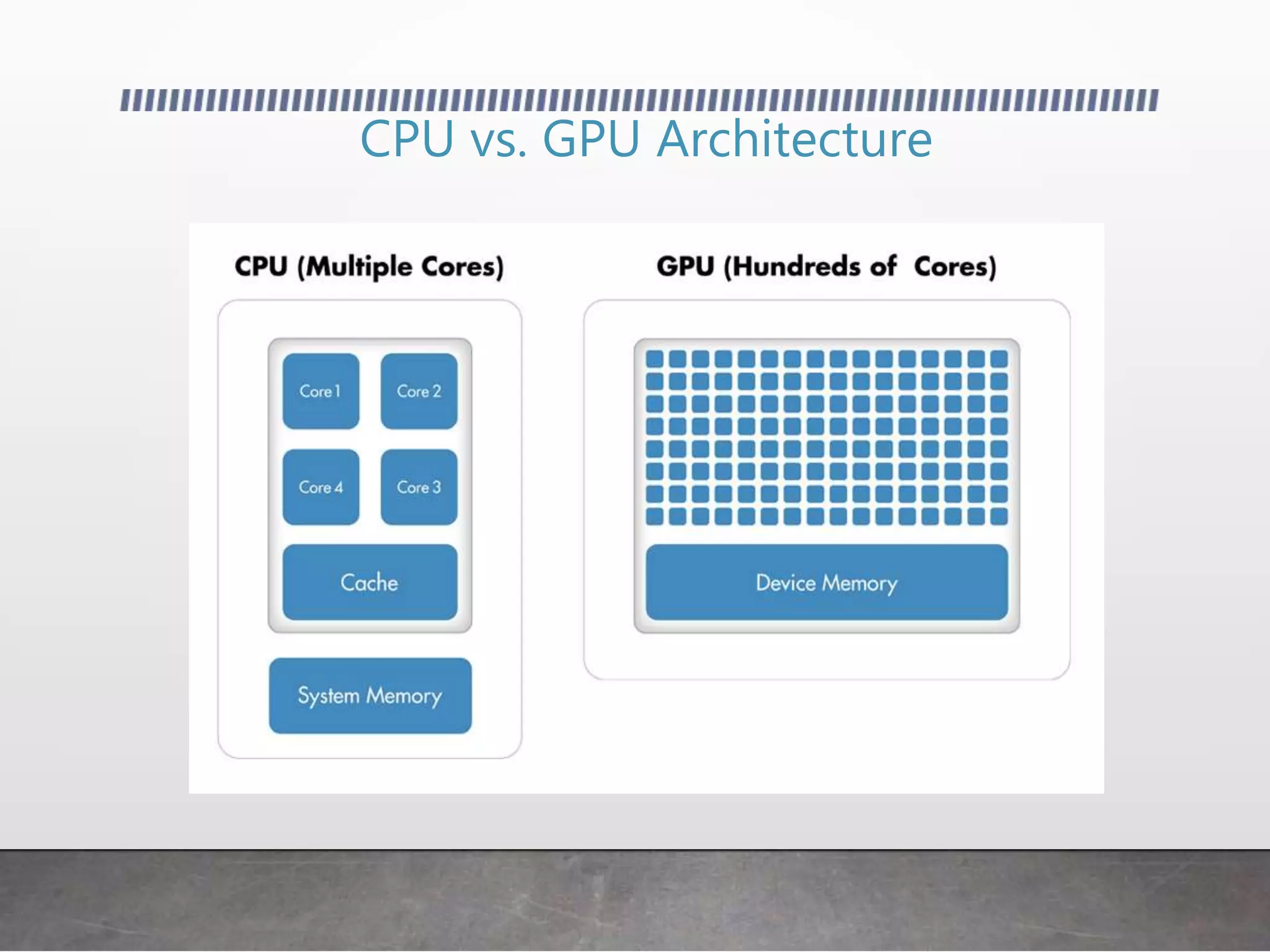
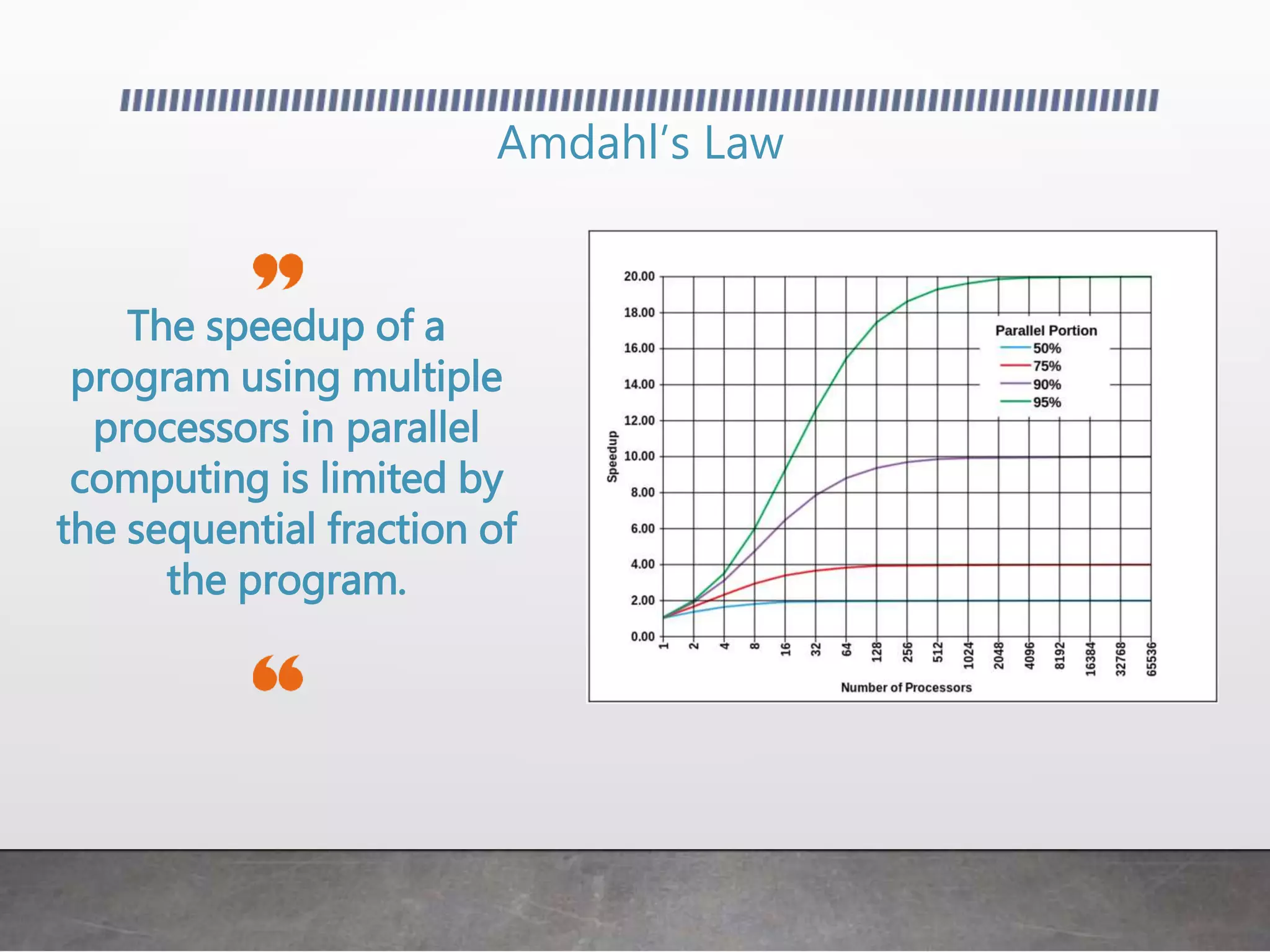
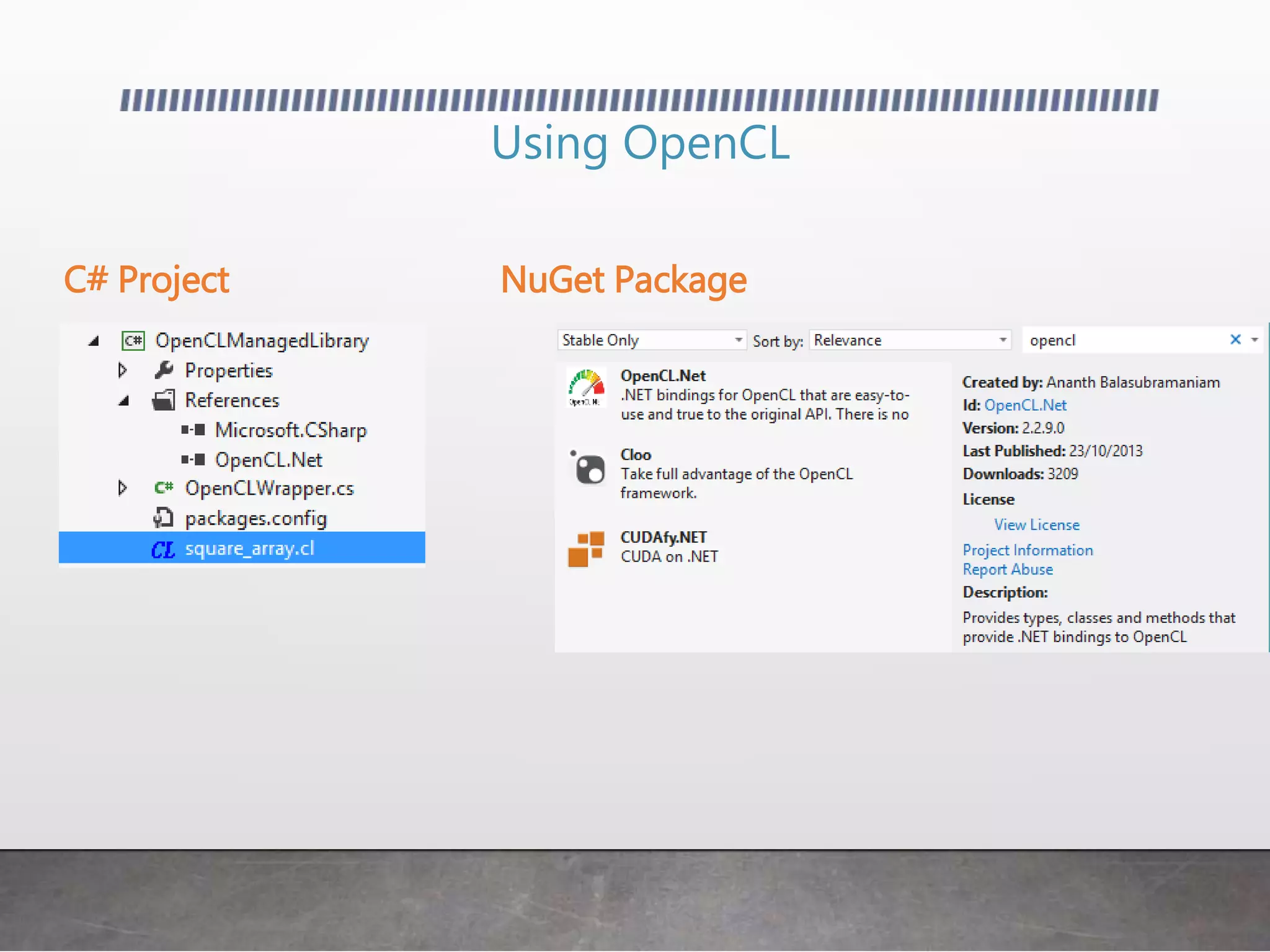
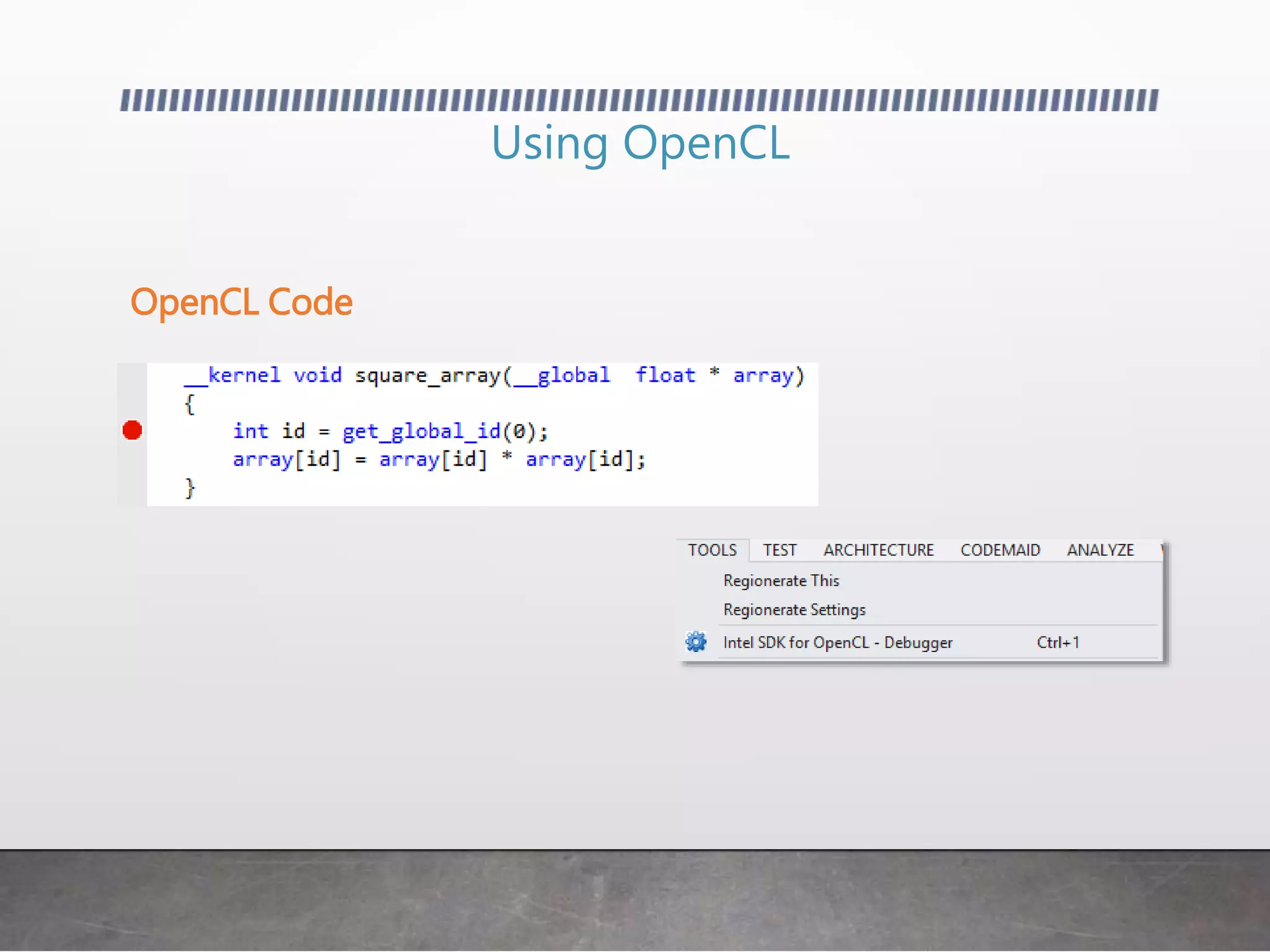
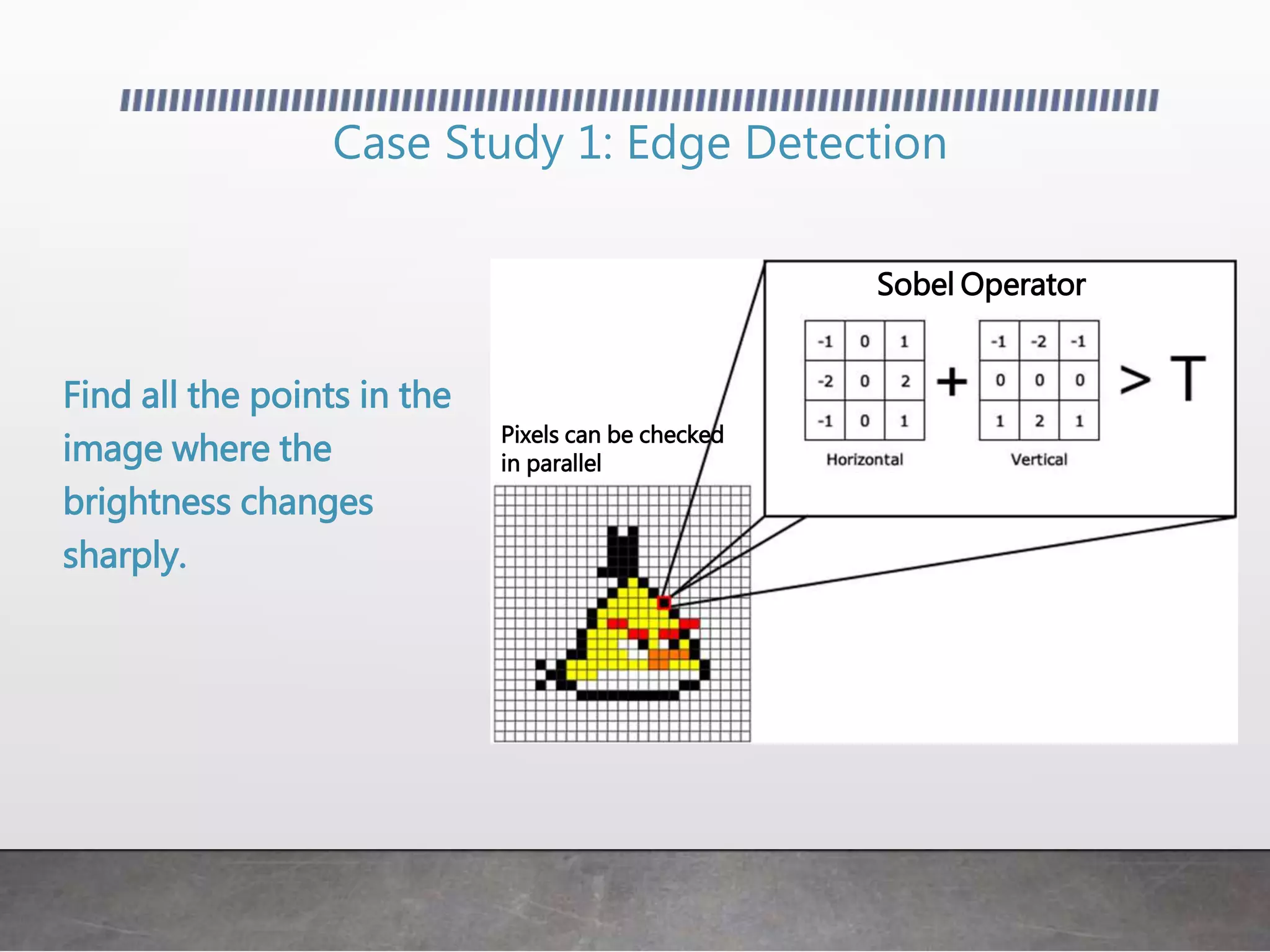
This document discusses using GPUs for general purpose computing. It begins by explaining that GPUs were traditionally used for graphics but can now be used to accelerate non-graphics applications through GPGPU. It then provides examples of problems that are well-suited to GPU parallelism and frameworks like OpenCL, CUDA, and C++ AMP that allow programming GPUs. It also demonstrates simple GPGPU applications like edge detection and password cracking that can be accelerated on a GPU.




![Parallelizing Your Code
void compute(float in[10000], float *out[10000])
{
for(int i=0; i < 10000; i++)
*out[i] = func(in[i]);
}
Texture Frame Buffer
Kernel](https://image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-7-2048.jpg)


![Using C++ AMP
extern "C" __declspec ( dllexport ) void _stdcall square_array(float* arr, int n)
{
array_view<float,1> dataView(n, &arr[0]);
parallel_for_each(dataView.extent, [=] (index<1> idx) restrict(amp)
{
dataView[idx] = dataView[idx] * dataView[idx];
});
dataView.synchronize();
}
Native DLL](https://image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-10-2048.jpg)
![Using C++ AMP
[DllImport("NativeAmpLibrary", CallingConvention = CallingConvention.StdCall)]
extern unsafe static void square_array(float* array, int length);
float[] arr = new[] { 1.0f, 2.0f, 3.0f, 4.0f };
fixed (float* arrPt = &arr[0]) {
square_array(arrPt, arr.Length);
}
Managed Code](https://image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-11-2048.jpg)
![Using Aparapi (OpenCL)
Aparapi Java Code
• Converts Java bytecode to
OpenCL at runtime
• Syntax somewhat similar to
C++ AMP
final float[] data = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
int gid = getGlobalId();
data[gid] = data[gid] * data[gid];
}
};
kernel.execute(Range.create(512));](https://image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-14-2048.jpg)












![Parallelizing Your Code
void compute(float in[10000], float *out[10000])
{
for(int i=0; i < 10000; i++)
*out[i] = func(in[i]);
}
Texture Frame Buffer
Kernel](https://crownmelresort.com/image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-7-2048.jpg)


![Using C++ AMP
extern "C" __declspec ( dllexport ) void _stdcall square_array(float* arr, int n)
{
array_view<float,1> dataView(n, &arr[0]);
parallel_for_each(dataView.extent, [=] (index<1> idx) restrict(amp)
{
dataView[idx] = dataView[idx] * dataView[idx];
});
dataView.synchronize();
}
Native DLL](https://crownmelresort.com/image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-10-2048.jpg)
![Using C++ AMP
[DllImport("NativeAmpLibrary", CallingConvention = CallingConvention.StdCall)]
extern unsafe static void square_array(float* array, int length);
float[] arr = new[] { 1.0f, 2.0f, 3.0f, 4.0f };
fixed (float* arrPt = &arr[0]) {
square_array(arrPt, arr.Length);
}
Managed Code](https://crownmelresort.com/image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-11-2048.jpg)


![Using Aparapi (OpenCL)
Aparapi Java Code
• Converts Java bytecode to
OpenCL at runtime
• Syntax somewhat similar to
C++ AMP
final float[] data = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
int gid = getGlobalId();
data[gid] = data[gid] * data[gid];
}
};
kernel.execute(Range.create(512));](https://crownmelresort.com/image.slidesharecdn.com/confoogpgpu-square-160226193356/75/General-Programming-on-the-GPU-Confoo-14-2048.jpg)




























![[4DEV][Łódź] Ivan Vaskevych - InfluxDB and Grafana fighting together with IoT...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdb-171113135140-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































