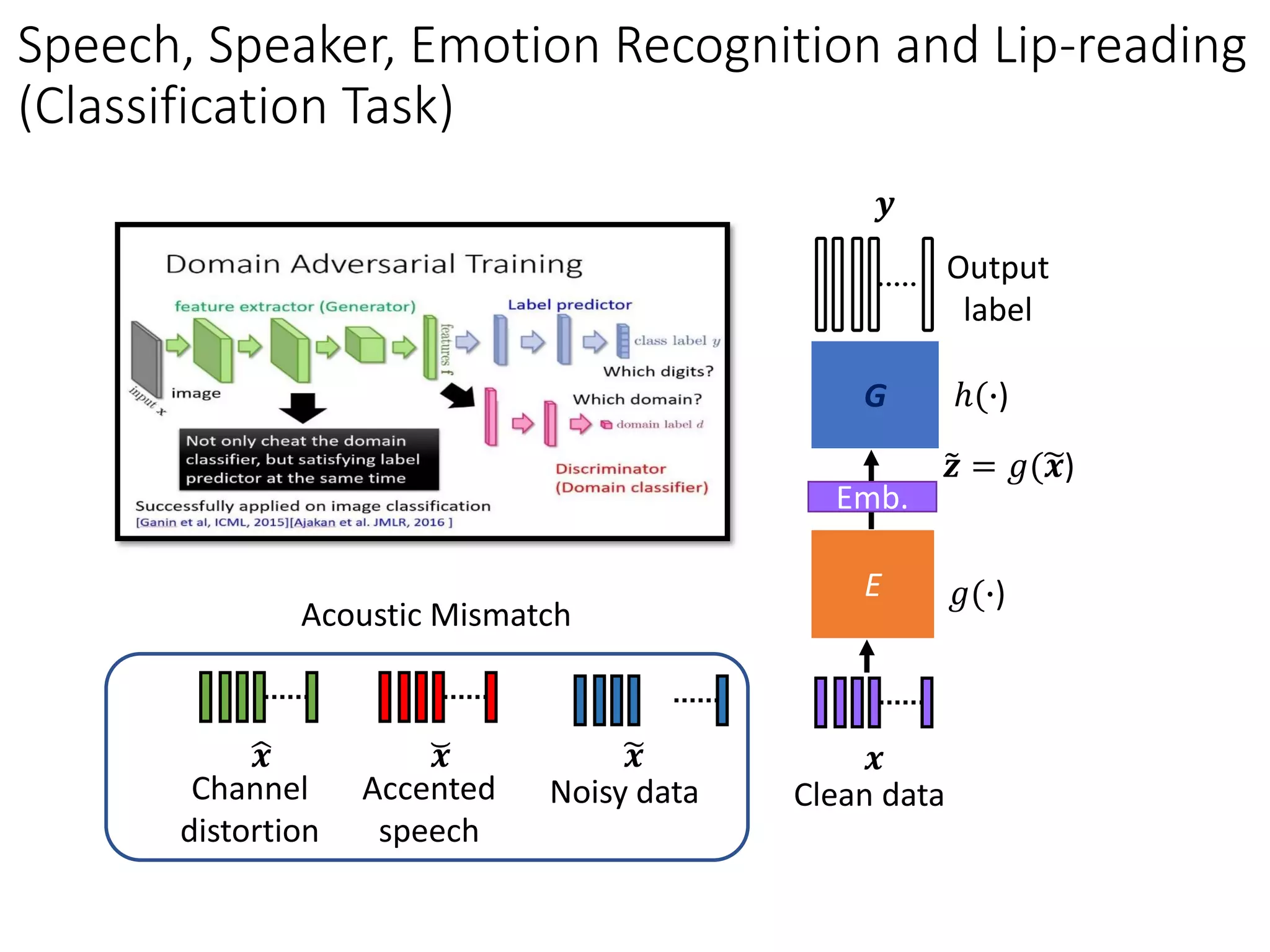
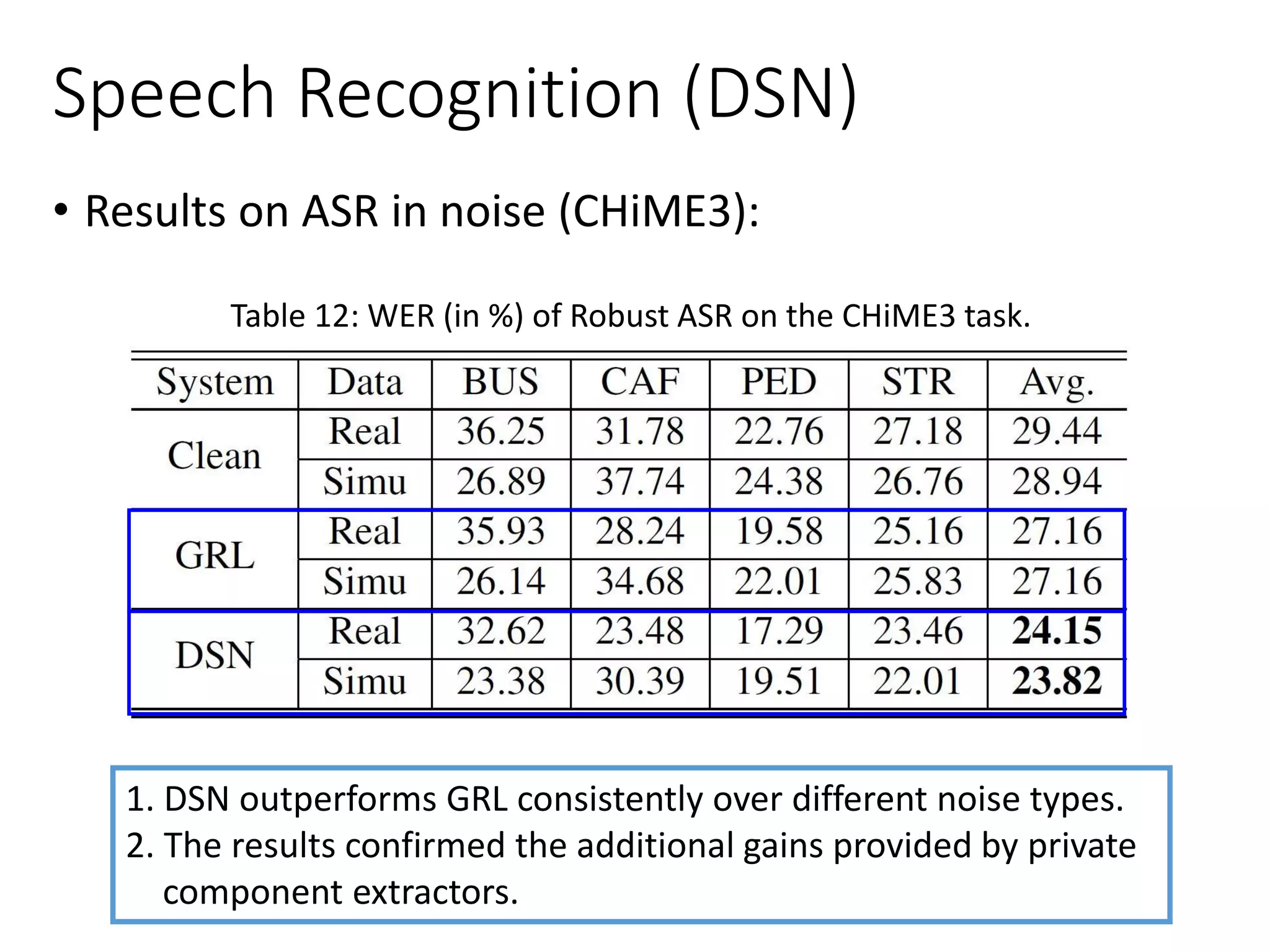
![Speech Recognition
• Unsupervised Adaptation with Domain Separation
Networks (DSN) [Meng et al., ASRU 2017]
R
PEt
R
PEs
𝒙
𝒙
Output 1
Senone
Clean data
E
GL1
𝒚
𝒙
Emb.
Noisy data
E
𝒙
Emb.𝒛 = 𝑔(𝒙) 𝒛 = 𝑔(𝒙)
𝑔(∙)𝑔(∙)
ℎ(∙)D
Output 2
Domain
𝒅](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-149-2048.jpg)

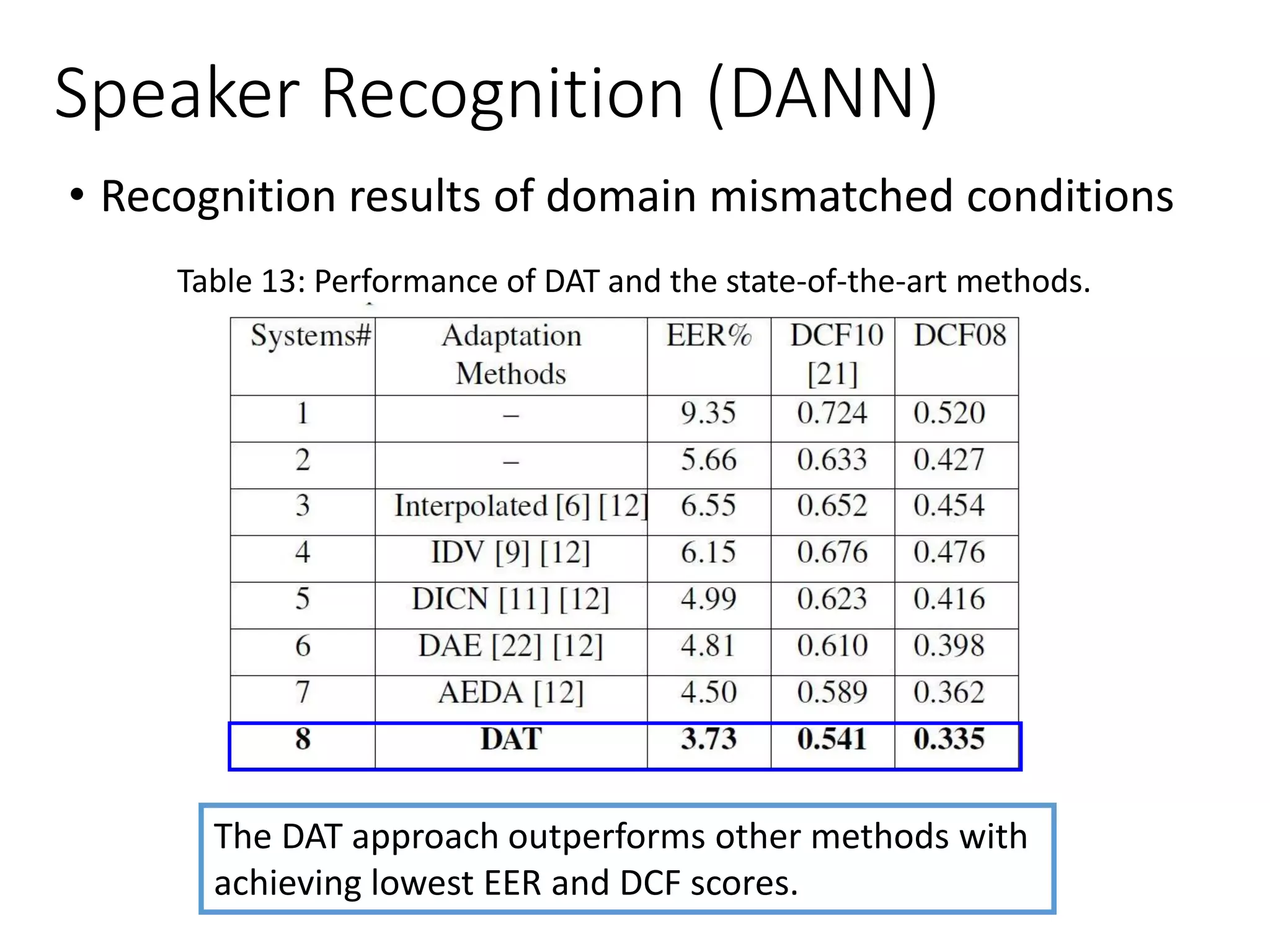
![Speaker Recognition
• Domain adversarial neural network (DANN)
[Wang et al., ICASSP 2018]
DANN
DANN
Pre-
processing
Pre-
processing
Scoring
Enroll
i-vector
Test
i-vector
Output 2
Domain
Output 1
Speaker
ID
Input
Acoustic feature
E
G D
GRL
𝑉𝑧𝑉𝑦
𝒛
𝒚
𝒙](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-152-2048.jpg)

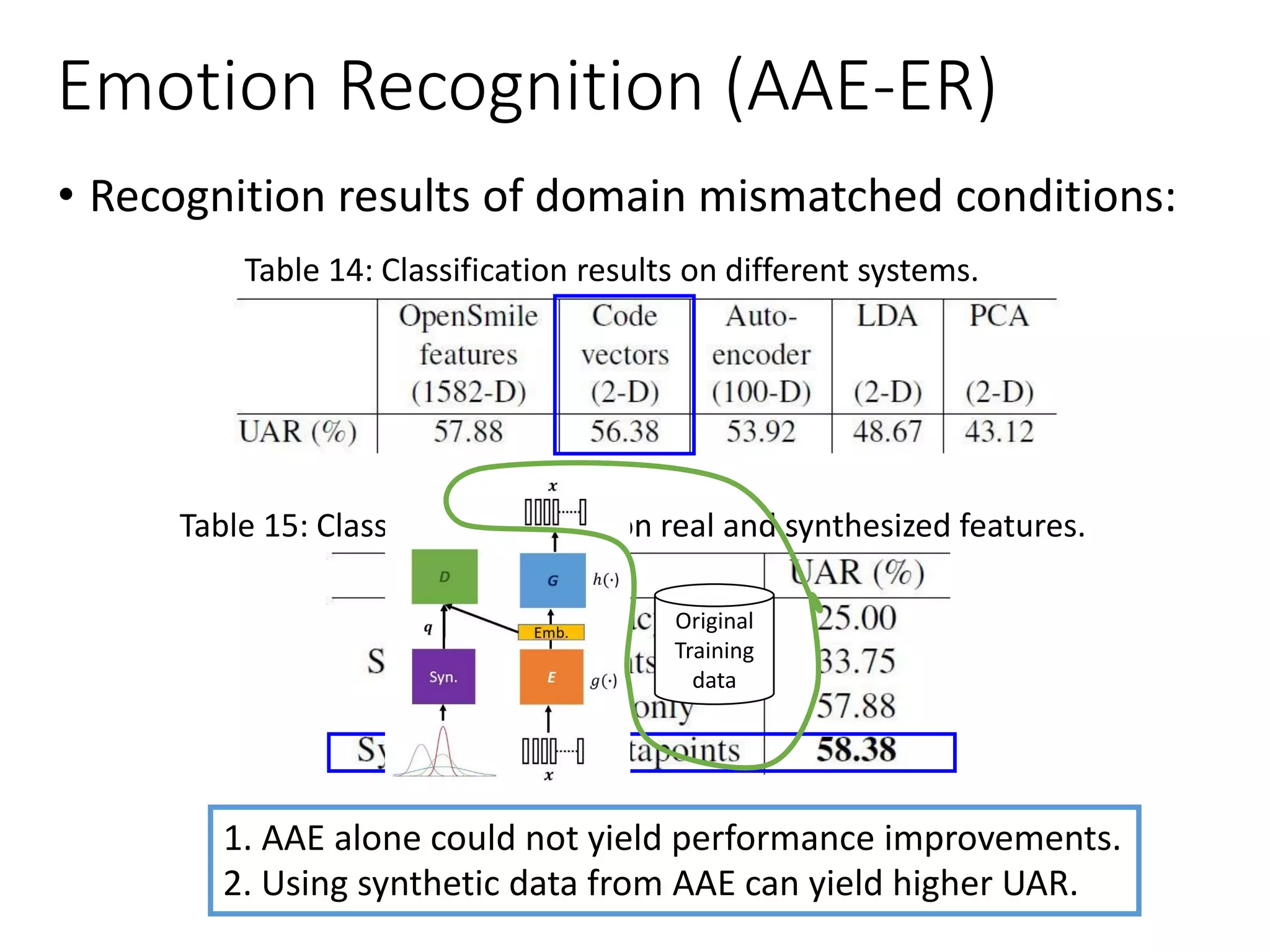
![Emotion Recognition
• Adversarial AE for emotion recognition (AAE-ER)
[Sahu et al., Interspeech 2017]
AE with GAN :
𝐻 ℎ 𝒛 , 𝒙 + λ 𝑉𝐺𝐴𝑁 (𝒒, 𝑔(𝒙))
E
D
𝒙
Emb.
Syn.
𝒛 = 𝑔(𝒙)
𝑔(∙)
ℎ(∙)
𝒒
𝒙
G
The distribution of code vectors](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-155-2048.jpg)

![Lip-reading
• Domain adversarial training for lip-reading (DAT-LR)
[Wand et al., Interspeech 2017]
Output 1
Words
E
G𝑉𝑦
Output 2
Speaker
D
GRL
𝑉𝑧
𝒛
𝒚
𝒙
𝑉𝑦=− σ𝑖 log 𝑃(𝑦𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐺)
𝑉𝑧=− σ𝑖 log 𝑃(𝑧𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐷)
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺
𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
𝜃 𝐷 ← 𝜃 𝐷 − ϵ
𝜕𝑉𝑧
𝜕𝜃 𝐷
Model update
Max
classification
accuracy
Max domain
accuracy
Max classification accuracy
Objective function
+𝛼
𝜕𝑉𝑧
𝜕𝜃 𝐸
and Min domain accuracy
~80% WAC](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-158-2048.jpg)










![Outline of Part III
Our Recent Works
• Noise adaptive speech enhancement [Interspeech 2019]
• MetricGAN for speech enhancement [ICML 2019]
• Multi-Target voice conversion [Interspeech 2018]
• Impaired speech conversion [Interspeech 2019]
• Pathological voice detection [NeurIPS workshop 2018]
[Mon-P-2-A]
[Wed-P-6-E]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-171-2048.jpg)
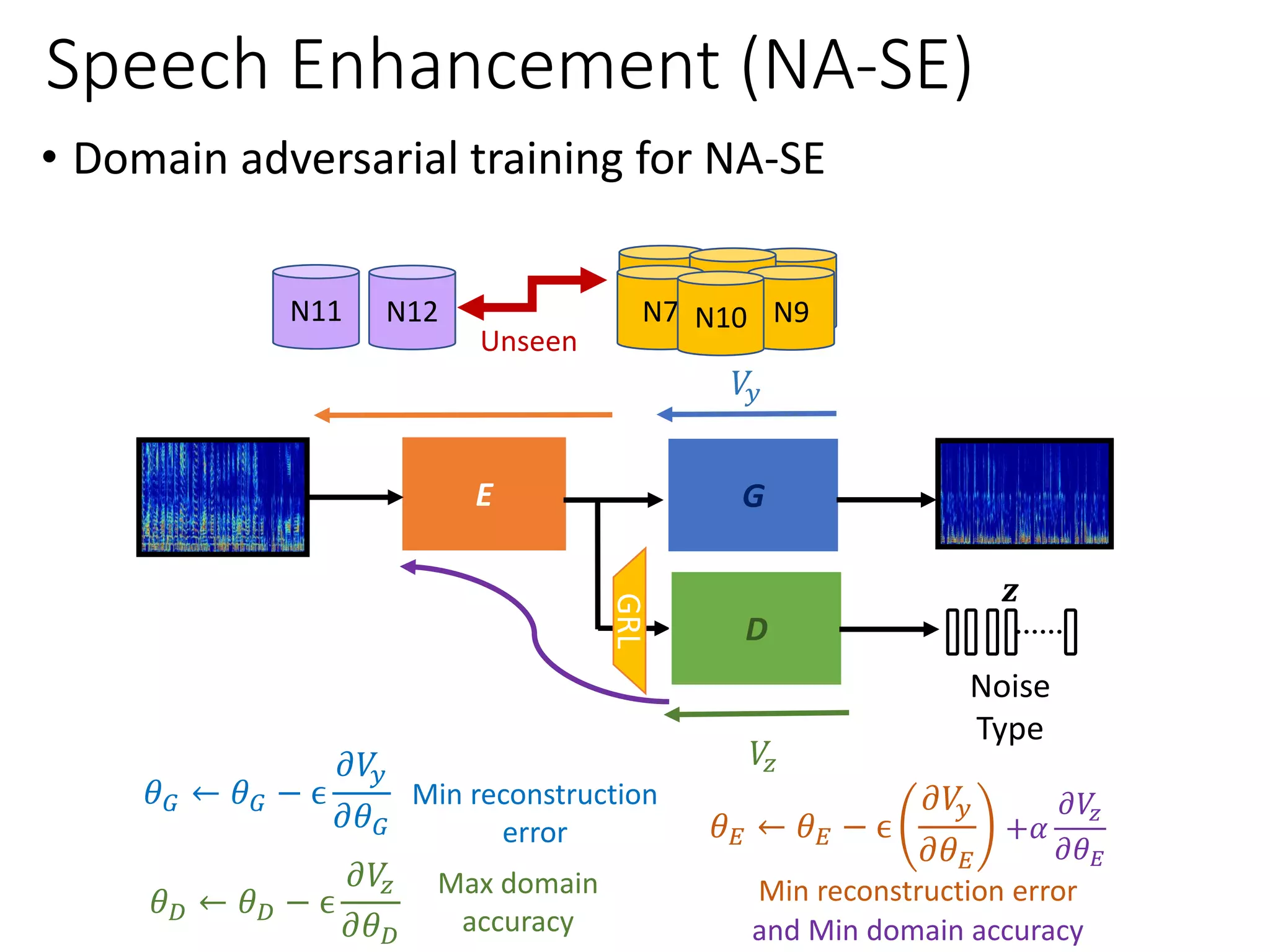
![Speech Enhancement
N5 N5N4
N7 N9N10N12
Unseen
N11
𝒛
E G
𝑉𝑦
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺 𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
Min reconstruction
error
Min reconstruction error
• Noise Adaptive Speech Enhancement (NA-SE)
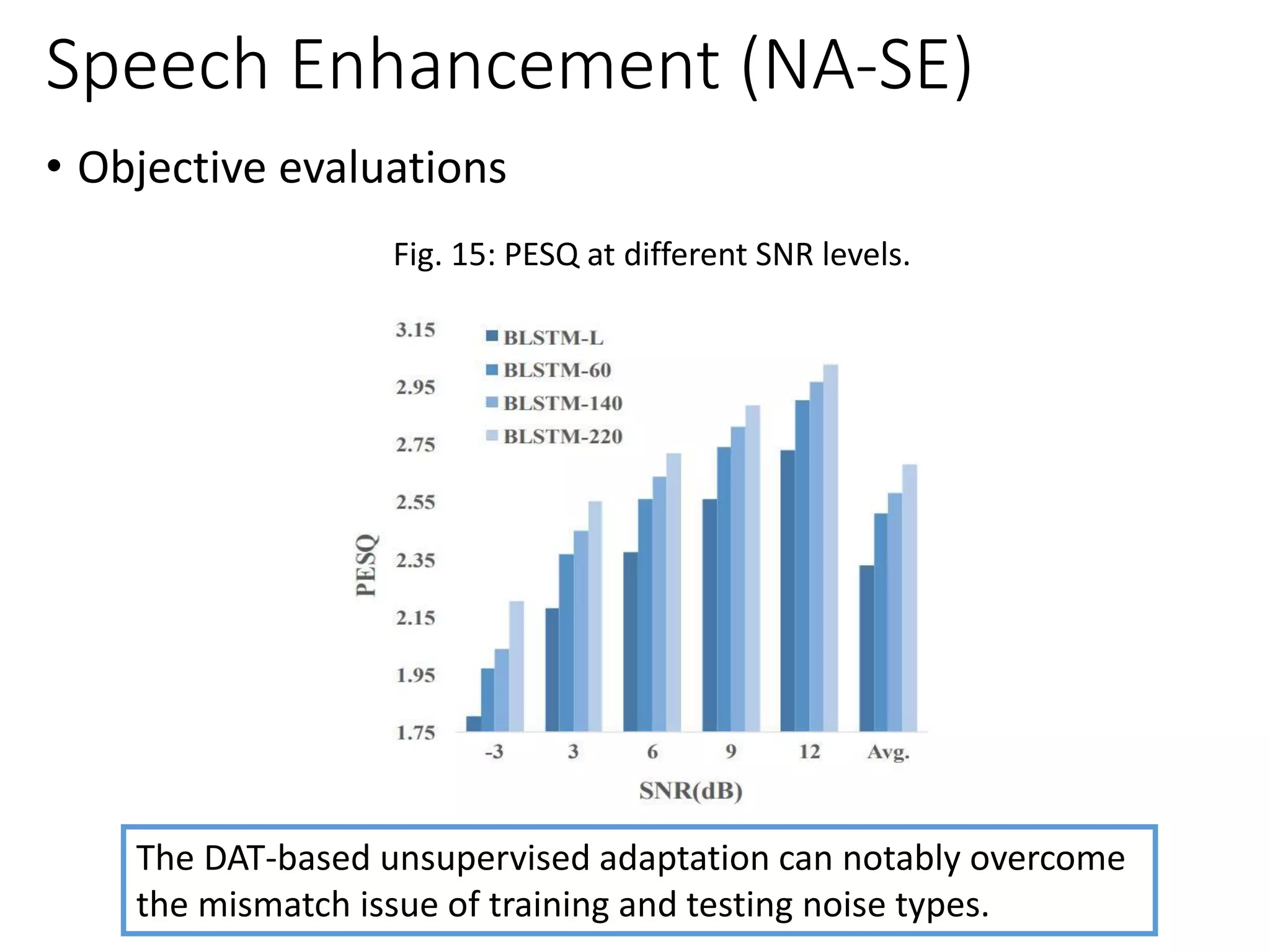
[Liao et al., Interspeech 2019] [Wed-P-6-E]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-172-2048.jpg)
![• GAN for spectral magnitude mask estimation (MMS-GAN)
[Pandey et al., ICASSP 2018]
D Scalar
Ref.
mask
Noisy
(Fake/Real)
Output
mask
Noisy
G
Noisy Output mask Ref. mask
Speech Enhancement](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-175-2048.jpg)
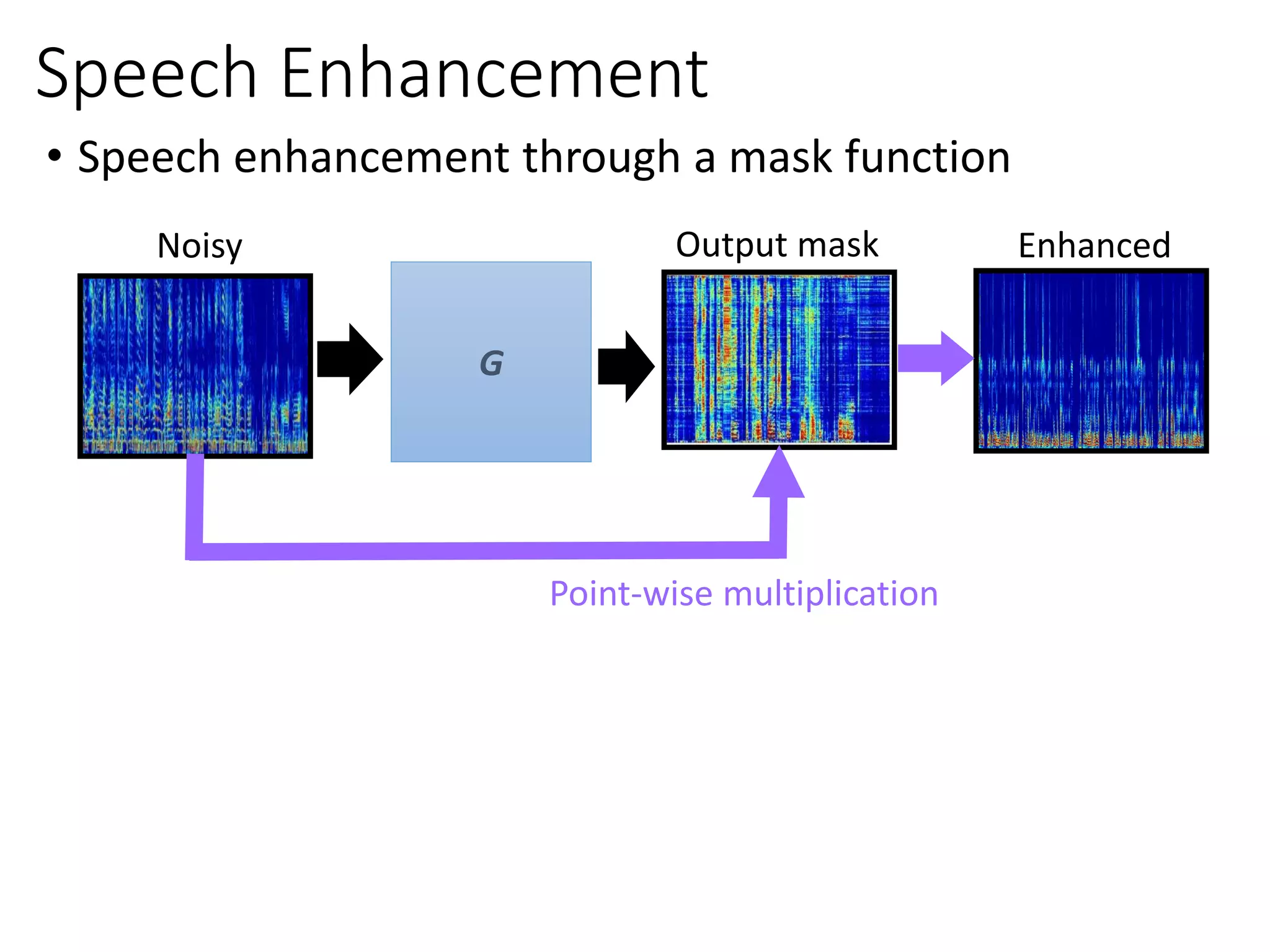
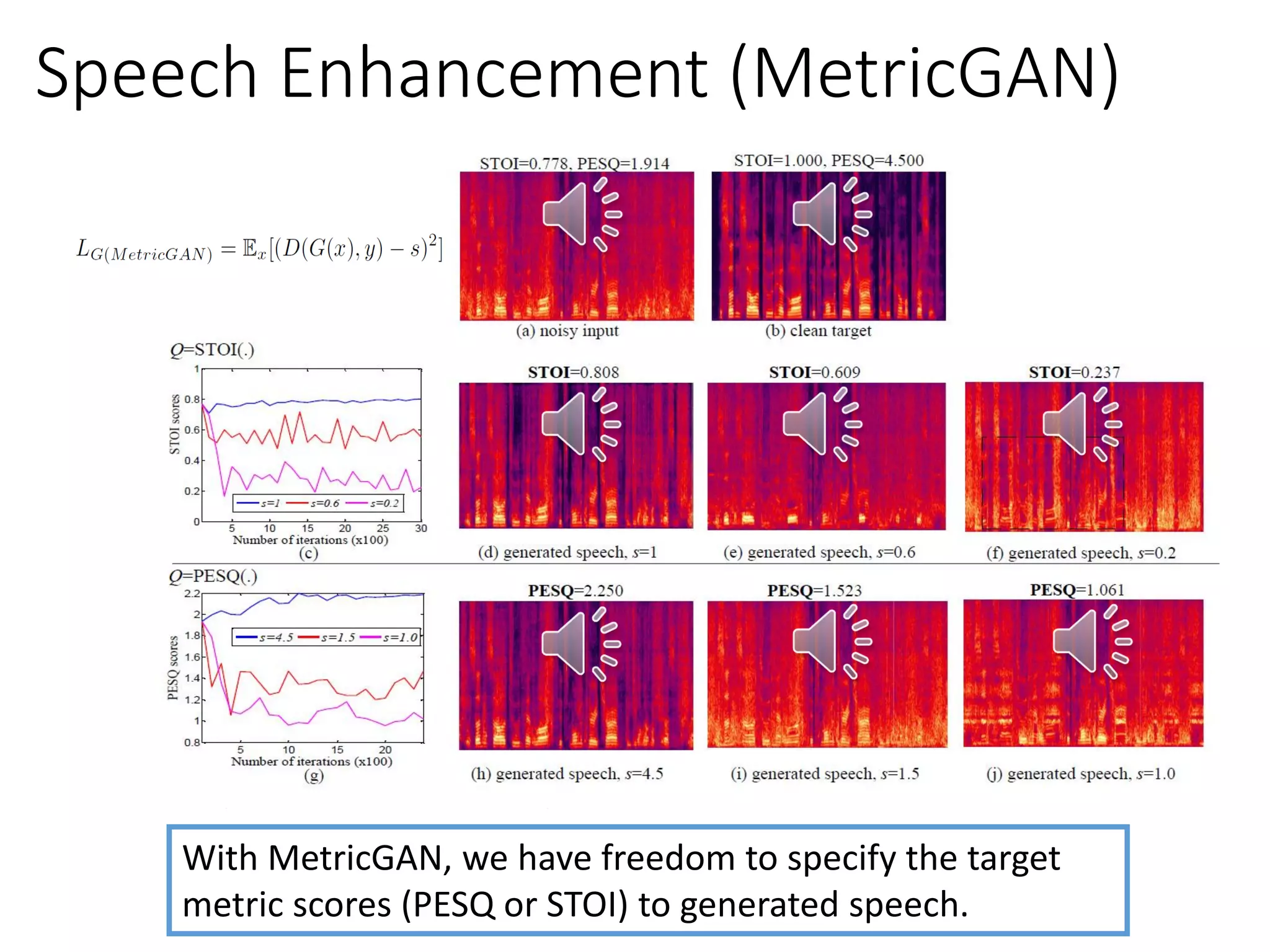
![• MetricGAN for Speech Enhancement [Fu et al., ICML 2019]
D Metric
Score
(0~1)
G
Noisy Spect. Output mask
Speech Enhancement
1.00.4
Clean
Spect.
Enhanced
Spect.
Enhanced Spect.
Point-wise multiplication](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-176-2048.jpg)
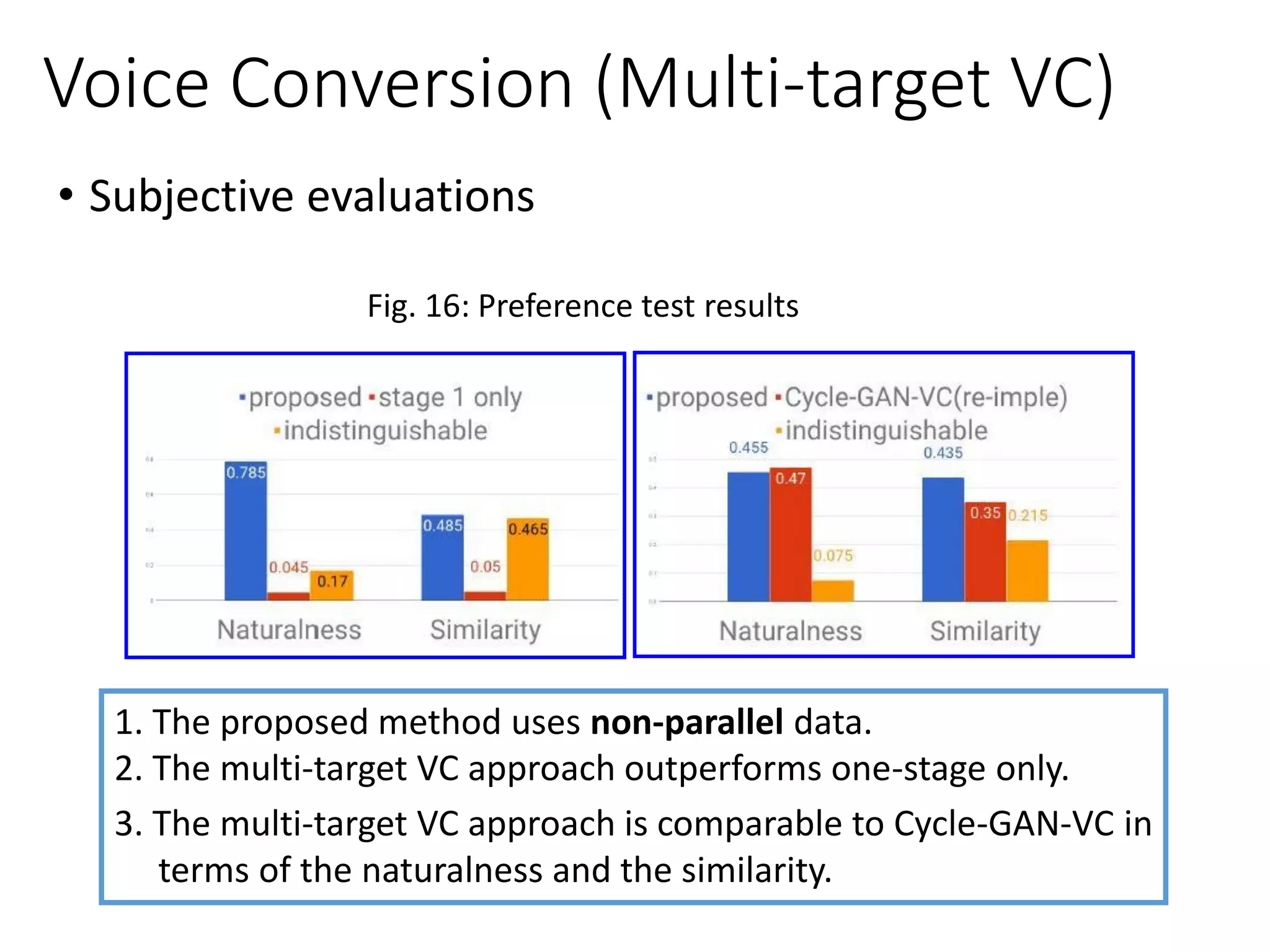
![• Multi-target VC [Chou et al., Interspeech 2018]
𝑒𝑛𝑐(𝒙)
𝒙
Voice Conversion
C
𝑬nc Dec
𝒚
𝒚 𝒚′····
𝑒𝑛𝑐(𝒙)
𝑬nc Dec
𝒚"
𝑮
𝒚"
D+C
Real
data
𝒙 𝑑𝑒𝑐(𝑒𝑛𝑐 𝒙 , 𝒚) 𝑑𝑒𝑐(𝑒𝑛𝑐 𝒙 , 𝒚′)
➢ Stage-1
➢ Stage-2
F/R
ID
···](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-178-2048.jpg)
![• Controller-generator-discriminator VC on Impaired
Speech [Chen et al., Interspeech 2019]
Voice Conversion
Previous applications: hearing aids; murmur to normal speech; bone-
conductive microphone to air-conductive microphone.
Before
Proposed: improving the speech intelligibility of surgical patients.
Target: oral cancer (top five cancer for male in Taiwan).
After Before After
[Mon-P-2-A]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-180-2048.jpg)
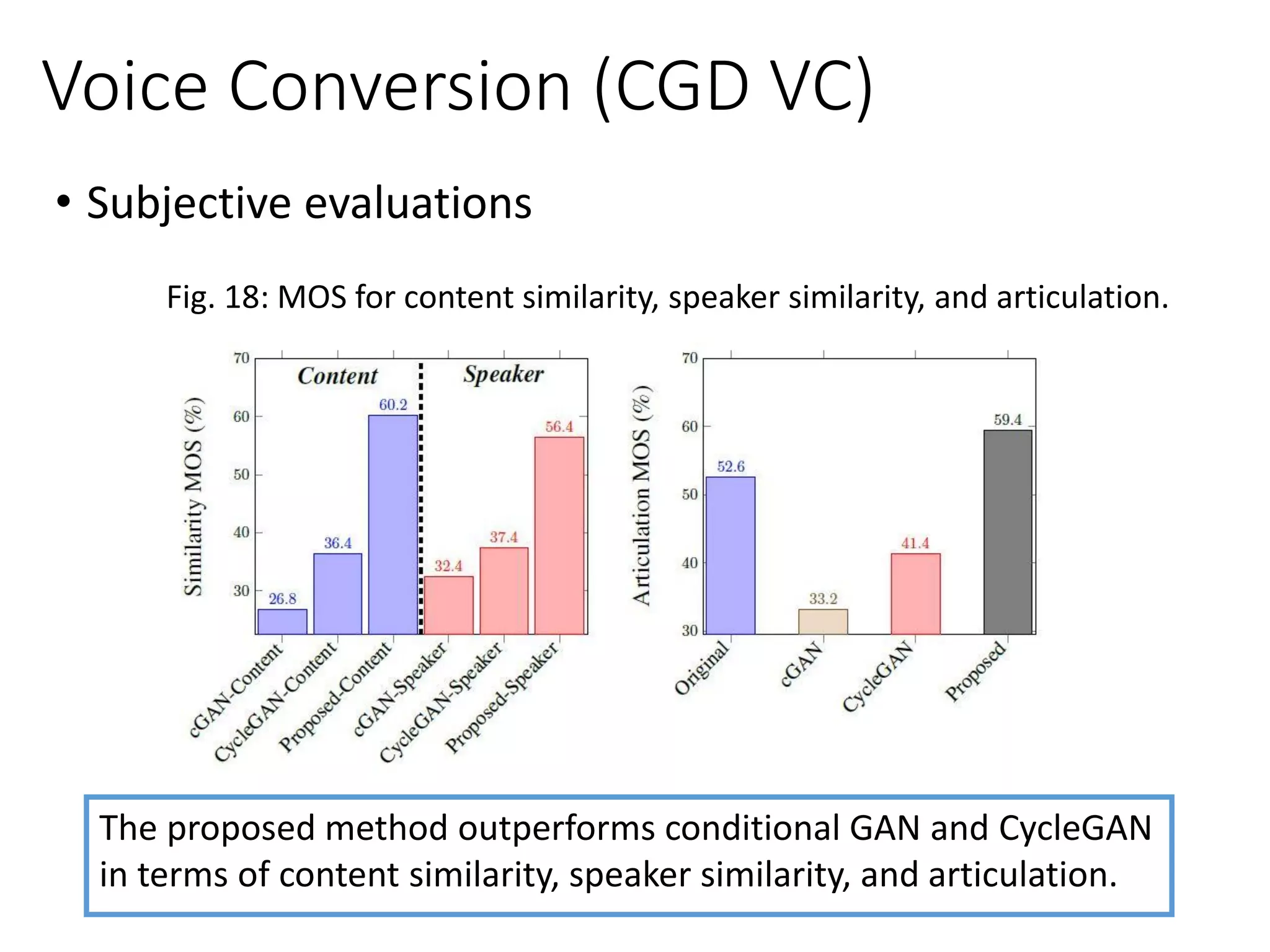
![• Controller-generator-discriminator VC (CGD VC) on
impaired speech [Chen et al., Interspeech 2019]
Voice Conversion
GD
Controller](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-181-2048.jpg)
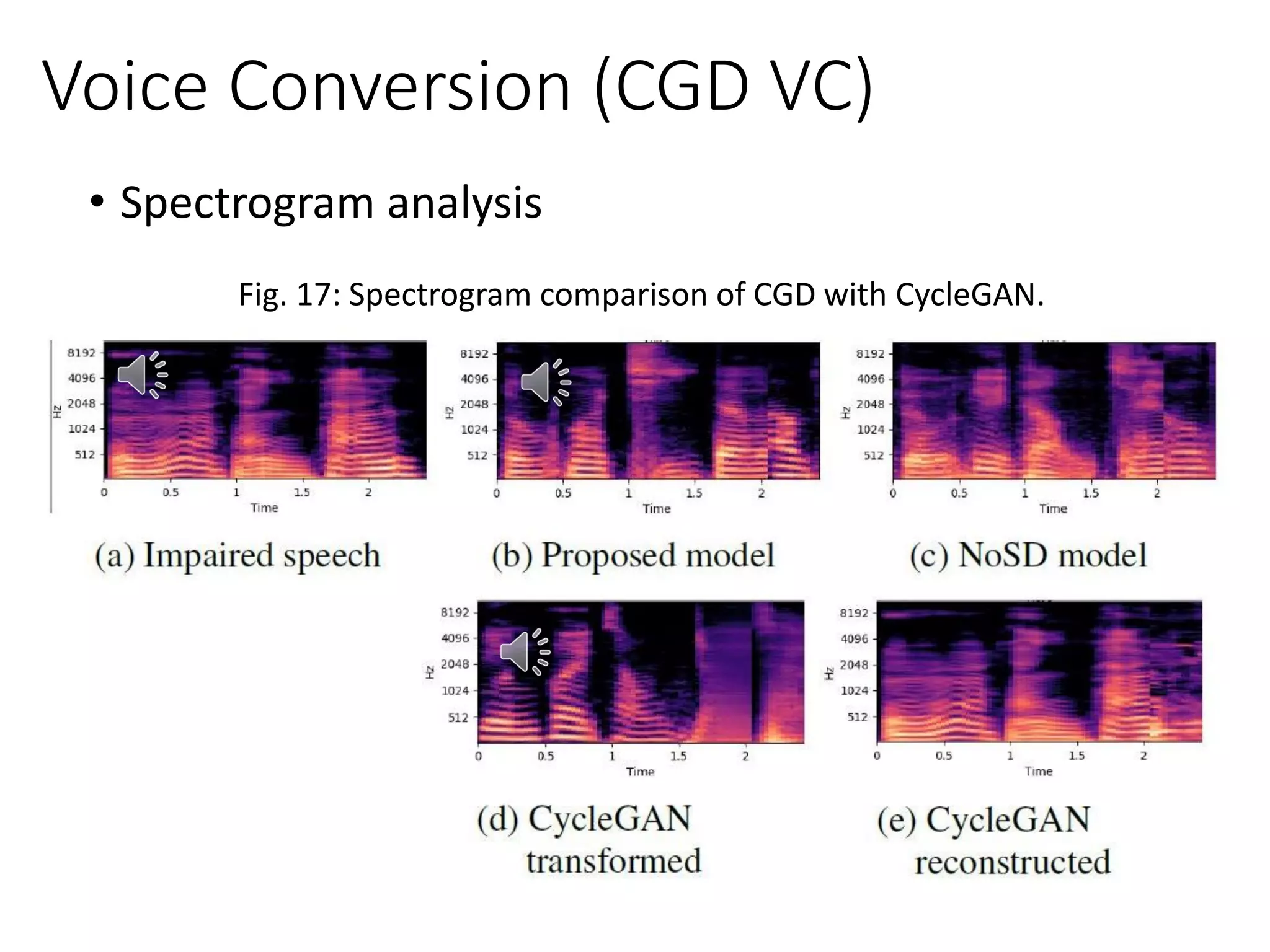
![Pathological Voice Detection
• Detection of Pathological Voice Using Cepstrum Vectors:
A Deep Learning Approach [Fang et al., Journal of Voice 2018]
GMM SVM DNN
MEEI 98.28 98.26 99.14
FEMH (M) 90.24 93.04 94.26
FEMH (F) 90.20 87.40 90.52
Table 17: Detection performance based on voice.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-184-2048.jpg)
![Pathological Voice Detection
• Robustness Against Channel [Hsu et al., NeurIPS Workshop 2018]
𝒛
E G
𝑉𝑦
D
𝑉𝑧
𝒚
DNN (S) DNN (T) DNN (FT) Unsup. DAT Sup. DAT
PR-AUC 0.8848 0.8509 0.9021 0.9455 0.9522
The unsupervised DAT notably increased the performance
robustness against channel effects and generated comparable
results as compared to supervised DAT.
𝒙
Table 18: Detection results of sup. and unsup. DAT under channel mismatches.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-185-2048.jpg)




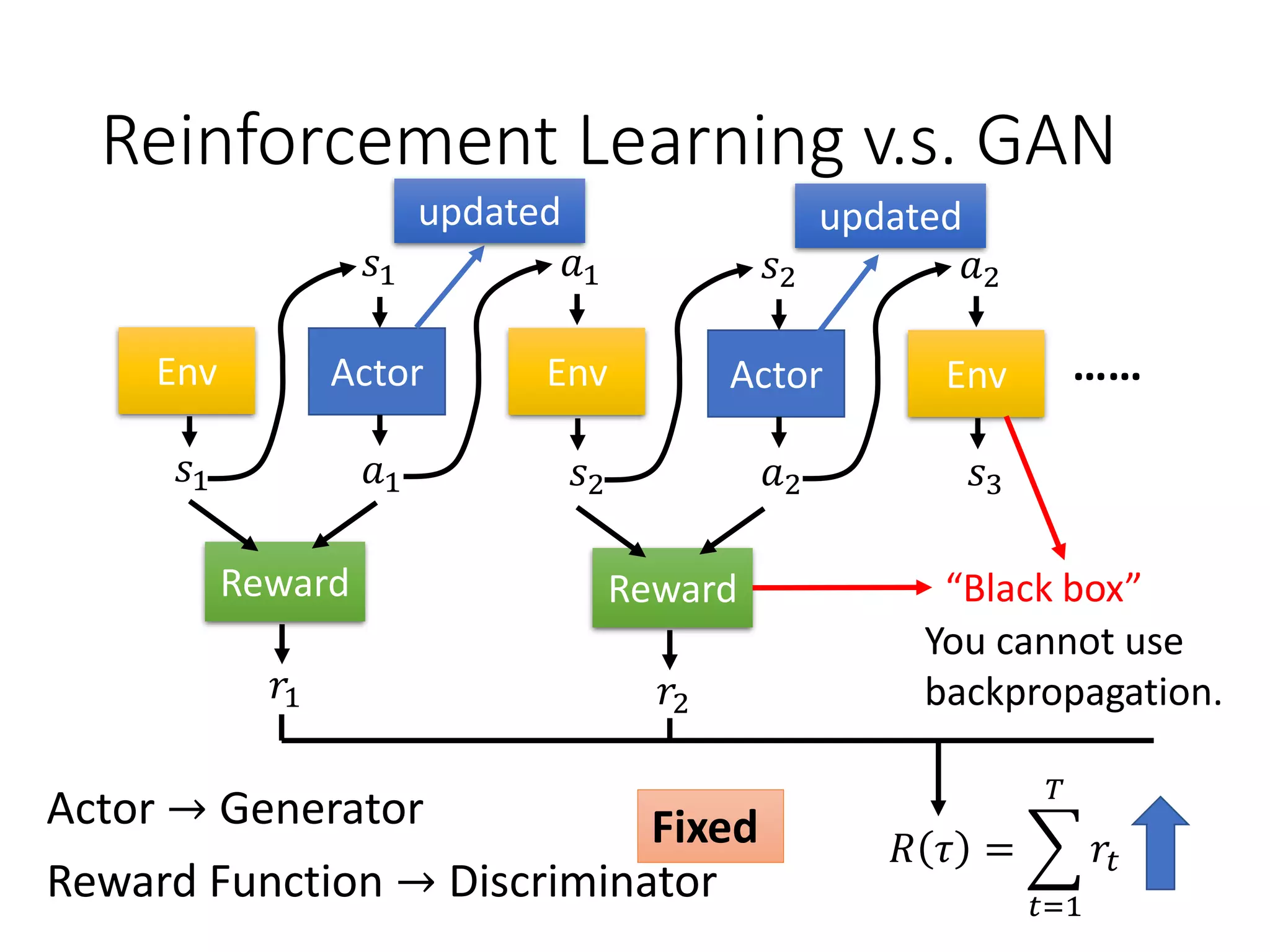
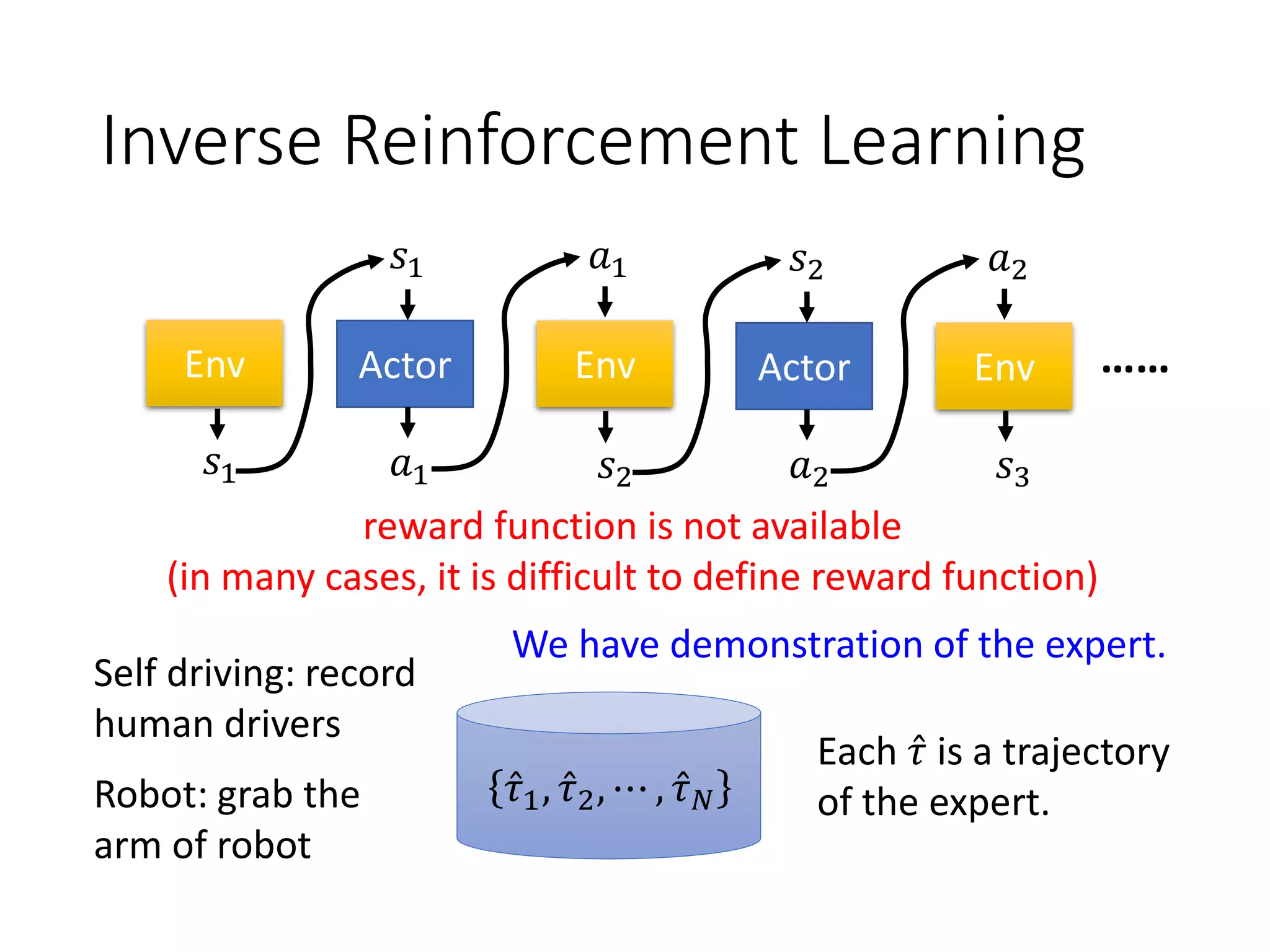
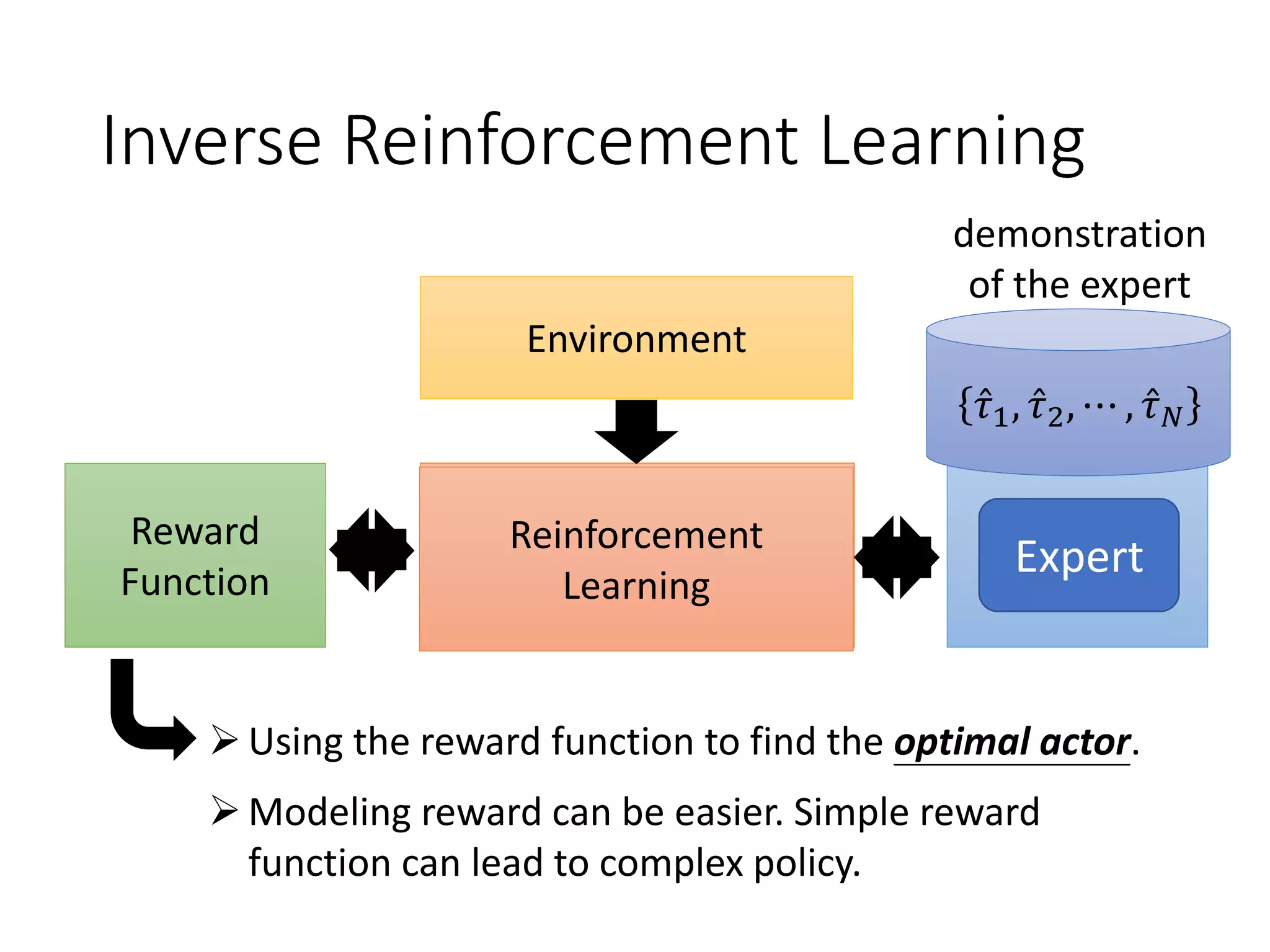
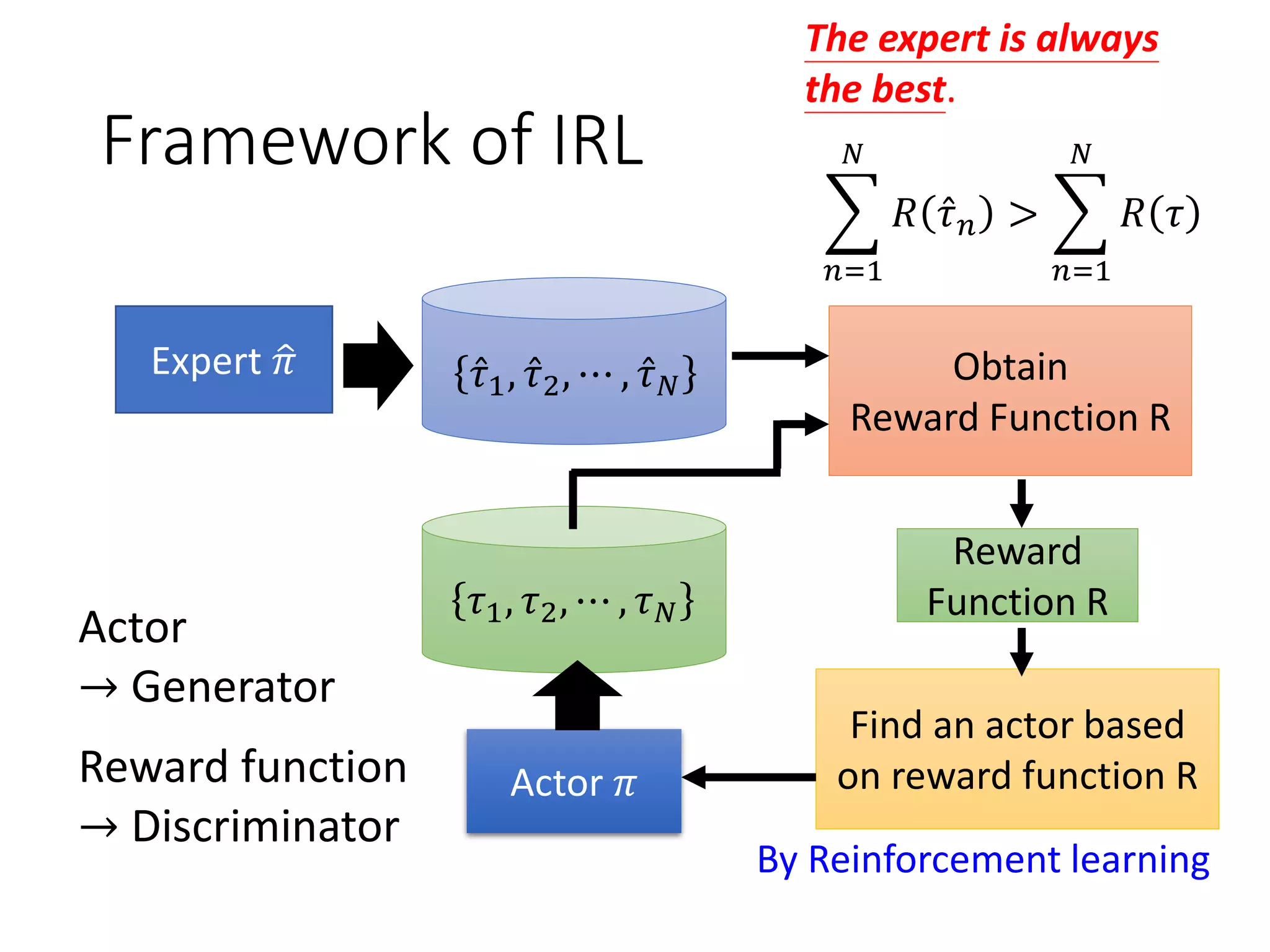
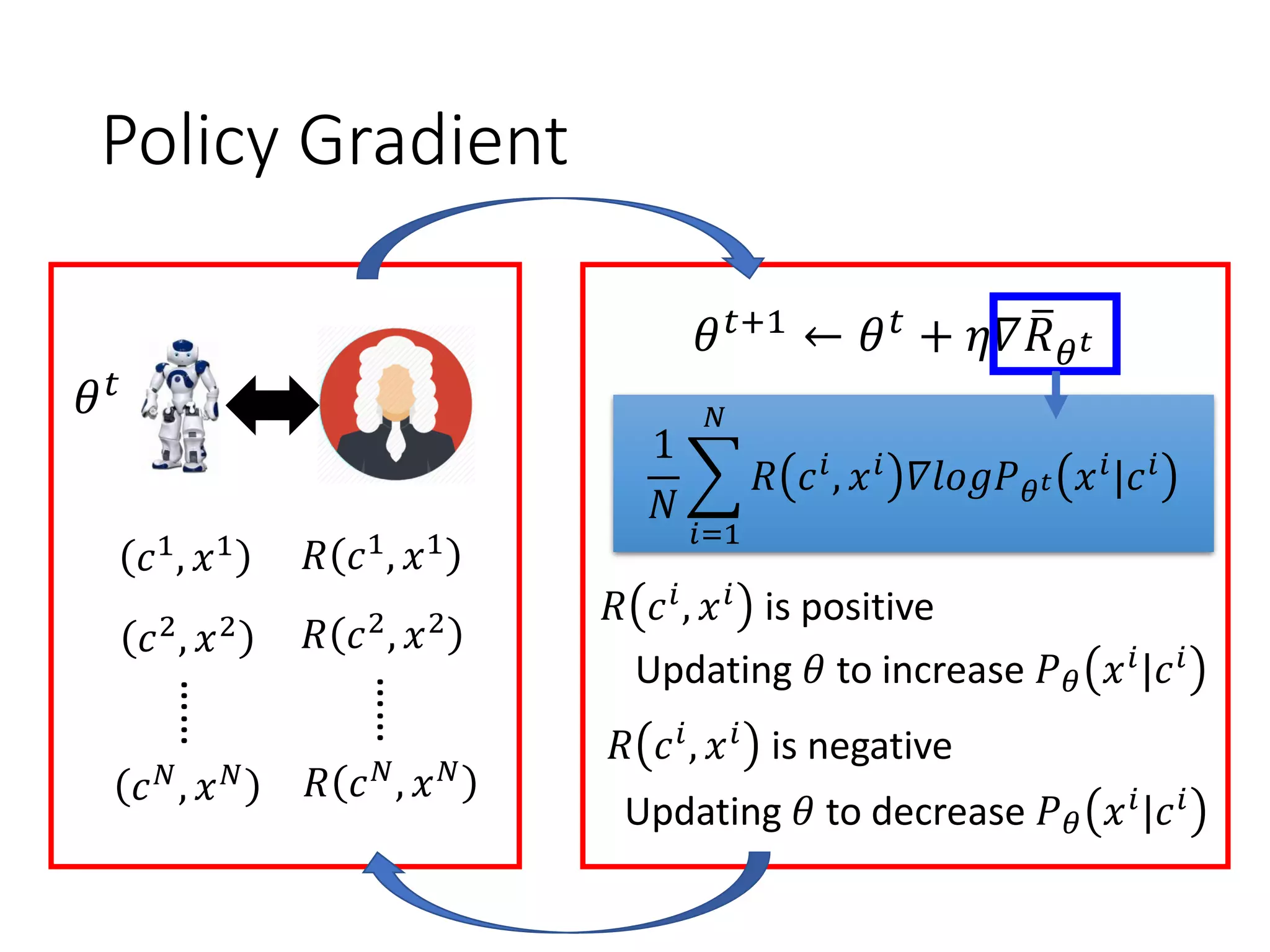
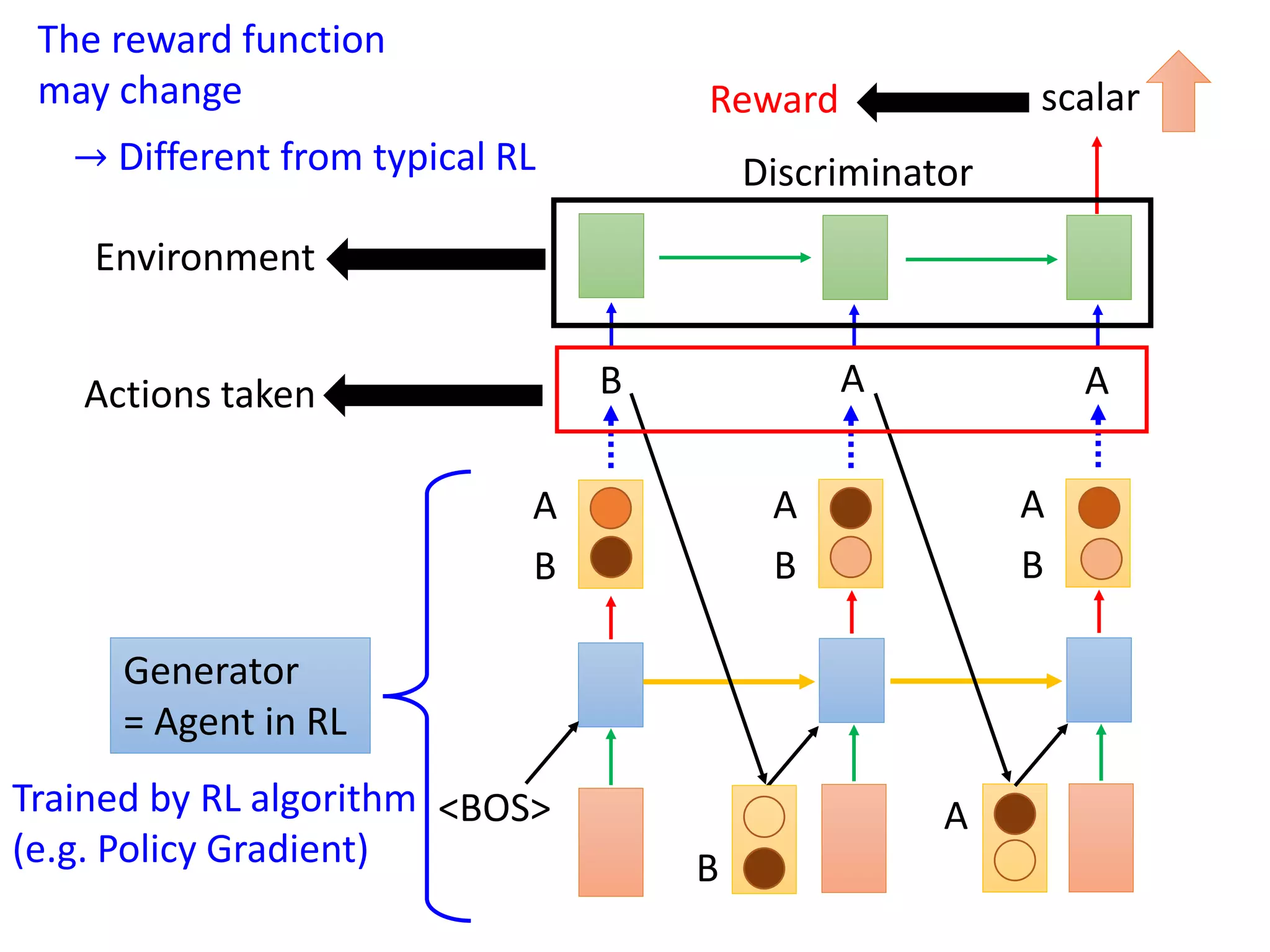
![Reinforcement Learning
Human
Input sentence c response sentence x
Chatbot
En De
response sentence x
Input sentence c
[Li, et al., EMNLP, 2016]
reward
𝑅 𝑐, 𝑥
Learn to maximize expected reward
E.g. Policy Gradient
human
“How are you?” “Not bad” “I’m John”
-1+1](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-192-2048.jpg)
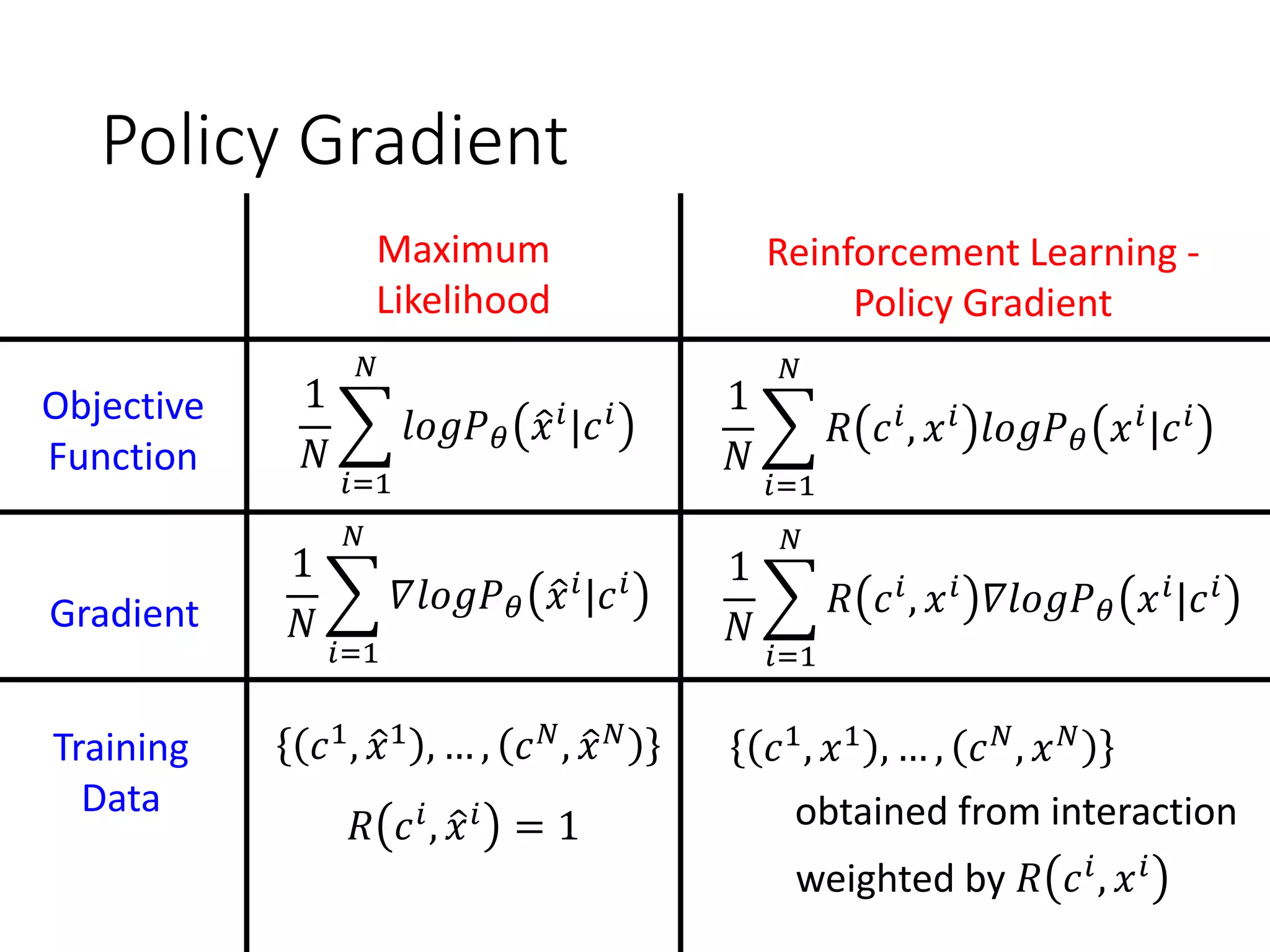
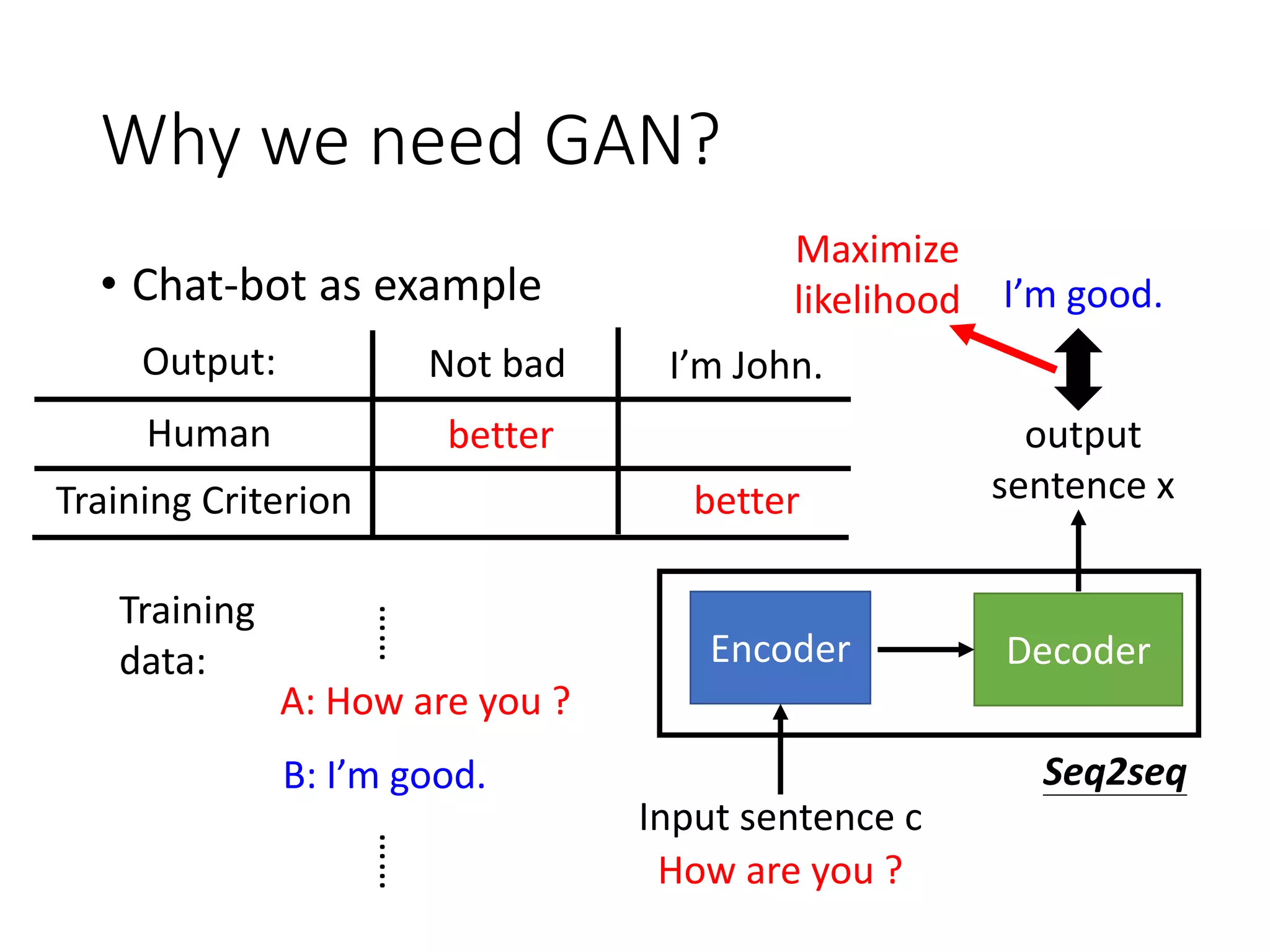
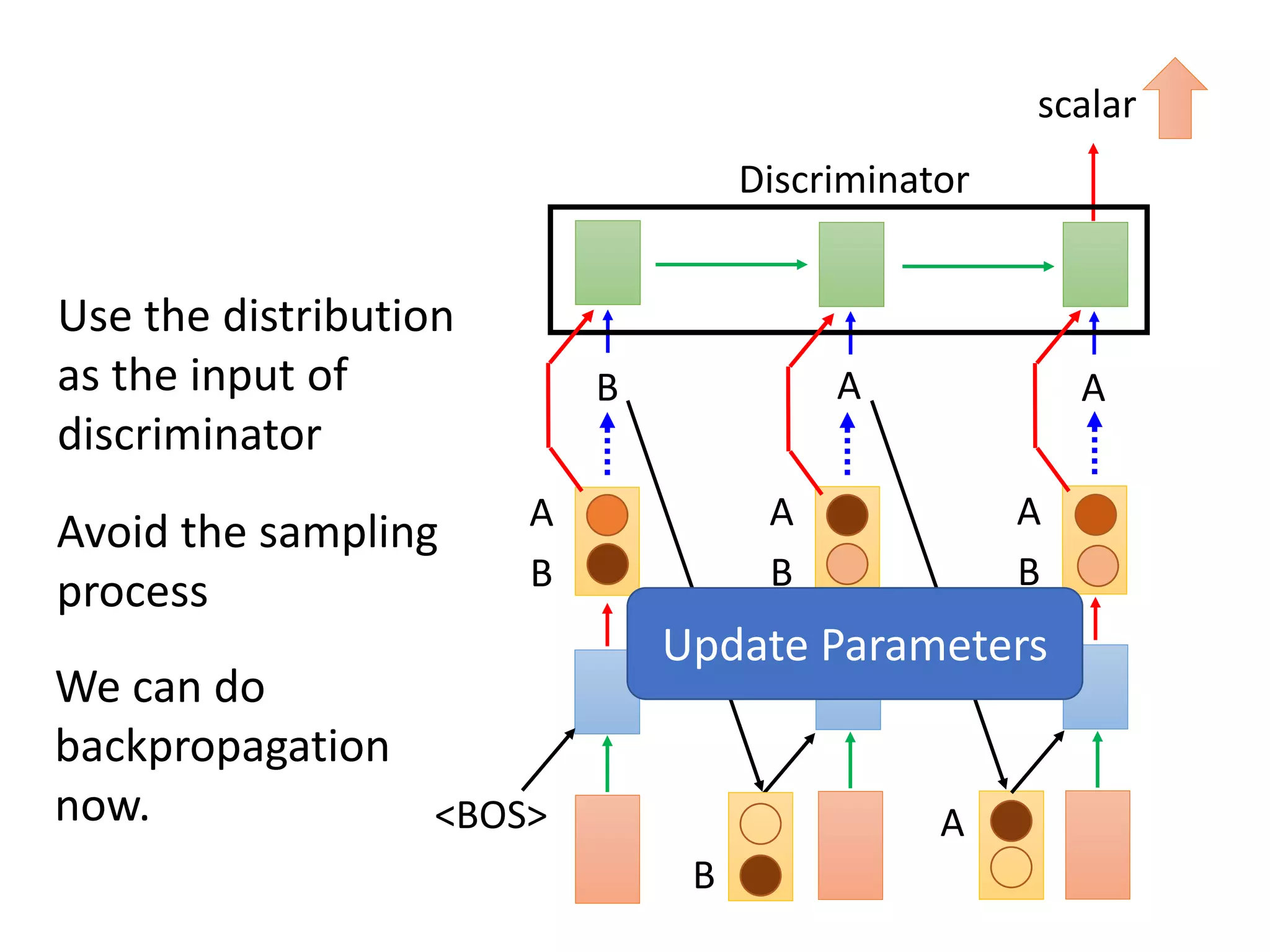
![Conditional GAN
Discriminator
Input sentence c response sentence x
Chatbot
En De
response sentence x
Input sentence c
reward
𝑅 𝑐, 𝑥
I am busy.
Replace human evaluation with
machine evaluation [Li, et al., EMNLP, 2017]
However, there is an issue when you train your generator.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-195-2048.jpg)
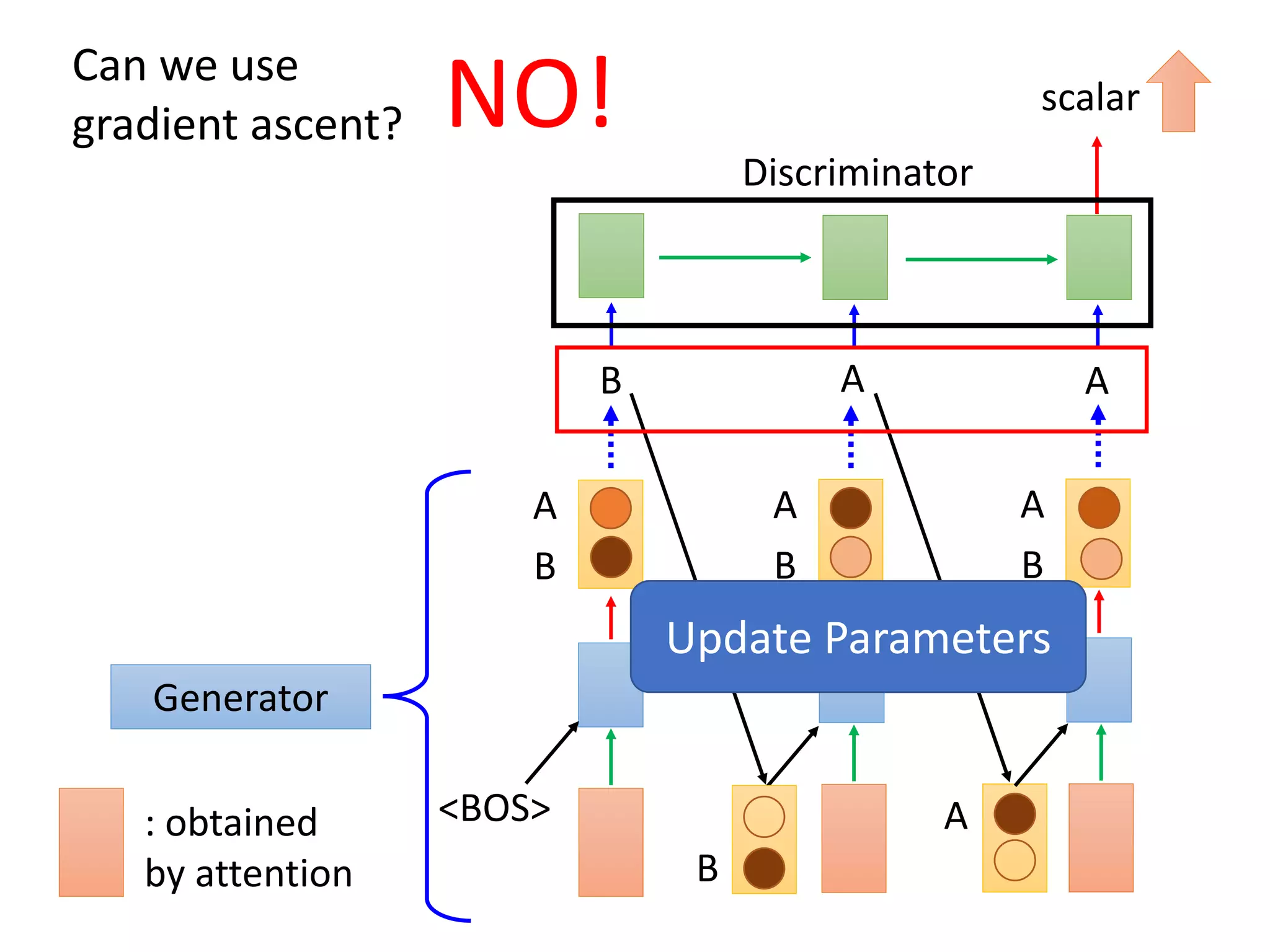
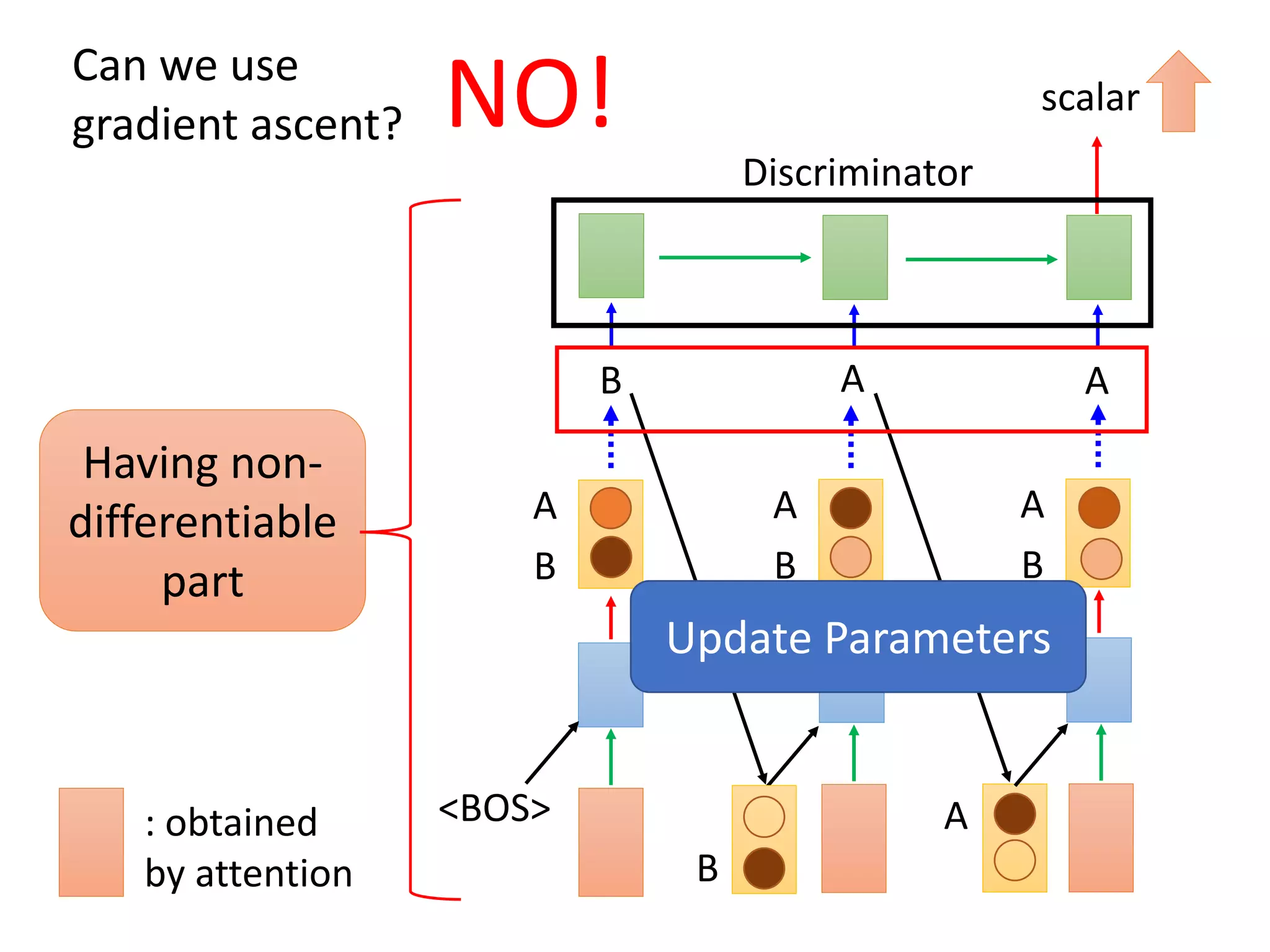
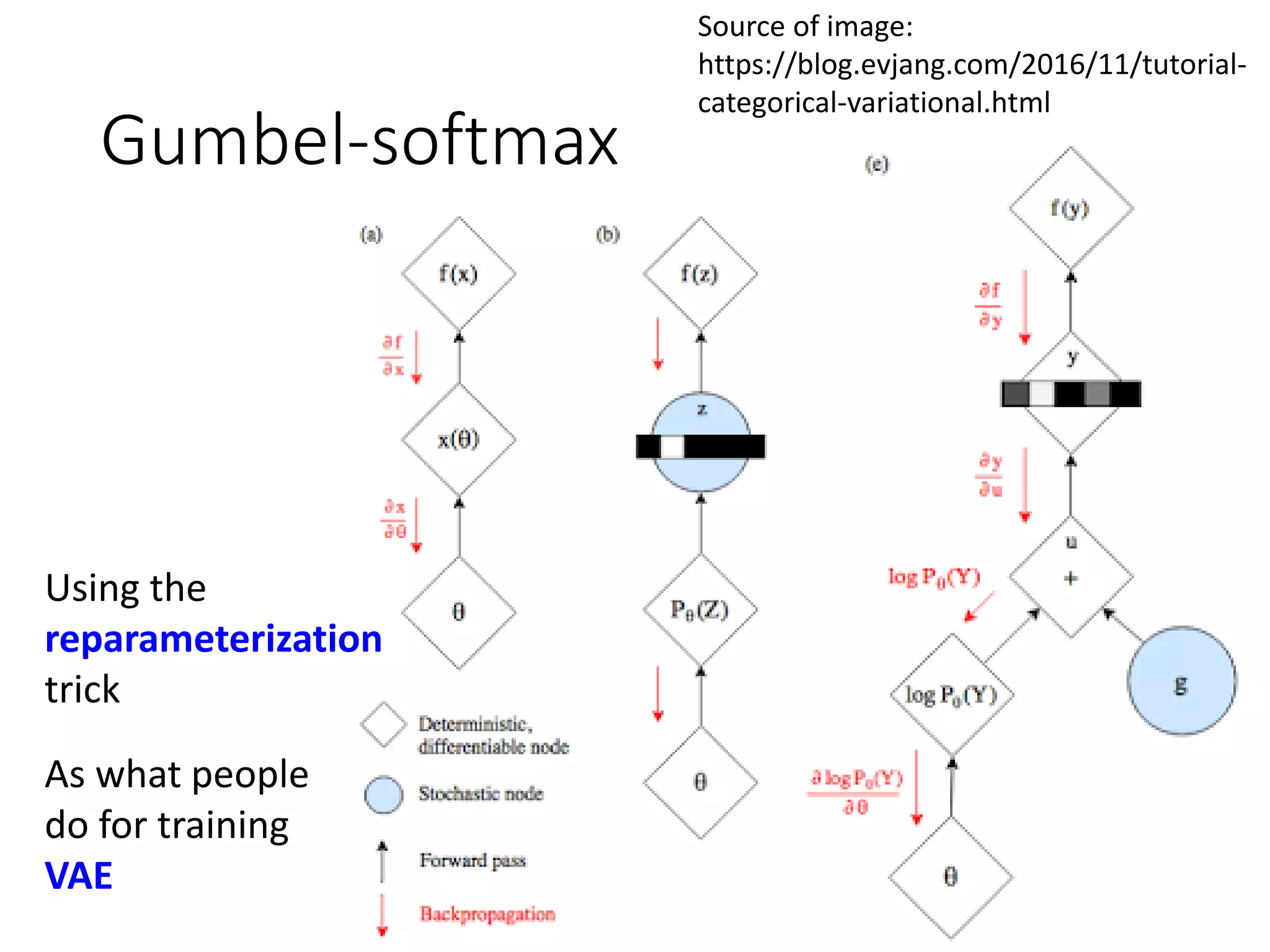
![Three Categories of Solutions
Gumbel-softmax
• [Matt J. Kusner, et al., arXiv, 2016][Weili Nie, et al. ICLR, 2019]
Continuous Input for Discriminator
• [Sai Rajeswar, et al., arXiv, 2017][Ofir Press, et al., ICML workshop, 2017][Zhen
Xu, et al., EMNLP, 2017][Alex Lamb, et al., NIPS, 2016][Yizhe Zhang, et al., ICML,
2017]
Reinforcement Learning
• [Yu, et al., AAAI, 2017][Li, et al., EMNLP, 2017][Tong Che, et al, arXiv,
2017][Jiaxian Guo, et al., AAAI, 2018][Kevin Lin, et al, NIPS, 2017][William
Fedus, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-198-2048.jpg)
![Three Categories of Solutions
Gumbel-softmax
• [Matt J. Kusner, et al., arXiv, 2016][Weili Nie, et al. ICLR, 2019]
Continuous Input for Discriminator
• [Sai Rajeswar, et al., arXiv, 2017][Ofir Press, et al., ICML workshop, 2017][Zhen
Xu, et al., EMNLP, 2017][Alex Lamb, et al., NIPS, 2016][Yizhe Zhang, et al., ICML,
2017]
Reinforcement Learning
• [Yu, et al., AAAI, 2017][Li, et al., EMNLP, 2017][Tong Che, et al, arXiv,
2017][Jiaxian Guo, et al., AAAI, 2018][Kevin Lin, et al, NIPS, 2017][William
Fedus, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-200-2048.jpg)
![Three Categories of Solutions
Gumbel-softmax
• [Matt J. Kusner, et al., arXiv, 2016][Weili Nie, et al. ICLR, 2019]
Continuous Input for Discriminator
• [Sai Rajeswar, et al., arXiv, 2017][Ofir Press, et al., ICML workshop, 2017][Zhen
Xu, et al., EMNLP, 2017][Alex Lamb, et al., NIPS, 2016][Yizhe Zhang, et al., ICML,
2017]
Reinforcement Learning
• [Yu, et al., AAAI, 2017][Li, et al., EMNLP, 2017][Tong Che, et al, arXiv,
2017][Jiaxian Guo, et al., AAAI, 2018][Kevin Lin, et al, NIPS, 2017][William
Fedus, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-203-2048.jpg)

![Tips for Sequence Generation
GAN
• Usually the generator are fine-tuned from a model learned
by maximum-likelihood.
• However, with enough hyperparameter-tuning and tips,
ScarchGAN can train from scratch.
[Cyprien de Masson
d'Autume, et al.,
arXiv 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-206-2048.jpg)
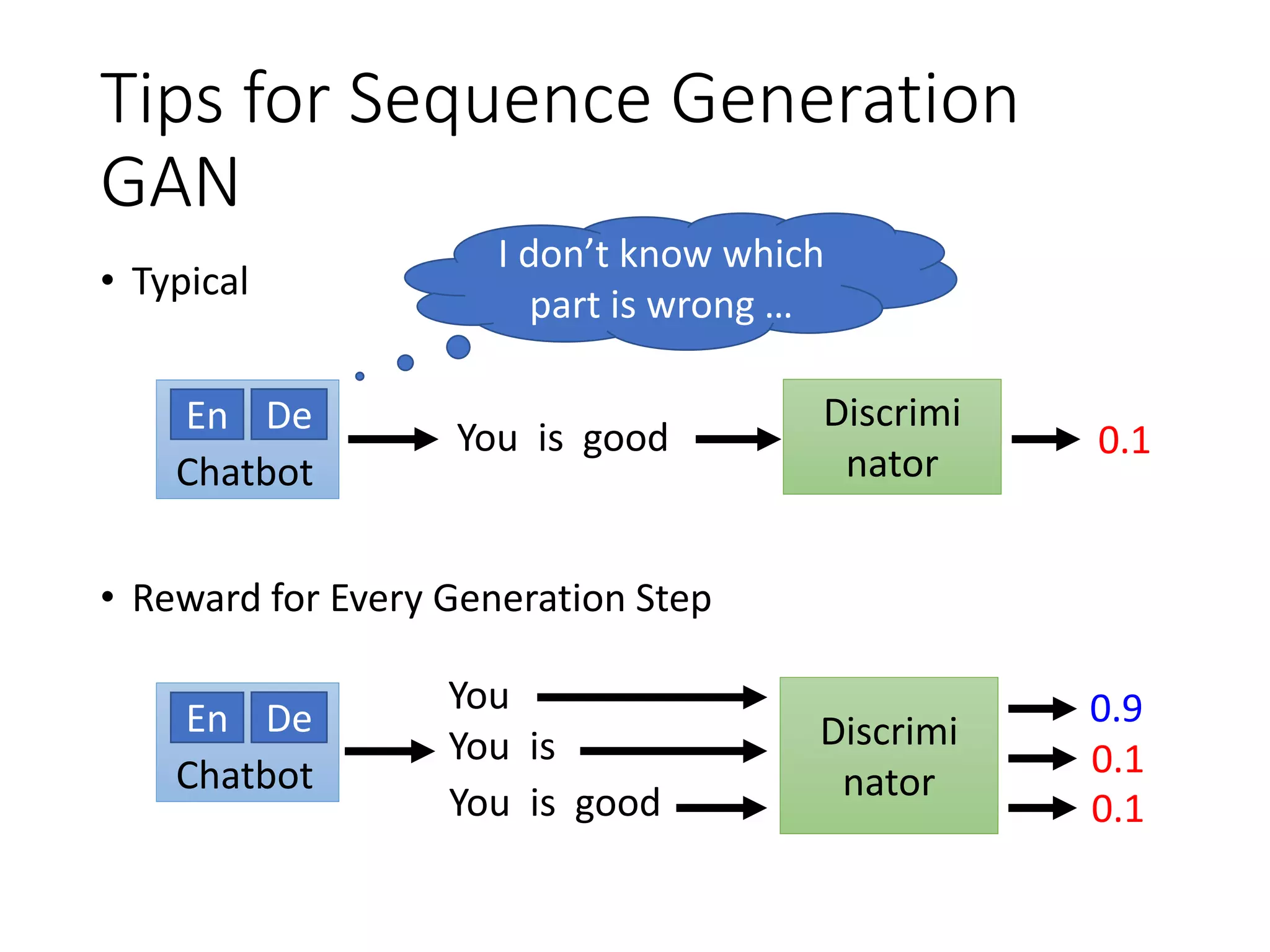
![Tips for Sequence Generation
GAN
• Reward for Every Generation Step
Discrimi
natorChatbot
En De 0.9
0.1
0.1
You
You is
You is good
Method 2. Discriminator For Partially Decoded Sequences
Method 1. Monte Carlo (MC) Search [Yu, et al., AAAI, 2017]
[Li, et al., EMNLP, 2017]
Method 3. Step-wise evaluation[Tual, Lee, TASLP, 2019][Xu, et al., EMNLP,
2018][William Fedus, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-208-2048.jpg)
![Empirical Performance
• MLE frequently generates “I’m sorry”, “I don’t
know”, etc. (corresponding to fuzzy images?)
• GAN generates longer and more complex responses.
• Find more comparison in the survey papers.
• [Lu, et al., arXiv, 2018][Zhu, et al., arXiv, 2018]
• However, no strong evidence shows that GANs are
better than MLE.
• [Stanislau Semeniuta, et al., arXiv, 2018] [Guy Tevet, et al., arXiv, 2018]
[Massimo Caccia, et al., arXiv, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-209-2048.jpg)
![More Applications
• Supervised machine translation [Wu, et al., arXiv
2017][Yang, et al., arXiv 2017]
• Supervised abstractive summarization [Liu, et al., AAAI
2018]
• Image/video caption generation [Rakshith Shetty, et al., ICCV
2017][Liang, et al., arXiv 2017]
• Data augmentation for code-switching ASR [Mon-P-
1-D] [Chang, et al., INTERSPEECH 2019]
If you are trying to generate some sequences,
you can consider GAN.](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-210-2048.jpg)

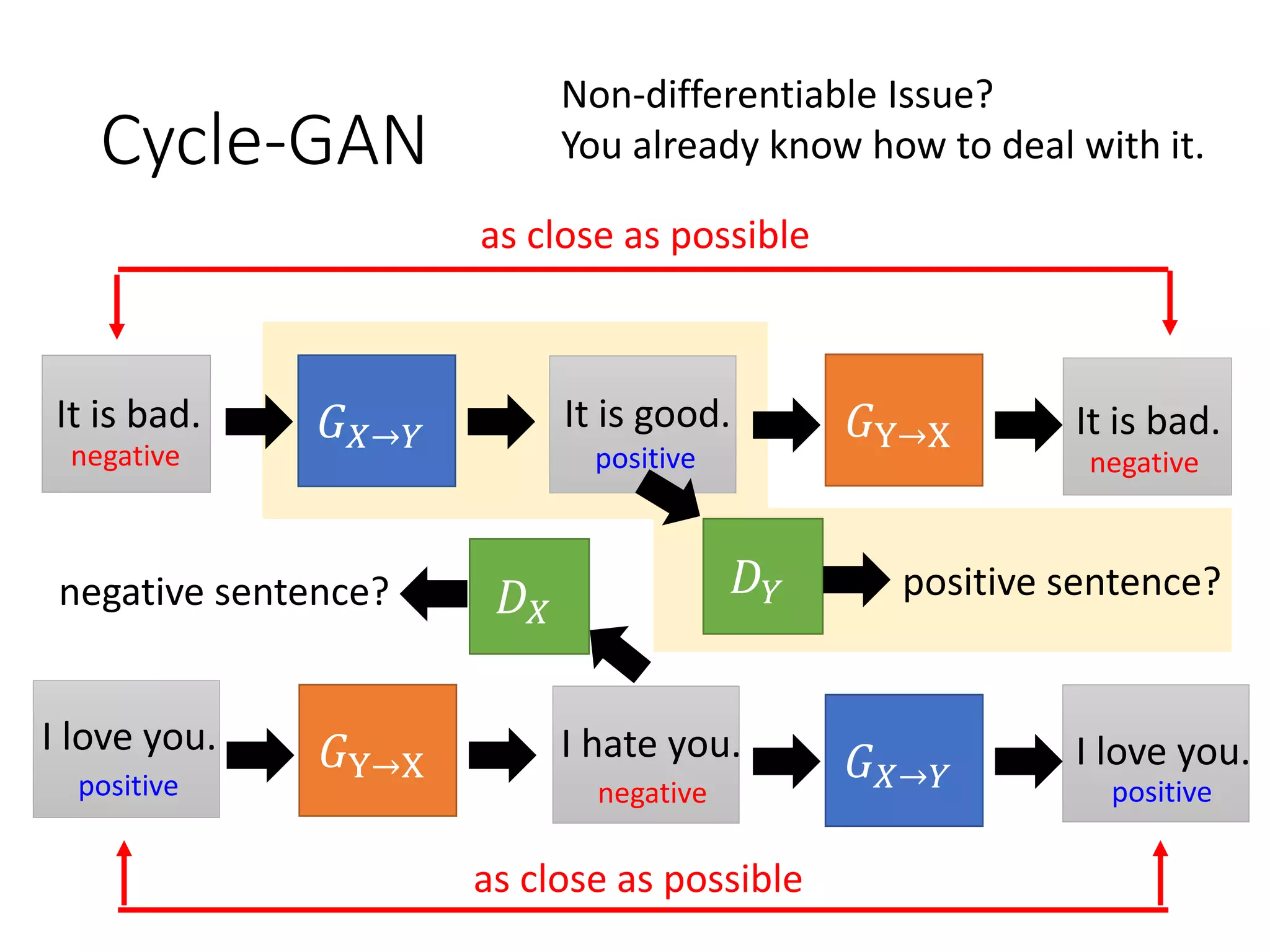
![✘ Negative sentence to positive sentence:
it's a crappy day -> it's a great day
i wish you could be here -> you could be here
it's not a good idea -> it's good idea
i miss you -> i love you
i don't love you -> i love you
i can't do that -> i can do that
i feel so sad -> i happy
it's a bad day -> it's a good day
it's a dummy day -> it's a great day
sorry for doing such a horrible thing -> thanks for doing a
great thing
my doggy is sick -> my doggy is my doggy
my little doggy is sick -> my little doggy is my little doggy
Cycle GAN
感謝 王耀賢 同學提供實驗結果
[Lee, et al.,
ICASSP, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-215-2048.jpg)
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋 𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared Latent Space
Positive
Sentence
Positive
Sentence
Negative
Sentence
Negative
Sentence
Decoder hidden layer as discriminator input
[Shen, et al., NIPS, 2017]
From 𝐸𝑁𝑋 or 𝐸𝑁𝑌
Domain
Discriminator
𝐸𝑁𝑋 and 𝐸𝑁𝑌 fool the
domain discriminator
[Zhao, et al., arXiv, 2017]
[Fu, et al., AAAI, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-216-2048.jpg)
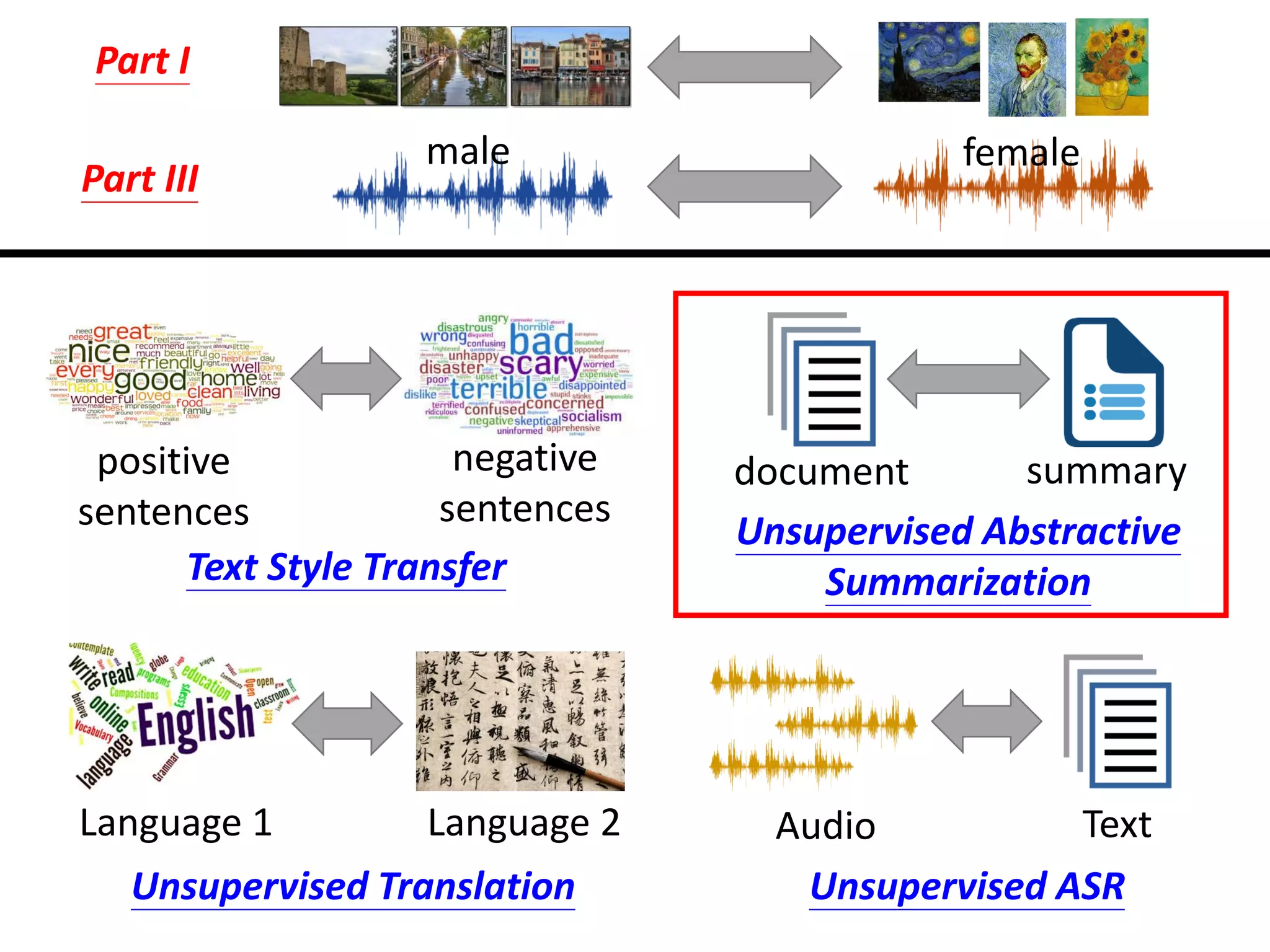

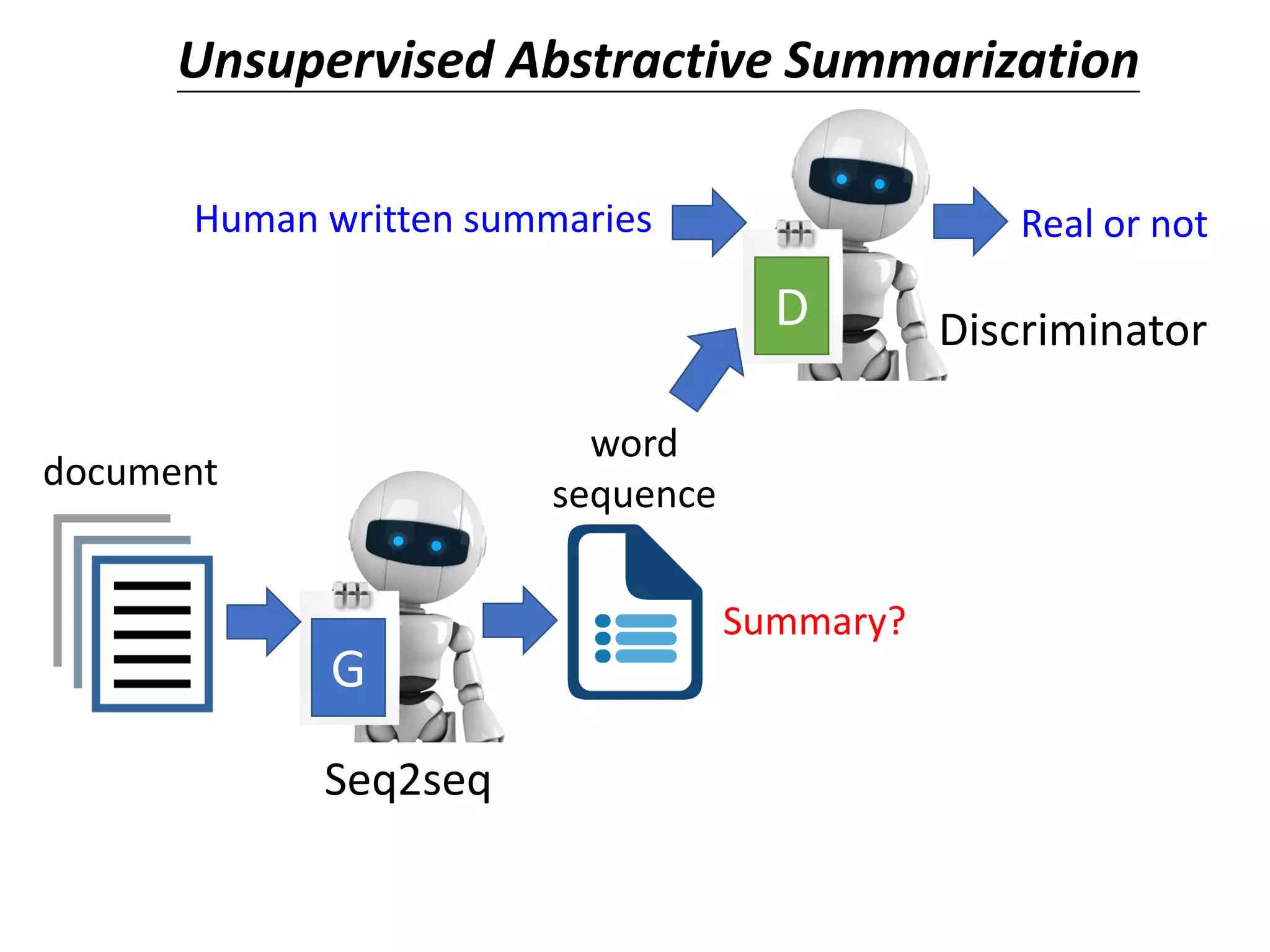
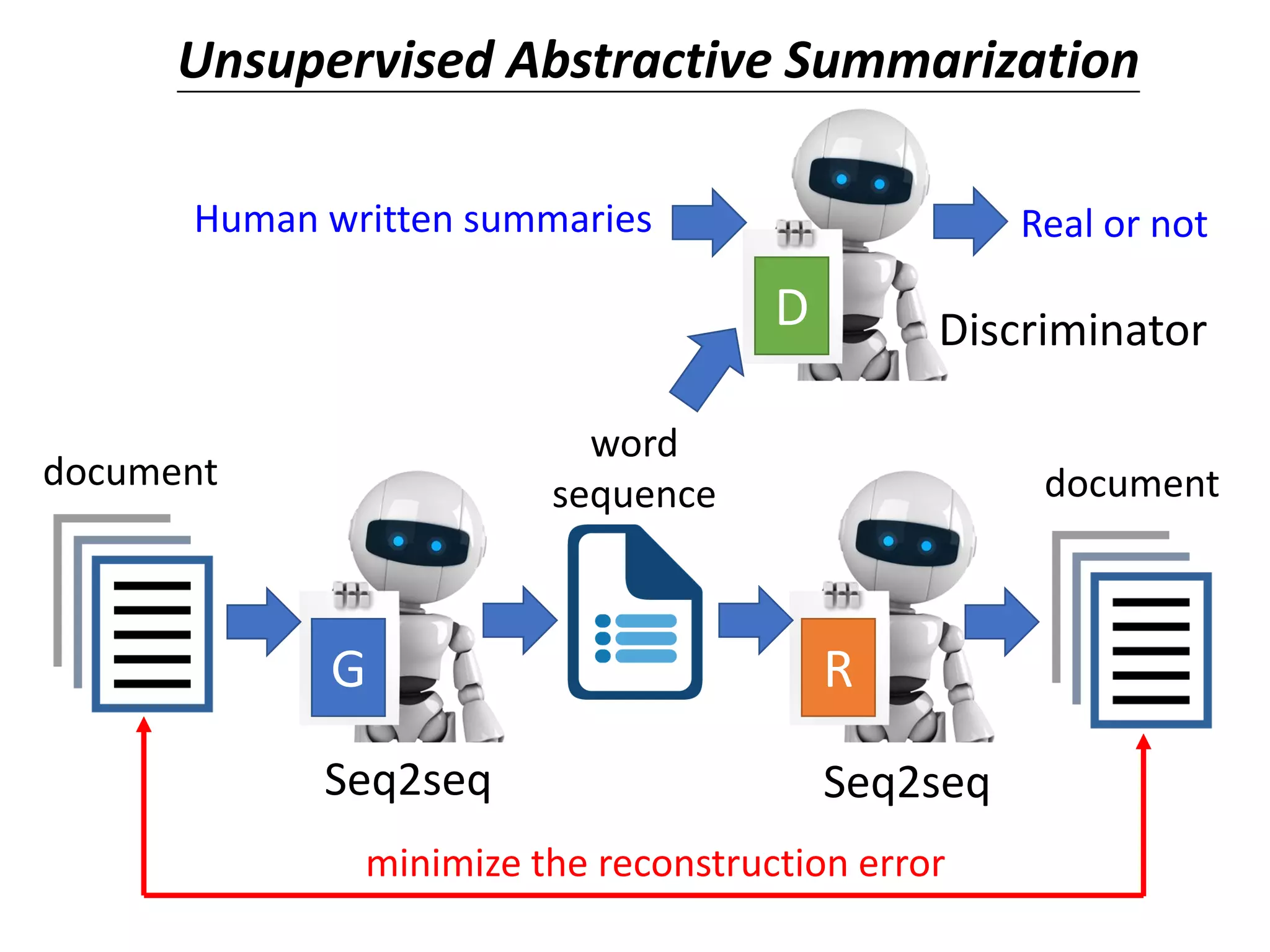
![Unsupervised Abstractive
Summarization
• Now machine can do abstractive summary by
seq2seq (write summaries in its own words)
summary 1
summary 2
summary 3
seq2seq document
Domain Y Domain X[Wang, et al., EMNLP, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-219-2048.jpg)

![Experimental results
ROUGE-1 ROUGE-2 ROUGE-L
Supervised 33.2 14.2 30.5
Trivial 21.9 7.7 20.5
Unsupervised
(matched data)
28.1 10.0 25.4
Unsupervised
(no matched data)
27.2 9.1 24.1
English Gigaword (Document title as summary)
• Matched data: using the title of English Gigaword to train
Discriminator
• No matched data: using the title of CNN/Diary Mail to
train Discriminator
[Wang, Lee, EMNLP 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-224-2048.jpg)
![Semi-supervised Learning
25
26
27
28
29
30
31
32
33
34
0 10k 500k
ROUGE-1
Number of document-summary pairs used
WGAN Reinforce Supervised
3.8M pairs are used.Approaches to deal with the discrete issue.
unsupervised
semi-supervised
[Wang, Lee,
EMNLP 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-225-2048.jpg)
![More Unsupervised
Summarization
• Unsupervised summarization with language prior
• Unsupervised multi-document summarization
[Eric Chu, Peter Liu,
ICML 2019]
[Christos Baziotis, etc al.,
NAACL 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-226-2048.jpg)
![G
Input
Sentence
D
Said by
Trump?
Discriminator
R
Dialogue Response Generation
minimize the reconstruction error
Make the US great again
I would build a great wall
you are fired
What Trump has said
Chat
Bot
Generated
Response
Input
Sentence
(Reconstruct)
[Su, et al., INTERSPEECH, 2019]
(Thu-P-9-C)
General
Dialogues](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-227-2048.jpg)
![Unsupervised learning
with 10M sentences
Supervised learning with
100K sentence pairs
=
supervised
unsupervised
[Alexis Conneau, et al., ICLR, 2018]
[Guillaume Lample, et al., ICLR, 2018]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-229-2048.jpg)
![Towards Unsupervised ASR
- Cycle GAN
G
ASR
Text
R
TTS
D
Real Text?
Discriminator
minimize the reconstruction error (speech chain)
how are you
good morning
i am fine
Real
Text
[Andros Tjandra, et al., ASRU 2017]
[Liu, et al., INTERSPEECH 2018]
[Yeh, et al., ICLR 2019]
[Chen, et al., INTERSPEECH 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-231-2048.jpg)
![Towards Unsupervised ASR
- Cycle GAN
• Unsupervised setting on TIMIT (text and audio are
unpair, text is not the transcription of audio)
• 63.6% PER (oracle boundaries)
• 41.6% PER (automatic segmentation)
• 33.1% PER (automatic segmentation)
• Semi-supervised setting on Librispeech
[Liu, et al., INTERSPEECH 2018]
[Yeh, et al., ICLR 2019]
(Tue-P-4-B)[Chen, et al., INTERSPEECH 2019]
[Liu, et al., ICASSP 2019]
[Tomoki Hayashi, et al., SLT 2018]
[Takaaki Hori, et al., ICASSP 2019]
[Murali Karthick Baskar, et al., INTERSPEECH 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-232-2048.jpg)
![Towards Unsupervised ASR
- Shared Latent Space
Text
Encoder
Audio
Encoder
Audio
Decoder
Text
Decoder
this is text this is text
Unsupervised setting on Librispeech: 76.3% WER
WSJ with 2.5 hours paired data: 64.6% WER
LJ speech with 20 mins paired data: 11.7% PER
[Chen, et al., SLT 2018]
Unsupervised speech translation is also possible!
[Chung, et al., NIPS 2018]
[Jennifer Drexler, et al., SLT 2018]
[Ren, et al., ICML 2019]
[Chung, et al., ICASSP 2019]](https://image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-233-2048.jpg)



































![Progressive GAN
[Tero Karras, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-23-2048.jpg)
![The first GAN
[Ian J. Goodfellow, et al., NIPS, 2014]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-24-2048.jpg)
![Today ……
[Andrew Brock, et al., arXiv, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-25-2048.jpg)
![[David Bau, et al., ICLR 2019]
Does the generator have the concept
of objects?
Some neurons correspond to specific
objects, for example, tree](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-26-2048.jpg)
![Remove the neurons for tree
[David Bau, et al., ICLR 2019]
Activate the neurons for tree](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-27-2048.jpg)


![Conditional GAN
D
(original)
scalar𝑥
G
𝑧Normal distribution
x = G(c,z)
c: train
x is real image or not
Image
Real images:
Generated images:
1
0
Generator will learn to
generate realistic images ….
But completely ignore the
input conditions.
[Scott Reed, et al, ICML, 2016]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-30-2048.jpg)
![Conditional GAN
D
(better)
scalar
𝑐
𝑥
True text-image pairs:
G
𝑧Normal distribution
x = G(c,z)
c: train
Image
x is realistic or not +
c and x are matched or not
(train , )
(train , )(cat , )
[Scott Reed, et al, ICML, 2016]
1
00](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-31-2048.jpg)
![x is realistic or not +
c and x are matched
or not
Conditional GAN - Discriminator
[Takeru Miyato, et al., ICLR, 2018]
[Han Zhang, et al., arXiv, 2017]
[Augustus Odena et al., ICML, 2017]
condition c
object x
Network
Network
Network
score
Network
Network
(almost every paper)
condition c
object x
c and x are matched
or not
x is realistic or not
+](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-32-2048.jpg)

![Conditional GAN - Image-to-image
G
𝑧
x = G(c,z)
𝑐
[Phillip Isola, et al., CVPR, 2017]
Image translation, or pix2pix](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-34-2048.jpg)
![as close as
possible
Conditional GAN - Image-to-image
• Traditional supervised approach
NN Image
It is blurry.
Testing:
input L1
e.g. L1
[Phillip Isola, et al., CVPR, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-35-2048.jpg)
![Conditional GAN - Image-to-image
Testing:
input L1 GAN
G
𝑧
Image D scalar
GAN + L1
L1
[Phillip Isola, et al., CVPR, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-36-2048.jpg)
![Conditional GAN
- Sound-to-image
Gc: sound Image
"a dog barking sound"
Training Data
Collection
video
[Wan, et al., ICASSP 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-37-2048.jpg)


![Conditional GAN - Image-to-label
F1 MS-COCO NUS-WIDE
VGG-16 56.0 33.9
+ GAN 60.4 41.2
Inception 62.4 53.5
+GAN 63.8 55.8
Resnet-101 62.8 53.1
+GAN 64.0 55.4
Resnet-152 63.3 52.1
+GAN 63.9 54.1
Att-RNN 62.1 54.7
RLSD 62.0 46.9
The classifiers can have
different architectures.
The classifiers are
trained as conditional
GAN.
[Tsai, et al., ICASSP 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-40-2048.jpg)

![Conditional GAN
- Video Generation
Generator
Discrimi
nator
Last frame is real
or generated
Discriminator thinks it is real
[Michael Mathieu, et al., arXiv, 2015]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-42-2048.jpg)

![More about Video Generation
https://arxiv.org/abs/1905.08233
[Egor Zakharov, et al., arXiv, 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-44-2048.jpg)


![Domain Adversarial Training
feature extractor (Generator)
Discriminator
(Domain classifier)
image
Label predictor
Which digits?
Not only cheat the domain
classifier, but satisfying label
predictor at the same time
More speech-related applications in Part III.
Successfully applied on image classification
[Ganin et al, ICML, 2015][Ajakan et al. JMLR, 2016 ]
Which domain?](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-47-2048.jpg)





![Cycle GAN
𝐺 𝑋→𝑌
Domain X
Domain Y
𝐷 𝑌
Domain X
scalar
Input image
belongs to
domain Y or not
Become similar
to domain Y
Not what we want!
ignore input
[Tomer Galanti, et al. ICLR, 2018]
The issue can be avoided by network design.
Simpler generator makes the input and
output more closely related.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-53-2048.jpg)
![Cycle GAN
𝐺 𝑋→𝑌
Domain X
Domain Y
𝐷 𝑌
Domain X
scalar
Input image
belongs to
domain Y or not
Become similar
to domain Y
Encoder
Network
Encoder
Network
pre-trained
as close as
possible
Baseline of DTN [Yaniv Taigman, et al., ICLR, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-54-2048.jpg)
![Cycle GAN
𝐺 𝑋→𝑌
𝐷 𝑌
Domain Y
scalar
Input image
belongs to
domain Y or not
𝐺Y→X
as close as possible
Lack of information
for reconstruction
[Jun-Yan Zhu, et al., ICCV, 2017]
Cycle consistency](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-55-2048.jpg)

![Cycle GAN
Dual GAN
Disco GAN
[Jun-Yan Zhu, et al., ICCV, 2017]
[Zili Yi, et al., ICCV, 2017]
[Taeksoo Kim, et
al., ICML, 2017]
For multiple domains,
considering starGAN
[Yunjey Choi, arXiv, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-57-2048.jpg)
![Issue of Cycle Consistency
• CycleGAN: a Master of Steganography
[Casey Chu, et al., NIPS workshop, 2017]
𝐺Y→X𝐺 𝑋→𝑌
The information is hidden.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-58-2048.jpg)




![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋image
image
image
image
Minimizing reconstruction error
The domain discriminator forces the output of 𝐸𝑁𝑋 and
𝐸𝑁𝑌 have the same distribution.
From 𝐸𝑁𝑋 or 𝐸𝑁𝑌
𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared latent space
Training
Domain
Discriminator
𝐸𝑁𝑋 and 𝐸𝑁𝑌 fool the
domain discriminator
[Guillaume Lample, et al., NIPS, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-63-2048.jpg)
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋image
image
image
image
𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared latent space
Training
Cycle Consistency:
Used in ComboGAN [Asha Anoosheh, et al., arXiv, 017]
Minimizing reconstruction error](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-64-2048.jpg)
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋image
image
image
image
𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared latent space
Training
Semantic Consistency:
Used in DTN [Yaniv Taigman, et al., ICLR, 2017] and
XGAN [Amélie Royer, et al., arXiv, 2017]
To the same
latent space](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-65-2048.jpg)
![Sharing the parameters of encoders and decoders
Shared latent space
𝐸𝑁 𝑋
𝐸𝑁𝑌
𝐷𝐸 𝑋
𝐷𝐸 𝑌
Couple GAN[Ming-Yu Liu, et al., NIPS, 2016]
UNIT[Ming-Yu Liu, et al., NIPS, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-66-2048.jpg)












![Discriminator 𝐺∗
= 𝑎𝑟𝑔 min
𝐺
𝐷𝑖𝑣 𝑃𝐺, 𝑃𝑑𝑎𝑡𝑎
Discriminator
: data sampled from 𝑃𝑑𝑎𝑡𝑎
: data sampled from 𝑃𝐺
train
𝑉 𝐺, 𝐷 = 𝐸 𝑥∼𝑃 𝑑𝑎𝑡𝑎
𝑙𝑜𝑔𝐷 𝑥 + 𝐸 𝑥∼𝑃 𝐺
𝑙𝑜𝑔 1 − 𝐷 𝑥
Example Objective Function for D
(G is fixed)
𝐷∗ = 𝑎𝑟𝑔 max
𝐷
𝑉 𝐷, 𝐺Training:
Using the example objective
function is exactly the same as
training a binary classifier.
[Goodfellow, et al., NIPS, 2014]
The maximum objective value
is related to JS divergence.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-79-2048.jpg)

![𝐺∗
= 𝑎𝑟𝑔 min
𝐺
𝐷𝑖𝑣 𝑃𝐺, 𝑃𝑑𝑎𝑡𝑎max
𝐷
𝑉 𝐺, 𝐷
The maximum objective value
is related to JS divergence.
• Initialize generator and discriminator
• In each training iteration:
Step 1: Fix generator G, and update discriminator D
Step 2: Fix discriminator D, and update generator G
𝐷∗ = 𝑎𝑟𝑔 max
𝐷
𝑉 𝐷, 𝐺
[Goodfellow, et al., NIPS, 2014]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-81-2048.jpg)
![Using the divergence
you like ☺
[Sebastian Nowozin, et al., NIPS, 2016]
Can we use other divergence?](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-82-2048.jpg)








![WGAN
max
𝐷∈1−𝐿𝑖𝑝𝑠𝑐ℎ𝑖𝑡𝑧
𝐸 𝑥~𝑃 𝑑𝑎𝑡𝑎
𝐷 𝑥 − 𝐸 𝑥~𝑃 𝐺
𝐷 𝑥
Evaluate Wasserstein distance between 𝑃𝑑𝑎𝑡𝑎 and 𝑃𝐺
[Martin Arjovsky, et al., arXiv, 2017]
How to fulfill this constraint?D has to be smooth enough.
real
−∞
generated
D
∞
Without the constraint, the
training of D will not converge.
Keeping the D smooth forces
D(x) become ∞ and −∞](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-91-2048.jpg)
![• Original WGAN → Weight Clipping [Martin Arjovsky, et al.,
arXiv, 2017]
• Improved WGAN → Gradient Penalty [Ishaan Gulrajani,
NIPS, 2017]
• Spectral Normalization → Keep gradient norm
smaller than 1 everywhere [Miyato, et al., ICLR, 2018]
Force the parameters w between c and -c
After parameter update, if w > c, w = c; if w < -c, w = -c
Keep the gradient close to 1
max
𝐷∈1−𝐿𝑖𝑝𝑠𝑐ℎ𝑖𝑡𝑧
𝐸 𝑥~𝑃 𝑑𝑎𝑡𝑎
𝐷 𝑥 − 𝐸 𝑥~𝑃 𝐺
𝐷 𝑥
real
samples
Keep the gradient
close to 1
[Kodali, et al., arXiv, 2017]
[Wei, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-92-2048.jpg)
![More Tips
• Improved techniques for training GANs
• Tips in DCGAN [Alec Radford, et al., ICLR 2016]
• Guideline for network architecture design for
image generation
• Tips from Soumith
• https://github.com/soumith/ganhacks
• Tips from BigGAN [Andrew Brock, et al., arXiv, 2018]
[Tim Salimans, et al., NIPS, 2016]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-93-2048.jpg)

![Inception Score
Off-the-shelf
Image Classifier
𝑥 𝑃 𝑦|𝑥
Concentrated distribution
means higher visual quality
CNN𝑥1
𝑃 𝑦1|𝑥1
Uniform distribution
means higher variety
CNN𝑥2
𝑃 𝑦2|𝑥2
CNN𝑥3
𝑃 𝑦3|𝑥3
…
𝑃 𝑦 =
1
𝑁
𝑛
𝑃 𝑦 𝑛|𝑥 𝑛
[Tim Salimans, et al., NIPS, 2016]
𝑥: image
𝑦: class (output of CNN)
e.g. Inception net,
VGG, etc.
class 1
class 2
class 3](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-95-2048.jpg)
![Inception Score
=
𝑥
𝑦
𝑃 𝑦|𝑥 𝑙𝑜𝑔𝑃 𝑦|𝑥
−
𝑦
𝑃 𝑦 𝑙𝑜𝑔𝑃 𝑦
Negative entropy of P(y|x)
Entropy of P(y)
Inception Score
𝑃 𝑦 =
1
𝑁
𝑛
𝑃 𝑦 𝑛|𝑥 𝑛
𝑃 𝑦|𝑥
class 1
class 2
class 3
[Tim Salimans, et al., NIPS 2016]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-96-2048.jpg)
![Fréchet Inception Distance (FID)
blue points: latent representation of Inception net for
the generated images
red points: latent representation of Inception net for
the read images
FID =
Fréchet distance
between the two
Gaussians
[Martin Heusel, et al., NIPS, 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-97-2048.jpg)
![To learn more about evaluation …
Pros and cons of GAN evaluation measures
https://arxiv.org/abs/1802.03446
[Ali Borji, 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-98-2048.jpg)
















![Speech Enhancement
• Neural network models for spectral mapping
• Typical objective function
➢ Mean square error (MSE) [Xu et al., TASLP 2015], L1 [Pascual et al., Interspeech
2017], likelihood [Chai et al., MLSP 2017], STOI [Fu et al., TASLP 2018].
Enhancing
➢ GAN is used as a new objective function to estimate the parameters in G.
➢Model structures of G: DNN [Wang et al. NIPS 2012; Xu et al., SPL 2014], DDAE
[Lu et al., Interspeech 2013], RNN (LSTM) [Chen et al., Interspeech 2015;
Weninger et al., LVA/ICA 2015], CNN [Fu et al., Interspeech 2016].
G Output
Objective function](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-115-2048.jpg)
![Speech Enhancement
• Speech enhancement GAN (SEGAN) [Pascual et al., Interspeech 2017]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-116-2048.jpg)

![• Pix2Pix [Michelsanti et al., Interpsech 2017]
D Scalar
Clean
Noisy
(Fake/Real)
Output
Noisy
G
Noisy Output Clean
Speech Enhancement](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-118-2048.jpg)


![• Frequency-domain SEGAN (FSEGAN) [Donahue et al., ICASSP 2018]
D Scalar
Clean
Noisy
(Fake/Real)
Output
Noisy
G
Noisy Output Clean
Speech Enhancement](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-121-2048.jpg)



![• GAN for spectral magnitude mask estimation (MMS-GAN)
[Ashutosh Pandey and Deliang Wang, ICASSP 2018]
D Scalar
Ref.
mask
Noisy
(Fake/Real)
Output
mask
Noisy
G
Noisy Output mask Ref. mask
Speech Enhancement
We don’t know exactly what D functions.
Our ICML 2019 paper shed some lights on a potential future direction.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-125-2048.jpg)
![𝐺𝑆→𝑇 𝐺 𝑇→𝑆
as close as possible
𝐷 𝑇
Scalar: belongs to
domain T or not
𝐺 𝑇→𝑆 𝐺𝑆→𝑇
as close as possible
𝐷𝑆
Scalar: belongs to
domain S or not
Speech Enhancement (AFT)
• Cycle-GAN-based acoustic feature transformation (AFT)
[Mimura et al., ASRU 2017]
𝑉𝐹𝑢𝑙𝑙 = 𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌 +𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌
+𝜆 𝑉𝐶𝑦𝑐(𝐺 𝑋→𝑌, 𝐺 𝑌→𝑋)
Noisy Enhanced Noisy
Clean Syn. Noisy Clean](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-126-2048.jpg)


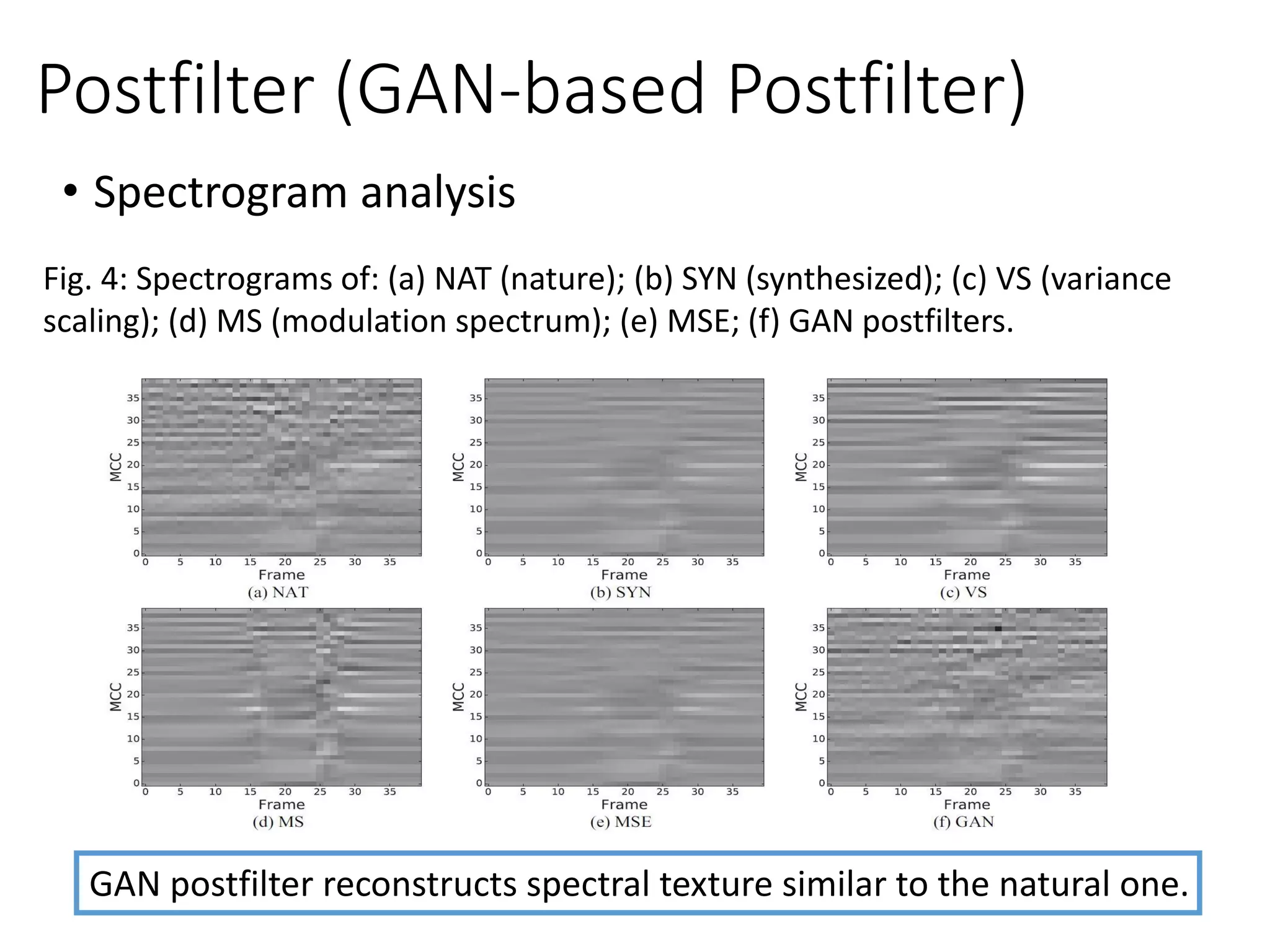
![• Postfilter for synthesized or transformed speech
➢ Conventional postfilter approaches for G estimation include global variance
(GV) [Toda et al., IEICE 2007], variance scaling (VS) [Sil’en et al., Interpseech
2012], modulation spectrum (MS) [Takamichi et al., ICASSP 2014],DNN with
MSE criterion [Chen et al., Interspeech 2014; Chen et al., TASLP 2015].
➢ GAN is used a new objective function to estimate the parameters in G.
Postfilter
Synthesized
spectral texture
Natural
spectral texture
G Output
Objective function
Speech
synthesizer
Voice
conversion
Speech
enhancement](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-129-2048.jpg)
![• GAN postfilter [Kaneko et al., ICASSP 2017]
➢ Traditional MMSE criterion results in statistical averaging.
➢ GAN is used as a new objective function to estimate the parameters in G.
➢ The proposed work intends to further improve the naturalness of
synthesized speech or parameters from a synthesizer.
Postfilter
Synthesized
Mel cepst. coef.
Natural
Mel cepst. coef.
D
Nature
or
Generated
Generated
Mel cepst. coef.
G](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-130-2048.jpg)



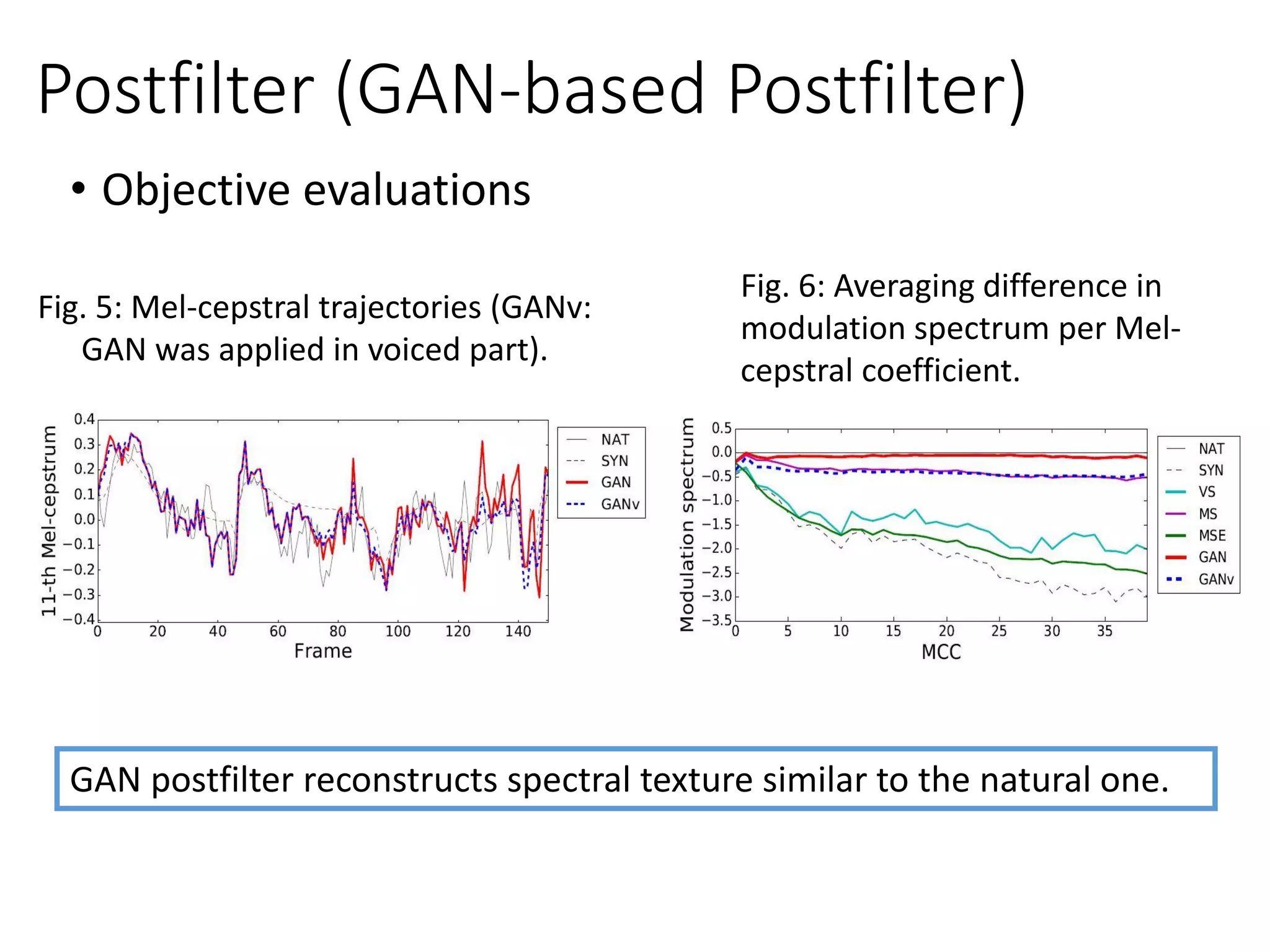
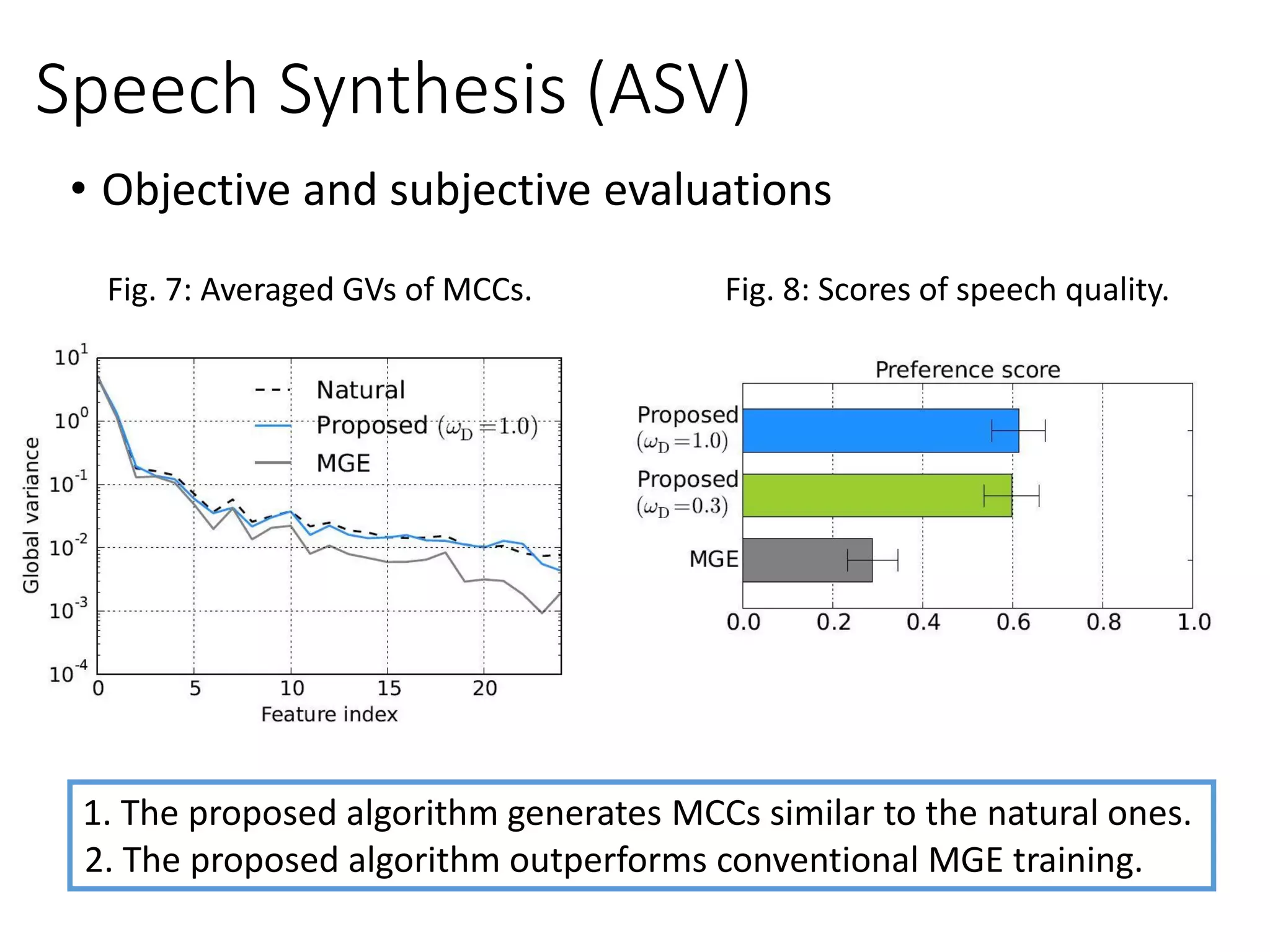
![Speech Synthesis
• Input: linguistic features; Output: speech parameters
𝒄ො𝒄
𝑮 𝑺𝑺
Natural
speech
parameters
Generated
speech
parameters
Linguistic
features
sp sp
Objective function
Minimum
generation error
(MGE), MSE
• Speech synthesis with anti-spoofing verification (ASV)
[Saito et al., ICASSP 2017]
𝐿 𝐷 𝒄, ො𝒄 = 𝐿 𝐷,1 𝒄 + 𝐿 𝐷,0 ො𝒄
𝐿 𝐷,1 𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log( 𝐷 𝒄 𝑡 )…NAT
𝐿 𝐷,0 ො𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log(1 − 𝐷 ො𝒄 𝑡 )…SYN
𝐿 𝒄, ො𝒄 = 𝐿 𝐺 𝒄, ො𝒄 + 𝜔 𝐷
𝐸 𝐿 𝐺
𝐸 𝐿 𝐷
𝐿 𝐷,1 ො𝒄
Minimum generation error (MGE)
with adversarial loss.
𝒄ො𝒄
𝑮 𝑺𝑺
Natural
speech
parameters
Generated
speech
parameters
Gen.
Nature
𝑫 𝑨𝑺𝑽𝝓(∙)
Linguistic
features
sp sp
MGE](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-134-2048.jpg)

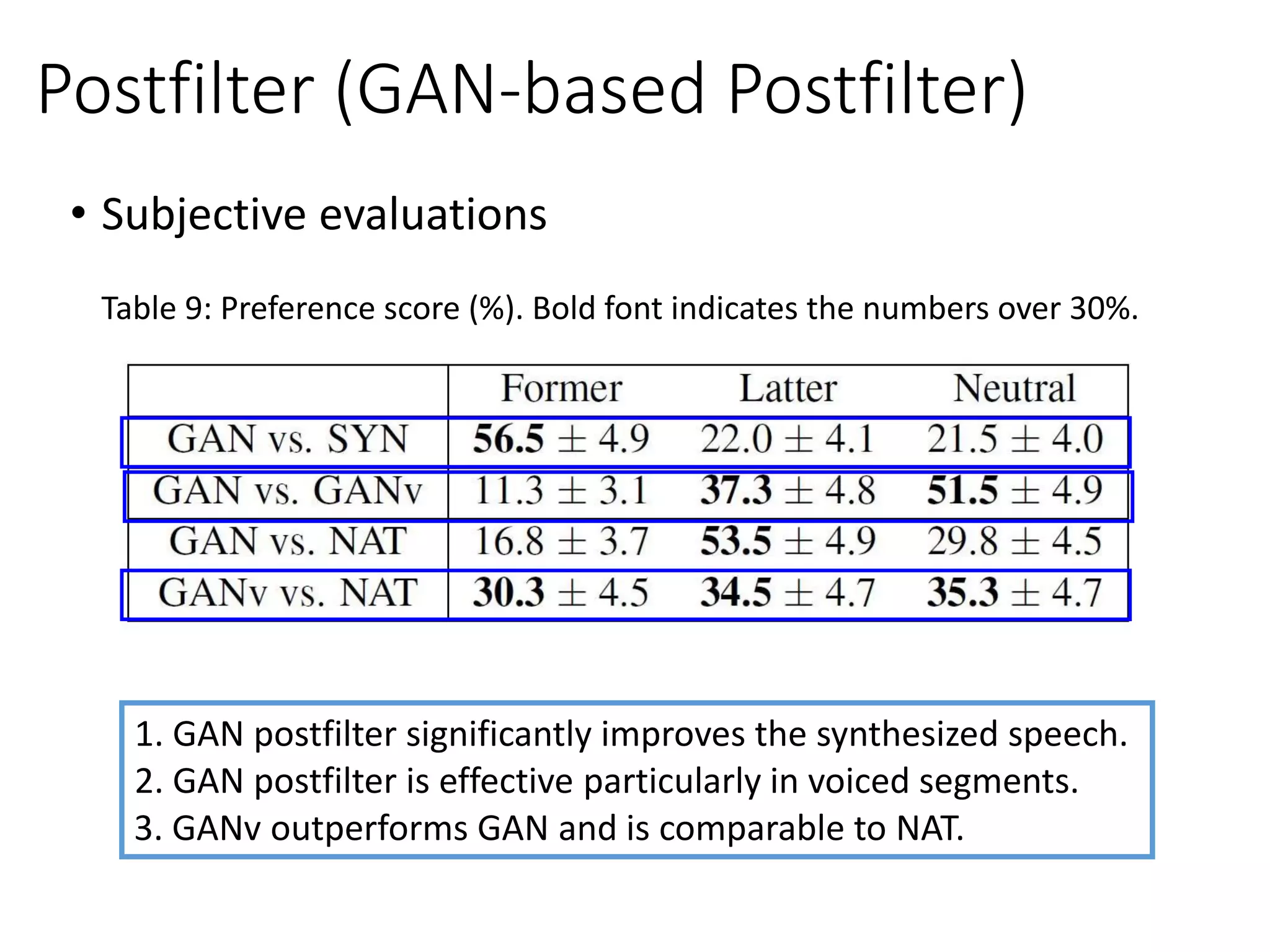
![• Speech synthesis with GAN (SS-GAN) [Saito et al., TASLP 2018]
𝐿 𝐷 𝒄, ො𝒄 = 𝐿 𝐷,1 𝒄 + 𝐿 𝐷,0 ො𝒄
𝐿 𝐷,1 𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log( 𝐷 𝒄 𝑡 )…NAT
𝐿 𝐷,0 ො𝒄 = −
1
𝑇
σ 𝑡=1
𝑇
log(1 − 𝐷 ො𝒄 𝑡 )…SYN
𝐿 𝒄, ො𝒄 = 𝐿 𝐺 𝒄, ො𝒄 + 𝜔 𝐷
𝐸 𝐿 𝐺
𝐸 𝐿 𝐷
𝐿 𝐷,1 ො𝒄
Minimum generation error (MGE)
with adversarial loss.
𝒄ො𝒄
Speech Synthesis
𝑮 𝑺𝑺
Natural
speech
parameters
Generated
speech
parameters
Gen.
Nature
𝑫𝝓(∙)
Linguistic
features
𝑫 𝑨𝑺𝑽
sp, f0, duration sp, f0, duration
MGE](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-136-2048.jpg)

![• Convert (transform) speech from source to target
➢ Conventional VC approaches include Gaussian mixture model (GMM) [Toda
et al., TASLP 2007], non-negative matrix factorization (NMF) [Wu et al., TASLP
2014; Fu et al., TBME 2017], locally linear embedding (LLE) [Wu et al.,
Interspeech 2016], variational autoencoder (VAE) [Hsu et al., APSIPA
2016], restricted Boltzmann machine (RBM) [Chen et al., TASLP
2014], feed forward NN [Desai et al., TASLP 2010], recurrent NN (RNN)
[Nakashika et al., Interspeech 2014].
Voice Conversion
G Output
Objective function
Target
speaker
Source
speaker](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-138-2048.jpg)
![• VAW-GAN [Hsu et al., Interspeech 2017]
➢Conventional MMSE approaches often encounter the “over-smoothing” issue.
➢ GAN is used a new objective function to estimate G.
➢ The goal is to increase the naturalness, clarity, similarity of converted speech.
Voice Conversion
D
Real
or
Fake
G
Target
speaker
Source
speaker
𝑉 𝐺, 𝐷 = 𝑉𝐺𝐴𝑁 𝐺, 𝐷 + 𝜆 𝑉𝑉𝐴𝐸 𝒙|𝒚](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-139-2048.jpg)

![• CycleGAN-VC [Kaneko et al., Eusipco 2018]
• used a new objective function to estimate G
𝑉𝐹𝑢𝑙𝑙 = 𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌 +𝑉𝐺𝐴𝑁 𝐺 𝑋→𝑌, 𝐷 𝑌
+𝜆 𝑉𝐶𝑦𝑐(𝐺 𝑋→𝑌, 𝐺 𝑌→𝑋)
Voice Conversion
𝑮 𝑺→𝑻 𝐺 𝑇→𝑆
as close as possible
𝑫 𝑻
Scalar: belongs to
domain T or not
Scalar: belongs to
domain S or not
𝐺 𝑇→𝑆 𝑮 𝑺→𝑻
as close as possible
𝑫 𝑺
Target Syn. Source Target
Source Syn. Target Source](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-141-2048.jpg)



![Speech Recognition
• Adversarial multi-task learning (AMT)
[Shinohara Interspeech 2016]
Output 1
Senone
Input
Acoustic feature
E
G𝑉𝑦
Output 2
Domain
D 𝑉𝑧
𝒛
𝒚
𝒙
GRL
𝑉𝑦=− σ𝑖 log 𝑃(𝑦𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐺)
𝑉𝑧=− σ𝑖 log 𝑃(𝑧𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐷)
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺
𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
𝜃 𝐷 ← 𝜃 𝐷 − ϵ
𝜕𝑉𝑧
𝜕𝜃 𝐷
Model update
Max
classification
accuracy
Max domain
accuracy
Max classification accuracy
Objective function
+𝛼
𝜕𝑉𝑧
𝜕𝜃 𝐸
and Min domain accuracy](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-145-2048.jpg)

![Speech Recognition
• Domain adversarial training for accented ASR (DAT)
[Sun et al., ICASSP2018]
Output 2
Domain
Output 1
Senone
Input
Acoustic feature
E
G D
GRL
𝑉𝑧𝑉𝑦
𝒛
𝒚
𝒙
𝑉𝑦=− σ𝑖 log 𝑃(𝑦𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐺)
𝑉𝑧=− σ𝑖 log 𝑃(𝑧𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐷)
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺
𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
𝜃 𝐷 ← 𝜃 𝐷 − ϵ
𝜕𝑉𝑧
𝜕𝜃 𝐷
Model update
Max
classification
accuracy
Max domain
accuracy
Max classification accuracy
Objective function
+𝛼
𝜕𝑉𝑧
𝜕𝜃 𝐸
and Min domain accuracy](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-147-2048.jpg)

![Speech Recognition
• Unsupervised Adaptation with Domain Separation
Networks (DSN) [Meng et al., ASRU 2017]
R
PEt
R
PEs
𝒙
𝒙
Output 1
Senone
Clean data
E
GL1
𝒚
𝒙
Emb.
Noisy data
E
𝒙
Emb.𝒛 = 𝑔(𝒙) 𝒛 = 𝑔(𝒙)
𝑔(∙)𝑔(∙)
ℎ(∙)D
Output 2
Domain
𝒅](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-149-2048.jpg)


![Speaker Recognition
• Domain adversarial neural network (DANN)
[Wang et al., ICASSP 2018]
DANN
DANN
Pre-
processing
Pre-
processing
Scoring
Enroll
i-vector
Test
i-vector
Output 2
Domain
Output 1
Speaker
ID
Input
Acoustic feature
E
G D
GRL
𝑉𝑧𝑉𝑦
𝒛
𝒚
𝒙](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-152-2048.jpg)


![Emotion Recognition
• Adversarial AE for emotion recognition (AAE-ER)
[Sahu et al., Interspeech 2017]
AE with GAN :
𝐻 ℎ 𝒛 , 𝒙 + λ 𝑉𝐺𝐴𝑁 (𝒒, 𝑔(𝒙))
E
D
𝒙
Emb.
Syn.
𝒛 = 𝑔(𝒙)
𝑔(∙)
ℎ(∙)
𝒒
𝒙
G
The distribution of code vectors](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-155-2048.jpg)


![Lip-reading
• Domain adversarial training for lip-reading (DAT-LR)
[Wand et al., Interspeech 2017]
Output 1
Words
E
G𝑉𝑦
Output 2
Speaker
D
GRL
𝑉𝑧
𝒛
𝒚
𝒙
𝑉𝑦=− σ𝑖 log 𝑃(𝑦𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐺)
𝑉𝑧=− σ𝑖 log 𝑃(𝑧𝑖|𝑥𝑖; 𝜃 𝐸, 𝜃 𝐷)
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺
𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
𝜃 𝐷 ← 𝜃 𝐷 − ϵ
𝜕𝑉𝑧
𝜕𝜃 𝐷
Model update
Max
classification
accuracy
Max domain
accuracy
Max classification accuracy
Objective function
+𝛼
𝜕𝑉𝑧
𝜕𝜃 𝐸
and Min domain accuracy
~80% WAC](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-158-2048.jpg)












![Outline of Part III
Our Recent Works
• Noise adaptive speech enhancement [Interspeech 2019]
• MetricGAN for speech enhancement [ICML 2019]
• Multi-Target voice conversion [Interspeech 2018]
• Impaired speech conversion [Interspeech 2019]
• Pathological voice detection [NeurIPS workshop 2018]
[Mon-P-2-A]
[Wed-P-6-E]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-171-2048.jpg)
![Speech Enhancement
N5 N5N4
N7 N9N10N12
Unseen
N11
𝒛
E G
𝑉𝑦
𝜃 𝐺 ← 𝜃 𝐺 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐺 𝜃 𝐸 ← 𝜃 𝐸 − ϵ
𝜕𝑉𝑦
𝜕𝜃 𝐸
Min reconstruction
error
Min reconstruction error
• Noise Adaptive Speech Enhancement (NA-SE)
[Liao et al., Interspeech 2019] [Wed-P-6-E]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-172-2048.jpg)


![• GAN for spectral magnitude mask estimation (MMS-GAN)
[Pandey et al., ICASSP 2018]
D Scalar
Ref.
mask
Noisy
(Fake/Real)
Output
mask
Noisy
G
Noisy Output mask Ref. mask
Speech Enhancement](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-175-2048.jpg)
![• MetricGAN for Speech Enhancement [Fu et al., ICML 2019]
D Metric
Score
(0~1)
G
Noisy Spect. Output mask
Speech Enhancement
1.00.4
Clean
Spect.
Enhanced
Spect.
Enhanced Spect.
Point-wise multiplication](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-176-2048.jpg)

![• Multi-target VC [Chou et al., Interspeech 2018]
𝑒𝑛𝑐(𝒙)
𝒙
Voice Conversion
C
𝑬nc Dec
𝒚
𝒚 𝒚′····
𝑒𝑛𝑐(𝒙)
𝑬nc Dec
𝒚"
𝑮
𝒚"
D+C
Real
data
𝒙 𝑑𝑒𝑐(𝑒𝑛𝑐 𝒙 , 𝒚) 𝑑𝑒𝑐(𝑒𝑛𝑐 𝒙 , 𝒚′)
➢ Stage-1
➢ Stage-2
F/R
ID
···](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-178-2048.jpg)

![• Controller-generator-discriminator VC on Impaired
Speech [Chen et al., Interspeech 2019]
Voice Conversion
Previous applications: hearing aids; murmur to normal speech; bone-
conductive microphone to air-conductive microphone.
Before
Proposed: improving the speech intelligibility of surgical patients.
Target: oral cancer (top five cancer for male in Taiwan).
After Before After
[Mon-P-2-A]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-180-2048.jpg)
![• Controller-generator-discriminator VC (CGD VC) on
impaired speech [Chen et al., Interspeech 2019]
Voice Conversion
GD
Controller](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-181-2048.jpg)


![Pathological Voice Detection
• Detection of Pathological Voice Using Cepstrum Vectors:
A Deep Learning Approach [Fang et al., Journal of Voice 2018]
GMM SVM DNN
MEEI 98.28 98.26 99.14
FEMH (M) 90.24 93.04 94.26
FEMH (F) 90.20 87.40 90.52
Table 17: Detection performance based on voice.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-184-2048.jpg)
![Pathological Voice Detection
• Robustness Against Channel [Hsu et al., NeurIPS Workshop 2018]
𝒛
E G
𝑉𝑦
D
𝑉𝑧
𝒚
DNN (S) DNN (T) DNN (FT) Unsup. DAT Sup. DAT
PR-AUC 0.8848 0.8509 0.9021 0.9455 0.9522
The unsupervised DAT notably increased the performance
robustness against channel effects and generated comparable
results as compared to supervised DAT.
𝒙
Table 18: Detection results of sup. and unsup. DAT under channel mismatches.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-185-2048.jpg)






![Reinforcement Learning
Human
Input sentence c response sentence x
Chatbot
En De
response sentence x
Input sentence c
[Li, et al., EMNLP, 2016]
reward
𝑅 𝑐, 𝑥
Learn to maximize expected reward
E.g. Policy Gradient
human
“How are you?” “Not bad” “I’m John”
-1+1](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-192-2048.jpg)


![Conditional GAN
Discriminator
Input sentence c response sentence x
Chatbot
En De
response sentence x
Input sentence c
reward
𝑅 𝑐, 𝑥
I am busy.
Replace human evaluation with
machine evaluation [Li, et al., EMNLP, 2017]
However, there is an issue when you train your generator.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-195-2048.jpg)


![Three Categories of Solutions
Gumbel-softmax
• [Matt J. Kusner, et al., arXiv, 2016][Weili Nie, et al. ICLR, 2019]
Continuous Input for Discriminator
• [Sai Rajeswar, et al., arXiv, 2017][Ofir Press, et al., ICML workshop, 2017][Zhen
Xu, et al., EMNLP, 2017][Alex Lamb, et al., NIPS, 2016][Yizhe Zhang, et al., ICML,
2017]
Reinforcement Learning
• [Yu, et al., AAAI, 2017][Li, et al., EMNLP, 2017][Tong Che, et al, arXiv,
2017][Jiaxian Guo, et al., AAAI, 2018][Kevin Lin, et al, NIPS, 2017][William
Fedus, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-198-2048.jpg)

![Three Categories of Solutions
Gumbel-softmax
• [Matt J. Kusner, et al., arXiv, 2016][Weili Nie, et al. ICLR, 2019]
Continuous Input for Discriminator
• [Sai Rajeswar, et al., arXiv, 2017][Ofir Press, et al., ICML workshop, 2017][Zhen
Xu, et al., EMNLP, 2017][Alex Lamb, et al., NIPS, 2016][Yizhe Zhang, et al., ICML,
2017]
Reinforcement Learning
• [Yu, et al., AAAI, 2017][Li, et al., EMNLP, 2017][Tong Che, et al, arXiv,
2017][Jiaxian Guo, et al., AAAI, 2018][Kevin Lin, et al, NIPS, 2017][William
Fedus, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-200-2048.jpg)


![Three Categories of Solutions
Gumbel-softmax
• [Matt J. Kusner, et al., arXiv, 2016][Weili Nie, et al. ICLR, 2019]
Continuous Input for Discriminator
• [Sai Rajeswar, et al., arXiv, 2017][Ofir Press, et al., ICML workshop, 2017][Zhen
Xu, et al., EMNLP, 2017][Alex Lamb, et al., NIPS, 2016][Yizhe Zhang, et al., ICML,
2017]
Reinforcement Learning
• [Yu, et al., AAAI, 2017][Li, et al., EMNLP, 2017][Tong Che, et al, arXiv,
2017][Jiaxian Guo, et al., AAAI, 2018][Kevin Lin, et al, NIPS, 2017][William
Fedus, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-203-2048.jpg)


![Tips for Sequence Generation
GAN
• Usually the generator are fine-tuned from a model learned
by maximum-likelihood.
• However, with enough hyperparameter-tuning and tips,
ScarchGAN can train from scratch.
[Cyprien de Masson
d'Autume, et al.,
arXiv 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-206-2048.jpg)

![Tips for Sequence Generation
GAN
• Reward for Every Generation Step
Discrimi
natorChatbot
En De 0.9
0.1
0.1
You
You is
You is good
Method 2. Discriminator For Partially Decoded Sequences
Method 1. Monte Carlo (MC) Search [Yu, et al., AAAI, 2017]
[Li, et al., EMNLP, 2017]
Method 3. Step-wise evaluation[Tual, Lee, TASLP, 2019][Xu, et al., EMNLP,
2018][William Fedus, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-208-2048.jpg)
![Empirical Performance
• MLE frequently generates “I’m sorry”, “I don’t
know”, etc. (corresponding to fuzzy images?)
• GAN generates longer and more complex responses.
• Find more comparison in the survey papers.
• [Lu, et al., arXiv, 2018][Zhu, et al., arXiv, 2018]
• However, no strong evidence shows that GANs are
better than MLE.
• [Stanislau Semeniuta, et al., arXiv, 2018] [Guy Tevet, et al., arXiv, 2018]
[Massimo Caccia, et al., arXiv, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-209-2048.jpg)
![More Applications
• Supervised machine translation [Wu, et al., arXiv
2017][Yang, et al., arXiv 2017]
• Supervised abstractive summarization [Liu, et al., AAAI
2018]
• Image/video caption generation [Rakshith Shetty, et al., ICCV
2017][Liang, et al., arXiv 2017]
• Data augmentation for code-switching ASR [Mon-P-
1-D] [Chang, et al., INTERSPEECH 2019]
If you are trying to generate some sequences,
you can consider GAN.](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-210-2048.jpg)




![✘ Negative sentence to positive sentence:
it's a crappy day -> it's a great day
i wish you could be here -> you could be here
it's not a good idea -> it's good idea
i miss you -> i love you
i don't love you -> i love you
i can't do that -> i can do that
i feel so sad -> i happy
it's a bad day -> it's a good day
it's a dummy day -> it's a great day
sorry for doing such a horrible thing -> thanks for doing a
great thing
my doggy is sick -> my doggy is my doggy
my little doggy is sick -> my little doggy is my little doggy
Cycle GAN
感謝 王耀賢 同學提供實驗結果
[Lee, et al.,
ICASSP, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-215-2048.jpg)
![𝐸𝑁 𝑋
𝐸𝑁𝑌 𝐷𝐸 𝑌
𝐷𝐸 𝑋 𝐷 𝑋
𝐷 𝑌
Discriminator
of X domain
Discriminator
of Y domain
Shared Latent Space
Positive
Sentence
Positive
Sentence
Negative
Sentence
Negative
Sentence
Decoder hidden layer as discriminator input
[Shen, et al., NIPS, 2017]
From 𝐸𝑁𝑋 or 𝐸𝑁𝑌
Domain
Discriminator
𝐸𝑁𝑋 and 𝐸𝑁𝑌 fool the
domain discriminator
[Zhao, et al., arXiv, 2017]
[Fu, et al., AAAI, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-216-2048.jpg)


![Unsupervised Abstractive
Summarization
• Now machine can do abstractive summary by
seq2seq (write summaries in its own words)
summary 1
summary 2
summary 3
seq2seq document
Domain Y Domain X[Wang, et al., EMNLP, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-219-2048.jpg)




![Experimental results
ROUGE-1 ROUGE-2 ROUGE-L
Supervised 33.2 14.2 30.5
Trivial 21.9 7.7 20.5
Unsupervised
(matched data)
28.1 10.0 25.4
Unsupervised
(no matched data)
27.2 9.1 24.1
English Gigaword (Document title as summary)
• Matched data: using the title of English Gigaword to train
Discriminator
• No matched data: using the title of CNN/Diary Mail to
train Discriminator
[Wang, Lee, EMNLP 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-224-2048.jpg)
![Semi-supervised Learning
25
26
27
28
29
30
31
32
33
34
0 10k 500k
ROUGE-1
Number of document-summary pairs used
WGAN Reinforce Supervised
3.8M pairs are used.Approaches to deal with the discrete issue.
unsupervised
semi-supervised
[Wang, Lee,
EMNLP 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-225-2048.jpg)
![More Unsupervised
Summarization
• Unsupervised summarization with language prior
• Unsupervised multi-document summarization
[Eric Chu, Peter Liu,
ICML 2019]
[Christos Baziotis, etc al.,
NAACL 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-226-2048.jpg)
![G
Input
Sentence
D
Said by
Trump?
Discriminator
R
Dialogue Response Generation
minimize the reconstruction error
Make the US great again
I would build a great wall
you are fired
What Trump has said
Chat
Bot
Generated
Response
Input
Sentence
(Reconstruct)
[Su, et al., INTERSPEECH, 2019]
(Thu-P-9-C)
General
Dialogues](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-227-2048.jpg)

![Unsupervised learning
with 10M sentences
Supervised learning with
100K sentence pairs
=
supervised
unsupervised
[Alexis Conneau, et al., ICLR, 2018]
[Guillaume Lample, et al., ICLR, 2018]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-229-2048.jpg)

![Towards Unsupervised ASR
- Cycle GAN
G
ASR
Text
R
TTS
D
Real Text?
Discriminator
minimize the reconstruction error (speech chain)
how are you
good morning
i am fine
Real
Text
[Andros Tjandra, et al., ASRU 2017]
[Liu, et al., INTERSPEECH 2018]
[Yeh, et al., ICLR 2019]
[Chen, et al., INTERSPEECH 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-231-2048.jpg)
![Towards Unsupervised ASR
- Cycle GAN
• Unsupervised setting on TIMIT (text and audio are
unpair, text is not the transcription of audio)
• 63.6% PER (oracle boundaries)
• 41.6% PER (automatic segmentation)
• 33.1% PER (automatic segmentation)
• Semi-supervised setting on Librispeech
[Liu, et al., INTERSPEECH 2018]
[Yeh, et al., ICLR 2019]
(Tue-P-4-B)[Chen, et al., INTERSPEECH 2019]
[Liu, et al., ICASSP 2019]
[Tomoki Hayashi, et al., SLT 2018]
[Takaaki Hori, et al., ICASSP 2019]
[Murali Karthick Baskar, et al., INTERSPEECH 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-232-2048.jpg)
![Towards Unsupervised ASR
- Shared Latent Space
Text
Encoder
Audio
Encoder
Audio
Decoder
Text
Decoder
this is text this is text
Unsupervised setting on Librispeech: 76.3% WER
WSJ with 2.5 hours paired data: 64.6% WER
LJ speech with 20 mins paired data: 11.7% PER
[Chen, et al., SLT 2018]
Unsupervised speech translation is also possible!
[Chung, et al., NIPS 2018]
[Jennifer Drexler, et al., SLT 2018]
[Ren, et al., ICML 2019]
[Chung, et al., ICASSP 2019]](https://crownmelresort.com/image.slidesharecdn.com/gan3hour-190915171456/75/Generative-adversarial-network-and-its-applications-to-speech-signal-and-natural-language-processing-INTERSPEECH-2019-tutorial-233-2048.jpg)















The document discusses Generative Adversarial Networks (GANs), outlining their basic principles, theoretical foundations, and diverse applications in speech and natural language processing. It covers different types of GANs, including traditional and conditional models, and explores their utility in generating images, video, and audio-to-image translations. Additionally, it references significant research contributions and advancements in the field since the inception of GANs.
Introduction to Generative Adversarial Networks (GANs), their diversity and historical context, with reference to over 500 types in the GAN ecosystem.
Foundation of GAN, including generators and discriminators, types of GANs, and an illustration on image generation.
Stepwise explanation of GAN training processes with illustrations, showcasing generator and discriminator updates during iterations.
Introduction of advanced GANs like StyleGAN, highlighting their evolution and improvements in image generation techniques.
Understanding the internal mechanisms of GANs, including loss functions, evaluation metrics, conditional GANs, and practical applications.
Applications of Conditional GANs in image-to-image translation, showcasing improvements and metrics comparisons for multiple architectures.
Exploring unsupervised conditional GANs, domain adaptation methods, and various approaches like CycleGAN for feature transformation.
Applications of GANs in speech processing, including speech enhancement, recognition tasks, and examples of techniques like SEGAN. Techniques in voice conversion through GANs, highlighting the use of GANs for improving speech intelligibility in various scenarios.
Discussion on GANs in NLP tasks, focusing on sequence generation, text style transfer, and summarization, with references to empirical results.
Empirical performance insights of GANs in NLP, outlining summary generation, translation, and evaluation methodologies in unsupervised settings.


















![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)















































